



Reinforcement-Learning-Based Path Planning: A Reward Function Strategy



Abstract
1. Introduction
- A reward function capable of finding a trade-off between trajectory distance and time when minimizing the number of turns.
- A neural network architecture to extract the optimal trajectory according to the proposed approach employing the Deep Q-Learning technique.
- A trajectory-tracking controller design based on Lyapunov’s stability criteria.
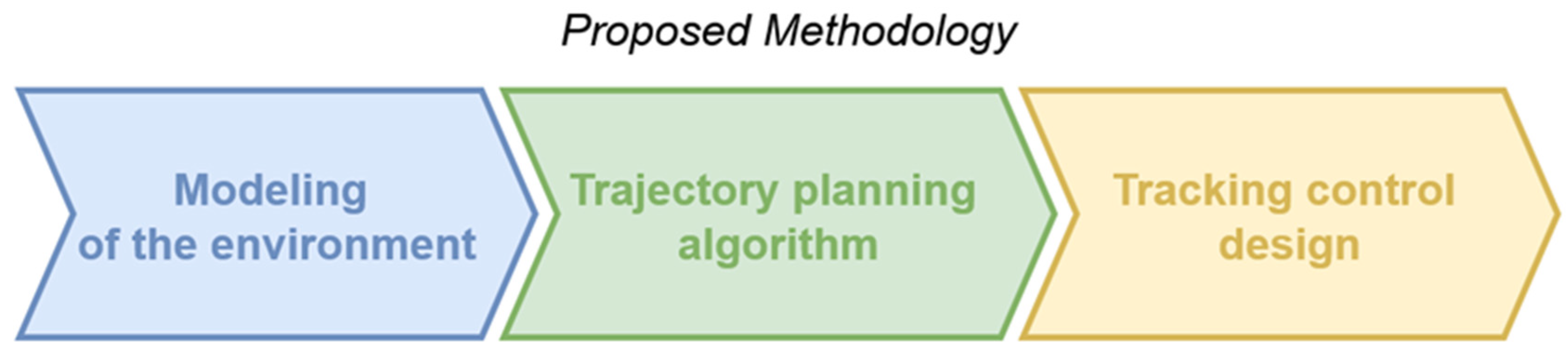
2. Proposed Methodology
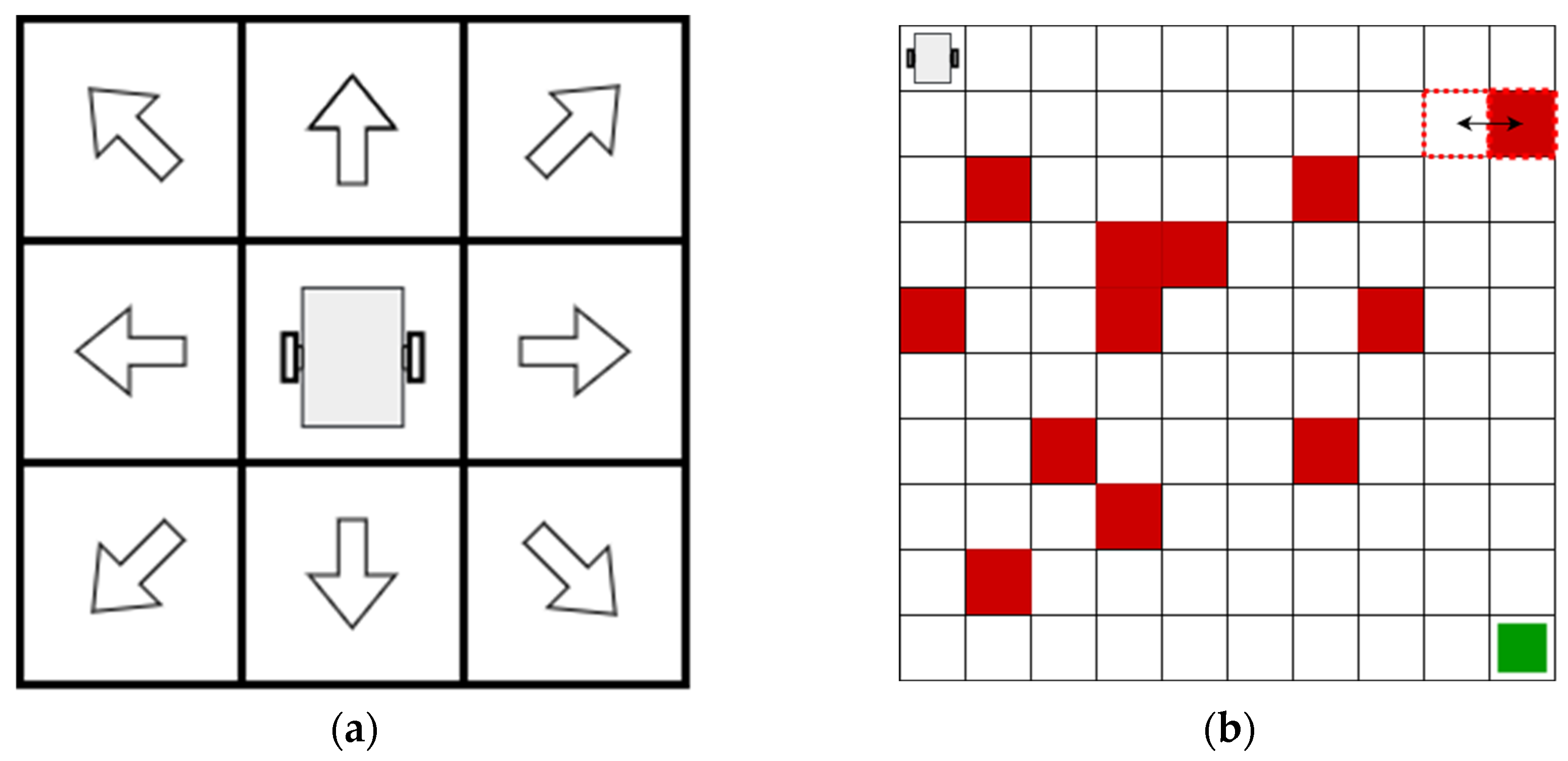
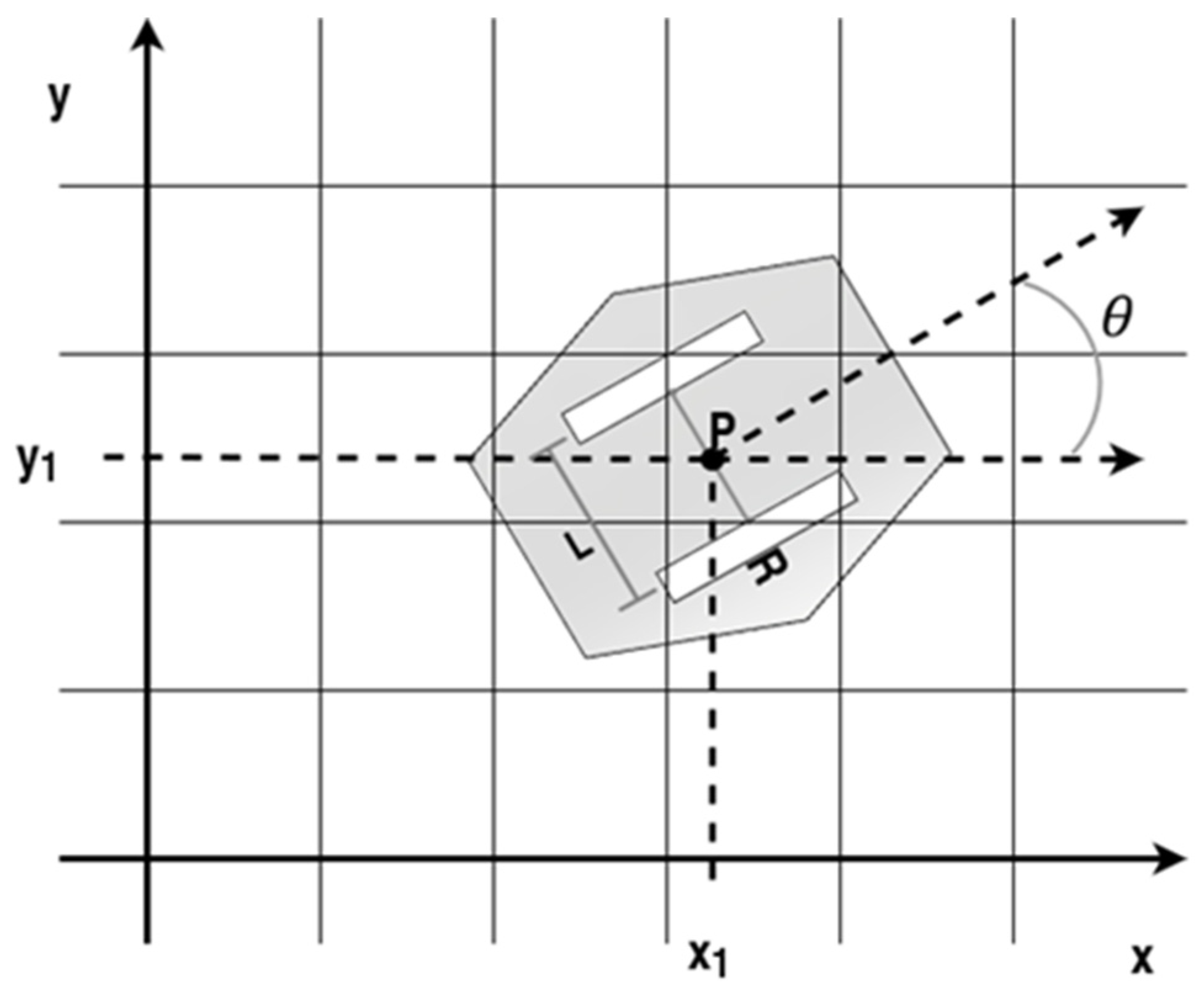
2.1. Environment Modeling
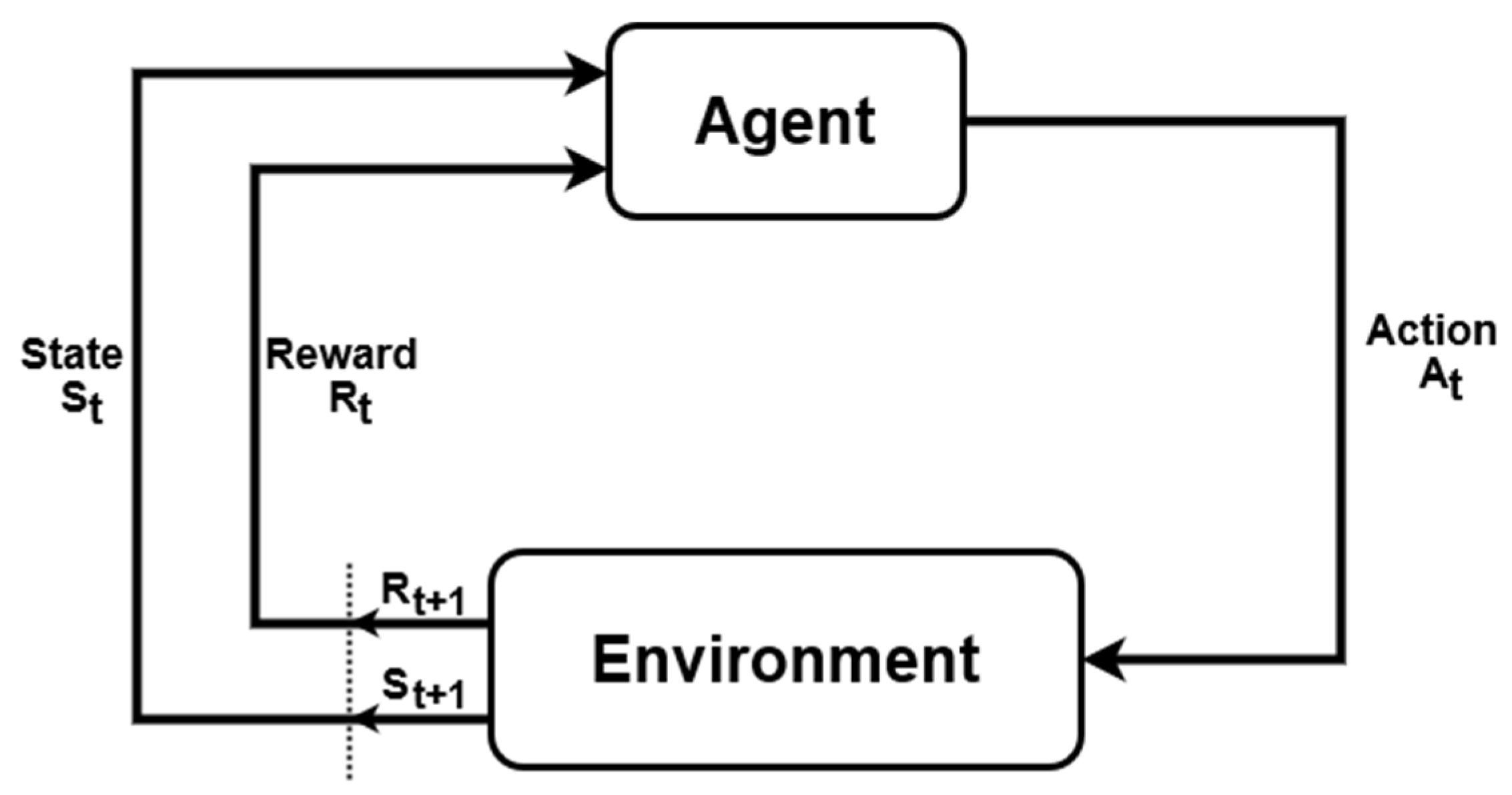
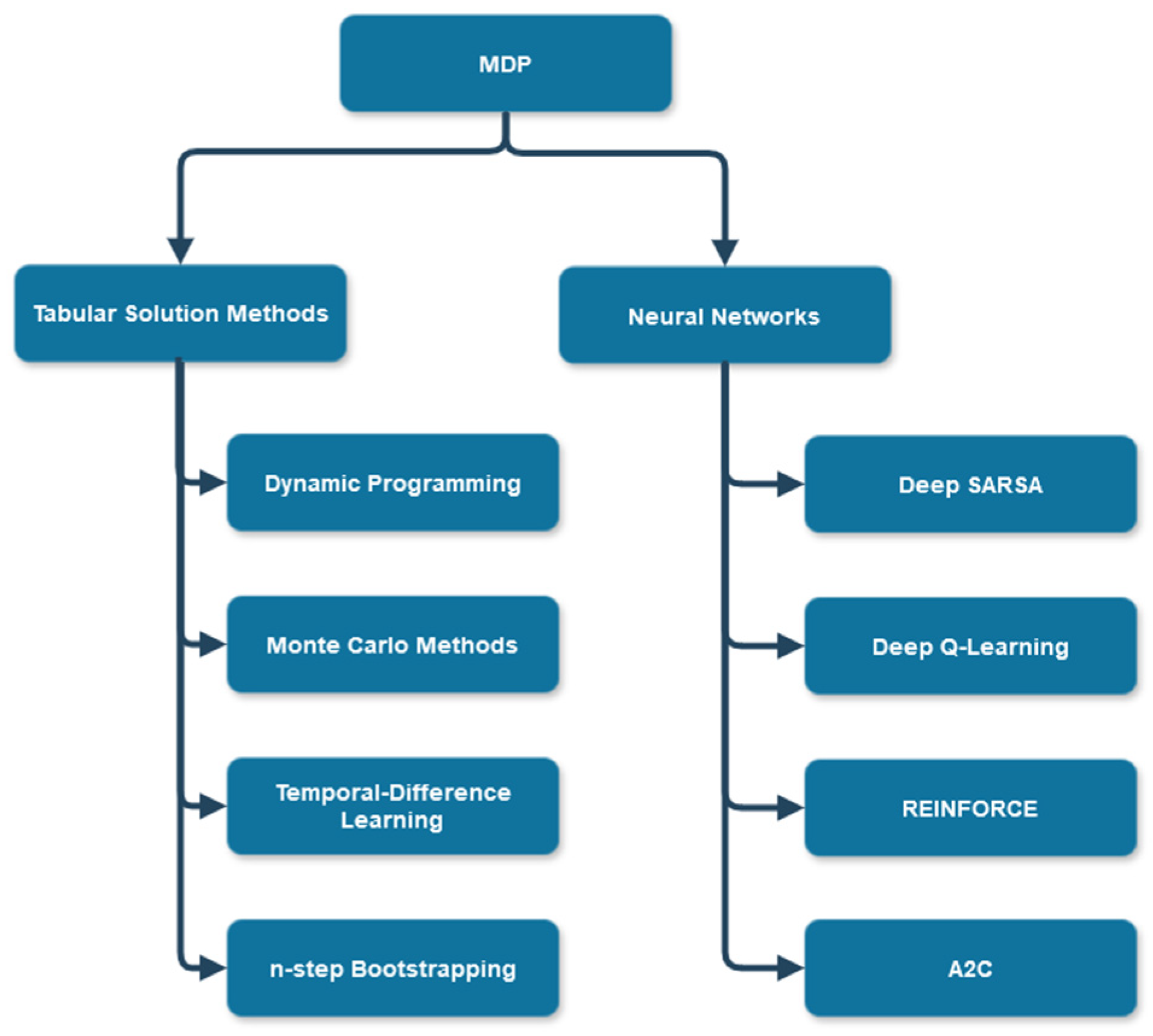
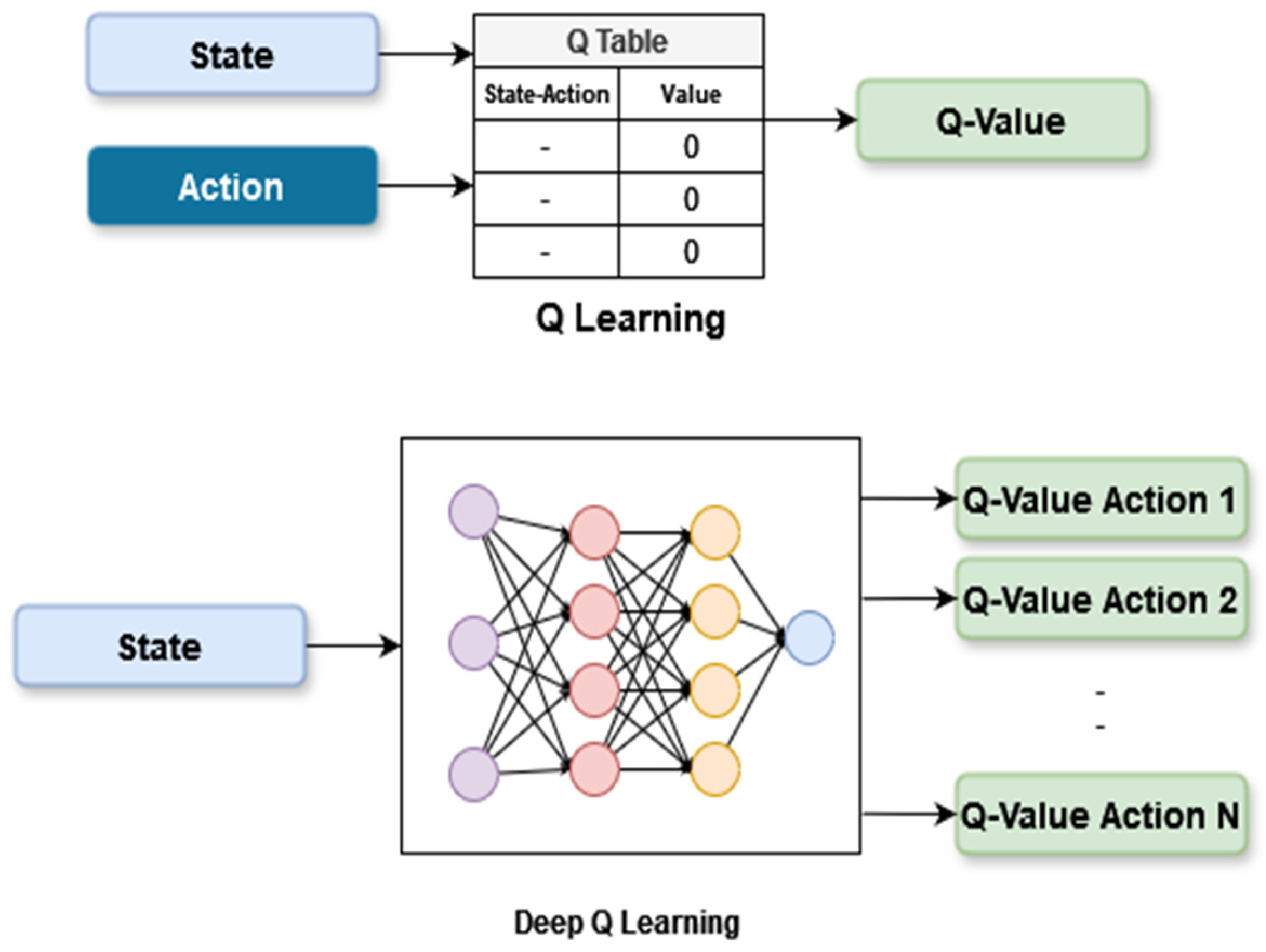
2.2. Reinforcement Learning and Q-Learning Algorithm
- An agent is an entity that perceives/explores an environment and makes decisions.
- An environment includes everything surrounding an agent and is generally assumed to be stochastic.
- Actions correspond to an agent’s movement in an environment.
- State is the representation of an agent over time.
- Reward is a numerical value that an agent tries to maximize by the selection of its actions.
- Policy represents a strategy used by an agent to select an action based on the present state.
| Algorithm 1: Policy Iteration | |
| 1: | Initialize |
| 2: | and arbitrarily, for all states |
| 3: | Policy Evaluation |
| 4: | Loop: |
| 5: | |
| 6: | Loor for each : |
| 7: | |
| 8: | |
| 9: | |
| 10: | Until |
| 11: | Policy Improvement |
| 12: | |
| 13: | Loop for each : |
| 14: | |
| 15: | |
| 16: | |
| 17: | |
| 18: | |
| Algorithm 2: Deep Q-Learning | |
| 1: | Input: learning rate |
| 2: | Initialize |
| 3: | q-value, |
| 4: | |
| 5: | Initialize buffer |
| 6: | Loop: episode |
| 7: | Restart environment |
| 8: | Loop: |
| 9: | Select action |
| 10: | Execute action and observe |
| 11: | Insert transition into the buffer |
| 12: | Compute loss function: |
| 13: | Update the NN parameters θ |
| 14: | End Loop |
| 15: | Every episode |
| 16: | End Loop |
| 17: | Output: Optimal policy and q-value approximation |
- Input layer: two fully connected neurons, one for the position and one for the position.
- Hidden layers: two fully connected layers with 64 neurons and the ReLU activation function.
- Output layer: a fully connected dense layer, which has 64 neurons as the input to the last hidden layer. It produces a vector that corresponds to the Q values for each possible action in an environment.
2.3. Controller Design for Path Tracking
2.3.1. Kinematic Model of a Differential Drive Robot
- The robot is treated as a rigid body, as evidenced by its elements.
- Displacement is minimized in a perpendicular direction to the rolling.
- There is no translational displacement between the wheel and the floor.
2.3.2. Lyapunov-Based Controller Design
| Algorithm 3: Lyapunov-Based Controller | |
| 1: | Initialize |
| 2: | . |
| 3: | Controller Calculation |
| 4: | Loop: |
| 5: | . |
| 6: | Jacobian matrix J(q(t)). |
| 7: | Control parameters. |
| 8: | |
| 9: | . |
| 10: | End Loop |
| 11: | Visualization |
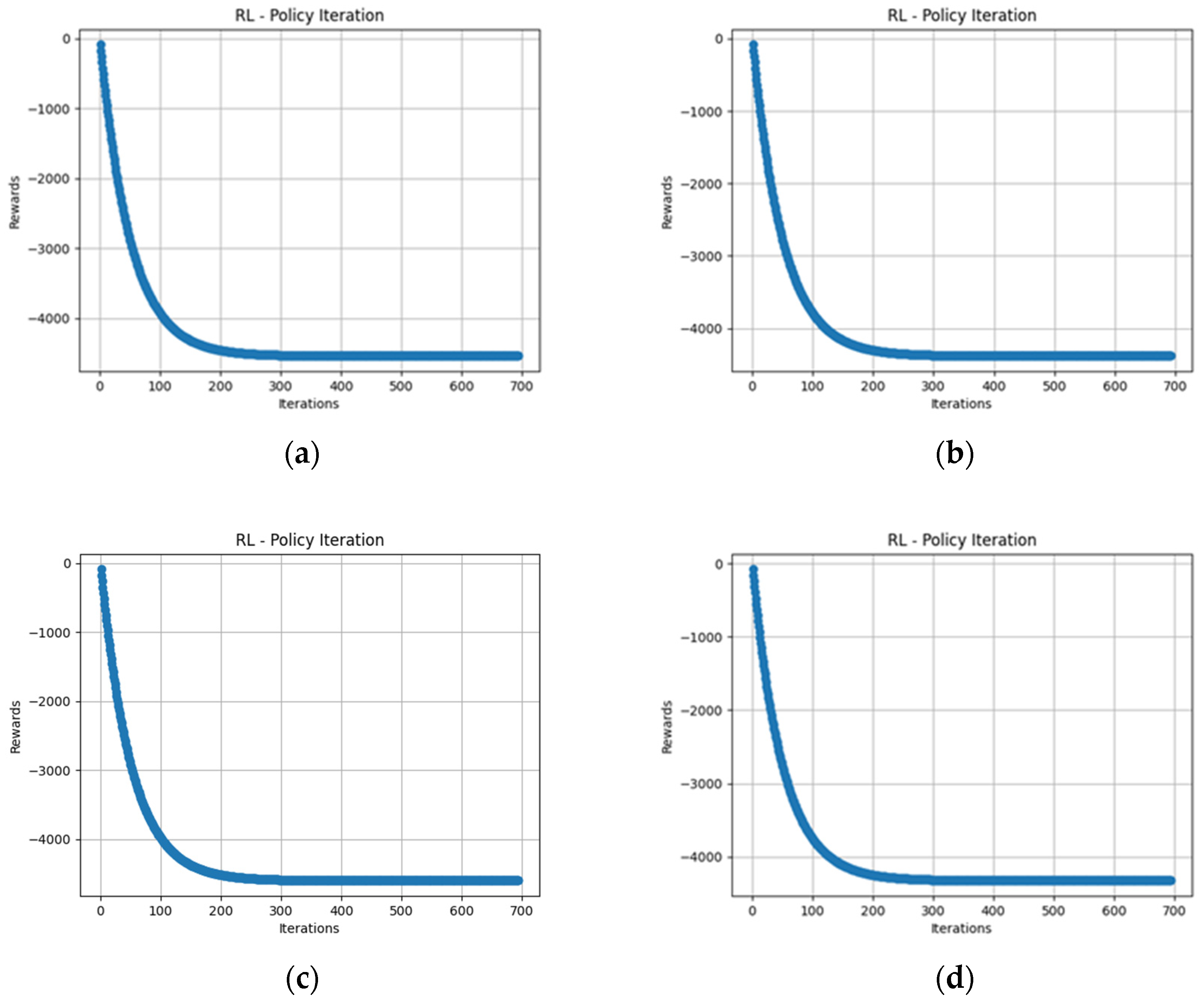
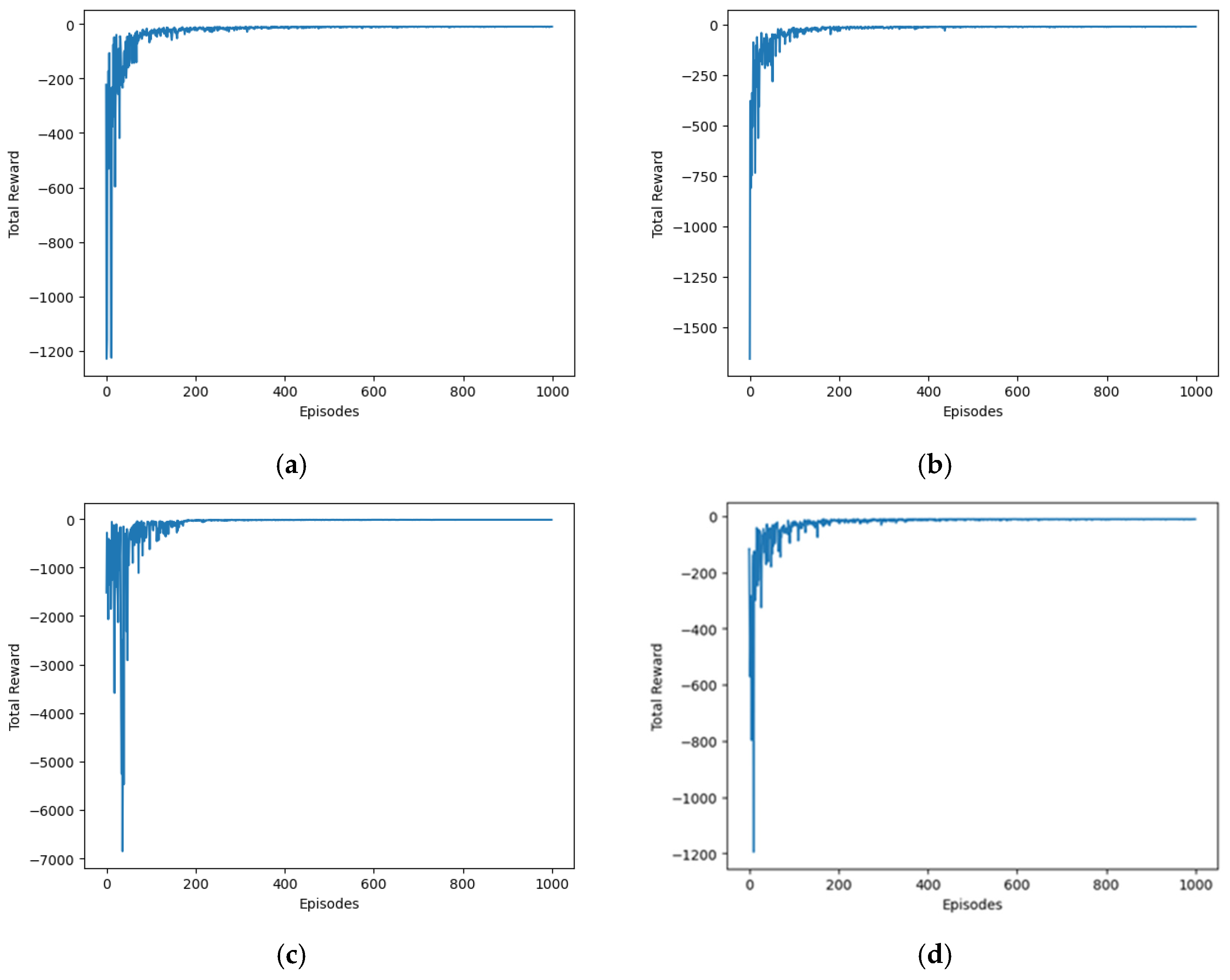
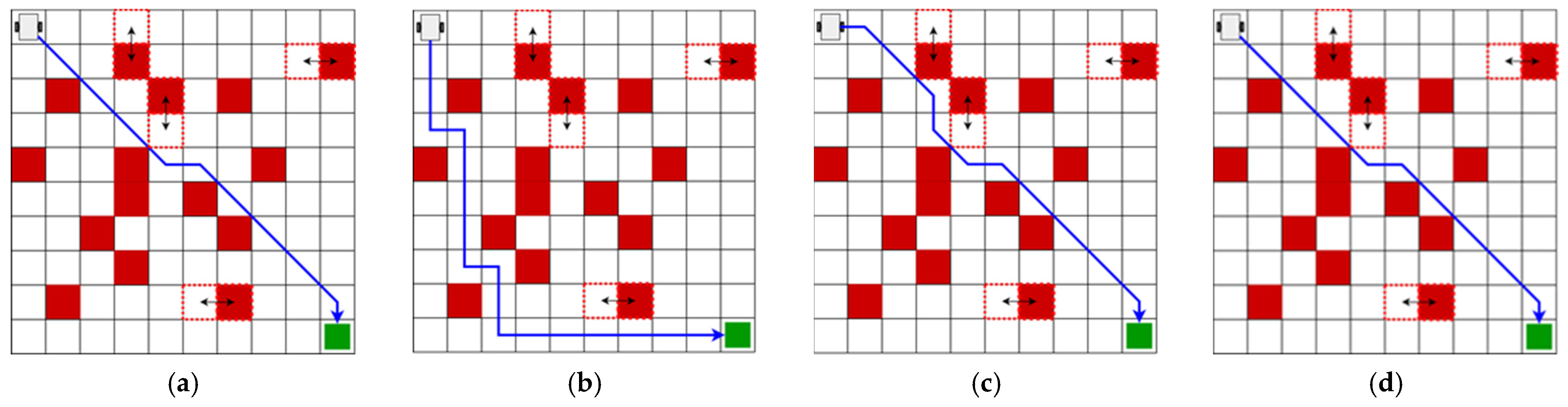
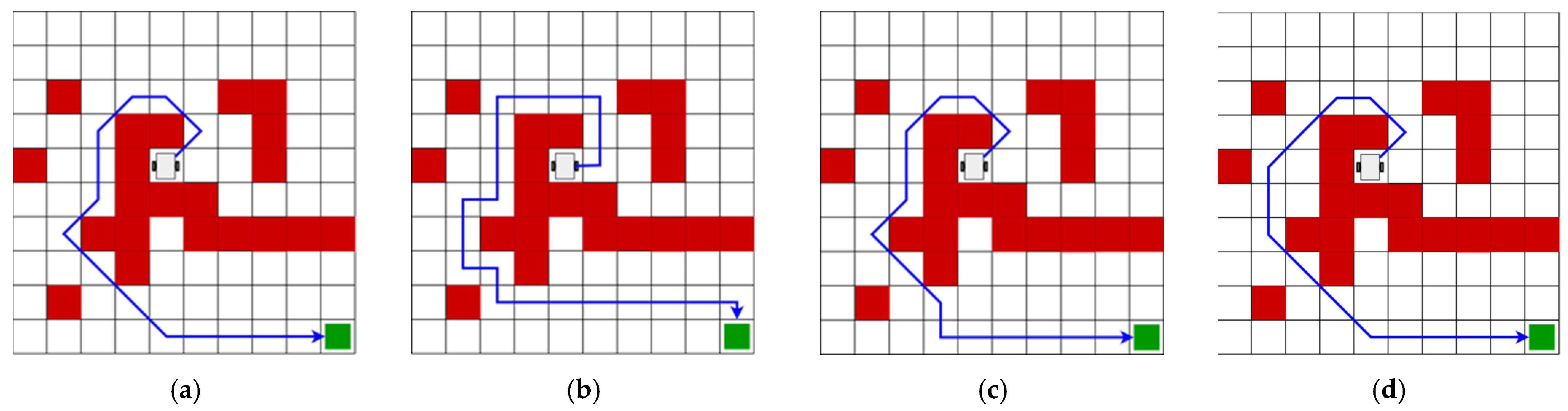
3. Results
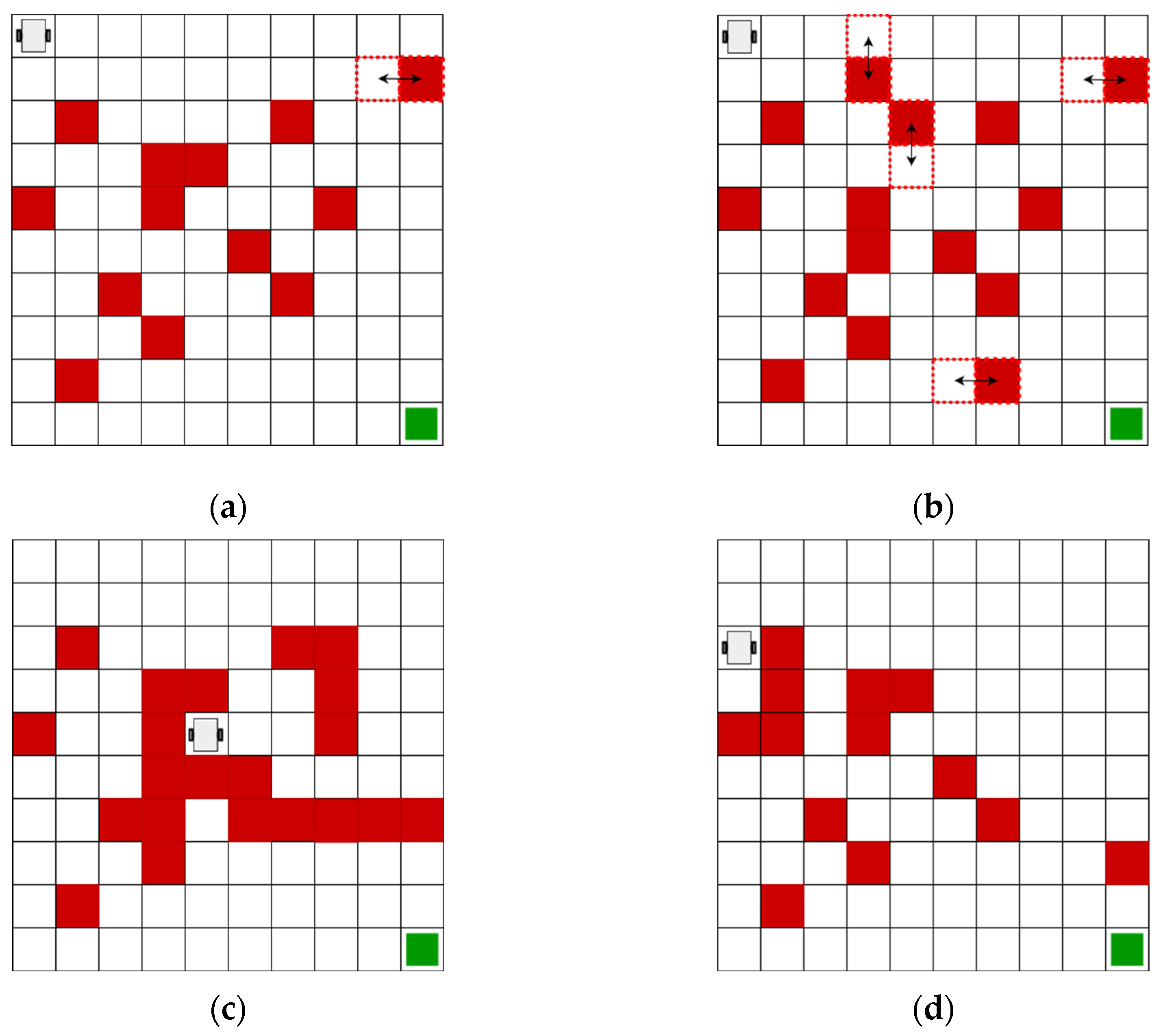
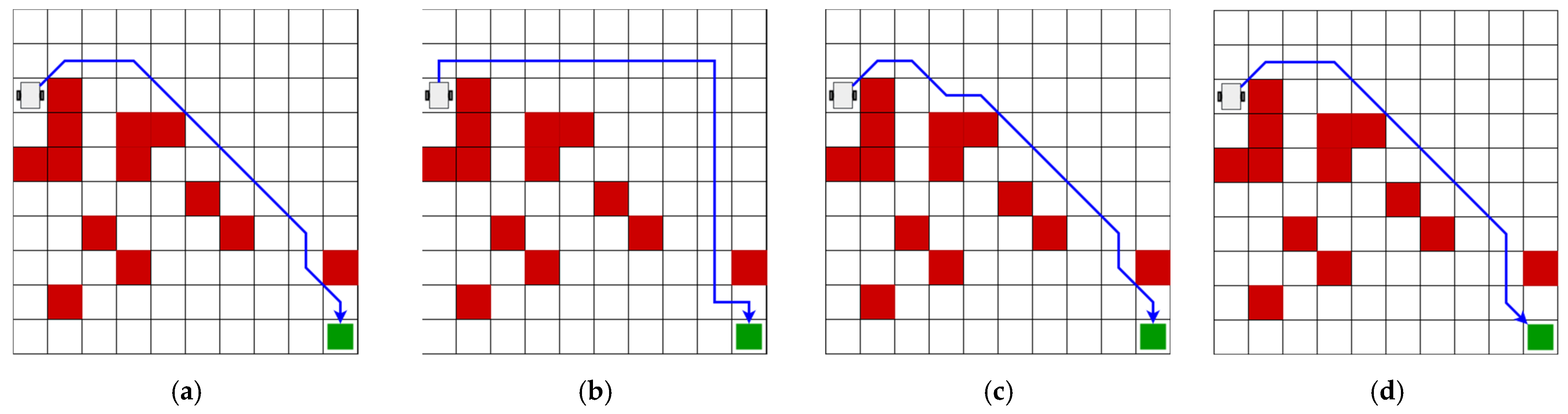
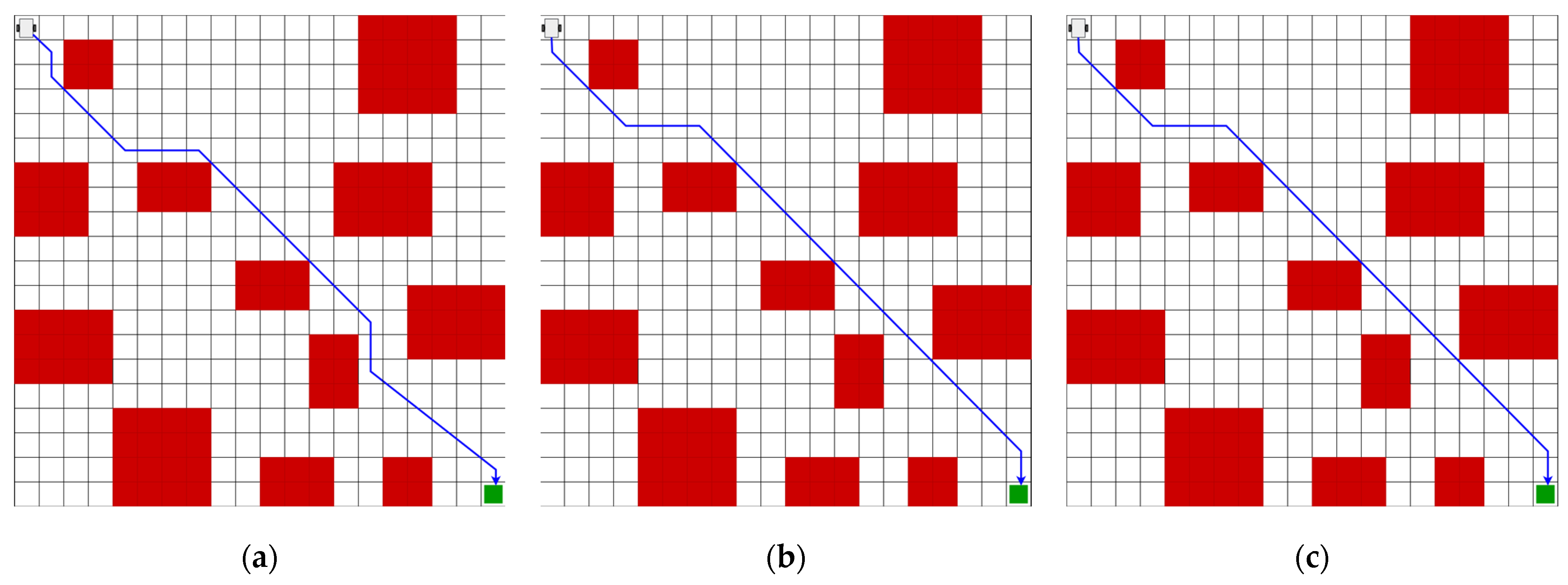
3.1. Evaluation of Trajectory-Planning Algorithms
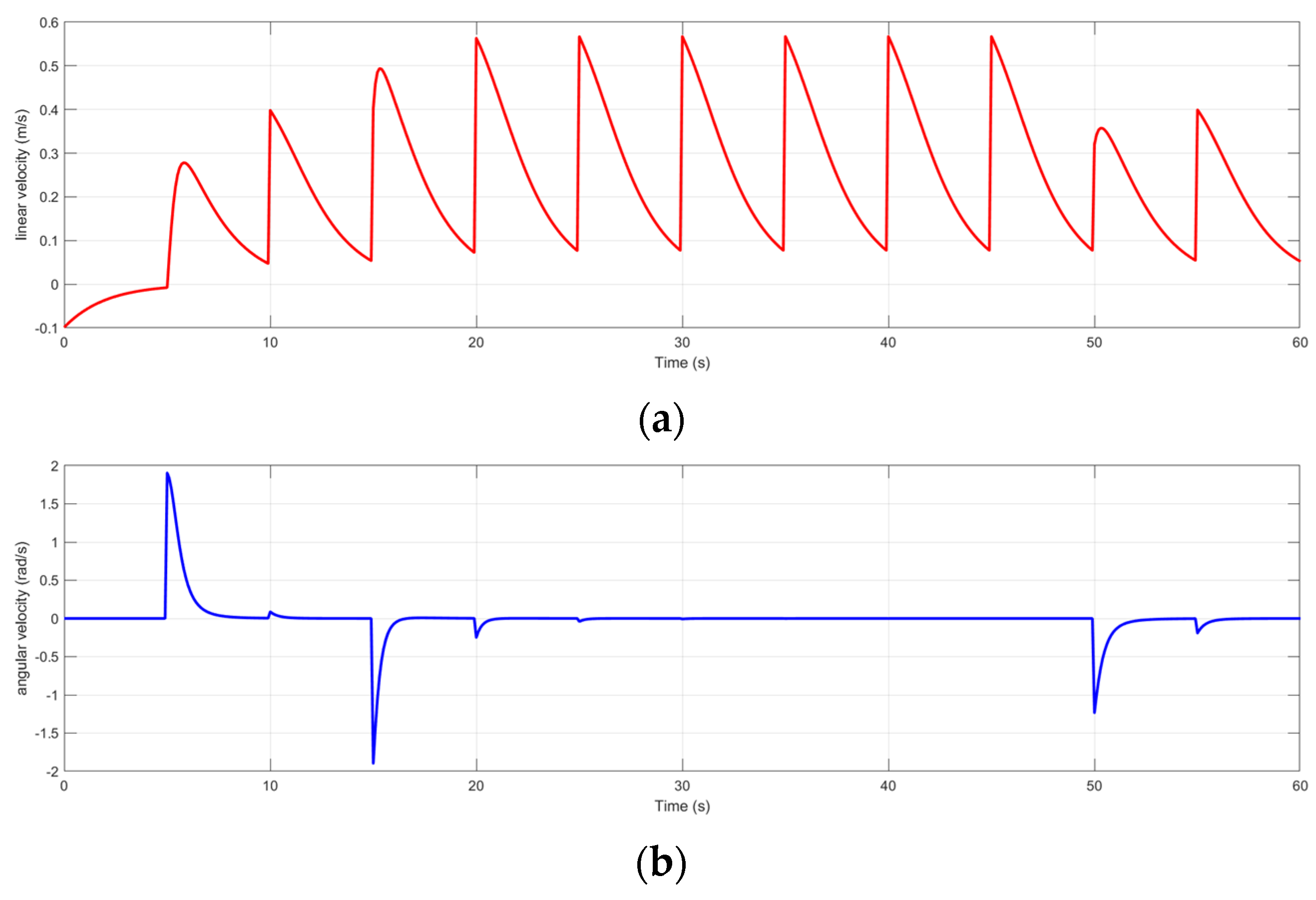
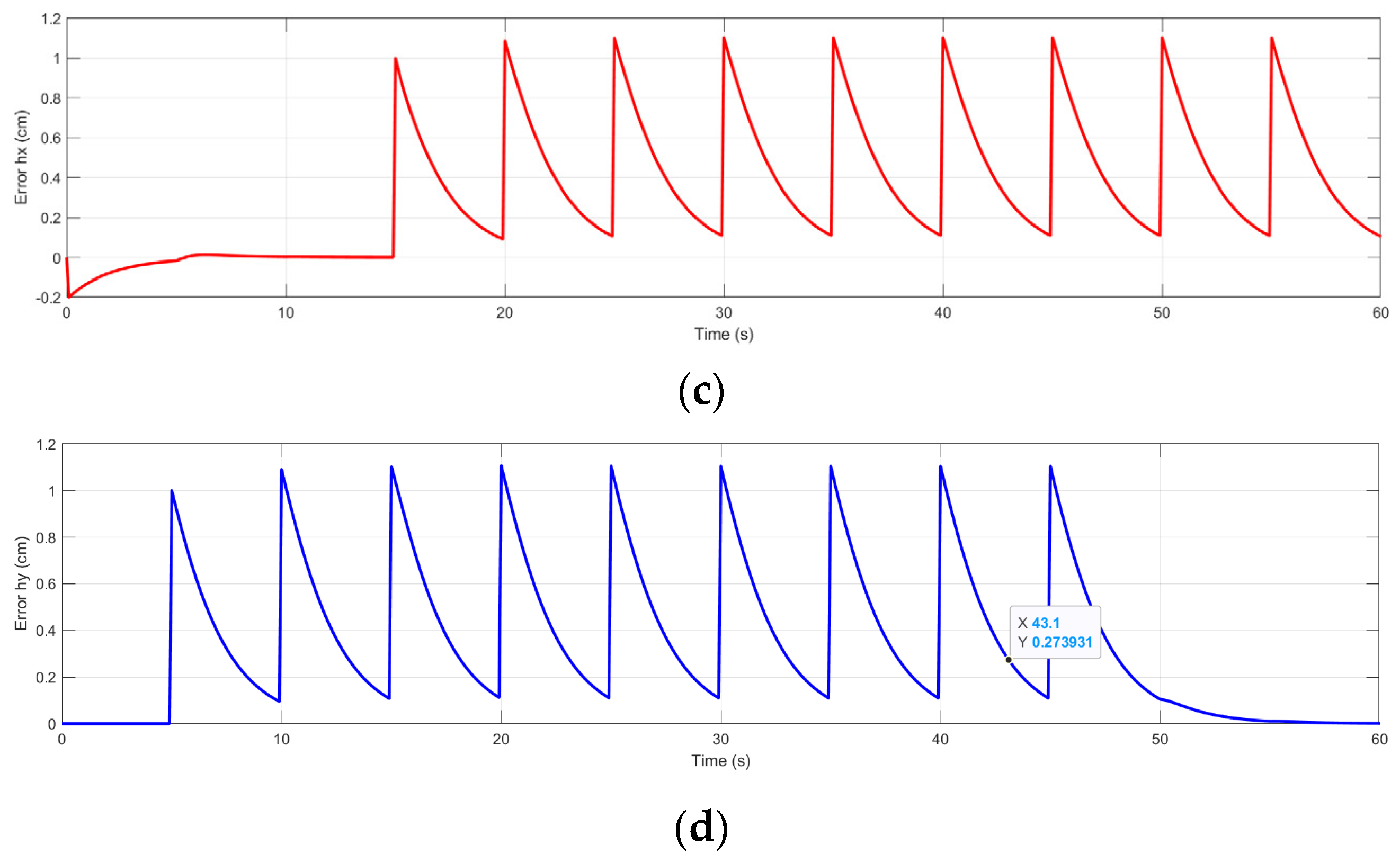
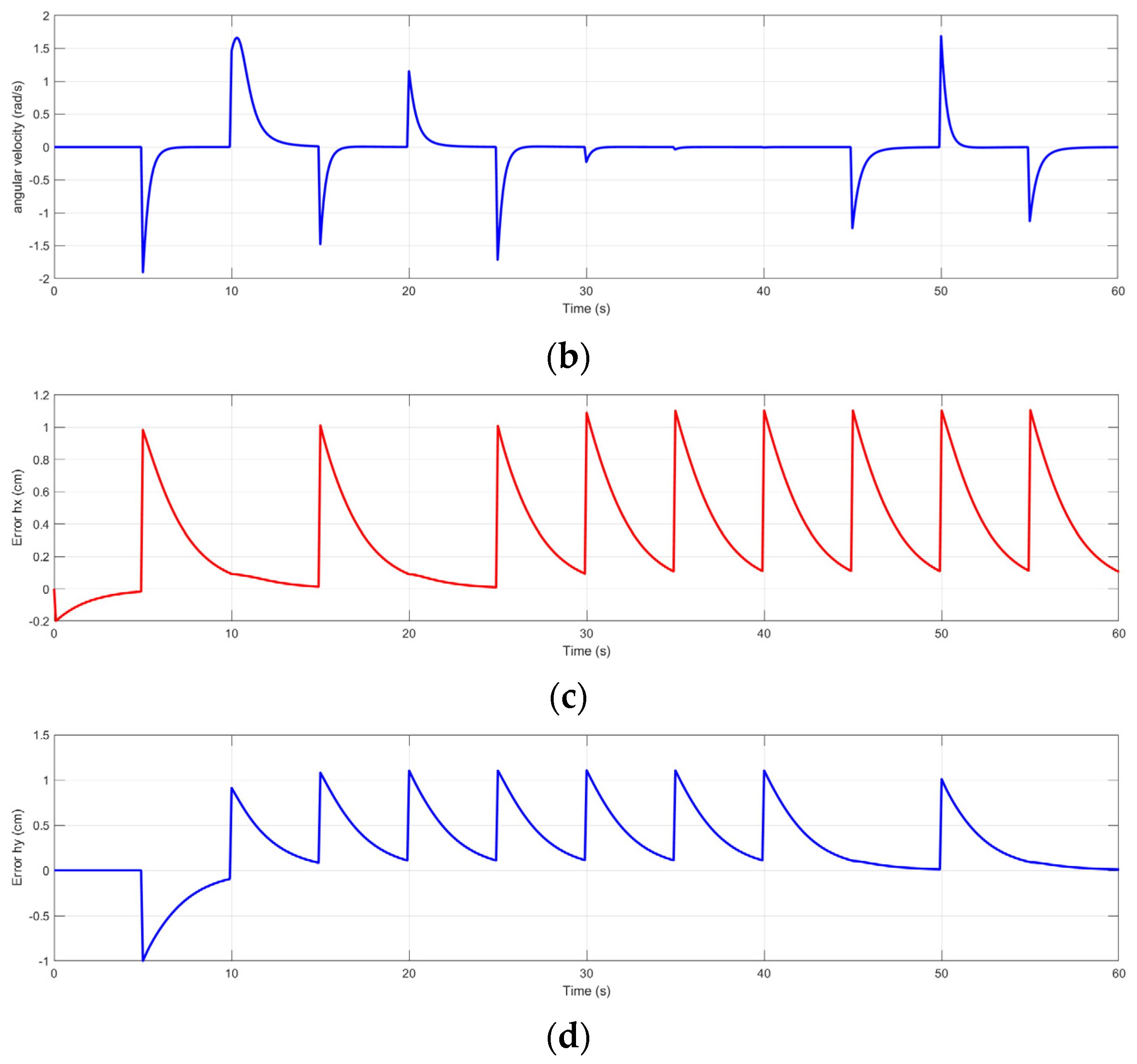
3.2. Results of the Trajectory-Tracking Controller Design
4. Discussion
5. Conclusions
6. Future Work
- Conduct a comparison of the controller’s performance in real environments against the results obtained analytically.
- Integrate deep learning algorithms to provide visual feedback for the robot and determine the locations of dynamic obstacles as well as the behavior in these environments, with the objective of updating the values of compensation dynamically.
- Study and propose techniques for interpolation to smooth trajectories between cells, which, combined with visual feedback, can generate new routes with constant velocities.
- Assess other algorithms based on reinforcement learning and establish new functions for rewards and the initiation of states.
- Evaluate the learning by reinforcement algorithms on maps with a larger number of cells to validate convergence.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohanty, P.K.; Singh, A.K.; Kumar, A.; Mahto, M.K.; Kundu, S. Path Planning Techniques for Mobile Robots: A Review. In Lecture Notes in Networks and Systems, Proceedings of the 13th International Conference on Soft Computing and Pattern Recognition (SoCPaR 2021); Springer: Cham, Switzerland, 2022; Volume 417. [Google Scholar] [CrossRef]
- Cheng, C.X.; Sha, Q.X.; He, B.; Li, G.L. Path planning and obstacle avoidance for AUV: A review. Ocean Eng. 2021, 235, 109355. [Google Scholar] [CrossRef]
- Loganathan, A.; Ahmad, N.S. A systematic review on recent advances in autonomous mobile robot navigation. Eng. Sci. Technol. 2023, 40, 101343. [Google Scholar] [CrossRef]
- Wu, M.; Yeong, C.F.; Su, E.L.M.; Holderbaum, W.; Yang, C. A review on energy efficiency in autonomous mobile robots. Robot. Intell. Autom. 2023, 43, 648–668. [Google Scholar] [CrossRef]
- Liu, L.X.; Wang, X.; Yang, X.; Liu, H.J.; Li, J.P.; Wang, P.F. Path planning techniques for mobile robots: Review and prospect. Expert Syst. Appl. 2023, 227, 120254. [Google Scholar] [CrossRef]
- Salama, O.A.A.; Eltaib, M.E.H.; Mohamed, H.A.; Salah, O. RCD: Radial Cell Decomposition Algorithm for Mobile Robot Path Planning. IEEE Access 2021, 9, 149982–149992. [Google Scholar] [CrossRef]
- Chen, G.; Luo, N.; Liu, D.; Zhao, Z.; Liang, C. Path planning for manipulators based on an improved probabilistic roadmap method. Robot. Comput. Integr. Manuf. 2021, 72, 102196. [Google Scholar] [CrossRef]
- Souza, R.M.J.A.; Lima, G.V.; Morais, A.S.; Oliveira-Lopes, L.C.; Ramos, D.C.; Tofoli, F.L. Modified Artificial Potential Field for the Path Planning of Aircraft Swarms in Three-Dimensional Environments. Sensors 2022, 22, 1558. [Google Scholar] [CrossRef]
- Lindqvist, B.; Agha-Mohammadi, A.A.; Nikolakopoulos, G. Exploration-RRT: A multi-objective Path Planning and Exploration Framework for Unknown and Unstructured Environments. arXiv 2021, arXiv:2104.03724. [Google Scholar] [CrossRef]
- Low, E.S.; Ong, P.; Low, C.Y. A modified Q-learning path planning approach using distortion concept and optimization in dynamic environment for autonomous mobile robot. Comput. Ind. Eng. 2023, 181, 109338. [Google Scholar] [CrossRef]
- Zaharuddeen, H.; Muhammed Bashir, M.A.; Abubakar, U.; Glory Okpowodu, U. Path Planning Algorithms for Mobile Robots: A Survey. In Motion Planning for Dynamic Agents; Zain Anwar, A., Amber, I., Eds.; IntechOpen: Rijeka, Croatia, 2023; Chapter 5. [Google Scholar]
- Gad, A.G. Particle Swarm Optimization Algorithm and Its Applications: A Systematic Review (Apr, 10.1007/s11831-021-09694-4, 2022). Arch. Comput. Method E 2023, 30, 3471. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Li, S.E. Reinforcement Learning for Sequential Decision and Optimal Control; Springer: Singapore, 2023. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; A Bradford Book: London, UK, 2018. [Google Scholar]
- Lan, W.; Jin, X.; Chang, X.; Wang, T.; Zhou, H.; Tian, W.; Zhou, L. Path planning for underwater gliders in time-varying ocean current using deep reinforcement learning. Ocean Eng. 2022, 262, 112226. [Google Scholar] [CrossRef]
- Li, Z.; Wu, L.; Xu, Y.; Moazeni, S.; Tang, Z. Multi-Stage Real-Time Operation of a Multi-Energy Microgrid with Electrical and Thermal Energy Storage Assets: A Data-Driven MPC-ADP Approach. IEEE Trans. Smart Grid 2022, 13, 213–226. [Google Scholar] [CrossRef]
- Gao, H.; Jiang, S.; Li, Z.; Wang, R.; Liu, Y.; Liu, J. A Two-stage Multi-agent Deep Reinforcement Learning Method for Urban Distribution Network Reconfiguration Considering Switch Contribution. IEEE Trans. Power Syst. 2024, 1–12. [Google Scholar] [CrossRef]
- Xu, C.; Zhao, W.; Chen, Q.; Wang, C. An actor-critic based learning method for decision-making and planning of autonomous vehicles. Sci. China Technol. Sci. 2021, 64, 984–994. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, X.; Xu, Y.; Guo, J. A Deep Q-network (DQN) Based Path Planning Method for Mobile Robots. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018; pp. 366–371. [Google Scholar]
- Low, E.S.; Ong, P.; Low, C.Y. An empirical evaluation of Q-learning in autonomous mobile robots in static and dynamic environments using simulation. Decis. Anal. J. 2023, 8, 100314. [Google Scholar] [CrossRef]
- Low, E.S.; Ong, P.; Low, C.Y.; Omar, R. Modified Q-learning with distance metric and virtual target on path planning of mobile robot. Expert Syst. Appl. 2022, 199, 117191. [Google Scholar] [CrossRef]
- Maoudj, A.; Hentout, A. Optimal path planning approach based on Q-learning algorithm for mobile robots. Appl. Soft Comput. 2020, 97, 106796. [Google Scholar] [CrossRef]
- Low, E.S.; Ong, P.; Cheah, K.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2019, 115, 143–161. [Google Scholar] [CrossRef]
- Chen, C.; Chen, X.-Q.; Ma, F.; Zeng, X.-J.; Wang, J. A knowledge-free path planning approach for smart ships based on reinforcement learning. Ocean Eng. 2019, 189, 106299. [Google Scholar] [CrossRef]
- Huo, F.; Zhu, S.; Dong, H.; Ren, W. A new approach to smooth path planning of Ackerman mobile robot based on improved ACO algorithm and B-spline curve. Robot. Auton. Syst. 2024, 175, 104655. [Google Scholar] [CrossRef]
- Elhoseny, M.; Tharwat, A.; Hassanien, A.E. Bezier Curve Based Path Planning in a Dynamic Field using Modified Genetic Algorithm. J. Comput. Sci. 2018, 25, 339–350. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian Decision Process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Pieters, M.; Wiering, M.A. Q-learning with experience replay in a dynamic environment. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Xie, M. Fundamentals of Robotics: Linking Perception to Action; World Scientific Publishing Company: Singapore, 2003. [Google Scholar]
- de Wit, C.A.C.; Siciliano, B.; Bastin, G. Theory of Robot Control; Springer: London, UK, 1996. [Google Scholar]
- Rapalski, A.; Dudzik, S. Energy Consumption Analysis of the Selected Navigation Algorithms for Wheeled Mobile Robots. Energies 2023, 16, 1532. [Google Scholar] [CrossRef]
- Lewis, F.L.; Dawson, D.M.; Abdallah, C.T. Robot Manipulator Control: Theory and Practice, Revised and Expanded; Taylor & Francis Group: Abingdon, UK, 2003. [Google Scholar]
- Tedrake, R. Underactuated Robotics. Algorithms for Walking, Running, Swimming, Flying, and Manipulation (Course Notes for MIT 6.832). 2023. Available online: http://underactuated.mit.edu (accessed on 8 May 2023).
- Kubo, R.; Fujii, Y.; Nakamura, H. Control Lyapunov Function Design for Trajectory Tracking Problems of Wheeled Mobile Robot. IFAC-PapersOnLine 2020, 53, 6177–6182. [Google Scholar] [CrossRef]
- Wu, Z.; Yin, Y.; Liu, J.; Zhang, D.; Chen, J.; Jiang, W. A Novel Path Planning Approach for Mobile Robot in Radioactive Environment Based on Improved Deep Q Network Algorithm. Symmetry 2023, 15, 2048. [Google Scholar] [CrossRef]
- Wang, W.; Wu, Z.; Luo, H.; Zhang, B. Path Planning Method of Mobile Robot Using Improved Deep Reinforcement Learning. J. Electr. Comput. Eng. 2022, 2022, 5433988. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Episodes | 100 |
| Learning rate | 1 × 10−6 |
| Average iteration | 550 |
| Discount rate, γ | 0.99 |
| Parameter | Value |
|---|---|
| Episodes | 1000 |
| Learning rate, α | 1 × 10−3 |
| Random probability starts | 1 |
| Random probability end | 1 × 10−2 |
| Random probability decay | 0.995 |
| Target update frequency, θ | 10 |
| Discount rate, γ | 0.99 |
| Memory size | 10,000 |
| Map | Algorithm | Distance (m) | No. Turns | Training Time (s) |
|---|---|---|---|---|
| Reinforcement learning | 13.89 | 3 | 112.40 | |
| 1 | Deep Q-Learning | 13.89 | 3 | 526.45 |
| A* (4 actions) | 22.00 | 10 | 0.011 | |
| A* (8 actions) | 13.89 | 4 | 0.015 | |
| Reinforcement Learning | 13.31 | 4 | 119.46 | |
| 2 | Deep Q-Learning | 13.31 | 4 | 556.49 |
| A* (4 actions) | 18.00 | 5 | 0.011 | |
| A* (8 actions) | 13.89 | 7 | 0.014 | |
| Reinforcement learning | 17.89 | 8 | 127.65 | |
| 3 | Deep Q-Learning | 17.89 | 7 | 687.87 |
| A* (4 actions) | 22.00 | 10 | 0.010 | |
| A* (8 actions) | 18.48 | 9 | 0.014 | |
| Reinforcement learning | 13.89 | 6 | 98.06 | |
| 4 | Deep Q-Learning | 13.89 | 4 | 447.16 |
| A* (4 actions) | 18.00 | 4 | 0.009 | |
| A* (8 actions) | 13.89 | 8 | 0.013 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaramillo-Martínez, R.; Chavero-Navarrete, E.; Ibarra-Pérez, T. Reinforcement-Learning-Based Path Planning: A Reward Function Strategy. Appl. Sci. 2024, 14, 7654. https://doi.org/10.3390/app14177654
Jaramillo-Martínez R, Chavero-Navarrete E, Ibarra-Pérez T. Reinforcement-Learning-Based Path Planning: A Reward Function Strategy. Applied Sciences. 2024; 14(17):7654. https://doi.org/10.3390/app14177654
Chicago/Turabian StyleJaramillo-Martínez, Ramón, Ernesto Chavero-Navarrete, and Teodoro Ibarra-Pérez. 2024. "Reinforcement-Learning-Based Path Planning: A Reward Function Strategy" Applied Sciences 14, no. 17: 7654. https://doi.org/10.3390/app14177654
APA StyleJaramillo-Martínez, R., Chavero-Navarrete, E., & Ibarra-Pérez, T. (2024). Reinforcement-Learning-Based Path Planning: A Reward Function Strategy. Applied Sciences, 14(17), 7654. https://doi.org/10.3390/app14177654