Abstract
This paper examines federated learning, a decentralized machine learning paradigm, focusing on privacy challenges. We introduce differential privacy mechanisms to protect privacy and quantify their impact on global model performance. Using evolutionary game theory, we establish a framework to analyze strategy dynamics and define utilities for different strategies based on Gaussian noise powers and training iterations. A differential privacy federated learning model (DPFLM) is analyzed within this framework. A key contribution is the thorough existence and stability analysis, identifying evolutionarily stable strategies (ESSs) and confirming their stability through simulations. This research provides theoretical insights for enhancing privacy protection in federated learning systems.
1. Introduction
In the era of the information age, the generation and accumulation of data is accelerating at an unprecedented rate. However, this vast amount of data is often fragmented across various locations and managed by multiple entities. Traditionally, analyzing such dispersed data has relied heavily on centralized processing, which requires the aggregation of data from various locations. As concerns over data security and privacy continue to grow, conventional approaches have become increasingly inadequate, often resulting in significant privacy leakages [1]. Specifically, when private data are used for model training, the trained models may inadvertently disclose sensitive information through their behavior or structure [2,3,4].
In recent years, federated learning (FL) has emerged as a novel machine learning (ML) paradigm, gradually gaining traction. The core idea of federated learning is to enable multiple clients to collaboratively train a shared machine learning model while keeping their data decentralized and locally stored. Although federated learning can protect client privacy to some extent, significant challenges remain. For example, Shokri et al. [5] introduced membership inference attacks, highlighting a significant privacy vulnerability within federated learning. In response to such challenges, recent studies have increasingly turned to advanced cryptographic tools, such as secure multi-party computation and differential privacy, to enhance privacy protection in federated learning [6]. For instance, Wei et al. [7] investigated the trade-off between convergence performance and differential privacy protection in federated learning under a unified noise scale. Hu et al. [8] examined the relationship between model accuracy and privacy protection with a uniform noise scale. Geyer et al. [9] studied the relationship between privacy loss and model performance. However, despite significant progress in addressing privacy concerns in federated learning, many critical questions remain open for exploration. For instance, while existing studies have highlighted the importance of privacy protection through techniques such as secure multi-party computation and differential privacy, there is still a need for more comprehensive frameworks to quantify privacy leakage and to understand the impact of privacy preferences on model performance. This gap underscores the ongoing and evolving nature of privacy protection in federated learning, making it a highly relevant and active area of research.
Game theory, particularly evolutionary game theory, provides a powerful framework for analyzing the strategic behavior of participants in federated learning systems. Traditional game theory focuses on systematically analyzing competitors to choose the best strategy for maximizing personal benefits [10]. In contrast, evolutionary game theory [11,12,13] emphasizes the evolution of strategies and changes at the population level. It is widely used for analyzing interactions between groups. In the context of federated learning, evolutionary game theory can effectively model the dynamic behavior of clients as they balance the trade-off between privacy protection and model performance. Clients aim to maximize their utility by selecting strategies that protect their privacy while still contributing to the global model’s accuracy. The concept of population share in evolutionary game theory can be used to reflect the proportion of clients adopting different strategies over time, capturing the evolving dynamics of client behavior [14]. Recently, incentive allocation mechanisms in evolutionary game theory have garnered academic attention [15,16,17]. A well-designed incentive mechanism can shape the behavioral patterns of the group during evolutionary games, reduce the selfish behavior of individuals, and thereby enhance group stability. Previous studies [18,19,20] have applied game theory ideas using various models but have not considered the impact of individual strategies on overall incentives.
In reality, individual strategy choices play a crucial role in determining the performance of the global model in federated learning and have a direct impact on the actual overall incentives. Given the decentralized nature of federated learning, where each client has the autonomy to choose strategies that balance privacy protection and model performance, understanding these choices and their collective impact is essential. Traditional game theory, while powerful, often focuses on individual strategy optimization and may not fully capture the dynamic and evolving nature of client behavior in federated settings. In contrast, evolutionary game theory provides a more comprehensive framework to analyze how individual strategies evolve over time and how these changes affect the overall system dynamics. This study leverages the strengths of evolutionary game theory to address the challenges posed by individual strategy choices in federated learning and makes several key contributions:
- Evolutionary game theory analysis: We employ evolutionary game theory to analyze the differential privacy protection problem in federated learning. Unlike traditional game theory, which focuses on individual strategy choices, our approach examines the dynamics of population shares, capturing how the collective behavior of participants evolves over time. This perspective provides a novel framework for understanding the interplay between privacy preferences and system performance.
- Impact of differential privacy mechanisms: We quantify the impact of differential privacy mechanisms on global model performance and reflect these impacts in the incentive pool. Additionally, we characterize privacy leakage to understand its effects on user utility, providing a comprehensive analysis of the trade-offs between privacy protection and model performance.
- Differential privacy federated learning model (DPFLM): We constructed DPFLM, a robust model that integrates differential privacy into federated learning. We also propose an algorithm to compute the utility of each strategy, enabling systematic analysis of the incentives associated with different privacy mechanisms.
- Existence and stability analysis: We conducted a thorough analysis of the existence of solutions in evolutionary game theory. For the two-strategy case, we derived closed-form results for the evolutionarily stable strategies (ESSs). For more general cases, we validate our theoretical findings through extensive simulations, demonstrating the practical applicability of our approach.
2. Related Work and Preliminaries
2.1. Gaussian Mechanism Differential Privacy in Federated Learning
The differential privacy (DP) mechanism is a privacy-preserving method designed to protect individual datums while still allowing meaningful statistical information to be extracted [21,22]. The core principle of differential privacy involves adding a controlled amount of noise during the computation of statistical information or data analysis. This noise obscures the contributions of individual data points, thereby preventing privacy breaches that target specific individuals.
Traditionally, differential privacy has been applied to centralized data at a trusted data center, where a trusted third party administers differential privacy measures and releases the processed data. This approach, known as centralized differential privacy, relies on a trusted third party data collector to ensure that the original data are not disclosed. However, identifying a truly trustworthy third-party data collector is challenging in real-world scenarios. This challenge has led to the development of localized differential privacy, which decentralizes the privacy-preserving process and assigns it to each data-owning user. This approach reduces the potential risk of privacy leakage. The localized differential privacy data processing framework is illustrated in Figure 1.
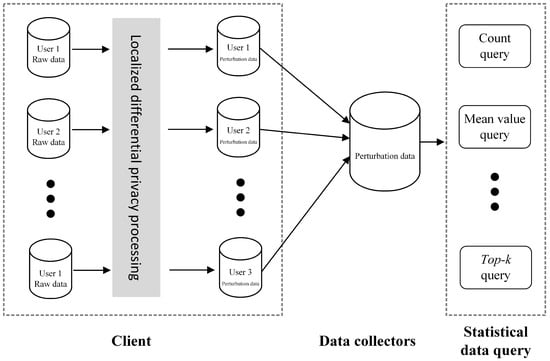
Figure 1.
Localized differential privacy data processing framework.
In Figure 1, the clients correspond to the participants in federated learning, with their raw data being the model’s post-training parameters. The data collector corresponds to the server, which aggregates and queries statistical data to form the global model. From the perspective of implementing differential privacy mechanisms for numerical data, there are two main approaches: Gaussian differential privacy and Bayesian differential privacy. While Bayesian differential privacy is suitable for smaller data samples, it has drawbacks such as high computational costs and the need for prior information [23,24]. In contrast, the Gaussian mechanism for differential privacy has low computational costs [25] and is easy to implement, making it ideal for handling real-time data and large-scale datasets [26]. Although the accuracy of Gaussian differential privacy is generally lower than that of Bayesian differential privacy, certain algorithms can enhance the accuracy of models using Gaussian mechanisms for differential privacy. For instance, in the work by Chuanxin et al. [27], the accuracy was improved threefold using the proposed Noisy-FL algorithm.
In this paper, we adopt the definition of -DP, as presented in [28], which is given by
where is the original dataset, and is a dataset that differs from by only a single data point. To be precise, is considered a neighboring dataset to if can be obtained from by either adding, removing, or modifying a single record. represents the set of possible output results. is the privacy budget, which controls the degree of privacy leakage. is the additional privacy budget, which controls the upper bound on the probability of privacy leakage. represents the application of a randomized perturbation algorithm in differential privacy. According to (1), a smaller value of implies that more noise is added, making it difficult to distinguish between the datasets and . This results in stronger privacy protection. In other words, when two datasets, and , with minor differences are perturbed by the randomized algorithm, , the resulting output dataset, , should have minimal differences. These differences are controlled by . The smaller the , the stronger the privacy protection. The implementation of differential privacy is illustrated in Figure 2.
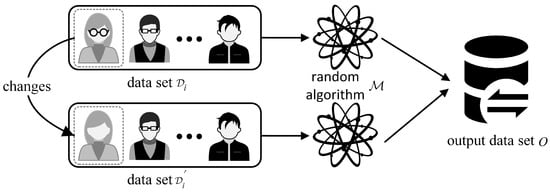
Figure 2.
Implementation of differential privacy.
In this study, different clients have different privacy budgets. This is because different clients may handle datasets with varying levels of sensitivity. For instance, some clients might possess highly sensitive personal data, while others deal with less sensitive information. Furthermore, clients may have different privacy requirements based on their specific contexts, regulations, or agreements. Since we implement a Gaussian mechanism, this translates to different powers of Gaussian noise. According to [29], during the Tth round of aggregation, the relationship between Gaussian noise power and privacy budget can be expressed as , where . When the range of gradient updates is limited, we can always find a finite constant, C, such that . Then, we can obtain
The equation calculates the standard deviation, , of the Gaussian noise, which is computed based on each client’s privacy budget. This calculation is based on their dataset size, D, the global training round number, T, the pre-defined privacy failure probability, , and the gradient clipping threshold, C. This calculated value is then used within the Gaussian mechanism to add noise to the gradient updates uploaded by that client, ensuring differential privacy protection.
2.2. Incentive Mechanisms in Federated Learning
In federated learning (FL), clients are rational actors who face critical challenges, such as potential privacy leakage risks, when participating in collaborative model training. These inherent costs create disincentives for client participation, leading to situations where a subset of clients may be reluctant to engage in the collaborative learning process. To address this fundamental challenge, the implementation of incentive mechanisms becomes essential. Specifically, a rationally structured incentive scheme can reward clients commensurate with their contributions, thereby motivating them to tolerate associated costs and actively participate in FL frameworks. Such mechanisms aim to align individual rationality with collective learning objectives by balancing computational costs, privacy risks, and model performance.
Significant research efforts have been devoted to developing optimized solutions from diverse perspectives. For instance, Muhammad et al. [30] proposed a reputation-rating algorithm to evaluate client trustworthiness, thereby enhancing global model performance through rigorous credibility assessment. Wang et al. [31] introduced a fair and robust federated learning (FRFL) framework, leveraging contract theory principles to design a client selection mechanism that mitigates free-riding behaviors while ensuring reliability. Weng et al. [32] developed DeepChain, a blockchain-enabled deep learning architecture that utilizes value-driven incentives to align client behaviors with collaborative objectives through cryptographic commitments. However, these seminal publications predominantly overlook the critical aspect of inter-client strategic interactions. As federated learning fundamentally constitutes an iterative multi-round process, it inherently embodies evolutionary game-theoretic characteristics, where clients dynamically adapt their training strategies in response to environmental feedback (e.g., reward distributions and peer behaviors). Evolutionary game theory provides essential analytical tools, such as replicator dynamics equations and evolutionarily stable strategies, which enable the establishment of a realistic behavioral modeling framework tailored to FL ecosystems. This paradigm captures continuous strategy evolution through population-level adaptation mechanisms, transcending the limitations of conventional static game models. For example, Zou et al. [33] constructed an evolutionary game model to analyze the long-term strategies of device participation in training, considering the resource heterogeneity of mobile devices. Their study revealed the driving mechanism of decision evolution in balancing resource constraints and benefits. In a decentralized setting, Cheng et al. [34] proposed a blockchain-based federated learning (BCFL) game framework. Through a two-stage “node selection-data sharing” strategy game, they demonstrated how blockchain transparency facilitates trust-building among participants and derived the conditions for cooperative benefit allocation under Nash equilibrium. Regarding the stability of complex federated networks, Hammoud et al. [35] designed a cloud federation formation model that integrates genetic algorithms with evolutionary games. Their findings proved that multi-round strategy adjustments can converge to a federated topology optimized for quality of service (QoS). In terms of security defense, Abou et al. [36] incorporated the probability of IIoT network attacks into the game payoff function and proposed the FedGame model. This model leverages evolutionary stable strategies (ESSs) to filter out collaborative alliances capable of resisting malicious node interference. These studies offer a systematic framework for designing incentive mechanisms in federated learning across multiple dimensions, including resource allocation, trust-building, topology optimization, and security defense. Hence, in this paper, we focus on evolutionary game analysis in federated learning to address these challenges and improve client participation and collaboration.
3. System Model and Evolutionary Game Formulation
3.1. System Model
We consider a differential privacy federated learning model comprising I clients, denoted by , and a central server. When the server initiates a training task, it assigns the task to the clients and offers incentives to those who participate. Clients, in turn, decide whether to engage in the training task and, if so, employ differential privacy mechanisms to protect the privacy of their local data. Specifically, they select appropriate numbers of local iterations, , and add Gaussian noise with power during model training and parameter uploading. The federated learning system model is illustrated in Figure 3.
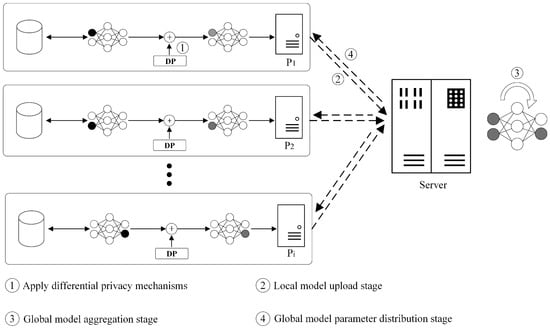
Figure 3.
Federated learning system model.
To analyze this model within the framework of evolutionary game theory, we define the following components:
- Players: The players in this game are the clients, denoted by .
- Strategies: The nth strategy available to a player can be expressed as , where is the number of local iterations per round, and is the Gaussian noise power. We assume there are N strategies in total, denoted by . Here, ‘strategies’ represent the different combinations of local iterations and Gaussian noise power that a client can choose. These strategies are formulated based on the practical application of differential privacy in FL. Different noise powers represent varying levels of privacy protection, with higher noise offering stronger privacy but potentially impacting model accuracy and, thus, the incentive pool. The number of local iterations also influences both model contribution and potential privacy leakage. These strategies are relevant to clients because they directly control the trade-off between their privacy protection and their potential utility. Clients with different privacy preferences or data sensitivity levels might choose different strategies.
- Population share: The population share represents the proportion of clients choosing a particular strategy within the strategy space. Let denote the proportion of the population that selects strategy , and it satisfies .
- Utility: The utility for each client is determined by their net income, which is the difference between the payoff obtained from the server and the training costs incurred. The utility for selecting strategy at time t is denoted by . For simplicity, this is subsequently abbreviated as .
In the framework of evolutionary game theory, each player can maximize their utility by adjusting their own strategy. The selection of strategies by clients is of significant importance because it directly impacts the trade-off between utility and privacy. An optimal strategy aims to maximize client utility while adhering to privacy constraints. For instance, a client prioritizing incentives above all else might choose a strategy that introduces minimal or no noise to their data. Although this could potentially maximize their contribution to an incentive pool, it would simultaneously lead to a substantial increase in privacy leakage, potentially undermining the overall privacy guarantees of the system. Conversely, if all clients were to adopt overly conservative strategies by adding excessive noise, the aggregated model would suffer from poor training quality, resulting in a diminished incentive pool and, ultimately, reduced utility for all clients. Therefore, the strategic selection of privacy mechanisms is crucial to achieving a delicate equilibrium, enabling clients to derive meaningful utility from participation while simultaneously ensuring robust privacy protection. In essence, effective strategy selection is key to balancing client incentives with the fundamental requirement of privacy preservation within the system. As the game progresses, players’ strategies will continuously evolve, making this process a dynamic adjustment. Overall, the population shares of different strategies will also change over time. The notations are summarized in Table 1.

Table 1.
List of notations.
3.2. Utility Function
The utility function in our model accounts for the impact of differential privacy on the training model. Specifically, the utility for each client is determined based on the upper bounds of convergence for both the global and local loss functions, as well as the strategies selected.
3.2.1. Incentive Pool
When clients conduct model training and employ differential privacy mechanisms, they upload their local model parameters to the server. The server then aggregates these parameters from all participants to generate a global model. The upper bound of convergence for the global loss function is used to estimate the algorithm’s convergence rate, thereby quantifying the impact of Gaussian noise and the number of iterations on model performance. The size of the incentive pool is determined based on the model’s performance. Drawing inspiration from [29], we express the global loss function as follows:
Here, represents the difference between the initial loss and the optimal loss. c is a constant. is the model learning rate. T is the number of global updates. G is the number of global iterations. l is the Lipschitz constant. bounds the variance of the stochastic gradients at each client, and bounds the difference between the gradient of a single client and the global one. From Equation (3), we observe that the larger the Gaussian noise added by the clients, the larger the loss, implying a slower convergence rate for the global model. Consequently, the size of the incentive pool is given by
where r is a constant determined by the server.
3.2.2. Payoff, Cost, and Utility
The incentive pool is shared among all clients. Since the noise added by the clients affects the performance of the model, and the larger the noise, the worse the performance of the local model, the payoff should be lower for clients with larger noise power. We assume that the client with noise power should receive a payoff proportional to . Given that the size of the incentive pool is , using normalization, the payoff for choosing noise power , denoted by , is given by
where A represents the basic reward granted by the server to participants for their involvement in the training process. We observe that the payoffs, , are determined by the population shares .
The cost arises from the impact of Gaussian noise on privacy leakage for each client. Most current studies measure privacy leakage through experiments, which, however, requires access to user data, contradicting the original intention of privacy protection. Liu et al. [29] conducted research on the theoretical measurement of privacy leakage, making it possible to theoretically quantify privacy leakage and apply it to various scenarios and datasets. Motivated by their results, we express the cost of strategy, , , as
Here, is the model learning rate. We emphasize that more local iterations make the model more suitable for the local dataset, increasing the likelihood of data leakage.
Summarizing the above, the utility for selecting strategy can be expressed as
Notice that is a function of . The following Algorithm 1 summarizes the calculation of the utility.
| Algorithm 1 Utility Calculation Algorithm. |
|
3.3. Replicator Dynamics
Replicator dynamics (RDs) is a widely used model that describes how strategies evolve over time in evolutionary game theory. It is primarily applied to study the dynamic processes of strategy selection and evolution [37]. Therefore, this study employs replicator dynamics to analyze the dynamic process of strategy selection and evolution in our federated learning system.
The utility for selecting strategy is given by Equation (7), and the average utility of the clients involved in the training can be given by the following expression:
In each federated learning task, clients can freely choose their strategies to maximize their utilities. Since the utility is related to the population share, clients cannot simply select the strategy with the minimum noise to achieve the largest size of the incentive pool. Based on the above analysis, the replicator dynamics equation for clients can be expressed as
Here, represents the positive learning rate, which controls the speed at which the clients adapt to different strategies. Based on replicator dynamics, when the utility of a client is lower than the average, it will adjust its strategy to obtain a higher utility. Often, at the end of the game, an equilibrium point will be reached.
4. Game Analysis
In this section, we investigate the existence and stability of the replicator dynamics described by Equation (9). Regarding existence, we demonstrate that the game has at least one stable point (equilibrium). Regarding stability, we show that once the game reaches equilibrium, it can return to the equilibrium state even if disturbed. First, we prove the boundedness of Equation (9) in Lemma 1.
Lemma 1.
For all , the first-order derivative of with respect to is bounded.
Proof of Lemma 1.
For ease of calculation, we omit t in the proof. Then, the coefficients of the first, second, and third terms in Equation (3) are constants. The sum of the first and second terms is denoted by B, and the coefficient of the third term is denoted by C. Thus, Equation (3) can be rewritten as
The derivative of with respect to can be given as follows:
This equation represents the partial derivative of the replicator dynamics equation with respect to the population share of strategy v, denoted as . It is derived using the product rule of differentiation. Specifically, considering as a product of two terms, and , its derivative with respect to is given by . To simplify the notation, we define
Thus, we can obtain
Since , , we can obtain that is bounded. Hence, is also bounded. □
Then, we can prove that the solution of (9) exists.
Theorem 1.
For all , the solution of (9) exists.
Proof of Theorem 1.
From Lemma 1, we can obtain that is bounded. In addition, it is straightforward to see that and are both continuous. Therefore, satisfies the Lipschitz condition with respect to . According to the Picard-Lindelöf theorem, for any given initial conditions, the system of differential equations has a unique solution in the region under consideration. □
Now, we analyze the stability of this evolutionary game. We begin with the definition of Nash equilibrium.
Definition 1.
The population state is called a Nash equilibrium of the game if for all feasible states in the population, the inequality holds, where [38].
In simpler terms, a Nash equilibrium is a fixed point of the ordinary differential equation, i.e.,
Suppose there exists another population state, , that attempts to invade the state by attracting a fraction of players . If the following condition holds for all , then is an evolutionarily stable strategy (ESS). The definition is given as follows.
Definition 2.
If there exists a neighborhood such that
then the population state is an ESS of the game.
In practice, when N is very large, it is difficult to find a closed-form solution for . Thus, we study the case of two strategies () to illustrate stability in the game. Other cases can also be analyzed using a similar method, but due to the complexity of the calculations, they are not listed in this paper. In the numerical simulation section, cases with more than two strategies are still considered. Taking two strategies as an example, the share of choosing strategy 1 is , and the share of choosing strategy 2 is . Based on the replicator dynamics and the constraint conditions, the following equations can be listed:
The utility for selecting strategy , can be expressed as
When I is sufficiently large, the influence of B on can be ignored, and we let
By substituting the above into Equation (15), we obtain the simplified expression of as follows:
Thus, , and in all solutions, we should have .
Further, we will study the evolutionary stability of four fixed points. In the cases of and , the shares of the two strategies are and , respectively. In these two cases, the forms are similar. Therefore, we only need to check the case of .
The ordinary differential equation in Equation (9) asymptotically stabilizes to an ESS when the replicator dynamics are continuous in time. If the Jacobian matrix of the ordinary differential equation is negative definite at the steady state, then the point is asymptotically stable. The Jacobian matrix of the ordinary differential equations for this two-strategy case can be given as
To simplify the calculation process and make the final result simpler, we assume so that
By substituting into Equation (20), we can obtain that
Then, we can obtain the following:
- When is an ESS, then the following inequalities must be satisfied:where .
- When is an ESS, then the following inequalities must be satisfied:
- When or , the condition that the Jacobian matrix of the ordinary differential equation is negative definite cannot be satisfied. Taking as an example, the following two conditions need to be satisfied:However, since and are both greater than 0, there is no solution that satisfies the conditions. Therefore, or are not stable points.
5. Numerical Results
In this section, we present numerical results to further substantiate our analysis and provide additional insights.
5.1. Utilities
In this subsection, we investigate the impact of different Gaussian noise powers on the utilities of various strategies in federated learning scenarios. Specifically, we analyze both two-strategy and four-strategy scenarios to understand how varying levels of noise affect the overall utility of the participating clients.
5.1.1. Two-Strategy Scenario
We first consider the model under a two-strategy scenario, with simulations examining the impact of varying Gaussian noise powers on the utilities. The parameters are set as follows: , , and . The basic incentive for training is set as , with a fixed population share of . Additionally, is held constant at , while the initial value of is set at and incremented by up to . The values of and are observed in the left figure of Figure 4.
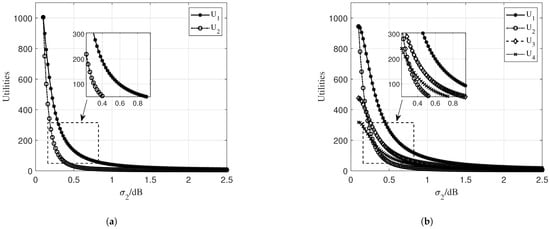
Figure 4.
Utilities for different scenarios: (a) Two-strategy scenario. (b) Four-strategy scenario.
As shown in the left figure of Figure 4, the utilities of the two parties are initially identical. However, as increases, the utilities of both parties begin to decrease, with a more pronounced impact on . This decline occurs because the continuous addition of Gaussian noise to affects the accuracy of model training, which, in turn, influences the size of the total incentive pool, ultimately leading to a reduction in the utilities of both parties.
5.1.2. Four-Strategy Scenario
In the right figure of Figure 4, we consider a scenario with four strategies. The parameters are set as , , , , , , and . The shares are set to , and the basic incentive for training is . Throughout the simulation, the values of , , and remain constant. We start with an initial value of and increment it by up to . By examining the utilities of different strategies, as shown in the figure, it is clear that the greater the Gaussian noise added to , the lower the utilities.
Overall, the results demonstrate that the utility of each strategy is significantly influenced by the level of Gaussian noise added during the training process. As the noise increases, the utility of the strategies decreases, highlighting the trade-off between privacy protection and model performance.
5.2. Stability Analysis
In this section, we conduct a comprehensive stability analysis to verify the theoretical results presented in the previous section. Through numerical simulations, we examine the stability of the system under different scenarios, including two-strategy, four-strategy, and eight-strategy cases. The goal is to demonstrate that the system converges to an ESS under various initial conditions and parameter settings.
Two-Strategy Scenario
We begin with a two-strategy scenario, where the system’s stability is analyzed under varying Gaussian noise powers. The parameters are set as follows: , , , , , , , and . Additional parameters include , , , and initial shares . The evolution of shares and utilities is shown in Figure 5.
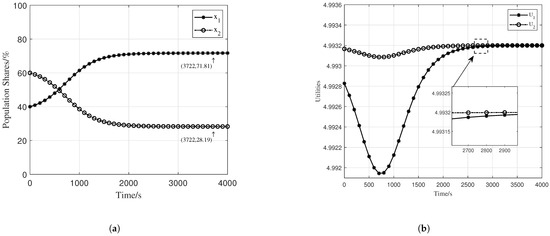
Figure 5.
Population shares and utilities for two-strategy scenario (Equation (23) holds): (a) Population shares. (b) Utilities.
The Jacobian matrix satisfies Equation (23), indicating that it is negative definite. The equilibrium point is calculated as . This implies that regardless of the initial shares, the system will eventually converge to this ESS. As shown in Figure 5, when the initial conditions satisfy Equation (23), the simulation results are consistent with the analytical results, thereby confirming the correctness of our previous analysis. From the right figure of Figure 5, we observe that when the system converges to the ESS, the utilities no longer change.
To further validate the stability analysis, we conducted a simulation for the second case where Equation (24) is satisfied. The number of clients is still set as . For Strategy , the Gaussian noise is set to with iterations. For Strategy , the Gaussian noise is with iterations. The learning rate is , and the basic incentive for training is still set as . Other parameters are set as , , and . The initial shares for selecting strategies were set to . In this scenario, the Jacobian matrix satisfies Equation (24), indicating that it is negative definite. Through computation, we obtained the equilibrium point .
As shown in the left figure of Figure 6, when the initial conditions satisfy Equation (24), the simulation results are consistent with the computed results, thereby verifying our analysis. From the right figure of Figure 6, it is evident that when the system converges to the ESS, the utilities no longer change.
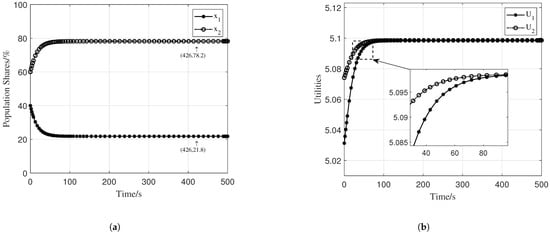
Figure 6.
Population shares and utilities for two-strategy scenario (Equation (24) holds): (a) Population shares. (b) Utilities.
5.3. Beyond Two-Strategy Scenario
Next, we consider a four-strategy scenario to further validate the stability analysis. The parameters are set as , , , , and . The values of to form an arithmetic sequence starting at with a common difference of . The initial shares for selecting strategies were set to . The numerical simulation results for this four-strategy scenario are shown in Figure 7. The equilibrium point is calculated as . The simulation result demonstrates that the system also reaches an evolutionarily stable strategy in the case of the four-strategy scenario.
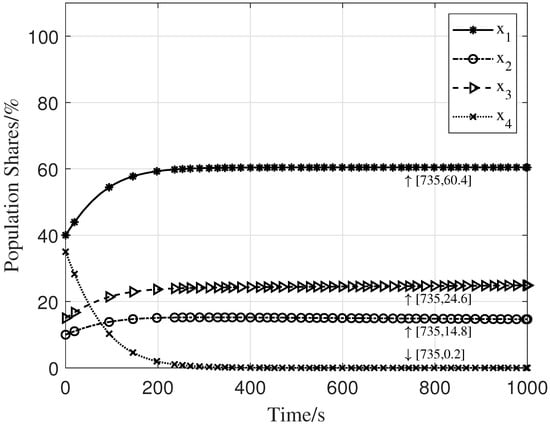
Figure 7.
Population shares for four-strategy scenario.
Finally, we extend the stability analysis to an eight-strategy scenario. The parameters are set as , , , , , , , , and . The values of to form an arithmetic sequence starting at with a common difference of . The initial shares for selecting strategies are set to . The simulation results for this eight-strategy scenario are shown in Figure 8. The equilibrium point is , where to are all . This simulation result demonstrates that the system also reaches an evolutionarily stable strategy in the eight-strategy case.
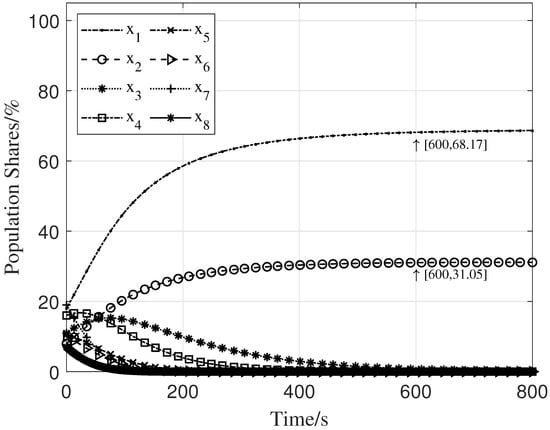
Figure 8.
Population shares for eight-strategy scenario.
These results further confirm that the system reaches an evolutionarily stable strategy, even with a larger number of strategies.
6. Conclusions
This study integrates the differential privacy afforded by the Gaussian mechanism into federated learning, employing both global loss functions and privacy leakage metrics to quantify the added noise. This approach helps to create a more realistic modeling scenario. We propose an incentive allocation algorithm tailored to the DPFLM framework. This algorithm is designed to consider the noise levels introduced by each client. It also takes into account the number of iterations. Crucially, our DPFLM, analyzed through the lens of evolutionary game theory, provides a valuable framework to understand and address the critical challenges of privacy and incentive design in federated learning.
Through theoretical analysis, particularly focusing on a two-strategy scenario, we derive detailed analytical results regarding the ESS. This analysis demonstrates how clients, acting strategically, balance their privacy concerns with the desire for incentives and how the system can evolve towards a stable equilibrium of privacy strategies. Extensive simulations across two-, four-, and eight-strategy scenarios further validate our theoretical findings and demonstrate the practical applicability of our approach in diverse settings. Our model supports federated learning by offering a framework to analyze the privacy-utility trade-off, providing insights into the dynamic evolution of client privacy strategies, and informing the design of effective incentive mechanisms that promote both client participation and privacy protection.
For future work, we suggest exploring the incorporation of additional factors, such as propagation delay and dataset size, which could significantly influence the model’s behavior. Furthermore, integrating federated learning with other advanced deep learning techniques could provide valuable insights into the impact of these factors and open up new avenues for research.
Author Contributions
Conceptualization, Z.N. and Q.Z.; methodology, Q.Z.; software, Q.Z.; validation, Z.N.; formal analysis, Z.N.; investigation, Q.Z.; resources, Q.Z.; data curation, Q.Z.; writing—original draft preparation, Z.N.; writing—review and editing, Z.N.; visualization, Q.Z.; supervision, Q.Z.; project administration, Q.Z.; funding acquisition, Z.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Zhejiang Provincial Natural Science Foundation of China under Grant LQ22F010008.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Liu, B.; Ding, M.; Shaham, S.; Rahayu, W.; Farokhi, F.; Lin, Z. When machine learning meets privacy: A survey and outlook. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, Y.; Qi, S.; Zhao, R.; Xia, Z.; Weng, J. Security and privacy on generative data in aigc: A survey. ACM Comput. Surv. 2024, 57, 1–34. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; IEEE: New York, NY, USA; pp. 3–18. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Hu, R.; Guo, Y.; Li, H.; Pei, Q.; Gong, Y. Personalized federated learning with differential privacy. IEEE Internet Things J. 2020, 7, 9530–9539. [Google Scholar] [CrossRef]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar] [CrossRef]
- Owen, G. Game Theory; Emerald Group Publishing: New Delhi, India, 2013. [Google Scholar]
- Hofbauer, J.; Sigmund, K. Evolutionary game dynamics. Bull. Am. Math. Soc. 2003, 40, 479–519. [Google Scholar] [CrossRef]
- Sandholm, W.H. Evolutionary game theory. In Complex Social and Behavioral Systems: Game Theory and Agent-Based Models; Springer: Berlin/Heidelberg, Germany, 2020; pp. 573–608. [Google Scholar] [CrossRef]
- Szabó, G.; Fath, G. Evolutionary games on graphs. Phys. Rep. 2007, 446, 97–216. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, L.; Xu, Z.; Li, H. Optimizing Privacy in Federated Learning with MPC and Differential Privacy. In Proceedings of the 2024 3rd Asia Conference on Algorithms, Computing and Machine Learning, Shanghai, China, 22–24 March 2024; pp. 165–169. [Google Scholar] [CrossRef]
- Khan, A.; Thij, M.t.; Thuijsman, F.; Wilbik, A. Incentive Allocation in Vertical Federated Learning Based on Bankruptcy Problem. arXiv 2023, arXiv:2307.03515. [Google Scholar] [CrossRef]
- Talajić, M.; Vrankić, I.; Pejić Bach, M. Strategic Management of Workforce Diversity: An Evolutionary Game Theory Approach as a Foundation for AI-Driven Systems. Information 2024, 15, 366. [Google Scholar] [CrossRef]
- He, Y.; Wu, H.; Wu, A.Y.; Li, P.; Ding, M. Optimized shared energy storage in a peer-to-peer energy trading market: Two-stage strategic model regards bargaining and evolutionary game theory. Renew. Energy 2024, 224, 120190. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Huang, P.Q. A novel incentive mechanism for federated learning over wireless communications. IEEE Trans. Artif. Intell. 2024, 5, 5561–5574. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Nie, J.; Hu, Q.; Xiong, Z.; Niyato, D.; Miao, C. Evolutionary Model Owner Selection for Federated Learning with Heterogeneous Privacy Budgets. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; IEEE: New York, NY, USA; pp. 980–985. [Google Scholar] [CrossRef]
- Du, J.; Jiang, C.; Chen, K.C.; Ren, Y.; Poor, H.V. Community-structured evolutionary game for privacy protection in social networks. IEEE Trans. Inf. Forensics Secur. 2017, 13, 574–589. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar] [CrossRef]
- Yang, C.; Qi, J.; Zhou, A. Wasserstein Differential Privacy. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 16299–16307. [Google Scholar] [CrossRef]
- Triastcyn, A.; Faltings, B. Federated learning with bayesian differential privacy. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: New York, NY, USA; pp. 2587–2596. [Google Scholar] [CrossRef]
- Triastcyn, A.; Faltings, B. Bayesian differential privacy for machine learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 9583–9592. [Google Scholar]
- Dong, J.; Roth, A.; Su, W.J. Gaussian differential privacy. J. R. Stat. Soc. Ser. Stat. Methodol. 2022, 84, 3–37. [Google Scholar] [CrossRef]
- Bu, Z.; Dong, J.; Long, Q.; Su, W.J. Deep learning with gaussian differential privacy. Harv. Data Sci. Rev. 2020, 2020, 10–1162. [Google Scholar] [CrossRef]
- Chuanxin, Z.; Yi, S.; Degang, W. Federated learning with Gaussian differential privacy. In Proceedings of the 2020 2nd International Conference on Robotics, Intelligent Control and Artificial Intelligence, Shanghai, China, 17–19 October 2020; pp. 296–301. [Google Scholar] [CrossRef]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Liu, T.; Di, B.; Wang, B.; Song, L. Loss-privacy tradeoff in federated edge learning. IEEE J. Sel. Top. Signal Process. 2022, 16, 546–558. [Google Scholar] [CrossRef]
- ur Rehman, M.H.; Salah, K.; Damiani, E.; Svetinovic, D. Towards blockchain-based reputation-aware federated learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Beijing, China, 27–30 April 2020; IEEE: New York, NY, USA; pp. 183–188. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Z.; Luan, T.H.; Li, R.; Zhang, K. Federated learning with fair incentives and robust aggregation for UAV-aided crowdsensing. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3179–3196. [Google Scholar] [CrossRef]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2438–2455. [Google Scholar] [CrossRef]
- Zou, Y.; Feng, S.; Niyato, D.; Jiao, Y.; Gong, S.; Cheng, W. Mobile device training strategies in federated learning: An evolutionary game approach. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; IEEE: New York, NY, USA; pp. 874–879. [Google Scholar] [CrossRef]
- Cheng, Z.; Wang, B.; Pan, Y.; Liu, Y. Strategic Analysis of Participants in BCFL-Enabled Decentralized IoT Data Sharing. Mathematics 2023, 11, 4520. [Google Scholar] [CrossRef]
- Hammoud, A.; Mourad, A.; Otrok, H.; Wahab, O.A.; Harmanani, H. Cloud federation formation using genetic and evolutionary game theoretical models. Future Gener. Comput. Syst. 2020, 104, 92–104. [Google Scholar] [CrossRef]
- Houda, Z.A.E.; Brik, B.; Ksentini, A.; Khoukhi, L.; Guizani, M. When Federated Learning Meets Game Theory: A Cooperative Framework to Secure IIoT Applications on Edge Computing. IEEE Trans. Ind. Inform. 2022, 18, 7988–7997. [Google Scholar] [CrossRef]
- Weibull, J.W. Evolutionary Game Theory; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Hofbauer, J.; Sandholm, W.H. Stable games and their dynamics. J. Econ. Theory 2009, 144, 1665–1693. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).