
NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification


Abstract
:1. Introduction
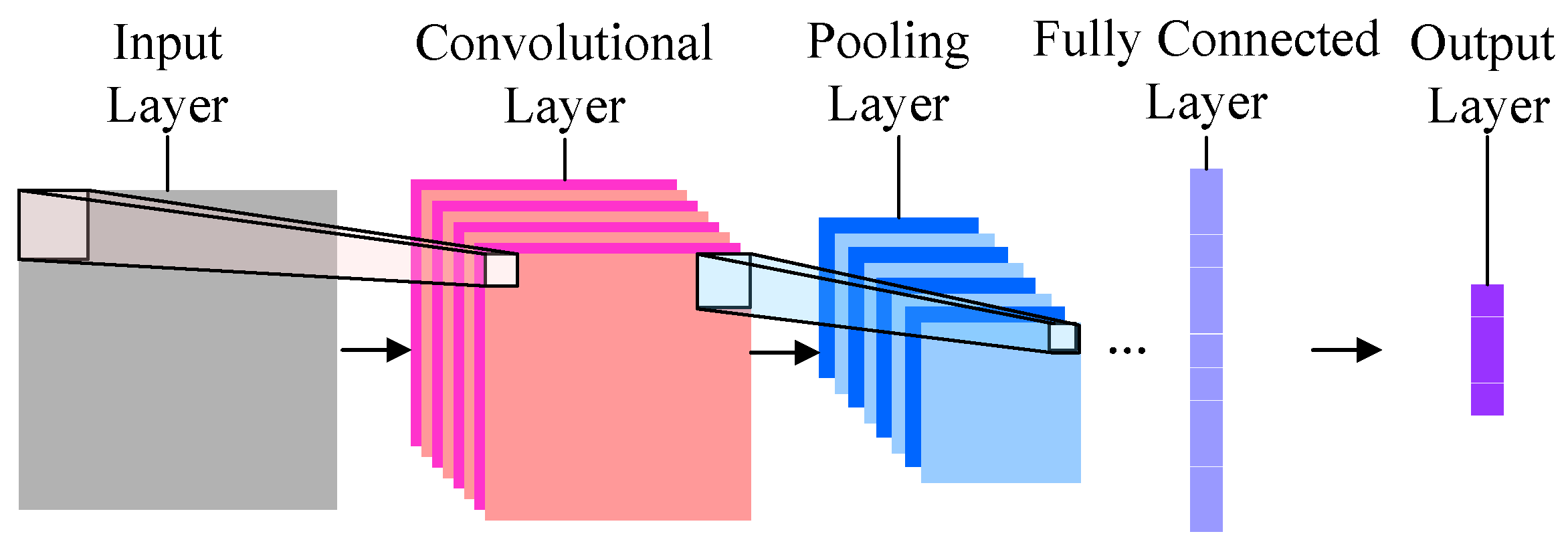
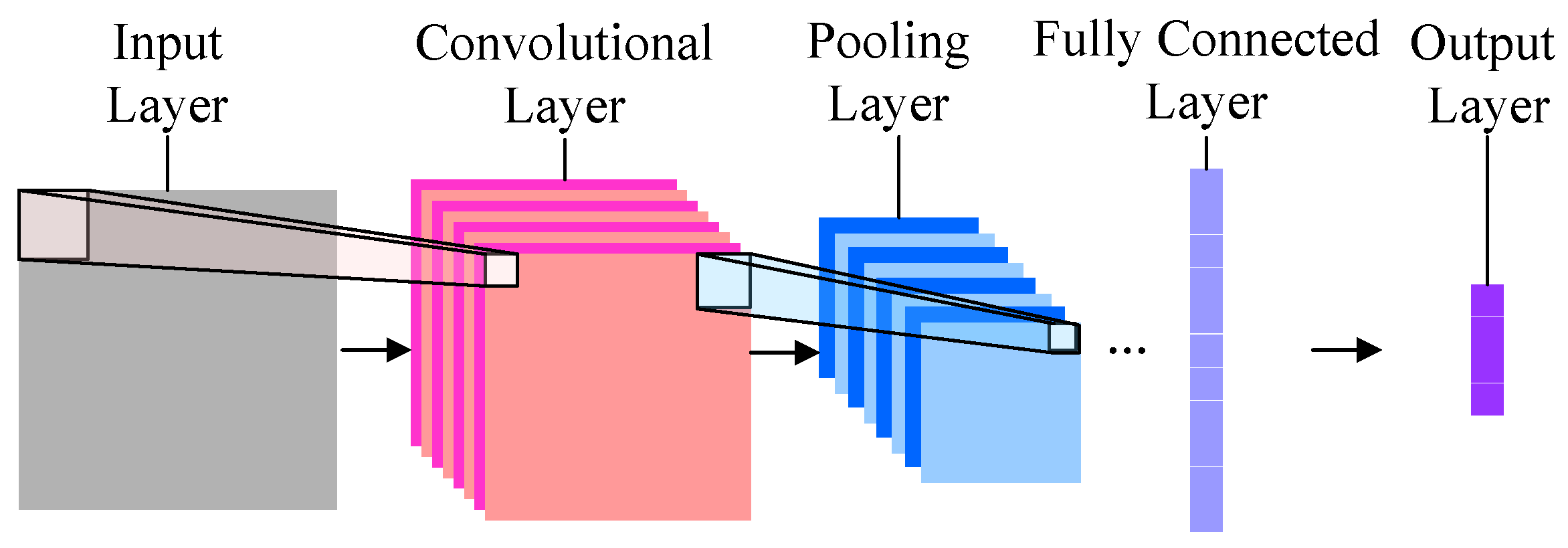
2. Convolutional Neural Networks
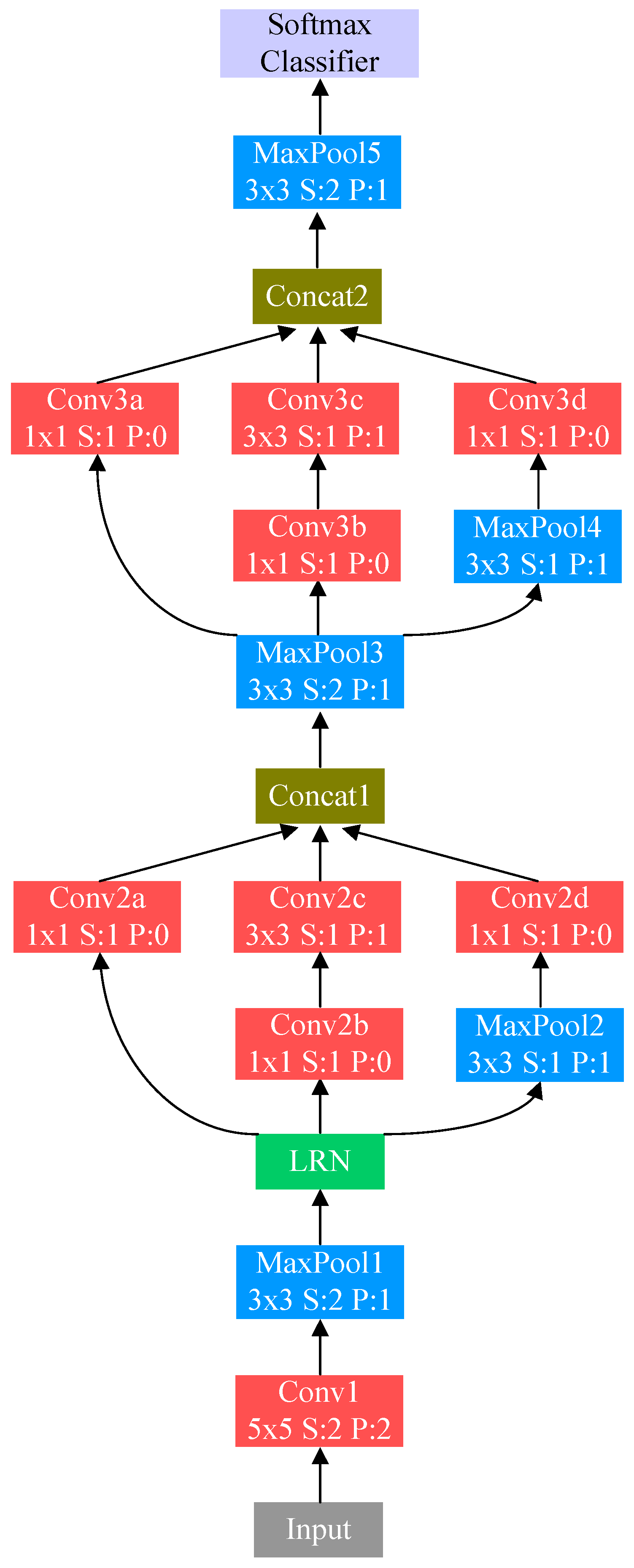
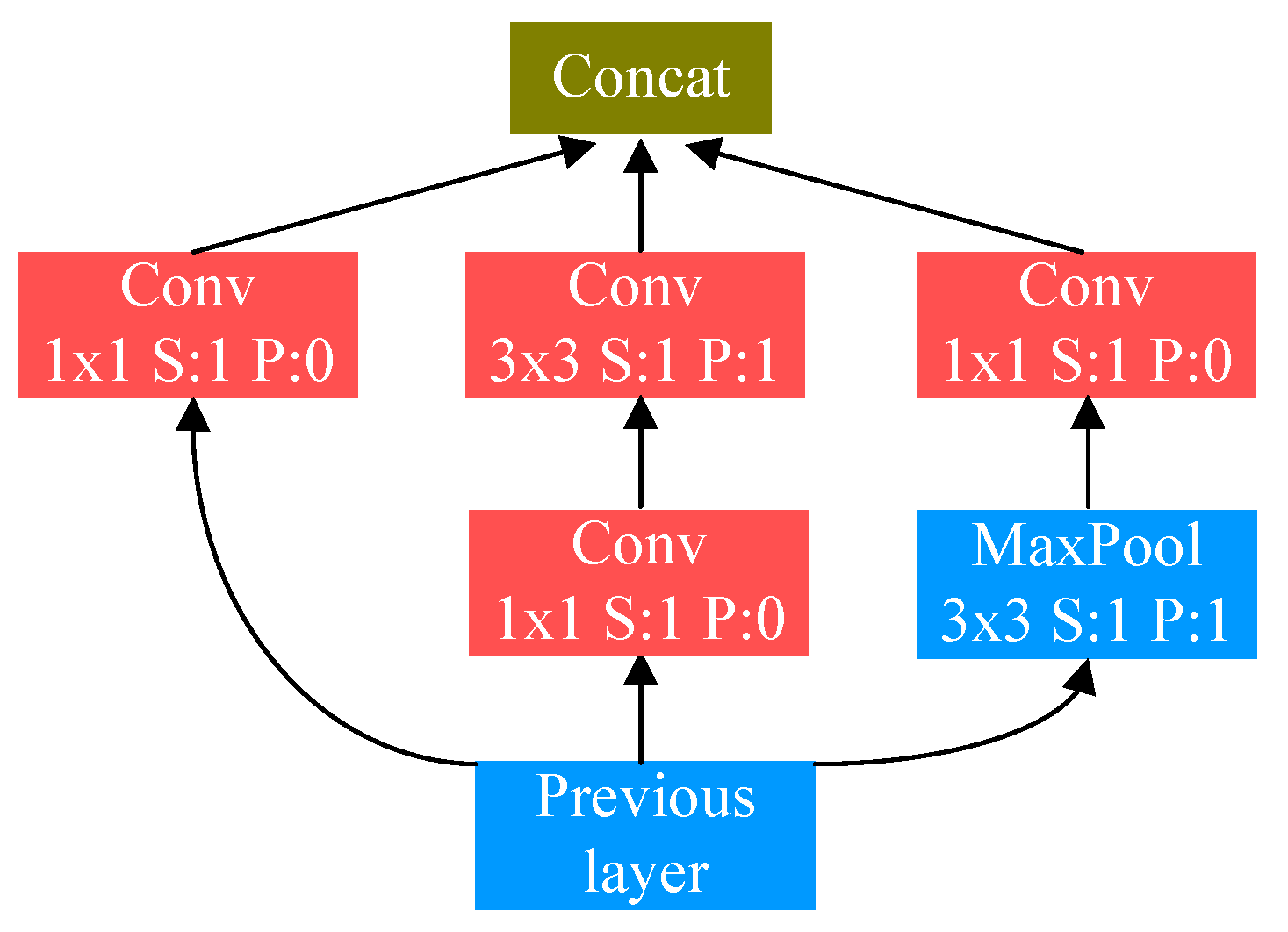
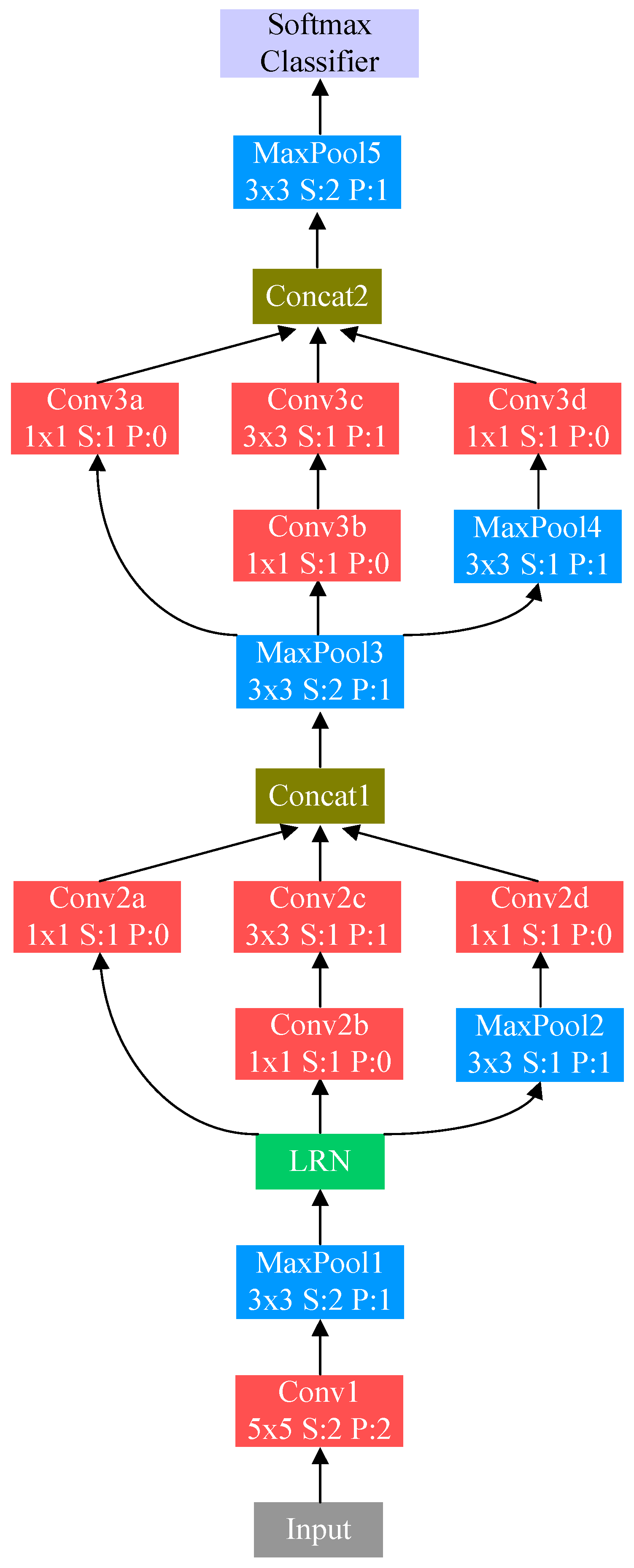
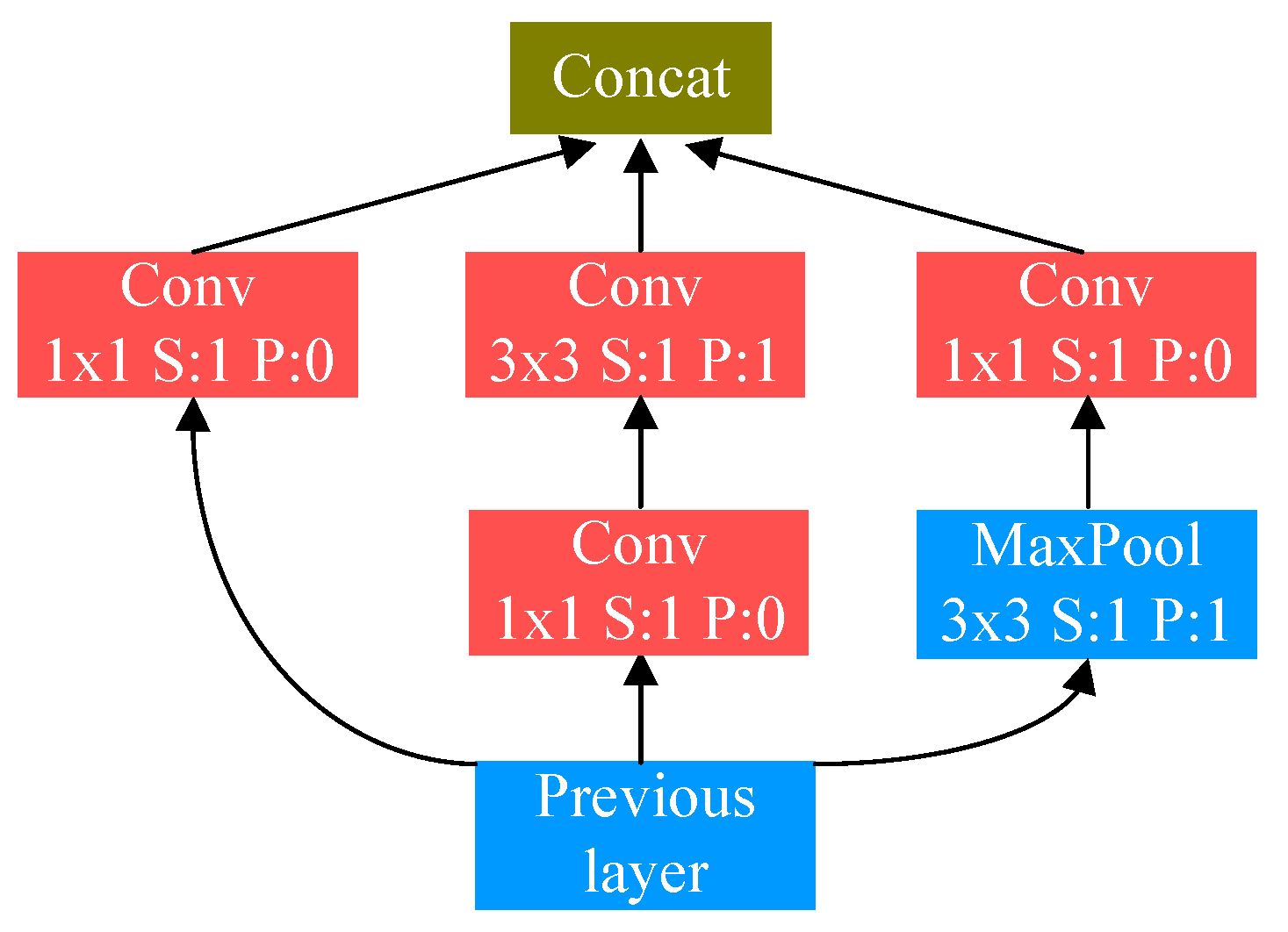
3. Proposed Network Architecture
4. Experiments and Analysis
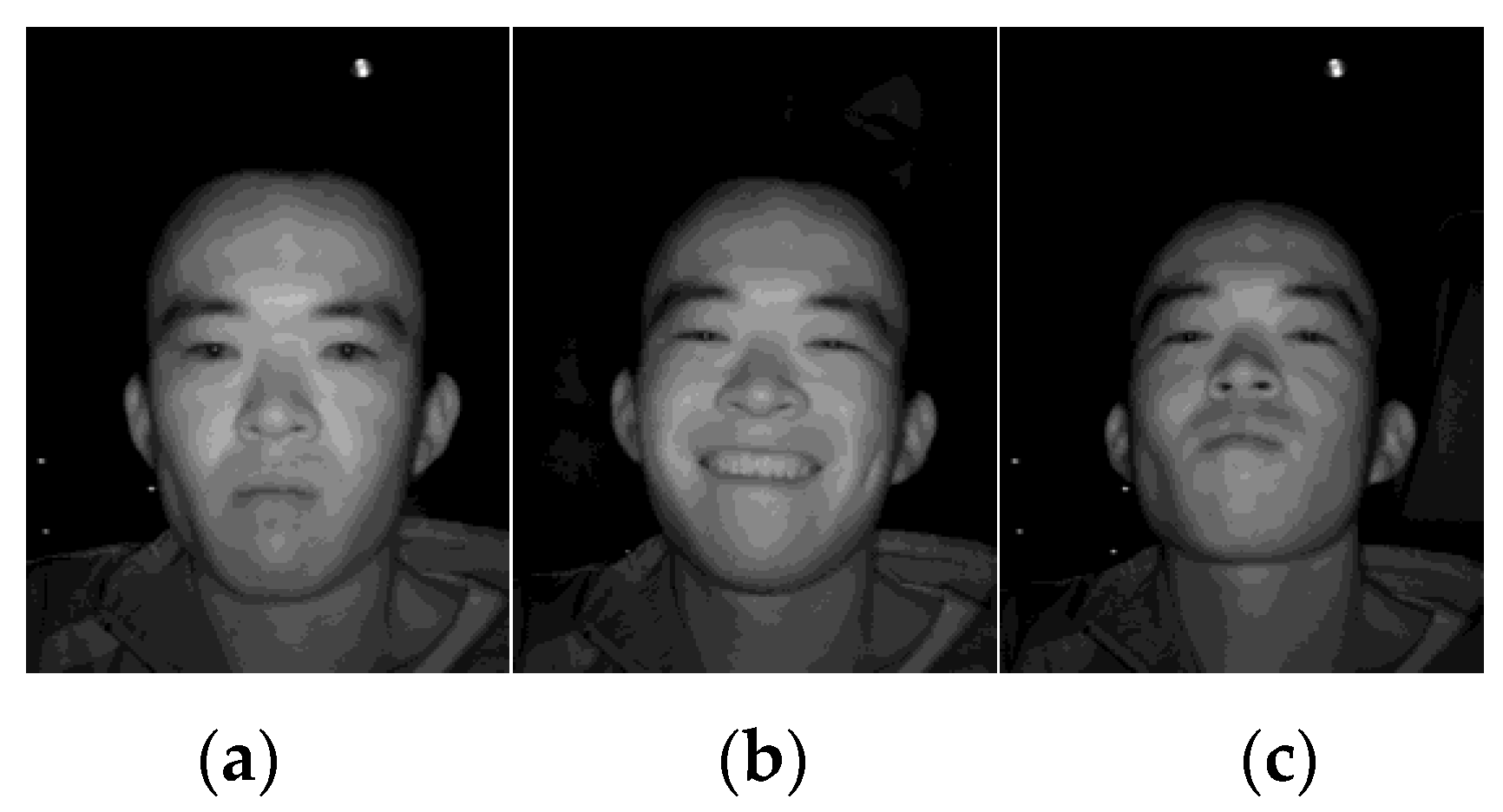
4.1. CASIA NIR Database
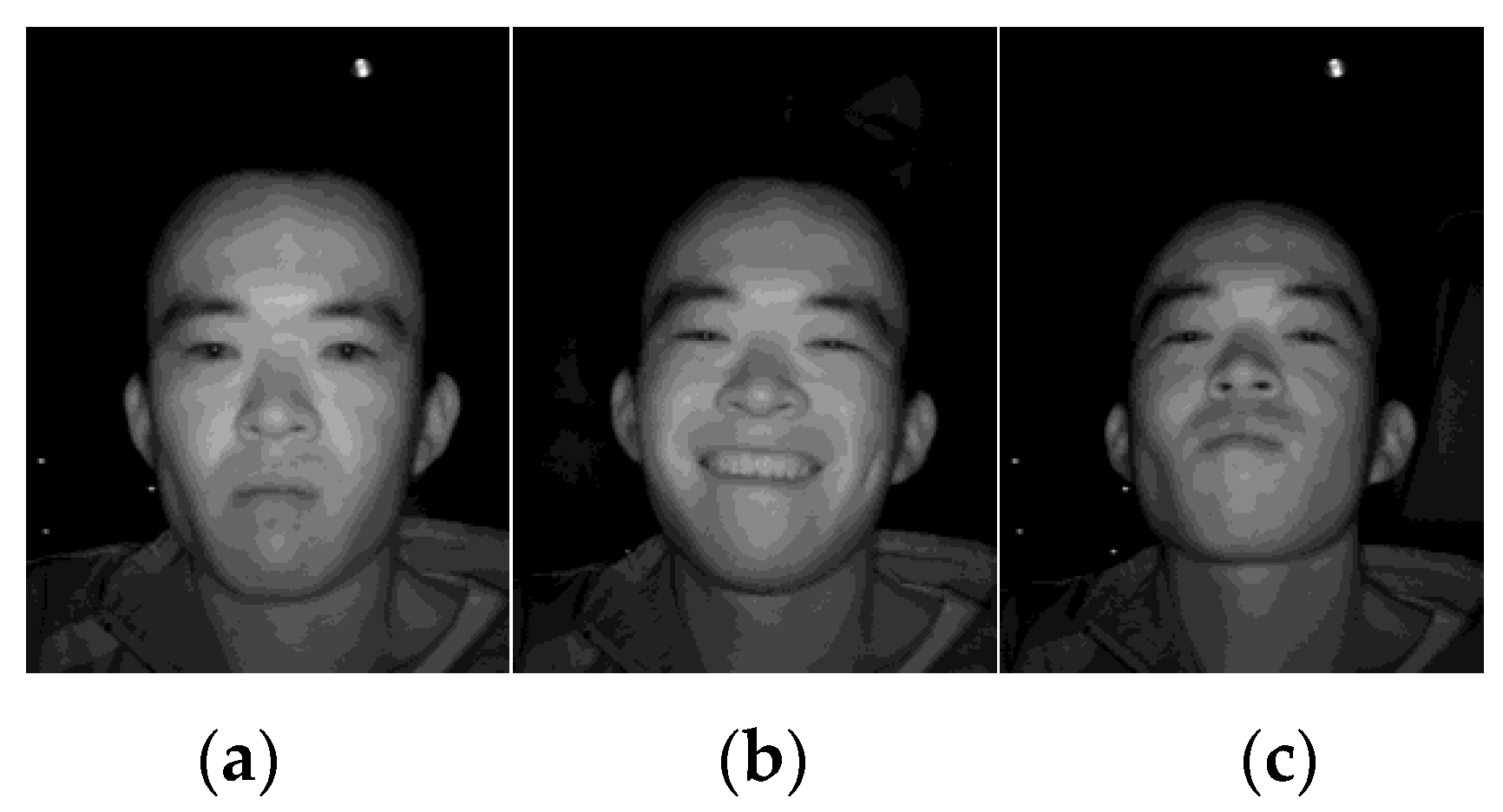
4.2. Data Analysis
4.3. Experimental Results Using Normal Faces
4.4. Experimental Results Using Images with Facial Expressions and Head Rotations
4.5. Experimental Results Using Images with Blur and Noise
4.6. Traning Time and Processing Time
5. Discussion and Conclusion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011.
- Arandjelović, O.; Hammoud, R.; Cipolla, R. Thermal and reflectance based personal identification methodology under variable illumination. Pattern Recognit. 2010, 43, 1801–1813. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Arandjelović, O.; Cipolla, R. Face set classification using maximally probable mutual modes. In Proceedings of the 18 International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006.
- Yin, Q.; Tang, X.; Sun, J. An associate-predict model for face recognition. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011.
- Adini, Y.; Moses, Y.; Ullman, S. Face recognition: the problem of compensating for changes in illumination direction. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 721–732. [Google Scholar] [CrossRef]
- Braje, W.L.; Kersten, D.; Tarr, M.J.; Troje, N.F. Illumination effects in face recognition. Psychobiology 1998, 26, 371–380. [Google Scholar]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005.
- Ochoa-Villegas, M.A.; Nolazco-Flores, J.A.; Barron-Cano, O.; Kakadiaris, I.A. Addressing the illumination challenge in two-dimensional face recognition: A survey. IET Comput. Vis. 2015, 9, 978–992. [Google Scholar] [CrossRef]
- Gökberk, B.; Salah, A.A.; Akarun, L.; Etheve, R.; Riccio, D.; Dugelay, J.-L. 3D face recognition. In Guide to Biometric Reference Systems and Performance Evaluation; Petrovska-Delacrétaz, D., Dorizzi, B., Chollet, G., Eds.; Springer: London, UK, 2009; pp. 263–295. [Google Scholar]
- Drira, H.; Amor, B.B.; Srivastava, A.; Daoudi, M.; Slama, R. 3D face recognition under expressions, occlusions, and pose variations. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2270–2283. [Google Scholar] [CrossRef] [PubMed]
- Liang, R.; Shen, W.; Li, X.-X.; Wang, H. Bayesian multi-distribution-based discriminative feature extraction for 3D face recognition. Inf. Sci. 2015, 320, 406–417. [Google Scholar] [CrossRef]
- Shen, L.; Zheng, S. Hyperspectral face recognition using 3d Gabor wavelets. In Proceedings of the 21st International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012.
- Uzair, M.; Mahmood, A.; Mian, A. Hyperspectral face recognition with spatiospectral information fusion and PLS regression. IEEE Trans. Image Process. 2015, 24, 1127–1137. [Google Scholar] [CrossRef] [PubMed]
- Cho, W.; Koschan, A.; Abidi, M.A. Hyperspectral face databases for facial recognition research. In Face Recognition across the Imaging Spectrum; Bourlai, T., Ed.; Springer: Cham, Switzerland, 2016; pp. 47–68. [Google Scholar]
- Hermosilla, G.; Ruiz-del-Solar, J.; Verschae, R.; Correa, M. A comparative study of thermal face recognition methods in unconstrained environments. Pattern Recognit. 2012, 45, 2445–2459. [Google Scholar] [CrossRef]
- Ghiass, R.S.; Arandjelović, O.; Bendada, A.; Maldague, X. Infrared face recognition: A comprehensive review of methodologies and databases. Pattern Recognit. 2014, 47, 2807–2824. [Google Scholar] [CrossRef]
- Choraś, R.S. Thermal face recognition. In Image Processing and Communications Challenges 7; Choraś, R.S., Ed.; Springer: Cham, Switzerland, 2016; pp. 37–46. [Google Scholar]
- Li, B.Y.L.; Mian, A.S.; Liu, W.; Krishna, A. Using kinect for face recognition under varying poses, expressions, illumination and disguise. In Proceedings of 2013 IEEE Workshop on Applications of Computer Vision, Clearwater Beach, FL, USA, 15–17 January 2013; pp. 186–192.
- Goswami, G.; Bharadwaj, S.; Vatsa, M.; Singh, R. On RGB-D face recognition using Kinect. In Proceedings of IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–2 October 2013.
- Li, B.Y.L.; Mian, A.S.; Liu, W.; Krishna, A. Face recognition based on Kinect. Pattern Anal. Appl. 2016, 19, 977–987. [Google Scholar] [CrossRef]
- Goswami, G.; Vatsa, M.; Singh, R. Face recognition with RGB-D images using Kinect. In Face Recognition across the Imaging Spectrum; Bourlai, T., Ed.; Springer: Cham, Switzerland, 2016; pp. 281–303. [Google Scholar]
- Li, S.Z.; Chu, R.; Liao, S.; Zhang, L. Illumination invariant face recognition using near-infrared images. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 627–639. [Google Scholar] [CrossRef] [PubMed]
- Li, S.Z.; Yi, D. Face recognition, near-infrared. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Farokhi, S.; Shamsuddin, S.M.; Sheikh, U.U.; Flusser, J. Near infrared face recognition: A comparison of moment-based approaches. In Innovation Excellence towards Humanistic Technology; Springer: Singapore, 2014; pp. 129–135. [Google Scholar]
- Farokhi, S.; Sheikh, U.U.; Flusser, J.; Shamsuddin, S.M.; Hashemi, H. Evaluating feature extractors and dimension reduction methods for near infrared face recognition systems. Jurnal Teknologi 2014, 70, 23–33. [Google Scholar] [CrossRef]
- Farokhi, S.; Shamsuddin, S.M.; Sheikh, U.U.; Flusser, J.; Khansari, M.; Jafari-Khouzani, K. Near infrared face recognition by combining Zernike moments and undecimated discrete wavelet transform. Digit. Signal Process. 2014, 31, 13–27. [Google Scholar] [CrossRef]
- Farokhi, S.; Sheikh, U.U.; Flusser, J.; Yang, B. Near infrared face recognition using Zernike moments and Hermite kernels. Inf. Sci. 2015, 316, 234–245. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708.
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 Classes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898.
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. 2014; arXiv:1411.7923. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Lécun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Twenty-sixth Annual Conference on Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–8 December 2012.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587.
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 July 2008.
- Abdel-Hamid, O.; Mohamed, A.-R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012.
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceeding of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013.
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010.
- Bouchard, G. Efficient bounds for the softmax function and applications to approximate inference in hybrid models. In Proceedings of NIPS 2007 workshop for approximate Bayesian inference in continuous/hybrid systems, Whistler, BC, Canada, 7–8 December 2007.
- Wilson, D.R.; Martinez, T.R. The general inefficiency of batch training for gradient descent learning. Neural Netw. 2003, 16, 1429–1451. [Google Scholar] [CrossRef]
- McDonnell, M.D.; Tissera, M.D.; Vladusich, T.; van Schaik, A.; Tapson, J. Fast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the “Extreme Learning Machine” algorithm. PLoS ONE 2015, 10, e0134254. [Google Scholar] [CrossRef] [PubMed]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When face recognition meets with deep learning: An evaluation of convolutional neural networks for face recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 13–16 December 2015; pp. 142–150.
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle type classification using a semi supervised convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Hayder, M.; Haider, A.; Naz, E. Robust Convolutional Neural Networks for Image Recognition. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 105–111. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. 2015; arXiv:1512.00567. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikinen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Castrillón, M.; Déniz, O.; Guerra, C.; Hernández, M. ENCARA2: Real-time detection of multiple faces at different resolutions in video streams. J. Vis. Commun. Image Represent. 2007, 18, 130–140. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678.
- Ren, J.; Jiang, X.; Yuan, J. Noise-resistant local binary pattern with an embedded error-correction mechanism. IEEE Trans. Image Process. 2013, 22, 4049–4060. [Google Scholar] [CrossRef] [PubMed]
- Kemelmacher-Shlizerman, I.; Seitz, S.; Miller, D.; Brossard, E. The MegaFace benchmark: 1 million faces for recognition at scale. 2016; arXiv:1512.00596. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Output Size |
|---|---|
| Input | 112 × 112 |
| Conv1 | 64 × 56 × 56 |
| Maxpool1 | 64 × 28 × 28 |
| LRN | 64 × 28 × 28 |
| Conv2a | 64 × 28 × 28 |
| Conv2b | 64 × 28 × 28 |
| Conv2c | 128 × 28 × 28 |
| Maxpool2 | 64 × 28 × 28 |
| Conv2d | 64 × 28 × 28 |
| Concat1 | 256 × 28 × 28 |
| Maxpool3 | 256 × 14 × 14 |
| Conv3a | 128 × 14 × 14 |
| Conv3b | 128 × 14 × 14 |
| Conv3c | 192 × 14 × 14 |
| Maxpool4 | 256 × 14 × 14 |
| Conv3d | 128 × 14 × 14 |
| Concat2 | 448 × 14 × 14 |
| Maxpool5 | 448 × 7 × 7 |
| Softmax Classifier | 197 × 1 × 1 |
| Test Set ID | Method to Generate |
|---|---|
| 1 | Exclude the training set |
| For each person, select three pictures of normal face | |
| Exclude the person if there is less than three pictures left | |
| 459 pictures from 153 persons are selected to form the test set | |
| 2 | Exclude the training set |
| Select all the other pictures, except the pictures of persons with glasses | |
| 2739 pictures are selected to form the test set | |
| 3 | Add motion blur to Test Set 2, with a length of nine pixels and an angle randomly sampled in the range of 0–360° |
| 4 | Add Gaussian blur to Test Set 2, with standard deviation of 0.5 |
| 5 | Add Gaussian blur to Test Set 2, with standard deviation of 2 |
| 6 | Add salt-pepper noise to Test Set 2, with density of 0.01 |
| 7 | Add salt-pepper noise to Test Set 2, with density of 0.1 |
| 8 | Add Gaussian noise to Test Set 2, with mean of 0 and variance of 0.001 |
| 9 | Add Gaussian noise to Test Set 2, with mean of 0 and variance of 0.01 |
| LBP + PCA | LBP Histogram | ZMUDWT | ZMHK | GoogLeNet softmax0 | GoogLeNet softmax1 | GoogLeNet softmax2 | NIRFaceNet | |
|---|---|---|---|---|---|---|---|---|
| Identification Rate (%) | 89.76 | 87.34 | 95.64 | 100 | 99.02 | 98.8 | 98.74 | 100 |
| LBP + PCA | LBP Histogram | ZMUDWT | ZMHK | GoogLeNet softmax0 | GoogLeNet softmax1 | GoogLeNet softmax2 | NIRFaceNet | |
|---|---|---|---|---|---|---|---|---|
| Identification Rate (%) | 80.94 | 87.34 | 90.18 | 96.5 | 95.64 | 95.15 | 94.73 | 98.28 |
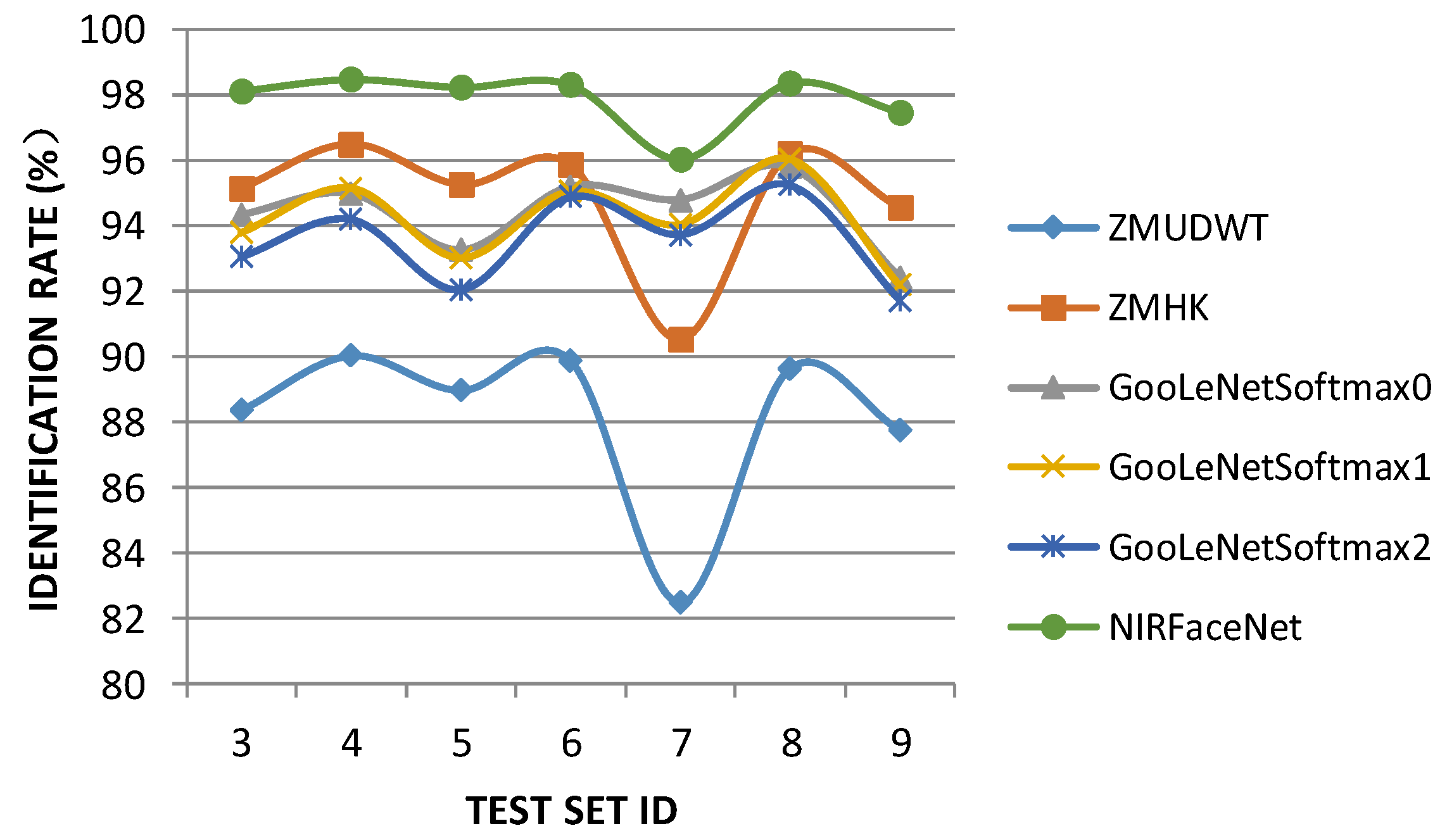
| Identification Rate (%) | Motion Blur | Gaussian Blur | Salt-Pepper Noise | Gaussian Noise | |||
|---|---|---|---|---|---|---|---|
| Test Set 3 (density 9) | Test Set 4 (density 0.5) | Test Set 5 (density 2) | Test Set 6 (density 0.01) | Test Set 7 (density 0.1) | Test Set 8 (density 0.001) | Test Set 9 (density 0.01) | |
| LBP + PCA | 30.92 | 76.85 | 30.27 | 78.02 | 20.45 | 0.99 | 0.66 |
| LBP Histogram | 54.14 | 82.99 | 46.4 | 81.38 | 12.6 | 1.61 | 1.35 |
| ZMUDWT | 88.35 | 90.03 | 88.97 | 89.89 | 82.48 | 89.63 | 87.77 |
| ZMHK | 95.14 | 96.50 | 95.25 | 95.87 | 90.51 | 96.20 | 94.56 |
| GoogLeNet softmax0 | 94.33 | 94.98 | 93.25 | 95.2 | 94.79 | 95.79 | 92.41 |
| GoogLeNet softmax1 | 93.79 | 95.15 | 93.03 | 95.05 | 94.04 | 96.03 | 92.20 |
| GoogLeNet softmax2 | 93.04 | 94.20 | 92.04 | 94.88 | 93.73 | 95.25 | 91.73 |
| NIRFaceNet | 98.12 | 98.48 | 98.24 | 98.32 | 96.02 | 98.36 | 97.48 |
| Method | Time (h) |
|---|---|
| GoogLeNet | 104 |
| NIRFaceNet | 30 |
| Methods | Processing Time(s) |
|---|---|
| LBP + PCA | 0.078 |
| LBP histogram | 0.069 |
| ZMUDWT | 0.315 |
| ZMHK | 0.214 |
| GoogLeNet | 0.07 |
| NIRFaceNet | 0.025 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, M.; Wang, C.; Chen, T.; Liu, G. NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification. Information 2016, 7, 61. https://doi.org/10.3390/info7040061
Peng M, Wang C, Chen T, Liu G. NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification. Information. 2016; 7(4):61. https://doi.org/10.3390/info7040061
Chicago/Turabian StylePeng, Min, Chongyang Wang, Tong Chen, and Guangyuan Liu. 2016. "NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification" Information 7, no. 4: 61. https://doi.org/10.3390/info7040061
APA StylePeng, M., Wang, C., Chen, T., & Liu, G. (2016). NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification. Information, 7(4), 61. https://doi.org/10.3390/info7040061