


Evaluating the Performance of Artificial Intelligence-Based Large Language Models in Orthodontics—A Systematic Review and Meta-Analysis


 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
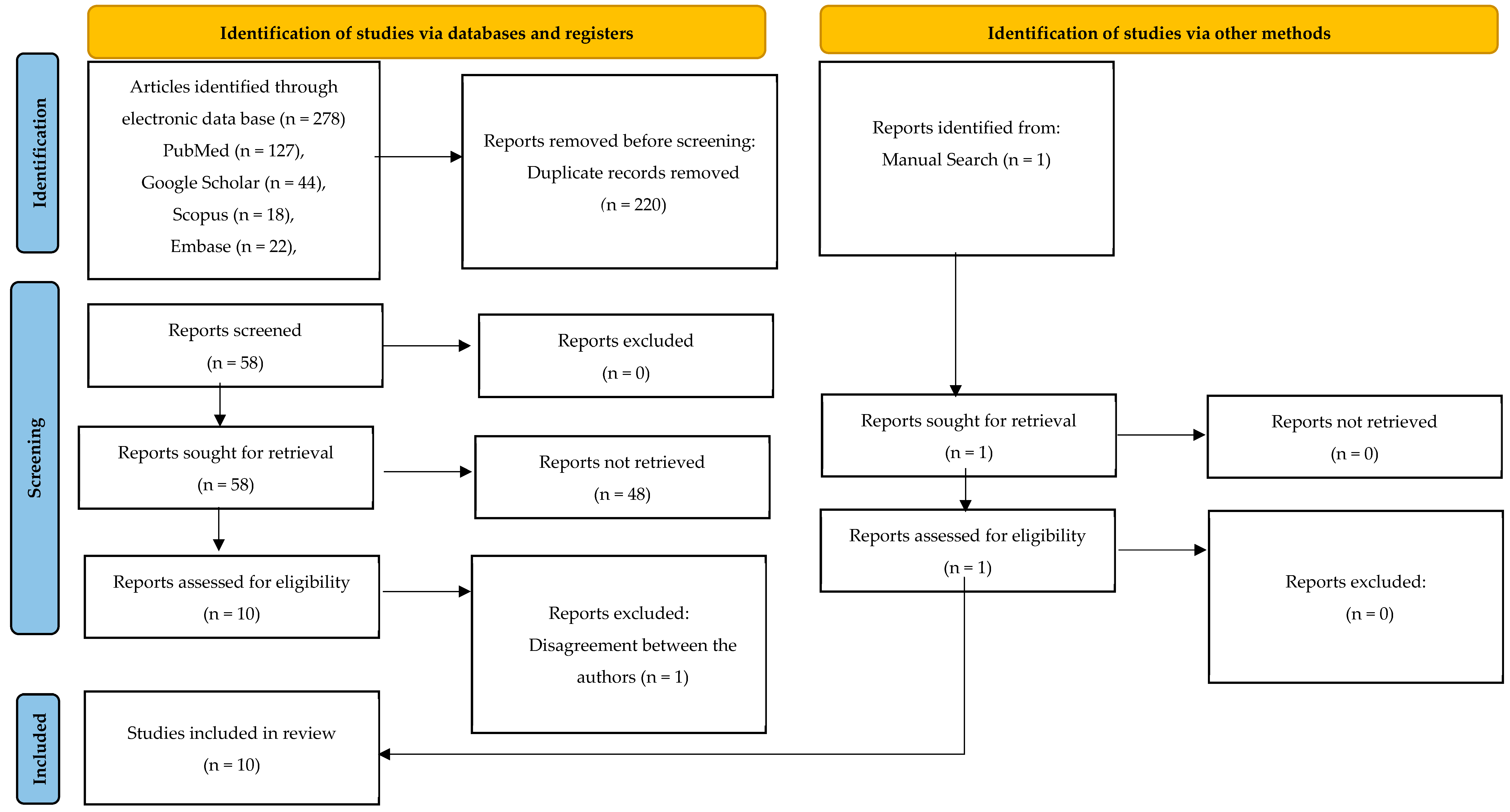
2.1. Search Strateg
2.2. Study Selection
2.3. Eligibility Criteria
3. Results
3.1. Data Extraction
3.2. Quality Assessment
3.3. Qualitative Data of the Studies
3.4. Study Characteristics
3.5. Outcome Measures
3.6. Risk of Bias (RoB) Assessment and Applicability Concerns
3.7. Statistical Protocol
4. Discussion
4.1. LLMs That Have Been Applied for Generating Answers to Questions Related to Orthodontics
4.2. Methods That Have Been Adopted for Assessing the Level of Accuracy and Reliability of the Responses Generated for Questions Related to Orthodontics
4.3. Application and Performance of AI Based LLMs for Answering Queries Related to the Specialty of Orthodontics
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsichlaki, A.; Chin, S.Y.; Pandis, N.; Fleming, P.S. How Long Does Treatment with Fixed Orthodontic Appliances Last? A Systematic Review. Am. J. Orthod. Dentofac. Orthop. 2016, 149, 308–318. [Google Scholar] [CrossRef]
- Crispino, R.; Mannocci, A.; Dilena, I.A.; Sides, J.; Forchini, F.; Asif, M.; Frazier-Bowers, S.A.; Grippaudo, C. Orthodontic Patients and the Information Found on the Web: A Cross-Sectional Study. BMC Oral Health 2023, 23, 860. [Google Scholar] [CrossRef]
- Mulimani, P.; Vaid, N. Through the Murky Waters of “Web-Based Orthodontics”, Can Evidence Navigate the Ship? APOS Trends Orthod. 2017, 7, 207–210. [Google Scholar] [CrossRef]
- Arun, M.; Usman, Q.; Johal, A. Orthodontic Treatment Modalities: A Qualitative Assessment of Internet Information. J. Orthod. 2017, 44, 82–89. [Google Scholar] [CrossRef] [PubMed]
- Daraz, L.; Morrow, A.S.; Ponce, O.J.; Beuschel, B.; Farah, M.H.; Katabi, A.; Alsawas, M.; Majzoub, A.M.; Benkhadra, R.; Seisa, M.O.; et al. Can Patients Trust Online Health Information? A Meta-Narrative Systematic Review Addressing the Quality of Health Information on the Internet. J. Gen. Intern. Med. 2019, 34, 1884–1891. [Google Scholar] [CrossRef]
- Thurzo, A.; Urbanová, W.; Novák, B.; Czako, L.; Siebert, T.; Stano, P.; Mareková, S.; Fountoulaki, G.; Kosnáčová, H.; Varga, I. Where Is the Artificial Intelligence Applied in Dentistry? Systematic Review and Literature Analysis. Healthcare 2022, 10, 1269. [Google Scholar] [CrossRef]
- Khanagar, S.B.; Al-Ehaideb, A.; Maganur, P.C.; Vishwanathaiah, S.; Patil, S.; Baeshen, H.A.; Sarode, S.C.; Bhandi, S. Developments, Application, and Performance of Artificial Intelligence in Dentistry—A Systematic Review. J. Dent. Sci. 2020, 16, 508–522. [Google Scholar] [CrossRef]
- Kishimoto, T.; Goto, T.; Matsuda, T.; Iwawaki, Y.; Ichikawa, T. Application of Artificial Intelligence in the Dental Field: A Literature Review. J. Prosthodont. Res. 2022, 66, 19–28. [Google Scholar] [CrossRef]
- Pandya, V.S.; Morsy, M.S.M.; Halim, A.A.; Alshawkani, H.A.; Sindi, A.S.; Mattoo, K.A.; Mehta, V.; Mathur, A.; Meto, A. Ultraviolet Disinfection (UV-D) Robots: Bridging the Gaps in Dentistry. Front. Oral Health 2023, 4, 1270959. [Google Scholar] [CrossRef] [PubMed]
- Labadze, L.; Grigolia, M.; Machaidze, L. Role of AI Chatbots in Education: Systematic Literature Review. Int. J. Educ. Technol. High. Educ. 2023, 20, 56. [Google Scholar] [CrossRef]
- Vaishya, R.; Misra, A.; Vaish, A. ChatGPT: Is This Version Good for Healthcare and Research? Diabetes Metab. Syndr. Clin. Res. Rev. 2023, 17, 102744. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Fergus, S.; Botha, M.; Ostovar, M. Evaluating Academic Answers Generated Using ChatGPT. J. Chem. Educ. 2023, 100, 1672–1675. [Google Scholar] [CrossRef]
- Eggmann, F.; Weiger, R.; Zitzmann, N.U.; Blatz, M.B. Implications of Large Language Models such as ChatGPT for Dental Medicine. J. Esthet. Restor. Dent. 2023, 35, 1098–1102. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Li, H.; Moon, J.T.; Purkayastha, S.; Celi, L.A.; Trivedi, H.; Gichoya, J.W. Ethics of Large Language Models in Medicine and Medical Research. Lancet Digit. Health 2023, 5, e333–e335. [Google Scholar] [CrossRef] [PubMed]
- Dipalma, G.; Inchingolo, A.D.; Inchingolo, A.M.; Piras, F.; Carpentiere, V.; Garofoli, G.; Azzollini, D.; Campanelli, M.; Paduanelli, G.; Palermo, A.; et al. Artificial Intelligence and Its Clinical Applications in Orthodontics: A Systematic Review. Diagnostics 2023, 13, 3677. [Google Scholar] [CrossRef]
- Beam, A.L.; Drazen, J.M.; Kohane, I.S.; Leong, T.-Y.; Manrai, A.K.; Rubin, E.J. Artificial Intelligence in Medicine. N. Engl. J. Med. 2023, 388, 1220–1221. [Google Scholar] [CrossRef] [PubMed]
- Abd-alrazaq, A.; AlSaad, R.; Alhuwail, D.; Ahmed, A.; Healy, P.M.; Latifi, S.; Aziz, S.; Damseh, R.; Alrazak, S.A.; Sheikh, J. Large Language Models in Medical Education: Opportunities, Challenges, and Future Directions. JMIR Med. Educ. 2023, 9, e48291. [Google Scholar] [CrossRef]
- Acar, A.H. Can Natural Language Processing Serve as a Consultant in Oral Surgery? J. Stomatol. Oral Maxillofac. Surg. 2024, 125, 101724. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Zhuang, Y.; Zhu, Y.; Iwinski, H.; Wattenbarger, M.; Wang, M.D. Retrieval-Augmented Large Language Models for Adolescent Idiopathic Scoliosis Patients in Shared Decision-Making. Available online: https://openreview.net/forum?id=Of21JJE4Kk (accessed on 24 September 2024).
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. Br. Med. J. 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Wolff, R.F.; Moons, K.G.M.; Riley, R.D.; Whiting, P.F.; Westwood, M.; Collins, G.S.; Reitsma, J.B.; Kleijnen, J.; Mallett, S. PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies. Ann. Intern. Med. 2019, 170, 51. [Google Scholar] [CrossRef] [PubMed]
- Alkhamees, A. Evaluation of Artificial Intelligence as a Search Tool for Patients: Can ChatGPT-4 Provide Accurate Evidence-Based Orthodontic-Related Information? Cureus 2024, 16, e65820. [Google Scholar] [CrossRef] [PubMed]
- Hatia, A.; Doldo, T.; Parrini, S.; Chisci, E.; Cipriani, L.; Montagna, L.; Lagana, G.; Guenza, G.; Agosta, E.; Vinjolli, F.; et al. Accuracy and Completeness of ChatGPT-Generated Information on Interceptive Orthodontics: A Multicenter Collaborative Study. J. Clin. Med. 2024, 13, 735. [Google Scholar] [CrossRef] [PubMed]
- Daraqel, B.; Wafaie, K.; Mohammed, H.; Cao, L.; Mheissen, S.; Liu, Y.; Zheng, L. The Performance of Artificial Intelligence Models in Generating Responses to General Orthodontic Questions: ChatGPT vs. Google Bard. Am. J. Orthod. Dentofac. Orthop. 2024, 165, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Vassis, S.; Powell, H.; Petersen, E.; Barkmann, A.; Noeldeke, B.; Kristensen, K.D.; Stoustrup, P. Large-Language Models in Orthodontics: Assessing Reliability and Validity of ChatGPT in Pretreatment Patient Education. Cureus 2024, 16, e68085. [Google Scholar] [CrossRef]
- Kılınç, D.D.; Mansız, D. Examination of the Reliability and Readability of Chatbot Generative Pretrained Transformer’s (ChatGPT) Responses to Questions about Orthodontics and the Evolution of These Responses in an Updated Version. Am. J. Orthod. Dentofac. Orthop. 2024, 165, 546–555. [Google Scholar] [CrossRef] [PubMed]
- Makrygiannakis, M.A.; Giannakopoulos, K.; Kaklamanos, E.G. Evidence-Based Potential of Generative Artificial Intelligence Large Language Models in Orthodontics: A Comparative Study of ChatGPT, Google Bard, and Microsoft Bing. Eur. J. Orthod. 2024, cjae017. [Google Scholar] [CrossRef]
- Dursun, D.; Geçer, R.B. Can Artificial Intelligence Models Serve as Patient Information Consultants in Orthodontics? BMC Med. Inform. Decis. Mak. 2024, 24, 211. [Google Scholar] [CrossRef] [PubMed]
- Kurt Demirsoy, K.; Buyuk, S.K.; Bicer, T. How Reliable Is the Artificial Intelligence Product Large Language Model ChatGPT in Orthodontics? Angle Orthod. 2024, 94, 602–607. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, O.M.; Gasparello, G.G.; Hartmann, G.C.; Casagrande, F.A.; Pithon, M.M. Assessing the Reliability of ChatGPT: A Content Analysis of Self-Generated and Self-Answered Questions on Clear Aligners, TADs and Digital Imaging. Dent. Press J. Orthod. 2024, 28, e2323183. [Google Scholar] [CrossRef] [PubMed]
- Naureen, S.; Kiani, H.G. Assessing the Accuracy of AI Models in Orthodontic Knowledge: A Comparative Study between ChatGPT-4 and Google Bard. J. Coll. Physicians Surg. Pak. 2024, 34, 761–766. [Google Scholar] [CrossRef]
- Rahaman, M.S.; Ahsan, M.M.T.; Anjum, N.; Rahman, M.M.; Rahman, M.N. The AI Race Is On! Google’s Bard and Openai’s Chatgpt Head to Head: An Opinion Article. SSRN Electron. J. 2023. [Google Scholar] [CrossRef]
- Cascella, M.; Semeraro, F.; Montomoli, J.; Bellini, V.; Piazza, O.; Bignami, E. The Breakthrough of Large Language Models Release for Medical Applications: 1-Year Timeline and Perspectives. J. Med. Syst. 2024, 48, 22. [Google Scholar] [CrossRef] [PubMed]
- Charnock, D.; Shepperd, S.; Needham, G.; Gann, R. DISCERN: An Instrument for Judging the Quality of Written Consumer Health Information on Treatment Choices. J. Epidemiol. Community Health 1999, 53, 105–111. [Google Scholar] [CrossRef]
- Meade, M.; Dreyer, C. Web-Based Information on Orthodontic Clear Aligners: A Qualitative and Readability Assessment. Aust. Dent. J. 2020, 65, 225–232. [Google Scholar] [CrossRef]
- Patel, A.; Cobourne, M.T. The Design and Content of Orthodontic Practise Websites in the UK Is Suboptimal and Does Not Correlate with Search Ranking. Eur. J. Orthod. 2014, 37, 447–452. [Google Scholar] [CrossRef]
- Seehra, J.; Cockerham, L.; Pandis, N. A Quality Assessment of Orthodontic Patient Information Leaflets. Prog. Orthod. 2016, 17, 15. [Google Scholar] [CrossRef] [PubMed]
- Zainab, A.; Sakkour, R.; Handu, K.; Mughal, S.; Menon, V.; Shabbir, D.; Mehmood, A. Measuring the Quality of YouTube Videos on Anxiety: A Study Using the Global Quality Scale and Discern Tool. Int. J. Community Med. Public Health 2023, 10, 4492–4496. [Google Scholar] [CrossRef]
- Livas, C.; Delli, K.; Ren, Y. Quality Evaluation of the Available Internet Information Regarding Pain during Orthodontic Treatment. Angle Orthod. 2012, 83, 500–506. [Google Scholar] [CrossRef]
- Weil, A.G.; Bojanowski, M.W.; Jamart, J.; Gustin, T.; Lévêque, M. Evaluation of the Quality of Information on the Internet Available to Patients Undergoing Cervical Spine Surgery. World Neurosurg. 2014, 82, e31–e39. [Google Scholar] [CrossRef] [PubMed]
- Dourado, G.B.; Volpato, G.H.; de Almeida-Pedrin, R.R.; Pedron Oltramari, P.V.; Freire Fernandes, T.M.; de Castro Ferreira Conti, A.C. Likert Scale vs Visual Analog Scale for Assessing Facial Pleasantness. Am. J. Orthod. Dentofac. Orthop. 2021, 160, 844–852. [Google Scholar] [CrossRef] [PubMed]
- Kincaid, J.; Fishburne, R.; Rogers, R.; Chissom, B. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel. Available online: https://stars.library.ucf.edu/istlibrary/56 (accessed on 22 November 2024).
- Phan, A.; Jubril, A.; Menga, E.; Mesfin, A. Readability of the Most Commonly Accessed Online Patient Education Materials Pertaining to Surgical Treatments of the Spine. World Neurosurg. 2021, 152, e583–e588. [Google Scholar] [CrossRef] [PubMed]
- Khanagar, S.B.; Albalawi, F.; Alshehri, A.; Awawdeh, M.; Iyer, K.; Alsomaie, B.; Aldhebaib, A.; Singh, O.G.; Alfadley, A. Performance of Artificial Intelligence Models Designed for Automated Estimation of Age Using Dento-Maxillofacial Radiographs—A Systematic Review. Diagnostics 2024, 14, 1079. [Google Scholar] [CrossRef]
- Khanagar, S.B.; Al-Ehaideb, A.; Vishwanathaiah, S.; Maganur, P.C.; Patil, S.; Naik, S.; Baeshen, H.A.; Sarode, S.S. Scope and Performance of Artificial Intelligence Technology in Orthodontic Diagnosis, Treatment Planning, and Clinical Decision-Making—A Systematic Review. J. Dent. Sci. 2021, 16, 482–492. [Google Scholar] [CrossRef] [PubMed]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in Medicine: An Overview of Its Applications, Advantages, Limitations, Future Prospects, and Ethical Considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Subramani, M.; Jaleel, I.; Krishna Mohan, S. Evaluating the Performance of ChatGPT in Medical Physiology University Examination of Phase I MBBS. Adv. Physiol. Educ. 2023, 47, 270–271. [Google Scholar] [CrossRef]
- Mello, M.M.; Guha, N. ChatGPT and Physicians’ Malpractice Risk. JAMA Health Forum 2023, 4, e231938. [Google Scholar] [CrossRef]
- Reis, F.; Lenz, C.; Gossen, M.; Volk, H.-D.; Drzeniek, N.M. Practical Applications of Large Language Models for Health Care Professionals and Scientists. JMIR Med. Inform. 2024, 12, e58478. [Google Scholar] [CrossRef]
- Harrer, S. Attention Is Not All You Need: The Complicated Case of Ethically Using Large Language Models in Healthcare and Medicine. eBioMedicine 2023, 90, 104512. [Google Scholar] [CrossRef] [PubMed]
- Lareyre, F.; Raffort, J. Ethical Concerns Regarding the Use of Large Language Models in Healthcare. EJVES Vasc. Forum 2024, 61, 1. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Research question | What is the performance of the most widely utilized AI-based LLMs in producing information pertinent to orthodontics? |
| Population | Patients or students seeking information related to orthodontics using LLMs |
| Intervention | Questions and prompts related to orthodontics |
| Comparison | Expert opinions, other AI-based LLMs |
| Outcome | Accuracy, sensitivity, specificity, precision |
| SI No. | Authors | Year of Publication | Study Design | Objective of the Study | No. of Samples Applied for Testing | Algorithm Architecture | Study Factor | Evaluation Methods | Comparison or Evaluvators | Evaluation Accuracy/Average Accuracy/Statistical Significance | Results (+) Effective, (−) Non Effective (N) Neutral | Study Outcomes | Authors Suggestions/Conclusions |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Alkhamees A [25] | 2024 | Observational study |
To evaluate the performance of ChatGPT-4 in terms of the accuracy, reliability, and quality of information generated on orthodontic topics (impacted canines, interceptive orthodontic treatment, and orthognathic surgery). | 60 most commonly asked questions | Deep Learning | ChatGPT version 4 | Likert Scale Ranking | Five experienced orthodontists |
The overall mean rating given by the experts across all questions and topics was 3.89 (SD = 0.386, n = 300 ratings), indicating that the quality was generally rated as good. The overall topic rating ranged from 3.61 to 4.04 on the five-point scale. The aggregate data showed clear rating patterns, as only 2.7% of all question–answer pairs were rated as very poor, while 68.7% were rated as good or very good. | Effective (+) | The AI system produced generally good quality information for all topics, where 68.7% were rated as good or very good | ChatGPT4 can provide generally good information on orthodontic topics |
| 2 | Hatia A et al. [26] | 2024 | Observational study | To evaluate the performance of ChatGPT-4 in terms of the accuracy and completeness in answering questions and solving clinical scenarios of interceptive orthodontics. | 21 clinical open-ended questions and 7 comprehensive clinical case scenarios | Deep Learning | ChatGPT version 4 | Accuracy using Likert scales in the range (1–6) and completeness using Likert scales in the range (1–3). | Ten specialized orthodontists | Accuracy for open-ended answers score 6 in 40.5% of cases, For completeness as score 3 in 50.5% of case. For clinical cases, the overall median score was 4.9/6 for accuracy and 2.5/3 for completeness. Accuracy of clinical case answers showed a score of 6 in 46% of cases and a score of 3 in 54.3% of cases for completeness. | Effective (+) | ChatGPT version 4 displayed a high level of accuracy and completeness and a great ability to solve difficult clinical cases, but the answers were not 100% accurate and complete. | ChatGPT displayed good accuracy and completeness; however, it is not yet sophisticated enough to replace the intellectual work of human beings. |
| 3 | Daraqel B et al. [27] | 2024 | Comparative study | To evaluate and compare the performance of ChatGPT-3.5 and Google Bard in terms of response accuracy, completeness, generation time, and response length when answering general orthodontic questions. | 100 questions in 10 orthodontic domains | Deep Learning | ChatGPT-3.5 and Google Bard | Accuracy for the responses was assessed with the information (AOI) index and response completeness was assessed using 10-point visual analog scale. | Five specialists as blinded and independent evaluators | The median accuracy score was 9 for ChatGPT and 8 for Google Bard. The median completeness score was similar in both models, with 8 for ChatGPT and 8 for Google Bard. The odds of accuracy and completeness were higher by 31% and 23% in ChatGPT than in Google Bard. Google Bard’s response generation time was significantly shorter than that of ChatGPT, by 10.4 s/question. | Effective (+) | Both ChatGPT and Google Bard generated responses that were rated with a high level of accuracy and completeness to the posed general orthodontic questions; however, acquiring answers was generally faster using the Google Bard model. | ChatGPT and Google Bard models have generated accurate and complete responses to orthodontic inquiries. |
| 4 | Vassis S et al. [28] | 2024 | Comparative study | To evaluate and compare the performance of ChatGPT-3.5 and ChatGPT-4 in terms of reliability and validity of informing patients about orthodontic side effects. | Self -formulated and Standardized prompts | Deep Learning | ChatGPT-3.5 and ChatGPT-4 GPT-3.5 |
Reliability and validity of informing was assessed using five-point Likert scale. | Two orthodontists, one postgraduate student |
The self-formulated prompts mentioned 6.7 different side effects for ChatGPT-3.5 (SD = 2.5) and 7.3 for ChatGPT-4 (SD = 3.3). The standardized prompts lead to a higher number of side effects mentioned, on average 7.8 for ChatGPT-3.5 (SD = 2.0) and 9.2 for ChatGPT-4 (SD = 2.6). The content validity of the GPT-4 answers was rated significantly higher than the GPT-3.5 answers (p < 0.001). | Effective (+) |
The patients perceived the GPT-generated information as more useful and more comprehensive. They experienced less nervousness when reading the AI-generated information. Nearly 80% of patients preferred the AI-generated information over the standard text. | Since the experts rated the AI-generated content generally as “neither deficient nor satisfactory, the information generated cannot replace a consultation at the orthodontic clinic. |
| 5 | Kılınc D. D et al. [29] | 2024 | Comparative study | To evaluate and compare the performance of ChatGPT-3.5 and ChatGPT-4 in terms of reliability and readability of responses to questions about orthodontics. | 34 questions about orthodontics [5 general questions and 29 treatment related questions]. | Deep Learning | ChatGPT-3.5 and ChatGPT-4 | Readability and reliability were assessed using the Flesch–Kincaid and DISCERN tests. | Two orthodontists | The mean DISCERN value for general questions was 2.96 ± 0.05, 3.04 ± 0.06, 2.38 ± 0.27, and 2.82 ± 0.31 for treatment-related questions; The mean Flesch–Kincaid Reading Ease Score for general questions was 29.28 ± 8.22, 25.12 ± 7.39, 47.67 ± 10.77, and 41.60 ± 9.54 for treatment-related questions; mean Flesch–Kincaid Grade Level for general questions was 14.52 ± 1.48, 14.04 ± 1.25, 11.90 ± 2.08, and 11.41 ± 1.88 for treatment-related questions. | Neutral | At the second evaluation, the reliability of the answers given increased Flesch Reading Ease Scores for questions decreased. | AI-generated answers in the second evaluation were definitely more satisfying and more comprehensive. However, the answers ChatGPT provided were not scientifically valid because none of the answers specified peer-reviewed references. |
| 6 | Makrygiannakis M.A. et al. [30] | 2024 | Comparative study | To evaluate and compare the performance of Google’s Bard and OpenAI’s ChatGPT-3.5 and ChatGPT-4 in terms of the clinical relevance of the responses to questions about orthodontics. | Ten questions about orthodontics | Deep Learning | Google’s Bard, OpenAI’s ChatGPT-3.5 and ChatGPT-4, and Microsoft’s Bing | Clinical relevance was assessed using a scale ranging from 0 to 10 points. | Two orthodontists | The LLM answers scoring the highest were those of Microsoft Bing Chat (average score = 7.1), followed by ChatGPT-4 (average score = 4.7), Google Bard (average score = 4.6), and finally ChatGPT-3.5 (average score 3.8). Microsoft Bing Chat statistically outperformed ChatGPT-3.5 (p-value = 0.017) and Google Bard (p-value = 0.029), as well, and ChatGPT-4 outperformed ChatGPT-3.5 (p-value = 0.011). | Effective (+) | All the LLMs displayed great potential in supporting evidence-based information in orthodontics. | Occasionally, the responses generated lacked comprehension, scientific accuracy, clarity, and relevance. Hence, these responses need to be considered with caution, as there is potential risk of making an incorrect decision. |
| 7 | Dursun D et al. [31] | 2024 | Comparative study | To evaluate and compare the performance of ChatGPT-3.5, ChatGPT-4, Gemini, and Copilo in terms of the accuracy, reliability, quality, and readability of responses generated for questions related to orthodontic clear aligners. | 20 questions extracted from Google search tool | Deep Learning | ChatGPT-3.5, ChatGPT-4, Gemini, and Copilot AI models. | Five-point Likert scale for accuracy, modified DISCERN scale for reliability, Global Quality Scale (GQS) for quality, and the Flesch Reading Ease Score (FRES) for readability | Comparison between the LLMs | ChatGPT-4 responses had the highest mean Likert score (4.5 ± 0.61), followed by Copilot (4.35 ± 0.81), ChatGPT-3.5 (4.15 ± 0.75), and Gemini (4.1 ± 0.72). The difference was significant (p > 0.05). Copilot had a significantly higher modified DISCERN and GQS score compared to both Gemini, ChatGPT-4, and ChatGPT-3.5 (p < 0.05). Gemini’s modified DISCERN and GQS score was statistically higher than ChatGPT-3.5 (p < 0.05). Gemini also had a significantly higher FRES compared to both ChatGPT-4, Copilot, and ChatGPT-3.5 (p < 0.05). The mean FRES for Gemini is 54.12 ± 10.27, indicating that Gemini’s responses are more readable than other chatbots. | Effective (+) | All chatbot models provided generally accurate, moderately reliable, and moderate to good quality answers to questions about the clear aligners. | In order to be fully effective, they need to be supplemented with more evidence-based information and improved readability. |
| 8 | Demirsoy K K et al. [32] | 2024 | Observational study | To evaluate the performance of ChatGPT in terms of accuracy, relevance and reliability of information. | Questions related to clear aligners (CA), lingual orthodontics (LO), esthetic braces (EB), and temporomandibular disorders (TMD) | Deep Learning | ChatGPT-4 | Assessment made by orthodontists, dental students, and individuals seeking orthodontic treatment. Global Quality Scale (GQS) and Quality Criteria for Consumer Health Information (DISCERN) scale. | Orthodontists, Senior dental students, Individuals seeking orthodontic treatment | The total mean DISCERN score for answers on CA for students was 51.7 ± 9.38, with 57.2 ± 10.73 for patients, and 47.4 6 4.78 for orthodontists (p < 0.001). GQS scores for LO among groups: students (3.53 ± 0.78), patients (4.40 ± 0.72), and orthodontists (3.63± 0.72) (p < 0.001). GQS scores for EB were > 3 in all three groups (students: 3.50 ± 0.78; patients: 4.17 ± 0.87; orthodontists: 3.50 ± 0.82). | Effective (+) | ChatGPT has significant potential in terms of usability for patient information and education in the field of orthodontics. | Even though ChatGPT demonstrates reasonable reliability in providing orthodontic information, ongoing refinement and customization is essential for optimizing its effectiveness in clinical practice. |
| 9 | Tanaka OM et al. [33] | 2024 | Observational study | To evaluate the performance of ChatGPT in terms of accuracy and quality information to answer questions on clear aligners, temporary anchorage devices, and digital imaging in orthodontics. | 45 questions | Deep Learning | ChatGPT-4.0 | Quality of information on 5-point Likert scale | Five orthodontists | The majority were considered as good 34 (15.1%) and very good 161 (71.6%). 11 (4.9%) were considered as very poor, 4 (1.8%) as poor, and 15 (6.7%) as acceptable. | Effective (+) | ChatGPT has proven effective in providing quality answers related to clear aligners, temporary anchorage devices, and digital imaging in orthodontics. | Before incorporating these AI models into the healthcare system, efforts must be directed towards enhancing their reliability. |
| 10 | Naureen S et al. [34] | 2024 | Comparative study | To evaluate and compare the performance of ChatGPT-4 and Google Bard in terms of knowledge accuracy in response to knowledge-based questions related to orthodontic diagnosis and treatment modalities. | 90 questions on mini implant-assisted rapid palatal expansion (MARPE), clear aligners (CA), and cone beam computed tomography (CBCT) | Deep Learning | ChatGPT-4 and Google Bard | Accuracy of the responses was assessed using a five-point Likert Scale Ranking | Two independent orthodontists | GPT-4 demonstrated superior performance, outperforming Google Bard significantly in the MARPE, CBCT, and CA categories, and achieved a higher mean score. A (p = 0.001) for MARPE and CBCT, while it was (p = 0.013) for CA. Overall, GPT-4 achieved a total score of 92.6%, surpassing Google Bard’s which was 72%. | Effective (+) | GPT-4 is more efficient than Google Bard in providing accurate and up-to-date information regarding recent trends in orthodontic treatment modalities. | It is crucial to recognize the intricate nature of AI capabilities and frequently assess their performance in specific fields. |
| Author, Year | Risk of Bias | Applicability | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1. Participants | 2. Predictors | 3. Outcome | 4. Analysis | 1. Participants | 2. Predictors | 3. Outcome | Risk of Bias | Applicability | |
| Alkhamees A et al. [25] 2024 | + | + | − | − | + | + | − | − | − |
| Hatia A et al. [26] 2024 | + | ? | + | − | + | ? | ? | − | ? |
| Daraquel B et al. [27] 2024 | + | + | + | + | + | + | ? | + | ? |
| Vassis et al. [28] 2024 | + | + | + | − | + | ? | ? | − | ? |
| Kilinc D.D et al. [29] 2024 | + | + | + | ? | + | + | + | ? | + |
| Makrygiannakis M.A et al. [30] 2024 | + | ? | + | ? | + | + | + | ? | + |
| Dursun D et al. [31] 2024 | + | − | + | − | + | ? | + | − | ? |
| Demirsoy et al. [32] 2024 | + | ? | + | ? | ? | ? | − | ? | − |
| Tanaka OM et al. [33] 2024 | + | ? | − | − | + | + | ? | − | ? |
| Naureen S et al. [34] 2024 | + | + | + | − | + | ? | + | − | ? |
 | |||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albalawi, F.; Khanagar, S.B.; Iyer, K.; Alhazmi, N.; Alayyash, A.; Alhazmi, A.S.; Awawdeh, M.; Singh, O.G. Evaluating the Performance of Artificial Intelligence-Based Large Language Models in Orthodontics—A Systematic Review and Meta-Analysis. Appl. Sci. 2025, 15, 893. https://doi.org/10.3390/app15020893
Albalawi F, Khanagar SB, Iyer K, Alhazmi N, Alayyash A, Alhazmi AS, Awawdeh M, Singh OG. Evaluating the Performance of Artificial Intelligence-Based Large Language Models in Orthodontics—A Systematic Review and Meta-Analysis. Applied Sciences. 2025; 15(2):893. https://doi.org/10.3390/app15020893
Chicago/Turabian StyleAlbalawi, Farraj, Sanjeev B. Khanagar, Kiran Iyer, Nora Alhazmi, Afnan Alayyash, Anwar S. Alhazmi, Mohammed Awawdeh, and Oinam Gokulchandra Singh. 2025. "Evaluating the Performance of Artificial Intelligence-Based Large Language Models in Orthodontics—A Systematic Review and Meta-Analysis" Applied Sciences 15, no. 2: 893. https://doi.org/10.3390/app15020893
APA StyleAlbalawi, F., Khanagar, S. B., Iyer, K., Alhazmi, N., Alayyash, A., Alhazmi, A. S., Awawdeh, M., & Singh, O. G. (2025). Evaluating the Performance of Artificial Intelligence-Based Large Language Models in Orthodontics—A Systematic Review and Meta-Analysis. Applied Sciences, 15(2), 893. https://doi.org/10.3390/app15020893