The goal in the remaining part of this section is the mathematical description of uncertainties of scalars in
Section 3.2.1, and of arrays/tables in
Section 3.2.2. There is a huge literature on the
mathematical description of uncertainties, see for example [
11,
20,
21,
22,
23]. The article of Riedmaier et al. [
11] provides a comprehensive literature overview. In [
12], some language constructs were proposed to describe uncertain values in the Modelica language. For linear models, structured and unstructured uncertainties, including uncertainties of unmodeled dynamics, were described in various ways, such as LFT (linear fractional transformation), see for example [
24]. These description forms are not used here, because this section discusses methods to model nonlinear systems with parametric uncertainties.
The treatment below is focused on providing the information in a way that it can be used by models described with the Modelica language [
4], FMI [
1,
2,
3], SSP [
25], Modia [
26] or similar modeling approaches. Furthermore, not only physical/measured quantities are considered, but the same description form is also used to define
requirements or
specifications. For example, a simulation result must match a
reference result with some uncertainty, or the result of a design must match some
criteria that are specified with an
uncertainty description.
3.2.1. Uncertainties of Scalars
Every physical quantity has inherent limits. Therefore, the upper and lower limits of a scalar value need to be defined, independent of the kind of the mathematical description of the uncertainty. Often, for example, an uncertainty of a physical quantity is described by a normal distribution. However, this does not make sense because this distribution defines probabilities for values in the range from to . Assume for example, a resistance of an electrical resistor is described with such a normal distribution and a Monte Carlo simulator selects a random value according to this distribution that is negative (although the probability might be very small), then the corresponding simulation makes no sense at all, because the physical resistance can only have positive values.
Furthermore, if a real-world product is used and certain parameters of this product are defined with tolerances or belong to certain tolerance classes according to some standard (for example a resistor with a tolerance of for the resistance value), then the manufacturer guarantees that the parameter value is within the specified tolerance. For this reason, the minimum information to be provided for a scalar parameter with an uncertainty description of any kind is
nominal—the nominal value of the scalar (e.g., determined by calibration).
lower—the lowest possible value of the uncertain scalar.
upper—the highest possible value of the uncertain scalar.
For example, the parameter R of a resistor has , and . It is also necessary to define the value of the scalar in a model that is used in the current simulation run, for example, the value used in an optimization run that determines improved control parameters, or the value used during a Monte Carlo simulation to propagate uncertainties to output variables. Typically, the value is used as default for the current value.
Often, it is inconvenient to provide absolute ranges and instead, relative or absolute deviations are more practical. In the eFMI (Functional Mock-up Interface for embedded systems) standard (
https://emphysis.github.io/pages/downloads/efmi_specification_1.0.0-alpha.4.html (accessed on 30 July 2022)) (Section 3.2.4)
tolerances for
reference results are defined in a similar way as tolerances for numerical integration algorithms. Due to its generality, this description form of eFMI is used here as well:
nominal—nominal value of the scalar.
relTol—relative tolerance of limits with respect to (default = 0.0).
absTol—absolute tolerance of limits with respect to (default = 0.0).
The
and
values can be computed from these parameters in the following way:
Examples:
Typically, either a description with or with is used, but not a combination of both. The alternative is therefore to introduce a flag to distinguish whether or is provided. However, the drawback is that an additional flag needs to be introduced and that one of the values is always ignored (and any given value might be confusing). Furthermore, there is an important use case, where the description with both and is useful: If reference results are provided (e.g., the results of a simulation or an experiment are required to be within some band around a provided reference solution), then a definition with is often practical together with as a band for small values of the reference around zero, where makes no sense.
The minimum information for an uncertainty description of a model parameter was defined above. Further properties can be defined due to numerous reasons why a model parameter is uncertain. The following list sketches some reasons for uncertainties according to [
20]:
Systematic errors, calibration errors, etc., in the measurement equipment;
Uncontrolled conditions of the measurement equipment (e.g., environment);
Differences in the parameter values of the same device, e.g., due to small variations in the production or the used materials;
Mathematical model does not reflect the physical system precisely enough;
Not enough knowledge about the physical system;
Uncontrolled conditions for the model inputs/environment and scenarios.
Uncertainties are typically classified as either
aleatory or
epistemic. [
20] provides the following definitions:
Aleatory—the inherent variation in a quantity that, given sufficient samples of the stochastic process, can be characterized via a probability density distribution.
Epistemic—uncertainty due to lack of knowledge by the modelers, analysts conducting the analysis, or experimentalists involved in validation.
An uncertainty can also consist of a combination of (a) and (b). An epistemic uncertainty can be reduced through increased understanding, or increased and more relevant data, whereas the statistical property of an aleatory uncertainty is usually inherent in the system and can thus not be reduced (this would require, e.g., to improve a production process).
An epistemic uncertainty is defined by an
interval. Besides the classification as interval, the above minimum description of an uncertainty by
,
(besides
) values is sufficient to define this type of uncertainty. Hereby, no probability distribution is known due to a lack of knowledge. Typical epistemic uncertainties are the load of a vehicle, aircraft or robot. Interval arithmetic or Monte Carlo samples might be used for analysis, see [
27]. In the latter case, approximated intervals are computed for interested output variables, but no stochastic distributions are determined as for aleatory uncertainties. If both epistemic and aleatory uncertainties are present, an interval might be divided in a grid and for every grid value, a Monte Carlo simulation is performed for the aleatory uncertainties. An interested output variable is computed as a
set of probability distributions and presented as a probability distribution area, see [
22].
The parameters of the
TruncatedNormal distribution are computed from the proposed
TruncatedNormalTolerance parameterization in the following way:
Examples of the uncertainty description of a resistance
R with this parameterization are given in
Table 2. Specifications are sometimes given in the form of the first column in this table, which was the motivation for the specific (intuitive) parameterization via
TruncatedNormalTolerance. The corresponding probability density functions are shown in
Figure 3.
There are various standards of technical systems to describe uncertainties of a product:
If an industrial standard is used that only defines tolerances (without a statistical distribution), the corresponding uncertainty would be typically defined as an IntervalTolerance or Interval uncertainty.
The determination of the uncertainty distribution of a parameter might be difficult, if the parameter value cannot be directly measured. In [
29], new methods were proposed and evaluated, e.g., to infer the uncertainty distributions of model parameters of a DC-motor from test-bench measurements.
3.2.2. Uncertainties of Arrays
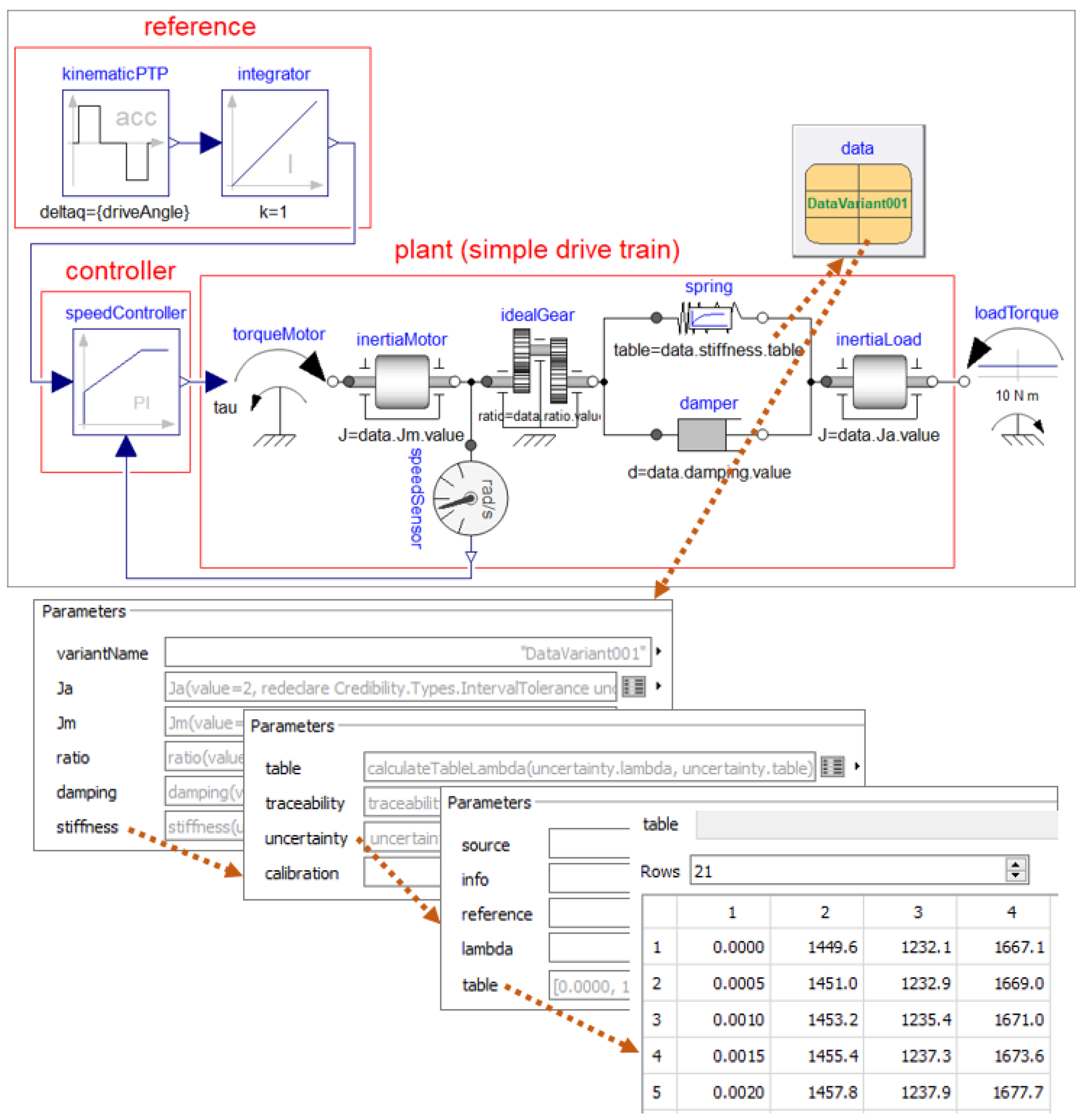
Submodels are often approximated by tables of a characteristic property that have been determined by measurements, for example a table defining friction torque as a function of the relative angular velocity, or a table defining mass flow rate through a valve as a function of the valve position. Tables of this kind are basically defined with two or more dimensional arrays. Inputs of a system are often defined by tables as a function of time. The outputs of a system might be checked against reference outputs (for example, determined from the previous version of the model or tool, from another tool or from an analytically known solution) defined by tables as a function of time. The computed solution is then required to be within the uncertainty ranges of the reference tables. All these examples have parameter arrays, where the uncertainties of the array elements need to be described.
If a characteristic is determined by detailed measurements, then typically, for every element, the upper and lower limits are known from the available measurement data, see for example [
30] for a force–velocity dependency of automotive shock absorbers. This means that the measurements can be summarized by a
nominal array that has been determined by the calibration process and arrays
lower and
upper of the same size that define lower and upper limits, so all measured data of the respective characteristic are between these limits. Furthermore, it must be defined how to interpolate between the table values, given the vectors of the independent variables (an
n-dimensional table is defined by
n vectors of independent variables). Often, a linear interpolation is used for tables derived from measurements. In
Table 3, examples for this proposed kind of parameterization are given.
For simplicity, it might often be sufficient to define statistical properties by a scalar that holds for all elements, instead of providing statistical properties individually for every array element. For this reason,
Table 3 also proposes parameterizations with
relTol and
absTol that hold for every array element. For example, the elements of an aerodynamic coefficient table might have an uncertainty of 50% based on previous experience, or the reference results should be reproduced within a relative tolerance of 0.1%.
The question arises how a parameter array can be used to compute the uncertainty distributions of output variables. For scalar parameters, the standard Monte Carlo simulation method is based on the approach to draw sufficient numbers of random numbers according to the respective distributions and for each set of selected parameter values perform a simulation. Such a procedure might not be directly applicable to parameter arrays, because randomly selected elements of an array might give a table that does not represent physics (for example, if the table output is a monotonically increasing function of the input, then this property might be lost if table elements are randomly selected).
For simplicity, the following (new) method is proposed for 1D tables. A generalization to multidimensional tables is straightforward. A 1D table defines a function
that computes the output
y from the input
u by interpolation in a table. The table is defined by a grid vector
, and an output vector
, so that
is the output value for
. The output
is computed from the nominal value
, lower and upper limits
by a convex combination defined with uncertain parameter
, so that
results in
,
results in
and
results in
:
During the Monte Carlo simulation, random values are drawn for
and new values of the output vector
are computed for every such selection and used in the corresponding simulation. It might be necessary to adapt the lower/upper arrays so that monotonicity requirements are fulfilled by
(e.g.,
). An example is given in
Figure 4, where this table interpolation method is applied to the stiffness of a gearbox described by a rotational spring constant
c as a function of the relative angle
.
is the output
for
.
The advantage of this method is that an uncertainty table can be managed in the model just like a standard table, that is, the rules for data interpolation or for extrapolation outside of the u limits apply seamlessly. Moreover, epistemic or aleatory uncertainty definitions can be used for the calculation of . The additional computational effort to compute once per simulation is just marginal.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}