4.1. SP-EGA
This section will be used to introduce how our algorithm SP-EGA is designed when the data volume can be processed by the GPU in a single pass.
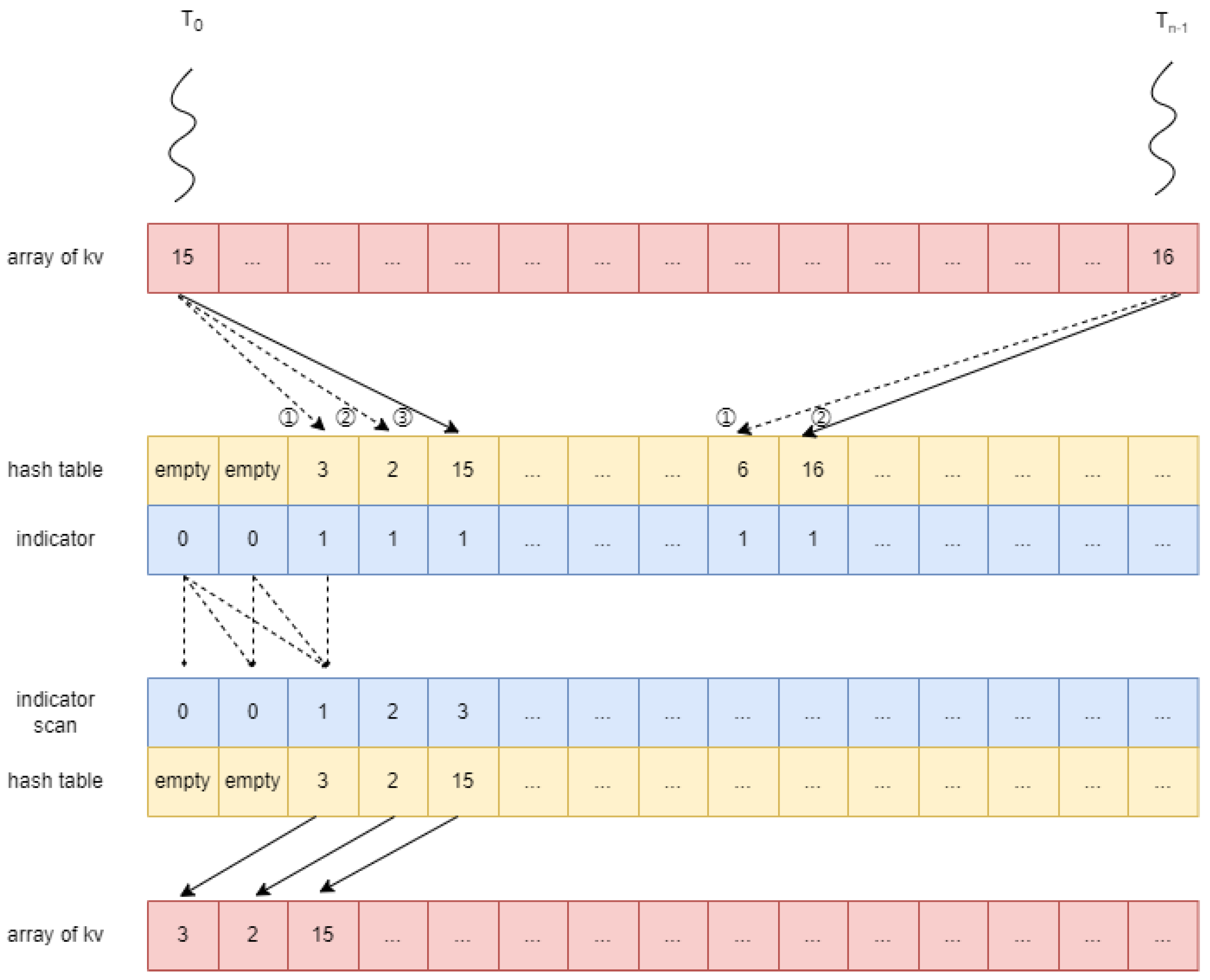
Figure 2 illustrates SP-EGA’s five-stage workflow.
SP-EGA employs three sequential memory buffers, similar to LPHGA, to maintain consistent space utilization. For clarity in explanation, we utilize distinct colors to represent each memory buffer: the first buffer is designated as the red array, the second as the yellow array, and the third as the blue array. In both the red and yellow arrays, each item corresponds to a key-value pair, while each item in the blue array is an integer. All three arrays have the same length, denoted as L.
4.1.1. Phase 1: No Probe Hash into Partial Hash Table
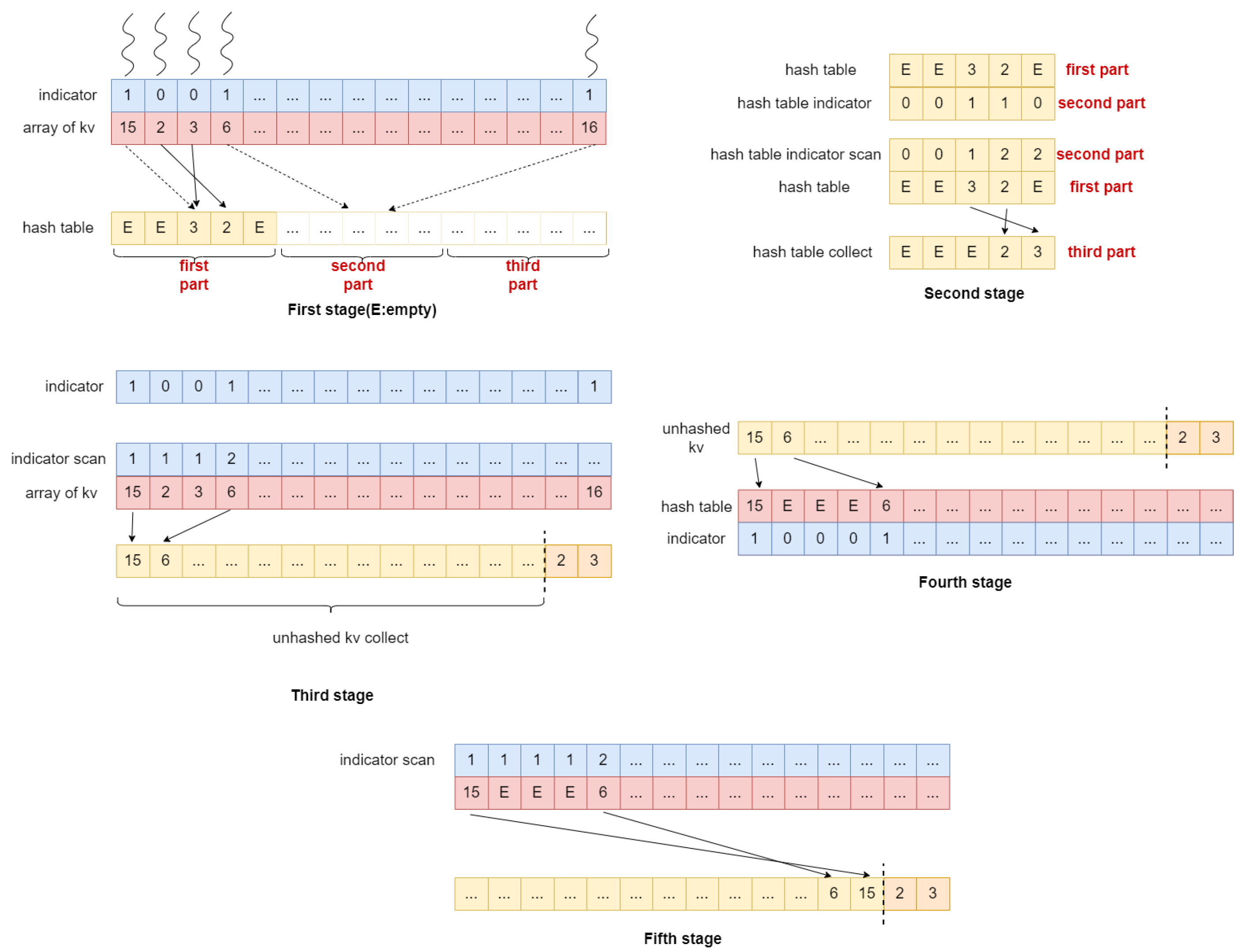
First, we clarify the roles of the three arrays in this stage. The red array is utilized to store the key-value pairs, while the blue array serves as an indicator of whether the key-value pairs in the red array have been inserted into the hash table. If a key-value pair located at index i in the red array has been inserted into the hash table, then the i-th item in the blue array is set to 0; otherwise, it is set to 1. The yellow array is divided into three parts: the first part functions as the hash table during this stage, the second part acts as the hash table indicator (where the i-th item in the hash table indicator is set to 1 if the corresponding slot in the hash table is not empty), and the third part remains unused in this stage.
Next, we describe the process of this stage. Each thread is responsible for a key-value pair and calculates the hash value of the key. Let us denote the hash value of the key as . Each thread computes the insertion position via and attempts insertion. There are three possible scenarios:
The insertion location is not within the first part of the yellow array.
The insertion location is within the first part of the yellow array, but a key is already present at that location.
The insertion location is within the first part of the yellow array, and no key is present at that location.
In scenarios (1) and (2), the key is not inserted into the hash table, and the indicator is set to 1. In scenario (3), the key is inserted into the hash table, and the indicator is set to 0.
4.1.2. Phase 2: Collect Key/Value in Hash Table
In this stage, only the yellow array is utilized. The first two parts of the yellow array function similarly to the previous stage, while the third part is designated for collecting key-value pairs from the hash table. To determine where each key-value pair should be collected, we first perform an in-place scan of the hash table indicator. Subsequently, we utilize threads to collect key-value pairs from the hash table, with each thread responsible for one item in the hash table. For thread , it first checks whether the key is empty; if it is empty, the thread returns immediately. If it is not empty, the thread reads the i-th item in the hash table indicator, which indicates the collection location of the key-value pair, and collects the key-value pair into the collection array.
4.1.3. Phase 3: Collect Unhashed Key/Value Pairs
In this stage, the blue and red arrays function similarly to the first stage. The right part of the yellow array is used to collect key-value pairs from the last stage, while the remaining part is used to collect key-value pairs that were unhashed in the first stage. The process is analogous to that of the second stage. We first perform an in-place scan of the key-value indicator array. Each thread is responsible for one key-value pair in the key-value array. For thread , it first checks if the key-value pair is unhashed by evaluating the result of . If the result equals 1, then this key-value pair is considered unhashed. If the key-value pair is unhashed, it is collected into the collection array based on the i-th item of the indicator scan result; otherwise, returns immediately.
4.1.4. Phase 4: Hash Aggregate Remaining Key/Value Pairs Using Linear Probe
In this stage, the unhashed key-value pairs have been collected into the left part of the yellow array. This stage aims to hash aggregate these key-value pairs. The red array serves as the hash table, while the blue array functions as the hash table indicator. Each thread is responsible for one key-value pair in the key-value array. For thread , it first calculates the hash value of the key. Let us denote the hash value as . The thread then calculates the insertion location in the hash table using and attempts to insert the key-value pair at this location. There are three possible scenarios:
The key at the insertion location is empty.
The key at the insertion location is the same as the key that is responsible for.
The key at the insertion location is different from the key that is responsible for.
In scenario (1), inserts the key-value pair into the hash table and sets the indicator to 1. In scenario (2), aggregates the value with the value in the hash table. In scenario (3), linearly probes the hash table to find an empty position, which leads it back to scenario (1).
4.1.5. Phase 5: Collect Key/Value Pairs in Hash Table and Combine with Previous Results
This stage is similar to the second stage. We first perform an in-place scan of the hash table indicator (blue array). Then, we collect the key-value pairs from the hash table (red array) based on the scan results and place them into positions that are close to the corresponding positions in the collection array (yellow array) from the second stage.
4.1.6. Summary
In stages one to two, SP-EGA does not perform linear probing but instead ignores the key-value pairs that require probing. This has two benefits: first, for a significant portion of key-value pairs, we do not perform linear probing; second, in the remaining stages, we have already generated some GA results (in stage one to two), which we can temporarily store and then clear the hash table. This way, when we perform GA on the remaining key-value pairs (stages three to five), since the hash table size is sufficiently large relative to the remaining key-value pairs, even if we use linear probing at this point, it will not result in excessively long probing distances. Longer probing distances mean more atomic operations, which are very costly for GPUs and can even be considered the primary overhead in the GPU GA. Through the algorithm design of SP-EGA, we significantly reduce the average probing distance for all key-value pairs. Although we need to incur some additional data movement to combine the GA results from the two stages, it is worthwhile.
4.2. MP-EGA
Consider a scenario where the volume of data exceeds the storage capacity of the GPU. In such cases, SP-EGA is no longer applicable. A viable solution is to segment the data into multiple partitions, ensuring that each partition fits within the GPU’s memory constraints. In this scenario, we designed the MP-EGA algorithm. Below, we first discuss the key design points of MP-EGA and then present the algorithm flow of MP-EGA.
Determining the optimal number of partitions is crucial. If the number of partitions is too small, some partitions may not fit into the GPU memory, leading to inefficiencies. Conversely, if the number of partitions is excessively large, we may not fully utilize the GPU’s computational capabilities. Therefore, we need a partitioning strategy that achieves balance between memory constraints and computational efficiency. Even if we choose the right number of partitions, there may still be some partitions that are too large or too small (depending on the key/val pairs distribution). We need strategies to handle these partitions that are too large or too small. Since MP-EGA is a heterogeneous algorithm, it needs to copy data back and forth between the CPU and the GPU. Thus, we need a way to reduce copying overhead.
4.2.1. Using Balls into Bins Model to Determine Number of Partitions
We can partition the data into P partitions, ensuring that each partition fits within the GPU memory, which reduces the problem to that discussed in the previous section. However, determining the optimal number of partitions is critical. Too many partitions result in smaller partition sizes, leading to insufficient GPU utilization. Additionally, an excessive number of partitions increases the number of GPU kernel invocations, which raises the fixed costs associated with these invocations. Conversely, too few partitions lead to larger partition sizes, potentially exceeding the GPU memory limits.
Although we cannot guarantee that each partition will fit within GPU memory, it is acceptable for only a very small portion of partitions to exceed this limit. Intuitively, increasing the number of partitions reduces the probability of any single partition exceeding GPU memory. We can analyze this problem using the “balls into bins” model, where we consider the group of key-value pairs as balls and the partitions as bins. Given the limited GPU memory, the number of groups in each partition is also constrained.
Let k represent the maximum number of groups allowed in each partition. Our goal is to ensure that the number of balls (key-value pairs) in each bin (partition) remains below k. While we cannot guarantee that the number of balls in some bins will not exceed k, we aim to keep the probability of this occurrence very low. Intuitively, as we increase the number of bins, the probability of any single bin exceeding k diminishes.
The question then arises: how many bins are sufficient? We have established the following theorem to address this question.
Theorem 1. Consider n balls randomly distributed across m bins. k is a positive integer greater than 1. p is a real number greater than 0 and less than 1. Let . If , then we have Proof. First, let us define some events as follows: : “bin i has at least k balls”, : “the subset whose size is k of n balls falls into the bin”, C: “at least one bin has at least k balls”, D: “all bins have at most balls”.
Suppose n balls have s subsets whose size are k; it is obvious that . We can conclude that , so we have .
Since
, we have
Since we desire that
and we have
, it is equivalent to prove
From (1) and (2), we know that if we can prove that
then we could prove (2).
From Stirling’s approximation, we have
From (3) and (5), we know that we should prove
Taking the logarithm of both sides of inequality (6), we obtain
Suppose
, then inequality (6) is equivalent to
. Since the function
f is monotonically increasing (for
), and we have
and
, there must exist
such that
We can verify that . Thus, we conclude that if , then . □
Using this theorem, we can determine the sufficient number of partitions. Assuming our hash function distributes the data randomly across partitions, we can set p to a very small value and choose the partition number as . This approach ensures that the probability of any partition exceeding GPU memory remains very low.
4.2.2. Using Feedback Load to Handle Large Partitions
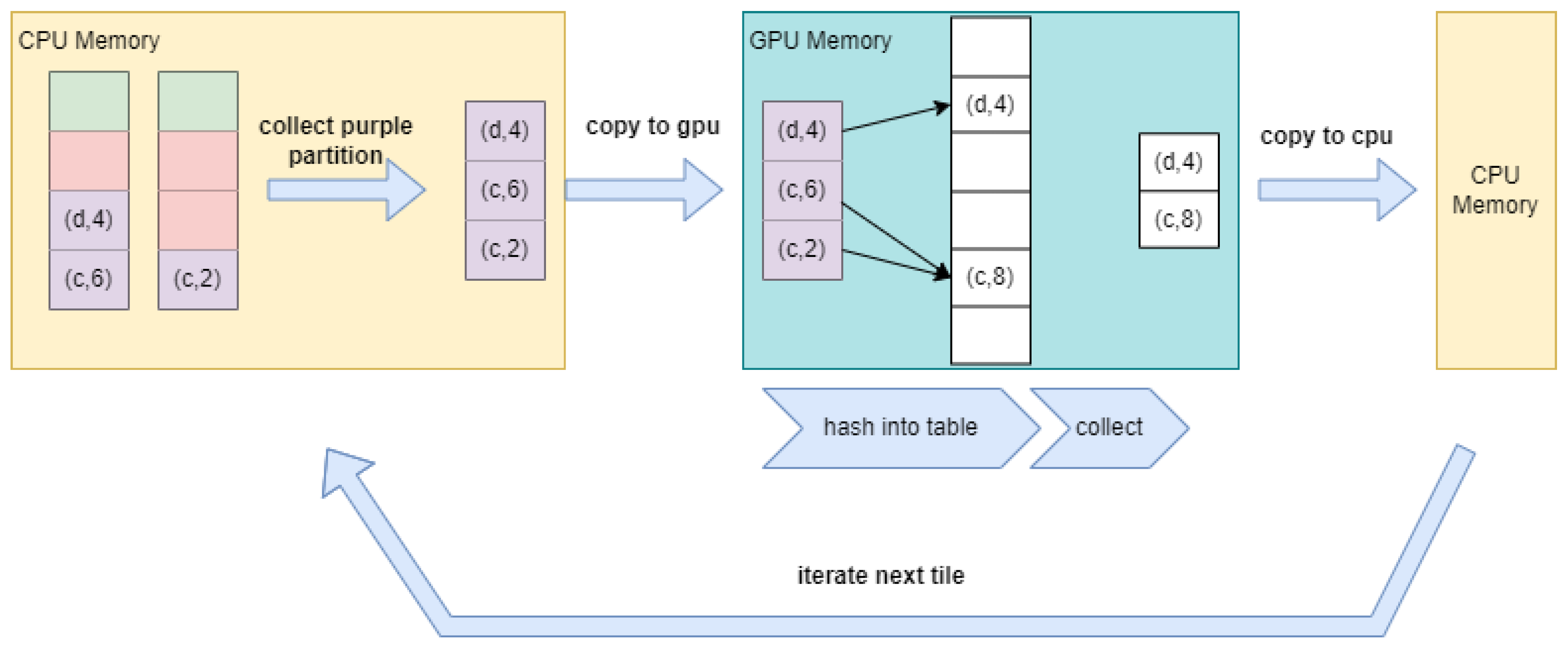
Assuming we partition the data based on the hash values of the keys, the unknown distribution of the data may result in some partitions being too large for GPU memory. In this case, we must consider how to process large partitions efficiently. One approach is to handle such partitions on the CPU; however, even if the partition is too large for the CPU memory, the GA results might still fit within GPU memory; thus, this method might miss the opportunity to leverage GPU processing, which could lead to performance degradation. Alternatively, processing the partition on the GPU may be viable, but if the GA results exceed GPU memory, we would need to reprocess the partition, incurring additional performance costs.
First, we must recognize that even if the partition size exceeds GPU memory, the GA results may still fit within the available GPU memory. Therefore, we need a method to determine whether the GA results within a partition exceed the GPU global memory limit. A natural approach is to load key-value pairs into GPU memory that correspond to the available free space in the hash table and then calculate the GA result. This process is repeated until either all key-value pairs fit in GPU memory or the hash table is full, leaving some key-value pairs unprocessed.
However, a limitation of this method is that, in later rounds, the free space in the hash table may become very small, which means fewer and fewer key-value pairs are transferred between the CPU and GPU, resulting in inefficient use of PCIe bandwidth and GPU computational resources.
Our solution introduces a dynamic memory reservation strategy that strategically allocates overflow buffers through a feedback-driven control mechanism. This approach achieves high device utilization with relatively low space overhead. We define two threshold values for the hash table: and . Here, represents the minimum acceptable load factor, while denotes the maximum load factor.
In each iteration, we first calculate how many additional key/value pairs can be loaded into the hash table based on and the number of key/value pairs already present in the hash table. We then compute the GA results for the newly loaded key/value pairs. If the number of results exceeds the threshold, we consider the hash table to be “full”, then we process the remaining key/value pairs on the CPU. Conversely, if the result count is below the threshold, we conclude that the hash table is not full and can continue loading key/value pairs based on the threshold and the current result count.
This process is repeated until all key/value pairs fit in GPU memory or the hash table is full, leaving some key/value pairs that are processed in a CPU. In each round, we ensure that the minimum data transfer volume between the CPU and GPU is no less than . By avoiding excessively small data transfer volumes between the GPU and CPU, we can more fully utilize the PCIe bandwidth.
4.2.3. Using Greedy Merge to Handle Small Partitions
When many partitions are generated, some may be very small, which is inefficient for GPU processing. Thus, it is necessary to merge small partitions into larger ones. We formalize the partition merging problem through the following mathematical framework: Let all partitions form a set, with the assumption that no partition’s size exceeds k (due to the limitations imposed by GPU global memory capacity). We can merge two partitions if the sum of their sizes is less than k. The challenge lies in merging partitions such that the total number of merged partitions is minimized. A naive approach that traverses all merging possibilities would result in unacceptable time complexity, necessitating the development of a more efficient solution.
Our core idea is to merge the two smallest partitions. The algorithm terminates when the merge size of these two partitions exceeds k. The detailed algorithm is as follows: we first construct a min-heap based on partition sizes. If the heap size is equal to 1 or the merge size of the two smallest partitions exceeds k, we terminate the algorithm. Otherwise, we pop the two smallest partitions, merge them into a new partition, and continue merging the current smallest partition until the next merge would exceed k. This process is repeated until the algorithm terminates. The pseudocode for our algorithm can be found in Algorithm 1.
Next, we will demonstrate the efficiency of the algorithm through the following theorem.
Theorem 2. Suppose , , , . Now, divide A into x disjoint subsets such that . We call this process a cut, and we define the degree of the cut as x. A cut is optimal if its degree is the smallest among all cuts. Suppose that the optimal cut is ; then, we can find a cut whose degree is y and in time complexity.
Proof. Since the total number of partitions is limited, we know that the optimal cut must exist. Suppose that the optimal cut is . In the initial situation, we can assume that set A is divided into n parts: , where , . So the initial cut is . Suppose are sorted by in ascending order. Let and . Then, we merge into one set and obtain the new cut .
Suppose that after
t such iterations, we obtain the cut
, which satisfies
. The degree of cut
is
y. Let
. Then,
Since
, we have
.
Since and , we have . Combining and , we obtain , which implies . So is the cut we found.
Now, let us analyze the time complexity. In every iteration, we merge at least two sets, so the degree of the new cut decreases by at least 1. The initial degree is n, so the number of iterations is . In each iteration, we insert the merged set into an ordered set list, and the time complexity of this operation is . Initially, we sort the initial cut, which has a time complexity of . Therefore, the overall time complexity is . □
| Algorithm 1: Partition Merge Algorithm |
![Applsci 15 03693 i001]() |
4.2.4. Using Multi-Stream to Hide Copy Latency
In this scenario, where the volume of data exceeds the storage capacity of the GPU, data must be copied from the CPU to the GPU and vice versa. If data copying and processing occur sequentially, copy latency may become a bottleneck in the overall process. To mitigate this, we need to explore strategies that allow for overlapping data transfer and computation, thereby hiding copy latency and improving overall performance.
In CUDA, a stream is defined as a sequence of commands that are executed in order. Commands within different streams can be executed concurrently, enabling efficient utilization of GPU resources.
To mitigate copy latency, we can leverage multiple streams. Since the key/value pairs in different partitions are independent, we can allocate one stream to process one partition. Each stream is managed by a dedicated CPU thread. The CPU thread first copies data from the CPU to the GPU, then the GPU processes the data and subsequently transfers the results back to the CPU.
This approach allows for overlapping data transfer and computation: while one stream is engaged in copying data between the CPU and GPU, another stream can simultaneously process data on the GPU. Consequently, this strategy effectively hides copy latency, enhancing overall performance and throughput.
4.2.5. MP-EGA Algorithm Flow
Based on the above discussions, we can comprehensively describe the algorithm flow of MP-EGA. The algorithm is divided into two phases: the partition-generating phase and the partition-processing phase.
The partition-generating phase is shown in
Figure 3. The pseudo code of this phase can be referred to in Algorithm 2. Suppose the key/val array is stored in the CPU memory, we divided the key/val array into T tiles such that each tile could be processed in GPU memory. Each tile is either processed by a GPU or CPU. In a CPU, each tile is processed by t threads. In a GPU, each tile is processed by a CUDA stream and we have s CUDA streams in order to hide copy latency. Next, we will clarify how a CPU and GPU will process the tile.
In the GPU, we could focus on one stream since each stream does the same thing. In each stream, we first copy the key/val array from a CPU to GPU, and then we process the key/val tile using the SP-EGA. After we obtain the GA results, we could compute the partition results. Three CUDA kernels are used to compute the partition result.
The first kernel computes the index within the partition for each key/value pair. Each thread block is responsible for a subset of key/value pairs in the tile. Given P partitions, each GPU thread atomically increments the counter of the partition to which the key/value pair belongs, yielding the index of each key/value pair within the thread block. We then atomically increment the global counter of the partitions to obtain the index of each key/value pair within the partition. The second kernel computes the prefix sum of the global counters of the partitions. The third kernel calculates the final index of each key/value pair within the tile by adding the index within the partition (computed by the first kernel) to the global position of the partition (computed by the second kernel).
| Algorithm 2: MP-EGA partition algorithm |
![Applsci 15 03693 i002]() |
In the CPU, we can focus on a single thread since each thread performs the same operations. Each thread is responsible for a subset of key/value pairs in a tile and maintains a local partition counter array. For each key/value pair, we first determine the partition it belongs to, increment the local partition counter, and obtain the local index within the partition. Each thread is responsible for specific partitions and can add its local partition counter to the global partition counter, yielding the position of the local partition in the global context. We then compute the global index of each key/value pair within the partition by adding the local index within the partition to the global position of the partition. Finally, we scan the global partition counter to determine the position of each partition in the final result, allowing us to compute the final index of each key/value pair by adding the global index within the partition to the position of the partition.
After processing all tiles, each tile produces its own partition result. However, some partition results may be too small. To address this, we can merge the results of smaller partitions into larger ones. The partition merge algorithm is outlined in the accompanying algorithm.
Each partition result is distributed across the partition results of each tile. Consequently, copying a single partition to the GPU may require multiple transfers, specifically T copies, which can hinder the efficient utilization of PCIe bandwidth. Therefore, we first merge the partition results on the CPU before proceeding to the next phase.
Next, we introduce the partition-processing phase, as illustrated in
Figure 4. The pseudo code for this phase can be referred to in Algorithm 3. In this phase, each partition is processed using a CUDA stream. For simplicity, we will focus on the operations occurring within a single stream. Initially, we copy the partition result from the CPU to the GPU. It is important to note that the size of the partition result is not fixed, unlike the size of the key/value tiles in the partition-generating phase.
| Algorithm 3: MP-EGA partition process algorithm |
![Applsci 15 03693 i003]() |
We must consider two scenarios: when the size of the partition result fits within GPU memory and when it exceeds GPU memory. If the partition result fits in GPU memory, we can directly process it on the GPU. Conversely, if the partition result exceeds GPU memory, we will employ the method described in the section titled “Using Feedback Load to Handle Large Partitions”. In cases where the partition is too large for the GPU, we will process the remaining key/value pairs on the CPU and combine these results with those computed on the GPU. After processing all partitions, we will obtain the final results.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}