5.1. Big-Data Tools
Big data is a collection of different software tools based on the same distributed principle. These software tools are interdependent and, jointly, they represent a big-data solution. Such a rich portfolio is a response to market requirements for solving specific types of big data problems. BDPfPM uses several open-source big-data tools. In this subsection, we present basic information about the open-source big data tools used in BDPfPM.
BDPfPM uses the following big-data tools: HDFS (Hadoop Distributed File System), Apache HBase, OpenTSDB (Open Time-Series Database), Apache Spark, Hadoop YARN (Yet Another Resource Negotiator), and ZooKeeper.
HDFS is a file system distributed across multiple servers [
39]. It is an open-source technology designed to run on commodity hardware that meets the requirements for a cost-effective solution. HDFS is a framework that enables a unique file system across multiple servers. There are two role types on HDFS: namenodes, and datanodes. Together, they form HDFS clusters in the master–slave structure. Namenodes split incoming data into blocks and save them on datanodes. There are multiple copies for every block to increase fault tolerance in hardware failures. The secondary namenode ensures high availability. Furthermore, HDFS implements checksum for the stored data to provide data integrity. Data replication, secondary namenode, and checksums jointly provide high availability and reliability on both the hardware and the software layer. The HDFS capacity can be easily expanded without any downtime, either by adding new disks to existing servers or by adding new datanodes.
Traditional relational databases are not suitable for huge amounts of data. Even if it were possible to save all the data onto a relational database, the size of tables would be enormous and the query performance would be poor. Professional solutions might provide adequate performance (e.g., IBM Netezza, Teradata, Vertica), but their price is a limiting factor [
23]. Even NoSQL (Not Only SQL) databases, such as MongoDB are not able to satisfy BDPfPM requirements for scalability and query performance because of the large amount of data. Apache HBase is a non-relational, distributed database that uses HDFS as a file system to store tables. According to [
40], HBase is designed to host very large tables, with millions of columns and billions of rows. Furthermore, HBase is optimized for random read–write access to large data volumes. Obviously, HBase is suitable for real-time data processing, such as the processing of time-series data, as in our case. Furthermore, high-performance random read–write data access ensures data reading with minimal latency, which satisfies BDPfPM query-performance requirements.
OpenTSDB is a distributed time-series database. OpenTSDB simplifies the process of storing and analyzing the large amount of time-series data generated by endpoints (for example, sensors, servers, and applications). OpenTSDB uses the HBase service to store and retrieve data [
41]. HBase uses a data schema that is highly optimized for fast data aggregations of similar time-series data to minimize storage space. Using OpenTSDB endpoints (HTTP API, telnet protocol, or built-in graphical user interface), data can be accessed directly, without the need for direct access to HBase. Multiple instances of OpenTSDB can run on different hosts to achieve high availability. OpenTSDB instances work independently using the same underlying HBase tables. Furthermore, multiple instances are used to split the read–write load. According to [
41], one data point comprises the metric name, UNIX timestamp, value, and set of tags, where tags are key-value pairs that describe the collected data point in more detail.
Apache Spark is an open-source, distributed, in-memory processing engine. It is one of the most popular processing frameworks in the big-data industry. Similar to HDFS, Spark is also based on the master–slave architecture, which comprises master and slave nodes. Spark was initially developed for batch processing. Currently, this tool is used for both batch and stream processing, structured data (Spark SQL), and machine learning. Spark can be run on different environments, such as Hadoop, Apache Mesos, Kubernetes, or standalone clusters [
42]. Spark supplies developers with high-level APIs in Java, Scala, Python, R, and SQL [
42]. Since Spark is used for in-memory processing, Spark is slightly more demanding in terms of RAM (Random-access memory). As an alternative to batch processing, Apache MapReduce can be used. In comparison to Spark, MapReduce is up to 100 times slower due to I/O disk latency, but more cost-effective, since it requires less RAM.
Apache YARN is a cluster-resource manager and job tracker. YARN separates the resource-management layer from the processing layer. This framework enables different processing engines to run jobs and perform data aggregations using shared hardware resources. YARN dynamically allocates the resources and schedules the application processing [
43].
Apache ZooKeeper performs big-data cluster coordination and provides a highly available distributed system. It is a centralized service for maintaining configurations, naming, and providing synchronization in distributed services [
44]. Zookeeper simplifies the development process by enabling more robust cluster implementations [
45].
Regarding the implementation aspect, big-data platforms (such as our proposed BDPfPM) can be implemented on-premises or in the cloud. For on-premises implementation, in addition to pure Apache, other distributions can be used, such as Cloudera or Hortonworks. Rather than maintaining on-premises hardware, many companies choose to use cloud-computing services. This trend is becoming increasingly popular. Currently, there are many cloud providers, such as AWS (Amazon Web Services), Microsoft Azure, and GCP (Google Cloud Platform) [
15]. There are two main approaches to cloud implementation: IaaS (Infrastructure as a Service) and PaaS (Platform as a Service). In the case of IaaS implementation, the same approach as in on-premises implementation is used, with the exception that virtual machines are provisioned instead of bare metal servers. In the case of PaaS implementation, cloud providers offer their implementation for the mentioned services. Accordingly, it is necessary to use appropriate services. For example, if the whole architecture is implemented on GCP, Google Bigtable is used instead of HBase.
5.2. BDPfPM Architecture
In this subsection, we present the BDPfPM architecture and describe all its components. Furthermore, we describe the collected-data flow across the architecture, and how the BDPfPM achieves HFC-network-performance monitoring.
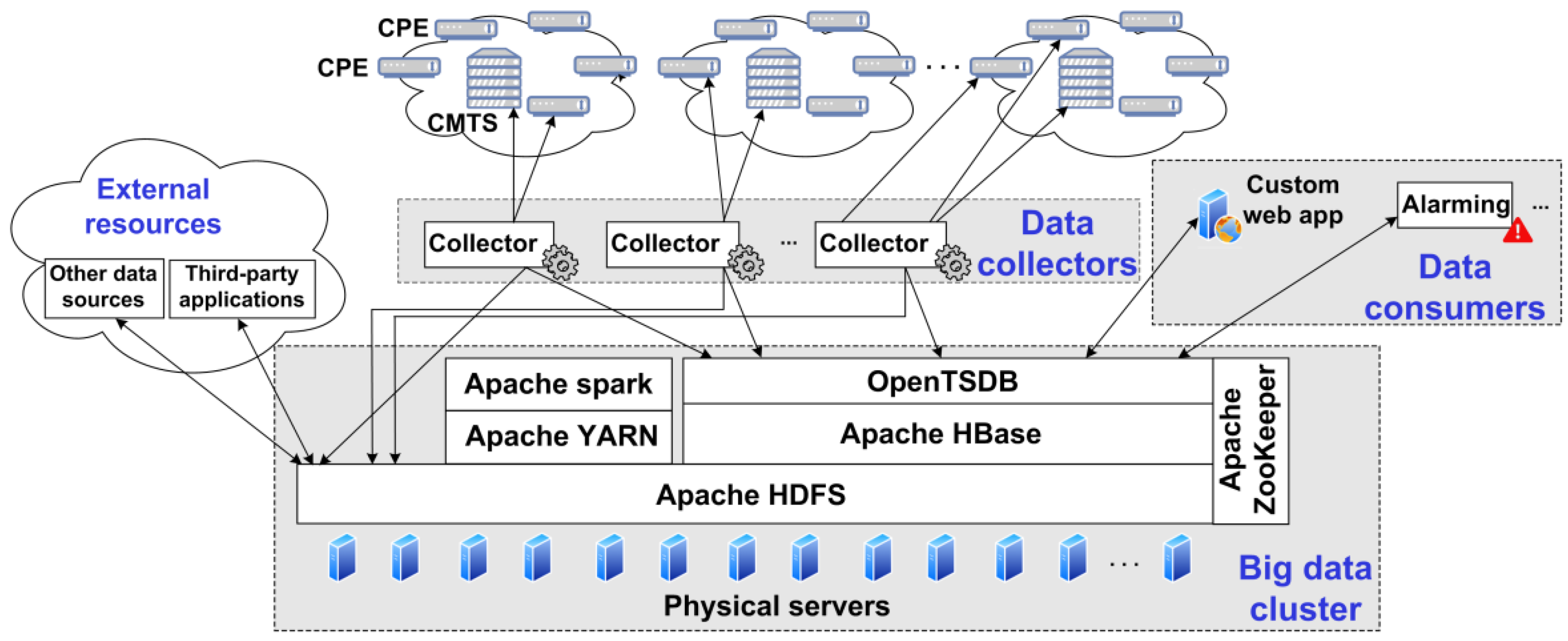
The logical architecture of BDPfPM is shown in
Figure 2. The architecture comprises the following parts: monitored equipment, data collectors, big-data cluster, and data consumers.
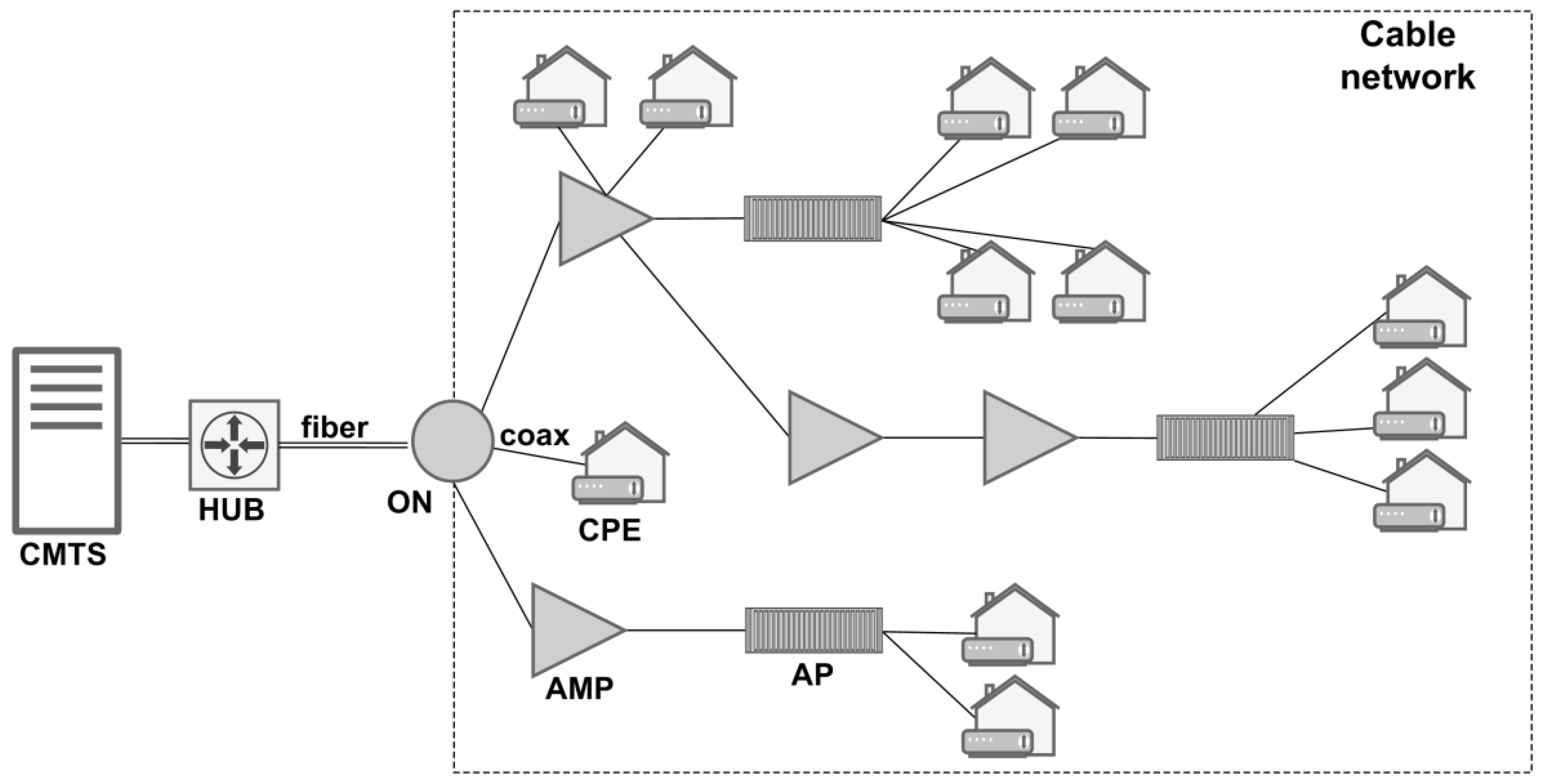
The monitored equipment are the devices in the HFC network capable of communicating with data collectors, such as CMTSs, cable modems, and set-top boxes. Cable modems and set-top boxes are CPE equipment on users’ premises. Performance metrics are collected from the network devices (CMTSs and CPEs) using SNMP. SNMP is chosen because all the intelligent devices (CMTSs, CPEs) in the HFC network support SNMP.
Table 1 shows a recommendation for the performance metrics collected from the CMTSs and CPEs that can be used for performance-monitoring purposes. All the metrics in
Table 1 are used in BDPfPM. Other metrics can be added to the collector in case they are required. This table presents a more detailed representation of the performance metrics proposed in [
23], with a given collection frequency (CF). The main difference between the list given in [
23] and
Table 1 is in the separate presentation of the metrics collected from CMTS, but related to the CPE equipment. The CMTS performance metrics in
Table 1 are given for one Cisco CMTS model (uBR10000), while CPE performance metrics are given for Cisco’s CM model (EPC3928) because it is not possible to show all the performance metrics, given the variety of manufacturers and devices in the HFC network (Variety challenge). More details (like OID values) regarding performance metrics given in
Table 1 can be found in [
46]. Furthermore,
Table 1 provides the performance-metrics collection frequency set for the real HFC network in which BDPfPM operates. Note that the
CF values can be modified if necessary.
Data collectors are responsible for collecting data from the monitored equipment and transmitting the collected data to the big-data cluster. However, the importance of data collected from CMTSs and from CPEs differs. Furthermore, the responsiveness and availability of CMTSs are significantly higher compared to CPEs. Furthermore, not all performance metrics are equally important. Thus, the regular collection frequencies for CMTSs and CPEs differ. The same applies to the performance metrics. In BDPfPM, the collection frequency for CPEs, TCPE, is set to 1 h, while for CMTSs collection frequency, TCMTS, is set in the range from 1 to 60 min, depending on the collected performance metric. Note that the parameters TCPE and TCMTS can be set differently if required. Furthermore, the collection period for devices that are troubleshot is set to seconds during the troubleshooting process.
The data-collection layer has a manager that assigns to each collector a list of devices from which data, i.e., performance metrics, are collected. The assignment algorithm is simple. The manager uses a data-collector configuration to access a list of the CMTSs and CPEs connected to them. The data-collector configuration is a result of the MAC-IP-mapping mechanism described in
Section 5.6. The manager passes a list of CMTSs in round-robin fashion. The round-robin method was selected because it is simple to implement. Given that the round-robin method achieved satisfying performances in our case, other methods were not considered. When data from CPEs served by currently passed CMTS in the list need to be collected, the manager sends a list of CPEs to a randomly chosen collector from the list of free collectors. The list of the CPEs passed to the collector also contains the IP addresses of the CPEs. These IP addresses are necessary because SNMP is used for data collection. One collector (four cores, eight GB RAM) can support collection from up to 25,000 CPEs for a
TCPE value set to 1 h. In a similar fashion, CMTSs are assigned to collectors. CMTSs are assigned with a collection frequency set to a minimum
TCMTS value, and the manager passes a list of performance metrics that need to be collected in that collection period. For example, according to the
CF values in
Table 1,
cdxCmtsCmTotal would be collected in every collection period, while
ifInErrors would be collected in every fifth collection period.
The collected data are enriched with appropriate tags, as explained in
Section 5.4. Once the data are collected and enriched, they are sent directly to OpenTSDB using a web socket. Furthermore, a copy of the same data is saved to a file and written to the HDFS for data-aggregation purposes.
The big-data cluster performs storage and processing functions. The big-data cluster can additionally use data from external data sources and third-party applications. The total capacity of the cluster depends on the number of monitored devices, collection frequency, and defined retention policy. Since there is no official standard, the data-retention policy depends on operator preferences. Since the collected data are not related to the personal data, there is no regulation that enforces the data-retention policy. Our practice has shown that the data-retention period should be in the range of 3–6 months, depending on operator preferences and storage capacities. This retention period is sufficient for network troubleshooting and performance management. In BDPfPM, the data-retention period is set to 6 months. The information obtained from the processing of collected data is used by data consumers. Data consumers can be, for example, alarm systems, network operation center dashboards, call-center reporting software, etc.
Figure 2 shows that the big-data cluster comprises several big-data tools: OpenTSDB (Open Time-Series Database), Apache HBase, HDFS (Hadoop Distributed File System), Apache Spark, Hadoop YARN (Yet Another Resource Negotiator), and ZooKeeper. Collectors send messages that carry collected data to OpenTSDB. OpenTSDB accepts the incoming messages, reads them and verifies their format, and stores them in appropriate HBase tables. HBase stores table files to the HDFS, which stores the data on physical discs. Spark performs data aggregations. YARN allocates resources to jobs and enables different processing frameworks to use common hardware. YARN is used as a resource manager for batch jobs in the BDPfPM. Zookeeper provides synchronization between distributed services. The proposed big-data cluster satisfies all the initial requirements in terms of BDPfPM robustness, scalability, high availability, fault tolerance, and performance. The big-data cluster represents the central point of the overall architecture shown in
Figure 2.
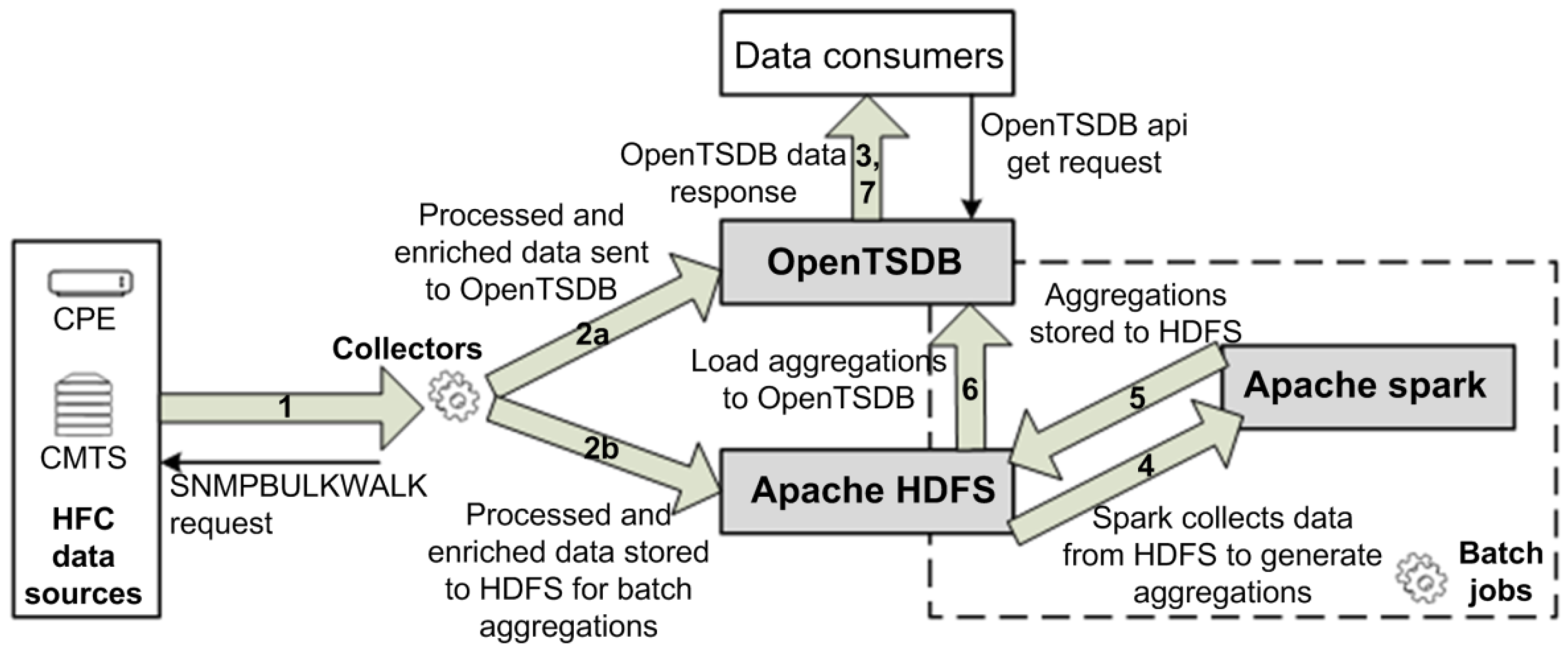
Figure 3 summarizes the previously described data collection and processing in the form of a collected-data flow from data sources in the HFC network to BDPfPM and data consumers. The collector sends the requests to the monitored devices and receives the data from data sources (1). The processed and enriched data are sent to the OpenTSDB using web sockets (2a). In parallel, the collector stores the copy of the data to the file and uploads it to the HDFS (2b). The data in OpenTSDB are ready for consumption immediately upon arrival (3). The data saved to the HDFS are further processed in batch jobs using the Apache Spark framework (4). The aggregations are stored back on theHDFS (5) and uploaded to OpenTSDB (6) for consumption (7).
The collected data are used for the performance monitoring of the HFC network. The main purpose of the collected data is the detection of weak spots in the network that need to be repaired to increase the overall HFC network performance and user QoE (quality of experience). This is explained in detail in a separate section (
Section 6) as the main application of the collected data in BDPfPM.
As discussed at the end of
Section 5.1, there are several ways to implement BDPfPM. BDPfPM is implemented and tested using on-premises hardware and Cloudera 5.14 distribution. The on-premises hardware approach was selected because the telecom service provider for which the BDPfPM was originally developed requested it. The implementation is performed on the 2-namenode/6-datanode cluster and each server comprises 32-core Intel Xeon CPUE5-2630 with 2.4GHz and 64GB RAM. This setup is deployed in a real HFC network. During the initial phase of deployment, the BDPfPM parameters (such as collection frequencies, number of retries, timeout values, and other parameters, discussed in later subsections) were tuned to optimize the BDPfPM performance. Thus, all the parameter values proposed in the following sections and subsections are based on the results of the experiments conducted in the real HFC network environment.
5.3. Data Schema
BDPfPM uses OpenTSDB to store the performance metrics collected from the HFC network. According to [
41], OpenTSDB provides several ways to analyze and manipulate the collected data. In this subsection, we discuss the data-schema possibilities, and we propose a data schema that improves the query performance.
By using tags, it is possible to separate data points from different data sources. In this way, the data collected for one particular metric and a different set of tags can be easily observed, either separately or in groups [
41], by using filtering or grouping. For example,
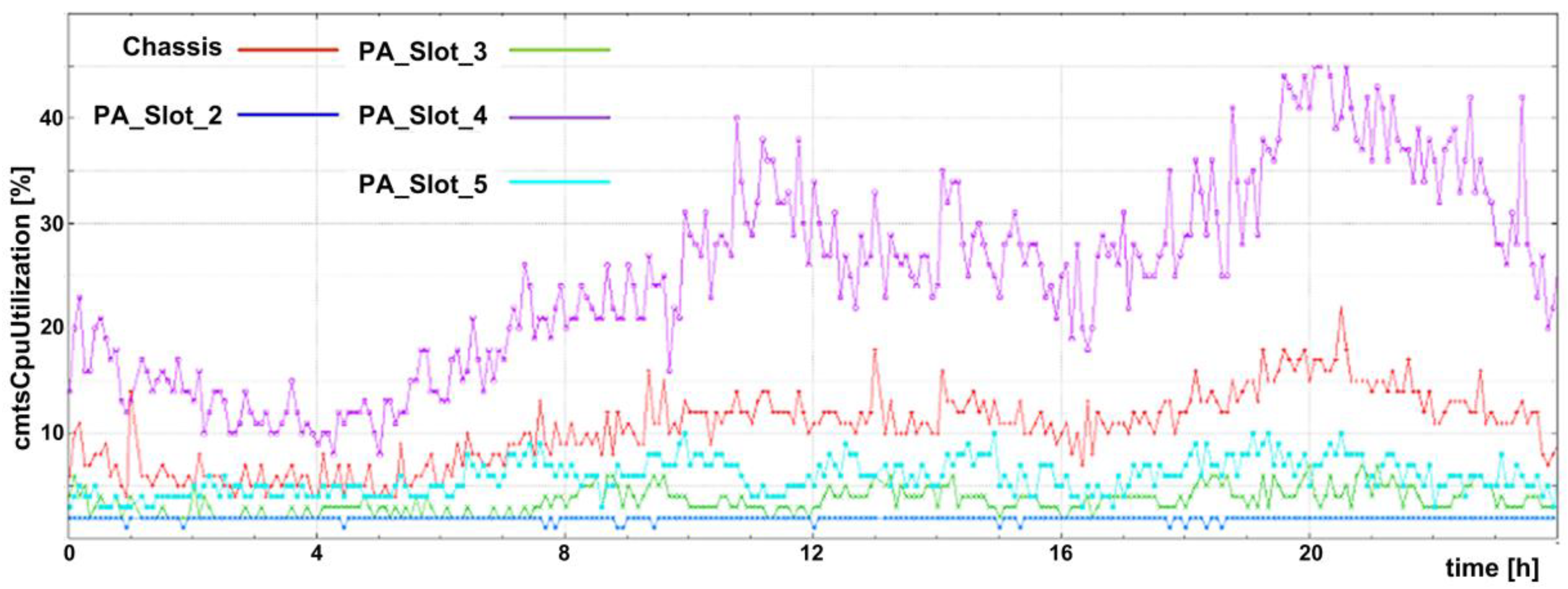
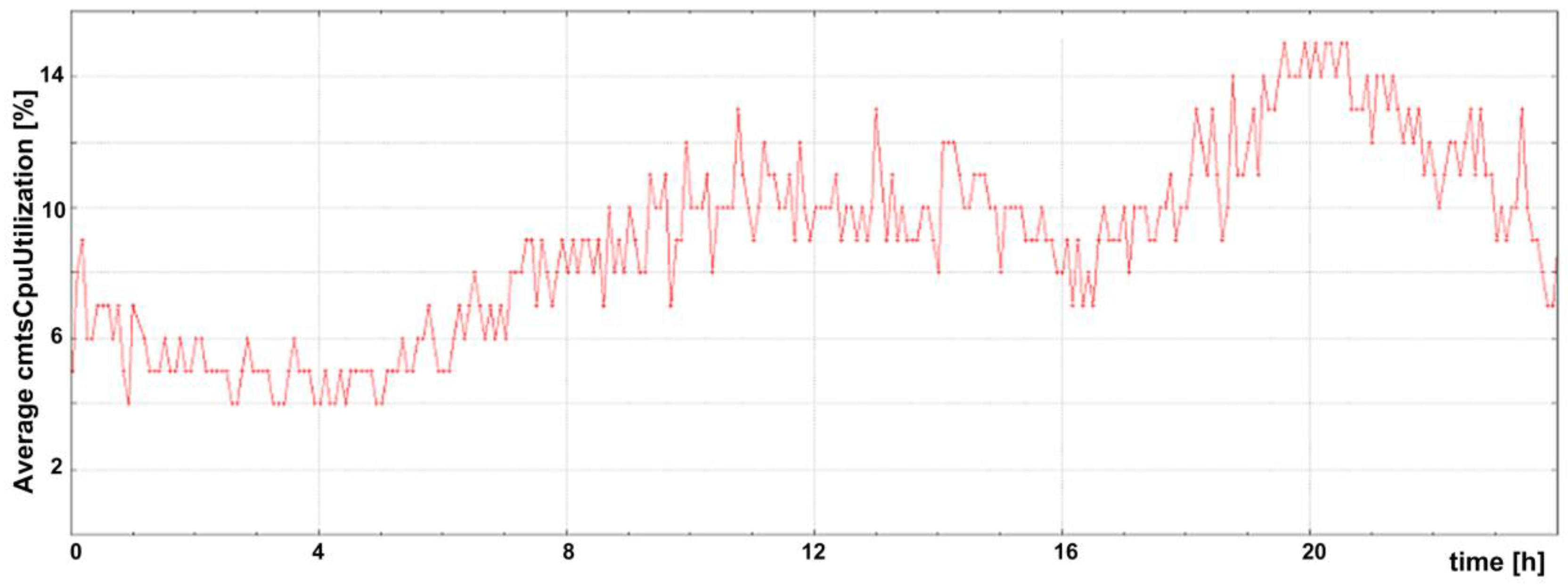
Figure 4 shows the CMTS CPU (central processing unit) utilization per unit (tag “entity_name”) for one day. The graph in
Figure 4 was generated using raw data collected from a CMTS device, named TEST-CMTS, that comprises five CPU units (their “entity_name” values are used in the legend of
Figure 4). Note that the values of the tag, “entity_name”, are given in
Table 2. Since filtering was not used, the CPU utilization for all five units is shown in the graph. Using filtering by tag, it is possible to observe data only for a particular unit instead of the whole set. For example, if the filter were set to entity_name=Chassis, the graph in
Figure 4 would show CPU utilization only for the Chassis unit. On the other hand, grouping merges multiple individual time series into one [
41]. An example of grouping is shown in
Figure 5.
Figure 5 shows the average CPU utilization for the same dataset as shown in
Figure 4. The average CPU utilization is generated automatically from the raw data by omitting the tag, “entity_name”, from the query and setting “avg” as the aggregation type. The OpenTSDB web–user interface was used to generate the graphs in
Figure 4 and
Figure 5. In addition to the basic data aggregation types, OpenTSDB supports downsampling, as well as some advanced data aggregation types that are not within the scope of this paper.
Table 2 contains the data points for one KPI (
cmtsCpuUtilisation) from two different data sources (TEST-CMTS and TEST-CMTS2) collected in one period of time (1584658859). When a user creates a query to collect the data for a particular metric, OpenTSDB performs data filtering based on given tags and time range. The query execution, i.e., data filtering time is directly proportional to the number of data points collected for one metric in one iteration. In HFC networks, there are millions of CPEs, each with several interfaces for data collection. Thus, data filtering for one device and its entities can be extremely slow, resulting in poor query performance.
To overcome this challenge, we propose a new data schema, in which the tag for the name of the monitored device (for example, the MAC address for the CPE, the hostname for the CMTS) is changed to the metric name (for example,
cmtsCpuUtilisation is now named as
cmtsCpuUtilisation_TEST-CMTS). In this way, a new metric is created for each device. This is a reasonable decision because queries relate to a particular device in most cases (for example, in call-center reports or troubleshooting reports for one particular modem). In this way, we increase the query performance by around 1300 times, according to our test scenario. In our test scenario, there are one million devices with four interfaces. The initial query time for extracting the data for one device from a group of one million devices was 307.041 s, while obtaining the same data from the proposed new data schema took 234 milliseconds. The testing was performed on the big-data-cluster setup described at the end of
Section 5.2.
The downside of the proposed novel data schema is the impossibility of creating the group queries related to a particular device for other tags (for example, the queries grouped for all the modems per model type). However, it is not necessary to perform this kind of aggregation in a timely manner. Therefore, it is performed using Spark daily aggregation jobs. If the proposed data schema is used, one should be careful with the number of created metrics. According to [
41], metrics are encoded with three bytes, giving 2
3×8 − 1 = 16,777,215 unique metrics. However, the number of bytes used for encoding the metric can be tuned via configuration, as in OpenTSDB version 2.2.
5.4. Data Collectors
The data-collection layer needs to be defined after the initial architecture for data storage is established. Data collectors are software components that collect data from sources, enrich data, and then format and send these data to the storage layer. The storage layer in BDPfPM comprises OpenTSDB for data consumption and HDFS as a stage for data aggregation, as shown in
Figure 3. Some publicly available collectors can be used [
41]. However, publicly available collectors usually cannot cover specific use cases, domains, and specific needs. Therefore, the custom development of data collectors is necessary.
Data collectors are created per integration domain. The integration domain is a logical unit for which monitoring is performed. For example, the integration domains can be DOCSIS, MPLS (multi-protocol label switching), UPS (uninterruptible power supply), QoS (quality of service), etc. Even these integration domains are further broken down into manufacturers, different models, and software versions. For example, Cisco CMTSs have different OIDs (Object Identifiers) and MIB (Management Information Base) tree structures from CASA or Motorola CMTSs; the Cisco CMTS Remote PHY platform differs from traditional Cisco HFC deployment [
47].
The integration domain of interest for the BDPfPM is the DOCSIS domain for CMTS and CPE equipment. The DOCSIS domain covers the performance metrics defined in [
23], such as the user, environment, and interface statistics for CMTSs, and the CPE statistics collected from CMTSs (metrics collected from CMTSs but concerning the CPEs) and directly from CPEs. Other domains, such as MPLS, WiFi, and others, will be a part of future work. Special attention is given to data-collector latency and efficiency because there are many monitored devices in the HFC network.
Client–server communication is used between the data collectors and data sources, in which the data collectors have a client role and the data sources have a server role. Since a custom data collector was developed, the integration with data sources can be established in a variety of ways, depending on its communication capabilities. REST API, JDBC (Java Database Connectivity), SNMP, HTTP (web crawling), subscriber–broker communication, file parsing (for example, log, or any other type of file that can be processed) are some of the possible approaches. The SNMP protocol is used for both CMTS and CPE equipment in BDPfPM. The SNMP was selected because all the CMTS and CPE devices currently installed in the HFC network support this protocol. However, other protocols and approaches will be added to BDPfPM in the future.
The SNMP protocol is configured with read-only permission on the monitored devices. The data collector uses appropriate community string and IP addresses to communicate with the monitored devices. Communication is established via SNMPGET and SNMPBULKWALK, depending on whether one or multiple responses are expected. SNMPBULKWALK is used instead of SNMPWALK because of its superior efficiency and faster query response.
In terms of timeout and number of retries, the SNMP configuration can significantly affect the data collector’s overall performance. In situations in which a monitored device is highly available, such as CMTS, the retry and timeout can be set to reasonable values, such as a timeout of two seconds and three retries (we propose these values based on the tests conducted in the real network). However, in the case of CPE monitoring, there is no guarantee that a monitored CPE device is available. Furthermore, the number of these devices in the HFC network is in the order of hundreds of thousands or millions. Thus, a significant increase in execution time occurs because data collectors spend a huge number of processing resources that are reserved a priori only for waiting for the responses from unavailable CPEs. The timeout and retry time should be carefully selected to minimize the impact of this phenomenon. After conducting tests in the real network, we suggest a one-second timeout and one retry for CPEs in order to provide optimal results. If the monitored device does not answer the query after 1 s, the device is most likely unavailable.
The collected data (performance metrics) are enriched with an appropriate set of tags. Measurement by itself has little value without tags. The tags are information-packed in key-value pairs that uniquely define the source of the measurement [
41]. There are two types of tag: mandatory and optional. During data-collector development, it is necessary to find all the tags that describe the measurement, identify mandatory tags, and filter only those that are of interest. The mandatory tags are all the tags necessary to distinguish data by source. In the example shown in
Table 2, the device_name and entity_name tags are mandatory because these tags separate CPU utilization per device and processor unit. If some of these tags were omitted, the collected measurements would have the same set of tags, causing the overlap of collected data, leading to inaccurate information.
Optional tags are used to further enrich the measurement. The greater the number of different tags, the greater the number of different aggregation types that can be performed. For example, the CPE vendor and model are not relevant when data are collected. However, these tags are used later for data aggregation and analysis, which provide insights into performance for each of the vendors and models. These insights are valuable sources of information when acquiring new equipment. One should not exaggerate the use of optional tags, but use only those that are used for data aggregation. If a tag is found to be important, it can be added later without disturbing the previous measurements. Aggregation per new tag is available from the moment of its addition.
There are four types of metrics in CMTS data collection:
Environment;
Upstream;
Downstream;
MAC domain.
Environment metrics provide information regarding the physical health of a device (such as processor utilization, free memory, and temperature), while upstream, downstream, and MAC domain metrics are related to KPIs (such as SNR—signal-to-noise-ratio, CNR—carrier-to-noise ratio, error rate, and throughput) collected on the levels they describe [
23]. These metrics share common tags, such as device_name, device_type, device_vendor, and company_name. However, the tags regarding interfaces differ according to their groups. For example, upstream interfaces are connected to load balance groups, while downstream interfaces are not.
Data can be sent to OpenTSDB in a variety of ways; web socket and file import are the most common. Both of these approaches are used in BDPfPM. Web socket is used to send data from data collectors to OpenTSDB, while file import is used for importing Spark aggregation results into OpenTSDB.
Before data are sent through a web socket, the data collector needs to check whether OpenTSDB is available and establish a connection. The OpenTSDB availability check is performed because of the congestion problem that occurs due to the large amount of incoming traffic. To overcome this problem, we defined a list of OpenTSDBs and their appropriate communication ports. The data collector randomly selects one OpenTSDB from the list, checks its availability, and sends the data. If the selected OpenTSDB is unavailable, another option from the list is selected, and the procedure is repeated. The data collector tries to send the data until it uses up all the OpenTSDBs from the list. In this way, OpenTSDBs’ high availability and even load distribution are ensured.
Data can also be sent to OpenTSDB using file import. This is possible only in situations in which collectors and OpenTSDB share hardware. This method is rarely used in data collectors. However, this method can be extremely useful in situations in which Spark aggregation results are imported in OpenTSDB. This is possible since these two are installed on the same hardware, according to the proposed architecture. The results are imported directly from the file. Thus, the socket load is reduced and the availability is increased.
Due to the specific data schema that is used (metrics are further broken to metric_device-name as described in
Section 5.3), the data stored in OpenTSDB are not suitable for batch aggregation. To overcome this challenge, the data collector, in addition to sending messages to OpenTSDB, stores a copy of the collected data in text files and uploads these files to HDFS. How long the data are stored on HDFS depends on the aggregation requirements. Note that this retention period additionally increases the storage capacity requirements. For example, to support weekly aggregations, the minimum required retention period for keeping the raw data on Apache HDFS is 7 days. A buffer for a couple of additional days is usually added in case there is a problem with the aggregation. Therefore, to support weekly aggregations, a 10-day retention period would be sufficient. In the case of other aggregations, such as daily or monthly, the retention periods would be defined in similar fashion.
5.5. Data Aggregations
Raw data collected directly from the network are useful for performance monitoring, troubleshooting, and other daily operations. The collected data can be aggregated to provide deeper insight into the state of the network. Using proper data aggregations, telecom service providers can obtain valuable information for decision making and business planning. This topic highlights all the possibilities of BDPfPM win terms of aggregations, but does not list all those that have been developed, as they exceed the scope of this paper. Each aggregation type is enforced by a concrete example.
There are several different types of data aggregation, depending on the desired goal. Aggregations can be split into time and spatial aggregations. Time aggregations are aggregations of data collected during a certain period (for example, daily, weekly, monthly) into one data point. Spatial aggregations are aggregations of different data sources in each period.
Figure 5 from
Section 5.3 represents an example of spatial aggregation. TEST-CMTS CPU utilization is aggregated into a single average value for every collection interval. In this way, the overall CPU utilization of the monitored device is obtained. This is a much better way of monitoring devices’ CPU utilization because the temporary peaks of individual cores are mitigated. Depending on the moment of execution, batch or stream aggregation are used. Batch aggregation is performed after the data are collected. On the other hand, stream aggregation catches the data at their source and performs aggregation in real time. In this paper, we focus on batch aggregation.
BDPfPM uses big-data aggregation tools due to the large amount of data that need to be processed. In comparison to traditional data-processing methods, big data performs distributed processing in a master–slave manner. This approach is scalable because it uses load distribution across multiple servers. We use Spark as a data-aggregation processing tool in BDPfPM (for batch aggregation).
There are two types of data aggregation in BDPfPM: OpenTSDB and batch aggregation. OpenTSDB can perform both time and spatial aggregations using its built-in functionalities. Spatial aggregations are performed based on tag grouping in the request query. Time aggregations are performed using the downsampling feature. Using these functionalities, OpenTSDB provides a simple interface to perform complex and effective aggregations from raw data. Thousands of data points are aggregated in the order of milliseconds. OpenTSDB is especially useful when aggregation for one particular device is required (CMTS or CPE in HFC network).
Batch aggregations are used to provide deeper insights based on the collection of large data sets. Batch aggregations are slow because of the enormous amount of data that is processed and are therefore not time-sensitive. Apache Spark is used for batch aggregations in BDPfPM. In practice, batch aggregations are useful in many different applications. In HFC networks, these aggregations are used to provide better insights into the network performance on a variety of levels. These levels are defined per application. One example of a hierarchy that is typically used is: upstream, MAC domain, CMTS, city, territorial direction, state, and company, respectively. The levels up to CMTS are used to observe the statistics for a particular device, while higher levels are used for company analysis. Most batch aggregations are performed using the data collected from CPEs because they give insights into the state of the network from the end-user’s perspective.
One example is network availability based on CPE data, which gives telecom service providers information about the network availability on different hierarchy levels from the end-user’s point of view. This metric is created based on CPE availability time; the availability of every CPE is calculated on a daily basis. The end-user’s point of view is important because measuring network unavailability from this perspective gives a direct insight into users’ quality of experience. Another example of batch processing is performance monitoring for network devices that cannot provide statistics about their health (non-intelligent devices). The raw data collected from CPEs are combined with the network topology to obtain information regarding the health of devices that cannot be monitored directly, such as APs, AMPs, and ONs.
Data aggregations can be used beyond the performance-monitoring application in our proposed BDPfPM. For example, the raw data collected from CPEs can be combined with user-service-agreement information. The first potential application of such data aggregation is to isolate all the clients that have premium packets, but poor quality of service. The second potential application is to isolate heavy users with small subscription packets to offer them larger subscription packets. These simple examples show the promising potential of BDPfPM for applications beyond performance monitoring.
5.6. Performance Comparison
In this subsection, we compare the proposed BDPfPM to other solutions. However, the solutions used by telecom service providers are usually not presented in the available literature. In this paper, we compare BDPfPM to the big-data framework for performance management in mobile networks (BDFMN) presented in [
36], since it is the most similar solution to BDPfPM in the literature.
BDFMN is not actually implemented in the real network, but it uses data sets from the real network. Based on these data sets, data-set replicas are generated for testing purposes. BDFMN is simulated for a mobile network of 15 million subscribers in [
36]. Base stations are data sources in the case of BDFMN. Other network elements (e.g., core network elements) are not considered in BDFMN. Thus, monitoring in BDFMN does not cover all the devices in the network. BDPfPM monitors the complete network and all its elements, including non-intelligent network elements, as discussed in the following section. Base stations for different mobile network generations (2G, 3G, 4G, 5G) were thought to coexist in the experiment, and the number of base stations simulated in the experiment was 13,300. Thus, the number of data sources in BDPfPM is significantly larger than in BDFMN, because BDPfPM collects data from devices associated with subscribers, i.e., CPE devices. Regarding availability and responsiveness, CMTSs and base stations are similar. However, in BDPfPM, there are CPE devices from which data are also collected. Subscribers can power off their CPE devices whenever they wish. This represents an additional challenge for the data-collection layer because data-collector resources can be wasted in trying to collect data from unavailable devices. BDPfPM successfully addresses these challenges, and there is no certainty that BDFMN would successfully address these challenges, since it was not tested for such cases.
BDFMN uses a collection period of 15 min. Regarding BDPfPM, the collection period is similar for metrics collected from CMTSs—for most of these metrics, the collection period is set to 5 min. CPE metrics are typically collected on an hourly basis, except in troubleshooting cases, in which the data collection period is set in the order of seconds. BDFMN collects XML files from the base stations and, for this reason, Flume is used for data collection, along with the SFTP (SSH File Transfer Protocol). On the other hand, BDPfPM uses custom-made data collectors that use the SNMP to collect performance metrics. Thus, differences regarding data collectors are a consequence of different network-element capabilities and data presentations. An additional difference is that BDPfPM enriches the collected data with appropriate tags, which gives extra flexibility and a higher level of granularity during data aggregations, as explained in
Section 5.3. To store data, both BDPfPM and BDFMN use HDFS. The storage requirements in BDFMN are around 26 GB on a daily basis [
36]. In the case of BDPfPM, for a network comprising around one million subscribers (the real HFC network in which BDPfPM is deployed), the storage requirements are around 320 GB. Obviously, the Volume challenge is greater in the case of BDPfPM, which is a consequence of the performance-monitoring coverage of all the network devices, including a great number of CPEs. For batch processing, BDPfPM uses Spark, while BDFMN uses Hive.
An important aspect is deployment. BDPfPM operates in the real network, while BDFMN uses the proposed framework, which uses data sets from the real network (along with data-set replicas). This makes an important difference, because actual deployments usually carry some unpredictable problems and challenges, as we discuss in
Section 7 (BDPfPM deployment experiences). Furthermore, BDPfPM is used to estimate the health of devices that are not capable of performing measurements (non-intelligent devices), as explained in the following section. This is a challenge that is not analyzed in BDFMN.
Table 3 summarizes the comparison between BDPfPM and BDFMN. BDFMN is noted as being partially deployed in the real network because it uses data sets from the real network.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}