
Disaggregation Model: A Novel Methodology to Estimate Customers’ Profiles in a Low-Voltage Distribution Grid Equipped with Smart Meters

 and
and
Abstract
1. Introduction
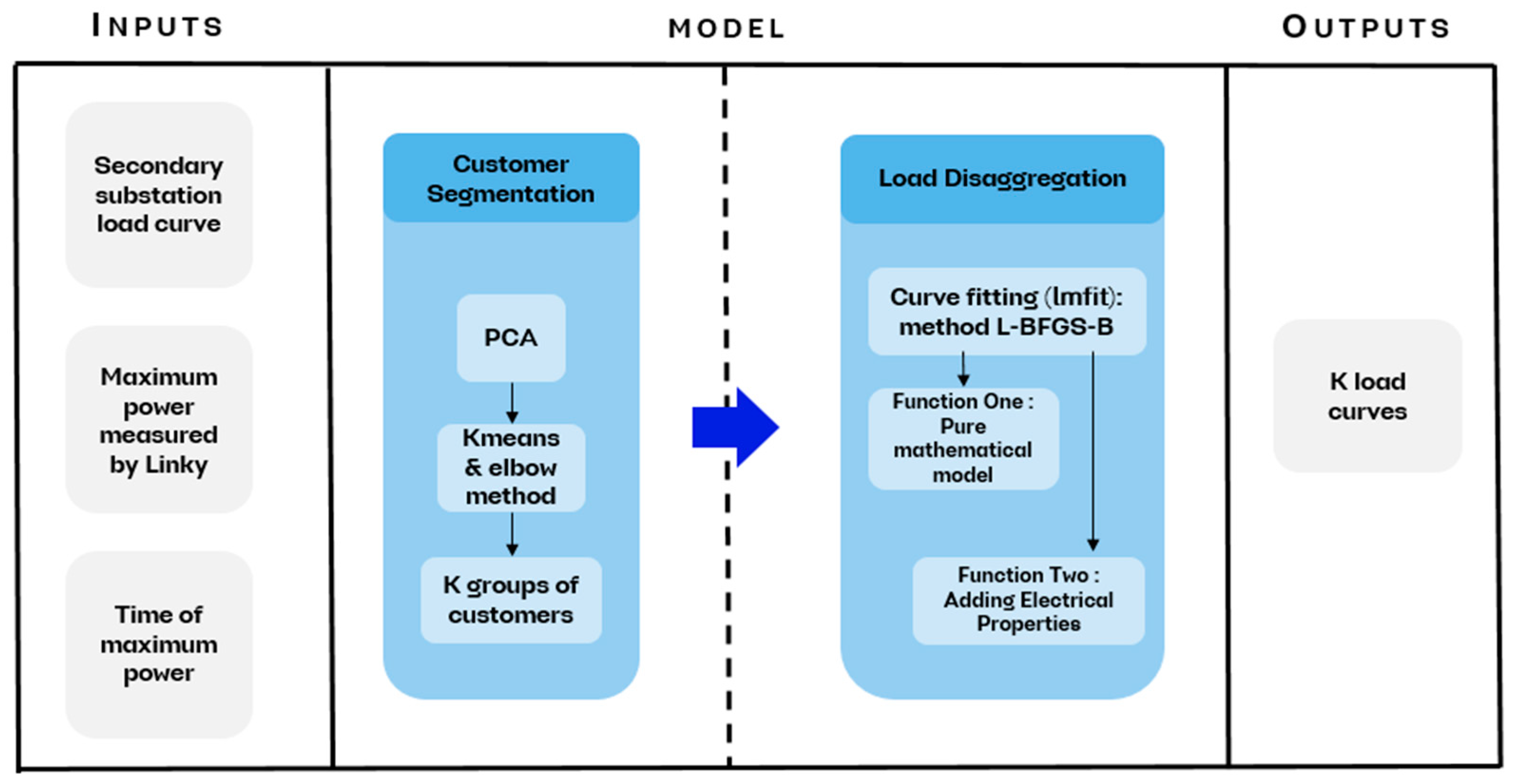
2. Materials and Methods
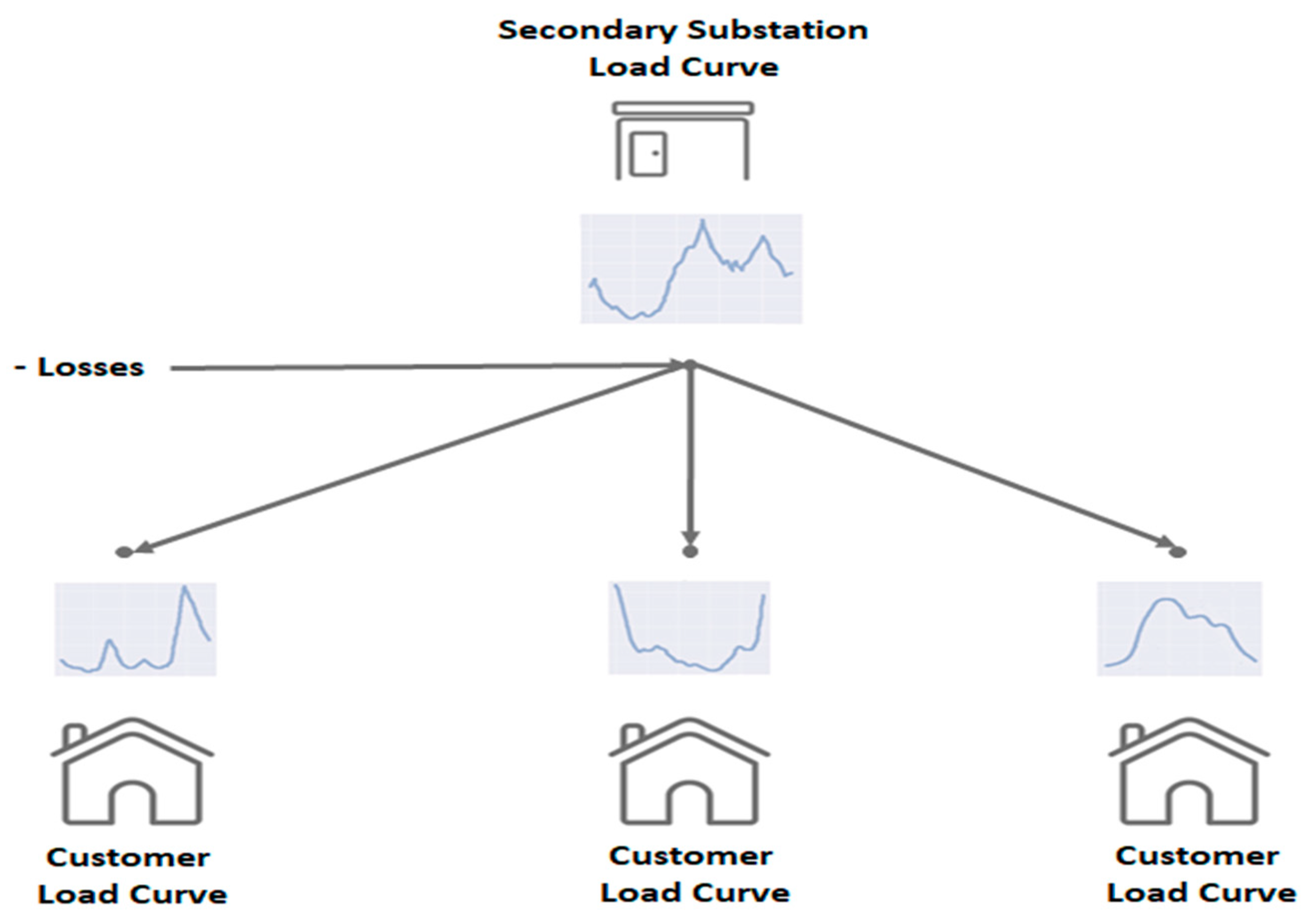
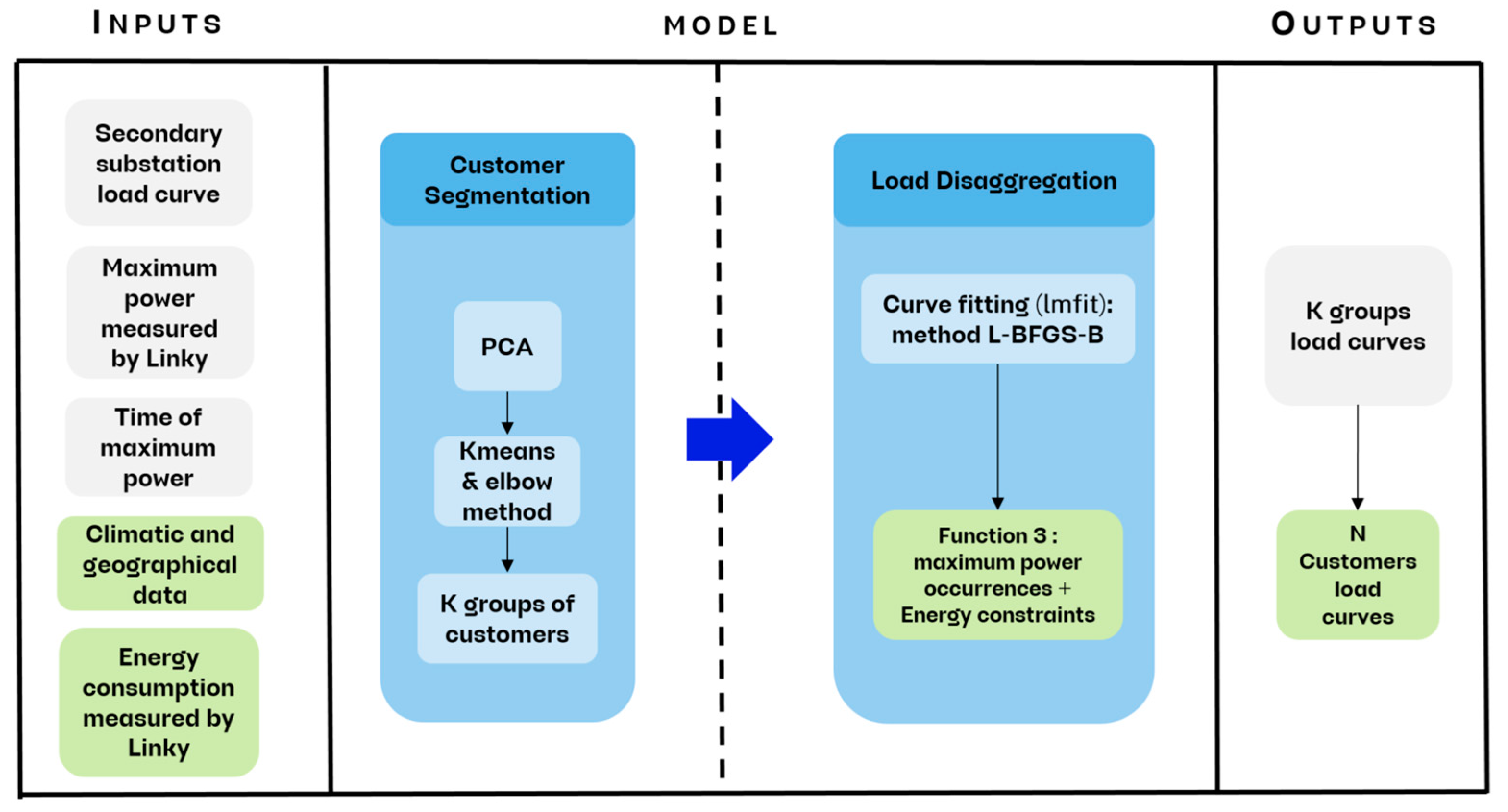
- Customer Segmentation: The N customers of a substation share similar characteristics, either because they belong to the same categories (residential, professional, etc.) or because they have similar consumption habits. From this perspective, the segmentation (or the number of clusters) of these customers is performed to identify K groups of similar customers among the N customers of the substation, where K < N.
- Secondary Substation Load Disaggregation: The load curve of the substation is then disaggregated into K curves, representing the K groups of similar customers at the substation. These K curves are then adjusted in energy to assign to each customer the curve of the group to which they belong.
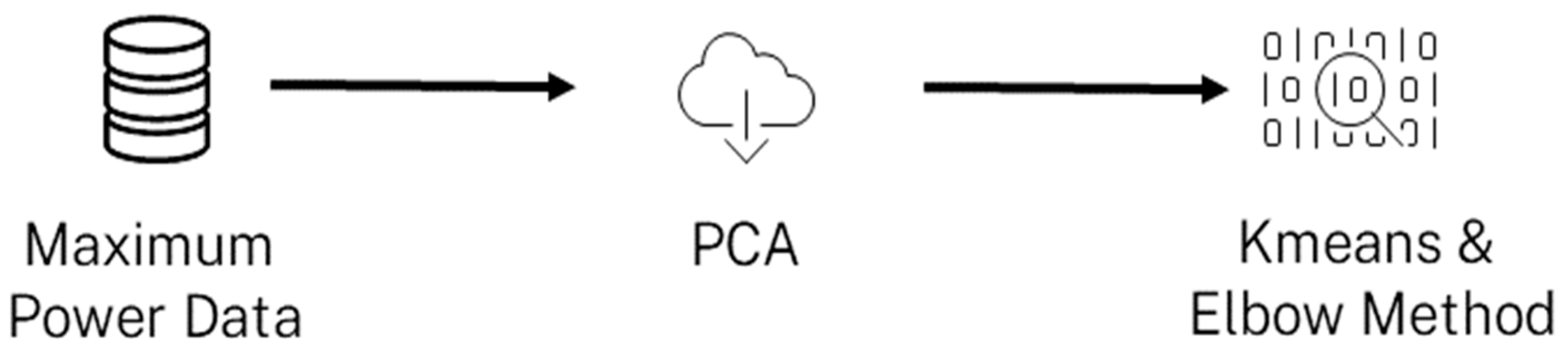
- The load curve of the substation.
- The maximum power value in watts measured by Linky for all customers connected in the substation.
- The time of day (hours and minutes) when the maximum power occurred.
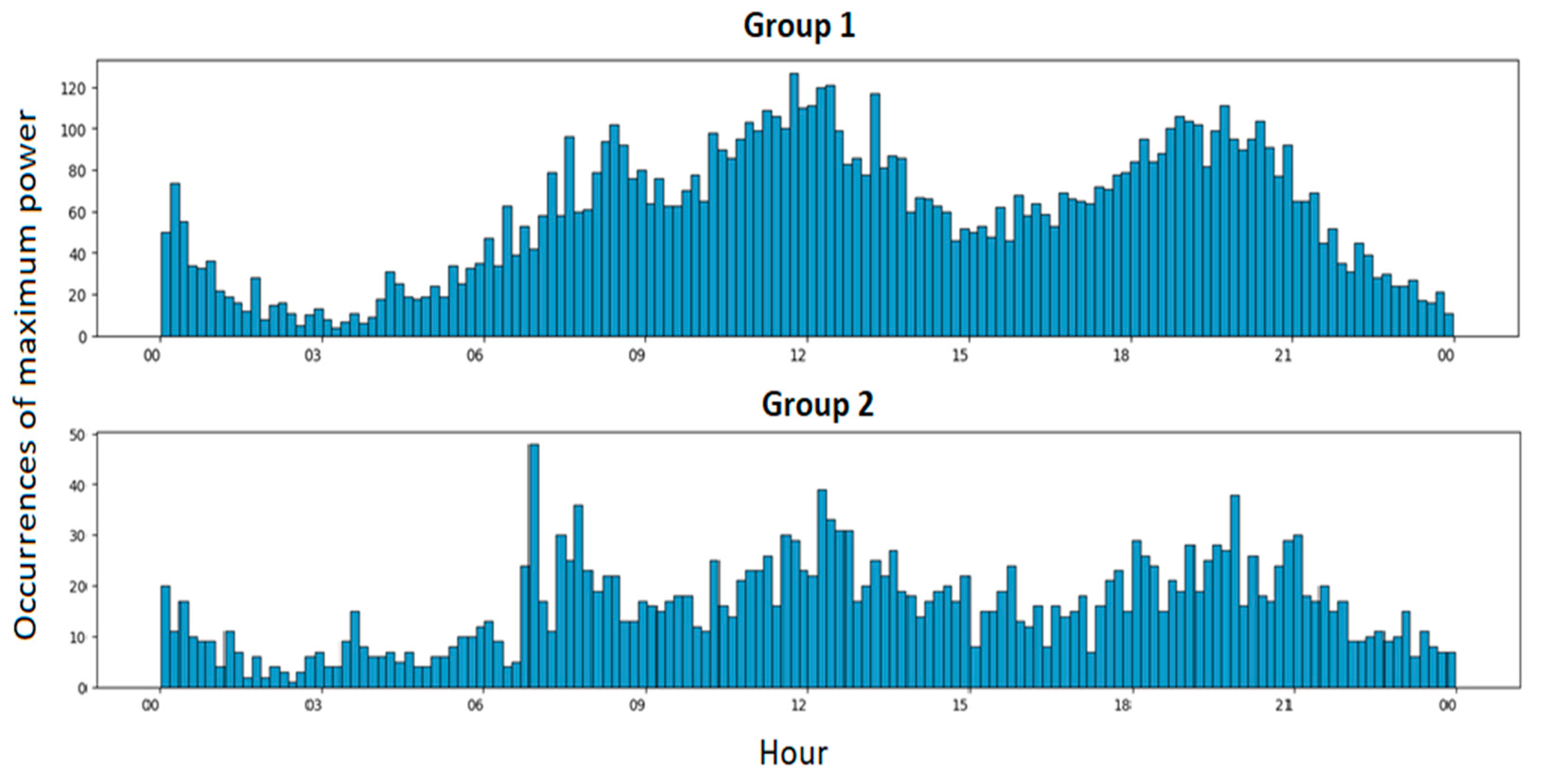
2.1. Customer Segmentation
2.2. Secondary Substation Load Disaggregation
2.2.1. Function One—Pure Mathematical Model
2.2.2. Function Two—Adding Electrical Properties to the Purely Mathematical Model
2.3. Global Vision of the Model
2.4. Error Evaluation
3. Results
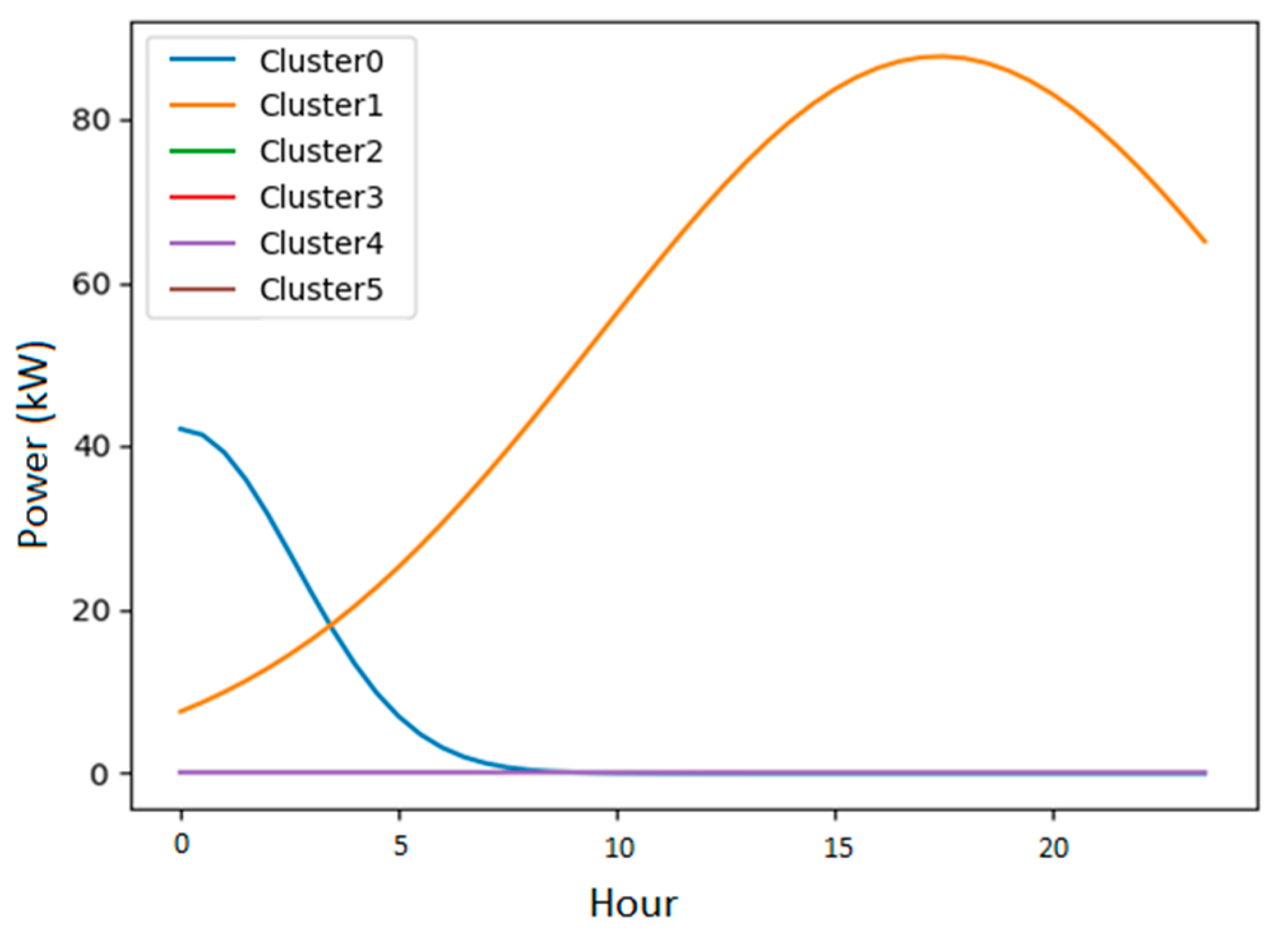
3.1. Results for One Random Secondary Substation
3.2. Results for All Secondary Substations in the Dataset
4. Discussion
5. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Commission. ‘Fit for 55’: Delivering the EU’s 2030 Climate Target on the Way to Climate Neutrality; Communication from the Commission to the European Parliament, the European Council, the Council, the European Economic and Social Committee and the Committee of the Regions; European Commission: Brussels, Belgium, 2021. [Google Scholar]
- Open Data Enedis. Enedis. Available online: https://data.enedis.fr/pages/accueil (accessed on 4 February 2024).
- Consommation d’énergie par Usage du Résidentiel. Données Et Études Statistiques Pour Le Changement Climatique, L’énergie, L’environnement, Le Logement et Les Transports. Available online: https://www.statistiques.developpement-durable.gouv.fr/consommation-denergie-par-usage-du-residentiel (accessed on 4 February 2024).
- Torquato, R.; Salles, D.; Pereira, C.O.; Meira, P.C.M.; Freitas, W. A comprehensive assessment of PV hosting capacity on Low-Voltage distribution systems. IEEE Trans. Power Deliv. 2018, 33, 1002–1012. [Google Scholar] [CrossRef]
- Saad, S.N.M.; Van Der Weijde, A.H. Evaluating the Potential of Hosting Capacity Enhancement Using Integrated Grid Planning modeling Methods. Energies 2019, 12, 3610. [Google Scholar] [CrossRef]
- García, E.J.; Moreno-Muñoz, A.; Santiago, I.; Moreno-Garcia, I.M.; Milanés-Montero, M.I. PV hosting capacity analysis and enhancement using high resolution stochastic modeling. Energies 2017, 10, 1488. [Google Scholar] [CrossRef]
- Chudjakov, N. Enel: Italy Reaping First-Mover Benefits of Smart Meters. 2010. Available online: https://www.euractiv.com/section/climate-environment/interview/enel-italy-reaping-first-mover-benefits-of-smart-meters/ (accessed on 4 February 2024).
- The Circular Smart Meter: Sustainable Innovation by Enel. Available online: https://www.enel.com/company/stories/articles/2022/03/circular-smart-meter-regenerated-plastic (accessed on 4 February 2024).
- SmartMeter FAQ|PG&E. Available online: https://www.pge.com/en_US/residential/save-energy-money/analyze-your-usage/your-usage/view-and-share-your-data-with-smartmeter/smartmeter-faq.page (accessed on 4 February 2024).
- Smart Metering & Infrastructure Program Business Case|BC Hydro. Available online: https://www.bchydro.com/content/dam/BCHydro/customer-portal/documents/projects/smart-metering/smi-program-business-case.pdf (accessed on 4 February 2024).
- Jensterle, M. System Integration of Renewables and Smart Grids in Korea: Supporting Germany’s Energy Dialogue with Japan and Korea; Short Scientific Report. 2019. Available online: https://nbn-resolving.org/urn:nbn:de:bsz:wup4-opus-74320 (accessed on 4 February 2024).
- Smart Meter Project|TEPCO. Available online: https://www.tepco.co.jp/en/pg/development/domestic/smartmeter-e.html (accessed on 4 February 2024).
- La CRE: Favorable à la Généralisation du Compteur Linky. CRE. Available online: https://www.cre.fr/documents/Presse/Communiques-de-presse/la-cre-favorable-a-la-generalisation-du-compteur-linky (accessed on 4 February 2024).
- Refaat, S.S.; Abu-Rub, H.; Mohamed, A. Big data better energy management and control decisions for distribution systems in smart grid. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3115–3120. [Google Scholar]
- Zainab, A.; Ghrayeb, A.; Syed, D.; Abu-Rub, H.; Refaat, S.S.; Bouhali, O. Big Data Management in Smart Grids: Technologies and Challenges. IEEE Access 2021, 9, 73046–73059. [Google Scholar] [CrossRef]
- Qays, M.O.; Ahmad, I.; Abu-Siada, A.; Hossain, M.L.; Yasmin, F. Key communication technologies, applications, protocols and future guides for IoT-assisted smart grid systems: A review. Energy Rep. 2023, 9, 2440–2452. [Google Scholar] [CrossRef]
- Barbier, T. Modélisation de la Consommation Electrique à Partir de Grandes Masses de Données pour la Simulation des Alternatives Energétiques du futur. Energie Electrique; Université Paris Sciences et Lettres: Paris, France, 2017. [Google Scholar]
- Suganthi, L.; Samuel, A.A. Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 2012, 16, 1223–1240. [Google Scholar] [CrossRef]
- Shao, Z.; Fu, C.; Yang, S.; Zhou, K. A review of the decomposition methodology for extracting and identifying the fluctuation characteristics in electricity demand forecasting. Renew. Sustain. Energy Rev. 2017, 75, 123–136. [Google Scholar] [CrossRef]
- Runge, J.; Zmeureanu, R. Forecasting Energy use in buildings Using Artificial Neural Networks: A review. Energies 2019, 12, 3254. [Google Scholar] [CrossRef]
- Swan, L.G.; Ugursal, V.I. Modeling of end-use energy consumption in the residential sector: A review of modeling techniques. Renew. Sustain. Energy Rev. 2009, 13, 1819–1835. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, S.; Shen, C. A review of electric load classification in smart grid environment. Renew. Sustain. Energy Rev. 2013, 24, 103–110. [Google Scholar] [CrossRef]
- Tureczek, A.M.; Nielsen, P.S.; Madsen, H. Electricity consumption clustering using smart meter data. Energies 2018, 11, 859. [Google Scholar] [CrossRef]
- Räsänen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545. [Google Scholar] [CrossRef]
- RTE. Consommation Française d’électricité: Caractéristiques et Methods de Prévision; Techical Report; RTE: Dublin, Ireland, 2014. [Google Scholar]
- Albert, A.; Rajagopal, R. Thermal profiling of residential energy use. IEEE Trans. Power Syst. 2015, 30, 602–611. [Google Scholar] [CrossRef]
- Gouveia, J.P.; Seixas, J.; Mestre, A. Daily electricity consumption profiles from smart meters—Proxies of behavior for space heating and cooling. Energy 2017, 141, 108–122. [Google Scholar] [CrossRef]
- Jang, M.-S.; Jeong, H.C.; Kim, T.-G.; Suh, D.H.; Joo, S.-K. Empirical analysis of the impact of COVID-19 social distancing on residential electricity consumption based on demographic characteristics and load shape. Energies 2021, 14, 7523. [Google Scholar] [CrossRef]
- Shi, J.; Liu, N.; Wang, J.; Ruan, G.; Fan, M.; Sun, K. Characterizing load profile-based enterprise profiling under COVID-19 lockdown policy: A provincial case in China. Int. J. Electr. Power Energy Syst. 2024, 155, 109567. [Google Scholar] [CrossRef]
- Carvalho, M.; De Mello Delgado, D.B.; De Lima, K.M.; De Camargo Cancela, M.; Siqueira, C.A.D.S.; De Souza, D.L.B. Effects of the COVID-19 pandemic on the Brazilian electricity consumption patterns. Int. J. Energy Res. 2020, 45, 3358–3364. [Google Scholar] [CrossRef]
- Grandjean, A.; Adnot, J.; Binet, G. A review and an analysis of the residential electric load curve models. Renew. Sustain. Energy Rev. 2012, 16, 6539–6565. [Google Scholar] [CrossRef]
- Bartels, R.; Fiebig, D.G.; Garben, M.; Lumsdaine, R. An end-use electricity load simulation model. Util. Policy 1992, 2, 71–82. [Google Scholar] [CrossRef]
- Gao, B.; Liu, X.; Zhu, Z. A Bottom-Up model for household load profile based on the consumption behavior of residents. Energies 2018, 11, 2112. [Google Scholar] [CrossRef]
- Fischer, D.; Surmann, A.; Lindberg, K.B. Impact of emerging technologies on the electricity load profile of residential areas. Energy Build. 2020, 208, 109614. [Google Scholar] [CrossRef]
- Damianakis, N.; Mouli, G.R.C.; Bauer, P.; Yu, Y. Assessing the grid impact of Electric Vehicles, Heat Pumps & PV generation in Dutch LV distribution grids. Appl. Energy 2023, 352, 121878. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Short term electricity forecasting using individual smart meter data. Procedia Comput. Sci. 2014, 35, 589–597. [Google Scholar] [CrossRef]
- Estebsari, A.; Rajabi, R. Single residential load forecasting using deep learning and image encoding techniques. Electronics 2020, 9, 68. [Google Scholar] [CrossRef]
- Sevlian, R.A.; Rajagopal, R. A model for the effect of aggregation on short term load forecasting. In Proceedings of the 2014 IEEE PES General Meeting|Conference & Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-Intrusive Load Monitoring Approaches for Disaggregated Energy Sensing: A survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef]
- Wong, Y.F.; Şekercioğlu, Y.A.; Drummond, T.; Wong, V.S. Recent approaches to non-intrusive load monitoring techniques in residential settings. In Proceedings of the 2013 IEEE Computational Intelligence Applications in Smart Grid (CIASG), Singapore, 16–19 April 2013; pp. 73–79. [Google Scholar] [CrossRef]
- Hosseini, S.S.; Agbossou, K.; Kélouwani, S.; Cardenas, A. Non-intrusive load monitoring through home energy management systems: A comprehensive review. Renew. Sustain. Energy Rev. 2017, 79, 1266–1274. [Google Scholar] [CrossRef]
- Proedrou, E. A comprehensive review of residential electricity load profile models. IEEE Access 2021, 9, 12114–12133. [Google Scholar] [CrossRef]
- Bro, R.; Smilde, A.K. Principal component analysis. Anal. Methods 2014, 6, 2812–2831. [Google Scholar] [CrossRef]
- Hartigan, J.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. Appl. Stat. 1979, 28, 100. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method For Identification of The Best Customer Profile Cluster. IOP Conf. Ser. Mater. Sci. Eng. 2018, 336, 012017. [Google Scholar] [CrossRef]
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011. [Google Scholar]
- Levy, E.C. Complex-curve fitting. IRE Trans. Autom. Control 1959, AC-4, 37–43. [Google Scholar] [CrossRef]
- Newville, M.; Ingargiola, A.; Stensitzki, T.; Allen, D.B. LMFIT: Non-Linear Least-Square Minimization and Curve-Fitting for Python. Astrophys. Source Code Libr. 2016, ascl-1606. [Google Scholar] [CrossRef]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Reconstituer les Flux de Responsabilité d’équilibre—RTE Portail Services. Portail Services RTE. Available online: https://www.services-rte.com/fr/decouvrez-nos-offres-de-services/le-role-des-gestionnaires-de-res/reconstituez-les-flux-re.html (accessed on 4 February 2024).
- Enedis. «Règles de gestion mises en oeuvre par Enedis pour le traitement des données dans le processus de Reconstitution des Flux». Disponible. Available online: https://www.enedis.fr/sites/default/files/import/Enedis-NOI-CF_103E.pdf (accessed on 4 February 2024).
- Scipy. Signal.Find_Peaks—SciPy v1.11.3 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.find_peaks.html (accessed on 4 February 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Customer | Maximum Power Day in 1 | Occurrence in Day 1 | Maximum Power Day in 2 | Occurrence in Day 2 | Maximum Power Day in D | Occurrence in Day D |
|---|---|---|---|---|---|---|
| 1 | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) |
| 2 | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) |
| … | … | … | … | … | … | … |
| N | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) | Value (kW) | (hh:mm) |
| Group | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Customers | 72 | 74 | 5 | 3 | 24 | 20 |
| SMAPE | Function 1 | Function 2 |
|---|---|---|
| Minimal (%) | 4.09 | 1.60 |
| Mean (%) | 6.36 | 2.64 |
| Maximum (%) | 10.81 | 3.99 |
| Quantity of Groups | 4 | 5 | 6 | 7 |
|---|---|---|---|---|
| Number of Substations | 4 | 23 | 16 | 5 |
| SMAPE | Function 1 | Function 2 |
|---|---|---|
| Minimal (%) | 8.43 | 2.93 |
| Mean (%) | 17.86 | 4.91 |
| Maximum (%) | 60.15 | 7.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milis, G.R.; Gay, C.; Alvarez-Herault, M.-C.; Caire, R. Disaggregation Model: A Novel Methodology to Estimate Customers’ Profiles in a Low-Voltage Distribution Grid Equipped with Smart Meters. Information 2024, 15, 142. https://doi.org/10.3390/info15030142
Milis GR, Gay C, Alvarez-Herault M-C, Caire R. Disaggregation Model: A Novel Methodology to Estimate Customers’ Profiles in a Low-Voltage Distribution Grid Equipped with Smart Meters. Information. 2024; 15(3):142. https://doi.org/10.3390/info15030142
Chicago/Turabian StyleMilis, Guilherme Ramos, Christophe Gay, Marie-Cécile Alvarez-Herault, and Raphaël Caire. 2024. "Disaggregation Model: A Novel Methodology to Estimate Customers’ Profiles in a Low-Voltage Distribution Grid Equipped with Smart Meters" Information 15, no. 3: 142. https://doi.org/10.3390/info15030142
APA StyleMilis, G. R., Gay, C., Alvarez-Herault, M.-C., & Caire, R. (2024). Disaggregation Model: A Novel Methodology to Estimate Customers’ Profiles in a Low-Voltage Distribution Grid Equipped with Smart Meters. Information, 15(3), 142. https://doi.org/10.3390/info15030142