

Deep Supervised Hashing by Fusing Multiscale Deep Features for Image Retrieval †



Abstract
1. Introduction
- 1.
- Integration of Structural Information: Multiscale deep hashing allows for the integration of structural information from images at multiple levels of granularity. Different scales capture varying levels of structural details in the image. By considering these multiple scales, the model can learn to encode both low-level details and high-level structural features, resulting in more informative hash codes.
- 2.
- Feature Hierarchy: Deep neural networks used in multiscale hashing often have multiple layers, each capturing features at different abstraction levels. Lower layers capture finer details, while higher layers capture more abstract features or structures. This hierarchical feature representation helps strike a balance by encoding both fine-grained structural details and higher-level abstract information, addressing the trade-off.
- 3.
- Adaptability to Task-Specific Needs: Multiscale deep hashing can be tailored to the specific requirements of the retrieval task. For tasks where preserving structural information is crucial, appropriate design choices can be made to prioritize encoding such information in the hash codes.
- 4.
- Quantization and Bit Allocation: Hashing involves quantization of continuous features into binary codes. The bit allocation strategy can be optimized to balance between capturing structural information and achieving high retrieval accuracy. Techniques like adaptive bit allocation can be employed to allocate more bits to preserve crucial structural details while still maintaining retrieval accuracy.
- 5.
- Learning Objectives and Loss Functions: The design of learning objectives and loss functions can be customized to emphasize the preservation of structural information. Including terms in the loss function that encourage the preservation of certain structural features can guide the learning process.
2. Related Works
3. Proposed Method
3.1. Problem Definition
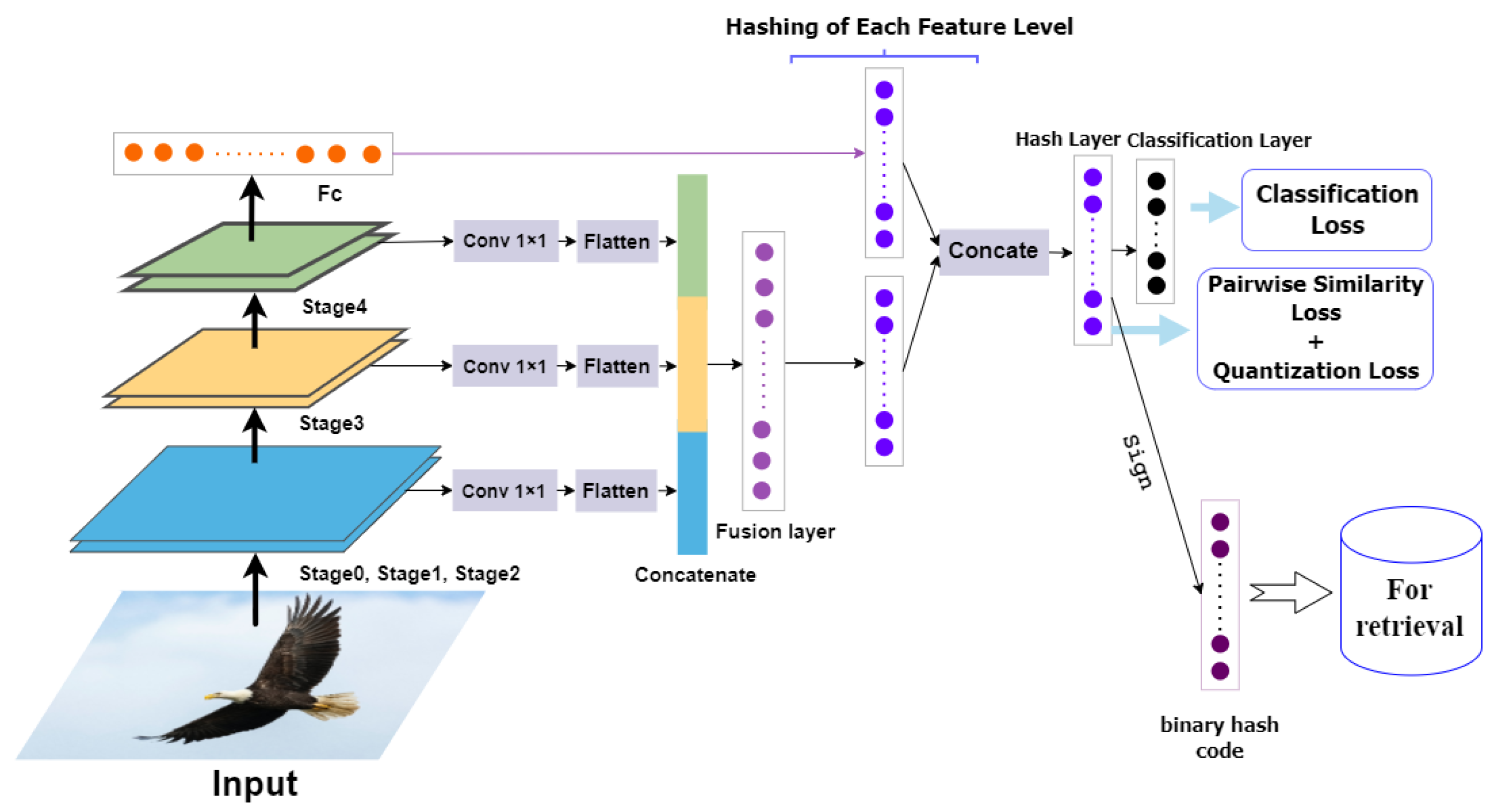
3.2. Model Architecture
3.3. Objective Function
3.3.1. Pairwise Similarity Loss
3.3.2. Quantization Loss
3.3.3. Classification Loss
4. Experiments
4.1. Datasets
4.2. Experimental Settings
4.3. Evaluation Metrics
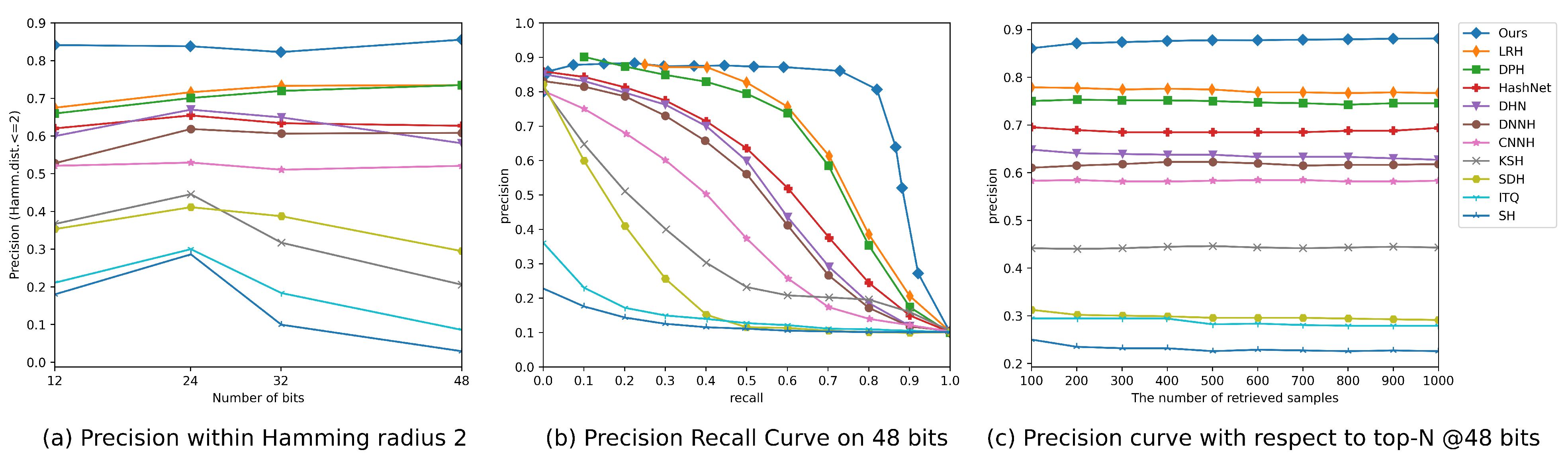
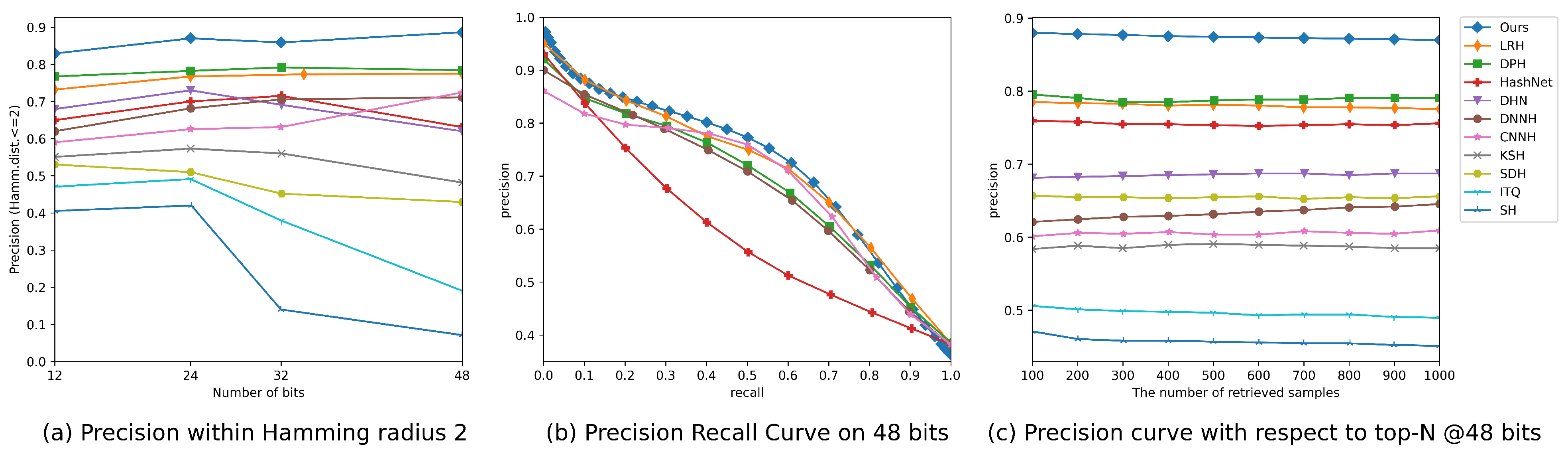
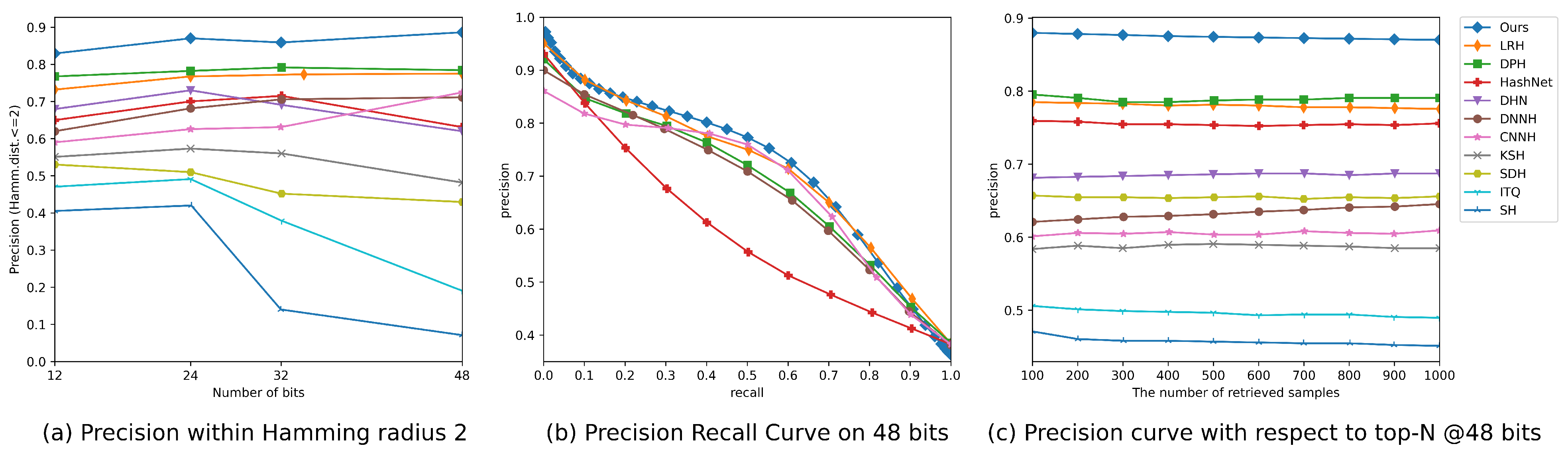
4.4. Results Discussion
4.5. Ablation Studies
- (1)
- In our ablation studies, we explored different fundamental feature extractors. Specifically, we replaced VGG19 with VGG13 and VGG16, and the performance of these models on the CIFAR-10 dataset is presented in Table 3. The table illustrates that using deeper neural networks can improve image retrieval performance, leading us to choose VGG19 as our primary feature extractor.
- (2)
- Ablation studies on multi-level image representations for improved hash learning: In our ablation studies, we conducted a thorough investigation into the impact of different levels of image representations on the performance of our DSHFMDF method. Unlike many existing approaches that primarily focus on extracting semantic information from the penultimate layer in fully connected networks, we recognized the importance of structural information that contains crucial semantic details for effective hash learning. To address this, we considered using feature maps from various layers, ranging from low-level to high-level features.Table 4 presents the results of these experiments, focusing on the retrieval performance using different feature maps on CIFAR-10. Notably, we observed that utilizing features from ‘’ led to the most significant average mAP score of 69%, emphasizing the importance of high-level features in capturing semantic information. In contrast, using features from ‘conv 3–5’ yielded an average mAP score of only 59.4%, which reflects the significance of low-level and structural details. Furthermore, our proposed DSHFMDF method outperformed other methods, achieving an average mAP score of 82.15%. This result demonstrated that combining features from different scales, including both low-level and high-level features, significantly enhanced the performance of our method.In Figure 5, we display the Precision–Recall curves of DSHFMDF in the case of various scale features. Our DSHFMDF retains over 80% Precision and nearly identical Precision–Recall curves at 12, 24, 36, and 48 hash bits. DSHFMDF achieves superior Precision and Recall with the same hash code length compared to other methods. The binary hash codes perform best when all feature scales are used. This proves that high-level characteristics are more effective in carrying information when creating hash codes. While low-level features can contribute supplementary information to the high-level features information, low-level features cannot entirely take the place of high-level characteristics. The information contained in each scale’s features is essential. This further demonstrates how well DSHFMDF makes use of all scales’ features.
- (3)
- Ablation studies of the objective function: We conducted ablation studies on our objective function to assess the influence of Pairwise Quantization Loss and Classification Loss constraints, which examine the impact of hash coding and classification on CIFAR-10. We based our experiments on the proposed DSHFMDF method, where and are the key parameters for and . When , the model is referred to as DSHFMDF-J3, and when , it is DSHFMDF-J2. As shown in Table 5, if and are not set to zero, each component in the suggested loss function contributes to hash code creation, resulting in a performance improvement. Both and yield similar enhancements because they reduce quantization errors and preserve semantics in the overall model. Eliminating either or may reduce the model’s performance.
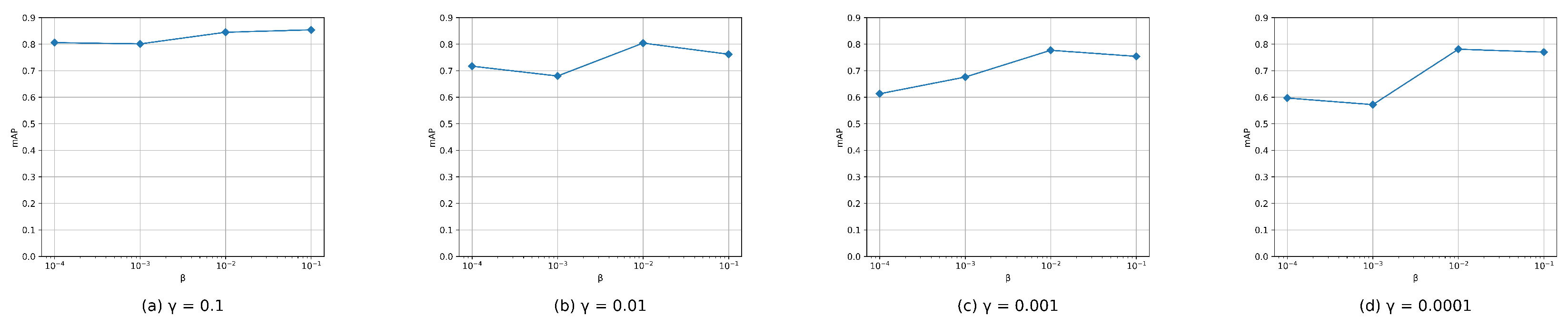
4.6. Parameter Sensitivity Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DSHFMDF | Deep Supervised Hashing by Fusing Multiscale Deep Features |
| CBIR | Content-Based Image Retrieval |
| FPN | Feature Pyramid Network |
| CNN | Convolutional Neural Network |
| DCNN | Deep Convolutional Neural Network |
References
- Yan, C.; Shao, B.; Zhao, H.; Ning, R.; Zhang, Y.; Xu, F. 3D room layout estimation from a single RGB image. IEEE Trans. Multimed. 2020, 22, 3014–3024. [Google Scholar] [CrossRef]
- Yan, C.; Li, Z.; Zhang, Y.; Liu, Y.; Ji, X.; Zhang, Y. Depth image denoising using nuclear norm and learning graph model. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–17. [Google Scholar] [CrossRef]
- Li, S.; Chen, Z.; Li, X.; Lu, J.; Zhou, J. Unsupervised variational video hashing with 1d-cnn-lstm networks. IEEE Trans. Multimed. 2019, 22, 1542–1554. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, T.; Song, J.; Sebe, N.; Shen, H.T. A survey on learning to hash. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 769–790. [Google Scholar] [CrossRef]
- Gionis, A.; Indyk, P.; Motwani, R. Similarity search in high dimensions via hashing. In Proceedings of the VLDB, Edinburgh, UK, 7–10 September 1999; Volume 99, pp. 518–529. [Google Scholar]
- Andoni, A.; Indyk, P. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun. ACM 2008, 51, 117–122. [Google Scholar] [CrossRef]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef]
- Liu, W.; Wang, J.; Mu, Y.; Kumar, S.; Chang, S.F. Compact hyperplane hashing with bilinear functions. arXiv 2012, arXiv:1206.4618. [Google Scholar]
- Gong, Y.; Kumar, S.; Rowley, H.A.; Lazebnik, S. Learning binary codes for high-dimensional data using bilinear projections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 484–491. [Google Scholar]
- Lin, G.; Shen, C.; Wu, J. Optimizing ranking measures for compact binary code learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 613–627. [Google Scholar]
- Kulis, B.; Darrell, T. Learning to hash with binary reconstructive embeddings. Adv. Neural Inf. Process. Syst. 2009, 22, 1042–1050. [Google Scholar]
- Strecha, C.; Bronstein, A.; Bronstein, M.; Fua, P. LDAHash: Improved matching with smaller descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 66–78. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Shen, C.; Suter, D.; Van Den Hengel, A. A general two-step approach to learning-based hashing. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2552–2559. [Google Scholar]
- Lin, G.; Shen, C.; Shi, Q.; Van den Hengel, A.; Suter, D. Fast supervised hashing with decision trees for high-dimensional data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1963–1970. [Google Scholar]
- Chen, Z.; Zhou, J. Collaborative multiview hashing. Pattern Recognit. 2018, 75, 149–160. [Google Scholar] [CrossRef]
- Cui, Y.; Jiang, J.; Lai, Z.; Hu, Z.; Wong, W. Supervised discrete discriminant hashing for image retrieval. Pattern Recognit. 2018, 78, 79–90. [Google Scholar] [CrossRef]
- Song, J.; Gao, L.; Liu, L.; Zhu, X.; Sebe, N. Quantization-based hashing: A general framework for scalable image and video retrieval. Pattern Recognit. 2018, 75, 175–187. [Google Scholar] [CrossRef]
- Erin Liong, V.; Lu, J.; Wang, G.; Moulin, P.; Zhou, J. Deep hashing for compact binary codes learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2475–2483. [Google Scholar]
- Zhu, H.; Long, M.; Wang, J.; Cao, Y. Deep hashing network for efficient similarity retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Lai, H.; Pan, Y.; Liu, Y.; Yan, S. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Cakir, F.; He, K.; Bargal, S.A.; Sclaroff, S. Hashing with mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2424–2437. [Google Scholar] [CrossRef]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep image retrieval: Learning global representations for image search. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 241–257. [Google Scholar]
- Jiang, Q.Y.; Li, W.J. Asymmetric deep supervised hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shen, F.; Gao, X.; Liu, L.; Yang, Y.; Shen, H.T. Deep asymmetric pairwise hashing. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1522–1530. [Google Scholar]
- Jin, Z.; Li, C.; Lin, Y.; Cai, D. Density sensitive hashing. IEEE Trans. Cybern. 2013, 44, 1362–1371. [Google Scholar] [CrossRef]
- Li, X.; Wang, H. Adaptive Principal Component Analysis. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), Society for Industrial and Applied Mathematics: Virtual Conference, Originally Scheduled in Alexandria, Alexandria, VA, USA, Virtual. 28–30 April 2022; pp. 486–494. [Google Scholar] [CrossRef]
- Li, X.; Wang, H. On Mean-Optimal Robust Linear Discriminant Analysis. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; pp. 1047–1052. [Google Scholar] [CrossRef]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral hashing. Adv. Neural Inf. Process. Syst. 2008, 21, 1753–1760. [Google Scholar]
- Liu, W.; Wang, J.; Ji, R.; Jiang, Y.G.; Chang, S.F. Supervised hashing with kernels. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2074–2081. [Google Scholar]
- Norouzi, M.; Fleet, D.J. Minimal loss hashing for compact binary codes. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Shen, F.; Shen, C.; Liu, W.; Tao Shen, H. Supervised discrete hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Li, W.J.; Wang, S.; Kang, W.C. Feature learning based deep supervised hashing with pairwise labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Cao, Y.; Liu, B.; Long, M.; Wang, J. Hashgan: Deep learning to hash with pair conditional wasserstein gan. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1287–1296. [Google Scholar]
- Zhuang, B.; Lin, G.; Shen, C.; Reid, I. Fast training of triplet-based deep binary embedding networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5955–5964. [Google Scholar]
- Liu, B.; Cao, Y.; Long, M.; Wang, J.; Wang, J. Deep triplet quantization. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 755–763. [Google Scholar]
- Yang, H.F.; Lin, K.; Chen, C.S. Supervised learning of semantics-preserving hash via deep convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 437–451. [Google Scholar] [CrossRef]
- Wang, M.; Zhou, W.; Tian, Q.; Li, H. A general framework for linear distance preserving hashing. IEEE Trans. Image Process. 2017, 27, 907–922. [Google Scholar] [CrossRef] [PubMed]
- Shen, F.; Xu, Y.; Liu, L.; Yang, Y.; Huang, Z.; Shen, H.T. Unsupervised deep hashing with similarity-adaptive and discrete optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 3034–3044. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, J. Leveraging Deep Features Enhance and Semantic-Preserving Hashing for Image Retrieval. Electronics 2022, 11, 2391. [Google Scholar] [CrossRef]
- Ma, Z.; Guo, Y.; Luo, X.; Chen, C.; Deng, M.; Cheng, W.; Lu, G. Dhwp: Learning high-quality short hash codes via weight pruning. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4783–4787. [Google Scholar]
- Fu, C.; Wang, G.; Wu, X.; Zhang, Q.; He, R. Deep momentum uncertainty hashing. Pattern Recognit. 2022, 122, 108264. [Google Scholar] [CrossRef]
- Lin, J.; Li, Z.; Tang, J. Discriminative Deep Hashing for Scalable Face Image Retrieval. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 2266–2272. [Google Scholar]
- Yang, Y.; Geng, L.; Lai, H.; Pan, Y.; Yin, J. Feature pyramid hashing. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 114–122. [Google Scholar]
- Redaoui, A.; Belloulata, K. Deep Feature Pyramid Hashing for Efficient Image Retrieval. Information 2023, 14, 6. [Google Scholar] [CrossRef]
- Ng, W.W.; Li, J.; Tian, X.; Wang, H.; Kwong, S.; Wallace, J. Multi-level supervised hashing with deep features for efficient image retrieval. Neurocomputing 2020, 399, 171–182. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 31 July 2022).
- Bai, J.; Li, Z.; Ni, B.; Wang, M.; Yang, X.; Hu, C.; Gao, W. Loopy residual hashing: Filling the quantization gap for image retrieval. IEEE Trans. Multimed. 2019, 22, 215–228. [Google Scholar] [CrossRef]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini Island, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Redaoui, A.; Belloulata, K. Deep Supervised Hashing with Multiscale Feature Fusion (DSHMFF). In Proceedings of the NCNETi’23, The 1st National Conference on New Educational Technologies and Informatics, Guelma, Algeria, 3–4 October 2023. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Cao, Z.; Long, M.; Wang, J.; Yu, P.S. Hashnet: Deep learning to hash by continuation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5608–5617. [Google Scholar]
- Bai, J.; Ni, B.; Wang, M.; Li, Z.; Cheng, S.; Yang, X.; Hu, C.; Gao, W. Deep progressive hashing for image retrieval. IEEE Trans. Multimed. 2019, 21, 3178–3193. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| conv Block | Layers | Kernel Size | Feature Size |
|---|---|---|---|
| 1 | conv2D conv2D# MaxPooling | , | |
| 2 | conv2D conv2D# MaxPooling | , | |
| 3 | conv2D conv2D conv2D conv2D# MaxPooling | , , | |
| 4 | conv2D conv2D conv2D conv2D# MaxPooling | , , | |
| 5 | conv2D conv2D conv2D conv2D# MaxPooling | , , |
| Method | CIFAR-10 (MAP) | NUS-WIDE (MAP) | ||||||
|---|---|---|---|---|---|---|---|---|
| 12 Bits | 24 Bits | 32 Bits | 48 Bits | 12 Bits | 24 Bits | 32 Bits | 48 Bits | |
| SH [30] | 0.127 | 0.128 | 0.126 | 0.129 | 0.454 | 0.406 | 0.405 | 0.400 |
| ITQ [8] | 0.162 | 0.169 | 0.172 | 0.175 | 0.452 | 0.468 | 0.472 | 0.477 |
| KSH [31] | 0.303 | 0.337 | 0.346 | 0.356 | 0.556 | 0.572 | 0.581 | 0.588 |
| SDH [33] | 0.285 | 0.329 | 0.341 | 0.356 | 0.568 | 0.600 | 0.608 | 0.637 |
| CNNH [54] | 0.439 | 0.511 | 0.509 | 0.522 | 0.611 | 0.618 | 0.625 | 0.608 |
| DNNH [21] | 0.552 | 0.566 | 0.558 | 0.581 | 0.674 | 0.697 | 0.713 | 0.715 |
| DHN [20] | 0.555 | 0.594 | 0.603 | 0.621 | 0.708 | 0.735 | 0.748 | 0.758 |
| HashNet [55] | 0.609 | 0.644 | 0.632 | 0.646 | 0.643 | 0.694 | 0.737 | 0.750 |
| DPH [56] | 0.698 | 0.729 | 0.749 | 0.755 | 0.770 | 0.784 | 0.790 | 0.786 |
| LRH [49] | 0.684 | 0.700 | 0.727 | 0.730 | 0.726 | 0.775 | 0.774 | 0.780 |
| DFEH [41] | 0.6753 | 0.7216 | - | 0.7864 | 0.5674 | 0.5788 | 0.5863 | 0.5921 |
| DHWP [42] | 0.730 | 0.729 | 0.735 | 0.752 | 0.796 | 0.813 | 0.818 | 0.822 |
| DMUH [43] | 0.772 | 0.815 | 0.822 | 0.826 | 0.792 | 0.818 | 0.825 | 0.829 |
| Ours | 0.779 | 0.827 | 0.835 | 0.845 | 0.823 | 0.851 | 0.851 | 0.863 |
| Method | 12 Bits | 24 Bits | 32 Bits | 48 Bits | conv Layers Num |
|---|---|---|---|---|---|
| VGG13 | 0.726 | 0.788 | 0.792 | 0.806 | 10 |
| VGG16 | 0.770 | 0.831 | 0.819 | 0.826 | 13 |
| VGG19 | 0.779 | 0.827 | 0.835 | 0.845 | 16 |
| Method | CIFAR-10 (MAP) | |||
|---|---|---|---|---|
| 12 Bits | 24 Bits | 32 Bits | 48 Bits | |
| 0.610 | 0.667 | 0.725 | 0.758 | |
| –5 | 0.493 | 0.595 | 0.619 | 0.669 |
| DSHFMDF | 0.779 | 0.827 | 0.835 | 0.845 |
| Method | CIFAR-10 (MAP) | |||
|---|---|---|---|---|
| 12 Bits | 24 Bits | 32 Bits | 48 Bits | |
| DSHFMDF-J2 | 0.652 | 0.792 | 0.790 | 0.790 |
| DSHFMDF-J3 | 0.656 | 0.655 | 0.783 | 0.744 |
| DSHFMDF | 0.779 | 0.827 | 0.835 | 0.845 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Redaoui, A.; Belalia, A.; Belloulata, K. Deep Supervised Hashing by Fusing Multiscale Deep Features for Image Retrieval. Information 2024, 15, 143. https://doi.org/10.3390/info15030143
Redaoui A, Belalia A, Belloulata K. Deep Supervised Hashing by Fusing Multiscale Deep Features for Image Retrieval. Information. 2024; 15(3):143. https://doi.org/10.3390/info15030143
Chicago/Turabian StyleRedaoui, Adil, Amina Belalia, and Kamel Belloulata. 2024. "Deep Supervised Hashing by Fusing Multiscale Deep Features for Image Retrieval" Information 15, no. 3: 143. https://doi.org/10.3390/info15030143
APA StyleRedaoui, A., Belalia, A., & Belloulata, K. (2024). Deep Supervised Hashing by Fusing Multiscale Deep Features for Image Retrieval. Information, 15(3), 143. https://doi.org/10.3390/info15030143