
Tomato Young Fruits Detection Method under Near Color Background Based on Improved Faster R-CNN with Attention Mechanism


Abstract
:1. Introduction
2. Materials and Methods
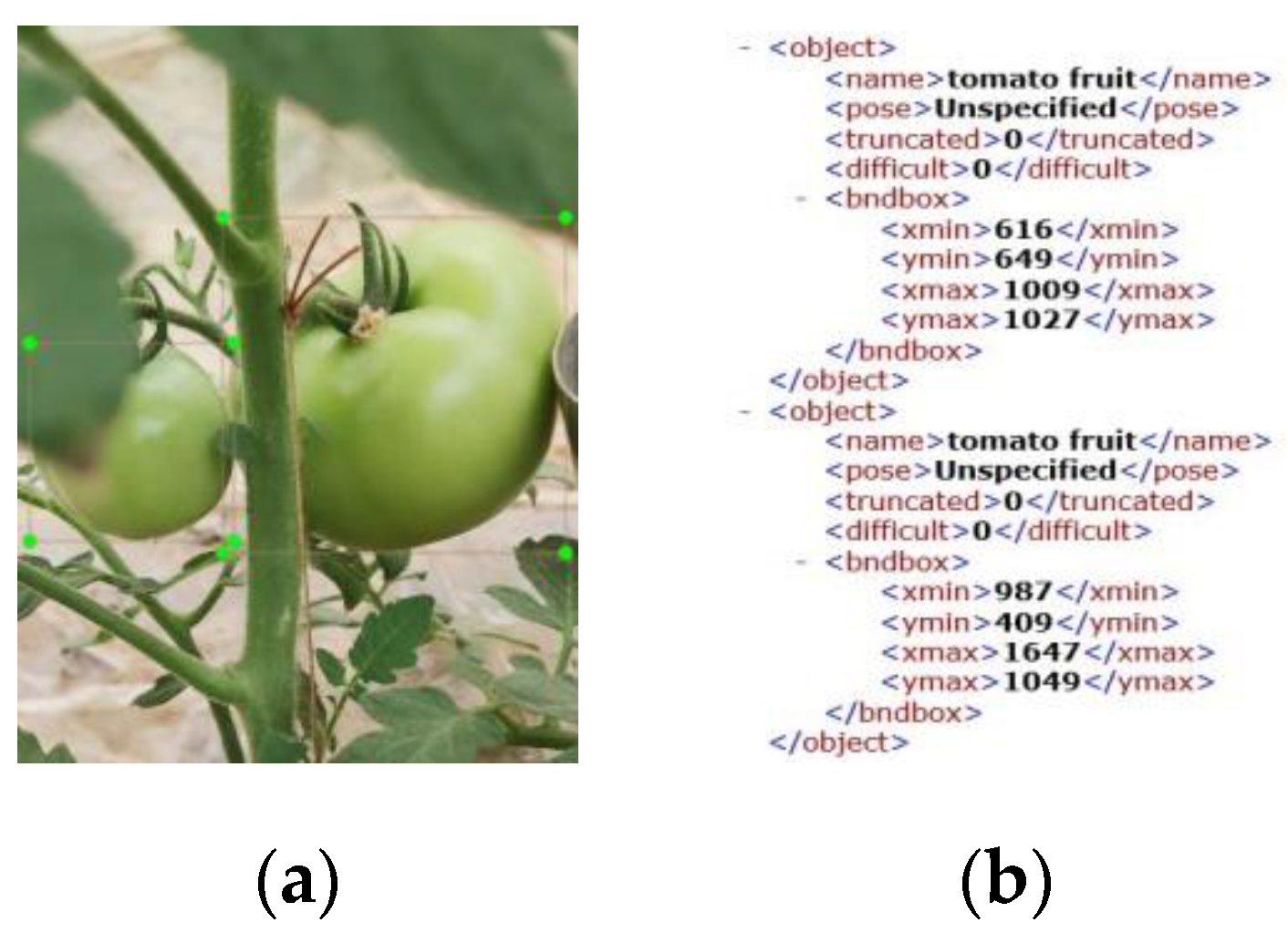
2.1. Data Sources
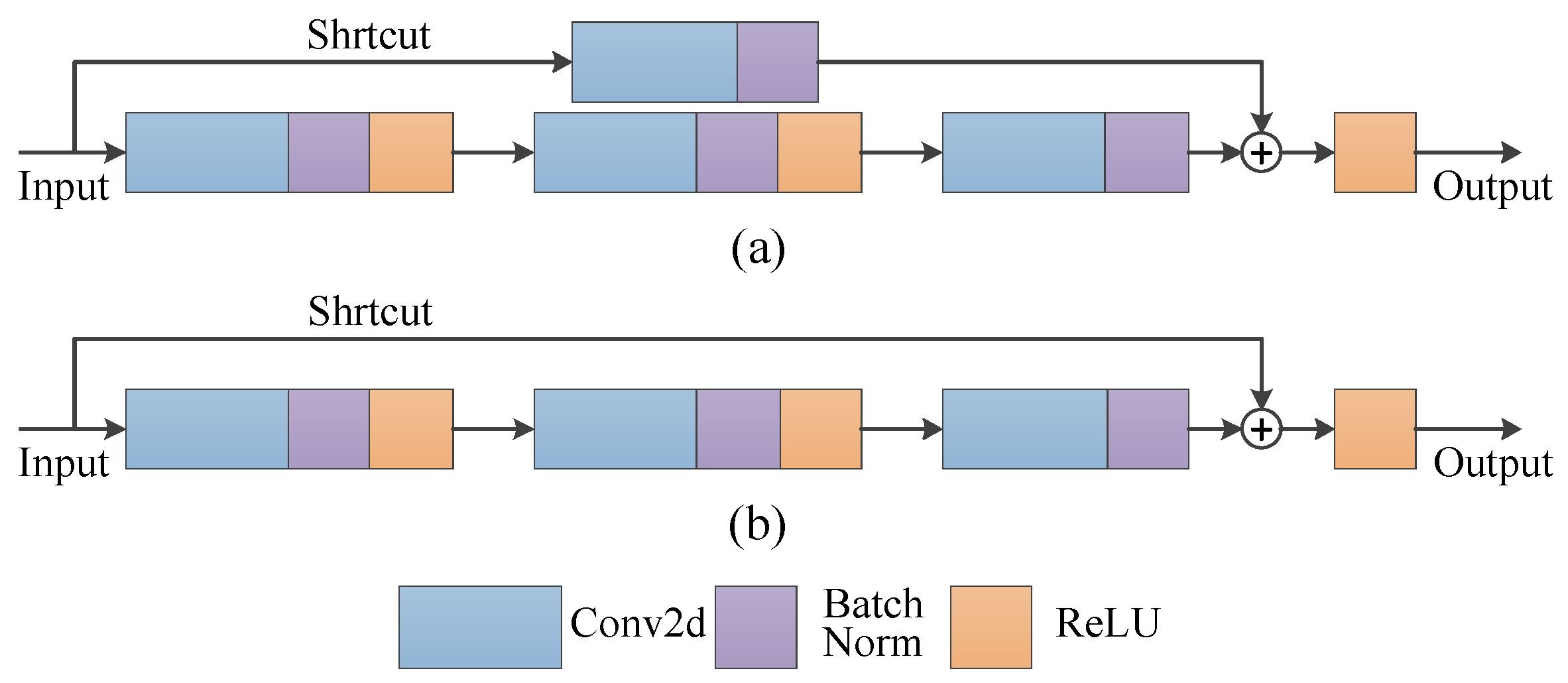
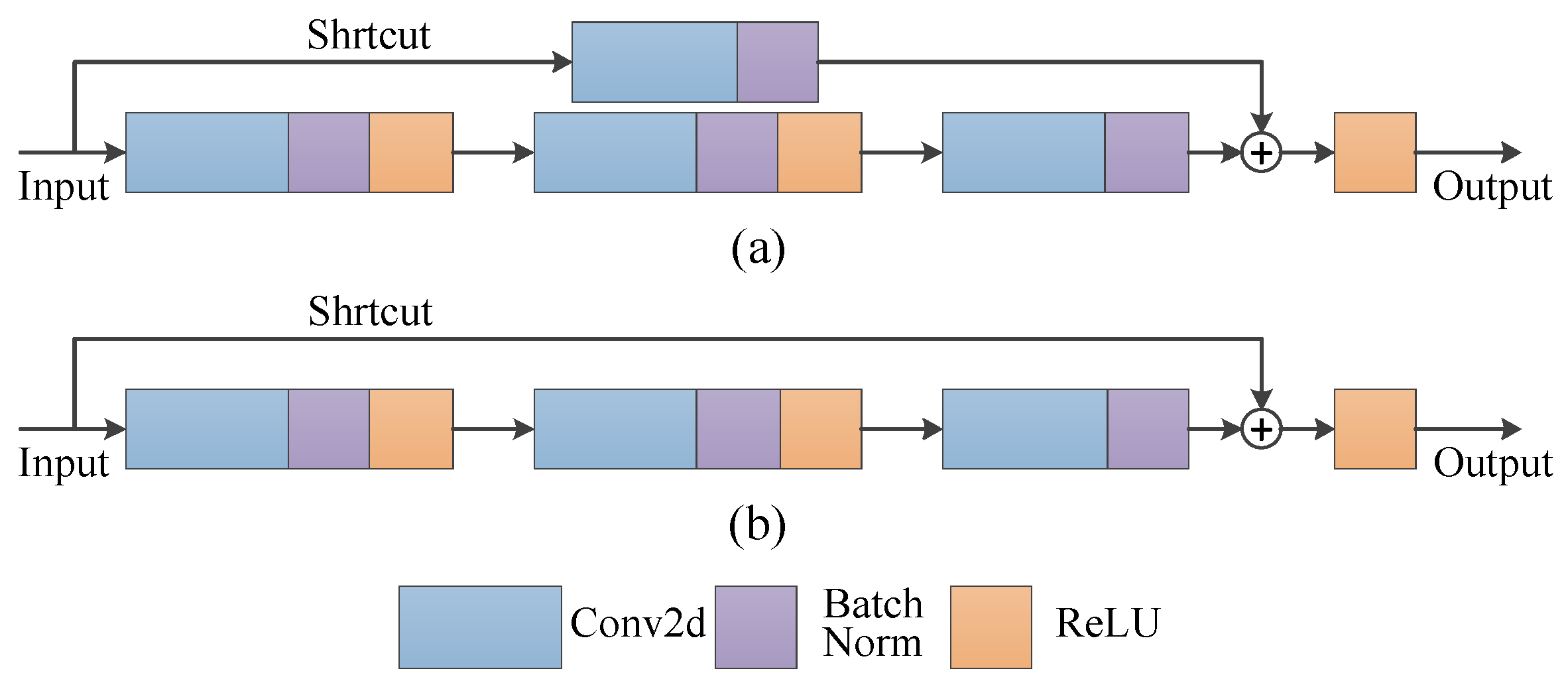
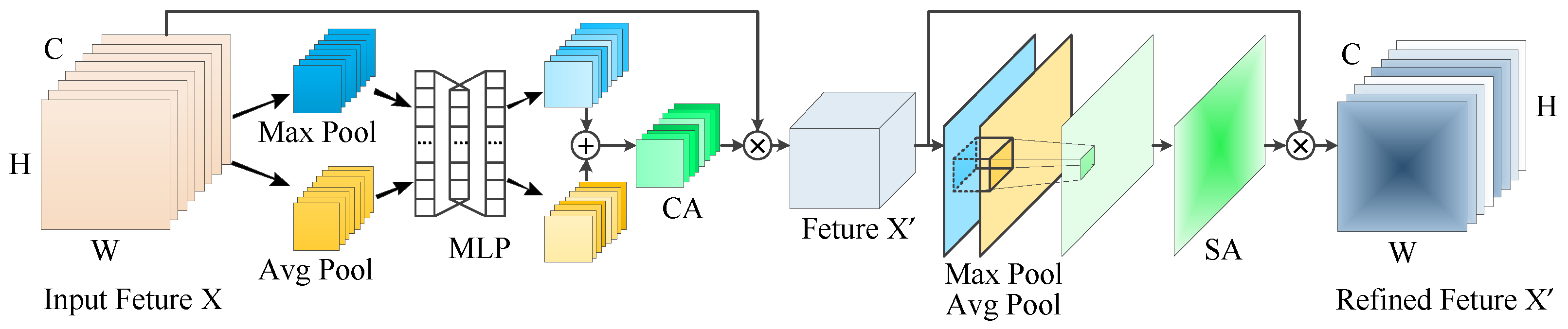
2.2. Feature Extraction Network
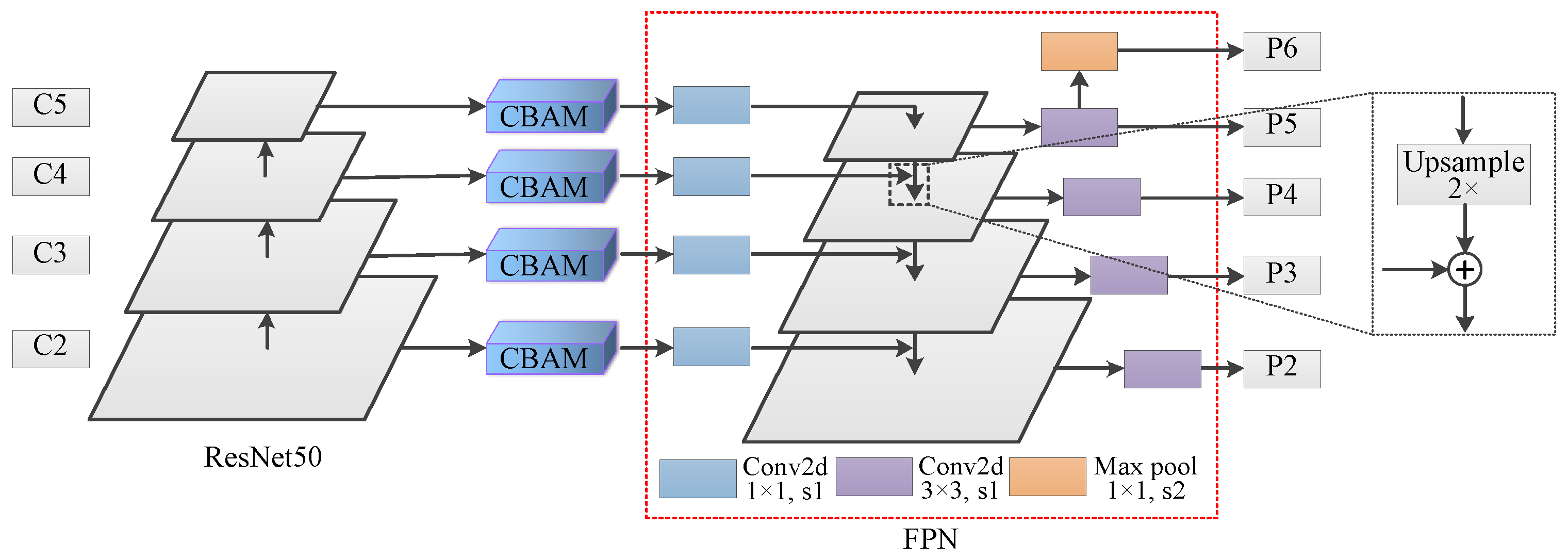
2.3. Multi-Scale Feature Fusion
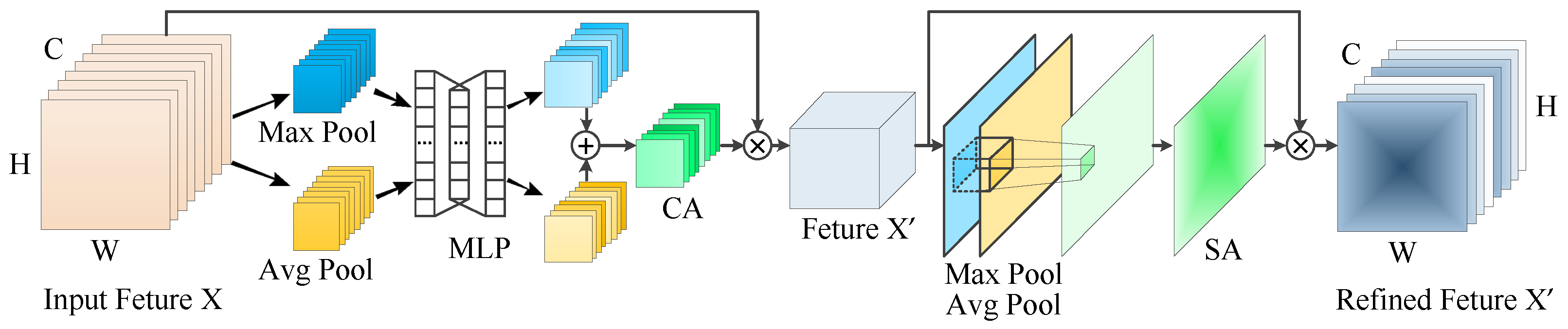
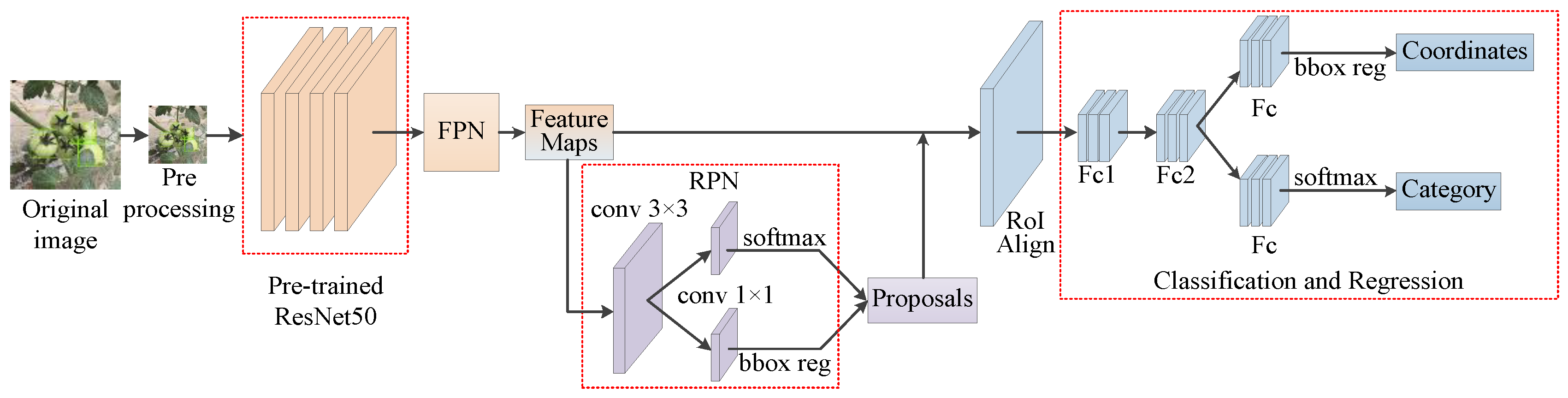
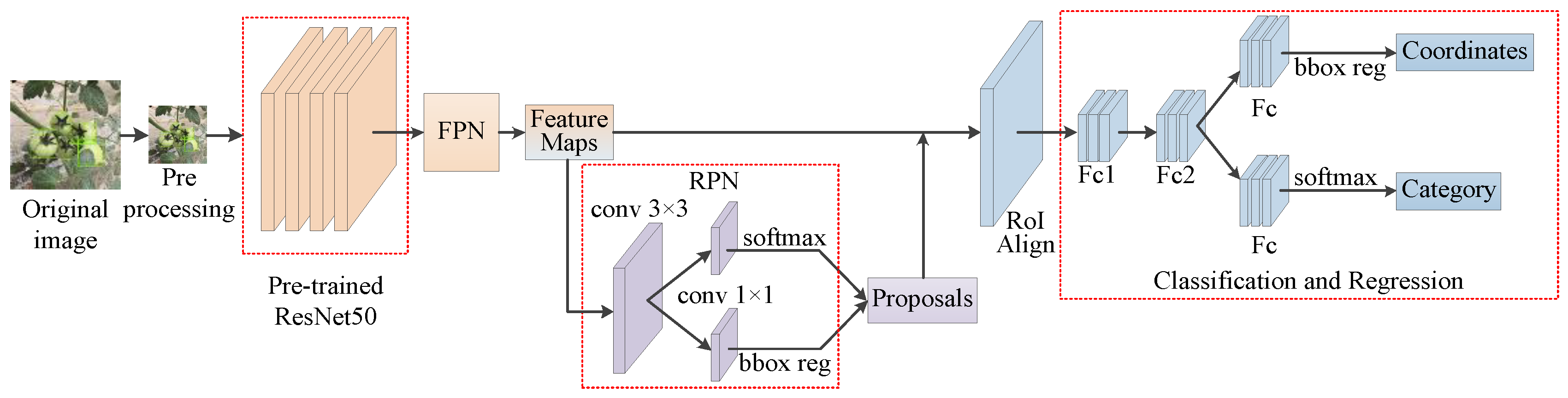
2.4. The Network Architecture of Improved Faster R-CNN with Attention Mechanism
3. Results and Discussion
3.1. Model Training Details
3.2. Evaluation Indicators of Model Performance
3.3. Results and Discussion
3.3.1. Feature Map and Heat Map of Improved Feature Extraction Module
3.3.2. Detection Effect of Soft-NMS on Densely Distributed Young Fruits
3.3.3. Improved Faster R-CNN with Attention Mechanism Detection Performance for Tomato Young Fruit
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Slatnar, A.; Mikulic-Petkovsek, M.; Stampar, F.; Veberic, R.; Marsic, N.K. Influence of cluster thinning on quantitative and qualitative parameters of cherry tomato. Eur. J. Hortic. Sci. 2020, 85, 30–41. [Google Scholar] [CrossRef]
- Xu, Z.; Jia, R.; Liu, Y.; Zhao, C.; Sun, H. Fast Method of Detecting Tomatoes in a Complex Scene for Picking Robots. IEEE Access 2020, 8, 55289–55299. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Kang, H.; Zhou, H.; Chen, C. Visual Perception and Modeling for Autonomous Apple Harvesting. IEEE Access 2020, 8, 62151–62163. [Google Scholar] [CrossRef]
- Li, J.; Huang, W.; Zhao, C. Machine vision technology for detecting the external defects of fruits—a review. Imaging Sci. J. 2015, 63, 241–251. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agr. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. Robust Tomato Recognition for Robotic Harvesting Using Feature Images Fusion. Sensors 2016, 16, 173. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Zhang, B.; Zhou, J.; Xiong, Y.; Gu, B.; Yang, X. Automatic Recognition of Ripening Tomatoes by Combining Multi-Feature Fusion with a Bi-Layer Classification Strategy for Harvesting Robots. Sensors 2019, 19, 612. [Google Scholar] [CrossRef] [Green Version]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On Plant Detection of Intact Tomato Fruits Using Image Analysis and Machine Learning Methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef] [Green Version]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agr. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Chao, X.; Sun, G.; Zhao, H.; Li, M.; He, D. Identification of Apple Tree Leaf Diseases Based on Deep Learning Models. Symmetry 2020, 12, 1065. [Google Scholar] [CrossRef]
- Yang, G.; He, Y.; Yang, Y.; Xu, B. Fine-Grained Image Classification for Crop Disease Based on Attention Mechanism. Front. Plant Sci. 2020, 11, 600854. [Google Scholar] [CrossRef]
- Quan, L.; Feng, H.; Li, Y.; Wang, Q.; Zhang, C.; Liu, J.; Yuan, Z. Maize seedling detection under different growth stages and complex field environments based on an improved Faster R-CNN. Biosyst. Eng. 2019, 184, 1–23. [Google Scholar] [CrossRef]
- Wang, D.; Li, C.; Song, H.; Xiong, H.; Liu, C.; He, D. Deep Learning Approach for Apple Edge Detection to Remotely Monitor Apple Growth in Orchards. IEEE Access 2020, 8, 26911–26925. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Afonso, M.; Fonteijn, H.; Fiorentin, F.S.; Lensink, D.; Mooij, M.; Faber, N.; Polder, G.; Wehrens, R. Tomato Fruit Detection and Counting in Greenhouses Using Deep Learning. Front. Plant Sci. 2020, 11, 571299. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agr. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Z.; Wu, J.; Hu, Q.; Zhao, C.; Tan, C.; Teng, L.; Luo, T. An improved Yolov3 based on dual path network for cherry tomatoes detection. J. Food Process. Eng. 2021, 44, e13803. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network. Trans. Chin. Soc. Agric. Eng. 2019, 35, 156–163. [Google Scholar]
- Nguyen, T.T.; Vandevoorde, K.; Wouters, N.; Kayacan, E.; De Baerdemaeker, J.G.; Saeys, W. Detection of red and bicoloured apples on tree with an RGB-D camera. Biosyst. Eng. 2016, 146, 33–44. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based 3D fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Mi, Z.; Zhang, X.; Su, J.; Han, D.; Su, B. Wheat Stripe Rust Grading by Deep Learning With Attention Mechanism and Images From Mobile Devices. Front. Plant Sci. 2020, 11, 558126. [Google Scholar] [CrossRef]
- Wang, P.; Niu, T.; Mao, Y.; Zhang, Z.; Liu, B.; He, D. Identification of Apple Leaf Diseases by Improved Deep Convolutional Neural Networks With an Attention Mechanism. Front. Plant Sci. 2021, 12, 723294, in press. [Google Scholar] [CrossRef] [PubMed]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. arXiv 2017, arXiv:1710.11063. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR2006), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Morning | Noon | Evening | |
|---|---|---|---|
| Sunny |  |  |  |
| Cloudy |  |  |  |
| Configuration Item | Value |
|---|---|
| CPU | Intel® Xeon(R) Gold 5217 CPU@3.00 GHz |
| GPU | NVIDIA TESLA V100 (32 GB) |
| Operating System | Ubuntu 18.04.5 LTS 64 |
| RAM | 251.4 GB |
| Hard Disk | 8 TB |
| Original Image | CBAM | C2 | C3 | C4 | C5 |
|---|---|---|---|---|---|
 | No |  | 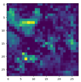 | 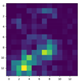 |  |
| Yes |  |  |  |  | |
 | No |  |  |  |  |
| Yes |  | 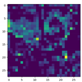 |  |  |
| Original Image |  |  |  | |||
|---|---|---|---|---|---|---|
| Heat Map | Fine-Grained | Heat Map | Fine-Grained | Heat Map | Fine-Grained | |
| With CBAM |  |  |  |  |  |  |
| Without CBAM |  |  | 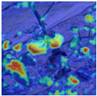 |  |  |  |
| No.1 | No.2 | No.3 | |
|---|---|---|---|
NMS |  |  |  |
Soft-NMS |  | 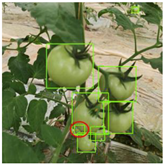 | 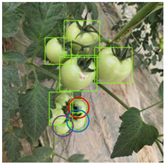 |
| Model. | Testing Time/s | Mean Average Precision/% | Mean Average Recall/% | Frames per Second | Average Testing Time/s |
|---|---|---|---|---|---|
| Faster R-CNN | 22 | 94.26 | 89.64 | 10.22 | 0.097 |
| Our method | 19 | 98.46 | 94.38 | 11.84 | 0.084 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Niu, T.; He, D. Tomato Young Fruits Detection Method under Near Color Background Based on Improved Faster R-CNN with Attention Mechanism. Agriculture 2021, 11, 1059. https://doi.org/10.3390/agriculture11111059
Wang P, Niu T, He D. Tomato Young Fruits Detection Method under Near Color Background Based on Improved Faster R-CNN with Attention Mechanism. Agriculture. 2021; 11(11):1059. https://doi.org/10.3390/agriculture11111059
Chicago/Turabian StyleWang, Peng, Tong Niu, and Dongjian He. 2021. "Tomato Young Fruits Detection Method under Near Color Background Based on Improved Faster R-CNN with Attention Mechanism" Agriculture 11, no. 11: 1059. https://doi.org/10.3390/agriculture11111059
APA StyleWang, P., Niu, T., & He, D. (2021). Tomato Young Fruits Detection Method under Near Color Background Based on Improved Faster R-CNN with Attention Mechanism. Agriculture, 11(11), 1059. https://doi.org/10.3390/agriculture11111059