

Design and Implementation of a Camera-Based Tracking System for MAV Using Deep Learning Algorithms


Abstract
:1. Introduction
- Object detection from the image: DL-based methods have achieved state-of-the-art performance on various UAV datasets, such as UAVDT, VisDrone, and DOTA. However, there are still some issues, such as small object detection, occlusion handling, and domain adaptation. Some of the representative methods are Faster R-CNN, YOLO, and SSD, which use different network architectures and loss functions to balance accuracy and speed [7,8].
- Object detection from the video: DL-based methods have improved the performance of object detection from the video by exploiting temporal information, such as optical flow, motion vectors, and recurrent neural networks. However, there are still some challenges, such as video compression artifacts, motion blur, and background clutter. Some of the representative methods are FGFA, DFF, and STSN, which use different ways to aggregate features from multiple frames and enhance temporal consistency [9,10].
- Object tracking from the video: DL-based methods have achieved remarkable results on various UAV tracking benchmarks, such as UAV123, UAVDT, and VisDrone. However, there are still some difficulties, such as scale variation, illumination change, and occlusion. Some of the representative methods are SiamFC, SiamRPN, and ATOM, which use different strategies to learn a similarity measure between the target and the candidates and optimize the tracking performance.
2. Materials and Methods
2.1. Detection of Objects
2.1.1. Strategies
2.1.2. YOLO
2.2. Multi-Objekt-Tracking
Processing Method
2.3. DeepSORT
2.3.1. SORT
2.3.2. SORT with a Deep Association Metric
- Calculate the Mahalanobis distance and the cosine distance using the new detections.
- Create the cost matrix using the weighted sum of both metrics, considering the thresholds set.
- Iterate over tracks that could not yet be assigned to a detection.
- (a)
- Linear mapping of these tracks with non-matching detections using the created cost matrix and the Hungarian method.
- (b)
- Update the matching and non-matching detections.
- Return the updated detections.
2.4. Parrot ANAFI
3. Implementation
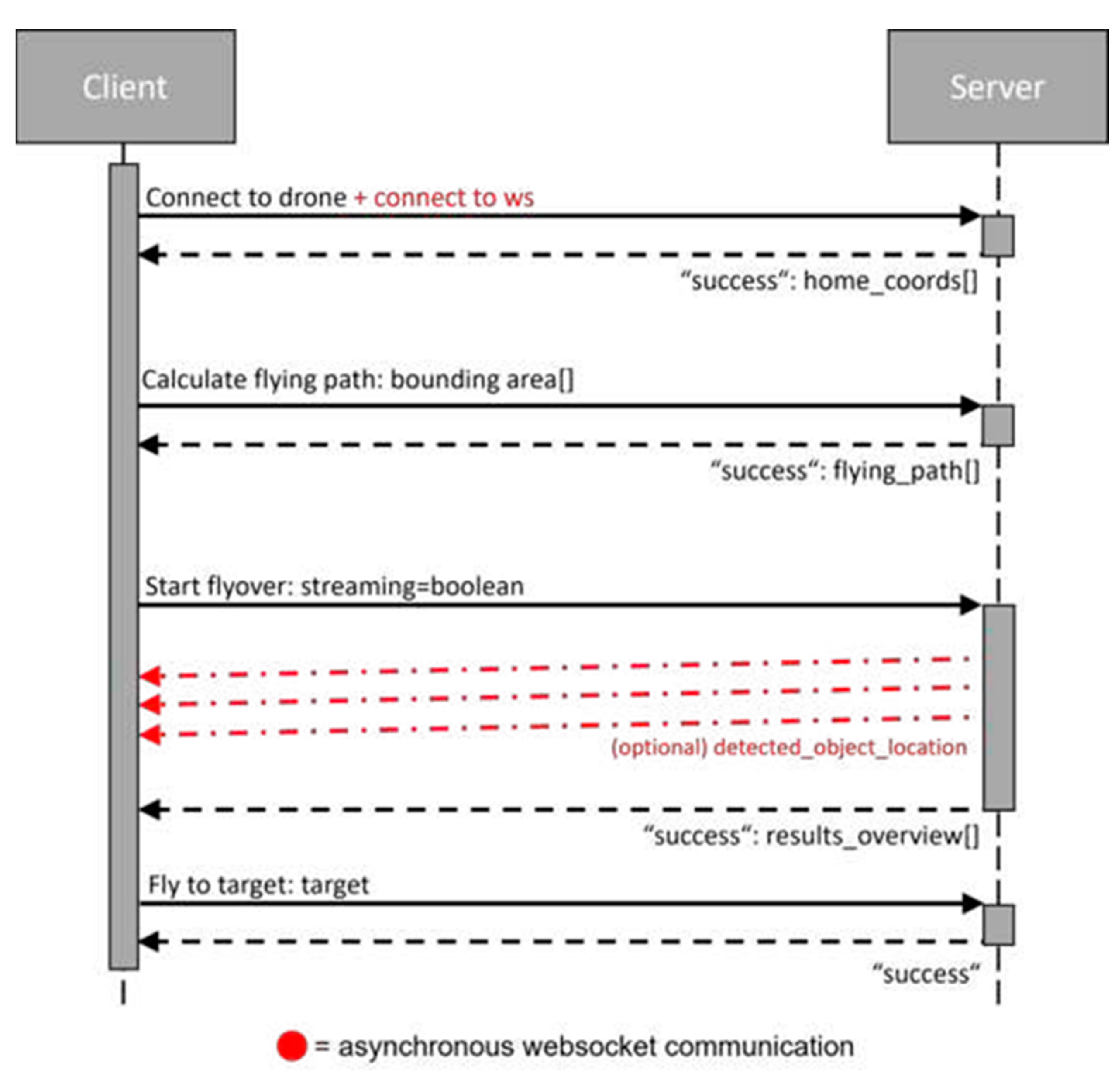
3.1. System Structure and Communication
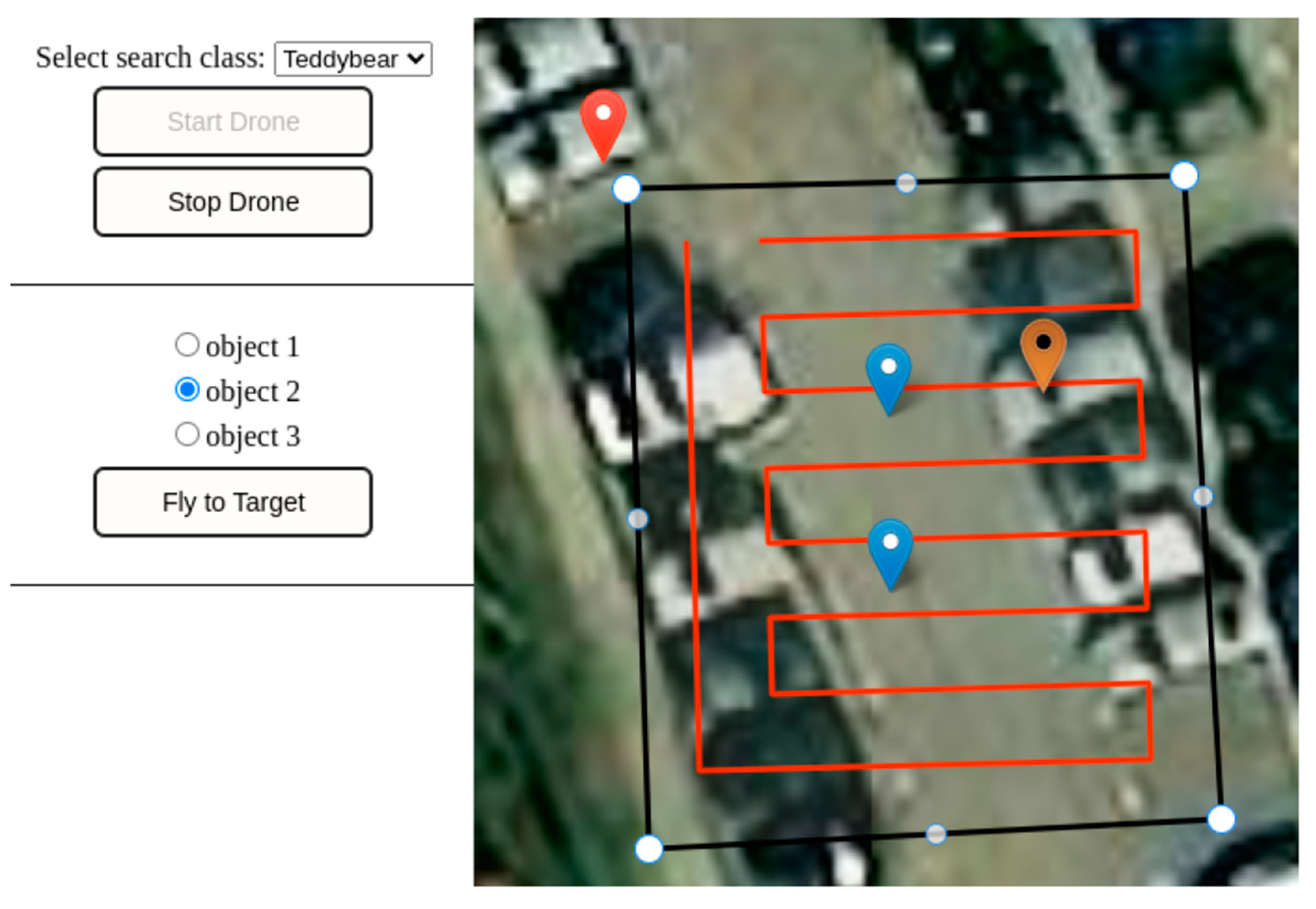
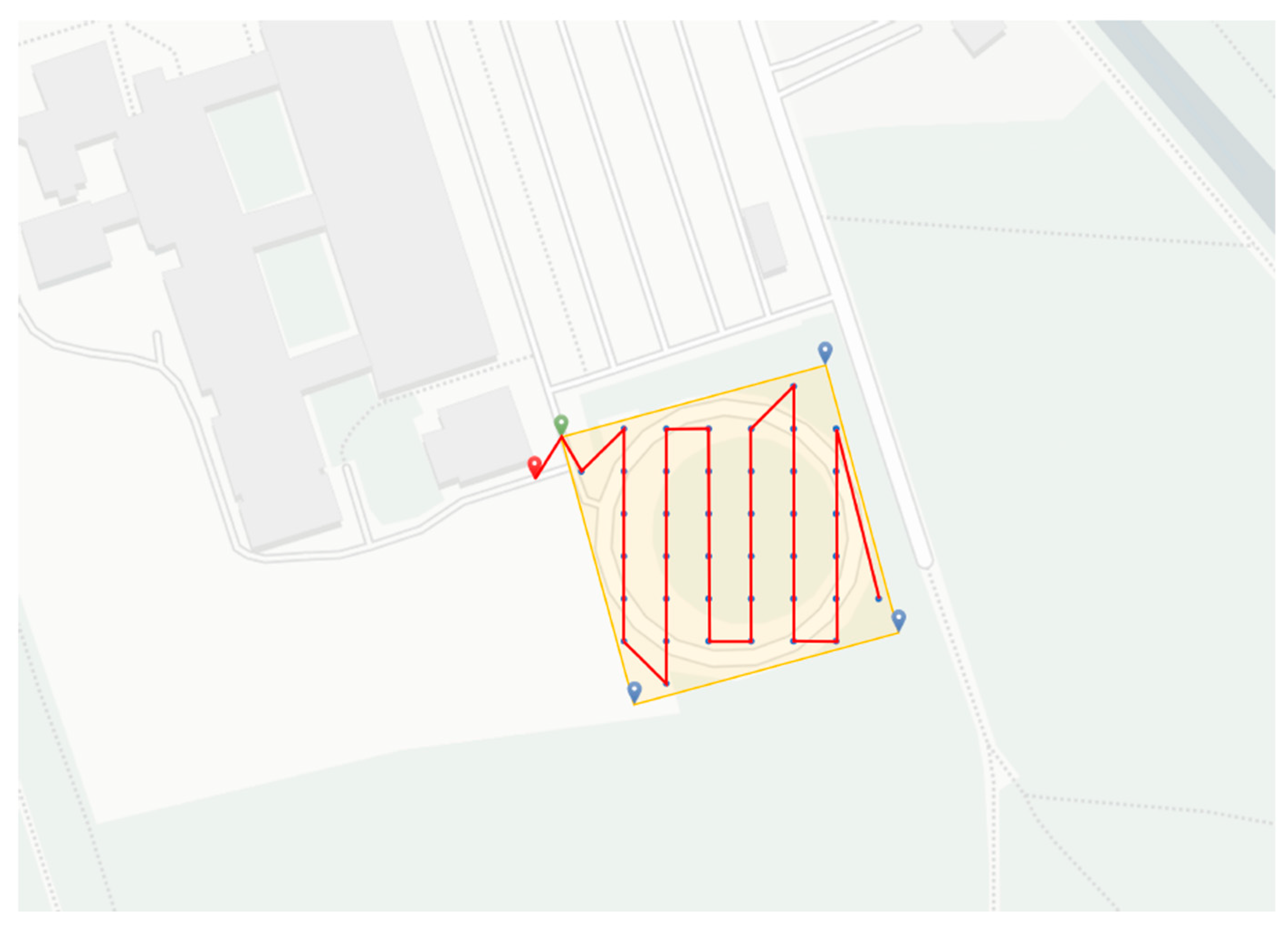
3.2. Calculation of the Flight Route
- The corner point of the polygon closest to the position of the drone is declared as the starting point and added to the flight path.
- All flight path points are assigned the status “unseen”.
- As long as points with this status exist, the following steps are repeated continuously:
- First, the calculation of the distance between the current position point and all unseen flight route points takes place. The Haversine distance [41] is used to calculate the distance.
- Next, the point with the shortest distance is determined as the next current situation point. However, points in unfavorable situations can be ignored and lead to a duplication of the flight route. Using a threshold, these points are included in the decision of the next attitude point.
- The new situation point is removed from the set of “unseen” points and added to the flight route.
- If there are no further points with the status “unseen”, it can be assumed that there is full coverage, and the planning process of the flight path can be completed.
3.3. Tracker with Its Own Matching Cascade
4. Evaluation
4.1. Evaluation Simulation Environment
4.2. Real World Evaluation of the Overall System
- Could all objects be detected correctly or were there more false detections?
- Did identity switches occur within a scene?
- Did identity switches occur during the second flight, or could the objects be assigned correctly again?
- How precise was the determination of the GPS coordinates?
- Can the system process the data in real time? How many frames per second can be processed?
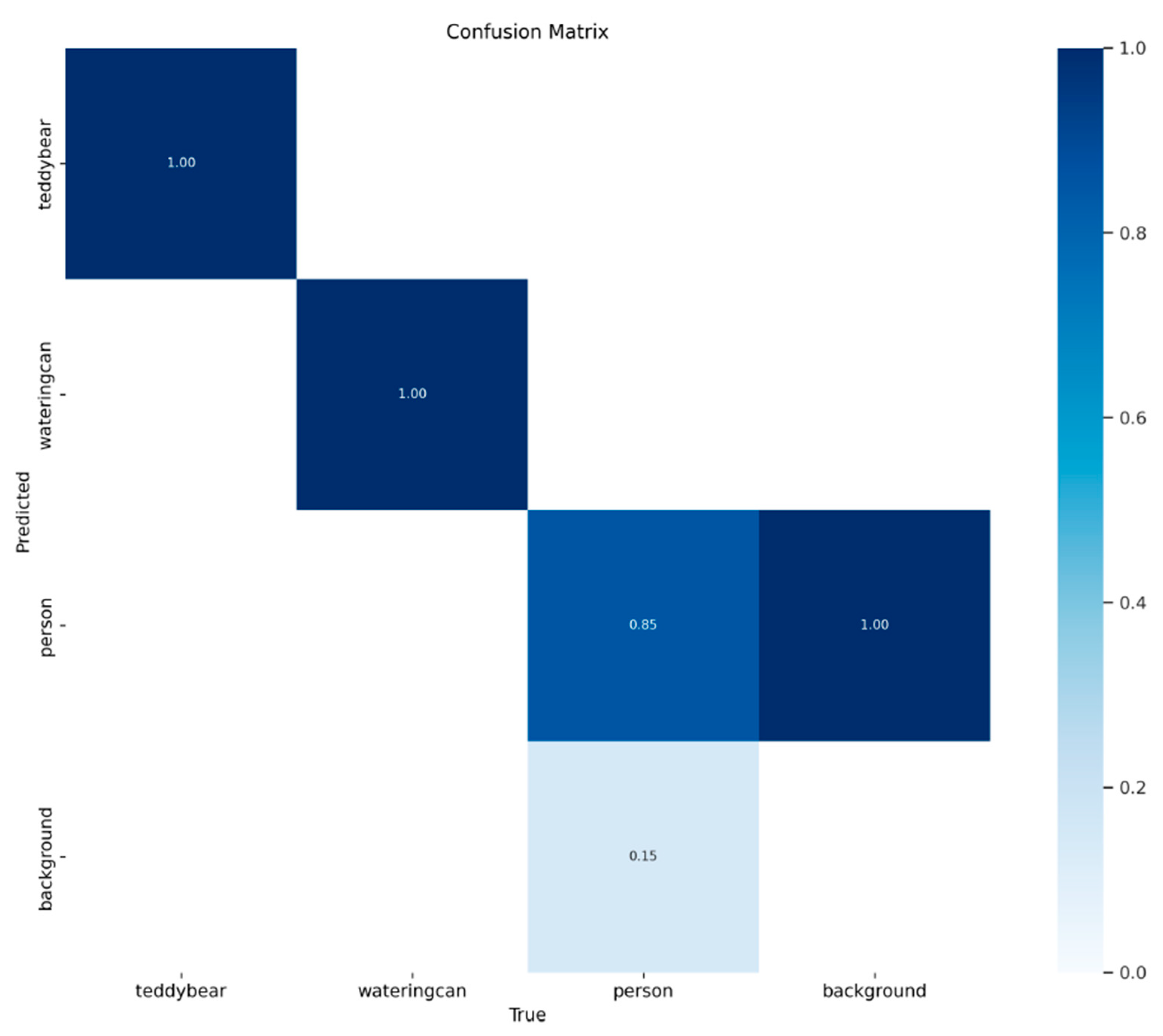
4.3. Detecting Changes to Objects Using Cosine Similarity
4.4. Object Detection with Minimal Data Input
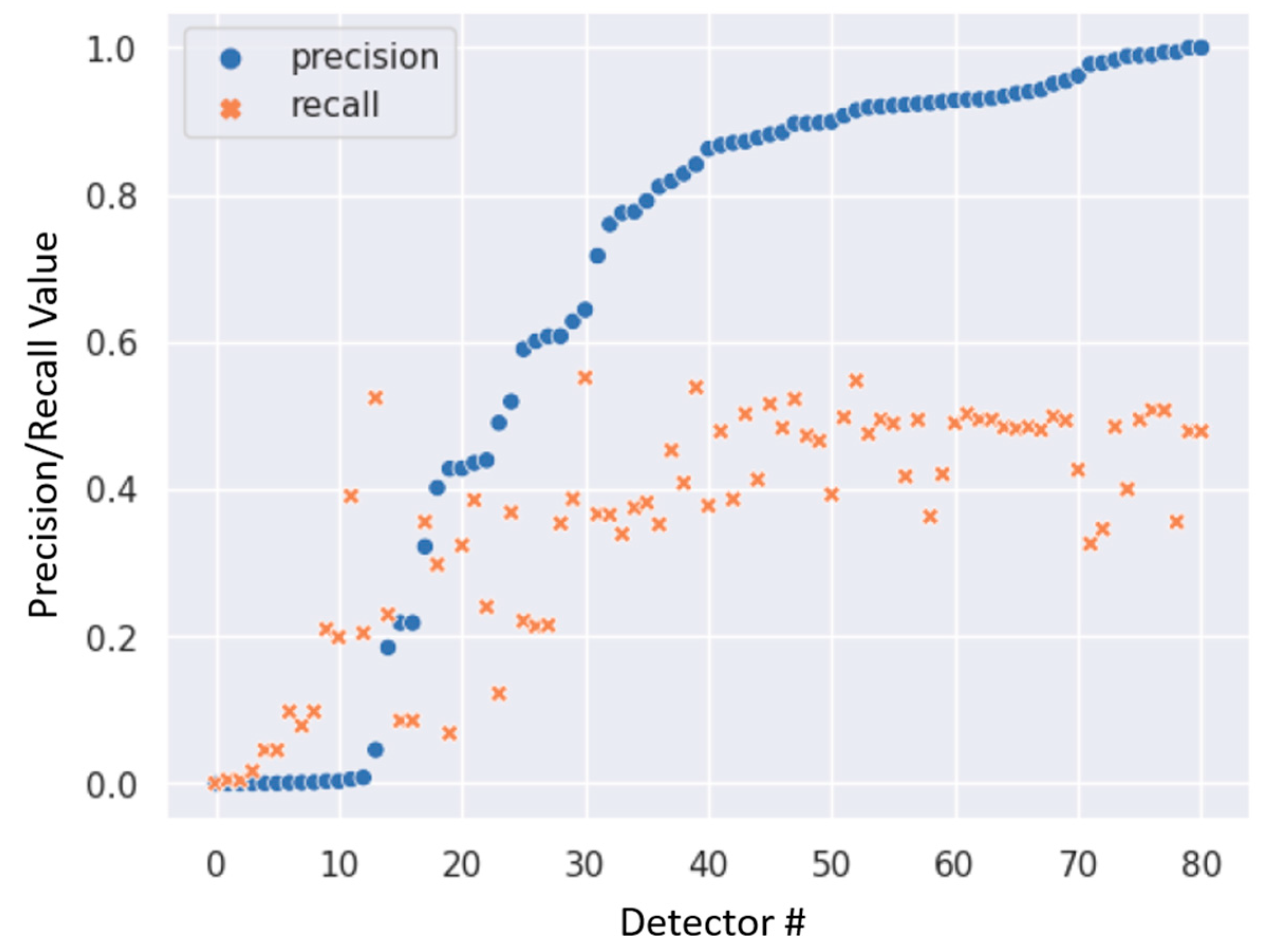
4.5. Discussion of Deep Learning Algorithms Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truth | Detected | ||||
|---|---|---|---|---|---|
| Flight Duration | Teddy Bears | Person | Teddy Bears | Person | |
| 1. | 00:02:43 | 3 | 1 | 5 | 5 |
| 2. | 00:01:23 | 3 | 1 | 3 | 3 |
| 3. | 00:00:45 | 3 | 0 | 4 | 1 |
| 4. | 00:01:15 | 3 | 0 | 3 | 0 |
| 5. | 00:03:12 | 3 | 1 | 3 | 2 |
| 6. | 00:01:32 | 2 | 0 | 2 | 0 |
| 7. | 00:02:15 | 3 | 1 | 3 | 0 |
| 8. | 00:01:53 | 3 | 0 | 3 | 1 |
| 9. | 00:01:06 | 3 | 1 | 3 | 1 |
| 10. | 00:02:25 | 3 | 0 | 3 | 0 |
| 11. | 00:03:41 | 3 | 0 | 2 | 1 |
| 12. | 00:05:32 | 3 | 1 | 3 | 1 |
| 13. | 00:04:12 | 3 | 0 | 3 | 0 |
| Total | 38 | 6 | 40 | 15 | |
| True Positives | False Positives | False Negatives | ||||
|---|---|---|---|---|---|---|
| Teddy Bears | Person | Teddy Bears | Person | Teddy Bears | Person | |
| 1. | 3 | 1 | 2 | 4 | 0 | 0 |
| 2. | 3 | 1 | 0 | 2 | 0 | 0 |
| 3. | 3 | 0 | 1 | 1 | 0 | 0 |
| 4. | 3 | 0 | 0 | 0 | 0 | 0 |
| 5. | 3 | 1 | 0 | 1 | 0 | 0 |
| 6. | 2 | 0 | 0 | 0 | 0 | 0 |
| 7. | 3 | 0 | 0 | 0 | 0 | 1 |
| 8. | 3 | 0 | 0 | 1 | 0 | 0 |
| 9. | 3 | 1 | 0 | 0 | 0 | 0 |
| 10. | 3 | 0 | 0 | 0 | 0 | 0 |
| 11. | 2 | 0 | 0 | 1 | 1 | 0 |
| 12. | 3 | 0 | 0 | 1 | 0 | 0 |
| 13. | 3 | 0 | 0 | 0 | 0 | 0 |
| Total: | 37 | 4 | 3 | 11 | 1 | 1 |
| Ground-Truth Objects | Detected Objects | True Positives | False Positives | False Negatives | |
|---|---|---|---|---|---|
| 1. | 3 | 3 | 3 | 0 | 0 |
| 2. | 3 | 3 | 3 | 0 | 0 |
| 3. | 3 | 3 | 3 | 0 | 0 |
| 4. | 3 | 3 | 3 | 0 | 0 |
| 5. | 3 | 3 | 3 | 0 | 0 |
| Total: | 15 | 15 | 15 | 0 | 0 |
| YOLOv5n | 5 | 10 | 15 | 20 | 50 |
|---|---|---|---|---|---|
| 10 | 0.000042 | 0.00019 | 0.025 | 0.00056 | 0.025 |
| 50 | 0.0049 | 0.034 | 0.058 | 0.281 | 0.395 |
| 250 | 0.396 | 0.4065 | 0.388 | 0.407 | 0.608 |
| 500 | 0.2886 | 0.47191 | 0.403 | 0.535 | 0.679 |
| YOLOv5s | |||||
| 10 | 0.000099 | 0.00084 | 0.00084 | 0.00288 | 0.245 |
| 50 | 0.045 | 0.17 | 0.107 | 0.119 | 0.4555 |
| 250 | 0.4597 | 0.4886 | 0.495 | 0.475 | 0.61347 |
| 500 | 0.41 | 0.5147 | 0.474 | 0.676 | 0.4955 |
| YOLOv5m | |||||
| 10 | 0.00195 | 0.00145 | 0.00779 | 0.00433 | 0.0673 |
| Number of Images | ||||
|---|---|---|---|---|
| YOLOv5n | 75 | 100 | 150 | 500 |
| 10 | 0.0799 | 0.1657 | 0.386 | 0.513 |
| 50 | 0.352 | 0.435 | 0.528 | 0.572 |
| 250 | 0.428 | 0.454 | 0.548 | 0.689 |
| 500 | 0.6955 | 0.375 | 0.526 | 0.58196 |
| YOLOv5s | ||||
| 10 | 0.2799 | 0.37027 | 0.411 | 0.549 |
| 50 | 0.44449 | 0.455 | 0.52977 | 0.55443 |
| 250 | 0.5386 | 0.50692 | 0.5668 | 0.58534 |
| 500 | 0.561 | 0.51969 | 0.55095 | 0.55583 |
| YOLOv5m | ||||
| 10 | 0.473 | 0.487 | 0.527 | 0.54845 |
References
- Merz, M.; Pedro, D.; Skliros, V.; Bergenhem, C.; Himanka, M.; Houge, T.; Matos-Carvalho, J.; Lundkvist, H.; Cürüklü, B.; Hamrén, R.; et al. Autonomous UAS-Based Agriculture Applications: General Overview and Relevant European Case Studies. Drones 2022, 6, 128. [Google Scholar] [CrossRef]
- Elmokadem, T.; Savkin, A.V. Towards Fully Autonomous UAVs: A Survey. Sensors 2021, 21, 6223. [Google Scholar] [CrossRef] [PubMed]
- Benarbia, T.; Kyamakya, K. A literature review of drone-based package delivery logistics systems and their implementation feasibility. Sustainability 2022, 14, 360. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W.T. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Oliveira, D.A.B.; Pereira, L.G.R.; Bresolin, T.; Ferreira, R.E.P.; Dorea, J.R.R. A review of deep learning algorithms for computer vision systems in livestock. Livest. Sci. 2021, 253, 104700. [Google Scholar] [CrossRef]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep Learning for Unmanned Aerial Vehicle-Based Object Detection and Tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 91–124. [Google Scholar] [CrossRef]
- Hossain, S.; Lee, D.-J. Deep Learning-Based Real-Time Multiple-Object Detection and Tracking from Aerial Imagery via a Flying Robot with GPU-Based Embedded Devices. Sensors 2019, 19, 3371. [Google Scholar] [CrossRef]
- Shen, Y.T.; Lee, Y.; Kwon, H.; Conover, D.M.; Bhattacharyya, S.S.; Vale, N.; Gray, J.D.; Leong, G.J.; Evensen, K.; Skirlo, F. Archangel: A Hybrid UAV-Based Human Detection Benchmark with Position and Pose Metadata. IEEE Access 2023, 11, 80958–80972. [Google Scholar] [CrossRef]
- Fei, S.; Hassan, M.A.; Xiao, Y.; Su, X.; Chen, Z.; Cheng, Q.; Duan, F.; Chen, R.; Ma, Y. UAV-based multi-sensor data fusion and machine learning algorithm for yield prediction in wheat. Precis. Agric. 2023, 24, 187–212. [Google Scholar] [CrossRef]
- Alhafnawi, M.; Salameh, H.B.; Masadeh, A.; Al-Obiedollah, H.; Ayyash, M.; El-Khazali, R.; Elgala, H. A Survey of Indoor and Outdoor UAV-Based Target Tracking Systems: Current Status, Challenges, Technologies, and Future Directions. IEEE Access 2023, 11, 68324–68339. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Lo, L.-Y.; Yiu, C.; Tang, Y.; Yang, A.-S.; Li, B.; Wen, C.-Y. Dynamic Object Tracking on Autonomous UAV System for Surveillance Applications. Sensors 2021, 21, 7888. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Tang, L.; Hupy, J.P.; Wang, Y.; Shao, G. A commentary review on the use of normalized difference vegetation index (NDVI) in the era of popular remote sensing. J. For. Res. 2021, 32, 1–6. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 11, 257–276. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; Available online: https://arxiv.org/pdf/1504.08083 (accessed on 10 August 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. Available online: https://arxiv.org/pdf/1406.4729 (accessed on 15 August 2023). [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhou, F.; Zhao, H.; Nie, N. Safety Helmet Detection Based on YOLOv5. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021. [Google Scholar]
- Snegireva, D.; Perkova, A. Traffic Sign Recognition Application Using Yolov5 Architecture. In Proceedings of the 2021 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 5–11 September 2021. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Azhar, M.I.H.; Zaman, F.H.K.; Tahir, N.M.; Hashim, H. People Tracking System Using DeepSORT. In Proceedings of the 10th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 August 2020. [Google Scholar]
- Du, Y.; Song, Y.; Yang, B.; Zhao, Y.; Zhao, Y. StrongSORT: Make DeepSORT Great Again. IEEE Trans. Multimed. 2022; early access. [Google Scholar]
- Pereira, R.; Carvalho, G.; Garrote, L.; Nunes, U.J. Sort and Deep-SORT Based Multi-Object Tracking for Mobile Robotics: Evaluation with New Data Association Metrics. Appl. Sci. 2022, 12, 1319. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.U.B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Gustafsson, F. Statistical Sensor Fusion, 3rd ed.; Studentlitteratur AB: Lund, Sweden, 2018. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Gai, Y.; He, W.; Zhou, Z. Pedestrian Target Tracking Based on DeepSORT with YOLOv5. In Proceedings of the 2nd International Conference on Computer Engineering and Intelligent Control (ICCEIC), Chongqing, China, 12–14 November 2021. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Deep SORT. 2017. Available online: https://github.com/nwojke/deep_sort (accessed on 1 April 2023).
- Wang, Y.; Yang, H. Multi-target Pedestrian Tracking Based on YOLOv5 and DeepSORT. In Proceedings of the 2022 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2022. [Google Scholar]
- Parrot. Parrot ANAFI. Professional Drone Camera 4K HDR. 2023. Available online: https://www.parrot.com/en/drones/anafi (accessed on 15 August 2023).
- Developers, A.I. Create an API Key Esri Leaflet. 2023. Available online: https://developers.arcgis.com/esri-leaflet/authentication/createan-api-key/ (accessed on 1 September 2023).
- WGS 84-WGS84-World Geodetic System 1984, Used in GPS. EPSG:4326. 2023. Available online: https://epsg.io/4326 (accessed on 1 April 2023).
- Al Enezi, W.; Verbrugge, C. Offine Grid-Based Coverage path planning for guards in games. arXiv 2020, arXiv:2001.05462. [Google Scholar] [CrossRef]
- Cabreira, T.M.; Ferreira, P.R.; Franco, C.D.; Buttazzo, G.C. Grid-Based Coverage Path Planning with Minimum Energy Over Irregular-Shaped Areas with Uavs. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019. [Google Scholar]
- Gonzalez, E.; Alvarez, O.; Diaz, Y.; Parra, C.; Bustacara, C. BSA: A Complete Coverage Algorithm. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005. [Google Scholar]
- Alkan, H.; Celebi, H. The Implementation of Positioning System with Trilateration of Haversine Distance (PIMRC). In Proceedings of the 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications, Istanbul, Turkey, 8–11 September 2019. [Google Scholar]
- Evan, L. Deep SORT Realtime. 2021. Available online: https://github.com/levan92/deep_sort_realtime (accessed on 15 April 2023).
- Omelianenko, I. Hands-On Neuroevolution with Python: Build High Performing Artificial Neural Network Architectures Using Neuroevolution-Based Algorithms; Packt Publishing Ltd.: Birmingham, UK, 2019; p. 368. [Google Scholar]
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. Multiple object tracking performance metrics and evaluation in a smart room environment. In Proceedings of the Sixth IEEE International Workshop on Visual Surveillance, VS 2006, Graz, Austria, 13 May 2006. [Google Scholar]
- Rahutomo, F.; Kitasuka, T.; Aritsugi, M. Semantic Cosine Similarity. 2012. Available online: https://api.semanticscholar.org/CorpusID:18411090 (accessed on 10 September 2023).
- Tips for Best Training Results—YOLOv5 Docs. Available online: https://docs.ultralytics.com/yolov5/tips_for_best_training_results/ (accessed on 10 April 2023).
- Hensel, S.; Marinov, M.; Dreher, A.; Trendafilov, D. Monocular Depth Estimation for Autonomous UAV Navigation Based on Deep Learning. In Proceedings of the 2023 XXXII International Scientific Conference Electronics (ET), Sozopol, Bulgaria, 13–15 September 2023. [Google Scholar]













| Number of Training Data | 5 | 10 | 15 | 20 | 50 | 75 | 100 | 150 |
|---|---|---|---|---|---|---|---|---|
| Epochs | 10 | 50 | 250 | 500 | ||||
| Batch Size | 2 | 4 | 8 | 16 | 32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hensel, S.; Marinov, M.B.; Panter, R. Design and Implementation of a Camera-Based Tracking System for MAV Using Deep Learning Algorithms. Computation 2023, 11, 244. https://doi.org/10.3390/computation11120244
Hensel S, Marinov MB, Panter R. Design and Implementation of a Camera-Based Tracking System for MAV Using Deep Learning Algorithms. Computation. 2023; 11(12):244. https://doi.org/10.3390/computation11120244
Chicago/Turabian StyleHensel, Stefan, Marin B. Marinov, and Raphael Panter. 2023. "Design and Implementation of a Camera-Based Tracking System for MAV Using Deep Learning Algorithms" Computation 11, no. 12: 244. https://doi.org/10.3390/computation11120244
APA StyleHensel, S., Marinov, M. B., & Panter, R. (2023). Design and Implementation of a Camera-Based Tracking System for MAV Using Deep Learning Algorithms. Computation, 11(12), 244. https://doi.org/10.3390/computation11120244