
A Simple Neural-Network-Based Decoder for Short Binary Linear Block Codes


Abstract
1. Introduction
- (1)
- Multi-class NN-based decoding framework is presented, where only the received signal sequence acts as the input and one fully connected layer is required.
- (2)
- (3)
- The decoding performance of the proposed decoder is close to the well-known SOD algorithm [12], which requires plenty of candidate codewords for evaluation and is involved in complicated Gaussian elimination.
- (4)
- The presented multi-class NN-based decoder is general and applicable to different short linear block codes with no additional HDD required as compared to the Chase-type algorithm [11].
2. Preliminaries of Conventional Soft Decision Decoder
2.1. Message Encoding Process
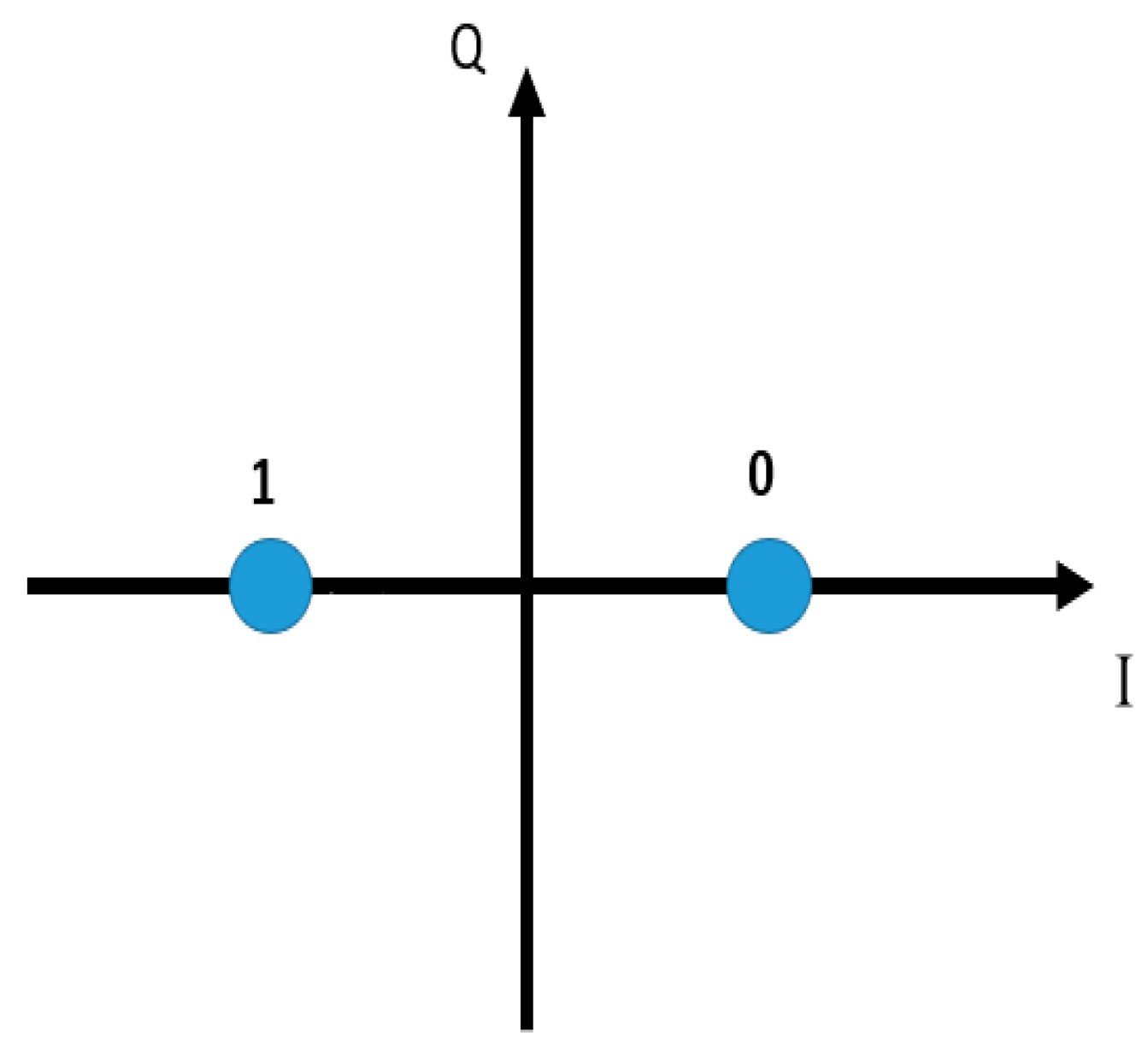
2.2. Data Transmission over Channels
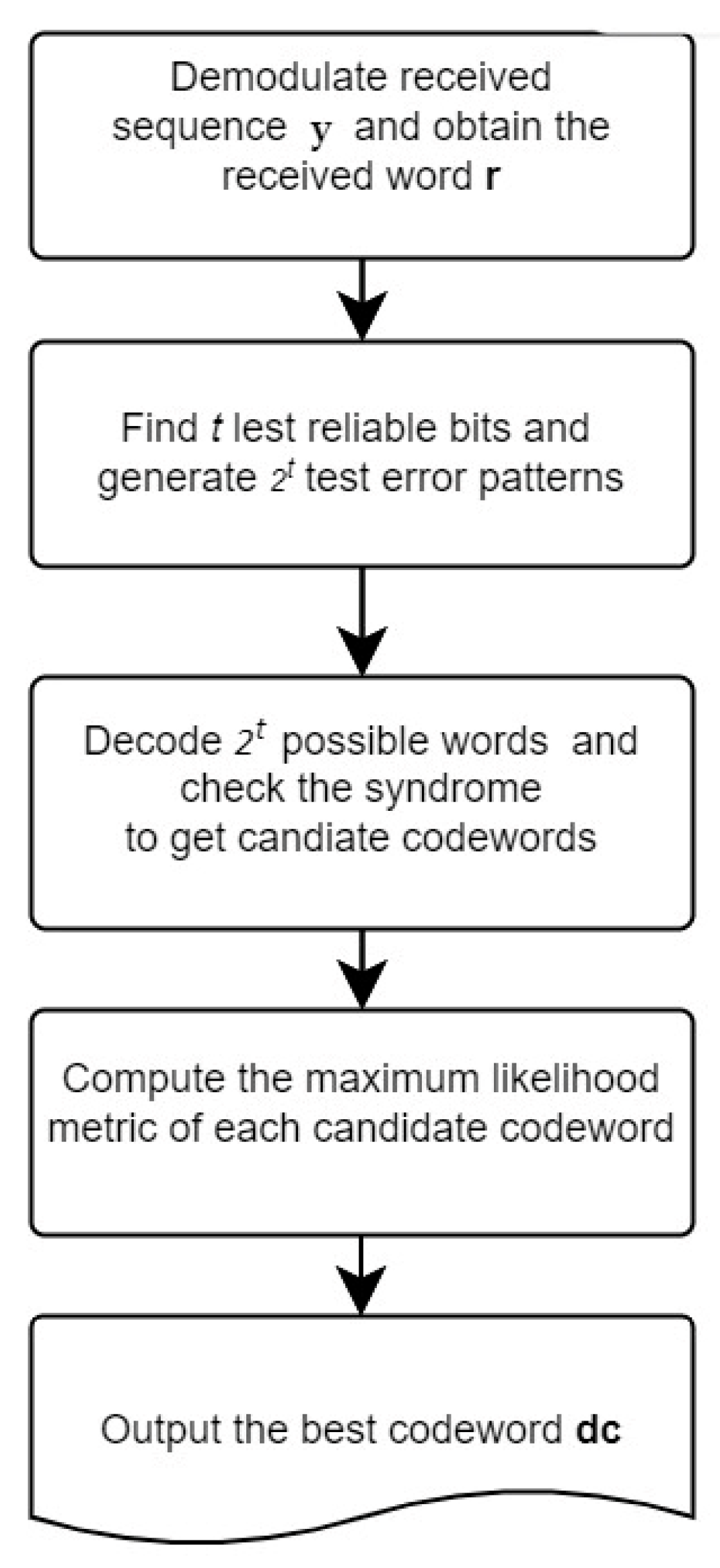
2.3. Chase-II Decoding Algorithm
- Step 1: Obtain the received signal sequence y and demodulate it as the received word r.
- Step 2: Find the t least reliable bits and generate 2t test error patterns.
- Step 3: Decode 2t words and check their syndromes. The decoded word with zero syndrome will be viewed as the candidate codeword dr.
- Step 4: Evaluate and compute the maximum likelihood metric of the codeword dr.
- Step 5: Output the best codeword as dc with the minimum value of .
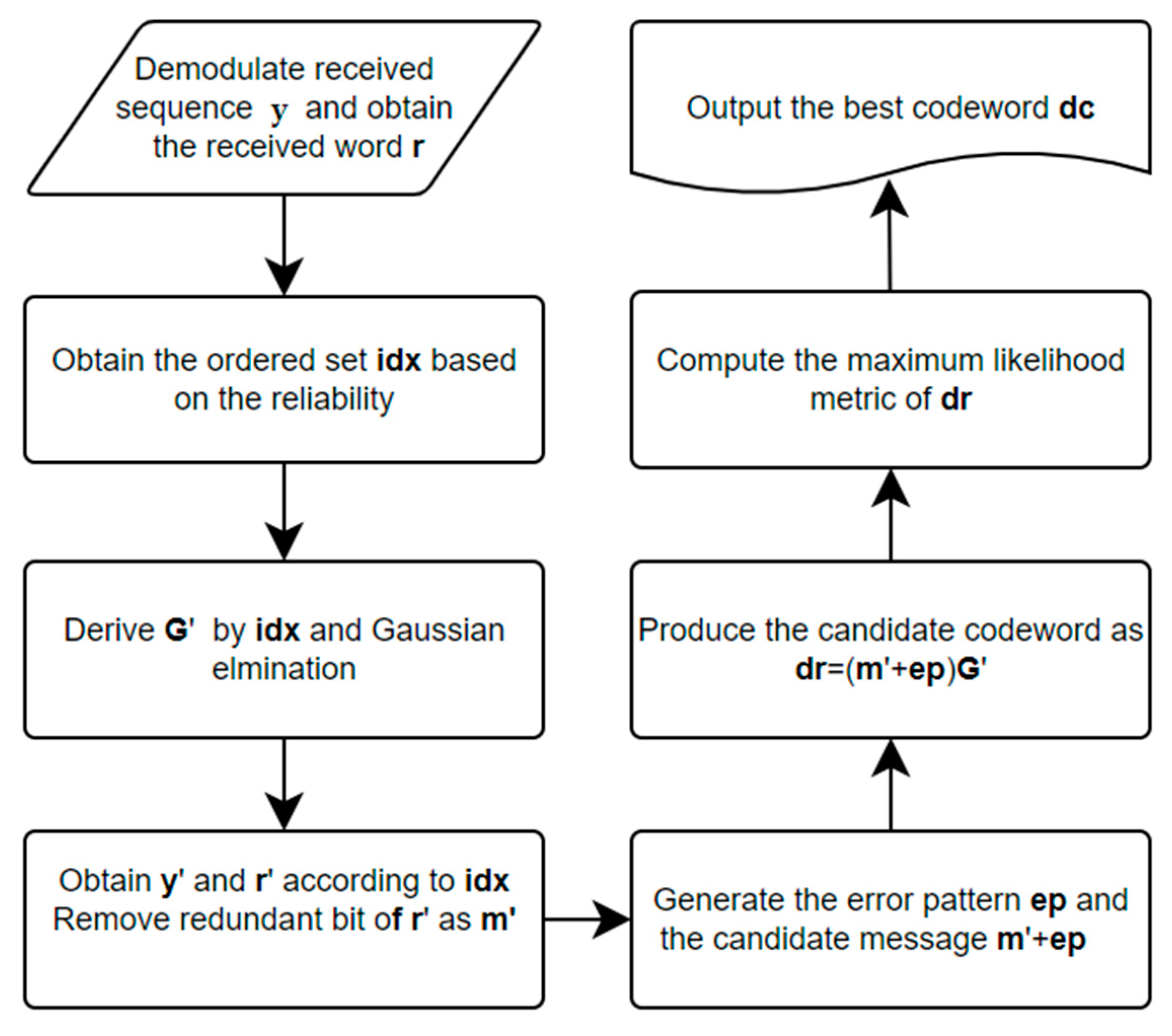
2.4. Ordered Statistics Decoding (OSD)
- Step 1: Obtain the signal sequence y and obtain the ordered index set of reliability idx. where , for .
- Step 2: Permute G according to idx and perform Gaussian elimination as a systematic form . If the form is unavailable, reorder idx based on the reliability.
- Step 3: Permute y and r as y’ and r’ according idx. Let m’ be the first k bits of r’.
- Step 4: Generate the test error patterns for m’, where the Hamming weight of ep is less than or equal to w. As a result, there are possible candidate messages. The candidate codewords dr will be obtained by G’.
- Step 5: Evaluate and compute the maximum likelihood metric of the codeword dr
- Step 6: Output the best codeword as dc with the minimum value of .
3. Deep Learning-Based Decoder
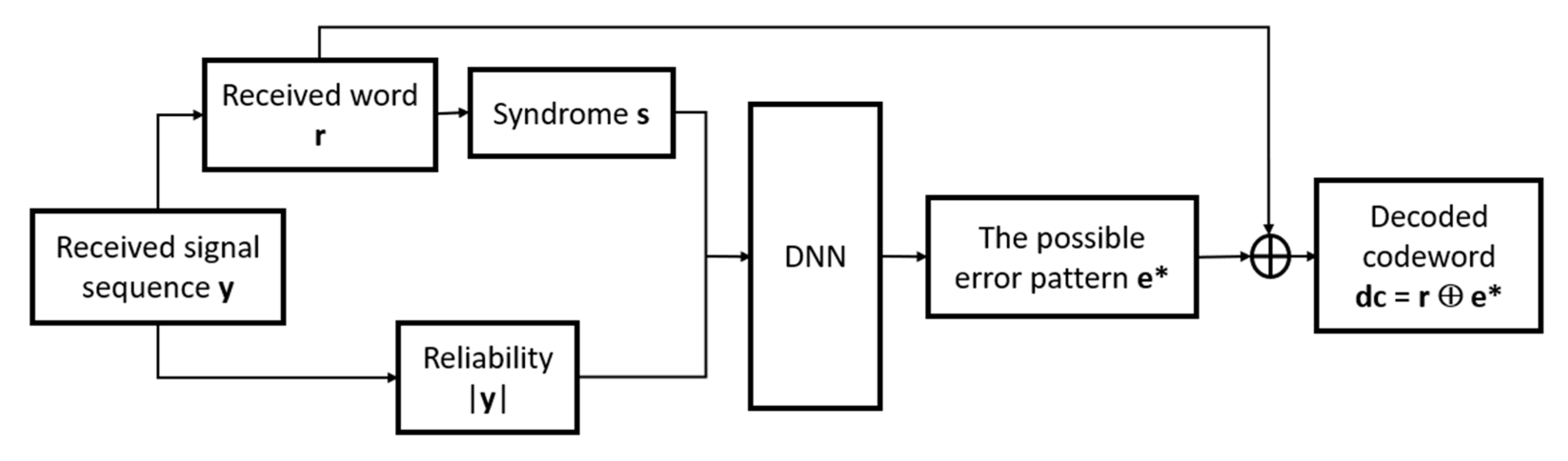
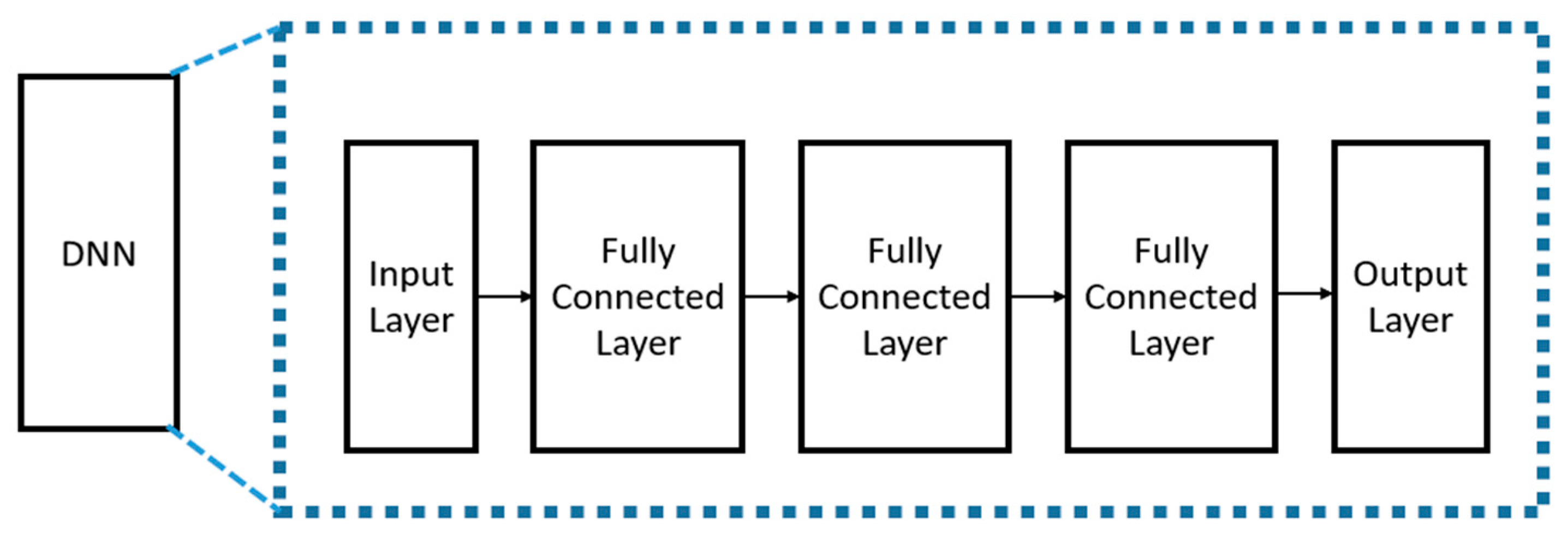
3.1. Soft Decision Decoding Based on DNN-Based Binary Classification
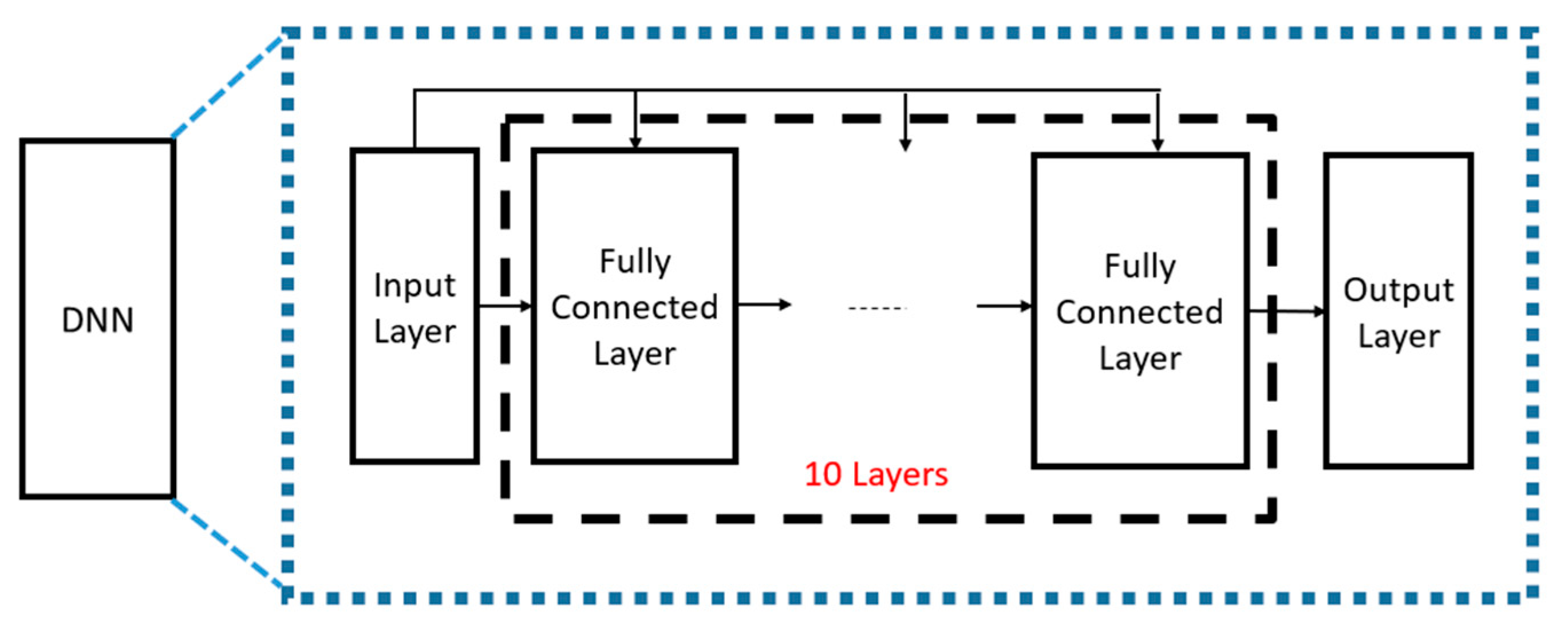
3.2. DNN-Based Denoiser for Soft Decision Decoding
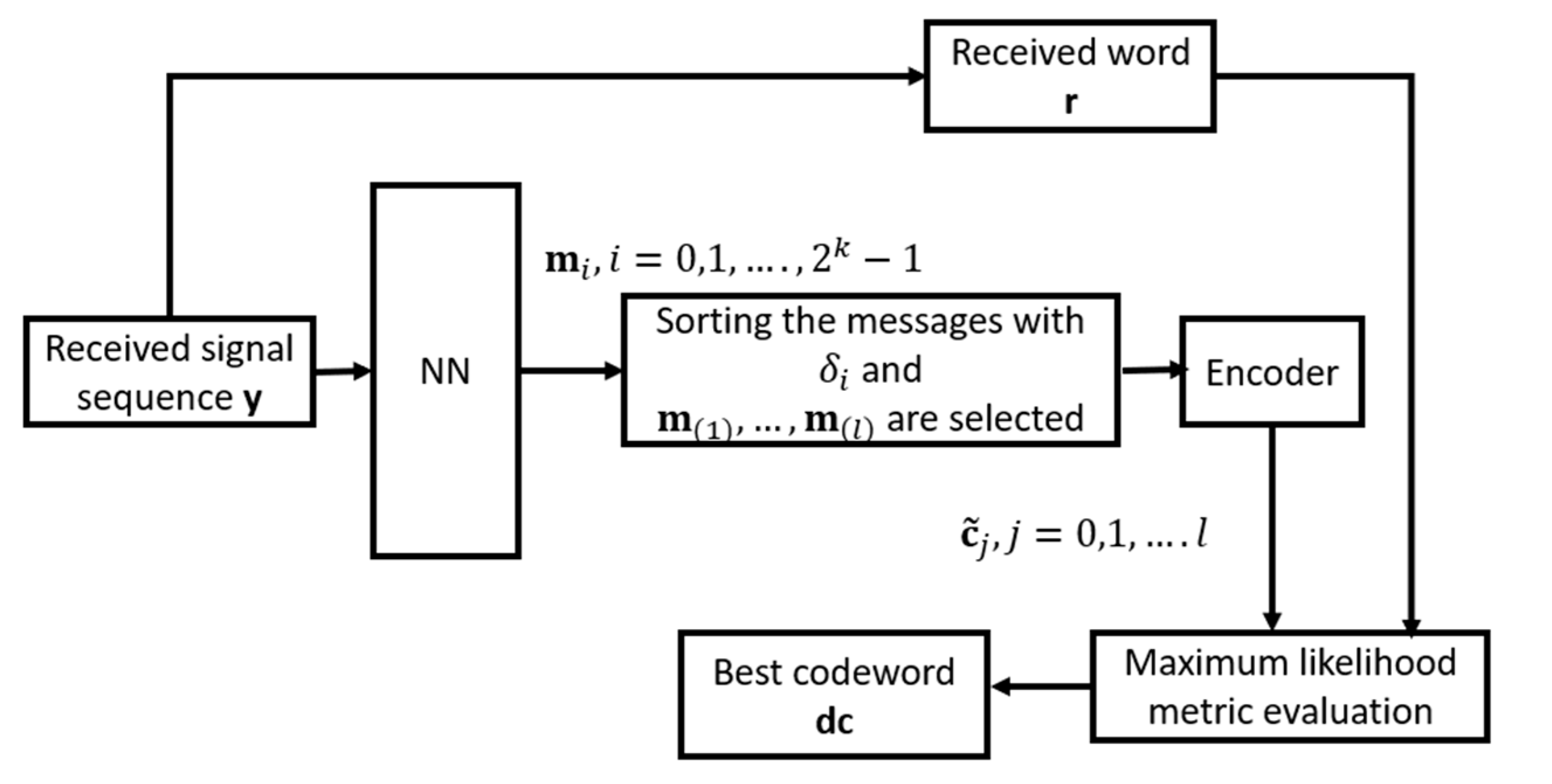
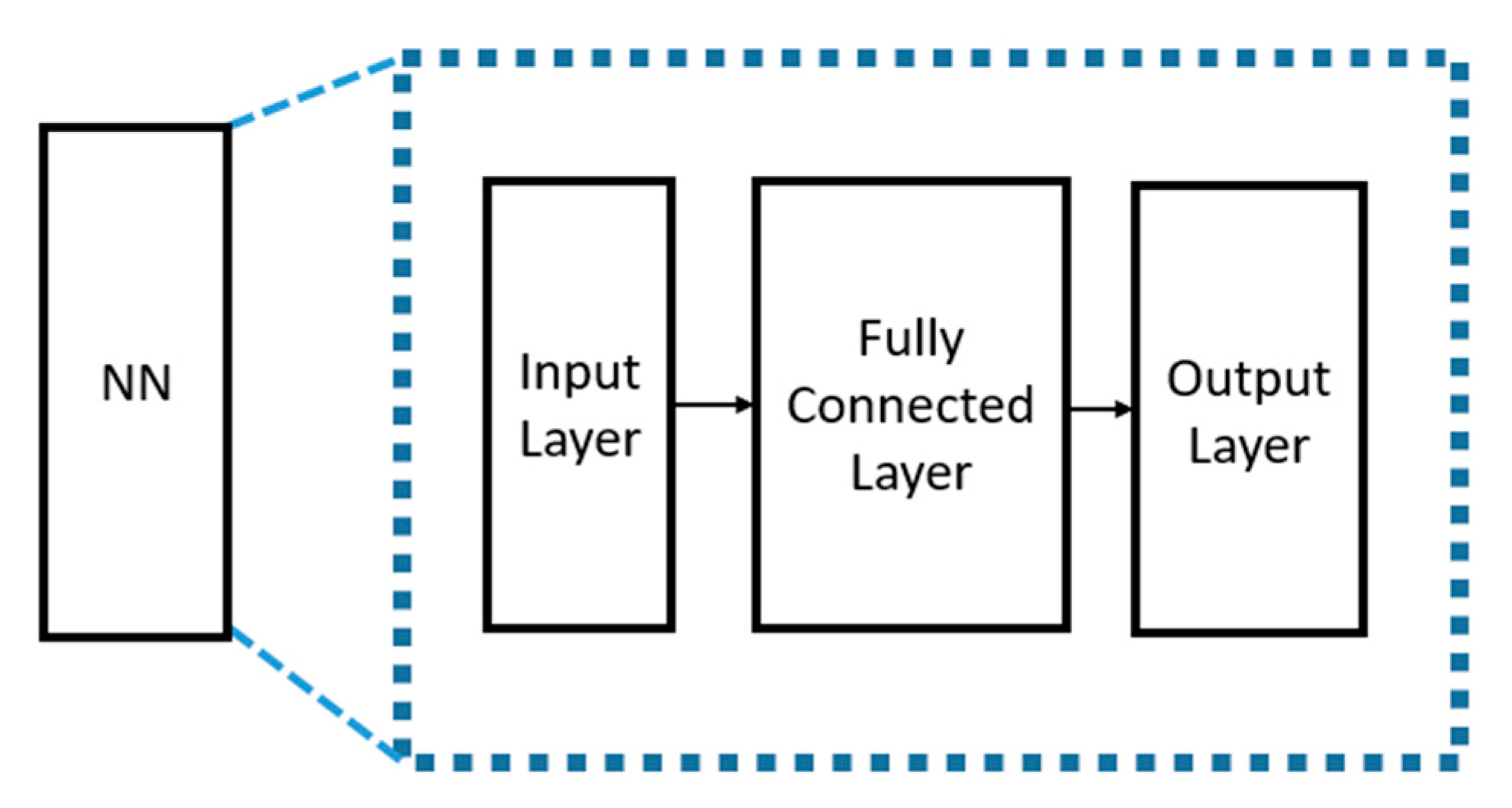
4. Proposed Multi-Class Neural Network-Based Decoder
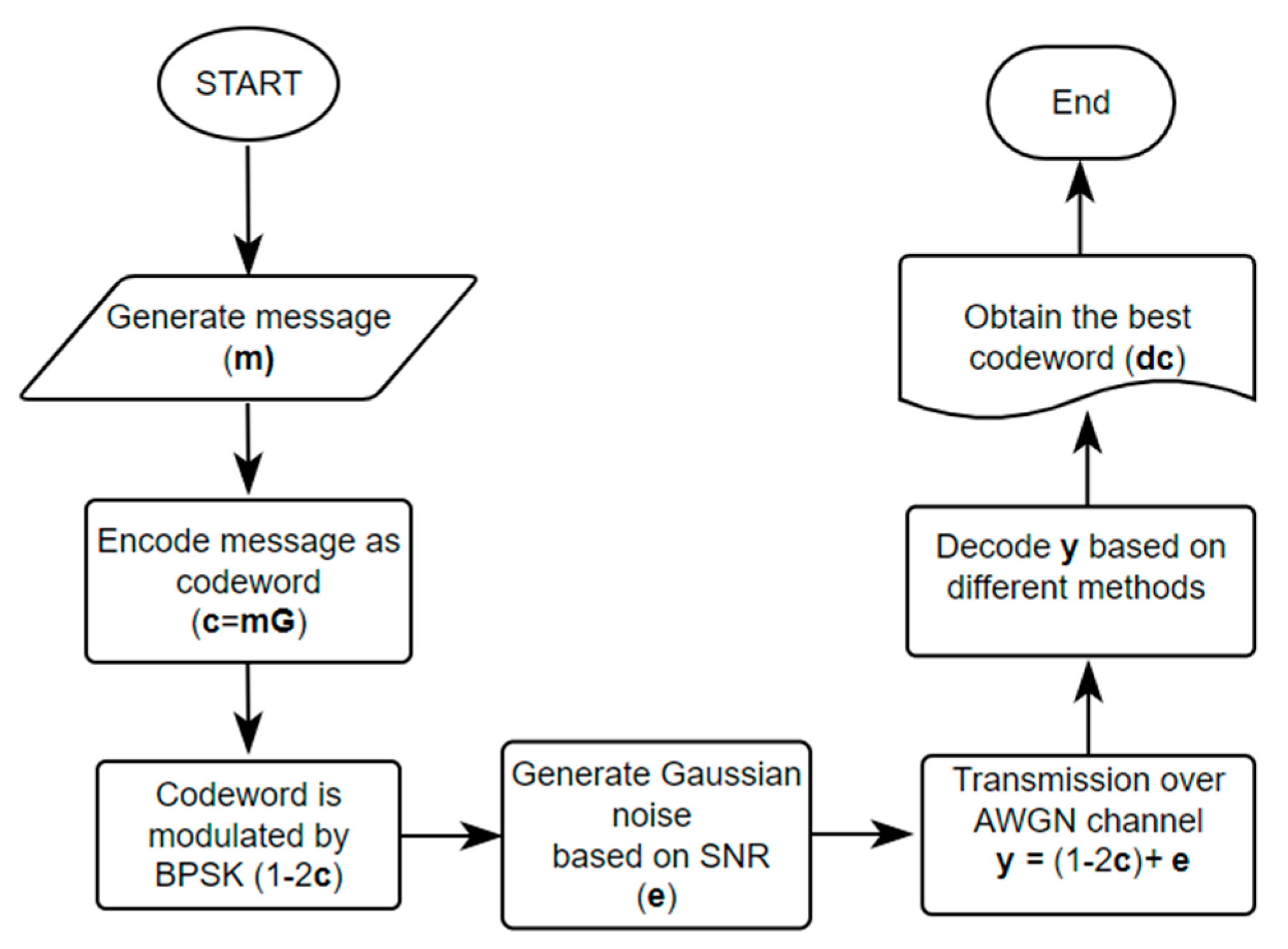
5. Dataset Generation and Neural Network Training
- Randomly generate a message m.
- Encode m to produce the codeword c.
- Use BPSK modulation and AWGN to generate the received signal sequence y.
- Repeat steps 1–4 one million times to produce the dataset.
- Divide the dataset into the training and validation sets with a ratio of 9:1.
5.1. Generation of Received Signal by BPSK over AWGN Channel
| Algorithm 1 Generative Algorithm of Additive White Gaussian Noise |
| Input: codeword c, SNR γ |
| Output: received signal sequence y |
| 1: Compute N0 by (14) |
| 2: for i = 0, 1, …, n−1 do |
| 3: Generate Gaussian noise ei N(0, N0/2) |
| 4: if ci = 1 then |
| 5: yi= −1 + ei |
| 6: else |
| 7: yi= 1 + ei |
| 8: end if |
| 9: end for |
| 10: return y |
5.2. Training of Neural Network
6. Experimental Results of Decoding by Proposed Multi-class NN-Based Decoder
6.1. Simulation Environment and Procedure
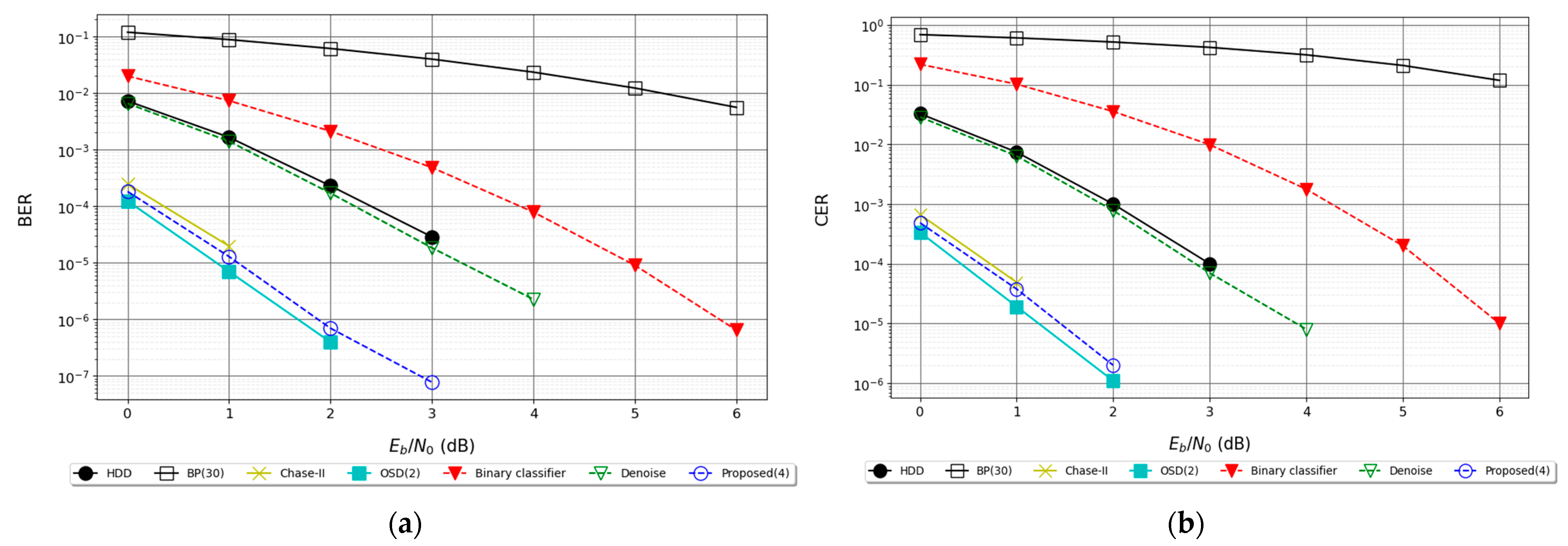
6.2. Experimental Results
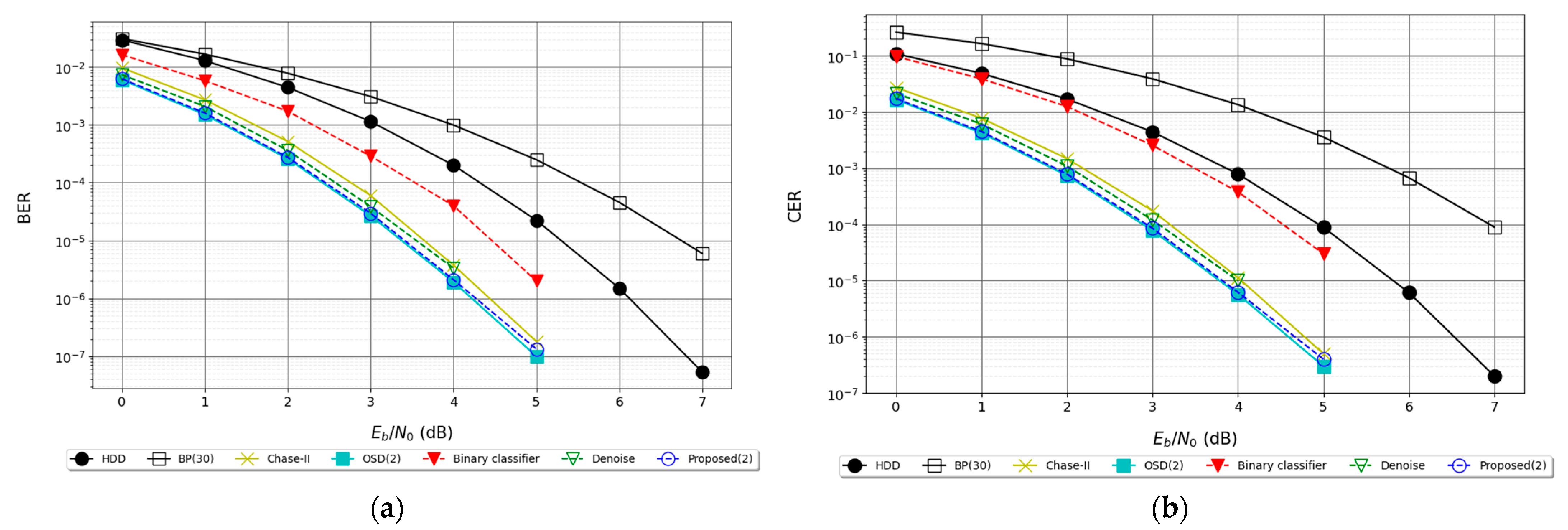
6.2.1. Results for BCH (15, 7) Code
6.2.2. Results for BCH (15, 5)
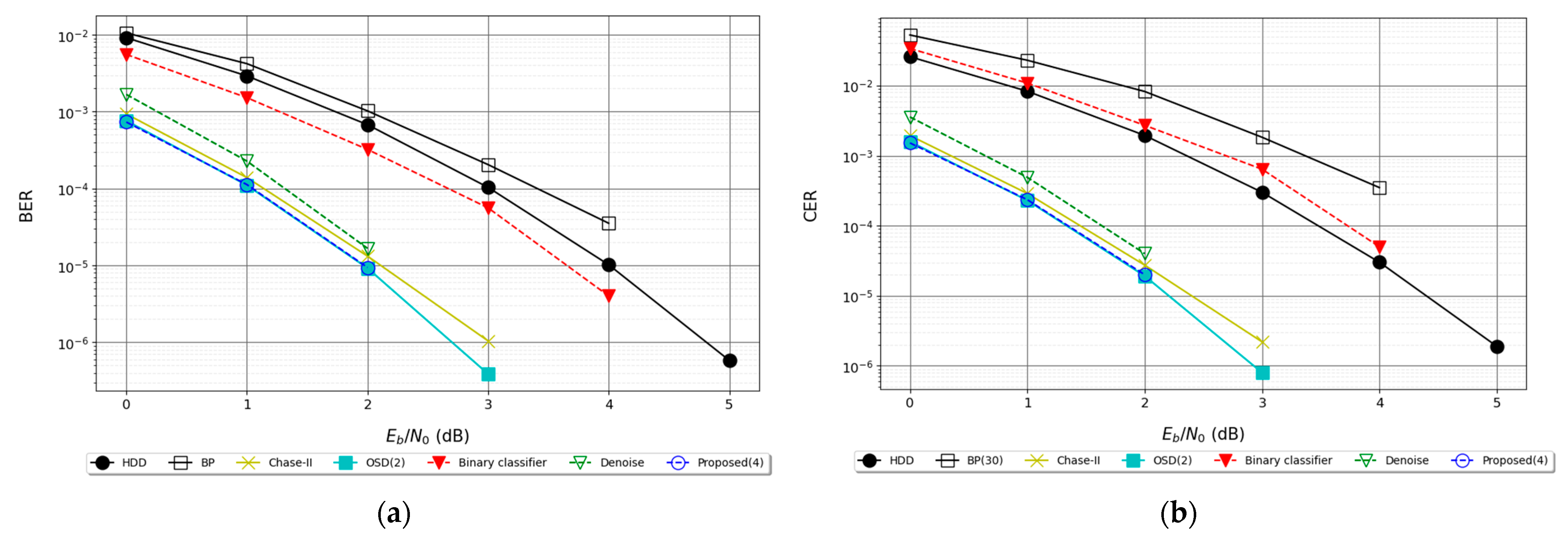
6.2.3. Results for QR (23, 12) Code
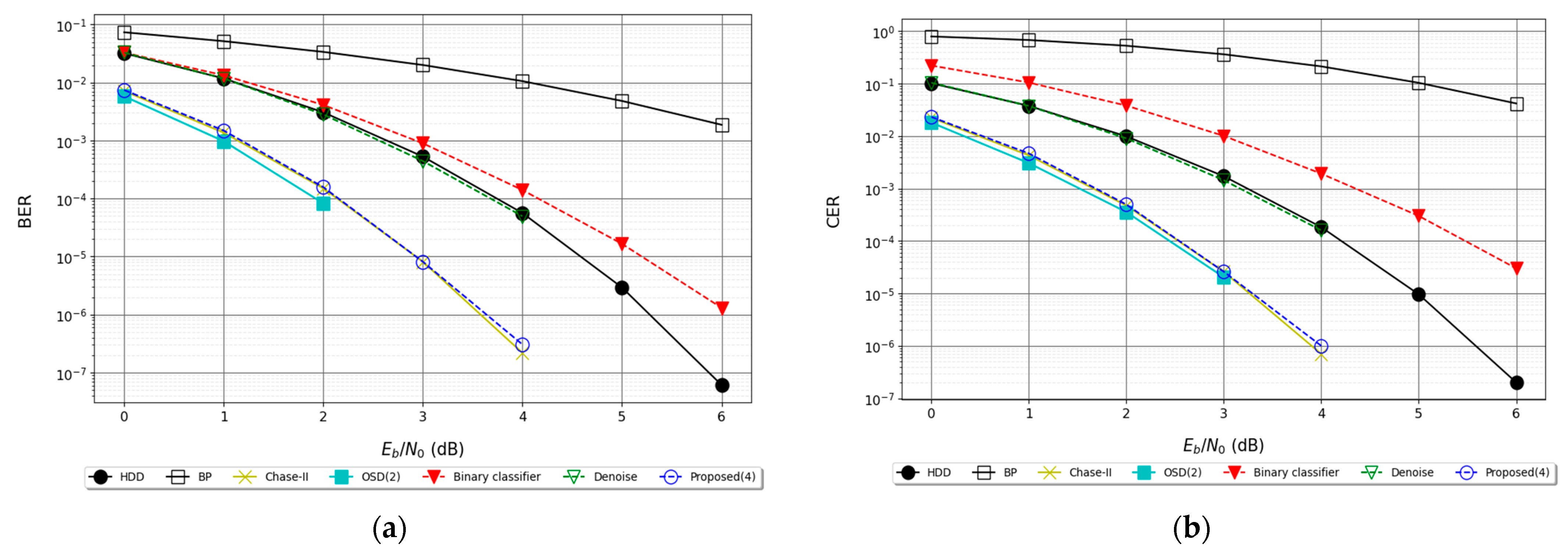
6.2.4. Results for BCH (31, 11) Code
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Esposito, A.; Rampone, S.; Tagliaferri, R. A neural network for error correcting decoding of binary linear codes. Neural Netw. 1994, 7, 195–202. [Google Scholar] [CrossRef]
- Tallini, L.G.; Cull, P. Neural nets for decoding error-correcting codes. In Proceedings of the IEEE Technical applications Conference and Workshops Northcon/95 Conference Record, Portland, OR, USA, 10–12 October 1995; p. 89. [Google Scholar] [CrossRef]
- Bruck, J.; Blaum, M. Neural networks, error-correcting codes, and polynomials over the binary n-cube. IEEE Trans. Inf. Theory 1989, 35, 976–987. [Google Scholar] [CrossRef]
- Xu, C.; Van Luong, T.; Xiang, L.; Sugiura, S.; Maunder, R.G.; Yang, L.-L.; Hanzo, L. Turbo Detection Aided Autoencoder for Multicarrier Wireless Systems: Integrating Deep Learning Into Channel Coded Systems. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 600–614. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, U.; Fisseha, H.H.; Sunwoo, M.H. Deep Learning aided BP-Flip Decoding of Polar Codes. In Proceedings of the 2022 IEEE 4th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Incheon, Republic of Korea, 13–15 June 2022; pp. 114–117. [Google Scholar] [CrossRef]
- Guo, X.; Chang, T.-H.; Wang, Y. Model-Driven Deep Learning ADMM Decoder for Irregular Binary LDPC Codes. IEEE Commun. Lett. 2022, 27, 571–575. [Google Scholar] [CrossRef]
- Li, W.; Tian, Q.; Zhang, Y.; Tian, F.; Li, Z.; Zhang, Q.; Wang, Y. A rate-compatible punctured Polar code decoding scheme based on deep learning. In Proceedings of the 2022 20th International Conference on Optical Communications and Networks (ICOCN), Shenzhen, China, 12–15 August 2022; pp. 1–3. [Google Scholar] [CrossRef]
- Lu, Y.; Zhao, M.; Lei, M.; Wang, C.; Zhao, M. Deep learning aided SCL decoding of polar codes with shifted-pruning. China Commun. 2023, 20, 153–170. [Google Scholar] [CrossRef]
- Dong, R.; Lu, F.; Dong, Y.; Yan, H. The Negative BER Loss Function for Deep Learning Decoders. IEEE Commun. Lett. 2022, 26, 1824–1828. [Google Scholar] [CrossRef]
- Pearl, J. Reverend Bayes on Inference Engines: A Distributed Hierarchical Approach. In Probabilistic and Causal Inference: The Works of Judea Pearl; Association for Computing Machinery: New York, NY, USA, 2022; pp. 129–138. [Google Scholar] [CrossRef]
- Chase, D. Class of algorithms for decoding block codes with channel measurement information. IEEE Trans. Inf. Theory 1972, 18, 170–182. [Google Scholar] [CrossRef]
- Fossorier, M.; Lin, S. Soft-decision decoding of linear block codes based on ordered statistics. IEEE Trans. Inf. Theory 1995, 41, 1379–1396. [Google Scholar] [CrossRef]
- Bennatan, A.; Choukroun, Y.; Kisilev, P. Deep Learning for Decoding of Linear Codes—A Syndrome-Based Approach. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1595–1599. [Google Scholar] [CrossRef]
- Zhu, H.; Cao, Z.; Zhao, Y.; Li, D. A Novel Neural Network Denoiser for BCH Codes. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC), Chongqing, China, 9–11 August 2020; pp. 272–276. [Google Scholar] [CrossRef]
- Morelos-Zaragoza, R.H. The Art of Error Correcting Coding; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Nachmani, E.; Marciano, E.; Lugosch, L.; Gross, W.J.; Burshtein, D.; Be'Ery, Y. Deep Learning Methods for Improved Decoding of Linear Codes. IEEE J. Sel. Top. Signal Process. 2018, 12, 119–131. [Google Scholar] [CrossRef]
- Kavvousanos, E.; Paliouras, V. Hardware Implementation Aspects of a Syndrome-based Neural Network Decoder for BCH Codes. In Proceedings of the 2019 IEEE Nordic Circuits and Systems Conference (NORCAS): NORCHIP and International Symposium of System-on-Chip (SoC), Helsinki, Finland, 29–30 October 2019. [Google Scholar] [CrossRef]
- Benammar, M.; Piantanida, P. Optimal Training Channel Statistics for Neural-based Decoders. In Proceedings of the 2018 52nd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 2157–2161. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.-W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numbers of Nodes | Activation Function | |
|---|---|---|
| Input layer | n | |
| Fully connected layer | 2k | ReLU |
| Output layer | 2k | Softmax |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, K.; Lin, Y.-W.; Chu, S.-I.; Chang, H.-C.; Cho, M.-Y. A Simple Neural-Network-Based Decoder for Short Binary Linear Block Codes. Appl. Sci. 2023, 13, 4371. https://doi.org/10.3390/app13074371
Hsieh K, Lin Y-W, Chu S-I, Chang H-C, Cho M-Y. A Simple Neural-Network-Based Decoder for Short Binary Linear Block Codes. Applied Sciences. 2023; 13(7):4371. https://doi.org/10.3390/app13074371
Chicago/Turabian StyleHsieh, Kunta, Yan-Wei Lin, Shao-I Chu, Hsin-Chiu Chang, and Ming-Yuan Cho. 2023. "A Simple Neural-Network-Based Decoder for Short Binary Linear Block Codes" Applied Sciences 13, no. 7: 4371. https://doi.org/10.3390/app13074371
APA StyleHsieh, K., Lin, Y.-W., Chu, S.-I., Chang, H.-C., & Cho, M.-Y. (2023). A Simple Neural-Network-Based Decoder for Short Binary Linear Block Codes. Applied Sciences, 13(7), 4371. https://doi.org/10.3390/app13074371