
Multi-Branch Attention-Based Grouped Convolution Network for Human Activity Recognition Using Inertial Sensors

Abstract
:1. Introduction
- (1)
- A new multi-branch neural network is proposed, in which each branch consists of two layers of grouped convolution + dual attention submodule.
- (2)
- A new method of sensor data input and processing is proposed. Sensor data collected at different positions of the human body are separated and fed into different network branches for training and testing independently.
- (3)
- We test our method on three large HAR datasets. The experimental results show that our network outperforms existing state-of-the-art methods.
2. Related Works
3. Proposed Method
3.1. Sensor Data Preprocessing
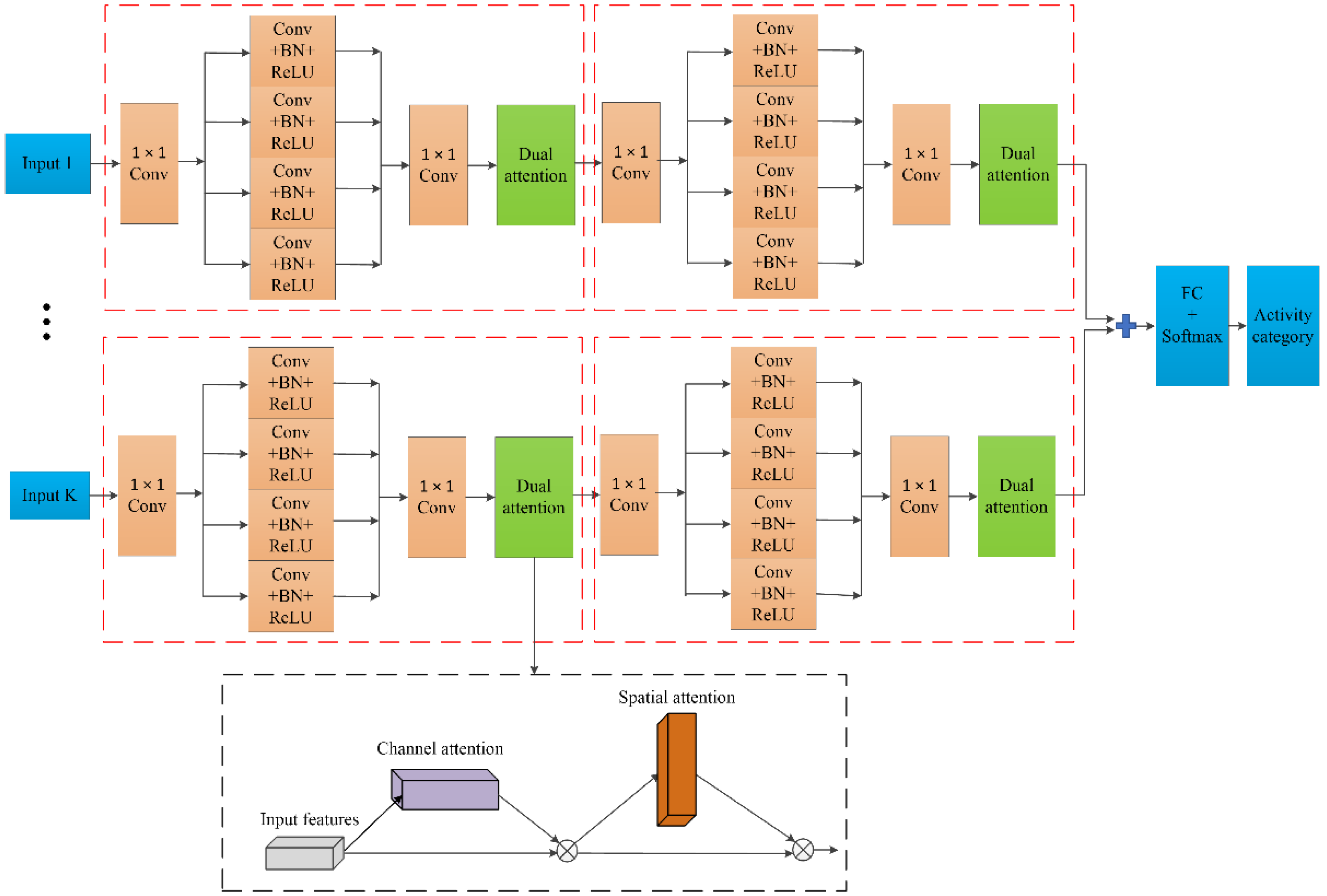
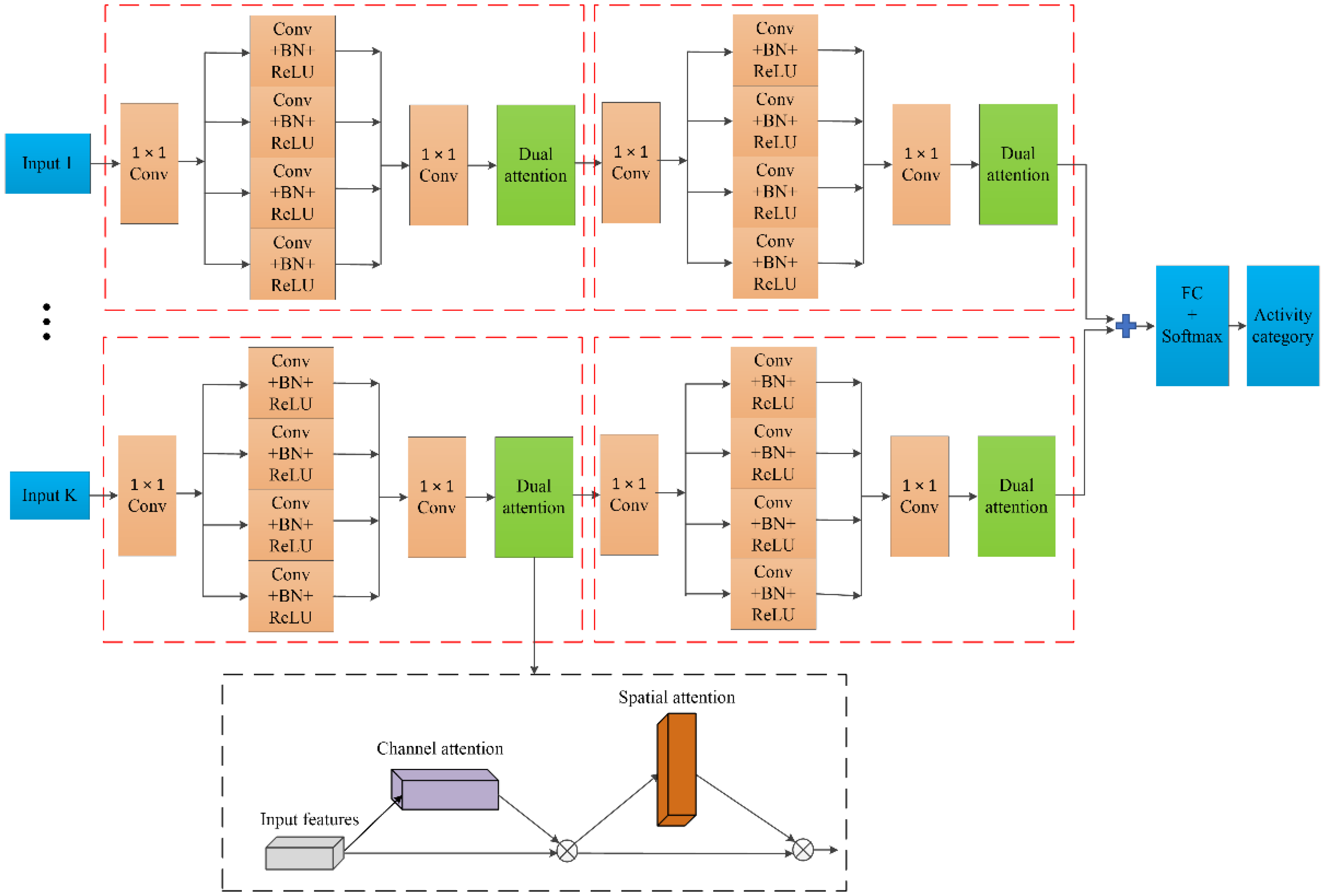
3.2. Network Architecture
3.3. Dual Attention Mechanism
3.4. Multi-Branch Network
4. Experiments
4.1. Experimental Datasets
- (1)
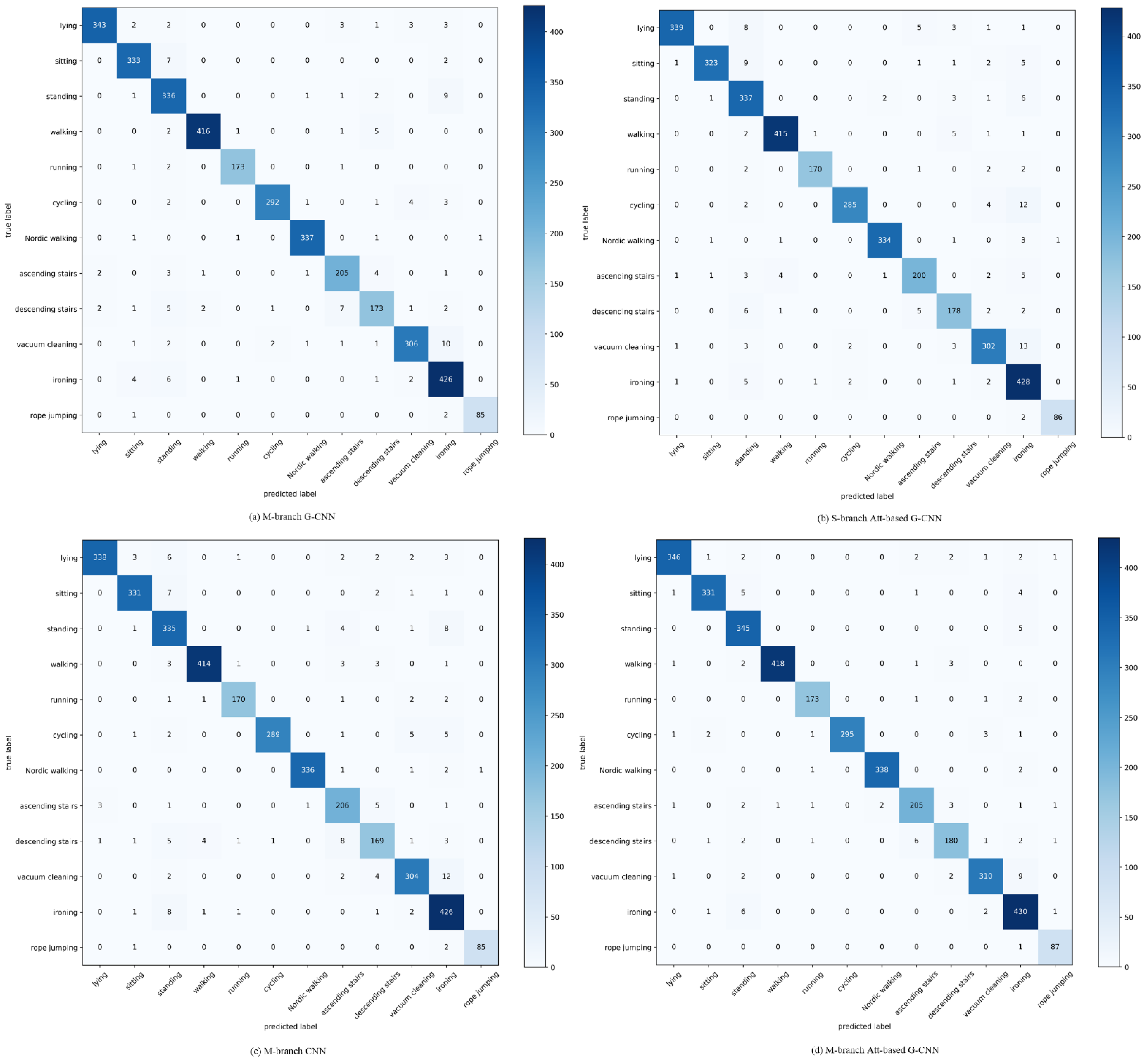
- PAMAP2 [31]: This dataset was completed by nine subjects, and each subject was asked to complete 12 protocol activities, including lying, sitting, standing, walking, running, Nordic walking, ascending stairs, descending stairs, vacuum cleaning, ironing, and rope jumping, and 6 optional activities, including watching TV, computer work, car driving, folding laundry, house cleaning, and playing soccer. They are all human daily activities. In this paper, we only tested 12 protocol activities. Three IMUs were placed on the chest, wrist, and ankle of each subject, respectively. Each IMU consisted of an accelerometer, gyroscope, and magnetometer. In our experiment, the inertial sensor data were collected at 100 Hz and downsampled to 33 Hz to reduce the amount of data in subsequent processing. Only the accelerometer and gyroscope data from the protocol activities were used for analysis. The sliding window length was set to 168 (5.12 s) and the overlap rate was set to 78%. The sliding window length and overlap are consistent with [19]. All the segments of the dataset were randomly separated into two parts, including a training set (80%) and a test set (20%).
- (2)
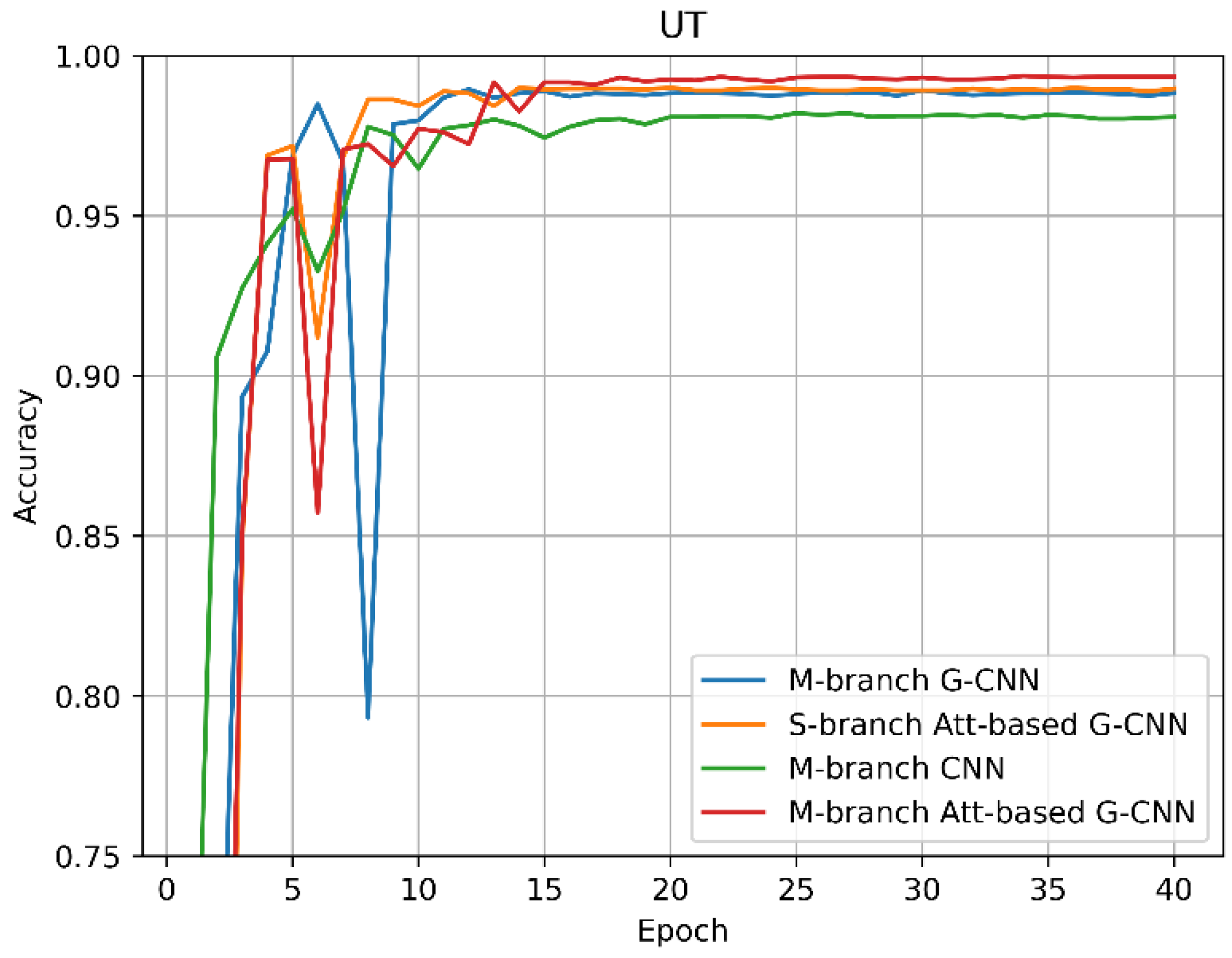
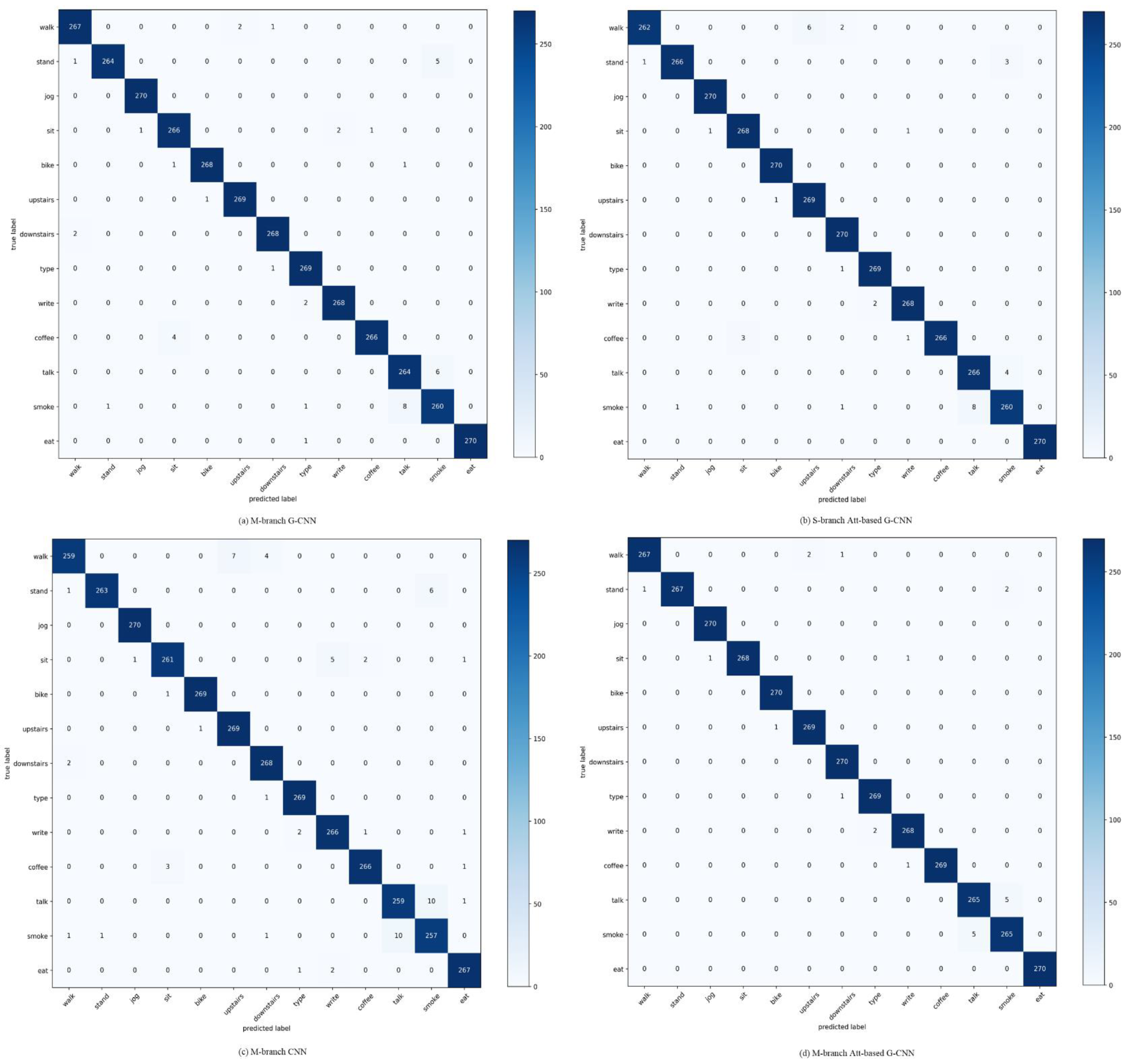
- UT-dataset [15]: The dataset was completed by 10 subjects. The subjects were asked to perform 13 activities, including walking, standing, jogging, sitting, biking, going upstairs, going downstairs, typing, writing, drinking coffee, talking, smoking, and eating. Two sensors were placed on the subject’s wrist and ankle, respectively. Each sensor included an accelerometer, a linear accelerometer, a gyroscope, and a magnetometer. In this paper, we have only used data from the accelerometer and gyroscope. The sensor sampling frequency was 50 Hz. The sliding window length was 200 (4 s) and the overlap rate was 50%, which are the same as [26]. Like the PAMAP2, the segments of UT were randomly separated into two parts, including a training set (70%) and a test set (30%).
- (3)
- OPPORTUNITY [32,33]: The dataset was completed by 12 subjects. All of the subjects were required to perform various daily activities. Each of them wore 7 IMUs and 12 three-axis acceleration sensors to ensure that rich activity data could be collected. The sampling frequency of all sensors was 30 Hz. We used the data from five IMUs (upper body) and two other IMUs (two shoes) to test. For the five IMUs worn on the upper body, we only used the data from 3-axis gyroscope and 3-axis accelerometer. For the two IMUs attached to two shoes, we used the 3-axis Euler angles and 3-axis body acceleration. The test data had a total of 42 dimensions. The sliding window was set to 30 (1 s), and the overlap rate was 50%, which are consistent with [21,25]. The whole dataset was randomly divided into two parts, including 70% of the training set and 30% of the test set.
4.2. Experimental Settings
4.3. Experimental Result and Discussion
4.3.1. Results on PAMAP2
4.3.2. Results on UT
4.3.3. Results on OPPORTUNITY
4.3.4. Comparison with Related Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, J.; Chen, Y.; Hao, S. Deep learning for sensorbased activity recognition: A survey. Pattern Recogn. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Zhang, Y.; Bao, J.; Zhang, Y.; Deng, H. Human Activity Recognition Based on Motion Sensor Using U-Net. IEEE Access 2019, 7, 75213–75226. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, C.; Xiang, S.; Ding, J.; Wu, M.; Li, X. Smartphone Sensor-Based Human Activity Recognition Using Feature Fusion and Maximum Full a Posteriori. IEEE Trans. Instrum. Meas. 2020, 69, 3992–4001. [Google Scholar] [CrossRef]
- Ordonez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human Activity Recognition with Smartphone and Wearable Sensors Using Deep Learning Techniques: A Review. IEEE Sens. J. 2021, 21, 13029–13040. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Huang, W.; Zhang, L.; Gao, W.; Min, F.; He, J. Shallow Convolutional Neural Networks for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.; Elhoseny, M.; Song, H. ST-DeepHAR: Deep Learning Model for Human Activity Recognition in IoHT Applications. IEEE Internet Things J. 2021, 8, 4969–4979. [Google Scholar] [CrossRef]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Bloomfield, R.A.; Teeter, M.G.; Mcisaac, K.A. A Convolutional Neural Network Approach to Classifying Activities Using Knee Instrumented Wearable Sensors. IEEE Sens. J. 2020, 20, 14975–14983. [Google Scholar] [CrossRef]
- Imran, H.A. UltaNet: An Antithesis Neural Network for Recognizing Human Activity Using Inertial Sensors Signals. IEEE Sens. Lett. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Complex Human Activity Recognition Using Smartphone and Wrist-Worn Motion Sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; De Munari, I. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, L.; Tang, Y.; Liu, Y.; Wu, H.; He, J. Real-Time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices. IEEE Sens. J. 2022, 22, 5889–5901. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, L.; Min, F.; He, J. Multi-scale Deep Feature Learning for Human Activity Recognition Using Wearable Sensors. IEEE Trans. Ind. Electron. 2022. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual Attention Network for multimodal human activity recognition using wearable sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Tong, L.; Ma, H.; Lin, Q.; He, J.; Peng, L. A Novel Deep Learning Bi-GRU-I Model for Real-Time Human Activity Recognition Using Inertial Sensors. IEEE Sens. J. 2022, 22, 6164–6174. [Google Scholar] [CrossRef]
- Mahmud, S.; Tonmoy, M.T.H.; Bhaumik, K.K.; Rahman, A.K.M.M.; Amin, M.A.; Shoyaib, M.; Khan, M.A.H.; Ali, A.A. Human Activity Recognition from Wearable Sensor Data Using Self-Attention. In Proceedings of the 24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 1–8. [Google Scholar]
- Buffelli, D.; Vandin, F. Attention-Based Deep Learning Framework for Human Activity Recognition with User Adaptation. IEEE Sens. J. 2021, 21, 13474–13483. [Google Scholar] [CrossRef]
- Shavit, Y.; Klein, I. Boosting Inertial-Based Human Activity Recognition with Transformers. IEEE Access 2021, 9, 53540–53547. [Google Scholar] [CrossRef]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Liu, T.; Wang, S.; Liu, Y. A lightweight neural network framework using linear grouped convolution for human activity recognition on mobile devices. J. Supercomput. 2022, 78, 6696–6716. [Google Scholar] [CrossRef]
- Huan, R.; Jiang, C.; Ge, L.; Shu, J.; Zhan, Z.; Chen, P.; Chi, K.; Liang, R. Human Complex Activity Recognition with Sensor Data Using Multiple Features. IEEE Sens. J. 2022, 22, 757–775. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. A Lightweight Deep Convolutional Neural Network with Squeeze-and-Excitation Modules for Efficient Human Activity Recognition using Smartphone Sensors. In Proceedings of the 2021 2nd International Conference on Big Data Analytics and Practices (IBDAP), Bangkok, Thailand, 26–27 August 2021; pp. 23–27. [Google Scholar]
- Reiss, A.; Hendeby, G.; Stricker, D. Confidence-based Multiclass AdaBoost for Physical Activity Monitoring. In Proceedings of the ACM International Symposium on Wearable Computers, Zurich, Switzerland, 8–12 September 2013; pp. 13–20. [Google Scholar]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.D.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recogn. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Forster, K.; Troster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar]
- Teng, Q.; Wang, K.; Zhang, L.; He, J. The Layer-Wise Training Convolutional Neural Networks Using Local Loss for Sensor-Based Human Activity Recognition. IEEE Sens. J. 2020, 20, 7265–7274. [Google Scholar] [CrossRef]
- Teng, Q.; Zhang, L.; Tang, Y.; Song, S.; Wang, X.; He, J. Block-Wise Training Residual Networks on Multi-Channel Time Series for Human Activity Recognition. IEEE Sens. J. 2021, 21, 18063–18074. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Backbone | |||
|---|---|---|---|---|
| M-Branch G-CNN | S-Branch Att-Based G-CNN | M-Branch CNN | M-Branch Att-Based G-CNN | |
| Layer 1 | C-B-R 1 × 1, 64 | C-B-R 1 × 1, 64 | C-B-R 3 × 3, 64 | C-B-R 1 × 1, 64 |
| G-C-B-R 3 × 3, 16 × 4 | G-C-B-R 3 × 3, 16 × 4 | G-C-B-R 3 × 3, 16 × 4 | ||
| C-B-R 1 × 1, 64 | C-B-R 1 × 1, 64 | C-B-R 1 × 1, 64 | ||
| Dual attention | Dual attention | |||
| Layer 2 | C-B-R 1 × 1, 32 | C-B-R 1 × 1, 32 | C-B-R 3 × 3, 32 | C-B-R 1 × 1, 32 |
| G-C-B-R 3 × 3, 8 × 4 | G-C-B-R 3 × 3, 8 × 4 | G-C-B-R 3 × 3, 8 × 4 | ||
| C-B-R 1 × 1, 32 | C-B-R 1 × 1, 32 | C-B-R 1 × 1, 32 | ||
| Dual attention | Dual attention | |||
| Layer 3 | Flatten, FC, Dropout (0.5), Softmax | |||
| Method | Accuracy | F1-Score | Paras | Flops | |
|---|---|---|---|---|---|
| M-branch G-CNN | mean | 96.19 | 96.15 | 1.219 M | 10.567 M |
| std | 0.09 | ||||
| S-branch Att-based G-CNN | mean | 95.45 | 95.55 | 1.181 M | 10.492 M |
| std | 0.12 | ||||
| M-branch CNN | mean | 95.63 | 95.51 | 1.219 M | 10.566 M |
| std | 0.03 | ||||
| Our network | mean | 97.35 | 97.03 | 1.221 M | 10.573 M |
| std | 0.08 |
| Method | Accuracy | F1-Score | Paras | Flops | |
|---|---|---|---|---|---|
| M-branch G-CNN | mean | 98.83 | 98.83 | 1.037 M | 9.063 M |
| std | 0.04 | ||||
| S-branch Att-based G-CNN | mean | 98.97 | 98.97 | 1.018 M | 9.026 M |
| std | 0.04 | ||||
| M-branch CNN | mean | 98.09 | 98.09 | 1.037 M | 9.062 M |
| std | 0.03 | ||||
| Our network | mean | 99.34 | 99.35 | 1.038 M | 9.067 M |
| std | 0.04 |
| Method | Accuracy | F1-Score | Paras | Flops | |
|---|---|---|---|---|---|
| M-branch G-CNN | mean | 90.42 | 75.12 | 0.9 M | 7.2 M |
| std | 0.05 | ||||
| S-branch Att-based G-CNN | mean | 89.31 | 71.81 | 0.79 M | 7 M |
| std | 0.07 | ||||
| M-branch CNN | mean | 89.07 | 72.08 | 0.9 M | 7.2 M |
| std | 0.07 | ||||
| Our network | mean | 90.83 | 76.16 | 0.9 M | 7.2 M |
| std | 0.03 |
| Methods | Acc | F1-Score | Paras | Flops | |
|---|---|---|---|---|---|
| PAMAP2 | Multi-scale CNN [18] | 93.75 | 93.66 | 1.20 M | 220.5 M |
| Hybrid Model [26] | 96.01 | 95.52 | 75.6 K | 897.3 M | |
| CNN + local loss [34] | 93.95 | - | - | - | |
| ResNet + attention [19] | 93.16 | - | 3.51 M | - | |
| Linear Grouped CNN [25] | 91.46 | - | 8.83 M | 39.7 M | |
| Our network | 97.35 | 97.03 | 1.22 M | 10.5 M | |
| UT | DT [15] | - | 90.32 | - | - |
| KNN [15] | - | 92.50 | - | - | |
| Hybrid Model [26] | 99.7 | 99.7 | - | - | |
| Our network | 99.34 | 99.35 | 1.03 M | 9 M | |
| OPPORTUNITY | Linear Grouped CNN [25] | 81.54 | - | 2.24 M | 536.79 M |
| Self-attention [21] | - | 67 | - | - | |
| ResNet + attention [19] | 82.75 | - | 1.57 M | - | |
| Teng et al. [35] | 83.06 | - | - | - | |
| Our network | 90.83 | 76.16 | 0.913 M | 7.25 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, L.; Liu, F. Multi-Branch Attention-Based Grouped Convolution Network for Human Activity Recognition Using Inertial Sensors. Electronics 2022, 11, 2526. https://doi.org/10.3390/electronics11162526
Li Y, Wang L, Liu F. Multi-Branch Attention-Based Grouped Convolution Network for Human Activity Recognition Using Inertial Sensors. Electronics. 2022; 11(16):2526. https://doi.org/10.3390/electronics11162526
Chicago/Turabian StyleLi, Yong, Luping Wang, and Fen Liu. 2022. "Multi-Branch Attention-Based Grouped Convolution Network for Human Activity Recognition Using Inertial Sensors" Electronics 11, no. 16: 2526. https://doi.org/10.3390/electronics11162526
APA StyleLi, Y., Wang, L., & Liu, F. (2022). Multi-Branch Attention-Based Grouped Convolution Network for Human Activity Recognition Using Inertial Sensors. Electronics, 11(16), 2526. https://doi.org/10.3390/electronics11162526