
Ensemble Learning-Based Weed Detection from a Duck’s Perspective Using an Aquatic Drone in Rice Paddies †



Abstract
1. Introduction
- Do not use chemically synthesized fertilizers or pesticides;
- Do not employ genetically modified technologies;
- Employ agricultural production methods that minimize the environmental impacts of agricultural activities to the maximum extent.
2. Related Works
2.1. Deep Learning-Based Image Recognition
2.1.1. Semantic Segmentation
2.1.2. Transfer Learning
2.1.3. Ensemble Learning
- Bagging (bootstrap aggregation): This method involves random division of a dataset and independent training of multiple models. The final prediction is obtained by averaging the model outputs.
- Boosting: Models are trained sequentially, with each new model focusing on correcting errors made by previous models.
- Stacking: This approach combines the outputs of multiple models by feeding them into a metamodel that learns how to integrate their predictions best.
2.2. Weed Segmentation
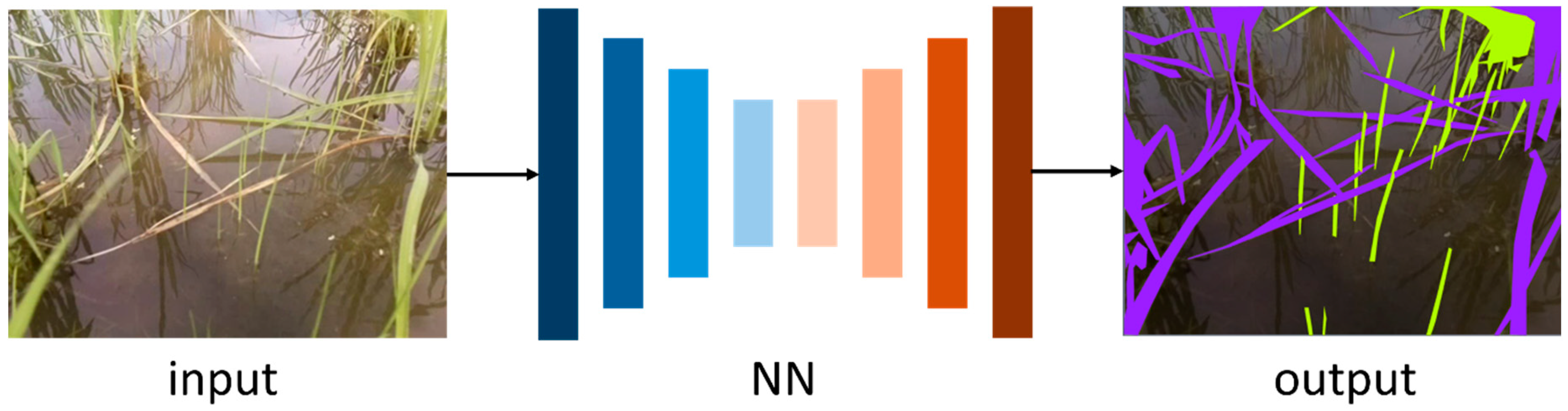
3. Method
3.1. Dataset
3.2. Neural Network
3.2.1. UNet++
3.2.2. DeepLabV3+
3.3. Training Method
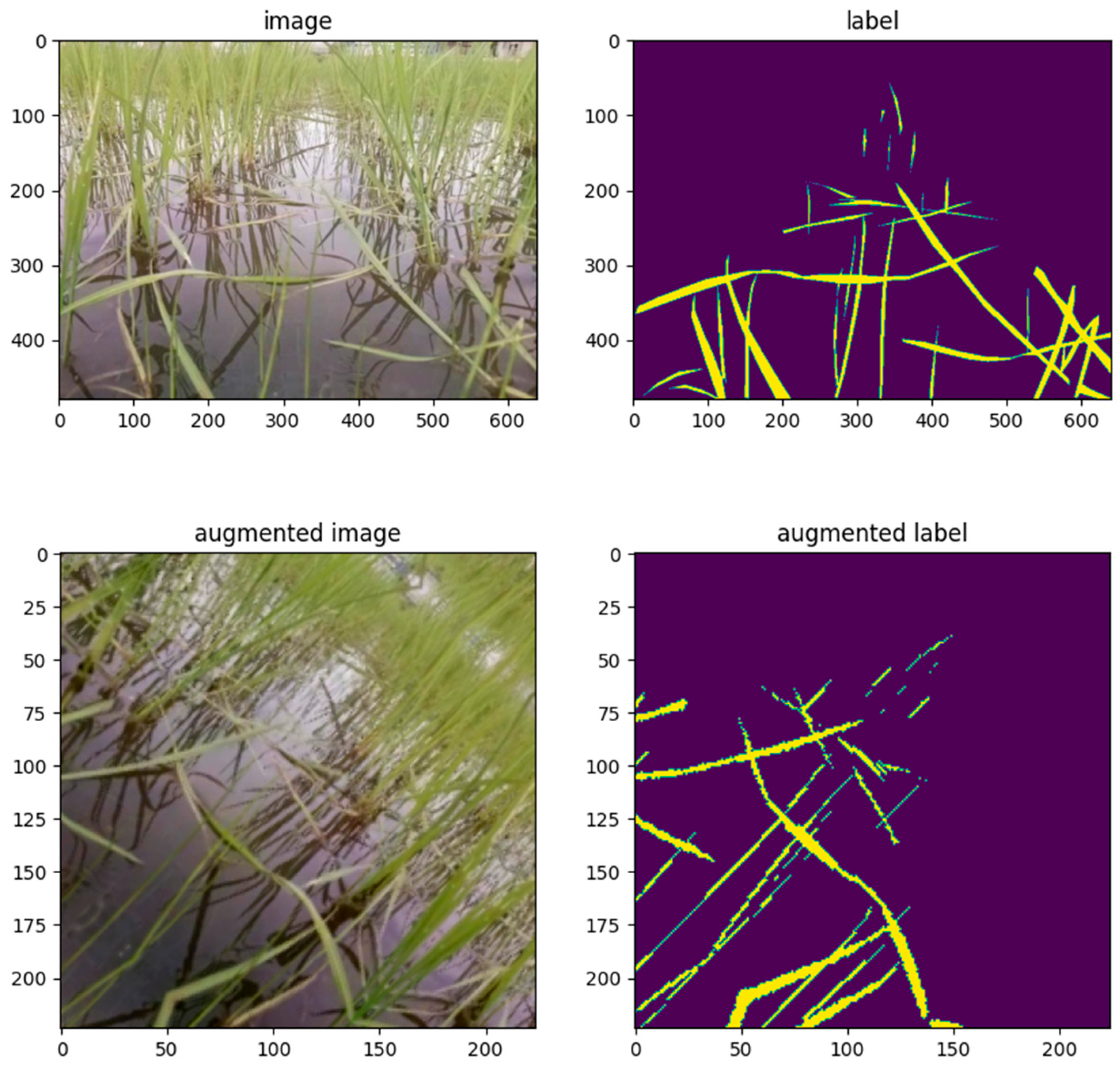
3.3.1. Data Augmentation
3.3.2. Loss Function
3.3.3. Optimizer
3.3.4. Early Stopping
3.4. Bagging
4. Experimentation
4.1. Making Dataset
4.1.1. Data Collection
4.1.2. Annotation
4.1.3. Data Splitting
4.2. Models
4.3. Training
4.3.1. Data Augmentation Used
4.3.2. Loss Function Used
4.4. Bagging
5. Evaluation
5.1. Metrics
- True Positive (TP): The number of pixels correctly predicted as weeds when the GT was also weeds.
- False Negative (FN): The number of pixels incorrectly predicted as the background when the GT was weeds.
- False Positive (FP): The number of pixels incorrectly predicted as weeds when the GT is the background.
- True Negative (TN): The number of pixels correctly predicted as background when the GT is also the background.
5.1.1. IoU
5.1.2. mIoU
5.1.3. Precision
5.1.4. Recall
5.1.5. Accuracy
5.2. Training Results
5.3. Comparison with Related Works
6. Conclusions
6.1. Conclusion
6.2. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ministry of Agriculture, Forestry and Fisheries (MAFF): Measures for Achievement of Decarbonization and Resilience with Innovation (MeaDRI). Available online: https://www.maff.go.jp/j/kanbo/kankyo/seisaku/midori/attach/pdf/index-10.pdf (accessed on 10 April 2025).
- Ministry of Agriculture, Forestry and Fisheries (MAFF): Survey of Organic Farmers on Their Awareness and Intentions Regarding Organic Farming and Other Initiatives. Available online: https://www.maff.go.jp/j/finding/mind/attach/pdf/index-75.pdf (accessed on 10 April 2025).
- Ministry of Agriculture, Forestry and Fisheries (MAFF): Current Status of Smart Agriculture. Available online: https://www.maff.go.jp/j/kanbo/smart/attach/pdf/index-165.pdf (accessed on 10 April 2025).
- Iseki Co., Ltd. NEWGREEN Inc: Aigamo Robot. Available online: https://aigamo.iseki.co.jp/ (accessed on 10 April 2025).
- Routrek Networks Co., Ltd. ZeRo.agri. Available online: https://www.routrek.co.jp/service/ (accessed on 11 April 2025).
- Kubota Corporation. DRH1200A-A. Available online: https://agriculture.kubota.co.jp/product/combineDRH-1200A-A/index.html (accessed on 11 April 2025).
- Nileworks Inc. Nile-JZ. Available online: https://www.nileworks.co.jp/product/nile-jz/ (accessed on 11 April 2025).
- Song, W.; He, H.; Dai, J.; Jia, G. Spatially adaptive interaction network for semantic segmentation of high-resolution remote sensing images. Sci. Rep. 2025, 15, 15337. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhu, Z.; Xu, R.; Feng, Y.; Xiao, L. Research on Image Classification and Semantic Segmentation Model Based on Convolutional Neural Network. J. Comput. Electron. Inf. Manag. 2024, 12, 94–100. [Google Scholar] [CrossRef]
- Stanford Vision Lab, Stanford University; Princeton University. IMAGE NET. Available online: https://image-net.org/index.php (accessed on 10 April 2025).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 10 April 2025).
- Sagi, O.; Rokach, L. Ensemble learning: A survey. WIREs Data Min. Knowl Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Rosle, R.; Che’Ya, N.N.; Ang, Y.; Rahmat, F.; Wayayok, A.; Berahim, Z.; Fazlil Ilahi, W.F.; Ismail, M.R.; Omar, M.H. Weed Detection in Rice Fields Using Remote Sensing Technique: A Review. Appl. Sci. 2021, 11, 10701. [Google Scholar] [CrossRef]
- Hasan, A.S.M.M.; Sohel, F.; Diepeveen, D.; Laga, H.; Jones, M.G.K. Weed Recognition using Deep Learning Techniques on Class-imbalanced Imagery. arXiv 2021, arXiv:2112.07819. [Google Scholar]
- Zou, K.; Chen, X.; Wang, Y.; Zhang, C.; Zhang, F. A modified U-Net with a specific data argumentation method for semantic segmentation of weed images in the field. Comput. Electron. Agric. 2021, 187, 106242. [Google Scholar] [CrossRef]
- Ma, X.; Deng, X.; Qi, L.; Jiang, Y.; Li, H.; Wang, Y.; Xing, X. Fully convolutional network for rice seedling and weed image segmentation at the seedling stage in paddy fields. PLoS ONE 2019, 14, e0215676. [Google Scholar] [CrossRef]
- Yang, Q.; Ye, Y.; Gu, L.; Wu, Y. MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field. Agriculture 2023, 13, 1176. [Google Scholar] [CrossRef]
- Asuka, S.; Machida, K.; Nakamura, T.; Shimizu, I.; Ookawa, T.; Nakajo, H. Weed Detection from the Duck’s Perspective Using Aqua-Drone in Rice Paddies. In Proceedings of the 2024 IEEE 13th Global Conference on Consumer Electronics (GCCE), Kitakyushu, Japan, 29 October–1 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 219–223. [Google Scholar]
- Yu, H.; Yang, Z.; Tan, L.; Wang, Y.; Sun, W.; Sun, M.; Tang, Y. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. arXiv 2018, arXiv:1807.10165. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2017, arXiv:1609.04747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, M.; Soltanolkotabi, M.; Oymak, S. Gradient Descent with Early Stopping is Provably Robust to Label Noise for Overparameterized Neural Networks. arXiv 2019, arXiv:1903.11680. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Dwyer, B.; Nelson, J.; Solawetz, J. Roboflow (Version 1.0). Available online: https://roboflow.com/ (accessed on 10 April 2025).
- Morales, J.; Saldivia, C.; Lobo, R.; Pino, M.D.; Muñoz, M.; Caniggia, G.; Catalán, J.; Hayde, R.; Poblete, V. Visual analysis of deep learning semantic segmentation applied to petrographic thin sections. Sci. Rep. 2025, 15, 14612. [Google Scholar] [CrossRef]
- Hertel, R.; Benlamri, R. A deep learning segmentation-classification pipeline for X-ray-based COVID-19 diagnosis. Biomed. Eng. Adv. 2002, 3, 1000041. [Google Scholar] [CrossRef]
- Kaushal, A.; Gupta, A.K.; Sehgal, V.K. A semantic segmentation framework with UNet-pyramid for landslide prediction using remote sensing data. Sci. Rep. 2024, 14, 30071. [Google Scholar] [CrossRef]
- Iakubovskii, P. Segmentation Models Pytorch. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 10 April 2025).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Use | Samples |
|---|---|
| Training | 160 |
| Validation | 20 |
| Test | 20 |
| Sum | 200 |
| Function |
|---|
| HorizontalFlip |
| ShiftScaleRotate |
| RandomBrightnessContrast |
| GT/Pred | Positive | Negative |
|---|---|---|
| Positive | TP (True Positive) | FN (False Negative) |
| Negative | FP (False Positive) | TN (True Negative) |
| Model | IoU | mIoU | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| Unet++_1 | 0.407 | 0.687 | 0.587 | 0.545 | 0.968 |
| Unet++_2 | 0.420 | 0.694 | 0.579 | 0.591 | 0.970 |
| Unet++_3 | 0.408 | 0.688 | 0.561 | 0.580 | 0.970 |
| Unet++_bagging | 0.441 | 0.706 | 0.618 | 0.581 | 0.971 |
| DeepLabV3+_1 | 0.268 | 0.613 | 0.425 | 0.427 | 0.960 |
| DeepLabV3+_2 | 0.285 | 0.622 | 0.442 | 0.441 | 0.960 |
| DeepLabV3+_3 | 0.285 | 0.621 | 0.453 | 0.429 | 0.959 |
| DeepLabV3+_bagging | 0.292 | 0.626 | 0.471 | 0.422 | 0.962 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asuka, S.; Nakamura, T.; Shimizu, I.; Ookawa, T.; Nakajo, H. Ensemble Learning-Based Weed Detection from a Duck’s Perspective Using an Aquatic Drone in Rice Paddies. Appl. Sci. 2025, 15, 7440. https://doi.org/10.3390/app15137440
Asuka S, Nakamura T, Shimizu I, Ookawa T, Nakajo H. Ensemble Learning-Based Weed Detection from a Duck’s Perspective Using an Aquatic Drone in Rice Paddies. Applied Sciences. 2025; 15(13):7440. https://doi.org/10.3390/app15137440
Chicago/Turabian StyleAsuka, Soma, Tetsuya Nakamura, Ikuko Shimizu, Taiichiro Ookawa, and Hironori Nakajo. 2025. "Ensemble Learning-Based Weed Detection from a Duck’s Perspective Using an Aquatic Drone in Rice Paddies" Applied Sciences 15, no. 13: 7440. https://doi.org/10.3390/app15137440
APA StyleAsuka, S., Nakamura, T., Shimizu, I., Ookawa, T., & Nakajo, H. (2025). Ensemble Learning-Based Weed Detection from a Duck’s Perspective Using an Aquatic Drone in Rice Paddies. Applied Sciences, 15(13), 7440. https://doi.org/10.3390/app15137440