Abstract
Emotion recognition is a crucial aspect of human–computer interaction, particularly in the field of marketing and advertising. Call centers play a vital role in generating positive client experiences and maintaining relationships. As individuals increasingly rely on computers for daily tasks, there is a growing need to improve human–computer interactions. Research has been conducted on emotion recognition, in three main areas: facial expression-based, voice-based, and text-based. This study focuses on emotion recognition on incoming customer calls to call centers, which plays a vital role in customer experience and company satisfaction. The study uses real-life customer data provided by Turkish Mobile Operators to analyze the customer’s emotional state and inform call center employees about the emotional state. The model created in this research is a significant milestone for sentiment analysis in the Turkish language, demonstrating the ability to acquire fundamental patterns and categorize emotional expressions. The objective is to analyze the emotional condition of individuals using audio data received from phone calls, focusing on identifying good, negative, and neutral emotional states. Deep learning techniques are employed to analyze the results, with an accuracy value of 0.91, which is acceptable for our partner the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation.
1. Introduction
According to Aristotle (384–322 BCE), emotions are the various feelings that cause individuals to alter their judgments and are accompanied by either pain or pleasure. These emotions include anger, pity, fear, and similar feelings, along with their corresponding opposites. Emotion is a diverse category that includes a broad range of significant psychological processes. Certain emotions can be quite specific, as they pertain to a single individual, object, or situation. Other emotions, such as anxiety, joy, or depression, are highly universal. Certain emotions can be fleeting and just minimally conscious, such as a rapid surge of humiliation or a sudden outburst of rage. Some experiences, like enduring love or lingering resentment, can persist for extended periods of time, ranging from hours to months or even years. In such cases, they might become a lasting characteristic of a person’s personality. An emotion might be characterized by noticeable physical manifestations, such as a facial expression, or it can remain imperceptible to onlookers. An emotion might encompass conscious awareness and introspection, such as when an individual fully immerses themselves in it, or it can go by largely unrecognized and unacknowledged by the person experiencing it. An emotion might be substantial, indicating it is crucial for one’s physical existence or mental well-being, or it can be insignificant or dysfunctional. A feeling can be either socially acceptable or unacceptable. It can be considered a societal obligation, such as experiencing remorse after performing an unlawful act or feeling grief at a tragedy [1].
Wilhelm Wundt introduced the three-dimensional theory of emotions in the late 19th century. This theory categorizes emotions into three dimensions:
- Pleasure–Displeasure: This dimension encompasses subjective sensations of positivity or negativity. It encompasses happiness, contentment, sadness, and anger.
- Tension–Relaxation: This dimension delineates the physiological arousal or tension associated with an emotion. Emotions encompass fear, excitement, relief, and serenity.
- Excitement–Calm: Assesses the intensity of a feeling’s excitement or tranquility. Joy, surprise, boredom, and fatigue are all components of it.
Wundt’s tridimensional theory of emotions was an initial endeavor to categorize and comprehend human feelings. While it impacted subsequent research on emotions, contemporary psychological theories now encompass cognitive appraisal, social and cultural factors, and physiological responses [2].
To simplify matters, researchers commonly categorize emotions into two groups: “positive” and “negative”, concerning properties of emotion that scientific researchers refer to as “affective valence”. The hypothesis termed the ‘affective modules’ hypothesis is referred to here. The “affective modes” hypothesis suggests that a brain module can have diverse affective functions by being in multiple neurobiological states. This indicates that the emotional function or positive/negative value influenced by a brain module does not have to stay consistently steady but instead might vary dynamically in different circumstances [3]. Hence, a person’s feelings could change rapidly between good and bad.
Presently, individuals are depending progressively more on computers to carry out their everyday activities, hence intensifying the necessity to enhance human–computer connections. The absence of fundamental knowledge hinders a computer’s ability to perceive and produce emotions. Consequently, extensive research has been carried out on the recognition of emotions. Emotion recognition can be categorized into three primary domains: facial expression recognition, speech-based emotion recognition, and text-based emotion recognition. Emotion recognition in text is the automated process of assigning an emotion to a selected text from a predetermined collection of emotion descriptors. Emotion recognition in text is crucial due to the prevalence of text as the primary means of human–computer interaction. This includes various forms, such as text messages, emails, online conversation forums, reviews of products, blogs on the web, and social media platforms like Twitter, YouTube, Instagram, or Facebook. Emotion identification in text has various applications in industries such as business, education, psychology, and others, where there is a requirement to comprehend and analyze emotions [4].
Implicit emotion recognition in text is a challenging job in natural language processing (NLP) that requires natural language understanding (NLU). Text emotion recognition can be categorized into various levels: document, paragraph, sentence, and word level. The challenge arises at the sentence level when emotions are conveyed through the meanings of words and their connections. As the level progresses, the problem becomes more intricate. However, it is important to note that not all thoughts are conveyed with clarity, as they may involve the use of sarcasm, irony, and metaphors. An emotion can be successfully recognized using a keyword-based technique. Nevertheless, the occurrence of an emotion keyword does not consistently correspond to the conveyed sentiment. For instance, the words “Do I seem happy to you!” and “I am devoid of happiness” contain the emotion term “happy” but fail to convey that specific emotion. In addition, a statement can convey emotion even without the use of an explicit emotion word.
Scientists have been motivated to develop and apply automatic algorithms to identify emotional expressions to enhance intelligent human–machine interaction [5,6]. Consequently, the discipline of affective computing has garnered significant interest from researchers over the past decade due to its diverse application areas, including multi-modal human–computer interaction, security, education, health care, advertising, and marketing [7,8,9].
In the field of marketing and advertising, call centers are key elements for businesses. A call center is a group of customer service experts that handle telephone inquiries from potential or existing customers on a company’s offerings or products. Some call centers prioritize customer pleasure and provide help, while others emphasize sales growth, lead creation, and customer acquisition. Call centers are essential for generating a positive client experience. Hence, they must consistently provide excellent service to foster relationships. Consequently, call center staff must possess extensive expertise, exhibit patience, and demonstrate helpfulness when engaging with clients [10]. Since call center employees are the first to interact with customers, recognition of customer emotions is essential for call center responders to respond appropriately and adequately. At this point, it would be better to use emotion recognition systems and direct the customer to a more or less experienced call center employee, depending on their emotional state, in terms of customer experience, the reaction of the call center employee, and company satisfaction.
Currently, individuals are increasingly relying on computers to perform their daily tasks, leading to a growing need for improving human–computer interactions. A computer’s capacity to recognize and generate emotions is impeded by a lack of essential knowledge. As a result, a significant amount of research has been conducted on the identification of emotions [11,12,13,14,15,16,17].
In this article, we conducted a study on emotion recognition on incoming customer calls to call centers, which plays a vital role in terms of customer experience and company satisfaction. This study aims to analyze the customer’s emotion on an incoming customer call and to inform the call center employee who answers the call about the emotional state of the customer call according to the customer’s emotional state. The fact that the customer’s emotional state is known by the call center employees who answer the call is of great importance in terms of their sensitivity and performance in handling the call. As a result, any improvement in this area will positively affect the company’s customer experience. The emotion analysis system will make the job of the call center employee easier and increase their performance.
The paper’s novelty lies in our study of speech emotion recognition using call center speech data, specifically real-life customer data provided by “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri Inc.” We focused on recognizing speech emotion based on a hybrid model, which utilizes text and voice attributes. The prevailing theme in the literature on speech emotion recognition is a focus on examining the voice qualities of speech and speakers. Furthermore, the datasets utilized by researchers have predominantly been captured in a controlled studio setting and performed by skilled voice actors. Nevertheless, in actuality, individuals convey their emotions through speech using more authentic intonations and less proficient language. For instance, an individual who is experiencing fear or confusion should not be expected to articulate with accuracy in terms of diction and language. This has the potential to result in the failure of the proposed models that were previously used on actual speech data. Upon analyzing the literature pertaining to emotion recognition in text, it becomes evident that the majority of studies focus on analyzing corpora and lexicons. Experts have meticulously crafted and annotated the corpora and lexicons. Utilizing these works in actual spoken language data can also result in failure. The dataset used in the article was obtained from actual call center calls in the Turkish language. It consisted of a training set containing 520,000 original sentences and a test set containing 48,000 sentences. The allegorical structure of the Turkish language and the fact that many different words can be used for a single emotion pose a challenging structure for the emotion recognition system. For example, there are 84 different words in the Turkish language that mean sadness, and each of these words indicates differences in the level of sadness a person can have. Additionally, we annotated the data using Ekman’s emotional labels. The uniqueness and importance of this study lie in the utilization of authentic human voice data, specifically obtained from call center conversations involving consumers of the Turkish mobile operator Turkcell. This feature sets our work apart in the field of emotion recognition, namely, in the domains of speech and text analysis. Furthermore, the utilization of the speech-to-text technique we employ poses a challenge to the identification of emotions based on both vocal and textual aspects, hence enhancing the significance of our work.
2. Related Work
Diverse approaches have been utilized to discern emotions in written language. Research has been conducted on techniques that utilize keywords to detect and precisely categorize explicit emotions. Several alternative methods have been specifically introduced to identify implicit emotions in text. The approaches used in this study include keyword-based methods [18,19,20,21], rule-based methods [22,23], classical learning-based methods [4,24,25,26], deep learning methods [27,28,29,30], and hybrid methods [31,32,33,34]. This paper employs algorithms that use deep learning to determine emotions in text, given the complex nature of our methodology. Consequently, the subsequent sections of the paper mostly concentrate on deep learning methodologies.
2.1. Deep Learning Approaches in Text-Based Emotion Recognition
The field of machine learning, known as deep learning, is a subfield of machine learning in which computer programs learn from their experiences and comprehend the world through the lens of a hierarchy of concepts. Each concept is defined in terms of its relationship to concepts that are more straightforward. Through the use of this method, a computer program is able to acquire more complex ideas by constructing them on the basis of more basic ones. Long short-term memory (LSTM) is the deep learning model that is utilized the most in this context. LSTM is a specialized type of recurrent neural network (RNN) that has the ability to efficiently manage long-term dependencies. It is possible for LSTM to solve the problem of vanishing or exploding gradients that are typical of RNNs. In [35], the primary steps of the LSTM algorithm for emotion recognition in text are presented. The first step is to preprocess text on the dataset containing the emotions. Lemmatization, tokenization, and the removal of stop words are all possible procedures that are included in the preprocessing steps. Following this step, the embedding layer is constructed and then fed into one or more layers of the LSTM classifier. After that, the output is fed into a dense neural network (DNN) that has units equal to the number of emotion labels and a sigmoid activation function in order to carry out the classification.
Basile et al. introduced a deep learning model designed to identify and classify emotions in written conversations. The four submodels that make up the model are as follows: the sentence-encoder submodel, the three-input submodel (INP3), the two-output submodel (OUT2), and the bidirectional encoder representations from transformers (BERT) submodel. The INP3 submodel processes each segment of the dialog by inputting it into two Bi-LSTM layers, and then applying an attention layer. The results are combined and inputted into three DNNs. The OUT2 submodel shares the identical architecture with the INP3 submodel. However, the three sections of the conversation are combined and treated as a single input. Furthermore, an extra DNN is incorporated subsequent to the attention layer to generate an additional output, specifically, a classification of the dialog as either emotional or non-emotional. The objective of this submodel is to mitigate the impact of an imbalanced dataset. The sentence-encoder submodel utilizes a feed-forward network that incorporates a fine-tuned universal sentence encoder (USE). It selectively employs only the first and third segments of the dialog. The BERT submodel approaches the problem by representing it as a sentence-pair classification task, utilizing only the first and third utterances of the dialog. This submodel is integrated with a lexical normalization mechanism. Various classification techniques were evaluated, including support vector machines (SVM), SVM with normalization (SVM-n), logistic regression, naive Bayes, JRip rule learner, random forest, and J48. The results indicate that the features acquired by the INP3 and OUT2 submodels yield superior performance compared to the characteristics acquired by the USE and BERT submodels. Nevertheless, the combination of the four submodels yields the most optimal performance outcome using SVM-n [27].
Baziotis et al. introduced a deep learning model designed for the purpose of recognizing many emotions in English tweets. Their model comprised a Bi-LSTM with two layers, which was enhanced with a multilayer self-attention mechanism. They employed the ekphrasis tool to analyze the text. The preprocessing procedures encompassed Twitter-specific tokenization, spell correction, word normalization, word segmentation, and word annotation. Given the scarcity of training data, they employed a transfer learning method by initially training the Bi-LSTMs on the SemEval-2017, Task 4A dataset. In addition, they gathered a dataset consisting of 550 million English tweets. This dataset was utilized to compute word statistics that are essential for text preprocessing, training word2vec embeddings, and affective word embeddings. The empirical findings indicated that transfer learning did not surpass the performance of the model initialized randomly. Their model achieved the highest position among all the teams in the SemEval-2018 competition [28].
Du and Nie introduced a deep learning approach that utilizes pretrained word embeddings to represent tweets. The embeddings were inputted into a gated recurrent unit (GRU), and the classification was achieved using a dense neural network. Their model obtained the 15th position among the teams in the SemEval-2018 competition. Abdullah and Shaikh defined emotion recognition in tweets as a problem of classifying emotions into two categories.Tweet representation was achieved via word embeddings. The embeddings were inputted into four deep neural networks. The output of the fourth deep neural network was standardized to either one or zero using a threshold value of 0.5. Their model attained the 4th position for Arabic and the 17th position for English among the participating teams in the SemEval-2018 competition [36].
Ezen-Can and Can proposed transforming a multi-label emotion recognition issue into a binary classification problem. This method facilitated the utilization of distinct model architectures and parameters for each individual emotion label. The authors employed three gated recurrent unit layers, with two of them being bidirectional. Given the large size of the training dataset, an autoencoder was constructed to utilize unlabeled tweets for the purpose of acquiring weights that could be employed in the classifiers. Pretrained embeddings were utilized to represent emojis, phrases, and hashtags. Their outcomes were above the baseline, although they fell short of the achievements of the other participants. Their model obtained the 24th position among the teams in the SemEval-2018 competition [37].
Ge et al. introduced a deep learning model designed to identify and classify emotions in textual conversations. Three pretrained embeddings, specifically word2vec-twitter, GloVe, and ekphrasis, were utilized. The input to the model consists of an embedding layer, which is then sent via a bidirectional long short-term memory layer, followed by an attention layer and a convolutional neural network (CNN) layer. The results of the Bi-LSTM and the CNN are combined, and global max-pooling is performed. The pooling scores are inputted into a deep neural network that uses a softmax activation function to perform classification. The findings indicate that the utilization of pretrained embeddings resulted in enhanced performance. In addition, the model effectively acquired both local and long-term characteristics by merging the outputs of the Bi-LSTM and CNN layers [29].
Li et al. introduced a deep learning model that uses word embeddings to represent tweets. The embeddings were inputted into a long short-term memory model. The model assigned a score to each emotion label for classification and selected the labels with the highest three scores. Their model attained the 23rd position in the SemEval-2018 competition [30].
Ma et al. introduced a deep learning model designed to identify and classify emotions in written conversations. In order to address the issue of encountering words that are not included in the lexicon when utilizing pretrained word embeddings, the emojis are substituted with an appropriate term that conveys the intended emotion. The embeddings are inputted into a Bi-LSTM layer, while an attention mechanism enhances the importance of the emotion words. The inner product is derived from the output of the Bi-LSTM and the attention weights and then sent into another Bi-LSTM layer. Subsequently, the output of the Bi-LSTM layer undergoes global max-pooling and global average pooling and is processed by the final tensor. The pooling scores are inputted into an LSTM layer and subsequently into a DNN with a softmax activation function. The results indicate a lack of proficiency in accurately identifying the cheerful emotion category [38].
Meisheri and Dey introduced a resilient depiction of a tweet. Two parallel architectures were devised to build the representation utilizing different pretrained embeddings. The initial architecture derived the embedding matrix by combining emoji2vec, GloVe, and character-level embeddings. The resulting matrix was inputted into a bidirectional long short-term memory model. Subsequently, the result of each time step was inputted into an attention layer. The second architecture utilized pretrained GloVe embeddings, which were trained on a Twitter corpus, to construct the embedding matrix. The matrix was inputted into a separate Bi-LSTM, and the output of the Bi-LSTM was subjected to max-pooling. The results of the two architectures were combined and subsequently inputted into two completely connected networks. Their model earned second place among the teams in the SemEval-2018 competition [39].
Ragheb and his colleagues introduced a deep learning algorithm designed to identify and classify emotions in written conversations. The three segments of the discussion are combined and fed into the embedding layer. The output of the embedding layer is sent through three consecutive layers of Bi-LSTM, which are trained using average stochastic gradient descent. Subsequently, a self-attention mechanism is employed on the initial and last segments of the talk, followed by an average pooling operation. The disparity between the two combined scores is used as an input to a two-deep neural network, which is then followed by a softmax function to produce the emotion labels. The language model was trained using the Wikitext-103 dataset. The results indicate a lack of proficiency in identifying the cheerful emotion category [35].
A deep learning model was presented by Rathnayaka and colleagues for the purpose of detecting multi-label emotions in microblogs. During the preprocessing stage, they utilized the ekphrasis tool. The word embedding procedure known as GloVe was utilized. The embedding layer is inputted into two Bi-GRU layers. After that, the first attention layer receives input from the embedding layer as well as the output of the first Bi-GRU layer. Additionally, the embedding layer, the output of the first Bi-GRU layer, and the output of the second Bi-GRU layer are all inputs that are supplied into the second attention layer. After that, the two attention layers are joined together and fed into a deep neural network that has a sigmoid activation function in order to carry out the classification. They attained cutting-edge outcomes with their model [40].
Seyeditabari et al. defined emotion recognition in text as a problem of classifying text into two categories. Two word embedding models, namely, ConceptNet Numberbatch and fastText, were utilized. The embedding layer is inputted into a bidirectional gated recurrent unit layer. Subsequently, a combination of global max-pooling and average pooling layers is employed. The pooling scores are inputted into a deep neural network, and a sigmoid layer is used to carry out the classification. The findings indicate that deep learning models have the ability to acquire more meaningful characteristics, leading to a significant enhancement in performance [41].
Shrivastava et al. introduced a sophisticated deep learning model designed specifically for the purpose of recognizing emotions in multimedia text. The word2vec model was employed to construct the word embeddings. The embedding layer is inputted into the convolutional layers, subsequently followed by a max-pooling layer and a DNN layer. The output of the deep neural network is subsequently inputted into an attention layer. The categorization is executed using the softmax function. The findings indicate that the accuracy of the emotion labels anger and fear surpasses that of other emotion labels; however, the ability to correctly identify and the overall performance of the emotion label happy outperform that of the other emotion labels [42].
Wang et al. employed a convolutional neural network for the purpose of addressing multi-label emotion recognition. The studies were carried out on the NLPCC2014 Emotion Analysis in Chinese Weibo Text (EACWT) task and the Chinese blog dataset Ren_CECps. The empirical findings demonstrated that the CNN, aided by word embedding, surpasses robust benchmarks and attains exceptional performance [43].
Xiao proposed a deep learning model for the purpose of recognizing emotions in textual conversations. The ekphrasis tool was employed for text preparation. The researchers performed fine-tuning on several models, including the universal language model (ULM), the BERT model, OpenAI’s Generative Pretraining (GPT) model, the DeepMoji model, and a DeepMoji model trained with NTUA embedding. According to the results, the ULM model demonstrated superior performance compared to the other models. The DeepMoji model, trained with NTUA embedding, had the second highest performance. Nevertheless, combining these models yielded the highest outcome. The models were integrated by calculating the unweighted average of the posterior probabilities for each model. The emotion class with the highest average probability was then chosen [44].
2.2. Deep Learning Approaches in Voice-Based Emotion Recognition
The speech emotion recognition system has two sequential steps: (1) Determine the appropriate characteristic of speech, and (2) determine a decision-making class that is based on the feelings that are stated. The vast majority of research conducted in the field of speech emotion recognition mainly concentrates on stage (2) due to its significance in bridging the gap between the challenges in this domain and the classification methods.
Emotion identification systems have historically relied on traditional categorization. There are primarily two broad classifications of classifiers: standard classifiers and deep learning classifiers.
Standard classifiers encompass classification algorithms, such as artificial neural networks (ANNs) [45], support vector machines (SVM) [46,47], hidden Markov models (HMMs) [48,49,50,51], Gaussian mixture models (GMMs) [52,53,54], K-nearest neighbors (K-NN) [46,55], decision trees (DTs) [56,57,58], linear discriminant analysis (LDA) [56,59,60,61], and the maximum likelihood method [62]. On the other hand, deep learning classifiers, such as convolution neural networks, deep neural networks, recurrent neural networks, deep belief networks (DBNs), long short-term memory, and deep Boltzmann machine (DBM), are used for speech emotion recognition. There is a lack of consensus over which classification is more suitable. Each type appears to possess distinct benefits and constraints.
Deep neural networks are computational models inspired by the structure and functioning of the human brain. The task of speech emotion recognition has been shown to be difficult due to the variability of emotional states in various contexts. There exist multiple architectures in this domain, with the convolutional neural network being the most renowned and extensively employed. A convolutional neural network is a very proficient and transparent technique in the field of deep learning.
Vryzas et al. suggested that the CNN architecture be utilized in speech emotion recognition (SER) for the purpose of accurately identifying emotions in continuous speech. The database used for the model training is the Acted Emotional Speech Dynamic Database (AESDD). The CNN design surpasses earlier models in both accuracy and efficiency by a margin of 8.4%, eliminating the need for manual feature extraction. Data augmentation enhances the ability of a system to handle unexpected situations and apply knowledge to new scenarios. It also improves the system’s ability to perform well on a wide range of tasks. The unsupervised feature extraction step enables real-time systems to be implemented effectively [63].
Badshah et al. proposed a technique for recognizing voice emotions using spectrograms and a deep convolutional neural network. The model is composed of three convolutional layers and three fully connected layers. It is designed to extract distinctive features from spectrogram images and generates predictions for seven different moods. The model underwent training using spectrograms from the Berlin emotions dataset and employed transfer learning by utilizing a pretrained AlexNet model. The initial findings indicate that the recently trained method surpasses the fine-tuned model in reliably and efficiently forecasting emotions [64].
Xie et al. present a unique approach to voice recognition that combines frame-level speech data with attention-based long short-term memory recurrent neural networks. Waveforms are analyzed to extract speech features at the frame level, ensuring that the original timing relations of the speech are preserved. Two enhancement tactics are suggested for LSTM models by utilizing the attention mechanism: altering the forgetting gate of conventional LSTM while maintaining performance and implementing an attention mechanism to both the temporal and feature dimensions in the ultimate output. The suggested approach has been tested extensively on CASIA, eNTERFACE, and GEMEP emotion corpora, and the results show that it performs better than the most advanced algorithms currently available [65].
Zhao et al. proposed creating advanced emotional recognition characteristics by utilizing convolutional neural networks and long short-term memory networks. Two 1D CNN LSTM networks and one 2D CNN LSTM network were created to acquire both local and global emotion-related characteristics from speech and log-Mel spectrograms. Both networks share a comparable structure, including four local feature learning blocks (LFLBs) and one long short-term memory layer. The networks that were built, which integrate the advantages of both networks, were assessed using two standard datasets. The experiments demonstrated that the presented networks, particularly the 2D CNN LSTM network, outperformed conventional methods, such as DBN and CNN. The 2D CNN LSTM network acquired recognition accuracies of 95.33% and 95.89% on the Berlin EmoDB and 89.16% and 52.14% on IEMOCAP, respectively. In comparison, the accuracy attained by DBN and CNN was 73.78% and 40.02% [66].
Qayyum et al. suggested a novel speech emotion detection system created by employing a convolutional neural network and utilizing a dedicated dataset together with a state-of-the-art graphics processing unit for the purposes of training, classification, and testing. The model attains a remarkable accuracy of 83.61%, surpassing comparable tasks on the dataset, showcasing the efficacy of CNN in speech recognition [67].
Nam and Lee suggested employing a cascaded denoising convolutional neural network (DnCNN)-CNN structure for the purpose of categorizing emotions in Korean and German languages under noisy circumstances. The architecture comprises two stages: the initial stage employs residual learning to remove noise, while the subsequent step carries out categorization. The DnCNN-CNN surpasses the baseline CNN in terms of overall accuracy for each of the languages. In the context of the Korean language, the DnCNN-CNN model achieves a precision rate of 95.8%, whereas the CNN model has a little lower precision rate of 93.6%. The DnCNN-CNN model achieves an average accuracy of 59.3–76.6% for the German language, whereas the CNN model achieves an average accuracy of 39.4–58.1%. The discoveries provide fresh perspectives on the understanding of emotions in speech under challenging circumstances and have ramifications for the development of speech emotion detection systems that are applicable across different languages [68].
Christy et al. propose a classification and prediction model that employs multiple techniques, such as linear regression, random forest, decision trees, support vector machines, and convolutional neural networks. The paradigm categorizes human emotions into the following categories: neutral, calm, happy, surprised, sad, afraid, and disgusted. The RAVDEES dataset was used to evaluate the model, and the CNN achieved an accuracy of 78.20% in emotion recognition [69].
Yao et al. created a system that combines three classifiers: a recurrent neural network, a convolution neural network, and a deep neural network. The paradigm was employed for the categorical identification of four distinct emotions: anger, happiness, neutrality, and sadness. The frame-level low-level descriptors (LLDs), segment-level Mel-spectrograms (MSs), and utterance-level outputs of high-level statistical functions (HSFs) were individually inputted into the DNN, RNN, and CNN models. They obtained three distinct models: MS-CNN, LLD-RNN, and HSF-DNN. The CNN and RNN outputs were amalgamated through the utilization of the attention mechanism-based weighted-pooling method. The categorization of discrete categories and the regression of continuous characteristics were both carried out simultaneously as part of a multi-task learning method that was used in order to acquire generalized features. In order to merge the power of various classifiers during the process of recognizing various emotional states, a confidence-based fusion technique was devised. Three studies were carried out to identify emotions using the IEMOCAP corpus. The weighted accuracy of the proposed fusion system was 57.1%, while the unweighted accuracy was 58.3%. These results are substantially higher than those of each individual classifier [70].
Alghifari et al. sought to employ deep neural networks to identify the emotions expressed in human speech. The MFCC, which stands for Mel-frequency cepstral coefficient, is obtained by extracting features from raw audio data and then training them into a DNN. The trained neural network is assessed using labeled emotion speech audio, and the accuracy of emotion recognition is measured. The quantity of neurons and layers is modified in accordance with the accuracy rate of the MFCCs. An optimal network is utilized to introduce and validate a bespoke database. The optimal setup for speech emotion recognition (SER) consists of 13 MFCCs, 12 neurons, and two layers for three emotions. For four emotions, the recommended configuration is 25 MFCC, 21 neurons, and four layers. These settings result in an overall recognition rate of 96.3% for three emotions and 97.1% for four emotions. This research represents a focal point for the recognition of emotions in speech because of its difficult nature but exciting potential for the future. The optimal setup for SER involves using 13 MFCC features, 12 neurons, and two layers to classify three emotions. For four emotions, it is recommended to use 25 MFCC features, 21 neurons, and four layers [71].
Rejaibi et al. introduce a sophisticated framework based on deep recurrent neural networks to identify and forecast the degree of depression using speech. The method captures both low-level and high-level audio characteristics from recordings, enabling the prediction of Patient Health Questionnaire scores and a binary classification of depression diagnosis. The framework demonstrates superior performance compared to the most advanced techniques on the DAIC-WOZ database, achieving an overall accuracy of 76.27% and a root mean square error of 0.4 [72].
Zheng and Yang offer a voice emotion recognition model that utilizes an enhanced deep belief network and replaces conventional activation functions with rectified linear units (Relu). This model has the ability to automatically identify six different emotions: anger, fear, joy, tranquility, sorrow, and surprise. It achieves a recognition rate of 84.94%, which is higher than the recognition rates achieved by classic DBN and BP models [73].
Valiyavalappil Haridas et al. presented a novel emotion recognition system that utilizes a Taylor series-based deep belief network (Taylor-DBN). The method eliminates background noise from speech and extracts characteristics such as the tone power ratio and MKMFCC values. Experiments conducted on various datasets demonstrate negligible deviations in performance across many areas and languages. The model surpasses previous models in terms of the false rejection rate, false acceptance rate, and accuracy [74].
Huang et al. presented a novel approach for feature extraction by employing deep neural networks to automatically extract emotional elements from speech inputs. The method employs a stack of five deep belief networks and integrates numerous consecutive frames to generate high-dimensional features. The characteristics are subsequently entered into a nonlinear SVM classifier, yielding a speech emotion recognition multiple classifier system with an 86.5% recognition rate [75].
Poon-Feng et al. proposed a technique to improve the classification recall of a deep Boltzmann machine used for emotion recognition from voice. The approach entails partitioning the input data into distinct subsets, training each subset separately, and subsequently evaluating the outcomes using SVM classifiers and the DBM algorithm. This approach is appropriate for datasets that are not evenly distributed [76].
Bautista et al. examined the application of parallel convolutional neural network networks for the purpose of automatic speech emotion recognition tasks. The researchers utilized the Ryerson Audio-Visual Dataset of Speech and Song (RAVDESS) for training the networks. The researchers integrated a convolutional neural network with attention-based networks to effectively capture and represent both spatial and temporal characteristics. In order to enhance the training data, techniques such as SpecAugment, additive white Gaussian noise, Tanh distortion, and room impulse response were implemented. CNN’s image classification capabilities were utilized to convert the raw audio data into Mel-spectrograms. In order to represent temporal feature representations, Transformer and BLSTM-Attention modules were implemented. The proposed architectures were evaluated against standalone CNN architectures, attention-based networks, and hybrid architectures. The Parallel CNN-Transformer network had a maximum accuracy of 89.33%, while the Parallel CNN-BLSTM-Attention Network achieved an accuracy of 85.67%. These results are promising, especially considering that the parallel models have far fewer training parameters compared to non-parallel hybrid models [77].
Quck et al. describe the creation of EmoRec, an iOS app specifically built to forecast emotions based on audio input. The platform provides a user friendly interface for users to capture and submit audio data, which can be utilized for future emotion recognition research. The application utilizes deep learning algorithms that are most effective when applied to extensive datasets, hence enhancing the outcomes. The article provides a comprehensive account of the entire development process, encompassing design, optimization, and testing. It also delves into the outcomes of the process and outlines potential future endeavors [78].
The popularity of automatic speech emotion detection is increasing because of its capacity to identify emotions in speech. Nevertheless, speaking frequently includes moments of quiet that may not be pertinent to the expression of emotion. In order to enhance performance, Atmaja and Akagi suggested implementing a mix of silence removal and attention models. The findings indicate that this strategy surpasses the performance of solely employing noise removal or attention models in the task of speech emotion recognition [79].
Abdelhamid et al. suggested a novel data augmentation algorithm that enhances the speech emotions dataset by incorporating noise fractions. According to the authors, the hyperparameters of contemporary deep learning models are either manually crafted or altered during the training process; however, this does not ensure that the optimal settings are achieved. The authors present an enhanced deep learning model that optimizes these parameters, leading to improved recognition outcomes. The model comprises a convolutional neural network that incorporates local feature-learning blocks and a long short-term memory layer. This architecture enables the model to learn both local and long-term correlations in the log-Mel-spectrogram of input speech samples. Using the stochastic fractal search (SFS)-guided whale optimization algorithm, the learning rate and label smoothing regularization factor are optimized. The approach achieves the most optimal global solution by balancing the exploration and exploitation of search agents’ positions. The proposed method is evaluated using four speech emotion datasets, reaching recognition accuracies of 98.13%, 99.76%, 99.47%, and 99.50% for each dataset, respectively. A statistical examination of the results highlighted the robustness of the proposed methodology [80].
Kaya et al. investigated the application of long short-term memory models in the field of cross-corpus acoustic emotion recognition. The approach utilizes a method that predicts the valence and arousal of each frame to classify the impact of each speech. The technique was utilized on the ComParE 2018 challenge datasets, demonstrating encouraging outcomes on both the development and test sets of the Self-Assessed Affect Sub-Challenge. When used with the baseline system, the cross-corpus prediction-based technique enhances performance. The results indicate that the method is appropriate for both time-continuous and syllable-level cross-corpus acoustic emotion identification tasks [81].
3. Materials and Methods
This study presents three main approaches to detecting emotions from audio and text data. First, a text-based classification model is used to classify emotional states from the data obtained by transcribing audio recordings into text. Second, a voice-based classification model is developed to estimate emotional states by extracting features from audio data directly. Third, a more comprehensive analysis is performed by combining the results of these two methods. This study compares the three methods and focuses on determining the most effective approach. We also tested our dataset with other pretrained emotion detection models, such as DistilBERT and RoBERTa.
3.1. Dataset Properties
The dataset used in the project was created from a training dataset comprising 520,000 sentences, while the test dataset contained 48,000 sentences. A distinct dataset utilized in the validation phase comprised 100,000 sentences and is affiliated with Turkcell. The accuracy rate was determined using the primary test dataset from which the results were derived. This dataset was carefully prepared for emotional analysis and designed to have an unbalanced label distribution. We have to declare that this dataset belongs to Turkcell (İstanbul, Türkiye). The audio files are encoded in 8-bit channel WAV format. This format offers an efficient framework for managing and examining audio data.
The audio data were transcribed into text utilizing Turkcell’s proprietary speech-to-text algorithm. Turkcell experts also verified the accuracy of the transcription process during the labeling phase.
The labeling procedure was executed by experts from the Turkcell call center. This process verified the accuracy of audio data transcription and assessed whether the speech conveyed the emotional context. Experts conducted tagging by verifying that the speech was accurately transcribed and that the underlying emotional tone was appropriately conveyed.
Audio files are stored in the cloud. MFCC features are derived from audio data utilizing the Java programming language. The TarsosDSP library utilized in Java is favored for computing the MFCC feature vectors of audio data. The extracted MFCC features are subsequently converted to CSV format and stored. Each CSV file comprises MFCC features and corresponding labels, along with specified links to the audio files. These data serve as the primary source for the system’s training and testing phases.
This study utilized real-world data sourced from a dataset containing 100,000 call center interactions supplied by Turkcell Global Bilgi. This dataset contains authentic customer interactions from Turkcell and was utilized during the model’s testing and validation phases. The tests conducted on these data yielded a high accuracy rate through the integration of text and voice-based classification models.
The most common words that occur in the dataset are:
| • | “bir” | (one) | (213,794 times) |
| • | “ve” | (and) | (180,040 times) |
| • | “çok” | (very) | (147,731 times) |
| • | “bu” | (this) | (103,081 times) |
| • | “için” | (for) | (64,202 times) |
| • | “ürün” | (product) | (57,019 times) |
| • | “daha” | (more) | (53,731 times) |
| • | “ama” | (but) | (52,372 times) |
| • | “da” | (also) | (50,740 times) |
The number of unique words that occur in the dataset is 666,748 unique words, indicating that the model was trained with a large vocabulary. Table 1 shows the distribution of sentence lengths in the dataset, and Table 2 shows the label distribution in the dataset.

Table 1.
Sentence lengths distribution of dataset.
Table 2.
Label distribution of dataset.
The label distribution in the dataset is unbalanced, with fewer negative emotions. This distribution reflects the situation where correct classification of negative emotions is critical, especially in applications where negative feedback is essential, such as customer service. The smaller number of negative emotions is a deliberate choice to make the model more sensitive to this class and increase its ability to recognize such labels correctly. This approach aims to increase the overall accuracy and improve the model’s performance on more challenging tasks, such as correctly detecting negative emotions. These dataset features and label distribution are vital to the model’s training process and subsequent emotion classification success.
3.2. Text-Based Classification Model and Analysis of Its Layers
The text-based classification approach is specifically developed to perform sentiment classification on textual data derived from audio sources. This model comprises a sequence of deep learning layers designed to comprehend and analyze the characteristics of textual material. Each layer is designed with a distinct objective to enhance the efficiency and precision of the model.
3.2.1. The Embedding Layer
The primary objective of this layer is to transform textual data into a numerical representation and generate word vectors. The primary significance of this layer is its ability to transform individual words into compact vectors of a predetermined dimension. This method facilitates the capture of semantic links between words and enables the model to engage in more profound learning of the text. Word embedding allows the model to comprehend the semantic significance of words and the surrounding context in order to identify crucial contexts for sentiment analysis.
3.2.2. Bidirectional GRU Layer
The function of this layer is to analyze the semantic content of the texts within the framework of time series. The inclusion of this layer is crucial as it allows the gated recurrent unit layer to effectively capture and understand long-term relationships within the texts. Due to its bidirectional structure, it is capable of analyzing the text both in the past-to-future and future-to-past directions. The bidirectional structure facilitates a more comprehensive comprehension of emotional emotions in the text and enhances the precision of categorization.
3.2.3. Attention Mechanism
The purpose of this layer is to concentrate on the essential information within the text. The attention mechanism in this layer facilitates the model in discerning the crucial components of the text and assigns greater significance to these components. This layer plays a crucial role in identifying the sections of a text that contain significant emotional content, particularly in lengthy texts. The attention mechanism enhances the model’s overall performance by enabling it to disregard irrelevant information and capture crucial emotional cues.
3.2.4. Flatten and Dense Layers
The primary function of these layers is to preprocess the acquired features in order to facilitate the categorization process. The flatten layer is crucial because it generates a singular, long vector from the outputs of the preceding layers. This is inputted into the dense layer. The dense layer utilizes the trained weights on the vectors to predict the output classes, which include positive, negative, and neutral. The softmax function, employed as the activation function, yields a probability distribution for each emotional state, enabling the model to choose the emotional state with the highest probability.
The seamless integration of these layers enables the text-based categorization model to provide precise emotional categorization with a high level of accuracy on textual input. The model’s architecture was devised by amalgamating strategies that leverage deep learning theories and exhibit exceptional performance in real-world scenarios.
3.2.5. Text-Based Classification Model Training
The text-based model was created via deep learning methodologies employing tensorflow. The training method of the model was meticulously designed, taking into account the magnitude and variety of the dataset.
The suggested model was trained for a total of ten epochs during the training procedure. The batch size was set to 128 samples for each training cycle. As the optimizer, Adam’s optimization technique was applied. The initial learning rate was set at a high value and was subsequently manually decreased as the training advanced. This approach was initially implemented to ensure rapid acquisition of learning, followed by the establishment of stability.
The model’s loss value at the end of the training was recorded as 0.02, serving as a performance evaluation. The accuracy rate was quantified at 91%. The inclusion of a confusion matrix in the results section offers a more comprehensive examination of the model’s performance. This matrix displays the model’s classification accuracy for each individual class and is an essential tool for analyzing incorrect classifications.
This information offers a thorough perspective on the training process of the model, including the specific technical parameters employed and the methods used to evaluate the produced results. Furthermore, the model’s impressive accuracy rate and low loss value serve as evidence of its success in text-based sentiment analysis. The sentiment analysis method is integrated and based on a strong foundation. Its purpose is to further improve the capabilities of sentiment classification.
3.3. Voice-Based Classification
The spectral aspects of the voice signal spectrum are extracted and enhance the characteristics of the prosodic components. These aspects encompass the frequency content of speech and the different emotions are characterized by distinct forms. The key spectral components utilized in emotion recognition include the Mel-frequency cepstral coefficient, linear prediction coefficient (LPC), linear prediction cepstral coefficient (LPCC), gamma tone frequency cepstral coefficient (GFCC), perceptual linear prediction (PLP), and formants.
The characteristics of audio signals encompass emotional indications that are absent in textual data. For instance, fluctuations in an individual’s vocal intonation might serve as indicators of their level of enthusiasm or tension, and stress can signify crucial elements of speech. Hence, voice analysis is crucial for gaining a more profound comprehension of one’s emotional condition.
Our approach involves obtaining characteristics, such as Mel-frequency cepstral coefficients, from audio recordings and utilizing machine learning methods, such as support vector machines, to estimate emotional states. This technique utilizes direct audio analysis to accurately identify emotional states by analyzing various audio aspects. The training process of the model is evaluated using various parameter configurations, and its performance is assessed.
The primary components of the audio data in this model are the MFCC characteristics. The MFCC is a useful speech characteristic that captures a significant amount of information from the sounds of speech and presents the signal spectrum in a straightforward and succinct manner. It has the ability to capture various characteristics of voice, such as intonation, emphasis, and subtlety [82,83].
The MFCC process involves dividing speech signals into time frames of equal size, which may overlap. The MFCC is calculated for each frame and considered as a feature of that frame. Thus, for every sample, we will generate a matrix that encompasses identical characteristics as the MFCC vectors. The global features appropriate for this case include the values of the minimum, maximum, mean, median, mode, standard deviation, and variance.
Figure 1 displays a comprehensive graphic illustrating the process of collecting Mel-frequency cepstral coefficients from an audio source.
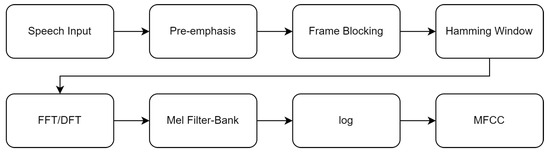
Figure 1.
Block diagram illustrating the process of generating the Mel-frequency cepstral coefficients.
Voice-Based Model and Test Processes
The voice-based categorization model trains multiple machine learning models utilizing MFCC features collected from audio recordings. The models encompass support vector machines, support vector regression, and logistic regression.
The support vector machines model distinguishes between distinct emotion classes by constructing a hyperplane in the feature space. Support vector machines are particularly efficient for datasets with a large number of dimensions and demonstrate strong performance on intricate characteristics, such as Mel-frequency cepstral coefficients.
Support vector regression utilizes regression analysis to generate a continuous output. This paradigm can be employed to quantify the magnitude of an emotion, such as assessing the level of happiness or sadness experienced by an individual.
Logistic regression is a probabilistic statistical model employed for classification purposes. Logistic regression is employed to categorize an emotional state as positive or negative, particularly in situations involving two distinct classes or binary dilemmas.
Typically, the effectiveness of these models is assessed using metrics like accuracy and the F1-score. The model’s capacity for generalization is assessed by subjecting it to various audio recordings during the testing phase. This procedure elucidates the model’s reaction to real-world data and ability to categorize emotions.
3.4. Integrated Sentiment Analysis
Our paper employed two methodologies to examine the results of the two fundamental models, voice-based and text-based, in order to enhance the dependability and precision of emotion classification. Figure 2 shows the proposed emotion recognition system design.
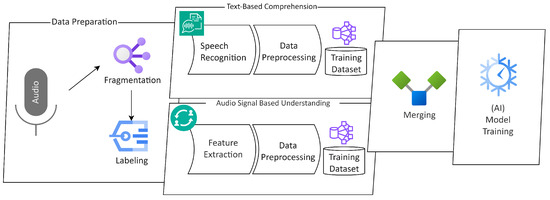
Figure 2.
Proposed emotion recognition system design.
3.4.1. Weighting with Deterministic Approach
The initial approach is the manual weighting technique. This method integrates the prediction outcomes of the text-based and voice-based models by applying a specific weighting factor to their multiplication. Various weighting ratios were evaluated, and the performance outcomes were assessed:
When employing a ratio of 60% text to 40% voice, the model attained an accuracy rate of approximately 87%. While this ratio may be applicable in scenarios where the text-based model is robust, it was insufficient to enhance the model’s overall accuracy rate.
The accuracy rate remained approximately 85% when employing a 90% text to 10% voice ratio. This ratio yielded suboptimal results due to the diminished efficacy of the voice-based model.
The 75% text to 25% voice ratio yielded optimal performance, achieving an accuracy rate of 91.2% in the conducted tests.
This ratio represents the scenario in which the contributions of both models are most equilibrated, thereby optimizing overall accuracy. The manual weighting method permits flexible adjustment and optimization of weights based on the scenario. The tests indicated that a ratio of 75% text to 25% voice yielded the most optimal results.
3.4.2. Re-Labeling and Re-Training with Logistic Regression
The alternative approach relies on employing logistic regression for predictive analysis. Logistic regression enhances the final predictions by conducting regression analysis on the outputs of the text and voice models. This method establishes an interaction between the outputs of the two models to optimize accuracy rates, with the weights determined automatically.
The logistic regression method enhances the model’s accuracy without necessitating manual weight adjustments. This method yields optimal results in large datasets through rapid optimization. This method demonstrated efficacy comparable to the manual weighting technique, achieving an accuracy rate of approximately 91%.
We enhanced the efficacy of both methods by relying on their accuracy rates. The 75% to 25% ratio emerged as the manual weighting outcome that yielded the greatest success.
4. Results and Discussion
The model created in this research is a crucial milestone for conducting sentiment analysis in the Turkish language. The preliminary findings indicate that the model has the ability to acquire fundamental patterns and has the potential to categorize emotional expressions. Current research endeavors are focused on enhancing the performance of the model on a comprehensive dataset and facilitating its more efficient utilization in practical situations.
Our objective is to analyze the emotional condition of individuals using audio data received from phone calls. We specifically concentrated on identifying good, negative, and neutral emotional states in our findings, employing deep learning techniques. Table 3 presents the prediction outcomes of the model using actual data from the real world, which consists of 100,000 sentences. With the help of the data in Table 3, we can calculate the accuracy value of the real-world test data as 0.91, which is an acceptable accuracy level for our partner the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation (İstanbul, Türkiye).
Table 3.
Confusion matrix of real world data.
Table 4 demonstrates that our model attained a precision value of 0.9381 for positive emotions, 0.9268 for negative emotions, and 0.8707 for neutral emotions. The recall value for positive emotions is 0.8723, whereas the recall value for negative emotions is 0.9355 and 0.9161 for neutral emotions. The F1-scores for positive, negative, and neutral emotions can be determined using the following values: positive emotions = 0.9040, negative emotions = 0.9311, and neutral emotions = 0.8928.
Table 4.
Statistical analysis of real-world data.
To assess the efficacy of the text and audio-based models utilized in our study, several existing pretrained emotion classification models were analyzed and compared. Among these models were:
– DistilBERT: DistilBERT, a transformer-based model, underwent training on an extensive dataset before being fine-tuned on our specific dataset.
– RoBERTa: Likewise, RoBERTa is a pretrained model that was fine-tuned on our dataset for the purpose of emotion classification.
The pretrained models were evaluated using a real-world dataset comprising 100,000 sentences supplied by Turkcell Global Bilgi. In the evaluations, the RoBERTa model attained an accuracy of approximately 77%, whereas the DistilBERT model yielded an accuracy of 79%. These rates serve as a benchmark for the overall performance of existing models in emotion classification. Despite the adaptation of the fine-tuned models to our dataset, they did not attain a success rate as high as that of our integrated text and audio-based model. The following is an illustration of a confusion matrix derived from the RoBERTa model in Table 5:
Table 5.
Confusion matrix of RoBERTa on real-world data.
Table 5 illustrates the performance of the RoBERTa model, which yielded an accuracy rate of approximately 77%. The DistilBERT model underwent analogous testing and attained an accuracy rate of 79%. Nonetheless, the necessity for increased processing power and large model sizes in real-world applications transforms their performance benefits into drawbacks. Consequently, our integrated text and voice model offers superior accuracy and processing efficiency.
Based on the statistical analysis and the obtained data, it is evident that our model is capable of effectively differentiating between positive, negative, and neutral emotions, albeit with a small margin of error. The data utilized in our model consist of authentic, real-world information obtained from call center calls. These data have not been previously documented and are solely derived from human sources. The uniqueness of the project lies in our utilization of authentic human vocal data. All recordings in other similar works are conducted in a controlled studio environment and do not involve spontaneous discussions between two individuals. Additionally, we employed a hybrid model that converts speech into text and utilizes these textual data to examine the semantic emotion within the context of the interaction.
This work is an ongoing project collaboration between Sakarya University and the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation. As the project advances, we will enhance the model, expand the dataset used for emotion recognition, and use the model in a live system.
Author Contributions
Conceptualization, Y.Y., H.D., H.T. and T.A.; methodology, H.D.; software, H.D.; validation, H.D. and Y.Y.; formal analysis, Y.Y.; investigation, Y.Y.; resources, H.T. and T.A.; data curation, H.T. and T.A.; writing—original draft preparation, H.D.; writing—review and editing, Y.Y., H.D., H.T. and T.A.; visualization, Y.Y.; supervision, Y.Y., H.D., H.T. and T.A.; project administration, H.T., Y.Y. and T.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets presented in this article are not readily available because of the Law of Personal Data Protection Authority. Requests to access the datasets should be directed to the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation.
Acknowledgments
This paper is a result of an ongoing project between Sakarya University and the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation. We thank the “Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri” Incorporation for the call center conversations data.
Conflicts of Interest
Authors Hüseyin Tiryaki and Tekin Altun were employed by the company Turkcell Global Bilgi Pazarlama Danışmanlık ve Çağrı Servisi Hizmetleri Inc. Yüksel Yurtay and Hüseyin Demirci declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Solomon, R. Emotion|Definition, Examples, Scope, Structures, & Facts; Britannica: Edinburgh, UK, 2024. [Google Scholar]
- Balzer, W.; Sneed, J.D.; Moulines, C.U. Structuralist Knowledge Representation: Paradigmatic Examples; BRILL: Leiden, The Netherlands, 2000. [Google Scholar] [CrossRef]
- Berridge, K.C. Affective valence in the brain: Modules or modes? Nat. Rev. Neurosci. 2019, 20, 225–234. [Google Scholar] [CrossRef] [PubMed]
- Anusha, V.; Sandhya, B. A Learning Based Emotion Classifier with Semantic Text Processing. In Proceedings of the Advances in Intelligent Informatics, Hyderabad, India, 28–30 November 2015; El-Alfy, E.S.M., Thampi, S.M., Takagi, H., Piramuthu, S., Hanne, T., Eds.; Springer: Cham, Switzerland, 2015; pp. 371–382. [Google Scholar] [CrossRef]
- Sebe, N.; Cohen, I.; Gevers, T.; Huang, T.S. Multimodal Approaches for Emotion Recognition: A Survey; SPIE: San Jose, CA, USA, 2005; pp. 56–67. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- Ashraf, A.B.; Lucey, S.; Cohn, J.F.; Chen, T.; Ambadar, Z.; Prkachin, K.M.; Solomon, P.E. The painful face—Pain expression recognition using active appearance models. Image Vis. Comput. 2009, 27, 1788–1796. [Google Scholar] [CrossRef] [PubMed]
- Littlewort, G.C.; Bartlett, M.S.; Lee, K. Automatic coding of facial expressions displayed during posed and genuine pain. Image Vis. Comput. 2009, 27, 1797–1803. [Google Scholar] [CrossRef]
- Ryan, A.; Cohn, J.F.; Lucey, S.; Saragih, J.; Lucey, P.; De la Torre, F.; Rossi, A. Automated Facial Expression Recognition System. In Proceedings of the 43rd Annual 2009 International Carnahan Conference on Security Technology, Zurich, Switzerland, 5–8 October 2009; pp. 172–177, ISSN 2153-0742. [Google Scholar] [CrossRef]
- Wren, H. What Is a Call Center? Definition, Types, and How They Work. 2021. Available online: https://www.zendesk.com/blog/ultimate-guide-call-centers/ (accessed on 14 October 2024).
- Gunes, H.; Pantic, M. Automatic, Dimensional and Continuous Emotion Recognition. Int. J. Synth. Emot. 2010, 1, 68–99. [Google Scholar] [CrossRef]
- Patil, S.; Kharate, G.K. A Review on Emotional Speech Recognition: Resources, Features, and Classifiers. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; pp. 669–674. [Google Scholar] [CrossRef]
- France, D.; Shiavi, R.; Silverman, S.; Silverman, M.; Wilkes, M. Acoustical properties of speech as indicators of depression and suicidal risk. IEEE Trans. Biomed. Eng. 2000, 47, 829–837. [Google Scholar] [CrossRef]
- Mikuckas, A.; Mikuckiene, I.; Venckauskas, A.; Kazanavicius, E.; Lukas, R.; Plauska, I. Emotion Recognition in Human Computer Interaction Systems. Elektron. Elektrotechnika 2014, 20, 51–56. [Google Scholar] [CrossRef]
- Nicholson, J.; Takahashi, K.; Nakatsu, R. Emotion Recognition in Speech Using Neural Networks. Neural Comput. Appl. 2000, 9, 290–296. [Google Scholar] [CrossRef]
- Yoon, W.J.; Cho, Y.H.; Park, K.S. A Study of Speech Emotion Recognition and Its Application to Mobile Services. In Ubiquitous Intelligence and Computing; Indulska, J., Ma, J., Yang, L.T., Ungerer, T., Cao, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4611, pp. 758–766. [Google Scholar] [CrossRef]
- Falk, T.; Wai-Yip, C. Modulation Spectral Features for Robust Far-Field Speaker Identification. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 90–100. [Google Scholar] [CrossRef]
- Ma, C.; Prendinger, H.; Ishizuka, M. Emotion Estimation and Reasoning Based on Affective Textual Interaction. In Proceedings of the Affective Computing and Intelligent Interaction, Beijing, China, 22–24 October 2005; Tao, J., Tan, T., Picard, R.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 622–628. [Google Scholar] [CrossRef]
- Perikos, I.; Hatzilygeroudis, I. Recognizing Emotion Presence in Natural Language Sentences. In Proceedings of the Engineering Applications of Neural Networks, Halkidiki, Greece, 13–16 September 2013; Iliadis, L., Papadopoulos, H., Jayne, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 30–39. [Google Scholar] [CrossRef]
- Shivhare, S.N.; Garg, S.; Mishra, A. EmotionFinder: Detecting emotion from blogs and textual documents. In Proceedings of the Communication & Automation International Conference on Computing, Pune, India, 26–27 February 2015; pp. 52–57. [Google Scholar] [CrossRef]
- Tao, J. Context based emotion detection from text input. In Proceedings of the INTERSPEECH 2004—ICSLP 8th International Conference on Spoken Language Processing ICC Jeju, Jeju Island, Republic of Korea, 4–8 October 2004; pp. 1337–1340. [Google Scholar] [CrossRef]
- Lee, S.Y.M.; Chen, Y.; Huang, C.R. A Text-driven Rule-based System for Emotion Cause Detection. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; Inkpen, D., Strapparava, C., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 45–53. [Google Scholar]
- Udochukwu, O.; He, Y. A Rule-Based Approach to Implicit Emotion Detection in Text. In Proceedings of the Natural Language Processing and Information Systems, Passau, Germany, 17–19 June 2015; Biemann, C., Handschuh, S., Freitas, A., Meziane, F., Métais, E., Eds.; Springer: Cham, Switzerland, 2015; pp. 197–203. [Google Scholar] [CrossRef]
- Alm, C.O.; Roth, D.; Sproat, R. Emotions from Text: Machine Learning for Text-based Emotion Prediction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 579–586. [Google Scholar]
- Aman, S.; Szpakowicz, S. Identifying Expressions of Emotion in Text. In Proceedings of the Text, Speech and Dialogue, Pilsen, Czech Republic, 3–7 September 2007; Matoušek, V., Mautner, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 196–205. [Google Scholar] [CrossRef]
- Rajalakshmi, S.; Rajendram, S.M.; Mirnalinee, T.T. SSN MLRG1 at SemEval-2018 Task 1: Emotion and Sentiment Intensity Detection Using Rule Based Feature Selection. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 324–328. [Google Scholar] [CrossRef]
- Basile, A.; Franco-Salvador, M.; Pawar, N.; Štajner, S.; Chinea Rios, M.; Benajiba, Y. SymantoResearch at SemEval-2019 Task 3: Combined Neural Models for Emotion Classification in Human-Chatbot Conversations. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 330–334. [Google Scholar] [CrossRef]
- Baziotis, C.; Nikolaos, A.; Chronopoulou, A.; Kolovou, A.; Paraskevopoulos, G.; Ellinas, N.; Narayanan, S.; Potamianos, A. NTUA-SLP at SemEval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive RNNs and Transfer Learning. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 245–255. [Google Scholar] [CrossRef]
- Ge, S.; Qi, T.; Wu, C.; Huang, Y. THU_NGN at SemEval-2019 Task 3: Dialog Emotion Classification using Attentional LSTM-CNN. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 340–344. [Google Scholar] [CrossRef]
- Li, M.; Dong, Z.; Fan, Z.; Meng, K.; Cao, J.; Ding, G.; Liu, Y.; Shan, J.; Li, B. ISCLAB at SemEval-2018 Task 1: UIR-Miner for Affect in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 286–290. [Google Scholar] [CrossRef]
- Amelia, W.; Maulidevi, N.U. Dominant emotion recognition in short story using keyword spotting technique and learning-based method. In Proceedings of the 2016 International Conference On Advanced Informatics: Concepts, Theory and Application (ICAICTA), Penang, Malaysia, 16–19 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Gee, G.; Wang, E. psyML at SemEval-2018 Task 1: Transfer Learning for Sentiment and Emotion Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 369–376. [Google Scholar] [CrossRef]
- Gievska, S.; Koroveshovski, K.; Chavdarova, T. A Hybrid Approach for Emotion Detection in Support of Affective Interaction. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 352–359, ISSN 2375-9259. [Google Scholar] [CrossRef]
- Haggag, M. Frame Semantics Evolutionary Model for Emotion Detection. Comput. Inf. Sci. 2014, 7, 136. [Google Scholar] [CrossRef]
- Ragheb, W.; Azé, J.; Bringay, S.; Servajean, M. LIRMM-Advanse at SemEval-2019 Task 3: Attentive Conversation Modeling for Emotion Detection and Classification. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 251–255. [Google Scholar] [CrossRef]
- Du, P.; Nie, J.Y. Mutux at SemEval-2018 Task 1: Exploring Impacts of Context Information On Emotion Detection. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 345–349. [Google Scholar] [CrossRef]
- Ezen-Can, A.; Can, E.F. RNN for Affects at SemEval-2018 Task 1: Formulating Affect Identification as a Binary Classification Problem. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 162–166. [Google Scholar] [CrossRef]
- Ma, L.; Zhang, L.; Ye, W.; Hu, W. PKUSE at SemEval-2019 Task 3: Emotion Detection with Emotion-Oriented Neural Attention Network. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 287–291. [Google Scholar] [CrossRef]
- Meisheri, H.; Dey, L. TCS Research at SemEval-2018 Task 1: Learning Robust Representations using Multi-Attention Architecture. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 291–299. [Google Scholar] [CrossRef]
- Rathnayaka, P.; Abeysinghe, S.; Samarajeewa, C.; Manchanayake, I.; Walpola, M.J.; Nawaratne, R.; Bandaragoda, T.; Alahakoon, D. Gated Recurrent Neural Network Approach for Multilabel Emotion Detection in Microblogs. arXiv 2019, arXiv:1907.07653. [Google Scholar] [CrossRef]
- Seyeditabari, A.; Tabari, N.; Gholizadeh, S.; Zadrozny, W. Emotion Detection in Text: Focusing on Latent Representation. arXiv 2019, arXiv:1907.09369. [Google Scholar] [CrossRef]
- Shrivastava, K.; Kumar, S.; Jain, D.K. An effective approach for emotion detection in multimedia text data using sequence based convolutional neural network. Multimed. Tools Appl. 2019, 78, 29607–29639. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, S.; Wang, D.; Yu, G.; Zhang, Y. Multi-label Chinese Microblog Emotion Classification via Convolutional Neural Network. In Proceedings of the Web Technologies and Applications, Suzhou, China, 23–25 September 2016; Li, F., Shim, K., Zheng, K., Liu, G., Eds.; Springer: Cham, Switzerland, 2016; pp. 567–580. [Google Scholar] [CrossRef]
- Xiao, J. Figure Eight at SemEval-2019 Task 3: Ensemble of Transfer Learning Methods for Contextual Emotion Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 220–224. [Google Scholar] [CrossRef]
- Issa, D.; Fatih Demirci, M.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Dujaili, M.J.A.; Ebrahimi-Moghadam, A.; Fatlawi, A. Speech emotion recognition based on SVM and KNN classifications fusion. Int. J. Electr. Comput. Eng. (IJECE) 2021, 11, 1259–1264. [Google Scholar] [CrossRef]
- Sun, L.; Zou, B.; Fu, S.; Chen, J.; Wang, F. Speech emotion recognition based on DNN-decision tree SVM model. Speech Commun. 2019, 115, 29–37. [Google Scholar] [CrossRef]
- Venkataramanan, K.; Rajamohan, H.R. Emotion Recognition from Speech. arXiv 2019, arXiv:1912.10458. [Google Scholar] [CrossRef]
- Mao, S.; Tao, D.; Zhang, G.; Ching, P.C.; Lee, T. Revisiting Hidden Markov Models for Speech Emotion Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6715–6719. [Google Scholar] [CrossRef]
- Praseetha, V.M.; Joby, P.P. Speech emotion recognition using data augmentation. Int. J. Speech Technol. 2022, 25, 783–792. [Google Scholar] [CrossRef]
- Zimmermann, M.; Ghazi, M.M.; Ekenel, H.K.; Thiran, J.P. Visual Speech Recognition Using PCA Networks and LSTMs in a Tandem GMM-HMM System; Springer: Cham, Switzerland, 2017; Volume 10117, pp. 264–276, arXiv:1710.07161. [Google Scholar]
- Palo, H.K.; Chandra, M.; Mohanty, M.N. Emotion recognition using MLP and GMM for Oriya language. Int. J. Comput. Vis. Robot. 2017, 7, 426. [Google Scholar] [CrossRef]
- Patnaik, S. Speech emotion recognition by using complex MFCC and deep sequential model. Multimed. Tools Appl. 2023, 82, 11897–11922. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Wang, C.; Ren, Y.; Zhang, N.; Cui, F.; Luo, S. Speech emotion recognition based on multi-feature and multi-lingual fusion. Multimed. Tools Appl. 2022, 81, 4897–4907. [Google Scholar] [CrossRef]
- Mao, J.W.; He, Y.; Liu, Z.T. Speech Emotion Recognition Based on Linear Discriminant Analysis and Support Vector Machine Decision Tree. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5529–5533, ISSN 1934-1768. [Google Scholar] [CrossRef]
- Juanjuan, Z.; Ruiliang, M.; Xiaolong, Z. Speech emotion recognition based on decision tree and improved SVM mixed model. Trans. Beijing Inst. Technol. 2017, 37, 386–390+395. [Google Scholar] [CrossRef]
- Jacob, A. Modelling speech emotion recognition using logistic regression and decision trees. Int. J. Speech Technol. 2017, 20, 897–905. [Google Scholar] [CrossRef]
- Waghmare, V.B.; Deshmukh, R.R.; Janvale, G.B. Emotions Recognition from Spoken Marathi Speech Using LPC and PCA Technique. In New Trends in Computational Vision and Bio-Inspired Computing: Selected Works Presented at the ICCVBIC 2018, Coimbatore, India; Smys, S., Iliyasu, A.M., Bestak, R., Shi, F., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 81–88. [Google Scholar] [CrossRef]
- Lingampeta, D.; Yalamanchili, B. Human Emotion Recognition using Acoustic Features with Optimized Feature Selection and Fusion Techniques. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 221–225. [Google Scholar] [CrossRef]
- Kurpukdee, N.; Koriyama, T.; Kobayashi, T.; Kasuriya, S.; Wutiwiwatchai, C.; Lamsrichan, P. Speech emotion recognition using convolutional long short-term memory neural network and support vector machines. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1744–1749. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, L. An investigation of speech-based human emotion recognition. In Proceedings of the IEEE 6th Workshop on Multimedia Signal Processing, Siena, Italy, 29 September–1 October 2004; pp. 15–18. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. continuous speech emotion recognition with convolutional neural networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech Emotion Classification Using Attention-Based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Abdul Qayyum, A.B.; Arefeen, A.; Shahnaz, C. Convolutional Neural Network (CNN) Based Speech-Emotion Recognition. In Proceedings of the 2019 IEEE International Conference on Signal Processing, Information, Communication & Systems (SPICSCON), Dhaka, Bangladesh, 28–30 November 2019; pp. 122–125. [Google Scholar] [CrossRef]
- Nam, Y.; Lee, C. Cascaded Convolutional Neural Network Architecture for Speech Emotion Recognition in Noisy Conditions. Sensors 2021, 21, 4399. [Google Scholar] [CrossRef]
- Christy, A.; Vaithyasubramanian, S.; Jesudoss, A.; Praveena, M.D.A. Multimodal speech emotion recognition and classification using convolutional neural network techniques. Int. J. Speech Technol. 2020, 23, 381–388. [Google Scholar] [CrossRef]
- Yao, Z.; Wang, Z.; Liu, W.; Liu, Y.; Pan, J. Speech emotion recognition using fusion of three multi-task learning-based classifiers: HSF-DNN, MS-CNN and LLD-RNN. Speech Commun. 2020, 120, 11–19. [Google Scholar] [CrossRef]
- Alghifari, M.F.; Gunawan, T.S.; Kartiwi, M. Speech Emotion Recognition Using Deep Feedforward Neural Network. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 554. [Google Scholar] [CrossRef]
- Rejaibi, E.; Komaty, A.; Meriaudeau, F.; Agrebi, S.; Othmani, A. MFCC-based Recurrent Neural Network for automatic clinical depression recognition and assessment from speech. Biomed. Signal Process. Control 2022, 71, 103107. [Google Scholar] [CrossRef]
- Zheng, H.; Yang, Y. An Improved Speech Emotion Recognition Algorithm Based on Deep Belief Network. In Proceedings of the 2019 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 12–14 July 2019; pp. 493–497. [Google Scholar] [CrossRef]
- Valiyavalappil Haridas, A.; Marimuthu, R.; Sivakumar, V.G.; Chakraborty, B. Emotion recognition of speech signal using Taylor series and deep belief network based classification. Evol. Intell. 2022, 15, 1145–1158. [Google Scholar] [CrossRef]
- Huang, C.; Gong, W.; Fu, W.; Feng, D. A Research of Speech Emotion Recognition Based on Deep Belief Network and SVM. Math. Probl. Eng. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Poon-Feng, K.; Huang, D.Y.; Dong, M.; Li, H. Acoustic emotion recognition based on fusion of multiple feature-dependent deep Boltzmann machines. In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, Singapore, 12–14 September 2014; pp. 584–588. [Google Scholar] [CrossRef]
- Bautista, J.L.; Lee, Y.K.; Shin, H.S. Speech Emotion Recognition Based on Parallel CNN-Attention Networks with Multi-Fold Data Augmentation. Electronics 2022, 11, 3935. [Google Scholar] [CrossRef]
- Quck, W.Y.; Huang, D.Y.; Lin, W.; Li, H.; Dong, M. Mobile acoustic Emotion Recognition. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 170–174, ISSN 2159-3450. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Akagi, M. Speech Emotion Recognition Based on Speech Segment Using LSTM with Attention Model. In Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 40–44. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Kaya, H.; Fedotov, D.; Yeşilkanat, A.; Verkholyak, O.; Zhang, Y.; Karpov, A. LSTM Based Cross-corpus and Cross-task Acoustic Emotion Recognition. In Proceedings of the Interspeech 2018. ISCA, Los Angeles, CA, USA, 2–6 June 2018; pp. 521–525. [Google Scholar] [CrossRef]
- Lokesh, S.; Devi, M.R. Speech recognition system using enhanced mel frequency cepstral coefficient with windowing and framing method. Clust. Comput. 2019, 22, 11669–11679. [Google Scholar] [CrossRef]
- Yang, Z.; Huang, Y. Algorithm for speech emotion recognition classification based on Mel-frequency Cepstral coefficients and broad learning system. Evol. Intell. 2022, 15, 2485–2494. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).