Abstract
In the field of low-altitude aerial drone data fusion, the fusion of infrared and visible light images remains challenging due to issues such as large modal differences, insufficient cross-modal alignment, and limited global context modeling. Traditional methods struggle to extract complementary information across modalities, while deep learning methods often lack sufficient global receptive fields (convolutional neural networks) or fail to preserve local details (standard Transformers). To address these issues, we propose a Cross-modal Guided Dual-Branch Network (CGDBN) that combines convolutional neural networks and Transformer architecture. Our framework contribution: We designed a Target-modal Feature Extraction Mechanism (TMFEM) module with specialized thermal characteristics for infrared feature extraction, which does not require processing of visible light features; we introduced Simplified Linear Attention Blocks (SLABs) into our framework to improve global context capture as a module; we designed a Cross-Modal Interaction Mechanism (CMIM) module for bidirectional feature interaction; and we designed a Density Adaptive Multimodal Fusion (DAMF) module that weights modal contributions based on content analysis. This asymmetric design recognizes that different types of images have different characteristics and require targeted processing. The experimental results on AVMS, M3FD, and TNO datasets show that the proposed model has a peak signal-to-noise ratio (PSNR) of 16.2497 on the AVMS dataset, which is 0.9971 higher than the best benchmark method YDTR (peak signal-to-noise ratio: approximately 15.2526). The peak signal-to-noise ratio on the M3FD dataset is 16.5044, which is 0.7480 higher than the best benchmark method YDTR (peak signal-to-noise ratio of approximately 15.7564). The peak signal-to-noise ratio on the TNO dataset is 17.3956, which is 0.7934 higher than the best benchmark method YDTR (peak signal-to-noise ratio: approximately 16.6022), and the overall performance on all other indicators is among the top in all comparison models. This method has broad application prospects in fields such as drone data fusion.
1. Introduction
The fusion of infrared and visible light images plays a crucial role in enhancing the perception ability of drones in challenging environments. Drone platforms typically operate under complex real-world conditions, and single modal imaging has been proven insufficient for robust visual interpretation in various scenarios such as low light navigation, adverse weather, and blurry object detection.
The main challenge in fusing infrared and visible light images lies in their inherent heterogeneity. Infrared sensors measure thermal radiation and provide reliable target detection in darkness, fog, or smoke [], but often suffer from low spatial resolution, insufficient texture details, and noise. In contrast, visible light images provide high-resolution texture, and clear structural boundaries under sufficient lighting, but their performance significantly decreases when poor lighting or thermal contrast is the main discriminative signal []. The current methods all face three core difficulties that need to be overcome: differences in features between different modalities, balancing local feature extraction and global dependency relationships, and appropriate integration strategy.
The current fusion methods have shown significant limitations in comprehensively addressing these challenges. Traditional methods based on multiscale transformations such as wavelets, NSCT, or sparse representations rely on manual rules and lack adaptability [,], often failing to achieve a context-sensitive balance between thermal saliency and structural clarity. The use of CNN’s deep learning methods improves fusion quality by learning representations, but their local receptive fields inherently limit the modeling of long-range dependencies [], which are crucial for associating infrared thermal targets with structural components in visible light images.
Recently, Transformer-based methods have overcome the limitations of global modeling, but have encountered new difficulties in feature representation and cross-modal interaction []. The standard transformer architecture treats images as isolated patch sequences, thereby disrupting spatial relationships, which is crucial for image fusion. In addition, existing transformer fusion models often lack specialized designs for the unique characteristics of infrared and visible modes, which handle both inputs inconsistently rather than utilizing their complementarity.
To address these limitations, we introduced the CGDBN, which combines CNN-based local feature extraction with Transformer-based global modeling through multiple innovations. Our main contributions include the following:
- 1.
- A dual branch architecture that integrates CNN and Transformer components, introduces SLAB, and enables effective global context modeling.
- 2.
- An asymmetric processing strategy that uses a dedicated TMFEM module to subject infrared images to specialized thermal feature extraction.
- 3.
- CMIM module is used to achieve adaptive feature interaction between infrared and visible branches.
- 4.
- A DAMF module strategy based on dynamic balance mode contribution of local content features.
2. Related Work
Infrared and visible image fusion research encompasses three primary approaches: traditional mathematical transformation methods, CNN-based deep learning techniques, and recent Transformer-based architectures. This section examines these categories and positions our method within the current landscape.
2.1. Traditional Image Fusion Method
Traditional fusion methods rely on mathematical transformations and handcrafted features. Multiscale decomposition techniques form the foundation, where images decompose into frequency subbands for coefficient-level fusion. Representative methods include wavelet transforms [], shearlet transforms [], Non-Subsampled Contourlet Transform (NSCT) [], and spatial domain clustering approaches [].
The method based on sparse representation utilizes the learned dictionary to extract and fuse sparse coefficients [,]. These approaches excel at preserving detailed structures but require computationally intensive optimization.
The variational optimization method adopts a complex regularization strategy and an energy minimization framework [,]. Although these methods are effective for handling complex imaging conditions, they involve iterative processes with significant computational overhead.
Overall, traditional techniques exhibit good performance without the need for large training datasets, but they are fundamentally limited by three key issues: (1) they rely on manually designed features and fixed fusion rules, lacking adaptability to different scenarios; (2) theya re unable to model semantic relationships between modalities; (3) they lack targeted processing for differentiating features between infrared thermal radiation and visible light texture.
2.2. Image Fusion Method Based on Deep Learning
The emergence of deep learning, especially convolutional neural networks (CNNs), has fundamentally changed image fusion by automatically learning feature representations and fusion strategies from data. This eliminates manual feature engineering and promotes more adaptive fusion mechanisms.
Early CNN-based methods established end-to-end mapping from source images to fused outputs [,]. Although superior to traditional methods, these methods adopt relatively shallow architectures, limiting their ability to model complex inter modal relationships and remote dependencies.
Subsequent research introduced deeper and more complex architectures to address these limitations. Han et al. [] proposed an unsupervised U-Net-based fusion network for visible and near-infrared processing, utilizing an encoder–decoder structure for multilevel feature representation. Lv et al. [] developed a framework that combines multiscale transformations with CNN for texture detail and salient object extraction. Shen et al. [] developed DFA-Net, a multiscale dense feature aware network whose attention mechanism is optimized for the fusion of infrared and visible light images of unmanned aerial vehicles. However, the increase in network depth will bring about training complexity and higher computational requirements.
Generative Adversarial Networks (GANs) have been used to enhance visual perception through adversarial training [,]. Although GAN-based methods can generate results with perceived attractiveness, they often suffer from training instability and require careful hyperparameter optimization, which limits their practical deployment.
The two-stage fusion strategy separates feature extraction from the application of fusion rules to provide greater flexibility. Hou et al. [] proposed VIF-Net, an unsupervised adaptive learning method that can preserve complementary information across modalities. Liu et al. introduced [] an efficient CNN method that can combine low light enhancement and feature difference guided fusion. These methods can independently optimize the feature extraction and fusion stages.
Recently, some studies have begun to utilize explainable artificial intelligence (XAI) to design feature-preserving loss functions for retaining critical features in image processing tasks. For example, Dong et al. [] proposed a feature-preserving loss for medical image denoising that maintains medical features through gradient-based XAI, which is conceptually close to the structural and frequency constraints used in our method.
Despite significant progress, CNN-based methods still face inherent limitations that have not been resolved: (1) the local receptive field of convolution operations fundamentally limits their ability to model global contextual relationships, which are crucial for robust multimodal fusion; (2) most methods treat infrared and visible light modes symmetrically, ignoring their fundamentally different characteristics; (3) the existing methods lack clear adaptive and content-aware fusion mechanisms, which cannot dynamically balance modal contributions based on local image features.
2.3. Transformer-Based Image Fusion Method
The Transformer architecture was originally developed for natural language processing and has achieved significant success in computer vision tasks, including image fusion. Unlike CNN, Transformer adopts a self-attention mechanism to effectively simulate global dependencies and remote semantic relationships, addressing a key limitation of convolution methods. Vision Transformer (ViT) [] lays the foundation for Transformer-based fusion by processing image patches into labeled sequences. Lin et al. [] introduced DS-TransUNet, which integrates Transformer modules with convolutional layers to combine local and global representations. This hybrid approach demonstrates the improved ability to capture cross-modal correlations while preserving structural details.
The quadratic computational complexity of standard Transformers poses challenges for high-resolution image processing. To address this, researchers developed efficient variants. Ma et al. [] proposed SwinFusion, adapting Swin Transformer architecture with shifted window attention to constrain computations within local regions. Ding et al. [] investigated linear attention mechanisms, maintaining global modeling while reducing computational costs. Another noteworthy efficient Transformer is the Reformer [], originally designed for high-resolution image restoration. It introduces Multi Dconv Head Transfer Attention (MDTA) and Gated Dconv Feedforward Network (GDFN), reducing computational complexity to a linear scale relative to input size while still capturing global context. The excellent feature extraction capability of Restormer makes it a popular pillar for subsequent fusion methods, as it balances the efficiency and representation ability of high-resolution images.
The hybrid architecture that combines Transformers with other components has become a promising direction. Xu et al. [] developed EMFusion, which integrates CNN with Transformers for local feature extraction for global context modeling. Du et al. [] introduced CTFusion, which combines convolutional and Transformer layers with mask reconstruction for multimodal feature learning. ResSCFuse [] combines a Restormer-based attention module with CNN and introduces a semi-coupled feature reconstruction network (SCFRNet) to solve the feature confusion problem in traditional autoencoders. The network uses shared convolutional kernels to extract cross-modal shared features and private kernels to capture modal-specific information. However, the shared private kernel strategy runs independently in each branch without dynamic interaction between modalities, which limits its ability to utilize complementary information to enhance feature representation.
Recent progress has focused on modal adaptation and cross-modal attention mechanisms. Park et al. [] proposed CMTFusion, which utilizes cross-modal transformer modules to enhance complementary information extraction. However, its cross-modal interaction mechanism is mainly unidirectional, using the features of one modality to regulate the other modality, lacking the process of bidirectional interaction and mutual promotion. Zhao et al. [] introduced CDDFuse, which uses correlation-driven dual-branch feature decomposition to separate the basic and detailed information of different fusion strategies. However, the design focuses on feature decomposition rather than modality specific processing, and its fusion strategy is also fixed. Wang et al. [] developed CTUnet to capture semantic and local features across multiple scales. Luo et al. [] proposed CPIFuse, a lightweight Restormer network designed specifically for polarization image fusion. This model constructs a U-Net architecture by combining convolution and Transformer modules, and innovatively designs a composite loss function based on polarization physical properties.
Although Transformer-based methods have advanced in this field, there are still several key gaps: (1) most existing Transformers handle infrared and visible light modes symmetrically and have not explored asymmetric extraction methods in depth; (2) cross-modal interaction mechanisms are often simplified and lack bidirectional guidance capabilities; (3) the existing fusion strategies usually adopt fixed rules rather than content adaptation methods.
2.4. Analysis
The above survey reveals three fundamental research gaps that existing methods have not fully addressed: (1) Symmetric handling of asymmetric modes. The current methods mainly symmetrically process infrared and visible light images, although they have their own unique features. Infrared images have unique temperature-based contrast and thermal targets, while visible light images provide high-resolution textures. This symmetrical processing method fails to utilize the unique advantages of each mode. (2) Limited cross-modal guidance. The existing fusion frameworks lack complex bidirectional interaction mechanisms that enable each modality to guide the processing of the other modality. Visible light images should provide texture detail guidance to enhance the information richness of infrared targets, while infrared images should provide thermal guidance to identify important areas in visible light images. (3) Fixed fusion strategy. At present, most methods adopt static fusion rules or fixed weight combinations, lacking adaptability based on dynamic balance of modal contributions based on local content features. This will result in poor fusion performance of different schemes.
These principles are embodied by our CGDBN framework, where asymmetric feature processing is performed in the TMFEM module. The CMIM module realizes two-way information interaction between modalities. The DAMF module performs adaptive feature fusion by dynamically balancing modal contributions through the analysis of features. These fundamental contributions distinguish our approach from existing ones.
3. Materials and Methods
3.1. Method Overview
The proposed CGDBN addresses the challenges of feature differences between different modalities in infrared and visible light image fusion, balancing global and local feature extraction, and developing adaptive fusion strategies. Among them, the design motivation of the asymmetric processing of this architecture comes from the feature difference between visible and infrared images: infrared images contain unique thermal characteristics such as temperature contrast, thermal target signals, etc., while visible images contain texture details that infrared images do not have. The asymmetric processing design can extract the features of the two modalities more deeply, so as to improve the performance of the model.
Figure 1 illustrates the asymmetric dual-branch architecture comprising seven interconnected components. The Encoding stage provides initial feature extraction, followed by the Feature Extraction Basic Mechanism (FEBM) module for enhanced foundational representations. The TMFEM module processes only the infrared branch with dedicated extraction strategies for thermal characteristics. The visible branch bypasses the TMFEM module and proceeds directly to the CMIM module. The CMIM module facilitates bidirectional communication between branches. The SLAB introduces global context modeling for long-range dependencies. The DAMF module performs intelligent feature integration based on content analysis, while the Decoder reconstructs the final output.
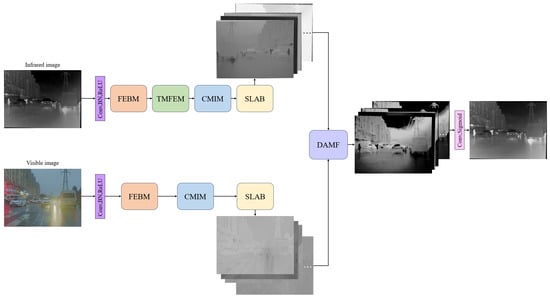
Figure 1.
Network architecture and module structures.
The architectural philosophy centers on asymmetric modality processing that reflects inherent differences between thermal and visible imaging. Infrared thermal radiation exhibits unique characteristics including temperature-based contrast, thermal target signatures, and specific noise patterns requiring specialized extraction.
Figure 2 shows the overall network flow. The process loads visible and infrared datasets, converts to grayscale, then uses overlapping cropping to generate patches with set size and step size, allowing high-definition feature extraction while avoiding excessive complexity. The network structure and loss function are initialized, followed by loading the optimizer and learning rate. Training proceeds through epochs with loss recording and weight saving until completion. Testing loads the trained weights and test images, performs the same grayscale transformation, then forward propagation produces fusion results. Post-processing adjusts output values to appropriate ranges and saves fused images.
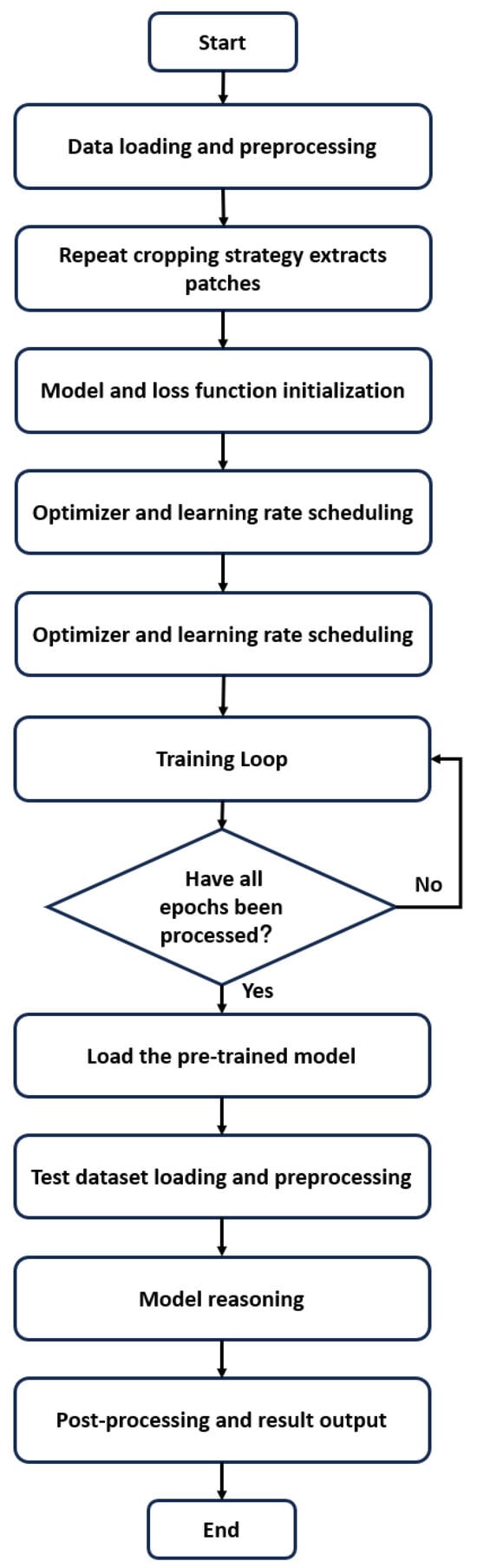
Figure 2.
Overall flowchart.
3.2. Network Architecture
The specific structure of each module is shown in Figure 3.
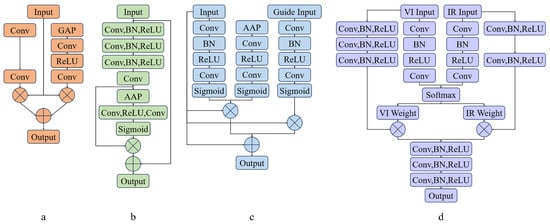
Figure 3.
The specific structure of each module. In the figure, (a) represents the FEBM module, (b) represents the TMFEM module, (c) represents the CMIM module, and (d) represents the DAMF module.
3.2.1. Encoder
The encoder transforms raw input imagery into feature representations suitable for specialized processing. Each input modality—infrared and visible —undergoes identical encoding to ensure consistent feature dimensionality while preserving modality-specific characteristics. The process maintains spatial resolution through carefully designed padding that prevents information loss at boundaries.
The encoder implements three-stage transformation. Mirror padding extends image boundaries using reflective values, addressing boundary condition problems that degrade fusion quality near edges. A convolutional layer extracts initial features while maintaining spatial dimensions through unit stride. Batch normalization and ReLU activation provide training stability and non-linear modeling capabilities.
This design establishes a foundation for subsequent stages by creating representations that preserve spatial relationships while enabling effective gradient flow. Identical processing of both modalities ensures that downstream modules receive compatible formats, facilitating cross-modal interaction.
where represents mirror padding, denotes convolution with stride 1, represents batch normalization, and denotes ReLU activation.
3.2.2. FEBM Module
The FEBM module functions as an attention-based processing stage that enriches basic encoder representations. Figure 3a shows the module structure. This addresses the limitation that raw convolutional features often lack sufficient discriminative power for complex fusion tasks by implementing dual-branch attention mechanisms operating simultaneously on spatial and channel dimensions.
The spatial attention branch captures local relationships and inter-pixel dependencies through two-stage convolution. Initial convolution reduces channels from C to , creating compressed representation focused on essential spatial patterns. Subsequent convolution further reduces channels to unity, generating spatial attention maps identifying spatially important regions. This enables network focus on regions containing significant structural or thermal information while suppressing background noise.
The channel attention branch captures global inter-channel dependencies through global average pooling followed by channel-wise transformations. Global average pooling aggregates spatial information across channels, creating descriptors capturing global context. Two successive convolutions with intermediate ReLU activation learn channel importance weights, enabling emphasis on features contributing most to fusion quality.
This dual attention ensures that subsequent stages receive improved features highlighting both spatially and semantically important information.
where ⊙ represents element-wise multiplication for integrating complementary spatial and channel information.
3.2.3. TMFEM Module
The TMFEM module operates exclusively on the infrared branch to address distinct thermal imagery characteristics. This asymmetric design stems from fundamental differences between infrared and visible modalities. Infrared sensors capture thermal radiation patterns with unique temperature-based contrast, thermal target signatures, and specific noise characteristics. The TMFEM module can solve two important problems in infrared feature extraction: firstly, using dilated convolution to expand the receptive field and adapt to different sizes of thermal targets without losing resolution, and the dilation rate is 2; the second is to suppress noise through thermal attention. This specific processing ensures high-fidelity thermal feature output, providing a reliable foundation for subsequent cross-modal interactions.
Figure 3b shows the TMFEM module structure implementing dual-path architecture for thermal target extraction and thermal attention generation. The thermal target extraction branch employs cascaded convolutions with dilated operations to capture thermal characteristics across multiple scales, and the cascade consists of 2 convolutional layers, both with 3 × 3 convolutional cores. Dilated convolutions expand receptive fields without spatial resolution reduction, enabling the capture of thermal targets varying significantly in size. The thermal attention branch generates pixel-wise attention weights through global average pooling followed by channel transformations, creating thermal significance maps guiding extraction toward thermally important regions.
Thermal target extraction begins with convolutional layers progressively refining thermal representations, and the channel size of the cascade convolutional layers is the same, exactly the same as the number of channels of the module’s input feature (the default configuration is 64). Each layer incorporates batch normalization and ReLU activation, maintaining training stability while enabling non-linear feature learning. The cascaded structure captures both local thermal variations and broader patterns characterizing different target types.
Thermal attention operates through global average pooling aggregating spatial information across channels, followed by two successive convolutions. The first reduces dimensionality while maintaining essential thermal information, and the second generates attention weights through sigmoid activation.
The final output combines thermal extraction and attention through element-wise multiplication, followed by residual connection preserving original infrared characteristics:
This specialized processing enables enhanced thermal target definition while preserving boundary characteristics essential for fusion quality. The module specifically addresses thermal contrast enhancement and target localization challenges unique to infrared imagery.
3.2.4. CMIM Module
The CMIM module ensures that both modalities benefit from cross-modal guidance: the visible light branch obtains thermal target information through infrared features, while the infrared branch obtains texture information through visible light features. This bidirectional optimization process generates interactive feature representations, which are beneficial for generating fused images in the future.
Figure 3c shows the CMIM module structure implementing bidirectional attention facilitating controlled information exchange. The module operates on the principle that each modality can provide guidance to improve the other—visible imagery can provide structural guidance, improving infrared target localization, while infrared imagery provides thermal guidance, identifying important visible regions.
Cross-modal attention employs three distinct types capturing different inter-modal relationships. Channel attention identifies which feature channels in the guiding modality are most relevant for processing the target modality. This enables the selective transfer of relevant channel information while filtering irrelevant or harmful information. Spatial attention identifies spatial regions in the target modality for processing based on spatial patterns in the guiding modality. Texture attention addresses textural information transfer, particularly important for improving visible processing based on infrared thermal patterns.
Cross-modal attention uses three different types to capture different relationships between modalities, and to determine which feature channels in the channel attention recognition guided modality are most relevant to the processing target modality. This enables the selective transmission of relevant channel information while filtering out irrelevant or harmful information. Spatial attention is different from standard spatial attention, as our design directly affects the input features of the target modality (rather than guiding features). It generates spatial weight maps through convolution operations, identifies spatial regions in the target modality that need to be enhanced or suppressed, and ensures the accurate alignment of cross-modal information in space. Texture attention specifically extracts high-frequency details and edge information by convolving guided features. This design enables it to capture texture patterns in the guided modality and transfer these texture details to the target modality through attention weights, thereby enhancing the texture fidelity of the fused image.
For the infrared branch guided by visible information, the module extracts channel, spatial, and texture attention maps from visible features. These maps apply to infrared features through element-wise multiplication and additive combinations. Channel attention helps infrared processing focus on feature channels corresponding to structurally important regions identified in visible imagery. Spatial attention guides infrared extraction toward regions containing important structural information. Texture attention enables the transfer of textural guidance, improving infrared target boundary definition.
The processing mechanism combines multiple attention mechanisms through operations that preserve original modality characteristics while incorporating complementary information. Processed features result from multiplicative combinations of original features with different attention maps, plus additive terms introducing guided information at controlled magnitudes.
The bidirectional nature ensures that both modalities benefit from cross-modal guidance. The visible branch receives guidance from infrared features, helping identify thermally significant regions, while the infrared branch receives structural guidance from visible features. This mutual improvement creates enriched feature representations combining specialized infrared processing with complementary visible modality processing.
3.2.5. SLAB
SLAB [] has achieved its performance through two innovations: one is the progressive re-parameterized BatchNorm (PRepBN), which gradually transitions from LayerNorm to re-parameterized BatchNorm (RepBN) through linear decay hyperparameters during training. RepBN can flexibly adjust the feature distribution to avoid training collapse, and can also be fused with linear layers during inference, eliminating the delay of real-time statistical calculation of LayerNorm and solving the problem of Swin relying on LayerNorm and Flatten using BatchNorm’s inaccuracy. The other is to simplify linear attention (SLA), using ReLU as the kernel function and combining deep convolution, which not only maintains O (NC2) linear complexity (N is the number of tokens, C is the feature dimension), but also reduces it. The computational cost also compensates for the lack of local feature capture, avoiding the shortcomings of traditional attention with high complexity and Swin window segmentation of features. Compared with Swin Transformer, Flatten Transformer, and traditional Transformer in tasks such as image classification, object detection, and language modeling, SLAB significantly reduces inference latency and improves throughput while maintaining or improving microliter accuracy.
The Simplified Linear Attention Block introduces global context modeling capabilities complementing local feature extraction strengths of convolutional operations. While CNNs excel at capturing local patterns, they face inherent limitations in modeling long-range dependencies and global contextual relationships crucial for understanding scene-level patterns in fusion tasks.
SLAB addresses this by implementing linear attention, capturing global dependencies across the entire image domain while maintaining practical applicability. The mechanism transforms input features into query, key, and value representations through learned linear projections, following fundamental attention paradigm with modifications improving stability and performance for image processing.
The attention mechanism begins with generating query, key, and value matrices through separate linear transformations of input features. These transformations create different perspectives—queries represent “what information to seek”, keys represent “what information is available”, and values represent “actual information content”. The learned projections enable network adaptation of these representations specifically for fusion requirements.
A critical innovation in SLAB lies in applying ELU activation followed by unit offset to query and key representations. This transformation ensures numerical stability and improved gradient flow during training while maintaining fundamental attention properties. ELU activation provides smooth gradients for negative values while maintaining linear behavior for positive values, and unit offset ensures strictly positive attention weights.
Linear attention computation follows a reformulated approach, maintaining global modeling capabilities while addressing quadratic complexity limitations. Key–value interaction computes first, creating global context representation, followed by query–context interaction, producing final attention output.
Here, the specific value of is set to . This ensures numerical stability by preventing division by zero errors when approaches zero, while also mitigating numerical overflow and gradient explosion issues.
SLAB integrates progressive re-parameterized batch normalization and residual learning within dual-residual structure improving training stability and feature learning. The first residual connection integrates linear attention output with input features, while the second incorporates multilayer perceptron performing feature transformation and refinement.
where represents simplified linear attention operation, denotes progressive re-parameterized batch normalization, and represents two-layer perceptron for feature refinement.
Progressive re-parameterized batch normalization introduces learnable parameters enabling adaptive normalization behavior during training while maintaining standard normalization properties during inference. This facilitates improved training dynamics while ensuring consistent inference behavior.
3.2.6. DAMF Module
The DAMF module solves the problems of feature differences between different modalities in infrared and visible light image fusion, balancing between global and local feature extraction, and adaptive fusion strategies. Therefore, regardless of the data situation, the network can adaptively find the optimal fusion strategy based on the characteristics of the data itself, avoiding the problem of insufficient feature extraction ability caused by fixed fusion strategies. Figure 3d shows the module structure.
The DAMF module implements this adaptive behavior through four-stage processing: density estimation, adaptive weight generation, feature refinement, and weighted fusion.
Density estimation analyzes the information content of each modality through convolutional operations assessing local feature significance and information richness. The density estimation network employs bottleneck architectures with batch normalization and ReLU activations creating robust density maps reflecting information content distribution across spatial locations.
Adaptive weight generation transforms density estimates into fusion weights through softmax operation ensuring proper normalization while introducing bias accounting for different information characteristics of each modality. Visible light density receives a scaling factor of 1.2, reflecting the observation that visible imagery often provides essential structural information for preservation in fusion results.
The scaling factor represents a design choice based on extensive experimentation reflecting complementary roles of infrared and visible information in typical fusion scenarios. This bias ensures structural information from visible imagery and receives appropriate emphasis while allowing infrared thermal information to dominate where it provides superior content.
Feature refinement applies modality-specific extraction operations, preparing features for optimal fusion. Infrared refinement employs cascaded convolutions with batch normalization, extracting thermal target representation while maintaining spatial accuracy. Visible refinement implements processing operations designed to extract and preserve fine-grained textural details.
Refinement networks implement different architectural strategies optimized for each modality’s characteristics. Infrared refinement focuses on thermal target extraction and boundary preservation, while visible refinement emphasizes texture preservation and detail extraction through conventional operations.
Weighted fusion combines refined features according to adaptive weights, creating spatially varying fusion behavior adapting to content characteristics. Weighted combination preserves important information from both modalities while emphasizing the most informative modality in each spatial region.
Final integration employs a fusion convolution network combining weighted features into unified representation. This network implements cascaded convolutions with batch normalization and ReLU activations, learning optimal combination strategies for weighted features while ensuring smooth spatial transitions and artifact suppression.
The fusion convolution network represents a learned integration strategy adapting to characteristics of weighted features from both modalities. Through training on diverse fusion scenarios, this network learns to create seamless combinations preserving important information while suppressing potential artifacts from the weighted combination process.
3.2.7. Decoder
The decoder performs the final transformation from high-level fused features to output imagery through streamlined reconstruction. The module implements a single convolutional operation followed by sigmoid activation, ensuring proper output range normalization.
The convolution reduces feature dimension to required output channels while performing a learned linear combination of features. Sigmoid activation ensures that output values remain within the range, preventing artifacts and ensuring proper image reconstruction.
3.3. Loss Function Design
To optimize the network, we adopted a multicomponent loss function that combines structural similarity (SSIM) and spatial frequency (SF) loss, aiming to simultaneously maintain the structural integrity and texture details of the input image. The design of this loss function follows the YDTR [], and its effectiveness has been fully validated in the task of infrared and visible light image fusion.
3.3.1. Structural Similarity Loss (SSIM Loss)
Structural similarity loss preserves perceptual quality and structural relationships between fused outputs and input modalities. The SSIM metric captures luminance, contrast, and structural similarities corresponding closely to human visual perception, making it ideal for fusion quality assessment.
The loss function incorporates separate SSIM terms for both modalities ensuring balanced structural information preservation:
3.3.2. Spatial Frequency Loss (SF Loss)
Spatial frequency loss preserves texture richness and detail information by maintaining frequency characteristics of input imagery. Spatial frequency captures the rate of change in pixel intensities, providing a measure of image detail and texture content.
Modality-specific spatial frequency losses ensure preservation of texture characteristics from both input modalities:
3.3.3. Total Loss Function
The complete loss function combines all components with weighted parameters that control the relative importance of different loss terms:
The weighting parameters are preset as hyperparameters to balance the contribution of different loss terms to model optimization.
4. Results
4.1. Experimental Configuration and Evaluation Framework
We conducted experiments using six established image quality metrics and six representative baseline methods spanning classical to state-of-the-art approaches. The evaluation metrics include average gradient (AG) for edge retention, mutual information (MI) for cross-modal information preservation, spatial frequency (SF) for texture detail assessment, structural similarity index (SSIM) for perceptual quality, peak signal-to-noise ratio (PSNR) for signal fidelity, and mean square error (MSE) for pixel-level accuracy. Higher values indicate superior quality for all metrics except MSE.
Six fusion algorithms were selected for comparison: DenseFuse [], FusionGAN [], YDTR [], SwinFusion [], ITFuse [], CDDFuse [], and CMTFusion [], representing different methodological approaches in IR–Vis image fusion.
Three benchmark datasets were used for experimental verification, among which the AVMS [] dataset was used for training, validation, and testing, and the MFD [] dataset and TNO [] dataset were used to test the generalization ability of the proposed method.
The AVMS dataset consists of 600 pairs of visible and infrared images captured by professional unmanned aerial vehicles (UAVs) under different conditions, including day, dusk, night, and complex weather. The images cover a variety of scenes such as residential areas, roads, campuses, farmland, etc., with different shooting distances and perspectives. A total of 8991 carefully annotated instances are provided in seven object categories, including 8046 cars, 526 pedestrians, and 138 tents, among others. This dataset has the characteristics of multiple perspectives, multiple lighting conditions, multiple weather conditions, multiple targets, multiple scenes, and multiple shooting distances. Its wide coverage, strong challenges, and highly diverse advantages make it a high-quality dataset. The images in the VMS dataset are randomly divided into training set, validation set, and test set, with a ratio of 4:1:1.
The M3FD dataset was developed by the research team at Dalian University of Technology. Images were captured using synchronized systems equipped with binocular optical cameras and infrared sensors, ensuring highly registered pairs. The dataset comprises 4200 image pairs acquired across Dalian University campus, major roads in Jinzhou District, and Jinshitan Beach. It includes six target categories: person, car, bus, motorcycle, light, and truck.
The TNO dataset, released by the Netherlands Organisation for Applied Scientific Research, provides multiband image collections featuring enhanced visual, near-infrared, and long-wave infrared nighttime imagery from various military and surveillance scenarios. These images depict diverse objects and targets—people and vehicles—against different backgrounds, including rural and urban environments.
Implementation used ZOTAC GTX 5070 TI GPU acceleration (Hong Kong, China) for GPU acceleration. We preprocessed the converted multichannel input to grayscale (to avoid inconsistent experimental settings, all baseline models used also underwent grayscale conversion during inference). During model training and inference, pixel values were normalized to the range of [0, 1]. When performing quantitative calculations of indicators, in order to maintain consistency with existing research, all indicator calculations were performed within the pixel value range of [0, 255]. Training employed overlapping patches of with 50% overlap, while inference used full-resolution images. Training configuration: batch size 16, 20 epochs; the values of loss weights w1, w2, w3, and w4 were set to 0.85, 0.9, 0.0005, and 0.0015; Adam optimizer with learning rate 0.001, learning rate scheduling using StepLR strategy. When the validation loss did not decrease for five consecutive epochs, an early stop was triggered.
4.2. Ablation Experiment
In order to evaluate the respective contributions and necessity of each component in the proposed fusion network, a series of ablation experiments were conducted on the AVMS dataset, including ablation experiments on the necessity of asymmetric design for TMFEM module; an ablation experiment with a fixed parameter of 0.5 in the CMIM module; an ablation experiment with a fixed parameter of 1.2 in the DAMF module; and ablation experiments for five important modules: the FEBM module, the TMFEM module, the CMIM module, SLAB, and the DAMF module. The fusion performance was evaluated using six widely adopted image quality metrics: PSNR, SSIM, MSE, AG, MI, and SF.
4.2.1. Ablation Experiment of Asymmetric Design of TMFEM Module
TMFEM is an asymmetric module that is only set on the IR branch. To verify the effectiveness of this model setting, ablation experiments were conducted.The visual comparison chart of the experimental results of asymmetric design is shown in Figure 4.

Figure 4.
Visual comparison of the ablation study on the asymmetric design of the TMFEM module. The red boxes mark the key areas where differences are manifested.
As shown in Table 1, w/o TMFEM refers to the model after removing the TMFEM module on the IR branch, while VI + TMFEM refers to adding a TMFEM module at the symmetrical position of the VI branch that is the same as the one on the IR branch. The experimental results showed that the proposed model achieved first place in four indicators, namely, AG (54.8581), MI (1.0322), SF (21.3091), and PSNR (17.3825); it ranked second on both indicators, SSIM (0.7046) and MSE (2285.9549), respectively. On the AG index, the proposed model beat the second place VI + TMFEM model (54.4383) by 0.4198. In terms of MI indicators, the proposed model beat the second place VI + TMFEM model (0.9832) by 0.0490. In terms of SF indicators, the proposed model beat the second place VI + TMFEM model (21.1642) by 0.1449. On the PSNR metric, the proposed model beat the second-ranked w/o TMFEM model (17.2146) by 0.1679. In terms of SSIM indicators, the proposed model only differed from the top-ranked w/o TMFEM model (0.7074) by 0.0028. In terms of MSE index, there was only a difference of 211.3830 compared to the first place VI + TMFEM model (2074.5719).

Table 1.
Performance comparison of asymmetric design ablation research of the TMFEM module. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
For the performance of various indicators, the proposed model leads comprehensively in AG, MI, SF, and PSNR, indicating that it has better edge preservation ability, cross-modal information transmission, texture detail preservation, and signal fidelity. The suboptimal performance of SSIM and MSE reflects that there is still room for improvement in the model’s structural consistency and error control. Overall, the specialized processing of asymmetric design leads in most key indicators, especially in thermal target feature extraction and global information modeling, which verifies the effectiveness of specialized processing for the unique characteristics of infrared images.
4.2.2. Ablation Experiment with Parameters in CMIM Module
In Formula (11) of Section 3.2.4, texture attention was multiplied by a coefficient of 0.5, and ablation experiments were conducted to explain the validity of this coefficient’s value. The visual comparison diagram of the ablation experiment of this module is shown in Figure 5.

Figure 5.
Visual comparison of the ablation study on the parameter 0.5 of CMIM module. The red boxes indicate the regions most affected by this parameter variation.
As shown in Table 2, the ablation experiment results of the CMIM module showed that the proposed model achieved first place in two indicators, namely, MI (1.0322) and PSNR (17.3825). At the same time, it ranked second on one indicator, SF (21.3091). In terms of MI indicators, the proposed model beat the second place model with CMIM parameter set to 1.5 (1.0207) by 0.0115. On the PSNR metric, the proposed model beat the second place CMIM with a parameter setting of 1.5 model (17.2772) 0.1053. In terms of SF indicators, the proposed model differed by only 0.1721 from the model with the first place, the CMIM parameter set to 0.6 (21.4812). In addition, although the model with the CMIM parameter set to 0.05 also achieved first place in two indicators, it did not achieve second place in any indicator, which means that the overall performance of the model is not as good as the proposed model.
Table 2.
Performance comparison of the CMIM module’s parameter ablation studies. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
From the performance of various indicators, the proposed model leads in MI and PSNR, indicating that it has better cross-modal information transmission and signal fidelity. The suboptimal performance of SF reflects the model’s excellent ability in preserving texture details. However, the relative lag in AG, SSIM, and MSE indicates that there is still room for improvement in edge preservation, structural consistency, and error control. Overall, the experimental results indicate that the proposed model outperforms other parameter settings, demonstrating the effectiveness of the parameter 0.5 adjusted through extensive experimentation in the proposed model.
4.2.3. Ablation Experiment with Parameters in DAMF Module
In Formula (21) of Section 3.2.6, the density estimation of VI features is multiplied by a coefficient of 1.2. An ablation experiment was conducted to explain the effectiveness of the coefficient value.The visual comparison diagram of the ablation experiment of the DAMF module is shown in Figure 6.

Figure 6.
Visual comparison of the ablation study on the parameter 0.5 of DAMF module. The red boxes indicate the regions most affected by this parameter variation.
As shown in Table 3, the experimental results showed that the proposed model achieved first place in two indicators, namely, MI (1.0322) and PSNR (17.3825). At the same time, AG (54.8581) and SF (21.3091) ranked second for both indicators. On the MI index, the proposed model beat the second place model with a coefficient set to 2.0 (1.0237) by 0.0085. On the PSNR metric, the proposed model beat the second-ranked model with a parameter set to 2.0 (17.3742) by 0.0083. On the AG index, the proposed model differed by only 0.8611 from the model with the first parameter set to 1.5 (55.7192). In terms of SF indicators, there was only a difference of 0.0464 compared to the model with the first parameter set to 1.5 (21.3555). Although the model with a parameter set to 0.12 also achieved first place on two metrics, it failed to achieve second place on any metric, indicating a gap in its overall performance compared to the proposed model. From the performance of various indicators, the proposed model leads in MI and PSNR, indicating that it has better cross-modal information transmission and signal fidelity. The suboptimal performance of AG and SF reflects the model’s good ability in edge preservation and texture detail preservation. Overall, the proposed model performs excellently in key information transmission and signal fidelity, achieving the best balance between highlighting thermal targets and preserving texture details in the ablation experiment.
Table 3.
Performance comparison of the DAMF module’s parameter ablation studies. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
4.2.4. Module Ablation Experiment
In order to verify the effectiveness of each module in the proposed model, the following experiments were conducted for comparison. The visual comparison image of the experiment is shown in Figure 7.

Figure 7.
Visual comparison of the comprehensive module ablation study. The red boxes draw attention to the key areas impacted by removing individual modules.
As shown in Table 4, the experimental results showed that the proposed model achieved first place in four indicators, namely, AG (54.8581), MI (1.0322), SF (21.3091), and PSNR (17.3825). In the AG indicator, the proposed model led the second place w/o TMFEM model (53.8664) by 0.9917. In terms of MI indicators, the proposed model beat the second place w/o CMIM model (1.0022) by 0.0300. In terms of SF indicators, the proposed model beat the second place w/o CMIM model (21.1500) by 0.1591. On the PSNR metric, the proposed model beat the second-ranked w/o TMFEM model (17.2146) by 0.1679. From the performance of various indicators, the proposed model leads comprehensively in AG, MI, SF, and PSNR, indicating that it has better edge preservation ability, cross-modal information transmission, texture detail preservation, and signal fidelity. On the whole, the complete model is better than removing the variants of any module in most key indicators, which verifies the necessity and effectiveness of the design of each module.
Table 4.
Performance comparison of module ablation studies. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
4.3. Analysis on AVMS Dataset
Figure 8 shows a visual comparison of representative AVMS samples. Table 5 shows the data performance of the proposed model on the AVMS dataset. In the comparative experiment of the AVMS dataset, the proposed model achieved first place in two indicators, namely, SSIM (0.7301) and PSNR (16.2497). At the same time, it ranked second on both indicators, namely, MI (1.2587) and SF (18.1132). In terms of SSIM indicators, the proposed model beat the second ranked YDTR model (0.7159) by 0.0142. In terms of PSNR indicators, the proposed model beat the second ranked YDTR model (15.2526) by 0.9971. In terms of MI indicators, the proposed model only differed from the top-ranked CDDFuse model (1.3026) by 0.0439. In terms of SF indicators, there was only a difference of 2.5571 compared to the first place CDDFuse model (20.6703). Among the other indicators, the average gradient (AG) ranked fourth (42.5526) and the mean squared error (MSE) ranked third (2859.1860), both located in the first half of all eight models, indicating that the proposed model has strong performance in all indicators.

Figure 8.
Visual analysis on the AVMS dataset. The red box emphasizes the areas of significant differences from the baseline method.
Table 5.
Performance comparison on the AVMS dataset. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
From the performance of various indicators, the proposed model leads in SSIM and PSNR, indicating that it has better structural consistency and signal fidelity in visual perception, and can better preserve the overall structure and detail information of the input image. The suboptimal performance of MI and SF reflects the model’s good ability to preserve cross-modal information and texture details. Overall, the proposed model visually presents clearer object contours, more natural contrast, and richer texture layers, while also demonstrating stability in noise control and error suppression, achieving an efficient balance between highlighting thermal targets and preserving texture details in the fusion results.
4.4. Analysis of Generalization Experimental Results on M3FD Dataset
Figure 9 shows a visual comparison of representative M3FD samples. Table 6 shows the quantitative comparison of all fusion methods on the M3FD dataset. In the performance comparison of the M3FD dataset, the proposed model achieved first place in two indicators, namely, PSNR (16.5044) and SF (15.4167). It ranked second on both indicators, SSIM (0.7173) and MI (1.1140), respectively. In terms of PSNR indicators, the proposed model beat the second-ranked YDTR model (15.7564) by 0.7480. In terms of SF indicators, the proposed model beat the second place CDDFuse model (15.1078) by 0.3089. In terms of SSIM indicators, the proposed model only differed from the top-ranked DenseFuse model (0.7252) by 0.0079. In terms of MI indicators, there was only a difference of 0.1998 compared to the first place CDDFuse model (1.3138). Among the other indicators, the average gradient (AG) ranked third (48.5746) and the mean squared error (MSE) ranked fourth (3177.2302), both located in the first half of all eight models, indicating that the proposed model maintains good performance in all evaluation dimensions.

Figure 9.
Visual comparison on M3FD dataset. The red box emphasizes the areas of significant differences from the baseline method.
Table 6.
Performance comparison on the M3FD dataset. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
From the analysis of performance indicators, the proposed model’s leading advantages in PSNR and SF demonstrate its outstanding ability in signal fidelity and texture detail preservation. The suboptimal performance of SSIM and MI validates their effectiveness in structural consistency and cross-modal information fusion. Visually, the model excels in the clarity of thermal target contours, richness of background details, and naturalness of the overall image. It also demonstrates significant advantages in noise suppression and artifact control, achieving high-quality fusion of infrared thermal radiation information and visible light texture features.
4.5. Analysis of Generalization Experimental Results on TNO Dataset
We also performed experiments on the TNO dataset to test the generalization capabilities of the proposed model. Figure 10 shows a visual comparison of representative TNO samples, and Table 7 shows the quantitative comparison of all fusion methods on the TNO dataset. In the generalization test of the TNO dataset, the proposed model achieved first place in two key indicators, namely, PSNR (17.3956) and SSIM (0.7230). At the same time, it ranked second on one indicator, namely, MSE (2494.8075). In terms of PSNR indicators, the proposed model beat the second-ranked YDTR model (16.6022) by 0.7934. On the SSIM metric, it beat the second-ranked YDTR model (0.7145) by 0.0085. In terms of MSE index, the proposed model differed from the first-ranked ITFuse model (2019.0836) by 475.7239. Among the other indicators, spatial frequency (SF) ranked third (11.6000), average gradient (AG) ranked fifth (36.8721), and mutual information (MI) ranked fifth (0.8685). Most indicators are still at the mid to upper reaches of all eight models, indicating that the proposed model still has reliable generalization ability in different scenarios.

Figure 10.
Visual analysis on TNO dataset. The red box emphasizes the areas of significant differences from the baseline method.
Table 7.
Performance on the TNO dataset. Bold indicates best results, underline indicates second-best performance. ↑ indicates higher is better, ↓ indicates lower is better.
From a visual perspective, the proposed model exhibits excellent cross-domain adaptability on the TNO dataset: its significant lead in PSNR and SSIM indicates that it can effectively maintain the global structural consistency and local detail authenticity of images. The suboptimal performance of MSE reflects its performance in pixel-level precision control. Visually, the model can still clearly present the contour of hot targets in complex scenes while maintaining the natural transition of visible light textures. It can also effectively suppress noise in low-contrast areas, and the overall fusion result achieves a good balance between target saliency, detail richness, and visual comfort.
4.6. Performance Summary
From the experimental results, it can be concluded that the proposed model achieved first place in SSIM and PSNR metrics, and second place in MI and SF metrics on the AVMS dataset. Among the other models, only CDDFuse achieved first place in two metrics (MI and SF), but the model only achieved second place in one metric. The proposed model achieved first place in SF and PSNR metrics and second place in MI and SSIM metrics on the M3FD dataset. Only DenseFuse also achieved first place in two metrics (SSIM and MSE), but the model did not achieve second place on any metric. The proposed model achieved first place in SSIM and PSNR metrics on the TNO dataset, and second place in MSE metric. Only SwinFusion achieved first place in both metrics (AG and SF), but the model failed to achieve second place in any metric. Compared with other models, our model is the most advanced in terms of data integration on six indicators. This validates the balanced multimodal feature extraction and fusion achieved by the proposed model through a specially designed network model. Considering that the AVMS dataset comes from aerial images taken by drones, while the M3FD dataset and TNO dataset were used to test the generalization ability of the proposed model come from street view images, the large difference between data sources and imaging conditions highlights the robustness and generalization ability of the proposed model.
5. Conclusions
The proposed cross-modal guided dual-branch network with asymmetric processing achieved significant performance improvement in infrared and visible light image fusion tasks. The experimental results confirm that the combination of TMFEM module’s specialized infrared processing and traditional visible light processing effectively solves the trade-off between computational efficiency and fusion quality inherent in traditional symmetric methods. The asymmetric architecture achieves targeted thermal feature extraction while maintaining efficient texture processing, and the consistent performance of the AVMS, M3FD, and TNO datasets confirms the robustness and generalization ability of this method.
This study makes significant progress: asymmetric processing strategies recognize the fundamental difference between infrared thermal characteristics and visible texture characteristics, and apply specialized processing only in physically appropriate situations. The introduction of SLAB ensures the global modeling capability for scene level understanding; the CMIM module enables effective information exchange between asymmetric processed infrared and conventional processed visible light branches; the DAMF module dynamically adjusts the contribution weight of each modality based on the image content. The significant improvement in indicator data indicates that the fused image maintains high structural similarity with the input image, while achieving better signal quality through computationally efficient asymmetric processing.
However, this study also has some shortcomings. Firstly, for small-sized targets, the structure of the proposed model may not be sufficient to fully capture their features, resulting in factors such as dilated convolution and thermal attention in the TMFEM module limiting the size of the proposed model. Secondly, when the contrast of the image is low, it may result in a small difference between the target and background, which may lead to a flat overall distribution of the image feature map without obvious peak areas. The DAMF module may not be able to correctly calculate the appropriate weights when generating adaptive weights, resulting in insufficient fusion, etc. Finally, it was found during the experiment that the PSNR value was high while the MSE value was high. The reason was that the MSE value of the proposed model fluctuated relatively largely compared to other models in some cases, and its performance in the MSE index was not stable enough. In the future, the proposed model will be further optimized to address the above shortcomings so that it can better handle the fusion of images under extreme conditions (such as images with small-sized targets or images with low contrast due to poor shooting conditions), and perform better and more stably in various indicators.
In future plans, in addition to optimizing the performance of the proposed model, there are also plans to expand the research in several directions, including the following:
- 1.
- Develop a more lightweight architecture to further reduce the parameters and computational complexity of edge computing deployment. For example, transform SLAB’s attention mechanism into a local global hybrid attention mechanism, use CNN to efficiently extract local texture features of visible light branches, and, at the same time, use the compact version of Transformer to conduct sparse global modeling of key thermal targets of infrared branches, thereby further reducing memory access costs.
- 2.
- Expand the method of video sequence fusion by combining temporal consistency and motion information, such as adding temporal attention branches on the basis of the original framework and modeling the dependency relationships between consecutive frames. To solve the problem of modal asynchrony, lightweight optical flow estimation is integrated in the preprocessing stage, which dynamically registers misaligned areas (such as moving vehicles) by estimating the motion vectors between visible light and infrared frames.
- 3.
- Explore joint optimization with downstream computer vision tasks and establish an end-to-end multitask learning framework, such as integrating the fusion module of the proposed model with the detector through a shared feature encoder. The encoder simultaneously learns to optimize the fusion quality and cross-modal features of detection accuracy. In the extension of semantic segmentation, semantic information is used to guide the fusion weights, and the feature fusion module is improved to receive semantic masks output by lightweight segmentation heads, dynamically adjust modal contributions, prioritize infrared features in hot target areas, and prioritize visible light textures in non-hot target areas such as buildings. Multitask loss is used for adjustment during training.
- 4.
- The proposed model currently does not consider image registration in the image fusion preprocessing step, but defaults to using already registered image fusion datasets. When the model is transferred to an unregistered data mart, performance degradation may occur. In the future, research will be conducted on fusion methods for unregistered datasets, integrating feature-based alignment networks or deformable attention mechanisms directly into fusion networks, or developing unregistered fusion methods. In addition, we plan to exploring self-monitoring techniques to detect and compensate for geometric differences between modalities.
This study provides an efficient and stable solution for infrared and visible light image fusion by matching asymmetric processing with modal requirements. With the advancement of deep learning technology and the improvement of computing power, image fusion based on differentiated feature extraction of different modalities may play an increasingly important role in various applications.
Author Contributions
T.Z.: Conceptualization, methodology, software, validation, writing—original draft. G.W.: Supervision, methodology, writing—review and editing, project administration. J.C.: Resources, methodology, writing—review and editing, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are publicly available. The AVMS dataset [], the M3FD dataset [], and the TNO dataset [] can be obtained from their respective sources as cited in the references.
Acknowledgments
The authors would like to thank the reviewers for their valuable comments and suggestions, and the Hebei Key Laboratory of Intelligent Information Perception and Processing for providing computational resources. The authors also appreciate the creators of the AVMS, M3FD, and TNO datasets for making their data public, which made this research possible.
Conflicts of Interest
Authors Tingyu Zhu, Jinyong Chen were employed by the company The 54th Research Institute of CETC. The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Yang, Y.; Que, Y.; Huang, S.; Lin, P. Multimodal sensor medical image fusion based on type-2 fuzzy logic in NSCT domain. IEEE Sens. J. 2016, 16, 3735–3745. [Google Scholar] [CrossRef]
- Petrovic, V.S.; Xydeas, C.S. Gradient-based multiresolution image fusion. IEEE Trans. Image Process. 2004, 13, 228–237. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Ma, S.; Liu, J. DCDR-GAN: A Densely Connected Disentangled Representation Generative Adversarial Network for Infrared and Visible Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 549–561. [Google Scholar] [CrossRef]
- Vibashan, V.S.; Valanarasu, J.M.J.; Oza, P.; Patel, V.M. Image Fusion Transformer. In Proceedings of the International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3566–3570. [Google Scholar]
- Singh, R.; Khare, A. Multimodal medical image fusion using daubechies complex wavelet transform. In Proceedings of the IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–13 April 2013; pp. 869–873. [Google Scholar]
- Li, P.; Wang, H.; Li, X.; Hu, H.; Wei, H.; Yuan, Y.; Zhang, Z.; Qi, G. A novel Image Fusion Framework based on Non-Subsampled Shearlet Transform (NSST) Domain. In Proceedings of the Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 1409–1414. [Google Scholar]
- Chen, Z.; Zhang, C.; Wang, P. High-quality fusion for visible and infrared images based on the double NSCT. In Proceedings of the 7th International Congress on Image and Signal Processing, Dalian, China, 14–16 October 2014; pp. 223–227. [Google Scholar]
- Zhao, L.; Wang, Y.; Hu, Y.; Dai, H.; Xi, Y.; Ning, F.; He, Z.; Liang, G.; Zhang, Y. An image fusion algorithm based on image clustering theory. Vis. Comput. 2025, 41, 5517–5537. [Google Scholar] [CrossRef]
- Ting, L.; Jian, C. A new algorithm for image fusion via sparse representation. In Proceedings of the International Conference on Automatic Control and Artificial Intelligence (ACAI 2012), Xiamen, China, 24–26 March 2012; pp. 151–154. [Google Scholar]
- Tabarsaii, S.; Aghagolzade, A.; Ezoji, M. Sparse Representation-based Multi-focus Image Fusion in a Hybrid of DWT and NSCT. In Proceedings of the 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–9 March 2019; pp. 251–256. [Google Scholar]
- Li, X.; Yuan, Y.; Wang, Q. Hyperspectral and Multispectral Image Fusion via Nonlocal Low-Rank Tensor Approximation and Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 550–562. [Google Scholar] [CrossRef]
- Jian, W.; Chunxia, Q.; Xiufei, Z.; Ke, Y.; Ping, R. A multi-source image fusion algorithm based on gradient regularized convolution sparse representation. J. Syst. Eng. Electron. 2020, 31, 447–459. [Google Scholar] [CrossRef]
- Prabhakar, K.; Srikar, V.S.; Babu, R.V. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4724–4732. [Google Scholar]
- Zhang, C.-J.; Guo, J.-X.; Ma, L.-M.; Lu, X.-Q.; Liu, W.-C. TCCL-DenseFuse: Infrared and Water Vapor Satellite Image Fusion Model Using Deep Learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2023, 16, 4778–4800. [Google Scholar] [CrossRef]
- Han, Q.; Jung, C. Deep Selective Fusion of Visible and Near-Infrared Images Using Unsupervised U-Net. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 4172–4183. [Google Scholar] [CrossRef] [PubMed]
- Lv, H.; Deng, B.; Li, X. Research on Image Fusion Technology of Infrared and Visible Image Based on MST and CNN. In Proceedings of the IEEE 4th International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Dali, China, 12–14 October 2022; pp. 1395–1399. [Google Scholar]
- Shen, S.; Li, D.; Mei, L.; Xu, C.; Ye, Z.; Zhang, Q.; Hong, B.; Yang, W.; Wang, Y. DFA-Net: Multi-Scale Dense Feature-Aware Network via Integrated Attention for Unmanned Aerial Vehicle Infrared and Visible Image Fusion. Drones 2023, 7, 517. [Google Scholar] [CrossRef]
- Le, Z.; Huang, J.; Fan, F.; Tian, X.; Ma, J. A Generative Adversarial Network For Medical Image Fusion. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 September 2020; pp. 370–374. [Google Scholar]
- Yanli, L.; Zimu, L.; Junce, F.; Gu, Y. An Unsupervised GAN-based Quality-enhanced Medical Image Fusion Network. In Proceedings of the IEEE Conference on Telecommunications, Optics and Computer Science (TOCS 2022), Dalian, China, 11–12 December 2022; pp. 429–432. [Google Scholar]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imag. 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, G.; Shi, Y.; Tian, Y.; Zhang, L. Efficient feature difference-based infrared and visible image fusion for low-light environments. Vis. Comput. 2025, 41, 7839–7854. [Google Scholar] [CrossRef]
- Dong, G.; Basu, A. Medical image denoising via explainable AI feature preserving loss. arXiv 2024, arXiv:2310.20101. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Jia, D.; Guo, J.; Han, K.; Wu, H.; Zhang, C.; Xu, C.; Chen, X. GeminiFusion: Efficient Pixel-wise Multimodal Fusion for Vision Transformer. arXiv 2024, arXiv:2406.01210. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.H.; Hayat, M.; Khan, F.S.; Yang, M. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5718–5729. [Google Scholar]
- Xu, H.; Ma, J. EMFusion: An unsupervised enhanced medical image fusion network. Inf. Fusion 2021, 76, 177–186. [Google Scholar] [CrossRef]
- Du, K.; Fang, L.; Chen, J.; Chen, D.; Lai, H. CTFusion: CNN-transformer-based self-supervised learning for infrared and visible image fusion. Math. Biosci. Eng. 2024, 21, 6710–6730. [Google Scholar] [CrossRef]
- Wang, P.; Zhou, Y.; Yang, G.; Wu, H. ResSCFuse: A Fusion Network for Infrared and Visible Images Based on Restormer Attention and Semi-Coupled Feature Reconstruction Net. In Proceedings of the 4th International Conference on Digital Society and Intelligent Systems, Sydney, Australia, 20–22 November 2024; pp. 243–249. [Google Scholar]
- Park, S.; Vien, A.G.; Lee, C. Cross-Modal Transformers for Infrared and Visible Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 770–785. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5906–5916. [Google Scholar]
- Wang, X.; Zhu, C.; Li, J. CTUnet: A Novel Paradigm Integrating CNNs and Transformers for Medical Image Segmentation. In Proceedings of the International Joint Conference on Neural Networks (IJCNN 2024), Yokohama, Japan, 30 June–5 July 2024; pp. 1–6. [Google Scholar]
- Luo, Y.; Zhang, J.; Li, C. CPIFuse: Toward realistic color and enhanced textures in color polarization image fusion. Inf. Fusion 2025, 120, 103111. [Google Scholar] [CrossRef]
- Guo, J.; Chen, X.; Tang, Y.; Wang, Y. SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization. arXiv 2024, arXiv:2405.11582. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y. YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer. IEEE Trans. Multimed. 2023, 25, 5413–5428. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y. ITFuse: An interactive transformer for infrared and visible image fusion. Pattern Recognit. 2024, 156, 110822. [Google Scholar] [CrossRef]
- Jie, Y.; Xu, Y.; Li, X.; Zhou, F.; Lv, J.; Li, H. FS-Diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution. Inf. Fusion 2025, 121, 103146. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5792–5801. [Google Scholar]
- Alexander, T. TNO Image Fusion Dataset; TNO: The Hague, The Netherlands, 2014. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).