
G-TS-HRNN: Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network


Abstract
1. Introduction
1.1. Hopfield Recurrent Neural Network: Main Knowledge
1.2. State of the Art
1.3. Contributions
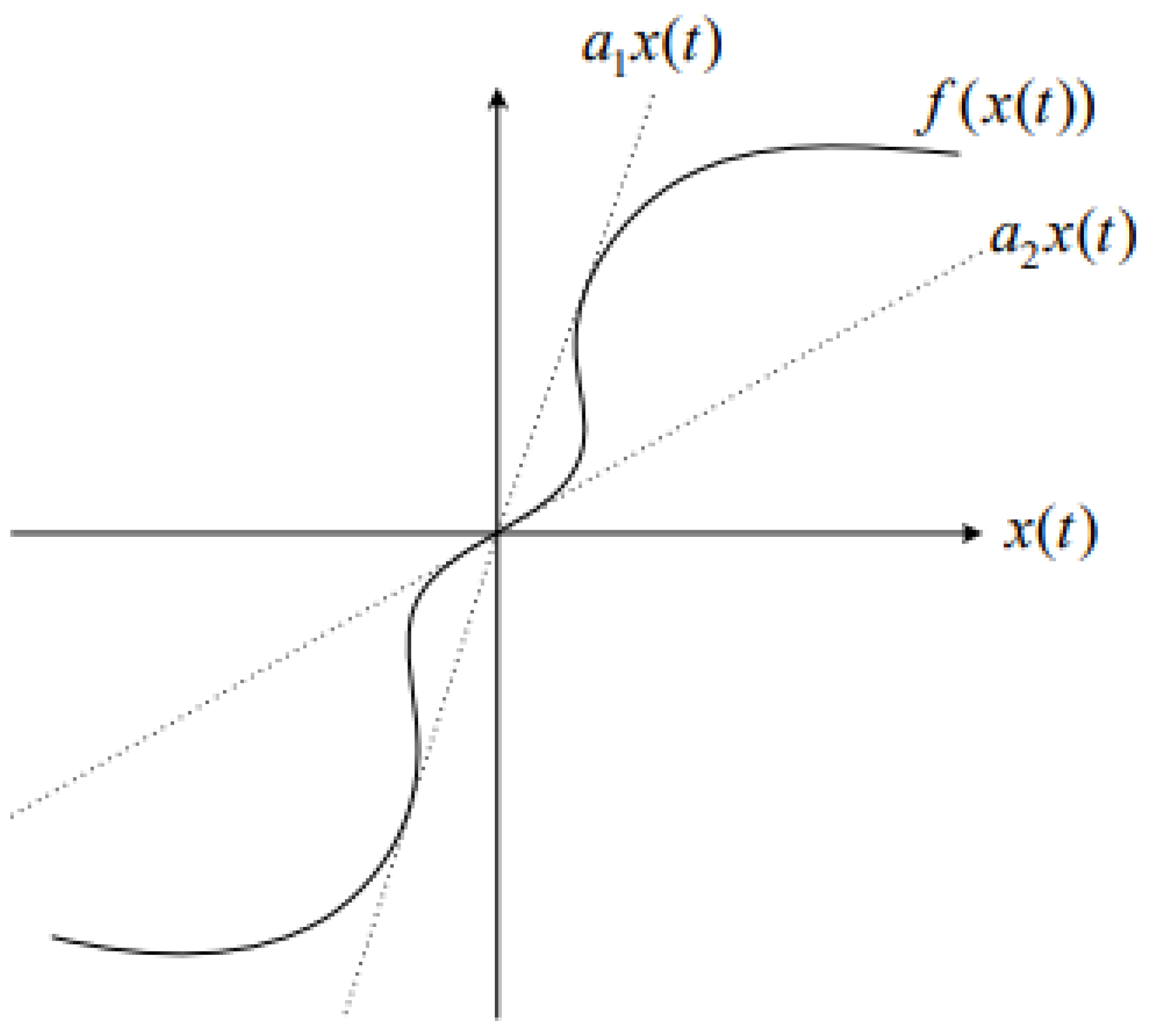
2. Sector Nonlinearity to Takagi–Sugeno Fuzzy Model
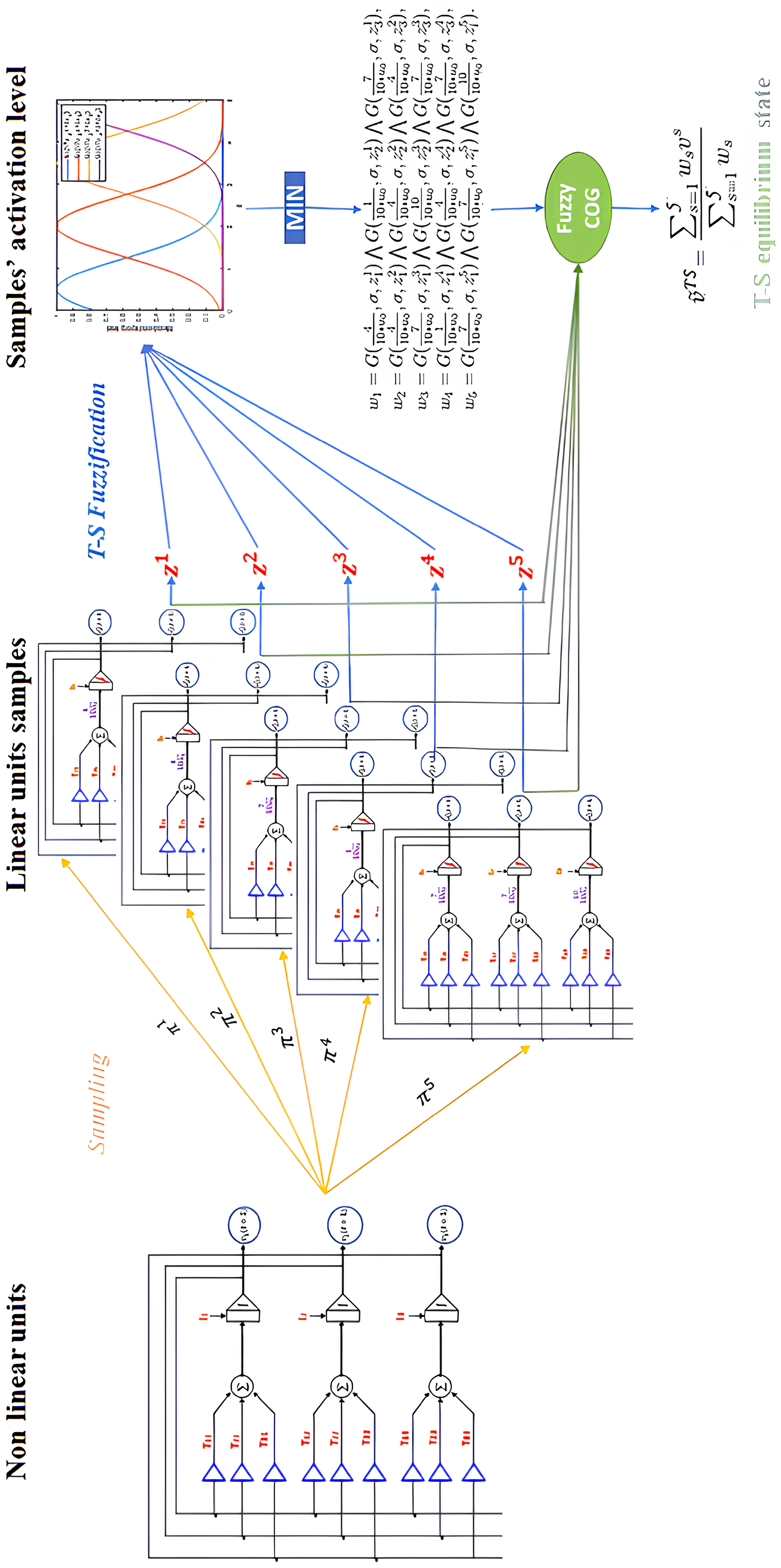
3. Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network (G-TS-HRNN)
4. G-TS-HRNN for the Classification Problem Using Vector Support Machine
- if is , is , and is ,
- then
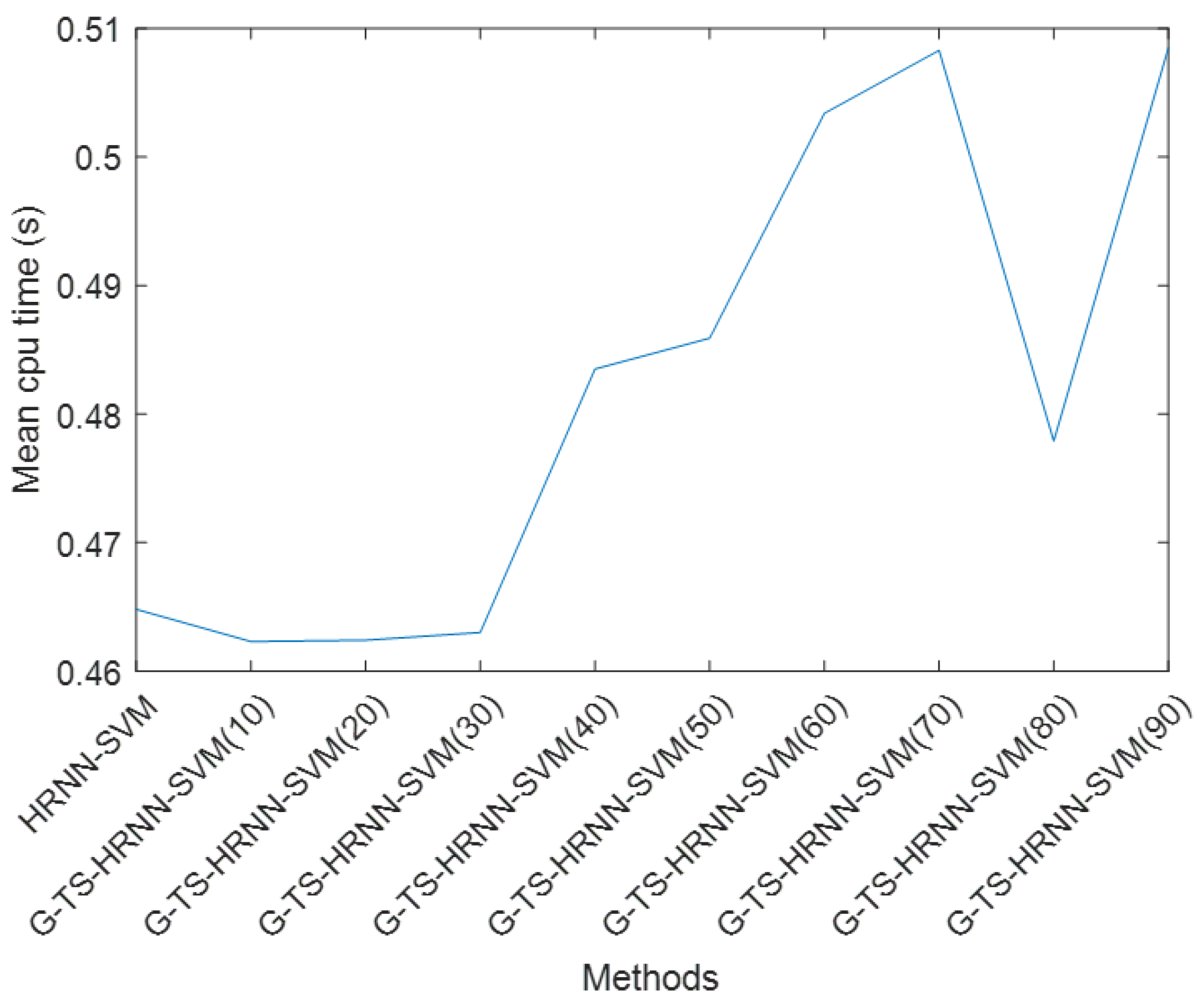
5. Experimentation
5.1. Testing and Benchmarking on Blind Entities
5.2. Application to the Classification Problem
- Precision: Precision is the number of positive samples compared to the ones that the classifier labels positive and is used to evaluate the accuracy of the classifier’s predictions.
- Recall: Recall is the number of samples that were correctly predicted as positive compared to actual positive samples. The importance of such a metric can be observed in sensitive applications whereby accurate predictions of rare instances are essential.
- F-Measure: The F-Measure is
- Geometric mean: The geometric mean is a metric that is employed to calculate the balance of performances in terms of the classification of minority and majority classes. It is effective when evaluating classifiers when addressing imbalanced data.
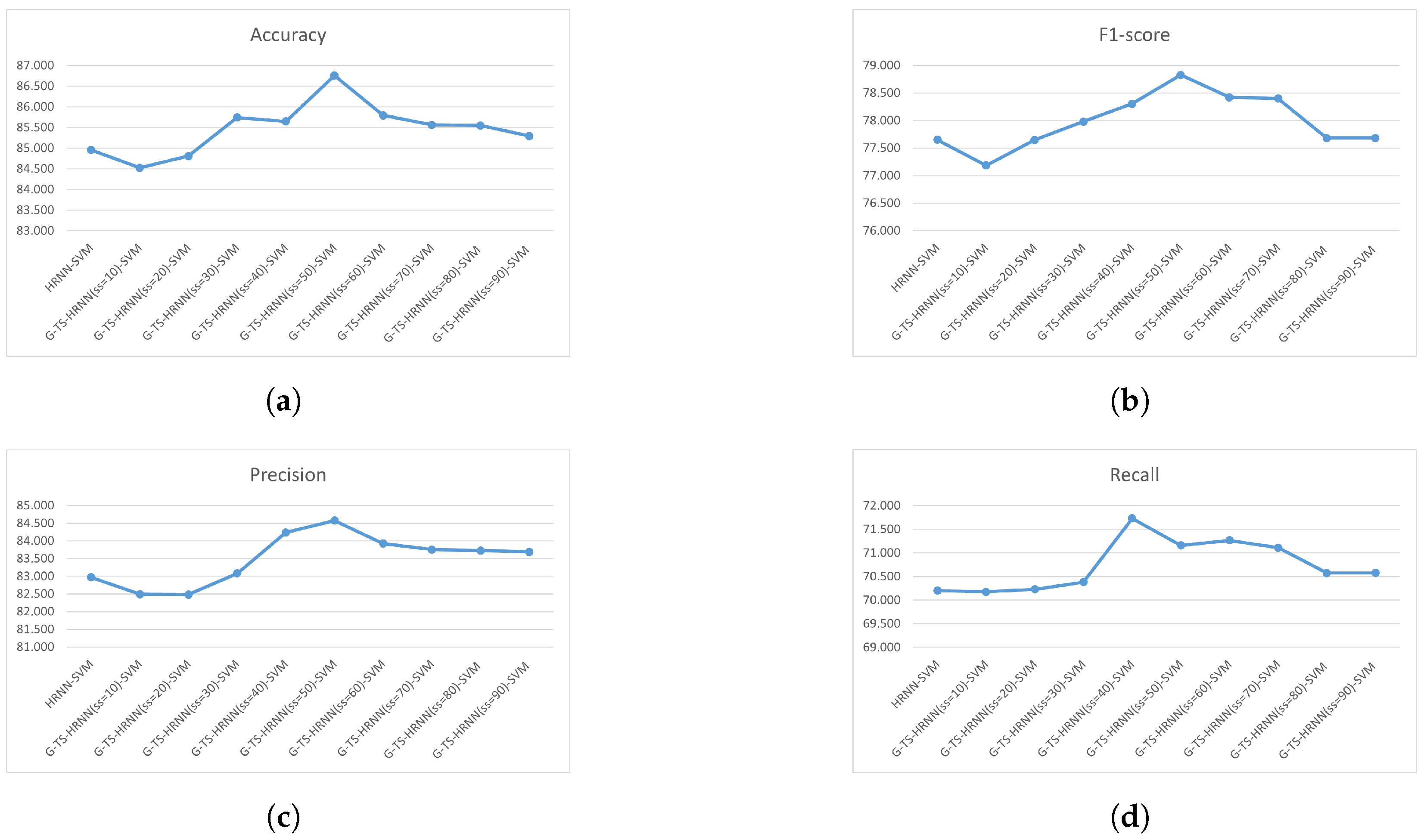
- Physics and Chemistry: the only data set from this field is wine. From Table 3, we have CI(G-TS-HRNN-SVM-50) = ±0.12; CI(G-TS-HRNN-SVM-60) = ±0.09; CI(G-TS-HRNN-SVM-70) = ±0.12. Thus, the most stable version in this field is G-TS-HRNN-SVM-60.
- Biology: the data sets from this field are Iris, Abalone, Ecoli, and Seed. From Table 3, we have CI(G-TS-HRNN-SVM-50) = ±0.20; CI(G-TS-HRNN-SVM-60) = ±0.17; CI(G-TS-HRNN-SVM-70) = ±0.14. Thus, the most stable version in this field is G-TS-HRNN-SVM-70.
- Health and Medicine: the data sets from this field are Liver, Spect, and Pima. From Table 3, we have CI(G-TS-HRNN-SVM-50) = ±0.18; CI(G-TS-HRNN-SVM-60) = ±0.17; CI(G-TS-HRNN-SVM-70) = ±0.13. Thus, the most stable version in this field is G-TS-HRNN-SVM-70.
- Social Science: the only data set from this field is Balance. From Table 3, we have CI(G-TS-HRNN-SVM-50) = ±0.19; CI(G-TS-HRNN-SVM-60) = ±0.16; CI(G-TS-HRNN-SVM-70) = ±0.12. Thus, the most stable version in this field is G-TS-HRNN-SVM-70.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVM-HRNN | T-S SVM-HRNN sample size = 10 | |||||||
| Accuracy | F1-score | Precision | Recall | Accuracy | F1-score | Precision | Recall | |
| Iris | 95.93 | 94.65 | 89.88 | 94.87 | 96.92 | 93.10 | 87.95 | 95.61 |
| Abalone | 81.22 | 42.66 | 83.28 | 33.04 | 79.67 | 40.93 | 83.43 | 31.57 |
| Wine | 80.79 | 77.86 | 73.53 | 74.64 | 79.27 | 77.30 | 74.38 | 74.86 |
| Ecoli | 87.33 | 97.04 | 97.43 | 97.59 | 87.35 | 95.25 | 96.35 | 98.40 |
| Balance | 79.70 | 70.61 | 56.02 | 64.97 | 80.27 | 71.28 | 55.78 | 63.46 |
| Liver | 80.42 | 77.75 | 77.90 | 70.14 | 78.95 | 77.99 | 78.74 | 70.11 |
| Spect | 94.69 | 93.17 | 91.97 | 71.62 | 94.32 | 92.96 | 90.67 | 72.08 |
| Seed | 85.35 | 83.34 | 92.41 | 75.41 | 85.71 | 83.11 | 91.72 | 75.06 |
| Pima | 79.20 | 61.78 | 84.32 | 49.55 | 78.25 | 62.77 | 83.41 | 50.45 |
| T-S SVM-HRNN sample size = 20 | T-S SVM-HRNN sample size = 30 | |||||||
| Accuracy | F1-score | Precision | Recall | Accuracy | F1-score | Precision | Recall | |
| Iris | 94.50 | 95.48 | 89.70 | 95.26 | 96.83 | 94.58 | 90.27 | 94.51 |
| Abalone | 80.67 | 43.92 | 82.45 | 32.67 | 80.23 | 44.05 | 83.39 | 32.09 |
| Wine | 80.22 | 76.48 | 73.85 | 75.65 | 81.94 | 77.52 | 74.60 | 74.38 |
| Ecoli | 87.60 | 96.63 | 96.35 | 96.44 | 87.13 | 96.44 | 97.47 | 98.86 |
| Balance | 81.14 | 70.73 | 54.77 | 64.24 | 81.36 | 71.74 | 55.75 | 65.33 |
| Liver | 79.55 | 77.19 | 79.11 | 70.20 | 82.21 | 78.60 | 77.67 | 71.03 |
| Spect | 93.68 | 92.10 | 90.66 | 72.68 | 95.78 | 93.38 | 91.55 | 71.54 |
| Seed | 86.77 | 84.63 | 92.13 | 76.62 | 86.43 | 84.23 | 92.16 | 74.54 |
| Pima | 79.15 | 61.69 | 83.32 | 48.30 | 79.79 | 61.31 | 84.88 | 51.16 |
| T-S SVM-HRNN sample size = 40 | T-S SVM-HRNN sample size = 50 | |||||||
| Accuracy | F1-score | Precision | Recall | Accuracy | F1-score | Precision | Recall | |
| Iris | 97.27 | 94.96 | 91.94 | 94.84 | 96.23 | 97.01 | 92.19 | 95.11 |
| Abalone | 81.50 | 44.17 | 83.46 | 35.02 | 82.26 | 43.47 | 85.40 | 35.41 |
| Wine | 81.27 | 78.83 | 75.32 | 76.35 | 82.62 | 79.57 | 75.14 | 75.43 |
| Ecoli | 88.74 | 97.29 | 99.14 | 98.11 | 89.16 | 97.43 | 99.33 | 97.82 |
| Balance | 80.10 | 70.49 | 55.55 | 67.25 | 82.12 | 72.13 | 58.25 | 65.46 |
| Liver | 82.65 | 78.40 | 79.50 | 71.65 | 82.89 | 78.35 | 78.46 | 71.14 |
| Spect | 94.57 | 93.27 | 94.17 | 73.79 | 96.64 | 95.27 | 92.99 | 72.62 |
| Seed | 85.98 | 83.59 | 93.71 | 76.79 | 87.28 | 83.96 | 94.57 | 77.12 |
| Pima | 78.76 | 63.74 | 85.37 | 51.78 | 81.64 | 62.25 | 84.86 | 50.33 |
| T-S SVM-HRNN sample size = 60 | T-S SVM-HRNN sample size = 70 | |||||||
| Accuracy | F1-score | Precision | Recall | Accuracy | F1-score | Precision | Recall | |
| Iris | 97.51 | 95.27 | 91.09 | 95.53 | 96.69 | 95.65 | 89.88 | 94.72 |
| Abalone | 82.30 | 43.32 | 84.65 | 32.78 | 80.78 | 44.51 | 84.52 | 33.93 |
| Wine | 82.53 | 78.44 | 75.02 | 76.74 | 81.03 | 77.47 | 75.17 | 75.63 |
| Ecoli | 88.30 | 98.40 | 98.21 | 99.42 | 86.88 | 98.87 | 96.96 | 98.69 |
| Balance | 81.03 | 71.57 | 56.64 | 66.38 | 81.17 | 71.42 | 56.24 | 66.04 |
| Liver | 80.37 | 77.57 | 79.77 | 71.47 | 80.98 | 78.62 | 77.88 | 71.50 |
| Spect | 95.92 | 93.92 | 92.93 | 71.73 | 94.72 | 92.92 | 93.71 | 73.17 |
| Seed | 85.28 | 84.75 | 92.46 | 76.43 | 87.06 | 83.06 | 93.66 | 75.34 |
| Pima | 78.90 | 62.55 | 84.58 | 50.90 | 80.78 | 63.10 | 85.76 | 50.96 |
| T-S SVM-HRNN sample size = 80 | T-S SVM-HRNN sample size = 90 | |||||||
| Accuracy | F1-score | Precision | Recall | Accuracy | F1-score | Precision | Recall | |
| Iris | 95.28 | 95.43 | 91.41 | 95.41 | 96.53 | 94.04 | 90.06 | 95.65 |
| Abalone | 81.74 | 42.52 | 85.01 | 33.75 | 80.96 | 43.28 | 84.73 | 33.52 |
| Wine | 82.51 | 77.17 | 73.22 | 75.19 | 81.59 | 79.41 | 74.87 | 75.33 |
| Ecoli | 88.20 | 97.13 | 98.32 | 97.72 | 88.89 | 96.47 | 97.76 | 98.22 |
| Balance | 81.11 | 71.22 | 56.97 | 64.84 | 80.78 | 70.69 | 55.16 | 65.32 |
| Liver | 79.93 | 77.05 | 79.41 | 71.30 | 79.77 | 77.70 | 78.71 | 69.47 |
| Spect | 95.97 | 93.52 | 91.36 | 71.22 | 95.73 | 92.30 | 93.09 | 72.87 |
| Seed | 85.19 | 82.75 | 93.82 | 75.02 | 84.86 | 83.92 | 94.00 | 74.52 |
| Pima | 80.00 | 62.36 | 84.01 | 50.72 | 78.56 | 61.36 | 84.83 | 50.29 |
References
- Mitra, S.; Hayashi, Y. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Trans. Neural Netw. 2000, 11, 748–768. [Google Scholar] [CrossRef] [PubMed]
- Shihabudheen, K.V.; Pillai, G.N. Recent advances in neuro-fuzzy system: A survey. Knowl.-Based Syst. 2018, 152, 136–162. [Google Scholar] [CrossRef]
- Yen, J.; Wang, L.; Gillespie, C.W. Improving the interpretability of TSK fuzzy models by combining global learning and local learning. IEEE Trans. Fuzzy Syst. 1998, 6, 530–537. [Google Scholar] [CrossRef]
- Du, M.; Behera, A.K.; Vaikuntanathan, S. Active oscillatory associative memory. J. Chem. Phys. 2024, 160, 055103. [Google Scholar] [CrossRef]
- Abdulrahman, A.; Sayeh, M.; Fadhil, A. Enhancing the analog to digital converter using proteretic hopfield neural network. Neural Comput. Appl. 2024, 36, 5735–5745. [Google Scholar] [CrossRef]
- Roudani, M.; El Moutaouakil, K.; Palade, V.; Baïzri, H.; Chellak, S.; Cheggour, M. Fuzzy Clustering SMOTE and Fuzzy Classifiers for Hidden Disease Predictions; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2024; Volume 1093. [Google Scholar]
- El Moutaouakil, K.; Bouhanch, Z.; Ahourag, A.; Aberqi, A.; Karite, T. OPT-FRAC-CHN: Optimal Fractional Continuous Hopfield Network. Symmetry 2024, 16, 921. [Google Scholar] [CrossRef]
- Uykan, Z. On the Working Principle of the Hopfield Neural Networks and its Equivalence to the GADIA in Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3294–3304. [Google Scholar] [CrossRef] [PubMed]
- Talaván, P.M.; Yáñez, J. The generalized quadratic knapsack problem. A neuronal network approach. Neural Netw. 2006, 19, 416–428. [Google Scholar] [CrossRef] [PubMed]
- Talaván, P.M.; Yáñez, J. A continuous Hopfield network equilibrium points algorithm. Comput. Oper. Res. 2005, 32, 2179–2196. [Google Scholar] [CrossRef]
- El Ouissari, A.; El Moutaouakil, K. Intelligent optimal control of nonlinear diabetic population dynamics system using a genetic algorithm. Syst. Res. Inf. Technol. 2024, 1, 134–148. [Google Scholar]
- Kurdyukov, V.; Kaziev, G.; Tattibekov, K. Clustering Methods for Network Data Analysis in Programming. Int. J. Commun. Netw. Inf. Secur. 2023, 15, 149–167. [Google Scholar]
- Singh, H.; Sharma, J.R.; Kumar, S. A simple yet efficient two-step fifth-order weighted-Newton method for nonlinear models. Numer. Algorithms 2023, 93, 203–225. [Google Scholar] [CrossRef]
- Bu, F.; Zhang, C.; Kim, E.H.; Yang, D.; Fu, Z.; Pedrycz, W. Fuzzy clustering-based neural network based on linear fitting residual-driven weighted fuzzy clustering and convolutional regularization strategy. Appl. Soft Comput. 2024, 154, 111403. [Google Scholar] [CrossRef]
- Sharma, R.; Goel, T.; Tanveer, M.; Al-Dhaifallah, M. Alzheimer’s Disease Diagnosis Using Ensemble of Random Weighted Features and Fuzzy Least Square Twin Support Vector Machine. IEEE Trans. Emerg. Top. Comput. Intell. 2025; early access. [Google Scholar] [CrossRef]
- Smith, K.A. Neural networks for combinatorial optimization: A review of more than a decade of research. Informs J. Comput. 1999, 11, 15–34. [Google Scholar] [CrossRef]
- Joya, G.; Atencia, M.A.; Sandoval, F. Hopfield neural networks for optimization: Study of the different dynamics. Neurocomputing 2002, 43, 219–237. [Google Scholar] [CrossRef]
- Wang, L. On the dynamics of discrete-time, continuous-state Hopfield neural networks. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 1998, 45, 747–749. [Google Scholar]
- Demidowitsch, B.P.; Maron, I.A.; Schuwalowa, E.S. Metodos Numericos de Analisis; Paraninfo: Madrid, Spain, 1980. [Google Scholar]
- Bagherzadeh, N.; Kerola, T.; Leddy, B.; Brice, R. On parallel execution of the traveling salesman problem on a neural network model. In Proceedings of the IEEE International Conference on Neural Networks, San Diego, CA, USA, 21–24 June 1987; Volume III, pp. 317–324. [Google Scholar]
- Brandt, R.D.; Wang, Y.; Laub, A.J.; Mitra, S.K. Alternative networks for solving the traveling salesman problem and the list-matching problem. In Proceedings of the International Conference on Neural Network (ICNN’88), San Diego, CA, USA, 24–27 July 1988; Volume II, pp. 333–340. [Google Scholar]
- Wu, J.K. Neural Networks and Simulation Methods; Marcel Dekker: New York, NY, USA, 1994. [Google Scholar]
- Abe, S. Global convergence and suppression of spurious states of the Hopfield neural networks. IEEE Trans. Circuits Syst. 1993, 40, 246–257. [Google Scholar] [CrossRef]
- Wang, L.; Smith, K. On chaotic simulated annealing. IEEE Trans. Neural Netw. 1998, 9, 716–718. [Google Scholar] [CrossRef]
- Jin, Q.; Mokhtari, A. Non-asymptotic superlinear convergence of standard quasi-Newton methods. Math. Program. 2023, 200, 425–473. [Google Scholar] [CrossRef]
- Ogwo, G.N.; Alakoya, T.O.; Mewomo, O.T. Iterative algorithm with self-adaptive step size for approximating the common solution of variational inequality and fixed point problems. Optimization 2023, 72, 677–711. [Google Scholar] [CrossRef]
- Gharbia, I.B.; Ferzly, J.; Vohralík, M.; Yousef, S. Semismooth and smoothing Newton methods for nonlinear systems with complementarity constraints: Adaptivity and inexact resolution. J. Comput. Appl. Math. 2023, 420, 114765. [Google Scholar] [CrossRef]
- Candelario, G.; Cordero, A.; Torregrosa, J.R.; Vassileva, M.P. Generalized conformable fractional Newton-type method for solving nonlinear systems. Numer. Algorithms 2023, 93, 1171–1208. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 24 December 2024).
- Breiding, P.; Rose, K.; Timme, S. Certifying zeros of polynomial systems using interval arithmetic. ACM Trans. Math. Softw. 2023, 49, 1–14. [Google Scholar] [CrossRef]
- Bhuvaneswari, S.; Karthikeyan, S. A Comprehensive Research of Breast Cancer Detection Using Machine Learning, Clustering and Optimization Techniques. In Proceedings of the 2023 IEEE International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 28–29 July 2023. [Google Scholar]
- Zimmermann, H.-J. Fuzzy Set Theory—And Its Applications, 4th ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Rajafillah, C.; El Moutaouakil, K.; Patriciu, A.M.; Yahyaouy, A.; Riffi, J. INT-FUP: Intuitionistic Fuzzy Pooling. Mathematics 2024, 12, 1740. [Google Scholar] [CrossRef]
- Sugeno, M.; Kang, G. Structure identification of fuzzy model. Fuzzy Sets Syst. 1988, 28, 15–33. [Google Scholar] [CrossRef]
- Sugeno, M. Fuzzy Control; North-Holland, Publishing Co.: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Mehran, K. Takagi-sugeno fuzzy modeling for process control. Ind. Autom. Robot. Artif. Intell. 2008, 262, 1–31. [Google Scholar]
- Kawamoto, S.; Tada, K.; Ishigame, A.; Taniguchi, T. An approach to stability analysis of second order fuzzy systems. In Proceedings of the IEEE International Conference on Fuzzy Systems, San Diego, CA, USA, 8–12 March 1992; pp. 1427–1434. [Google Scholar]
- Tanaka, K. A Theory of Advanced Fuzzy Control; Springer: Berlin, Germany, 1994. [Google Scholar]
- Mercer, J. Functions of positive and negative type, and their connection the theory of integral equations. Philos. Trans. R. Soc. Lond. 1909, 209, 415–446. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Pandey, R.K.; Agrawal, O.P. Comparison of four numerical schemes for isoperimetric constraint fractional variational problems with A-operator. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Boston, MA, USA, 2–5 August 2015; American Society of Mechanical Engineers: New York City, NY, USA, 2015; Volume 57199. [Google Scholar]
- Kumar, K.; Pandey, R.K.; Sharma, S. Approximations of fractional integrals and Caputo derivatives with application in solving Abel’s integral equations. J. King Saud Univ.-Sci. 2019, 31, 692–700. [Google Scholar] [CrossRef]
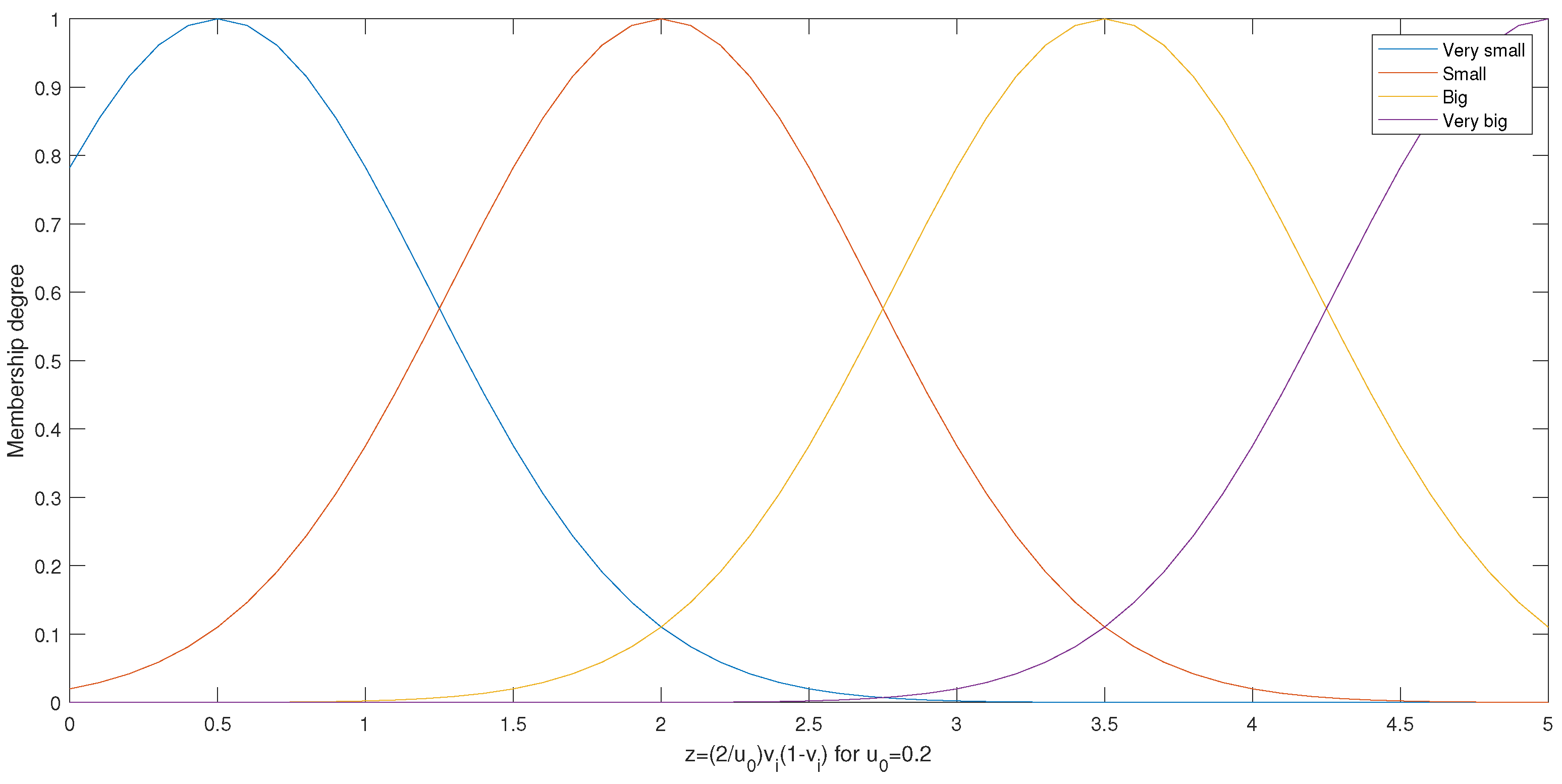



| Data Set | Features | Samples | Nomber of Classes | Subject Aria |
| Wine | 13 | 178 | 3 | Physics and Chemistry |
| Iris | 4 | 150 | 4 | Biology |
| Pima | 8 | 768 | 2 | Health and Medicine |
| Ecoli | 7 | 336 | 7 | Biology |
| Abalone | 8 | 4117 | 3 | Biology |
| Haberman | 3 | 306 | 2 | Health and Medicine |
| Balance | 4 | 625 | 5 | Social Science |
| Liver | 6 | 345 | 2 | Health and Medicine |
| Seed | 7 | 210 | 3 | Biology |
| Data Set | Best Performance | Best Method | Performance Improvement Percent | |||||||||
| Accuracy | F1-Score | Precision | Recall | Accuracy | F1-Score | Precision | Recall | Accuracy | F1-Score | Precision | Recall | |
| Iris | 97.51 | 97.01 | 92.19 | 95.65 | GTS-HRNN-60 | GTS-HRNN-50 | GTS-HRNN-50 | GTS-HRNN-80 | 1.62 | 2.43 | 2.51 | 0.82 |
| Abalone | 82.3 | 44.51 | 85.4 | 35.41 | GTS-HRNN-60 | GTS-HRNN-70 | GTS-HRNN-50 | GTS-HRNN-50 | 1.31 | 4.16 | 2.48 | 6.69 |
| Wine | 82.62 | 79.57 | 75.32 | 76.74 | GTS-HRNN-50 | GTS-HRNN-50 | GTS-HRNN-40 | GTS-HRNN-60 | 2.21 | 2.15 | 2.38 | 2.74 |
| Ecoli | 89.16 | 98.87 | 99.33 | 99.42 | GTS-HRNN-50 | GTS-HRNN-70 | GTS-HRNN-50 | GTS-HRNN-60 | 2.05 | 1.85 | 1.91 | 1.84 |
| Balance | 82.12 | 72.13 | 58.25 | 67.25 | GTS-HRNN-50 | GTS-HRNN-50 | GTS-HRNN-50 | GTS-HRNN-40 | 2.95 | 2.11 | 3.83 | 3.39 |
| Liver | 82.89 | 78.62 | 79.77 | 71.65 | GTS-HRNN-50 | GTS-HRNN-70 | GTS-HRNN-90 | GTS-HRNN-40 | 2.98 | 1.11 | 2.34 | 2.11 |
| Spect | 96.64 | 95.27 | 94.17 | 73.79 | GTS-HRNN-50 | GTS-HRNN-50 | GTS-HRNN-40 | GTS-HRNN-40 | 2.02 | 2.20 | 2.34 | 2.94 |
| Seed | 87.28 | 84.75 | 94.57 | 77.12 | GTS-HRNN-50 | GTS-HRNN-60 | GTS-HRNN-50 | GTS-HRNN-50 | 2.21 | 1.66 | 2.28 | 2.22 |
| Pima | 81.64 | 63.74 | 85.76 | 51.78 | GTS-HRNN-50 | GTS-HRNN-40 | GTS-HRNN-70 | GTS-HRNN-40 | 2.99 | 3.07 | 1.68 | 4.31 |
| Data Set | G-TS-HRNN-SVM Sample Size = 50 | G-TS-HRNN-SVM Sample Size = 60 | G-TS-HRNN-SVM Sample Size = 70 | |||||||||
| Accuracy (CI) | F1-Score (CI) | Precision (CI) | Recall (CI) | Accuracy (CI) | F1-Score (CI) | Precision (CI) | Recall (CI) | Accuracy (CI) | F1-Score (CI) | Precision (CI) | Recall (CI) | |
| Iris | ±0.14 | ±0.20 | ±0.03 | ±0.03 | ±0.08 | ±0.17 | ±0.05 | ±0.07 | ±0.09 | ±0.02 | ±0.13 | ±0.09 |
| Abalone | ±0.15 | ±0.02 | ±0.09 | ±0.18 | ±0.02 | ±0.09 | ±0.08 | ±0.15 | ±0.05 | ±0.14 | ±0.12 | ±0.10 |
| Wine | ±0.10 | ±0.09 | ±0.06 | ±0.12 | ±0.05 | ±0.09 | ±0.03 | ±0.01 | ±0.12 | ±0.12 | ±0.10 | ±0.09 |
| Ecoli | ±0.03 | ±0.03 | ±0.16 | ±0.11 | ±0.03 | ±0.07 | ±0.03 | ±0.02 | ±0.04 | ±0.08 | ±0.06 | ±0.04 |
| Balance | ±0.05 | ±0.19 | ±0.09 | ±0.04 | ±0.04 | ±0.16 | ±0.17 | ±0.04 | ±0.11 | ±0.07 | ±0.12 | ±0.05 |
| Liver | ±0.18 | ±0.01 | ±0.18 | ±0.17 | ±0.05 | ±0.07 | ±0.17 | ±0.12 | ±0.04 | ±0.07 | ±0.09 | ±0.08 |
| Spect | ±0.04 | ±0.16 | ±0.04 | ±0.13 | ±0.08 | ±0.03 | ±0.11 | ±0.13 | ±0.06 | ±0.05 | ±0.06 | ±0.04 |
| Seed | ±0.17 | ±0.17 | ±0.06 | ±0.08 | ±0.02 | ±0.14 | ±0.02 | ±0.12 | ±0.10 | ±0.08 | ±0.14 | ±0.13 |
| Pima | ±0.11 | ±0.17 | ±0.04 | ±0.11 | ±0.16 | ±0.08 | ±0.05 | ±0.09 | ±0.12 | ±0.08 | ±0.13 | ±0.04 |
| CPU time (s) | |||||
| Data set/Method | HRNN-SVM | TS-HRNN-SVM(10) | TS-HRNN-SVM(20) | TS-HRNN-SVM(30) | TS-HRNN-SVM(40) |
| iris | 1.71525 | 1.71234 | 1.71302 | 1.71363 | 1.72697 |
| Wine | 0.1676 | 0.16469 | 0.16537 | 0.16598 | 0.17932 |
| Pima | 2.8306 | 2.82769 | 2.82837 | 2.82898 | 2.84232 |
| Haberman | 0.0234 | 0.02049 | 0.02117 | 0.02178 | 0.03512 |
| Balance | 0.0086 | 0.00569 | 0.00637 | 0.00698 | 0.02032 |
| Libra | 0.0087 | 0.00579 | 0.00647 | 0.00708 | 0.02042 |
| Liver | 0.1294 | 0.12649 | 0.12717 | 0.12778 | 0.14112 |
| Seed | 0.0033 | 0.00039 | 0.00107 | 0.00168 | 0.01502 |
| Spect | 0.0054 | 0.00249 | 0.00317 | 0.00378 | 0.01712 |
| Segment | 0.0624 | 0.05949 | 0.06017 | 0.06078 | 0.07412 |
| Vehicle | 0.1581 | 0.15519 | 0.15587 | 0.15648 | 0.16982 |
| CPU time (s) | |||||
| Data set/Method | TS-HRNN-SVM(50) | TS-HRNN-SVM(60) | TS-HRNN-SVM(70) | TS-HRNN-SVM(80) | TS-HRNN-SVM(90) |
| iris | 1.74433 | 1.74855 | 1.76142 | 1.72725 | 1.75843 |
| Wine | 0.19668 | 0.20090 | 0.21377 | 0.17960 | 0.21078 |
| Pima | 2.85968 | 2.86390 | 2.87677 | 2.84260 | 2.87378 |
| Haberman | 0.05248 | 0.05670 | 0.06957 | 0.03540 | 0.06658 |
| Balance | 0.03768 | 0.04190 | 0.05477 | 0.02060 | 0.05178 |
| Libra | 0.03778 | 0.04200 | 0.05487 | 0.02070 | 0.05188 |
| Liver | 0.15848 | 0.16270 | 0.17557 | 0.14140 | 0.17258 |
| Seed | 0.03238 | 0.03660 | 0.04947 | 0.01530 | 0.04648 |
| Spect | 0.03448 | 0.03870 | 0.05157 | 0.01740 | 0.04858 |
| Segment | 0.09148 | 0.09570 | 0.10857 | 0.07440 | 0.10558 |
| Vehicle | 0.18718 | 0.19140 | 0.20427 | 0.16910 | 0.20128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bahou, O.; Roudani, M.; El Moutaouakil, K. G-TS-HRNN: Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network. Information 2025, 16, 141. https://doi.org/10.3390/info16020141
Bahou O, Roudani M, El Moutaouakil K. G-TS-HRNN: Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network. Information. 2025; 16(2):141. https://doi.org/10.3390/info16020141
Chicago/Turabian StyleBahou, Omar, Mohammed Roudani, and Karim El Moutaouakil. 2025. "G-TS-HRNN: Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network" Information 16, no. 2: 141. https://doi.org/10.3390/info16020141
APA StyleBahou, O., Roudani, M., & El Moutaouakil, K. (2025). G-TS-HRNN: Gaussian Takagi–Sugeno Hopfield Recurrent Neural Network. Information, 16(2), 141. https://doi.org/10.3390/info16020141