Abstract
The gearbox is a core component of drilling rigs, valued for its high efficiency and load capacity. However, prolonged operation under heavy loads makes it prone to wear and failure. Complicating diagnosis, the vibration signals generated are highly complex and nonlinear. To achieve accurate fault diagnosis under varying operating conditions, we propose a novel method named T-DCAx, which integrates a Dual-path Convolutional Attention network, an extended Long Short-Term Memory network (xLSTM), and a Transformer. Our model leverages the complementary strengths of these components: the xLSTM module, enhanced with exponential gating and a novel memory mechanism, excels at modeling long-term temporal dependencies and mitigating gradient vanishing issues. The Transformer module effectively captures global contextual information through self-attention. These are synergized with a dual-path convolutional attention structure to ensure effective joint learning of both local–temporal and global patterns. Finally, a dedicated gearbox test platform was established to collect vibration signals under various conditions and fault types. The proposed T-DCAx method was validated on this dataset and demonstrated superior performance against several benchmark methods in comparative analyses.
1. Introduction
Gearboxes are critical components in core drilling rig, widely applied due to their high efficiency, reliability, and load capacity [1]. Their complex internal structure and continuous high-load operation result in a high failure rate, reducing overall system reliability [2]. Effective fault diagnosis is essential to enhance maintenance efficiency and reduce production losses.
Conventional fault diagnosis approaches primarily depend on signal processing techniques combined with classical machine learning algorithms. For example, techniques such as wavelet transform (WT) [3] and empirical mode decomposition (EMD) [4] are used to extract features from vibration signals, and then support vector machines (SVM) [5] or artificial neural networks (ANN) [6] are used for classification. However, these methods often exhibit poor performance when dealing with complex and non-stationary signals, as they rely heavily on manual feature extraction, which limits generalization and introduces operator-dependent bias [7].
With the rise of deep learning (DL), CNNs and RNNs have been applied for fault diagnosis due to their feature extraction capabilities [5,6,7,8]. For example, Janssens et al. [9] used CNNs to classify machinery health based on frequency-domain features, while Zhi et al. [10] proposed a CNN-LSTM model leveraging wavelet-based denoising. However, CNNs may lose information in long sequences [11], and RNNs suffer from long-term dependency limitations [12].
To overcome these limitations, attention mechanisms (AMs) [13] have been incorporated into deep learning models to better capture sequential dependencies. Jin et al. [14] applied a time series Transformer (TST) for rotating machinery fault detection. However, while effective in modeling global context, Transformers lack explicit temporal dynamics modeling.
To further improve model performance, research trends are gradually shifting from single models to hybrid architectures that integrate multiple advantages. For example, in the field of drilling overflow detection. Yin et al. [15] proposed a TCN-BiGRU-AT model, which uses a temporal convolutional network (TCN) to capture local features, a bidirectional GRU to model long-term state evolution, and combines an attention mechanism to dynamically focus on key abnormal signals, significantly improving the accuracy of early detection. This fully demonstrates the effectiveness of hybrid architectures in processing complex industrial signals. Meanwhile, the attention mechanism itself is also constantly evolving. Jiang et al. [16] introduced a coordinate attention mechanism in bearing fault diagnosis, which can effectively enhance the ability to capture key features. These works provide a solid theoretical and practical foundation for building a DCA-xLSTM module that integrates convolution, xLSTM, and attention. Nevertheless, a formidable challenge persists in the specific context of drilling rig gearboxes: developing a model that exhibits robustness against intense noise and fluctuating operational conditions, while also comprehensively exploiting both the global contextual information and local temporal dependencies inherent in vibration signals. While the work of Fang et al. [17] directly addresses drilling machinery using a BiLSTM, it inadequately accounts for global dependencies. Similarly, the framework introduced by Siddique et al. [18], despite its merits in feature extraction, is predominantly designed for acoustic emission signals. To address these identified limitations, the T-DCAx model proposed in this paper is designed to fuse the global representation power of the Transformer with the refined sequential modeling offered by DCA-xLSTM.
To address these challenges, we propose a fault diagnosis approach that combines a Transformer with a Dual-Path Convolutional Attention-enhanced xLSTM (DCA-xLSTM). xLSTM enhances long-term dependency modeling, while the dual-channel attention mechanism focuses on global-local features. The Transformer encoder extracts global representations from vibration signals via self-attention, and DCA-xLSTM performs temporal modeling to detect fault-related changes. Final classification is achieved through a fully connected layer and SoftMax.
To validate the proposed T-DCAx model, we conducted experiments on vibration signals from a gearbox test platform under various fault conditions. Comparative results with CA-MCNN, DCA-BiGRU, and Transformer baselines demonstrate the superior diagnostic accuracy and robustness of T-DCAx.
In summary, the contributions of this paper are as follows:
- (1)
- A novel T-DCAx framework is proposed for gearbox fault detection, combining dual-path convolutional attention and xLSTM with Transformer to handle noise and complex conditions.
- (2)
- DCA-xLSTM enhances key feature extraction by integrating global-local attention and long-term sequence learning, improving robustness under complex working conditions.
- (3)
- Based on the proposed DCA-xLSTM structure, the encoder of Transformer is combined with self-attention to capture global dependencies, and the T-DCAx network is proposed. In this way, the network pays attention to the overall information and improves the fault diagnosis accuracy of the proposed method.
This hybrid approach is supported by recent studies that highlight the complementary strengths of sequence models and attention mechanisms. For instance, in complex temporal tasks like assembly action classification, xLSTM has demonstrated superior generalization capability compared to standalone Transformers and traditional LSTMs, particularly in handling long sequences and adapting to new operational data [19]. Similarly, the effectiveness of tandem architectures coupling LSTM for long-term dependency modeling and Transformer for global context capture has been validated in engineering design domains, achieving highly consistent performance by integrating the advantages of both models [20]. These works collectively affirm the rationale behind our T-DCAx design, which synergistically leverages the temporal modeling of xLSTM and the global representation power of Transformer to address the challenges of complex vibration signal analysis.
2. Related Work
2.1. Transformer
The Transformer fundamentally adopts an encoder–decoder architecture composed of multiple stacked encoders and decoders [21]. The overall structure of the Transformer is shown in Figure 1. The encoder module, positioned on the left, incorporates multi-head attention mechanisms and fully connected layers to transform input data into feature vectors. The decoder module on the right receives the encoder’s output and predicted results. The decoder consists of masked multi-head attention, multi-head cross attention, and a fully connected layer to output the conditional probability of the final result.
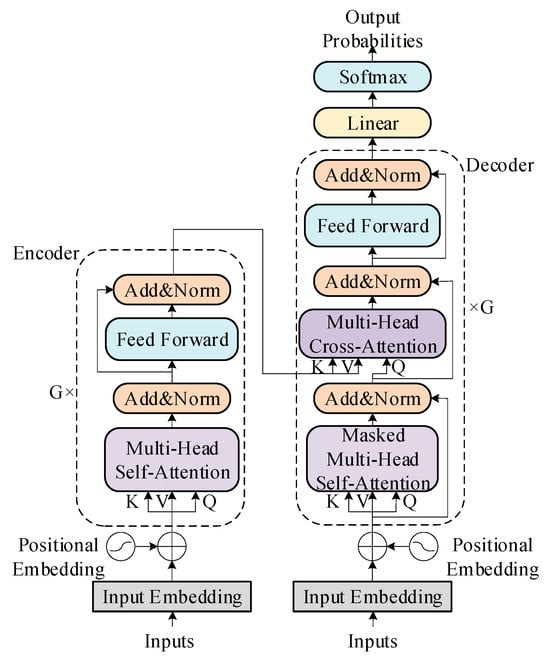
Figure 1.
The architecture of the Transformer. The Multi-Head Attention module utilizes the Query (Q), Key (K), and Value (V) matrices, which are projected from the same input. Q is compared against K to compute attention scores, which are then used to weight V to produce the output, enabling the model to focus on different parts of the input sequence. G represents the number of stacks of encoder and decoder.
The Transformer employs positional encoding to retain information about the relative or absolute order of sequence elements. The excellent performance of the Transformer architecture mainly stems from its innovatively designed parallel attention processing structure.
2.2. Xlstm
The xLSTM [22] model builds upon and extends the principles of the classical Long Short-Term Memory (LSTM) network. To provide context for the innovations in xLSTM, we first briefly review the core equations of a standard LSTM cell, which form the basis of the sLSTM block and are partially illustrated in Figure 2.
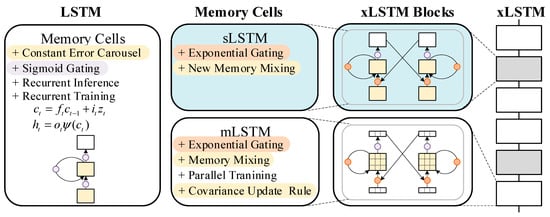
Figure 2.
The architecture of the xLSTM.
The LSTM addresses the vanishing gradient problem through a gating mechanism that regulates the flow of information. Its operation is governed by the following equations:
where ct, ct−1 are the cell state (memory) at time t and t − 1, respectively. This is the key component for long-term information retention. ht: The hidden state at time t, which serves as the output of the cell. ft: The forget gate, which controls how much of the previous cell state is retained. it: The input gate, which controls how much of the new candidate information is added to the cell state. ot: The output gate, which controls how much of the cell state is used to compute the output hidden state. zt: The candidate cell state, a vector containing new potential values to be added to the memory. : Typically, the tanh activation function.
sLSTM, which uses scalar memory updates to retain multi-dimensional temporal features and reduce information loss. mLSTM, which employs matrix memory for faster feature selection and improved noise suppression, supporting parallel processing for better long-term sequence modeling.
Additionally, xLSTM incorporates exponential gating and normalization. These mechanisms dynamically balance feature retention and noise suppression, enabling robust fault pattern extraction from noisy vibration signals.
3. The Proposed T-DCAx Method
3.1. Build the DCA-xLSTM Model
In intelligent fault diagnosis, various network architectures and optimization strategies can be integrated to achieve notable performance improvements, among which CNN-RNN has been applied to a certain extent. However, the performance of CNN–RNN models under strong noise conditions has not been thoroughly investigated. In addition, conventional optimization algorithms and training strategies limit their potential.
In addition, in fault diagnosis, xLSTM significantly improves the modelling ability of traditional LSTM for long sequences through matrix memory units and an exponential gating mechanism. In vibration signal analysis, fault features (such as periodic impact of bearing cracks) often span hundreds or even thousands of time steps, and xLSTM can effectively capture such long-range dependencies. To balance temporal feature extraction capability and computational efficiency, one sLSTM block and one mLSTM block were combined in a single-stage configuration, following the layer order of [s, m]. This structure enables the model to first capture local sequential dependencies through the sLSTM and subsequently enhance long-term temporal representations via the mLSTM.
Therefore, the DCA-xLSTM intelligent fault diagnosis method is first constructed, which consists of data enhancement, dual-path convolutional attention, xLSTM, GAP and a diagnosis layer. The structure of DCA-xLSTM is shown in Figure 3.
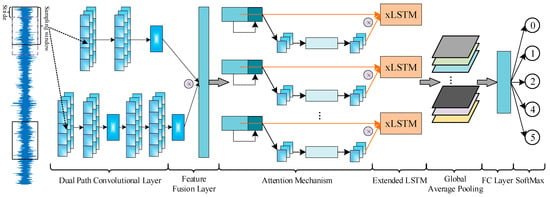
Figure 3.
The architecture of the DCA-xLSTM.
3.1.1. Dual Path Convolution and Feature Fusion
The dual-path convolution layer extracts high- and low-frequency signal features using different-sized convolution kernels. Larger kernels capture low-frequency features and enhance noise robustness. Meanwhile, smaller kernels increase network depth through multiple nonlinear activation layers to improve discrimination capability. This combination broadens the model, extracting multi-scale features for xLSTM to learn advanced features. Features are fused via element-wise product, enriching each channel. To improve DCA-xLSTM adaptability across domains, AdaBN replaces BN to enhance generalization [23].
3.1.2. D-Signal Attention Mechanism
Figure 4 shows a 1D signal attention mechanism used in this paper. To compute channel-wise attention, the dimensionality of the input feature matrix is first reduced through global pooling. In order to calculate the attention between channels, it is necessary to compress the dimension of the input feature matrix, and global pooling is usually used. The cth channel GMP calculation equation is as follows:
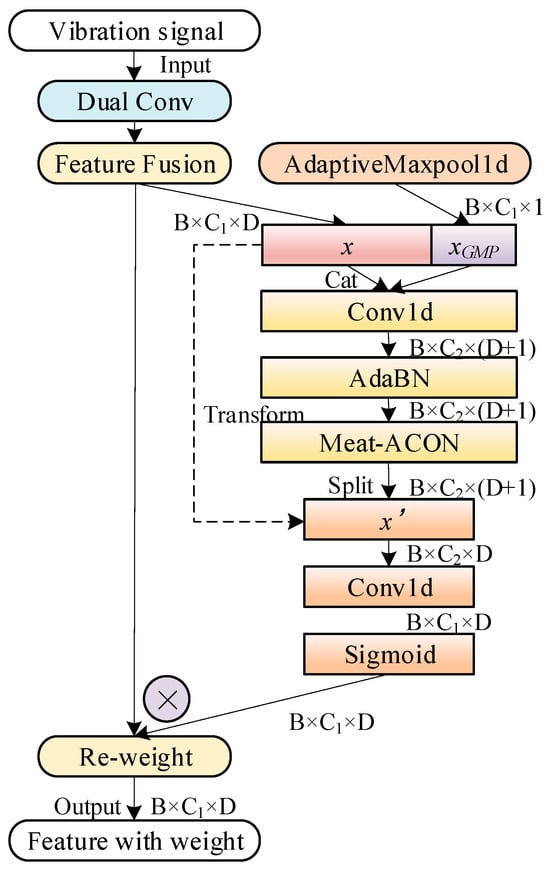
Figure 4.
The architecture of the Attention Block. The input feature map has a shape of (B, C, D), where B denotes the batch size, C denotes the number of channels, and D denotes the length of the 1D signal sequence. The mechanism employs Global Max Pooling (GMP) over the sequence dimension D to generate channel-wise statistics.
In addition, in order to capture spatial location information, it is better to establish the relationship between and x, so they are connected together and fed into the shared 1 × 6 convolution mapping function F1. The dependency is encoded to produce the intermediate feature connection matrix f, calculated as follows:
where δ is 1D-Meta-ACON activation function.
Then f is split into x′ and other feature matrices. Since the transformed original feature matrix x′ contains not only the critical pulse spectrum information but also the original signal feature x, only x′ is retained. Another 1 × 1 convolution mapping function F2 transforms x′ into the same number of channels as x, as shown in Equation (4).
where is sigmoid. is the characteristic matrix.
The final output yc is shown in Equation (5).
Aiming at the nonlinearity of vibration signals, a new activation function 1D-Meta-ACON [24] is introduced. It is neither ReLU nor Swish, but takes both into account and generalizes them to a general form. It is a form that can learn whether to activate or not. This design aligns with the principles of the 1D signal attention mechanism, emphasizing the central regions of the signal and thus enhancing the model’s generalization and transfer capabilities. 1D-Meta-ACON, as shown in Equation (6).
where in the forward propagation, βc is initially calculated. The feature vector x takes the D-dimensional mean, and after being transformed by F3 and F4 (1 × 1 convolution), βc between (0, 1) is obtained by Sigmoid to control whether to activate or the degree of activation, and 0 means inactivation.
where the adaptive variables p1 and p2 are set, and p = p1 − p2 is set. The activation output (fa) obtained is returned, and p1 and p2 are adaptively adjusted through back propagation.
1D-Meta-ACON is a general form that not only solves the dead neuron problem but also requires only a few parameters to learn whether to activate or not.
3.2. Proposed the T-DCAx
The Transformer architecture can be implemented in three configurations: encoder-only, decoder-only, and encoder–decoder structures. For fault diagnosis, we adopt the encoder-only structure to build the T-DCAx.
- (1)
- The dual convolutional layer extracts high- and low-frequency features using large and small kernels, respectively. Large kernels enhance low-frequency learning and noise robustness, while small kernels deepen the network. Their combination enables multi-scale feature extraction for subsequent xLSTM processing. Feature fusion is performed via element-wise product.
- (2)
- In xLSTM, the mLSTM module stores multi-dimensional time-series features (e.g., vibration energy across bands), while the sLSTM module with exponential gating enhances key feature selection and suppresses noise, improving robustness.
- (3)
- The Transformer encoder complements DCA-xLSTM with multi-head attention, capturing frequency-diverse features and enhancing global context modeling.
As shown in Figure 5, the input signal is processed simultaneously through the DCA-xLSTM and Transformer branches. Their high-level features are concatenated along the feature dimension and passed to a fully connected (FC) layer for classification.
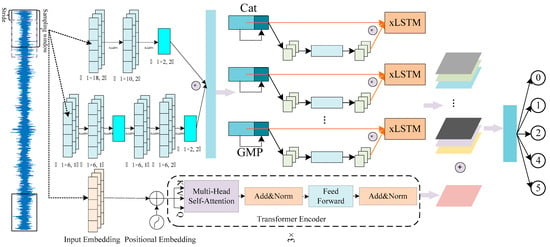
Figure 5.
Overall schema for the proposed network architecture of T-DCAx.
3.3. The Overall Framework of the Proposed T-DCAx for Fault Diagnosis
The whole framework of the proposed method is shown in Figure 6.
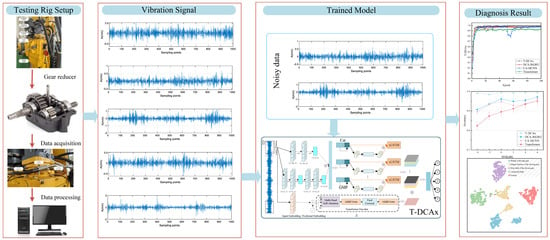
Figure 6.
The whole framework of the proposed method.
Step 1: Design of experimental test platform and collection of vibration signals. For the gearbox fault diagnosis method based on vibration signals, an experimental platform is built. Subsequently, the vibration signal of the gearbox is collected using the built plat-form.
Step 2: Construction of T-DCAx model. In this study, the construction of T-DCAx model mainly includes three parts, and the specific steps are as follows:
- −
- First, build a dual-path convolutional attention and extended long short-term memory network (DCA-xLSTM) based on attention mechanism. xLSTM introduces exponential gating and memory structure, which improves its ability to handle long-term dependencies in time sequence and alleviates the problem of gradient disappearance.
- −
- Secondly, build a Transformer method. Transformers are good at using self-attention to capture global context and pay attention to holistic information.
- −
- Third, arrange DCA-xLSTM and Transformer in parallel, and finally fuse the output features of the two models.
Step 3: Set the experimental environment and various parameters, and then use the collected gearbox vibration signal to train DCA-xLSTM.
Step 4: Use the trained fault diagnosis model to test the test set. Then, through the comparative experiment with the benchmark model, the effectiveness and superiority of the proposed method are verified.
4. Experimental Verifications
4.1. Experimental Data Description
4.1.1. Experimental Platform Construction
The gearbox test platform, shown in Figure 7, includes a main control module, servo motor (power source), gearbox samples with preset faults, three acceleration sensors for vibration monitoring, a professional data acquisition system, and a magnetic powder brake for load simulation. As depicted in Figure 8, the servo motor connects to the reducer input via a shaft, with the output linked to an adjustable load to mimic real conditions. A distributed sensor network captures multi-dimensional vibration signals in real time. Motor control and data storage are synchronized via a host computer. Core component specifications are provided in Table 1.

Figure 7.
Gearbox test platform.
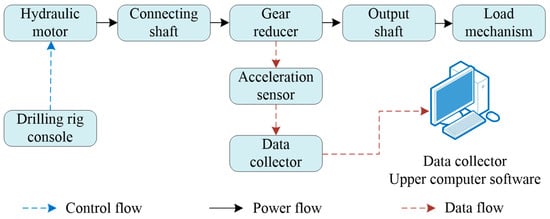
Figure 8.
The structure of test system.

Table 1.
The main module parameters of the test system.
The data acquisition process includes the following steps:
- (1)
- Initializing the motor control unit to execute start/stop commands and dynamic speed/mode switching based on preset strategies.
- (2)
- Configuring the multi-channel signal acquisition system, including sensor calibration, sensitivity adjustment, and sampling rate settings.
- (3)
- Activating the system to collect real-time vibration signals via the acceleration sensors, transmit it to the computer through the data acquisition device, and process it using dedicated software. Experimental progress is tracked and all core parameters are archived to ensure result accuracy and repeatability.
In the experiment, three acceleration sensors are used to collect the working data of the gearbox. The measurement points are arranged as shown in Figure 9.

Figure 9.
Distribution of sensor measuring points.
4.1.2. Experimental Design
In order to deeply study the signal performance of gearboxes with different fault types under complex variable working conditions, this experiment designed a total of 6 different working conditions under different speeds and loads. The motor speed is divided into 2 levels, 590 rpm and 1180 rpm. The load is 3 levels, 0 N·m (no load), 400 N·m, and 1200 N·m. The specific detailed working conditions are summarized in Table 2. The original vibration signals of the 5 gearbox states at S5L0 are shown in Figure 10.
Table 2.
Details of the gearbox under different working conditions.
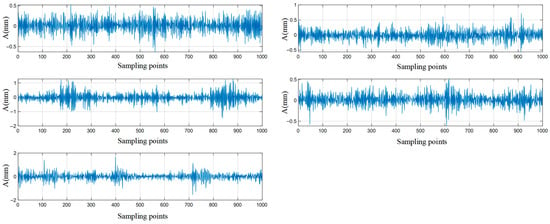
Figure 10.
Original vibration signals of five gearbox states at S5L0.
The test process is described by taking the gearbox with driving gear pitting fault as an example:
- (1)
- Build the complete test platform. Install the gearbox and three acceleration sensors as designed, check key assembly parameters, and adjust each subsystem until stable operation is achieved.
- (2)
- Set the load torque to 0 N·m and motor speed to 590 rpm (working condition S5L0). Collect vibration signals from the faulty gearbox and repeat three times to ensure data reliability.
- (3)
- After the driving gear pitting test is completed, the machine is shut down to organize and archive the relevant vibration signals, and then the next faulty component is replaced to prepare for a new round of tests.
- (4)
- After completing the tests of all faulty components in sequence, the test platform is closed and cleaned, and all experimental data are summarized and archived to prepare for subsequent data processing, fault analysis and classification.
The sensor placement scheme was determined through comparative experiments, using fault detection accuracy as the primary evaluation criterion. According to the different health states and working conditions of the gearbox, the collected vibration signals are made into a data set. The conditional collection scheme is shown in Table 3.
Table 3.
Conditional collection scheme.
As can be seen from Table 3, the data set includes data under 1 sampling frequency, 2 speed values and 5 fault types. The failure modes involved are four types: driving gear pitting, driving gear fatigue fracture, driven gear wear failure and compound fault. The compound fault is a combination of driving gear pitting and driven gear wear failure. They are all common faults of gearboxes during operation. The faulty workpiece is shown in Figure 11.

Figure 11.
(a) Pitting of the driving gear. (b) Fatigue fracture of the driving gear. (c) Wear fault of the driven gear.
4.1.3. Dataset Settings
Using the collected signal data, we constructed datasets with varying prediction difficulties. Each sample is derived from raw signal data with a fixed length of 1024. The data was split into training and test sets, with the training set designed to simulate real scenarios and the test set used for accurate performance evaluation.
To simulate variable speeds and loads, four datasets (D1–D4) were built by controlling the number of working conditions included, as shown in Table 4. Each fault class in every dataset contains the same number of samples; only the working condition types vary. More conditions imply higher classification difficulty.
Table 4.
Dataset setup conditions.
To improve diagnostic performance, data augmentation was performed. As illustrated in Figure 12, assuming that the sliding window is l, it will be replaced from ith to l, where the adjacent samples are set with overlapping values.
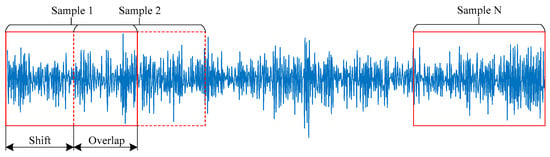
Figure 12.
Overlap sampling.
4.2. Experimental Environment Setting and T-DCAx Parameter Settings
To evaluate model performance, experiments were conducted using data from the gearbox fault test platform under various working conditions. Noise was added to assess robustness. During training, cross-entropy loss was used as the loss function, and Adam was adopted as the optimization algorithm [25]. The xLSTM module consists of one sLSTM and one mLSTM block arranged sequentially. The input size and hidden size of both blocks were empirically set to 124 and 64, respectively, based on the feature dimensions output from the preceding convolutional attention module. The number of attention heads was fixed to 2, which achieved the best trade-off between representation diversity and training stability.
The projection factors for sLSTM and mLSTM were set to 4/3 and 2, respectively, as suggested in the original xLSTM paper, to ensure sufficient expansion in the feature projection space.
The parameter settings were determined through preliminary experiments comparing several configurations—e.g., increasing the hidden size to 128 or stacking multiple sLSTM/mLSTM blocks—which showed no significant improvement in diagnostic accuracy but increased training time and risk of overfitting. Therefore, the current configuration was selected as the optimal balance between performance and computational cost. The T-DCAx parameter settings are shown in Table 5.
Table 5.
The structural parameters of the proposed model.
The environmental resources used in this experiment are shown in Table 6.
Table 6.
Experimental platform environment.
4.3. Experimental Analysis
4.3.1. Comparison of Different Methods
To evaluate the effectiveness of T-DCAx, comparative experiments were conducted with DCA-BiGRU [26], CA-MCNN [27], and Transformer [21] under working conditions D1–D4. Each model was trained for 100 batches using identical settings. Every dataset contained 5000 samples (1024 points each), with 1000 per fault type, split into training, validation, and test sets in a 2:2:1 ratio.
Figure 13 and Figure 14 show the validation accuracy and loss curves. CA-MCNN and Transformer exhibited significant oscillations, indicating poor robustness and convergence. In contrast, DCA-BiGRU and T-DCAx—both incorporating time-series learning—achieved more stable performance and higher diagnostic accuracy. By leveraging the complementary strengths of DCA, xLSTM, and the Transformer, the proposed T-DCAx achieved the fastest convergence and highest stability. This confirms the contribution of each component to the overall model performance.
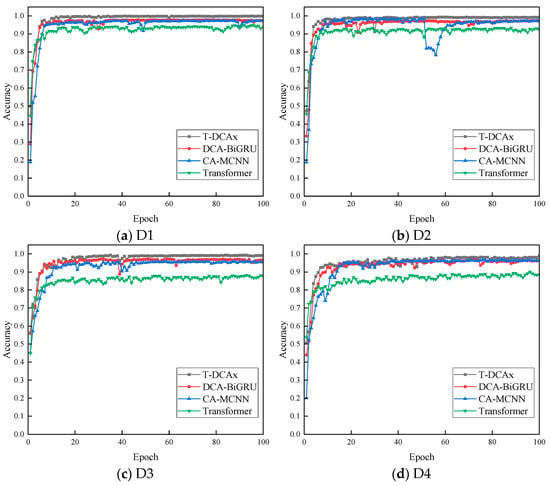
Figure 13.
Accuracy trend chart of different models.
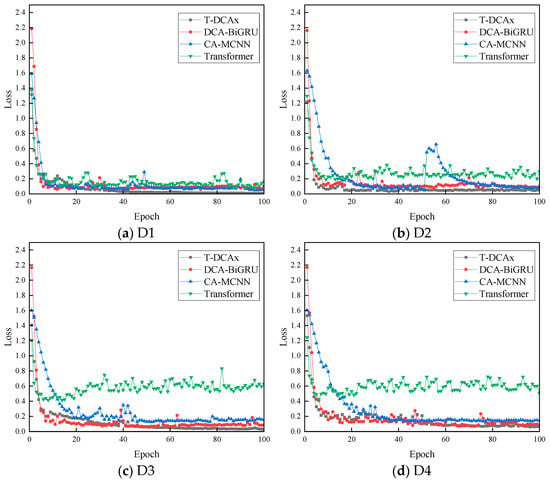
Figure 14.
Loss trend chart of different models.
To ensure the reliability and reproducibility of the experimental results, each model was trained and tested five times independently under identical settings. The most complex D4 dataset was selected. The average accuracy and standard deviation were calculated to reduce the influence of random initialization and stochastic training. In addition, the inference speed was evaluated to assess the computational efficiency of each model during practical deployment.
The results, summarized in Table 7, demonstrate that the proposed T-DCAx model not only achieves the highest average diagnostic accuracy but also maintains competitive inference speed.
Table 7.
Comparison of diagnostic performance, training stability, and convergence efficiency among different models.
Table 7 presents the statistical results of five independent experiments for each model, including the average accuracy, standard deviation, average training time, and minimum number of epochs required for convergence. The proposed T-DCAx model achieves the highest average accuracy of 99.42%, outperforming DCA-BiGRU, CA-MCNN, and Transformer by 3.31%, 4.61%, and 9.89%, respectively. In addition, T-DCAx exhibits the lowest standard deviation (0.525%), indicating superior stability and robustness across multiple runs.
Although the total training time of T-DCAx is influenced by its more complex architecture, it achieves significantly faster convergence, requiring only 9 epochs to converge, which is 2–14 epochs faster than the other models. This demonstrates its superior training efficiency in terms of learning speed from the data. Furthermore, its inference speed remains competitive, making it suitable for real-time diagnosis applications. Overall, these results confirm that the T-DCAx model not only delivers the best diagnostic accuracy and generalization performance but also maintains high computational efficiency and convergence speed, making it well-suited for real-time fault diagnosis applications.
4.3.2. Experimental Verification and Analysis of Noise Immunity
To evaluate noise robustness, vibration signals with added noise (SNR = −4, −2, 0, 2, 4, 6 dB) were used to test the proposed model against DCA-BiGRU, CA-MCNN, and Transformer. Four datasets (D1–D4) with varying classification difficulty simulated variable speeds and loads. Figure 15 shows the comparative fault diagnosis results.
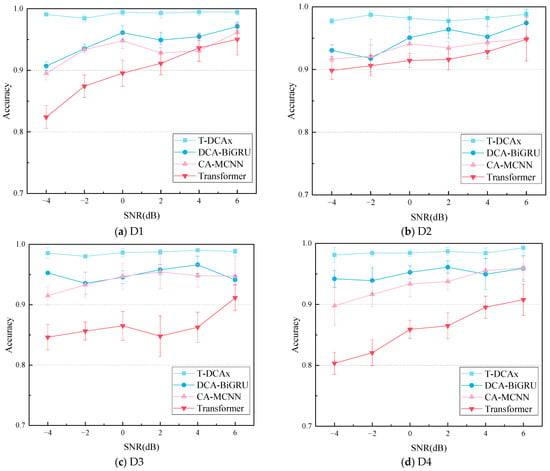
Figure 15.
Test accuracy under different signal-to-noise ratios.
As shown in Figure 15, all models show reduced accuracy under noise, especially on the most complex dataset D4, which contains six working conditions. At SNR = 6 dB, DCA-BiGRU, CA-MCNN, and Transformer achieve 95.92%, 95.98%, and 90.78% accuracy, respectively, while the proposed model maintains 99.27%. At SNR = −4 dB, their accuracies drop to ~80%, ~90%, and ~95%, while ours still achieves 99.27%, demonstrating remarkable robustness against noise.
To further assess noise impact, t-SNE visualization on dataset D1 at SNR = −4 dB was conducted for all four models, as shown in Figure 16.
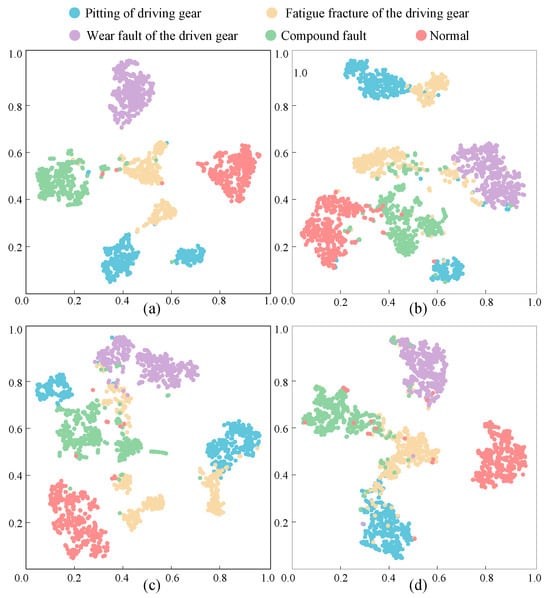
Figure 16.
Feature visualization based on t-SNE method. (a) T-DACx (b) DCA-BiGRU (c) CA-MCNN (d) Transformer.
The t-SNE visualization in Figure 16 reveals that DCA-BiGRU and CA-MCNN struggle to distinguish fatigue fracture and compound fault of the driving gear, showing significant overlap. CA-MCNN partially differentiates these states, while WDCNN fails to separate pitting and fatigue fracture, with notable overlap. At SNR = −4 dB, T-DCAx effectively distinguishes all five gearbox health states, with minor overlaps between fatigue fracture and compound fault due to low data discriminability and high noise. Driven gear wear and no-fault states are most identifiable, while fatigue fracture and compound fault are prone to misdiagnosis. Overall, t-SNE results confirm T-DCAx’s robust fault feature learning and stability in low-SNR, noisy conditions.
5. Conclusions
This paper introduced T-DCAx, a novel deep learning framework that synergistically integrates dual-path convolutional attention, xLSTM, and Transformer for fault diagnosis of drilling rig gearboxes. The experimental investigations lead to several pivotal findings that underscore the model’s effectiveness and practical utility.
The primary findings and their significance are threefold:
First, the proposed T-DCAx model demonstrates a significant advantage in diagnostic accuracy and robust generalization capability under complex and noisy operational conditions. Its consistent performance across varying speeds, loads, and low signal-to-noise ratios is not merely a numerical improvement over benchmarks like DCA-BiGRU and CA-MCNN. More importantly, it signifies a crucial step towards real-world reliability. This robustness suggests that T-DCAx is less susceptible to the environmental variations common in industrial settings, thereby enhancing its potential for deployment in practical monitoring systems where operating conditions are seldom stable.
Second, the successful fusion of temporal feature extraction and global context modeling within T-DCAx validates a promising architectural paradigm for analyzing complex vibration signals. The fact that our model effectively bridges the strengths of xLSTM (for long-term temporal dependencies) and Transformer (for global context) addresses a recognized gap in the literature, where models often excel in one aspect at the expense of the other. This contribution is primarily methodological, offering a new and effective blueprint for constructing hybrid deep learning models in the domain of mechanical fault diagnosis.
Third, the t-SNE visualizations provide compelling evidence that T-DCAx learns highly discriminative and well-separated feature representations even under severe noise. This goes beyond achieving high accuracy; it reveals the model’s intrinsic capability to capture the underlying fault characteristics distinctly from noise interference. This finding is significant as it builds trust in the model’s decision-making process and confirms its ability to learn genuine fault patterns rather than superficial correlations in the data.
In summary, the T-DCAx model not only delivers the best diagnostic accuracy and generalization performance but also exhibits rapid convergence during training, making it a computationally efficient and practical solution for fault diagnosis.
In light of these findings, the T-DCAx framework presents a substantial value for advancing the state of intelligent maintenance in the energy and drilling sectors. For future work, we plan to extend this approach to diagnose other critical components of the drilling system and to investigate its efficacy under more extreme conditions of data scarcity and class imbalance.
Author Contributions
All authors contributed to the study conception and design. Conceptualization, material preparation, methodology, data collection and analysis were performed by Y.D., J.L., P.G., X.T. and H.M. The first draft of the manuscript was written by X.W. and all authors commented on previous versions of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study does not involve ethical approval.
Informed Consent Statement
There are no human participants in this article and informed consent is not required.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.
Conflicts of Interest
The authors declare no conflicts of interests.
Abbreviations
The following abbreviations are used in this manuscript:
| WT | Wavelet transform |
| EMD | Empirical mode decomposition |
| SVM | Support vector machine |
| ANN | Artificial neural networks |
| DL | Deep learning |
| AMs | Attention mechanisms |
| TST | Time series transformer |
| DCA | Dual-path convolutional attention-enhanced |
References
- Yang, Q.; Li, X.; Cai, H.; Hsu, Y.M.; Lee, J.; Yang, C.H.; Li, Z.L.; Lin, M.Y. Fault prognosis of industrial robots in dynamic working regimes: Find degradation in variations. Measurement 2021, 173, 108545. [Google Scholar] [CrossRef]
- Wang, H.; Huang, H.; Bi, W.; Ji, G.; Zhou, B.; Zhuo, L. Deep and ultra-deep oil and gas well drilling technologies: Progress and prospect. Nat. Gas Ind. B 2022, 9, 141–157. [Google Scholar] [CrossRef]
- Wang, S.; Tian, J.; Liang, P.; Xu, X.; Yu, Z.; Liu, S.; Zhang, D. Single and simultaneous fault diagnosis of gearbox via wavelet transform and improved deep residual network under imbalanced data. Eng. Appl. Artif. Intell. 2024, 133, 108146. [Google Scholar] [CrossRef]
- Yuzgec, U.; Dokur, E.; Balci, M. A novel hybrid model based on Empirical Mode Decomposition and Echo State Network for wind power forecasting. Energy 2024, 300, 131546. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, Z.; Shao, Y. Fast Support Vector Machine with Low-Computational Complexity for Large-Scale Classification. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 4151–4163. [Google Scholar] [CrossRef]
- Kim, Y.-S.; Kim, M.K.; Fu, N.; Liu, J.; Wang, J.; Srebric, J. Investigating the impact of data normalization methods on predicting electricity consumption in a building using different artificial neural network models. Sustain. Cities Soc. 2025, 118, 105570. [Google Scholar] [CrossRef]
- YWu, Y.; Song, Y.; Wang, W.; Lv, Z.; Zhang, K.; Zhao, X.; Fan, Y.; Cui, Y. Application of multi-scale information semi-supervised learning network in vibrating screen operational state recognition. Measurement 2024, 238, 115264. [Google Scholar]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Zhi, Z.; Liu, L.; Liu, D.; Hu, C. Fault detection of the gear reducer based on CNN-LSTM with a novel denoising algorithm. IEEE Sens. J. 2022, 22, 2572–2581. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Al-Selwi, S.M.; Hassan, M.F.; Abdulkadir, S.J.; Muneer, A.; Sumiea, E.H.; Alqushaibi, A.; Ragab, M.G. RNN-LSTM: From applications to modeling techniques and beyond—Systematic review. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102068. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Jin, Y.; Hou, L.; Chen, Y. A Time Series Transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Yin, H.; Zhou, Y.; Li, Q.; Zhao, X.; Wei, Q. Early kick detection based on multi-scale temporal modelling and interpretability framework. Process. Saf. Environ. Prot. 2025, 206, 108177. [Google Scholar] [CrossRef]
- Jiang, Y.; Qiu, Z.; Zheng, L.; Dong, Z.; Jiao, W.; Tang, C.; Sun, J.; Xuan, Z. Recursive prototypical network with coordinate attention: A model for few-shot cross-condition bearing fault diagnosis. Appl. Acoust. 2025, 231, 110442. [Google Scholar] [CrossRef]
- Fang, K.; Tong, L.; Xu, X.; Cai, J.; Peng, X.; Omar, M.; Bashir, A.K.; Wang, W. Robust Fault Diagnosis of Drilling Machinery Under Complex Working Conditions Based on Carbon Intelligent Industrial Internet of Things. IEEE Internet Things J. 2025, 12, 34663–34678. [Google Scholar] [CrossRef]
- Umar, M.; Siddique, M.F.; Kim, J.-M. Burst-informed acoustic emission framework for explainable failure diagnosis in milling machines. Eng. Fail. Anal. 2025, 185, 110373. [Google Scholar] [CrossRef]
- Neves, M.; Neto, P. Classification of assembly tasks combining multiple primitive actions using Transformers and xLSTMs. arXiv 2025, arXiv:2505.18012. [Google Scholar] [CrossRef]
- Shi, Z.; Chen, C.; Zhang, D.; Song, Y.; Sun, X. Inverse design and spatial optimization of SFAM via deep learning. Int. J. Mech. Sci. 2025, 306, 110855. [Google Scholar] [CrossRef]
- Hou, Y.; Li, T.; Wang, J.; Ma, J.; Chen, Z. A lightweight transformer based on feature fusion and global–local parallel stacked self-activation unit for bearing fault diagnosis. Measurement 2024, 236, 115068. [Google Scholar] [CrossRef]
- Beck, M.; Pöppel, K.; Spanring, M.; Auer, A.; Prudnikova, O.; Kopp, M.; Klambauer, G.; Brandstetter, J.; Hochreiter, S. xLSTM: Extended long short-term memory. arXiv 2024, arXiv:2405.04517. [Google Scholar]
- Jalayer, M.; Orsenigo, C.; Vercellis, C. Fault detection and diagnosis for rotating machinery: A model based on convolutional LSTM, Fast Fourier and continuous wavelet transforms. Comput. Ind. 2021, 125, 103378. [Google Scholar] [CrossRef]
- Li, Y.; Wang, N.; Shi, J.; Hou, X.; Liu, J. Adaptive Batch Normalization for practical domain adaptation. Pattern Recognit. 2018, 80, 109–117. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Liu, M.; Sun, J. Activate or not: Learning customized activation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8032–8042. [Google Scholar]
- Zhang, X.; He, C.; Lu, Y.; Chen, B.; Zhu, L.; Zhang, L. Fault diagnosis for small samples based on attention mechanism. Measurement 2022, 187, 110242. [Google Scholar] [CrossRef]
- Huang, Y.-J.; Liao, A.-H.; Hu, D.-Y.; Shi, W.; Zheng, S.-B. Multi-scale convolutional network with channel attention mechanism for rolling bearing fault diagnosis. Measurement 2022, 203, 111935. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).