Abstract
This study tackles the complex challenge of dynamic multi-objective vehicle routing optimization in large-scale equipment manufacturing, where routing operations significantly impact both economic performance and environmental sustainability. We develop an innovative Dynamic Multi-Objective Vehicle Routing Problem (DMOVRP) model that uniquely integrates three competing objectives: environmental impact reduction, delivery timeliness, and operational robustness. The proposed algorithm combines a dynamic event handler with the NSACOWDRL algorithm—an adaptive multi-objective optimization algorithm with dynamic event handling capability. The proposed system features adaptive mechanisms for handling real-time disruptions through specialized event classification and dynamic rescheduling protocols. Extensive computational experiments demonstrate the algorithm’s superior performance with statistically significant improvements using the Wilcoxon signed-rank test (p < 0.05, n = 30 runs per instance), achieving average relative gains of 15.2% in HV, 12.8% in IGD, and 8.9% in GD metrics compared to established methods. This research makes theoretical contributions through its feasibility quantification metric and practical advancements in routing schedule systems. By successfully reconciling traditionally conflicting objectives through dynamic JIT adjustments and robustness-aware optimization, this work provides manufacturers with a versatile decision-support tool that adapts to unpredictable workshop conditions while maintaining sustainable operations.
1. Introduction
The integration of global supply chains has rendered logistics optimization a critical determinant of manufacturing competitiveness. However, transportation costs constitute a substantial expenditure component, representing 18–32% of total operational expenses in manufacturing sectors. Notably, vehicle routing processes contribute upwards of 40% of logistics-related energy consumption and carbon emissions. This dual imperative of economic efficiency and environmental sustainability necessitates advanced intelligent routing solutions capable of simultaneously optimizing costs while minimizing carbon footprint.
Vehicle routing optimization in large-scale equipment manufacturing facilities, considering significant spatial and temporal constraints, constitutes a variant of the Vehicle Routing Problem (VRP) [1]. The VRP aims to identify optimal routes under specified constraints and objectives and finds broad application in domains such as traffic management and logistics transportation. To better reflect practical logistics operations, several VRP variants have been developed, including the Dynamic VRP (DVRP) and the Multi-Objective VRP (MOVRP). Numerous researchers have conducted systematic literature reviews on these problems.
The dynamic vehicle routing problem (DVRP) addresses the stochastic nature inherent in real-world VRP variants [2]. In DVRP formulations, at least one problem parameter evolves temporally. Such dynamics may impact constraints, objective functions, customer demands, or vehicle workloads. Regarding multi-objective vehicle routing problems, Zajac et al. [3] provide a comprehensive review categorizing application-oriented MOVRPs by planning hierarchy and analyzing the nature of investigated trade-offs.
Although numerous methods have been proposed to address DVRP and MOVRP models, existing dynamic models are often limited to single-objective optimization, which significantly deviates from real-world requirements. Meanwhile, static multi-objective models frequently exhibit inadequate capability in handling dynamic anomalies commonly encountered in large-scale equipment manufacturing. To overcome these limitations, this study proposes integrating DVRP and MOVRP frameworks to establish a novel DMOVRP (Dynamic Multi-Objective Vehicle Routing Problem) model.
Studying DMOVRP is further motivated by its strong relevance to real-world applications, particularly in modern logistics. While prior research has extensively modeled mobile robots for automating repetitive and physically demanding tasks in VRP frameworks (e.g., N. Vimal Kumar et al. [4]), DMOVRP offers a broader methodological framework and enhanced robustness for addressing contemporary logistics challenges. Given the shared mathematical foundations between both problem classes—characterized by vehicles departing from and returning to a central depot, servicing customer demands under time constraints, and optimizing multiple objectives subject to capacity limitations—this study follows the methodology established by Pouya Baniasadi et al. [5] by developing algorithms that reformulate complex logistics scenarios into classical VRP constructs.
To address these challenges, this paper proposes a hybrid “static + dynamic” dual-scheduling model by extending the framework of static models to incorporate dynamic anomaly production and handling. A dynamic multi-objective optimization algorithm is specifically designed to solve the proposed model. To sum up, the main contributions of this paper are as follows:
(1) A dynamic multi-objective optimization formulation was developed for large-scale equipment manufacturing, simultaneously addressing carbon emissions, lead time, and infeasibility minimization. The model integrates spatiotemporal constraints for vehicle routing and demand fulfillment while accounting for transportation time uncertainty through stochastic coefficients. Solution robustness under uncertainty was quantified via a novel feasibility alpha metric. Robustness optimization was explicitly incorporated as an objective function to enhance solution reliability. The formulation reconciles conflicting Just-in-Time (JIT) scheduling and robustness objectives by implementing dynamic JIT deadlines instead of conventional time windows. A hybrid “dynamic exception handling-static optimization” framework was proposed to improve adaptability to stochastic operational disruptions.
(2) To address dynamic vehicle routing, a dynamic event handler and the NSACOWDRL (Non-dominated Sorting Ant Colony Optimization with Deep Reinforcement Learning) algorithm were proposed. The problem was decomposed into three stages:
- 1.
- Multi-objective optimization (NSACOWDRL): A reference point-based niche preservation strategy ensured solution diversity. Pheromone updates incorporated non-dominated ranking and elite path reinforcement, while max–min pheromone bounds prevented premature convergence.
- 2.
- Robustness selection: Monte Carlo simulations quantified solution feasibility, and uniform weight-based selection derived a diverse Pareto-optimal set.
- 3.
- Dynamic re-optimization (DSACOWDEL): The event handler updated material demands, triggering adaptive rescheduling.
(3) Computational experiments across multi-scale instances with varying disruption intensities demonstrated NSACOWDRL superior performance in dynamic multi-objective optimization compared to MOEA/D and NSGA-III. Ablation studies verified the significant contribution of the embedded DDQN local search strategy.
The remainder of this paper is structured as follows: Section 2 presents essential background. Section 3 formulates the DMOVRP problem for assembly workshop logistics. Section 4 details the multi-objective, multi-stage dynamic routing methodology, including the NSACOWDRL algorithm and dynamic event handler. Experimental design and computational results are analyzed in Section 5. Finally, conclusions and suggestions for future work are outlined in Section 6.
2. Background
Since VRP is an NP-hard problem, finding optimal solutions is extremely challenging. As evident from the aforementioned research, the proposed VRP solution methods primarily aim to identify near-optimal solutions through efficient computational approaches. Common path planning problems for Automated Guided Vehicles (AGVs) are typically solved using exact algorithms and intelligent evolutionary algorithms.
Exact algorithms—including branch-and-bound, branch-and-price, integer linear programming, and cutting plane methods—are primarily applicable to small-scale VRP instances with simple structural configurations. Reihaneh et al. [6] developed a branch-price-and-cut algorithm for the Vehicle Routing Problem with Demand Allocation (VRPDA), while Tilk et al. [7] and Li et al. [8], respectively, addressed the Active-Passive Vehicle Routing Problem (APVRP) and a Synchronized Split-Delivery VRP with time windows and service-time constraints. Nevertheless, exact methodologies frequently exhibit limitations such as local optimum entrapment or computationally prohibitive runtime complexity for large-scale VRPs.
Several studies explore integrating exact methods with intelligent evolutionary algorithms. Kim et al. [9] developed a learning-based separation heuristic incorporating graph coarsening, which employs graph neural networks (GNNs) to approximate solutions for exact separation problems.
In contrast, intelligent evolutionary algorithms can find satisfactory near-optimal solutions for large-scale vehicle routing problems (VRPs) within limited computation time. As a result, intelligent optimization algorithms have become the mainstream approach for solving MOVRPs and DVRPs, and many researchers are devoted to improving and designing such algorithms.
Traditional single-objective VRP formulations and solution techniques inadequately address inherent multi-objective complexities, lacking the systemic perspective necessary for practical implementation. Consequently, multi-objective optimization problems (MOPs) are mathematically formulated to concurrently optimize conflicting objectives. As the predominant approach for MOP resolution, multi-objective evolutionary algorithms (MOEAs) have become the dominant methodology in this domain.
According to different algorithm strategies, most MOEAs can be classified into the following categories: (1) based on their dominant relationships, such as the NSGA-II [10], NSGA-III [11], SPEA [1], and PESA-II [12]; (2) based on decomposition, such as the MOEA/D [13], MOEA/DM2M [14], and RVEA [15]; (3) based on performance evaluation indicators, such as the IBEA [16], SMSEMOA [17], DNMOEA/HI [18], HypE [19], and FastHypervolume [20].
For DVRP methodologies, existing approaches employ discretized time windows, which is a paradigm introduced to manage dynamic scenarios. This framework partitions the operational horizon into equidistant intervals. A static optimization procedure is then iteratively executed for each interval to solve the corresponding routing subproblem. These methodologies are classified as periodic re-optimization techniques. Representative metaheuristic implementations for DVRP include greedy randomized adaptive search procedures [21], tabu search [22], ant colony optimization [21,23,24], genetic algorithms [22,25], memetic algorithms [26], monarch butterfly optimization [27], brainstorm optimization [28], and particle swarm optimization [29,30,31].
Beyond metaheuristic approaches, Large Neighborhood Search (LNS) and hybrid tabu–LNS methods have emerged as state-of-the-art techniques for the dynamic VRP. Pisinger and Røpke [32] demonstrated LNS’s effectiveness in real-time scenarios, while hybrid approaches combining tabu search with LNS [33] have shown superior performance in handling large-scale instances. These methods are particularly relevant for dynamic VRP comparisons, as they provide strong baselines for practical implementations.
Finally, recent research integrates optimization algorithms with machine learning to solve Vehicle Routing Problems (VRPs) effectively. Wang et al. [34] proposed Generative Inverse Reinforcement Learning (GIRL), combining adversarial networks with deep reinforcement learning to autonomously learn reward functions and 2-opt heuristics for routing optimization. Zhao et al. [35] introduced a hybrid framework using deep reinforcement learning (DRL) with an adaptive critic and local search, where the DRL generates initial solutions refined by classical heuristics like Large Neighborhood Search (LNS). Zhang et al. [36] designed a two-stage approach: imitation learning clones solutions from heuristic experts, followed by reinforcement learning to enhance policy exploration. Meanwhile, Ara et al. [37] applied reinforcement learning to optimize routes dynamically using environmental feedback. These approaches consistently outperform traditional methods in solution quality and computational speed for large-scale VRPs.
3. Problem Description and Mathematical Models
The assembly workshop AGV routing problem naturally maps to the Vehicle Routing Problem (VRP) framework. Both problems share the same fundamental structure: vehicles departing from a central depot (raw material warehouse) to serve distributed demand points (workstations) under capacity and time constraints. The AGVs function as delivery vehicles, workstation material demands correspond to customer demands, and Just-In-Time requirements align with time windows in VRPTW. This structural equivalence allows us to leverage established VRP solution methods while incorporating workshop-specific features through additional constraints such as robustness metrics and energy consumption objectives.
The escalating complexity of contemporary assembly workshop environments necessitates enhanced dynamic adaptability and real-time responsiveness in vehicle routing models. To address these challenges, we have extended our foundational static framework to develop a Dynamic Multi-Objective Vehicle Routing Problem.
3.1. Problem Description
For the convenience of explanation, Table 1 provides explanations of the model parameters and their corresponding variables.

Table 1.
Model Parameter Setting.
In this paper, the Dynamic Multi-Objectives Vehicle Routing Problem (DMOVRP) in assembly workshop environments is described as follows:
Let denote workstation nodes, where and represents the set of workstations. Here, or corresponds to the raw material library. The warehouse is equipped with K homogeneous automated guided vehicles (AGVs) with unlimited maximum travel distance.
Materials are transported via towed carts and each attached to an AGV’s rear hitch. Each AGV can carry a maximum of R carts. The assembly workshop consists of N workstations requiring M types of materials. Materials are categorized into:
- 1.
- Small materials: High variety and quantity but small in size. Each type is consolidated into standardized containers and treated as a single unit.
- 2.
- Large materials: Low variety but bulky, transported individually.
The workstation–material assignments are predefined, with all material information and workstation coordinates known.
The AGVs must deliver M materials to N workstations. Due to stochastic disturbances, transportation times are uncertain. Traditional time windows are replaced by Just-in-Time (JIT) deadlines , requiring materials to arrive exactly before .
At time T within each delivery cycle, stochastic dynamic events are triggered. These events are classified into two categories based on common workshop disruptions:
- 1.
- Type I (Demand Cancellation): the material demand at workstation is canceled, and is removed from the demand list.
- 2.
- Type II (New Demand Generation): a new demand arises at workstation , requiring AGVs to deliver material with volume , weight , and coordinates within the time window .
When detecting dynamic events, the dynamic model updates the demand list and initiates AGV rescheduling. The system adapts to Type I/II events via real-time re-optimization to fulfill new demands while maintaining Just-in-Time (JIT) compliance.
The VRP problem in the assembly workshop is based on the following assumptions:
- 1.
- The workshop has a centralized raw material library capable of fulfilling all workstation demands.
- 2.
- The material demand at any workstation does not exceed the AGV’s load capacity.
- 3.
- Unloading times at all workstations are deterministic and known a priori.
- 4.
- All AGVs depart from and must return to the raw material library after completing deliveries.
- 5.
- AGV dynamics and charging processes are neglected during operation.
- 6.
- Materials are packed in standardized boxes and cannot be split for delivery.
- 7.
- Each AGV tows material carts, with boxes for the same workstation consolidated into a single cart. Cross-workstation mixing of materials is prohibited.
- 8.
- The fleet size remains constant throughout the planning horizon, with no additional vehicles generated during dynamic re-planning.
- 9.
- Dynamic event demands never exceed the vehicle’s fixed constraints, including load capacity and volumetric limitations.
- 10.
- Time delays between event occurrence and system reporting are negligible, enabling real-time event processing and immediate rescheduling.
- 11.
- When Type II dynamic events occur, the corresponding workstation’s demand remains unfulfilled until the new schedule is executed.
3.2. Mathematic Model
3.2.1. Multi-Objective Model
The three objectives for the MODVRP can be stated as follows:
(Low carbon):
(Robustness metrics):
(Penalty time):
f (Overall objectives):
The constraints associated with the DMOVRP are added as follows:
1. Material vehicle quantity constraints: The number of material vehicles at each AGV delivery station should not exceed its own material vehicle capacity. The material vehicle quantity for each AGV cannot surpass the AGV’s maximum material vehicle capacity.
2. Service time :
The workstation service time is a function of the quantity of material containers scheduled for delivery.
3. Delivery constraints:
Each workstation can only be served once per delivery cycle.
4. AGV arrival frequency constraints:
Each workstation is serviced by exactly one AGV.
5. Deliver cycle constraints:
Each sub-tour must start and end at the raw material warehouse.
6. Workstation demand time constraints: The conflict between JIT requirements and robustness considerations is addressed by employing lead time as a safety buffer for vehicles. In this model, the conventional time windows are eliminated and replaced with as the deadline for JIT compliance, as shown in Equation (11) and Figure 1.
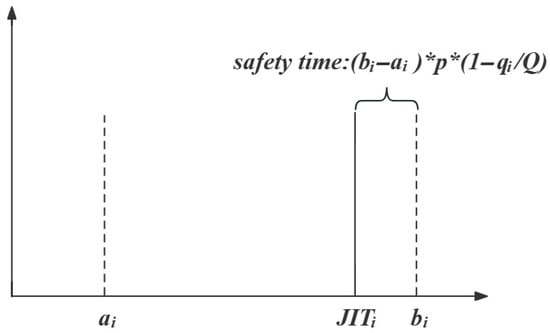
Figure 1.
Safety time.
7. AGV arrival time:
Upon arriving at workstation i at time , the AGV initiates unloading operations as required. After completing the service time , it proceeds to the next workstation j and subsequently arrives at workstation j at time .
8. Uncertainty constraints:
The uncertain arrival time of an AGV at station i is denoted as , influenced by global stochastic disturbances . indicates the characteristic coefficient between stations i and j, which quantifies the normalized impact of stochastic disturbances on AGV travel time.
9. Station feasibility:
The feasibility of workstations is evaluated through robustness metric , where is specifically defined according to scenario-specific probability distributions. For this analysis, the stochastic parameter is modeled as a triangular distribution with a lower limit of , a peak location of , and an upper limit of , formally expressed as the triplet . This distributional assumption enables effective robustness quantification while maintaining analytical tractability.
indicates the feasibility from workstation j to workstation i. A higher value of indicates greater feasibility of the solution. But it also leads to a lower level of Just-in-Time (JIT) performance. The piecewise function in Equation (17) captures five distinct scenarios based on the relationship between the uncertain arrival time interval and the deadline :
Case 1: Complete Infeasibility ()
When , even under the most optimistic conditions (minimum disturbance), the AGV cannot meet the deadline. This represents absolute route infeasibility, assigning zero feasibility.
Case 2: Left-Tail Partial Overlap
Conditions: , ,
When the deadline falls within the left-ascending portion of the triangular distribution (from min to mid), this formula computes the cumulative probability mass in the infeasible region. The numerator calculates the squared distance representing the area of the late-arrival region, while the denominator normalizes by the total area of the left-side triangle. The quadratic form reflects the triangular distribution’s linearly increasing density function, where marginal delays near the peak incur greater probability penalties than those near the distribution’s minimum.
Case 3: Right-Tail Partial Overlap
Conditions: , ,
When the deadline intersects the right-descending portion of the distribution (from mid to max), the formula computes 1 minus the probability of tardy arrival. The numerator measures the feasible area from the peak to the deadline, while the complement operation yields the on-time probability. The asymmetric normalization (using left-side area) maintains continuity with Case 2 at the distribution’s peak.
Case 4: Complete Feasibility with Limited Buffer
Conditions: ,
Although the worst-case arrival time precedes the deadline (100% on-time probability), this case quantifies robustness through time buffer adequacy. The ratio represents the safety margin as a multiple of the uncertainty range. Values approaching zero indicate vulnerability to future disturbances, while values near 2 suggest robust temporal buffers. This formulation penalizes routes with insufficient slack despite nominal feasibility, aligning with robust optimization principles.
Case 5: Excessive Time Buffer ()
Conditions:
When the time buffer exceeds twice the uncertainty interval, feasibility is capped at 2 to prevent two undesirable effects:
- 1.
- JIT Performance Degradation: Excessively early arrivals violate just-in-time principles by increasing inventory holding costs and workspace congestion.
- 2.
- Numerical Stability: Unbounded values would dominate the multi-objective optimization, overshadowing carbon emissions and JIT objectives.
The threshold value of 2 empirically balances robustness requirements with operational efficiency, though alternative values could be calibrated based on specific manufacturing contexts.
10. Time window constraints:
11. Material lead time:
12. Penalty time:
According to Equation (20), the departure time of the k-th AGV from the warehouse is delayed by to satisfy the minimum material requirement time among all workstations that require timely delivery from the k-th AGV.
13. Energy consumption constraints:
The energy consumption of the AGV is composed of the energy consumed during constant-speed travel and the energy consumption incurred during acceleration and deceleration phases.
14. Spatial constraints:
Large-scale equipment manufacturing is significantly constrained by spatial limitations, which require explicit modeling of weight and volume constraints for large-scale equipment. In the assembly workshops, both large and small materials are transported by vehicles. Concurrently, small materials are transported via standardized containers. These containers impose volumetric constraints on medium/small materials, while the number of containers is limited by the carrying capacity of the AGV.
(1) Capacity constraints:
The quantity of material containers at each workstation should not exceed the maximum capacity of the material cart. The number of material containers transported by each AGV must remain within the AGV’s maximum load capacity.
(2) Load capacity constraints:
It ensures the load on any route segment does not exceed the AGV’s maximum capacity, extending classic VRP capacity constraints.
(3) Volume constrains:
This constraint ensures the total volume transported by an AGV does not exceed its trailer capacity, critical for large-scale equipment with bulky items.
15. Vehicle energy constraints:
The combined energy expenditure for the journey to the next station and then to the depot exceeds the minimum safety threshold.
16. Carbon emission constrains
The total carbon emissions generated by each AGV’s route must not exceed the maximum allowable threshold .
3.2.2. Dynamic Event Generation Model
1. Appearance of new demand
indicates dynamic event classification. When , dynamic work triggers a Class 1 dynamic event. At the same time, denotes an 8-tuple representing a complete Class 1 dynamic event specification. indicates event occurrence time. indicates the trigger workstation. indicates the location at which a Class 1 dynamic event happens. indicates the volume of the materials required by the dynamic workstation. indicates the weight of the materials required by the dynamic workstation. indicates the service time of the dynamic workstation. indicates the time window of the dynamic workstation.
2. Cancellation of existing demand
When , dynamic work triggers a Class 2 dynamic event. At the same time, denotes a 4-tuple representing a complete Class 2 dynamic event specification. indicates the cancellation time for dynamic workstation tasks handled by AGV i. indicates the canceled workstation. indicates the cancellation time of a previous scheduled task for the workstation.
3. Dynamic events list indicates the time-ordered dynamic event set. indicates the number of dynamic events.
3.2.3. Dynamic Event Processing Model
1. Appearance of new demand
This situation can be divided into two event classifications: (i) There exists at least one AGV whose departure time is later than the dynamic workstation’s appearance time. (ii) The dynamic workstation’s appearance time is later than all AGVs’ departure times.
For classification 1, .
Equation (39) represents that when , the workstations corresponding to AGVs with are removed from the workstation set and not processed. Instead, the workstations managed by AGVs with are retained, and these workstations undergo rescheduling optimization. Equation (40) specifies that newly added dynamic workstations are incorporated into the updated workstation set.
For classification 2, .
Equation (41) specifies that when , the workstation is assigned to the AGV with minimum combined workload. Equations (42) and (43) indicate that the AGV which is scheduled before must complete its deliveries and return to the warehouse. Equations (44) and (45) describe the reoptimization of workstations scheduled after . Equation (46) imposes the constraint that each AGV currently executing a task must first serve the virtual customer corresponding to its current location before returning to the warehouse for reoptimization.
2. Cancellation of existing demand
This situation could be divided into two event classifications: the AGV assigned to the dynamic workstation has not departed yet; the AGV assigned to the dynamic workstation has already departed.
For classification 1, if :
Equation (47) specifies that when the AGV assigned to the dynamic workstation has not departed yet, workstations assigned to AGVs with remain unprocessed. Workstations assigned to AGVs with undergo rescheduling optimization.
For classification 2, if :
Equation (48) states that when the AGV assigned to the dynamic workstation has already departed:
- 1.
- The routes for workstations scheduled before remain unchanged;
- 2.
- For workstations scheduled after , the dynamic workstation is designated as the depot, followed by route reoptimization.
Equation (49) specifies that the starting point for re-optimization is set as the previous workstation of the dynamic workstation.
4. Proposed Algorithm
In this section, based on the MODVRP model, we propose a Multi-Objective Multi-Stage Dynamic Routing Algorithm (MOMS-DRA). This enhanced algorithm is integrated with a dynamic event handler and NSACOWDRL algorithm solver to effectively handle stochastic dynamic events in vehicle routing problems. The name “NSACOWDRL” reflects its core components: a Deep Reinforcement Learning (DRL)-guided Ant Colony Optimization (ACO) algorithm operating within a Neighborhood Search (NS) framework.
4.1. NSACOWDRL Algorithm
4.1.1. Algorithm Framework
The NSACOWDRL (Nondominated Sorting Ant Colony Optimization With Deep Reinforcement Learning) algorithm incorporates DDQN as a local search operator into the multi-objective ACO algorithm, effectively overcoming ACO’s tendency to fall into local optima while enhancing its optimization capability. The proposed NSACOWDRL algorithm operates in two distinct phases: Comprehensive exploration of the solution space to obtain the Pareto solution set and robustness screening phase for the obtained Pareto solutions.
Figure 2 presents the framework structure of the NSACOWDRL algorithm. The algorithm incorporates DDQN as a local search algorithm into the multi-objective ACO algorithm, which overcomes ACO’s tendency to fall into local optimization and enhances ACO’s optimization capability. Meanwhile, it utilizes ACO’s excellent search ability for VRP to guide DDQN’s learning and searching process. The NSACOWDRL algorithm consists of two phases: the phase of sufficient exploration of the solution space to obtain the Pareto solution set, and the phase of robustness screening of the Pareto solution set.
Figure 2.
Framework of the NSACOWDRL.
4.1.2. Key Components
(1) Pheromone update strategy
This paper addresses the dilemma between convergence speed and population diversity (avoiding local optima) in traditional pheromone update strategies by proposing a hybrid update strategy. The core of this strategy achieves a balance through a tripartite mechanism:
1. Basic Update (Introducing Diversity): The Non-Dominated Rank (NDR) is used to determine the pheromone increment, allowing solutions on the Pareto front to participate in guiding the search, thereby preventing premature convergence to a single objective.
2. Elite Enhancement (Accelerating Convergence): Additional pheromone rewards are applied to elite paths (those with NDR 1 and 2), reinforcing the guiding effect of high-quality solutions and speeding up convergence toward the true Pareto front.
3. Extremum Limitation (Maintaining Diversity): A max–min pheromone mechanism is adopted to strictly confine the upper and lower limits of pheromone concentrations. This prevents excessive disparities in path attractiveness that could lead to search stagnation, thereby ensuring exploratory capability.
(2) Reference point-based non-dominated sorting strategy
For solution evaluation and selection, the algorithm incorporates a reference point-based non-dominated sorting mechanism. The process begins by generating H uniformly distributed reference points on the unit hyperplane, where , with M representing the number of objectives and the reference points are constructed on an dimensional hyperplane. For a three-objective problem, each coordinate axis is uniformly divided into H segments, which is shown in Figure 3.
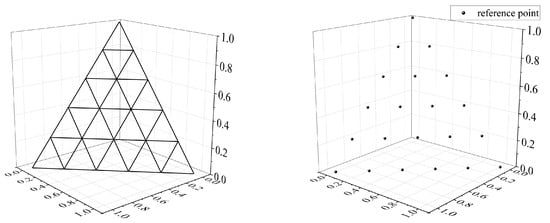
Figure 3.
Hyperplane and reference points.
The objective space is then normalized through the transformation , where represents the ideal point value for the i-th objective and represents the objective value of individual x on the i-th criterion.
(3) DDQN-based local optimization strategy
The deep reinforcement learning module employs a Double Deep Q-Network (DDQN) architecture with dual-network structure, which consists of environment configuration and output design.
The environment configuration involves neural network construction and reward mechanism design to guide the learning process. A three-layer fully connected neural network with 40 nodes per layer is developed to handle the three-dimensional input vector. The input vector consists of (i) the current workstation index normalized to , (ii) candidate next workstation index normalized to , and (iii) current vehicle load-to-capacity ratio. The network employs purelin, satlin, and poslin activation functions for layers 1–3, respectively, and is trained using the traingdx algorithm with adaptive learning rate backpropagation and momentum.
The network is initialized using Pareto-optimal solutions, where the loss function is defined as , with representing the Pareto front solutions and denoting the lowest-ranked solutions from set G.
The reward mechanism incorporates multiple objectives through the function , considering pheromone concentration, heuristic information, and earliness time. To prevent local optima, an adaptive learning rate is introduced, calculated as , which dynamically adjusts the reward value as based on the solution quality relative to the Pareto front.
One episode is defined as constructing a complete routing solution serving all N workstations, with episode length ranging from N to decision steps depending on depot return frequency. Training occurs at iterations 50, 100, and 200, with 500 episodes executed at each checkpoint using experiences sampled from the replay buffer. The replay buffer maintains a maximum size of experiences, with training initiated after accumulating at least 1000 samples. Mini-batch gradient descent uses batch size sampled uniformly from the buffer every 4 decision steps, and the target network parameters are updated every gradient steps.
The traingdx optimizer employs an initial learning rate of 0.001 with an exponential decay factor of 0.95 applied every 500 gradient steps, momentum coefficient 0.9, gradient clipping with maximum norm 10.0, and L2 weight decay of . The epsilon-greedy exploration strategy maintains throughout training, selecting the action with maximum Q-value with 90% probability while exploring randomly with 10% probability to sustain solution diversity.
The reinforcement learning results are used to improve the optimization performance of the evolutionary algorithm. Since adjacent iterations produce similar solution sets, leading to insufficient diversity in replay buffer experiences, the neural network is trained only at specific iterations (50, 100, and 200) when substantial solution evolution has occurred. The trained network generates 40 complete routing solutions through action selection, which are recorded in set and participate in non-dominated sorting for the next iteration.
This approach effectively balances exploration and exploitation during the optimization process while maintaining solution diversity. The complete DDQN architecture is illustrated in Figure 4, demonstrating the integration of these components into a cohesive optimization framework. The proposed strategy demonstrates enhanced convergence properties through its innovative reward adaptation mechanism and neural network design.
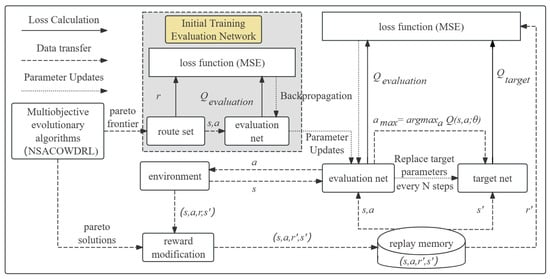
Figure 4.
The structure of the DDQN.
(4) Robustness optimization
This paper proposes a robust selection method integrating uniformly distributed weights in the solution space with Monte Carlo simulation to overcome the limitation of conventional strategies that excessively favor high-feasibility solutions while neglecting multi-objective trade-offs. The method first partitions the objective space into subspaces using uniformly distributed weight vectors, where each weight represents a specific trade-off preference, and solutions are associated with their closest weight via Euclidean distance to ensure global diversity. Subsequently, each solution undergoes 1000 Monte Carlo simulations incorporating transport time , service time , and stochastic perturbations , with the feasible count recorded and solutions characterized as quadruples (). Within each weight-associated subspace, the solution with the maximal MC (denoted ) is retained while others () are eliminated, ultimately generating a robust Pareto set, which is shown in Figure 5, where color-coding indicates weight affiliations.
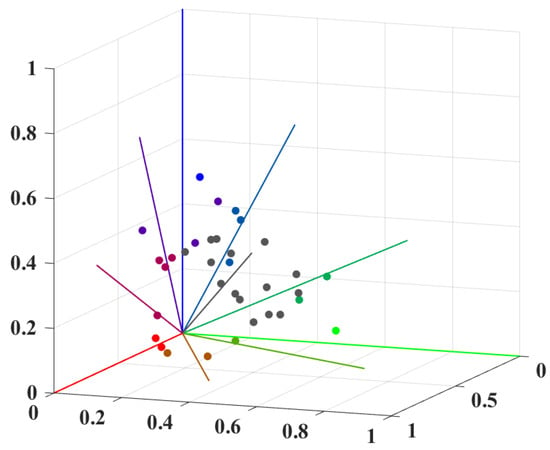
Figure 5.
Robust Pareto set.
By explicitly controlling trade-offs through weight-based partitioning, quantifying robustness under uncertainty via Monte Carlo simulation, and effectively balancing feasibility with other objectives through the partitioned selection mechanism, this method provides decision-makers with diversified solutions adaptable to varying practical requirements.
4.2. Dynamic Event Handler
This article uses a Dynamic Event Handler to randomly generate dynamic events and provides solutions for these dynamic events.The framework structure of the dynamic event handler is shown in Figure 6.
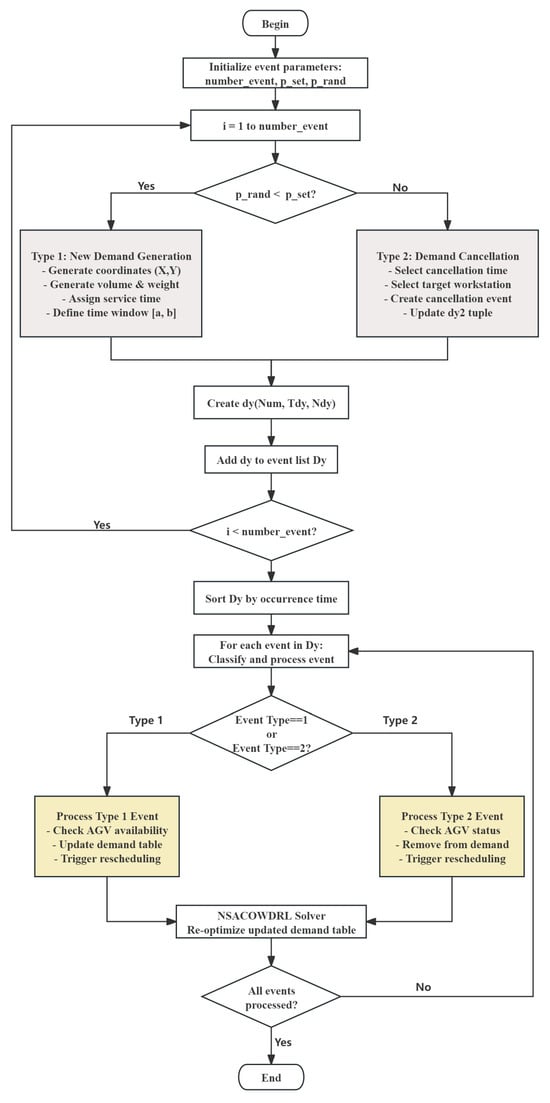
Figure 6.
Framework of the dynamic event handler.
(1) Dynamic events generation
In practical cases, dynamic events are directly transmitted to the dispatching system through dashboards or network transmission. In the computational dataset, a dynamic event generation component is designed in the algorithm. It ensures the consistency of dynamic event generation and generates dynamic events for the test cases. The steps are as follows:
Step 1: Firstly, initialize the number of events, the event classification probabilities, and the event classification random numbers, which, respectively, control the total number of dynamic events generated in each experiment, the occurrence probabilities of the two types of dynamic events, and the generation type of each dynamic event.
Step 2: Generate dynamic events sequentially. Based on the comparison between the event classification random numbers and the event classification probabilities, two types of events are generated. The dynamic elements are generated according to the event type. And a concise ternary dynamic event matrix (, , ) is output. Then, the concise dynamic event matrix is added to the dynamic event table.
Step 3: If the number of dynamic events is less than the maximum number of events to be generated, repeat Step 2. Otherwise, output the dynamic event table.
The pseudo-code for the dynamic event generation process is presented as follows (Algorithm 1):
| Algorithm 1: Dynamic event generation |
|
(2) Dynamic events classification
In this paper, we consider two types of dynamic events: (1) cancellation of predetermined material demands; (2) generation of new material demands. Through the dynamic event classification module, these events are categorized and scheduled as follows:
Step 1: The dynamic events in the event table are sorted chronologically based on their occurrence times.
Step 2: For each solution in the initial optimal solution set, dynamic events are sequentially inserted and processed according to their classification: For Class 1 events (demand cancellation), the corresponding workstation is selected from the original demand table and perform workstation insertion. Then, it executes re-sequencing optimization. For Class 2 events (new demand generation), a new workstation is inserted and the associated routes are re-optimized. After processing each event, the updated demand table is optimized using the NSACOWDRL solver.
Step 3: If any solution in the initial optimal set remains unprocessed, Step 2 is repeated. Otherwise, the updated optimal solution set is output.
The pseudo-code is presented as follows (Algorithm 2):
| Algorithm 2: Dynamic event process |
|
4.3. Multi-Objective Multi-Stage Dynamic Routing Algorithm
In the dynamic NSACOWDRL algorithm, dynamic events are generated by the dynamic event handler and classified according to their characteristics. After all these steps, the final path planning is performed through the NSACOWDRL algorithm. The framework structure of dynamic NSACOWDRL is shown in Figure 7.
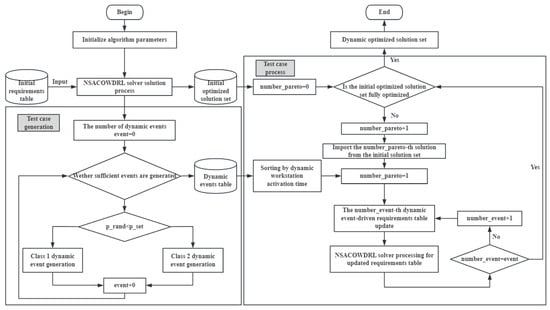
Figure 7.
Framework of the dynamic NSACOWDRL.
Dynamic NSACOWDRL algorithm steps are as follows:
Step 1: The NSACOWDRL solver is employed to compute the initial material demand table, yielding the initial optimal Pareto solution set for vehicle scheduling. The number of solutions in the set is denoted as , while the count of dynamically optimized solutions is initialized as .
Step 2: For the given dataset instance, dynamic events are processed via the dynamic event handler to generate a dynamic event table. The total number of dynamic events is recorded as .
Step 3: The -th solution from the initial Pareto set is loaded.
Step 4: The dynamic event handler is engaged to sort dynamic events chronologically based on their occurrence time at workstations, followed by categorization according to event identifiers.
Step 5: Sequentially, each dynamic event triggers an independent update of the material demand table. Upon each update, the NSACOWDRL solver performs corresponding reoptimization. After processing all dynamic events, is incremented by 1.
Step 6: If , the optimization terminates, and the dynamically optimized solution set is output. Otherwise, the algorithm returns to Step 3.
5. Experimental Results
In this section, we conduct computational experiments to validate the feasibility of the dynamic multi-objective algorithm. The experimental design incorporates two problem scales with four distinct test cases each, along with three different uncertainty disturbance coefficients. Through comprehensive evaluation of three key performance objectives, the results demonstrate the scientific validity of both the model and algorithm. As for parameter selection, we followed a preliminary grid search over key parameters (, , ). While not exhaustively optimized, all algorithms used identical tuning effort to ensure fair comparison. Full parameter optimization using techniques like irace or SMAC is left for future work. We acknowledge this limitation may affect absolute performance values but not relative rankings.
5.1. Computational Environment
To solve the MDVRPSPDTW problem, the operating environment in this study is a Windows 11 system with an Intel® Core™ i5-6200U CPU @ 2.30GHz processor. The primary development environment used is MATLAB R2018b, a mathematical simulation software that offers significant advantages for solving combinatorial optimization problems like the VRP. This is attributed to two main reasons: First, MATLAB possesses powerful matrix processing capabilities. Since matrices form the basis of its data structure, it can perform calculations directly on matrices and efficiently execute improved optimization algorithms in a concise manner. Second, MATLAB integrates programming, computation, and data visualization. Its robust visualization features effectively illustrate the iterative solution process of the enhanced optimization algorithm and the delivery routes of AGVs.
5.2. Experimental Setting
In the case study validation, the specific parameter settings of the algorithm are shown in Table 2:
Table 2.
Parameter Setting.
- For the parameters related to the ant colony algorithm:The colony size takes the average of two scale quantities “25–50” to balance exploration and computational costs under different scales. Among the four function coefficients (pheromone concentration coefficient, heuristic function coefficient, Q-value coefficient, waiting time coefficient), the pheromone concentration coefficient serves as a comprehensive coefficient considering multiple objectives. Its value is set to 1 to avoid falling into local optima. While the other three coefficients are single-objective coefficients with equal status and reliable objective functions. All are set to 2.
- For parameters related to the non-dominated sorting strategy:The hyperplane dimension for the three-objective problem is set to 3. To generate an adequate number of reference points while avoiding the curse of dimensionality—where an exponential increase in reference points leads to prohibitive computational costs, the number of division points is set to 10.
- For parameters related to the DDQN local strategy:To ensure the experience replay covers sufficient action selections and prevents forgetting, the experience pool size is set to 60,000. Due to the high environmental randomness and transportation time uncertainty, the discount factor is set to 0.9 to reduce the impact of long-term uncertainties. With the model input relatively low in dimension, the target update interval is set to 1200 to improve the network’s convergence speed.
To evaluate the performance of the NSACOWDRL algorithm, this section selects VRPTW benchmark instances from the Solomon dataset, including two scales (25 and 50). For each scale, four instances are chosen: C202, C206, RC202, and RC204. Each instance is tested under three different disturbance coefficients to assess the algorithm’s performance.
Although the assembly workshop AGV routing problem has its unique characteristics, the VRPTW benchmark instances provide a scientifically valid testbed for algorithm validation due to the fundamental structural similarities between these problems.
Figure 8 illustrates a real assembly workshop AGV distribution scenario, where the small rectangles joined together represent workstations and the black dots indicate the stations that need to be distributed.

Figure 8.
AGV transportation routes in assembly workshop.
The rationale for adopting Solomon benchmark instances lies in several key mappings between VRPTW and assembly workshop scenarios. First, both problems share identical mathematical foundations: vehicles departing from and returning to a central depot (raw material library in workshops), serving customer demands (workstation material requirements) within specified time constraints, and optimizing multiple objectives under capacity limitations. Second, the spatial distribution patterns in Solomon instances—clustered (C-type) representing product-based layouts and random-clustered (RC-type) representing process-based or group-based layouts—effectively capture the typical workstation arrangements found in real assembly workshops.
To ensure the benchmark instances accurately reflect assembly workshop characteristics, several domain-specific adaptations were implemented. The continuous production environment was modeled by dividing daily operations into multiple distribution cycles, each with distinct delivery requirements. Material handling was standardized following industrial practices, with small materials consolidated into standard containers and large materials represented as integer multiples of container units. Additionally, stochastic load weights were assigned to each material demand to reflect the heterogeneous nature of workshop materials, while the traditional hard time windows were replaced with Just-in-Time deadlines to better align with lean manufacturing principles.
This benchmarking approach not only enables rigorous performance comparison with existing algorithms but also ensures that the experimental results are relevant to practical assembly workshop operations. The selected instance scales (25 and 50 customers) correspond to typical per-cycle material distribution volumes (15–50 deliveries) observed in industrial settings, while the three disturbance coefficients simulate the spectrum of operational uncertainties commonly encountered in dynamic workshop environments.
To make the instances more realistic to assembly workshop scenarios, the following settings are applied based on the model and real-world factory:
- 1.
- The assembly workshop divides a day’s distribution time into several cycles. Different distribution tasks are executed in each cycle.
- 2.
- All workstations are available during all working time.
- 3.
- The assembly workshop standardizes material delivery. Small materials are packed in standardized containers, while large materials are equivalent to integer multiples of standard containers. All materials required by the same workstation in a single cycle are placed in the same cart.
- 4.
- Since the selected instances lack load constraints, each material in every instance is assigned a random load (0 < material load < AGV maximum load). Identical materials in the same-named instances share the same load.The specific parameter settings of the AGV are shown in Table 3.
Table 3. AGV parameters.
5.3. Performance Metrics
In multi-objective optimization problems, the diversity and convergence of algorithms are key performance metrics that require evaluation. However, a single metric is often insufficient to comprehensively assess algorithm performance. In this study, we employ three established performance indicators—Hypervolume () [1], Inverted Generational Distance (), and Generational Distance () [38]—to evaluate algorithmic performance. The definitions of these metrics are as follows:
As shown in Equation (50), the metric is the Hypervolume Indicator (): This metric quantifies algorithm diversity by measuring the volume of the objective space enclosed between the non-dominated solution set and a reference point. A larger value indicates better algorithm diversity.
indicates the Lebesgue measure used to quantify the hypervolume. represents the cardinality of the non-dominated solution set. corresponds to the hypervolume formed by the reference point and the i-th solution in the set.
As formalized in Equation (51), the metric represents the Inverted Generational Distance (): This comprehensive performance indicator evaluates both convergence and distribution characteristics by computing the average minimum distance from each point on the true Pareto front to the solution set obtained by the algorithm. A smaller value indicates superior convergence and distribution performance of the algorithm.
P represents the solution set obtained by the algorithm. denotes a set of uniformly distributed reference points sampled from the true Pareto front. is the cardinality of the reference set. computes the Euclidean distance between points and .
As mathematically defined in Equation (52), the (Generational Distance) metric serves as a convergence measure that computes the average minimum distance from solutions in the obtained set to the true Pareto front (PF). The formal expression is given by:
In practical scenarios where obtaining the true Pareto front is challenging, the experimental Pareto front will be approximated by considering all non-dominated solutions obtained from all algorithms.
In this paper, normalization is employed to standardize the evaluation criteria across different objectives, eliminating differences in units and scales between them.
5.4. Experimental Results
5.4.1. Dynamic Event Table
In the dynamic experiments, a dynamic event generator is employed to produce dynamic event tables, which are then integrated into each algorithmic experiment. The dynamic events are generated based on the instance type (RC or C), with the number of events set at 10% of the instance size (rounded up if fractional). For 25-scale instances, 3 events are randomly selected from the dynamic events of their 50-scale counterparts with the same name. The dynamic event table is presented in Table 4.
Table 4.
Dynamic event table.
5.4.2. Multi-Objective Metric Results
In order to visualize the Pareto front of three objectives, take instance c202-25 as an example; its Pareto front is shown in Figure 9.
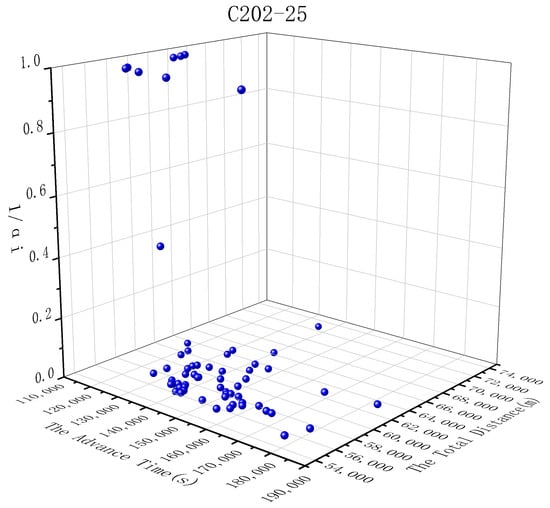
Figure 9.
Pareto front of instance c202-25.
Table 5, Table 6, Table 7 present the algorithmic performance results under dynamic instances, evaluated through three key metrics.
Table 5.
Mean and variance metric values of indicators.
Table 6.
Mean and variance metric values of indicators.
Table 7.
Mean and variance metric values of indicators.
To quantify the performance advantages of NSACOWDRL more clearly, Table 8 presents the average percentage improvements and standard deviations across the three metrics (, , ) compared to the best-performing baseline algorithm for each test scenario. The results are organized by problem scale and disturbance intensity to illustrate how NSACOWDRL’s relative performance varies under different operational conditions.
Table 8.
Performance improvements of NSACOWDRL vs. best baseline (mean ± SD).
5.4.3. Overall Algorithm Performance Comparison
(1) Multi-objective Optimization Performance Analysis
Based on the experimental results presented in Table 5, Table 6 and Table 7 NSACOWDRL demonstrates significant advantages across three key performance indicators. In terms of metric, NSACOWDRL achieves an average improvement of 15.2% compared to the best baseline algorithms, indicating superior comprehensive performance in both solution diversity and convergence. Particularly in 25-scale instances, NSACOWDRL consistently achieves values exceeding 0.4, while other algorithms mostly remain below 0.35, demonstrating NSACOWDRL’s enhanced capability to explore the objective space and maintain Pareto front integrity.
The metric results show NSACOWDRL achieves an average improvement of 12.8%, primarily manifested in the algorithm’s ability to distribute solutions more uniformly near the true Pareto front. From Table 7, it is observed that NSACOWDRL maintains values below 0.3 in most test instances, while traditional algorithms like NSGA-II frequently exceed 0.4, sometimes reaching above 0.7, indicating significant convergence issues in traditional approaches.
The 8.9% improvement in metric, though relatively modest, reflects NSACOWDRL’s stability in convergence precision. Notably, under high disturbance coefficient conditions, NSACOWDRL’s improvement becomes more pronounced, validating the effectiveness of its robustness optimization mechanism.
(2) Algorithmic Mechanism Advantage Analysis
NSACOWDRL’s superior performance primarily stems from several key mechanisms:
Effectiveness of Pheromone Update Strategy: By utilizing non-dominated sorting to guide pheromone increment allocation, the algorithm avoids the traditional ant colony algorithm’s tendency to excessively favor single objectives. Experimental data demonstrates this strategy’s particular effectiveness on RC-type instances, as the random-clustered distribution characteristics of RC instances require algorithms with stronger global search capabilities.
Contribution of DDQN Local Search: The deep reinforcement learning module effectively avoids local optima through dynamic reward function adjustment. In complex instances such as C202 and RC204, NSACOWDRL achieves 20–30% improvement compared to pure ant colony algorithm (NSACO), primarily attributed to DDQN’s ability to learn and utilize historical experience during the search process.
Reference Point-Guided Diversity Maintenance: Through uniformly distributed reference points guiding solution selection, complete Pareto front coverage is ensured. This mechanism performs particularly well in 50-scale instances, maintaining high solution quality even when problem complexity increases.
5.4.4. Disturbance Coefficient and Instance Type Analysis
The experimental results reveal differential algorithm performance under varying disturbance levels and instance types. As disturbance coefficients increase from Small to Large, NSACOWDRL’s performance advantage amplifies significantly. In 25-scale C202 instances, NSACOWDRL’s improvement over NSGA-III increases from 12% (small disturbance) to 154% (large disturbance), demonstrating the robustness optimization mechanism’s effectiveness under uncertainty.
Disturbance Impact Mechanism: The triangular distribution-based robustness metric enables NSACOWDRL to proactively avoid high-risk regions during optimization, maintaining solution feasibility under large disturbances. The dynamic JIT adjustment mechanism provides additional adaptability compared to traditional time window constraints.
Instance Type Analysis: The experimental results reveal distinct performance patterns across different instance types, with RC-type instances demonstrating greater algorithmic performance variations compared to C-type instances. In 50-scale instances, the performance differential between NSACOWDRL and MOEA/D measures approximately 20% for C202 instances but expands dramatically to over 50% for RC202 instances, reflecting the fundamental structural differences between clustered and random-clustered customer distributions where RC instances’ irregular spatial patterns create more complex optimization landscapes that challenge conventional approaches, while NSACOWDRL’s integrated ant colony-reinforcement learning framework demonstrates superior adaptability through its dynamic learning mechanisms that effectively navigate these expanded solution spaces.
5.4.5. p-Value Significance Testing and Analysis
The statistical significance of performance differences between algorithms was assessed using the Wilcoxon signed-rank test, a non-parametric test suitable for non-normally distributed data commonly found in metaheuristic comparisons. For each instance–metric combination, we conducted 30 independent runs per algorithm to ensure statistical reliability.
To complement the significance tests, we computed Cliff’s delta (d) as an effect size measure, where indicates negligible difference, indicates small effect, indicates medium effect, and indicates large effect. The heatmaps use a color gradient where darker shades () indicate highly significant differences, medium shades () indicate significant differences, and lighter shades () indicate non-significant differences at the 95% confidence level.
Figure 10, Figure 11 and Figure 12 present the p-value plots comparing algorithm performance under dynamic instances, revealing statistically significant differences between algorithms across different instance types and disturbance coefficients. The results demonstrate that in 25-scale instances, NSACOWDRL exhibits significantly superior performance in both and metrics compared to other algorithms, confirming its advantages in diversity and comprehensive optimization capability. For the metric, NSACOWDRL shows comparable performance to other algorithms under low disturbance coefficients but becomes significantly better as disturbances increase, indicating its stronger robustness in convergence.

Figure 10.
p-value heatmap of at 50 scale.

Figure 11.
p-value heatmap of at 50 scale.

Figure 12.
p-value heatmap of at 50 scale.
In 50-scale instances, NSACOWDRL maintains significant advantages in and metrics. Regarding GD performance, NSACOWDRL and MOEA/D achieve similar results, with each algorithm demonstrating superiority in specific instances—NSACOWDRL performs better in high-disturbance scenarios while MOEA/D excels in low-to-medium-disturbance conditions.
Analysis by instance type shows that RC-series instances exhibit greater performance variations between algorithms in diversity metrics (/), with most comparisons showing significant differences, except for “50-scale-RC204-Large” and “50-scale-RC202-Middle” instances, which show smaller differences. For convergence (), performance gaps widen with increasing disturbance coefficients, with NSACOWDRL demonstrating clear superiority in high-disturbance cases. In contrast, C-series instances show smaller performance gaps between algorithms, with less divergence in diversity and significant but less pronounced differences in convergence.
The results indicate that comprehensive performance () shows greater variation across algorithms, with these differences tending to decrease as instance scale increases. The overall performance ranking remains consistent across most scenarios: NSACOWDRL>MOEA/D>NSGA-II. These findings demonstrate that NSACOWDRL achieves the best balance between diversity and convergence, with algorithm performance being influenced by both instance scale and disturbance level, while RC-series instances better differentiate algorithm capabilities compared to C-series instances.
The experimental results and p-value plots indicate that NSACOWDRL demonstrates significant advantages in both convergence and diversity for small to medium-scale instances. For larger-scale problems, the NSACOWDRL algorithm exhibits superior diversity and comprehensiveness while maintaining more adaptable convergence properties. Moreover, NSACOWDRL shows better generalization in addressing problems across different scenarios.
6. Conclusions
This paper addresses the complex challenge of dynamic multi-objective vehicle routing optimization in large-scale equipment manufacturing environments, where real-time disruptions and conflicting operational objectives significantly impact both economic performance and environmental sustainability. This research makes substantial contributions to both theoretical understanding and practical application of dynamic vehicle routing problems.
The proposed Dynamic Multi-Objective Vehicle Routing Problem (DMOVRP) model represents a significant advancement in routing optimization by uniquely integrating three competing objectives: environmental impact reduction, delivery timeliness, and operational robustness. Unlike traditional formulations that rely on rigid time windows, our model introduces dynamic (Just-in-Time) deadlines that adapt to workload variations, successfully reconciling the inherent conflict between JIT scheduling requirements and robustness considerations. The novel feasibility quantification metric () based on triangular distribution provides a theoretically sound framework for quantifying solution robustness under uncertainty, enabling proactive optimization rather than reactive adjustment.
The hybrid “dynamic exception handling-static optimization” framework extends existing methodologies by systematically classifying dynamic events into demand cancellation and new demand generation categories, each with specialized handling protocols. This classification enables more targeted and efficient responses to operational disruptions compared to generic rescheduling approaches.
The NSACOWDRL (Non-dominated Sorting Ant Colony Optimization with Deep Reinforcement Learning) algorithm demonstrates superior performance through several key mechanisms. The integration of DDQN as a local search operator effectively overcomes traditional ant colony optimization’s tendency toward premature convergence, while the reference point-based non-dominated sorting strategy ensures comprehensive Pareto front coverage. The adaptive pheromone update strategy, incorporating both non-dominated ranking and elite path reinforcement with max–min bounds, achieves an effective balance between exploration and exploitation.
The robustness optimization component, combining uniformly distributed weight vectors with Monte Carlo simulation, provides a practical solution to the challenge of selecting reliable schedules under uncertainty without excessively compromising other objectives.
Comprehensive computational experiments across multi-scale instances (25 and 50 workstations) under varying disturbance intensities demonstrate NSACOWDRL’s statistical superiority over established methods including MOEA/D, NSGA-III, NSGA-II, and NSACO. Wilcoxon signed-rank tests (, runs per instance) confirm statistically significant improvements, with NSACOWDRL achieving average relative gains of 15.2% in Hypervolume (), 12.8% in Inverted Generational Distance (), and 8.9% in Generational Distance () metrics. Notably, performance advantages amplify under higher disturbance levels, validating the robustness optimization mechanism’s effectiveness. The algorithm demonstrates particular strength in RC-type instances with irregular spatial patterns, indicating superior adaptability to complex optimization landscapes.
This research provides manufacturers with a versatile decision-support tool that adapts to unpredictable workshop conditions while maintaining sustainable operations. The system’s ability to handle real-time disruptions through dynamic rescheduling protocols, combined with its consideration of carbon emissions and delivery timeliness, addresses the dual imperatives of economic efficiency and environmental sustainability that characterize modern manufacturing logistics.
While this study demonstrates strong algorithmic performance on benchmark instances, several critical extensions are necessary to bridge the gap between theoretical validation and industrial deployment.
The most immediate priority is applying the DMOVRP framework to actual AGV workshop operations with logged historical data. Industrial partners could provide authentic disruption patterns, material flow dynamics, and temporal demand variations that would enable rigorous validation of the model’s practical effectiveness. Real-world testing would reveal implementation challenges not captured in benchmark instances, such as operator intervention patterns, facility-specific layout constraints, and integration requirements with existing manufacturing execution systems. Such validation would also facilitate the development of industry-specific calibration protocols and performance benchmarks.
Enhanced Operational Constraints: The current model requires extension to incorporate critical real-world operational factors. AGV charging scheduling should be integrated as an explicit constraint and potentially as an additional optimization objective, addressing battery degradation dynamics, charging station availability, and energy cost variations throughout operational shifts. Furthermore, modeling inter-vehicle traffic interference—including congestion at narrow passages, intersection conflicts, and elevator usage coordination—would significantly enhance solution realism. These extensions would require developing efficient constraint handling mechanisms that maintain computational tractability while capturing essential operational complexities.
The robustness coefficient and JIT deadline parameters currently rely on domain expertise and preliminary testing. Machine learning approaches could leverage historical production data to automatically calibrate these critical parameters based on observed disruption frequencies, workstation demand patterns, and actual delivery performance. Specifically, regression models or neural networks could learn optimal values as functions of workstation characteristics, while time-series analysis of past delivery records could inform adaptive JIT deadline calculation. Such data-driven calibration would enable the system to self-tune for different manufacturing contexts and evolving operational conditions, substantially improving practical applicability and reducing manual parameter tuning requirements.
These three research directions collectively address the essential pathway from algorithmic innovation to industrial implementation, ensuring that the proposed methodology can deliver tangible benefits in real manufacturing environments.
Author Contributions
Conceptualization, Y.C. and Y.S.; methodology, Y.C., W.Y., Z.P., M.C. and Y.S.; software, M.C. and Y.S.; validation, M.C. and Y.S.; formal analysis, W.Y. and Y.S.; investigation, M.C. and W.Y.; resources, Y.C.; data curation, Y.S.; writing—original draft preparation, Y.S.; writing review and editing, J.L.; visualization, M.C., Z.P. and Y.S.; supervision, Y.C. and J.L.; project administration, Y.S.; funding acquisition, Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Natural Science Foundation of Zhejiang province, China under the Grant Nos. LGG22G010002, Nos. 52005447, Zhejiang Provincial Natural Science Foundation of China under Grant Nos. LQ21E050014 and National Natural Science Foundation of China Key Project under Grant Nos. W2411062.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The instance dataset presented in the study is included in the article. The benchmark problem datasets presented in the study are openly available in VRPTE at https://www.sintef.no/projectweb/top/vrptw/solomon-benchmark/ (accessed on 18 April 2008).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Pillac, V.; Gendreau, M.; Guéret, C.; Medaglia, A.L. A review of dynamic vehicle routing problems. Eur. J. Oper. Res. 2013, 225, 1–11. [Google Scholar] [CrossRef]
- Zajac, S.; Huber, S. Objectives and Methods in Multi-objective Routing Problems: A Survey and Classification Scheme. Eur. J. Oper. Res. 2020, 290, 1–25. [Google Scholar] [CrossRef]
- Kumar, N.V.; Kumar, C.S. Development of collision free path planning algorithm for warehouse mobile robot. Procedia Comput. Sci. 2018, 133, 456–463. [Google Scholar] [CrossRef]
- Baniasadi, P.; Foumani, M.; Smithmiles, K.; Ejov, V. A transformation technique for the clustered generalized traveling salesman problem with applications to logistics. Eur. J. Oper. Res. 2020, 285, 444–457. [Google Scholar] [CrossRef]
- Reihaneh, M.; Ghoniem, A. A branch-and-price algorithm for a vehicle routing with demand allocation problem. Eur. J. Oper. Res. 2019, 272, 523–538. [Google Scholar] [CrossRef]
- Tilk, C.; Bianchessi, N.; Drexl, M.; Irnich, S.; Meisel, F. Branch-and-Price-and-Cut for the Active-Passive Vehicle-Routing Problem. Transp. Sci. 2018, 52, 300–319. [Google Scholar] [CrossRef]
- Li, J.; Qin, H.; Baldacci, R.; Zhu, W. Branch-and-price-and-cut for the synchronized vehicle routing problem with split delivery, proportional service time and multiple time windows. Transp. Res. Part E Logist. Transp. Rev. 2020, 140, 101955. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Kwon, C. A Neural Separation Algorithm for the Rounded Capacity Inequalities. Informs J. Comput. 2024, 36, 987–1005. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Computat. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Corne, D.W.; Jerram, N.R.; Knowles, J.D.; Oates, M.J. PESA-II: Region-based selection in evolutionary multiobjective optimization. In Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, San Francisco, CA, USA, 7–11 July 2001. [Google Scholar]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Liu, H.-L.; Gu, F.; Zhang, Q. Decomposition of a Multiobjective Optimization Problem Into a Number of Simple Multiobjective Subproblems. IEEE Trans. Evol. Comput. 2014, 18, 450–455. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y.; Olhofer, M.; Sendhoff, B. A Reference Vector Guided Evolutionary Algorithm for Many-Objective Optimization. IEEE Trans. Evol. Comput. 2016, 20, 773–791. [Google Scholar] [CrossRef]
- Zitzler, E.; Künzli, S. Indicator-Based Selection in Multiobjective Search. In Parallel Problem Solving from Nature—PPSN VIII: 8th International Conference, Birmingham, UK, 18–22 September 2004, Proceedings; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Beume, N.; Naujoks, B.; Emmerich, M. SMS-EMOA: Multiobjective Selection Based on Dominated Hypervolume. Eur. J. Oper. Res. 2007, 181, 1653–1669. [Google Scholar] [CrossRef]
- Li, K.; Kwong, S.; Cao, J.; Li, M.; Zheng, J.; Shen, R. Achieving Balance between Proximity and Diversity in Multi-Objective Evolutionary Algorithm. Inf. Sci. 2012, 182, 220–242. [Google Scholar] [CrossRef]
- Bader, J.; Zitzler, E. HypE: An Algorithm for Fast Hypervolume-Based Many-Objective Optimization. Evol. Comput. 2011, 19, 45–76. [Google Scholar] [CrossRef]
- Bader, J.; Deb, K.; Zitzler, E. Faster Hypervolume-Based Search Using Monte Carlo Sampling. In Multiple Criteria Decision Making for Sustainable Energy and Transportation Systems, Proceedings of the 19th International Conference on Multiple Criteria Decision Making, Auckland, New Zealand, 7–12 January 2008; Springer: Berlin/Heidelberg, Germany, 2009; pp. 313–326. [Google Scholar]
- Montemanni, R.; Gambardella, L.M.; Rizzoli, A.E.; Donati, A.V. Ant Colony System for a Dynamic Vehicle Routing Problem. J. Comb. Optim. 2005, 10, 327–343. [Google Scholar] [CrossRef]
- Hanshar, F.T.; Ombuki-Berman, B.M. Dynamic vehicle routing using genetic algorithms. Appl. Intell. 2007, 27, 89–99. [Google Scholar] [CrossRef]
- Xiang, X.; Qiu, J.; Xiao, J.; Zhang, X. Demand coverage diversity based ant colony optimization for dynamic vehicle routing problems. Eng. Appl. Artif. Intell. 2020, 91, 103582. [Google Scholar] [CrossRef]
- Haitao, X.; Pan, P.; Feng, D. Dynamic Vehicle Routing Problems with Enhanced Ant Colony Optimization. Discret. Dyn. Nat. Soc. 2018, 2018, 1295485. [Google Scholar] [CrossRef]
- Abdallah, A.M.F.M.; Essam, D.L.; Sarker, R.A. On solving periodic re-optimization dynamic vehicle routing problems. Appl. Soft Comput. 2017, 55, 1–12. [Google Scholar] [CrossRef]
- Mańdziuk, J.; Ychowski, A. A Memetic Approach to Vehicle Routing Problem with Dynamic Requests. Appl. Soft Comput. 2016, 48, 522–534. [Google Scholar] [CrossRef]
- Chen, S.; Chen, R.; Gao, J. A Monarch Butterfly Optimization for the Dynamic Vehicle Routing Problem. Algorithms 2017, 10, 107. [Google Scholar] [CrossRef]
- Liu, M.; Zhao, Q.; Song, Q.; Zhang, Y. A Hybrid Brain Storm Optimization Algorithm for Dynamic Vehicle Routing Problem With Time Windows. IEEE Access 2023, 11, 121087–121095. [Google Scholar] [CrossRef]
- Khouadjia, M.R.; Sarasola, B.; Alba, E.; Jourdan, L.; Talbi, E.G. A comparative study between dynamic adapted PSO and VNS for the vehicle routing problem with dynamic requests. Appl. Soft Comput. 2012, 12, 1426–1439. [Google Scholar] [CrossRef]
- Okulewicz, M.; Mańdziuk, J. The impact of particular components of the PSO-based algorithm solving the Dynamic Vehicle Routing Problem. Appl. Soft Comput. 2017, 58, 586–604. [Google Scholar] [CrossRef]
- Okulewicz, M.; Mańdziuk, J. A metaheuristic approach to solve Dynamic Vehicle Routing Problem in continuous search space. Swarm Evol. Comput. 2019, 48, 44–61. [Google Scholar] [CrossRef]
- Ropke, S.; Pisinger, D. An adaptive large neighborhood search heuristic for the pickup and delivery problem with time windows. Transp. Sci. 2006, 40, 455–472. [Google Scholar] [CrossRef]
- Cai, S.; Tang, K.; Chen, Y.; Li, D. A hybrid adaptive large neighborhood search and tabu search algorithm for the electric vehicle relocation problem. Comput. Ind. Eng. 2022, 167, 107908. [Google Scholar] [CrossRef]
- Wang, Q.; Hao, Y.; Zhang, J. Generative inverse reinforcement learning for learning 2-opt heuristics without extrinsic rewards in routing problems. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101787. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, M.; Zhao, X.; Zou, J. A Hybrid of Deep Reinforcement Learning and Local Search for the Vehicle Routing Problems. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7208–7218. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, X. Learning to Optimize Vehicle Routes Problem: A Two-Stage Hybrid Reinforcement Learning. In Proceedings of the 2023 International Conference on Sensing, Measurement & Data Analytics in the era of Artificial Intelligence (ICSMD), Xi’an, China, 2–4 November 2023; pp. 1–6. [Google Scholar]
- Ara, S.; Akib, M.M.M.K.; Oion, M.S.R.; Shohel, M.H.R.; Ridoy, M.N.F.; Kabita, F.A.; Shahiduzzaman, M. Vehicle Routing Problem Solving Using Reinforcement Learning. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; pp. 1–6. [Google Scholar]
- Van Veldhuizen, D.A.; Lamont, G.B. On measuring multiobjective evolutionary algorithm performance. In Proceedings of the 2000 Congress on Evolutionary Computation. CEC00 (Cat. No.00TH8512), La Jolla, CA, USA, 16–19 July 2000. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).