
Enhanced Drag Force Estimation in Automotive Design: A Surrogate Model Leveraging Limited Full-Order Model Drag Data and Comprehensive Physical Field Integration


Abstract
1. Introduction
1.1. Gradient-Based Approaches
1.2. Surrogate Modeling
1.3. Shape Parametrization
1.4. Adding Information from Available Volume Fields
1.5. Scope, Objectives, and Structure of the Paper
- Low-dimensional reparametrization of the vehicle geometry.
- Incorporation of physical fields to enrich the data and raise the information content without additional CFD computations; this represents the biggest difference from traditional methods.
- Reliance on physical formulas for calculating drag forces.
- Ability to compute sensitivities, i.e., accuracy for small geometry variations.
1.6. Related Works
2. Methodology
2.1. Drag Force Evaluation Methods
2.2. Shape Encoding
Discretized Formalism
- Offline stage: assume that a snapshot database of shape displacementsis available. From an SVD analysis or a QR factorization of D, compute an orthogonal reduced basis . Define the matrix,
- Online stage: for a query CAD parameter , compute a mesh of the shape . Then, compute the discrete displacement field and the POD coefficients vector,
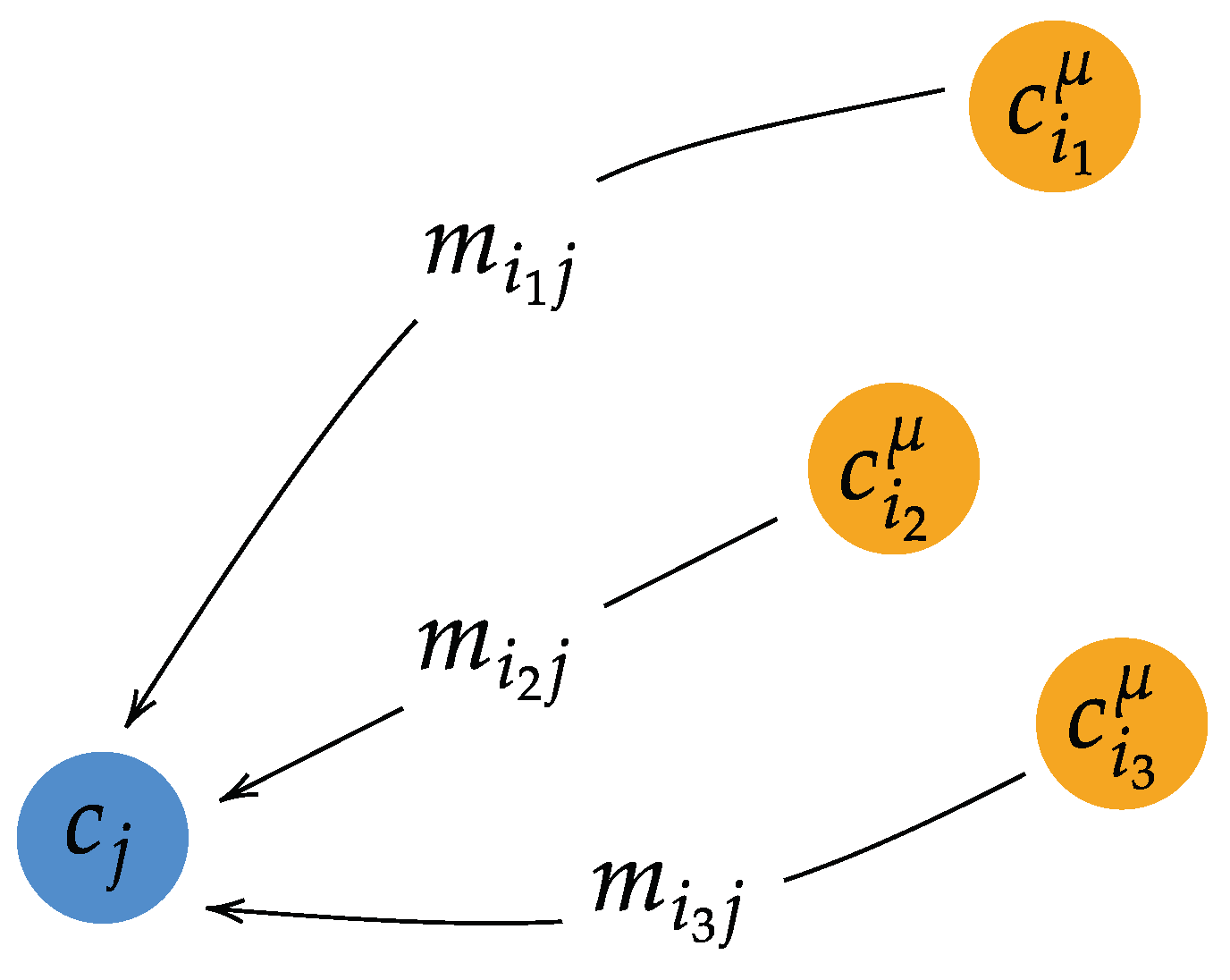
2.3. Knowledge Extraction and Reduced-Order Representation in the Cutting Plane
- Compute the snapshot matrix of field forces by collecting results of the high-fidelity CFD solver for the training shapes:
- Extract the modes , by performing either principal component analysis or QR factorization of matrix U, depending on the number of snapshots. Then, define the matrix,For very limited snapshot data, it is preferable to use a QR factorization. In this case, we have and with , an upper triangular matrix. Since the matrix P is semi-orthogonal, we have .
2.4. Parametric Surrogate Model
2.5. Online Stage: Drag Force Evaluation
2.6. Summary
| Algorithm 1 ROM far-field Offline Phase—Learning phase for a set of training shapes with FOM results |
|
| Algorithm 2 ROM far-field Online Phase—Prediction of a new “query” shape , |
|
3. Numerical Experiments, Results, and Discussion
3.1. High-Fidelity Simulation
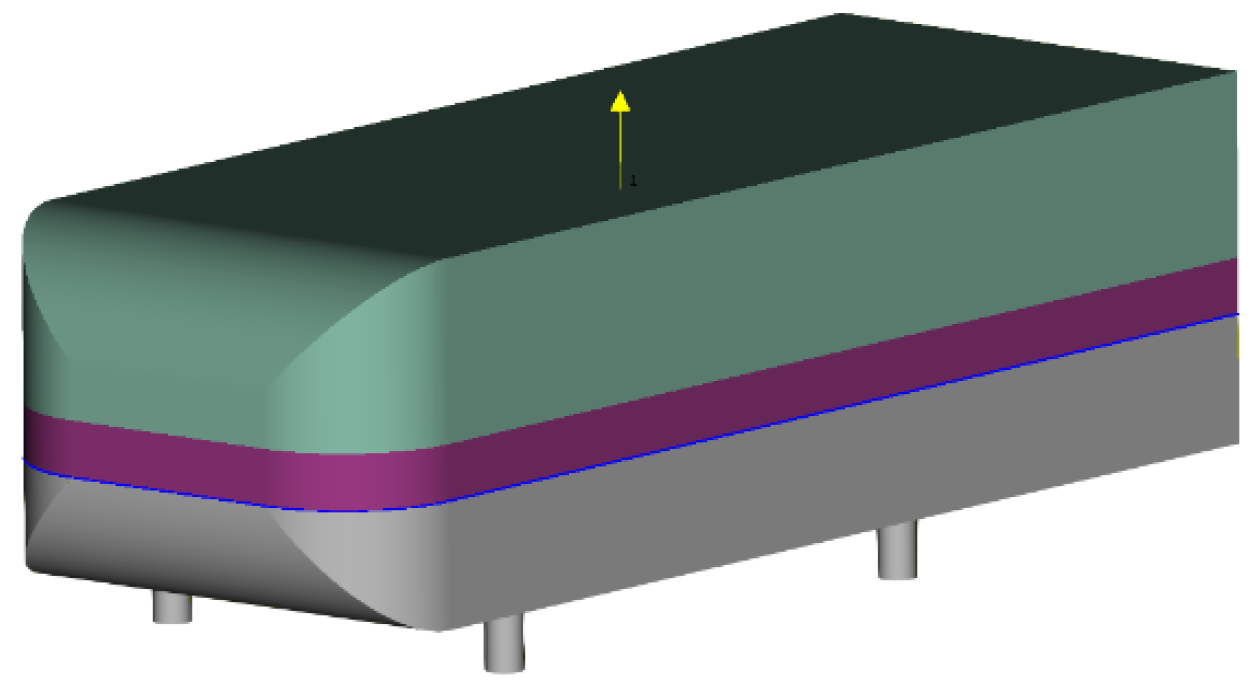
3.2. Simplified Geometry “S2A”
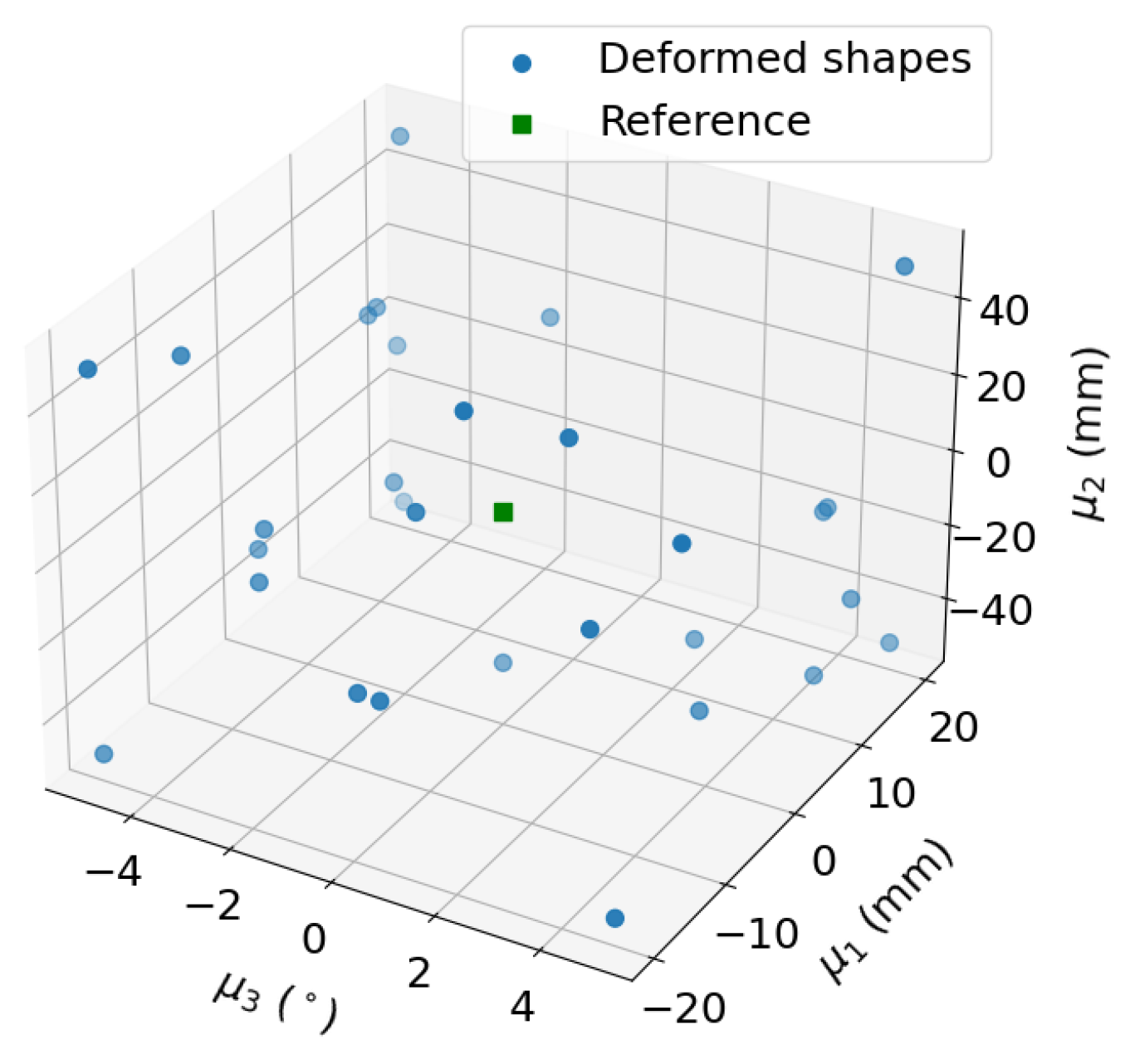
3.3. Data Generation and Preprocessing
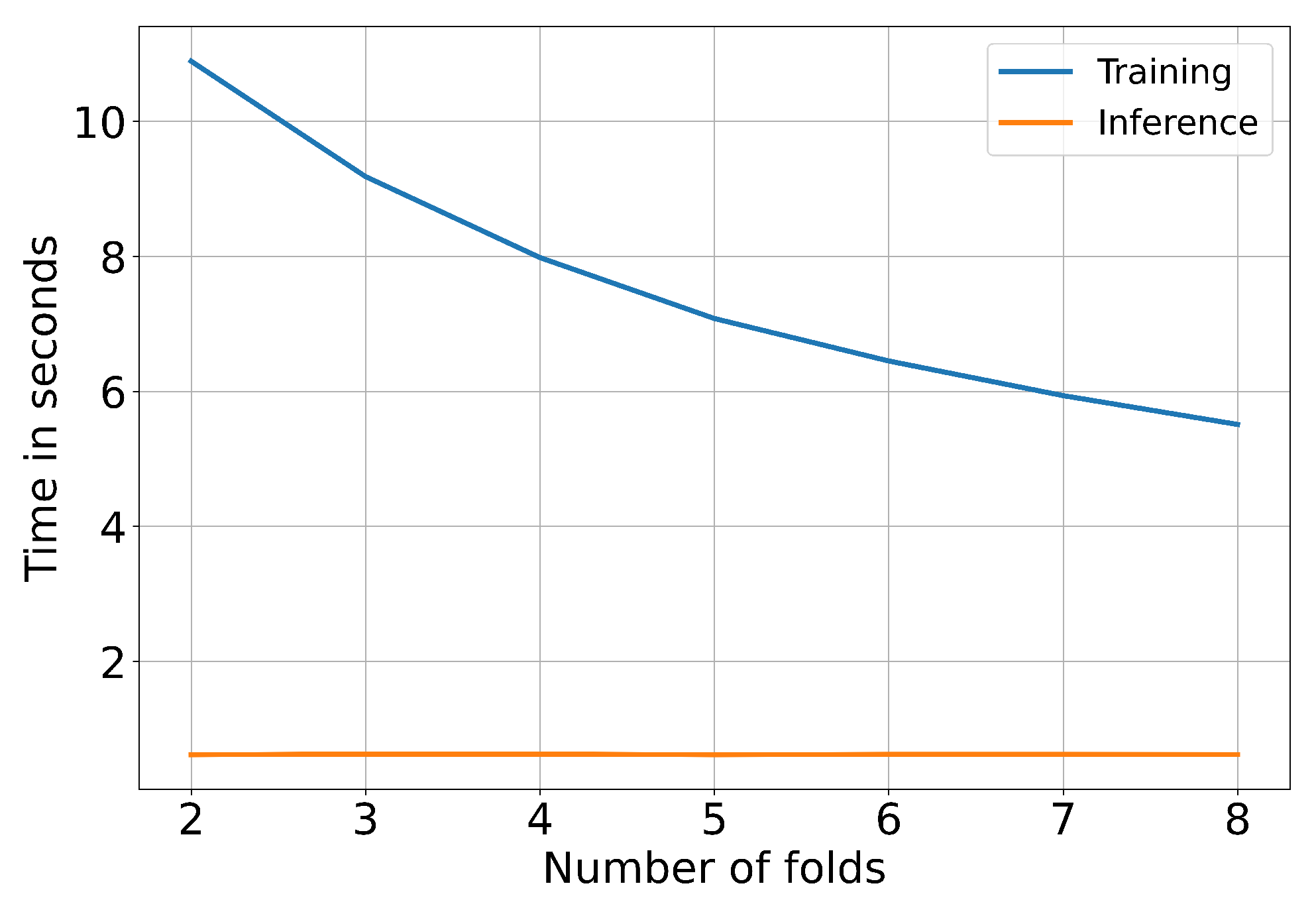
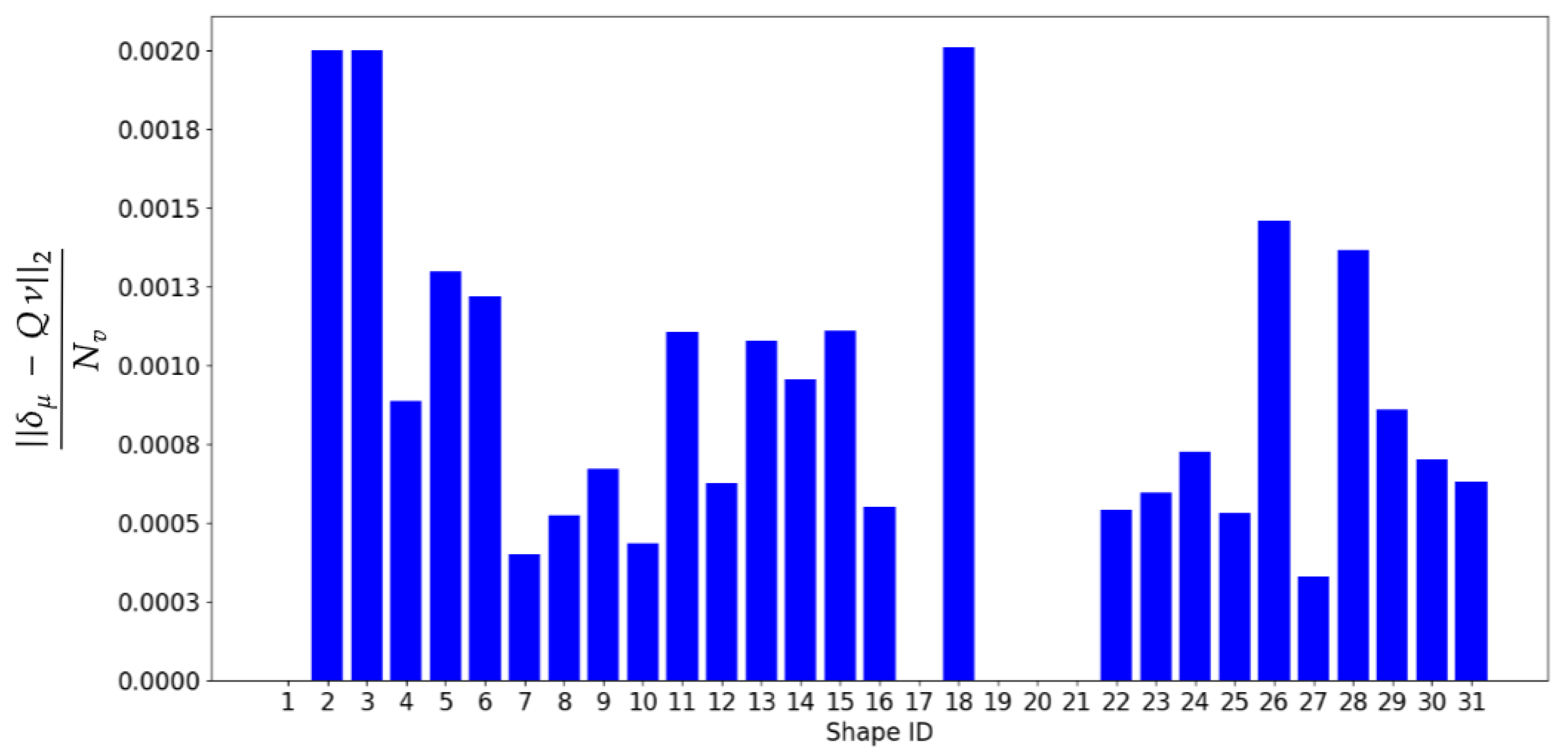
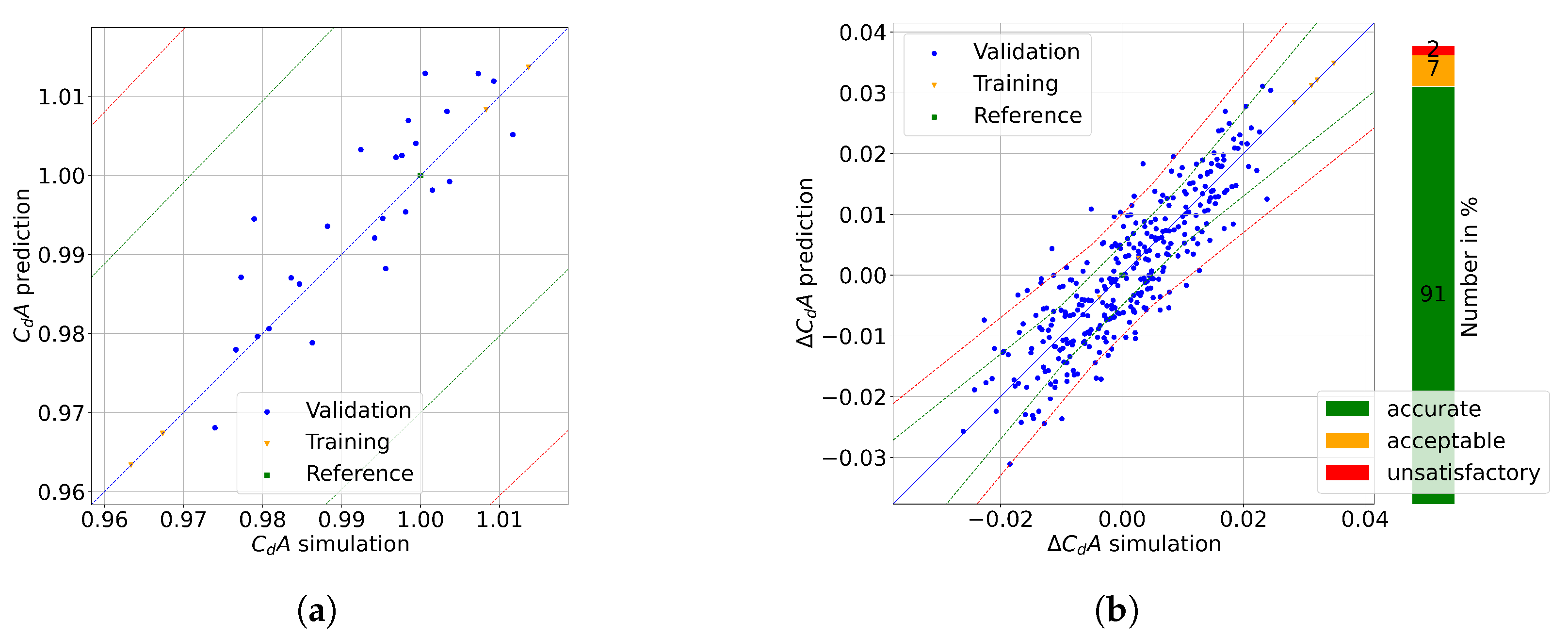
3.4. Model Performance
- for the Relaxed Kendall Accurate coefficient;
- for the Relaxed Kendall Acceptable coefficient.
3.5. Surrogate Model Construction
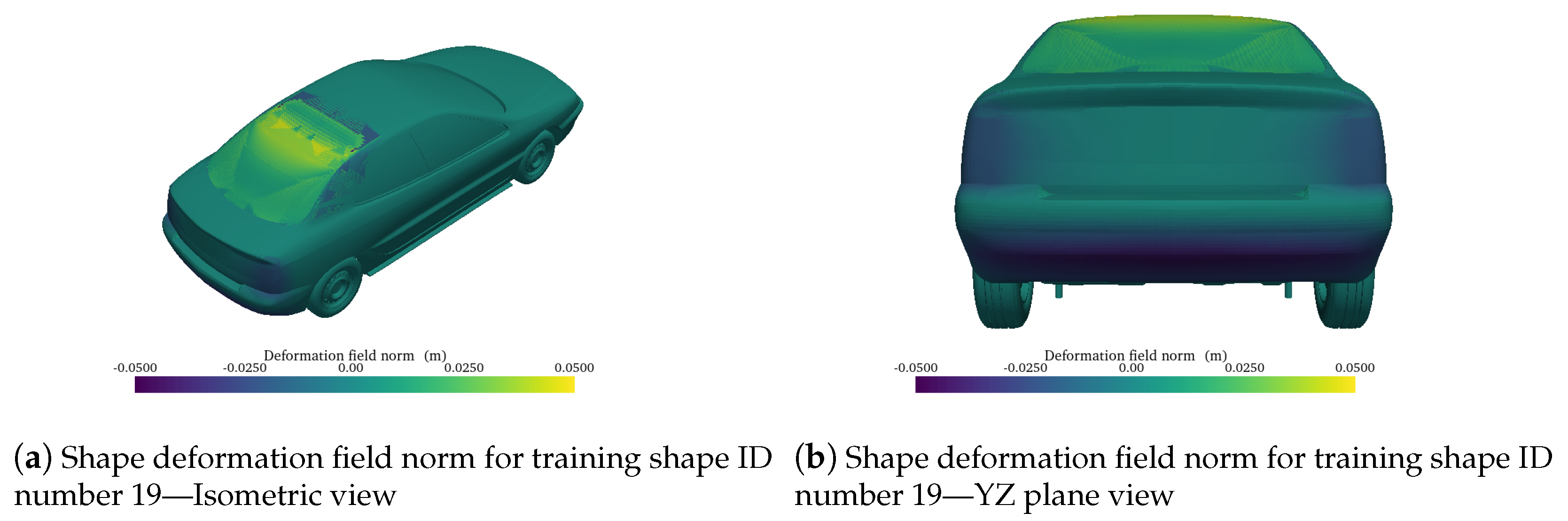
3.5.1. Shape Encoding
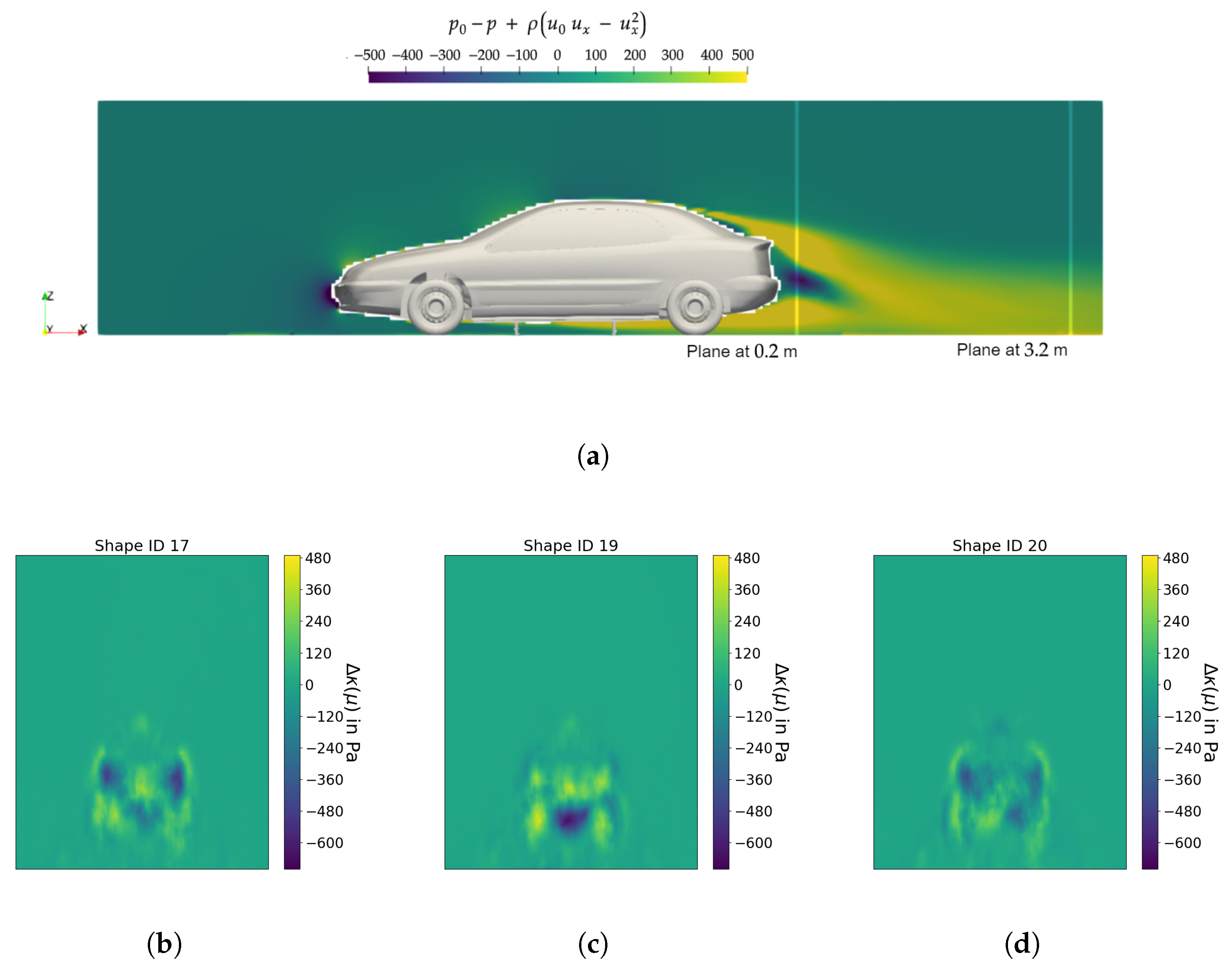
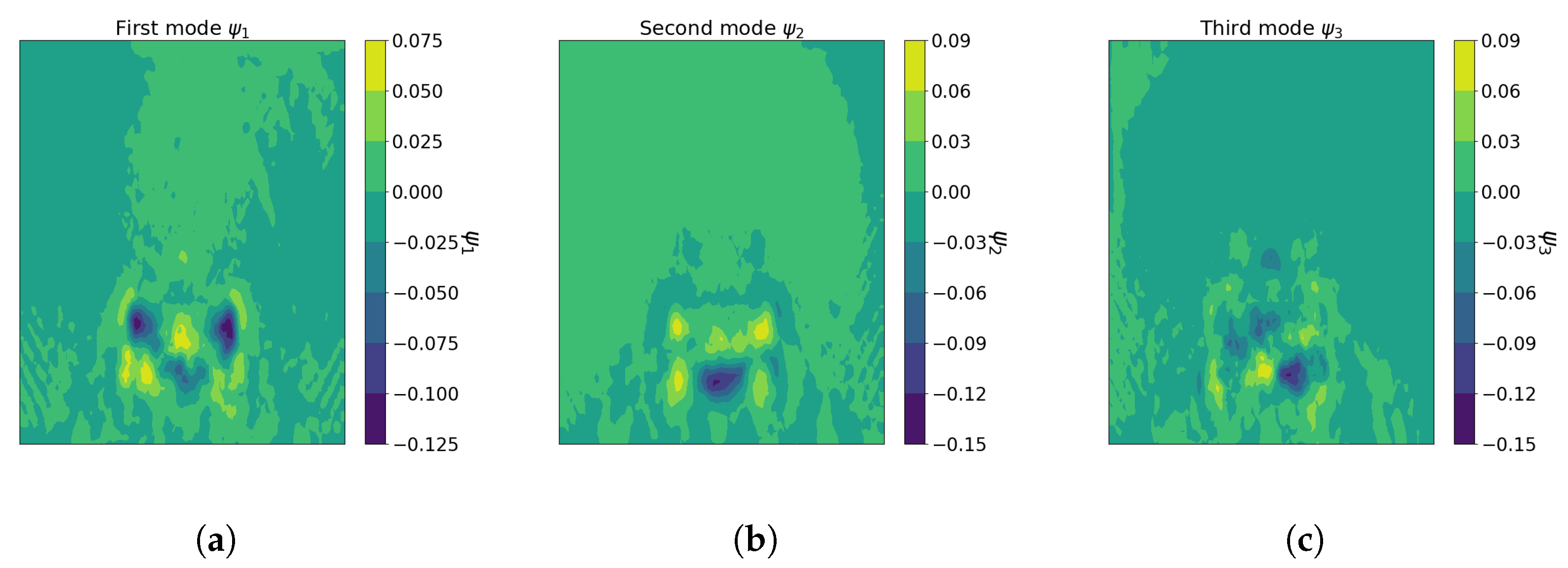
3.5.2. Computation of the Flow Field Modes on a Wake Cutting Plane
3.6. Surrogate Model Evaluation
4. Concluding Remarks and Perspectives
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CFD | Computational Fluid Dynamics |
| LBM | Lattice Boltzmann Method |
| POD | Principal Orthogonal Decomposition |
| RSM | Response Surface Model |
| HF | High-fidelity (computation) |
| AI | Artificial Intelligence |
| NN | Neural Network |
| LLE | Locally Linear Embedding |
| CNN | Convolutional Neural Network |
| SUV | Sport Utility Vehicle |
| Drag coefficient times frontal area | |
| LES | Large Eddy Simulation |
| SGS | Subgrid Scale |
| Reynolds number | |
| Drag force component in the x-direction | |
| p | Static pressure |
| Infinite unperturbed pressure | |
| Unit vector in the x-direction | |
| Viscous stress tensor | |
| Kinematic viscosity | |
| Velocity gradient tensor | |
| Vehicle’s surface | |
| Tangential unit vector | |
| Cutting plane in the wake of the vehicle | |
| Fluid density | |
| Freestream velocity | |
| Velocity component in the x-direction | |
| CAD | Computer-Aided Design |
| Shape parameter vector | |
| Domain of admissible shape parameters |
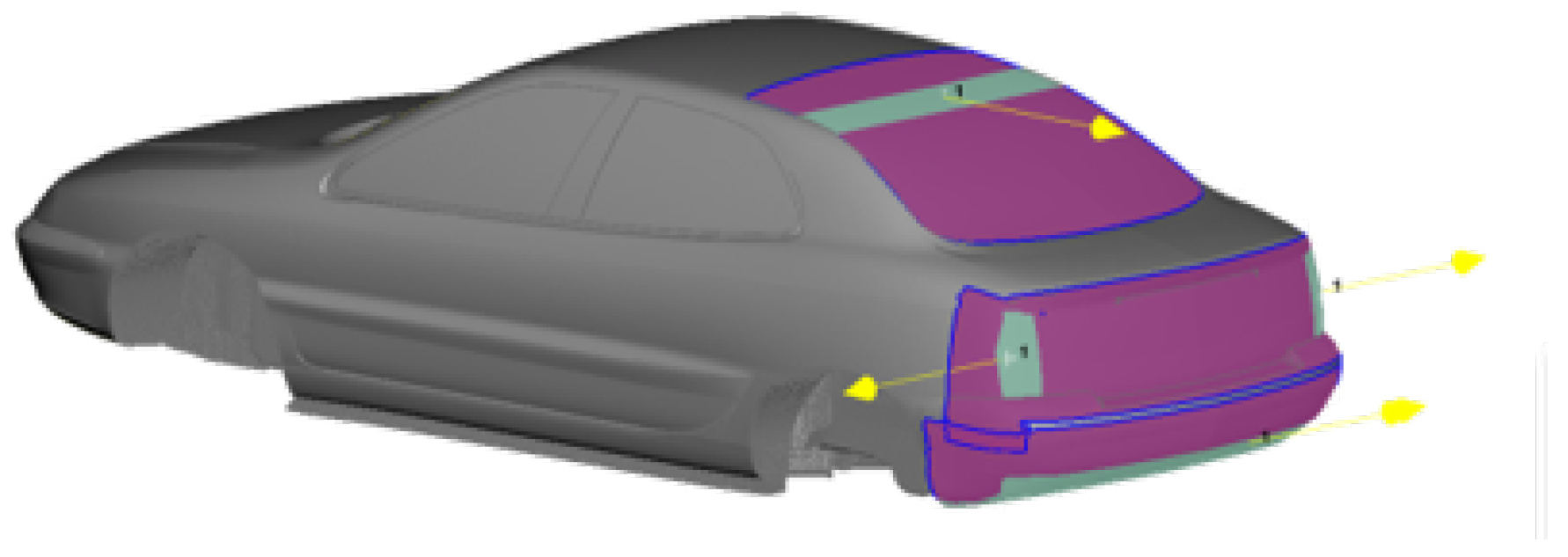
Appendix A. Mesh Matching
Appendix A.1
References
- Lions, J.L.; Magenes, E. Non-Homogeneous Boundary Value Problems and Applications; Springer: Berlin/Heidelberg, Germany, 1972. [Google Scholar]
- Pironneau, O. On optimum design in fluid mechanics. J. Fluid Mech. 1974, 64, 97–110. [Google Scholar] [CrossRef]
- Jameson, A. Aerodynamic design via control theory. J. Sci. Comput. 1988, 3, 233–260. [Google Scholar] [CrossRef]
- Jameson, A. Optimum aerodynamic design using CFD and control theory, AIAA paper 95-1729. In Proceedings of the AIAA 12th Computational Fluid Dynamics Conference, San Diego, CA, USA, 19–22 June 1995. [Google Scholar]
- Cheylan, I.; Fritz, G.; Ricot, D.; Sagaut, P. Shape Optimization Using the Adjoint Lattice Boltzmann Method for Aerodynamic Applications. AIAA J. 2019, 57, 1–16. [Google Scholar] [CrossRef]
- Hardy, R.L. Multiquadric equations of topography and other irregular surfaces. J. Geophys. Res. 1971, 76, 1905–1915. [Google Scholar] [CrossRef]
- Buhmann, M.D. Radial Basis Functions: Theory and Implementation; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- MacKay, D.J.C. Introduction to Gaussian processes. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 133–166. [Google Scholar]
- Brunton, S.L.; Bernd, R.N.; Koumoutsakos, P. Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef]
- Pearson, K. On Lines and Planes of Closest Fit to Systems of Points in Space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Lumley, J. Stochastic Tools in Turbulence; Academic Press: New York, NY, USA, 1970. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Umetani, N.; Bickel, B. Learning three-dimensional flow for interactive aerodynamic design. ACM Trans. Graph. 2018, 37, 1–10. [Google Scholar] [CrossRef]
- Li, X.; Xie, C.; Sha, Z. Part-Aware Product Design Agent Using Deep Generative Network and Local Linear Embedding. In Proceedings of the Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2021. [Google Scholar]
- Badías, A.; Curtit, S.; González, D.; Alfaro, I.; Chinesta, F.; Cueto, E. An augmented reality platform for interactive aerodynamic design and analysis. Int. J. Numer. Methods Eng. 2019, 120, 125–138. [Google Scholar] [CrossRef]
- Song, B.; Yuan, C.; Permenter, F.; Arechiga, N.; Ahmed, F. Surrogate Modeling of Car Drag Coefficient with Depth and Normal Renderings. In Proceedings of the ASME 2023 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Volume 3A: 49th Design Automation Conference (DAC), Boston, MA, USA, 20–23 August 2023. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Rosset, N.; Cordonnier, G.; Duvigneau, R.; Bousseau, A. Interactive design of 2D car profiles with aerodynamic feedback. Comput. Graph. Forum 2023, 42, 427–437. [Google Scholar] [CrossRef]
- Guo, X.; Li, W.; Iorio, F. Convolutional Neural Networks for Steady Flow Approximation. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining Association for Computing Machinery, New York, NY, USA, 13–17 August 2016; pp. 481–490. [Google Scholar]
- Jacob, S.; Mrosek, M.; Othmer, C.; Köstler, H. Deep Learning for Real-Time Aerodynamic Evaluations of Arbitrary Vehicle Shapes. SAE Int. J. Passeng. Veh. Syst. 2022, 15, 77–90. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med Image Comput.-Comput.-Assist. Interv. 2015, 9351, 234–241. [Google Scholar]
- Heft, A.; Indinger, T.; Adams, N. Introduction of a New Realistic Generic Car Model for Aerodynamic Investigation. SAE Tech. Pape 2012-01-0168 2012. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Svoboda, J.; Bronstein, M.M. Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5115–5124. [Google Scholar]
- Baqué, P.; Remelli, E.; Fleuret, F.; Fua, P. Geodesic Convolutional Shape Optimization. In Proceedings of the 35th ICML, Stockholm, Sweden, 10–15 July 2018; pp. 481–490. [Google Scholar]
- Durasov, N.; Lukoyanov, A.; Donier, J.; Fua, P. DEBOSH: Deep Bayesian Shape Optimization. arXiv 2021, arXiv:2109.13337. [Google Scholar]
- Remelli, E.; Lukoianov, A.; Richter, S.R.; Guillard, B.; Bagautdinov, T.; Baque, P.; Fua, P. MeshSDF: Differentiable Iso-Surface Extraction. Adv. Neural Inf. Process. Syst. 2020, 33, 22468–22478. [Google Scholar]
- Gunpinar, E.; Coskun, U.C.; Ozsipahi, M.; Gunpinar, S. A Generative Design and Drag Coefficient Prediction System for Sedan Car Side Silhouettes based on Computational Fluid Dynamics. Comput.-Aided Des. 2019, 111, 1–10. [Google Scholar] [CrossRef]
- Ando, K.; Takamura, A.; Saito, I. Automotive aerodynamic design exploration employing new optimization methodology based on CFD. SAE Int. J. Passeng. Cars-Meek Syst. 2010, 3, 398–406. [Google Scholar] [CrossRef]
- Bertram, A.; Othmer, C.; Zimmermann, R. Towards Real-time Vehicle Aerodynamic Design via Multi-fidelity Data-driven Reduced Order Modeling. In Proceedings of the 2018 AIAA/ASCE/AHS/ASC Structures, Structural Dynamics, and Materials Conference, Kissimmee, FL, USA, 8–12 January 2018. [Google Scholar]
- Clancy, L.J. Aerodynamics; Wiley: Hoboken, NJ, USA, 1975. [Google Scholar]
- Anderson, J. Fundamentals of Aerodynamics, 6th ed.; McGraw-Hill: New York, NY, USA, 2016. [Google Scholar]
- Onorato, M.; Costelli, A.; Garrone, A. Drag Measurement Through Wake Analysis. SAE Tech. Pape. 840302 1984, 85–93. [Google Scholar]
- Sagaut, P. Large Eddy Simulation for Incompressible Flows; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Feydy, J.; Séjourné, T.; Vialard, F.-X.; Amari, S.-I.; Trouve, A.; Peyré, G. Interpolating between Optimal Transport and MMD using Sinkhorn Divergences. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 2681–2690. [Google Scholar]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Nelsen, R.B. Kendall tau metric. Encycl. Math. 2001, 3, 226–227. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shape ID | Set | Shape ID | Set | ||
|---|---|---|---|---|---|
| 1 | 1.0000 | Reference | 17 | 1.0075 | Training |
| 2 | 0.9820 | Validation | 18 | 0.9974 | Validation |
| 3 | 0.9939 | Validation | 19 | 1.0168 | Training |
| 4 | 0.9836 | Validation | 20 | 0.9632 | Training |
| 5 | 1.0011 | Validation | 21 | 0.9616 | Training |
| 6 | 1.0046 | Validation | 22 | 0.9987 | Validation |
| 7 | 0.9994 | Validation | 23 | 0.9761 | Validation |
| 8 | 0.9831 | Validation | 24 | 0.9790 | Validation |
| 9 | 1.0088 | Validation | 25 | 0.9952 | Validation |
| 10 | 0.9921 | Validation | 26 | 0.9858 | Validation |
| 11 | 1.0054 | Validation | 27 | 0.9712 | Validation |
| 12 | 0.9844 | Validation | 28 | 0.9943 | Validation |
| 13 | 0.9785 | Validation | 29 | 1.0101 | Validation |
| 14 | 0.9955 | Validation | 30 | 1.0043 | Validation |
| 15 | 0.9969 | Validation | 31 | 0.9775 | Validation |
| 16 | 1.0100 | Validation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naffer-Chevassier, K.; De Vuyst, F.; Goardou, Y. Enhanced Drag Force Estimation in Automotive Design: A Surrogate Model Leveraging Limited Full-Order Model Drag Data and Comprehensive Physical Field Integration. Computation 2024, 12, 207. https://doi.org/10.3390/computation12100207
Naffer-Chevassier K, De Vuyst F, Goardou Y. Enhanced Drag Force Estimation in Automotive Design: A Surrogate Model Leveraging Limited Full-Order Model Drag Data and Comprehensive Physical Field Integration. Computation. 2024; 12(10):207. https://doi.org/10.3390/computation12100207
Chicago/Turabian StyleNaffer-Chevassier, Kalinja, Florian De Vuyst, and Yohann Goardou. 2024. "Enhanced Drag Force Estimation in Automotive Design: A Surrogate Model Leveraging Limited Full-Order Model Drag Data and Comprehensive Physical Field Integration" Computation 12, no. 10: 207. https://doi.org/10.3390/computation12100207
APA StyleNaffer-Chevassier, K., De Vuyst, F., & Goardou, Y. (2024). Enhanced Drag Force Estimation in Automotive Design: A Surrogate Model Leveraging Limited Full-Order Model Drag Data and Comprehensive Physical Field Integration. Computation, 12(10), 207. https://doi.org/10.3390/computation12100207