
OMRoadNet: A Self-Training-Based UDA Framework for Open-Pit Mine Haul Road Extraction from VHR Imagery


 ,
,  ,
,  ,
,
Abstract
1. Introduction
2. Dataset and Methodology
2.1. Study Areas and Data Preparation
- 1.
- Source Domain: The DeepGlobe Road Extraction dataset [31], comprising 8000 satellite images (1024 × 1024 pixels, 0.5 m resolution) with pixel-level road masks. These images cover structured urban and rural roads in Thailand, Indonesia, and India, characterized by regular layouts, clear edges, and contextual features like adjacent vegetation.
- 2.
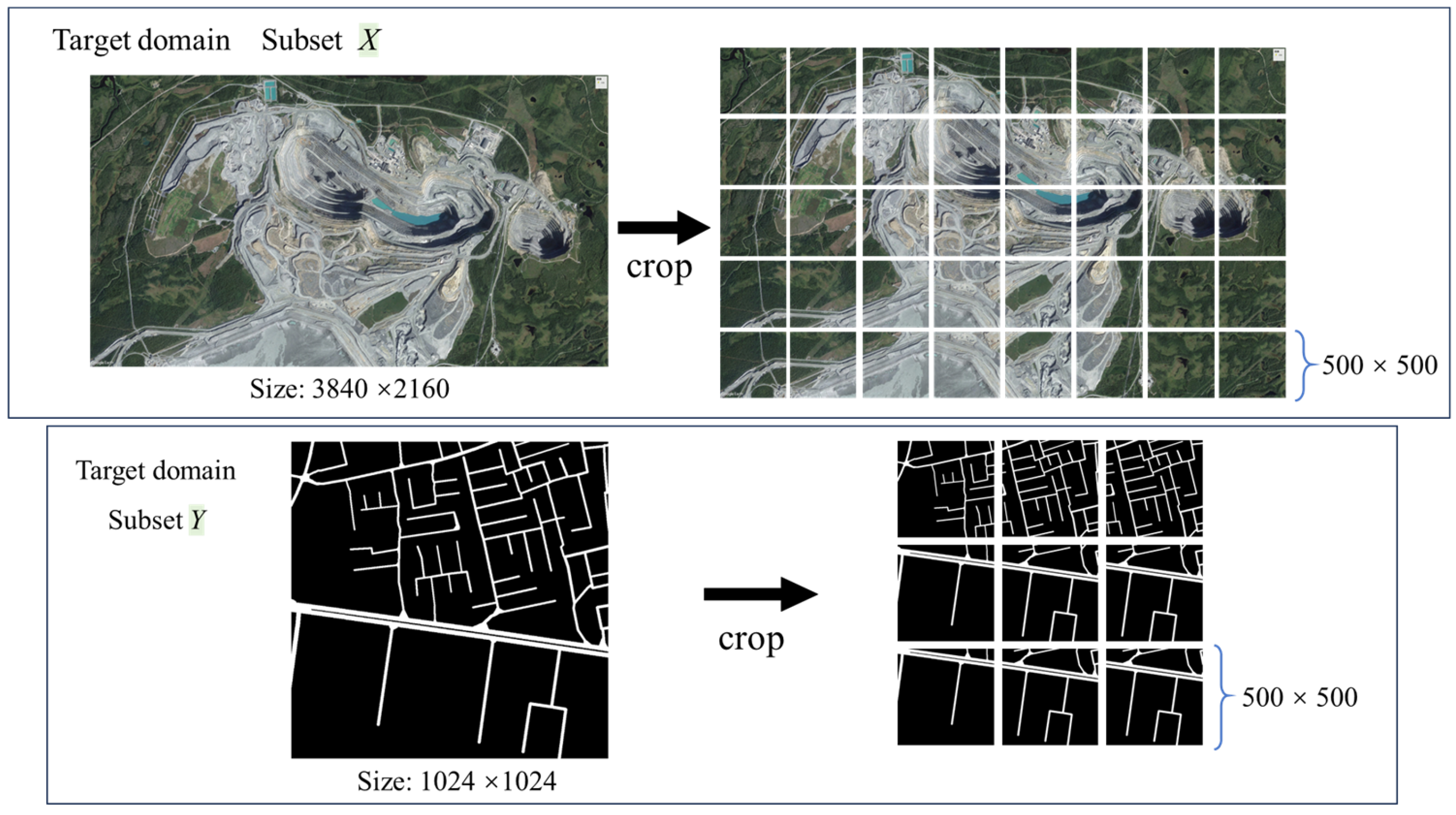
- Target Domain: Unlabeled VHR imagery of open-pit mines, divided into two subsets:
- (1)
- Subset X: 2700 high-resolution images (cropped to 500 × 500 pixels from the original 3840 × 2160 scenes) sourced from Google Earth, capturing diverse mining operations. The study area covers typical open-pit mining areas in multiple regions around the world, including coal mines, iron mines, and copper mines in Australia, South Africa, Chile, and other locations. These regions feature significant topographical variations and complex road structures, reflecting the diverse characteristics of open-pit mine roads under different climatic zones and geological conditions, combining both universality and challenges. Open-pit mine roads in remote sensing images usually show irregular structures, blurred boundaries, and complex spectral changes. Road characteristics are significantly affected by differences in mineral types and operational disturbances.
- (2)
- Subset Y: 2700 randomly selected road masks from DeepGlobe, resized to 500 × 500 pixels. These masks serve as initial pseudo-labels [32] but lack spatial correspondence to Subset X.
2.2. Methodology
2.2.1. Framework Overview
- (1)
- Cyclic GAN Architecture
- (2)
- Cross-Domain Adaptation Strategy
- (3)
- Self-Training Mechanism
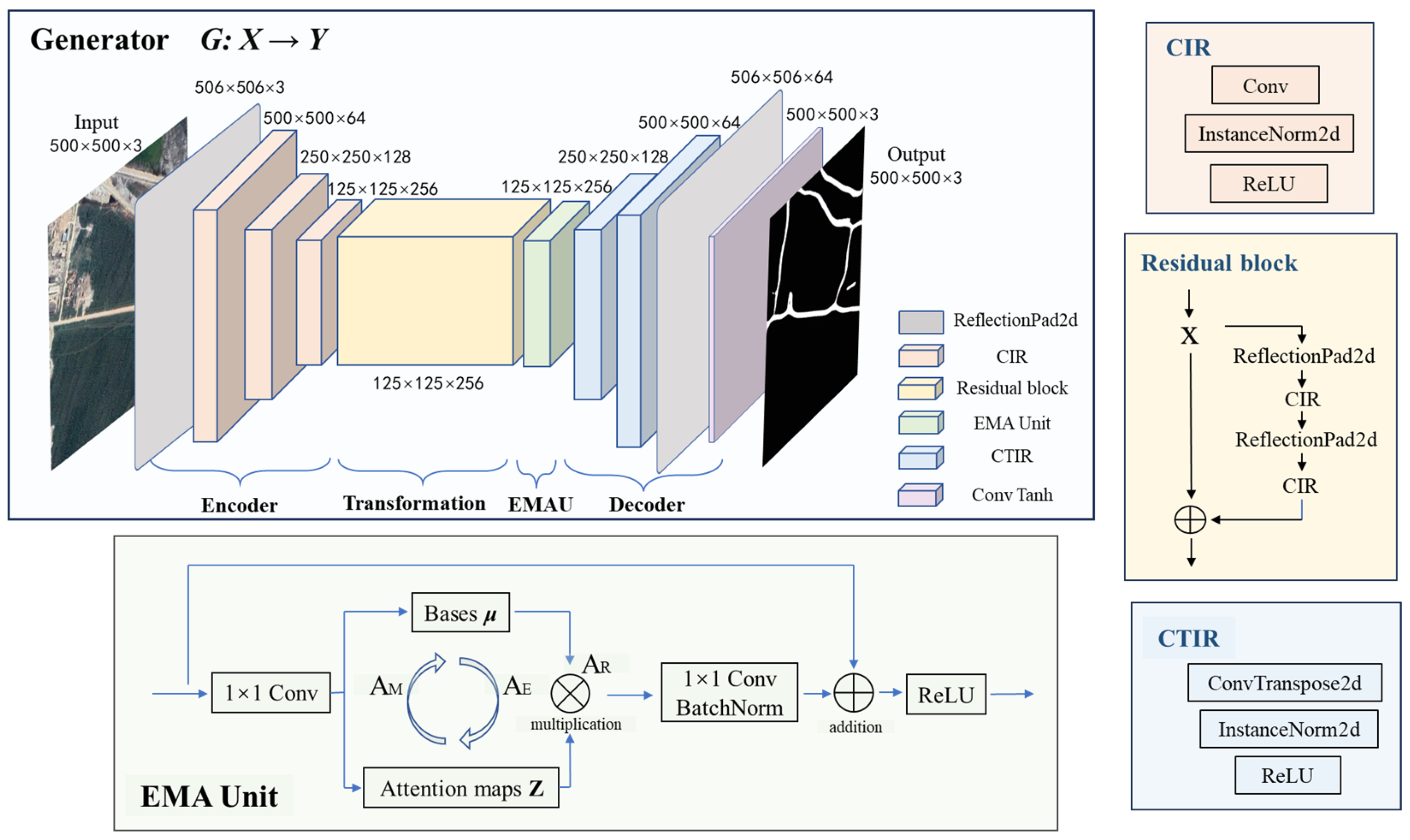
2.2.2. Component Design
- (1)
- Dual-Generator Architecture
- (2)
- PatchGAN Discriminator
2.2.3. Loss Formulation
- (1)
- Adversarial Learning Objective
- (2)
- Cycle-Consistency Constraint
- (3)
- Identity Preservation Mechanism
- (4)
- Multi-Objective Optimization
2.2.4. Implementation Pipeline
- (1)
- Data Preprocessing and Augmentation
- (2)
- Adversarial Training Protocol
- a.
- Generator Forward Pass: For a batch , compute and reconstruct .
- b.
- Discriminator Update: Evaluate and (for ), then optimize via gradient ascent on .
- c.
- Generator Backward Pass: Calculate cyclic gradients through and , propagating errors to update G and F.
- d.
- Domain Alignment: Apply gradient reversal layers (GRL) after every third epoch to enforce feature space alignment between X and Y.
- (3)
- Dynamic Pseudo-Label Refinement
- (4)
- Hardware Configuration
3. Results and Analysis
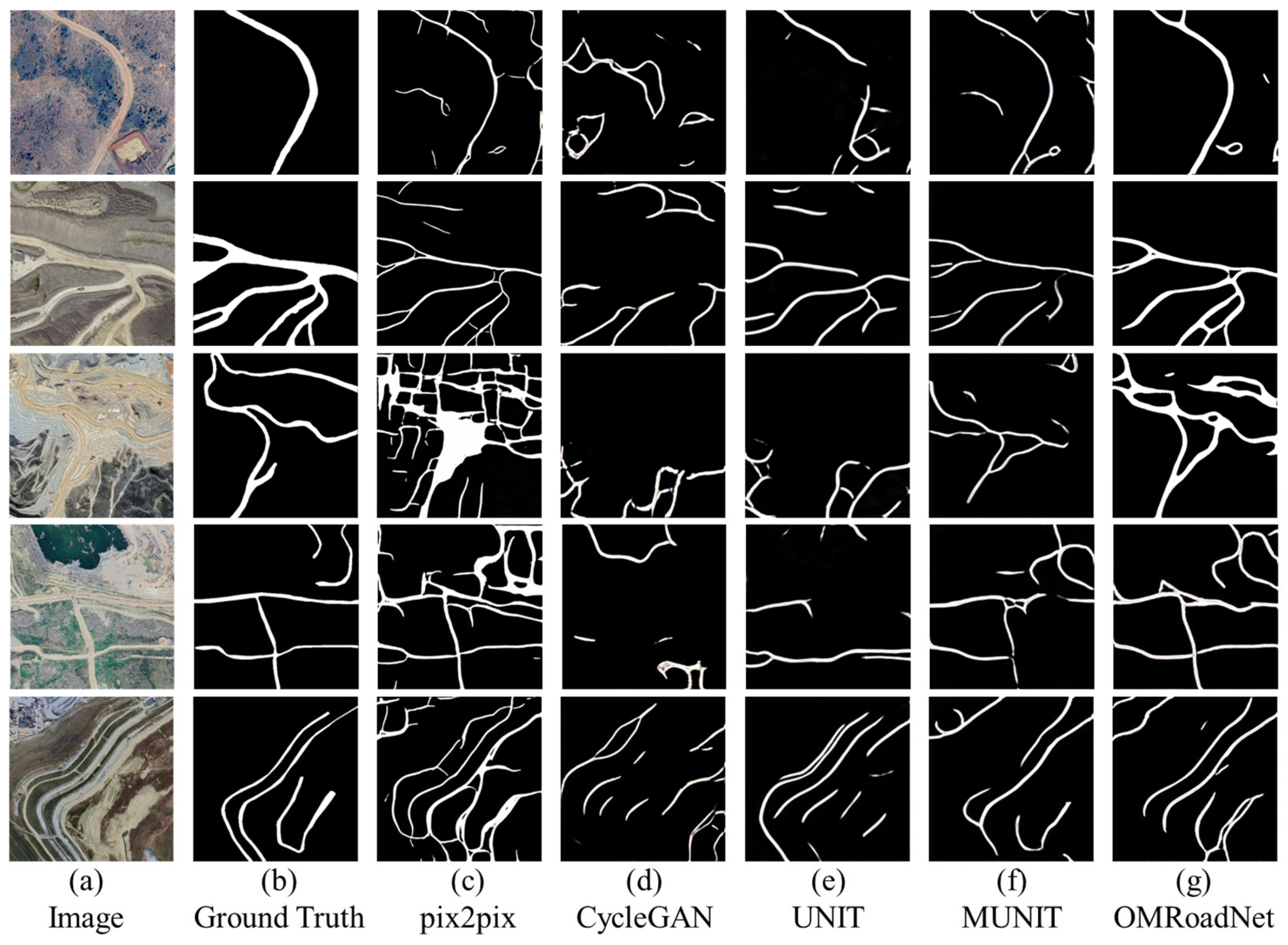
3.1. Cross-Domain Comparative Evaluation
3.2. Ablation Study on Framework Components
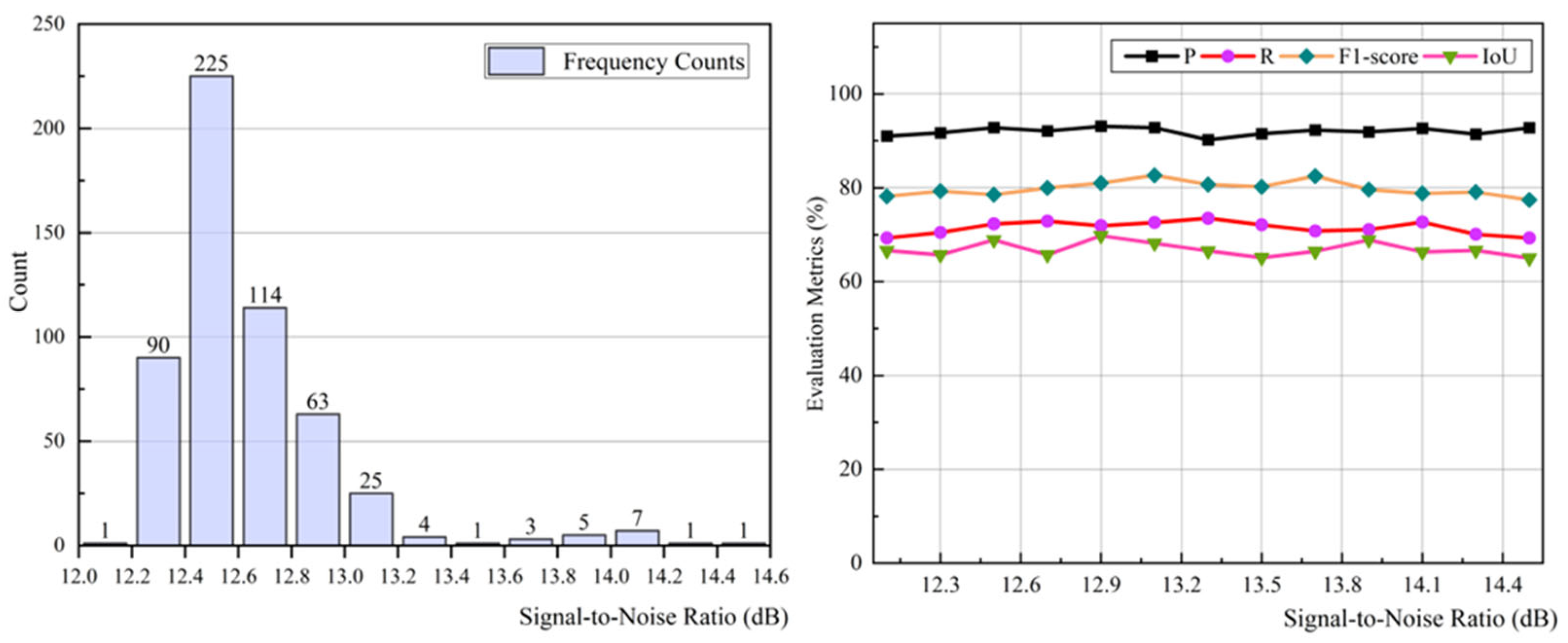
3.3. SNR-Based Robustness Verification
3.4. Operational Constraints Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, Q.; Zhu, Y.; Lu, H.; Shi, K.; Niu, Z. Improving University Faculty Evaluations via multi-view Knowledge Graph. Future Gener. Comput. Syst. 2021, 117, 181–192. [Google Scholar] [CrossRef]
- Liu, S.; Liu, L.; Kozan, E.; Corry, P.; Masoud, M.; Chung, S.; Li, X. Machine Learning for Open-Pit Mining: A Systematic Review. Int. J. Min. Reclam. Environ. 2025, 39, 1–39. [Google Scholar] [CrossRef]
- Teng, S.; Li, X.; Li, Y.; Li, L.; Xuanyuan, Z.; Ai, Y.; Chen, L. Scenario Engineering for Autonomous Transportation: A New Stage in Open-Pit Mines. IEEE Trans. Intell. Veh. 2024, 9, 4394–4404. [Google Scholar] [CrossRef]
- He, L.; Pan, R.; Wang, Y.; Gao, J.; Xu, T.; Zhang, N.; Wu, Y.; Zhang, X. A Case Study of Accident Analysis and Prevention for Coal Mining Transportation System Based on FTA-BN-PHA in the Context of Smart Mining Process. Mathematics 2024, 12, 1109. [Google Scholar] [CrossRef]
- Zhu, M.; Zhao, L.; Liu, L.; Wu, H.; Ruan, S.; Luo, Y.; Li, Y. Deamination Mechanism of Modified Magnesium Slag Using Wet Aging and Its Performance Evolution as Backfill Material. J. Environ. Manag. 2025, 375, 124219. [Google Scholar] [CrossRef]
- Wang, Z.; Luo, Z.; Zhu, Q.; Peng, S.; Ran, L.; Zhang, Y.; Wang, L.; Chen, Y.; Hu, Z.; Luo, J. A Road-Detail Preserving Framework for Urban Road Extraction From VHR Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5400913. [Google Scholar] [CrossRef]
- Wang, Q.; Ding, X.; Tong, X.; Atkinson, P.M. Spatio-Temporal Spectral Unmixing of Time-Series Images. Remote Sens. Environ. 2021, 259, 112407. [Google Scholar] [CrossRef]
- Hosseini, S.; Pourmirzaee, R. Green Policy for Managing Blasting Induced Dust Dispersion in Open-Pit Mines Using Probability-Based Deep Learning Algorithm. Expert Syst. Appl. 2024, 240, 122469. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, J.; Xiao, J. Bibliometric Analysis and Review of Mine Ventilation Literature Published Between 2010 and 2023. Heliyon 2024, 10, e26133. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, J.; Xue, Y.; Wen, L.; Shi, D. Optimization of Airflow Distribution in Mine Ventilation Networks Using the Modified Sooty Tern Optimization Algorithm. Min. Metall. Explor. 2024, 41, 239–257. [Google Scholar] [CrossRef]
- He, L.; Gao, J.; Leng, J.; Wu, Y.; Ding, K.; Ma, L.; Liu, J.; Pham, D.T. Disassembly Sequence Planning of Equipment Decommissioning for Industry 5.0: Prospects and Retrospects. Adv. Eng. Inform. 2024, 62, 102939. [Google Scholar] [CrossRef]
- Schroedl, S.; Wagstaff, K.; Rogers, S.; Langley, P.; Wilson, C. Mining GPS Traces for Map Refinement. Data Min. Knowl. Discov. 2004, 9, 59–87. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, Q.; Li, J.; Ai, M. Learning From GPS Trajectories of Floating Car for CNN-Based Urban Road Extraction With High-Resolution Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1836–1847. [Google Scholar] [CrossRef]
- Naicker, R.; Mutanga, O.; Peerbhay, K.; Odebiri, O. Estimating High-Density Aboveground Biomass Within a Complex Tropical Grassland Using Worldview-3 Imagery. Environ. Monit. Assess. 2024, 196, 370. [Google Scholar] [CrossRef]
- Gu, Q.; Xue, B.; Ruan, S.; Li, X. A Road Extraction Method for Intelligent Dispatching Based on MD-LinkNeSt Network in Open-Pit Mine. Int. J. Min. Reclam. Environ. 2021, 35, 656–669. [Google Scholar] [CrossRef]
- Yue, J.; Qin, K.; Shi, M.; Jiang, B.; Li, W.; Shi, L. Event-Trigger-Based Finite-Time Privacy-Preserving Formation Control for Multi-UAV System. Drones 2023, 7, 235. [Google Scholar] [CrossRef]
- ISO 21384-3; Unmanned Aircraft Systems—Part 3: Operational Procedures. ISO: Geneva, Switzerland, 2023.
- Tang, J.; Lu, X.; Ai, Y.; Tian, B.; Chen, L. Road Detection for autonomous truck in mine environment. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 839–845. [Google Scholar]
- Cao, X.; Yu, S.; Zheng, D.; Cui, H. Nail Planting to Enhance the Interface Bonding Strength in 3D Printed Concrete. Autom. Constr. 2022, 141, 104392. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-Scale and Multi-Task Deep Learning Framework for Automatic Road Extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Yuan, G.; Li, J.; Liu, X.; Yang, Z. Weakly Supervised Road Network Extraction for Remote Sensing Image Based Scribble Annotation and Adversarial Learning. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 7184–7199. [Google Scholar] [CrossRef]
- Song, J.; Li, J.; Chen, H.; Wu, J. MapGen-GAN: A Fast Translator for Remote Sensing Image to Map Via Unsupervised Adversarial Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2341–2357. [Google Scholar] [CrossRef]
- Wu, C.; Guo, Y.; Guo, H.; Yuan, J.; Ru, L.; Chen, H.; Du, B.; Zhang, L. An Investigation of Traffic Density Changes Inside Wuhan During the COVID-19 Epidemic with GF-2 Time-Series Images. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102503. [Google Scholar] [CrossRef] [PubMed]
- Xiao, D.; Yin, L.; Fu, Y. Open-Pit Mine Road Extraction From High-Resolution Remote Sensing Images Using RATT-UNet. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3002205. [Google Scholar] [CrossRef]
- He, Z.; Jia, M.; Wang, L. UACNet: A Universal Automatic Classification Network for Microseismic Signals Regardless of Waveform Size and Sampling Rate. Eng. Appl. Artif. Intell. 2023, 126, 107088. [Google Scholar] [CrossRef]
- He, Z.; Xu, X.; Rao, D.; Peng, P.; Wang, J.; Tian, S. PSSegNet: Segmenting the P- and S-Phases in Microseismic Signals through Deep Learning. Mathematics 2024, 12, 130. [Google Scholar] [CrossRef]
- Sharma, P.; Kumar, R.; Gupta, M.; Nayyar, A. A Critical Analysis of Road Network Extraction Using Remote Sensing Images with Deep Learning. Spat. Inf. Res. 2024, 32, 485–495. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Zhou, D.; Chen, Z. StripUnet: A Method for Dense Road Extraction from Remote Sensing Images. IEEE Trans. Intell. Veh. 2024, 1–13. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, W.; Jiskani, I.M.; Wang, Z. Extracting Unstructured Roads for Smart Open-Pit Mines Based on Computer Vision: Implications for Intelligent Mining. Expert Syst. Appl. 2024, 249, 123628. [Google Scholar] [CrossRef]
- Xie, Q.; Luong, M.-T.; Hovy, E.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar]
- Wang, J.; Ma, A.; Zhong, Y.; Zheng, Z.; Zhang, L. Cross-Sensor Domain Adaptation for High Spatial Resolution Urban Land-Cover Mapping: From Airborne to Spaceborne Imagery. Remote Sens. Environ. 2022, 277, 113058. [Google Scholar] [CrossRef]
- Dou, Q.; Ouyang, C.; Chen, C.; Chen, H.; Heng, P.-A. Unsupervised Cross-Modality Domain Adaptation of Convnets for Biomedical Image Segmentations with Adversarial Loss. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Stockholm, Sweden, 2018; pp. 691–697. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Hu, A.; Chen, S.; Wu, L.; Xie, Z.; Qiu, Q.; Xu, Y. WSGAN: An Improved Generative Adversarial Network for Remote Sensing Image Road Network Extraction by Weakly Supervised Processing. Remote Sens 2021, 13, 2506. [Google Scholar] [CrossRef]
- Ren, Z.; Wang, L.; He, Z. Open-Pit Mining Area Extraction from High-Resolution Remote Sensing Images Based on EMANet and FC-CRF. Remote Sens. 2023, 15, 3829. [Google Scholar] [CrossRef]
- Song, J.; Chen, H.; Du, C.; Li, J. Semi-MapGen: Translation of Remote Sensing Image Into Map via Semisupervised Adversarial Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4701219. [Google Scholar] [CrossRef]
- Chen, X.; Chen, S.; Xu, T.; Yin, B.; Peng, J.; Mei, X.; Li, H. SMAPGAN: Generative Adversarial Network-Based Semisupervised Styled Map Tile Generation Method. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4388–4406. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| pix2pix | 78.85 | 68.77 | 73.47 | 58.06 |
| CycleGAN | 81.63 | 68.79 | 74.66 | 59.57 |
| UNIT | 85.16 | 71.80 | 77.91 | 63.81 |
| MUNIT | 82.89 | 75.01 | 78.76 | 64.96 |
| OMRoadNet | 92.16 | 71.89 | 80.77 | 67.75 |
| Model | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| no-EMAU | 67.81 | 71.80 | 69.75 | 53.55 |
| no- | 87.83 | 65.55 | 75.08 | 60.10 |
| no-UDA | 90.43 | 59.31 | 71.64 | 55.81 |
| no-self-training | 87.11 | 62.43 | 72.74 | 57.15 |
| no-TTUR | 91.48 | 65.67 | 76.45 | 61.88 |
| OMRoadNet | 92.16 | 71.89 | 80.77 | 67.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Ren, Z.; Xu, X.; He, Z.; Lai, W.; Li, Z.; Shi, Y. OMRoadNet: A Self-Training-Based UDA Framework for Open-Pit Mine Haul Road Extraction from VHR Imagery. Appl. Sci. 2025, 15, 6823. https://doi.org/10.3390/app15126823
Tian S, Ren Z, Xu X, He Z, Lai W, Li Z, Shi Y. OMRoadNet: A Self-Training-Based UDA Framework for Open-Pit Mine Haul Road Extraction from VHR Imagery. Applied Sciences. 2025; 15(12):6823. https://doi.org/10.3390/app15126823
Chicago/Turabian StyleTian, Suchuan, Zili Ren, Xingliang Xu, Zhengxiang He, Wanan Lai, Zihan Li, and Yuhang Shi. 2025. "OMRoadNet: A Self-Training-Based UDA Framework for Open-Pit Mine Haul Road Extraction from VHR Imagery" Applied Sciences 15, no. 12: 6823. https://doi.org/10.3390/app15126823
APA StyleTian, S., Ren, Z., Xu, X., He, Z., Lai, W., Li, Z., & Shi, Y. (2025). OMRoadNet: A Self-Training-Based UDA Framework for Open-Pit Mine Haul Road Extraction from VHR Imagery. Applied Sciences, 15(12), 6823. https://doi.org/10.3390/app15126823