Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network



Abstract

1. Introduction
2. Related work
2.1. Manipulated and Computer-Generated Face Image Detection Using CNN
2.2. Generative Adversarial Networks (GANs)
3. Preliminary
3.1. Generative Adversarial Network
3.2. Imbalanced Scenario
4. Methodology
4.1. The Proposed CGFace Model
4.1.1. Dropout Layer
4.1.2. Batch Normalization
4.1.3. Adam Optimization
4.2. Gradient Boosting for the Imbalanced Data Problem
4.3. Detailed Implementation of the Two Dataset
4.3.1. Equilibrium
4.3.2. Balancing the Losses
4.3.3. Convergence Measure
- should go to 0 as images are reconstructed better and better after each time step.
- ) should stay close to 0 (so that the losses are balanced).
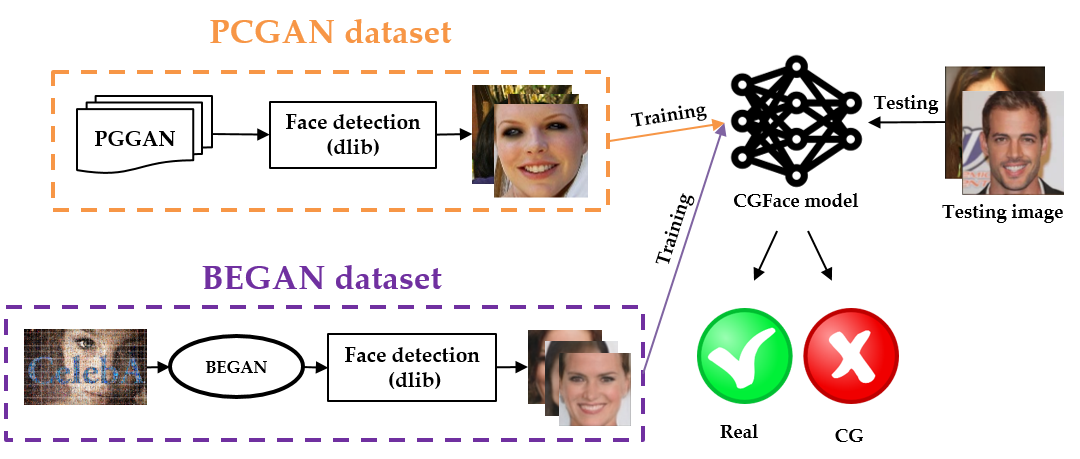
4.4. Face Detection Module
5. Experimental Results
5.1. Evaluation Metric: ROC Curve
5.2. Dataset
5.2.1. PCGAN
5.2.2. BEGAN
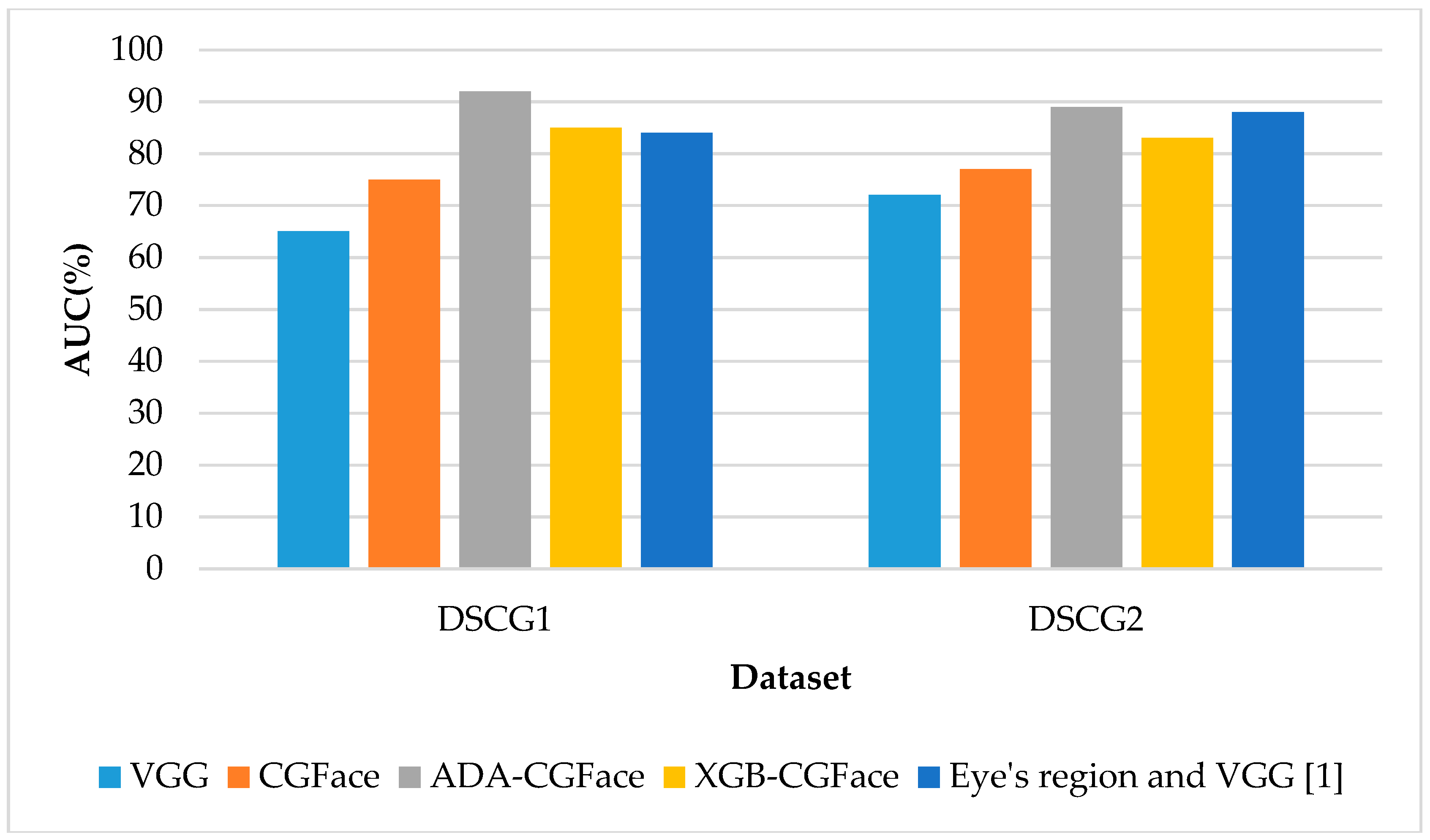
5.3. Evaluation of the CGFace Model
5.4. Evaluation of the CGFace, IF-CGFace Model on the PCGAN Dataset
5.4.1. Balanced Scenario
5.4.2. Imbalanced Scenario
5.5. Compare the Model Performance with Recent Researches
5.6. Training and Validation Time Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Carvalho, T.; de Rezende, E.R.; Alves, M.T.; Balieiro, F.K.; Sovat, R.B. Exposing Computer Generated Images by Eye’s Region Classification via Transfer Learning of VGG19 CNN. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. Preprint arXiv, 2017; arXiv:1710.10196. [Google Scholar]
- Huynh, H.D.; Dang, L.M.; Duong, D. A New Model for Stock Price Movements Prediction Using Deep Neural Network. In Proceedings of the Eighth International Symposium on Information and Communication Technology, Nha Trang City, Vietnam, 7–8 December 2017. [Google Scholar]
- Nguyen, T.N.; Thai, C.H.; Nguyen-Xuan, H.; Lee, J. Geometrically nonlinear analysis of functionally graded material plates using an improved moving Kriging meshfree method based on a refined plate theory. Compos. Struct. 2018, 193, 268–280. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Thai, C.H.; Nguyen-Xuan, H.; Lee, J. NURBS-based analyses of functionally graded carbon nanotube-reinforced composite shells. Compos. Struct. 2018. [Google Scholar] [CrossRef]
- Bunk, J.; Bappy, J.H.; Mohammed, T.M.; Nataraj, L.; Flenner, A.; Manjunath, B.S.; Chandrasekaran, S.; Roy-Chowdhury, A.K.; Peterson, L. Detection and localization of image forgeries using resampling features and deep learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image Splicing Localization Using a Multi-Task Fully Convolutional Network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning Rich Features for Image Manipulation Detection. Preprint arXiv, 2018; arXiv:1805.04953. [Google Scholar]
- Han, X.; Morariu, V.; Larry Davis, P.I. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. MesoNet: A Compact Facial Video Forgery Detection Network. In Proceedings of the 2018 IEEE Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces. Preprint arXiv, 2018; arXiv:1803.09179. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Wang, C.; Xu, C.; Wang, C.; Tao, D. Perceptual adversarial networks for image-to-image transformation. IEEE Trans. Image Process. 2018, 27, 4066–4079. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2, p. 4. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.H. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1. [Google Scholar]
- Dang, L.M.; Hassan, S.I.; Im, S.; Mehmood, I.; Moon, H. Utilizing text recognition for the defects extraction in sewers CCTV inspection videos. Comput. Ind. 2018, 99, 96–109. [Google Scholar] [CrossRef]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2016; pp. 217–225. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017. [Google Scholar] [CrossRef]
- Berthelot, D.; Schumm, T.; Metz, L. BEGAN: boundary equilibrium generative adversarial networks. Preprint arXiv, 2017; arXiv:1703.10717. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. Preprint arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Preprint arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. Preprint arXiv, 2012; arXiv:1212.5701. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
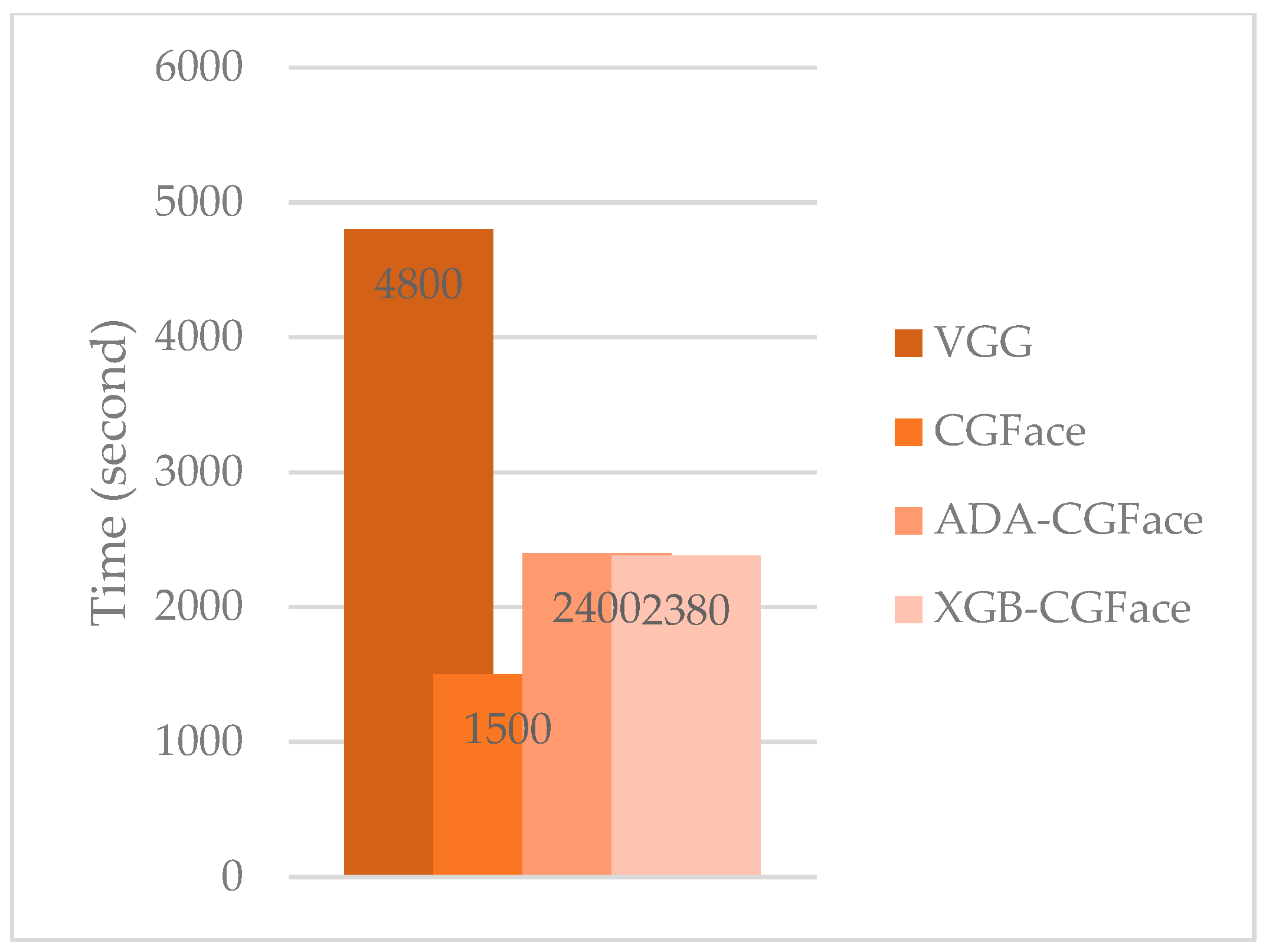{kind=link}
| Layer | Configuration | Output (Rows, Cols, Channels) |
|---|---|---|
| Input | 64 × 64 | |
| Convolution_1 | 5 × 5 with 8 kernels | (60, 60, 8) |
| Convolution_2 | 5 × 5 with 8 kernels | (56, 56, 8) |
| Maxpool_1 | 2 × 2 | (28, 28, 8) |
| Dropout_1 | Probability at 0.2 | (28, 28, 8) |
| Convolution_3 | 3 × 3 with 16 kernels | (26, 26, 16) |
| Maxpool_2 | 2 × 2 | (13, 13, 16) |
| Dropout_2 | Probability at 0.2 | (13, 13, 16) |
| Convolution_4 | 3 × 3 with 16 kernels | (11, 11, 32) |
| Maxpool_3 | 2 × 2 | (5, 5, 32) |
| Dropout_3 | Probability at 0.2 | (5, 5, 32) |
| Convolution_5 | 3 × 3 with 16 kernels | (3, 3, 64) |
| Dropout_4 | Probability at 0.2 | (3, 3, 64) |
| Flatten | Length: 576 | (576) |
| Dense | Length: 256 | (256) |
| Dense | Length: 2 | (2) |
| Prediction | |||
|---|---|---|---|
| Normal | CG | ||
| Actual | Normal | TP (True positive) | FN (False negative) |
| CG | FP (False positive) | TN (True negative) | |
| Model | Classifier | Accuracy (%) | AUC |
|---|---|---|---|
| VGG16 | Softmax | 76 | 80.5 |
| CGFace | Softmax | 98 | 81 |
| ADA-CGFace | AdaBoost | 97.3 | 89.4 |
| XGB-CGFace | XGB | 92.6 | 84.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, L.M.; Hassan, S.I.; Im, S.; Lee, J.; Lee, S.; Moon, H. Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network. Appl. Sci. 2018, 8, 2610. https://doi.org/10.3390/app8122610
Dang LM, Hassan SI, Im S, Lee J, Lee S, Moon H. Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network. Applied Sciences. 2018; 8(12):2610. https://doi.org/10.3390/app8122610
Chicago/Turabian StyleDang, L. Minh, Syed Ibrahim Hassan, Suhyeon Im, Jaecheol Lee, Sujin Lee, and Hyeonjoon Moon. 2018. "Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network" Applied Sciences 8, no. 12: 2610. https://doi.org/10.3390/app8122610
APA StyleDang, L. M., Hassan, S. I., Im, S., Lee, J., Lee, S., & Moon, H. (2018). Deep Learning Based Computer Generated Face Identification Using Convolutional Neural Network. Applied Sciences, 8(12), 2610. https://doi.org/10.3390/app8122610