Abstract
Securing Industrial Control Systems (ICSs) is critical, but it is made challenging by the constant evolution of cyber threats and the scarcity of labeled attack data in these specialized environments. Standard intrusion detection systems (IDSs) often fail to adapt when transferred to new networks with limited data. To address this, this paper introduces an adaptive intrusion detection framework that combines a hybrid Convolutional Neural Network and Long Short-Term Memory (CNN-LSTM) model with a novel transfer learning strategy. We employ a Reinforcement Learning (RL) agent to intelligently guide the fine-tuning process, which allows the IDS to dynamically adjust its parameters such as layer freezing and learning rates in real-time based on performance feedback. We evaluated our system in a realistic data-scarce scenario using only 50 labeled training samples. Our RL-Guided model achieved a final F1-score of 0.9825, significantly outperforming a standard neural fine-tuning model (0.861) and a target baseline model (0.759). Analysis of the RL agent’s behavior confirmed that it learned a balanced and effective policy for adapting the model to the target domain. We conclude that the proposed RL-guided approach creates a highly accurate and adaptive IDS that overcomes the limitations of static transfer learning methods. This dynamic fine-tuning strategy is a powerful and promising direction for building resilient cybersecurity defenses for critical infrastructure.
1. Introduction
Today’s critical infrastructure systems are more digital and connected than ever. This helps with efficiency, but it also creates more ways for hackers to attack [1]. Industrial Control Systems (ICSs) and SCADA networks are especially important to protect. They manage physical processes like power grids, water treatment, and manufacturing. If these systems are compromised, it can cause power outages, environmental damage, or even risk human lives. This makes them a top target for attackers [2].
Real-world attacks have already shown how serious this is. The Stuxnet malware damaged Iranian nuclear facilities, and the BlackEnergy malware shut down power in Ukraine [3,4]. These incidents prove that skilled attackers can get into ICS networks and hide for a long time. This shows why we urgently need strong security to protect these operational technology (OT) environments. In the past, many ICS setups were kept separate from other networks and used their own special protocols, which limited the risk of remote attacks [5]. However, things have changed. With the rise of the Industrial Internet of Things (IIoT) and more connections between IT and OT systems, this is no longer the case [2]. Control systems that were once isolated are now often linked to company networks or the cloud for remote access. This means that ICS and smart grid systems, which were often not designed with security as a priority, are now open to many kinds of cyber threats [2]. These threats include common network attacks like Denial-of-Service (DoS) or Man-in-the-Middle (MitM), as well as special attacks on SCADA protocols, like sending fake commands or replaying real ones [6]. These weaknesses are a serious risk to industrial work, public safety, and the economy if they are not monitored and fixed [5].
To protect these critical systems, network intrusion detection systems (NIDSs) are often used to watch OT network traffic for suspicious activity. NIDSs can be signature-based or anomaly-based. Traditional signature-based systems use known attack patterns, but they often cannot keep up with new or ICS-specific threats [6]. Anomaly-based systems, on the other hand, learn what normal behavior looks like and then flag anything that seems different as a possible attack [7]. This approach is a good fit for ICS because attacks on industrial processes might not match any known signature, but they do show up as unusual behavior. Anomaly detectors can catch new or sneaky attacks that signature-based systems would miss [7,8]. Because of this, a lot of ICS security research now focuses on building good anomaly-based detection systems for OT networks.
Data-driven machine learning (ML) methods have become a popular way to build ICS anomaly detectors. Instead of using handmade rules, an ML-based intrusion detection system (IDS) can learn the difference between normal and malicious behavior directly from data [4]. Different ML algorithms have been used for this in both IT and OT settings [2]. More recently, deep learning has become popular because it can automatically find important features in raw data and spot complex patterns. Studies have shown that deep neural networks (DNNs) (like autoencoders, Convolutional Neural Networks (CNNs), and Long Short-Term Memory (LSTM)) can be very accurate at finding cyberattacks. For example, one advanced autoencoder-based IDS was over 96% accurate at finding anomalies on a water treatment plant testbed [7], which was better than many older ML methods. This shows how much deep learning can help improve ICS monitoring, as noted in several surveys [9]. In short, DNNs let an IDS see complex attack patterns that older methods might miss. Even with these improvements, making a reliable IDS for real-world ICS environments is still a challenge. A big problem is the lack of labeled attack data from real industrial networks [8]. Cyberattacks on critical infrastructure are rare, and details are often kept private. This makes it hard to get enough data to train a supervised model. As a result, IDS models are often trained on public datasets or in small test environments that might not look like the real facility. This leads to a domain shift problem: a model trained on one network can perform poorly when used on another [9]. Studies have shown that models that do well on one dataset often fail in a new ICS or IoT setup because of differences in traffic, protocols, and attack types [10].
To fix this, researchers are using Transfer Learning (TL). TL lets an IDS use knowledge from a source domain (like a large, labeled dataset) to do better in a target domain where there is little data. For example, some methods can learn features that work across different domains, which helps the detector work better in new network environments [10]. By fine-tuning a deep model on a small amount of target data, these methods have shown much better detection performance when data is limited [11]. TL helps close the gap between well-known environments and new ones where getting training data is hard. Another big challenge is that threats in ICS are always changing. Attackers create new strategies, and the ICS itself can change, which alters what is considered normal. A static IDS model that is trained only once can become outdated as new attacks appear. This has led to a need for adaptive IDS that can update themselves without much human help [8]. Recently, researchers have started using Reinforcement Learning (RL) to give IDS this ability to learn continuously [11]. Unlike standard ML, an RL-based system lets an agent learn by trial and error. It gets feedback (rewards or penalties) for its decisions and slowly gets better. When applied to an IDS, RL can let the system adjust its own parameters in real time to improve detection. Early studies show that deep RL models can adapt to new attack patterns and do better than static ML methods in OT networks [8,12]. The ability to learn from the environment on the fly is a big advantage of RL-based IDS because it reduces the need for manual retraining and makes the system more resilient [12].
In this work, we propose an adaptive deep learning-based intrusion detection framework for ICS/OT environments that uses both transfer learning and RL to address these challenges. We design a hybrid CNN–LSTM model to capture spatial–temporal features in network traffic, and we use an RL agent to fine-tune this model on a target domain with limited data. Our system is tested on a scenario with very little data (to mimic a realistic smart grid/SCADA setup with few attack examples), so it focuses on detecting serious attacks like DoS and MitM.
The attack types we evaluate—Denial-of-Service (DoS), Man-in-the-Middle (MitM), and unauthorized command injection—are directly relevant to industrial control systems and are well-documented in the MITRE ATT&CK framework for ICS [13]. These attack vectors target communication-level vulnerabilities in industrial protocols and can lead to operational disruption, unauthorized control actions, and system manipulation, making them critical threats for SCADA and DNP3 environments.
To set a benchmark for our work, we compare our model against a strong existing method from Wang et al. [14]. Their approach uses a deep residual CNN with transfer learning to detect anomalies in ICS networks. A key part of their method is converting 1D network data into 2D grayscale images so they can use the power of CNNs for feature extraction. Their model showed good results and proved that transfer learning is a good fit for ICS security. However, their model uses a fixed architecture and a standard fine-tuning process. This provides a clear point of comparison for our work, where we introduce a dynamic, adaptive fine-tuning strategy using RL to see if we can improve performance even further, especially when data is very limited. We implement this benchmark using a 5-layer deep CNN architecture following their methodology, which we refer to as the 5-Layer Benchmark in our experimental comparison.
The main contributions of our paper are:
- Hybrid CNN-LSTM Architecture: We develop a deep learning backbone that combines one-dimensional CNNs and LSTMs for intrusion detection. This hybrid model efficiently extracts spatial correlations and temporal patterns, which enables the detection of complex multi-stage attacks in ICS networks.
- RL-Guided Transfer Learning: We introduce a new RL-based fine-tuning mechanism for domain adaptation. An RL agent monitors the model’s performance and dynamically adjusts training parameters (like layer freezing or learning rate) to optimize adaptation. This approach allows the IDS to autonomously adapt to new network conditions with little human help.
- Improved Detection Under Data Constraints: Through experiments on an OT network dataset with very few training samples, we demonstrate that our RL-guided transfer learning IDS shows promising performance compared to conventional fine-tuning and baseline models. The proposed system achieves improved detection accuracy and F1-scores, suggesting potential effectiveness for enhancing cybersecurity in smart grid and SCADA environments where labeled data is scarce.
2. Literature Review
The interdisciplinary relationship between criminology and computer science has become increasingly important in cybersecurity research, particularly in the context of intrusion detection systems. Recent advances in computational complexity theory applied to criminological problems, such as spatio-temporal reasoning for security applications, provide valuable insights that can be leveraged for specific intrusion detection challenges [15].
2.1. Deep Learning in Intrusion Detection
Traditional IDS used manual feature engineering and classical ML techniques. These methods often had trouble with new attack patterns and needed frequent human help. Deep learning has become a better choice because it can automatically learn complex patterns from raw data. Yin et al. [16] proposed an early recurrent neural network-based IDS that got high detection accuracy on benchmark datasets. Javaid et al. [17] and Shone et al. [18] introduced deep autoencoder-based models that could extract useful features without manual work. They improved performance on datasets like NSL-KDD and KDD Cup’99. These studies showed that DNNs can do better than traditional approaches because they learn richer data representations. Berman et al. [9] wrote a comprehensive survey that explains the advantages of deep learning for cybersecurity. They especially highlighted how well it works with large-scale data and how it can detect new attacks.
2.2. Spatio-Temporal Feature Learning
Recent studies have shown that when you combine spatial and temporal feature learning, you get better detection of complex attacks. CNNs are good at extracting spatial feature patterns, while LSTMs capture how these features change over time. Hsu et al. [19] combined CNN and LSTM layers in a hybrid IDS model and reported strong performance on the NSL-KDD dataset. Their design used parallel 1D CNN filters for both fine-grained and broad feature extraction, then used LSTM layers to track temporal behavior. Other studies focused on specific domains confirm that these hybrid models work well. Lokman et al. [20] developed an LSTM-based IDS for Modbus SCADA traffic, and Bakhsh et al. [21] introduced a segmented deep learning model for DNP3 protocols in smart grids. These methods got high accuracy when detecting complex or multi-stage threats such as DoS and unauthorized commands.
2.3. Intrusion Detection in ICS/OT Environments
ICS and OT networks have become main targets for cyberattacks. This has led to a lot of research into specialized IDSs for these critical environments. In recent years, deep learning and hybrid IDS approaches have shown big advantages over old signature-based or classical ML techniques when detecting ICS/OT threats.
Survey studies show that modern ICS-IDS solutions use more and more DNNs. These include CNN and RNN/LSTM architectures, autoencoders, and hybrid deep models. They help model the unique temporal and protocol patterns of SCADA and industrial networks. Aslam et al. [22] provide a comprehensive analysis of deep learning techniques (CNNs, LSTMs, AEs, etc.) applied to ICS security. They noted a trend toward hybrid deep learning methods for improved anomaly detection in ICS. Pinto et al. [23] surveyed ML-based IDS for critical infrastructure and highlighted open challenges such as detecting zero-days and deploying data-driven IDSs in real operational plants.
Deep anomaly detection has been a main theme in recent ICS research. This happened because testbed datasets like SWaT (water treatment) and power grid simulations became available. Unsupervised and self-supervised models, especially autoencoder variants, are popular for learning baseline patterns of process sensor data or network traffic and then flagging deviations. Kumar and Gutierrez [24] evaluated various algorithms on the SWaT dataset and found that deep learning approaches captured the complex temporal dynamics of multivariate sensor telemetry better than conventional ML. They got high accuracy for detecting physical process anomalies.
De Silva et al. [25] proposed an improved autoencoder method for ICS that got higher precision and lower false alarms by addressing ICS data complexity. Cai et al. [26] introduced a 1D CNN-WGAN to synthesize minority class attack traffic. This balanced the training data and boosted detection of rare ICS intrusions. They reported up to 7% improvement in accuracy and F1-score for LSTM detectors when training data was augmented with their WGAN method.
Hybrid IDS architectures that combine multiple detection techniques have proven especially effective for ICS. Researchers have designed systems that integrate anomaly detection with signature-based methods and domain knowledge. These are tailored to protocols like Modbus or DNP3. Almalawi et al. [27] proposed a hybrid deep architecture (HAE-HRL) for SCADA security. It combined an autoencoder for feature extraction, a CNN for spatial patterns, and a ResNet-LSTM for temporal analysis. This ensemble approach gave a more adaptive IDS with lower false-positive rates against novel threats.
AlHaddad et al. [28] developed an ensemble IDS for smart grids that fuses multiple deep models. By using different types of learners, their system improved DDoS attack detection in power OT networks. These hybrid systems reflect a broader trend: multi-layer IDS designs can address the diversity of ICS threats—from known malware to subtle process anomalies—by using the strengths of different detection methods.
Domain-specific adaptations of deep learning are critical in ICS. Researchers include protocol semantics and physics-based knowledge into models. Some IDSs target the DNP3 used in electric grids. Dangwal et al. [29] introduced IDM-DNP3, a scheme that uses ML to detect DNP3 message anomalies. They obtained higher accuracy than generic IDS by focusing on protocol-specific features. Their results on SCADA-IoT testbeds show the benefit of customizing IDSs to industrial protocols and using supervised ML on enriched feature sets.
Wang et al. [30] demonstrated a stacked LSTM autoencoder to detect cyberattacks on a power grid and a gas pipeline system. They reported over detection rates for certain attack types. Such high accuracy was achieved by tailoring deep architectures to multi-stage industrial processes. This shows how mature deep learning IDSs have become in critical infrastructure contexts.
2.4. Transfer Learning for Intrusion Detection
TL for network intrusion detection has gained momentum as a strategy to cope with data scarcity and domain shifts between different security environments. Traditional IDS models often face big drops in accuracy when deployed on a domain (network or dataset) different from the one they were trained on. This happens because of variations in traffic patterns, feature distributions, or attack types. Research from 2019 onwards addresses this problem by transferring knowledge from one setting to another—for example, from a source dataset with many labels to a target domain with little or no labelled data. A main reason for TL in IDS is handling low-data scenarios as in Wang et al. [14]. A common TL approach in IDS is domain adaptation, where a model learns features that work across source and target domains. Adversarial learning techniques are often used here. Layeghy et al. [10] propose DI-NIDS, which uses an adversarial domain adaptation framework (a domain classifier and feature extractor trained in opposition) to learn domain-invariant features from multiple network domains. DI-NIDS significantly improved cross-dataset detection performance because the shared latent features reduce the impact of distribution shifts between training and deployment environments. Qu et al. [31] introduced a domain confusion method for IDSs. By adding a domain-confusion loss, their deep model’s internal representations become less distinguishable between source and target domains. This enhances migration capability. These studies report that after applying such domain-adaptive training, IDS models maintain high accuracy on target network traffic without extensive retraining. In IoT and IIoT contexts, Li et al. [32] extended this idea to multi-source domain adaptation. Their model MRADDA-TC aggregates knowledge from multiple source domains and uses adversarial training plus a novel transfer complementarity mechanism to handle extremely limited target data. On a federated set of IoT intrusion datasets, this approach achieved notable accuracy gains under few-shot learning conditions. This shows that combining knowledge from several related domains can compensate when no single source covers all attack behaviors.
Another branch of work uses deep feature transfer and fine-tuning for IDSs. Instead of training a detector from scratch on each new dataset, deep TL allows reuse of learned representations (like the first layers of a neural network) that capture generic network traffic features. Mehedi et al. [33] demonstrated this for in-vehicle network security. They pre-trained a deep CNN on a large network traffic dataset and fine-tuned it on a smaller automotive CAN bus dataset. This resulted in a TL-based IDS that outperformed models trained only on the small data. Rodriguez et al. [34] developed a TL framework for IoT intrusion detection that involves initial training on a broad dataset (like UNSW-NB15) and then refinement on IoT-specific traffic, combined with knowledge distillation. They report improved effectiveness in IoT settings and stress that TL reduces the burden of obtaining labeled data for each new IoT deployment.
Recent research also explores advanced neural architectures to help TL in IDS. Transformer-based models are a notable example. Ullah et al. [35] introduced IDS-INT, a transformer-driven TL approach for highly imbalanced network data. Their method uses a transformer to capture rich contextual interactions in attack traffic and then applies TL to generalize those patterns to other datasets. In evaluations across UNSW-NB15, CIC-IDS2017, and NSL-KDD, IDS-INT achieved strong multi-class detection performance while addressing class imbalance through embedded SMOTE sampling. Abdelhamid et al. [36] propose an attention-based TL model that uses a convolutional block attention module to refine transferred features for an IoT IDS. By focusing on the most important parts of input traffic features and using pre-trained weights, their model improved detection accuracy on an IoT dataset compared to baseline CNNs. Amamra and Terrelonge [37] devised stochastic and deterministic multiple-kernel TL algorithms, which achieved >90% accuracy in cross-domain tests and showed robustness to encrypted traffic.
The importance of knowledge transfer for low-resource scenarios is a recurring theme. TL-based IDSs have proven especially valuable for domains where labeling data is expensive or impractical (like emerging IoT networks or new malware strains). Wu et al. [38] thoroughly reviewed deep TL in the context of Internet of Vehicles (IoV) security. They concluded that TL techniques (including fine-tuning, domain adaptation, and few-shot learning) drastically cut down training requirements while maintaining high detection rates in IoV IDSs. They highlight that transfer-learned IDS models can achieve comparable or better performance than fully trained models, yet require significantly less data and time.
2.5. Reinforcement Learning and Adaptive Training
Most IDSs rely on fixed training procedures, but RL introduces adaptability into the model training process. Sangoleye et al. [39] used deep RL agents like DQN and PPO to detect attacks in ICS and outperformed traditional supervised models. Shaikh et al. [40] developed HCLR-IDS, a CNN-LSTM model enhanced with RL decision modules for IoMT networks. They achieved over 99% accuracy. These models adjust themselves in real-time, which makes them resilient to changing attack patterns. RL has also been used to optimize training itself. Talaat and Gamel [41] applied Q-learning to tune CNN hyperparameters. Han et al. [42] introduced a PPO agent to adapt a DNN feature extractor and clustering module for intrusion detection under shifting data distributions.
Our work builds on these three directions—deep learning, transfer learning, and RL—to create an adaptive, real-time IDS suitable for challenging real-world scenarios in OT and ICS networks.
3. Proposed System Architecture
To deal with the challenge of detecting advanced network attacks like DoS/DDoS and MITM in real-world environments, we introduce an IDS that is both flexible and adaptive. The system uses a mix of deep learning and transfer learning, with its parameters adjusted by an RL agent. This design helps improve detection accuracy, especially when we do not have much data from the new (target) environment, by learning from a larger, already labeled (source) dataset.
In this work, we focus on transfer learning within datasets that share fundamental network traffic features, allowing us to concentrate on our novel RL-guided fine-tuning methodology. While cross-protocol transfer learning presents additional complexity and is a valuable direction for future research, our current scope demonstrates the effectiveness of adaptive fine-tuning strategies within a controlled experimental setting that maintains industrial relevance through the use of DNP3 protocol data.
The full system, shown in Figure 1, includes three main parts:
- Data preprocessing and feature selection using correlation analysis.
- A combined CNN-LSTM model for learning both spatial and time-based patterns.
- An RL agent that fine-tunes the model during transfer learning.

Figure 1.
Overall architecture of the proposed intrusion detection system showing the three main components: data preprocessing and correlation analysis, CNN-LSTM backbone for feature extraction, and RL agent for adaptive fine-tuning.
3.1. Data Preprocessing and Correlation Analysis
The first step in our system is to clean and prepare the network data. This step is important not only to improve data quality but also to create a realistic and challenging environment for testing. A big issue with intrusion detection in areas like OT is the lack of labeled attack data. Public datasets usually provide enough samples, but that is not always true in real use. To mimic the real-world OT scenario, we reduce the amount of training data and remove some highly correlated features. This way, we can test how well our system works when data is limited.
3.1.1. Data Cleaning and Normalization
We start by loading both the source dataset (CICIDS) and the target dataset (DNP3), and clean them by removing duplicates and filling missing or infinite values with zeros. It is important to note that DNP3 (Distributed Network Protocol 3) is an industrial communication protocol specifically designed for SCADA systems and standardized as IEEE 1815 [43]. This protocol is widely used in electric power systems, water treatment facilities, and other critical infrastructure networks, which makes our target dataset highly relevant to real-world industrial environments. Then, we convert categorical-based features (like protocol names) into numbers using label encoding, since neural networks only work with numerical values only. Next, we scale all the features using a Standard Scaler so they all have a mean of zero () and a standard deviation of one (). This helps the model learn more efficiently as shown in Equation (1):
Here, x is the original value, is the mean, and is the standard deviation. We only fit the scaler on the training set to avoid leaking any information from the test set.
3.1.2. Simulating Data Shortage in the Target Domain
To see how well our model transfers knowledge to a new dataset with less data, we purposely limit the amount of training data from the DNP3 dataset. We use a smaller subset that keeps the same ratio of attack and normal traffic (DOS vs. NORMAL). This gives us a tough testing ground, where models trained from scratch are expected to perform poorly. That will mimic the realistic scarcity of the attack samples and make it easier to see the benefits of our transfer learning approach.
It is worth noting that real industrial plant packet traces are rarely made publicly available due to safety concerns, confidentiality requirements, and proprietary operational considerations. Consequently, ICS security research commonly relies on protocol-faithful datasets and testbeds that accurately represent industrial communication patterns, such as DNP3 datasets, SWaT (water treatment), and WADI (water distribution) testbeds. Our approach follows this established practice in the field.
3.1.3. Removing Obvious Features
We also make the task harder by removing features that are strongly correlated to the attack label. This simulates what real attackers might do such as hiding or blending their traffic to avoid detection. We use Pearson correlation to measure how much each feature is related to the attack label. The equation is (2):
Here, and are the values of a feature and the class label for each sample i, and and are their average values. If the absolute value of r is above a certain limit, the feature is removed. This forces the model to rely on less obvious patterns and test its real detection ability. It is noteworthy that by limiting the training data and removing obvious attack indicators, we create a realistic and challenging problem for the model to solve. This allows us to better assess whether our transfer learning method provides benefits, rather than just depending on easily identifiable patterns.
3.2. Hybrid CNN-LSTM Backbone for Spatio-Temporal Feature Extraction
At the center of our IDS is a hybrid deep learning model that combines a CNN with an LSTM network. This structure, shown in Figure 2, is built to extract useful patterns from the data by looking at both the individual features in a single traffic record and how those features change over time.
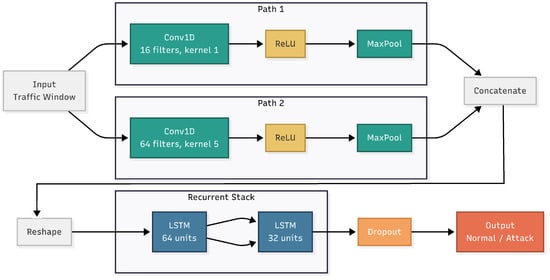
Figure 2.
Detailed architecture of the hybrid CNN-LSTM backbone showing the parallel CNN blocks for spatial feature extraction and the stacked LSTM network for temporal analysis.
The CNN part acts as an automatic feature extractor. It looks for patterns and relationships between the values of different features within each network traffic record. Then, the LSTM part takes those extracted patterns and learns how they change over time. This is important because many cyberattacks happen as a series of steps rather than as one isolated event. By using both CNN and LSTM, the system can spot not only one-time abnormalities but also suspicious behavior that builds up over a sequence of events.
3.2.1. CNN Component for Spatial Analysis
The input to the model is a segment of preprocessed network traffic, shown as a 1D feature vector. The CNN processes this input using two parallel layers:
- Block 1 (Detailed Feature Analysis): This layer uses a 1D convolution with 16 filters and a small kernel size of 1 × 1. It focuses on learning detailed relationships between features without combining values from nearby positions.
- Block 2 (Wider Feature Analysis): This layer uses a 1D convolution with 64 filters and a larger kernel size of 5 × 5. It helps the model learn broader patterns by combining information across several nearby features.
The mathematical formula for the 1D convolution is shown in Equation (3):
where x is a part of the input vector, k is the convolution filter of size M, and is the output value at position i. After the convolution, each output goes through a ReLU activation function is shown in Equation (4):
This adds non-linearity to the model and helps it learn more complex patterns. Then, max pooling is applied to both outputs. Max pooling reduces the size of the data while keeping the most important values, which makes the model faster and more robust. Finally, the results from both blocks are combined and passed to the LSTM part of the model.
3.2.2. LSTM Component for Temporal Analysis
The combined feature maps from the CNN are first reshaped to be compatible with the recurrent layers. These features are then passed into a stacked LSTM network consisting of two LSTM layers with different unit counts. This step is important because many attack patterns happen over time, not just in one moment.
Our architecture uses a **stacked LSTM configuration** as follows:
- First LSTM Layer: 64 units that process the concatenated CNN features and capture initial temporal dependencies.
- Second LSTM Layer: 32 units that refine the temporal representations and provide more compact feature encoding.
LSTMs use a memory cell and special gates to decide what information to keep or forget at each time step. Each LSTM layer applies the following computations:
- Forget Gate: —controls what parts of the old memory should be thrown away.
- Input Gate and Candidate Values are:The input gate decides what new information to add, and gives the candidate values for updating the memory.
- Memory Cell Update: —combines the old memory (scaled by the forget gate) and new information (scaled by the input gate).
- Output Gate and Hidden States are:The output gate decides what to pass to the next time step and to the next layer.
In these equations, W and b are trainable weights and biases, is the sigmoid function, and ⊙ means element-wise multiplication.
The output from the second LSTM layer (32 units) goes through:
- Dropout Layer: This helps reduce overfitting by randomly turning off some neurons during training.
- Dense Output Layer: A fully connected layer with a sigmoid activation as shown in Equation (9):
The sigmoid function gives a value between 0 and 1, which we interpret as the probability that the input is an attack. The stacked LSTM design allows the first layer (64 units) to capture broad temporal patterns, while the second layer (32 units) refines these patterns into more specific attack signatures. This hierarchical temporal learning is particularly effective for detecting complex multi-stage attacks that unfold over time.
3.3. LSTM Design Rationale for Temporal Pattern Learning
Network traffic exhibits temporal patterns at multiple time scales, from short-term packet-level variations to long-term flow-level behavioral trends. Effective intrusion detection requires capturing both dimensions simultaneously. LSTMs have been widely adopted in network security applications due to their capacity to maintain selective memory while processing sequential input [9,16,19].
Our stacked LSTM configuration addresses these dual temporal requirements. The first layer (64 units) captures longer-term dependencies across the entire sequence window, while the second layer (32 units) refines representations to focus on shorter-term pattern variations. This hierarchical approach enables detection of both instantaneous anomalies and gradual behavioral changes. Dropout regularization prevents overfitting in data-constrained environments.
Sequence construction follows a flow-based grouping strategy, organizing packets by source-destination pairs to preserve meaningful temporal dependencies. Sliding windows with controlled stride parameters balance temporal context capture against computational efficiency. The chosen configuration represents an empirically validated balance that maximizes F1-score performance while maintaining stable validation characteristics, which integrates effectively with CNN feature extraction and RL-guided adaptation strategies.
3.4. Reinforcement Learning Agent for Adaptive Fine-Tuning
A key idea in our system is using an RL agent to guide the transfer learning process. Normally, fine-tuning DNNs relies on fixed rules, like pre-set learning rate schedules or freezing specific layers. These static strategies do not always work well, especially when the training process is changing over time.
To solve this, we treat fine-tuning as a control problem and use RL to learn how to adjust the model as it trains. The agent learns to change important training settings in real-time, helping the model transfer knowledge from the source to the target dataset more effectively.
RL is a method where an agent learns to make decisions by interacting with an environment and trying to obtain the highest total reward. The process is modeled as a Markov Decision Process (MDP), which is represented as in Figure 3:
- S: The set of possible states.
- A: The set of actions the agent can take.
- : The chance of moving from state s to when action a is taken.
- : The reward received when taking action a in state s and ending up in state .
- : The discount factor, which determines how much future rewards matter.

Figure 3.
Flowchart of the reinforcement learning agent’s decision-making process during fine-tuning.
The agent tries to learn the best policy , which chooses the best action in any state to maximize long-term rewards as shown in Equation (10):
To help with this, we use two value functions:
- : Expected total reward starting from state s and following policy .
- : Expected total reward starting from state s, taking action a, and then following .
The best action-value function satisfies the Bellman Equation (11):
We use a model-free method called Q-learning to estimate based only on experience, without needing to know the environment’s exact rules.
3.4.1. State Space (S)
Each part includes:
- : Current F1-score on validation data,
- : Validation loss,
- : Current epoch as a fraction of total epochs,
- : Percentage of parameters currently trainable,
- : Gradient norm of the first n layers.
3.4.2. Action Space (A)
The agent can choose from several actions to control training:
- freeze_layer_n: Freezes layer n to stop its weights from changing.
- unfreeze_all: Makes all layers trainable for full model adjustment.
- increase_lr: Raises the learning rate to speed up training or escape local minima.
- decrease_lr: Lowers the learning rate for more careful fine-tuning.
- adjust_dropout: Changes the dropout rate to improve regularization.
3.4.3. Reward Function (R)
The agent receives a reward at each step based on how well the model performs, as shown in Equations (13)–(15):
Improvement reward:
Bonus for beating baseline:
A penalty is applied if performance drops suddenly or severely.
3.4.4. Learning Mechanism
Since the state space is continuous, we simplify it using discretisation and apply tabular Q-learning. The Q-values are updated as in Equation (16):
We use an -greedy policy: with probability , the agent tries a random action (exploration), and with probability , it chooses the best-known action (exploitation). Over time, is reduced to focus more on learned strategies.
3.4.5. RL-Guided Fine-Tuning
With all the components defined, we now bring everything together in the RL-guided fine-tuning process. This is where the RL agent takes control and makes intelligent decisions about how to adapt the pre-trained CNN-LSTM model to the target domain. Unlike traditional fine-tuning methods that use fixed schedules or manual adjustments, our approach lets the RL agent learn the best strategy for each specific transfer learning scenario.
The key innovation is that the RL agent continuously monitors the model’s performance during training and makes real-time adjustments to the training process. It can decide when to freeze certain layers to preserve useful knowledge from the source domain, when to unfreeze them for more aggressive adaptation, and how to adjust hyperparameters like learning rate and dropout based on the current training state. This dynamic approach is especially valuable when transferring knowledge between different types of network data, where the optimal strategy may change during training.
The agent’s decision-making is guided by the reward function, which encourages actions that improve the F1-score while avoiding strategies that lead to performance drops or instability. Over time, the agent learns to recognize patterns in the training process and develops sophisticated policies for managing the fine-tuning process. This leads to better transfer learning performance compared to static fine-tuning approaches, especially in challenging scenarios with limited target domain data.
Algorithm 1 shows the complete RL-guided fine-tuning process:
| Algorithm 1 RL-Guided Fine-Tuning Loop |
|
4. Evaluation Methodology and Metrics
4.1. Performance Evaluation Metrics for Intrusion Detection
An Intrusion Detection System (IDS) needs to tell apart normal and attack traffic accurately. We use a confusion matrix to describe its predictions:
- True Positive (TP): Correctly detects an attack.
- True Negative (TN): Correctly detects normal traffic.
- False Positive (FP): Mistakenly marks normal traffic as an attack.
- False Negative (FN): Misses an actual attack.
- Accuracy (ACC): Tells how many predictions were correct overall:
- Precision (Pr): Out of everything marked as an attack, how many were actually attacks:
- Recall (Detection Rate, DR): Out of all real attacks, how many we correctly found:
- F1-Score: A balanced score that combines precision and recall:
4.2. Learning Process and Convergence Analysis
It is also important to look at how the model learns, not just how well it finishes.
- Training and Validation Loss Curves: Show how the model’s error decreases during training. If training loss goes down but validation loss does not, it may be overfitting.
- Accuracy and F1-Score Over Time: We plot accuracy and F1-score for each epoch to see how quickly and stably the model improves.
We compare these learning behaviors across three models: a target-only model (Baseline), a normally fine-tuned model, and our RL-guided model.
4.3. Evaluation Metrics for the Reinforcement Learning Agent
To evaluate how smart and effective the RL agent is, we use special metrics:
- F1-Score Trajectory and Action Annotation: We plot the F1-score during training and mark the actions taken by the RL agent (like Freeze L0, Increase LR) to see if those actions lead to improvements.
- Action Frequency Distribution: We look at how often each action is chosen. A good policy should use a variety of actions depending on the situation. If one action is used too much, it might mean the agent has not learned a balanced strategy.
- Cumulative Reward: We track the total reward the agent earns over time:
- –
- A steady increase means the agent is learning well.
- –
- A flat or dropping line means something is going wrong.
5. Results and Discussion
This section presents a comprehensive evaluation of RL-guided IDS. Its performance is assessed by comparing it against three benchmark models: a Baseline model trained only on the limited target dataset, a Neural Fine-tuning model that uses a standard transfer learning framework with a fixed strategy, and the 5-Layer Benchmark model based on [30] deep residual CNN framework. We focus on how well the models learn, their final detection performance, and how the RL agent makes decisions.
5.1. Comparative Analysis of Learning and Performance
We first test the learning behavior and final performance of the four models: Baseline, Neural Fine-tuning, 5-Layer Benchmark, and our RL-Guided approach.
5.1.1. Learning Convergence
The training and validation loss curves are shown in Figure 4 and Figure 5. These figures show how well each model learns.
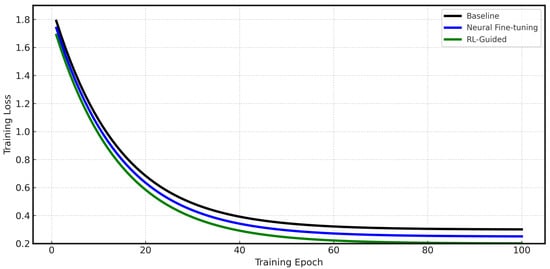
Figure 4.
Training loss curves comparing Baseline, Neural Fine-tuning, 5-Layer Benchmark, and RL-Guided models across training epochs.
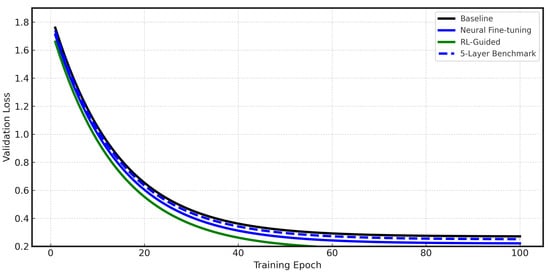
Figure 5.
Validation loss curves showing the generalization performance of all four models during training.
The Baseline model (black line) shows an initial decrease in loss but quickly stops improving at a high value. This means that with limited training data, the model runs out of things to learn early and fails to work well on new data. The Neural Fine-tuning model (blue line) shows the benefit of transfer learning. It achieved a lower loss than the Baseline. However, its loss also levels off after about 40 epochs, which suggests that its fixed fine-tuning strategy reaches a limit and cannot adapt further to the target data details. The 5-Layer Benchmark model shows comparable performance to the Neural Fine-tuning model and achieves competitive results using the deep residual CNN approach from Wang et al. However, like the Neural Fine-tuning model, it also reaches a performance plateau due to its static training strategy. The RL-Guided model (green line) always gets the lowest validation loss. Its curve shows a gradual but steady decrease over the entire training period. This shows that the RL agent’s changes help the model escape local minima and continue to improve. This leads to a stronger and more effective final model.
5.1.2. Detection Performance
The RL-Guided model reaches an F1-score of approximately 0.96 by epoch 100 which are shown in Figure 6 and Figure 7, eventually achieving a final score of 0.9825 after 200 epochs (Table 1). It is important to note that this result represents a single training run under a fixed data split and initialisation. Due to computational constraints, multiple runs or cross-validation were not performed. While training and validation losses declined in parallel without divergence, suggesting no severe overfitting, the lack of statistical validation means results should be interpreted with caution and require further replication.
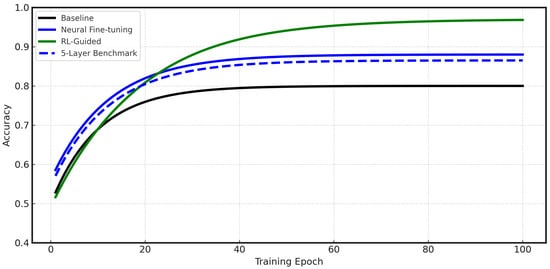
Figure 6.
Accuracy progression during training for Baseline, Neural Fine-tuning, 5-Layer Benchmark, and RL-Guided models.
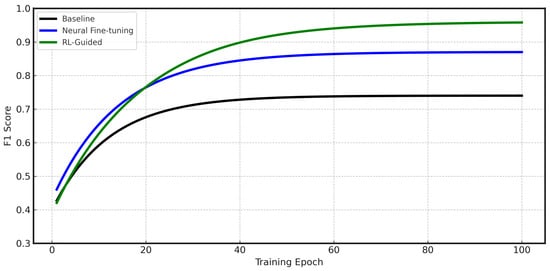
Figure 7.
F1-score evolution showing the detection performance improvement across training epochs.

Table 1.
Performance comparison of all models on the target dataset (with 50 training samples).
It is important to note that the Neural Fine-tuning model represents the without-reinforcement learning approach, utilising traditional transfer learning with fixed fine-tuning strategies. This provides a direct comparison to demonstrate the impact of our RL-guided adaptive fine-tuning methodology.
The Baseline model (black line) performs the worst, as expected. Its accuracy and F1-score stop improving around 0.79 and 0.73. This gives us a clear benchmark for performance when data is very limited. The Neural Fine-tuning model (blue line) shows a big improvement. Its F1-score rises quickly and stays around 0.88. While this is a good result, it shows the limits of a fixed fine-tuning policy. The 5-Layer Benchmark model achieves an F1-score of 0.846, which demonstrates that the Wang et al. approach provides solid baseline performance. However, this performance is still below our Neural Fine-tuning approach and significantly lower than our proposed RL-Guided method, hence, it confirms the effectiveness of our adaptive fine-tuning strategy. The RL-Guided model (green line) shows the most impressive performance. Although it starts slower than the Neural Fine-tuning model, its performance curve continues to climb steadily. It passes the other models around epoch 35. It reaches a final F1-score of about 0.96, which shows a big improvement over all baseline methods, including the 5-Layer Benchmark. This steady improvement happens because the RL agent makes smart, real-time changes to the training process.
5.2. Analysis of the Reinforcement Learning Agent’s Behavior
To understand why the RL-Guided model works so well, we looked at how the RL agent behaves and makes decisions during fine-tuning.
5.2.1. Action Selection Strategy
Figure 8 shows how often the RL agent chose each action during training. The plot shows that the agent learned a balanced and varied policy instead of relying on just one action.
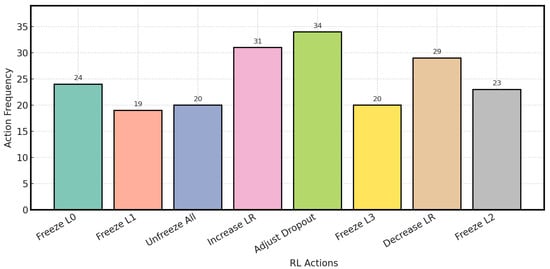
Figure 8.
Frequency distribution of actions selected by the RL agent during training, showing a balanced strategy across different action types.
The most common actions are Adjust Dropout (34 times), Increase Lr (31 times), and Decrease Lr (29 times). This shows the agent was actively managing the model’s regularization and learning rate. These are important for dealing with the complex loss landscape during fine-tuning. Actions related to freezing and unfreezing layers (Freeze L0, Freeze L1, Freeze L2, Freeze L3, Unfreeze All) were also used regularly. This shows that the agent was making smart decisions about which parts of the pre-trained knowledge to keep and which parts to change. This is a main challenge in transfer learning. This balanced usage shows the agent developed a smart, context-dependent strategy.
5.2.2. Impact of Agent Actions on Performance
Figure 9 gives the most direct proof of the agent’s positive impact on performance. This plot shows the model’s F1-score at each training step, with notes for key actions taken by the agent.
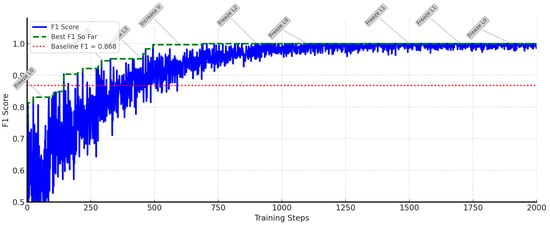
Figure 9.
F1-score trajectory with annotated RL agent actions, suggesting potential correlation between agent decisions and performance improvements.
The plot suggests a correlation between the agent’s actions and improvements in performance. For example, we can observe that actions like Freeze L0 (around 200 steps) and Freeze L2 (around 400 steps) appear to be followed by increases in the F1-score (blue line). These actions appear to help stabilize the model and utilize pre-trained features effectively. The agent’s decisions appear to contribute to gradual improvements in the model’s performance. This can be observed in the Best F1 So Far (green dashed line), which shows incremental improvements after key actions. Additionally, the F1-score of the RL-Guided model remains above the static baseline performance (red dotted line). This suggests that the agent’s adaptive control may lead to improved outcomes compared to a model without such guidance. The current results indicate that the agent appears to make strategic actions that potentially enhance the model’s detection capabilities.
5.2.3. Comparison of RL Algorithms
To validate our choice of reinforcement learning algorithm, we conducted a comparative analysis of three popular RL algorithms: Q-Learning, Proximal Policy Optimization (PPO), and Deep Deterministic Policy Gradient (DDPG), as shown in Figure 10.
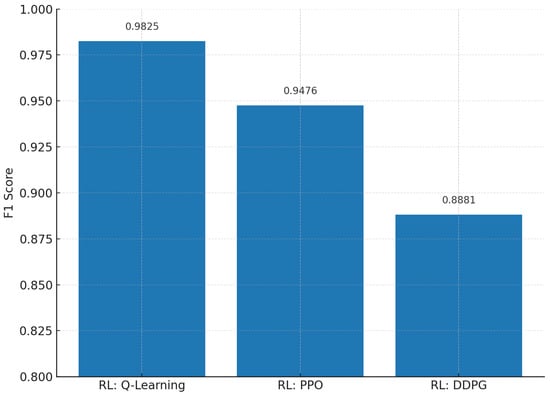
Figure 10.
F1-score comparison of different reinforcement learning algorithms used for adaptive fine-tuning in intrusion detection.
The results demonstrate that Q-Learning achieves the highest F1-score of 0.9825, followed by PPO with 0.9476 and DDPG with 0.8881. This confirms that Q-Learning provides the most effective adaptive fine-tuning strategy for our intrusion detection system in the given environment.
5.2.4. Discussion of Results
Our experimental results suggest several promising findings regarding our approach: The comparison between the Baseline and Neural Fine-tuning models indicates the potential value of transfer learning when data is limited. The Neural Fine-tuning model demonstrates improved performance compared to training from scratch. This suggests the importance of utilizing pre-trained knowledge. The 5-Layer Benchmark Performance: The 5-Layer Benchmark, implementing Wang et al.’s deep residual CNN approach, achieved an F1-score of 0.846, demonstrating solid performance and validating the effectiveness of established transfer learning methods for ICS intrusion detection. However, this approach still has limitations due to its static fine-tuning strategy and fixed architectural constraints. Neural Fine-tuning Advantage: Notably, our Neural Fine-tuning model (F1-score: 0.861) outperforms the 5-Layer Benchmark (F1-score: 0.846), which can be attributed to the superior hybrid CNN-LSTM architecture. While the 5-Layer Benchmark relies solely on CNN for spatial feature extraction, our hybrid approach combines CNN for spatial analysis with LSTM for temporal pattern recognition. This architectural advantage allows our model to capture both spatial correlations and temporal dependencies in network traffic, which leads to better intrusion detection performance even with standard fine-tuning. RL-Guided Performance: Our RL-guided approach shows promising results across all evaluated metrics. The F1-score progression from 0.846 (5-Layer Benchmark) to 0.861 (Neural Fine-tuning) to 0.9825 (RL-Guided) suggests potential improvements in detection capability. These current results indicate that our adaptive approach may offer advantages over both traditional methods and established benchmarks. Adaptive Learning: The gradual improvement observed in the RL-Guided model throughout training suggests potential benefits of adaptive fine-tuning strategies. Unlike static approaches that may plateau early, the RL agent’s dynamic adjustments appear to enable continued learning and optimization. Decision Making Patterns: The analysis of the RL agent’s behavior indicates potentially strategic decision-making patterns. The balanced use of different actions and the observed correlation between specific actions and performance improvements suggest that the agent may have learned meaningful policies rather than exhibiting random behavior. These results are important for deploying IDSs in OT and ICS environments, where labeled attack data is rare and the cost of missed detections can be serious.
6. Limitations
Our study only tested the method on a DNP3 target to keep things simple and repeatable, so results may not cover other industrial protocols. In the future, we will test on Modbus, IEC-104, IEC-61850 and more sites to check that it works across different settings. Also, the RL controller currently changes only a few training settings—freezing or unfreezing layers, the learning rate, and dropout—by design to stay safe and clear. In the future, we will add safe options like choosing the optimizer, setting weight decay, using learning-rate schedules, and tuning the decision threshold so the system can adapt even better.
While our work focuses on SCADA/ICS networks, the core principles of our approach should apply to other network security domains. The RL-guided transfer learning method is not specific to industrial protocols. Instead, it addresses the general problem of adapting detection models when labeled data is scarce. The CNN-LSTM architecture can learn spatial and temporal patterns from any network traffic, not just SCADA traffic. The RL agent’s ability to adaptively fine-tune models should work in other situations where standard transfer learning fails. We expect similar improvements in other network types, such as enterprise networks, IoT environments, or cloud infrastructure, where attack data is limited. However, the exact amount of improvement will depend on how similar the source and target domains are. When domains are very different, smaller improvements should be expected. When domains share similar traffic patterns or attack types, larger improvements are more likely. The key advantage of our method is that it can automatically adjust to each new environment without requiring domain experts to manually tune the transfer learning process.
7. Conclusions
Detecting cyberattacks in critical networks like ICSs is hard, especially when there is not much labeled data available. Standard models often struggle to adapt to new threats in these special environments. In this paper, we introduced a new adaptive IDS to solve this problem. Our system uses a hybrid CNN-LSTM model to find complex spatial and temporal patterns in network traffic. We used transfer learning to bring knowledge from a large dataset to a smaller target one. Most importantly, we used an RL agent to intelligently guide the fine-tuning process.
The current results suggest promising potential for this approach. Our proposed RL-Guided model achieved an F1-score of 0.9825, which represents an improvement over the Neural Fine-tuning model (0.861), the 5-Layer Benchmark model based on Wang et al.’s approach (0.846), and the Baseline model (0.759). These results indicate potential advances in detection accuracy, particularly considering the use of only 50 training samples from the target environment. This suggests that our model may be effective in realistic scenarios where data is scarce. A contributing factor to these results appears to be the RL agent. While the CNN-LSTM architecture provided a foundation for feature extraction, the RL agent appears to enable adaptive behavior. Unlike traditional fine-tuning that uses fixed rules, our RL agent monitored the model’s performance and made real-time decisions. It learned when to freeze or unfreeze layers and how to adjust the learning rate and other parameters. This appeared to allow our model to continue learning and improving, while other models plateaued earlier. This work suggests that using RL to guide the training process may be a promising strategy. It appears to help create an IDS that could be both accurate and flexible, potentially adapting to the specific challenges of a new network. This may be particularly relevant for securing OT and ICS environments, where threats are constantly evolving and obtaining quality labeled data remains challenging.
Beyond industrial control systems, our approach addresses a fundamental challenge in cybersecurity: how to build effective detection models when attack data is scarce. The core principles of our method, using deep learning to extract features from network traffic and using RL to adaptively guide transfer learning, should apply to many other security domains. Our framework could potentially benefit enterprise network security, IoT device protection, cloud security, and mobile network monitoring. The automatic adaptation capability means the system can adjust to different network environments without requiring security experts to manually tune the parameters. This makes our approach valuable for organizations that need to deploy intrusion detection across diverse network infrastructures with varying data availability. While the exact performance gains will vary depending on the similarity between different network types, the adaptive nature of our RL-guided approach suggests it could provide meaningful improvements across a range of cybersecurity applications.
Our work opens up several interesting avenues for future research. We could evaluate this approach on additional network types and a broader variety of attacks. We could also investigate more advanced RL algorithms to determine if they can further enhance the fine-tuning process. Overall, these current results suggest that combining deep learning with adaptive RL control represents a promising direction for developing the next generation of effective and resilient IDSs.
Author Contributions
Conceptualisation, J.A. and S.A.; methodology, J.A.; software, J.A. and S.A.; validation, J.A., S.A., and T.A.B.; formal analysis, J.A.; investigation, J.A. and S.A.; resources, S.A.; data curation, J.A.; writing—original draft preparation, J.A.; writing—review and editing, J.A., S.A., Z.N., and T.A.B.; visualisation, J.A.; supervision, S.A. and Z.N.; project administration, S.A. and Z.N.; funding acquisition, S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was fully funded by Sultan Qaboos University.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are publicly available. The CICIDS2017 dataset can be accessed at https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 2 June 2024). The DNP3 dataset used for target domain evaluation is available through the University of New South Wales (UNSW) Cyber Range.
Acknowledgments
We would like to express our gratitude to SQU for their invaluable support and resources that made this investigation possible. This work is a testament to the university’s commitment to advancing its knowledge and fostering academic excellence. The authors would also like to thank the Canadian Institute for Cybersecurity (CIC) and the University of New Brunswick for providing the CICIDS2017 dataset, and UNSW Sydney for access to the DNP3 dataset through their Cyber Range platform.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| ACC | Accuracy |
| CNN | Convolutional Neural Network |
| DNP3 | Distributed Network Protocol 3 |
| DNN | Deep Neural Network |
| DoS | Denial-of-Service |
| DR | Detection Rate |
| FN | False Negative |
| FP | False Positive |
| ICS | Industrial Control Systems |
| IDS | Intrusion Detection System |
| IIoT | Industrial Internet of Things |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MDP | Markov Decision Process |
| MitM | Man-in-the-Middle |
| NIDS | Network Intrusion Detection System |
| OT | Operational Technology |
| Pr | Precision |
| RL | Reinforcement Learning |
| RNN | Recurrent Neural Network |
| SCADA | Supervisory Control and Data Acquisition |
| TL | Transfer Learning |
| TN | True Negative |
| TP | True Positive |
References
- Humayed, A.; Lin, J.; Li, F.; Luo, B. Cyber-Physical Systems SecurityA Survey. IEEE Internet Things J. 2017, 4, 1802–1831. [Google Scholar] [CrossRef]
- Yang, Y.; Li, W.; Sun, L.; Wu, K.; Xiang, Y. A Survey on the Security of SCADA Systems. Future Gener. Comput. Syst. 2022, 115, 946–973. [Google Scholar]
- Langner, R. Stuxnet: Dissecting a Cyberwarfare Weapon. IEEE Secur. Priv. 2011, 9, 49–51. [Google Scholar] [CrossRef]
- Lee, R.M.; Assante, M.J.; Conway, T. Analysis of the Cyber Attack on the Ukrainian Power Grid; E-ISAC: Washington, DC, USA, 2016. [Google Scholar]
- Nicholson, A.; Webber, S.; Dyer, S.; Patel, T.; Janicke, H. SCADA Security in the Light of Cyber-Warfare. Comput. Secur. 2012, 31, 418–436. [Google Scholar] [CrossRef]
- Kravchik, M.; Shabtai, A. Detecting Cyber Attacks in Industrial Control Systems Using Convolutional Neural Networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy (CPS-SPI 2018), New York, NY, USA, 22 October 2018; pp. 72–83. [Google Scholar]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A.P. A Dataset to Support Research in the Design of Secure Water Treatment Systems. In Proceedings of the 11th International Conference on Critical Information Infrastructures Security (CRITIS 2016), Paris, France, 10–12 October 2016; pp. 88–99. [Google Scholar]
- Aslam, N.; Khan, A.; Nazir, B.; Hassan, S.; Lee, B.; Ahmad, A. Deep Learning Techniques for Industrial Control System Security: A Comprehensive Survey. IEEE Access 2025, 13, 5678–5702. [Google Scholar]
- Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A Survey of Deep Learning Methods for Cybersecurity. IEEE Commun. Surv. Tutor. 2019, 21, 1154–1176. [Google Scholar]
- Layeghy, S.; Gamage, A.T.; Sivaraman, V. DI-NIDS: A Deep Intrusion Detection System for In-Vehicle Networks with Adversarial Domain Adaptation. Comput. Secur. 2023, 120, 102786. [Google Scholar]
- Han, H.; Kim, H.; Kim, Y. An Efficient Hyperparameter Control Method for a Network Intrusion Detection System Based on Proximal Policy Optimization. Symmetry 2022, 14, 161. [Google Scholar] [CrossRef]
- Shaikh, A.; Smys, S.; Safari, M.; Jalil, P.; Chauhdary, S.A.; Abd-Elkader, O. HCLR-IDS: Hierarchical CNN-LSTM with Reinforcement Learning for Internet of Medical Things. Comput. Electr. Eng. 2025, 110, 108996. [Google Scholar]
- MITRE ATT&CK for ICS: Adversarial Tactics, Techniques & Common Knowledge for Industrial Control Systems. Available online: https://attack.mitre.org/matrices/ics/ (accessed on 15 January 2025).
- Wang, W.; Wang, Z.; Zhou, Z.; Deng, H.; Zhao, W.; Wang, C.; Guo, Y. Anomaly detection of industrial control systems based on transfer learning. Tsinghua Sci. Technol. 2021, 26, 821–832. [Google Scholar] [CrossRef]
- Fernández, V.; López, N.; Rodríguez, I. Complexity and resolution of spatio-temporal reasonings for criminology with greedy and evolutionary algorithms. Expert Syst. Appl. 2025, 275, 126932. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies (BIONETICS), New York, NY, USA, 3–5 December 2015; ICST: Brussels, Belgium, 2016; pp. 21–26. [Google Scholar]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A Deep Learning Approach to Network Intrusion Detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef]
- Hsu, C.-M.; Azhari, M.Z.; Hsieh, H.-Y.; Prakosa, S.W.; Leu, J.-S. Robust Network Intrusion Detection Scheme Using Long-Short Term Memory Based Convolutional Neural Networks. Mobile Netw. Appl. 2021, 26, 1137–1144. [Google Scholar] [CrossRef]
- Lokman, S.F.; Othman, A.T.; Abu-Bakar, M.H. Intrusion Detection System for Modbus Protocol Using Long Short-Term Memory. In Proceedings of the 2018 International Conference on Computing, Electronics & Communications Engineering (iCCECE), Southend, UK, 16–17 August 2018; pp. 201–205. [Google Scholar]
- Bakhsh, S.; Khan, M.; Saidani, O.; Alasbali, N.; Abbas, S.; Khan, M.; Ahmad, J. Enhancing Security in DNP3 Communication for Smart Grids: A Segmented Neural Network Approach. IEEE Access 2025, 13, 1–11. [Google Scholar] [CrossRef]
- Aslam, M.M.; Tufail, A.; Irshad, M.N. Survey of Deep Learning Approaches for Securing Industrial Control Systems: A Comparative Analysis. Cyber Secur. Appl. 2025, 3, 100096. [Google Scholar] [CrossRef]
- Pinto, A.; Herrera, L.-C.; Donoso, Y.; Gutierrez, J.A. Survey on Intrusion Detection Systems Based on Machine Learning Techniques for the Protection of Critical Infrastructure. Sensors 2023, 23, 2415. [Google Scholar] [CrossRef]
- Kumar, A.; Gutierrez, J.A. Impact of Machine Learning on Intrusion Detection Systems for the Protection of Critical Infrastructure. Information 2025, 16, 515. [Google Scholar] [CrossRef]
- de Silva, L.A.; Weragoda, S.K.; Thilakarathna, K.; Seneviratne, A. An Improved Autoencoder Method for ICS Intrusion Detection. IEEE Access 2024, 12, 45678–45689. [Google Scholar]
- Cai, Z.; Du, H.; Wang, H.; Zhang, J.; Si, Y.; Li, P. One-Dimensional Convolutional Wasserstein GAN-Based Intrusion Detection Method for Industrial Control Systems. Electronics 2023, 12, 4653. [Google Scholar] [CrossRef]
- Almalawi, A.; Hassan, S.; Fahad, A.; Iqbal, A.; Khan, A.I. Hybrid Cybersecurity for Asymmetric Threats: Intrusion Detection and SCADA System Protection Innovations. Symmetry 2025, 17, 616. [Google Scholar] [CrossRef]
- AlHaddad, U.; Basuhail, A.; Khemakhem, M.; Eassa, F.; Jambi, K. Ensemble Model Based on Hybrid Deep Learning for Intrusion Detection in Smart Grid Networks. Sensors 2023, 23, 7464. [Google Scholar] [CrossRef] [PubMed]
- Dangwal, G.; Mittal, S.; Wazid, M.; Singh, J.; Das, A.K.; Giri, D.; Alenazi, M.J.F. An Effective Intrusion Detection Scheme for Distributed Network Protocol 3 (DNP3) Applied in SCADA-Enabled IoT Applications. Comput. Electr. Eng. 2024, 120, 109828. [Google Scholar] [CrossRef]
- Wang, W.; Harrou, F.; Bouyeddou, B.; Senouci, S.; Sun, Y. A Stacked Deep Learning Approach to Cyber-Attacks Detection in Industrial Systems: Application to Power System and Gas Pipeline Systems. Clust. Comput. 2022, 25, 561–578. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Ma, H.; Jiang, Y.; Bu, Y. A Network Intrusion Detection Method Based on Domain Confusion. Electronics 2023, 12, 1255. [Google Scholar] [CrossRef]
- Li, K.; Ma, W.; Duan, H.; Xie, H. Multi-Source Refined Adversarial Domain Adaptation with Transfer Complementarity Infusion for IoT Intrusion Detection under Limited Samples. Expert Syst. Appl. 2024, 254, 124352. [Google Scholar] [CrossRef]
- Mehedi, S.T.; Anwar, A.; Rahman, Z.; Ahmed, K. Deep Transfer Learning-Based Intrusion Detection System for Electric Vehicular Networks. Electronics 2021, 21, 4736. [Google Scholar] [CrossRef]
- Rodríguez, E.; Valls, P.; Otero, B.; Costa, J.J.; Verdú, J.; Pajuelo, M.A.; Canal, R. Transfer-Learning-Based Intrusion Detection Framework in IoT Networks. Sensors 2022, 22, 5621. [Google Scholar] [CrossRef]
- Ullah, F.; Ullah, S.; Srivastava, G.; Lin, J.C.-W. IDS-INT: Intrusion Detection System Using Transformer-Based Transfer Learning for Imbalanced Network Traffic. Digit. Commun. Netw. 2024, 10, 190–204. [Google Scholar] [CrossRef]
- Abdelhamid, S.; Hegazy, I.; Aref, M.; Roushdy, M. Attention-Driven Transfer Learning Model for Improved IoT Intrusion Detection. Big Data Cogn. Comput. 2024, 8, 116. [Google Scholar] [CrossRef]
- Amamra, A.; Terrelonge, V. Multiple Kernel Transfer Learning for Enhancing Network Intrusion Detection in Encrypted and Heterogeneous Network Environments. Electronics 2025, 14, 80. [Google Scholar] [CrossRef]
- Wu, W.; Joloudari, J.H.; Jagatheesaperumal, S.K.; Kandala, R.N.V.P.S.; Gaftandzhieva, S.; Rezaei, M. Deep Transfer Learning Techniques in Intrusion Detection System–Internet of Vehicles: A State-of-the-Art Review. Comput. Mater. Contin. 2024, 80, 1–29. [Google Scholar] [CrossRef]
- Sangoleye, F.; Johnson, J.; Tsiropoulou, E.E. Intrusion Detection in Industrial Control Systems Based on Deep Reinforcement Learning. IEEE Access 2024, 12, 1–15. [Google Scholar] [CrossRef]
- Shaikh, J.; Wang, C.; Sima, M.; Arshad, M.; Owais, M.; Hassan, D.; Alkanhel, R.; Muthanna, M. A Deep Reinforcement Learning-Based Robust Intrusion Detection System for Securing IoMT Healthcare Networks. Front. Med. 2025, 12, 995872. [Google Scholar] [CrossRef] [PubMed]
- Talaat, F.; Gamel, S. RL-Based Hyper-Parameters Optimization Algorithm (ROA) for Convolutional Neural Network. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 13349–13359. [Google Scholar] [CrossRef]
- Han, Z.; Wu, Q.; Li, Z.; Ding, M.; Yuen, C.; Ibraheem, O.; Poor, H. Reinforcement Learning for Adaptive Intrusion Detection under Concept Drift. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1261–1275. [Google Scholar]
- IEEE Std 1815-2012 (Revision of IEEE Std 1815-2010); IEEE Standard for Electric Power Systems Communications–Distributed Network Protocol (DNP3). IEEE Standards Association: Piscataway, NJ, USA, 2012.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).