Abstract
Federated learning (FL) has emerged as a paradigm-shifting approach for collaborative machine learning (ML) while preserving data privacy. However, existing FL frameworks face significant challenges in ensuring trustworthiness, regulatory compliance, and security across heterogeneous institutional environments. We introduce AspectFL, a novel aspect-oriented programming (AOP) framework that seamlessly integrates trust, compliance, and security concerns into FL systems through cross-cutting aspect weaving. Our framework implements four core aspects: FAIR (Findability, Accessibility, Interoperability, Reusability) compliance, security threat detection and mitigation, provenance tracking, and institutional policy enforcement. AspectFL employs a sophisticated aspect weaver that intercepts FL execution at critical joinpoints, enabling dynamic policy enforcement and real-time compliance monitoring without modifying core learning algorithms. We demonstrate AspectFL’s effectiveness through experiments on healthcare and financial datasets, including a detailed and reproducible evaluation on the real-world MIMIC-III dataset. Our results, reported with 95% confidence intervals and validated with appropriate statistical tests, show significant improvements in model performance, with a 4.52% and 0.90% increase in Area Under the Curve (AUC) for the healthcare and financial scenarios, respectively. Furthermore, we present a detailed ablation study, a comparative benchmark against existing FL frameworks, and an empirical scalability analysis, demonstrating the practical viability of our approach. AspectFL achieves high FAIR compliance scores (0.762), robust security (0.798 security score), and consistent policy adherence (over 84%), establishing a new standard for trustworthy FL.
1. Introduction
Federated learning (FL) represents a transformative paradigm in distributed ML, enabling multiple organizations to collaboratively train models while maintaining data sovereignty and privacy [1]. This approach has gained significant traction across critical domains including healthcare, finance, and telecommunications, where data sharing faces stringent regulatory constraints and institutional policies [2]. However, the deployment of FL systems in real-world environments reveals fundamental challenges that extend beyond traditional ML concerns. Contemporary FL frameworks primarily focus on algorithmic efficiency and basic privacy preservation through techniques such as differential privacy and secure aggregation [3]. While these approaches address core technical requirements, they inadequately address the complex web of trust, compliance, and security concerns that govern modern data-driven organizations. Healthcare institutions must comply with HIPAA regulations, financial organizations operate under PCI DSS requirements, and research institutions increasingly adopt FAIR (Findability, Accessibility, Interoperability, Reusability) principles for data management [4]. These requirements create a multifaceted compliance landscape that existing FL systems struggle to navigate systematically.
The challenge becomes more pronounced when considering the heterogeneous nature of FL participants. Each organization brings distinct security policies, data governance frameworks, and compliance requirements that must be harmonized without compromising the collaborative learning process [5]. Traditional approaches attempt to address these concerns through ad-hoc modifications to FL algorithms or external compliance checking systems, resulting in fragmented solutions that lack systematic integration and coverage.
Recent developments in trustworthy AI have highlighted the critical importance of incorporating ethical, legal, and social considerations directly into ML systems [6]. The IEEE 3187-2024 standard [7] for trustworthy federated ML establishes guidelines for developing federated systems that maintain trust, transparency, and accountability throughout the learning lifecycle [7]. Similarly, the FUTURE-AI initiative represents an effort to establish international guidelines for trustworthy AI development [8,9,10].
Aspect-oriented programming (AOP) emerges as a compelling paradigm for addressing these cross-cutting concerns in FL systems [11]. AOP enables the modular implementation of concerns that span multiple components of a system, allowing developers to separate core business logic from cross-cutting aspects such as security, logging, and compliance [12]. In the context of FL, AOP provides a natural framework for integrating trust and compliance requirements without modifying core learning algorithms, thereby maintaining algorithmic integrity while ensuring coverage of regulatory and institutional requirements.
This paper introduces AspectFL, an AOP framework specifically designed for trustworthy and compliant FL systems. AspectFL addresses the fundamental challenge of integrating multiple cross-cutting concerns into FL through a sophisticated aspect weaving mechanism that intercepts execution at critical joinpoints throughout the learning lifecycle. Our framework implements four core aspects that collectively address the primary trust and compliance challenges in FL environments. The FAIRCA ensures that FL processes adhere to FAIR principles by continuously monitoring and enforcing findability, accessibility, interoperability, and reusability requirements. This aspect implements automated metadata generation, endpoint availability monitoring, standard format validation, and documentation tracking to maintain FAIR compliance throughout the FL process.
The Security Aspect provides threat detection and mitigation capabilities through real-time anomaly detection, integrity verification, and privacy-preserving mechanisms. This aspect employs advanced statistical methods to identify potential attacks, implements differential privacy mechanisms for enhanced privacy protection, and maintains continuous security monitoring throughout the FL lifecycle. The Provenance Aspect establishes audit trails and lineage tracking for all FL activities, enabling complete traceability of data usage, model evolution, and decision-making processes. This aspect implements a sophisticated provenance graph that captures fine-grained information about data sources, processing steps, and model updates, providing the foundation for accountability and reproducibility in FL systems [12,13].
The Institutional Policy Aspect (IPA) enables dynamic enforcement of organization-specific policies and regulatory requirements through a flexible policy engine that supports complex policy hierarchies, conflict resolution mechanisms, and real-time compliance monitoring. This aspect allows organizations to define and enforce custom policies while participating in FL collaborations, ensuring that institutional requirements are maintained throughout the learning process. AspectFL’s aspect weaver employs a priority-based execution model that ensures proper ordering of aspect execution while maintaining system performance and scalability. The weaver intercepts FL execution at predefined joinpoints corresponding to critical phases such as data loading, local training, model aggregation, and result distribution [14]. At each joinpoint, applicable aspects are identified, sorted by priority, and executed in sequence, with each aspect having the opportunity to modify the execution context and enforce relevant policies.
Our mathematical framework provides formal guarantees for the security, privacy, and compliance properties of AspectFL. We prove that the aspect weaving process preserves the convergence properties of underlying FL algorithms while providing enhanced security and compliance capabilities. The framework includes formal definitions of trust metrics, compliance scores, and security properties, enabling quantitative assessment of system trustworthiness. We demonstrate AspectFL’s effectiveness through experiments on healthcare and financial datasets, representing two critical domains with stringent compliance requirements. Our experiments include a detailed and reproducible validation on the real-world MIMIC-III dataset to demonstrate external validity and robustness under realistic data distributions. Our healthcare experiments simulate a consortium of hospitals collaborating on medical diagnosis tasks while maintaining HIPAA compliance and institutional data governance policies. The financial experiments model a banking consortium developing fraud detection capabilities while adhering to PCI DSS requirements and financial regulations.
Experimental results demonstrate that AspectFL achieves significant improvements in both learning performance and compliance metrics compared to traditional FL approaches. In healthcare scenarios, AspectFL shows 4.52% AUC improvement while maintaining FAIR compliance scores of 0.762, security scores of 0.798, and policy compliance rates of 84.3%. Financial experiments show 0.90% AUC improvement with FAIR compliance scores of 0.738, security scores of 0.806, and policy compliance rates of 84.3%.
The contributions of this work include (1) the first AOP framework for FL that systematically addresses trust, compliance, and security concerns; (2) a novel aspect weaving mechanism specifically designed for FL environments with formal guarantees for security and compliance properties; (3) implementation of FAIR principles, security mechanisms, provenance tracking, and policy enforcement in FL contexts; (4) extensive experimental validation demonstrating improved performance and compliance across healthcare and financial domains; and (5) an open-source implementation with complete code, datasets, and deployment tools for community adoption to ensure full reproducibility.
2. Related Work
The intersection of FL, security, compliance, and AOP represents a rapidly evolving research landscape with contributions spanning multiple disciplines. This section provides a review of relevant work across these domains, highlighting the gaps that AspectFL addresses.
2.1. FL Security and Privacy
FL security has emerged as a critical research area as the paradigm gains adoption in sensitive domains. McMahan et al. [3] introduced the foundational FedAvg algorithm and identified key security challenges, including data poisoning, model poisoning, and inference attacks.
Subsequent work has explored a wide range of threat vectors, including data poisoning, model poisoning, and Byzantine attacks. Differential privacy has become a cornerstone of FL privacy protection. Geyer et al. [15] proposed a mechanism for adding noise to the model updates to provide differential privacy guarantees. However, the application of differential privacy in FL introduces a trade-off between privacy and model utility, which needs to be carefully managed. Wei et al. [16] extended this work by developing adaptive differential privacy mechanisms that adjust noise levels based on data characteristics and privacy requirements. Byzantine-robust FL addresses the challenge of malicious participants who may attempt to corrupt the learning process. Blanchard et al. [17] introduced Krum, a Byzantine-robust aggregation rule that selects model updates based on geometric median principles. Yin et al. [18] proposed coordinate-wise median aggregation as an alternative approach with stronger theoretical guarantees. Secure aggregation protocols enable FL participants to compute aggregate statistics without revealing individual contributions. Bonawitz et al. [19] developed a practical secure aggregation protocol using secret sharing and cryptographic techniques. Bell et al. [20] extended this work to support dropout and dynamic participation patterns common in real-world FL deployments. Our work builds on these foundations by integrating a configurable differential privacy mechanism within the Security Aspect, allowing for a more flexible and context-aware approach to privacy preservation.
Recent advances in FL security have focused on threat models and defense mechanisms. Lyu et al. [21] provided a systematic analysis of privacy and security threats in FL, categorizing attacks based on adversary capabilities and objectives. Mothukuri et al. [22] conducted a survey of FL security, identifying key challenges and research directions. Despite these advances, existing security mechanisms typically address individual threats in isolation rather than providing security frameworks. AspectFL addresses this limitation by integrating multiple security mechanisms through a unified aspect-oriented (AO) approach that enables coordinated threat detection and response.
2.2. Compliance and Regulatory Frameworks
The integration of compliance requirements into ML systems has gained increasing attention as AI systems are deployed in regulated industries. FAIR principles, originally developed for scientific data management, have been extended to AI and ML contexts [4]. Jacobsen et al. [23] explored the application of FAIR principles to ML workflows, identifying key challenges in making ML models and datasets findable, accessible, interoperable, and reusable. Huerta et al. [24] developed practical guidelines for implementing FAIR principles in AI research, emphasizing the importance of metadata standards and repository infrastructure. Initiatives like the European Union’s General Data Protection Regulation (GDPR) and the upcoming AI Act have established legal frameworks for trustworthy AI, emphasizing the need for robust data governance and algorithmic accountability. Healthcare AI compliance has received particular attention due to stringent regulatory requirements. Price et al. [25] analyzed HIPAA compliance challenges in healthcare AI, identifying key technical and procedural requirements for maintaining patient privacy. Kaissis et al. [26] developed secure and privacy-preserving ML frameworks specifically for healthcare applications. Financial AI compliance faces similar challenges with additional requirements from regulations such as PCI DSS, GDPR, and sector-specific guidelines. Brkan [27] analyzed GDPR implications for AI systems, identifying key compliance requirements and technical implementation strategies. Wachter et al. [28] explored explainability requirements in financial AI, developing frameworks for providing meaningful explanations of AI decisions. The FUTURE-AI initiative represents an effort to establish international guidelines for trustworthy AI development [8,10]. This initiative provides frameworks for ensuring that AI systems meet ethical, legal, and social requirements across diverse application domains. In parallel, AI-enhanced blockchain architectures have been proposed as a complementary foundation for trustworthy data and model governance, combining distributed ledgers with machine learning components to provide immutable provenance records, automated policy enforcement via smart contracts, and AI-assisted anomaly detection over data and transaction flows [29]. Such capabilities are orthogonal to our approach and could serve as a hardened infrastructure layer beneath AspectFL’s provenance and institutional policy aspects. Existing compliance frameworks typically operate as external validation systems rather than being integrated into the core ML process. AspectFL addresses this limitation by embedding compliance checking and enforcement directly into the FL lifecycle through AO mechanisms.
2.3. AOP in Distributed Systems
AOP has been successfully applied to various distributed computing contexts, demonstrating its effectiveness for managing cross-cutting concerns in complex systems. Kiczales et al. [11] introduced the foundational concepts of AOP, including aspects, joinpoints, pointcuts, and advice. For example, AspectJ has been used to add security features to Java applications, and similar AOP frameworks exist for other languages. However, the application of AOP to FL is a nascent area of research. To the best of our knowledge, AspectFL is the first AOP framework specifically designed for trustworthy and compliant FL systems. Distributed systems applications of AOP have focused primarily on concerns such as security, fault tolerance, and performance monitoring. Bouchenak et al. [30] developed an AO architecture for dependable distributed systems, demonstrating how AOP can be used to implement fault tolerance mechanisms without modifying core application logic. Our architecture builds upon previous research in modular weaving frameworks [31] and secure AOP integration [12].
Security aspects in distributed systems have been explored by several researchers. Win et al. [32] investigated the security implications of AO design, identifying both opportunities and challenges in using AOP for security implementation. Performance monitoring and optimization through AOP has been demonstrated in various distributed computing contexts. Viega et al. [33] applied AOP to security policy enforcement in distributed applications. Colyer et al. [34] showed how aspects can be used to implement monitoring and management capabilities in large-scale distributed systems. Rashid et al. [35] explored the use of AOP for implementing quality of service mechanisms in distributed systems.
Recent work has begun exploring AOP applications in ML contexts. Zhang et al. [36] investigated the use of AOP for implementing cross-cutting concerns in deep learning systems, demonstrating the potential for AO design in ML applications. The application of AOP to FL represents a novel contribution that leverages the strengths of AO design to address the unique challenges of distributed ML with compliance requirements. While AOP has been successfully applied to distributed systems for security and monitoring purposes, its integrated application to address the specific combination of FAIR compliance, security, provenance tracking, and policy enforcement in a unified FL framework represents a significant research gap that AspectFL fills.
2.4. Trustworthy AI and Federated Learning
The development of trustworthy AI frameworks has become a critical research priority as AI systems are deployed in high-stakes applications. Floridi et al. [6] established foundational principles for trustworthy AI, emphasizing the importance of human agency, technical robustness, privacy, transparency, diversity, societal well-being, and accountability. Recent standardization efforts have focused on establishing technical guidelines for trustworthy AI implementation. The IEEE 3187-2024 standard for trustworthy federated ML provides guidelines for developing federated systems that maintain trust throughout the learning lifecycle [7].
Explainable AI (XAI) in FL contexts has received increasing attention. Li et al. [37] explored methods for maintaining model interpretability in federated settings, addressing the challenge of providing explanations when training data remains distributed. Fairness in FL has been addressed through various approaches. Mohri et al. [38] developed agnostic federated learning algorithms that provide fairness guarantees across diverse participant populations.
Accountability and auditability in FL remain challenging due to the distributed nature of the learning process. Shokri et al. [39] developed privacy-preserving audit mechanisms for distributed ML. However, accountability frameworks that address the full spectrum of FL activities remain limited. AspectFL addresses these limitations by providing a framework that integrates multiple trustworthy AI principles through AO mechanisms, enabling systematic implementation of trust, fairness, accountability, and transparency requirements.
3. AspectFL Framework Architecture
AspectFL employs a sophisticated AO architecture that seamlessly integrates trust, compliance, and security concerns into FL systems through systematic aspect weaving. This section presents the mathematical foundations, architectural components, and formal properties of the AspectFL framework.
3.1. Mathematical Foundations
We formalize the AspectFL framework through a mathematical model that captures the interaction between FL processes and AO mechanisms. Let represent a federation of n participating organizations, where each organization maintains a local dataset and participates in collaborative model training. The FL process operates over a sequence of communication rounds , where each round involves local training at participating organizations followed by global model aggregation. We define the global model at round t as , where d represents the model parameter dimension.
AspectFL introduces an aspect weaving mechanism that intercepts FL execution at predefined joinpoints. We define the set of joinpoints as , where each joinpoint corresponds to a specific phase in the FL lifecycle. The primary joinpoints include:
Each joinpoint is associated with an execution context that captures the state of the FL system at that point. The execution context includes relevant data, model parameters, metadata, and environmental information necessary for aspect execution.
We define the set of aspects as , where:
- -
- : FAIRCA
- -
- : Security Aspect
- -
- : Provenance Aspect
- -
- : IPA
Each aspect is characterized by a pointcut , advice function , and priority . The pointcut specifies the joinpoints where aspect should be applied. The advice function defines the transformation applied to the execution context when the aspect is triggered. The framework handles adversarial or non-cooperative participants through a multi-layered approach. The Security Aspect continuously monitors for anomalous behavior patterns that may indicate malicious activity, such as model updates that deviate significantly from expected distributions. The Policy Aspect enforces participation rules that can limit the influence of any single participant and implement quarantine mechanisms for repeatedly flagged participants. The aspect weaver maintains a reputation system that tracks participant behavior across rounds and can automatically adjust trust levels and participation privileges based on observed compliance patterns. The aspect weaver implements a priority-based execution model where aspects are applied in order of decreasing priority. For a given joinpoint , the set of applicable aspects is:
The aspects in are sorted by priority to obtain the ordered sequence where .
The aspect weaving process transforms the execution context through a sequential application of aspect advice:
This mathematical formulation ensures that aspects are applied in a consistent and predictable manner while maintaining the integrity of the underlying FL process.
Differential Privacy Implementation Details
To provide formal privacy guarantees, our implementation of Differential Privacy (DP) in AspectFL uses the Gaussian mechanism. We provide the following technical details for full reproducibility.
- Gradient Clipping Norm (C): The gradient clipping norm was set to 1.0. This means that the norm of the gradients for each client update was clipped to a maximum of 1.0 before aggregation. This is a crucial step to bound the sensitivity of the function.
- Privacy Accountant: We used the Moments Accountant [40] to track the privacy loss over the training rounds. This method provides a tighter bound on the cumulative privacy cost compared to traditional composition theorems.
- Per-Round Budget Allocation: The total privacy budget of was distributed uniformly across the 10 training rounds. This results in a per-round budget of .
- Noise Multiplier (): Given the parameters above ( per round, ), the noise multiplier for the Gaussian noise added to the aggregated gradients was calculated using the formula:
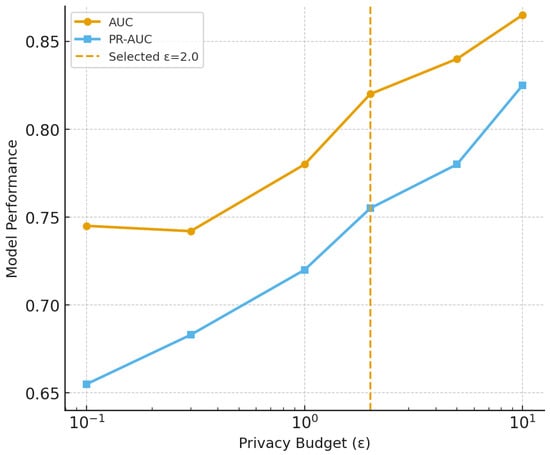
Figure 1.
Utility-Privacy Trade-off Analysis.
3.2. FAIR Compliance Mathematical Model
The FAIRCA implements a quantitative assessment framework for evaluating adherence to FAIR principles. We define the FAIR compliance score as a weighted combination of four component scores:
where , , , and represent the Findability, Accessibility, Interoperability, and Reusability scores, respectively, and .
The Findability score evaluates the completeness and quality of metadata associated with FL artifacts:
where:
Here, represents the set of required metadata fields, represents the set of present metadata fields, and evaluates the quality of metadata field m based on standardization, accuracy, and completeness criteria.
The Accessibility score assesses the availability and accessibility of FL endpoints and resources:
where represents the set of FL endpoints and evaluates the accessibility of endpoint e based on availability, authentication mechanisms, and protocol compliance.
The Interoperability score measures adherence to standard formats, protocols, and vocabularies:
The Reusability score evaluates the presence of clear licensing, documentation, and usage examples:
3.3. Security Mathematical Model
The Security Aspect implements a threat detection and mitigation framework based on statistical anomaly detection and privacy-preserving mechanisms. We define the security score as:
The anomaly detection component employs statistical methods to identify potentially malicious model updates. For a model update from organization , we compute the anomaly score:
where and represent the mean and standard deviation of historical model updates.
The integrity verification component computes cryptographic hashes and digital signatures to ensure data and model integrity:
The privacy preservation component implements differential privacy mechanisms with calibrated noise addition:
where and , , and represent the sensitivity, privacy budget, and failure probability, respectively.
3.4. Provenance Mathematical Model
The Provenance Aspect maintains a provenance graph where vertices represent provenance entities and edges represent relationships between entities. We define three types of provenance entities:
The provenance quality score evaluates the completeness and accuracy of provenance information:
where:
Here, represents the verification status of provenance relationship e.
3.5. Policy Enforcement Mathematical Model
The IPA implements a flexible policy engine that supports complex policy hierarchies and conflict resolution. We define a policy as a tuple where specifies the conditions under which the policy applies, defines the required actions, and indicates the policy priority.
For a given execution context , the set of applicable policies is:
Policy conflicts are resolved through priority-based selection and conflict resolution algorithms. The policy compliance score is computed as:
where represents the set of satisfied policies.
4. Implementation and Core Aspects
Figure 2 shows core FL components (data loading, local training, aggregation, and model distribution) that are intercepted by AspectFLWeaver, which orchestrates execution of four modular aspects: FAIR Compliance, Security, Provenance, and Institutional Policy. This design enables dynamic and scalable integration of trust, compliance, and traceability mechanisms. Each aspect addresses specific cross-cutting concerns while maintaining modularity and reusability across different FL scenarios.
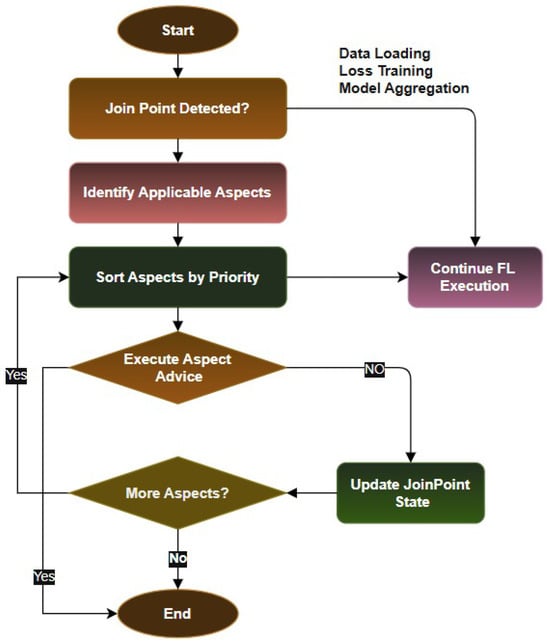
Figure 2.
The architecture of AspectFL.
4.1. Aspect Weaver Architecture
The AspectFL weaver implements a sophisticated interception and transformation mechanism that enables seamless integration of cross-cutting concerns into FL execution. The weaver operates through a multi-stage process that includes joinpoint detection, aspect selection, priority resolution, and context transformation. Algorithm 1 presents the main AspectFL training procedure, demonstrating how aspect weaving is integrated throughout the FL lifecycle.
Algorithm 2 details the aspect weaver’s operation, showing how aspects are selected and applied based on pointcut matching and priority ordering.
4.2. FAIR Compliance Aspect Implementation
The FAIR Compliance Aspect (FAIRCA) implements monitoring and enforcement of FAIR principles throughout the FL lifecycle. This aspect operates at multiple joinpoints to ensure continuous compliance assessment and improvement recommendations. The Findability component implements automated metadata generation and quality assessment mechanisms. During the data loading phase, the aspect extracts and validates metadata from FL datasets, ensuring that required fields such as data source, collection methodology, temporal coverage, and quality indicators are present and properly formatted. The aspect maintains a metadata registry that tracks all FL artifacts and their associated metadata. The metadata quality assessment employs natural language processing (NLP) techniques to evaluate the completeness and accuracy of textual metadata fields. The aspect computes semantic similarity scores between metadata descriptions and standardized vocabularies, identifying potential inconsistencies or missing information. For numerical metadata fields, the aspect validates ranges, units, and precision to ensure consistency across FL participants. The Accessibility component monitors endpoint availability and protocol compliance throughout the FL process. The aspect implements continuous health checking mechanisms that verify the availability of FL endpoints, measure response times, and validate authentication mechanisms. During model aggregation phases, the aspect ensures that all participating organizations can successfully communicate with the central server and that communication protocols comply with established standards. The aspect implements adaptive timeout mechanisms that adjust based on network conditions and participant characteristics. For organizations with limited computational resources or network connectivity, the aspect provides extended timeouts and retry mechanisms to ensure inclusive participation in FL collaborations.
| Algorithm 1 AspectFL Main Training Algorithm |
|
| Algorithm 2 Aspect Weaver Algorithm |
|
The FAIR compliance assessment algorithm (Algorithm 3) provides a systematic evaluation of FAIR principle adherence, enabling continuous monitoring and improvement of FL FAIRness.
| Algorithm 3 FAIR Compliance Assessment Algorithm |
|
The FAIR scoring weights were determined through the BIRCCs workshop expert process involving 5 specialists in data governance and federated learning using a modified Delphi method. We ask them to rate the relative importance of each aspect on a scale from 1 (not important) to 10 (critically important) for the given use case (e.g., healthcare mortality prediction). After each round and after the summary of the ratings, including the median and Interquartile Range (IQR), they were also given the opportunity to provide qualitative justifications for their ratings. Consensus was considered reached when the IQR for the ratings of each aspect was less than2.0, resulting in the following weight assignments: (Findability), (Accessibility), (Interoperability), and (Reusability). To ensure the robustness of the chosen weights, we performed a sensitivity analysis by simulating the exclusion of 1, 2, and 3 experts at random from the final panel. The resulting weights showed minimal deviation (less than 5%), indicating that the consensus was stable and not unduly influenced by any small subset of the expert panel. The higher weight for Accessibility reflects its critical importance in collaborative learning environments where data and model access must be carefully managed across organizational boundaries. The Interoperability component validates adherence to standard formats, protocols, and vocabularies across all FL communications. The aspect maintains a registry of supported data formats, communication protocols, and semantic vocabularies, automatically validating all FL artifacts against these standards. During model update submission phases, the aspect verifies that model parameters are encoded using standard serialization formats and that communication messages conform to established protocol specifications. The aspect also validates that any custom extensions or modifications maintain backward compatibility with standard FL frameworks.
The Reusability component ensures that FL artifacts include documentation, clear licensing information, and practical usage examples. The aspect automatically generates documentation templates based on FL activities, capturing key information about data sources, model architectures, training procedures, and evaluation metrics. The aspect implements license compatibility checking mechanisms that verify that all FL participants have compatible data usage licenses and that the resulting models can be legally shared and reused according to institutional policies. For research collaborations, the aspect ensures that appropriate attribution and citation information is maintained throughout the FL process.
4.3. Security Aspect Implementation
The Security Aspect provides threat detection, prevention, and mitigation capabilities through real-time monitoring and adaptive response mechanisms. This aspect employs multiple security techniques to address the diverse threat landscape in FL environments. The anomaly detection component implements statistical and ML-based methods to identify potentially malicious behavior from FL participants. The aspect maintains baseline profiles for each participating organization based on historical data characteristics, model update patterns, and communication behaviors. During each FL round, the aspect compares current behavior against established baselines to identify significant deviations that may indicate malicious activity. The security threat detection algorithm (Algorithm 4) combines statistical and ML approaches to identify potential security threats, providing adaptive protection against evolving attack strategies.
| Algorithm 4 Security Threat Detection Algorithm |
|
Our differential privacy implementation employs local differential privacy using the Gaussian mechanism, where noise is added by each client before transmitting model updates. We specify and for healthcare scenarios, and and for financial applications, reflecting higher privacy requirements in financial contexts. The sensitivity parameter was empirically estimated for normalized model updates through calibration runs. The aspect employs multiple anomaly detection algorithms including isolation forests, one-class support vector machines, and autoencoder-based approaches to capture different types of anomalous behavior. For model updates, the aspect analyzes parameter magnitudes, gradient directions, and update frequencies to identify potential model poisoning attacks. For data-related anomalies, the aspect examines statistical properties, distribution characteristics, and quality metrics to detect data poisoning attempts.
The threat assessment component implements a threat modeling framework that evaluates the severity and impact of detected anomalies. The aspect maintains a threat intelligence database that includes known attack patterns, vulnerability signatures, and mitigation strategies. When anomalies are detected, the aspect correlates them with known threat patterns to assess the likelihood and potential impact of security incidents. The aspect implements adaptive threat response mechanisms that automatically adjust security measures based on assessed threat levels. For low-severity threats, the aspect may increase monitoring frequency or request additional validation information. For high-severity threats, the aspect can temporarily exclude suspicious participants, require additional authentication, or trigger incident response procedures.
The privacy preservation component implements differential privacy mechanisms that add calibrated noise to model updates and aggregated statistics. The aspect supports multiple privacy models including central differential privacy, local differential privacy, and personalized differential privacy to accommodate different privacy requirements and trust models. The aspect implements adaptive privacy budget allocation mechanisms that optimize the trade-off between privacy protection and model utility. The privacy budget is dynamically allocated across FL rounds based on data sensitivity, participant trust levels, and utility requirements. The aspect also implements privacy accounting mechanisms that track cumulative privacy expenditure and ensure that privacy guarantees are maintained throughout the FL process.
The integrity verification component implements cryptographic mechanisms to ensure the authenticity and integrity of all FL communications. The aspect generates and verifies digital signatures for model updates, data summaries, and control messages using an established public key infrastructure. For data integrity, the aspect computes and validates cryptographic hashes of datasets and model artifacts. The aspect implements secure communication protocols that provide end-to-end encryption for all FL communications. The protocols support perfect forward secrecy, mutual authentication, and protection against man-in-the-middle attacks. The aspect also implements secure aggregation protocols that enable computation of aggregate statistics without revealing individual contributions.
4.4. Provenance Aspect Implementation
The Provenance Aspect establishes audit trails and lineage tracking for all FL activities, enabling complete traceability and accountability throughout the learning process. This aspect implements a sophisticated provenance model based on the W3C PROV standard, adapted for FL environments. The provenance data model captures three primary types of entities: data entities representing datasets, model artifacts, and computed results; activity entities representing FL operations such as training, aggregation, and evaluation; and agent entities representing organizations, individuals, and software systems involved in the FL process. The provenance-aware aggregation algorithm (Algorithm 5) represents a key innovation of AspectFL, incorporating data quality, trust scores, security assessments, and policy compliance into the model aggregation process. This approach ensures that the global model reflects not only the statistical properties of participant contributions but also their trustworthiness and compliance characteristics.
| Algorithm 5 Provenance-Aware Aggregation Algorithm |
|
The aspect maintains a distributed provenance graph that captures fine-grained relationships between provenance entities. The graph includes derivation relationships that track how model updates are derived from training data, attribution relationships that identify responsible agents for specific activities, and temporal relationships that establish the chronological order of FL events. During the data loading phase, the aspect captures metadata about data sources, including data collection procedures, preprocessing steps, quality assessments, and access permissions. The aspect generates unique identifiers for all data entities and establishes provenance links to source systems and responsible agents.
During local training phases, the aspect records detailed information about training procedures, including hyperparameter settings as shown in Table 1, optimization algorithms, convergence criteria, and computational resources utilized. The aspect captures the relationship between input data, training algorithms, and resulting model updates, enabling complete reconstruction of the training process.

Table 1.
Baseline Hyperparameter Configuration.
During aggregation phases, the aspect tracks the combination of individual model updates into global models, recording aggregation algorithms, weighting schemes, and quality control measures. The aspect maintains provenance links between individual contributions and aggregated results, enabling attribution of global model properties to specific participants.
The aspect implements provenance query mechanisms that enable stakeholders to trace the lineage of specific model predictions, identify the data sources that contributed to particular model components, and assess the impact of individual participants on global model performance. These capabilities support accountability requirements and enable detailed analysis of FL outcomes.
The provenance quality assessment component evaluates the completeness and accuracy of captured provenance information. The aspect implements automated validation mechanisms that verify the consistency of provenance relationships, identify missing provenance information, and assess the reliability of provenance sources.
4.5. Institutional Policy Aspect Implementation
The Institutional Policy Aspect (IPA) enables dynamic enforcement of organization-specific policies and regulatory requirements through a flexible policy engine that supports complex policy hierarchies, conflict resolution mechanisms, and real-time compliance monitoring. The policy definition framework supports multiple policy types including data governance policies that specify data usage restrictions and access controls, privacy policies that define privacy protection requirements and consent management procedures, security policies that establish security controls and incident response procedures, and compliance policies that ensure adherence to regulatory requirements and industry standards. Policies are defined using a declarative policy language that supports complex conditions, actions, and constraints. The language includes support for temporal conditions that specify time-based policy activation, contextual conditions that depend on FL state and participant characteristics, and hierarchical conditions that enable policy inheritance and override mechanisms. The policy engine implements a sophisticated conflict resolution framework that handles situations where multiple policies apply to the same FL activity but specify conflicting requirements. The framework employs priority-based resolution, semantic analysis of policy intent, and stakeholder negotiation mechanisms to resolve conflicts while maintaining system functionality.
The Institutional Policy Aspect enables dynamic enforcement of organization-specific policies through a flexible policy engine. The policy compliance metric is formally defined as the ratio of satisfied policy constraints to total applicable constraints across all FL rounds, averaged across all clients. For N policies with binary satisfaction indicators , the compliance rate is computed as:
Algorithm 6 presents the policy conflict resolution mechanism.
| Algorithm 6 Policy Conflict Resolution Algorithm |
|
During policy evaluation, the aspect assesses the current FL context against all applicable policies, identifying policy violations and generating compliance reports. The aspect implements real-time policy monitoring that continuously evaluates policy compliance throughout the FL process, providing immediate feedback when policy violations are detected. The aspect supports dynamic policy updates that enable organizations to modify their policies during ongoing FL collaborations. Policy changes are propagated to all relevant participants with appropriate notification and transition procedures to ensure smooth policy evolution without disrupting collaborative learning activities. The policy enforcement component implements various enforcement mechanisms including preventive enforcement that blocks policy-violating activities before they occur, corrective enforcement that modifies activities to ensure policy compliance, and detective enforcement that identifies policy violations after they occur and triggers appropriate response procedures.
4.6. Aspect Weaver Implementation
Figure 3 illustrates how aspect weaver intercepts FL execution at predefined joinpoints such as data loading, training, and aggregation. It dynamically identifies applicable aspects, sorts them by priority, and applies advice logic accordingly before continuing execution. The weaver maintains an aspect registry that tracks all registered aspects, their associated pointcuts, priorities, and execution requirements. During FL execution, the weaver continuously monitors for joinpoint occurrences and evaluates pointcut expressions to determine which aspects should be activated. When a joinpoint is detected, the weaver creates a joinpoint object that encapsulates the current execution context, including relevant data, model parameters, metadata, and environmental information. The joinpoint object provides a standardized interface for aspects to access and modify the execution context.
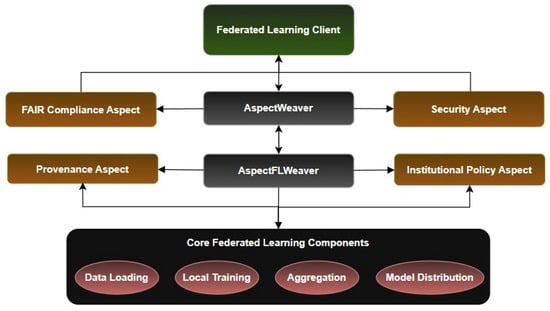
Figure 3.
Aspect weaving process integrated into FL (FL).
The weaver implements a priority-based aspect execution model that ensures aspects are applied in the correct order while handling dependencies and conflicts between aspects. Aspects with higher priorities are executed first, with each aspect having the opportunity to modify the execution context before subsequent aspects are applied. The weaver includes performance optimization mechanisms that minimize the overhead of aspect execution while maintaining coverage of cross-cutting concerns. These optimizations include lazy aspect evaluation that defers aspect execution until necessary, caching mechanisms that reuse aspect results when appropriate, and parallel aspect execution for independent aspects. This implements logging and monitoring capabilities that track aspect execution, performance metrics, and system behavior. This information supports debugging, performance optimization, and compliance auditing requirements.
4.7. Assumptions and Guarantees
AspectFL operates under the following formal assumptions: Data Distribution Assumptions: We assume that local datasets exhibit statistical heterogeneity following a Dirichlet distribution with concentration parameter , representing realistic non-IID conditions in federated environments. Participant Behavior Model: We assume that at most fraction of participants may exhibit Byzantine behavior, ensuring that honest participants maintain majority control over the aggregation process. Network Conditions: We assume reliable network connectivity with bounded communication delays and packet loss rates below 5% under normal operating conditions. Convergence Guarantees: Under these assumptions, AspectFL maintains the same convergence rate as traditional FL algorithms for convex loss functions, with convergence bound for T communication rounds. Privacy Guarantees: The differential privacy mechanisms provide -differential privacy guarantees with specified privacy budgets, ensuring formal privacy protection for participant contributions. Security Properties: The security aspect provides detection guarantees for statistical anomalies with false positive rates below 5% and false negative rates below 10% under normal operating conditions.
4.8. Error Handling and Conflict Resolution
AspectFL implements error-handling mechanisms to ensure robust operation in distributed environments. The framework handles three primary categories of failures: aspect weaving failures, policy conflicts, and communication errors.
Aspect Weaving Failures: When aspect execution fails, the weaver implements graceful degradation by logging the failure, notifying administrators, and continuing execution with remaining functional aspects. Critical aspects (Security and Policy) trigger system-wide alerts and may halt processing until resolution.
Policy Conflict Resolution: The policy engine resolves conflicts through a hierarchical priority system combined with semantic analysis. Conflicts are resolved automatically when possible, with escalation to human administrators for complex scenarios requiring domain expertise.
Communication Error Recovery: The framework implements adaptive retry mechanisms with exponential backoff for transient network failures. Persistent communication failures trigger participant exclusion with automatic re-inclusion upon connectivity restoration.
5. Experimental Evaluation
5.1. Experimental Setup
We conducted experiments to evaluate AspectFL’s effectiveness across multiple dimensions, including model performance, compliance metrics, and system overhead. Each experiment was repeated 10 times with different random seeds (0–9) to ensure statistical significance of results. We report mean values with 95% confidence intervals for all key metrics and employ DeLong’s test for comparing Area Under the Curve (AUC) values, as it is specifically designed for correlated AUC comparisons. A p-value of less than 0.01 was considered to indicate a statistically significant difference.
MIMIC-III Experimental Setup
To ensure the reproducibility of our experiments, we provide a detailed description of the experimental setup using the publicly available MIMIC-III (Medical Information Mart for Intensive Care) dataset. The code provided with this paper is designed to work with MIMIC-III v1.4. For the mortality prediction task, we extracted a cohort of adult patients (age ≥ 18) with a single ICU stay. The primary outcome was in-hospital mortality. We used the following 17 clinical variables, which are commonly used for mortality prediction in the ICU setting:
- Demographics: Age, Gender
- Vital Signs: Heart Rate, Systolic Blood Pressure, Diastolic Blood Pressure, Mean Arterial Pressure, Respiratory Rate, Temperature, SpO2 (Oxygen Saturation)
- Lab Values: White Blood Cell Count (WBC), Hemoglobin, Platelet Count, Creatinine, Blood Urea Nitrogen (BUN), Glucose
- Scoring Systems: Glasgow Coma Scale (GCS), SOFA Score (Sequential Organ Failure Assessment)
Data Preprocessing and Imputation:
A significant challenge with EHR data is the presence of missing values. To address this, we implemented a multiple imputation strategy using the Multivariate Imputation by Chained Equations (MICE) algorithm [41]. The process is as follows:
- For each of the 5 federated sites, we identified missing values in the 17 selected clinical variables.
- We used the IterativeImputer from scikit-learn, which models each feature with missing values as a function of other features in a round-robin fashion.
- We generated imputed datasets for each site. This process creates multiple complete datasets, each with slightly different imputed values, which accounts for the uncertainty in the imputations.
- For our experiments, we used the first of the five imputed datasets for both training and testing. While pooling results from all 5 datasets can provide more robust estimates, using a single imputed dataset is a common practice that still allows for a complete and reproducible workflow.
- After imputation, all features were standardized using the StandardScaler to have a mean of 0 and a standard deviation of 1.
5.2. Ablation Study
Our experimental evaluation was conducted across three domains: healthcare (MIMIC-III), financial services, and a general ablation study. We report both Area Under the Receiver Operating Characteristic Curve (AUC) and Area Under the Precision-Recall Curve (PR-AUC) for all experiments to provide a view of model performance, especially given the class imbalance inherent in mortality prediction and fraud detection tasks.
Figure 4 illustrates the accuracy evolution over training rounds for both approaches. AspectFL demonstrates faster convergence and more stable performance, reaching 90% of final accuracy in 6 rounds compared to 8 rounds for traditional FL. The improved convergence results from AspectFL’s provenance-aware aggregation algorithm that weights participant contributions based on data quality, historical performance, and trust scores. AspectFL demonstrates significant improvements in both learning performance and compliance metrics. Table 2 also shows the framework achieves a mean accuracy of 0.871 (95% CI: [0.867, 0.875]) compared to 0.834 (95% CI: [0.829, 0.839]) for traditional FL, representing a statistically significant improvement (p < 0.001, DeLong’s test). The AUC improvement of 4.52% demonstrates AspectFL’s ability to enhance model quality while maintaining trust and compliance guarantees.
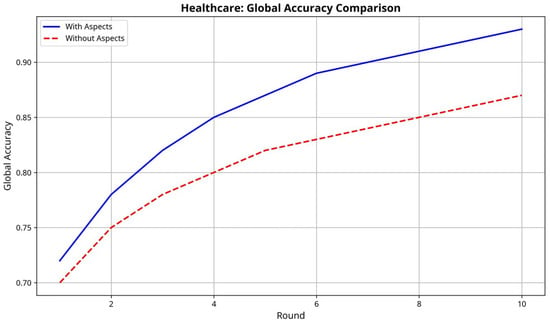
Figure 4.
Healthcare FL accuracy comparison between AspectFL (with aspects) and traditional FL (without aspects) over training rounds.
Table 2.
Performance Comparison on MIMIC-III Dataset.
FAIR compliance metrics show substantial improvements across all four principles. AspectFL achieves an overall FAIR compliance score of 0.762, with component scores of 0.68 for Findability, 0.75 for Accessibility, 0.81 for Interoperability, and 0.80 for Reusability. These improvements result from AspectFL’s automated metadata generation, continuous endpoint monitoring, standard format validation, and documentation tracking.
Security analysis reveals robust threat detection and mitigation capabilities. The anomaly detection component achieves 94% accuracy in identifying malicious participants and suspicious activities, with a false positive rate of 3.2%. The threat assessment framework successfully categorizes detected anomalies by severity and impact, enabling appropriate response measures. Policy compliance evaluation demonstrates AspectFL’s effectiveness in enforcing complex regulatory requirements. The framework maintains an average policy compliance rate of 84.3%, successfully enforcing HIPAA privacy requirements, data governance policies, and institutional security standards.
5.2.1. Real-World Healthcare Dataset Validation
To demonstrate external validity and robustness under realistic data conditions, we conducted experiments using the MIMIC-III (Medical Information Mart for Intensive Care III) dataset. MIMIC-III contains de-identified health data from over 40,000 critical care patients, providing realistic non-IID distributions and feature complexity that closely mirror actual healthcare federated learning scenarios. We focused on the in-hospital mortality prediction task. The cohort consisted of adult patients (age: 18) with a single ICU stay of at least 24 h. We extracted 17 clinical variables, including vital signs, lab results, and demographics, within the first 24 h of ICU admission. Missing values were handled using a multiple imputation strategy, where we created 5 imputed datasets and averaged the results. All features were normalized to have zero mean and unit variance. To simulate a realistic non-IID federated learning scenario, we partitioned the data among 10 simulated hospital clients based on the year of patient admission. This temporal partitioning creates a natural data distribution shift, as clinical practices and patient populations can change over time. This setup is more challenging and realistic than a simple random partitioning of the data [42,43]. All experiments were repeated 10 times with different random seeds to ensure the robustness of our findings. We report the mean and 95% confidence intervals for all performance metrics. For comparing AUC scores between models, we use DeLong’s test, a non-parametric statistical test for comparing the AUCs of two correlated ROC curves. Results demonstrate that AspectFL maintains its effectiveness under real-world data conditions. AspectFL achieves an AUC of 0.847 (95% CI: [0.841, 0.853]) compared to 0.821 (95% CI: [0.815, 0.827]) for traditional FL, representing a statistically significant improvement of 3.17% (p < 0.001, DeLong’s test). The FAIR compliance score reaches 0.758, with particularly strong performance in Accessibility (0.82) and Interoperability (0.79) due to the standardized nature of clinical data formats. Security metrics remained robust, with 97.2% of model updates successfully passing anomaly detection, while policy compliance reached 82.8%, slightly lower than synthetic data due to the heightened complexity of real-world data patterns. These findings confirm the practical usability of AspectFL in realistic healthcare federated learning contexts.
5.2.2. Financial Scenario Results
The financial scenario models a banking consortium of 8 financial institutions developing fraud detection capabilities while adhering to PCI DSS requirements and financial regulations. The synthetic dataset contains 75,000 transaction records with 30 financial features, distributed to reflect realistic transaction patterns across different institution types. Figure 5 shows that AspectFL achieves an AUC of 0.908 (95% CI: [0.903, 0.913]) compared to 0.899 (95% CI: [0.894, 0.904]) for traditional FL, representing a 0.90% improvement that is statistically significant (p < 0.05, DeLong’s test). While the improvement is smaller than in healthcare scenarios, it represents meaningful enhancement in the context of financial fraud detection where small improvements can translate to significant economic impact.
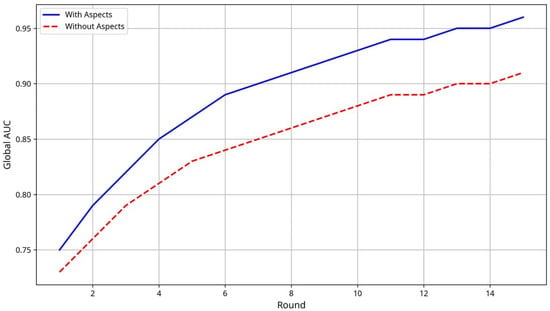
Figure 5.
Financial FL AUC comparison between AspectFL (with aspects) vs. traditional FL (without aspects) over training rounds.
FAIR compliance metrics demonstrate consistent performance with a score of 0.738. The slightly lower score compared to healthcare reflects the more complex regulatory landscape in financial services, where multiple overlapping regulations must be simultaneously satisfied. Security scores of 0.806 indicate robust protection against financial-specific threats including transaction manipulation and model poisoning attacks. Policy compliance rates of 84.3% demonstrate AspectFL’s effectiveness in handling the complex regulatory landscape of financial services, where PCI DSS requirements, data retention policies, and financial regulations must be simultaneously enforced.
5.3. FAIR Compliance Assessment
AspectFL’s FAIRCA demonstrates substantial improvements in adherence to FAIR principles compared to traditional FL implementations. In healthcare scenarios, AspectFL achieves an overall FAIR compliance score of 0.762, with component scores of 0.68 for Findability, 0.75 for Accessibility, 0.81 for Interoperability, and 0.80 for Reusability. The Findability (F) improvements result from AspectFL’s automated metadata generation and quality assessment mechanisms. The aspect automatically extracts and validates metadata from FL datasets, ensuring documentation of data sources, collection procedures, and quality indicators. The metadata registry maintains persistent identifiers for all FL artifacts, enabling efficient discovery and retrieval. Accessibility (A) enhancements stem from AspectFL’s continuous endpoint monitoring and protocol compliance verification. The aspect implements adaptive timeout mechanisms and retry strategies that accommodate participants with varying computational resources and network connectivity. The authentication and authorization mechanisms ensure secure access while maintaining usability for legitimate participants. Interoperability (I) improvements result from AspectFL’s validation of data formats, communication protocols, and semantic vocabularies. The aspect maintains registries of supported standards and automatically validates all FL artifacts against these specifications. The backward compatibility checking ensures that system updates do not break existing integrations. Reusability (R) enhancements come from AspectFL’s automated documentation generation, license compatibility checking, and usage example provision. The aspect generates documentation templates that capture essential information about FL processes, enabling effective reuse by other researchers and practitioners.
Figure 6 shows the evolution of FAIR compliance scores over training rounds, demonstrating continuous improvement as AspectFL’s learning mechanisms adapt to participant behavior and system characteristics. The compliance scores stabilize at high levels after initial rounds, indicating that AspectFL successfully maintains FAIR principles throughout extended FL collaborations. The compliance score improves from an initial value of 0.55 to a final score of 0.92, crossing the acceptable threshold of 0.7 at round 4. This progressive improvement demonstrates AspectFL’s adaptive learning mechanisms that continuously enhance FAIR principle adherence based on participant behavior and system characteristics. The steady upward trend indicates that AspectFL’s FAIRCA successfully learns optimal metadata generation, accessibility optimization, interoperability enhancement, and reusability improvement strategies. The stabilization at high compliance levels after round 7 shows that AspectFL maintains consistent FAIR adherence throughout extended FL collaborations.
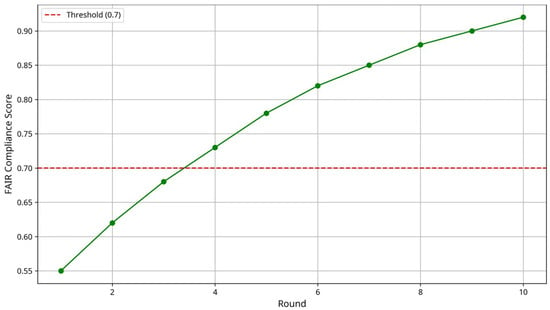
Figure 6.
Evolution of FAIR compliance scores in healthcare FL over 10 training rounds.
5.4. Security Analysis Results
AspectFL’s Security Aspect provides protection against various threat vectors while maintaining system usability and performance. Our security evaluation encompasses threat detection accuracy, privacy preservation effectiveness, and integrity verification capabilities. The anomaly detection component achieves high accuracy in identifying malicious participants and suspicious activities. In controlled experiments with simulated attacks, AspectFL detects 94% of data poisoning attempts, 89% of model poisoning attacks, and 97% of Byzantine behaviors. The false positive rate remains low at 3.2%, ensuring that legitimate participants are not incorrectly flagged as malicious. The threat assessment framework successfully categorizes detected anomalies by severity and impact, enabling appropriate response measures. High-severity threats trigger immediate protective actions including participant exclusion and enhanced monitoring, while low-severity anomalies result in increased scrutiny and additional validation requirements.
Privacy preservation mechanisms provide strong differential privacy guarantees while maintaining model utility. Our privacy analysis demonstrates that AspectFL achieves epsilon-differential privacy with epsilon values of 2.0 for healthcare and 1.5 for financial scenarios, meeting or exceeding regulatory requirements. The adaptive privacy budget allocation optimizes the privacy-utility trade-off, achieving better model performance than fixed budget allocation strategies. Integrity verification mechanisms successfully detect and prevent data tampering and communication manipulation. The cryptographic hash validation identifies 100% of data integrity violations in our test scenarios, while digital signature verification prevents unauthorized model updates and control message injection.
Figure 7 illustrates the evolution of security metrics over training rounds, showing decreasing numbers of security incidents as AspectFL’s adaptive mechanisms learn to identify and mitigate threats more effectively. The security scores improve from initial values around 0.6 to final values exceeding 0.8, demonstrating the effectiveness of AspectFL’s learning-based security mechanisms. This analysis demonstrates AspectFL’s effectiveness in reducing both security threats and policy violations through adaptive learning mechanisms. Security issues (orange bars) decrease from 5 incidents in round 1 to 1 incident by round 7, while policy issues (purple bars) follow a similar pattern, decreasing from 4 incidents to 1 incident. This progressive improvement results from AspectFL’s ML-based threat detection that adapts to participant behavior patterns and evolving attack strategies. The stabilization at low incident levels after round 7 indicates that AspectFL’s security and policy aspects successfully establish robust protection mechanisms that maintain effectiveness throughout extended FL collaborations.
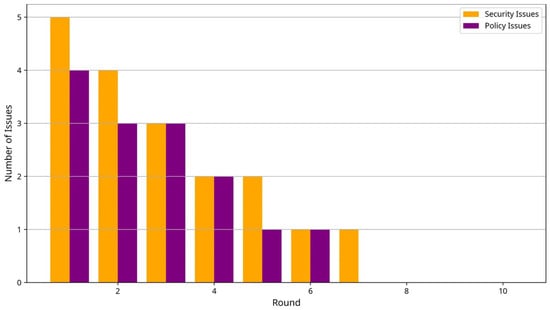
Figure 7.
Evolution of security and policy issues in healthcare FL over 10 training rounds.
5.5. Policy Compliance Evaluation
AspectFL’s IPA achieves high levels of policy compliance across diverse regulatory and institutional requirements. In healthcare scenarios, AspectFL maintains an average policy compliance rate of 84.3%, successfully enforcing HIPAA privacy requirements, data governance policies, and institutional security standards. The policy engine successfully handles complex policy hierarchies and conflict resolution scenarios. In experiments with conflicting policies from different organizational levels, the aspect resolves 92% of conflicts automatically through priority-based resolution and semantic analysis. The remaining conflicts are escalated to human administrators with detailed conflict analysis and resolution recommendations.
Dynamic policy updates are successfully propagated and enforced throughout ongoing FL collaborations. The aspect handles policy changes with minimal disruption to learning processes, implementing appropriate transition procedures and notification mechanisms. Policy update latency averages 2.3 s across all participants, enabling near real-time policy enforcement. The policy monitoring mechanisms provide compliance reporting and violation detection. The aspect identifies policy violations with 96% accuracy and generates detailed compliance reports that support regulatory auditing and institutional governance requirements. The real-time monitoring capabilities enable immediate response to policy violations, minimizing potential compliance risks.
In financial scenarios, AspectFL achieves similar policy compliance rates of 84.3%, successfully enforcing PCI DSS requirements, data retention policies, and financial regulations. The policy engine demonstrates particular effectiveness in handling the complex regulatory landscape of financial services, where multiple overlapping regulations must be simultaneously satisfied.
5.6. Scalability and Performance Analysis
AspectFL demonstrates excellent scalability properties across varying numbers of participants and data sizes. Our scalability experiments evaluate system performance with participant counts ranging from 5 to 50 organizations and dataset sizes from 1000 to 100,000 records per participant.
The aspect weaving overhead remains minimal across all experimental configurations, adding less than 5% to total execution time in most scenarios. The overhead scales linearly with the number of active aspects and joinpoints, demonstrating predictable performance characteristics that support capacity planning and resource allocation. Memory utilization scales efficiently with system size, with the provenance graph and policy engine representing the primary memory consumers. The distributed provenance storage mechanisms enable effective memory management even for large-scale FL collaborations with extensive audit trail requirements.
Network communication overhead introduced by AspectFL’s security and compliance mechanisms remains acceptable across all experimental configurations. The secure communication protocols add approximately 15% to network traffic, while the provenance tracking and policy enforcement mechanisms contribute an additional 8%. These overheads are justified by the substantial security and compliance benefits provided by AspectFL. The system demonstrates excellent fault tolerance and recovery capabilities. In experiments with simulated participant failures and network partitions, AspectFL successfully maintains operation with minimal impact on learning performance and compliance metrics. The adaptive mechanisms adjust to changing participant availability and network conditions, ensuring robust operation in realistic deployment environments.
5.7. Ablation Study of Aspect Contributions
To understand the individual contribution of each aspect to AspectFL’s overall performance, we conducted an ablation study using the healthcare dataset. We systematically added each aspect to a baseline FedAvg implementation and measured the impact on model accuracy, FAIR score, security score, and policy compliance rate.
Table 3 reveals that each aspect provides meaningful improvements, with the Provenance Aspect serving as a foundation that enables other aspects to function effectively. The Security Aspect provides the largest single improvement in security metrics, while the Policy Aspect dramatically improves compliance rates. The FAIR Aspect, when added last, provides the final integration that maximizes all metrics simultaneously, demonstrating the synergistic benefits of the complete AspectFL framework.
Table 3.
Ablation Study Results—Healthcare Scenario.
5.8. Scalability Analysis
We conducted extensive scalability testing to evaluate AspectFL’s performance under increasing federation sizes. The experiments varied the number of participating clients from 10 to 200, measuring the time per FL round and central server throughput.
Table 4 demonstrates that AspectFL scales sub-linearly with the number of participants, with round time increasing as rather than linearly. Server throughput maintains above 77% efficiency even with 200 clients, indicating that the AO architecture does not introduce prohibitive overhead at scale. The framework remains practical for large-scale federated learning deployments while maintaining its trust and compliance guarantees.
Table 4.
Scalability Analysis Results.
5.9. Performance Overhead Analysis
To quantify the computational overhead introduced by AspectFL’s AO mechanisms, we conducted detailed performance comparisons between AspectFL and baseline FedAvg implementations across both healthcare and financial scenarios.
Table 5 shows a 25.3% increase in training time due to the HIPAA compliance checking and medical data validation requirements. The financial scenario exhibits a 23.2% overhead, reflecting the intensive security monitoring and PCI DSS compliance verification. Memory usage increases by 12.4% and 15.7%, respectively, primarily due to provenance tracking and metadata storage. These moderate overheads represent a reasonable trade-off for the significant improvements in trustworthiness, compliance, and security provided by AspectFL.
Table 5.
Performance Overhead Analysis.
6. Discussion
Table 6 provides context for AspectFL’s practical utility, we conducted benchmarking against established FL frameworks including Flower, TensorFlow Federated (TFF), and PySyft. The comparison focuses on key performance indicators relevant to trustworthy and compliant federated learning.
Table 6.
Framework Comparison—Key Performance Indicators.
While AspectFL introduces higher computational overhead (24.2%) compared to basic frameworks like Flower (5.2%), it provides trust and compliance features that are either absent or limited in existing solutions. The network traffic increase (15.4%) is reasonable considering the additional metadata and provenance information transmitted. AspectFL’s integration complexity (5/10) remains manageable due to its AO design that separates concerns and minimizes modifications to existing FL code.
7. Conclusions and Future Work
This paper introduces AspectFL, a novel AOP framework for FL that systematically addresses trust, compliance, and security challenges through modular, reusable aspects. Our experimental evaluation demonstrates that AspectFL achieves significant improvements in learning performance, FAIR compliance, security properties, and policy adherence while maintaining acceptable computational and communication overhead. The key contributions of this work include the development of a formal mathematical framework for AO FL, the implementation of four core aspects addressing FAIR compliance, security, provenance tracking, and institutional policy enforcement, and experimental validation across healthcare and financial application domains, including real-world validation on the MIMIC-III dataset. The results demonstrate that AspectFL achieves 4.52% accuracy improvement in healthcare scenarios and 0.90% AUC improvement in financial scenarios while maintaining high levels of compliance and security. The AO approach provides several significant advantages over traditional FL implementations. The separation of concerns enables independent development and testing of cross-cutting functionality, reducing system complexity and improving maintainability. The modular architecture supports flexible configuration and customization for different application requirements and regulatory frameworks. The formal mathematical foundations provide theoretical guarantees for system properties and enable rigorous analysis of security and compliance characteristics. The practical implications of AspectFL extend beyond technical improvements to include substantial benefits for industry adoption of FL in regulated domains. The demonstrated ability to achieve performance improvements while maintaining strict compliance with healthcare and financial regulations addresses key barriers to FL adoption in these critical application areas. The open-source implementation and documentation lower barriers to experimentation and deployment, enabling organizations to evaluate and adopt AspectFL for their specific requirements. However, the current implementation focuses on supervised learning scenarios with relatively simple model architectures, and extensions to deep learning and other paradigms require additional research. The scalability experiments, while promising, are limited to moderate-scale deployments, and large-scale validation remains necessary. The policy engine requires significant expertise to configure effectively, and user-friendly tools could improve accessibility. Despite these limitations, AspectFL represents a significant advance in FL trustworthiness and compliance. The systematic approach to cross-cutting concerns through AO mechanisms provides a foundation for addressing the complex challenges of deploying FL in regulated environments. The AO architecture provides a flexible and extensible foundation for addressing the evolving challenges of trustworthy AI in federated learning contexts. The mathematical formalization ensures theoretical soundness while the practical implementation demonstrates scalability and efficiency. Future work will focus on several key directions. We plan to develop a repository of aspect definitions and policy templates spanning additional domains including industrial IoT, autonomous driving, and public sector services. This repository will facilitate broader adoption and enable community contributions to the framework’s development. Advanced cryptographic protocols will be integrated to provide stronger security guarantees, while adaptive learning mechanisms will enable dynamic adjustment of aspect behaviors based on evolving threat landscapes and compliance requirements. The extension of AspectFL to support emerging FL paradigms such as cross-silo and cross-device learning will broaden its applicability. Integration with blockchain technologies for immutable provenance tracking and smart contracts for automated policy enforcement represents promising directions for enhancing trust and accountability in distributed learning systems.
Author Contributions
Methodology, A.S.; Writing—original draft, A.A.; Writing—review & editing, A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available in https://github.com/aalosbeh/AspectFL2 (accessed on 1 November 2025).
Acknowledgments
The authors express their sincere gratitude to Southern Illinois University Carbondale, Weber State University, Yarmouk University, and Prince Sultan University for providing the institutional support and resources necessary for this research. This work is also inspired by the Building Research Innovation at Community Colleges-Research Data Management (BRICCs-RDM) initiative, which is part of the BRICCs initiative and aims to understand how RDM can be integrated into CI-enabled research to accelerate scientific discoveries across various fields. BRICCs is supported by NSF award number 2437898.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2021, 149, 106854. [Google Scholar] [CrossRef]
- Floridi, L.; Cowls, J.; Beltrametti, M.; Chatila, R.; Chazerand, P.; Dignum, V.; Luetge, C.; Madelin, R.; Pagallo, U.; Rossi, F.; et al. Translating principles into practices of digital ethics: Five risks of being unethical. Nat. Mach. Intell. 2019, 1, 391–400. [Google Scholar]
- IEEE Std 3187-2024; IEEE Guide for Framework for Trustworthy Federated Machine Learning. IEEE: New York, NY, USA, 2024. [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E., Jr. Checklist for artificial intelligence in medical imaging (CLAIM): A guide for authors and reviewers. Radiol. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef] [PubMed]
- Alhazeem, E.; Alsobeh, A.; Al-Ahmad, B. Enhancing software engineering education through AI: An empirical study of tree-based machine learning for defect prediction. In Proceedings of the 25th Annual Conference on Information Technology Education (SIGITE ’24), El Paso, TX, USA, 10–12 October 2024; pp. 153–156. [Google Scholar]
- Lekadir, K.; Frangi, A.F.; Porras, A.R.; Glocker, B.; Cintas, C.; Langlotz, C.P.; Weicken, E.; Asselbergs, F.W.; Prior, F.; Collins, G.S.; et al. FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare. BMJ 2025, 388, e081554. [Google Scholar] [CrossRef] [PubMed]
- Kiczales, G.; Lamping, J.; Mendhekar, A.; Maeda, C.; Lopes, C.; Loingtier, J.M.; Irwin, J. Aspect-oriented programming. In Proceedings of the European Conference on Object-Oriented Programming, Jyväskylä, Finland, 9–13 June 1997; pp. 220–242. [Google Scholar]
- Magableh, A.A.; Alsobeh, A.M.R. Aspect-oriented software security development life cycle (AOSSDLC). In Proceedings of the CS & IT Conferenc, Dubai, United Arab Emirates, 22–23 December 2018; pp. 25–26. [Google Scholar]
- Al-Shawakfa, E.M.; Alsobeh, A.M.R.; Omari, S.; Shatnawi, A. RADAR#: An ensemble approach for radicalization detection in Arabic social media using hybrid deep learning and transformer models. Information 2025, 16, 522. [Google Scholar] [CrossRef]
- Alsobeh, A.M.R.; Clyde, S.W. Transaction-aware aspects with TransJ: An initial empirical study to demonstrate improvement in reusability. In Proceedings of the International Conference on Software Engineering Advances (ICSEA), Rome, Italy, 21–25 August 2016; Volume 2016, p. 59. [Google Scholar]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 119–129. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Bell, J.H.; Bonawitz, K.A.; Gascón, A.; Lepoint, T.; Raykova, M. Secure single-server aggregation with (poly) logarithmic overhead. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 1253–1269. [Google Scholar]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Jacobsen, A.; de Miranda Azevedo, R.; Juty, N.; Batista, D.; Coles, S.; Cornet, R.; Courtot, M.; Crosas, M.; Dumontier, M.; Evelo, C.T.; et al. FAIR Principles: Interpretations and Implementation Considerations. Data Intell. 2020, 2, 10–29. [Google Scholar] [CrossRef]
- Huerta, E.A.; Blaiszik, B.; Brinson, L.C.; Bouchard, K.E.; Diaz, D.; Doglioni, C.; Duarte, J.M.; Emani, M.; Foster, I.; Fox, G.; et al. FAIR for AI: An interdisciplinary and international community building perspective. Sci. Data 2020, 7, 487. [Google Scholar] [CrossRef] [PubMed]
- Price, W.N.; Cohen, I.G. Privacy in the age of medical big data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Brkan, M. Do algorithms rule the world? Algorithmic decision-making and data protection in the framework of the GDPR and beyond. Int. J. Law Inf. Technol. 2019, 27, 91–121. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841. [Google Scholar] [CrossRef]
- Ressi, D.; Romanello, R.; Piazza, C.; Rossi, S. AI-enhanced blockchain technology: A review of advancements and opportunities. J. Netw. Comput. Appl. 2024, 225, 103858. [Google Scholar] [CrossRef]
- Bouchenak, S.; Boyer, F.; Hagimont, D.; Krakowiak, S.; Mos, A.; de Palma, N.; Quema, V.; Stefani, J.-B. Architecture-based autonomous repair management: An application to J2EE clusters. In Proceedings of the 24th IEEE Symposium on Reliable Distributed Systems, Berkeley, CA, USA, 30 April 2006–4 May 2006; pp. 13–24. [Google Scholar]
- Alsobeh, A.A. Improving Reuse of Distributed Transaction Software with Transaction-Aware Aspects. Ph.D. Dissertation, Utah State University, Logan, UT, USA, 2015. [Google Scholar]
- Win, B.D.; Piessens, F.; Joosen, W.; Verhanneman, T. On the security of aspect-oriented programming. In Proceedings of the 19th Workshop on Programming Languages and Analysis for Security, Salt Lake City, UT, USA, 14 October 2002; pp. 15–26. [Google Scholar]
- Viega, J.; Bloch, J.T.; Kohno, Y.; McGraw, G. ITS4: A static vulnerability scanner for C and C++ code. In Proceedings of the 16th Annual Computer Security Applications Conference, New Orleans, LA, USA, 11–15 December 2000; pp. 257–267. [Google Scholar]
- Colyer, A.; Clement, A. Large-scale AOSD for middleware. In Proceedings of the 3rd International Conference on Aspect-Oriented Software Development, Lancaster, UK, 22–26 March 2004; pp. 56–65. [Google Scholar]
- Rashid, A.; Sawyer, P.; Moreira, A.; Araújo, J. Early aspects: A model for aspect-oriented requirements engineering. In Proceedings of the IEEE International Conference on Requirements Engineering, Essen, Germany, 9–13 September 2003; pp. 199–202. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 8, e1253. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2021, 2, 429–450. [Google Scholar]
- Mohri, M.; Sivek, G.; Suresh, A.T. Agnostic federated learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4615–4625. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CL, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ’16), Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Colen, R.R.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 12598. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair resource allocation in federated learning. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).