
Optimization and Prediction Techniques for Self-Healing and Self-Learning Applications in a Trustworthy Cloud Continuum

 ,
,  ,
,  , and
, and {kind=link}
{kind=link}
Abstract
:1. Introduction
2. Motivation and Related Work
2.1. Deployment Configuration Optimization Supported by AI Methods
- Non-dominated sorting genetic algorithm II (NSGA-II, [9]): The NSGA-II is one of the most used and recognized MOO methods. Essentially, it is a generational genetic algorithm, which employs a ranking procedure for easing the estimation of the crowding distance density and the convergence of the Pareto. This also contributes to the enhancing of population diversity.
- Strength Pareto evolutionary algorithm 2 (SPEA2, [10]): the main advantages of this reputed method are: (i) the improvement of the fitness assignment pattern (which considers the number of individuals dominated), (ii) the incorporation of a nearest neighbor density estimator for more fine guidance of the search procedure, and (iii) a novel archive truncation technique, which assures the preservation of boundary solutions.
- Multi-objective evolutionary algorithm based on decomposition (MOEA/D, [11]): MOEA/D is characterized by the decomposition of the MOO problem into several scalar subproblems, optimizing them in a simultaneous way. Specifically, each subproblem is tackled employing information from its nearer neighborhood problems. This last feature makes MOEA/D be a less demanding method in comparison with other similar strategies.
- Speed-constrained multi-objective particle swarm optimization (SMPSO, [12]): this method is based on the well-known particle swarm optimization algorithm. Thus, the principal feature of this method is the use of a velocity constraint mechanism to avoid particles flying beyond the limits of the search space. This method employs an external bounded-sized archive for storing the non-dominated solutions encountered along with the search procedure, from which the leader is also selected.
- Multi-objective cellular genetic algorithm (MOCell, [13]): the MOCell is a recently proposed MOO algorithm that is inspired by the reputed cellular genetic algorithm family. This method also employs an external archive for saving non-dominated solutions, and it implements a feedback mechanism in which solutions from this archive are drawn and used in the selection step of the algorithm.
- Non-dominated sorting genetic algorithm III (NSGA-III): this successful method follows the same philosophy and structure of the above-mentioned NSGA-II. NSGA-III is principally characterized by emphasizing a non-dominated population of individuals near a group of supplied reference points.
- Multi-objective evolutionary algorithm based on dominance and decomposition (MOEA/DD): this advanced and successful method unifies some efficient concepts, combining dominance and decomposition-based approaches, for many-objective optimization.
- Strength Pareto evolutionary algorithm based on reference direction (SPEA/R): This method is an extension of the above mentioned SPEA, introducing a reference direction-based density estimator, a new fitness assignment procedure, and a new environmental selection mechanism.
2.2. Self-Learning with AI for Data Streams in the Presence of Concept Drift and Anomalies
- It implies that an expert would have to be focused on deciding which is the best moment to train the models again.
- Nowadays, data are produced in the form of fast streams.
- Data are affected by non-stationary phenomena that occur fast, and a human cannot successfully detect changes in a real-fashion environment.
- Ingesting new data as it becomes available (incremental learning);
- Detecting by itself changes (drifts) in data distribution and automatically retraining after this occurs;
- Warning the system when anomalies are detected;
- Self-optimizing and self-calibrating in case of performance issues due to concept drift or anomalies.
- These models are based on algorithms that are usually more difficult to fine-tune;
- Overfitting can be a great concern;
- The stability of the model must be assured;
- False alarms (drift detections) may provoke that the retraining process is useless, even degrading the performance of the model;
- An anomaly must not be confused with a drift.
2.2.1. Data Stream Analysis
- Each sample or batch is processed only once on arrival. Stream data analysis solutions should be able to process information sequentially, accordingly to its arrival. These solutions must not put the resources (mainly memory space and processing time restrictions) at risk;
- The processing time must be small and constant, without exceeding the ratio in which new samples arrive. Otherwise, some kind of temporal storage should be considered;
- The stream data analysis solution should use only a preallocated amount of main memory;
- The model/algorithm on which this stream data analysis solution is based should be completely trained before the next sample arrives.
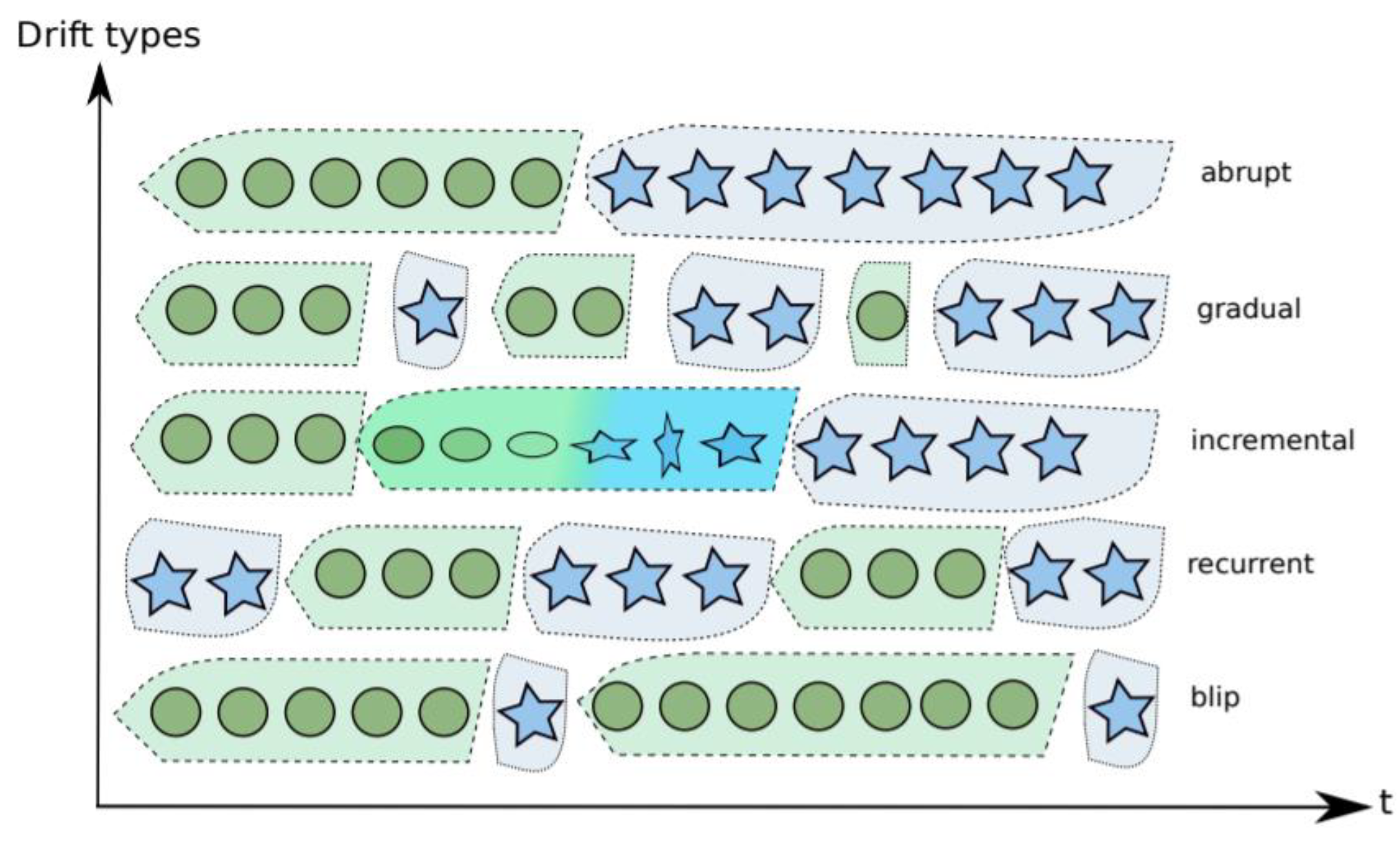
2.2.2. Concept Drift Detection
2.2.3. Anomaly Detection
2.3. Self-Healing Techniques for the Autonomous Implementation of Corrective Actions at Run-Time
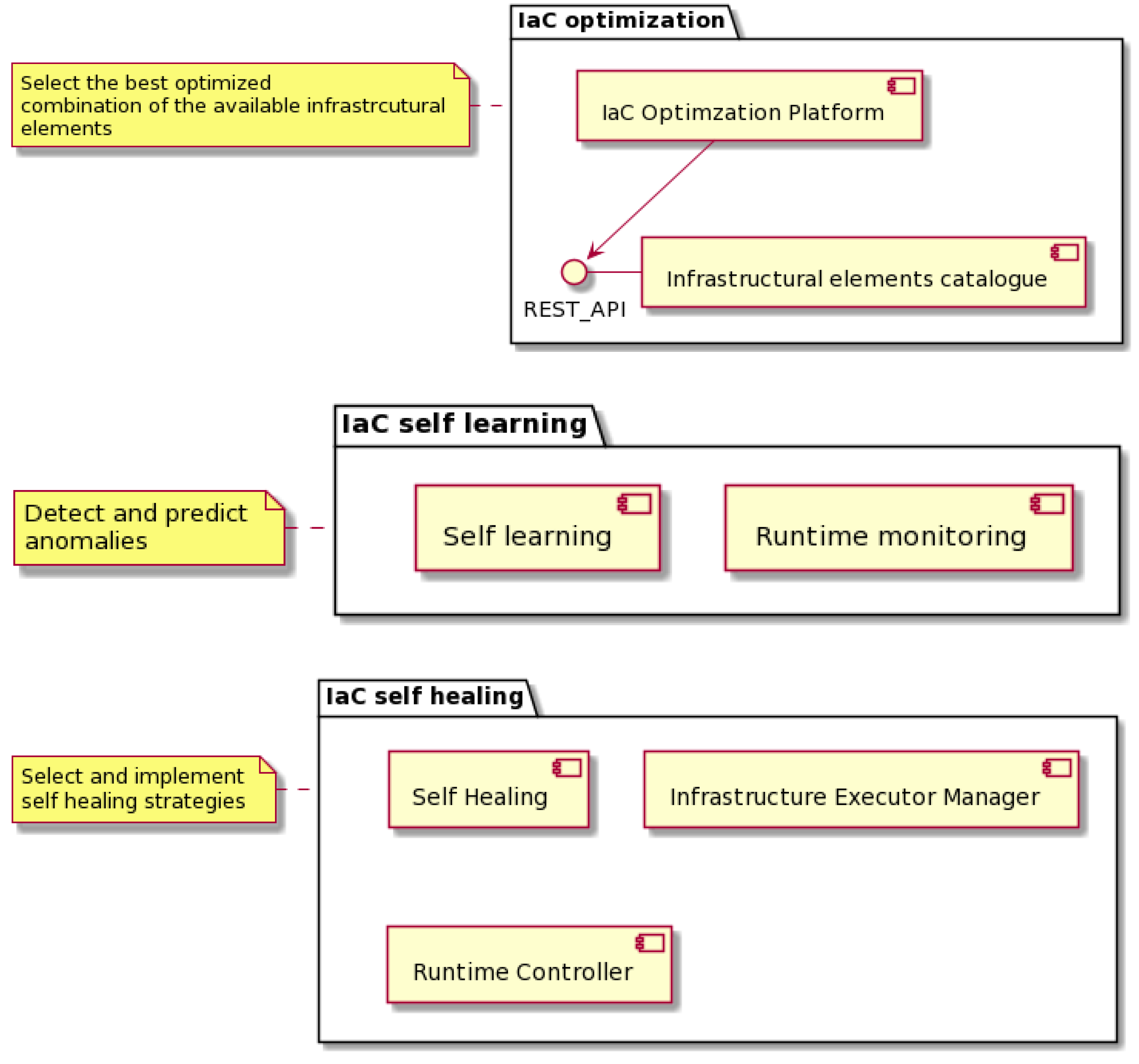
3. PIACERE Approach for Optimized and Self-Healed IaC
3.1. IaC Optimization
3.2. IaC Self-Learning
3.3. IaC self-Healing
- Classification of the event: Classification of the event detected by the self-learning component. The events identified can be of different nature for different reasons:
- Predicted failure vs. already detected failure: available time for the self-healing process.
- The main cause of the event: it can be caused by a software failure or by a CSLA violation in the infrastructural element.
- Others to be analyzed: NFR affected, components affected, etc.
- Selection of a self-healing strategy: Based on the initial classification and on the ruleset, the best self-healing strategy will be selected. This strategy may imply selecting a new set of infrastructural elements and consequently regenerating the IaC with these new requirements so that the new deployment schema is realized. In this case, the self-healing strategy should cover not only the bringing up of the new infrastructural elements but also the teardown of the previous infrastructure.
- Orchestration of the self-healing process: Once the strategy is selected, it has to be executed. The different modules in charge of implementing the self-healing activities need to be executed properly. In PIACERE, the run-time controller will be responsible for orchestrating the process, the related tasks, and the relevant components.
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lynn, T.; Xiong, H.; Dong, D.; Momani, B.; Gravvanis, G.; Filelis-Papadopoulos, C.; Elster, A.; Khan, M.M.Z.M.; Tzovaras, D.; Giannoutakis, K.; et al. CLOUDLIGHTNING: A Framework for a Self-organising and Self-managing Heterogeneous Cloud. In Proceedings of the 6th International Conference on Cloud Computing and Services Science, Rome, Italy, 23–25 April 2016; pp. 333–338. [Google Scholar] [CrossRef]
- Alonso, J.; Orue-Echevarria, L.; Escalante, M.; Benguria, G. DECIDE: DevOps for Trusted, Portable and Interoperable Multi-Cloud Applications towards the Digital Single Market; Parque Científico y Tecnológico de Bizkaia: Bizkaia, Spain, 2017. [Google Scholar] [CrossRef]
- Kennedy, J. Swarm Intelligence; Springer: Berlin, Germany, 2006; pp. 187–219. [Google Scholar] [CrossRef]
- Zedadra, O.; Savaglio, C.; Jouandeau, N.; Guerrieri, A.; Seridi, H.; Fortino, G. Towards a Reference Architecture for Swarm Intelligence-Based Internet of Things; Springer: Berlin, Germany, 2018; pp. 75–86. [Google Scholar] [CrossRef] [Green Version]
- Darwish, A.; Hassanien, A.E.; Das, S. A survey of swarm and evolutionary computing approaches for deep learning. Artif. Intell. Rev. 2019, 53, 1767–1812. [Google Scholar] [CrossRef]
- Marler, R.; Arora, J. Survey of multi-objective optimization methods for engineering. Struct. Multidiscip. Optim. 2004, 26, 369–395. [Google Scholar] [CrossRef]
- Osaba, E.; Martinez, A.D.; Del Ser, J. Evolutionary Multitask Optimization: A Methodological Overview, Challenges and Future Research Directions. arXiv 2021, arXiv:2102.02558. Available online: http://arxiv.org/abs/2102.02558 (accessed on 23 March 2021).
- Del Ser, J.; Osaba, E.; Molina, D.; Yang, Y.-S.; Salcedo-Snaz, S.; Camacho, D.; Das, S.; Suganthan, P.N.; Coello, A.C.; Herrera, F. Bio-inspired computation: Where we stand and what’s next. Swarm Evolut. Comput. 2019, 48, 220–250. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength pareto evolutionary algorithm. Comput. Sci. 2001, 103. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Nebro, A.J.; Durillo, J.J.; García-Nieto, J.; Coello, C.C.; Luna, F.; Alba, E. SMPSO: A new PSO-based metaheuristic for multi-objective optimization. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Multi-Criteria Decision-Making(MCDM), Nashville, TN, USA, 30 March–2 April 2009; pp. 66–73. [Google Scholar] [CrossRef]
- Nebro, A.J.; Durillo, J.J.; Luna, F.; Dorronsoro, B.; Alba, E. MOCell: A cellular genetic algorithm for multiobjective optimization. Int. J. Intell. Syst. 2009, 24, 726–746. [Google Scholar] [CrossRef] [Green Version]
- Bechikh, S.; Elarbi, M.; Ben Said, L. Many-Objective Optimization Using Evolutionary Algorithms: A Survey; Springer: Cham, Switzerland, 2016; pp. 105–137. [Google Scholar] [CrossRef]
- Alonso, J.; Stefanidis, K.; Orue-Echevarria, L.; Blasi, L.; Walker, M.; Escalante, M.; Lopez, M.; Dutkowski, S. DECIDE: An Extended DevOps Framework for Multi-cloud Applications. In Proceedings of the 2019 3rd International Conference on Cloud and Big Data Computing, Oxford, UK, 28–30 August 2019; pp. 43–48. [Google Scholar] [CrossRef] [Green Version]
- Arostegi, M.; Torre-Bastida, A.; Bilbao, M.N.; Del Ser, J. A heuristic approach to the multicriteria design of IaaS cloud infrastructures for Big Data applications. Expert Syst. 2018, 35, e12259. [Google Scholar] [CrossRef]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Rappa, M.A. The utility business model and the future of computing services. IBM Syst. J. 2004, 43, 32–42. [Google Scholar] [CrossRef] [Green Version]
- Herodotou, H.; Dong, F.; Babu, S. No one (cluster) size fits all: Automatic cluster sizing for data-intensive analytics. In Proceedings of the 2nd ACM Symposium on Cloud Computing, Cascais, Portugal, 26–28 October 2011; p. 18. [Google Scholar] [CrossRef]
- Nawaratne, R.; Alahakoon, D.; De Silva, D.; Chhetri, P.; Chilamkurti, N. Self-evolving intelligent algorithms for facilitating data interoperability in IoT environments. Futur. Gener. Comput. Syst. 2018, 86, 421–432. [Google Scholar] [CrossRef]
- Rajput, P.K.; Sikka, G. Multi-agent architecture for fault recovery in self-healing systems. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 2849–2866. [Google Scholar] [CrossRef]
- Doersch, C.; Zisserman, A. Multi-task self-supervised visual learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2051–2060. [Google Scholar]
- Gogna, A.; Majumdar, A. Semi supervised autoencoder. In Proceedings of the International Conference on Neural Information Processing, Kyoto, Japan, 16–21 October 2016; pp. 82–89. [Google Scholar]
- Pathak, K.; Kapila, J. Reinforcement evolutionary learning method for self-learning. arXiv 2018, arXiv:1810.03198. [Google Scholar]
- Cerquitelli, T.; Proto, S.; Ventura, F.; Apiletti, D.; Baralis, E. Automating concept-drift detection by self-evaluating predictive model degradation. arXiv 2019, arXiv:1907.08120. [Google Scholar]
- Lu, J.; Liu, A.; Song, Y.; Zhang, G. Data-driven decision support under concept drift in streamed big data. Complex. Intell. Syst. 2019, 6, 157–163. [Google Scholar] [CrossRef] [Green Version]
- Ramakrishnan, A.K.; Preuveneers, D.; Berbers, Y. Enabling Self-learning in Dynamic and Open IoT Environments. Procedia Comput. Sci. 2014, 32, 207–214. [Google Scholar] [CrossRef]
- Carreño, A.; Inza, I.; Lozano, J.A. Analyzing rare event, anomaly, novelty and outlier detection terms under the supervised classification framework. Artif. Intel. Rev. 2020, 53, 3575–3594. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Gomes, H.M.; Read, J.; Bifet, A.; Barddal, J.P.; Gama, J. Machine learning for streaming data: State of the art, challenges, and opportunities. ACM SIGKDD Explor. Newslet. 2019, 21, 6–22. [Google Scholar] [CrossRef]
- López Lobo, J. New Perspectives and Methods for Stream Learning in the Presence of Concept Drift. Ph.D. Thesis, University of Pais Vasco, Barrio Sarriena, Spain, 2018. [Google Scholar]
- Radanliev, P.; De Roure, D.C.; Nurse, J.R.C.; Montalvo, R.M.; Cannady, S.; Santos, O.; Maddox, L.; Burnap, P.; Maple, C. Future developments in standardisation of cyber risk in the Internet of Things (IoT). SN Appl. Sci. 2020, 2, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Domingos, P.; Hulten, G. A General Framework for Mining Massive Data Streams. J. Comput. Graph. Stat. 2003, 12, 945–949. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Bifet, A.; Read, J.; Pfahringer, B.; Holmes, G. Evaluation methods and decision theory for classification of streaming data with temporal dependence. Mach. Learn. 2014, 98, 455–482. [Google Scholar] [CrossRef] [Green Version]
- Bahri, M.; Bifet, A.; Gama, J.; Gomes, H.M.; Maniu, S. Data Stream Analysis: Foundations, Major Tasks and Tools; Wiley: Hoboken, NJ, USA, 2021; p. e1405. [Google Scholar]
- Hu, H.; Kantardzic, M.; Sethi, T.S. No Free Lunch Theorem for concept drift detection in streaming data classification: A review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 10, e1327. [Google Scholar] [CrossRef]
- Barros, R.S.M.; Santos, S.G.T.C. A large-scale comparison of concept drift detectors. Inf. Sci. 2018, 451–452, 348–370. [Google Scholar] [CrossRef]
- Hawkins, D.M. Identification of Outliers; Springer: Berlin, Germany, 1980. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier Analysis; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Peng, H.-K.; Marculescu, R. Multi-Scale Compositionality: Identifying the Compositional Structures of Social Dynamics Using Deep Learning. PLoS ONE 2015, 10, e0118309. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. Endorsed Transact. Safe. 2016, 3, e2. [Google Scholar] [CrossRef] [Green Version]
- Serhani, M.A.; El-Kassabi, H.T.; Shuaib, K.; Navaz, A.N.; Benatallah, B.; Beheshti, A. Self-adapting cloud services orchestration for fulfilling intensive sensory data-driven IoT workflows. Futur. Gener. Comput. Syst. 2020, 108, 583–597. [Google Scholar] [CrossRef]
- Angarita, R.; Manouvrier, M.; Rukoz, M. An Agent Architecture to Enable Self-Healing and Context-aware Web of Things Applications. In Proceedings of the International Conference on Internet of Things and Big Data (IoTBD 2016), Rome, Italy, 23–25 April 2016. [Google Scholar] [CrossRef]
- Gill, S.S.; Chana, I.; Singh, M.; Buyya, R. RADAR: Self-configuring and self-healing in resource management for enhancing quality of cloud services. Concurr. Comput. Pract. Exp. 2018, 31, e4834. [Google Scholar] [CrossRef]
- Gao, H.; Huang, W.; Yang, X.; Duan, Y.; Yin, Y. Toward service selection for workflow reconfiguration:An interface-based computing solution. Futur. Gener. Comput. Syst. 2018, 87, 298–311. [Google Scholar] [CrossRef]
- Toffetti, G.; Brunner, S.; Blöchlinger, M.; Spillner, J.; Bohnert, T.M. Self-managing cloud-native applications: Design, implementation, and experience. Futur. Gener. Comput. Syst. 2017, 72, 165–179. [Google Scholar] [CrossRef] [Green Version]
- El-Kassabi, H.T.; Serhani, M.A.; Dssouli, R.; Navaz, A.N. Trust enforcement through self-adapting cloud workflow orchestration. Futur. Gener. Comput. Syst. 2019, 97, 462–481. [Google Scholar] [CrossRef]
- RedHat Ansible. Available online: https://www.ansible.com/ (accessed on 27 January 2021).
- Hatch, T.S. SaltStack Documentation. Available online: https://docs.saltproject.io/en/latest/ (accessed on 12 April 2021).
- Webteam, P. Powerful Infrastructure Automation and Delivery | Puppet. Available online: https://puppet.com/ (accessed on 12 April 2021).
- Chef Automate. Available online: https://www.chef.io/products/chef-automate (accessed on 12 April 2021).
- Heat—OpenStack. Available online: https://wiki.openstack.org/wiki/Heat (accessed on 12 April 2021).
- AWS CloudFormation—Infraestructura Como Código y Aprovisionamiento de Recursos de AWS’. Amazon Web Services, Inc. Available online: https://aws.amazon.com/es/cloudformation/ (accessed on 12 April 2021).
- Terraform by HashiCorp, Terraform by HashiCorp. Available online: https://www.terraform.io/ (accessed on 12 April 2021).
- Swarm Mode Overview Docker Documentation. Available online: https://docs.docker.com/engine/swarm/ (accessed on 12 April 2021).
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 12 April 2021).
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-Scale Cluster Management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems, Bordeaux, France, 21–24 April 2015; p. 18. [Google Scholar] [CrossRef] [Green Version]
- Binz, T.; Breiter, G.; Leyman, F.; Spatzier, T. Portable Cloud Services Using TOSCA. IEEE Internet Comput. 2012, 16, 80–85. [Google Scholar] [CrossRef]
- Rossini, A.; Kritikos, K.; Nikolov, N.; Domaschka, J.; Griesinger, F.; Seybold, D.; Romero, D.; Orzechowski, M.; Kapitsaki, G.; Achilleos, A. The Cloud Application Modelling and Execution Language (CAMEL). Available online: https://oparu.uni-ulm.de/xmlui/handle/123456789/4378 (accessed on 29 July 2021).
- Home—Apache Brooklyn. Available online: https://brooklyn.apache.org/ (accessed on 12 April 2021).
- Spinnaker, Spinnaker. Available online: https://www.spinnaker.io/ (accessed on 12 April 2021).
- Davis, A.M. Software Requirements: Objects, Functions, and States; PTR Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Bifet, A. Classifier concept drift detection and the illusion of progress. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 11–15 June 2017; pp. 715–725. [Google Scholar]
- Luo, T.; Nagarajan, S.G. Distributed Anomaly Detection Using Autoencoder Neural Networks in WSN for IoT. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kakanakova, I.; Stoyanov, S. Outlier Detection via Deep Learning Architecture. In Proceedings of the 18th International Conference on Computer Systems and Technologies, Ruse, Bulgaria, 23–24 June 2017; pp. 73–79. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, J.; Orue-Echevarria, L.; Osaba, E.; López Lobo, J.; Martinez, I.; Diaz de Arcaya, J.; Etxaniz, I. Optimization and Prediction Techniques for Self-Healing and Self-Learning Applications in a Trustworthy Cloud Continuum. Information 2021, 12, 308. https://doi.org/10.3390/info12080308
Alonso J, Orue-Echevarria L, Osaba E, López Lobo J, Martinez I, Diaz de Arcaya J, Etxaniz I. Optimization and Prediction Techniques for Self-Healing and Self-Learning Applications in a Trustworthy Cloud Continuum. Information. 2021; 12(8):308. https://doi.org/10.3390/info12080308
Chicago/Turabian StyleAlonso, Juncal, Leire Orue-Echevarria, Eneko Osaba, Jesús López Lobo, Iñigo Martinez, Josu Diaz de Arcaya, and Iñaki Etxaniz. 2021. "Optimization and Prediction Techniques for Self-Healing and Self-Learning Applications in a Trustworthy Cloud Continuum" Information 12, no. 8: 308. https://doi.org/10.3390/info12080308
APA StyleAlonso, J., Orue-Echevarria, L., Osaba, E., López Lobo, J., Martinez, I., Diaz de Arcaya, J., & Etxaniz, I. (2021). Optimization and Prediction Techniques for Self-Healing and Self-Learning Applications in a Trustworthy Cloud Continuum. Information, 12(8), 308. https://doi.org/10.3390/info12080308