
Emotion Recognition on Call Center Voice Data


Abstract
1. Introduction
- Pleasure–Displeasure: This dimension encompasses subjective sensations of positivity or negativity. It encompasses happiness, contentment, sadness, and anger.
- Tension–Relaxation: This dimension delineates the physiological arousal or tension associated with an emotion. Emotions encompass fear, excitement, relief, and serenity.
- Excitement–Calm: Assesses the intensity of a feeling’s excitement or tranquility. Joy, surprise, boredom, and fatigue are all components of it.
2. Related Work
2.1. Deep Learning Approaches in Text-Based Emotion Recognition
2.2. Deep Learning Approaches in Voice-Based Emotion Recognition
3. Materials and Methods
3.1. Dataset Properties
| • | “bir” | (one) | (213,794 times) |
| • | “ve” | (and) | (180,040 times) |
| • | “çok” | (very) | (147,731 times) |
| • | “bu” | (this) | (103,081 times) |
| • | “için” | (for) | (64,202 times) |
| • | “ürün” | (product) | (57,019 times) |
| • | “daha” | (more) | (53,731 times) |
| • | “ama” | (but) | (52,372 times) |
| • | “da” | (also) | (50,740 times) |
3.2. Text-Based Classification Model and Analysis of Its Layers
3.2.1. The Embedding Layer
3.2.2. Bidirectional GRU Layer
3.2.3. Attention Mechanism
3.2.4. Flatten and Dense Layers
3.2.5. Text-Based Classification Model Training
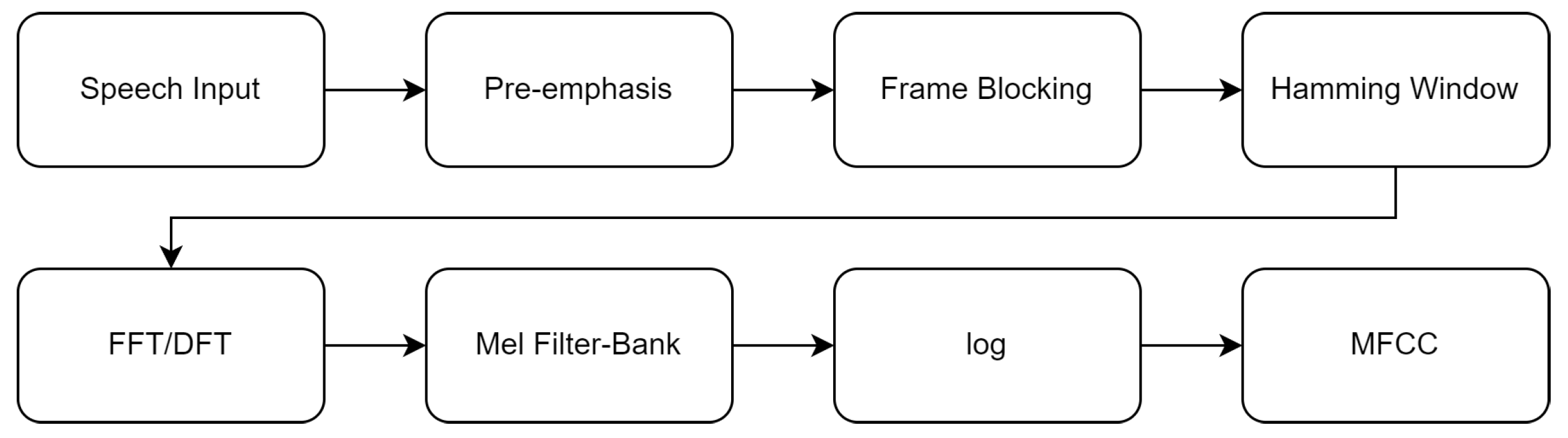
3.3. Voice-Based Classification
Voice-Based Model and Test Processes
3.4. Integrated Sentiment Analysis
3.4.1. Weighting with Deterministic Approach
3.4.2. Re-Labeling and Re-Training with Logistic Regression
4. Results and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Solomon, R. Emotion|Definition, Examples, Scope, Structures, & Facts; Britannica: Edinburgh, UK, 2024. [Google Scholar]
- Balzer, W.; Sneed, J.D.; Moulines, C.U. Structuralist Knowledge Representation: Paradigmatic Examples; BRILL: Leiden, The Netherlands, 2000. [Google Scholar] [CrossRef]
- Berridge, K.C. Affective valence in the brain: Modules or modes? Nat. Rev. Neurosci. 2019, 20, 225–234. [Google Scholar] [CrossRef] [PubMed]
- Anusha, V.; Sandhya, B. A Learning Based Emotion Classifier with Semantic Text Processing. In Proceedings of the Advances in Intelligent Informatics, Hyderabad, India, 28–30 November 2015; El-Alfy, E.S.M., Thampi, S.M., Takagi, H., Piramuthu, S., Hanne, T., Eds.; Springer: Cham, Switzerland, 2015; pp. 371–382. [Google Scholar] [CrossRef]
- Sebe, N.; Cohen, I.; Gevers, T.; Huang, T.S. Multimodal Approaches for Emotion Recognition: A Survey; SPIE: San Jose, CA, USA, 2005; pp. 56–67. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- Ashraf, A.B.; Lucey, S.; Cohn, J.F.; Chen, T.; Ambadar, Z.; Prkachin, K.M.; Solomon, P.E. The painful face—Pain expression recognition using active appearance models. Image Vis. Comput. 2009, 27, 1788–1796. [Google Scholar] [CrossRef] [PubMed]
- Littlewort, G.C.; Bartlett, M.S.; Lee, K. Automatic coding of facial expressions displayed during posed and genuine pain. Image Vis. Comput. 2009, 27, 1797–1803. [Google Scholar] [CrossRef]
- Ryan, A.; Cohn, J.F.; Lucey, S.; Saragih, J.; Lucey, P.; De la Torre, F.; Rossi, A. Automated Facial Expression Recognition System. In Proceedings of the 43rd Annual 2009 International Carnahan Conference on Security Technology, Zurich, Switzerland, 5–8 October 2009; pp. 172–177, ISSN 2153-0742. [Google Scholar] [CrossRef]
- Wren, H. What Is a Call Center? Definition, Types, and How They Work. 2021. Available online: https://www.zendesk.com/blog/ultimate-guide-call-centers/ (accessed on 14 October 2024).
- Gunes, H.; Pantic, M. Automatic, Dimensional and Continuous Emotion Recognition. Int. J. Synth. Emot. 2010, 1, 68–99. [Google Scholar] [CrossRef]
- Patil, S.; Kharate, G.K. A Review on Emotional Speech Recognition: Resources, Features, and Classifiers. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 30–31 October 2020; pp. 669–674. [Google Scholar] [CrossRef]
- France, D.; Shiavi, R.; Silverman, S.; Silverman, M.; Wilkes, M. Acoustical properties of speech as indicators of depression and suicidal risk. IEEE Trans. Biomed. Eng. 2000, 47, 829–837. [Google Scholar] [CrossRef]
- Mikuckas, A.; Mikuckiene, I.; Venckauskas, A.; Kazanavicius, E.; Lukas, R.; Plauska, I. Emotion Recognition in Human Computer Interaction Systems. Elektron. Elektrotechnika 2014, 20, 51–56. [Google Scholar] [CrossRef]
- Nicholson, J.; Takahashi, K.; Nakatsu, R. Emotion Recognition in Speech Using Neural Networks. Neural Comput. Appl. 2000, 9, 290–296. [Google Scholar] [CrossRef]
- Yoon, W.J.; Cho, Y.H.; Park, K.S. A Study of Speech Emotion Recognition and Its Application to Mobile Services. In Ubiquitous Intelligence and Computing; Indulska, J., Ma, J., Yang, L.T., Ungerer, T., Cao, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4611, pp. 758–766. [Google Scholar] [CrossRef]
- Falk, T.; Wai-Yip, C. Modulation Spectral Features for Robust Far-Field Speaker Identification. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 90–100. [Google Scholar] [CrossRef]
- Ma, C.; Prendinger, H.; Ishizuka, M. Emotion Estimation and Reasoning Based on Affective Textual Interaction. In Proceedings of the Affective Computing and Intelligent Interaction, Beijing, China, 22–24 October 2005; Tao, J., Tan, T., Picard, R.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 622–628. [Google Scholar] [CrossRef]
- Perikos, I.; Hatzilygeroudis, I. Recognizing Emotion Presence in Natural Language Sentences. In Proceedings of the Engineering Applications of Neural Networks, Halkidiki, Greece, 13–16 September 2013; Iliadis, L., Papadopoulos, H., Jayne, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 30–39. [Google Scholar] [CrossRef]
- Shivhare, S.N.; Garg, S.; Mishra, A. EmotionFinder: Detecting emotion from blogs and textual documents. In Proceedings of the Communication & Automation International Conference on Computing, Pune, India, 26–27 February 2015; pp. 52–57. [Google Scholar] [CrossRef]
- Tao, J. Context based emotion detection from text input. In Proceedings of the INTERSPEECH 2004—ICSLP 8th International Conference on Spoken Language Processing ICC Jeju, Jeju Island, Republic of Korea, 4–8 October 2004; pp. 1337–1340. [Google Scholar] [CrossRef]
- Lee, S.Y.M.; Chen, Y.; Huang, C.R. A Text-driven Rule-based System for Emotion Cause Detection. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; Inkpen, D., Strapparava, C., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 45–53. [Google Scholar]
- Udochukwu, O.; He, Y. A Rule-Based Approach to Implicit Emotion Detection in Text. In Proceedings of the Natural Language Processing and Information Systems, Passau, Germany, 17–19 June 2015; Biemann, C., Handschuh, S., Freitas, A., Meziane, F., Métais, E., Eds.; Springer: Cham, Switzerland, 2015; pp. 197–203. [Google Scholar] [CrossRef]
- Alm, C.O.; Roth, D.; Sproat, R. Emotions from Text: Machine Learning for Text-based Emotion Prediction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 579–586. [Google Scholar]
- Aman, S.; Szpakowicz, S. Identifying Expressions of Emotion in Text. In Proceedings of the Text, Speech and Dialogue, Pilsen, Czech Republic, 3–7 September 2007; Matoušek, V., Mautner, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 196–205. [Google Scholar] [CrossRef]
- Rajalakshmi, S.; Rajendram, S.M.; Mirnalinee, T.T. SSN MLRG1 at SemEval-2018 Task 1: Emotion and Sentiment Intensity Detection Using Rule Based Feature Selection. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 324–328. [Google Scholar] [CrossRef]
- Basile, A.; Franco-Salvador, M.; Pawar, N.; Štajner, S.; Chinea Rios, M.; Benajiba, Y. SymantoResearch at SemEval-2019 Task 3: Combined Neural Models for Emotion Classification in Human-Chatbot Conversations. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 330–334. [Google Scholar] [CrossRef]
- Baziotis, C.; Nikolaos, A.; Chronopoulou, A.; Kolovou, A.; Paraskevopoulos, G.; Ellinas, N.; Narayanan, S.; Potamianos, A. NTUA-SLP at SemEval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive RNNs and Transfer Learning. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 245–255. [Google Scholar] [CrossRef]
- Ge, S.; Qi, T.; Wu, C.; Huang, Y. THU_NGN at SemEval-2019 Task 3: Dialog Emotion Classification using Attentional LSTM-CNN. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 340–344. [Google Scholar] [CrossRef]
- Li, M.; Dong, Z.; Fan, Z.; Meng, K.; Cao, J.; Ding, G.; Liu, Y.; Shan, J.; Li, B. ISCLAB at SemEval-2018 Task 1: UIR-Miner for Affect in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 286–290. [Google Scholar] [CrossRef]
- Amelia, W.; Maulidevi, N.U. Dominant emotion recognition in short story using keyword spotting technique and learning-based method. In Proceedings of the 2016 International Conference On Advanced Informatics: Concepts, Theory and Application (ICAICTA), Penang, Malaysia, 16–19 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Gee, G.; Wang, E. psyML at SemEval-2018 Task 1: Transfer Learning for Sentiment and Emotion Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 369–376. [Google Scholar] [CrossRef]
- Gievska, S.; Koroveshovski, K.; Chavdarova, T. A Hybrid Approach for Emotion Detection in Support of Affective Interaction. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 352–359, ISSN 2375-9259. [Google Scholar] [CrossRef]
- Haggag, M. Frame Semantics Evolutionary Model for Emotion Detection. Comput. Inf. Sci. 2014, 7, 136. [Google Scholar] [CrossRef]
- Ragheb, W.; Azé, J.; Bringay, S.; Servajean, M. LIRMM-Advanse at SemEval-2019 Task 3: Attentive Conversation Modeling for Emotion Detection and Classification. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 251–255. [Google Scholar] [CrossRef]
- Du, P.; Nie, J.Y. Mutux at SemEval-2018 Task 1: Exploring Impacts of Context Information On Emotion Detection. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 345–349. [Google Scholar] [CrossRef]
- Ezen-Can, A.; Can, E.F. RNN for Affects at SemEval-2018 Task 1: Formulating Affect Identification as a Binary Classification Problem. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 162–166. [Google Scholar] [CrossRef]
- Ma, L.; Zhang, L.; Ye, W.; Hu, W. PKUSE at SemEval-2019 Task 3: Emotion Detection with Emotion-Oriented Neural Attention Network. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 287–291. [Google Scholar] [CrossRef]
- Meisheri, H.; Dey, L. TCS Research at SemEval-2018 Task 1: Learning Robust Representations using Multi-Attention Architecture. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 291–299. [Google Scholar] [CrossRef]
- Rathnayaka, P.; Abeysinghe, S.; Samarajeewa, C.; Manchanayake, I.; Walpola, M.J.; Nawaratne, R.; Bandaragoda, T.; Alahakoon, D. Gated Recurrent Neural Network Approach for Multilabel Emotion Detection in Microblogs. arXiv 2019, arXiv:1907.07653. [Google Scholar] [CrossRef]
- Seyeditabari, A.; Tabari, N.; Gholizadeh, S.; Zadrozny, W. Emotion Detection in Text: Focusing on Latent Representation. arXiv 2019, arXiv:1907.09369. [Google Scholar] [CrossRef]
- Shrivastava, K.; Kumar, S.; Jain, D.K. An effective approach for emotion detection in multimedia text data using sequence based convolutional neural network. Multimed. Tools Appl. 2019, 78, 29607–29639. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, S.; Wang, D.; Yu, G.; Zhang, Y. Multi-label Chinese Microblog Emotion Classification via Convolutional Neural Network. In Proceedings of the Web Technologies and Applications, Suzhou, China, 23–25 September 2016; Li, F., Shim, K., Zheng, K., Liu, G., Eds.; Springer: Cham, Switzerland, 2016; pp. 567–580. [Google Scholar] [CrossRef]
- Xiao, J. Figure Eight at SemEval-2019 Task 3: Ensemble of Transfer Learning Methods for Contextual Emotion Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2017; pp. 220–224. [Google Scholar] [CrossRef]
- Issa, D.; Fatih Demirci, M.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Dujaili, M.J.A.; Ebrahimi-Moghadam, A.; Fatlawi, A. Speech emotion recognition based on SVM and KNN classifications fusion. Int. J. Electr. Comput. Eng. (IJECE) 2021, 11, 1259–1264. [Google Scholar] [CrossRef]
- Sun, L.; Zou, B.; Fu, S.; Chen, J.; Wang, F. Speech emotion recognition based on DNN-decision tree SVM model. Speech Commun. 2019, 115, 29–37. [Google Scholar] [CrossRef]
- Venkataramanan, K.; Rajamohan, H.R. Emotion Recognition from Speech. arXiv 2019, arXiv:1912.10458. [Google Scholar] [CrossRef]
- Mao, S.; Tao, D.; Zhang, G.; Ching, P.C.; Lee, T. Revisiting Hidden Markov Models for Speech Emotion Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6715–6719. [Google Scholar] [CrossRef]
- Praseetha, V.M.; Joby, P.P. Speech emotion recognition using data augmentation. Int. J. Speech Technol. 2022, 25, 783–792. [Google Scholar] [CrossRef]
- Zimmermann, M.; Ghazi, M.M.; Ekenel, H.K.; Thiran, J.P. Visual Speech Recognition Using PCA Networks and LSTMs in a Tandem GMM-HMM System; Springer: Cham, Switzerland, 2017; Volume 10117, pp. 264–276, arXiv:1710.07161. [Google Scholar]
- Palo, H.K.; Chandra, M.; Mohanty, M.N. Emotion recognition using MLP and GMM for Oriya language. Int. J. Comput. Vis. Robot. 2017, 7, 426. [Google Scholar] [CrossRef]
- Patnaik, S. Speech emotion recognition by using complex MFCC and deep sequential model. Multimed. Tools Appl. 2023, 82, 11897–11922. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Wang, C.; Ren, Y.; Zhang, N.; Cui, F.; Luo, S. Speech emotion recognition based on multi-feature and multi-lingual fusion. Multimed. Tools Appl. 2022, 81, 4897–4907. [Google Scholar] [CrossRef]
- Mao, J.W.; He, Y.; Liu, Z.T. Speech Emotion Recognition Based on Linear Discriminant Analysis and Support Vector Machine Decision Tree. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5529–5533, ISSN 1934-1768. [Google Scholar] [CrossRef]
- Juanjuan, Z.; Ruiliang, M.; Xiaolong, Z. Speech emotion recognition based on decision tree and improved SVM mixed model. Trans. Beijing Inst. Technol. 2017, 37, 386–390+395. [Google Scholar] [CrossRef]
- Jacob, A. Modelling speech emotion recognition using logistic regression and decision trees. Int. J. Speech Technol. 2017, 20, 897–905. [Google Scholar] [CrossRef]
- Waghmare, V.B.; Deshmukh, R.R.; Janvale, G.B. Emotions Recognition from Spoken Marathi Speech Using LPC and PCA Technique. In New Trends in Computational Vision and Bio-Inspired Computing: Selected Works Presented at the ICCVBIC 2018, Coimbatore, India; Smys, S., Iliyasu, A.M., Bestak, R., Shi, F., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 81–88. [Google Scholar] [CrossRef]
- Lingampeta, D.; Yalamanchili, B. Human Emotion Recognition using Acoustic Features with Optimized Feature Selection and Fusion Techniques. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 221–225. [Google Scholar] [CrossRef]
- Kurpukdee, N.; Koriyama, T.; Kobayashi, T.; Kasuriya, S.; Wutiwiwatchai, C.; Lamsrichan, P. Speech emotion recognition using convolutional long short-term memory neural network and support vector machines. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1744–1749. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, L. An investigation of speech-based human emotion recognition. In Proceedings of the IEEE 6th Workshop on Multimedia Signal Processing, Siena, Italy, 29 September–1 October 2004; pp. 15–18. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. continuous speech emotion recognition with convolutional neural networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech Emotion Classification Using Attention-Based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Abdul Qayyum, A.B.; Arefeen, A.; Shahnaz, C. Convolutional Neural Network (CNN) Based Speech-Emotion Recognition. In Proceedings of the 2019 IEEE International Conference on Signal Processing, Information, Communication & Systems (SPICSCON), Dhaka, Bangladesh, 28–30 November 2019; pp. 122–125. [Google Scholar] [CrossRef]
- Nam, Y.; Lee, C. Cascaded Convolutional Neural Network Architecture for Speech Emotion Recognition in Noisy Conditions. Sensors 2021, 21, 4399. [Google Scholar] [CrossRef]
- Christy, A.; Vaithyasubramanian, S.; Jesudoss, A.; Praveena, M.D.A. Multimodal speech emotion recognition and classification using convolutional neural network techniques. Int. J. Speech Technol. 2020, 23, 381–388. [Google Scholar] [CrossRef]
- Yao, Z.; Wang, Z.; Liu, W.; Liu, Y.; Pan, J. Speech emotion recognition using fusion of three multi-task learning-based classifiers: HSF-DNN, MS-CNN and LLD-RNN. Speech Commun. 2020, 120, 11–19. [Google Scholar] [CrossRef]
- Alghifari, M.F.; Gunawan, T.S.; Kartiwi, M. Speech Emotion Recognition Using Deep Feedforward Neural Network. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 554. [Google Scholar] [CrossRef]
- Rejaibi, E.; Komaty, A.; Meriaudeau, F.; Agrebi, S.; Othmani, A. MFCC-based Recurrent Neural Network for automatic clinical depression recognition and assessment from speech. Biomed. Signal Process. Control 2022, 71, 103107. [Google Scholar] [CrossRef]
- Zheng, H.; Yang, Y. An Improved Speech Emotion Recognition Algorithm Based on Deep Belief Network. In Proceedings of the 2019 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 12–14 July 2019; pp. 493–497. [Google Scholar] [CrossRef]
- Valiyavalappil Haridas, A.; Marimuthu, R.; Sivakumar, V.G.; Chakraborty, B. Emotion recognition of speech signal using Taylor series and deep belief network based classification. Evol. Intell. 2022, 15, 1145–1158. [Google Scholar] [CrossRef]
- Huang, C.; Gong, W.; Fu, W.; Feng, D. A Research of Speech Emotion Recognition Based on Deep Belief Network and SVM. Math. Probl. Eng. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Poon-Feng, K.; Huang, D.Y.; Dong, M.; Li, H. Acoustic emotion recognition based on fusion of multiple feature-dependent deep Boltzmann machines. In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, Singapore, 12–14 September 2014; pp. 584–588. [Google Scholar] [CrossRef]
- Bautista, J.L.; Lee, Y.K.; Shin, H.S. Speech Emotion Recognition Based on Parallel CNN-Attention Networks with Multi-Fold Data Augmentation. Electronics 2022, 11, 3935. [Google Scholar] [CrossRef]
- Quck, W.Y.; Huang, D.Y.; Lin, W.; Li, H.; Dong, M. Mobile acoustic Emotion Recognition. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 170–174, ISSN 2159-3450. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Akagi, M. Speech Emotion Recognition Based on Speech Segment Using LSTM with Attention Model. In Proceedings of the 2019 IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 40–44. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Kaya, H.; Fedotov, D.; Yeşilkanat, A.; Verkholyak, O.; Zhang, Y.; Karpov, A. LSTM Based Cross-corpus and Cross-task Acoustic Emotion Recognition. In Proceedings of the Interspeech 2018. ISCA, Los Angeles, CA, USA, 2–6 June 2018; pp. 521–525. [Google Scholar] [CrossRef]
- Lokesh, S.; Devi, M.R. Speech recognition system using enhanced mel frequency cepstral coefficient with windowing and framing method. Clust. Comput. 2019, 22, 11669–11679. [Google Scholar] [CrossRef]
- Yang, Z.; Huang, Y. Algorithm for speech emotion recognition classification based on Mel-frequency Cepstral coefficients and broad learning system. Evol. Intell. 2022, 15, 2485–2494. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Statistics | Word |
|---|---|
| Average | 19.73 |
| Standard Deviation | 27.59 |
| Shortest Sentence | 1 |
| Longest Sentence | 724 |
| Label | Value |
|---|---|
| Positive | 235,949 |
| Negative | 153,825 |
| Neutral | 50,905 |
| Positive (Prediction) | Negative (Prediction) | Neutral (Prediction) | Total | |
|---|---|---|---|---|
| Positive | 27,216 | 792 | 3192 | 31,200 |
| Negative | 419 | 30,871 | 1710 | 33,000 |
| Neutral | 1376 | 1645 | 33,007 | 36,028 |
| Positive (Prediction) | Negative (Prediction) | Neutral (Prediction) | |
|---|---|---|---|
| Precision | 0.9381 | 0.9268 | 0.8707 |
| Recall | 0.8723 | 0.9355 | 0.9161 |
| F1-Score | 0.9040 | 0.9311 | 0.8928 |
| Positive (Prediction) | Negative (Prediction) | Neutral (Prediction) | Total | |
|---|---|---|---|---|
| Positive | 24,876 | 1938 | 4186 | 31,000 |
| Negative | 1197 | 29,101 | 2702 | 33,000 |
| Neutral | 2631 | 2209 | 31,160 | 36,028 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yurtay, Y.; Demirci, H.; Tiryaki, H.; Altun, T. Emotion Recognition on Call Center Voice Data. Appl. Sci. 2024, 14, 9458. https://doi.org/10.3390/app14209458
Yurtay Y, Demirci H, Tiryaki H, Altun T. Emotion Recognition on Call Center Voice Data. Applied Sciences. 2024; 14(20):9458. https://doi.org/10.3390/app14209458
Chicago/Turabian StyleYurtay, Yüksel, Hüseyin Demirci, Hüseyin Tiryaki, and Tekin Altun. 2024. "Emotion Recognition on Call Center Voice Data" Applied Sciences 14, no. 20: 9458. https://doi.org/10.3390/app14209458
APA StyleYurtay, Y., Demirci, H., Tiryaki, H., & Altun, T. (2024). Emotion Recognition on Call Center Voice Data. Applied Sciences, 14(20), 9458. https://doi.org/10.3390/app14209458