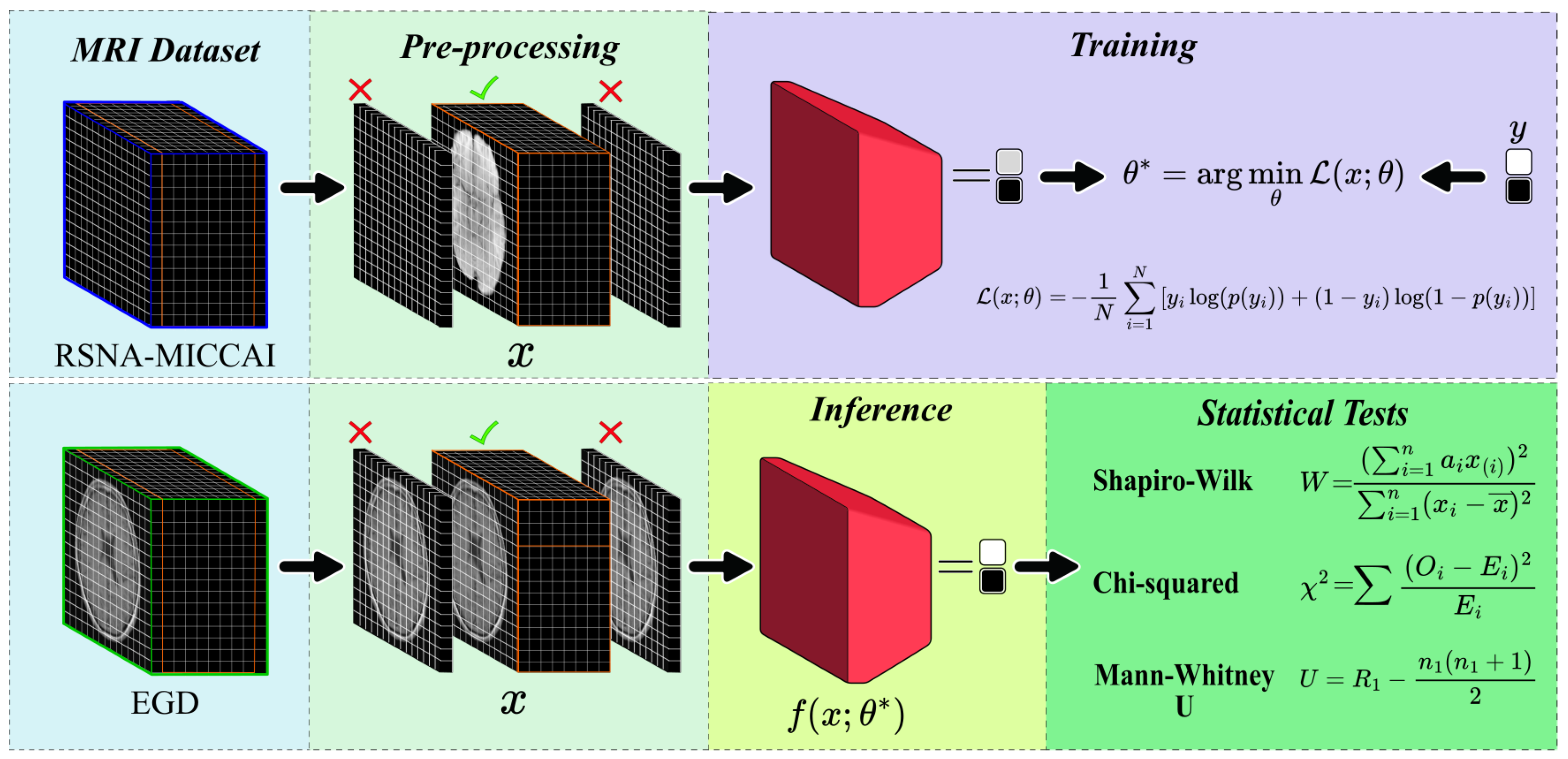
3.1. Training of the CNN Model for GBM Detection
In the RSNA-MICCAI data set, all patient MRI scans were analysed. It was determined that 27.7% did not contain useful diagnostic information, specifically completely black. Consequently, 72.3% of the remaining images, containing diagnostic-relevant information were retained for further analysis.
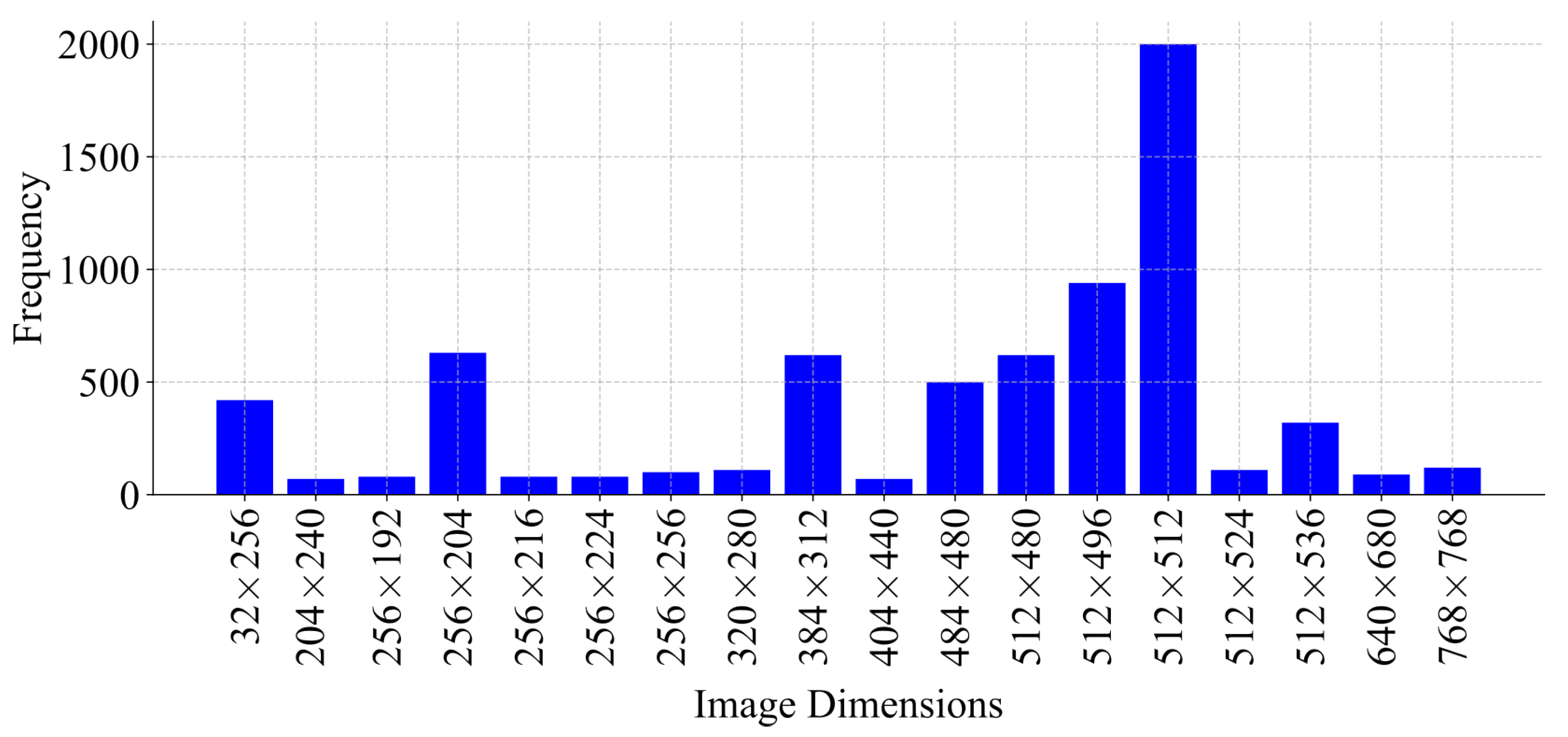
An analysis of the dimensions of these images was conducted, revealing variability not only across different patients but also within the same patients (
Figure 4). A resolution of 512 × 512 pixels was the most frequently observed, justifying its selection as the image standard dimension for preprocessing. Therefore, all images were resized to 512 × 512 pixels due to the predominant frequency in the data set. Images smaller than this resolution were padded, while larger images maintained uniformity.
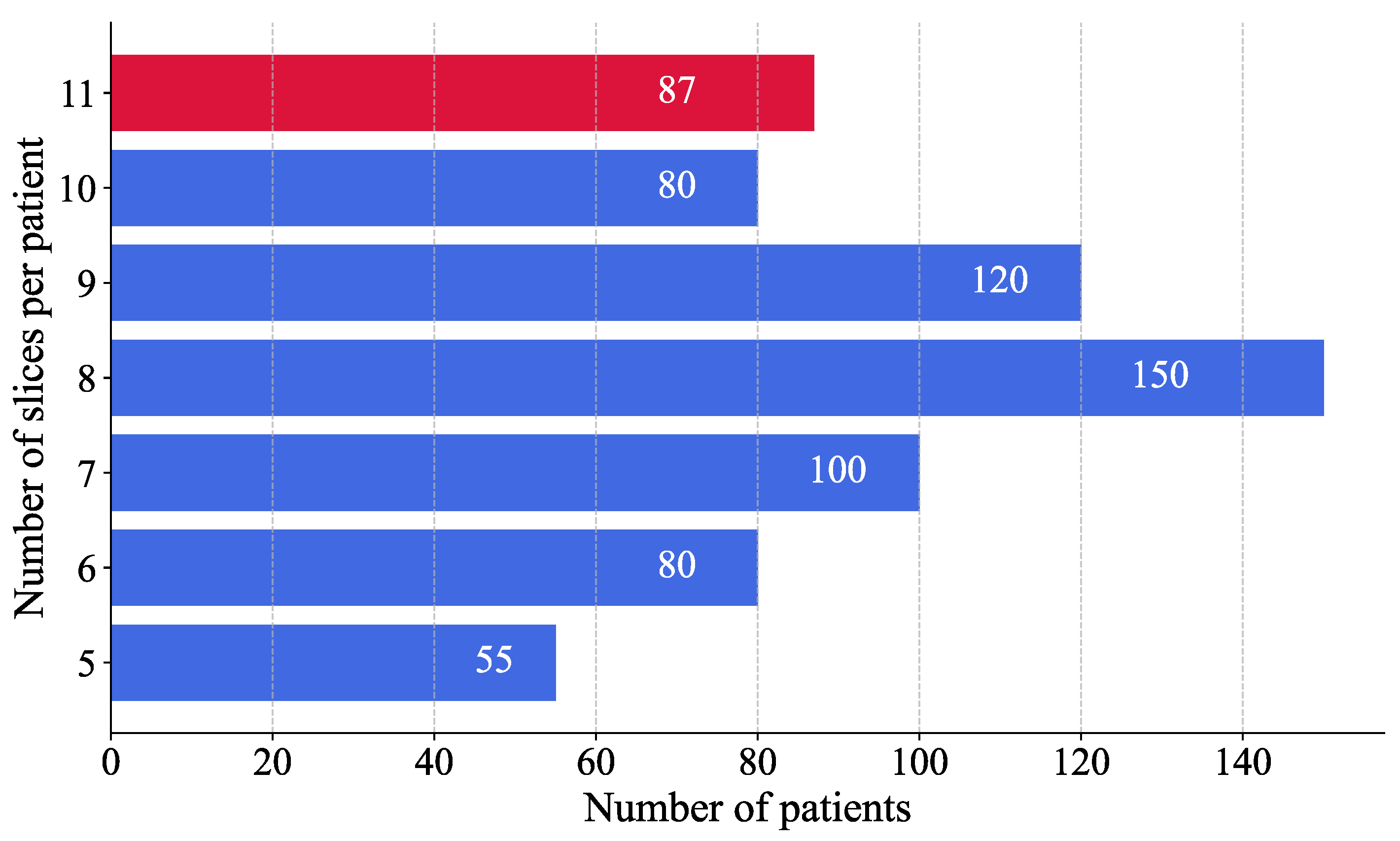
A histogram analysis was performed to assess the distribution of MRI images per patient (
Figure 5). The results showed that most patients had eight images. To ensure consistency across patient data and to avoid excluding individuals with fewer available MRI slices, the number of images per patient was standardised to eight, thereby maximising patient inclusion and minimising information loss. This selection, based on the modal value, facilitated the reconstruction of a volumetric representation of the brain from the most informative slices, approximated to a three-dimensional structure.
For patients with more than eight images, a binary mask was applied to each image to convert the values 0 to 255 into a binary scale, where pixels with a value greater than 1 were set to 1 and those with a value greater than 0 remained unchanged. This process identified images with the most significant informational content by measuring the area of non-zero pixels. Only the eight images with the highest information content were retained to ensure uniformity across the data set. In contrast, patients with less than eight images, the image containing the maximum diagnostic information was duplicated until eight images were reached, thereby preserving uniformity across the data set.
The impact of CNN depth on the performance of the GBM classification model was systematically analysed. A range of CNN configurations were evaluated, varying both the number of layers and the number of neurons per layer. Each value in the configuration sequence represents the number of neurons in the corresponding layer, illustrating the progressive increase in model complexity. The tested configurations ranged from simpler architectures with fewer layers and neurons {8, 16, 32} to more intricate structures, incorporating additional layers and higher neuron counts {8, 16, 32, 64, 128, 256}.
In order to select the optimal architecture, an incremental experiment was conducted, by progressively increasing the number of layers manner and evaluating their impact on the AUC-ROC metric. For each configuration, a different model was constructed using the Adam optimiser and a binary cross-entropy loss function for compilation. The models were evaluated through 5-fold cross-validation (
), wherein the data set was divided into five equal parts, with each subset serving once as the validation set while the remaining as the training sets [
39]. This approach ensured that each sample was used for both training and validation, improving robustness and generalisation. The training was performed with a learning rate of
, a batch size of 64, and a total of 200 training epochs. The model converged within 120 epochs, indicating stable performance across different depths.
A clear correlation between model performance and network architecture complexity was observed during the evaluation of CNN on the validation set. This complexity was mainly characterised by the number of convolutional layers. As shown in
Figure 6, the first experiment with a single-layer configuration {8} exhibited a baseline validation accuracy of approximately 32%. With the increasing depth of the architecture, the accuracy improved gradually to about 45% in architectures comprising more sophisticated configurations, such as {8, 32} and {8, 16, 32, 64}, which correspond to convolutional networks of three and four layers. The enhancement of accuracy was observed with the five-layer configuration {8, 16, 32, 64, 128}, which reached and stabilised at around 61% ± 0.3.
Models comprising fewer than five layers were found to lack the capacity to extract relevant features from MRI images, resulting in lower performance. Although deeper architectures, such as six-layer models, exhibited slightly higher performance, they introduced a greater standard deviation (0.038), indicating diminishing returns and potential overfitting.
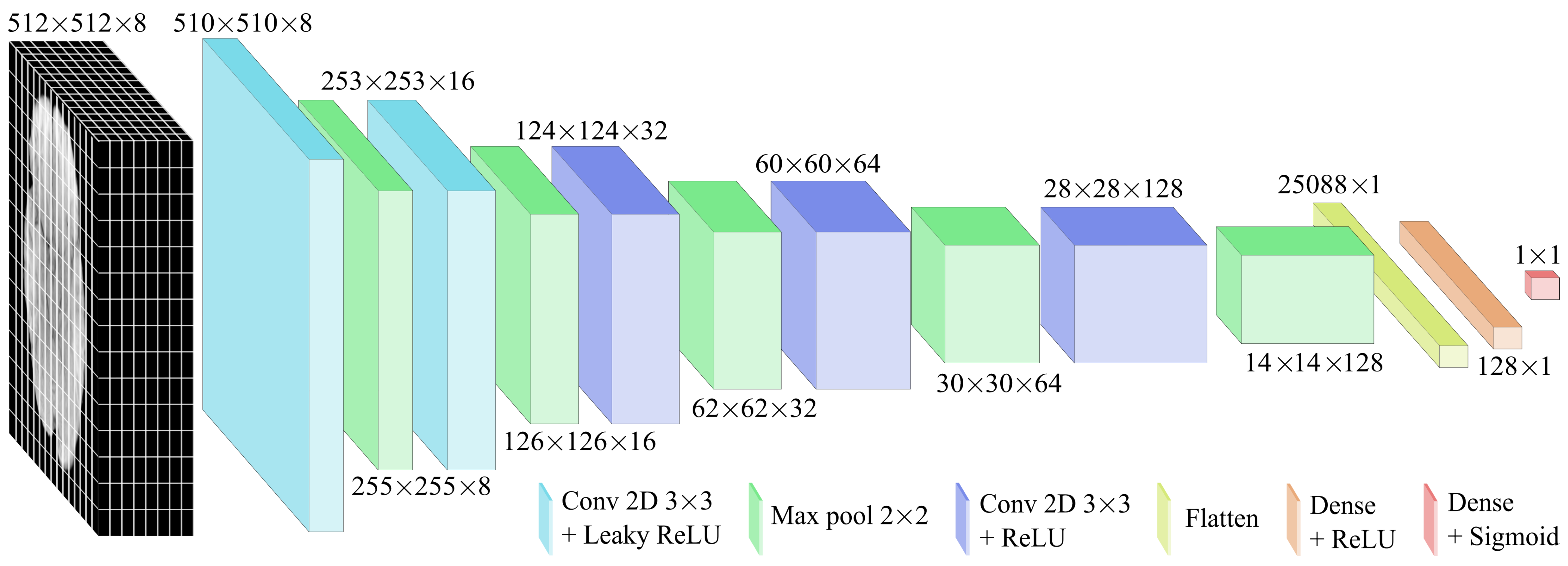
Based on these observations, the five-layer configuration was selected for final optimisation and evaluation. As shown in
Figure 7, this structure enabled the modelling of complex hierarchical patterns while maintaining stable training. Accordingly, two activation functions were applied based on their advantages. The Leaky ReLU function was used in the initial layers to mitigate the dead-neuron problem and improve the gradient flow for negative inputs, while ReLU was employed in deeper layers due to its computational efficiency and effectiveness in image processing. The specifications of the CNN model are detailed in
Table 3.
The Adam optimiser was selected for its adaptive learning rate properties, enabling efficient training and noise management. In order to determine the optimal configuration, a hyperparameter tuning process was performed by assessing several combinations of learning rates and batch sizes.
This exploration aimed to balance convergence behaviour and performance across evaluation metrics. As shown in
Table 4, a learning rate of
was selected after testing values between
and
. Higher rates led to oscillations, while lower rates slowed convergence. Furthermore, a batch size of 64 was determined as optimal among the tested values (32, 64, and 128), providing the best balance between speed and convergence stability. The model architecture consisted of 98.38 ×
trainable parameters, requiring approximately 384.3 kilobytes of memory, with 32-bit precision (4 bytes per parameter). This configuration enabled computational efficiency, facilitating rapid iterations during the development of the training pipeline.
Predictions were generated for the 87 patients in the hidden test set and submitted to the Kaggle platform, for model evaluation using the AUC-ROC metric. The model achieved a score of 0.63, surpassing all 1000 participating researchers and setting a new state of the art (
Table 5). The results are available in the “leaderboard” section of the Brain Tumor Radiogenomic Classification Challenge, conducted as part of the BraTS 2021 challenge, sponsored by the Radiological Society of North America and the Medical Image Computing and Computer Assisted Intervention Society. The reported scores are available in [
40].
3.2. Inference of the CNN Model on the EGD Data Set for Glioma Detection
The model was evaluated in the EGD data set, which contains clinical history data such as age and sex, to determine correlations with the model prediction.
Figure 8 summarises the model predictions in the Erasmus database, composed mainly of patients with glioma. Consequently, the bar graph represents only the
TP and
FP counts, while
TN and
FN values were absent due to the database inherent design.
The results showed that the model was generalizable across both age and sex groups, achieving an F1-score of 0.88 (
Table 6). However, in older patients, model predictions were more accurate, with an average accuracy of 57.29 years (±14.68) compared to 54.55 years (±14.22) of incorrect predictions (
Table 7). Furthermore, a sex-based comparison revealed a slightly higher correct prediction rate for men (79.39%) than women (77.70%) (
Table 8).
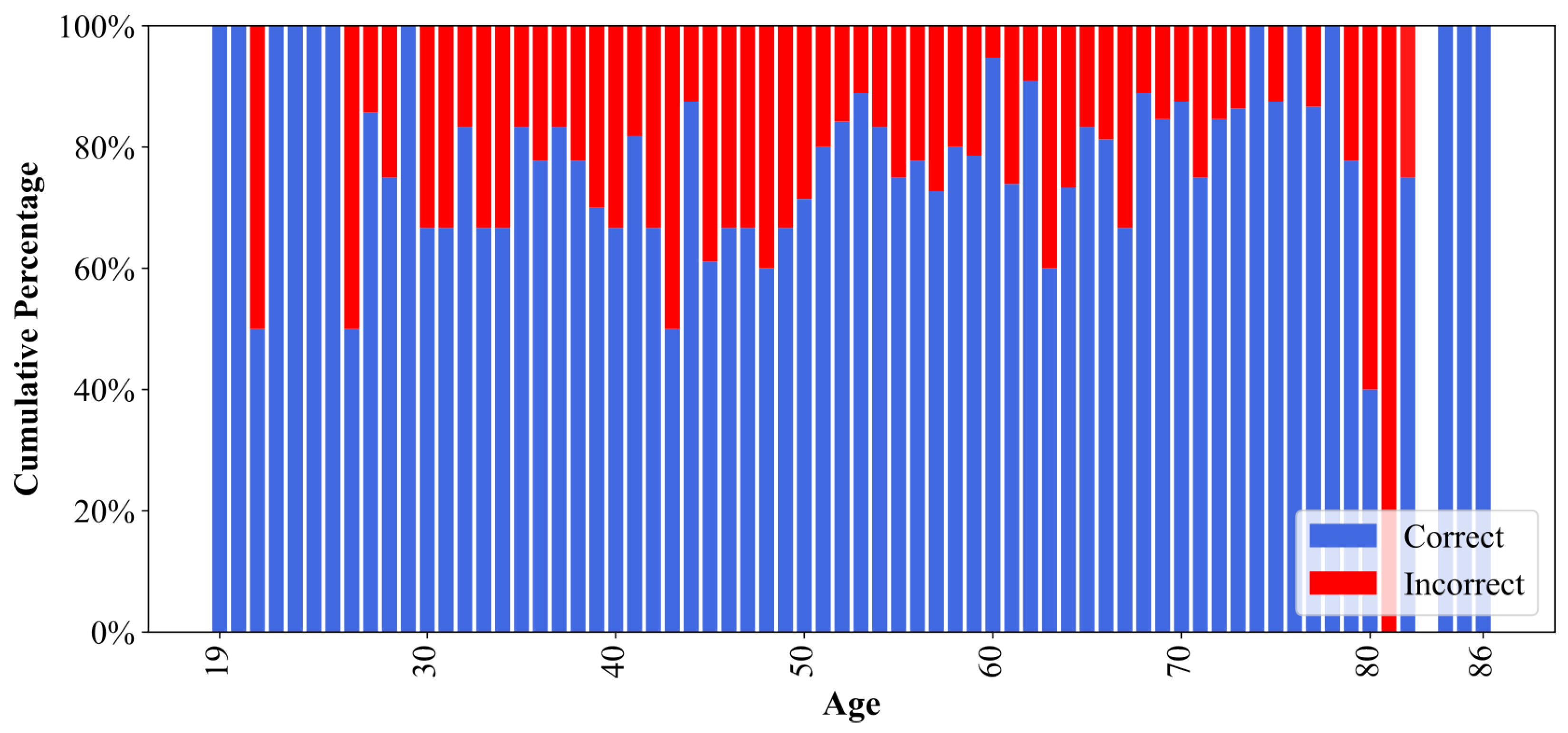
Although both groups exhibited comparable performance, the slight variations based on demographic factors suggested the possibility of subtle influences. As illustrated in
Figure 9, the model demonstrated suboptimal predictive accuracy for patients aged 80–81 years, with correct prediction rates falling below 50%. This led to an investigation into the potential bias in model predictions.
Statistical Analysis for Assessment of Demographic Bias
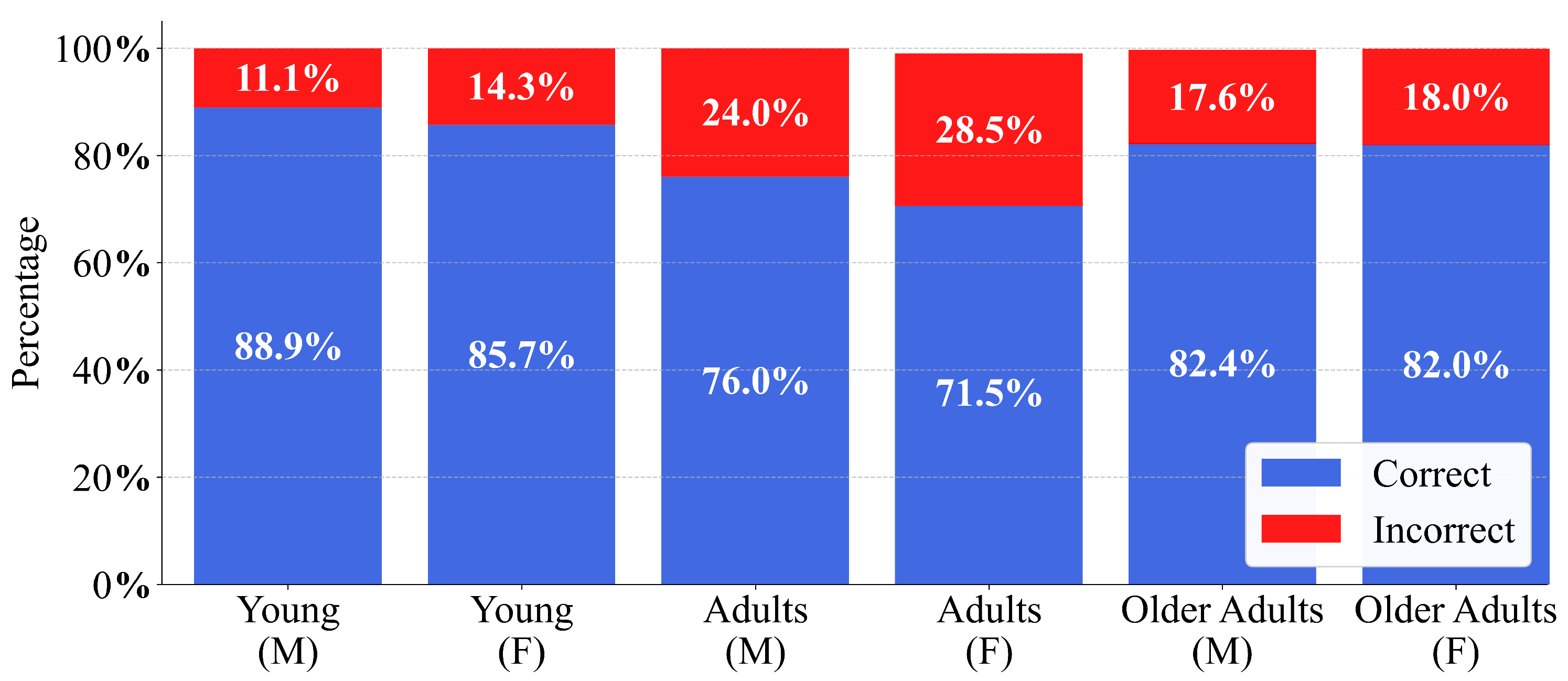
To analyse any significant variation in model performance, the patient cohort was stratified into three age groups: young (19–26 years), adults (27–59 years), and older adults (60–100 years) for both sexes, as proposed in [
41]. As illustrated in
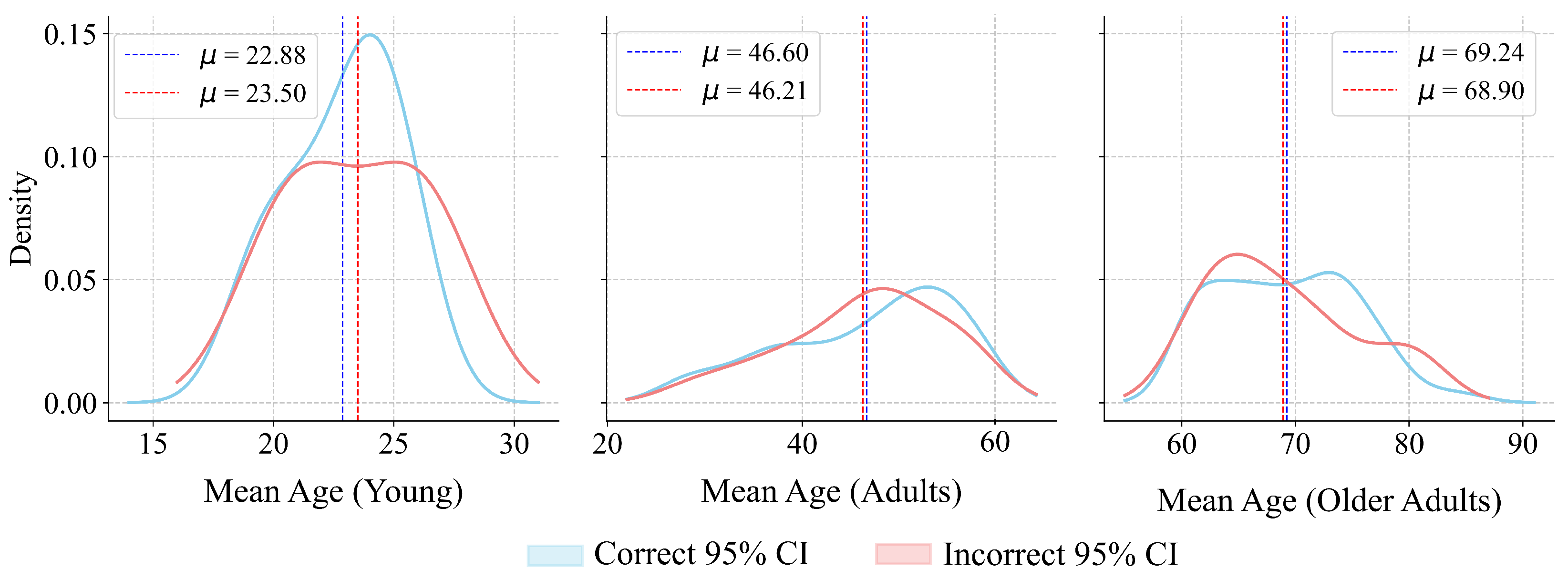
Figure 10, this age segmentation revealed a trend among age groups of both men and women, with the highest percentage of errors observed in adults, followed by older adults and then young patients, and slightly more pronounced in women. This led to the application of statistical tests to corroborate whether demographic factors, such as age and sex, exerted a significant influence on model performance and may have contributed to potential discrepancies in the predictions.
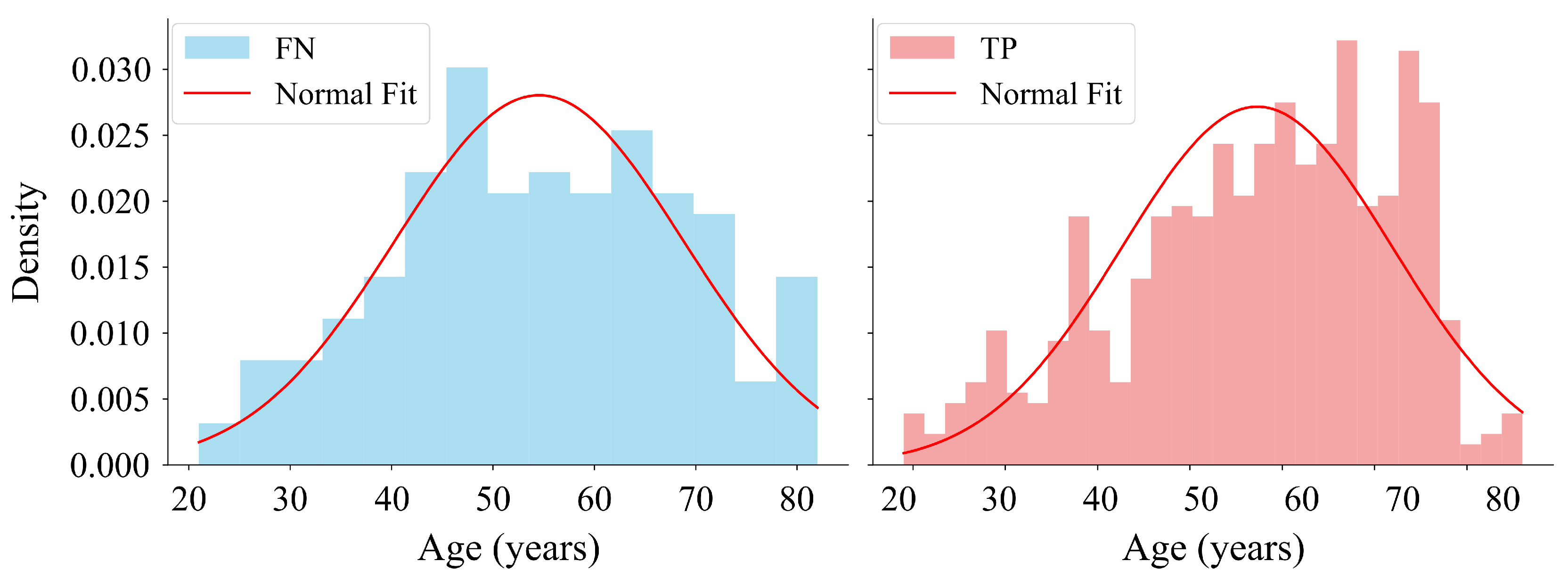
To assess the normal age distribution in the
FN and
TP groups (
Figure 8), the Shapiro–Wilk test was applied under the following hypotheses:
H0. The data follows a normal distribution.
H1. The data do not follows a normal distribution.
As outlined in
Table 9, the results of the Shapiro–Wilk test showed that the obtained
p-value for the
FN group followed a normal distribution. Conversely, the
TP group exhibited a
p-value lower than
, indicating a deviation from normality (
Figure 11). Regarding the confidence intervals, the slight overlap between the intervals
and
suggested that the difference between the two groups was not significant.
To evaluate differences in age distributions between prediction outcome groups within each cohort, the Mann–Whitney U test was applied under the following hypotheses:
H0. The distribution of ages differs between groups.
H1. There is an association between sex and prediction correctness.
As shown in
Table 10, the results of the Mann–Whitney U test indicated that none of the three age cohorts showed sufficient statistical evidence to reject
, suggesting the absence of age-related bias in model predictions. Regarding the confidence intervals, the 95% CIs for the difference in medians reinforce the lack of substantial differences between subgroups (
Figure 12). The obtained power values were calculated with the shift for each age cohort extracted from their data distributions. Despite the power values obtained for certain cohorts, the
p-values further support the acceptance of the null hypothesis.
To evaluate the association between sex and the correctness of model predictions, the Chi-squared test was applied under the following hypotheses:
H0. There is no association between sex and prediction correctness.
H1. There is an association between sex and prediction correctness.
As detailed in
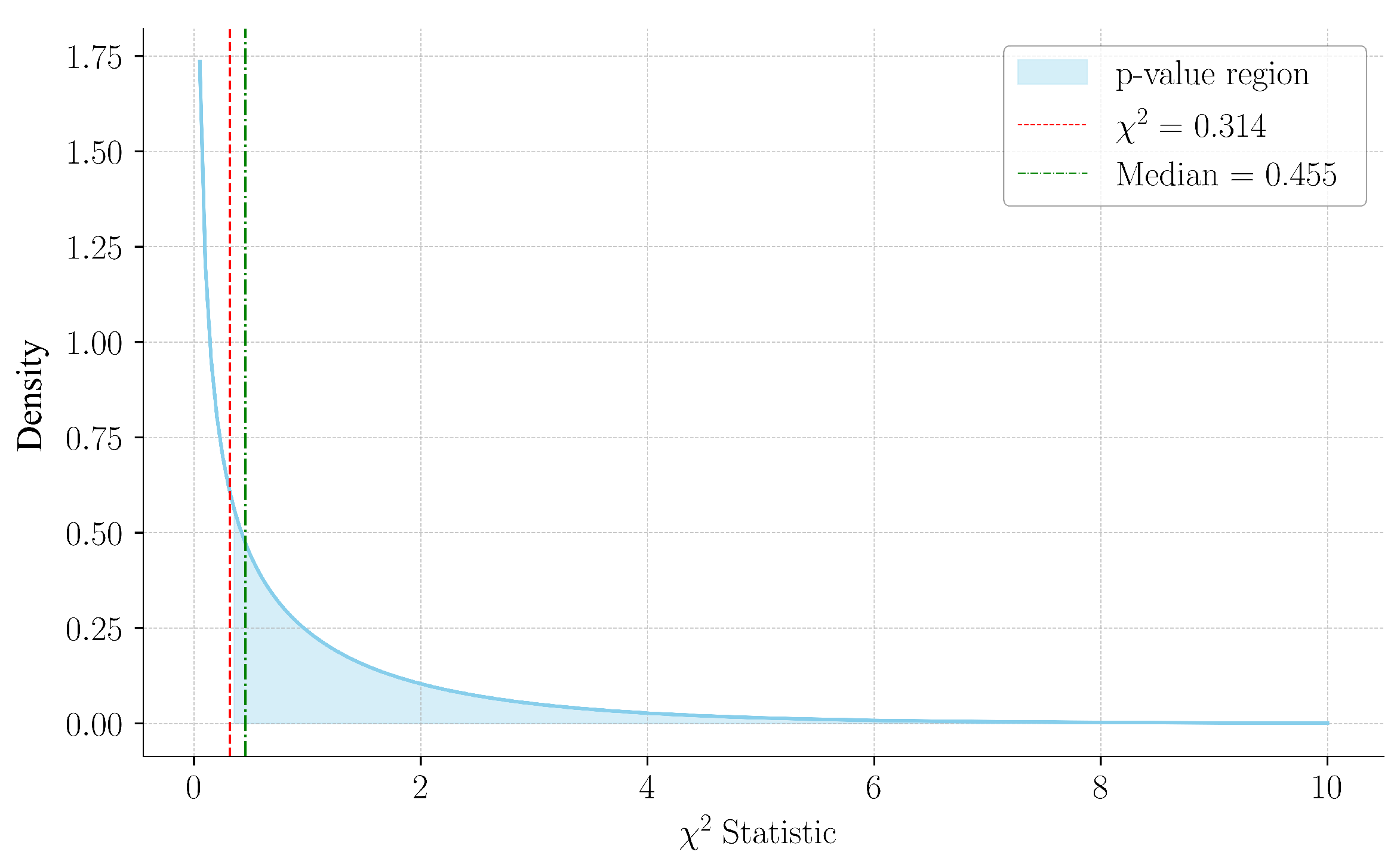
Table 11, the computed Chi-square statistic was 0.314, with a corresponding p-value of 0.575. The p-value was calculated as
. Since the statistic lies below the median of the distribution (
), this aligns with a non-significant result, as visualized in
Figure 13. The power analysis indicated a moderate capacity to detect a small effect size, thereby reinforcing the reliability of the results. These findings suggested that the statistical analysis did not provide strong evidence to confirm differences in accuracy based on sex, thereby supporting the generalisability of the model.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}