Abstract
The main purpose of chat robots is to realize intelligent interaction between human beings and chat robots. Generally, a complete conversation involves chat contexts. Before responding, human beings need to extract information from their chat contexts, and human beings are very good at extracting information. However, how to make the chatbots more complete in extracting appropriate contextual information has become a key issue for the chatbots in multi-round dialogues. Most research in recent years has paid attention to the point-to-point matching of responses and utterances at reciprocal granularity, such as SMN (Sequential Matching Network) and DAM (Deep Attention Matching Network), for which these parsing methods affect the effectiveness of the above networks to some extent. For example, DAM introduces an attention mechanism, which can obtain good results by parsing five levels of granularity of response and utterance through a self-attention module, and then matching the same level of granularity to mine similar spatial information in it. Based on the structure of DAM, this paper proposes an information-mining idea for improving DAM, which applies to those models with a multi-layer matching structure. Therefore, based on this idea, this paper presents two improved methods for DAM, so as to improve the accuracy of the information extraction from the contexts of the multiple round chats. The experiments show that the improved DAM has better results than that of the unimproved DAM, which are, respectively, R_2@1 increased by 0.425%, R_10@1 increased by 0.515%, R_10@2 increased by 0.341%, MAP (Mean Average Precision) increased by 0.358% in Douban data set, P@1 increased by 1.16%, R_10@1 increased by 1.17%, and these results are better than those state-of-the-art methods, and the improved methods presented in this paper can be used not only in DAM but also in other models with similar the point-to-point matching structures.
1. Introduction
Turing proposed in 1950 that building an automated chat agent (chatbot) is a long-term goal of AI [1]. Until 2015, most research on chatbots considered only the last utterance in the context of the chat as the basis for the response [2,3,4]. However, [5] has shown that using context as a reference provides richer information and also yields better results than using the last utterance as a reference. Currently, a major research topic on chatbots is to provide a chat context, including multiple rounds of utterances and multiple candidate responses, and to select the appropriate response from the candidate responses as the next answer in the context, i.e., the multi-round response selection.
Previous research has shown that a key to solving the multi-round response selection problem is how to efficiently parse the context and answer the utterances, SMN [6] uses GRU (Gated Recurrent Unit) [7] to parse the utterance and uses the output vector resulting from the process of GRU as the new granularity, DAM uses the attention mechanism to parse the utterance into multiple levels of granularities, the advantage of using the attention mechanism is that it uses less computation than RNN (Recurrent Neural Networks). DAM is a model consisting entirely of attention modules, which is based on the attention module proposed by the transformer [8], and is constructed by two core modules: (1) self-attention, which parses utterance and response into multiple levels of granularity in a stacked structure, with each level of granularity presenting the semantic information at a different level; (2) cross attention, which implements the cross attention between utterance and response, and explores the mapping space between them. The self-attention and cross-attention are the keys to the excellent performance of DAM. DAM symmetrically computes matching at the same level of granularity, which does extract a large amount of valid information, but this is incomplete. We argue that there is an interactive mapping space between the different levels of granularities and that the information in the space can be further explored to maximise the performance of DAM.
By analyzing the shortcomings of the enhanced deep attention matching model based on dislocation granularity matching (SM-DAM), a new “dislocation” matching method is proposed in this paper. At the same time, this paper also tries to combine the dislocation granularity matching method of SM-DAM and use four matrices to aggregate into 3D (three-dimensional) matrices for testing. In order to verify the above two improved methods proposed in this paper and comparison with DAM, the proposed methods are tested by Ubuntu Corps V1 (Canonical Ltd., Isle of Man, Britain) [8] and Douban conversation Corps (Douban Social Network, Beijing, China) [9].
The actual findings and innovations of this paper are summarized as follows:
- (1)
- The “dislocation” matching method proposed in this paper focuses on mining “dislocation” information in the “representation” stage of SM-DAM. Through the attention module, the granularity representation of response and utterance at different levels can achieve the cross-attention, so that the dependency information between the “dislocation” levels can be obtained more deeply (compared with the dislocation matching method of SM-DAM), and then the similarity matching can be performed. The experimental results show that the matching method proposed in this paper is effective, which also verifies the rationality and effectiveness of the processing step of mining the deep representation of the targeted point-to-point first, and then extracting the information from all the processed representations as a whole.
- (2)
- By the dislocation granularity matching method of SM-DAM, and using four matrices to aggregate into a 3D matrix for testing, it is found that the dislocation granularity matching method of SM-DAM and the information extracted by the method proposed in this paper have a large duplication, which shows that the multi-level dislocation cross-attention granularity matching method proposed in this paper is an improvement in the same nature of the dislocation granularity matching method of SM-DAM. In addition, it is possible to extract complete information using a simpler method, and the matching method proposed in this paper is a more complete information supplement method based on SM-DAM.
This paper is organized as follows: Section 1. Introduction; Section 2. Related work; Section 3. Improved DAM; Section 3.1. Deep Attention Matching Model; Section 3.2. Shifted Granularity Matching; Section 3.3. Multi-level Shifted Cross Attention Granularity Matching; Section 4. Experiments; Section 4.1. Dataset; Section 4.2. Evaluation Metric; Section 4.3. Comparison Methods; Section 4.4. Experiment Results; Section 5. Conclusions.
2. Related Work
Chatbots have a wide range of uses, which has led to a variety of different research directions. If they are classified by their functions, they can be divided into task-based chatbots [10], which are solving tasks with a specified domain and where the focus is on completing vertical tasks, and non-task-based ones [4,11], which are similar to general human-to-human communication without a compulsory purpose; If they are classified by their dialogue modes, they can be divided into single-round dialogues and multi-round dialogues. With the rapid development of artificial intelligence recently, further results have been achieved in chatbot research. Currently, there are three main research directions for chatbots: retrieval-based, generative-based, and knowledge graph-based.
The retrieval chatbots [2] are used to find the optimal response in a given corpus, by calculating the relevance of candidate responses for ranking and matching. It benefits from the development of big data, hardware computing power, and storage capacity. The limitation is that the language pattern of the robot’s responses will be relatively constant, which does not show the diversity of the language. Currently, the retrieval chatbots mostly select optimal candidate responses by computing the matching degree between utterances and responses [12,13,14,15,16,17,18,19]. SMN uses RNN to parse the information of utterances (including timing information) to generate new granular representations for more efficient matching. Zhang [20] proposed Deep Utterance Aggregation (DUA) based on SMN, employing self-matching attention to capture the vital information in each utterance. On the other hand, [21] discards RNN to extract semantic information and constructs a full attention model—DAM, which parses utterances into multi-layer granular representations through a self-attention mechanism, then uses the cross-attention module to extract the mapping space information between response and utterance, and finally selects the best candidate response by computing the matching degree between the representations.
The generative chatbots [10,22] learn the patterns inherent in language and represent the “knowledge” of the language in data through a process of “encode-decode” and then generate responses [23,24,25,26,27,28,29,30,31]. The responses do not exist in the corpus and are entirely “created” by the chatbots. Although the generative-based chatbots can generate utterances that do not exist in the corpus to break the limitations of response, in the spatially unbounded environment of open chat, it is difficult to learn from the large information space using the encoder-decoder structures, therefore, it is easy to generate meaningless responses.
The knowledge graph-based chatbots [32,33,34,35,36] solve the complex steps of learning logical reasoning by the knowledge graph, which can be continuously extended and improved, while the chatbots use the knowledge graph to handle complex logic between issues simply and efficiently. Finally, the captured logic is expressed as output in human language through a deep neural network.
Neural network machine translation (NMT) is the first time to introduce the attention mechanism into natural language processing, the attention mechanism is applied to NMT, which is a typical seq2seq model [37]. The encoder and decoder in the traditional NMT are implemented using RNN. The encoder encodes the input into a vector with a set dimension and length, which is used as the reference information for subsequent decoding operations. The decoder uses another RNN, and uses the middle vector as the reference to achieve decoding translation and obtain the target language. On the basis of the traditional NMT, Ref. [37] proposed the attention mechanism, which is used to connect the representation of each word of the source language learned on the encoder with the current word to be translated. After the model is trained, the alignment matrix of the source language and the target language can be obtained according to the attention matrix.
The attention mechanism is also a method widely used in the field of deep learning, which can make a model focus on data information differently through learning weight distribution. The reference to the attention mechanism well solves the problem of long-range gradient disappearance in the encoder and decoder structure [37,38]. In addition to integrating the attention mechanism into the generative chat robots, some studies have applied it to the retrieval chat robot model. The Deep Attention Matching Network [39] is a very successful retrieval chat robot model that has applied the attention mechanism, inspired by [40], the deep attention matching model applies the attention mechanism in the transformer into the model to replace RNN to capture the matching information of different granularity between utterances and responses, so that more levels and more granularity of information can be extracted, and the potential semantic relation can be obtained.
At present, the latest deep attention matching model [41,42,43,44,45] applies the attention mechanism in the transformer to multiple rounds of selective response chat problems and is completely composed of attention modules. It extracts information from multiple levels of response and utterance through the stack of self-attention modules, and represents it to the corresponding granularity, so as to solve the bottleneck of using RNN to only consider the shallow association information of the text. In addition to obtaining multi-layer granularity representation through the attention mechanism, the similarity matching between peer granularity to obtain the matching information between response and utterance is also a highlight of the model. Because the granularity of the same layer has a similar spatial structure, similarity matching can successfully extract important information.
3. Improved DAM
3.1. Deep Attention Matching Model
DAM consists of three main components: representation, matching, and aggregation. In the multi-round response selection problem, capturing the different granularities of matching information between response and utterance is the key to solving this problem. Before DAM, most models considered shallow textual and extract features using RNN. DAM replaces RNN with the attention component of the transformer and improves by removing the multi-headed part of the component. The component is called an attentive module in DAM, its input includes query, key, and value, which are denoted by Q, K, V:
where ei denotes the dimensional of the words with a value of 200. As with the encoding stage of the transformer, the first step is to do the Scaled Dot-Product Attention operation, then the weighting operation. The formulae are assumed as follows [21]
Next is to calculate the summation of Vatt and Q, followed by a layer of normalization [46] operations to prevent the gradient from exploding, and process by a forward feedback layer, and then do another summation and normalization operation to get the final output. Attentive Module (Q, K, V) will be used to denote the operation of the module.
3.1.1. Representation
The main component of the representation part is Attentive Module, which generates multi-level granularities. The input to the representation part is the word-embedded representation of response and utterance, which are defined as follows
where e represents the coded representation of each word in the sentence. This is then followed by Attentive Module, whose inputs Q, K, and V are the same. The attentive Module in this mode is called the self-attention layer. Different granularities can be obtained by stacking the self-attention layers, their definitions are specified as follows [21]
where, l denotes the number of layers in the stack, and finally both responses and utterances will get l + 1 representations.
In addition to using the self-attention to extract different granularities of each response and utterance, DAM also uses the cross-attention to mine information about mutual attention between the same level granularities of responses and utterances, it implemented uses the Attentive Module, but unlike the self-attention that input Q is Rl (Uil), the inputs K and V corresponds to Uil (Rl), and the formulae are set as follows [21]
3.1.2. Matching
With multi-level granularities of response and utterance and their cross-attentional granularities, the next step is to match the responses to the utterances. For the self-attention granularity vectors R0, R1, R2… and U0, U1, U2…, then forms a self-attentive matching matrix Mself. On the other side, the cross-attention vectors R0, R1, R2… and U0, U1, U2…, then forms the cross-attention matching matrix Mcross, which are specified by [21]
3.1.3. Aggregation
After getting Mself and Mcross, all 2D match matrices are aggregated into a large 3D matching image Q, the specific aggregation method is to align Mself and Mcross, therefore an additional dimension is added and the new dimension size is 2(L + 1), which can be computed as follows [21]
After the aggregation into a 3D matched image, feature extraction is performed twice in succession using convolution and maximum pooling, followed by a linear layer to convert the dimension to 1, which is used to represent the score of matches as follows [21]
where, the extracted feature is denoted by fmatch(c, r).
3.2. Shifted Granularity Matching
Explaining the meaning of each level of granularity in DAM is difficult, but we can make an analogy in another way, for a sentence, its granularity from shallow to deep can be represented as a whole sentence, small clause, phrase, and word. What is achieved in DAM is similarity matching at the same level of granularity, e.g., sentence-to-sentence, phrase-to-phrase. However, we believe that similarity matching is also possible between different levels, where sentences and words are related, for example, “colourful flowers bloom in the park” and “flowers”. In this view, DAM ignores the association between the different granularities, and the space of association can be further explored.
Therefore, we propose a shifted granularity matching approach, as shown in Figure 1. In the matching phase of the model, the granularity of the response is shifted and matched with the granularity of the utterance. For example, the 1st layer granularity of utterance is matched to the 2nd layer granularity of response, the 2nd layer granularity of utterance is matched to the 3rd layer granularity of response, and so on. Figure 1 assumes that there are 5 layers of the stacked self-attention, i.e., there are 5 layers of granularity representations. Uil denotes the ith utterance of the lth layer of granularity, and Rl denotes the lth layer of granularity of the responses. The shifted distance can not only be 1, the matching module with a shifted distance of 2 is illustrated in Figure 1b. When the shifted distance is d, U6−d… U5 and R1…Rd are not required to be matched, the following equation represents the definition of the shifted matrix,
where Uil[k]T denotes kth embedding vector in Uil, Rl+d[t] denotes tth vector in Rl+d, i denotes ith utterance, l denotes an lth layer of granularity, and d denotes the shifted distance.
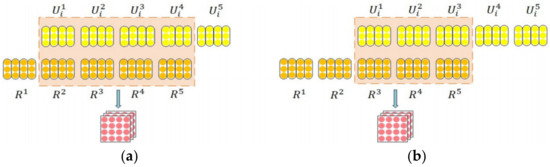
Figure 1.
Shifted granularity matching module. (a) In the matching phase of the model, the granularity representation of response is mismatched with the granularity representation of utterance for the multi-layer granularity representation generated by the stacked self attention modules. (b) a matching module with a misalignment distance of 2. In Figure 1, the yellow blocks represent the granularity of utterance, orange blocks represent the granularity of response. While the orange boxes are used for one-to-one matching. Finally, the red-shifted granularity matching matrix is generated.
Considering the full use of the information, we can make use of the unused granularities, we can match the tail of the utterance which is not matched with the head of the response. Figure 2a shows the model for a complete match at a shifted distance of 1, i.e., matching the representation at the 5th layer of the utterance with the representation at the 1st layer of the response, and Figure 2b shows the model for a complete match at a shifted distance of 2, which matched the representation at 4th and 5th layers of the utterance with the representation at 1st and 2nd layer of the response respectively.
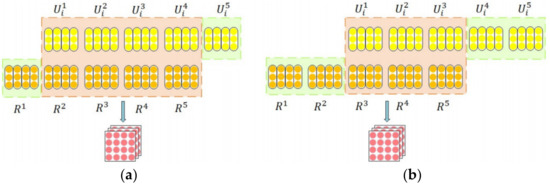
Figure 2.
Shifted granularity matching module in full matching. (a) a fully matched model when the dislocation distance is 1, that is, matching the representation of the 5th level granularity of utterance (green box) with the representation of the 1st level granularity of response. (b) a fully matched model when the dislocation distance is 2, matching the granularity representations of the 4th and 5th levels of utterance with the granularity representations of the 1st and 2nd levels of response, respectively. The green boxes on either side indicate head-to-tail granularity matching to achieve full matching.
In the aggregation phase, the matrix obtained from the shifted granularity matching module will be added to the matching part of DAM and together with the original self-attention matching matrix and the cross-attention matching matrix, it will be integrated into a new 3D matching matrix, each pixel value in the new matrix Qi,k,t is specified by
where, Mself ui,r,l, Mcross ui,rl, and Mself ui,r,l denote the self-attention matching matrix, the cross attention matching matrix, and the shifted matching, ⊕ denotes a concatenation operation, each pixel has 3(L + 1) − d channels, containing the matching degree between a segment pair with different granularity levels. The whole model is shown in Figure 3.
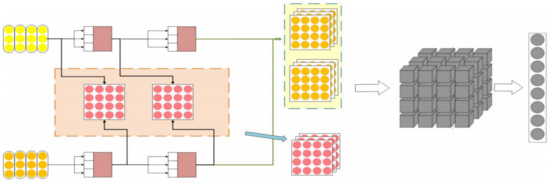
Figure 3.
Improved DAM with shifted granularity matching method, the output of the representation part (representation of utterance and response in different granularities) is matched and calculated by shift mode to obtain a new matrix (represented in red), which is arranged and aggregated into a 3D matrix (grey) with the other two matrices.
3.3. Multi-Level Shifted Cross Attention Granularity Matching
The shifted granularity matching method works in the “matching” phase of the model, where the input data is a granular representation of the stacked self-attention module, which is already processed data, and on the top of which the shifted information is extracted by the convolutional network. Thus, the “shifted” information we need to mine is conducted by the convolutional network alone. We believe that mining shifted information in this way is crude. In reference to DAM, in the “representation” phase, in addition to using a stacked self-attention module to obtain multi-level granularities of the sentences, in order to obtain information on the interactive representation of the response and the utterance, this stage uses the same structure of the attention module, with the granularities of the response and the utterance as input to the module. This process has already made preliminary mining of the information of the mapping relationship between response and utterance, and then the convolutional network does the second information extraction. Comparing the two kinds of information extraction modes, the former operates directly on representations of the two utterances, therefore, it is more focused and extracts information in a point-to-point mode, while the latter operates on a 3D matrix composed of all representations and extracts information on the correlation between all representations by the convolution network. Therefore, it operates on a whole object.
We believe that the advantage of DAM is that it purposefully extracts information on a point-to-point basis and outputs a corresponding representation, which is used in information processing as an input to overall information mining. The former information processing contributes significantly to the latter information mining. Instead of a point-to-point step for shifted information, the shifted granularity matching method uses a non-shifted point-to-point extraction representation for “shifted” information extraction in the overall information extraction step. Therefore, we propose a more optimized approach to information mining, where the “shifted” information is targeted by point-to-point mining and outputting a representation that is put into the overall information extraction.
As shown in Figure 4, we take the shifted response and the utterance granularities as Q, K, and V of the Attentive Module respectively, and call the new vector as the shifted cross-attention granularity. In the same way, the response and utterance are swapped and put into Attentive Module to obtain another shifted cross-attentional granularity. As shown in Figure 4, the expressions for the module are defined as follows:
where, the inputs are Query, Key, Value, l indicates the number of levels, and R denotes the response corresponding to the granularity, and U denotes the granularity of utterance, Rl denotes lth utterance in the context, for example, i is ith of a response. Finally, Ȓl and Ȗil represent the shifted cross-attention granularity of the corresponding layers of the response and utterance respectively.
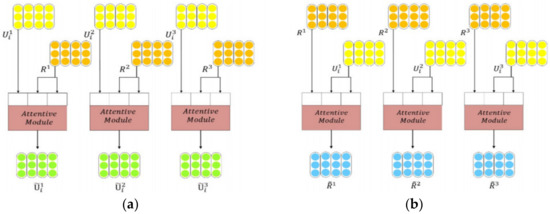
Figure 4.
Shifted cross attention of multi-level granularity. (a) The granularity of utterance is used as the Q input to the Attentive Module, and the granularity of response is used as the K and V inputs to the Attentive Module; (b) The granularity of response is used as the Q input to the attentive module and the granularity of utterance is used as the K and V input to Attentive Module. Finally, two different granularities of cross-attention are generated.
In the matching phase, the two shifted cross-attention granularities Ȓl and Ȗil are conducting similarity matching. As shown in Figure 5, with blue indicating the shifted cross-attention granularity generated in Figure 4 and green indicating the shifted cross-attention granularity generated in Figure 4, and the two granularities are paired at the same level and finally constructed into a 2D matching matrix, which can be computed by
where Ȗil [k]T denotes kth embedding vector in Ȗil, and Ȓl[t] denotes tth embedding vector in Ȓl.
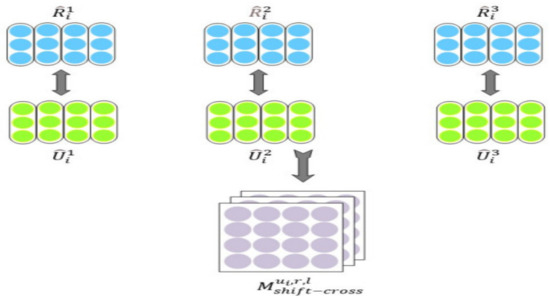
Figure 5.
Shifted cross-attention matching matrix.
Next, the new matching matrix is aggregated with the two original matrices into a 3D matrix. As shown in Figure 6, the new matching matrix is obtained through the multiple attention modules in the blue box and aggregated with the original self-attention and cross-attention matrices to form a new 3D matrix. Finally, the features are extracted by using twice convolution and maximum pooling as follows:
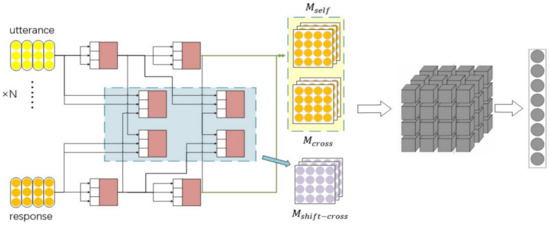
Figure 6.
Improved DAM with shifted cross-attention granularity matching method. A new granular representation is generated at the representation part (Blue box), then matched to generate a new matrix (represented in purple), which is finally aggregated with the other two matrices to form a 3D matrix.
4. Experiments
4.1. Dataset
To facilitate comparison with DAM, we experimented with the same data sets as DAM, Ubuntu dialogue corps, and Douban conversation corps. Ubuntu dialog corps is an English-based data set, which is collected from the chat records of relevant technologies under the Ubuntu system. It contains 500,000 training sets with different contexts. Each context has a positive candidate response and a negative candidate response. The training set also has a combination of 1 million pairs of contexts and responses. As shown in Table 1, the response with Label 1 is the correct candidate response, 0 is the wrong candidate response, and each context corresponds to two candidate responses. Both the verification set and the test set contain 50,000 different contexts, and each context has one positive candidate response and nine negative candidate responses, as shown in Table 2. The positive responses in the data set are all from real human beings’ communication, while other negative responses are randomly selected from other data.

Table 1.
Ubuntu Data Set (Training Set).
Table 2.
Ubuntu Data Set (Test Set).
The data of Douban conversation corps is collected from China’s online social platforms and is based on Chinese. The training set contains 1 million context-response pairs, and the verification set has 50,000 pairs. Table 3 illustrates an example. It can be seen that the context discusses topics related to “watching Friends” and “learning English”, while the positive candidate statements do discuss related topics, while the negative candidate statements have no relevance to the context. Each context in the training set and the verification set has a positive candidate response and a negative candidate response. The difference is that the test set has 1000 contexts, each context has 10 candidate response statements, and there are multiple positive candidate responses in these statements. As shown in Table 4.
Table 3.
Douban Data Set (Chinese Training Set).
Table 4.
Douban Data Set (Chinese Test Set).
The experimental parameters are designed as follows: similar to the deep attention matching model, the experiments use Tensorflow to build a neural network and are carried out on Ubuntu 16 operating system. The hardware platform is a six-core E5-2680 v4 CPU, 30GB memory, and NVIDIA GEFORCE RTX 3060 graphics card with 12.6 GB GPU memory. Referring to the deep attention matching model, the experiments set the maximum number of chat rounds as 9, and the maximum number of words per utterance is 50. Mikolov’s word2vec method is used to preprocess the training set. The size of the FNN parameter is set to 200, which is the same as the size of the embedded word vector. The stack number of self-attention modules is also set to 5. In the model, there are 32 [3, 3, 3] filters in the first convolution layer, with [1, 1] for the side, [3, 3, 3] for the maximum pooling layer, [3, 3, 3] for the side, and 16 [3, 3, 3] filters in the second convolution layer, [1, 1] for the side, [3, 3, 3] for the maximum pooling layer, and [3, 3, 3] for the side, and the batch-size is set to 256.
4.2. Evaluation Metric
We used MAP [47], Recall, MRR (Mean Reciprocal Rank) [48], and precision as the evaluation metric for the experiments. They are both commonly used for the multi-round response problem. A recall is primarily used to measure how well the model detects positive samples, that is, the ratio of true positives in true positives and false negatives, which is defined as follow
where k denotes the number of the true positive samples selected, for example, the correct responses, n denotes the total number of the candidate responses, and yi denotes the label of each candidate response in binary, the general uses of R2@1, R10@1, R10@2, R10@5. The precision measures primarily the prediction accuracy of the model, that is, the ratio of the true positives in the true positives and the false positives. MAP is essentially an average of the maximum recall for each category in a multicategory test. In the multi-round response problem, it first calculates the precision for each set of the chat corpus by [44]
MRR is commonly used to evaluate search algorithms, which is based on the assumption that there is only one correct result, i.e., the first result matches with a score of 1, the second match with a score of 0.5, and the nth match with a score of 1/n. The final score is the sum of all scores. The reciprocal rank is the inverse of the rank of the first correct answer. MRR is the mean of the inverse of the rank of multiple query utterances, which is specified by [49]
where ranki denotes the ranking of the first correct answer in the ith group.
4.3. Comparison Methods
In order to validate the effectiveness of the improved methods, we compare the experimental results of the proposed model with several classical models. In addition to DAM, there are the SMN model and the stacked multi-head attention [48], both of which propose models applicable to the two datasets previously mentioned. SMN matches each utterance and response to construct a 2D similarity matrix, and in addition to matching at the word embedding level, it uses GRU to obtain a granularity at the sub-sequence level and then obtains the utterance-response similarity matrix at that level of granularity, and finally extracts the matches by convolution and pooling as well. The stacked multi-head attention is optimized on the basis of DAM by using the multi-head attention to capture the semantic dependencies between the layers, thus obtaining a multi-layer granular representation with more information than DAM hierarchical capture approach.
4.4. Experiment Results
The comparative experiments compare the results with the deep attention matching models, SMN and SMHA, and also with the experimental results of SM-DAM to verify the effectiveness of the two dislocation methods proposed in this paper. Before comparing with the other models and the methods, it is necessary to determine the optimal number of dislocation matching layers and the granularity layer to be matched in the proposed method through the experiments. Since the maximum number of stacks of the self-aware modules is set to 5, and under the condition of dislocation, the maximum number of granularity layers that can be matched for dislocation is 5 (including the original representation), that is, it can start from layer 1 matching and increase to layer 5 matchings. In this paper, the number of matching layers needs to be continuous (better results can be obtained by determining the continuity through the experiments, and there is a repetition between the non-continuous and the dislocation greater than 1). In addition, the optimal dislocation distance needs to be determined. In this section, when the dislocation is determined to be 1 through the experiments, the result is the best.
The reason is that when the dislocation distance becomes larger, the mapping relation between granularity may disappear or the effective information cannot be expressed due to the large difference in spatial structure. Another explanation is that the independent attribute between the granularities is more improved, while the common similar space is compressed, which is difficult to be mined (or cannot be mined using the current convolution pooling model structure), and it is also easy to extract redundant information, affecting the results, the experimental results of other dislocation distances are not shown in this section. The results are shown in Figure 7 and Figure 8, where “n to m” represents the grain size from the nth layer to the mth layer. Figure 7 and Figure 8 only shows the experimental results of three or more layers (because the experimental results of less than three layers are not better than those of three layers, and the number is too large).
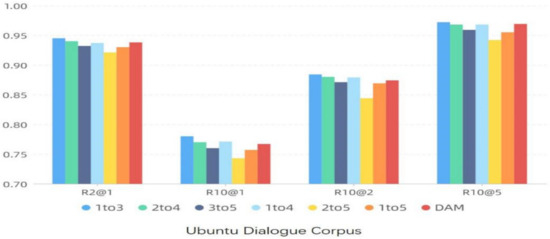
Figure 7.
Comparison test results of granularity size layer selection (Ubuntu Dialogue Corpus).
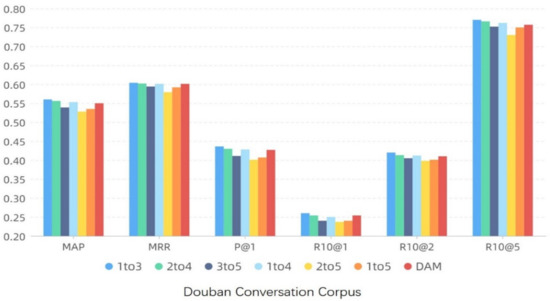
Figure 8.
Comparison test results of granularity size layer selection (Douban Conversation Corpus).
It can be found that the model obtains the best results under the setting of the granularity from the first layer to the third layer, but also under the condition that the number of layers is three, the effect of the later granularity layer is less obvious, and even reduces the accuracy. Then compare the results with 4 layers. The results from the first layer to the fourth layer are better than the results from the second layer to the fifth layer. Compared with the results of “1 to 4” and “1 to 5”, the former is better than the latter, while compared with the results of “1 to 5” and “2 to 5”, the former is better.
To sum up, it can be found that in the case of other layers, the effect of more than the fourth or fifth layers will be retrogressive. We believe that the dislocation granularity matching between the fourth and fifth layers will bring negative effects. On the contrary, a model that only uses three levels or less is better than a model that uses three levels. It can be considered that the first three levels have a promoting effect. The reason is that the deeper the granularity, the greater the spatial independence, and the smaller the dependence on public space. That is to say, it represents the unique semantics of the corresponding statement, and has its own attributes, rather than linguistic commonalities. Similarity matching of such granularity will bring error information and side effects to the model.
Table 5 shows the results of different shifted distances as well as full matching methods under the shifted granularity matching method, where n in DIS −n denotes the shifted distance, and if followed by β, it is the full granularity matching method. It can be seen that the effectiveness of the model is gradually reduced when the shifted distance becomes larger, and when the distance is 3, the results are comparable to the original DAM. Indicating that it is difficult to capture the association information while easily leading to negative effects when matching the granularities with large distances. On the other hand, the comparison in Table 5 also shows that full granularity matching does not bring good results, but makes the effectiveness worse.
Table 5.
Compare the results of different shift distances under the shifted granularity matching method.
The reasons for the above counter-effects are: (1) the distance between granularity levels is too large, resulting in large differences in the spatial structure of granularity, and the similarity space is too small. (2) the similarity space information between the long-distance granularity layers cannot be extracted by the similarity matching methods and the convolutional-pooling methods.
Table 6 shows the experimental results of the different matching methods under the multi-level shifted cross-attention granularity matching method. Since the maximum number of stacks of self-attention modules is 5, the maximum number of granularity layers that can be shifted matching is 5 (including the original representation), and the number of matching layers needs to be sequential (the experiments indicate that sequential gives better results). It is necessary to determine the optimal shifted distance, and the experiment shows that the results were optimal when the shifted distance was 1. The results are shown in Table 6 (the other shifted distances are not shown here), where “n to m “ denotes the distance from the nth layer granularity to the mth layer. Table 6 only shows the experimental result with 3 or more layers (the experiments with less than 3 layers did not give better results than when there were 3 layers).
Table 6.
Compare the results of the different matching methods under the multi-level shifted cross-attention granularity matching method.
It can be known that the model obtains the best results starting from 1st layer of granularity up to 3rd layer of granularity, while at the 3 layers, the further back in the granularity layers bring less effective results and even reduced accuracy. Then, comparing the results of matching at 4 granularities, the results from the 1st layer to the 4th layer are better than the results from the layer 2nd to the 5th layer, and comparing the results for “1 to 4” and “1 to 5”, the former are better than the latter.
In summary, it can be seen that the effect of an extra 4th layer or 5th layer is reversed when all other layers are the same, and we conjecture that the shifted granularity matching between the 4th layer and the 5th layer has a negative effect. The reason is that the deeper the granularity, the greater the spatial independence and the less dependence on the common space, i.e., it represents the unique semantics of the corresponding utterance, with its own properties, rather than the linguistic commonality, and the matching similarity to such granularity will bring distorted information to the model. The validity of this conjecture remains to be verified by subsequent experiments.
Table 7 shows the results of comparing several models under the Ubuntu and Douban datasets, where Ours-1 indicates the improved model using the shifted granularity matching with 1 shifted distance. It shows that our model outperforms DAM. The improvement to DAM on R10@1 is over 1.17%, and on R10@2 is over 0.80%. As for Douban corpus, the improvement to DAM on MAP is over 1.45%, on MRR is over 1.50%, on P@1 is over 0.94%, on R10@2 is over 3.67%, on R10@5 is over 1.59%. In terms of the magnitude of the improvement in each metric, it can be concluded that the shifted matching provides better information extraction.
Table 7.
The results of the comparison experiment for the two proposed methods.
In comparison with the other two methods, the shifted granularity matching method also achieves better results for several metrics. In the Ubuntu dataset, the improvement to the sequential matching network on R2@1 is over 1.62%, on R10@1 is over 6.89%, on R10@2 is over 4.01%, in the Douban dataset, on MAP is over 5.48%, on MRR is over 6.15%, on P@1 is over 8.56%, on R10@1 is over 10.30%, on R10@2 is over 7.32%, and on R10@5 is over 6.22%.
The reason is that the SMN does not use the attention mechanism to parse the utterance but uses GRU to obtain a granular representation of the subsequence, which is limited to long utterances when encoded in RNNs, and the extraction of interaction information between response and utterance in SMN is executed during convolution and pooling, while DAM uses the attention module to compute cross-attention between the two during the “representation” phase. Furthermore, the properties of RNN make it difficult to incrementally parse into multiple layers of granularity, which makes them less informative than DAM.
In contrast to the stacked multi-head attention, in the Ubuntu dataset, the improvement to the stacked multi-head attention on R10@1 is over 0.388%, on R10@2 is over 0.228%, in the Douban dataset, on R10@1 is over 1.18%, and on R10@2 is over 0.711%. The model structure proposed by the stacked multi-head attention is based on the premise that the closer the utterance is to the response the more relevant it is to the response, whereas the shifted granularity matching method is based on the premise that the whole utterances are equal to the response in terms of the model structure, these two different premises, the latter may be better adapted to the current dataset.
The “1 to 3” in Table 7 indicates the use of the 1st granularity to the 3rd granularity for matching under the multilevel shifted cross-attention granularity method, as it gets the best result. In comparison with DAM, in the Ubuntu dataset, the improvement to DAM on R2@1 is over 0.640%, on R10@1 is over 1.69%, on R10@2 is over 1.14%, in the Douban dataset, on MAP is over 1.82%, on P@1 is over 2.11%, on R10@1 is over 2.36%, on R10@2 is over 2.44%, and on R10@5 is over 1.72%. In comparison with the shifted granularity matching method, the multi-level shifted cross-attention granularity method achieves better results, in the Ubuntu dataset, the improvement to the shifted granularity matching method on R2@1 is over 0.425%, on R10@1 is over 0.515%, on R10@2 is over 0.341%, in the Douban dataset, on MAP is over 0.358%, on P@1 is over 1.16%, and on R10@1 is over 1.17%. This demonstrates that by implementing shifted matching in the “representation” stage upstream of the model, a better shifted matching granularity representation can be resolved to construct a better matching matrix. It demonstrates again the rationality and effectiveness of the processing step of targeting point-to-point mining before extracting information from the representation as a whole.
We verify the effectiveness of the two proposed methods through the ablation experiments. Referring to DAM, we select the matching matrix in the matching phase of the model to achieve ablation, for example, only the self-attention matching matrices or the cross-attention matching matrices are selected. We remove the self-attention matching matrices and the cross-attention matching matrices in the matching phase and keep only the new matrices, i.e., the final aggregated matrices are only formed by the new method proposed in this paper.
As shown in Table 8, the results of the model Mshift (using only the shifted granularity matching matrix) are worse than those of the model with only the self-attentive matching matrix or the cross-attentive matching matrix but are not so different as to suggest that the method is effective in extracting the semantic information and that the information extracted using this method is different from that extracted using the other two matching matrices. From the results of the comparison can be known that Mshift contains the supplementary information required in the original model. Mshift−cross indicates the ablation results of the multi-level shifted cross-attention granularity method. Comparing the results of the other two ablation experiments with the original model, it can be seen that the results are very close to those of DAM and better than those of the other two matching matrices.
Table 8.
The results of the ablation experiment for the two proposed methods.
We believe there may be several reasons:
- The multi-level shifted cross-attention granularity matching method can mine more information than that of the other two matching methods;
- The method can cover part of the information that can be mined using the cross-attention and self-attention matching, for example, there may be some overlap between them, but fails to be better than the full DAM in terms of results as it has not completely replaced both the matching methods;
- Mshift and Mcross are subject to interaction space through convolution and pooling after aggregation, but in the separate case, this space does not exist, thus reducing the mining of a portion of the information. Mshift−cross contains the interaction space of Mshift and Mcross parts, which can be extracted under the convolutional pooling;
- There is an overlap between the adjacent granularities, allowing for the partial substitution between the granularities so that the information extracted in the non-shifted case can still be overlapped under the shifted matching.
These conjectures give us new anticipation as to whether there is a better way to achieve lower computational effort and higher accuracy with less matching matrix that can cover a more comprehensive range of information.
5. Conclusions
This paper proposes two improved methods based on DAM with the idea of “shift”. The first improvement is to calculate the similarity of the shifted granularity in the matching stage and construct a new matching matrix to load the mapping information between the shifted granularities as a supplement to the original model. The second improvement, the multilevel shifted cross-attention granularity matching, is based on the shortcomings of the previously proposed method. To address the shortcomings of the shifted granularity matching method, it is still guided by the idea of “shift”, allowing for a deeper dependency mapping between the shifted granularities, with the improvement in the “representation” phase. Inspired by the decoder structure in the transformer, where the shifted response and utterance granularities are conducted the cross attention to obtain new shifted granularities, which is then used to construct a new matching matrix that complements the information. We have demonstrated the effectiveness of the two methods by comparative experiments.
What we need to do in the future can be summarized as follows: (1) The way to realize the idea of “dislocation” matching in this paper is at the cost of linearly increasing the calculation amount and memory of model training. To solve this problem, we need to consider how to ensure that the information in the “dislocation” can be mined with less computation and memory overhead. This will involve how to more effectively represent the overall mapping relationship between the response and utterance, and compress more information into a less granular representation; Moreover, the two methods proposed in this paper are to add a new matching matrix. Although the matrix has new information to be mined, it is not difficult to conclude from the ablation experiments that the matrix contains most of the existing information of the original matrix. How to reduce the extraction of redundant information is also the focus of future research. (2) The other problem that needs to be studied in the future is how to verify the mechanical principle of “dislocation”. Although better results can be obtained through dislocation, the interaction principle between the dislocation granularities has not been proved through experimental logic. What needs to be carried out in the future is to further study the principle of interaction between the different granularities, and prove the rationality of the “dislocation” idea proposed in this paper through visual results. At the same time, it can also be verified by the experiments that this dislocation matching method can be used not only in the depth attention matching model but also in other models with a similar point-to-point matching structure.
Author Contributions
Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation, K.H.; writing—review and editing, visualization, supervision, project administration, funding acquisition, N.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data used in this paper are open to all researchers in the world, the data can be freely used through Internet, and there is no copyright problem.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| DAM | Deep Attention Matching Network |
| GRU | Gated Recurrent Unit |
| NMT | Neural network machine translation |
| RCNN | Regions with Convolutional Neural Network Feature |
| RNN | Recurrent Neural Networks |
| SMN | Sequential Matching Network |
| SM-DAM | Enhanced deep attention matching model based on dislocation granularity matching |
References
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Berlin/Heidelberg, Germany, 2009; pp. 23–65. [Google Scholar]
- Ji, Z.; Lu, Z.; Li, H. An information retrieval approach to short text conversation. arXiv 2014, arXiv:1408. 6988. [Google Scholar]
- Wang, H.; Lu, Z.; Li, H.; Chen, E. A dataset for research on short-text conversations. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 935–945. [Google Scholar]
- Young, S.; Gašić, M.; Keizer, S.; Mairesse, F.; Schatzmann, J.; Thomson, B.; Yu, K. The hidden information state model: A practical framework for pomdp-based spoken dialogue management. Comput. Speech Lang. 2010, 24, 150–174. [Google Scholar] [CrossRef]
- Zhou, X.; Dong, D.; Wu, H.; Zhao, S.; Yu, D.; Tian, H.; Liu, X.; Yan, R. Multi-view response selection for human-computer conversation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 372–381. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. arXiv 2015, arXiv:1506.08909. [Google Scholar]
- Wu, Y.; Wu, W.; Xing, C.; Zhou, M.; Li, Z. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. arXiv 2016, arXiv:1612.01627. [Google Scholar]
- Ritter, A.; Cherry, C.; Dolan, B. Data-driven response generation in social media. In Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics (ACL): Edinburgh, UK, 2011. [Google Scholar]
- Young, S.; Gašić, M.; Thomson, B.; Williams, J.D. Pomdp-based statistical spoken dialog systems: A review. Proc. IEEE 2013, 101, 1160–1179. [Google Scholar] [CrossRef]
- Banchs, R.E.; Li, H. Iris: A chat-oriented dialogue system based on the vector space model. In Proceedings of the ACL 2012 System Demonstrations, Jeju, Republic of Korea, 8–14 July 2012; pp. 37–42. [Google Scholar]
- Gu, J.C.; Ling, Z.H.; Zhu, X.; Liu, Q. Dually interactive matching network for personalized response selection in retrieval-based chatbots. arXiv 2019, arXiv:1908.05859. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Kadlec, R.; Schmid, M.; Kleindienst, J. Improved deep learning baselines for ubuntu corpus dialogs. arXiv 2015, arXiv:1510.03753. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.V.; Charlin, L.; Liu, C.W.; Pineau, J. Training end-to-end dialogue systems with the ubuntu dialogue corpus. Dialogue Discourse 2017, 8, 31–65. [Google Scholar] [CrossRef]
- Lu, X.; Lan, M.; Wu, Y. Memory-based matching models for multi-turn response selection in retrieval-based chatbots. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Hohhot, China, 26–30 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 269–278. [Google Scholar]
- Wu, B.; Wang, B.; Xue, H. Ranking responses oriented to conversational relevance in chat-bots. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; Technical Papers. pp. 652–662. [Google Scholar]
- Yan, R.; Song, Y.; Wu, H. Learning to respond with deep neural networks for retrieval-based human-computer conversation system. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 55–64. [Google Scholar]
- Zhang, Z.; Li, J.; Zhu, P.; Zhao, H.; Liu, G. Modeling multi-turn conversation with deep utterance aggregation. arXiv 2018, arXiv:1806.09102. [Google Scholar]
- Zhou, X.; Li, L.; Dong, D.; Liu, Y.; Chen, Y.; Zhao, W.X.; Yu, D.; Wu, H. Multi-turn response selection for chatbots with deep attention matching network. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1118–1127. [Google Scholar]
- Shang, L.; Lu, Z.; Li, H. Neural responding machine for short-text conversation. arXiv 2015, arXiv:1503. 02364. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A diversity-promoting objective function for neural conversation models. arXiv 2015, arXiv:1510.03055. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Spithourakis, G.P.; Gao, J.; Dolan, B. A persona-based neural conversation model. arXiv 2016, arXiv:1603.06155. [Google Scholar]
- Serban, I.; Klinger, T.; Tesauro, G.; Talamadupula, K.; Zhou, B.; Bengio, Y.; Courville, A. Multiresolution recurrent neural networks: An application to dialogue response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Serban, I.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Shang, M.; Fu, Z.; Peng, N.; Feng, Y.; Zhao, D.; Yan, R. Learning to converse with noisy data: Generation with calibration. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Song, H.; Zhang, W.N.; Cui, Y.; Wang, D.; Liu, T. Exploiting persona information for diverse generation of conversational responses. arXiv 2019, arXiv:1905.12188. [Google Scholar]
- Vinyals, O.; Le, Q. A neural conversational model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Xing, C.; Wu, W.; Wu, Y.; Liu, J.; Huang, Y.; Zhou, M.; Ma, W.Y. Topic augmented neural response generation with a joint attention mechanism. arXiv 2016, arXiv:1606.08340 2. [Google Scholar]
- Zhu, Q.; Cui, L.; Zhang, W.; Wei, F.; Liu, T. Retrieval-enhanced adversarial training for neural response generation. arXiv 2018, arXiv:1809.04276. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Bordes, A.; Chopra, S.; Weston, J. Question answering with subgraph embeddings. arXiv 2014, arXiv:1406.3676. [Google Scholar]
- Yao, X.; Van Durme, B. Information extraction over structured data: Question answering with freebase. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 956–966. [Google Scholar]
- Yih, S.W.T.; Chang, M.W.; He, X.; Gao, J. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP, Beijing, China, 28–30 July 2015. [Google Scholar]
- Zhou, H.; Young, T.; Huang, M.; Zhao, H.; Xu, J.; Zhu, X. Commonsense knowledge aware conversation generation with graph attention. In Proceedings of the Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13 July 2018; pp. 4623–4629. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured attention networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Guanwen, M.; Jindian, S.; Shanshan, Y.; Da, L. Multi-turn response selection for chatbots with hierarchical aggregation network of multi-representation. IEEE Access 2019, 7, 111736–111745. [Google Scholar]
- Zhenyu, Z.; Xiaohui, Y.; Zhiquan, F. Self-attention Mechanism Fusion for Recommendation in Heterogeneous Information Network. Lect. Notes Electr. Eng. 2023, 917, 1147–1155. [Google Scholar]
- Niu, Z.Y.; Zhong, G.Q.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Stokel-Walker, C.; Van Noorden, R. What ChatGPT and generative AI mean for science. Nature 2023, 614, 214–216. [Google Scholar] [CrossRef]
- Huh, S. Are ChatGPTs knowledge and interpretation ability comparable to those of medical students in Korea for taking a parasitology examination? A descriptive study. J. Educ. Eval. Health Prof. 2023, 20, 1. [Google Scholar]
- King, M.R. A Conversation on Artificial Intelligence, Chatbots, and Plagiarism in Higher Education. Cell. Mol. Bioeng. 2023, 16, 1–2. [Google Scholar] [CrossRef]
- Zeng, M.J.; Xiao, N.F. Effective Combination of DenseNet and BiLSTM for Keyword Spotting. IEEE Access 2019, 7, 10767–10775. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999; Volume 463. [Google Scholar]
- Voorhees, E.M. The trec-8 question answering track report. In Proceedings of the 8th Text Retrieval Conference, Gaithersburg, Maryland, 17–19 November 1999; Volume 1999, pp. 77–82. Available online: https://www.researchgate.net/publication/2888359_The_TREC-8_Question_Answering_Track_Evaluation (accessed on 12 February 2023).
- Yu, C.; Jiang, W.; Zhu, D.; Li, R. Stacked multi-head attention for multi-turn response selection in retrieval-based chatbots. In Proceedings of the IEEE 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3918–3921. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).