
Recognition of Food Ingredients—Dataset Analysis

Abstract
1. Introduction
2. Related Works
- Research Questions;
- Inclusion Criteria;
- Research Strategy;
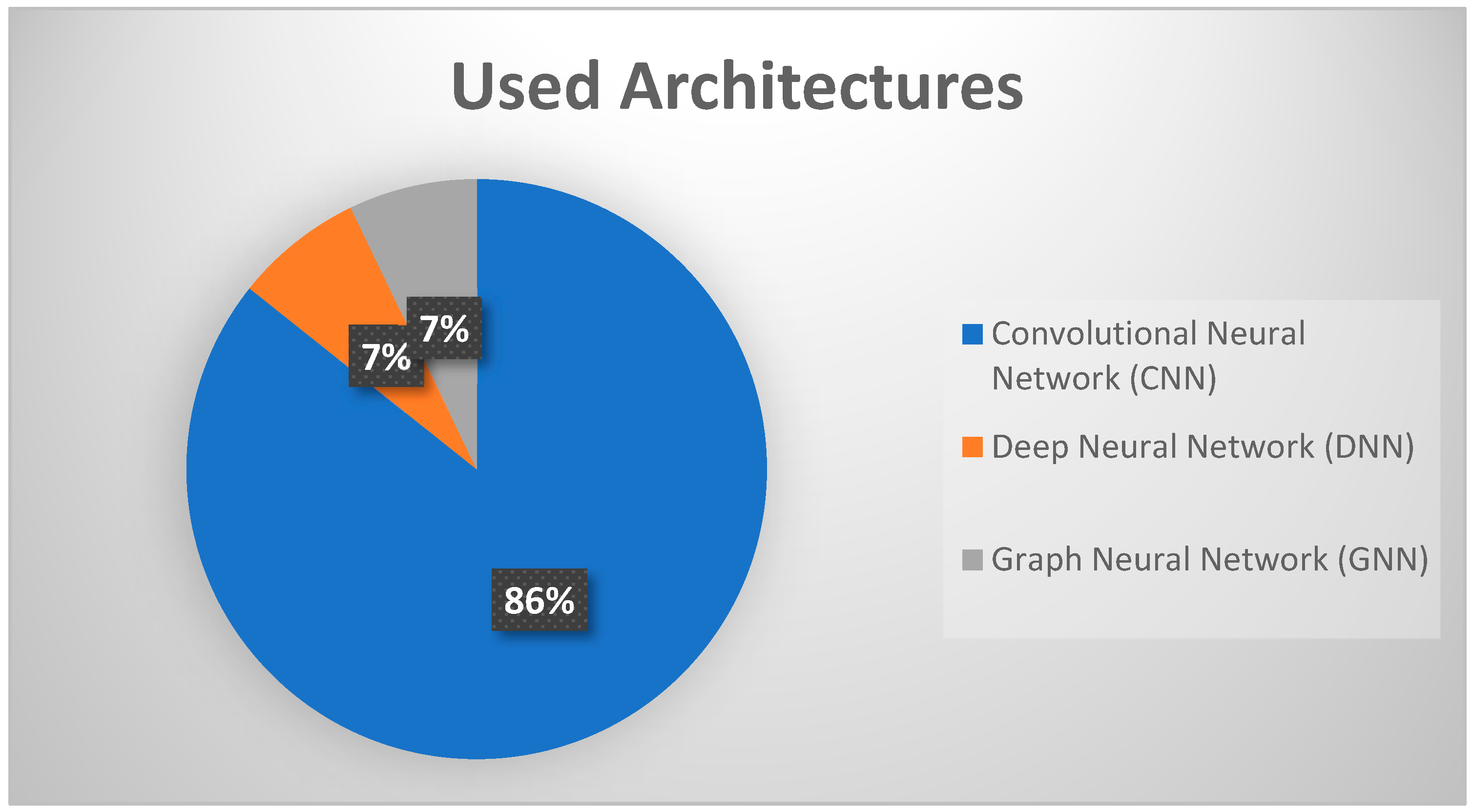
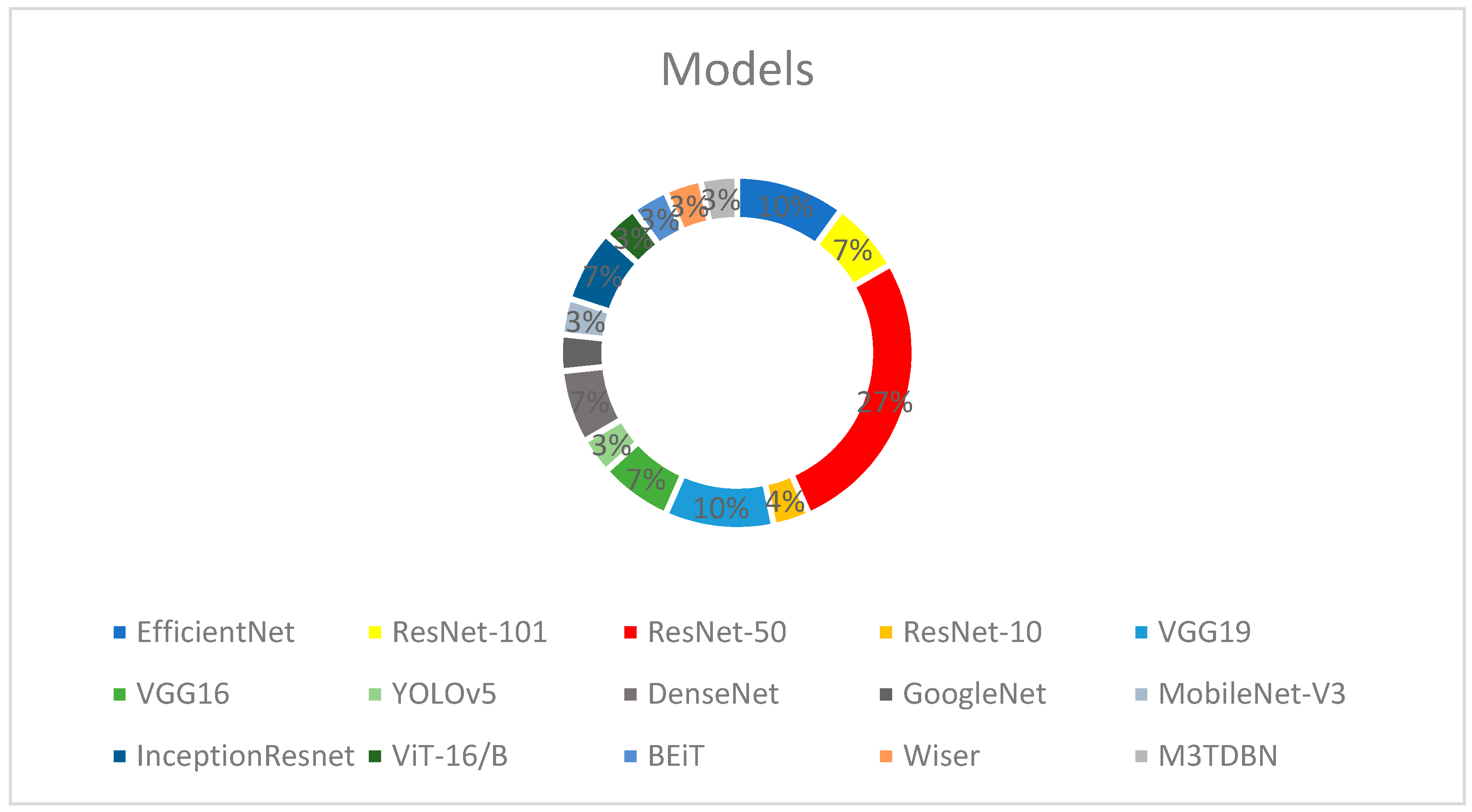
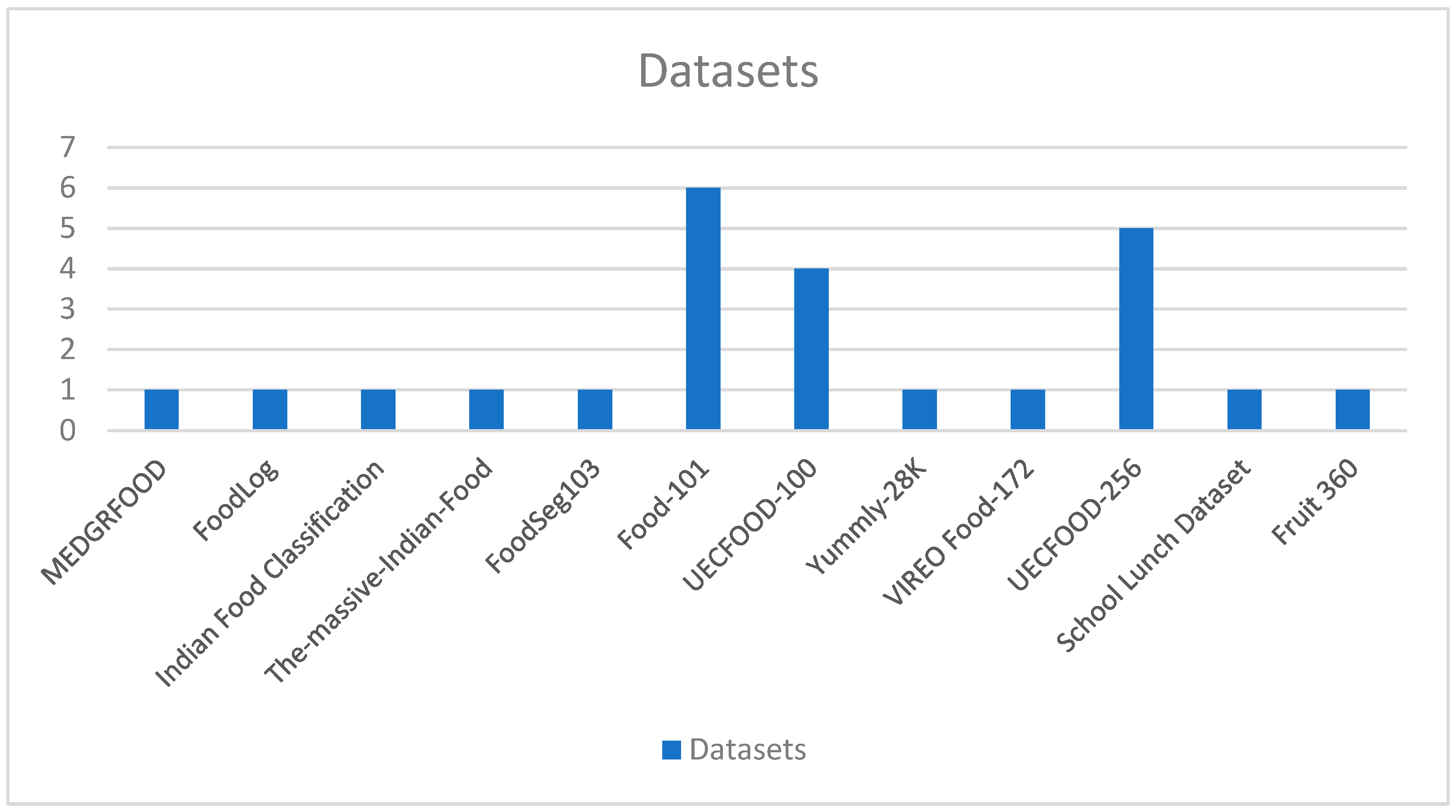
- Results;
- Data Extraction and Analysis;
- Discussion.
- Are there digital solutions capable of recognizing food from images of meals?
- Are there digital solutions that offer recipes based on recognizing ingredients or food images?
- Are there digital solutions that propose meals based on leftovers, taking into account the characteristics of each user?
- Criterion 1: Studies carried out between 2015 and 2023;
- Criterion 2: Studies written in English;
- Criterion 3: Studies in which the full text is available;
- Criterion 4: Studies that apply image recognition to cooked food;
- Criterion 5: Studies in which the dataset is available on the web.
3. Materials and Methods
3.1. ResNet-50 and Food-101 Features
3.2. Proposed Model for Ingredient Identification
3.3. Food-101 Problems and Alternatives
3.4. Comparison and Evaluation of Results
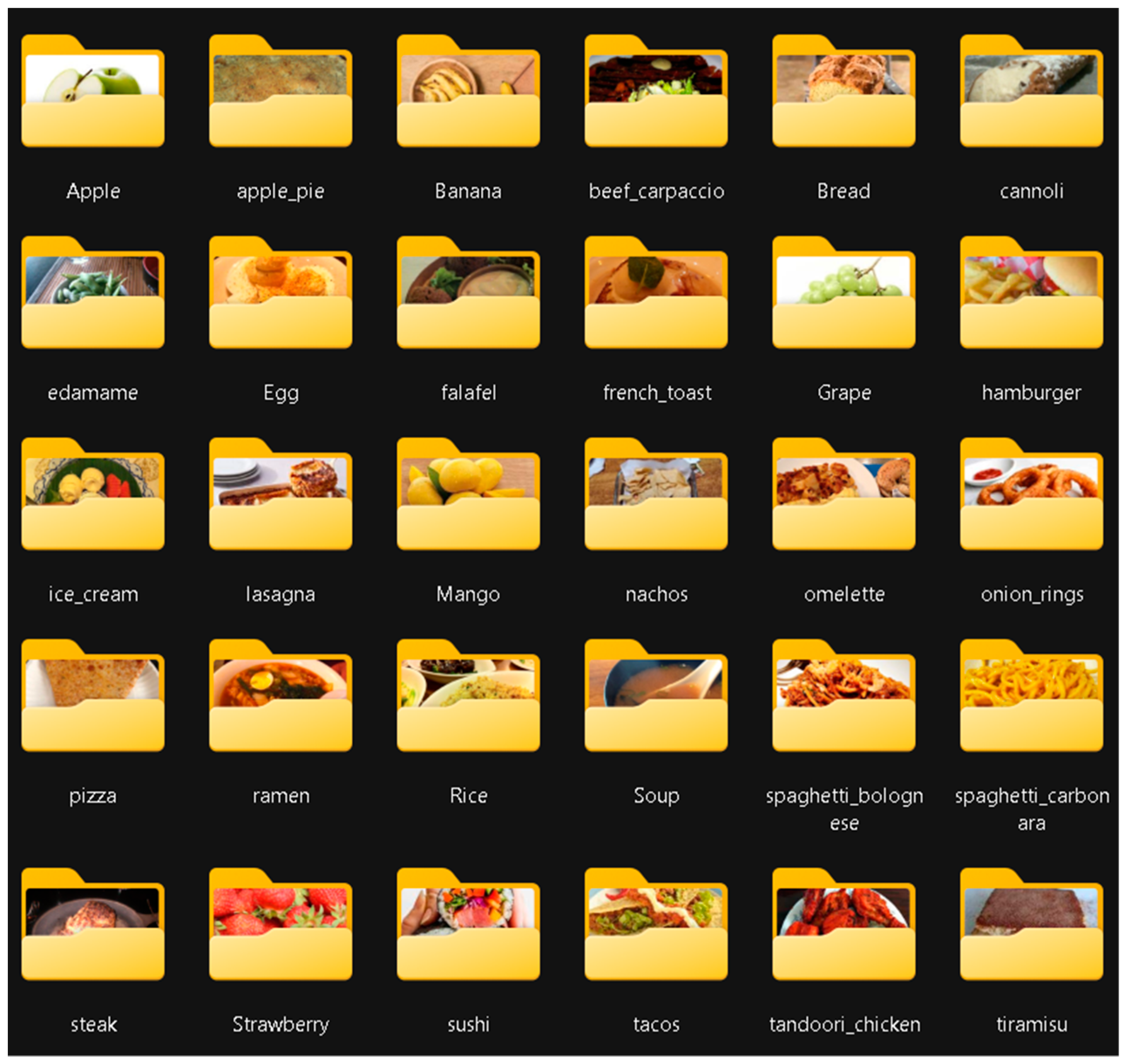
3.5. New Dataset
- 30 food classes;
- 32,020 images;
- Food, starter, or dessert images;
- Image format jpg;
- Images of different ways of cooking food.
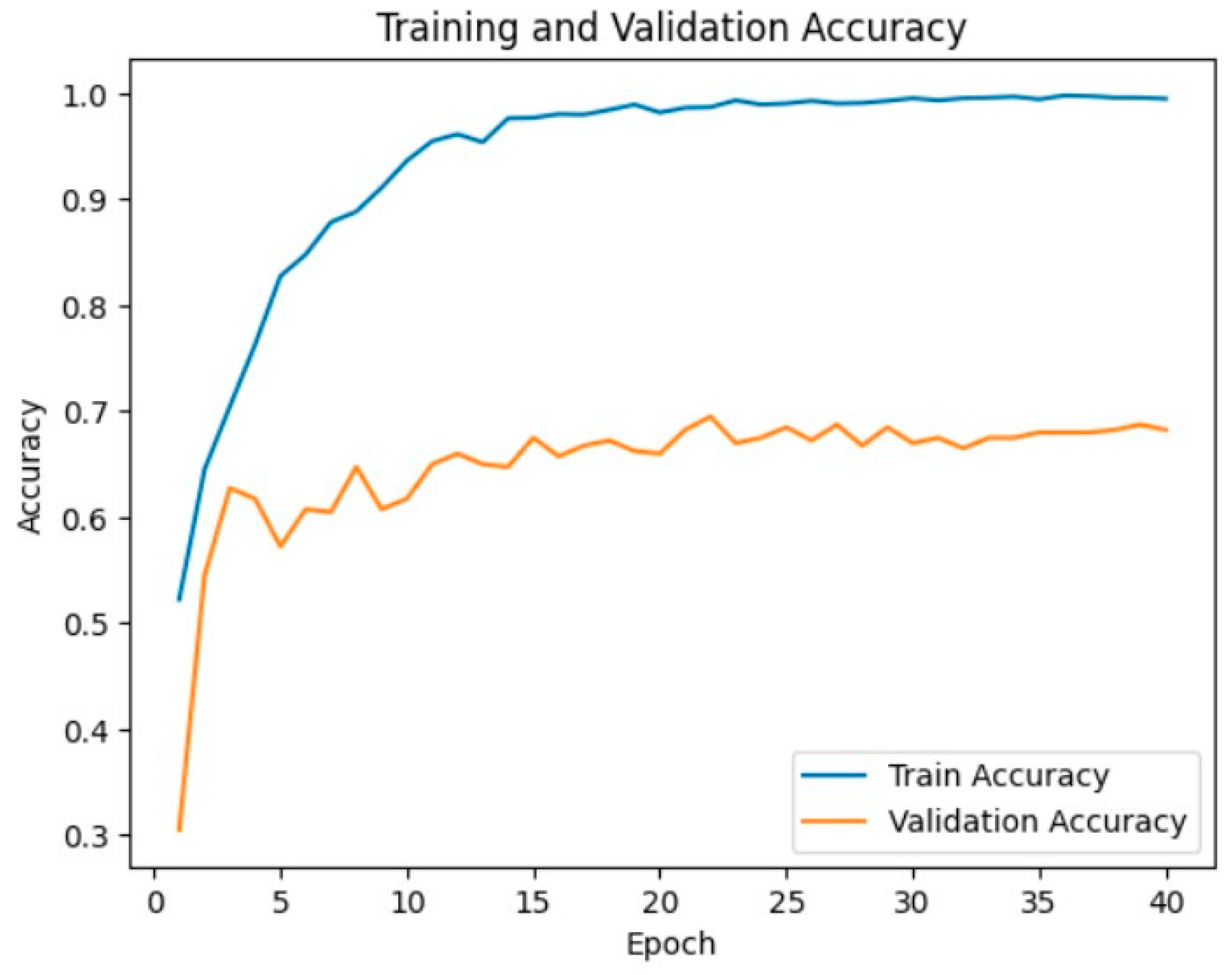
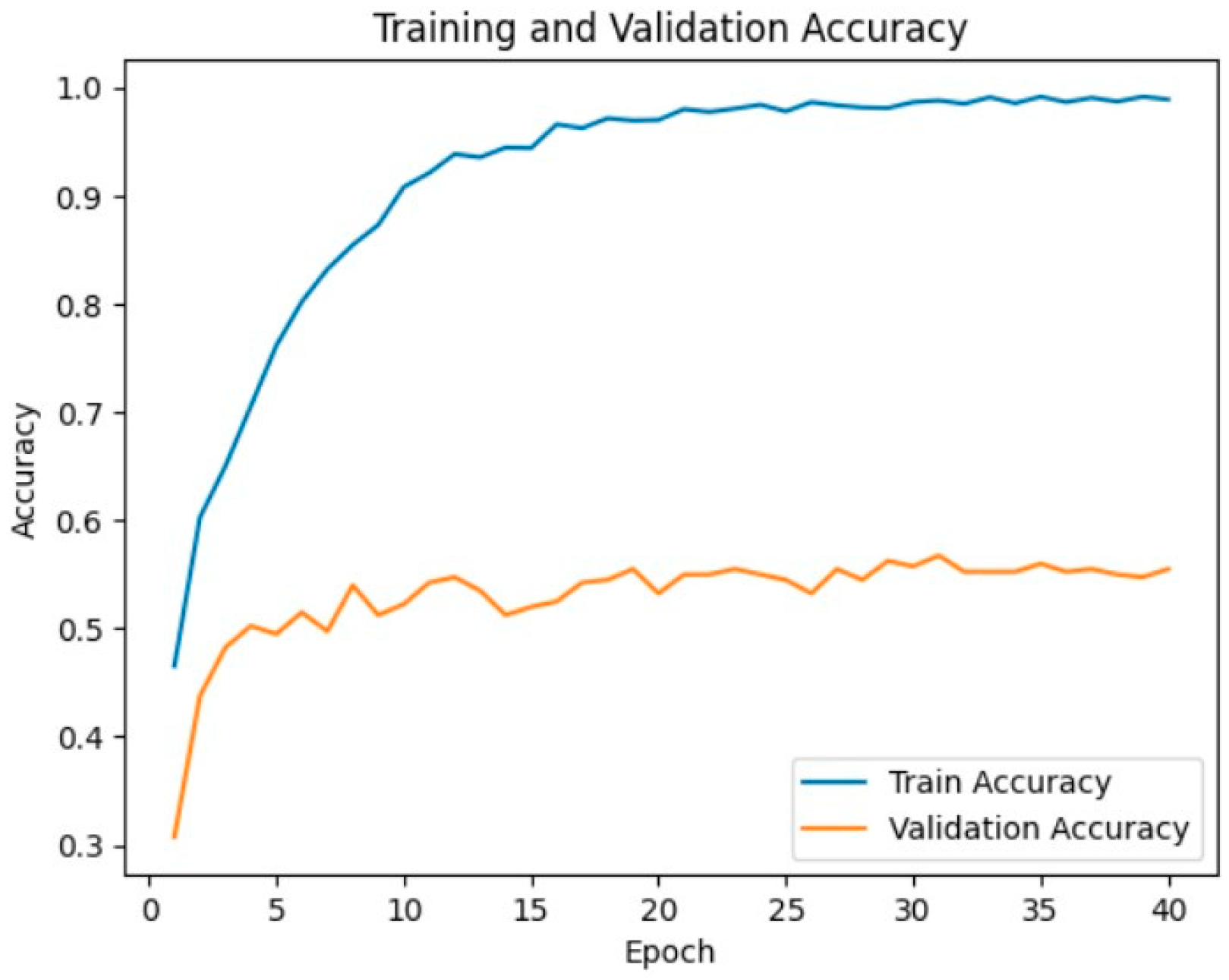
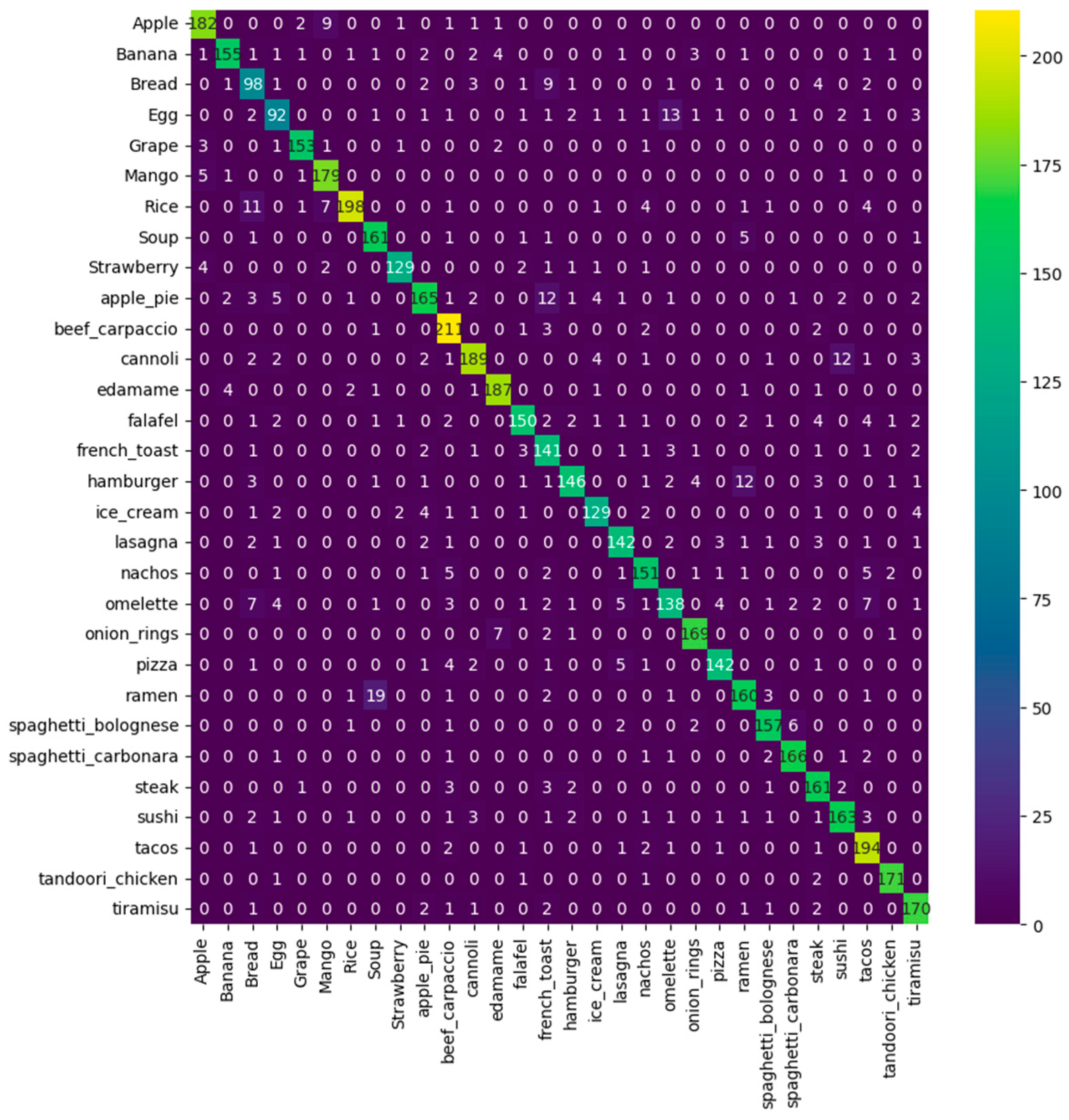
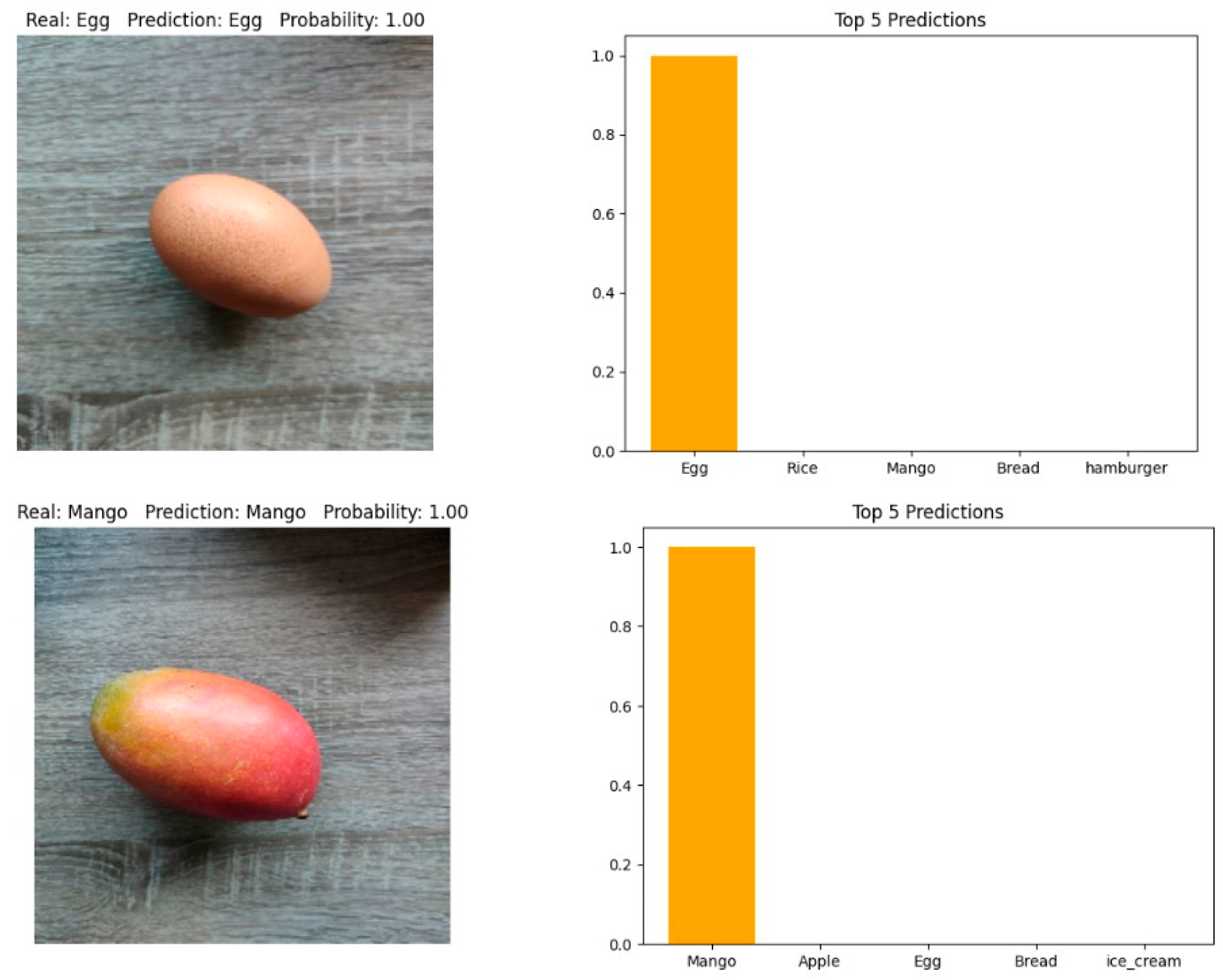
3.6. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Recommendation Systems: Applications and Examples in 2024. Available online: https://research.aimultiple.com/recommendation-system/ (accessed on 30 May 2024).
- Best Recipe Apps: The 7 Finest Apps for Cooking Inspiration|TechRadar. Available online: https://www.techradar.com/news/best-recipe-apps-the-7-finest-apps-for-cooking-inspiration (accessed on 30 May 2024).
- Spoonacular Recipe and Food API. Available online: https://spoonacular.com/food-api (accessed on 5 June 2024).
- Edamam—Food Database API, Nutrition API and Recipe API. Available online: https://www.edamam.com/ (accessed on 5 June 2024).
- TensorFlow. Available online: https://www.tensorflow.org/?hl=pt-br (accessed on 17 January 2024).
- Keras: Deep Learning for Humans. Available online: https://keras.io/ (accessed on 17 January 2024).
- NumPy. Available online: https://numpy.org/ (accessed on 17 January 2024).
- What Is a Dataset? Definition, Use Cases, Benefits, and Example|by Bright Data|Medium. Available online: https://medium.com/@Bright-Data/what-is-a-dataset-definition-use-cases-benefits-and-example-9aaf5ecc301e (accessed on 5 June 2024).
- Why Web Scraping: A Full List of Advantages and Disadvantages|by Teodora C.|Medium. Available online: https://raluca-p.medium.com/why-web-scraping-a-full-list-of-advantages-and-disadvantages-fdbb9e8ed010 (accessed on 5 June 2024).
- PRISMA. Available online: http://www.prisma-statement.org/?AspxAutoDetectCookieSupport=1 (accessed on 17 January 2024).
- IEEE Xplore. Available online: https://ieeexplore.ieee.org/Xplore/home.jsp (accessed on 17 January 2024).
- Scopus—Document Search. Available online: https://www.scopus.com/search/form.uri?display=basic#basic (accessed on 17 January 2024).
- ACM Digital Library. Available online: https://dl.acm.org/ (accessed on 17 January 2024).
- Morol, M.K.; Rokon, M.S.J.; Hasan, I.B.; Saif, A.M.; Khan, R.H.; Das, S.S. Food Recipe Recommendation Based on Ingredients Detection Using Deep Learning. In Proceedings of the 2nd International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 March 2022; ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2022; pp. 191–198. [Google Scholar] [CrossRef]
- Konstantakopoulos, F.S.; Georga, E.I.; Fotiadis, D.I. Mediterranean Food Image Recognition Using Deep Convolutional Networks. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Virtual, 1–5 November 2021; pp. 1740–1743. [Google Scholar] [CrossRef]
- Yu, Q.; Anzawa, M.; Amano, S.; Ogawa, M.; Aizawa, K. Food Image Recognition by Personalized Classifier. In Proceedings of the International Conference on Image Processing, ICIP, Athens, Greece, 7–10 October 2018; pp. 171–175. [Google Scholar] [CrossRef]
- Basrur, A.; Mehta, D.; Joshi, A.R. Food Recognition using Transfer Learning. In Proceedings of the IBSSC 2022—IEEE Bombay Section Signature Conference, Mumbai, India, 8–10 December 2022. [Google Scholar] [CrossRef]
- Wu, X.; Fu, X.; Liu, Y.; Lim, E.P.; Hoi, S.C.H.; Sun, Q. A Large-Scale Benchmark for Food Image Segmentation. In Proceedings of the MM 2021—Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 506–515. [Google Scholar] [CrossRef]
- Zhu, S.; Ling, X.; Zhang, K.; Niu, J. Food Image Recognition Method Based on Generative Self-supervised Learning. In Proceedings of the 2023 9th International Conference on Computing and Artificial Intelligence, Tianjin, China, 17–20 March 2023; ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2022; pp. 203–207. [Google Scholar] [CrossRef]
- Raman, T.; Kumar, S.; Paduri, A.R.; Mahto, G.; Jain, S.; Bindhu, K.; Darapaneni, N. CNN Based Study of Improvised Food Image Classification. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference, CCWC 2023, Las Vegas, NV, USA, 8–11 March 2023; pp. 1051–1057. [Google Scholar] [CrossRef]
- Min, W.; Jiang, S.; Sang, J.; Wang, H.; Liu, X.; Herranz, L. Being a supercook: Joint food attributes and multimodal content modeling for recipe retrieval and exploration. IEEE Trans. Multimed. 2017, 19, 1100–1113. [Google Scholar] [CrossRef]
- Gao, J.; Chen, J.; Fu, H.; Jiang, Y.G. Dynamic Mixup for Multi-Label Long-Tailed Food Ingredient Recognition. IEEE Trans. Multimed. 2023, 25, 4764–4773. [Google Scholar] [CrossRef]
- Zhao, H.; Yap, K.H.; Kot, A.C. Fusion learning using semantics and graph convolutional network for visual food recognition. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision, WACV 2021, Waikoloa, HI, USA, 3–8 January 2021; pp. 1710–1719. [Google Scholar] [CrossRef]
- Zahisham, Z.; Lee, C.P.; Lim, K.M. Food Recognition with ResNet-50. In Proceedings of the IEEE International Conference on Artificial Intelligence in Engineering and Technology, IICAIET 2020, Kota Kinabalu, Malaysia, 26–27 September 2020. [Google Scholar] [CrossRef]
- Tan, S.W.; Lee, C.P.; Lim, K.M.; Lim, J.Y. Food Detection and Recognition with Deep Learning: A Comparative Study. In Proceedings of the International Conference on ICT Convergence, Melaka, Malaysia, 23–24 August 2023; pp. 283–288. [Google Scholar] [CrossRef]
- Tasci, E. Voting combinations-based ensemble of fine-tuned convolutional neural networks for food image recognition. Multimed. Tools Appl. 2020, 79, 30397–30418. [Google Scholar] [CrossRef]
- A Deep Convolutional Neural Network for Food Detection and Recognition|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/8626720 (accessed on 18 January 2024).
- How to Achieve SOTA Accuracy on ImageNet with ResNet50|Deci. Available online: https://deci.ai/blog/resnet50-how-to-achieve-sota-accuracy-on-imagenet/ (accessed on 31 May 2024).
- Deep Residual Networks (ResNet, ResNet50) 2024 Guide—Viso.ai. Available online: https://viso.ai/deep-learning/resnet-residual-neural-network/ (accessed on 18 January 2024).
- Detailed Explanation of Resnet CNN Model.|by TANISH SHARMA|Medium. Available online: https://medium.com/@sharma.tanish096/detailed-explanation-of-residual-network-resnet50-cnn-model-106e0ab9fa9e (accessed on 20 January 2024).
- What Are Skip Connections in Deep Learning? Available online: https://www.analyticsvidhya.com/blog/2021/08/all-you-need-to-know-about-skip-connections/ (accessed on 20 January 2024).
- LearningRateScheduler|Tensorflow LearningRateScheduler. Available online: https://www.analyticsvidhya.com/blog/2021/06/decide-best-learning-rate-with-learningratescheduler-in-tensorflow/ (accessed on 2 June 2024).
- Selenium with Python—Selenium Python Bindings 2 Documentation. Available online: https://selenium-python.readthedocs.io/ (accessed on 2 June 2024).
- 11 Top Search Engines to Optimize For in 2024. Available online: https://www.oberlo.com/blog/top-search-engines-world (accessed on 2 June 2024).
- What Is the Confusion Matrix? Available online: https://h2o.ai/wiki/confusion-matrix/ (accessed on 2 June 2024).
- F1 Score in Machine Learning: Intro & Calculation. Available online: https://www.v7labs.com/blog/f1-score-guide (accessed on 2 June 2024).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Model | Description |
|---|---|---|
| [14] | ResNet-50 | The authors developed an algorithm to recommend recipes by recognizing ingredients in advance. They trained the ResNet-50 model over 20 epochs using transfer learning, and once the model was trained, it was used to recommend recipes. The model is capable of recognizing 32 ingredients, and thus, a 19 × 32 matrix was created in which the index is set to “1” when an ingredient is identified. Subsequently, a linear search is conducted on the database, resulting in the retrieval of a recipe with indexes set to “1” for the ingredients identified by ResNet-50 and “0” for the remaining ingredients. |
| [15] | EfficientNet-B2 | The authors propose a food recognition system. They trained the model on ImageNet to extract generic features and used fine-tuning to obtain better results. The model weights were adjusted in the last two blocks and three additional blocks were added, each containing a fully connected layer and a dropout layer. Finally, data augmentation techniques were applied to further reduce overfitting. The authors demonstrated that the use of fine-tuning significantly improves the model’s performance. |
| [16] | ResNet-50 | The authors have developed a method that adapts to users’ eating habits. Each user has their own database with their food records. Subsequently, a time-dependent food distribution model is employed, which takes into account the evolution of the user’s eating habits over time. This is achieved through the use of a vector weight optimization strategy, which optimizes the weight of the classifier vectors and thus better adapts to changes in eating habits. |
| [17] | ResNet VGG19 EfficientNet-B0 DenseNet | The authors propose an approach to recognize food dishes and consequently recommend recipes. Each dish is represented in a matrix with index ‘0’. After the model assigns a class to the image, the information is extracted from web pages using the web crawling method with the Beautiful Soup and Selenium libraries. The models are trained for 50 epochs using ImageNet transfer learning, and data augmentation is also applied. |
| [18] | ResNet-50 Vision Transformer 16/B | The authors have developed a framework for classifying ingredients in images of food dishes. The first module, ReLeM (ReciPe Language-Enhanced Multimodal), is designed to enhance the accuracy of ingredient segmentation. To achieve this, the visual representations of ingredients that appear in various dishes are integrated with the recipe language, recognizing that the same ingredient can be represented in different ways due to different preparation methods. The second module is tasked with classifying the segmented zones. The images are processed through a vision encoder, which is then followed by a vision decoder. Finally, segmentation models are employed to identify the ingredients in the image that have previously been classified. |
| [19] | BEiT | The authors propose a food image recognition method based on generative self-supervised learning. The objective is to enable the model to be trained on unlabeled datasets, allowing it to make segmentation predictions and circumvent the high costs associated with hiring specialized teams. To achieve this, the authors utilize the BEiT model, which has been pre-trained on ImageNet, to reconstruct portions of the image that are not visible. Subsequently, fine-tuning is employed to adapt the network to the dataset utilized by the authors (Food-101). |
| [20] | InceptionResnet V2 Resnet50 Densenet169 Wiser | The authors developed a method that focused on the importance of the quality of the training data. They used the U2-Net algorithm, which was designed to remove background objects from food images and improve model performance. After training several models, it was concluded that removing the background and using data augmentation techniques helped to improve the accuracy rate. |
| [21] | MultiTask Deep Belief Network (M3TDBN) | The authors propose a MultiTask Deep Belief Network (M3TDBN) that can identify ingredients in recipes through textual representation. The model considers various attributes related to the recipe, such as the type of cuisine and the type of dish. The Yummly-28K dataset, comprising 63,492 recipe images, was used to train the model. To identify the ingredients, it is necessary to pre-process the text, removing irrelevant information such as quantity. Transfer learning was employed using a convolutional neural network (CNN) pre-trained on the Food-101 dataset, which was then fine-tuned to the Yummly-28K dataset. The features extracted by this CNN were used as inputs for the M3TDBN model. It was concluded that incorporating additional information, such as the type of dish, significantly improved performance. |
| [22] | ResNet-50 ResNet-101 VGG-19 | To address the challenge of ingredient recognition in food images, the authors propose a D-Mixup (Dynamic Mixup) approach. The objective is to enhance the representation of minority ingredients, given the prevalence of significant disparities in the frequency of certain ingredients across most datasets. Additionally, this method mitigates the issue of datasets where test images exhibit high similarity to training images, which may not accurately reflect their true effectiveness in real-world scenarios. This structure also comprises a region-wise recognition network, which is responsible for identifying the ingredients present in each region. The results of this approach indicate that it improves performance on datasets that present these problems. |
| [23] | ResNet-10 EfficientNet-B0 | The authors propose a unified structure that encompasses two distinct approaches: many-shot learning and few-shot learning. Additionally, the structure employs a convolutional graph network (GCN) to capture relationships between different categories of food. To circumvent the issue of suboptimal performance in classes with limited image data (few-shot learning), this structure comprises two distinct phases. In the initial phase, semantic embeddings are generated utilizing the BERT (Bidirectional Encoder Representations from Transformers) model, thereby furnishing supplementary data on the specific type of food associated with each food category. Subsequent to this, a convolutional neural network (CNN) is employed to extract features from images comprising a multitude of samples, after which the integration of learning from numerous and few categories is achieved. In the second phase, the graph convolutional network (GCN) is integrated into the model to facilitate the comprehension of the interconnections and distinctions between categories. This approach has been demonstrated to yield a notable enhancement in performance compared to more sophisticated studies on few-category learning. |
| [24] | ResNet-50 | The authors propose a method that employs a convolutional neural network (CNN) ResNet-50 for food recognition, utilizing the fine-tuning technique following the initial training of the model on the ImageNet database. The images are then subjected to pre-processing, including resizing to a resolution of 224x224 pixels, and convolutional filters are applied to extract the most relevant features. It is observed that the greater the number of classes, the lower the accuracy. Conversely, the greater the number of instances per class, the greater the accuracy. |
| [25] | VGG-16 Resnet-50 Mobilenet-V3 YOLOv5 | The authors’ approach to food recognition divides the problem into two topics: binary classification and locating the food followed by its category. Binary classification identifies whether an image contains food or not, while food localization usually requires the use of bounding boxes, which are then used to classify several foods in the same image using convolutional neural networks (CNNs). |
| [26] | ResNet-101 GoogleNet VGG16/19 InceptionV3 | The authors propose an approach to food recognition that combines the results of different convolutional neural networks (CNNs) to determine the class of food using ensemble methods based on voting. There are two approaches to this type of method: hard voting and soft voting. In the first approach, each model makes a prediction, and the class with the most votes is assigned. In the second approach, the probability of each class is used and averaged, with the class with the highest value being chosen. Additionally, a Bayesian optimization algorithm is employed to identify the optimal weight for each CNN, considering its accuracy. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Louro, J.; Fidalgo, F.; Oliveira, Â. Recognition of Food Ingredients—Dataset Analysis. Appl. Sci. 2024, 14, 5448. https://doi.org/10.3390/app14135448
Louro J, Fidalgo F, Oliveira Â. Recognition of Food Ingredients—Dataset Analysis. Applied Sciences. 2024; 14(13):5448. https://doi.org/10.3390/app14135448
Chicago/Turabian StyleLouro, João, Filipe Fidalgo, and Ângela Oliveira. 2024. "Recognition of Food Ingredients—Dataset Analysis" Applied Sciences 14, no. 13: 5448. https://doi.org/10.3390/app14135448
APA StyleLouro, J., Fidalgo, F., & Oliveira, Â. (2024). Recognition of Food Ingredients—Dataset Analysis. Applied Sciences, 14(13), 5448. https://doi.org/10.3390/app14135448