Abstract
Background/Objectives: Multivessel coronary artery disease (CAD) remains a challenging condition requiring multidisciplinary decision-making, particularly when determining between percutaneous coronary intervention (PCI) and coronary artery bypass grafting (CABG). Recent advancements in artificial intelligence (AI), particularly generative language models like ChatGPT, present an opportunity to assist in the decision-making process. However, their ability to replicate human clinical judgment in complex scenarios, such as multivessel CAD, remains untested. Methods: The aim of this study was to evaluate the concordance between recommendations from AI (ChatGPT) and those from heart team (HT) in the management of multivessel CAD, with a focus on comparing treatment strategies such as PCI and CABG. A retrospective observational study was conducted on 137 patients with multivessel CAD, discussed at multidisciplinary HT meetings in 2024. Standardized clinical vignettes, including clinical and anatomical data, were presented to ChatGPT for treatment recommendations. The AI’s responses were compared with the HT’s decisions regarding PCI or CABG. Statistical analysis was performed to assess the level of agreement and predictive value of ChatGPT’s recommendations. Results: ChatGPT achieved an overall accuracy of 65% in its recommendations. The agreement rate was higher for CABG (82.4%) than for PCI (44.4%). Discordance was identified in 48 patients, with a notable bias towards recommending CABG. Factors such as age, diabetes, and chronic kidney disease were predictors of discordance, although no significant factors emerged for the PCI or CABG subgroups. Conclusions: AI, particularly ChatGPT, demonstrated modest concordance with HT decisions in the management of multivessel CAD, especially favoring CABG. While AI offers potential as a decision-support tool, its current limitations highlight the continued need for human clinical judgment in complex cases. Further research is required to optimize AI integration into clinical decision-making frameworks.
1. Introduction
Contemporary cardiology practice has increasingly embraced a multidisciplinary approach, with the heart team (HT) serving as a central reference point for addressing a wide range of indications and conditions. With the improvement in percutaneous treatment techniques, clinical guidelines have upgraded the role of HT in the decision-making process of many conditions. The initial evidence supporting the clinical utility of HT discussions first emerged in the context of multivessel coronary artery disease (CAD). This area has traditionally represented a “grey zone”, where both surgical and percutaneous revascularization approaches may be viable and offer distinct advantages and limitations [].
A thorough evaluation of factors such as clinical presentation, comorbidities, coronary anatomy, social conditions, and patient preference is, therefore, critical, requiring the HT to serve as the cornerstone of the entire therapeutic pathway within the modern cardiology ward [].
Despite their crucial role, HT meetings can be challenging to organize and may suffer from partial attendance. Furthermore, in high-volume centers, the sheer number of cases requiring discussion often leads to expedited analyses. This time pressure can result in superficial evaluations that fail to explore every nuance of a clinical case or, conversely, focus on less critical aspects of the scenario. Such limitations can ultimately compromise the effectiveness and utility of HT meetings.
In this context, artificial intelligence (AI), particularly generative large language models like ChatGPT 4.0, has emerged as a potentially game-changing tool []. These models excel at processing and synthesizing vast datasets, potentially enabling them to deliver rapid, evidence-based recommendations with high precision. In particular, the transformer architecture, introduced by Google in 2017, allows the computer to process words and their relationships in parallel, in order to create the most coherent answer possible [].
Few studies have investigated the ability of AI to deliver valuable recommendations in complex clinical scenarios. Notably, prior research has examined AI’s role in the management of valvular heart diseases, particularly severe aortic stenosis, showing encouraging data with a good concordance with HT decisions []. However, multivessel CAD presents unique challenges due to its intricate interplay of anatomical, procedural, and clinical considerations, making it a more demanding context for AI-assisted decision-making.
This study examines the concordance between ChatGPT’s recommendations and those of HTs in the management of multivessel CAD. By analyzing discrepancies, the study seeks to evaluate ChatGPT’s capacity to replicate nuanced clinical decision-making and to explore its potential as a complementary tool for decision support.
2. Materials and Methods
2.1. Study Population
The data were retrospectively collected from clinical records to include patients discussed at a multidisciplinary meeting in a high-volume Italian center in 2024. Our study was conducted in accordance with the principles of the Declaration of Helsinki. The study included all the patients with stable or stabilized multivessel CAD undergoing multidisciplinary HT discussion. Those patients receiving indication to medical management (without coronary revascularization) were excluded from the study.
2.2. Clinical Evaluation and Heart Team Meetings
HT meetings were conducted regularly and included interventional cardiologists, imaging specialists, cardiac surgeons, a vascular surgeon, an anesthesiologist, and a geriatrician. Each case underwent a comprehensive evaluation of clinical, echocardiographic, and anatomical parameters. This collaborative decision-making process consistently ensured the selection of the most appropriate management strategy for each patient. As this is a retrospective study, HT decisions were intrinsically blinded to any AI-derived recommendation.
2.3. Clinical Vignette Presented to ChatGPT
For each patient, a standardized clinical vignette was created, incorporating key clinical variables alongside a detailed description of the coronary anatomy and major anatomical (SYNTAX) and procedural risk scores (EuroSCORE II, STS Score). The vignette structure, phrasing, and sequence were identical for all cases, with only objective clinical and anatomical variables modified according to the individual patient. All non-numerical variables were selected from a predetermined set of clinically relevant options, rather than being freely modified, to minimize subjectivity and ensure consistency. This approach ensured that each vignette reflected the clinical factors routinely considered by heart teams when choosing between PCI and CABG, thus aligning the AI prompt with real-world multidisciplinary practice. Critical data, including the presence of bifurcations, left main disease or involvement by stenting, calcifications, and chronic total occlusions, were highlighted and meticulously documented. Treatment options were analyzed and processed using the artificial intelligence-powered chatbot known as the Chat Generative Pre-trained Transformer (ChatGPT), version 4.0 Omnia (GPT-4o), developed by OpenAI (OpenAI, L.L.C., San Francisco, CA). Social conditions were classified as poor if two or more of the following criteria were met: education below the second level (middle school), lack of fluency in Italian, absence of stable housing, poor hygienic conditions, unstable employment, or lack of living relatives. Regarding the evaluation of carotid arteries, stenoses < 50% were classified as non-significant. For each patient, two possible treatment strategies—percutaneous coronary intervention (PCI) or coronary artery bypass grafting (CABG)—were proposed to the AI for consideration. An example of a clinical vignette presented to ChatGPT, followed by the list of included variables and possible variable “status”, is shown in Figure 1A,B.

Figure 1.
(A) Example of standardized text that was used for each patient and submitted to ChatGPT; (B) list of the standardized clinical variables submitted to the AI. PCI: percutaneous coronary intervention; eGFR: estimated glomerular filtration rate; DAPT: dual antiplatelet therapy; LVEF: left ventricular ejection fraction; SYNTAX Score: Synergy Between PCI With Taxus and Cardiac Surgery Score; EuroSCORE II: European System for Cardiac Operative Risk Evaluation II; STS Score: Society of Thoracic Surgeons Score.
2.4. Outcomes
The interrogation of ChatGPT was performed by a physician blinded to the HT decision; the first response provided by the AI was accepted as valid without further interaction or discussion. Each case was presented to ChatGPT in a dedicated window to prevent the inheritance of data from previous cases. The AI’s responses were subsequently compared to the treatment recommendations provided by the HT. The primary outcome was the level of agreement between ChatGPT and the HT regarding the optimal treatment strategy (PCI or CABG).
2.5. Statistical Analysis
The data were summarized using descriptive statistics, with mean ± standard deviation (SD) for normally distributed continuous variables and median (interquartile range [IQR]) for non-normally distributed continuous variables. Frequencies with percentages were used for categorical variables. Group comparison was performed using Student’s t-test, Chi2 analysis, and multivariable logistic regression with and without bootstrapping. Sensitivity, specificity, positive and negative predictive values, and accuracy were calculated. All the analyses were carried out using SPSS Statistics version 29 (IBM).
3. Results
3.1. Patient Characteristics
A total of 137 consecutive patients with multivessel CAD suitable for coronary revascularization discussed during HT meetings were included in the study. Table 1 reports the main characteristics of the overall cohort. The mean age was 70.3 ± 8.6 years, with most patients presenting with chronic coronary syndromes (n =115, 83.9%) and preserved left ventricular ejection fraction (LVEF) (mean: 54.3% ± 8.2). A significant proportion of the cohort had diabetes mellitus (n = 58, 42.3%). Evidence of ischemia on non-invasive evaluation was available in nearly half of the population (n = 65, 47.4%). Only a minority of patients had previously undergone PCI (n = 22, 16.1%) or had significant carotid disease (n = 21, 15.3%). Coronary angiography revealed widespread significant CAD. The surgical risk, assessed using the STS Score mortality and EuroSCORE II, averaged 2.1 ± 2.2% and 2.1 ± 2.1%, respectively. Left main disease was identified in one in five patients (n = 28, 20.4%), while two-vessel disease was rare (n = 7, 5.1%). A considerable proportion of patients had at least one chronically occluded coronary vessel (n = 55, 40.2%). The mean SYNTAX score in the overall cohort was 25.2 ± 7.7. Main treatment recommendations provided by the HT and by the AI are summarized in Figure 2.

Table 1.
Characteristics of the overall population and subgroups (PCI vs. CABG).
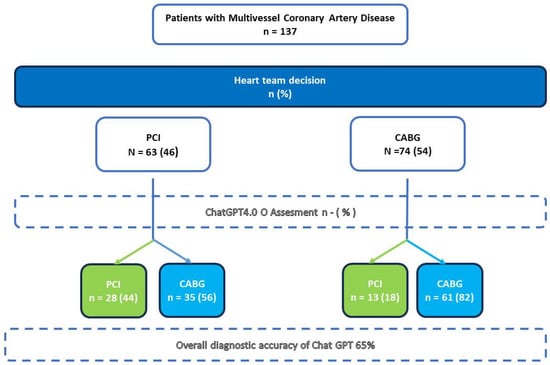
Figure 2.
Reclassification of treatment decisions for patients with multivessel coronary artery disease based on both heart team (HT) and ChatGPT assessments; PCI: percutaneous coronary intervention; CABG: coronary artery bypass grafting; ChatGPT: Chat Generative Pre-trained Transformer; HT: heart team.
3.2. Heart Team Decisions
According to the HT assessment, 63 (46%) patients were deemed eligible for PCI, while CABG was considered the preferable treatment option in 74 (54%) cases. Table 1 provides a detailed summary of the baseline characteristics of the overall study population, as well as those of each subgroup.
3.3. ChatGPT Decisions
The AI model provided a valid recommendation for all 137 patients in the cohort. For the majority of patients (n = 97, 70.1%), ChatGPT recommended CABG. The model achieved an overall accuracy of 65% and demonstrated a moderate Kappa coefficient of 0.276. The agreement rate (sensitivity) was relatively low for patients eligible for PCI (44.4%) but was higher for those deemed suitable for CABG (82.4%). The chatbot did not perform well in terms of positive predictive value (68.3%) or negative predictive value (63.5%) (Table 2).
Table 2.
Performance metrics for ChatGPT’s recommendations on PCI and CABG.
GPT-4o “misclassified” a total of 48 (35%) patients, recommending CABG instead of PCI for 35 patients and PCI instead of CABG for 13 patients. On univariate analysis, there were only a minority of factors that, taken alone, may be responsible for recommendation disagreement: when comparing the HT-indicated PCI cohort with the GPT-indicated PCI (theoretical) cohort (Table 3), the only barely significant differences were a slightly lower ejection fraction in the HT group (51 ± 10% vs. 56 ± 7%, p = 0.020) and a higher prevalence of hypertension (95.2% vs. 82.9%, p = 0.047). This was similar to the HT-indicated CABG cohort versus the ChatGPT-indicated CABG cohort (Table 4), and LVEF was slightly higher in the former (56.5 ± 8.45% vs. 53.5 ± 10.4%, p = 0.043). These differences are likely not clinically significant.
Table 3.
Comparison of characteristics for patients recommended for PCI by HT and ChatGPT.
Table 4.
Comparison of characteristics for patients recommended CABG by HT and ChatGPT.
After selecting some of the most relevant clinical variables—based on physician judgment—as inputs for the multivariate logistic regression, the predictors of overall discordance between AI and HT decisions identified were age, diabetes, and chronic kidney disease (Table 5).
Table 5.
Logistic regression analysis for factors likely associated with discordance between AI and heart team (HT) decisions.
To confirm the robustness of these findings, a bootstrapped logistic regression analysis with 5000 iterations was performed (Table 6). This analysis corroborated age and reduced renal function (eGFR ≤ 35 mL/min/1.73 m2) as independent predictors of discordance between AI and HT decisions (OR = 0.072, p = 0.034; OR = −1.660, p = 0.019, respectively). Additionally, a higher STS Score for mortality was significantly associated with reduced likelihood of discordance (OR = −0.564, p = 0.020), suggesting that in more complex or high-risk patients, AI recommendations tend to align more closely with heart team choices.
Table 6.
Logistic regression analysis after bootstrapping for factors associated with discordance between AI and heart team (HT) decisions.
4. Discussion
This paper explores the potential application of AI to aid clinical decision-making in the management of multivessel CAD. Our main findings are as follows:
- ChatGPT demonstrated only modest agreement with HT decision-making.
- No major identifiable clinical factors were found to drive treatment assignment by the AI model.
- ChatGPT’s recommendations were predominantly skewed towards CABG for most of the cohort.
The past couple of years have witnessed the explosive rise of general-purpose AI systems. Unlike earlier iterations, these technologies are not confined to selected, pre-specified tasks; instead, they are capable of addressing a vast array of problems across virtually every domain of human activity. Since late 2022, there has been a marked surge in interest and activity surrounding AI, with major corporations racing to integrate its capabilities into their services [].
In recent years, practical applications of AI have already demonstrated substantial value in the field of cardiology. For example, AI algorithms have achieved high accuracy in the detection of atrial fibrillation from ECGs and wearable devices, supported advanced mapping and outcome prediction in catheter ablation for atrial fibrillation, and improved the identification of heart failure patients most likely to benefit from cardiac resynchronization therapy through the integration of clinical and imaging data. These examples highlight the growing utility of AI as an adjunct in cardiology, particularly in domains where large volumes of complex data can be synthesized to guide more precise and personalized clinical decisions [].
In the field of cardiovascular interventions, the potential applications of AI have not been extensively explored. To our knowledge, two recently published studies have previously investigated the role of AI in clinical decision-making. Specifically, one study evaluated the ability of AI to classify treatment indications for severe aortic stenosis [], showing that ChatGPT’s decisions were consistent with those of the HT in a large proportion of cases. Another piece of research, more similar to our study, performed a comparison of the performance of the AI versus the HT in the setting of coronary revascularization, showing also a decent agreement [].
In our analysis, the performance of the AI was suboptimal, with an overall accuracy of 65%, which was notably worse than the results observed in the study on aortic stenosis []. This was particularly evident for patients receiving indication to PCI, for whom the AI achieved concordance in less than half of the cases (44.4%), compared to significantly better results for patients receiving indication to CABG (82.4%). Indeed, while decision-making in valvular disease typically relies on more abstractable and structured data, allowing for easier alignment with straightforward guideline applications, the same does not hold true for CAD. In fact, in the case of aortic stenosis, transcatheter aortic valve implantation is widely recognized as a first-line therapy in most cases, simplifying the decision-making process and reducing the variability in treatment recommendations.
Interestingly, our study reports a notable discrepancy in overall accuracy compared to the 82% rate described in the other published work in the same setting []; moreover, unlike our observations, that study demonstrated improved AI performance within specific patient subgroups. Several factors may account for these differences: variations in prompt formulation, despite providing identical information to the AI, could influence the output; differences in the clinical characteristics of the patient populations may also affect model performance; the other study employed version 4 of the model, whereas we utilized the newer version 4-o; and finally, discrepancies in the decision attitude of the HT, shaped by institutional experience and resource availability, might have influenced the preference for PCI or CABG as the optimal treatment strategy. Regardless of the underlying causes of this disagreement, it is essential to emphasize that even an 82% accuracy rate falls short of the standards typically expected for medical devices. In our opinion, these findings reflect a fundamental limitation of the AI’s response-generation mechanism.
AI models generate responses by evaluating the statistical relationships between words and their contexts, producing outputs based on the most likely word sequences within their training database. Given that the majority of the scientific literature on multivessel CAD has historically favored CABG over PCI, it was anticipated that the AI would exhibit a strong inclination toward recommending surgical revascularization. That said, in our study, it remains unclear which specific factors were most influential in skewing the AI model’s decisions toward CABG. The standard logistic regression model identified age, diabetes, and chronic kidney disease (CKD) as predictors of disagreement, while the bootstrapped analysis confirmed age and CKD as significant determinants of discordance but identified also the clinical risk scores (namely STS and EuroSCORE), that narrowly missed the threshold for significancy at the initial analysis. Notably, the SYNTAX score did not achieve statistical significance at the standard or at the bootstrapped logistic regression. These findings further highlight the differences in data analysis and interpretation by the HT compared to the AI; while the group of experts leveraged their indication on a multifaceted patient-tailored analysis, the AI strongly grounded its recommendation on the numerical risk scores, which can be more easily algorithmically processed.
On the other hand, it is precisely in this context that human evaluation demonstrates its superiority. Experienced clinicians bring a nuanced understanding that extends beyond the isolated results of primary endpoints of clinical trials, factoring both measurable and non-measurable variables into the decision-making process. Furthermore, clinicians consider a variety of contextual factors, including their own expertise with certain anatomies, the availability of specific devices, and center-specific logistical constraints that may significantly impact the outcomes of both CABG and PCI.
In our opinion, the primary value of the HT lies in its ability to ensure comparable outcomes while prioritizing the least invasive and most patient-centered treatment. This synthesis of technical and scientific knowledge with human experience ensures a holistic approach that AI systems currently lack. On the other hand, one potential advantage of integrating AI-based decision support into clinical workflows is the reduction in time required for case evaluation. In the conventional HT process, approximately 10 min is needed for an individual clinician to retrieve and organize case data, followed by around 5 min for presentation and 10 min for discussion and consensus-building, totaling about 25 min per case. In contrast, the AI approach requires a similar initial data collection phase (about 10 min), but the subsequent submission to the AI and review of its recommendation are almost instantaneous. While these estimates are theoretical and depend on the case complexity and institutional workflow, they suggest that AI could streamline decision-making and reduce overall time investment per case. Prospective studies will be necessary to confirm and quantify these potential efficiency gains.
A critical limitation of conversation-based large language models available at the time of our study is the inability to directly interpret structured imaging data or capture the subtle anatomical details and technical considerations that emerge from direct image review. Consequently, aspects such as lesion complexity, vessel characteristics, and the feasibility of different interventional approaches, which are integral to HT decision-making, may not be fully represented or weighted in the AI’s assessment. Since ChatGPT-4o was the only AI model tested in this study, we cannot make any statement on the performance of other models.
Another limitation of AI in clinical decision-making, as recently shown, is the dependency on subtle changes in prompt phrasing, variations in the assumed role of the user (e.g., user vs. physician), and differences between free and paid versions or models of the software. All these factors can produce substantial variations in the AI output [].
Table 7 offers a comprehensive comparison of the strengths and limitations of HT and AI.
Table 7.
Synthetic comparison between the HT and AI in decision-making for patients with multivessel coronary artery disease.
Beyond the technical limitations previously discussed, significant ethical, legal, and operational challenges persist in the integration of AI-driven decision support into the clinical management of multivessel CAD. From an ethical perspective, artificial intelligence cannot incorporate empathy, nuanced understanding of personal context, or the lived intentions and values of individual patients—dimensions that often prove decisive in complex clinical decisions. There is a risk that increased reliance on AI could depersonalize care and shift responsibility away from the clinical team, potentially undermining the physician’s central role as patient advocate and increasing the risk of “moral distancing” from critical choices.
Medico-legal considerations are equally important. The implementation of fully or partially AI-guided recommendations would require dedicated legal frameworks, as current systems are not designed to address liability for adverse outcomes that result from algorithm-generated advice, particularly in cases of disagreement between AI and heart team recommendations. Traditional models of clinical governance and accountability are not easily adaptable to such scenarios, raising unresolved questions about responsibility and transparency.
Additional concerns relate to patient data privacy and security, as the use of AI often involves uploading sensitive health information to privately operated servers, increasing the risk of unauthorized access or misuse. Furthermore, there is potential for outdated or inaccurate recommendations, given that the computational resources and online updates of these models are not always guaranteed, and offline datasets may become obsolete. These challenges underscore the need for stringent regulatory oversight and robust institutional policies to ensure the safe, effective, and equitable adoption of AI in clinical practice.
From a workflow perspective, careful integration is required to avoid introducing bias into multidisciplinary discussions. Ideally, AI should be interrogated before or after heart team meetings by independent, blinded operators to prevent influencing the collective decision-making process. Clear protocols and prospective studies should also be established for managing discordance between AI and HT recommendations and any potential disagreement that may arise among HT members in consequence of the AI input, in order to prioritize patient safety and maintain transparency. Of note, due to the nature of our study, it was not possible to retrospectively assess inter-observer variability within the HT members for the cases discussed, as such information was not systematically recorded in our institution.
5. Conclusions
The integration of AI into clinical decision-making in cardiology holds significant potential, yet its current limitations—both technical and ethical—highlight the need for caution. While AI can assist in standardizing recommendations, as seen in its preference for CABG in multivessel disease, it lacks the nuanced evaluation provided by experienced clinicians. Addressing challenges related to patient data privacy, algorithmic variability, and regulatory oversight will be essential to ensure that AI complements, rather than compromises, clinical judgment in the pursuit of safe and personalized care. Finally, future research should focus on evaluating similar AI models in a range of clinical settings beyond high-volume cardiology centers. Potential areas include emergency medicine (e.g., triage prioritization and resource allocation), primary care (e.g., chronic disease follow-up and risk stratification), oncology (e.g., decision support in multidisciplinary tumor boards), and intensive care units (e.g., early warning systems and clinical deterioration prediction).
Author Contributions
F.T.: original draft, visualization, methodology, conceptualization; R.C.: writing—review and editing, supervision; R.T.: visualization, methodology, conceptualization; S.M. (Simona Mariani): formal analysis, data curation, conceptualization; L.A.: methodology, investigation; S.M. (Stefano Migliaro): project administration, methodology, investigation. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
No submission to an ethics committee was made for this research, as the study is a retrospective, non-interventional analysis based solely on data obtained from routine clinical practice. The study did not involve any experimental treatments, prospective data collection, direct patient contact, or deviations from standard diagnostic or therapeutic procedures.
Informed Consent Statement
Informed consent was not obtained as the study involved only anonymized, retrospective data from standard clinical practice, with no patient interaction or intervention.
Data Availability Statement
Dataset may be available upon reasonable written request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vrints, C.; Andreotti, F.; Koskinas, K.C.; Rossello, X.; Adamo, M.; Ainslie, J.; Banning, A.P.; Budaj, A.; Buechel, R.R.; Chiariello, G.A.; et al. 2024 ESC Guidelines for the management of chronic coronary syndromes. Eur. Heart J. 2024, 45, 3415–3537. [Google Scholar] [CrossRef] [PubMed]
- Riojas, R.A.; Lawton, J.S.; Metkus, T.S., Jr. The heart team: The multidisciplinary approach to coronary artery disease. Vessel Plus 2024, 8, 6. [Google Scholar] [CrossRef] [PubMed]
- Johnson, K.W.; Torres Soto, J.; Glicksberg, B.S.; Shameer, K.; Miotto, R.; Ali, M.; Ashley, E.; Dudley, J.T. Artificial Intelligence in Cardiology. J. Am. Coll. Cardiol. 2018, 71, 2668–2679. [Google Scholar] [CrossRef] [PubMed]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Salihu, A.; Meier, D.; Noirclerc, N.; Skalidis, I.; Mauler-Wittwer, S.; Recordon, F.; Kirsch, M.; Roguelov, C.; Berger, A.; Sun, X.; et al. A study of ChatGPT in facilitating Heart Team decisions on severe aortic stenosis. EuroIntervention 2024, 20, e496–e503. [Google Scholar] [CrossRef] [PubMed]
- Wang, J. Principles and Applications of Artificial Intelligence (AI). In Algorithms: A Review of The Literature. Highlights in Science, Engineering and Technology; Darcy & Roy Press: Salem, OR, USA, 2023; pp. 76–84. [Google Scholar] [CrossRef]
- Cersosimo, A.; Zito, E.; Pierucci, N.; Matteucci, A.; La Fazia, V.M. A Talk with ChatGPT: The Role of Artificial Intelligence in Shaping the Future of Cardiology and Electrophysiology. J. Pers. Med. 2025, 15, 205. [Google Scholar] [CrossRef] [PubMed]
- Sudri, K.; Motro-Feingold, I.; Ramon-Gonen, R.; Barda, N.; Klang, E.; Fefer, P.; Amunts, S.; Attia, Z.I.; Alkhouli, M.; Segev, A.; et al. Enhancing Coronary Revascularization Decisions: The Promising Role of Large Language Models as a Decision-Support Tool for Multidisciplinary Heart Team. Circ. Cardiovasc. Interv. 2024, 17, e014201. [Google Scholar] [CrossRef] [PubMed]
- Salihu, A.; Gadiri, M.A.; Skalidis, I.; Meier, D.; Auberson, D.; Fournier, A.; Fournier, R.; Thanou, D.; Abbe, E.; Muller, O.; et al. Towards AI-assisted cardiology: A reflection on the performance and limitations of using large language models in clinical decision-making. EuroIntervention 2023, 19, e798–e801. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).