
Alignment of Unsupervised Machine Learning with Human Understanding: A Case Study of Connected Vehicle Patents


Abstract
Featured Application
Abstract
1. Introduction
2. Literature Review
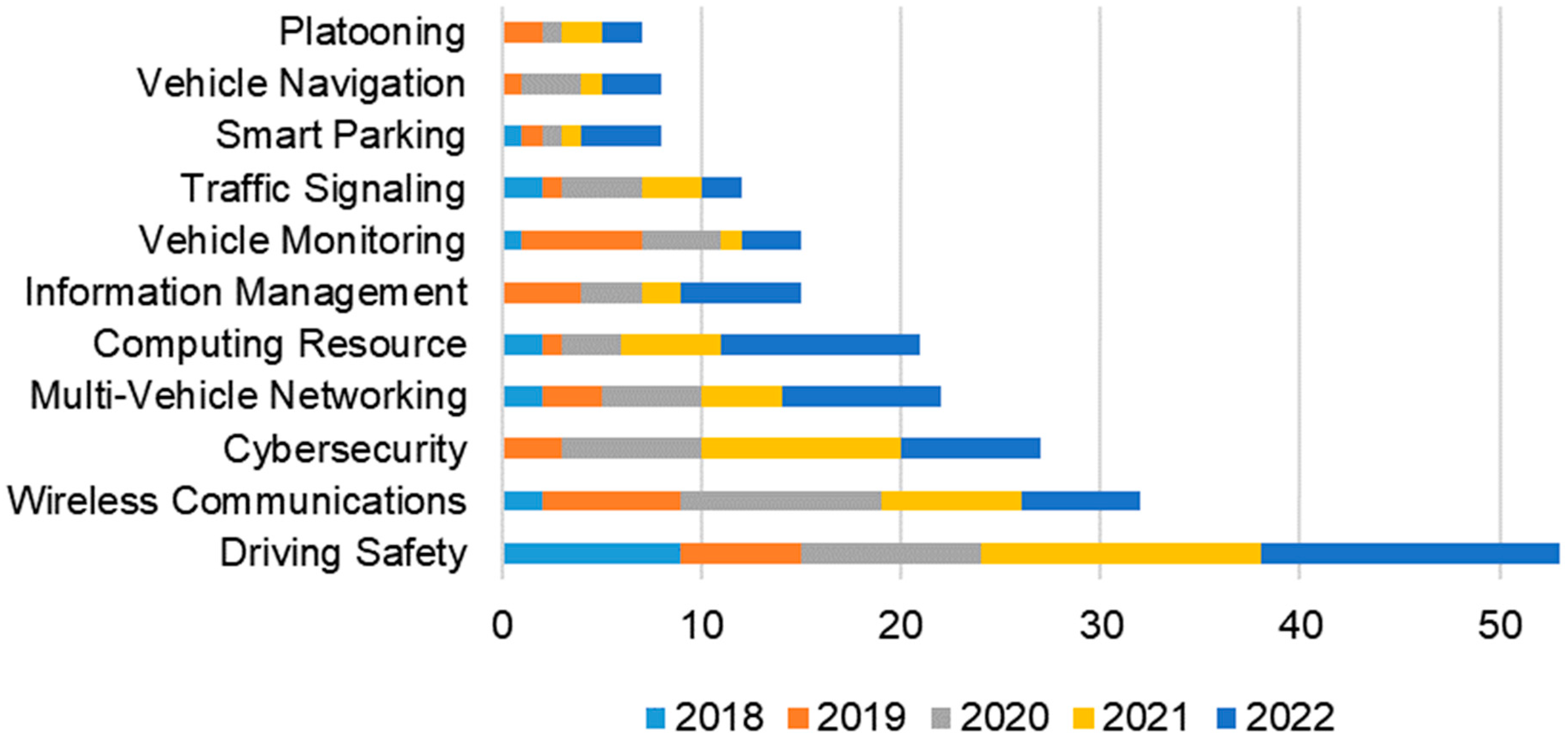
2.1. Connected Vehicles Trends
2.2. NLP in Patent Analysis
2.3. NLP Alignment Evaluation
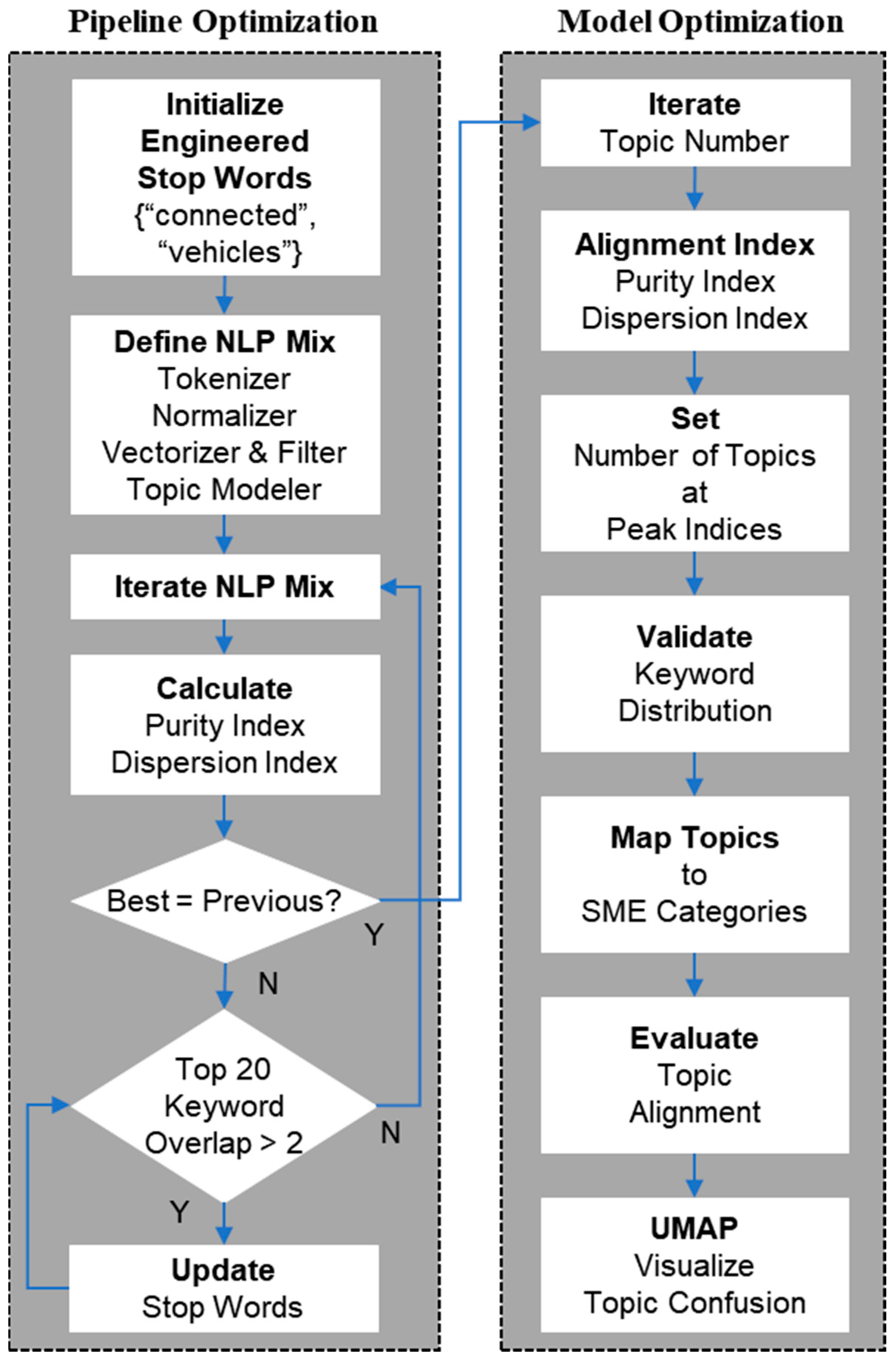
3. Methodology
3.1. Data Preparation
3.2. NLP Pipeline
3.3. Topic Alignment Index
3.4. Model Optimization
4. Results
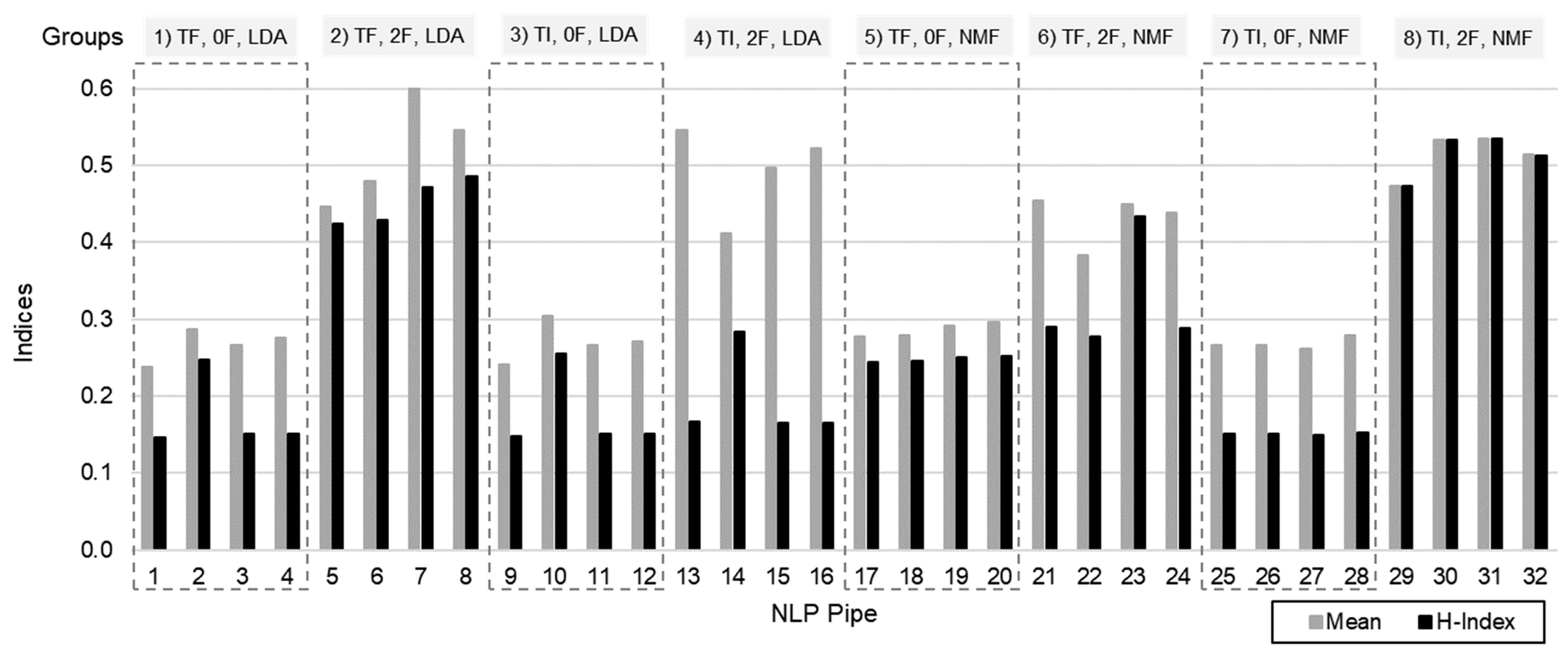
4.1. Pipeline Optimization
- 1.
- The vectorizer extremity filters improved the performance of both LDA (group 2 > group 1) and NMF (group 8 > group 7) topic modeling algorithms.
- 2.
- LDA had an edge over NMF when the pipeline included TF and 2F (group 2 > group 6).
- 3.
- NMF had an edge over LDA when the pipeline included TI and 2F (group 8 > group 4).
- 4.
- In all cases, stemmers performed at least as good as the lemmatizers.
4.2. Model Optimization
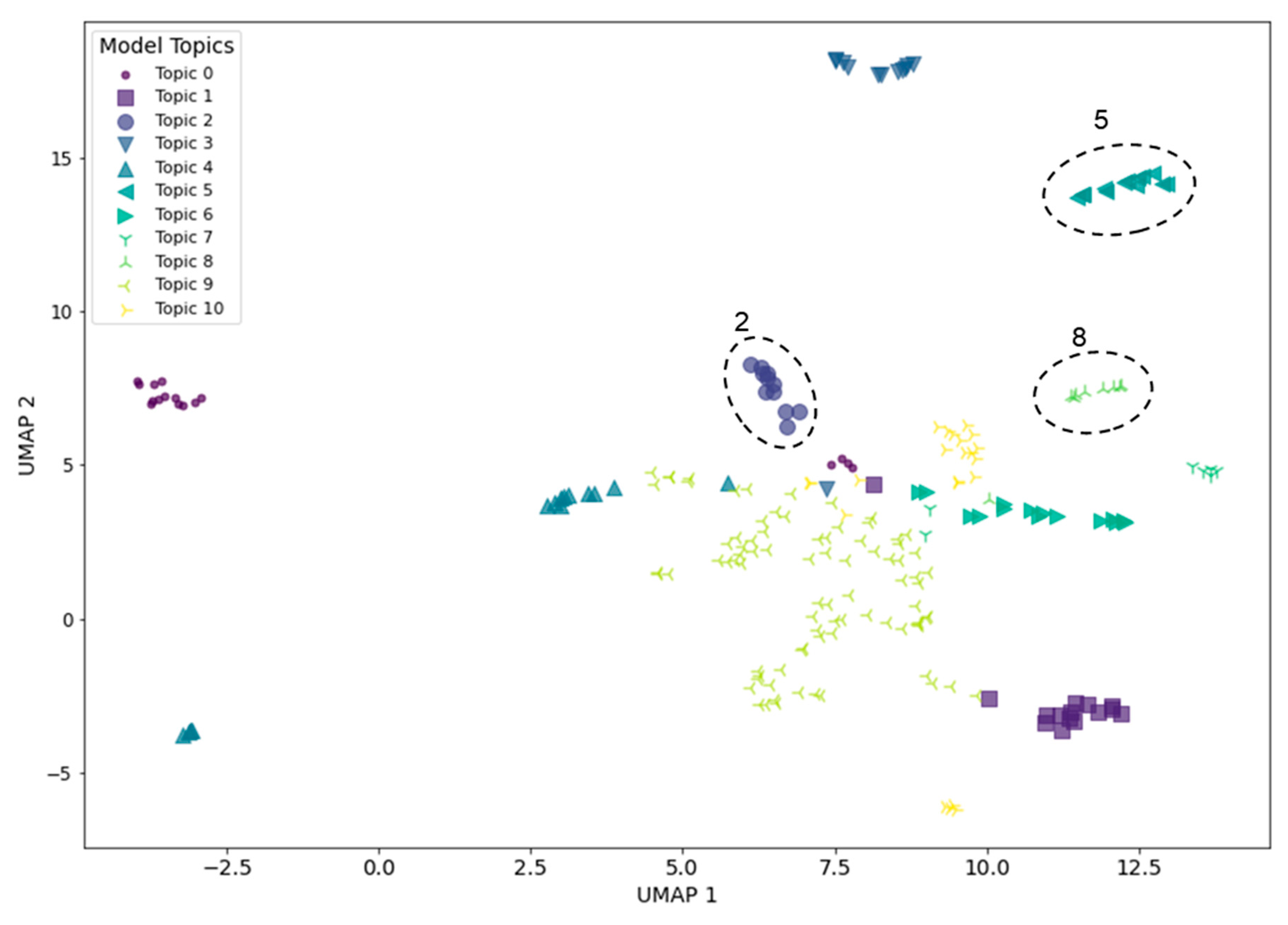
4.3. Misalignment Visualization
5. Discussion
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Casola, S.; Lavelli, A. Summarization, simplification, and generation: The case of patents. Expert Syst. Appl. 2022, 205, 117627. [Google Scholar] [CrossRef]
- Krestel, R.; Chikkamath, R.; Hewel, C.; Risch, J. A survey on deep learning for patent analysis. World Pat. Inf. 2021, 65, 102035. [Google Scholar] [CrossRef]
- Borghesani, V.; Armoza, J.; Hebart, M.N.; Bellec, P.; Brambati, S.M. The Three Terms Task—An open benchmark to compare human and artificial semantic representations. Sci. Data 2023, 10, 1–13. [Google Scholar] [CrossRef] [PubMed]
- USDOT. Vehicle-to-Everything (V2X) Communications Summit: Detailed Meeting Summary: Preparing for Connected, Interoperable Deployment Nationwide; United States Department of Transportation (USDOT): Washington, DC, USA, 2023. [Google Scholar]
- Nkenyereye, L.; Nkenyereye, L.; Jang, J.-W. Convergence of Software-Defined Vehicular Cloud and 5G Enabling Technologies: A Survey. Electronics 2023, 12, 2066. [Google Scholar] [CrossRef]
- Shichun, Y.; Zheng, Z.; Bin, M.; Yifan, Z.; Sida, Z.; Mingyan, L.; Yu, L.; Qiangwei, L.; Xinan, Z.; Mengyue, Z.; et al. Essential Technics of Cybersecurity for Intelligent Connected Vehicles: Comprehensive Review and Perspective. IEEE Internet Things J. 2023, 10, 21787–21810. [Google Scholar] [CrossRef]
- Rathore, R.S.; Hewage, C.; Kaiwartya, O.; Lloret, J. In-Vehicle Communication Cyber Security: Challenges and Solutions. Sensors 2022, 22, 6679. [Google Scholar] [CrossRef] [PubMed]
- Ju, Z.; Zhang, H.; Li, X.; Chen, X.; Han, J.; Yang, M. A Survey on Attack Detection and Resilience for Connected and Automated Vehicles: From Vehicle Dynamics and Control Perspective. IEEE Trans. Intell. Veh. 2022, 7, 815–837. [Google Scholar] [CrossRef]
- Hildebrand, B.; Baza, M.; Salman, T.; Tabassum, S.; Konatham, B.; Amsaad, F.; Razaque, A. A comprehensive review on blockchains for Internet of Vehicles: Challenges and directions. Comput. Sci. Rev. 2023, 48, 100547. [Google Scholar] [CrossRef]
- Khan, R.; Mehmood, A.; Iqbal, Z.; Maple, C.; Epiphaniou, G. Security and Privacy in Connected Vehicle Cyber Physical System Using Zero Knowledge Succinct Non Interactive Argument of Knowledge over Blockchain. Appl. Sci. 2023, 13, 1959. [Google Scholar] [CrossRef]
- Alanazi, F. A Systematic Literature Review of Autonomous and Connected Vehicles in Traffic Management. Appl. Sci. 2023, 13, 1789. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, Z.; LaClair, T.J.; Wang, C.; Shao, Y. Real-time control of connected vehicles in signalized corridors using pseudospectral convex optimization. Optim. Control. Appl. Methods 2023, 44, 2257–2277. [Google Scholar] [CrossRef]
- Gholamhosseinian, A.; Seitz, J. A Comprehensive Survey on Cooperative Intersection Management for Heterogeneous Connected Vehicles. IEEE Access 2022, 10, 7937–7972. [Google Scholar] [CrossRef]
- Xu, J.; Tian, Z. OD-Based Partition Technique to Improve Arterial Signal Coordination Using Connected Vehicle Data. Transp. Res. Rec. J. Transp. Res. Board 2022, 2677, 252–265. [Google Scholar] [CrossRef]
- Wang, B.; Han, Y.; Wang, S.; Tian, D.; Cai, M.; Liu, M.; Wang, L. A Review of Intelligent Connected Vehicle Cooperative Driving Development. Mathematics 2022, 10, 3635. [Google Scholar] [CrossRef]
- Cui, G.; Zhang, W.; Xiao, Y.; Yao, L.; Fang, Z. Cooperative Perception Technology of Autonomous Driving in the Internet of Vehicles Environment: A Review. Sensors 2022, 22, 5535. [Google Scholar] [CrossRef] [PubMed]
- Gao, B.; Wan, K.; Chen, Q.; Wang, Z.; Li, R.; Jiang, Y.; Mei, R.; Luo, Y.; Li, K. A Review and Outlook on Predictive Cruise Control of Vehicles and Typical Applications Under Cloud Control System. Mach. Intell. Res. 2023, 20, 614–639. [Google Scholar] [CrossRef]
- Islam, Z.; Abdel-Aty, M. Traffic conflict prediction using connected vehicle data. Anal. Methods Accid. Res. 2023, 39, 100275. [Google Scholar] [CrossRef]
- Schwarz, C.; Wang, Z. The Role of Digital Twins in Connected and Automated Vehicles. IEEE Intell. Transp. Syst. Mag. 2022, 14, 41–51. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Wu, J.-L.; Wang, J.W. Intelligent compilation of patent summaries using machine learning and natural language processing techniques. Adv. Eng. Inform. 2019, 43, 101027. [Google Scholar] [CrossRef]
- Joshi, U.; Hedaoo, M.; Fatnani, P.; Bansal, M.; More, V. Patent Classification with Intelligent Keyword Extraction. In Proceedings of the 2022 6th International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 26–27 August 2022; pp. 1–7. [Google Scholar]
- De Clercq, D.; Diop, N.-F.; Jain, D.; Tan, B.; Wen, Z. Multi-label classification and interactive NLP-based visualization of electric vehicle patent data. World Pat. Inf. 2019, 58, 101903. [Google Scholar] [CrossRef]
- Hyun, Y.-G.; Han, J.-H.; Chae, U.; Lee, G.-H.; Lee, J.-Y. A study on technical trend analysis related to semantic analysis of NLP through domestic/foreign patent data. J. Digit. Converg. 2020, 18, 137–146. [Google Scholar]
- Wu, H.; Shen, G.; Lin, X.; Li, M.; Zhang, B.; Li, C.Z. Screening patents of ICT in construction using deep learning and NLP techniques. Eng. Constr. Arch. Manag. 2020, 27, 1891–1912. [Google Scholar] [CrossRef]
- Arts, S.; Hou, J.; Gomez, J.C. Natural language processing to identify the creation and impact of new technologies in patent text: Code, data, and new measures. Res. Policy 2021, 50, 104144. [Google Scholar] [CrossRef]
- Puccetti, G.; Giordano, V.; Spada, I.; Chiarello, F.; Fantoni, G. Technology identification from patent texts: A novel named entity recognition method. Technol. Forecast. Soc. Chang. 2023, 186, 122160. [Google Scholar] [CrossRef]
- de Rezende, J.M.; Rodrigues, I.M.d.C.; Resendo, L.C.; Komati, K.S. Combining natural language processing techniques and algorithms LSA, word2vec and WMD for technological forecasting and similarity analysis in patent documents. Technol. Anal. Strat. Manag. 2022, 1–22. [Google Scholar] [CrossRef]
- Kherwa, P.; Bansal, P. Topic modeling: A comprehensive review. EAI Endorsed Trans. Scalable Inf. Syst. 2019, 7. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W.; Hassan, A. Topic modeling algorithms and applications: A survey. Inf. Syst. 2023, 112, 102131. [Google Scholar] [CrossRef]
- Meaney, C.; Stukel, T.A.; Austin, P.C.; Moineddin, R.; Greiver, M.; Escobar, M. Quality indices for topic model selection and evaluation: A literature review and case study. BMC Med. Inform. Decis. Mak. 2023, 23, 1–18. [Google Scholar] [CrossRef]
- Harrando, I.; Lisena, P.; Troncy, R. Apples to apples: A systematic evaluation of topic models. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Online, 1–3 September 2021. [Google Scholar]
- Vayansky, I.; Kumar, S.A.P. A review of topic modeling methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Rüdiger, M.; Antons, D.; Joshi, A.M.; Salge, T.-O. Topic modeling revisited: New evidence on algorithm performance and quality metrics. PLoS ONE 2022, 17, e0266325. [Google Scholar] [CrossRef]
- Hoyle, A.; Goel, P.; Hian-Cheong, A.; Peskov, D.; Boyd-Graber, J.; Resnik, P. Is automated topic model evaluation broken? The Incoherence of Coherence. Adv. Neural Inf. Process. Syst. 2021, 34, 2018–2033. [Google Scholar]
- WIPO. IP Facts and Figures; World Intellectual Property Organization (WIPO): Geneva, Switzerland, 2022. [Google Scholar]
- USPTO. Data Download Tables. U. P. [USPTO], 20 September 2023. Available online: https://patentsview.org/download/brf_sum_text (accessed on 2 October 2023).
- Lane, H.; Howard, C.; Hapke, H.M. Natural Language Processing in Action: Understanding, Analyzing, and Generating Text with Python; Manning Publications Co., Ltd.: Shelter Island, NY, USA, 2019. [Google Scholar]
- Garbhapu, V.K.; Bodapati, P. A comparative analysis of Latent Semantic analysis and Latent Dirichlet allocation topic modeling methods using Bible data. Indian J. Sci. Technol. 2020, 13, 4474–4482. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007. [Google Scholar]
- Becht, E.; McInnes, L.; Healy, J.; Dutertre, C.-A.; Kwok, I.W.H.; Ng, L.G.; Ginhoux, F.; Newell, E.W. Dimensionality reduction for visualizing single-cell data using UMAP. Nat. Biotechnol. 2018, 37, 38–44. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | SME Description |
|---|---|
| Computing Resource | Communications traffic to exchange sensor data and a wide range of other information, including the need for low latency to meet real-time demands, place additional burden on available computational resources. Objectives target optimal resource allocation and usage of onboard and cloud-based computing resources and optimize communications across multiple network interfaces and servers. |
| Cybersecurity | Growing wireless connectivity between vehicles and other things, including other vehicles, expands the vulnerability surface for cyber-attacks. Objectives address enhanced cybersecurity, including encryption, authentication, and intrusion detection methods. |
| Driving Safety | Objectives utilize vehicle-to-everything connectivity and sensors on other vehicles to enhance visibility and situational awareness, safely navigating in complex environments, including through intersections and among pedestrians, and avoiding collisions. |
| Information Management | Demand for efficient management of information across software applications and services scales with increased vehicle connections. Objectives ensure that systems present relevant information to vehicle operating and in-cabin infotainment systems to prevent data overload and prioritize information that is essential for vehicle operation, safety, and user experience. |
| Multi-vehicle Networking | Vehicle clusters can form and maintain microvehicular clouds to efficiently share and exchange information. Objectives address the efficient use of resources among vehicles to enable capabilities such as distributed data storage, collaborative computing, reliable communications, and service provisioning. |
| Platooning | The streamlined aerodynamics resulting from vehicles following each other more closely than normal (platooning) results in better fuel efficiency and improved traffic flow. Objectives address various ways to utilize wireless, sensors, and real-time control mechanisms to enable safer and more cost-efficient platooning and to alert law enforcement. |
| Smart Parking | Locating parking spaces in crowded and complex environments can be challenging and contribute to congestion. Objectives facilitate cooperative parking space searches, including charging for the “ego” vehicle by using sensors and microvehicular clouds or centralized services. |
| Traffic Signaling | Suboptimal traffic signal timing can exacerbate congestion. Objectives leverage wireless communications and sensors among vehicles to assess conditions and predict arrival times while dynamically optimizing traffic signaling for overall traffic impact. |
| Vehicle Monitoring | Objectives aim to enrich in-cabin experiences for passengers through display devices that provide various forms of information and entertainment, and via methods of preventing motion sickness by monitoring and predicting ride quality. |
| Vehicle Navigation | Objectives are to update electronic maps with real-time data from vehicles for more accurate navigation, and dynamically detecting environmental changes, including topography, emergency situations, and seasonal conditions such as flooding or snow, to inform about alternative routes. |
| Wireless Communications | Objectives address advancements in wireless communications such as lower latency cellular networks, quality of service, resilience in noisy environments, and interference. |
| Algorithm | Brief Description | Advantages | Disadvantages | |
|---|---|---|---|---|
| Tokenizer | Whitespace | Splits tokens based on whitespace. | Simple, fast. | Not suitable for languages where whitespace does not denote word boundaries. |
| Word | Splits text into words using NLTK’s word_tokenize. | Robust, handles punctuation. | Slower compared to whitespace tokenizer. | |
| Punke | Language-independent tokenizer. | Good for European languages, handles punctuation. | May not work well for languages with different sentence structures. | |
| Regexp | Tokenization based on regular expression patterns. | Highly customizable. | Requires good understanding of regular expressions. | |
| Sentence | Splits text into sentences. | Useful for document summarization and segmentation. | Not useful for word-level analysis. | |
| SpaCy | Tokenizer provided by the SpaCy library. | Fast, handles multiple languages, robust. | Requires installing the SpaCy library and language models. | |
| Normalizer | PorterStemmer | A well-known stemming algorithm. | Effective for English, reduces words to base form. | Over-stemming or under-stemming possible. |
| Lancaster Stemmer | More aggressive than Porter. | Reduces words to a basic form. | Can produce stems that are not meaningful words. | |
| Snowball Stemmer | Extends Porter to support multiple languages. | Language support, aggressive. | Over-stemming or under-stemming possible. | |
| WordNet Lemmatizer | Lemmatizer based on WordNet lexical database. | Produces valid words, less aggressive than stemming. | Slower, may require POS tags for accurate lemmatization. | |
| SpaCy Lemmatizer | Lemmatizer offered by the SpaCy library. | Fast, handles multiple languages, usually more accurate. | Requires installing the SpaCy library and language models. | |
| Vectorizer | CountVectorizer | Converts text to a matrix of token counts. | Simple, effective for most cases. | Does not consider semantic meaning, sensitive to frequent words. |
| TfidfVectorizer | Converts text to a matrix of TF-IDF features. | Considers global importance of words, less sensitive to frequent words. | Sensitive to the scale of the dataset, more computationally intensive than CountVectorizer. | |
| Topic Model | Latent Dirichlet Allocation | Most used topic modeling algorithm. | Effective for a wide range of topics, easy to interpret. | Requires choosing the number of topics a priori, may not be suitable for all types of text data. |
| Non-negative Matrix Factorization | Useful for topic modeling and other types of clustering. | Fast, easier to interpret than LDA. | Assumes linear structure, may not work well for all types of data. | |
| Latent Semantic Analysis | Also known as latent semantic indexing (LSI). | Good for capturing semantic meaning, less sensitive to word frequency. | High computational cost for large datasets. |
| Text Cleaning | Tokens |
|---|---|
| Unique tokens in the original corpus | 8872 |
| Number of English stop words | 179 |
| Number of engineered stop words | 372 |
| Unique tokens in cleaned corpus | 3058 |
| Number of filtered tokens in vectorized dictionary | 612 |
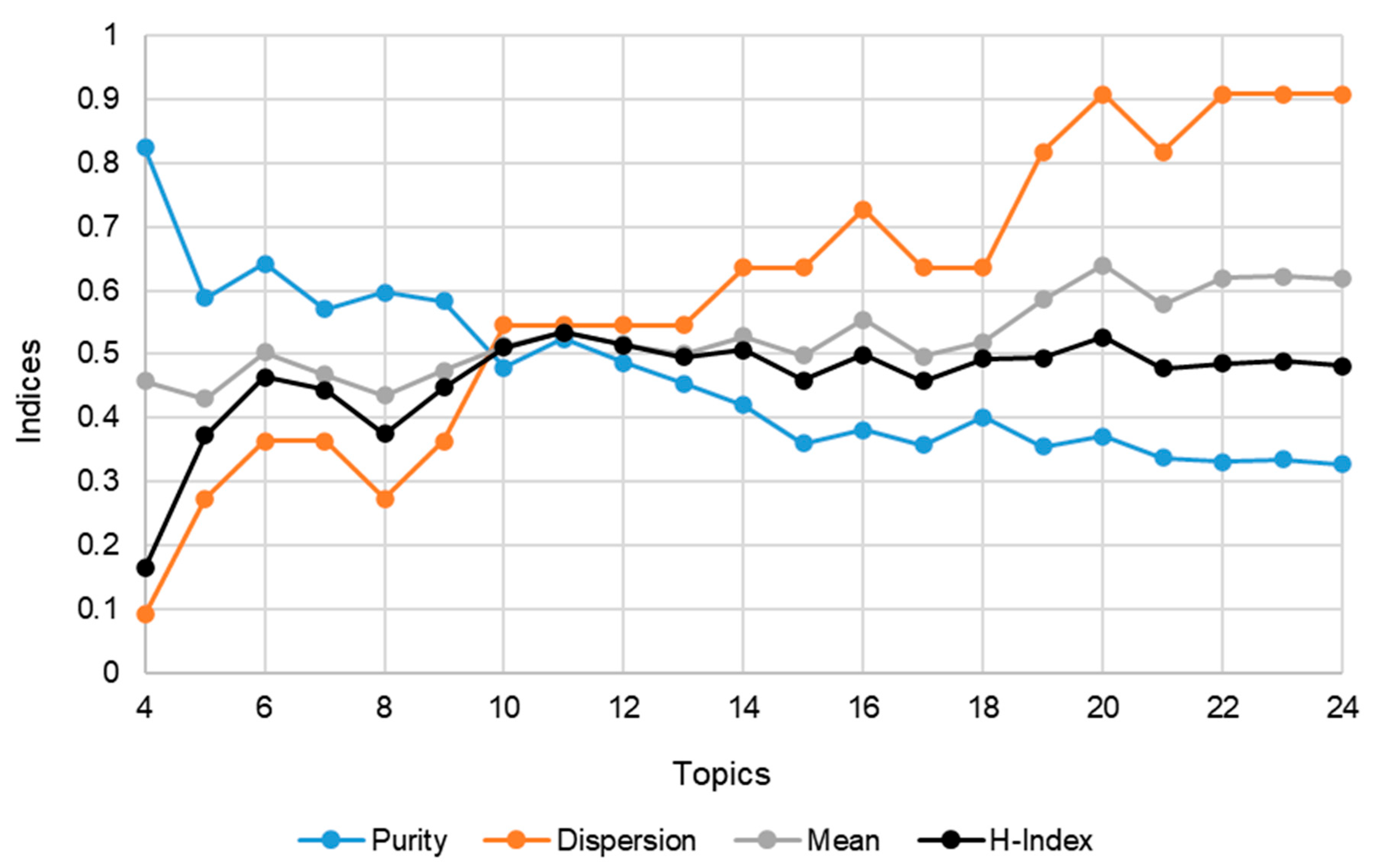
| Pipe | Tokenize & Normalize | TF | TI | 0F | 2F | LDA | NMF | Purity | Dispersion | Mean | H-Index |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Spacy T & Spacy L | x | x | x | 0.386 | 0.091 | 0.238 | 0.147 | |||
| 2 | Word T & Word L | x | x | x | 0.391 | 0.182 | 0.286 | 0.248 | |||
| 3 | Word T & Snowball S | x | x | x | 0.443 | 0.091 | 0.267 | 0.151 | |||
| 4 | Word T & Porter S | x | x | x | 0.462 | 0.091 | 0.276 | 0.152 | |||
| 5 | Spacy T & Spacy L | x | x | x | 0.347 | 0.545 | 0.446 | 0.424 | |||
| 6 | Word T & Word L | x | x | x | 0.323 | 0.636 | 0.480 | 0.429 | |||
| 7 | Word T & Snowball S | x | x | x | 0.349 | 0.727 | 0.636 | 0.472 | |||
| 8 | Word T & Porter S | x | x | x | 0.365 | 0.727 | 0.546 | 0.486 | |||
| 9 | Spacy T & Spacy L | x | x | x | 0.392 | 0.091 | 0.241 | 0.148 | |||
| 10 | Word T & Word L | x | x | x | 0.428 | 0.182 | 0.305 | 0.255 | |||
| 11 | Word T & Snowball S | x | x | x | 0.442 | 0.091 | 0.267 | 0.151 | |||
| 12 | Word T & Porter S | x | x | x | 0.452 | 0.091 | 0.271 | 0.151 | |||
| 13 | Spacy T & Spacy L | x | x | x | 1.000 | 0.091 | 0.545 | 0.167 | |||
| 14 | Word T & Word L | x | x | x | 0.641 | 0.182 | 0.412 | 0.283 | |||
| 15 | Word T & Snowball S | x | x | x | 0.904 | 0.091 | 0.498 | 0.165 | |||
| 16 | Word T & Porter S | x | x | x | 0.953 | 0.091 | 0.522 | 0.166 | |||
| 17 | Spacy T & Spacy L | x | x | x | 0.372 | 0.182 | 0.277 | 0.244 | |||
| 18 | Word T & Word L | x | x | x | 0.378 | 0.182 | 0.280 | 0.245 | |||
| 19 | Word T & Snowball S | x | x | x | 0.403 | 0.182 | 0.292 | 0.250 | |||
| 20 | Word T & Porter S | x | x | x | 0.411 | 0.182 | 0.297 | 0.252 | |||
| 21 | Spacy T & Spacy L | x | x | x | 0.728 | 0.182 | 0.455 | 0.291 | |||
| 22 | Word T & Word L | x | x | x | 0.585 | 0.182 | 0.383 | 0.277 | |||
| 23 | Word T & Snowball S | x | x | x | 0.537 | 0.364 | 0.450 | 0.434 | |||
| 24 | Word T & Porter S | x | x | x | 0.696 | 0.182 | 0.439 | 0.288 | |||
| 25 | Spacy T & Spacy L | x | x | x | 0.443 | 0.091 | 0.267 | 0.151 | |||
| 26 | Word T & Word L | x | x | x | 0.441 | 0.091 | 0.266 | 0.151 | |||
| 27 | Word T & Snowball S | x | x | x | 0.433 | 0.091 | 0.262 | 0.150 | |||
| 28 | Word T & Porter S | x | x | x | 0.468 | 0.091 | 0.279 | 0.152 | |||
| 29 | Spacy T & Spacy L | x | x | x | 0.493 | 0.455 | 0.474 | 0.473 | |||
| 30 | Word T & Word L | x | x | x | 0.522 | 0.545 | 0.534 | 0.533 | |||
| 31 | Word T & Snowball S | x | x | x | 0.524 | 0.545 | 0.535 | 0.535 | |||
| 32 | Word T & Porter S | x | x | x | 0.483 | 0.545 | 0.514 | 0.512 |
| T | Top 20 Keywords |
|---|---|
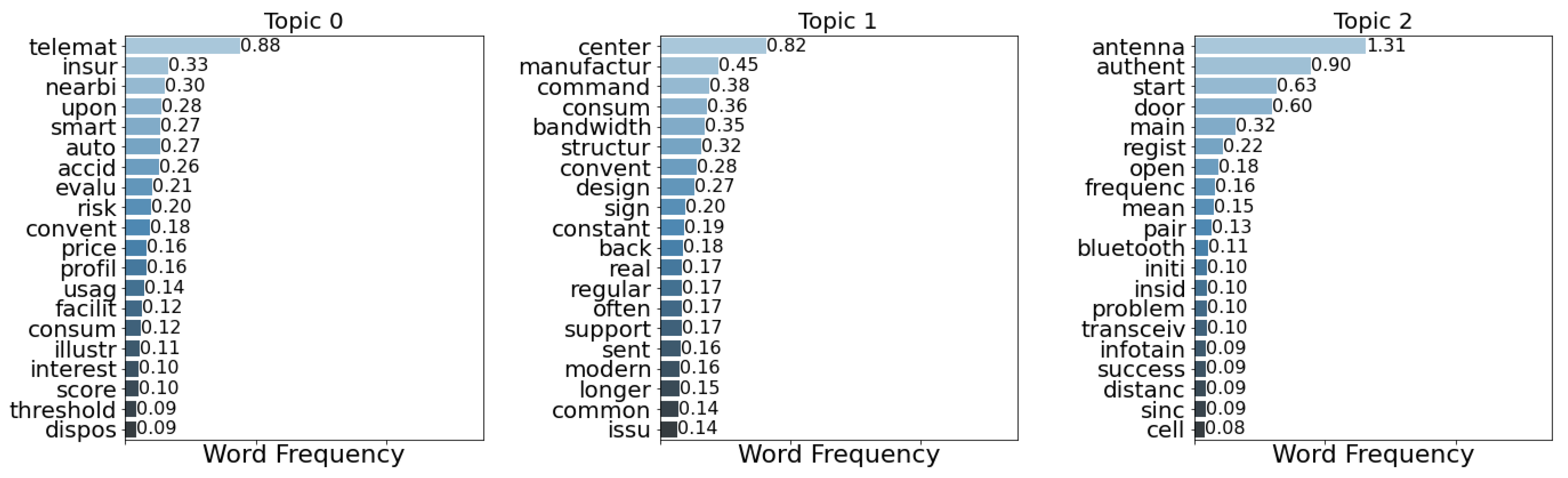
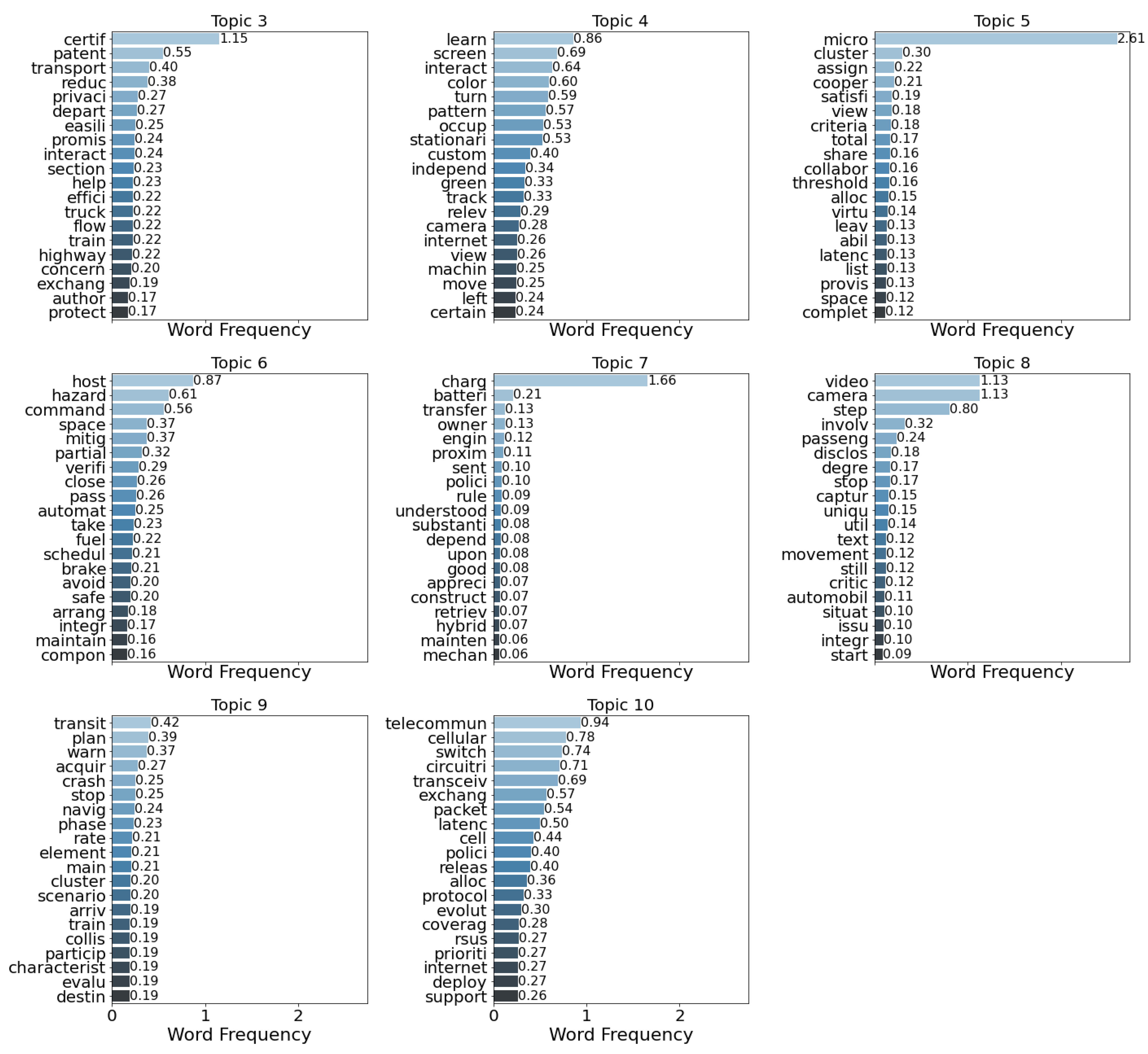
| 0 | telemat insur nearbi upon smart auto accid evalu risk convent price profil usag facilit consum illustr interest score threshold dispos |
| 1 | center manufactur command consum bandwidth structur convent design sign constant back real regular often support sent modern longer common issu |
| 2 | antenna authent start door main regist open frequenc mean pair bluetooth initi insid problem transceiv infotain success distanc sinc cell |
| 3 | certif patent transport reduc privaci depart easili promis interact section help effici truck flow train highway concern exchang author protect |
| 4 | learn screen interact color turn pattern occup stationari custom independ green track relev camera internet view machin move left certain |
| 5 | micro cluster assign cooper satisfi view criteria total share collabor threshold alloc virtu leav abil latenc list provis space complet |
| 6 | host hazard command space mitig partial verifi close pass automat take fuel schedul brake avoid safe arrang integr maintain compon |
| 7 | charg batteri transfer owner engin proxim sent polici rule understood substanti depend upon good appreci construct retriev hybrid mainten mechan |
| 8 | video camera step involv passeng disclos degre stop captur uniqu util text movement still critic automobil situat issu integr start |
| 9 | transit plan warn acquir crash stop navig phase rate element main cluster scenario arriv train collis particip characterist evalu destin |
| 10 | telecommun cellular switch circuitri transceiv exchang packet latenc cell polici releas alloc protocol evolut coverag rsus prioriti internet deploy support |
| SME Category | Most Frequent Topic | Purity |
|---|---|---|
| Computing Resource | 10 | 0.333 |
| Cybersecurity | 3 | 0.444 |
| Driving Safety | 9 | 0.472 |
| Information Management | 9 | 0.533 |
| Multi-Vehicle Networking | 5 | 0.318 |
| Platooning | 6 | 0.857 |
| Smart Parking | 7 | 0.375 |
| Traffic Signaling | 9 | 1.000 |
| Vehicle Monitoring | 9 | 0.400 |
| Vehicle Navigation | 9 | 0.625 |
| Wireless Communications | 9 | 0.406 |
| T | Majority SME Category | USC | Topic Model Keywords Relevant to SME Category |
|---|---|---|---|
| 0 | Driving Safety | 4 | insurance, accident, risk |
| 1 | Driving Safety | 5 | sign |
| 2 | Cybersecurity | 4 | authenticate, register |
| 3 | Cybersecurity | 1 | certificate, privacy |
| 4 | Driving Safety | 5 | green, camera, occupy, interact |
| 5 | Multi-Vehicle Networking | 4 | micro, anomali, slice |
| 6 | Platooning | 7 | platoon, host, gateway, command, trail, brake, automate |
| 7 | Smart Parking | 4 | charge, battery, transfer, promotion |
| 8 | Driving Safety | 3 | video camera, capture, situation, stop |
| 9 | Driving Safety | 11 | interfere, collision, crash, stop, navigation, warn |
| 10 | Wireless Communications | 6 | telecommunication, cellular, transceiver, packet, switch, cell |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bridgelall, R. Alignment of Unsupervised Machine Learning with Human Understanding: A Case Study of Connected Vehicle Patents. Appl. Sci. 2024, 14, 474. https://doi.org/10.3390/app14020474
Bridgelall R. Alignment of Unsupervised Machine Learning with Human Understanding: A Case Study of Connected Vehicle Patents. Applied Sciences. 2024; 14(2):474. https://doi.org/10.3390/app14020474
Chicago/Turabian StyleBridgelall, Raj. 2024. "Alignment of Unsupervised Machine Learning with Human Understanding: A Case Study of Connected Vehicle Patents" Applied Sciences 14, no. 2: 474. https://doi.org/10.3390/app14020474
APA StyleBridgelall, R. (2024). Alignment of Unsupervised Machine Learning with Human Understanding: A Case Study of Connected Vehicle Patents. Applied Sciences, 14(2), 474. https://doi.org/10.3390/app14020474