1. Introduction
Depth estimation is vital for extensive applications in practice, including augmented realities, autonomous driving and robotics, and it also could promote other computer vision task such as object detection and recognition. There are generally two manners to estimate the per-pixel depth of a scene, from a single monocular image or a pair of stereo images captured by a stereo camera. It is difficult for humans to infer the underlying 3D structure from a single image not to mention for computer vision algorithms, since a monocular image theoretically may correspond to numerous real-world scenes [
1]. This paper aims to address the problem of depth estimation from stereo images, which computes the disparity map by the horizontal difference between the corresponding pixels on the left and right images. If an object at position
in the left image is matched to position
in the right image, the depth of the pixel position is then formulated as
[
2], where
f is the focal length of the camera and
B is the distance between the camera centers.
The pipeline of traditional stereo-matching methods includes matching cost computation, cost aggregation, disparity regression and disparity refinement based on the local or global hand-crafted features [
3]. Along with the development of deep learning methods, Convolution Neural Networks (CNN) are used to directly design end-to-end deep models [
2,
4,
5,
6,
7,
8] for depth estimation. Although such methods produce compelling disparity estimation results, two major issues remain challenging: predicting accurate result on boundaries and texture-less areas and precisely restoring the resolution of a disparity map.
Kendall et al. [
5] proposed to firstly form 4D cost volume feature maps by concatenating left and right CNN feature maps across each disparity value, then employ 3D convolutions to filter the cost, and finally regress the disparity values with a differentiable soft-argmax operation. They trained the model end-to-end and obtained sub-pixel accuracy without additional post-processing or regularization. Chang et al. [
2] further proposed the PSMNet method with stacked hourglass 3D CNN for processing the cost volume. Their framework has become the pipeline of deep stereo matching methods.
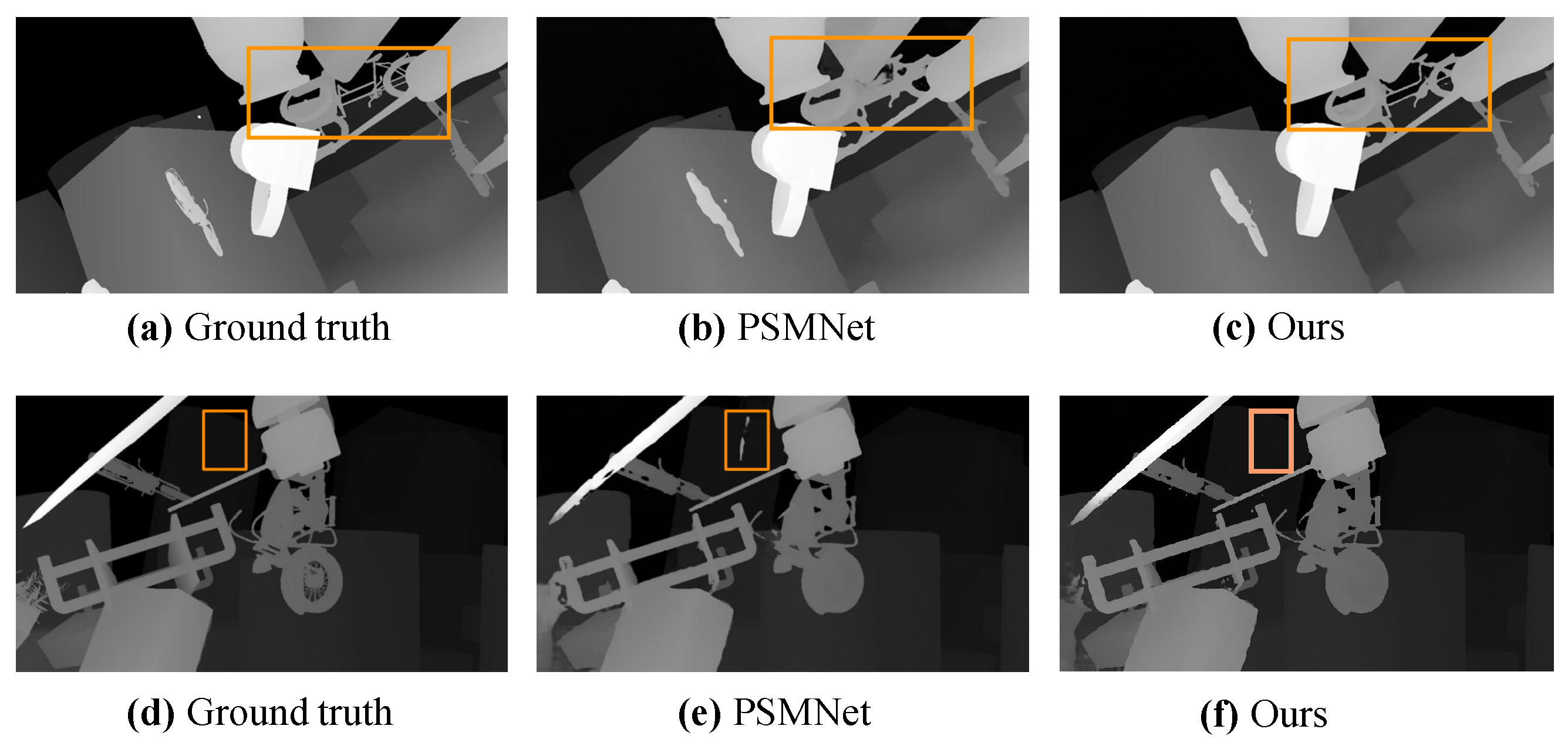
Figure 1 shows the disparity maps obtained by PSMNet [
2], from which we could see there are blurred boundaries and a deficient disparity continuity of the smooth region on the disparity maps. Many researchers have proposed methods to promote the disparity estimation by improving cost volume, such as forming the cost volume on area-based correlation [
9], building multi-scale cost volumes [
8] or packing a group-wise correlation map to form the cost volume [
10]. All these methods learn feature representations from right and left RGB stereo images to form cost volumes by different ways. The corresponding information between right and left images may be lost at the feature learning stage, since the disparities are predicted improperly on boundaries and large texture-less areas. The research in the biology field [
11] shows that when the spatial frequency information from the natural image enters the visual system through the retina, it might be dissected into three different frequency channels (low, medium and high components) in the superficial layer of the primary visual cortex. Inspired by them, we heuristically take multiple frequency inputs including a low-frequency component, RGB image and high-frequency component into CNN to extract abundant features for forming cost volume. In this way, the high-frequency component could emphasize the feature extraction on boundaries; meanwhile, the low-frequency component takes charge of texture-less smooth regions.
Following cost volume computation, learning-based methods also make use of a deep neural network to optimize the cost volume. High-level features which are learned to aggregate the cost volume with convolutions have lower resolution than original stereo images; in this case, they are weak in restructuring the original dense depth prediction precisely. Increasing the resolution operators, such as up-sampling, decoder and deconvolution, are consequently needed. A representative method [
2] learned 3D CNN to regularize cost volume by stacked multiple hourglass networks (encoder–decoder) in a top–down/bottom–up manner for regional support of context information. Furthermore, a lot of research is conducted on cost optimization to improve stereo matching, such as introducing non-local attention module [
4,
9], utilizing a recurrent unit to update disparity estimations at high resolution [
8], adding constraints to the cost volume with unimodal distribution peaked at true disparities [
12], or introducing a patch attention block to aggregate disparity information on the different surfaces of cost volume [
13]. Inspired by these methods and an up-sampling module in semantic segmentation [
14], we extract the context information of high-level cost volume features to weight low-level high-resolution features by an attention mechanism in stacked multiple hourglass networks. In this way, context information of the disparity between left and right images could be more fully utilized to obtain depth details when recovering the resolution of a disparity map.
In summary, we propose two simple but effective improving strategies based on an end-to-end framework PSMNet [
2] in this paper for stereo matching. Specifically, (1) we extract pixel-level high-frequency and low-frequency components named boundary and smooth maps, respectively, from stereo RGB images. Then, we feed them into a CNN model to feature extraction for cost volume computation. (2) To take advantage of context information in cost volume, we learn the relative importance of dense feature maps by the guidance of high-level features when processing cost volume to generate a dense disparity map. Our method is validated on SceneFlow and KITTI 2015 datasets. Experimental results show that the performance of our model with multiple frequency inputs and a context-guided attention strategy is better than that of the base network PSMNet [
2], and our method obtains competitive results compared to related state-of-the-art methods.
Roadmap. In
Section 2, we first introduce the related work. The proposed approach for depth estimation is described in
Section 3. Experiments are shown in
Section 4, and the conclusion is in
Section 5.
2. Related Work
A stereo matching algorithm generally consists of matching cost computation, cost aggregation, disparity computation and refinement. The matching cost measures the dissimilarity of the corresponding pixels, super-pixels or patches between the left and right images, which could be computed with hand-crafted features or learned features.
Matching cost computation. CNN has been widely utilized for computing the matching cost leveraging the development of deep learning in recent years. Zbontar et al. [
15] trained a deep Siamese network to compute the similarity between
patches to form matching cost. Luo et al. [
16] also proposed a Siamese network in which the computation of matching cost is treated as a multi-label classification problem. Post-processing steps, such as cost aggregation and smoothing, are still needed in these methods. Kendall et al. [
5] proposed an end-to-end model GC-Net for stereo matching by forming 4D cost volume feature maps, processing the cost with 3D convolutions and regressing disparity values with soft-argmax operation. Chang et al. [
2] proposed PSMNet to exploit global context information in stereo matching with a pyramid pooling module and stacked hourglass 3D CNN. These methods form the cost volume by concatenating left feature maps with their corresponding right feature maps across each disparity level, resulting in a 4D volume on height, width, disparity levels and the size of the feature map.
Recently, many researchers have proposed methods to promote the disparity estimation by improving cost volume. Li et al. [
9] utilized the area-based correlation to capture more local similarity in cost volume; then, they combined an hourglass module with non-local attention as the 3D feature matching module (Abc-Net). Wang et al. [
8] built multi-scale cost volumes and then adopted a recurrent unit to iteratively update disparity estimations at high resolution. Guo et al. [
10] proposed GwcNet to split the deep features into multiple groups along the channel dimension to obtain group-wise correlation maps, which are packed to form a 4D cost volume. Shen et al. [
17] proposed a fused cost volume representation to deal with the large domain difference and a cascade cost volume representation to alleviate the unbalanced disparity distribution. Daggal et al. [
18] proposed the DeepPruner method by reducing the computation of cost volume to achieve real-time stereo matching. Xu et al. [
19] presented a cost volume construction method by generating attention weight for cost volume with multi-level adaptive patch matching. Gu et al. [
20] proposed to build cost volume upon a feature pyramid encoding geometry and context at gradually finer scales. All these deep methods employed three-channel RGB images to feed into CNN for learning the matching cost. Different from them, we input multiple frequency images to extract more features about boundaries and texture-less smooth regions for forming cost volume; thus, the disparities on these locations could be recovered more accurately.
Auxiliary cues. Auxiliary cues have been exploited into stereo matching to improve the accuracy of depth estimation. Ladicky et al. [
21] jointly optimized stereo reconstruction and object segmentation by random field labeling. Guney et al. [
22] utilized the object information of vehicles to resolve ambiguities in stereo matching. Yamaguchi et al. [
23] proposed to jointly recover an image segmentation and a dense depth estimation, in which adjacent segments are encouraged to be similar if they belong to the same object. Menze et al. [
24] applied adaptive smoothness constraints for a dense stereo estimation with a conditional random field. Yang et al. [
25] proposed the SegStereo method by employing semantic features from segmentation for disparity estimation. Wang et al. [
26] proposed to incorporate gradient-domain smoothness prior and occlusion reasoning into a stereo network to help the network generalize better. Rao et al. [
27] proposed a multi-task learning architecture with visual attention mechanisms for semantic segmentation and disparity estimation. Zhang et al. [
28] proposed a co-learning framework with monocular and stereo branches to improve stereo performance. Song et al. [
29] proposed the EdgeStereo method, which is a multi-task learning network composed of a disparity estimation branch and an edge detection branch, in which the edge features are embedded into the disparity branch, providing fine-grained representations. Yang et al. [
30] designed a separate processing branch edge stream in parallel with the stereo stream to learn geometric information. These methods utilized auxiliary information such as object, semantics, edge or smoothness for stereo matching. Compared to these methods [
23,
24,
26] with smoothness constraints on a disparity map, our low-frequency input component could help the feature learning of texture-less regions for forming cost volume. Compared to [
29,
30], which estimates the disparity and edge simultaneously, we input the high-frequency edge information of the original image into a CNN model to assist feature learning.
Processing on cost volume. Chang et al. [
2] designed a stacked hourglass 3D CNN to regularize the cost volume, in which encoder–decoder architecture was used to aggregate context information on cost volume for pixel disparity prediction. Zhang et al. [
6] proposed GA-Net with cost aggregation layers for end-to-end stereo reconstruction to replace the use of 3D convolutions. Cheng et al. [
31] proposed a convolutional spatial propagation network (CSPN) to learn the affinity matrix, and they used it in a 3D version to propagate information along the disparity value space and scale space. Zhang et al. [
12] proposed to directly add constraints to the cost volume by filtering cost volume with unimodal distribution peaked at true disparities. Xu et al. [
32] proposed AANet to approximate the cross-scale cost aggregation algorithm with neural network layers to handle large texture-less regions. Tosi et al. [
7] proposed Stereo Mixture Density Networks (SMD-Nets) and formulated the stereo-matching task as a continuous estimation problem by bimodal mixture densities. Rao et al. [
13] introduced patch attention network (PA-Net) with a channel-attention mechanism to aggregate disparity information on the different surfaces of cost volume. Rao et al. [
4,
33] designed a non-local context attention network (NLCA-Net) to exploit the global context information for regularizing the cost volume. These methods improve stereo matching in terms of cost optimization; among them, the most relevant work to our method is attention-based methods [
4,
13,
33]. In their methods, attention-based feature learning on cost volume is carried out within the feature layer, while the cross layer attention mechanism is designed to process the 4D cost volume in our method; thus, more context information could be utilized to recover the disparity map.
Different from typical deep stereo matching methods and our proposed method, the most recent two methods do not build a full 4D cost volume. Tankovich et al. [
34] proposed a multi-resolution initialization step to infer disparity hypotheses and a propagation stage to refine the disparity. Li et al. [
35] proposed three stages of cascaded recurrent network to compute different scales of stereo correlation, and the former stage output disparity is fed to the next as an initialization to obtain a refined disparity iteratively.
3. Our Approach
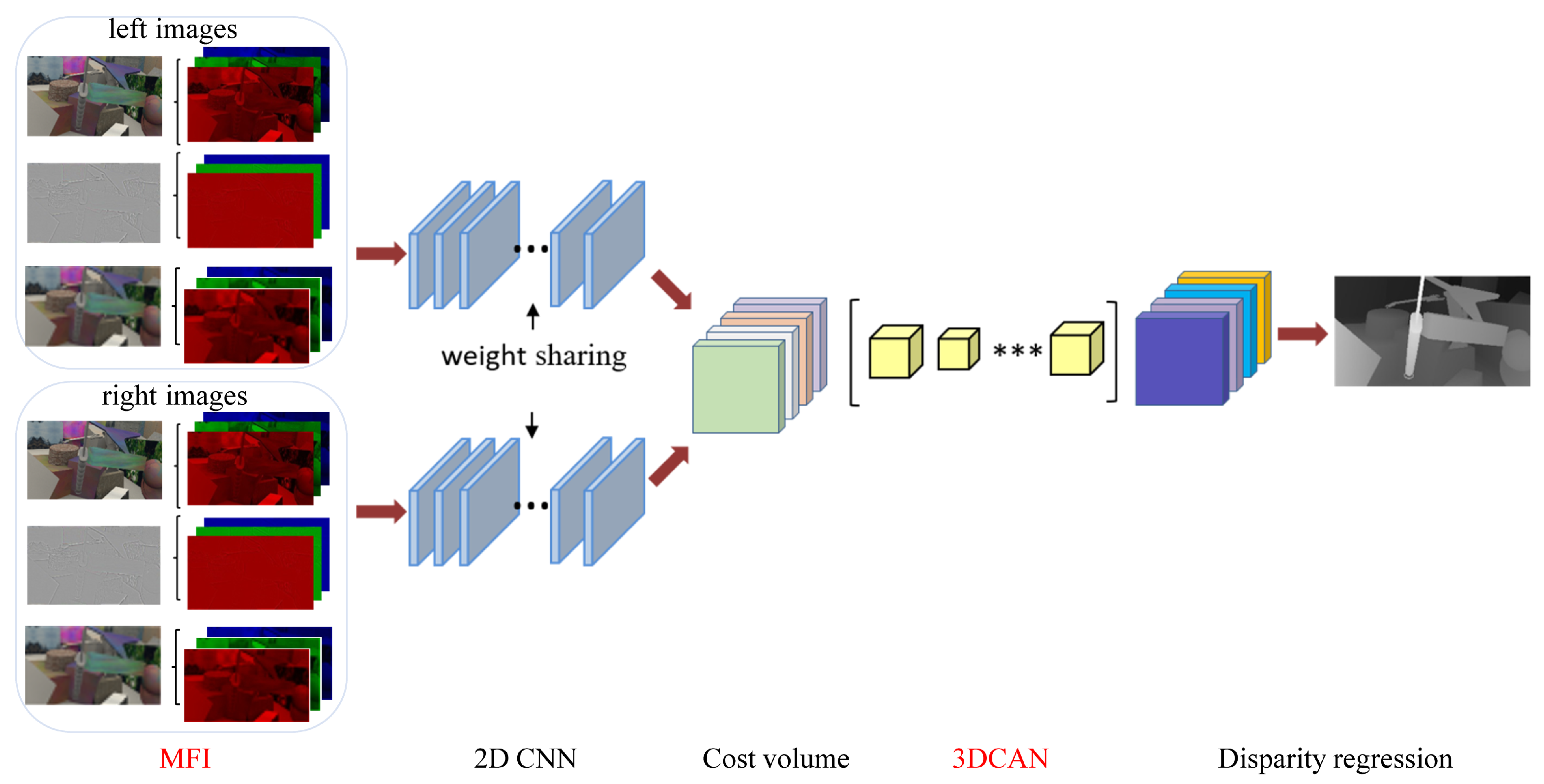
In this section, we describe the proposed multiple frequency input and context-guided attention network for stereo matching, and the whole architecture is shown in
Figure 2. Our architecture consists of five main steps, obtaining multiple frequency inputs, 2D CNN for feature extraction, forming cost volume, attention-based cost volume regularization and disparity regression. The stereo image pairs and the corresponding high-frequency and low-frequency components are utilized as the Multiple Frequency Input (MFI) into the two weight-sharing 2D convolution networks to obtain feature maps. The produced feature maps from the right and left images are adopted to form a 4D (height × width × disparity levels × feature size) cost volume across each disparity level. Then, the cost volume is fed into our 3D Context-guided Attention Network (3DCAN)-based stacked hourglass architecture. The 3DCAN optimizes the matching cost computed from the feature maps. Finally, a softmax operation is performed on the matching cost, and the cost volume is converted into probability to perform disparity regression to obtain disparity estimation results. We briefly introduce 2D CNN; then, MFI, 3DCAN and the loss function are described in following sections.
Multiple frequency input is fed into 2D CNN, which has three layers of
convolution filters, four basic residual blocks, and an SPP module [
2]. SPP uses four average pooling blocks to compress the output of residual blocks into four scales, which are then, respectively, followed by
convolution and up-sampling via bilinear interpolation to the same-sized feature maps. Then, the different levels of feature maps are concatenated as the output of 2D CNN.
3.1. Multiple Frequency Inputs
The input of convolutional neural network is generally an RGB three-channel image in all of the above-mentioned stereo matching methods, such as GC-Net [
5] and PSMNet [
2]. It is still a challenge issue to predict accurate disparities on boundaries and texture-less areas for existing methods, such as the estimation results by PSMNet [
2] shown in
Figure 1. From the figure, we could find that the disparities are inaccurate at the boundaries of the box marked objects in
Figure 1b and the continuous region in (d). This is because the correspondences of these regions are provided by the neighbor pixels, which belong to other objects or background during the matching processing between right and left images. Therefore, it prompts us to design a stereo matching network that could specially learn the representations of boundaries and continuous regions on images. The research in the biology field [
11] shows that when the spatial frequency information from natural images enters the visual system through retina, it might be dissected into three different frequency channels (low, medium and high components) in the superficial layer of the primary visual cortex. Inspired by this, we propose to firstly obtain the high-frequency and low-frequency components from an RGB image; then, we feed three of them together (multiple frequency) into a 2D CNN model. We suppose that the high-frequency component could emphasize the feature extraction on boundaries; meanwhile, the low-frequency component could emphasize the feature extraction for texture-less smooth regions.
In this paper, we refer to a nonlinear total variation algorithm [
36] to obtain multiple frequency images. We assume image
is composed of two parts, that is
, where
x and
y are coordinates.
S is expected to be obtained from image
I by the following function,
where
is the trade-off parameter.
S is reconstructed from the original image by minimizing the above function. The first item aims to ensure
S is similar to
I; thus,
S could preserve the effective information of the original image. The second item in the above function is the total variation norm, which could help obtain a smooth image
S. With
, we obtain the oscillating regions of the image. We intuitively name
S and
B as the smooth map and boundary map, respectively. Note that the three-channel smooth and boundary maps are separately computed from RGB images. We adopt the gradient descent method to optimize the above function and obtain its local minimum. Smooth and boundary maps are illustrated in
Figure 3 with a different trade-off parameter
. It could be seen that the more blurred smooth map is generated with a larger
.
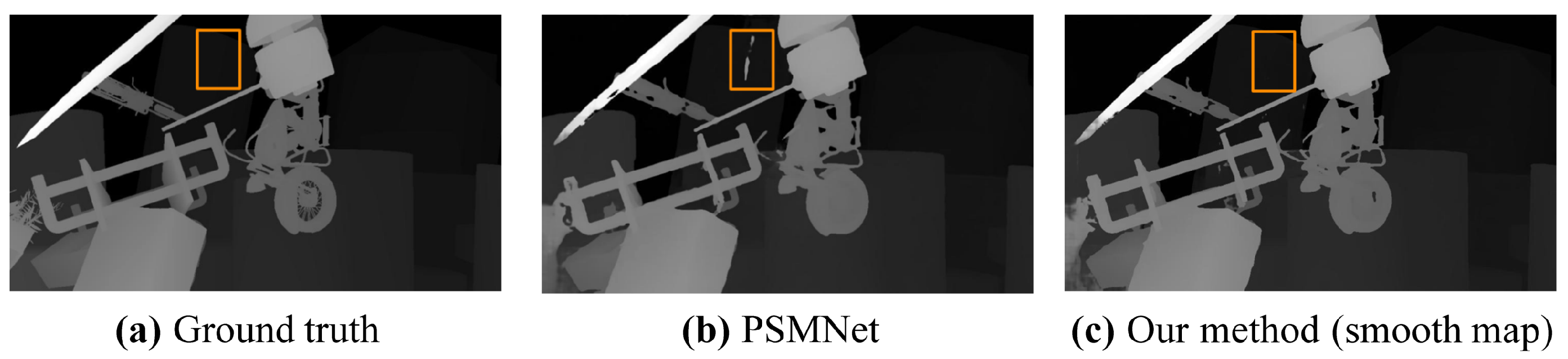
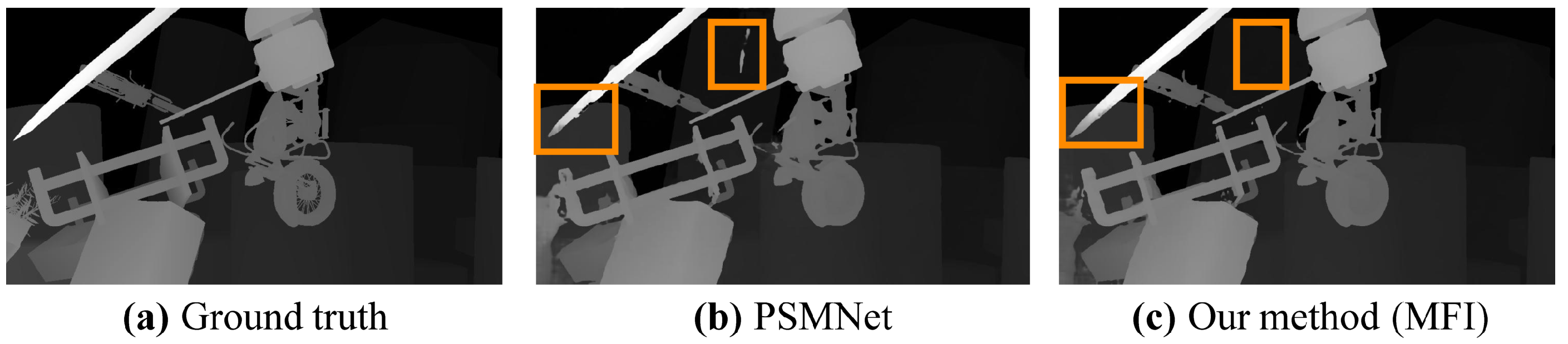
It could be seen that the boundary map emphasizes the high-frequency oscillating regions of the original image, while the smooth map emphasizes the low-frequency texture-less regions. Multiple frequency images including boundary maps, smooth maps and the original images are concatenated in channels as input and fed into 2D CNN to extract abundant features for forming the cost volume. Since the images contain RGB channels, our multiple frequency input (MFI) is nine channels. However, in ablation experiments (see
Section 4.2), inputs are with six channels made up of the original image and boundary (or smooth) map.
3.2. 3D Context-Guided Attention Network
In existing studies, matching cost between stereo images is usually processed by 3D CNN. A high-level feature extracted by 3D CNN generally has lower resolution than those of low-level features. Apparently, low resolution is not favorable for obtaining dense disparity estimation maps; hence, an effective up-sampling method is needed to restore the original resolution. We propose 3D Context-guided Attention Network (3DCAN) for processing 4D cost volume by gaining the context of high-level features as attention weight guiding low-level features to obtain more accurate disparity estimation results. Firstly, we describe the 3D Context-guided Attention module (3DCA); then, we utilize the module to comprise the network.
3D Context-guided Attention module. In our paper, the 4D cost volume consists of feature maps extracted from stereo image pairs and multiple frequency maps. We further process the cost volume in the way of encoder–decoder architecture as PSMNet [
2]. Down-sampling is performed in the encoder, and up-sampling is performed in the decoder. It is obvious that the spatial accuracy and details will be lost due to the resolution reduction caused by down-sampling. The important role of the decoder is to restore pixel localization.
We refer to [
14], a 2D attention-based up-sampling method, to propose our 3D up-sampling strategy, in which global pooling is performed on high-level cost volume to obtain context to guide the weighting of low-level information without excessive computational burden. Our 3DCA module is shown in
Figure 4. Firstly, we perform
convolution to adjust the output channels of high-level and low-level features. Then, up-sampling is taken to make channels of high-level features consistent with low-level features. Three-dimensional average pooling in the disparity dimension is used for high-level features to obtain global context information. Further operations include
convolution on the global context information with batch normalization and nonlinearity. Then, the output is used as an attention weight and multiplied with the low-level features. Finally, high-level features are up-sampled and added with the weighted low-level features to obtain high-resolution feature maps with context information. Through these steps, our module could take advantage of context information derived from high-level features weighting the low-level feature in the disparity dimension to restore accurate resolution.
3D Context-guided Attention network. The stacked hourglass model in PSMNet [
2] uses deconvolution operation in the decoder to obtain a high-resolution feature map. However, the input of the decoder is too small to provide reliable information for recovering a precise disparity map. Thus, we combine the 3D CNN architecture in PSMNet with our proposed 3DCA module, in which larger feature maps at low-level and high-level features are combined to learn the high-resolution cost features in the decoder, as shown in
Figure 5. The whole network is called 3D Context-guided Attention Network (3DCAN). Compared to PSMNet [
2], the deconvolution in the stacked hourglass is replaced with the 3DCA module, which can effectively deploy the context information obtained from high-level features to improve the performance of the network to recover pixel localization. The 3DCAN architecture has three outputs and losses. The loss function is described in the following section. As reported in [
2], training loss is calculated as the weighted summation of the three losses, and the final disparity map is the last of three outputs.
3.3. Loss
We utilize disparity regression as proposed in [
5] to convert the cost volume to disparity estimations and obtain the continuous disparity map. The size of the cost volume calculated by 3DCAN is
, where
D is the max disparity value, and the matching cost of a certain pixel under disparity
is
. After processing cost volume through 3DCAN, the cost is converted to probability through softmax operation
on the inverse of
. The disparity values are multiplied by the probabilities and summed over all disparity levels to obtain disparity estimation
. The formulation is
The equation is similar to the method first introduced in [
37], where it is referred to as a soft attention mechanism. We adopt the same loss function proposed in [
2], which is defined as
where
N is the number of pixels,
is the ground-truth disparity on pixel
i, and
is the predicted disparity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}