A New Approach of Hybrid Bee Colony Optimized Neural Computing to Estimate the Soil Compression Coefficient for a Housing Construction Project

 , and
, and 
Abstract
1. Introduction
2. Background of the Employed Artificial Intelligence Algorithms
2.1. Neural Computing Model
2.2. Artificial Bee Colony for Solving Continuous Optimization
3. Description of the Study Site and Collected Dataset
4. Proposed ANN with Hybridization of ABC and LM Algorithms for Compression Coefficient Estimation
5. Results and Discussions
6. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahmed, S.I.; Siddiqua, S. Compressibility behavior of soils: A statistical approach. Geotech. Geologi. Eng. 2016, 34, 2063–2070. [Google Scholar] [CrossRef]
- Chummar, A.V. Excessive settlement in buildings. In Proceedings of the First International Conference on Case Histories in Geotechnical Engineering, St. Louis, MO, USA, 6–11 May 1984. [Google Scholar]
- Srivastava, A.; Goyal, C.R.; Jain, A. Review of causes of foundation failures and their possible preventive and remedial measures. In Proceedings of the 4th KKU—International Engineering Conference, (KKU-IENC2012), Khon Kaen, Thailand, 10–11 May 2012. [Google Scholar]
- Anastasopoulos, I. Structural damage of a 5-storey building: Differential settlement due to construction of an adjacent building or because of construction defects? In Proceedings of the Seventh International Conference on Case Histories in Geotechnical Engineering, Chicago, IL, USA, 1–4 May 2013. [Google Scholar]
- Charles, R.D. Case history of two building experience large post construction settlements—Wilmington, delaware. In Proceedings of the Fourth International Conference on Case Histories in Geotechnical Engineering, St. Louis, MO, USA, 9–12 March 1998. [Google Scholar]
- Zhu, M.; Gary, T.B.; Bachus, R.C. Assessment of a building settlement and the litigation process—A case study. In Proceedings of the Sixth Congress on Forensic Engineering, San Francisco, CA, USA, 31 October –3 November 2012. [Google Scholar]
- Kim, Y.J.; Gajan, S.; Saafi, M. Settlement rehabilitation of a 35-year-old building: Case study integrated with analysis and implementation. Pract. Periodi. Struct. Des. Constr. 2011, 16, 215–222. [Google Scholar] [CrossRef]
- Mohammadzadeh, D.; Bolouri, B.J.; Alavi, A.H. An evolutionary computational approach for formulation of compression index of fine-grained soils. Eng. Appl. Artif. Intell. 2014, 33, 58–68. [Google Scholar] [CrossRef]
- Gulhati, S.K.; Datta, M. Geotechnical Engineering; Tata Mc Graw Hill Publishing Company Limited: New York, NY, USA, 2005. [Google Scholar]
- Mohammadzadeh, S.D.; Bolouri, B.J.; Vafaee, J.Y.S.H.; Alavi, A.H. Deriving an intelligent model for soil compression index utilizing multi-gene genetic programming. Environ. Earth Sci. 2016, 75, 262. [Google Scholar] [CrossRef]
- Tiwari, B.; Ajmera, B. New correlation equations for compression index of remolded clays. J. Geotech. Geoenviron. Eng. 2012, 138, 757–762. [Google Scholar] [CrossRef]
- Mohammadzadeh, S.; Kazemi, S.-F.; Mosavi, A.; Nasseralshariati, E.; Tah, J.H. Prediction of compression index of fine-grained soils using a gene expression programming model. Infrastructures 2019, 4, 26. [Google Scholar] [CrossRef]
- Terzaghi, K.; Peck, R.B.; Mesri, G. Soil Mechanics in Engineering Practice; John Wiley & Sons, Inc: Hoboken, NJ, USA, 1996. [Google Scholar]
- Polidori, E. On the intrinsic compressibility of common clayey soils. Eur. J. Environ. Civil Eng. 2015, 19, 27–47. [Google Scholar] [CrossRef]
- Puri, N.; Prasad, H.D.; Jain, A. Prediction of geotechnical parameters using machine learning techniques. Proced. Comput. Sci. 2018, 125, 509–517. [Google Scholar] [CrossRef]
- Moayed, R.Z.; Kordnaeij, A.; Mola-Abasi, H. Compressibility indices of saturated clays by group method of data handling and genetic algorithms. Neural Comput. Appl. 2017, 28, 551–564. [Google Scholar] [CrossRef]
- Kurnaz, T.F.; Dagdeviren, U.; Yildiz, M.; Ozkan, O. Prediction of compressibility parameters of the soils using artificial neural network. SpringerPlus 2016, 5, 1801. [Google Scholar] [CrossRef]
- Gupta, S.C.; Allmaras, R.R. Models to Assess the Susceptibility of Soils to Excessive Compaction; Springer: New York, NY, USA, 1987; pp. 65–100. [Google Scholar]
- Kirts, S.; Panagopoulos, O.P.; Xanthopoulos, P.; Nam, B.H. Soil-compressibility prediction models using machine learning. J. Comput. Civ. Eng. 2018, 32, 04017067. [Google Scholar] [CrossRef]
- McNabb, D.H.; Boersma, L. Nonlinear model for compressibility of partly saturated soils. Soil Sci. Soc. Am. J. 1996, 60, 333–341. [Google Scholar] [CrossRef]
- Pham, B.T.; Son, L.H.; Hoang, T.-A.; Nguyen, D.-M.; Tien Bui, D. Prediction of shear strength of soft soil using machine learning methods. Catena 2018, 166, 181–191. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.-D.; Nhu, V.-H. A swarm intelligence-based machine learning approach for predicting soil shear strength for road construction: A case study at trung luong national expressway project (vietnam). Eng. Comput. 2018, 35, 955–965. [Google Scholar] [CrossRef]
- Hashemi Jokar, M.; Mirasi, S. Using adaptive neuro-fuzzy inference system for modeling unsaturated soils shear strength. Soft Comput. 2017, 22, 4493–4510. [Google Scholar] [CrossRef]
- Mohammad Emami, N.; Rasool Amiri, K.; Mohammad Khodaiy, A.; Mahdi Shahbazi, R. Metaheuristic optimization approaches to predict shear-wave velocity from conventional well logs in sandstone and carbonate case studies. J. Geophys. Eng. 2018, 15, 1071. [Google Scholar]
- Chou, J.-S.; Yang, K.-H.; Lin, J.-Y. Peak shear strength of discrete fiber-reinforced soils computed by machine learning and metaensemble methods. J. Comput. Civ. Eng. 2016, 30, 04016036. [Google Scholar] [CrossRef]
- Tang, X.W.; Bai, X.; Hu, J.L.; Qiu, J.N. Assessment of liquefaction-induced hazards using bayesian networks based on standard penetration test data. Nat. Hazards Earth Syst. Sci. 2018, 18, 1451–1468. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Bui, D.T. Predicting earthquake-induced soil liquefaction based on a hybridization of kernel fisher discriminant analysis and a least squares support vector machine: A multi-dataset study. Bull. Eng. Geol. Environ. 2018, 77, 191–204. [Google Scholar] [CrossRef]
- Prayogo, D.; Susanto, Y.T.T. Optimizing the prediction accuracy of friction capacity of driven piles in cohesive soil using a novel self-tuning least squares support vector machine. Adv. Civ. Eng. 2018, 2018, 9. [Google Scholar] [CrossRef]
- Moayedi, H.; Hayati, S. Applicability of a cpt-based neural network solution in predicting load-settlement responses of bored pile. Int. J. Geomech. 2018, 18, 06018009. [Google Scholar] [CrossRef]
- Tekin, E.; Akbas, S.O. Predicting groutability of granular soils using adaptive neuro-fuzzy inference system. Neural Comput. Appl. 2017, 31, 1091–1101. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Tien Bui, D.; Liao, K.-W. Groutability estimation of grouting processes with cement grouts using differential flower pollination optimized support vector machine. Appl. Soft Comput. 2016, 45, 173–186. [Google Scholar] [CrossRef]
- Bishop, C.M. Information Science and Statistics. In Pattern Recognition and Machine Learning; Jordan, M.I., Robert, N., Bernhard, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford university press: Oxford, UK, 1995. [Google Scholar]
- Shahin, M.A. State-of-the-art review of some artificial intelligence applications in pile foundations. Geosci. Front. 2016, 7, 33–44. [Google Scholar] [CrossRef]
- Park, H.I.; Lee, S.R. Evaluation of the compression index of soils using an artificial neural network. Comput. Geotech. 2011, 38, 472–481. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Chen, C.-T.; Liao, K.-W. Prediction of chloride diffusion in cement mortar using multi-gene genetic programming and multivariate adaptive regression splines. Measurement 2017, 112, 141–149. [Google Scholar] [CrossRef]
- Tran, T.-H.; Hoang, N.-D. Predicting colonization growth of algae on mortar surface with artificial neural network. J. Comput. Civ. Eng. 2016, 30, 04016030. [Google Scholar] [CrossRef]
- Montavon, G.; Orr, G.; Müller, K.-R. Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Pham, B.T.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. Hybrid integration of multilayer perceptron neural networks and machine learning ensembles for landslide susceptibility assessment at himalayan area (india) using gis. Catena 2017, 149 Pt 1, 52–63. [Google Scholar] [CrossRef]
- Georgiou, P.; Plati, C.; Loizos, A. Soft computing models to predict pavement roughness: A comparative study. Adv. Civ. Eng. 2018, 2018, 8. [Google Scholar] [CrossRef]
- Ojha, V.K.; Abraham, A.; Snášel, V. Metaheuristic design of feedforward neural networks: A review of two decades of research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar] [CrossRef]
- Göçken, M.; Özçalıcı, M.; Boru, A.; Dosdoğru, A.T. Integrating metaheuristics and artificial neural networks for improved stock price prediction. Expert Syst. Appl. 2016, 44, 320–331. [Google Scholar] [CrossRef]
- Hacibeyoglu, M.; Ibrahim, M.H. A novel multimean particle swarm optimization algorithm for nonlinear continuous optimization: Application to feed-forward neural network training. Sci. Program. 2018, 2018, 9. [Google Scholar] [CrossRef]
- Rere, L.M.R.; Fanany, M.I.; Arymurthy, A.M. Metaheuristic algorithms for convolution neural network. Comput. Intell. Neurosci. 2016, 2016, 13. [Google Scholar] [CrossRef]
- Taheri, K.; Hasanipanah, M.; Golzar, S.B.; Majid, M.Z.A. A hybrid artificial bee colony algorithm-artificial neural network for forecasting the blast-produced ground vibration. Eng. Comput. 2017, 33, 689–700. [Google Scholar] [CrossRef]
- Ghasemiyeh, R.; Moghdani, R.; Sana, S.S. A hybrid artificial neural network with metaheuristic algorithms for predicting stock price. Cybern. Syst. 2017, 48, 365–392. [Google Scholar] [CrossRef]
- Tien Bui, D.; Le, H.V.; Hoang, N.-D. Gis-based spatial prediction of tropical forest fire danger using a new hybrid machine learning method. Ecol. Inform. 2018, 48, 104–116. [Google Scholar] [CrossRef]
- Kose, U. An ant-lion optimizer-trained artificial neural network system for chaotic electroencephalogram (eeg) prediction. Appl. Sci. 2018, 8, 1613. [Google Scholar] [CrossRef]
- Piotrowski, A.P. Differential evolution algorithms applied to neural network training suffer from stagnation. Appl. Soft Comput. 2014, 21, 382–406. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (abc) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (abc) algorithm and applications. Artif. Intell. Rev. 2014, 42, 21–57. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Hoang, N.-D.; Thanh, N.Q.; Nguyen, D.B.; Van Liem, N.; Pradhan, B. Spatial prediction of rainfall-induced landslides for the lao cai area (vietnam) using a hybrid intelligent approach of least squares support vector machines inference model and artificial bee colony optimization. Landslides 2017, 14, 447–458. [Google Scholar] [CrossRef]
- Ghaleini, E.N.; Koopialipoor, M.; Momenzadeh, M.; Sarafraz, M.E.; Mohamad, E.T.; Gordan, B. A combination of artificial bee colony and neural network for approximating the safety factor of retaining walls. Eng. Comput. 2018, 35, 647–658. [Google Scholar] [CrossRef]
- Baldo, N.; Manthos, E.; Pasetto, M. Analysis of the mechanical behaviour of asphalt concretes using artificial neural networks. Adv. Civ. Eng. 2018, 2018, 17. [Google Scholar] [CrossRef]
- Tien Bui, D.; Nhu, V.-H.; Hoang, N.-D. Prediction of soil compression coefficient for urban housing project using novel integration machine learning approach of swarm intelligence and multi-layer perceptron neural network. Adv. Eng. Inform. 2018, 38, 593–604. [Google Scholar] [CrossRef]
- Moayedi, H.; Mosallanezhad, M.; Rashid, A.S.A.; Jusoh, W.A.W.; Muazu, M.A. A systematic review and meta-analysis of artificial neural network application in geotechnical engineering: Theory and applications. Neural Comput. Appl. 2018, 1–24. [Google Scholar] [CrossRef]
- Sulewska, M.J. Applying artificial neural networks for analysis of geotechnical problems. Comput. Assist. Method. Eng. Sci. 2017, 18, 231–241. [Google Scholar]
- Tien Bui, D.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2019, 2019, 134413. [Google Scholar] [CrossRef]
- Ngo, P.T.; Hoang, N.D.; Pradhan, B.; Nguyen, Q.K.; Tran, X.T.; Nguyen, Q.M.; Nguyen, V.N.; Samui, P.; Tien Bui, D. A novel hybrid swarm optimized multilayer neural network for spatial prediction of flash floods in tropical areas using Sentinel-1 SAR imagery and geospatial data. Sensors 2018, 18, 3704. [Google Scholar] [CrossRef]
- Zhongya, Z.; Xiaoguang, J. Prediction of peak velocity of blasting vibration based on artificial neural network optimized by dimensionality reduction of fa-miv. Math. Probl. Eng. 2018, 2018, 12. [Google Scholar] [CrossRef]
- Gordan, B.; Koopialipoor, M.; Clementking, A.; Tootoonchi, H.; Tonnizam Mohamad, E. Estimating and optimizing safety factors of retaining wall through neural network and bee colony techniques. Eng. Comput. 2018, 35, 945–954. [Google Scholar] [CrossRef]
- Lera, G.; Pinzolas, M. Neighborhood based Levenberg-Marquardt algorithm for neural network training. IEEE Trans. Neural Netw. 2002, 13, 1200–1203. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Bui, K.T.T.; Prakash, I.; Chapi, K.; Bui, D.T. A novel artificial intelligence approach based on Multi-layer Perceptron Neural Network and Biogeography-based Optimization for predicting coefficient of consolidation of soil. Catena 2019, 173, 302–311. [Google Scholar] [CrossRef]
- Clayton, C.R. The Standard Penetration Test (spt): Methods and Use; Construction Industry Research and Information Association: London, UK, 1995. [Google Scholar]
- Matwork. Statistics and Machine Learning Toolbox User’s Guide. Matwork Inc.; Available online: https://www.mathworks.com/help/pdf_doc/stats/stats.pdf (accessed on 28 April 2018).
- Heaton, J. Volume 3 Deep Learning and Neural Networks. In Artificial Intelligence for Humans; Heaton Research: St. Louis, MO, USA, 2015. [Google Scholar]
- Nhu, V.-H.; Samui, P.; Kumar, D.; Singh, A.; Hoang, N.-D.; Bui, D.T. Advanced soft computing techniques for predicting soil compression coefficient in engineering project: A comparative study. Eng. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Snedecor, G.W.; Cochran, W.G. Statistical Methods, 8th ed.; Iowa State University Press: Iowa City, Iowa, 1989. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
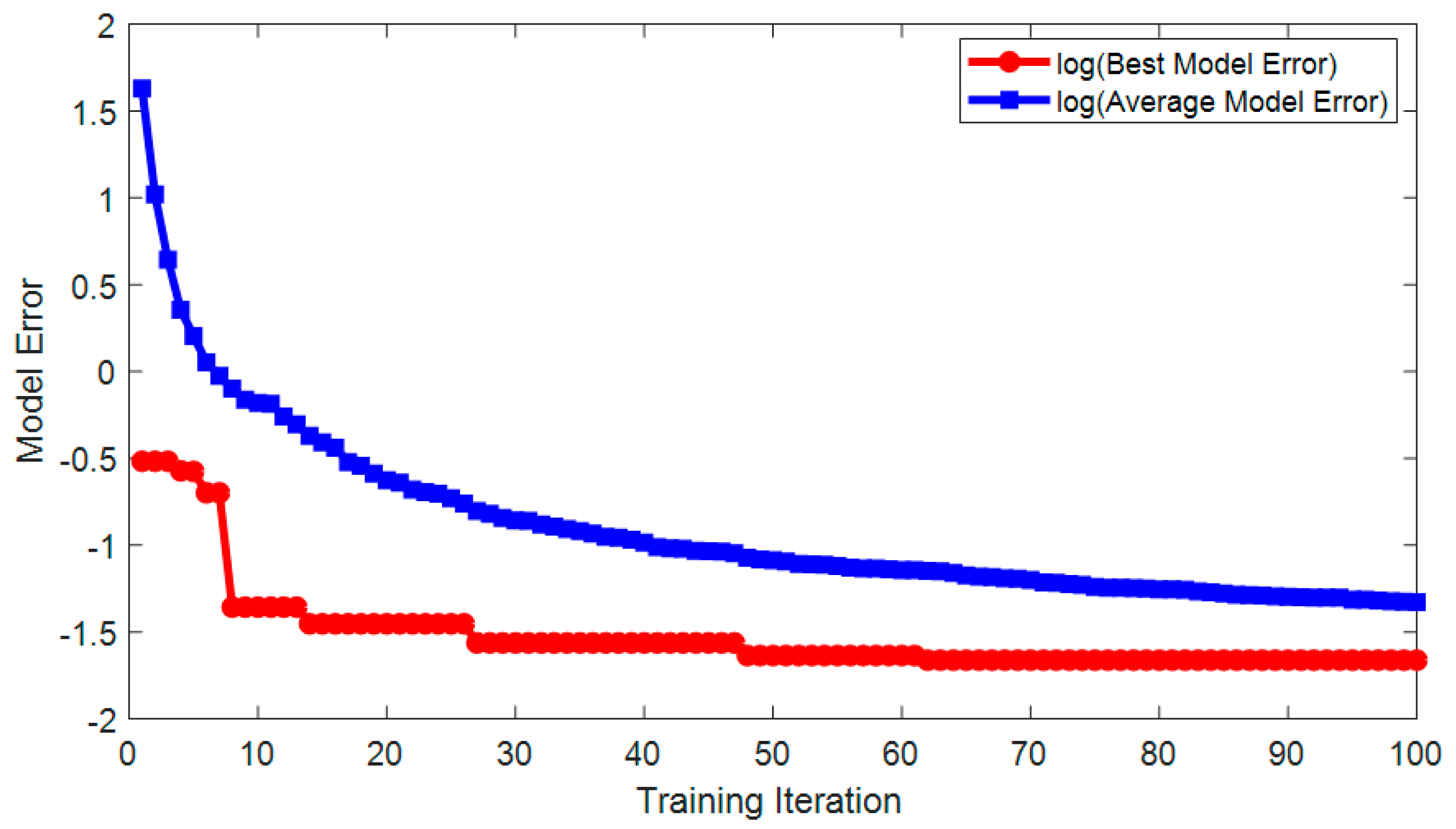{kind=link}
{kind=link}
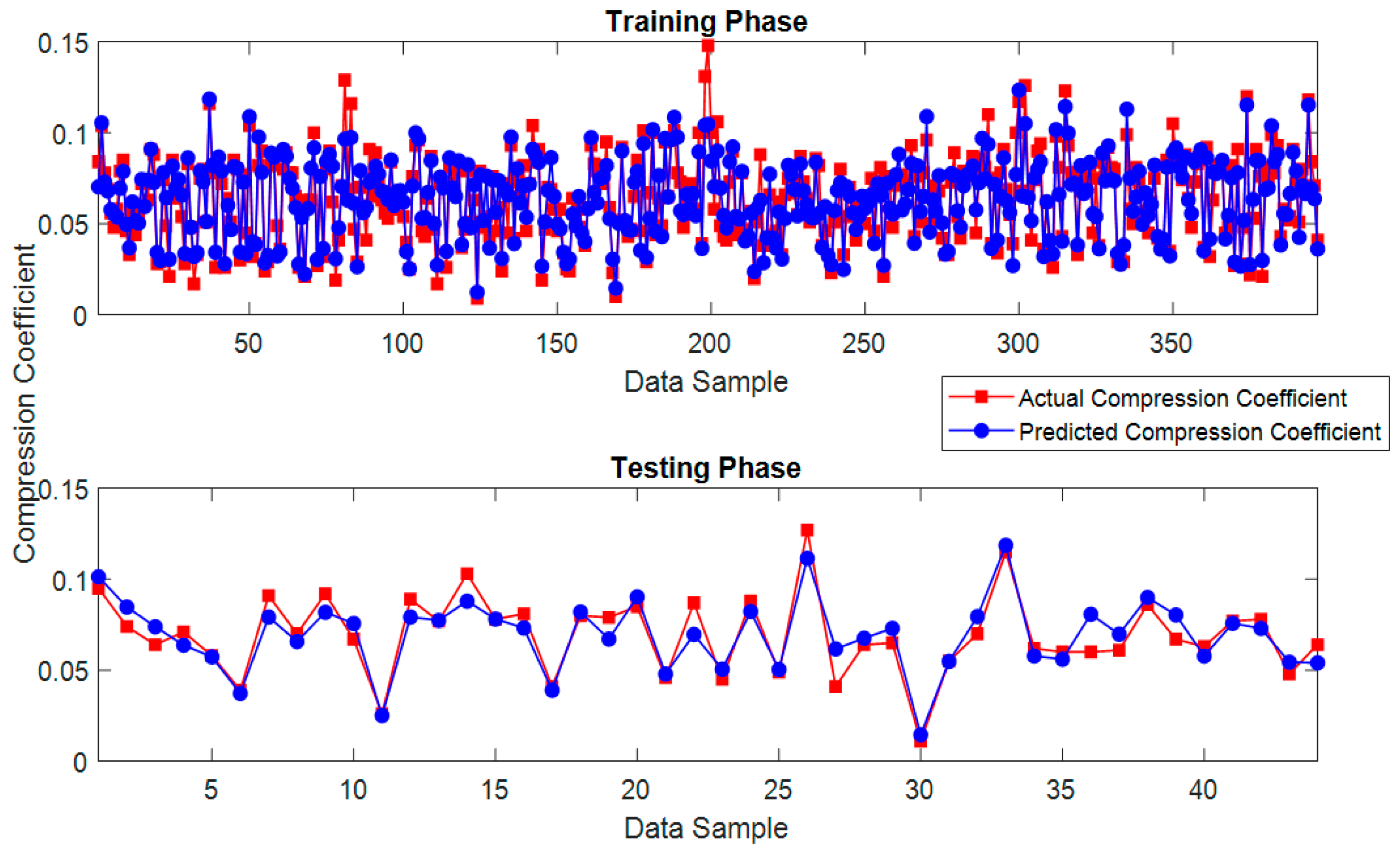{kind=link}
{kind=link}
| Variables | Unit | Notation | Min | Mean | Median | Std | Skewness | Kurtosis | Max |
|---|---|---|---|---|---|---|---|---|---|
| Sample depth | m | X1 | 1.80 | 17.99 | 17.80 | 10.02 | 0.39 | 2.88 | 52.80 |
| Sand percentage | % | X2 | 17.90 | 33.31 | 30.30 | 9.95 | 1.90 | 6.64 | 71.00 |
| Loam percentage | % | X3 | 22.10 | 43.32 | 44.80 | 5.61 | −1.72 | 5.95 | 51.40 |
| Clay percentage | % | X4 | 5.20 | 23.22 | 24.10 | 5.50 | −1.30 | 5.24 | 37.50 |
| Moisture content | % | X5 | 20.30 | 41.38 | 42.00 | 8.05 | −0.24 | 2.78 | 63.50 |
| Wet density | g/cm3 | X6 | 1.55 | 1.75 | 1.74 | 0.08 | 0.84 | 4.23 | 2.05 |
| Dry density | g/cm3 | X7 | 0.95 | 1.25 | 1.23 | 0.13 | 0.80 | 3.53 | 1.67 |
| Void Ratio | Unitless | X8 | 0.58 | 1.15 | 1.16 | 0.20 | −0.26 | 3.12 | 1.79 |
| Liquid limit | % | X9 | 23.20 | 43.92 | 44.50 | 5.88 | −0.60 | 3.52 | 58.30 |
| Plastic limit | % | X10 | 16.80 | 30.23 | 30.50 | 5.01 | −0.20 | 2.63 | 43.60 |
| Plastic index | % | X11 | 5.20 | 13.69 | 14.10 | 2.61 | −1.40 | 5.21 | 19.10 |
| Liquid index | Unitless | X12 | 0.11 | 0.81 | 0.77 | 0.29 | 0.85 | 4.36 | 1.99 |
| Compression coefficient | cm2/kG | Y | 0.01 | 0.06 | 0.07 | 0.02 | 0.15 | 2.89 | 0.15 |
| Data | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | Y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.00 | 3.80 | 37.30 | 44.70 | 18.00 | 50.10 | 1.69 | 1.13 | 1.32 | 51.30 | 39.20 | 12.10 | 0.90 | 0.09 |
| 2.00 | 5.80 | 45.90 | 37.00 | 17.10 | 48.30 | 1.65 | 1.11 | 1.38 | 49.50 | 37.20 | 12.30 | 0.90 | 0.08 |
| 3.00 | 7.80 | 40.20 | 40.30 | 19.50 | 47.80 | 1.72 | 1.16 | 1.27 | 48.40 | 36.90 | 11.50 | 0.95 | 0.07 |
| 4.00 | 9.80 | 33.30 | 45.80 | 20.90 | 52.20 | 1.63 | 1.07 | 1.43 | 53.20 | 39.10 | 14.10 | 0.93 | 0.09 |
| 5.00 | 3.80 | 43.10 | 41.30 | 15.60 | 46.10 | 1.69 | 1.16 | 1.28 | 47.50 | 37.10 | 10.40 | 0.87 | 0.09 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 437.00 | 45.40 | 38.50 | 16.10 | 45.20 | 1.71 | 1.18 | 1.25 | 46.40 | 35.20 | 11.20 | 0.89 | 0.08 | 0.08 |
| 438.00 | 48.40 | 35.30 | 16.30 | 42.40 | 1.68 | 1.18 | 1.25 | 43.60 | 32.70 | 10.90 | 0.89 | 0.08 | 0.04 |
| 439.00 | 40.20 | 42.60 | 17.20 | 48.20 | 1.71 | 1.15 | 1.30 | 49.20 | 36.80 | 12.40 | 0.92 | 0.07 | 0.08 |
| 440.00 | 35.50 | 42.30 | 22.20 | 42.10 | 1.73 | 1.22 | 1.18 | 43.50 | 31.60 | 11.90 | 0.88 | 0.08 | 0.03 |
| 441.00 | 44.40 | 39.70 | 15.90 | 43.90 | 1.74 | 1.21 | 1.17 | 44.20 | 33.60 | 10.60 | 0.97 | 0.06 | 0.07 |
| Phase | Performance | Prediction Models | |||
|---|---|---|---|---|---|
| ABC-LM-ANN | LM-ANN | ABC-ANN | RegTree | ||
| Training | RMSE | 0.009 | 0.009 | 0.010 | 0.005 |
| MAPE (%) | 12.117 | 11.730 | 14.674 | 6.374 | |
| MAE | 0.007 | 0.007 | 0.008 | 0.004 | |
| R2 | 0.860 | 0.873 | 0.821 | 0.955 | |
| Testing | RMSE | 0.009 | 0.010 | 0.010 | 0.010 |
| MAPE (%) | 10.705 | 12.400 | 14.029 | 12.862 | |
| MAE | 0.007 | 0.008 | 0.008 | 0.008 | |
| R2 | 0.840 | 0.811 | 0.792 | 0.810 | |
| Phase | Performance | Prediction Models | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC-LM-ANN | LM-ANN | ABC-ANN | RegTree | ||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||
| Training | RMSE | 0.008 | 0.000 | 0.009 | 0.001 | 0.011 | 0.000 | 0.005 | 0.000 |
| MAPE (%) | 10.981 | 0.453 | 11.585 | 1.246 | 15.059 | 1.053 | 5.949 | 0.332 | |
| MAE | 0.006 | 0.000 | 0.007 | 0.001 | 0.008 | 0.000 | 0.003 | 0.000 | |
| R2 | 0.876 | 0.009 | 0.869 | 0.017 | 0.811 | 0.014 | 0.962 | 0.004 | |
| Testing | RMSE | 0.010 | 0.001 | 0.010 | 0.001 | 0.012 | 0.001 | 0.012 | 0.002 |
| MAPE (%) | 12.586 | 1.822 | 13.042 | 1.520 | 16.852 | 3.561 | 15.015 | 1.965 | |
| MAE | 0.007 | 0.001 | 0.008 | 0.001 | 0.009 | 0.001 | 0.009 | 0.001 | |
| R2 | 0.841 | 0.039 | 0.817 | 0.046 | 0.788 | 0.057 | 0.744 | 0.060 | |
| (a) | ||||
| ABC-LM-ANN | LM-ANN | ABC-ANN | RegTree | |
| ABC-LM-ANN | x | 0.11792 | 0.0018945 | 1.14E−07 |
| LM-ANN | 0.11792 | x | 0.095532 | 7.83E−05 |
| ABC-ANN | 0.0018945 | 0.095532 | x | 0.020189 |
| RegTree | 1.14E−07 | 7.83E−05 | 0.020189 | x |
| (b) | ||||
| ABC-LM-ANN | LM-ANN | ABC-ANN | RegTree | |
| ABC-LM-ANN | x | + | ++ | ++ |
| LM-ANN | - | x | + | ++ |
| ABC-ANN | -- | - | x | ++ |
| RegTree | ++ | ++ | ++ | x |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samui, P.; Hoang, N.-D.; Nhu, V.-H.; Nguyen, M.-L.; Ngo, P.T.T.; Bui, D.T. A New Approach of Hybrid Bee Colony Optimized Neural Computing to Estimate the Soil Compression Coefficient for a Housing Construction Project. Appl. Sci. 2019, 9, 4912. https://doi.org/10.3390/app9224912
Samui P, Hoang N-D, Nhu V-H, Nguyen M-L, Ngo PTT, Bui DT. A New Approach of Hybrid Bee Colony Optimized Neural Computing to Estimate the Soil Compression Coefficient for a Housing Construction Project. Applied Sciences. 2019; 9(22):4912. https://doi.org/10.3390/app9224912
Chicago/Turabian StyleSamui, Pijush, Nhat-Duc Hoang, Viet-Ha Nhu, My-Linh Nguyen, Phuong Thao Thi Ngo, and Dieu Tien Bui. 2019. "A New Approach of Hybrid Bee Colony Optimized Neural Computing to Estimate the Soil Compression Coefficient for a Housing Construction Project" Applied Sciences 9, no. 22: 4912. https://doi.org/10.3390/app9224912
APA StyleSamui, P., Hoang, N.-D., Nhu, V.-H., Nguyen, M.-L., Ngo, P. T. T., & Bui, D. T. (2019). A New Approach of Hybrid Bee Colony Optimized Neural Computing to Estimate the Soil Compression Coefficient for a Housing Construction Project. Applied Sciences, 9(22), 4912. https://doi.org/10.3390/app9224912