1. Introduction
Alzheimer’s Disease (AD) is the most common cause of dementia in the elderly, characterized by the progressive deterioration of memory, language, and reasoning. Mild Cognitive Impairment (MCI) represents an intermediate clinical stage between normal aging and AD, with symptoms that do not yet interfere significantly with daily functioning. Although not all individuals with MCI progress to AD, longitudinal studies suggest that 10–15% progress annually, while others remain cognitively stable. Despite the absence of a definitive cure, current pharmacological treatments may delay symptom progression. Thus, the early identification of MCI patients at high risk for AD is essential to enable timely intervention and disease management [
1,
2].
Missing data remains a major challenge in neurodegenerative disease research, affecting the reliability and clinical relevance of findings. Despite advances in imputation techniques, key issues persist due to the complexity of multimodal datasets and the intrinsic difficulty of handling incomplete information. A critical obstacle is identifying the underlying mechanism of missingness—whether data are Missing Completely at Random (MCAR), Missing at Random (MAR), or Missing Not at Random (MNAR)—since each scenario demands a specific imputation strategy [
3,
4,
5,
6,
7,
8].
In practice, distinguishing between MAR and MNAR is particularly challenging, often requiring complex modeling and unverifiable assumptions. This uncertainty can introduce bias and compromise inference, especially when inappropriate imputation methods are used. Further complications include high levels of missingness [
3], multimodal data integration, cross-cohort variability, longitudinal dropout, and the absence of uncertainty quantification—all of which demand robust, innovative approaches to ensure analytical validity in neurodegenerative disease research.
Large-scale datasets like the Alzheimer’s Disease Neuroimaging Initiative (ADNI) [
9] are heavily affected by missing data, with up to 80% of patients presenting incomplete records [
10,
11]. Since many analytical methods require complete data, researchers are often forced to either discard incomplete entries—at the cost of statistical power and generalizability—or apply imputation techniques. While imputation preserves sample size, it can introduce systematic biases, reduce efficiency, and complicate statistical inference if not properly handled. Moreover, the choice of imputation strategy can significantly influence the performance, interpretability, and explainability of downstream machine learning (ML) models [
11,
12,
13].
The ADNI dataset supports the longitudinal tracking of dementia by capturing structural and functional brain changes across four stages: Cognitively Normal (CN), Significant Memory Concern (SMC), Mild Cognitive Impairment (MCI), and Alzheimer’s Disease (AD) [
3,
12]. In this study, we compare traditional statistical imputation methods (mean and median) with machine learning-based techniques, including missForest (MF)—a Random Forest-based algorithm [
13,
14,
15], —and the k-Nearest Neighbors imputer (kNNs) [
16]. We also evaluate Multivariate Imputation by Chained Equations (MICE) [
17,
18], a multiple imputation strategy that generates plausible values for missing entries by iteratively modeling each variable [
15,
19,
20]. We assessed the impact of each imputation method on classification performance by predicting dementia stages using the imputed datasets. The methods compared—mean, median, MF, kNNs, and MICE—were evaluated based on their ability to preserve or enhance predictive accuracy. To ensure a comprehensive evaluation across different modeling approaches, we employed three widely used classifiers: Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM). Classification outcomes were measured using standard metrics, including AUC, F1-score, precision, accuracy, and sensitivity.
This study built upon our prior investigations on missing data handling in neurological disorders. In Aracri et al. [
13], we conducted a simulation-based study comparing missForest and mean imputation under increasing levels of MCAR, assessing their impacts on the reconstruction of clinical, neuropsychological, and imaging variables in Alzheimer’s Disease data. In Aracri et al. [
14], we analyzed the influence of imputation strategies on the performance of tree-based classifiers in Parkinson’s Disease, focusing on classification accuracy and feature relevance. Most recently, in Aracri et al. [
15], we compared external versus internal imputation approaches in longitudinal Alzheimer’s Disease data, highlighting how different strategies affect diagnostic model performance over time.
The present study extends this line of research by systematically evaluating how imputation methods influence supervised classification outcomes in dementia staging, using multiple classifiers and statistical tests to assess significance on an independent test set without missing data. Beyond accuracy, we evaluate additional performance metrics—such as sensitivity, precision, and computational efficiency—to provide a more comprehensive comparison across models and imputation strategies. We also analyze feature importance to identify which variables most strongly influence classification outcomes under different imputation conditions. These enhancements offer deeper insight into how data quality and imputation choices affect model robustness and interpretability. This broader perspective not only improves the generalizability of our findings but also offers practical guidance for optimizing machine learning workflows in dementia research. Ultimately, our work contributes to the development of reliable, interpretable, and data-driven classification pipelines for clinical neuroscience applications.
3. Results
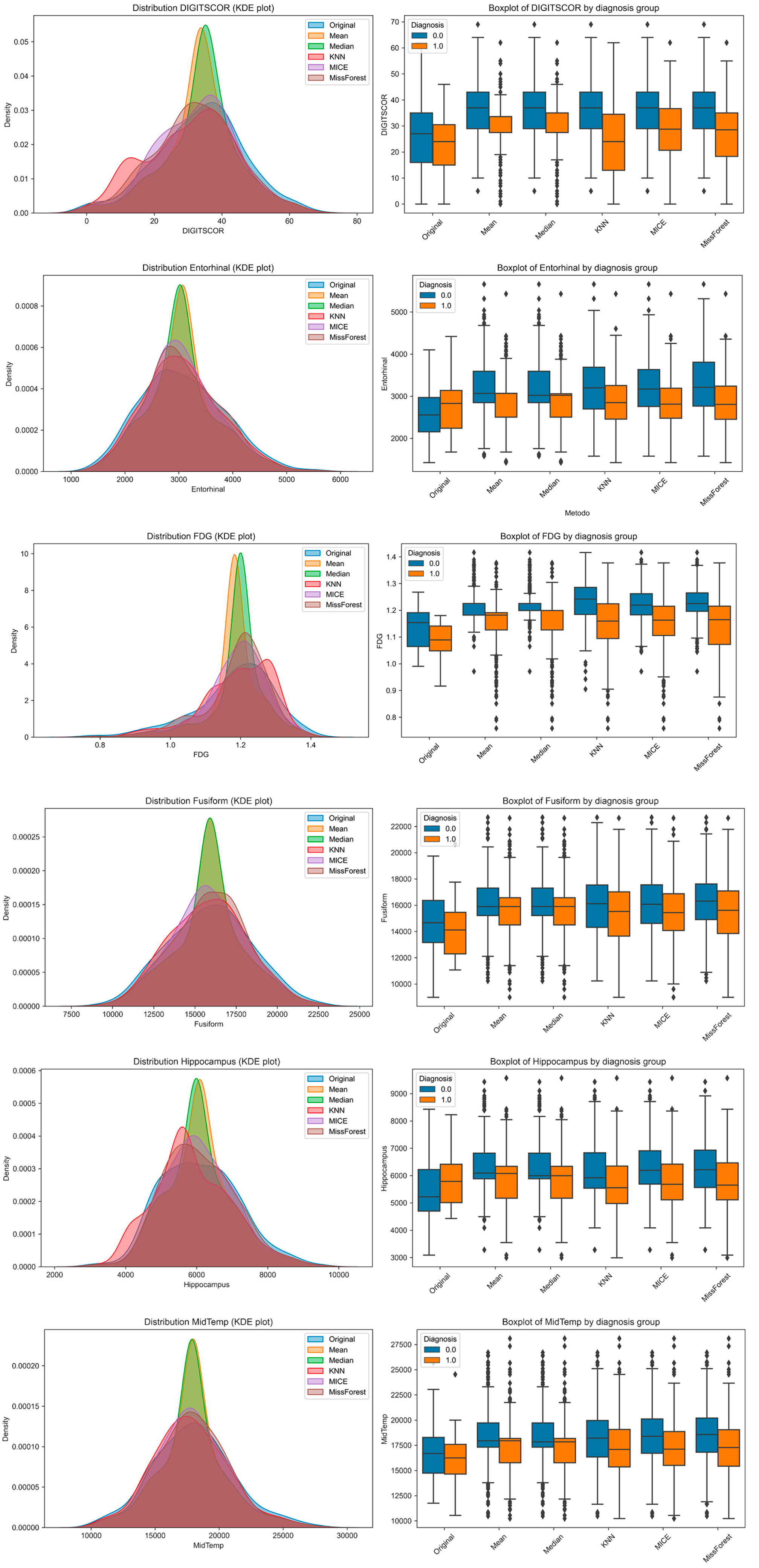
To explore how imputation methods affect the distributional properties of individual features and their separability across diagnostic groups, we visualized six representative variables using Kernel Density Estimation (KDE) plots and group-stratified boxplots (
Figure 3). These included one cognitive variable (DIGITSCOR), one PET-based metabolic marker (FDG), and four structural MRI-derived regional volumes (Entorhinal, Fusiform, Hippocampus, and Middle Temporal cortex). KDE plots allowed for performing a direct comparison between the original (complete) distribution and those resulting from each imputation method. Boxplots, stratified by diagnosis (MCI vs. AD), illustrate the extent to which group differences are preserved or distorted following imputation.
Notably, while all methods approximated the original distributions to varying degrees, missForest and MICE produced distributions more consistent with the original data. However, group separability was occasionally reduced, particularly with mean and median imputation, suggesting potential limitations in preserving clinically relevant signals.
Classification performance on the training set, averaged over five cross-validation folds, is reported in
Table 2 (Random Forest),
Table 3 (Logistic Regression), and
Table 4 (SVM). For Random Forest (
Table 2), mean imputation achieved the best accuracy (0.80 ± 0.033) and F1-score (0.78 ± 0.035), while median imputation provided a slightly lower but comparable performance. MICE yielded the lowest results across all metrics, suggesting that it may not be well-suited to RF in this dataset. Interestingly, missForest and kNNs did not perform as strongly as expected, with MF performing better than kNNs but still below mean and median. In the case of Logistic Regression (
Table 3), kNN imputation led to the highest performances across all metrics—accuracy (0.73 ± 0.038), precision (0.74 ± 0.05), recall (0.67 ± 0.082), and F1-score (0.70 ± 0.058)—indicating good compatibility with linear models in terms of signal preservation. Mean, median, and MICE imputations produced comparable but slightly lower results, while MF remained consistent but not superior.
For SVM (
Table 4), multiple imputation methods resulted in very similar accuracies (~0.72) and F1-scores (~0.69–0.70), with minor variations across imputation strategies. MICE yielded the highest recall (0.69 ± 0.091) and a balanced profile across all metrics. Interestingly, missForest and kNNs showed stronger performance in SVM than in RF, again confirming that the effectiveness of imputation methods is model-dependent. Overall, these training results emphasize the interaction between classifier type and imputation strategy. While mean imputation appeared most effective for Random Forest, kNNs was best suited to Logistic Regression, and MICE performed robustly across all metrics in SVM. This reinforces the importance of jointly considering both imputation and model choice during pipeline design.
The classification performances of the three models—Random Forest (RF), Logistic Regression (LR), and Support Vector Machine (SVM)—on the test set across different imputation methods are reported in
Table 5,
Table 6 and
Table 7. For RF, the highest F1-score (0.70) and recall (0.79) were obtained with MICE imputation, while mean imputation yielded the highest precision (0.65). Notably, kNNs and missForest consistently underperformed across all metrics in the RF model, suggesting reduced compatibility with ensemble-based classification in this setting. In the case of LR, MICE again provided the best overall performance, achieving the highest values for accuracy (0.81), precision (0.71), and F1-score (0.73), along with a strong recall (0.76). Mean and median imputations also performed well, whereas kNN imputation led to a substantial drop in recall (0.48) and F1-score (0.53), indicating poor sensitivity. SVM yielded the most robust recall (0.83) when combined with MICE, while median imputation resulted in the highest accuracy (0.81) and F1-score (0.74). All imputation methods except kNNs produced relatively balanced precision and recall values, reinforcing the observation that kNN imputation tends to impair classifier performance in this dataset. Overall, MICE emerged as the most consistent imputation strategy across models, particularly in preserving sensitivity (recall) and optimizing F1-score, which is especially relevant in clinical applications where minimizing false negatives is critical. Conversely, kNNs and missForest showed less stable behavior, highlighting the importance of tailoring imputation approaches to the classifier architecture and dataset characteristics.
To assess whether the differences in classification outcomes among models were statistically significant, we applied McNemar’s test to pairwise comparisons between classifiers on the test set (
Table 8). The results show that the differences between Random Forest (RF) and both Logistic Regression (LR) and Support Vector Machine (SVM) were statistically significant, with
p-values of 0.0059 and 0.0012, respectively. This indicates that RF produced a significantly different pattern of misclassifications compared to LR and SVM. In contrast, the comparison between LR and SVM yielded a McNemar statistic of 0.00 and a
p-value of 1.00, suggesting no significant difference in their classification decisions. These findings support the superior and distinct behavior of RF in this context, while LR and SVM appear to behave similarly in terms of misclassification patterns.
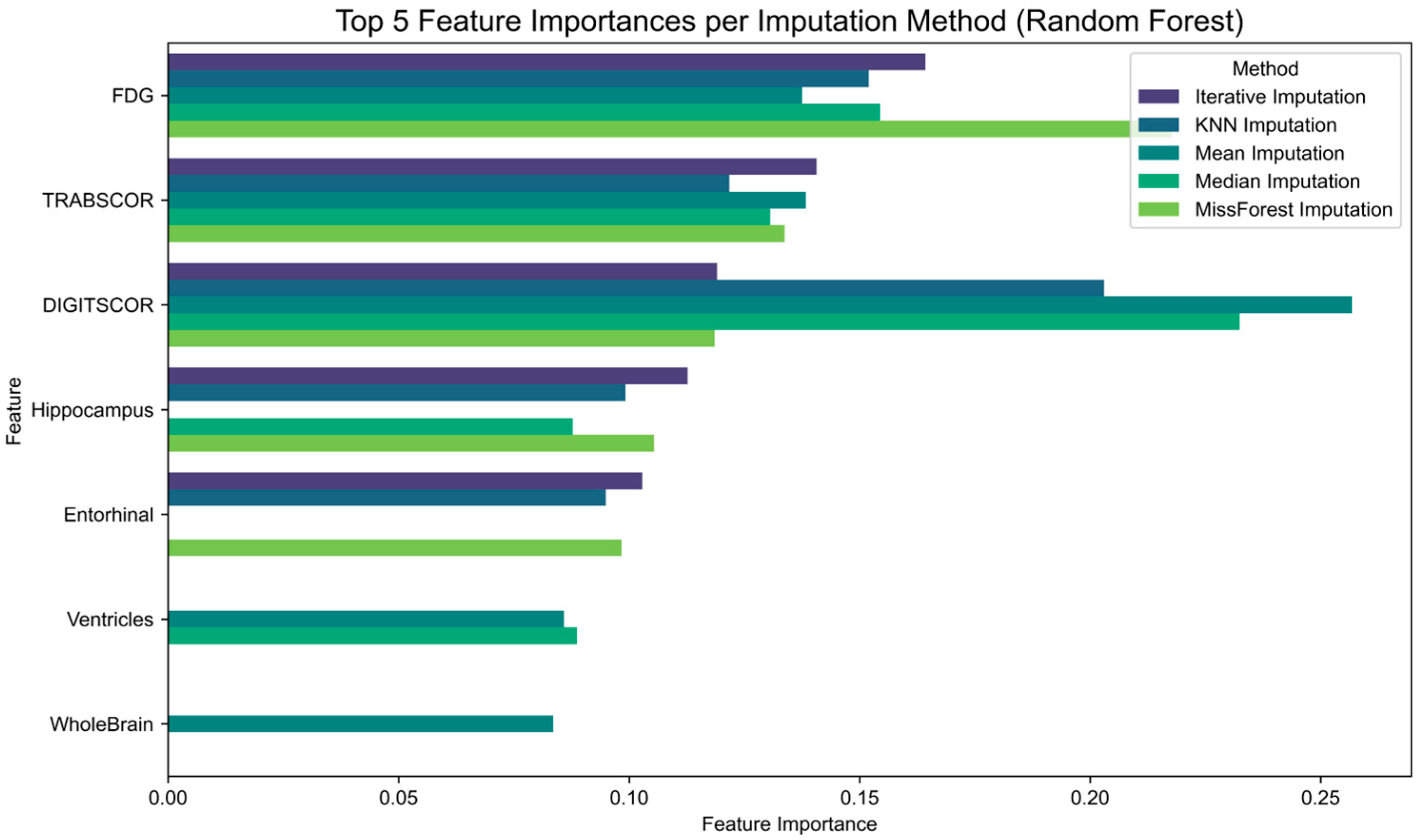
Finally, to assess the impact of imputation strategies on feature relevance, we examined the feature importance scores derived from Random Forest classifiers trained on each imputed dataset (
Figure 4). The results show that although some features consistently rank among the most informative across imputation methods, their relative importance varies depending on the technique applied. For instance, hippocampal volume and FDG uptake maintain high relevance across all conditions, while other features such as entorhinal cortex or cognitive scores exhibit greater variability.
4. Discussion
This study systematically investigated the impacts of five imputation methods—mean, median, k-Nearest Neighbors (kNNs), Multiple Imputation by Chained Equations (MICE), and missForest (MF)—on the classification of Alzheimer’s Disease (AD) and Mild Cognitive Impairment (MCI) using multimodal data from the ADNI cohort. By evaluating the performances of three classification models—Random Forest (RF), Logistic Regression (LR), and Support Vector Machine (SVM)—on an independent test set without missing data, we demonstrated that the choice of imputation strategy can significantly influence classification outcomes. Our findings emphasize that this impact varies not only across imputation techniques but also depending on the classifier used.
Among the evaluated imputation methods, MICE consistently yielded the highest classification accuracy with both RF and LR, while SVM performed best with median imputation. Although MF and kNNs have been reported in the literature as robust choices for mixed-type data, in our experiments, their performances were less stable and did not generalize as effectively across classifiers. McNemar’s test confirmed that RF differed significantly from both LR and SVM in terms of misclassification patterns, reinforcing the importance of matching imputation strategies to the model architecture.
Interestingly, simpler methods such as mean and median imputation delivered competitive performances, particularly when combined with RF. This suggests that in structured datasets like the ADNI, model capacity can partially compensate for the loss of information due to simplistic imputation. Nevertheless, these statistical approaches remain limited by their inability to preserve inter-variable relationships and may lead to biased estimates when missingness is not completely random.
Our findings are consistent with previous work by Aracri et al. [
13,
14,
15] and align with the recent literature [
20,
29], confirming the effectiveness of ML-based imputation methods—particularly missForest—in handling missing data within complex biomedical datasets. In prior studies, these approaches demonstrated improved classification performance in both cross-sectional and longitudinal settings, especially in predicting cognitive decline, modeling disease progression, and addressing class imbalance in multiclass scenarios such as Parkinson’s Disease and SWEDD [
14]. In our current work, we further confirm that ML-based imputation methods offer clear advantages over traditional statistical techniques in preserving inter-variable relationships and maintaining classification accuracy across multiple classifiers. Although all tested imputation methods produced acceptable results on a clean test set, ML-based techniques more consistently captured nuanced patterns and preserved clinically meaningful information—qualities that are crucial in real-world, heterogeneous datasets. These results highlight the importance of selecting imputation strategies that are not only statistically valid but also tailored to the structure, complexity, and intended analytical use of the data.
Clinically, the ability of MF and kNNs to maintain high sensitivity suggests their potential for reducing false negatives in diagnostic systems—an essential requirement for timely intervention in prodromal Alzheimer’s Disease. Conversely, the higher precision achieved by simpler imputation methods may be advantageous in contexts where false positives entail significant clinical or resource-related consequences. These trade-offs underscore the importance of aligning imputation and classification strategies with the specific objectives and risk profiles of clinical applications.
Beyond conventional imputation approaches, emerging deep learning-based methods offer new opportunities to enhance this balance. In particular, Generative Adversarial Networks for Synthetic Oversampling (GANSOs) [
30] have been proposed as a powerful tool for imputing missing values by modeling complex joint data distributions and generating realistic synthetic samples. This technique has shown promising results in psychiatric research, where datasets are frequently characterized by high dimensionality, small sample sizes, and non-random missingness—conditions also present in neurodegenerative disease studies.
While this study focused on Alzheimer’s Disease (AD) and Mild Cognitive Impairment (MCI), the proposed approach is generalizable to other neurodegenerative conditions and datasets that integrate neuroimaging, cognitive, and biomarker data [
31]. The imputation classification workflow that we present can be readily extended to more complex analytical tasks, such as multimodal data fusion, survival analysis, or uncertainty-aware AI systems—contexts in which imputation quality has a direct impact on both model interpretability and the reliability of clinical decision support.
Despite its strengths, this study presents several limitations that warrant consideration. First, we assumed a Missing at Random (MAR) mechanism without explicitly testing or modeling the missingness process. However, real-world clinical datasets often include values that are Missing Not at Random (MNAR), which would require more sophisticated techniques to avoid bias and ensure validity. Second, imputation was performed externally prior to model training. While this approach avoids information leakage into the test set, it does not consider potential interactions between imputation and classification. Future work could explore joint or end-to-end frameworks that integrate both steps to better reflect real-world workflows. Third, all imputation techniques were applied using default hyperparameters. Although this choice improved reproducibility and facilitates comparison, it may have limited the performance of algorithms such as missForest and kNNs, which are known to be sensitive to parameter tuning. Optimization strategies such as grid or randomized searches could enhance these methods and should be considered in future studies. Fourth, the analysis was restricted to baseline cross-sectional data. Longitudinal validation is essential to assess the temporal stability and clinical robustness of imputation methods, particularly in applications involving disease progression modeling or treatment response monitoring. Finally, an important yet underexplored issue concerns the estimation of the minimum sample size required to achieve reliable classification performance in the presence of missing data. In clinical research, where small samples and incomplete data often coexist, understanding this relationship is crucial. Salazar et al. [
32] recently proposed a proxy learning curve method based on the Bayes classifier to estimate the minimum number of samples needed to reach a desired classification accuracy. Although originally developed for complete data, this theoretical framework could be extended to imputed datasets. Integrating such approaches into future research would help to quantify the interplay between sample size, missingness, and model robustness in biomedical machine learning.
5. Conclusions
This study systematically evaluated the impacts of five imputation methods—mean, median, k-Nearest Neighbors (kNNs), Multiple Imputation by Chained Equations (MICE), and missForest (MF)—on the classification of Mild Cognitive Impairment (MCI) and Alzheimer’s Disease (AD) using multimodal data from the ADNI cohort. Classification was performed using three machine learning models: Random Forest (RF), Logistic Regression (LR), and Support Vector Machine (SVM). All models were trained on imputed datasets and tested on a clean, independent test set without missing values to ensure unbiased performance assessment.
Our findings show that MICE consistently yielded the highest classification accuracy with RF and LR, while SVM achieved its best performance with median imputation. McNemar’s test revealed significant differences in misclassification patterns between RF and the other classifiers, highlighting how model architecture interacts with the chosen imputation method. Although simple statistical imputations (mean, median) provided acceptable results, more sophisticated approaches like MICE demonstrated clear advantages in maintaining classification accuracy and generalizability.
Furthermore, the analysis of feature importance revealed that certain features retained their discriminative power across imputation methods, while others were more sensitive to the chosen strategy, underscoring the influence of imputation not only on overall performance but also on model interpretability.
These results emphasize the need to select imputation strategies that are tailored to both the data structure and the model in use. Future research should consider the joint optimization of imputation and classification workflows, explore deep learning-based imputation techniques, and extend validation to longitudinal datasets and real-world clinical settings. Such integration is essential for developing robust, interpretable, and reproducible machine learning pipelines in the context of neurodegenerative disease diagnostics.





{kind=link}
{kind=link}
{kind=link}
{kind=link}