Abstract
Translation-based Video Synthesis (TVS) has emerged as a transformative technology that enables sophisticated manipulation and generation of dynamic visual content. This comprehensive survey systematically examines the evolution of TVS methodologies, encompassing both image-to-video (I2V) and video-to-video (V2V) translation approaches. We analyze the progression from domain-specific facial animation techniques to generalizable diffusion-based frameworks, investigating architectural innovations that address fundamental challenges in temporal consistency and cross-domain adaptation. Our investigation categorizes V2V methods into paired approaches, including conditional GAN-based frameworks and world-consistent synthesis, and unpaired approaches organized into five distinct paradigms: 3D GAN-based processing, temporal constraint mechanisms, optical flow integration, content-motion disentanglement learning, and extended image-to-image frameworks. Through comprehensive evaluation across diverse datasets, we analyze the performance using spatial quality metrics, temporal consistency measures, and semantic preservation indicators. We present a qualitative analysis comparing methods evaluated on identical benchmarks, revealing critical trade-offs between visual quality, temporal coherence, and computational efficiency. Current challenges persist in long-term temporal coherence, with future research directions identified in long-range video generation, audio-visual synthesis for enhanced realism, and development of comprehensive evaluation metrics that better capture human perceptual quality. This survey provides a structured understanding of methodological foundations, evaluation frameworks, and future research opportunities in TVS. We identify pathways for advancing cross-domain generalization, improving computational efficiency, and developing enhanced evaluation metrics for practical deployment, contributing to the broader understanding of temporal video synthesis technologies.
1. Introduction
The rapid evolution of generative artificial intelligence has led to groundbreaking advancements in video synthesis and translation technologies, fundamentally altering the creation, manipulation, and understanding of dynamic visual content. Video translation, which includes image-to-video (I2V) synthesis that generates dynamic sequences from static images and video-to-video (V2V) synthesis that adapts existing video content across domains while retaining temporal integrity, has become a vital research area with diverse applications in entertainment, education, healthcare, autonomous systems, and digital content creation [1,2,3].
Although traditional image-to-image (I2I) translation has made significant strides in converting static visual content between domains, with methods, such as Pix2Pix [4], CycleGAN [5], and StarGAN [6] excelling in style transfer, domain adaptation, and semantic manipulation, the application of I2I methods to video data is hampered by their natural inability to model temporal continuity and ensure consistency across frames. As I2I models treat video frames independently, they are prone to temporal inconsistencies and flickering artifacts, where original content may vanish or new content may appear between frames. Moreover, I2I approaches often fail to capture and maintain motion properties essential for realistic video content [7,8].
To overcome these fundamental limitations of I2I methods in video synthesis, researchers have developed dedicated techniques for temporal content synthesis. Image-to-video translation deals with the unique task of generating temporal dynamics from static inputs while ensuring semantic consistency [2,9,10]. I2V translation has evolved from early approaches such as AffineGAN [2], which introduced novel facial animation via affine transformations in latent space, to more recent sophisticated methods such as FrameBridge [11], which employs data-to-data generative frameworks with Signal-to-Noise Ratio (SNR) aligned fine-tuning for efficient adaptation from pre-trained text-to-video diffusion models. Unlike I2V methods that generate motion from static content, V2V techniques utilize existing video dynamics for complex transformations that preserve motion and scene dynamics across domains.
V2V includes both paired and unpaired translation methods. Paired approaches use precisely aligned video pairs for training to enable direct supervision [1,12,13], while unpaired methods tackle scenarios where obtaining exact frame correspondence is difficult or impossible [8,14,15]. The vid2vid framework [1] laid the foundation for paired V2V methods by implementing a spatio-temporal objective function and a sequential GAN-based generators for creating consecutive video frames. Later advancements addressed temporal consistency challenges through global temporal coherence between source and generated videos [12], incorporating 3D scene understanding with Structure from Motion (SfM) [13], and employing a few-shot approach with a modified SPADE architecture [16]. Unpaired V2V translation has been segmented into specialized subfields, such as 3D GAN-based techniques treating videos as volumetric data [7], temporal constraint-based methods with explicit temporal modeling [14,15], optical flow-based techniques incorporating motion information between frames [8,17], content-motion disentanglement methods separating videos into static and dynamic components [3,18], and extended I2I frameworks with temporal modifications [19,20]. Figure 1a presents the overview of the I2V pipeline and Figure 1b presents the overview of the V2V pipeline.
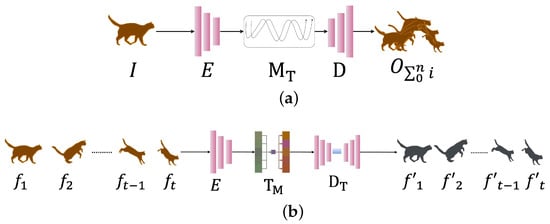
Figure 1.
(a) An overview of Image-to-Video (I2V) methods: The pipeline begins with an input image (I), from which an encoder (E) extracts essential visual and semantic features. A motion transformer () then utilizes a user-defined intensity scale or learned transformation to map motion into transformed features, and a decoder (D) constructs the video sequence () by decoding the motion-transformed features, ensuring temporal coherence and visual fidelity in the generated frames. (b) An overview of Video-to-Video (V2V) methods: The process starts with an input frame sequence (), which is processed by a feature extractor (E) to obtain spatial features. Temporal modeling () is then performed using temporal predictors or optical flow estimators to capture the dependencies and motion dynamics between consecutive frames, ensuring smooth and realistic motion transitions. A domain translator () subsequently generates the output frame sequence () in the target domain, preserving both the content and the learned temporal structure.
Beyond architectural innovations, assessing temporal video synthesis requires comprehensive evaluation frameworks. While traditional metrics such as Fréchet Inception Distance (FID) [21] and Peak Signal-to-Noise Ratio (PSNR) are useful for frame-level assessment, they fall short in capturing temporal relationships and motion consistency [22]. This inadequacy has led to the development of video-specific metrics, such as the Fréchet Video Distance (FVD) [22] and the Average Content Distance for identity (ACD-I) [3]. These metrics are designed to evaluate motion preservation and frame consistency, where smaller values indicate better model performance.
In contrast to preceding surveys [23,24,25], which predominantly concentrate on diffusion-based video synthesis models trained using text prompts or random noise, our survey explores video translation conditioned on visual information. This includes synthesis of video sequences from a single static image (image-to-video) and transforming existing video sequences (video-to-video). Previous surveys have also provided a limited analysis of early paradigms establishing GAN-based approaches. Moreover, they provide a limited discussion of loss functions which are pivotal for ensuring temporal coherence in video translation tasks. Our survey addresses these gaps in several ways. First, we provide a comprehensive review of video translation guided by visual information, encompassing foundational GAN-based methods to contemporary diffusion-based models. Second, we systemically categorize the loss functions, datasets, and evaluation metrics tailored for TVS. Lastly, we performed a task-specific quantitative analysis of various methodologies, allowing researchers to make well-informed choices regarding methodologies, and evaluation strategies within this field of study. This survey is organized as follows: Section 2 presents a comprehensive framework for TVS, establishing the taxonomy and technical foundations. Section 3 examines I2V translation methods and their progression from domain-specific to generalizable approaches. Section 4 provides in-depth analysis of V2V techniques, categorized into paired and unpaired methods with detailed sub-classifications. Section 5 offers a comprehensive overview of datasets, evaluation metrics, and loss functions. Section 6 presents a quantitative comparison on common benchmarks. Section 7 discusses future research directions and concludes with a summary of the findings and implications for the field.
2. Translation-Based Video Synthesis
Translation-based video synthesis represents a comprehensive framework for transforming visual content across temporal and domain boundaries. Unlike video generation approaches that create content from noise or text descriptions [26], TVS leverages existing visual information either from static images or video sequences to produce temporally coherent dynamic content in target domains.
Formally, TVS can be defined as learning a mapping function where the source domain contains static images or video sequences , and the target domain consists of video sequences . The fundamental challenge lies in preserving semantic content while ensuring temporal consistency.
where preserves semantic information, enforces frame-to-frame consistency, and ensures realistic appearance in the target domain.
TVS methods can be hierarchically organized based on input modality and training paradigm. Image-to-Video (I2V) translation generates temporal dynamics from static inputs, addressing the challenge of motion artifacts while maintaining appearance consistency with the source image. I2V incorporates methods ranging from parametric transformations in latent space [2] to diffusion-based frameworks with bridge models [11]. Video-to-Video (V2V) translation transforms existing video content across domains while preserving motion characteristics. This category encompasses both paired V2V methods that require frame-aligned training pairs, enabling direct supervision through explicit correspondence [1,13], and unpaired V2V approaches that operate without frame-level correspondence, learning domain mappings through cycle consistency and temporal constraints [8,14].
TVS requires maintaining consistency across frames by modeling long-range dependencies and ensuring smooth transitions. Methods address this challenge through optical flow warping [8], recurrent neural network [3], or attention mechanisms [27]. Motion preservation presents another critical challenge, as translating appearance while preserving motion patterns necessitates disentangling content from dynamics. Approaches include explicit motion modeling [18] and implicit learning through adversarial training [1]. Finally, computational efficiency remains a fundamental bottleneck, as processing video sequences demands significantly more resources than image translation. While recent methods attempt to mitigate this challenge through efficient architectures and progressive training [20], the computational complexity problem remains largely unsolved, limiting the practical deployment of TVS systems at scale.
3. Image-to-Video Translation
The potential of I2V translation to advance video generation lies in its ability to bridge the gap between static image processing and dynamic video synthesis. This capability enables applications where only static images are available and dynamic content is desired, such as creating animated portraits from photographs, generating promotional videos from product images, or producing educational content from still diagrams. I2V translation addresses the unique challenge of creating temporal dynamics from a single static input while preserving the appearance details and semantic content of the original image, a key limitation of image-to-image (I2I) translation. The datasets, evaluation metrics, and loss functions used in I2V translation are detailed in Section 5.
The evolution of I2V translation begins with AffineGAN [2] (Figure 2a), which pioneered facial expression animation through hidden affine transformations in latent space. The method employs dual encoders to extract facial contours and expression changes, constructing target latent codes as , where represents neutral face encoding, encodes expression direction, and modulates intensity through an inverse formulation . AffineGAN achieves more than 50% realism scores on CK+ dataset [28] for facial expression generation in Amazon Mechanical Turk tests, demonstrating the viability of latent space manipulation for facial animation. However, AffineGAN encounters substantial challenges in generating realistic backgrounds and managing non-facial domains. It particularly struggles with intricate textures and patterns beyond the facial area, confining its application to controlled settings with static backgrounds.
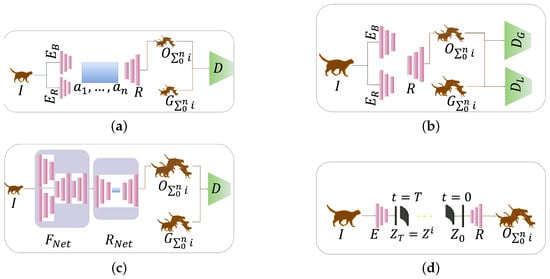
Figure 2.
Image-to-Video translation frameworks showing the evolution from basic facial animation to advanced diffusion models: (a) AffineGAN uses two encoders (base encoder for base facial features and residual encoder for facial contours and expression changes) that learn affine transformation parameters () to animate faces in latent space, with decoder R creating the output video and discriminator D comparing output video with ground truth [2]; (b) Fan et al. integrate facial landmark detection, employing separate discriminators for local facial regions (local discriminator ) and overall frame consistency (global discriminator ) to improve realism [9]; (c) Structure-aware multi-stage method processes input image I through a forecasting network () (consists of motion and image encoders/decoders) that predicts motion patterns and a refinement network () (consists of video encoder/decoder) that enhances temporal smoothness [10]; (d) FrameBridge encoder E encodes image I that is duplicated across temporal dimension to establish bridge process connecting static image priors with video targets, then decoder R generates coherent video sequence through learned neural prior that facilitates image animation [11].
To address the drawbacks of AffineGAN, Fan et al. [9] (Figure 2b) introduced a comprehensive framework for altering facial appearance that integrates neural network-based facial landmark prediction and incorporates distinct global and local discriminators to enhance the adversarial training process. Their method employs a novel neural network architecture that integrates user input into skip connections, facilitating the generation of controllable video clips of various lengths from a single face image. This method utilizes a base encoder, a residual encoder, and a decoder setup where the frame generator synthesizes subsequent frames by predicting residual motion between current and subsequent frames. The dual discriminator architecture ensures both local details through a local discriminator concentrating on particular facial regions (such as the mouth) and global consistency through a global discriminator evaluating entire frames. This method achieves 15% improvement on CK++ dataset in identity preservation compared to AffineGAN while maintaining facial consistency through the dual discriminator approach. However, similar to its predecessor, the model is still largely confined to facial domains and finds it challenging to generate complex backgrounds.
To overcome the single-domain limitation of previous facial-specific methods, Zhao et al. [10] (Figure 2c) introduce a unified two-stage model addressing both facial expression retargeting and human pose forecasting through a structure-aware approach via multi-stage generative adversarial networks. Their architecture implements a structural condition prediction network that first generates facial expressions or body poses, followed by motion forecasting networks for coarse video generation and motion refining networks for temporal coherence enhancement. The innovation lies in their motion refinement network, which utilizes a ranking loss to optimize temporal coherence. However, the two-stage architecture introduces computational overhead, and its adversarial loss leads to occasional suboptimal identity mapping that challenges real-time applications.
Recognizing the computational limitations and domain constraints of previous approaches, FrameBridge [11] (Figure 2d) introduces a paradigm shift through data-to-data generative frameworks. Unlike the computationally expensive two-stage architecture employed by Zhao et al. [10], FrameBridge operates as a single unified framework, eliminating the overhead of the previous multi-stage refinement process. The most significant computational advancement lies in replacing the uninformative Gaussian prior used in traditional diffusion models with a deterministic data point created by simply replicating the input image, allowing the model to start with actual image information rather than computationally expensive random noise generation. FrameBridge incorporates Signal-to-Noise Ratio (SNR) aligned fine-tuning (SAF) to align the marginal distribution of the bridge process with that of the diffusion process, enabling efficient fine-tuning from pre-trained text-to-video diffusion models rather than requiring complete retraining from scratch. The bridge process directly connects static image priors with video targets through the equation:
where represents the replicated input image, and are the drift and diffusion coefficients, respectively, h denotes the bridge function, c represents the conditioning information, and denotes the Wiener process. The utilization of a pre-trained video diffusion model, with its noise generation module replaced by an image-prior, demonstrates superior performance compared to its architectural backbone, the general-purpose video diffusion model [29], achieving an FVD score of 154 vs. 171 on the UCF-101 dataset [30]. This result highlights that initializing the generative process from a replicated input image rather than random Gaussian noise not only preserves more appearance information but also significantly enhances temporal consistency and overall video quality.
Similarly, I2V-Adapter [27] introduces a lightweight approach that integrates with pre-trained Text-to-Image models through a cross-frame attention mechanism, ensuring identity preservation while reducing computational overhead. This method represents a practical advancement in I2V deployment by enabling efficient fine-tuning of existing models without requiring complete retraining. The adapter-based design allows for controlled animation while maintaining consistency across frames, addressing both identity preservation and temporal coherence challenges through its cross-frame attention mechanism that enables the model to maintain consistency across frames while allowing for controlled animation.
Although these methodological advances demonstrate the progression from domain-specific facial animation to more generalizable frameworks, several challenges persist. Temporal consistency remains critical, particularly for extended sequences, where motion coherence becomes increasingly difficult to maintain. Domain specialization continues to limit broader applicability, with methods showing strong performance on facial expression datasets, yet encountering difficulties with diverse content domains.
4. Video-to-Video Translation
Video-to-video (V2V) translation represents a significant advancement beyond image-to-video (I2V) methods by operating directly on video data, enabling the transformation of dynamic content while preserving motion patterns and temporal relationships. This capability proves essential for applications requiring domain adaptation with realistic motion preservation, such as synthetic-to-real conversion for training data augmentation [7,14]. V2V translation can be divided into two primary categories based on the requirement of direct frame-to-frame correspondence: paired and unpaired approaches. Paired V2V translation requires precisely aligned video pairs during training, and unpaired V2V translation learns transformations between video domains without requiring exact frame-to-frame correspondences. The datasets, evaluation metrics, and loss functions used in V2V translation are detailed in Section 5.
4.1. Paired Video-to-Video Translation
Paired video-to-video translation builds the foundation of supervised video synthesis, where the availability of precisely aligned video pairs enables direct supervision during the training process. This approach leverages explicit correspondences between source and target domains to learn accurate mapping functions. The evolution begins with vid2vid [1] (Figure 3a), which established the foundational conditional GAN framework [4] for video synthesis. The architecture employs a sequential generator that synthesizes frames step by step using a Markov assumption: , where represents the generated frame at time t, denotes the source frame, and L is the temporal window size. The framework incorporates a conditional discriminator ( that includes a conditional image discriminator for frame realism and a conditional video discriminator for temporal dynamics. vid2vid demonstrates the viability of paired video translation with a better FID of 4.66 (vs. 5.57 for pix2pixHD [31]) on Cityscapes dataset [32]. However, the method struggles with maintaining consistent motion dynamics over longer sequences, resulting in temporal artifacts and quality degradation.
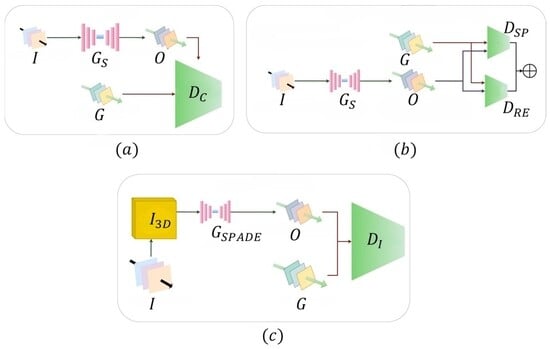
Figure 3.
Evolution of paired video-to-video translation: (a) vid2vid framework with sequential generator processing input video I to generate output video O, evaluated by conditional discriminator [1]; (b) vid2vid with global temporal consistency using dual discriminators: spatial discriminator and residual error discriminator for evaluation of generated video O from ground truth video G [12]; (c) world-consistent vid2vid incorporating 3D guidance images through SfM reconstruction, where the generator utilizes multi-SPADE normalization to process input video I and guidance information, evaluated by discriminator for geometric consistency [13].
Wei et al. [12] (Figure 3b) address vid2vid’s challenges with long-term consistency, by enhancing global temporal consistency using residual error analysis. Their key contribution involves calculating residual errors () individually for both the source and the generated videos by comparing warped and aligned frames: . Here, represents warping of each pixel p from the preceding frame , with optical flow W. Their method utilizes a dual-channel discriminator architecture that examines both real and synthesized frames along with the residual errors between the generated and actual outcomes. This innovative approach achieved superior performance with a Region Similarity score of 0.92 and Contour Accuracy of 0.96 on the DAVIS2017 dataset [33], compared to vid2vid’s scores of 0.73 and 0.78, respectively, demonstrating significant improvement in maintaining frame-to-frame consistency. However, the technique still faces challenges in maintaining long-term temporal coherence in intricate dynamic scenes.
Recognizing the persistent challenges of long-term consistency, World-consistent vid2vid [13] (Figure 3c) introduces 3D scene understanding through Structure-from-Motion (SfM) techniques [34]. The process begins by creating a 3D point cloud through feature extraction and matching, followed by camera pose estimation and triangulation. The SfM process utilizes COLMAP [35] to perform incremental reconstruction, where features are extracted using SIFT descriptors and matched across frames. The system projects 3D representations to generate physically grounded guidance images, processed through Multi-SPADE normalization [36]. This approach achieves an FID score of 49.89 on the Cityscapes dataset, significantly outperforming vid2vid (FID 69.07) for urban scene synthesis. However, the method faces challenges in handling dynamic scenes and requires substantial computational resources for accurate 3D reconstruction.
While world-consistent vid2vid achieved superior consistency, it requires extensive paired training data for each target domain. Few-shot vid2vid [16] addresses this data dependency by allowing the creation of contents for new subjects or domains with a few example images. The core advancement lies in a network weight generation module, which adjusts the model for a new domain during the test phase utilizing the given example images. The framework consists of three primary steps, i.e., processing the example images, generating dynamic weights, and performing adaptive video synthesis.
In the example image processing stage, the model takes K example images of the target domain along with their semantic representations (such as pose maps or segmentation masks). An example feature extractor analyzes these images to capture appearance characteristics such as clothing, facial features, or scene style. When multiple example images are provided, an attention mechanism combines features by computing relevance scores between each example and the current input frame, ensuring that the most appropriate visual patterns are emphasized for each synthesis step. During dynamic weight generation, a multi-layer perceptron converts the extracted features into network weights that configure the intermediate image synthesis network H. Unlike traditional approaches with fixed parameters, these weights are dynamically computed based on the provided examples, enabling adaptation to the new domain without retraining. The generated weights specifically target the spatial modulation branches of a SPADE generator, which control how semantic inputs are transformed into realistic images while preserving the appearance style of the example images. The adaptive synthesis process combines this dynamically configured network with the temporal consistency mechanisms of traditional vid2vid [1]. The model maintains smooth motion by incorporating previous frames from time to and uses optical flow warping to preserve temporal coherence in generating the frame . This architecture achieves remarkable efficiency, requiring only 1–5 example images, while maintaining high quality with a pose error of 6.01 pixels compared to 16.84 pixels for the baseline model PoseWarp [37] on the YouTube dancing videos dataset [16]. Despite reducing data dependency, performance remains heavily dependent on example image quality and struggles with complex scene dynamics.
Advancing toward real-time applications, StreamV2V [38] introduces diffusion-based frameworks for streaming video translation. The method maintains temporal consistency through a feature bank that archives information from past frames, enabling 20 FPS processing on a single GPU. The extended self-attention mechanism incorporates stored features: , where , , represent queries, keys, and values of the current frame, while and are stored features from the feature bank. This approach demonstrated 15× speed improvement over FlowVid [39] while maintaining competitive quality, addressing the computational limitations of previous methods.
The evolution of paired V2V translation demonstrates clear progression from initial temporal warping through global consistency mechanisms to 3D world-aware synthesis, few-shot generalization, and real-time processing. However, persistent challenges include extensive paired data requirements, temporal coherence across extended sequences, computational complexity for 3D reconstruction methods, and performance bounds limited by the diversity of training pairs. Domain gaps between training and test data continue to cause degraded performance in real-world scenarios.
4.2. Unpaired Video-to-Video Translation
Unpaired video-to-video translation emerges as a solution to address the fundamental limitations of paired methods, particularly the requirement for exhaustive frame-by-frame video alignment. While paired approaches struggle with obtaining precisely aligned video pairs and handling diverse domain translations, unpaired methods leverage inherent relationships between video domains without requiring explicit frame correspondences. Unpaired V2V methods can be categorized into five distinct classes: 3D GAN-based, temporal constraint-based, optical flow-based, content-motion disentanglement, and extended image-to-image translation approaches.
4.2.1. 3D GAN-Based Approaches
3D GAN-based approaches represent the earliest attempts to handle unpaired video translation by treating videos as three-dimensional tensors, enabling simultaneous processing of spatial and temporal information. Bashkirova et al. [7] established the foundation with spatio-temporal translators based on image-to-image networks [40]. Their architecture processes videos as 3D tensors with dimensions , where d represents temporal depth, and denote spatial dimensions. The framework employs two 3D generator networks ( and ) to transform volumetric images between domains X and Y, along with two 3D discriminator networks ( and ) to distinguish real from synthetic videos as shown in Figure 4. The method implements cycle consistency () ensuring that translated videos can be reverted through inverse translation. This approach demonstrates a Pixel Accuracy of 0.60 and a Human Subjective Score of 0.68 on GTA dataset [41], demonstrating the viability of volumetric video processing. However, the method faces significant limitations in maintaining spatio-temporal consistency due to lack of explicit regularization mechanisms, high memory usage for high-resolution videos, and inconsistent motion patterns from treating videos as static 3D volumes.
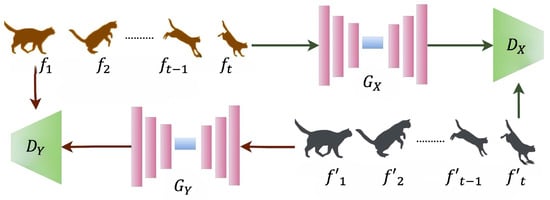
Figure 4.
3D GAN-based unpaired video translation using cycle consistency with dual generators and discriminators processing videos as volumetric tensors. Video frames from DomainX (frames ) are processed through generator and evaluated by discriminator . Similarly, DomainY frames (frames ) undergo translation through generator and evaluation by discriminator , enabling bidirectional domain translation while maintaining temporal consistency through volumetric processing [7].
4.2.2. Temporal Constraint-Based Approaches
Temporal constraint-based approaches emerge to address 3D GAN limitations in capturing detailed patterns and maintaining frame consistency through explicit temporal modeling mechanisms.
Recycle-GAN [14] introduces temporal factors into video translation through recurrent temporal predictors that capture dependencies in ordered sequences. The innovation lies in its dual loss functions, a recurrent loss () that trains temporal predictors using the previous two samples, and a recycle loss () that incorporates cycle consistency to temporal prediction, as illustrated in Figure 5. Recycle-GAN achieves an intersection over union (IoU) of 8.2 for image-to-label translation (image to corresponding semantic segmentation mask) on Viper dataset [42], demonstrating the temporal modeling capability. However, the method struggles with precise frame-to-frame modifications due to high-level temporal modeling that loses detailed motion information.
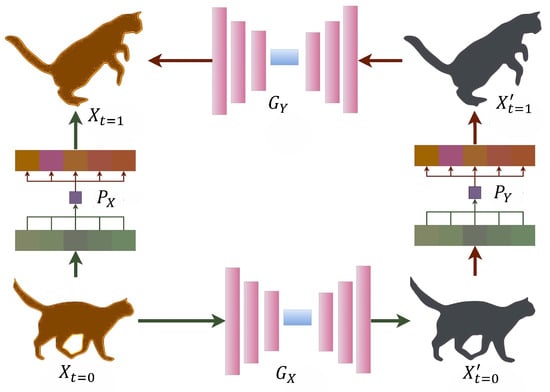
Figure 5.
Recycle-GAN framework for temporal constraint-based unpaired video translation. The architecture employs dual generators and with temporal predictors and to maintain temporal consistency. Input frame from the source domain is processed through generator to produce translated frame , while temporal predictor predicts next frame and from input and generated frames, respectively. The framework ensures cycle consistency through generator for frame reconstruction [14].
Addressing Recycle-GAN’s fine-grained variation limitations, Liu et al. [15] enhance the framework by introducing tendency-invariant loss (). The tendency-invariant loss ensures that the prevailing trends in frame modifications persist in the predicted frames, improving overall temporal consistency while maintaining the semantic content of the translations. The method demonstrates substantial improvements in performance, achieving better FID scores in various translation tasks (49.5 vs 53.4 for face-to-face transition, 112.2 vs. 118.3 for flower-to-flower transition) compared to the Recycle-GAN. Despite improvements, reliance on temporal predictors struggles with intricate pixel-level details crucial for photorealistic sequences. Figure 6 demonstrates the integration of optical flow estimation with cycle consistency mechanisms for unpaired video translation.
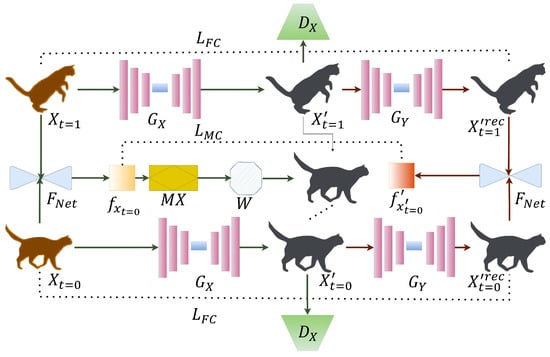
Figure 6.
MoCycle-GAN framework integrating optical flow estimation through FlowNet with motion translation constraints. The architecture incorporates frame cycle consistency () into motion cycle consistency () to transfer motion patterns between domains. Input frames and are processed through generators and reconstructed through , while FlowNet estimates optical flows from two consecutive input frames and from reconstructed frames. Motion translator and warping operation W ensure temporal coherence, with discriminators evaluating translated sequences for realistic motion transfer [8].
4.2.3. Optical Flow-Based Approaches
Optical flow-based approaches address the fundamental limitations of temporal constraint-based methods by introducing explicit motion modeling through pixel-level movement estimation. These methods are based on optical flow estimation networks providing robust foundations for motion analysis.
FlowNet [43] introduces learning optical flow with convolutional networks through two architectures: FlowNetSimple stacking input images together, and FlowNetCorr creating separate processing streams combined through correlation layers. The correlation layer performs multiplicative patch comparisons between feature maps, computing correlation as , where and represent multi-channel feature maps, and denote patch centers, k defines patch size, and represents inner product operation.
FlowNet 2.0 [44] advances optical flow estimation through a multi-stage stacked architecture that progressively refines motion estimates by warping consecutive video frames. The key innovation lies in its iterative warping mechanism, where each stage uses the motion estimates from the previous stage to geometrically transform and align two consecutive frames. The warping technique uses bilinear interpolation to obtain sub-pixel accuracy, acknowledging that natural object movement happens as a continuous flow in space rather than an abrupt shift between fixed pixel positions on the digital image grid.This progressive refinement approach allows FlowNet 2.0 to iteratively improve optical flow accuracy by reducing the motion discrepancy between consecutive frames at each stage of the stacked architecture.
Building upon these foundations, MoCycle-GAN [8] (Figure 6) represents a significant advancement by integrating optical flow with cycle consistency. The framework employs FlowNet for motion estimation and introduces motion translators transferring motion information between domains. The architecture implements three constraints: adversarial constraint () for realistic frame appearance, frame and motion cycle consistency constraints () for maintaining appearance and motion dynamics, and motion translation constraint () for enforcing temporal continuity among synthetic frames. The motion translator transforms primary optical flow into transferred flow in target domain. The integration of optical flow with cycle consistency enhances the effectiveness of MoCycle-GAN, achieving an IoU score of 13.2 compared to 11 for Recycle-GAN in the video-to-label translation task using the Viper dataset. Despite improvements, the method continues facing challenges with occlusions, complex non-rigid motions, and domain gaps that compromise motion estimation accuracy.
Addressing the limitation of MocCycle-GAN in handling occlusion and complex motion, STC-V2V [17] introduces sophisticated image warping algorithms with temporal consistency loss to explicitly penalize inconsistencies between generated frames. The method employs a recurrent generator (S: Source, T: Target) to process input frames using three sub-modules, i.e., an image generator , a flow estimator, and a fusion block. At each time step, the flow estimator computes the optical flow between two consecutive frames and . The fusion block learns to regress a fusion mask m that adaptively blends the warped pixels and the generated pixels into one frame. The method obtains an improved mIoU score of 35.14 compared to Recycle-GAN’s 25.10 for video-to-label translation. While improving occlusion handling, STC-V2V struggles with large motion displacements and complex scene dynamics where optical flow estimation becomes unreliable, with recurrent generator nature leading to error accumulation over long sequences.
To address traditional optical flow estimation limitations, Wang et al. [45] introduce synthetic optical flow to generate idealized motion representations specifically designed for cross-domain consistency. The method generates synthetic flow from static frames to simulate temporal motion and synthesize future frames through warping, which acts as flawless motion representation for both source and target domains. The approach introduces two unsupervised losses: unsupervised recycle loss () maintaining motion consistency across domains, and unsupervised spatial loss () enforcing consistency between frames and warped versions. Synthetic optical flow achieves superior performance with an mIoU of 13.71 on the Viper dataset compared to STC-V2V (9.09) for video-to-label translation task.
Similarly, FlowVid [39] addresses the limitations of all previous optical flow-based methods by treating optical flow as a soft guidance rather than hard constraints. Unlike synthetic optical flow methods that avoid estimation altogether, FlowVid acknowledges the imperfection in real optical flow and compensates through additional spatial conditioning. The approach performs flow warping from the first frame to subsequent frames. It includes additional spatial conditions (such as depth maps) along with temporal flow conditions. The method builds a video diffusion model on an inflated spatially controlled I2I model, training the model to predict the input video using spatial conditions c and temporal conditions (flow-warped video) f. The joint spatial–temporal condition rectifies an imperfect optical flow. When flow estimation is inaccurate (e.g., incorrect leg positions), spatial conditions provide correct positional information, and joint conditioning produces more consistent results.
Despite these advancements, optical flow-based methods still suffer from occlusion handling difficulties, complex non-rigid motion issues challenging brightness constancy assumptions, persistent domain gap problems when training and target domains differ significantly, and computational complexity with advanced motion modeling techniques.
4.2.4. Content-Motion Disentanglement Learning Approaches
Content-motion disentanglement learning represents a paradigm shift by explicitly separating static content features from dynamic motion patterns. Unlike optical flow methods tracking pixel-level movements or temporal constraint approaches relying on high-level predictors, these methods decompose videos into semantically meaningful components: content vectors capturing object identity and appearance, and motion codes encoding temporal dynamics and transformations.
MoCoGAN [3] establishes the foundational framework where each video is represented through a content code that remains constant throughout the sequence to preserve object identity, and a sequence of motion codes that vary temporally to capture dynamics. The architecture employs dual discriminators: image discriminator evaluating individual frame quality and video discriminator assessing temporal coherence across sequences. The content code is sampled once per video and shared across frames, while motion codes are generated through recurrent neural networks: , where represents random noise at time t. The generator combines these representations to synthesize frames using as illustrated in Figure 7. Despite innovations, the method faces constraints including recurrent neural network instability for long sequences and requiring careful balancing between content preservation and motion diversity to avoid identity inconsistency.
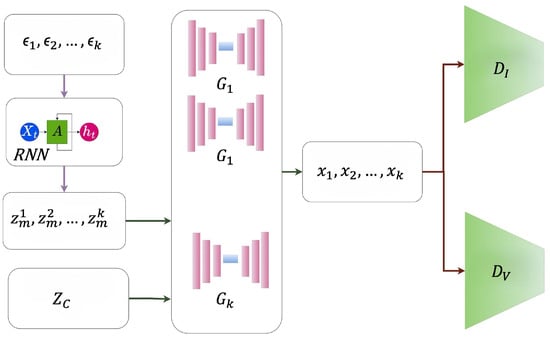
Figure 7.
MoCoGAN architecture for content-motion disentanglement learning. Random variables () generate motion codes () through RNN, while content vector () remains constant across all frames to preserve object identity. Multiple generators () produce video frames () using constant and the corresponding that are evaluated by both image discriminator for individual frame quality and video discriminator for temporal coherence assessment [3].
To address the instability and limited bidirectional processing of MoCoGAN, UVIT [18] introduces significant architectural improvements through an encoder–RNN–decoder framework that decomposes videos into content and style representations. The key innovation lies in the TrajGRU mechanism [46], which uses learned offsets to sample features from neighboring locations in both forward and backward directions by , where represents the hidden state at time t, incorporating information from past and future contexts. The framework introduces a novel video interpolation loss () that provides pixel-level supervision to train RNN components in a self-supervised manner. Using the Viper dataset for video-to-label translation, UVIT achieves a mIoU of 13.07 significantly outperforming ReCycleGAN (mIoU of 10.11), across all weather conditions. While UVIT addresses many earlier limitations, it introduces increased computational complexity due to the bidirectional processing and additional encoder-decoder components. The method also requires careful hyperparameter tuning for the video interpolation loss to achieve optimal performance.
4.2.5. Extended Image-to-Image Approaches
Extended image-to-image approaches utilize existing frameworks with temporal mechanisms while maintaining architectural simplicity and the training efficiency of image-based models.
HyperCon [19] pioneers the transformation of pre-trained image models into temporally consistent video models without fine-tuning through a systematic three-stage framework. The method first performs frame interpolation using Super SloMo [47] to insert i frames between consecutive frames in input video , creating interpolated video with an expanded frame count . Subsequently, the image-to-image translation model g processes each interpolated frame independently. Finally, temporal aggregation employs a sliding window approach where off-center context frames are aligned to reference frames via PWC-Net optical flow warping [48], followed by pixel-wise pooling: , where represents warped context frames and parameterizes temporal window size. Figure 8 shows the three-stage framework for transforming image models into temporally consistent video models. This approach leverages image models trained on datasets orders of magnitude larger than available video datasets, demonstrating effectiveness with 57.3% and 55.5% human preference scores for rain-princess and mosaic styles, respectively, on ActivityNet [49] and DAVIS2017 datasets.
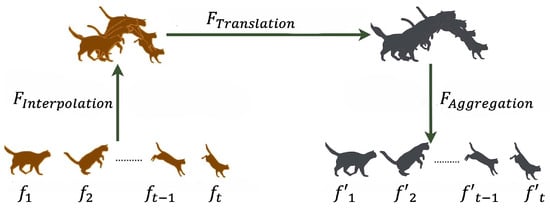
Figure 8.
Extended image-to-image framework for transforming pre-trained image models into temporally consistent video models. The process begins with frame interpolation () generating interpolated frame between input frames (), followed by frame translation () applying pre-trained image-to-image models independently to each frame, and concludes with frame aggregation () using temporal windowing with optical flow alignment to ensure consistency across the final output sequence () [19].
Rivoir et al. [50] further advance the extended I2I paradigm by combining neural rendering [51] with unpaired image translation [52] for surgical video synthesis where labeled data is severely limited. The method employs a global texture representation ‘tex’ that stores appearance information through ray casting, triplanar mapping, and bilinear interpolation. The novel lighting-invariant view-consistency loss compares feature vectors between differently illuminated views using cosine similarity rather than pixel-wise differences, achieving a better FID score of 26.8 compared to 61.5 for Recycle-GAN on laparoscopic datasets [52].
Similarly, StyleGAN-V [20] addresses computational inefficiency by treating videos as continuous signals mapping time coordinates to image frames, allowing arbitrary-length generation at arbitrary frame rates. Unlike MoCoGAN [3] that suffers from RNN instability, StyleGAN-V generates frames non-autoregressively with continuous motion representations and acyclic positional encoding to prevent looping. The discriminator aggregates temporal information through frame feature concatenation rather than expensive 3D convolutions, achieving an FVD score of 79.5 compared to 206.6 of MoCoGAN on SkyTimelapse dataset [53].
However, both HyperCon’s frame interpolation approach and StyleGAN-V’s extended video generation method achieve better visual consistency between frames at the cost of increased memory requirements limiting real-time applications.
The computational complexity and implementation difficulty associated with TVS methods exhibit pronounced variation across methodological categories, following a clear progression from image-to-video (I2V) to video-to-video (V2V) paradigms, and further intensifying from paired to unpaired frameworks. I2V methods, particularly those leveraging diffusion-based architectures such as FrameBridge [11] and I2V Adapter [27], typically require moderate to high computation. The principal challenges in these approaches stem from the need to maintain temporal visual consistency while synthesizing realistic motion, necessitating sophisticated architectural strategies to address the inherent complexity of temporal coherence. In comparison, paired V2V methods [1,12,13,16] are distinguished by their elevated model complexity and longer training times. These approaches frequently require multi-GPU configurations with substantial Video Random Access Memory (VRAM) capacity. Implementation is further complicated by the need for meticulously aligned paired datasets and the risk of memory bottlenecks, which can impede scalability and practical deployment. Unpaired V2V methods represent the most computationally intensive class within the TVS landscape, with subcategories presenting distinct resource profiles and implementation challenges. Approaches that incorporate explicit motion modeling or 3D convolutions [7] impose the greatest computational burden, characterized by very large models and significant resource requirements. These methods are particularly challenging due to issues of scalability and convergence stability. Temporal constraint-based techniques [14,15] require moderate to high resource allocation, with implementation difficulty arising primarily from the intricate balance between multiple loss functions and the need to ensure training stability. Similarly, optical flow-based methods [8,17,39,45] require moderate to high computation, facing specific challenges in accurate motion estimation and seamless integration of flow information. Content-motion disentanglement strategies [3,18] offer relatively moderate resource demands, yet present moderate to high implementation complexity, largely due to the sophisticated loss function design and modularity required to effectively separate content and motion representations. Extended image-to-image (I2I) frameworks [19,20,50] constitute the most accessible unpaired approach, with moderate computational requirements. However, these methods are persistently challenged by issues related to temporal consistency and the suppression of flicker artifacts.
5. Datasets, Evaluation Metrics, and Loss Functions
This section provides a comprehensive overview of the datasets, evaluation metrics, and loss functions used in different image-to-video and video-to-video translation research, organized by their primary applications and technical purposes.
5.1. Datasets
Video translation research employs diverse datasets organized by application domains, providing comprehensive benchmarks for evaluating methods across different scenarios. Table 1 presents an overview of the datasets categorized by their application. Human-centered datasets include facial expression and motion datasets where the Extended Cohn–Kanade (CK+) dataset [28] contains 593 videos across 8 emotion categories from 123 subjects at 640 × 480 resolution, focusing on “happy”, “angry”, and “surprised” expressions for emotion transfer tasks. The augmented CK++ dataset [28] provides RGB-scale videos from 65 volunteers with 214, 167, and 177 clips for the respective expressions averaging 21 frames per clip. MEAD [54] offers high-resolution (1024 × 1024) audio-visual content for emotional talking-face generation, while MUG [55] contains 86 subjects at 896 × 896 resolution covering six facial expressions. FaceForensics [56] provides 1000 news briefing videos for sketch-to-face synthesis.

Table 1.
Summary of representative datasets for translation-based video synthesis.
Human motion datasets encompass Human3.6M [57] with 3.6 million poses from 11 actors performing 15 activities providing 2D/3D joint positions, Penn Action [58] containing 2326 sequences of 15 actions with 13 joint annotations, YouTube Dancing Videos [16] with 1500 videos and 15,000 training clips for pose-to-human translation, and MannequinChallenge [59] offering 3040 training and 292 test sequences at 1024 × 512 resolution for pose synthesis.
Scene and environment datasets include urban driving datasets such as Cityscapes [32] with 5000 annotated images of 50 cities at 2048 × 1024 resolution for autonomous driving scenarios, Viper [41] extracted from Grand Theft Auto V with 77 sequences under varying conditions at 1920 × 1080, and Apolloscape [60] containing 73 Beijing street scenes with 100–1000 frame lengths. Indoor datasets include ScanNet [61] with video clips from 707 rooms yielding 1513 scnas at 1296 × 968 resolution, and DAVIS2017 [33] providing 150 high-quality videos with per-pixel foreground annotations.
General-purpose datasets include UCF-101 [30] with 13,320 videos across 101 action categories processed at 320 × 240 resolution, and MSR-VTT [62] containing 10,000 video–text pairs for multimodal understanding. Special-domain datasets include flower-to-flower translation datasets [14] for botanical style transfer tasks and laparoscopic datasets [52] containing surgical videos for medical video synthesis where labeled data is severely limited. Synthetic datasets include Moving MNIST [63] with digits following trajectories for temporal consistency testing, SkyTimelapse [53] at 256 × 256 resolution for natural scene translation, Volumetric MNIST [64] with erosion-transformed digits creating 30 × 84 × 84 volumes for domain translation, and MRCT [7] containing 225 MR [65] and 234 CT [66] images at 256 × 256 resolution for medical image translation.
5.2. Loss Functions
Loss functions in temporal video synthesis serve as training objectives that guide neural networks to generate high-quality videos with temporal consistency, semantic preservation, and visual quality across various applications.
5.2.1. Adversarial Loss
Adversarial loss enables realistic video content generation through competitive training between two networks: a generator that creates synthetic videos and a discriminator that distinguishes between real and fake content.
Standard GAN Loss [67] establishes the fundamental adversarial training objective where the generator learns to fool the discriminator while the discriminator learns to identify synthetic content:
where D represents the discriminator network that outputs authenticity scores, G denotes the generator network that creates synthetic videos from input x, y represents real video data from the target distribution , and denotes mathematical expectation. The generator minimizes this loss to create more realistic content, while the discriminator maximizes it to better distinguish real from synthetic videos.
5.2.2. Reconstruction Loss
Reconstruction loss ensures pixel-level correspondence between generated videos and ground-truth targets by measuring direct differences in pixel intensities or perceptual features.
L1 Reconstruction Loss measures the absolute pixel-wise differences between the target and the generated frames, promoting sharp edges and detailed preservation:
where and represent target and generated video frames, respectively, and denotes the L1 norm to calculate absolute differences.
L2 Reconstruction Loss measures squared pixel-wise differences, providing smoother optimization gradients:
where denotes the squared L2 norm, which squares the pixel differences.
Perceptual Loss [40] measures semantic similarity using features extracted from some pre-trained neural networks rather than raw pixel differences:
where represents feature representations from layer l of some pre-trained network such as VGG, denotes the number of features in layer l, and the summation occurs over multiple selected network layers to capture both low-level and high-level visual features.
5.2.3. Temporal Consistency Loss
Temporal consistency loss maintains coherent motion and appearance across consecutive video frames by enforcing smooth transitions and motion coherence.
Temporal Consistency Loss [17] enforces frame-to-frame consistency using optical flow warping with occlusion handling:
where represents the occlusion mask calculated from warping errors, denotes the frame generated at time t, represents the warping function using optical flow from frame t to , K is the sequence length, and controls occlusion sensitivity.
Warping Loss [17] measures temporal consistency by comparing frames with their optically warped predecessors:
where represents the difference between the current frame and the warped next frame, denotes the occlusion mask that excludes occluded pixels, represents optical flow between consecutive frames, p indexes pixel locations, and T denotes the total number of frames.
Recurrent Loss [14] measures the difference between the actual next frame in a video sequence and the frame predicted by the temporal predictor network:
where represents the temporal predictor network, denotes the frame at time and t, and is the ground-truth frame at time .
Recycle Loss [14] combines cycle consistency with temporal prediction:
where and are generators for domains X and Y, is the temporal predictor for domain Y, and the loss ensures consistency through domain translation and back-translation with temporal prediction.
Tendency Invariant Loss [15] preserves frame modification tendencies:
where represents prediction of frame from time t to , represents prediction of frame from time to t, and the second term captures the actual frame modification tendency in the original sequence.
5.2.4. Cycle Consistency Loss
Cycle consistency loss ensures bidirectional mapping consistency for unpaired domain translation by requiring that forward and backward transformations return to the original input.
Cycle Consistency Loss [5] ensures that the mappings between two domains are invertible by requiring perfect reconstruction after forward and backward translation:
where F and G represent the mappings between domains X and Y, ensuring that and for perfect cycle consistency.
Motion Cycle Consistency Loss [8] extends the cycle consistency to optical flow by ensuring that motion patterns are preserved through domain translation cycles:
where represents the confidence weights per-pixel, denotes the original optical flow at pixel i and time t, represents the reconstructed optical flow after cycle translation, and the superscript indexes individual pixels.
5.2.5. Specialized Loss
Specialized loss addresses specific challenges in temporal video synthesis such as identity preservation, content maintenance, and domain-specific requirements.
Identity Preservation Loss [9] maintains identity consistency in facial video synthesis by comparing deep facial features:
where extracts identity features using a pre-trained face recognition network, computes cosine similarity between feature vectors, and the loss penalizes identity drift by maximizing feature similarity between source and generated faces.
Prior Loss [11] trains neural networks to learn informed priors from duplicated input frames for bridging static images to dynamic videos:
where represents neural network parameters, denotes the video target representation, represents the input image representation, c indicates conditioning information, and represents the neural prior network.
FlowVid Loss [39] enables flow-conditioned diffusion training by measuring the difference between actual noise and the noise predicted by the diffusion model when conditioned on optical flow information:
where represents the noisy latent representation at diffusion timestep t, denotes the text prompt conditioning, c represents spatial condition information, f represents optical flow information, denotes ground truth Gaussian noise, represents the noise predicted by the network with parameters , and denotes the standard Gaussian distribution for noise sampling.
5.3. Evaluation Metrics
Evaluation metrics assess both spatial quality and temporal consistency of generated video sequences across different dimensions.
5.3.1. Spatial Quality Metrics
These metrics evaluate the visual fidelity and realism of individual video frames.
Fréchet Inception Distance (FID) [21] measures the distance between feature distributions:
where and are the mean and covariance of the real and generated image features respectively, represents matrix trace, and denotes matrix square root. Lower FID scores indicate better image quality and diversity.
Inception Score (IS) [68] evaluates quality and diversity through label distributions. For real image x and generated image y,
where is conditional label distribution from the Inception network, is marginal distribution, denotes Kullback–Leibler divergence, and ensures positive values. Higher IS scores indicate better performance.
Peak Signal-to-Noise Ratio (PSNR) measures pixel-level reconstruction quality:
where is maximum possible pixel value (typically 255 for 8-bit images), is the mean squared error between images, and provides decibel scale. Higher values indicate better reconstruction accuracy.
Structural Similarity Index (SSIM) [69] assesses perceptual similarity through luminance, contrast, and structure:
where are local means, are standard deviations, is covariance, and are small constants preventing division by zero. Values range from 0 to 1, with higher values indicating higher similarity.
Learned Perceptual Image Patch Similarity (LPIPS) [70] measures perceptual distance using deep features:
where are normalized features from layer l, are learned weights, ⊙ denotes element-wise multiplication, are spatial dimensions of layer l, and summation occurs over spatial locations .
5.3.2. Temporal Consistency Metrics
These metrics evaluate motion smoothness and coherence across video frames.
Fréchet Video Distance (FVD) [22] extends FID to video evaluation using I3D [71] features:
where subscript v denotes video features extracted using I3D network, and the other terms follow that in FID definition.
5.3.3. Semantic Consistency Metrics
These metrics evaluate preservation of semantic content and object identity.
Mean Intersection over Union (mIoU) measures overlap between predicted and ground truth segmentation:
where C is number of classes, , , are true positives, false positives, and false negatives for class c, respectively, and averaging occurs over all classes.
Pixel Accuracy [16] measures percentage of correctly classified pixels:
where summation occurs over all classes and pixels, providing overall classification accuracy.
Pose Error [16] measures absolute error in estimated poses:
where and are predicted and ground truth joint locations for N joints, and represents L2 norm. Lower values indicate better pose preservation.
Average Content Distance (ACD) [3] measures content consistency using face recognition features:
where extracts features from a pre-trained network, is the ground-truth video frame, is the generated video frame, and N is the total number of frames. Lower values indicate better content consistency.
5.3.4. Video Object Segmentation Metrics
Region Similarity [12] measures intersection-over-union between segmentation masks:
where M is estimated mask, G is ground truth mask, ∩ denotes intersection, and ∪ denotes union. Values range from 0 to 1, with higher scores indicating better segmentation accuracy.
Contour Accuracy [12] evaluates boundary precision using F-measure:
where and denote contour-based precision and recall between the estimated and the ground truth mask boundaries. Higher values indicate better boundary preservation.
5.3.5. Perceptual and Human Evaluation Metrics
Human Preference Score [72]: Subjective evaluation using human judgment:
where is the number of times a method is preferred by human evaluators and is total number of comparisons. Values range from 0 to 1, with higher scores indicating better perceived quality.
6. Quantitative Comparison
To provide meaningful comparisons of video translation methods with baseline I2Is and more advanced video diffusion models, we analyze methods evaluated on common datasets using consistent metrics. This analysis reveals performance trade-offs and architectural advantages across different approaches.
For urban scene segmentation on the Cityscapes dataset, several video-to-video translation methods demonstrate distinct performance characteristics when evaluated using FID and mIoU metrics. Pix2pixHD [31] establishes a baseline with an FID of 5.57 for frame-independent processing. Vid2vid [1] improves visual quality with an FID of 4.66, representing a 16% improvement, while simultaneously achieving 61.2 mIoU for semantic segmentation accuracy. The superior performance of vid2vid stems from its explicit temporal modeling through adversarial learning and optical flow warping, which maintains both visual coherence and semantic consistency across video frames. World-consistent vid2vid [13] sacrifices visual quality with a substantially higher FID of 49.89 but achieves improved segmentation performance at 64.8 mIoU. This trade-off occurs because the method prioritizes long-term geometric consistency through 3D scene understanding and multi-view constraints, leading to more semantically accurate, yet visually less appealing results.
In synthetic-to-real domain adaptation for autonomous driving on the Viper dataset, temporal modeling approaches demonstrate substantial improvements over frame-independent methods when evaluated using mIoU and pixel accuracy (PA) metrics. CycleGAN [5] achieves 8.2 mIoU and 54.3% PA through adversarial domain translation without temporal constraints. Recycle-GAN [14] incorporates a temporal predictor network, achieving 11.0 mIoU and 61.2% PA, representing 34% and 13% improvements, respectively. The temporal predictor enforces consistency by predicting future frames, reducing flickering artifacts and improving semantic coherence. MoCycle-GAN [8] further advances performance to 13.2 mIoU and 68.1% PA through explicit optical flow integration. The optical flow warping mechanism provides explicit motion modeling, enabling the network to distinguish between content changes due to motion versus domain differences. UVIT [18] achieves a comparable performance with 13.71 mIoU and 68.06% PA through content-motion disentanglement, where separate encoders handle static scene content and dynamic motion patterns, allowing for more robust domain adaptation.
For human motion synthesis on the Human3.6M dataset, architectural design choices significantly impact performance when measured using Peak Signal-to-Noise Ratio (PSNR). Zhao et al. [10] outperformed the hierarchical approach by Villegas et al. [73] with an improved performance of 22.6 PSNR vs. 19.2 PSNR using a two-stage approach that explicitly separates pose estimation from appearance generation. This 17.7% improvement results from the disentangled architecture that handles skeletal motion and visual appearance independently, reducing the complexity of the joint learning problem and enabling more accurate pose-conditioned video generation.
Evaluation of temporal consistency using FVD reveals the evolution of dynamic time lapse video generation quality across different architectural paradigms. On the SkyTimelapse dataset, MoCoGAN [3] achieves an FVD of 206.6 through separate motion and content generators. StyleGAN-V [20] substantially improves temporal consistency with an FVD of 79.5, representing a 61% reduction. This improvement stems from continuous-time neural representations that model video as a continuous function of time, eliminating discrete temporal artifacts and enabling smoother inter-frame transitions. For action recognition datasets, Video Diffusion [26] achieves an FVD of 171 on UCF-101, while FrameBridge [11] improves to 154 FVD through bridge model formulation. The bridge model connects discrete video frames through learned interpolation functions, reducing temporal inconsistencies and improving overall video quality. The quantitative results summarized in Table 2 provide an overview of the performance of state-of-the-art translation-based video synthesis methods evaluated on shared benchmark datasets, enabling direct comparison across task domains.
Table 2.
Performance comparison of TVS methods evaluated on common benchmark datasets.
Our analysis reveals that temporal-aware video generation methods consistently achieve superior performance compared to frame-independent baseline approaches, yielding improvements of 15–35% across evaluation metrics. Performance improvements stem from reduced temporal artifacts, improved motion modeling, and enhanced inter-frame consistency. Optical flow integration provides substantial benefits for motion-heavy tasks through explicit motion modeling, while content-motion disentanglement excels in cross-domain scenarios by separating static and dynamic scene components. Continuous-time representations demonstrate superior temporal consistency compared to discrete approaches, suggesting future directions for video generation architectures.
7. Future Directions and Conclusions
7.1. Future Research Directions
Based on current limitations and emerging trends, we identify four critical research frontiers for advancing TVS capabilities. The first major challenge involves long-range video generation, and memory constraints. Addressing this limitation requires developing hierarchical generation strategies with multi-scale temporal architectures that generate keyframes before interpolating details. Research should explore adaptive temporal resolution based on motion complexity, employing sparse sampling for static scenes and dense sampling for rapid motion. Additionally, novel attention mechanisms should maintain long-range dependencies through approaches such as sliding window attention with global context tokens, hierarchical memory banks storing multi-resolution features, and learned compression of temporal information.
The second frontier involves audio-visual synthesis, where incorporating synchronized audio enhances realism and enables new applications. This direction necessitates unified multimodal architectures generating coherent audio-visual content through shared latent spaces encoding both modalities [74], cross-modal attention mechanisms [75] ensuring synchronization, and physics-aware constraints [76] maintaining audiovisual correspondence. Temporal alignment presents particular challenges, requiring frame-level correspondence learning, sub-frame temporal resolution for accurate lip-sync, and dynamic time warping for flexible alignment. Furthermore, developing evaluation frameworks for audio-visual content demands new quality metrics including perceptual synchronization measures, semantic consistency between modalities, and human evaluation protocols for multimodal quality assessment.
The third critical area focuses on enhanced evaluation metrics, as current metrics inadequately capture video generation quality. Comprehensive frameworks should provide multi-dimensional evaluation beyond single scores, with VBench [77] demonstrating this direction through 16 quality dimensions. Future work should expand to physics adherence evaluation, narrative coherence for long videos, and style consistency across domains.
A fourth and increasingly urgent research frontier centers on the ethical considerations and social impacts associated with TVS technologies. The proliferation of advanced video translation architectures has substantially reduced the barriers to generating highly realistic synthetic content, thus amplifying the risks of malicious applications such as deepfake creation, explicit non-consensual material, political disinformation, and identity manipulation [78,79]. These challenges are compounded by persistent biases in training datasets, where imbalances in demographic representation across race, gender, age, and geography result in disparate model performance and exacerbate existing social inequities [80,81]. Technical safeguards are being developed, including digital watermarking [82], provenance tracking [83], and blockchain-based verification [84] to embed tamper-resistant signatures and maintain transparent records of content origin. Regulatory frameworks such as the European Union AI Act and China’s Deep Synthesis Provisions now require transparency, labeling, and user consent for synthetic media, and industry standards increasingly emphasize regular audits and responsible deployment practices [85], yet generalization to real-world scenarios remains a significant hurdle. Future research must prioritize the development of robust, generalizable, and fair video synthesis and detection systems to identify synthetic media and advance the understanding of the trade-offs between model capability and potential for harm to ensure responsible deployment.
7.2. Conclusions
This comprehensive survey has systematically examined Translation-based Video Synthesis, revealing significant progress from early domain-specific methods to contemporary frameworks capable of generating high-quality, temporally consistent videos across diverse domains. We have identified key technical innovations, persistent challenges, and promising research directions that will shape the field’s evolution.
The progression of I2V translation from facial animation techniques to generalizable diffusion-based frameworks demonstrates the field’s rapid advancement. Similarly, V2V translation has evolved from basic frame-dependent processing to sophisticated architectures incorporating 3D scene understanding, optical flow, and content-motion disentanglement. Our quantitative comparison reveals consistent patterns across methods, showing that temporal modeling, architectural choices create fundamental trade-offs between quality and consistency, and computational efficiency remains critical for practical deployment. The emergence of real-time systems such as StreamV2V achieving 20 FPS demonstrates the feasibility of interactive applications, marking a significant milestone in making TVS technology accessible for real-world deployment.
As TVS continues evolving, maintaining focus on both technical innovation and practical deployment will be essential. The advancement of TVS technology will not only transform content creation workflows but also democratize access to sophisticated video synthesis capabilities, enabling new forms of creative expression and communication across diverse applications and user communities.
Author Contributions
Conceptualization, P.S. and C.Z.; methodology, P.S.; validation, C.Z.; writing—original draft preparation, P.S.; writing—review and editing, C.Z.; visualization, P.S.; supervision, C.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACD | Average Content Distance |
| CK+ | Extended Cohn–Kanade Dataset |
| CK++ | Augmented Cohn–Kanade Dataset |
| FID | Fréchet Inception Distance |
| FPS | Frames Per Second |
| FVD | Fréchet Video Distance |
| GAN | Generative Adversarial Network |
| GTA | Grand Theft Auto |
| I2I | Image-to-Image |
| I2V | Image-to-Video |
| IoU | Intersection over Union |
| IS | Inception Score |
| LPIPS | Learned Perceptual Image Patch Similarity |
| LSTM | Long Short-Term Memory |
| mIoU | Mean Intersection over Union |
| MSE | Mean Squared Error |
| PA | Pixel Accuracy |
| PSNR | Peak Signal-to-Noise Ratio |
| RNN | Recurrent Neural Network |
| SAF | Signal-to-Noise Ratio Aligned Fine-tuning |
| SfM | Structure from Motion |
| SIFT | Scale-Invariant Feature Transform |
| SNR | Signal-to-Noise Ratio |
| SPADE | Spatially-Adaptive Normalization |
| SSIM | Structural Similarity Index |
| TVS | Translation-based Video Synthesis |
| UCF-101 | University of Central Florida Action Recognition Dataset |
| V2V | Video-to-Video |
References
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-Video Synthesis. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Shen, G.; Huang, W.; Gan, C.; Tan, M.; Huang, J.; Zhu, W.; Gong, B. Facial image-to-video translation by a hidden affine transformation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2505–2513. [Google Scholar]
- Tulyakov, S.; Liu, M.Y.; Yang, X.; Kautz, J. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1526–1535. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Bashkirova, D.; Usman, B.; Saenko, K. Unsupervised video-to-video translation. arXiv 2018, arXiv:1806.03698. [Google Scholar]
- Chen, Y.; Pan, Y.; Yao, T.; Tian, X.; Mei, T. Mocycle-gan: Unpaired video-to-video translation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 647–655. [Google Scholar]
- Fan, L.; Huang, W.; Gan, C.; Huang, J.; Gong, B. Controllable image-to-video translation: A case study on facial expression generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3510–3517. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Towards image-to-video translation: A structure-aware approach via multi-stage generative adversarial networks. Int. J. Comput. Vis. 2020, 128, 2514–2533. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Z.; Xiaoyu, C.; Wei, Y.; Zhu, J.; Chen, J. FrameBridge: Improving Image-to-Video Generation with Bridge Models. In Proceedings of the Forty-Second International Conference on Machine Learning, Vancouver, BC, Canada, 13–19 July 2025. [Google Scholar]
- Wei, X.; Zhu, J.; Feng, S.; Su, H. Video-to-video translation with global temporal consistency. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 18–25. [Google Scholar]
- Mallya, A.; Wang, T.C.; Sapra, K.; Liu, M.Y. World-consistent video-to-video synthesis. In Proceedings, Part VIII 16, Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 359–378. [Google Scholar]
- Bansal, A.; Ma, S.; Ramanan, D.; Sheikh, Y. Recycle-gan: Unsupervised video retargeting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Liu, H.; Li, C.; Lei, D.; Zhu, Q. Unsupervised video-to-video translation with preservation of frame modification tendency. Vis. Comput. 2020, 36, 2105–2116. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Tao, A.; Liu, G.; Kautz, J.; Catanzaro, B. Few-shot Video-to-Video Synthesis. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Park, K.; Woo, S.; Kim, D.; Cho, D.; Kweon, I.S. Preserving semantic and temporal consistency for unpaired video-to-video translation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1248–1257. [Google Scholar]
- Liu, K.; Gu, S.; Romero, A.; Timofte, R. Unsupervised multimodal video-to-video translation via self-supervised learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1030–1040. [Google Scholar]
- Szeto, R.; El-Khamy, M.; Lee, J.; Corso, J.J. HyperCon: Image-to-video model transfer for video-to-video translation tasks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3080–3089. [Google Scholar]
- Skorokhodov, I.; Tulyakov, S.; Elhoseiny, M. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3626–3636. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6629–6640. [Google Scholar]
- Unterthiner, T.; Van Steenkiste, S.; Kurach, K.; Marinier, R.; Michalski, M.; Gelly, S. Towards accurate generative models of video: A new metric & challenges. arXiv 2018, arXiv:1812.01717. [Google Scholar]
- Melnik, A.; Ljubljanac, M.; Lu, C.; Yan, Q.; Ren, W.; Ritter, H. Video Diffusion Models: A Survey. arXiv 2024, arXiv:2405.03150. [Google Scholar] [CrossRef]
- Xing, Z.; Feng, Q.; Chen, H.; Dai, Q.; Hu, H.; Xu, H.; Wu, Z.; Jiang, Y.G. A survey on video diffusion models. ACM Comput. Surv. 2024, 57, 1–42. [Google Scholar] [CrossRef]
- Sun, W.; Tu, R.C.; Liao, J.; Tao, D. Diffusion model-based video editing: A survey. arXiv 2024, arXiv:2407.07111. [Google Scholar]
- Ho, J.; Salimans, T.; Gritsenko, A.; Chan, W.; Norouzi, M.; Fleet, D.J. Video diffusion models. Adv. Neural Inf. Process. Syst. 2022, 35, 8633–8646. [Google Scholar]
- Guo, X.; Zheng, M.; Hou, L.; Gao, Y.; Deng, Y.; Wan, P.; Zhang, D.; Liu, Y.; Hu, W.; Zha, Z.; et al. I2v-adapter: A general image-to-video adapter for diffusion models. In Proceedings of the ACM SIGGRAPH 2024 Conference Papers, Denver, CO, USA, 27 July–1 August 2024; pp. 1–12. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lu, H.; Yang, G.; Fei, N.; Huo, Y.; Lu, Z.; Luo, P.; Ding, M. VDT: General-purpose Video Diffusion Transformers via Mask Modeling. In Proceedings of the International Conference on Representation Learning, Vienna, Austria, 7–11 May 2024; Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y., Eds.; Volume 2024, pp. 19259–19286. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild; Technical Report CRCV-TR-12-01; Center for Research in Computer Vision, University of Central Florida: Orlando, FL, USA, 2012. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–30 June 2016; pp. 3213–3223. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–30 June 2016; pp. 724–732. [Google Scholar]
- Longuet-Higgins, H.C. A computer algorithm for reconstructing a scene from two projections. Nature 1981, 293, 133–135. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Dalca, A.V.; Durand, F.; Guttag, J. Synthesizing images of humans in unseen poses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8340–8348. [Google Scholar]
- Liang, F.; Kodaira, A.; Xu, C.; Tomizuka, M.; Keutzer, K.; Marculescu, D. Looking Backward: Streaming Video-to-Video Translation with Feature Banks. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]
- Liang, F.; Wu, B.; Wang, J.; Yu, L.; Li, K.; Zhao, Y.; Misra, I.; Huang, J.B.; Zhang, P.; Vajda, P.; et al. Flowvid: Taming imperfect optical flows for consistent video-to-video synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 8207–8216. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Richter, S.R.; Hayder, Z.; Koltun, V. Playing for benchmarks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2213–2222. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Wang, K.; Akash, K.; Misu, T. Learning Temporally and Semantically Consistent Unpaired Video-to-video Translation Through Pseudo-Supervision From Synthetic Optical Flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2477–2486. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Deep learning for precipitation nowcasting: A benchmark and a new model. Adv. Neural Inf. Process. Syst. 2017, 30, 5622–5632. [Google Scholar]
- Jiang, H.; Sun, D.; Jampani, V.; Yang, M.H.; Learned-Miller, E.; Kautz, J. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9000–9008. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Rivoir, D.; Pfeiffer, M.; Docea, R.; Kolbinger, F.; Riediger, C.; Weitz, J.; Speidel, S. Long-term temporally consistent unpaired video translation from simulated surgical 3D data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 10–17 October 2021; pp. 3343–3353. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Pfeiffer, M.; Funke, I.; Robu, M.R.; Bodenstedt, S.; Strenger, L.; Engelhardt, S.; Roß, T.; Clarkson, M.J.; Gurusamy, K.; Davidson, B.R.; et al. Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 119–127. [Google Scholar]
- Zhang, J.; Xu, C.; Liu, L.; Wang, M.; Wu, X.; Liu, Y.; Jiang, Y. Dtvnet: Dynamic time-lapse video generation via single still image. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 300–315. [Google Scholar]
- Wang, K.; Wu, Q.; Song, L.; Yang, Z.; Wu, W.; Qian, C.; He, R.; Qiao, Y.; Loy, C.C. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 700–717. [Google Scholar]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Garda, Italy, 12–14 April 2010; pp. 1–4. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5137–5146. [Google Scholar]
- Li, Z.; Dekel, T.; Cole, F.; Tucker, R.; Snavely, N.; Liu, C.; Freeman, W.T. Learning the depths of moving people by watching frozen people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4521–4530. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Lille, France, 2015; pp. 843–852. [Google Scholar]
- Xu, X.; Dehghani, A.; Corrigan, D.; Caulfield, S.; Moloney, D. Convolutional neural network for 3d object recognition using volumetric representation. In Proceedings of the 2016 First International Workshop on Sensing, Processing and Learning for Intelligent Machines (SPLINE), Aalborg, Denmark, 6–8 July 2016; pp. 1–5. [Google Scholar]
- Akkus, Z.; Ali, I.; Sedlář, J.; Agrawal, J.P.; Parney, I.F.; Giannini, C.; Erickson, B.J. Predicting deletion of chromosomal arms 1p/19q in low-grade gliomas from MR images using machine intelligence. J. Digit. Imaging 2017, 30, 469–476. [Google Scholar] [CrossRef] [PubMed]
- Vallieres, M.; Kay-Rivest, E.; Perrin, L.J.; Liem, X.; Furstoss, C.; Aerts, H.J.; Khaouam, N.; Nguyen-Tan, P.F.; Wang, C.S.; Sultanem, K.; et al. Radiomics strategies for risk assessment of tumour failure in head-and-neck cancer. Sci. Rep. 2017, 7, 10117. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Wu, X.; Sun, K.; Zhu, F.; Zhao, R.; Li, H. Human preference score: Better aligning text-to-image models with human preference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2096–2105. [Google Scholar]
- Villegas, R.; Yang, J.; Zou, Y.; Sohn, S.; Lin, X.; Lee, H. Learning to generate long-term future via hierarchical prediction. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Sydney, Australia, 2017; pp. 3560–3569. [Google Scholar]
- Xing, Y.; He, Y.; Tian, Z.; Wang, X.; Chen, Q. Seeing and hearing: Open-domain visual-audio generation with diffusion latent aligners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 7151–7161. [Google Scholar]
- Ruan, L.; Ma, Y.; Yang, H.; He, H.; Liu, B.; Fu, J.; Yuan, N.J.; Jin, Q.; Guo, B. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10219–10228. [Google Scholar]
- Kushwaha, S.S.; Tian, Y. Vintage: Joint video and text conditioning for holistic audio generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 13529–13539. [Google Scholar]
- Huang, Z.; He, Y.; Yu, J.; Zhang, F.; Si, C.; Jiang, Y.; Zhang, Y.; Wu, T.; Jin, Q.; Chanpaisit, N.; et al. Vbench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 21807–21818. [Google Scholar]
- Alanazi, S.; Asif, S.; Caird-daley, A.; Moulitsas, I. Unmasking deepfakes: A multidisciplinary examination of social impacts and regulatory responses. Hum.-Intell. Syst. Integr. 2025, 1–23. [Google Scholar] [CrossRef]
- Ma’arif, A.; Maghfiroh, H.; Suwarno, I.; Prayogi, D.; Lonang, S.; Sharkawy, A.N. Social, legal, and ethical implications of AI-Generated deepfake pornography on digital platforms: A systematic literature review. Soc. Sci. Humanit. Open 2025, 12, 101882. [Google Scholar] [CrossRef]
- Parraga, O.; More, M.D.; Oliveira, C.M.; Gavenski, N.S.; Kupssinskü, L.S.; Medronha, A.; Moura, L.V.; Simões, G.S.; Barros, R.C. Fairness in Deep Learning: A survey on vision and language research. ACM Comput. Surv. 2025, 57, 1–40. [Google Scholar] [CrossRef]
- Kotwal, K.; Marcel, S. Review of demographic fairness in face recognition. IEEE Trans. Biom. Behav. Identity Sci. 2025. [Google Scholar] [CrossRef]
- Ren, K.; Yang, Z.; Lu, L.; Liu, J.; Li, Y.; Wan, J.; Zhao, X.; Feng, X.; Shao, S. Sok: On the role and future of aigc watermarking in the era of gen-ai. arXiv 2024, arXiv:2411.11478. [Google Scholar] [CrossRef]
- Longpre, S.; Mahari, R.; Obeng-Marnu, N.; Brannon, W.; South, T.; Gero, K.I.; Pentland, A.; Kabbara, J. Position: Data Authenticity, Consent, & Provenance for AI are all broken: What will it take to fix them? In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Mastoi, Q.u.A.; Memon, M.F.; Jan, S.; Jamil, A.; Faique, M.; Ali, Z.; Lakhan, A.; Syed, T.A. Enhancing Deepfake Content Detection Through Blockchain Technology. Int. J. Adv. Comput. Sci. Appl. 2025, 16. [Google Scholar] [CrossRef]
- Hagendorff, T. The ethics of AI ethics: An evaluation of guidelines. Minds Mach. 2020, 30, 99–120. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).