
Multi-Task Learning-Based Task Scheduling Switcher for a Resource-Constrained IoT System †




Abstract
1. Introduction
2. Related Work
2.1. Scheduling Algorithm
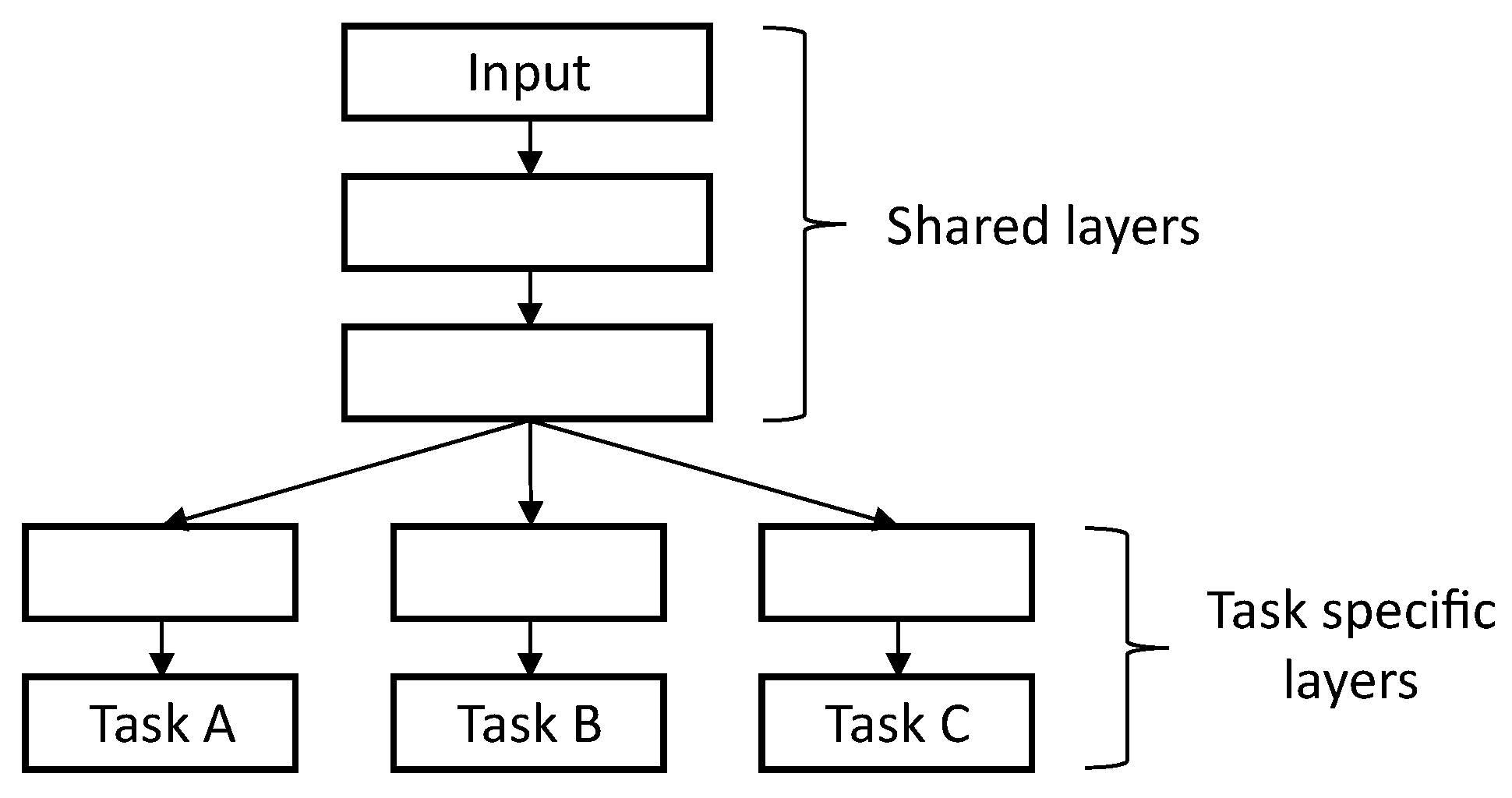
2.2. Multi-Task Learning
2.3. Previous Research
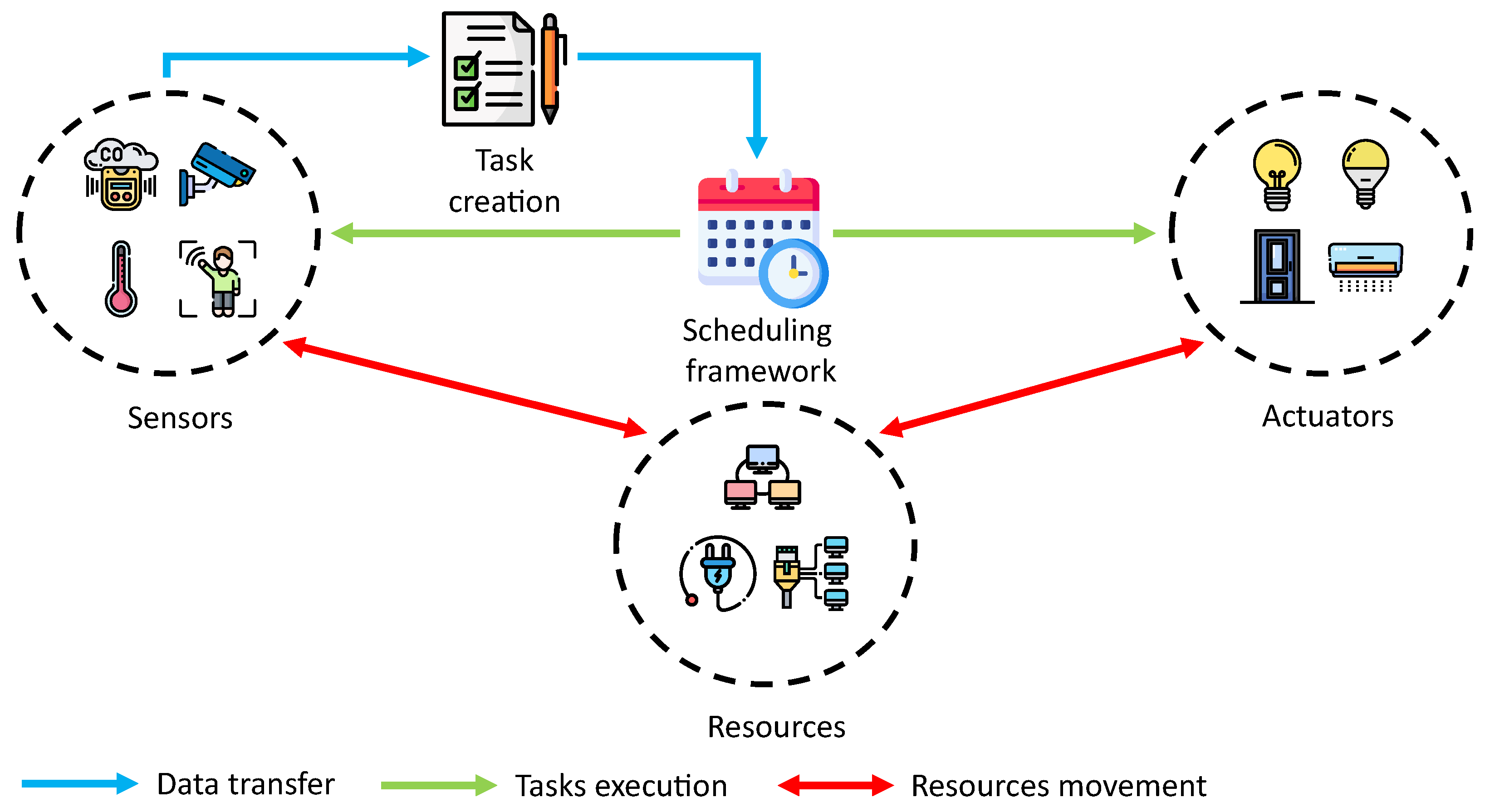
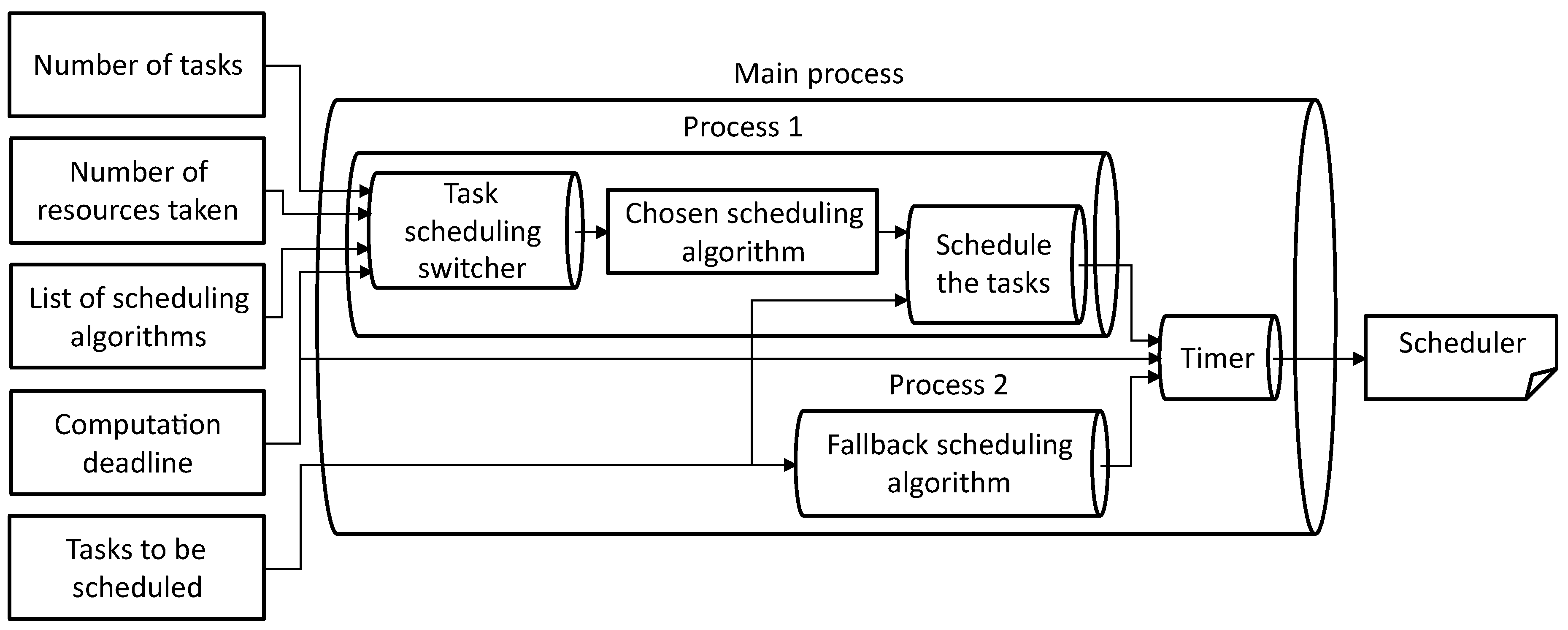
3. Modeling the Task Scheduling Switcher
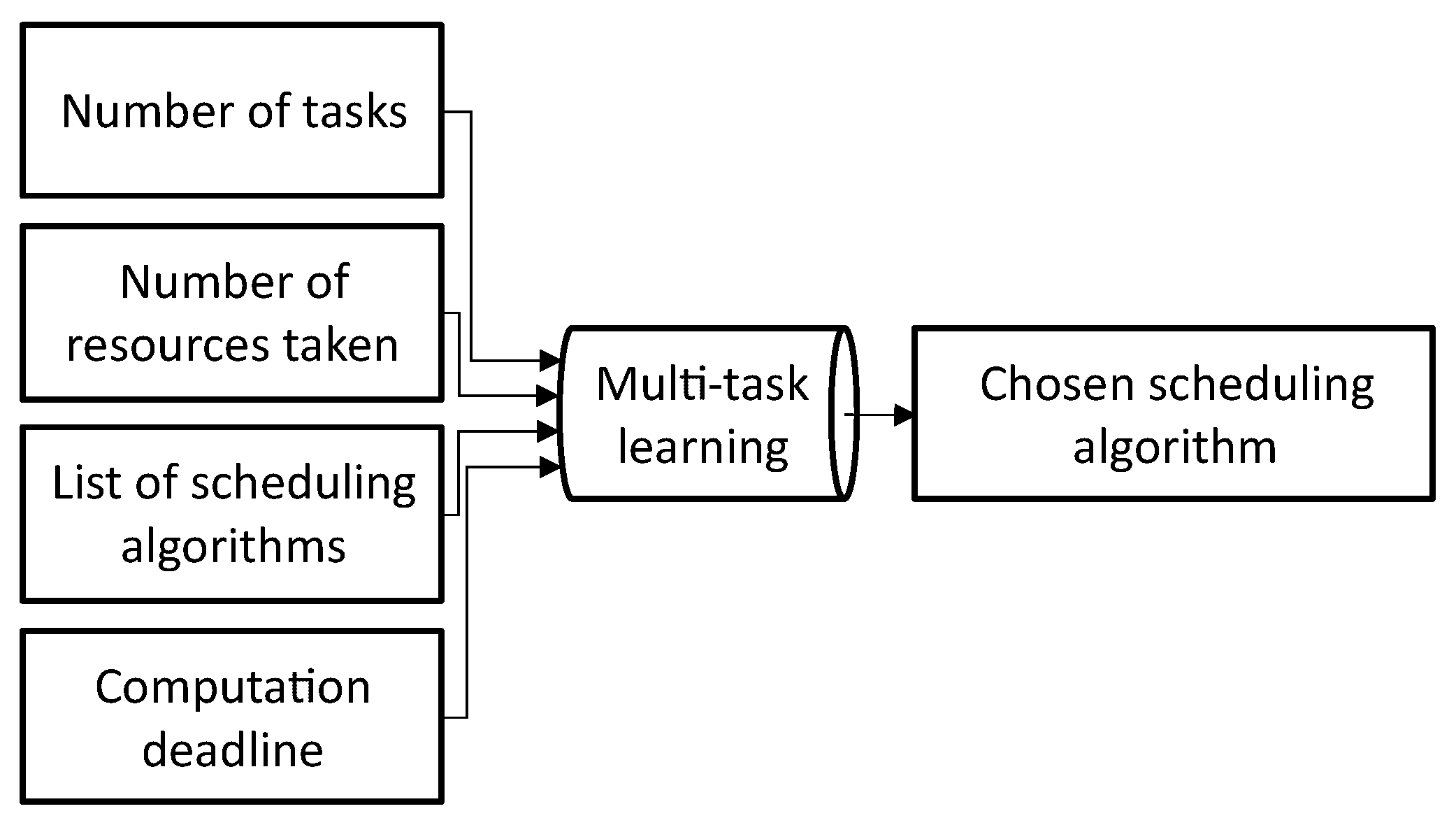
3.1. Task Scheduling Switcher Problem
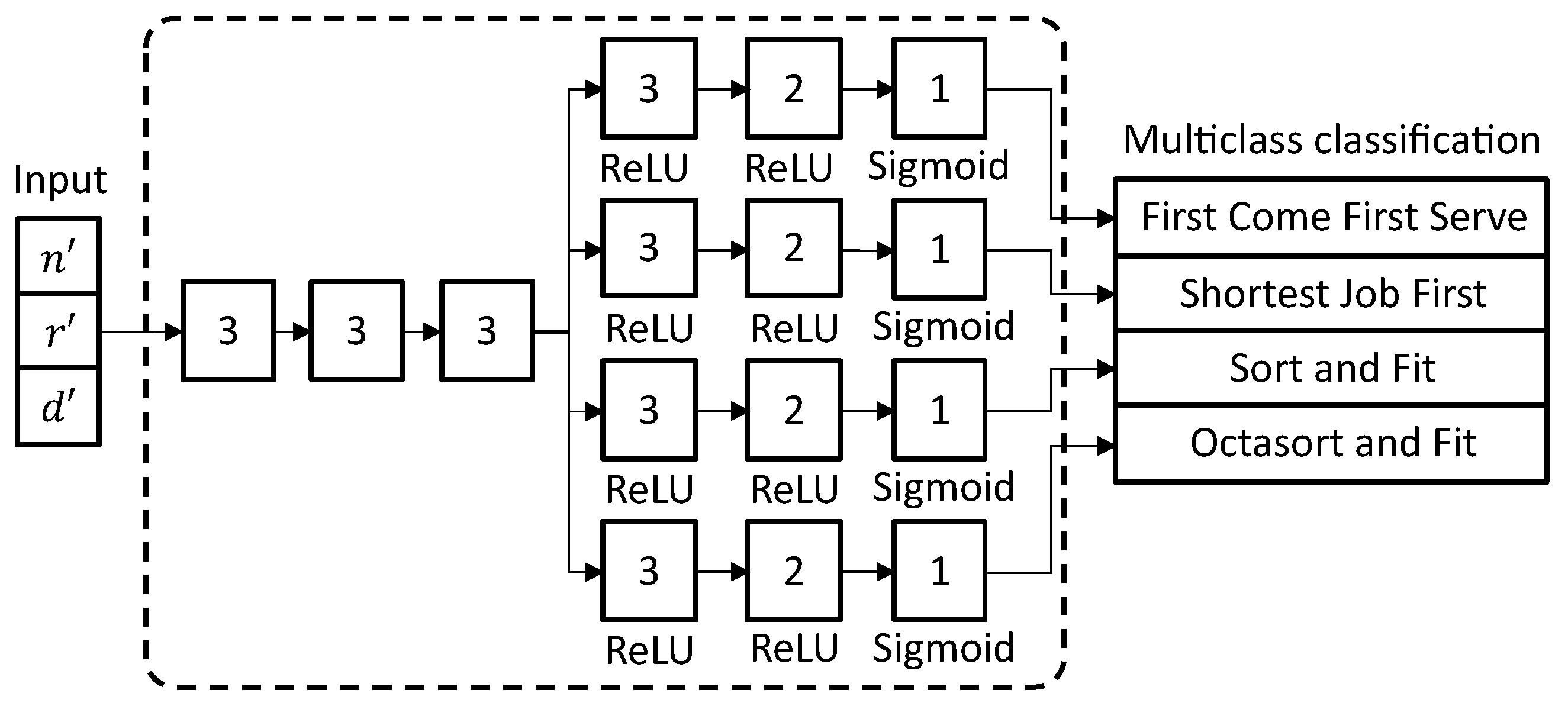
3.2. Multi-Task Learning Model
3.3. Scheduling Framework Implementation
4. Evaluation
4.1. Hardware Specification
4.2. Classification Accuracy
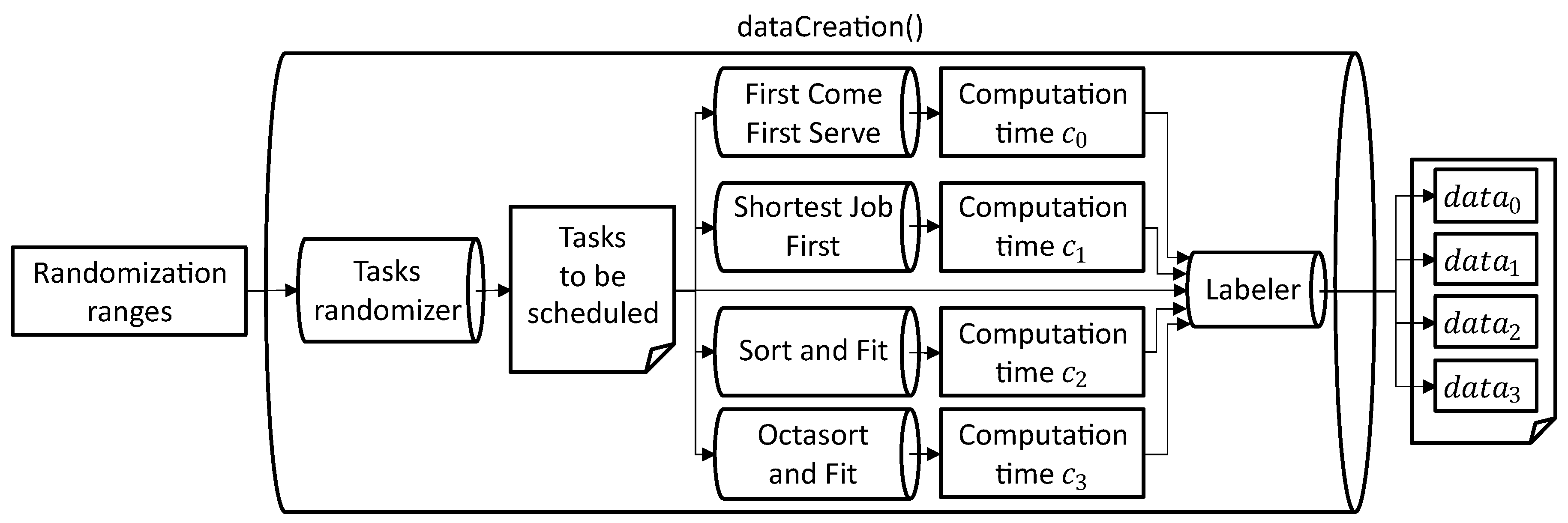
4.2.1. Dataset Creation
| Algorithm 1 Creating a dataset for training the MTL model. |
|
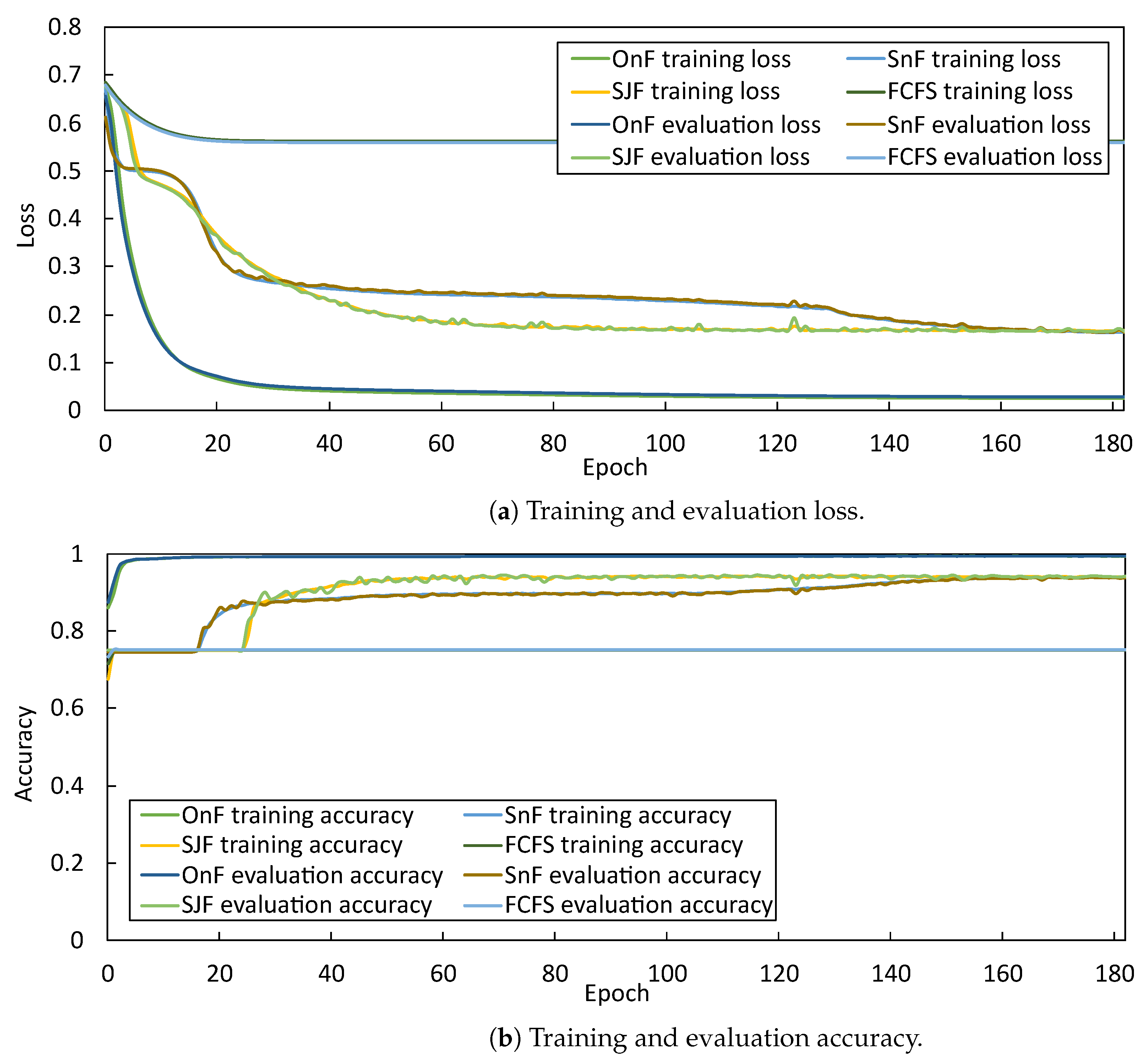
4.2.2. Post-Training Log
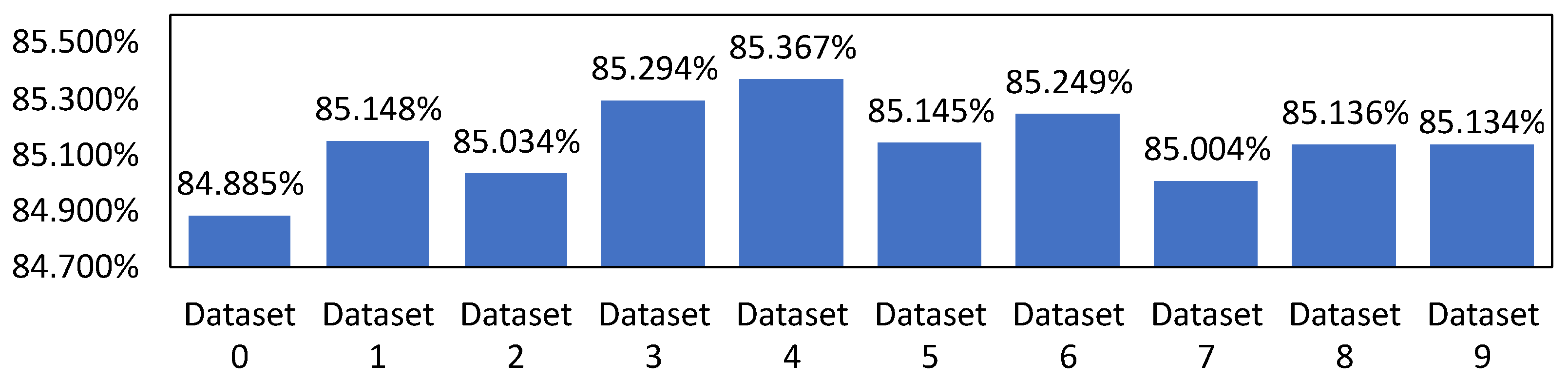
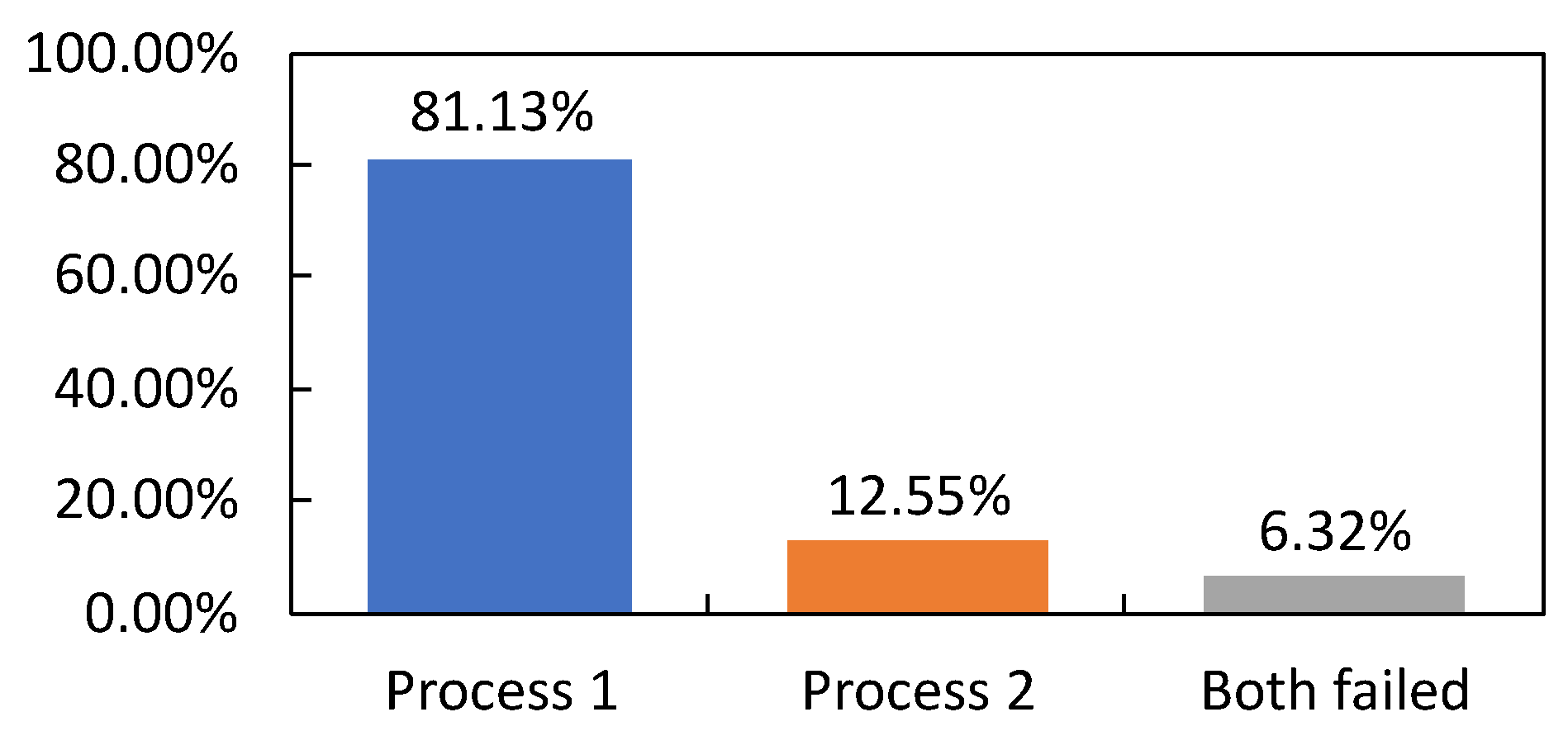
4.2.3. Cross-Validation Results
4.3. Benchmarking the Scheduling Framework
4.3.1. Benchmark Configuration
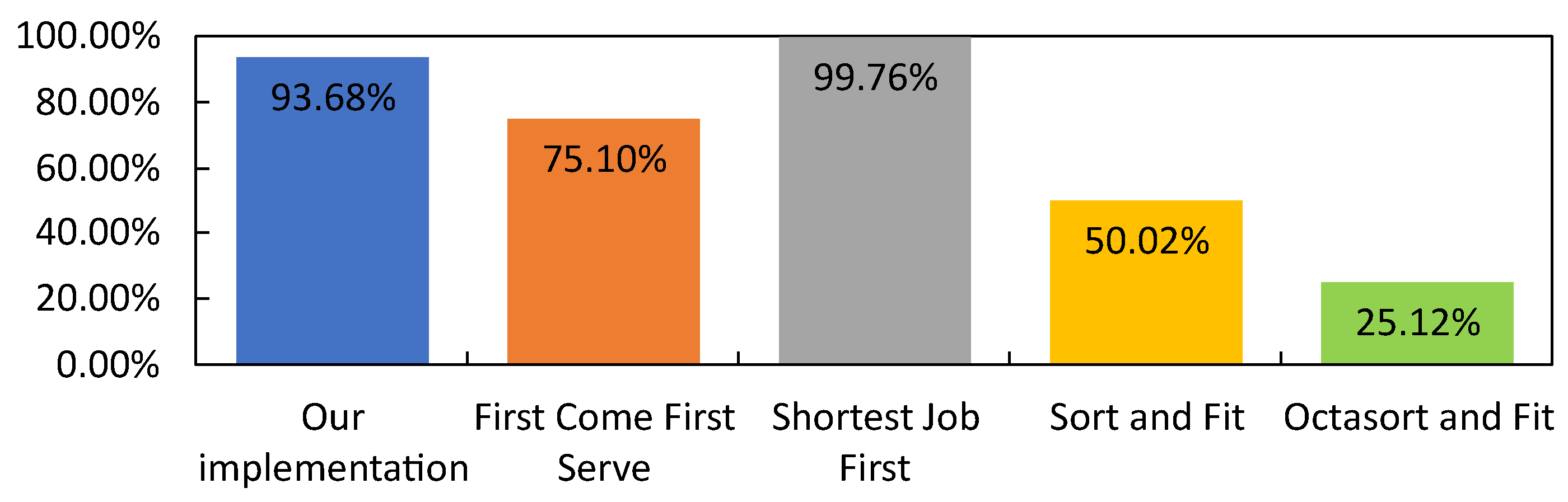
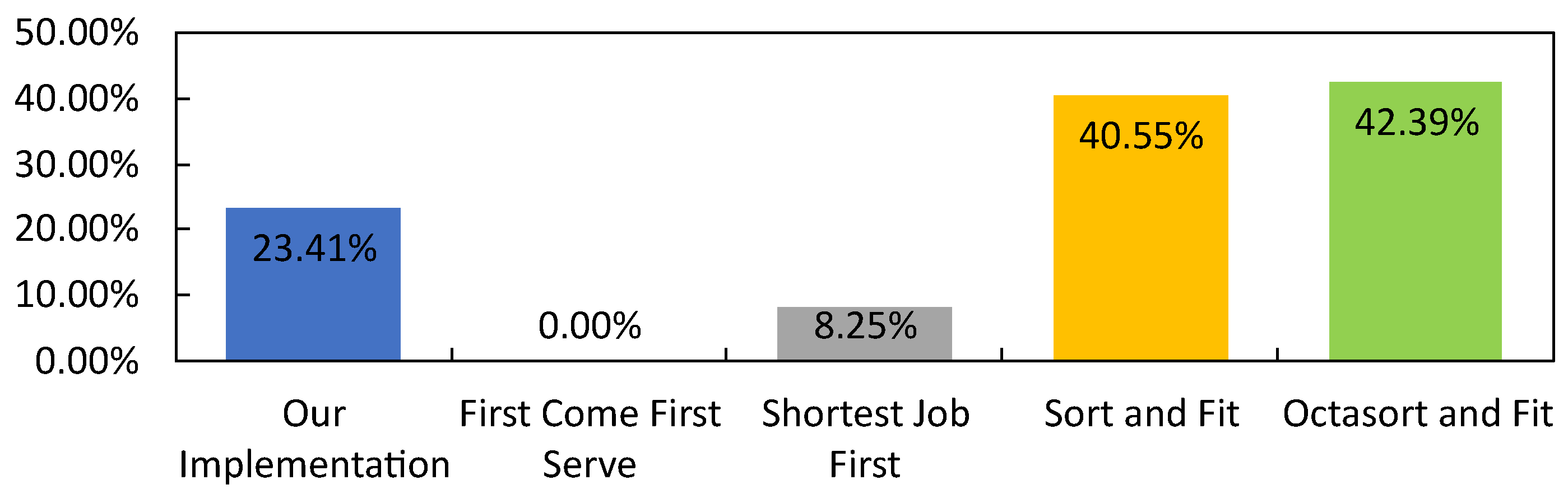
4.3.2. Benchmark Result
5. Validation
5.1. Simulating the Resource-Constrained Smart Office
5.2. Simulation Configuration
5.3. Simulation Result
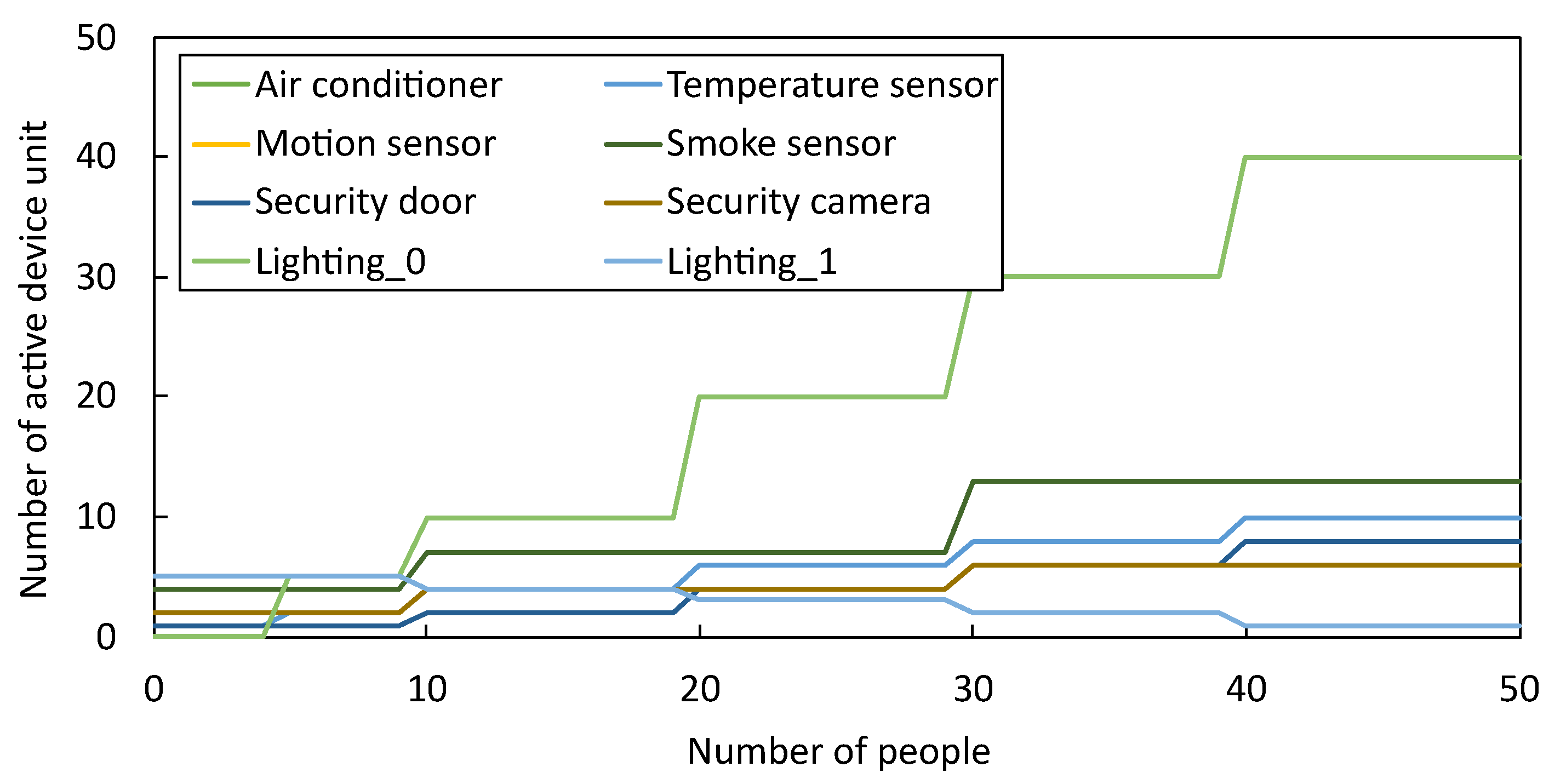
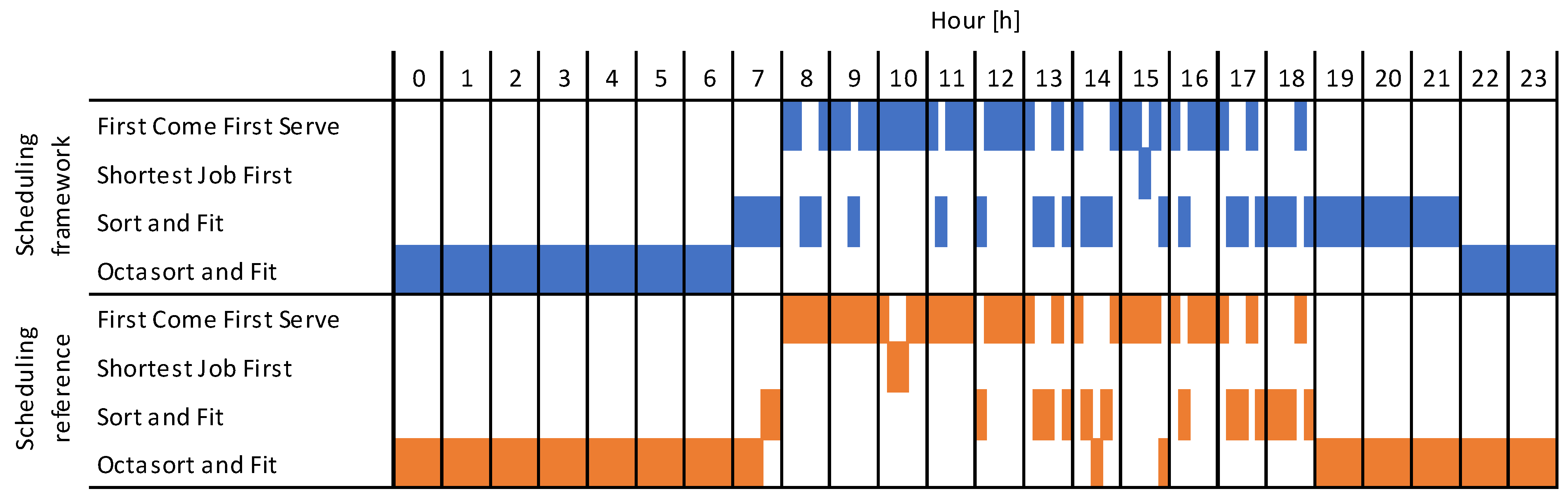
5.3.1. Sampled Scheduling Algorithm Switching
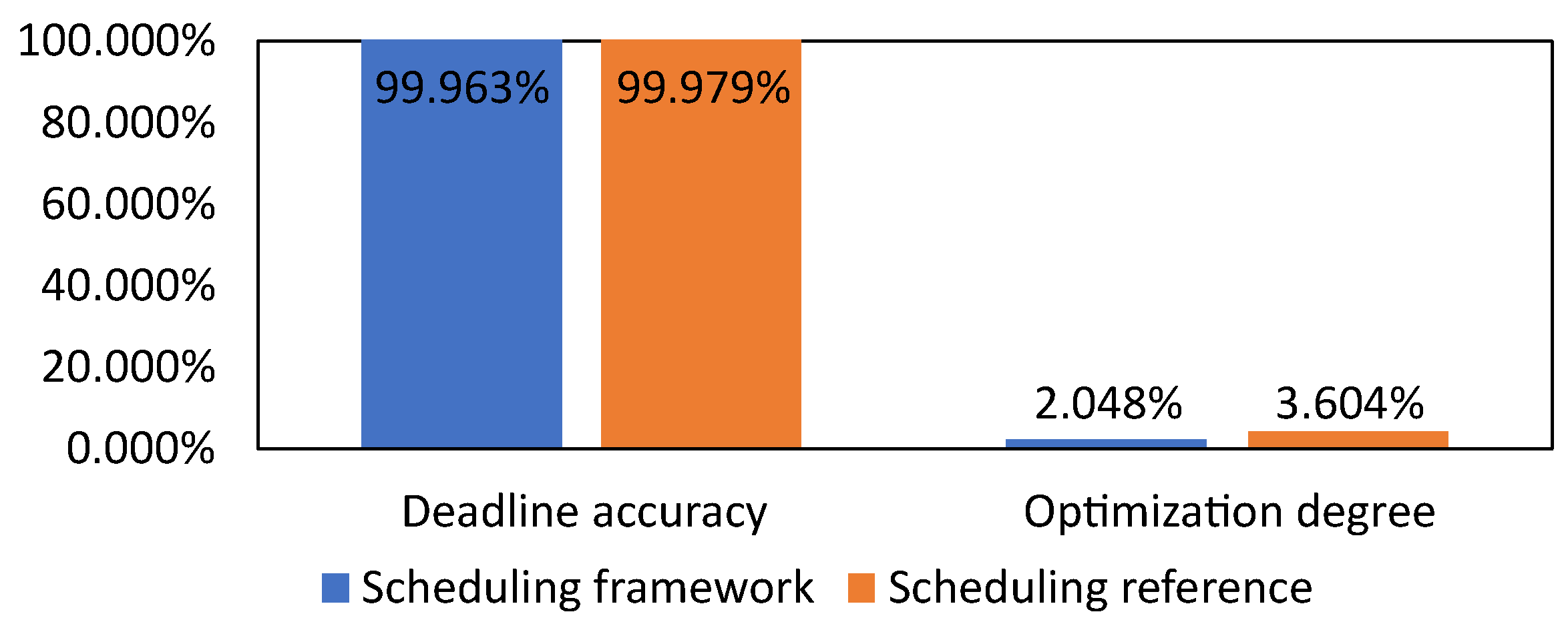
5.3.2. Deadline Accuracy and Optimization
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
 |
References
- Yugha, R.; Chithra, S. A survey on technologies and security protocols: Reference for future generation IoT. J. Netw. Comput. Appl. 2020, 169, 1–13. [Google Scholar] [CrossRef]
- Al-Jarrah, M.A.; Yaseen, M.A.; Al-Dweik, A.; Dobre, O.A.; Alsusa, E. Decision Fusion for IoT-Based Wireless Sensor Networks. IEEE Internet Things J. 2020, 7, 1313–1326. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Javadi, S.H.; Mohammadi, A.; Rossi, P.S. Bandwidth-Constrained Decentralized Detection of an Unknown Vector Signal via Multisensor Fusion. IEEE Trans. Signal Inf. Process. Over Netw. 2020, 6, 744–758. [Google Scholar] [CrossRef]
- Hwang, S.I.; Cheng, S.T. Combinatorial Optimization in Real-Time Scheduling: Theory and Algorithms. J. Comb. Optim. 2001, 5, 345–375. [Google Scholar] [CrossRef]
- Jha, H.; Chowdhury, S.; Ramya, G. Survey on various Scheduling Algorithms. Imp. J. Interdiscip. Res. 2017, 3, 1749–1752. [Google Scholar]
- Li, G.; Wu, Y.; Lin, D.; Zhao, S. Methods of Resource Scheduling Based on Optimized Fuzzy Clustering in Fog Computing. Sensors 2019, 19, 2122. [Google Scholar] [CrossRef] [PubMed]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. DISTILLER: Encrypted traffic classification via multimodal multitask deep learning. J. Netw. Comput. Appl. 2021, 1–19. [Google Scholar] [CrossRef]
- Leem, S.; Yoo, I.; Yook, D. Multitask Learning of Deep Neural Network-Based Keyword Spotting for IoT Devices. IEEE Trans. Consum. Electron. 2019, 65, 188–194. [Google Scholar] [CrossRef]
- Rafique, M.; Haider, Z.; Mehmood, K.; Zaman, M.S.U.; Irfan, M.; Khan, S.; Kim, C.-H. Optimal Scheduling of Hybrid Energy Resources for a Smart Home. Energies 2018, 11, 3201. [Google Scholar] [CrossRef]
- Cauteruccio, F. A framework for anomaly detection and classification in Multiple IoT scenarios. Future Gener. Comput. Syst. 2021, 114, 322–335. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Cinelli, L.; Fortino, G.; Savaglio, C.; Terracina, G.; Ursino, D.; Virgili, L. An approach to compute the scope of a social object in a Multi-IoT scenario. Pervasive Mob. Comput. 2020, 67, 101223. [Google Scholar] [CrossRef]
- Bebis, G.; Georgiopoulos, M. Feed-forward neural networks. IEEE Potentials 1994, 13, 27–31. [Google Scholar] [CrossRef]
- Kamilin, M.H.B.; Ahmadon, M.A.B.; Yamaguchi, S. Evaluation of Process Arrangement Methods Based on Resource Constraint for IoT System. In Proceedings of the 2020 8th International Conference on Information and Education Technology, Okayama, Japan, 28–30 March 2020; pp. 290–294. [Google Scholar]
- Choudhary, N.; Gautam, G.; Goswami, Y.; Khandelwal, S. A Comparative Study of Various CPU Scheduling Algorithms using MOOS Simulator. J. Adv. Shell Program. 2018, 5, 1–5. [Google Scholar]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098v1. [Google Scholar]
- Zhang, Q.; Wang, Z.; Wang, B.; Ohsawa, Y.; Hayashi, T. Feature Extraction of Laser Machining Data by Using Deep Multi-Task Learning. Information 2020, 11, 378. [Google Scholar] [CrossRef]
- Han, S.; Liu, X.; Han, X.; Wang, G.; Wu, S. Visual Sorting of Express Parcels Based on Multi-Task Deep Learning. Sensors 2020, 20, 6785. [Google Scholar] [CrossRef] [PubMed]
- Ahmadon, M.A.B.; Yamaguchi, S.; Mahamad, A.K.; Saon, S. Physical Device Compatibility Support for Implementation of IoT Services with Design Once, Provide Anywhere Concept. Information 2021, 12, 30. [Google Scholar] [CrossRef]
- Heger, J.; Grundstein, S.; Freitag, M. Online-scheduling using past and real-time data. An assessment by discrete event simulation using exponential smoothing. CIRP J. Manuf. Sci. Technol. 2017, 19, 158–163. [Google Scholar] [CrossRef]
- Jiang, X.; Guan, N.; Long, X.; Tang, Y.; He, Q. Real-time scheduling of parallel tasks with tight deadlines. J. Syst. Archit. 2020, 108, 101742. [Google Scholar] [CrossRef]
- Wu, C.X.; Liao, M.H.; Karatas, M.; Chen, S.Y.; Zheng, Y.J. Real-time neural network scheduling of emergency medical mask production during COVID-19. Appl. Soft Comput. 2020, 97, 106790. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C. TensorFlow: Large-scale machine learning on heterogeneous systems. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- tf.keras.callbacks.ModelCheckpoint. TensorFlow. 14 December 2020. Available online: www.tensorflow.org/api_docs/python/tf/keras/callbacks/ModelCheckpoint (accessed on 20 December 2020).
- tf.keras.callbacks.EarlyStopping. TensorFlow. 13 January 2021. Available online: www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping (accessed on 18 January 2021).
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2018; pp. 2704–2713. [Google Scholar]
- Post-Training Quantization. TensorFlow. 9 December 2020. Available online: www.tensorflow.org/lite/performance/post_training_quantization (accessed on 2 January 2021).
- Anaconda. (Individual Edition 2020.02), Anaconda Software Distribution. Available online: www.anaconda.com (accessed on 7 May 2020).
- CUDA Toolkit. (10.1.243). Nvidia. Available online: developer.nvidia.com/cuda-toolkit (accessed on 28 May 2020).
- Ord, K. Data adjustments, overfitting and representativeness. Int. J. Forecast. 2020, 36, 195–196. [Google Scholar] [CrossRef]
- Papagiannidis, S.; Marikyan, D. Smart offices: A productivity and well-being perspective. Int. J. Inf. Manag. 2020, 51, 102027. [Google Scholar] [CrossRef]
















| Scheduling Algorithm | Computation Time When Compared to Octasort and Fit | Task Execution Optimization When Compared to First Come First Serve |
|---|---|---|
| First Come First Serve | 91.76% | 0.00% |
| Shortest Job First | 95.67% | 8.29% |
| Sort and Fit | 50.87% | 40.76% |
| Octasort and Fit | 0.00% | 42.56% |
| Scheduling Algorithm | Computation Time | Task Execution Optimization | Flexible Optimization |
|---|---|---|---|
| Sort and Fit | ✓ | ✓ | |
| Online Scheduling | ✓ | ||
| Federated Scheduling | ✓ | ||
| Deep Reinforcement Learning | ✓ | ✓ | |
| Task Scheduling Switcher | ✓ | ✓ | ✓ |
| Training Parameters | Value |
|---|---|
| Dataset size | 100,000 |
| Epochs | 3000 |
| Batch size | 1000 |
| Training/Test | 7:3 |
| Type | OS | CPU | GPU | RAM |
|---|---|---|---|---|
| Specification | Windows 10 Pro 10.0.19042 Build 19042 | Intel i7-7700HQ 4 Cores (8 threads) 2.807GHz | GeForce GTX 1050 Ti Mobile variant | 12 GB |
| Randomization Ranges | Values |
|---|---|
| Number of tasks | 3∼100 |
| Number of resources | 1∼10 |
| Resource constraint | 10∼100 |
| Type of Device | Number of Unit | Resource Taken by One Unit | ||
|---|---|---|---|---|
| Electric [W] | Local Area Network [MB/s] | Wide Area Network [MB/s] | ||
| Air conditioner | 10 | 400 | 12 | 12 |
| Temperature sensor | 10 | 15 | 4 | 6 |
| Motion sensor | 8 | 20 | 6 | 8 |
| Smoke sensor | 13 | 16 | 10 | 15 |
| Security door | 8 | 100 | 3 | 5 |
| Security camera | 6 | 100 | 10 | 12 |
| Lighting_0 | 40 | 20 | 1 | 1 |
| Lighting_1 | 5 | 10 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bin Kamilin, M.H.; Bin Ahmadon, M.A.; Yamaguchi, S. Multi-Task Learning-Based Task Scheduling Switcher for a Resource-Constrained IoT System. Information 2021, 12, 150. https://doi.org/10.3390/info12040150
Bin Kamilin MH, Bin Ahmadon MA, Yamaguchi S. Multi-Task Learning-Based Task Scheduling Switcher for a Resource-Constrained IoT System. Information. 2021; 12(4):150. https://doi.org/10.3390/info12040150
Chicago/Turabian StyleBin Kamilin, Mohd Hafizuddin, Mohd Anuaruddin Bin Ahmadon, and Shingo Yamaguchi. 2021. "Multi-Task Learning-Based Task Scheduling Switcher for a Resource-Constrained IoT System" Information 12, no. 4: 150. https://doi.org/10.3390/info12040150
APA StyleBin Kamilin, M. H., Bin Ahmadon, M. A., & Yamaguchi, S. (2021). Multi-Task Learning-Based Task Scheduling Switcher for a Resource-Constrained IoT System. Information, 12(4), 150. https://doi.org/10.3390/info12040150