Abstract
Named entity recognition (NER) in few-shot scenarios plays a critical role in entity annotation for low-resource domains. However, existing methods are often limited to learning semantic features and intermediate representations specific to the source domain, which restricts their generalization capability when applied to unseen target domains and leads to prominent performance degradation. To address this issue, we propose a novel few-shot NER model based on contrastive learning. Specifically, the model enhances token representations through Gaussian distribution embedding and a self-attention mechanism, while adaptively optimizing the weighting parameters of the contrastive loss to achieve performance improvement. This design effectively mitigates overfitting and enhances the model’s generalization ability. Experiments on multiple datasets (including CoNLL2003, GUM, and Few-NERD) demonstrate that our approach achieves performance gains of 2.05% to 15.89% compared to state-of-the-art methods. These results confirm the effectiveness of our model in few-shot NER tasks and suggest its potential for broader application in low-resource information extraction scenarios.
1. Introduction
NER, the task of identifying and classifying rigid designators (e.g., persons, organizations, locations) in text, serves as a foundational pillar for numerous natural language processing (NLP) applications, including information retrieval, knowledge graph construction, and question answering [1,2]. While deep learning models, particularly those based on pre-trained language models like BERT, have achieved remarkable success on benchmark datasets, their performance heavily relies on the availability of large-scale, high-quality annotated data [3,4]. This dependency renders them brittle and impractical for many real-world scenarios where annotated data is scarce or expensive to acquire, such as in specialized medical, financial, or legal domains [5].
To overcome the data scarcity bottleneck, few-shot NER has emerged as a critical research direction [6,7,8]. The objective of few-shot NER is to equip a model with the ability to rapidly adapt and recognize novel entity types based on only a handful of labeled examples (the support set) for each type. Meta-learning and metric-based approaches have been primary drivers of progress in this area [9]. Prototypical Networks, for instance, learn a metric space where examples cluster around a prototype for each class, and have been effectively adapted for NER [10]. Building on this, Yang and Katiyar [11] introduced a simple yet powerful structured nearest neighbor learning method, StructShot, which enhances inference by incorporating Viterbi decoding to capture label dependencies. More recently, the paradigm of prompt-based learning has shown considerable promise. Methods like Template-free Prompt Tuning (TPT) [12] reformulate the NER task to better align with the pre-training objectives of language models, achieving strong performance without manual template engineering.
Despite these advancements, current few-shot NER methods are hampered by two fundamental, intertwined challenges rooted in their reliance on specific data resources and limited robustness in complex scenarios [13,14]. To address these limitations, we argue for a paradigm shift from the traditional deterministic point embeddings to distributional representations that explicitly model uncertainty and context [15]. In this paper, we propose a novel contrastive learning framework for few-shot NER built upon Gaussian Embeddings.
This work adopts Gaussian embeddings instead of traditional point embeddings, based on their inherent advantages in modeling uncertainty and hierarchical relationships in data-scarce scenarios. Although point embeddings perform exceptionally well with large amounts of annotated data, they compress each entity into a deterministic point in space, which can easily lead to overfitting in few-shot learning and struggles to capture intra-class variance [16]. Gaussian embeddings, by representing each entity as a distribution (with mean and variance), naturally possess capabilities critical for few-shot NER: (1) explicit modeling of uncertainty, (2) capturing asymmetric relationships and hierarchical structures, and (3) inductive learning and generalization abilities.
Recent studies have successfully applied Gaussian embeddings to various NLP tasks, such as sentence embeddings [15], few-shot knowledge graph completion [17], and dialogue systems [18], to handle semantic ambiguity and uncertainty. These works collectively demonstrate the value of distributional representations in scenarios with limited data and semantic complexity. Therefore, we hypothesize that combining Gaussian embeddings with contrastive learning can guide the model to learn more generalizable features and, through the regulatory role of their variances, mitigate the challenging ‘O-token’ interference problem in few-shot NER. We will provide empirical support for this design choice in Section 3 through ablation studies (comparing point embeddings and Gaussian embeddings) and visual analysis.
Leveraging this foundation, our model enhances Gaussian embeddings by integrating a Self-Attention Mechanism to dynamically refine the distribution parameters based on the entire token sequence. This allows the model to disambiguate entity boundaries and meanings by incorporating global contextual cues. Furthermore, we introduce an Adaptive Weighted Contrastive Loss during fine-tuning, which prioritizes learning from support samples that are more representative of the target domain, thereby improving adaptation efficiency.
Extensive experiments on standard few-shot NER benchmarks (CoNLL2003, OntoNotes, GUM, Few-NERD) demonstrate that our method establishes a new state-of-the-art. We further validate our design choices through ablation studies and qualitative analysis, showing consistent and significant performance gains over existing methods, including strong baselines like StructShot [11] and TPT [12].
In summary, the key contributions of this study are as follows: (1) We propose a novel few-shot NER approach that leverages the combination of Gaussian embeddings and the self-attention mechanism to optimize the distributional distance. (2) We demonstrate that the representations learned by our approach are better suited for adaptation to unseen classes, even with a minimal number of support samples. (3) We perform extensive evaluations using multiple datasets and experimental protocols, indicating that our approach consistently outperforms existing SOTA methods and establishes new benchmarks in nearly all tested scenarios.
2. Task and Methods
2.1. Task Formulation
Given a sequence of tokens {}, the NER task aims to learn a mapping function , where represents the input text sequence and denotes the corresponding entity label set. Specifically, NER requires predicting an entity label for each token in the sequence:
where is selected from a predefined entity category set , where represents the “non-entity” category, and consists of possible entity types.
Few-shot setting: Few-shot NER aims to predict entity labels for a given token sequence {} with minimal annotated data, where the label sets in training and testing are completely disjoint . In an N-way K-shot setting, the target domain contains N entity types, each with only K labeled examples forming the support set . The model must learn category representations from and generalize well on the query set :
Tagging Scheme: We follow the IO tagging scheme, where type I indicates that all tags are within the entity and type O indicates all other tags.
Evaluation Scheme: For comparison with state-of-the-art models, we use episode evaluation with its original authors. The performance of the model in this evaluation approach is measured by the micro-F1 scores of multiple test episodes. Each episode contains a K-shot support set and a K-shot unlabeled query set. The model is required to make predictions based on these two sets. While Few-NERD is explicitly designed for episode evaluation, traditional NER datasets (e.g., OntoNotes, CoNLL’03, WNUT’17, GUM) have their distinctive tag-set distributions. Thus, sampling test episodes from the actual test data perturbs the true distribution that may not represent the actual performance. So we decide to employ Yang and Katiyar’s approach [11], which involves taking multiple support sets from the original development set and making predictions based on these support sets on the original test set.
2.2. Details of the Method
Figure 1 shows the approximate workflow of our model. The combination of Gaussian embeddings and the self-attention mechanism are applied to optimize the difference in the distribution of different tokens over entity representations. First, the pre-trained language model BERT is used to generate contextualized representation of sentence tokens. Then, these contextualized representations of sentence tokens are passed through a Gaussian projection layer to generate embedding representations.
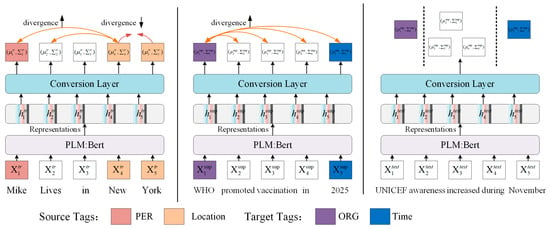
Figure 1.
Structural diagram of our model. The color behind “” in the figure represents the encoding of entities. (Left) Training in the source domain using PER and Location labels. (Middle) Fine-tuning in the target domain using ORG tags and Time tags. (Right) Assigning tags to the test samples.
For the Gaussian embedding of each entity, its self-attention scores with other entities in the sequence are calculated. The mean vector among them is utilized for the self-attention calculation. First, it is obtained through the linear transformation layer.
where ,, are the weight matrices, represents the sample serial number, and and represent the positions of the entities in the sequence.
Then the attention score is calculated as:
Here, is the embedding dimension. The attention scores are scaled by dividing by to prevent the dot-product results from being too large.
The attention score weights are obtained through the function:
Then the weighted contextual feature is:
The contextual feature is fused with the mean value of the original Gaussian embedding to obtain a new mean value:
The updated Gaussian embedding is represented as . This process is shown in Figure 2.
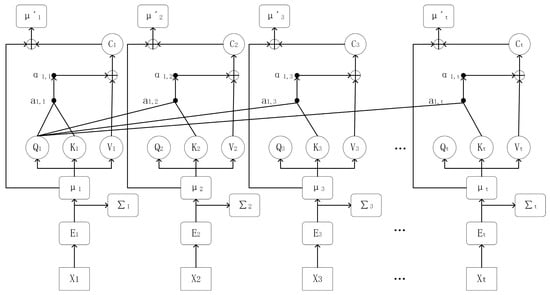
Figure 2.
Explanation of the Combination Principle of Gaussian Embedding and Self-attention Mechanism.
Integration of Self-Attention: Motivation and Justification. While the Gaussian embedding effectively models the uncertainty and distribution of individual tokens, its parameters ( and ) are initially derived from a single token’s contextualized representation from BERT. In few-shot NER, where contextual clues are paramount and label ambiguity is high, relying solely on these isolated representations can be suboptimal. The inclusion of the self-attention mechanism is therefore motivated by two primary reasons:
Contextual Refinement of Gaussian Distributions: The self-attention mechanism allows each entity’s Gaussian mean to be dynamically refined by aggregating information from all other tokens in the sequence. This process, formalized in Equations (2)–(6), generates a context-enhanced mean vector . For example, in the sentence “Apple is headquartered in Cupertino,” the token “Apple” could refer to either a fruit or the organization. The self-attention module can weigh the contextual significance of “headquartered” and “Cupertino,” thereby adjusting the Gaussian distribution of “Apple” towards the “ORG” class prototype. This results in more robust and context-sensitive distributional representations, which are crucial for the subsequent contrastive learning objective that relies on the distances between these distributions.
Enhanced Discrimination Against “O-tokens”: A significant challenge in few-shot NER is the prevalence of “O-tokens” (non-entities), which might share superficial similarities with entity tokens in the source domain but represent true entities in the target domain. By focusing the Gaussian refinement on the interactions between potential entity representations, the self-attention mechanism helps to isolate and emphasize the features that are most discriminative for entity classes. This reduces the risk of “O-tokens” inadvertently pulling the Gaussian distributions of true entities in the embedding space, thereby preserving the purity of the entity clusters formed during contrastive learning.
In summary, the self-attention mechanism is not merely an add-on but a crucial component that enables our model to produce contextually calibrated Gaussian embeddings. This synergy ensures that the distributional distances optimized in the contrastive loss are based on the most semantically informed and discriminative representations possible, which is a key factor in our model’s improved generalization in few-shot scenarios.
2.3. Training
The model is trained in the source domain . Batches of samples with a size of are obtained through random sampling without replacement. The contrastive loss is optimized by calculating the Kullback–Leibler (KL) divergence among all valid tokens in the sampled batches and incorporating an adaptive weighting strategy. First, if the labels of two entities and are the same, that is , they are classified as positive examples; if the labels of the two entities are different, they are classified as negative examples. The calculation method of the KL divergence between them is as follows:
Since the KL divergence is directional and not symmetric, the KL divergences in both directions need to be considered:
Then, the Gaussian embedding loss between the positive samples in the sample batch and all other valid tokens within the same batch is calculated:
In the source domain training phase, we use the aforementioned contrastive loss without weighting, meaning all sample pairs are treated as equally important.
2.4. Model Finetuning
In order to further improve the adaptability of the model to the target domain, after the model is trained with the source domain training set, we use a small support set composed of target domain data samples to fine-tune our model.
During fine-tuning, we introduce an adaptive weighting strategy to make the model focus more on token pairs that are representative of the target domain. For each sample in the fine-tuning batch, we calculate its cosine similarity with all samples in the target domain support set :
Here, and are the feature vectors of sample and a support set sample , respectively. The representative weight for sample is then computed as the average of its similarities to all support set samples:
This weight reflects how well sample aligns with the overall characteristics of the target domain. Example: Suppose the support set contains 5 samples. For a given source sample , we compute its cosine similarity with each of these 5 support samples, resulting in similarities [0.8, 0.6, 0.9, 0.5, 0.7]. The representative weight for would be = (0.8 + 0.6 + 0.9 + 0.5 + 0.7)/5 = 0.7.
The fine-tuning contrastive loss is then calculated as a weighted sum:
Owing to the few-shot nature of the scenario, all these small quantities of samples are assembled into a single batch. And precisely because of this reason, the model has a relatively high risk of overfitting. Therefore, during the fine-tuning phase on the target domain, the weighted contrastive loss of each iteration is recorded. If the weighted contrastive loss of the current iteration is greater than or equal to that of the previous iteration, and this situation persists for the set patience value (e.g., set to 1), then we stop the fine-tuning.
2.5. Inference
After the model has been trained and fine-tuned using the training data and support data, we extract the pre-trained language model BERT for inference to complete the prediction of new data. Meanwhile, it is found that the representations before the Gaussian transformation layer contain more information than the final output representations, which is more beneficial for improving the inference performance. Therefore, a method similar to that of Wang et al. [19] is applied to calculate the representations of the BERT test data and the representations of the support set data. In the BERT representation space, it is a process where the support set sample closest to the test sample is identified, and then the label of this support set sample is assigned to the test sample :
Here, is the BERT representation of each token in the support set. Similarly, for the test dataset, is obtained, which is the BERT representation when .
2.6. Essential Parameters Setting
To facilitate reproduction, we provide the following implementation details:
Optimizer: AdamW is adopted. Learning rate: set to 1 × 10−5 (including both training and fine-tuning learning rates). Batch size: training batch is set to 8, evaluation batch to 16; the entire support set is used as a single batch for support set fine-tuning. Training epochs: 50, with an early stopping patience of 3. Hyperparameter tuning: learning rate [1 × 10−6, 5 × 10−5], batch size [8, 16, 32], early stopping patience [1, 3, 5]; Gaussian embedding dimension: l = 128.
3. Experiments and Results
3.1. Datasets
In our experiments, we used four standard NER datasets from different domains. They are the CoNLL2003 dataset in the news domain, the OntoNotes dataset in the general domain, and the GUM dataset in the mixed domain. The GUM dataset contains data from various domains such as interviews, news articles, instrumental texts, and travel guides. The mixture of domains makes it a challenging dataset. Table 1 provides a brief introduction to these datasets.

Table 1.
Brief Introduction to the Datasets.
Among them is the Few-NERD dataset [20], which contains 66 fine-grained entities and 8 coarse-grained entities, and is much more abundant than previous datasets. It includes 188,238 sentences and 4,601,160 words from Wikipedia. It is the first few-shot NER dataset and also one of the largest manually annotated NER datasets.
3.2. Baseline Models
In order to effectively evaluate the performance of the model, we compared it with several other few-shot NER models under the same dataset. Firstly, tag-set extension and domain transfer tasks are carried out on traditional NER datasets to measure the performance of the model [11]. Then, the model is evaluated on the few-NERD dataset.
Additionally, the NNShot model (a nearest neighbor-based metric method) and the Structshot model (a Viterbi decoding-based model) are selected as our baseline models, along with the latest template-free prompt tuning models EntLM.
3.3. Tag-Set Extension and Domain Transfer Settings
In order to test whether the model can recognize the labels of new entity types that have not been seen in the dataset, we randomly and evenly divide the OntoNotes dataset into three groups, A, B and C, according to entity types. Two of these groups are applied as the training set, and the other group is used as the test set. Additionally, a small number of samples from the test group are utilized to form the support set [11]. During the training process, all the labels in the test set are set as “O” labels to simulate the situation where the model encounters new entity types, so as to test the generalization ability of the model and its adaptability to new labels. The experimental results are revealed in Table 2.
Table 2.
F1 scores of the model in Tag-set Extension on the OntoNotes. * indicates statistically significant improvement over the best baseline (p < 0.05).
To ensure the robustness of our results, we performed statistical significance testing using a paired t-test over multiple independent runs (n = 5) for each experimental setting. The reported improvements are marked with asterisks when they are statistically significant compared to the strongest baseline (p-value < 0.05).
In addition, we set the OntoNotes dataset as the source domain to evaluate the few-shot recognition performance of the model in CoNLL2003, GUM, and Few-NERD. The experimental results are shown in Table 3.
Table 3.
F1 scores of the model in Domain Transfer with OntoNotes as the source domain. * indicates statistically significant improvement over the best baseline (p < 0.05).
3.4. Few-NERD Setting
We conducted the experiments on the FEW-NERD dataset separately, because the division of this dataset is rather unusual. There are two different ways of division. One is called Intra, and it can be regarded as entity recognition within the domain. The other is called Inter, and it can be regarded as entity recognition between domains.
For the division in the Intra mode, the development set and the test set are divided according to coarse-grained types. Specifically, it is classified according to coarse-grained entities. That is, the training set includes “People”, “Art”, “Product”, and “MISC”. The validation set includes “Event” and “Building”. The test set includes “ORG” and “LOC”. From the perspective of coarse-grained types, there is no overlap among the categories of the training set, the development set, and the test set.
In contrast, the division mode of Inter is relatively simple. It is classified according to fine-grained entities. In each coarse-grained type, 60% of the fine-grained entity classes are randomly selected as the training set, 20% as the validation set, and 20% as the test set. Since there is a “sharing” situation in the coarse-grained types. Precisely because of this situation of “sharing coarse-grained types”, the restrictive conditions of the Inter mode division are relatively loose. Therefore, the Intra mode division is more challenging in model experiments, because it requires the model to have a higher adaptability under different category divisions.
3.5. Results and Analysis
The F1 scores of our model in tag-set extension and domain transfer are demonstrated in Table 2 and Table 3, respectively. Judging from the experimental results, our model has generally achieved the best experimental performance. The statistical significance testing confirms that our improvements over the baselines are not due to random chance, with most comparisons yielding p-values < 0.05.
Due to the special division mode of the Few-NERD dataset, we conduct experiments according to different division modes, and the experimental results are displayed in Table 4 and Table 5.
Table 4.
Experimental results (F1 scores) of the model in FEW-NERD (Inter).
Table 5.
Experimental results (F1 scores) of the model in FEW-NERD (Intra).
In terms of the results, “Ours” demonstrates a significant performance improvement as the number of samples increases (from 1-shot to 5-shot to 10-shot) in the 5-way scenario, and it leads other models by a large margin in the 10-shot setting. In the 10-way scenario, its overall performance is better than that of NNShot and EntLM. Although it is slightly inferior to StructShot, its average score (56.28) is higher than all the compared models, which verifies the effectiveness of the method.
For further discussion, “Ours” has obvious advantages in few-shot scenarios with relatively sufficient samples and a moderate number of categories. However, there is still room for optimization in the 10-way few-shot scenario. In the future, improvements can be made in aspects such as category semantic enhancement and multi-task learning. This experiment clearly shows the performance boundaries of the model and provides an experimental basis for method innovation in few-shot NER.
Under the Intra division, from the results, in the 5-way scenario, as the number of samples increases from 1-shot to 10-shot, “Ours” achieves a significant performance improvement and leads all comparison models by a large margin in all shot settings. In the 10-way scenario, its overall performance far surpasses that of NNShot and StructShot, and it also outperforms EntLM. The comprehensive average score (45.38) is much higher than that of all comparison models, fully verifying the effectiveness of the method in the few-shot NER task within categories.
Further analysis combined with the previous results of the FEW-NERD (Inter.) scenario shows that “Ours” has a larger lead over the baselines in the Intra scenario, indicating that the model is more adaptable to the in-category scenario, while there is still room for optimization in the inter-category scenario. In the future, we can further optimize the category generalization ability in the 10-way few-shot scenario from the directions of meta-learning and prompt learning. This experiment also provides an experimental reference for the method design of few-shot NER in different scenarios of in-category and inter-category.
3.6. Ablation Experiments
To verify the effectiveness of the modules, we conduct an ablation study on the OntoNotes dataset under the tag-set extension setting (as described in Section 3.3). We compare the full model with several variants: w/o Gaussian Embedding, w/o Self-Attention, w/o Adaptive Weight, and w/o Fine-tuning. We conducted experiments on three different datasets and obtained valid results in all cases, indicating that our research method is effective. The experimental results are shown in Table 6.
Table 6.
Performance of different models on datasets.
As can be seen, the full model achieves the best performance in both 1-shot and 5-shot settings. Removing Gaussian embeddings leads to a significant drop in performance (e.g., 5.2% in 1-shot and 8.1% in 5-shot), indicating that Gaussian embeddings are crucial for capturing distributional uncertainty and improving generalization. The removal of self-attention also causes a notable decrease (2.3% in 1-shot and 4.5% in 5-shot), demonstrating that self-attention helps incorporate contextual information for better entity representations. Without adaptive weights, the model performance declines (1.6% in 1-shot and 3.1% in 5-shot), suggesting that the adaptive weighting strategy effectively balances the contrastive loss. Finally, without fine-tuning, the model suffers the largest performance drop (7.3% in 1-shot and 12.8% in 5-shot), highlighting the importance of domain adaptation using a small support set. These results confirm that each component of our model contributes to the overall performance.
3.7. Qualitative Analysis
To intuitively demonstrate the advantages of our model, we present a qualitative case study by comparing the prediction results of our model with three baseline models (NNShot, StructShot and EntLM) on specific examples from the GUM dataset under the 5-shot domain transfer setting. As shown in Table 7, we select two representative sentences where our model correctly identifies entities that the baselines fail to recognize.
Table 7.
Case study comparing our model with baselines. The underlined and bolded phrases are the target entities. Correctly identified entities are highlighted in green, while errors are marked in red.
Analysis of Example Sentence 1: NNShot, StructShot, and EntLM all correctly identified “free jazz concert” as an event but failed to recognize “Presidio” as a location, whereas our model successfully detected both accurately. We attribute this to the effectiveness of our Gaussian embedding enhanced by self-attention. “Presidio” can be a challenging entity as it might not appear frequently in the support set. However, our model’s Gaussian embeddings capture the distributional semantics and uncertainty of token representations. The self-attention mechanism allows the model to leverage the context “concert in the Presidio”, strengthening the representation of “Presidio” by associating it with the event entity “concert”. This contextual fusion enables the model to infer that “Presidio” is likely a location, even with limited examples, whereas the baseline models, which rely on simpler metric learning or source-domain-biased representations, lack this nuanced understanding.
Analysis of Example Sentence 2: The baseline model completely missed the entity “Washington” and misclassified it as “O”, while our model correctly identified “Washington” as GPE. In this case, “Washington” is highly ambiguous; it can refer to a person, a state, or a city. The baseline models, which primarily learn from the source domain (OntoNotes), might be biased towards more common usages or struggle with domain shift to the GUM dataset. Our contrastive learning objective with adaptive weights explicitly optimizes the model to pull the representations of similar entities (like different GPEs) closer and push dissimilar ones apart in the embedding space, making it more robust to such ambiguities. The Gaussian embedding’s ability to model variance helps the model be more “cautious” and generalizable when encountering polysemous words like “Washington” in a new context, leading to a correct prediction.
In summary, these qualitative examples corroborate our quantitative findings, demonstrating that our model, through its enhanced representation learning and contrastive optimization, is more capable of handling challenging cases involving contextual dependency and entity ambiguity in few-shot settings.
4. Conclusions
This paper introduced a novel contrastive learning model for Few-Shot NER, which leverages Gaussian distributional embeddings refined by a self-attention mechanism. Our work yields three principal findings with broader implications for few-shot learning:
First, we demonstrate that modeling uncertainty via Gaussian embeddings is critical for generalization, as confirmed by the significant performance drop when reverting to point embeddings in our ablation study (Table 6). Second, the self-attention mechanism is essential for dynamically contextualizing these distributional representations, with its removal notably degrading results. Finally, the adaptive weighting in the contrastive loss effectively prioritizes informative samples, further boosting few-shot performance.
The primary impact of our work is twofold. Practically, it provides a robust solution for low-resource NER that requires minimal adaptation. Methodologically, it establishes a compelling paradigm of fusing probabilistic representations with deep contextual networks for few-shot scenarios.
Notwithstanding its strong general-domain performance, our model may underperform in highly specialized domains (e.g., medicine, finance). A prospective error analysis reveals that this stems from three core challenges: (1) Out-of-distribution terminology, where domain-specific tokens (e.g., medical acronyms) are poorly captured by the general-purpose BERT embeddings, confusing the Gaussian representation; (2) Fundamental semantic shifts, where the same word carries a different entity sense across domains (e.g., “capsule” as a dosage form vs. a product), which the contrastive objective may not fully rectify with limited shots; and (3) Increased structural complexity, such as nested and fine-grained entities, which our flat sequence-labeling approach is not designed to handle. These points delineate the current boundaries of our work and chart a clear course for future research towards domain-adaptive and structurally aware few-shot learning.
Lastly, our work touches upon the broader epistemological evolution within AI, moving from rule-based systems to data-driven machine learning models [21]. This paradigm, while powerful, underscores that our model operates as a statistical estimator rather than a symbolic reasoner. Recognizing this distinction is crucial for guiding future research towards developing more interpretable and ethically aware NLP systems, particularly as they are applied to sensitive domains.
Author Contributions
Conceptualization, Y.Z.; methodology, Y.Z.; software, Y.Z.; validation, L.M.; formal analysis, Y.Z.; investigation, Y.Z. and L.M.; resources, Y.Z.; data curation, W.C.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z. and L.M.; visualization, Y.Z.; supervision, L.M.; project administration Y.Z. and L.M.; funding acquisition, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are included within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Seow, W.L.; Chaturvedi, I.; Hogarth, A.; Mao, R.; Cambria, E. A review of named entity recognition: From learning methods to modelling paradigms and tasks. Artif. Intell. Rev. 2025, 58, 315. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Xu, G.; Ren, M. A novel large-language-model-driven framework for named entity recognition. Inf. Process. Manag. 2025, 62, 17. [Google Scholar] [CrossRef]
- Gardazi, N.M.; Daud, A.; Malik, M.K.; Bukhari, A.; Alsahfi, T.; Alshemaimri, B. BERT applications in natural language processing: A review. Artif. Intell. Rev. 2025, 58, 166. [Google Scholar] [CrossRef]
- Wu, Y.; Jin, Z.; Shi, C.; Liang, P.; Zhan, T. Research on the application of deep learning-based BERT model in sentiment analysis. Appl. Comput. Eng. 2024, 67, 263–269. [Google Scholar] [CrossRef]
- Karim, M.; Khan, S.; Van, D.H.; Liu, X.; Wang, C.; Qu, Q. Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact. Future Internet 2025, 17, 353. [Google Scholar] [CrossRef]
- Chen, J.; Lin, H.; Han, X.; Lu, Y.; Jiang, S.; Dong, B.; Sun, L. Few-Shot Named Entity Recognition via Superposition Concept Discrimination; ELRA and ICCL: Torino, Italy, 2024. [Google Scholar]
- Ji, S.; Kong, F. A Novel Three-Stage Framework for Few-Shot Named Entity Recognition; ELRA and ICCL: Torino, Italy, 2024. [Google Scholar]
- Zhou, C.; Huang, B.; Ling, Y. A Chinese Few-Shot Named-Entity Recognition Model Based on Multi-Label Prompts and Boundary Information. Appl. Sci. 2025, 15, 5801. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, B.; Fan, J. KCL: Few-Shot Named Entity Recognition with Knowledge Graph and Contrastive Learning; ELRA and ICCL: Torino, Italy, 2024. [Google Scholar]
- Guo, Q.; Dong, Y.; Tian, L.; Kang, Z.; Zhang, Y.; Wang, S. BANER: Boundary-Aware LLMs for Few-Shot Named Entity Recognition. arXiv 2024, arXiv:2412.02228. [Google Scholar]
- Yang, Y.; Katiyar, A. Frustratingly Simple Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Ma, R.; Zhou, X.; Gui, T.; Tan, Y.; Li, L.; Zhang, Q.; Huang, X.-J. Template-Free Prompt Tuning for Few-Shot NER; Association for Computational Linguistics: Seattle, WA, USA, 2022. [Google Scholar]
- Zhang, Y.; Yu, Z.; Huang, Y.; Tang, J. CLLMFS: A Contrastive Learning enhanced Large Language Model Framework for Few-Shot Named Entity Recognition. arXiv 2024, arXiv:2408.12834. [Google Scholar] [CrossRef]
- Xue, X.; Zhang, C.; Xu, T.; Niu, Z. Robust few-shot named entity recognition with boundary discrimination and correlation purification. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI Press: Washington, DC, USA, 2024; p. 2156. [Google Scholar]
- Yoda, S.; Tsukagoshi, H.; Sasano, R.; Takeda, K. Sentence Representations via Gaussian Embedding; Association for Computational Linguistics: St. Julian’s, Malta, 2024. [Google Scholar]
- Gao, B.; Wang, X.; Yang, Y.; Clifton, D. Optimization-Inspired Few-Shot Adaptation for Large Language Models. arXiv 2025, arXiv:2505.19107. [Google Scholar]
- Li, Q.; Guo, S.; Chen, Y.; Ji, C.; Sheng, J.; Li, J. Uncertainty-Aware Relational Graph Neural Network for Few-Shot Knowledge Graph Completion. arXiv 2024, arXiv:2403.04521. [Google Scholar]
- Pandey, G.; Contractor, D.; Joshi, S. Mix-and-Match: Scalable Dialog Response Retrieval Using Gaussian Mixture Embeddings; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022. [Google Scholar]
- Wang, Y.; Chao, W.L.; Weinberger, K.Q.; Van Der Maaten, L. SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning. arXiv 2019, arXiv:1911.04623. [Google Scholar]
- Ding, N.; Xu, G.; Chen, Y.; Wang, X.; Han, X.; Xie, P.; Zheng, H.T.; Liu, Z. Few-NERD: A Few-Shot Named Entity Recognition Dataset; Association for Computational Linguistics: Online, 2021. [Google Scholar]
- Barbierato, E.; Gatti, A.; Incremona, A.; Pozzi, A.; Toti, D. Breaking Away from AI: The Ontological and Ethical Evolution of Machine Learning. IEEE Access 2025, 13, 55627–55647. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).