Abstract
Reinforcement learning-based controllers for safety-critical applications, such as autonomous driving, are typically trained in simulation, where a vehicle model is provided during the learning process. However, an inaccurate parameterization of the vehicle model used for training heavily influences the performance of the reinforcement learning agent during execution. This inaccuracy is either caused by changes due to environmental influences or by falsely estimated vehicle parameters. In this work, we present our approach of combining dynamics randomization with reinforcement learning to overcome this issue for a path-following control task of an autonomous and over-actuated robotic vehicle. We train three independent agents, where each agent experiences randomization for a different vehicle dynamics parameter, i.e., the mass, the yaw inertia, and the road-tire friction. We randomize the parameters uniformly within predefined ranges to enable the agents to learn an equally robust control behavior for all possible parameter values. Finally, in a simulation study, we compare the performance of the agents trained with dynamics randomization to the performance of an agent trained with the nominal parameter values. Simulation results demonstrate that the former agents obtain a higher level of robustness against model uncertainties and varying environmental conditions than the latter agent trained with nominal vehicle parameter values.
1. Introduction
Artificial intelligence has accelerated the development of autonomous vehicles, notably over the past decade [1,2]. It has successfully been applied for several autonomous driving tasks, including motion planning [3,4] and motion control [5]. Especially the application of reinforcement learning for motion control has gained increasing interest, where so-called agents are trained to approximate optimal control policies [6,7]. Agents for safety-critical applications, such as autonomous driving, are often trained in simulation, where a learning model of the system needs to be provided. This allows a safe training of agents without risking dangerous accidents involving humans or the destruction of the real-world system, which is especially important since the agents explore different and possibly unsafe actions during training in order to find an optimal control policy. Additionally, training in simulation is fast and scalable. After the training process is successfully completed, agents are then transferred to and executed on the real-world system. However, agents often show poor results during execution if specific dynamics parameters of the learning model are uncertain at training time or if they differ from the actual values of the system due to an inaccurate system identification process [8]. Furthermore, parameter values might change and vary over time due to environmental influence. In the case of autonomous vehicles, these issues often occur since it is not possible to determine the values of specific dynamics parameters beforehand that will be valid for every driving scenario. For example, an agent can be trained with the nominal vehicle mass and perform well in this particular use case. However, the performance of the agent might decrease drastically if humans or a heavy load are onboard, since this additional load changes the dynamical behavior of the system. Similarly, the tire-road friction depends on the current weather condition and frequently changes over time. On a sunny day, the road-tire friction will be higher than on a snowy one. These uncertainties need to be considered in the learning model to enable the training of robust agents for the application of motion control tasks for autonomous driving.
In the field of robotics, dynamics randomization [8,9,10] is being applied to circumvent this issue of parameter uncertainty during the reinforcement learning training process. Here, the values of certain dynamics parameters are randomized within a predefined range at the start of each training episode. This forces the agents to learn robust control behavior for all values within the given range. In [8], the authors leverage dynamics randomization to learn robust reinforcement learning policies for the locomotion of a quadruped robot. They randomize dynamics such as mass, motor friction, and inertia. Similarly, the authors of [9] successfully apply dynamics randomization for an object pushing task, where both the dynamics of the robotic arm as well as the dynamics of the moved object are randomized. In [10], robust control policies are learned for a robot pivoting task. In all three cases, robust policies are successfully generated for the respective target application. However, the control problem addressed in our work is significantly different since neither a robotic arm nor a walking robot is being trained but rather an autonomous and over-actuated robotic vehicle. The effect of uncertain dynamics parameters on the performance of reinforcement learning agents for vehicle motion control still needs to be investigated.
In [11], the authors apply dynamics randomization in the context of autonomous driving and randomize certain elements of the vehicle, such as the steering response and the latency of the system. Nevertheless, randomization was not applied to important dynamics parameters of the vehicle model, such as the mass and the road-tire friction. These values play an important role and have a major impact on the overall dynamical behavior of vehicles. Therefore, it is still necessary to examine the influence that the aforementioned dynamics parameters might have on agents for vehicle motion control if they are uncertain.
1.1. Contribution of This Paper
The contribution of this paper is threefold. First, we enable the training of agents for motion control tasks in autonomous driving with increased robustness against parametric uncertainties and varying parameter values. This is done by applying dynamics randomization to a reinforcement learning-based path following control (PFC) problem for the over-actuated and robotic vehicle ROboMObil [12,13] at the German Aerospace Center.
Secondly, we train several reinforcement learning agents where each agent experiences randomization for a different parameter of the vehicle dynamics. The first agent encounters randomization in the mass in order to examine the effect of different vehicle loads on the agent’s control performance. The second agent undergoes randomization of the inertia value since the inertia value is difficult to measure and is therefore often only roughly estimated. The third agent is trained with a randomized tire-road friction coefficient, since this value frequently changes based on the current weather.
Lastly, we perform a detailed sim-to-sim study and extensively compare the performance and robustness of the agents trained with dynamics randomization to the performance of an agent trained with fixed nominal parameters. We additionally give insight on the influence particular dynamics parameters might have on agents for the control task at hand. This sim-to-sim study provides valuable information for a substantiated preparation for robust applications on the real-world vehicle.
1.2. Paper Overview
The remainder of this work is organized as follows. In Section 2, the problem addressed in this work is stated. Section 3 presents the reinforcement learning framework for the path-following control problem and introduces the dynamics randomization scheme applied to the agents. Section 4 describes the training setup. In Section 5, we assess the robustness and performance of the trained agents. Lastly, in Section 6, we conclude this work and give an outlook.
1.3. Notation
Several reference coordinate systems are considered for the path-following control problem. More specifically, a path frame, a vehicle frame, and an inertial frame are utilized, which are represented by the superscripts , and , respectively. Furthermore, the subscripts and denote whether a value within the control problem denotes a property of the path or the vehicle.
2. Problem Statement
Figure 1 shows the action loop for the path following control task considered in this work. First, suitable sensors should detect the path boundaries, and the planned path should be closely followed. Afterwards, the path is forwarded to the reinforcement learning-based path-following controller, which is trained in simulation with the vehicle model of the target vehicle.
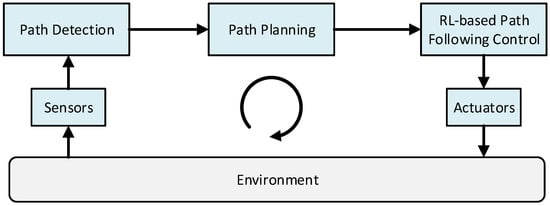
Figure 1.
The action loop for the considered path following control task.
Reinforcement learning agents in simulation-based environments are usually trained with fixed model parameter values. In autonomous driving, however, some vehicle dynamics parameters might be uncertain or might change over time due to environmental influence. This might negatively affect the agents’ performance during their execution if the parameters cannot be determined beforehand or change after training. Figure 2 qualitatively shows this for a path-following motion control task. Let represent the dynamics parameter of the vehicle model. Furthermore, assume that is a fixed value for that is applied to the vehicle learning model during training. On the left side of Figure 2, it can be seen that the agent performs well after training and during execution if the actual parameter of the vehicle equals the parameter . However, on the right side, the agent is not able to provide a satisfying control performance during execution and drives off the road since the true parameter of the vehicle differs from the fixed value used during training. The possibility of such an unrobust control behavior poses a major security risk.
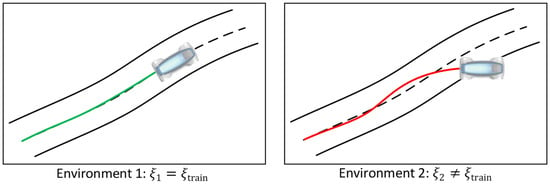
Figure 2.
The performance of agents during execution for different values of a representative dynamics parameter . (Left): The true parameter of the vehicle in the first environment equals the value applied during the simulation-based training and the agent shows a satisfying path following control performance. (Right): The actual vehicle parameter in the second environment differs from and the agent shows a poor path following control performance.
To overcome this issue and train robust agents for a path-following control task in the presence of uncertain and changing dynamics parameters, we apply dynamics randomization during the reinforcement learning process in this work. The underlying path following control problem considered in this paper is based on our previous work in [14] and is introduced in detail in Appendix A. We assume that the path boundaries can be detected in each time step and that a path planning module, such as in [15], is given. Furthermore, the learning model of the controlled vehicle is based on the extended non-linear single-track model of the ROboMObil [12] (c.f. Appendix B). We assume that a nonlinear observer, such as in [16], estimates the necessary states for the reinforcement learning controller.
3. Learning-Based Path following Control with Parametric Uncertainties
In deep reinforcement learning [17], a neural network represents the agent and interacts with an environment, receiving a reward in each time step. Here, the reward encodes the control goal. Based on the observed state of the environment, the agent applies an action and obtains a reward. The agent learns to solve a predefined control task by maximizing the expected sum of rewards in the environment. For the interested reader, the fundamentals of deep reinforcement learning are introduced in more detail in Appendix C. In this section, we introduce the observation space of the environment, the action space of the agent, and the reward function design for the path following control task at hand. Furthermore, the dynamics randomization scheme is presented.
3.1. Oberservation Space of the Path following Control Environment
The agents trained for the path following control task should minimize certain errors between the ROboMObil and the path, which is assumed to be provided by the ROboMObil’s path planning module [15,18]. More specifically, the agents should minimize the vehicle’s lateral position error and orientation error to the path. Furthermore, the agents should closely track the demanded velocity in the tangential direction of the path, i.e., minimize the velocity error (cf. Appendix A).
To successfully minimize these errors and learn the control task, the agents require a suitable observation space during training that contains all the necessary information regarding the environment. In this work, the observation vector , also called the state, is chosen based on our previous work in [14]. Here, the aforementioned errors and as well as the velocity error in the lateral direction of the path (cf. Appendix A), are provided for the observation vector. Furthermore, the path curvature and the front and rear steering angles and of the ROboMObil are incorporated into the observation vector . Lastly, the observation vector in the time step is extended with the observation of the aforementioned values from the previous time step , which incorporates beneficial rate information into the learning process. This leads to the observation vector being
with
3.2. Action Space of the Agents
The control inputs the agent can apply to the extended non-linear single-track model of the ROboMObil [12] are the front and rear axle steering rates and and the front and rear in-wheel torques and , respectively. Both steering rates and are limited by the maximal steering rate :
Besides providing the steering rates to the vehicle, the agent also commands the front and rear in-wheel torques and . The torques are limited by the maximum torque :
3.3. Design of the Reward Function
The design of the reward function provides a crucial degree of freedom in reinforcement learning. As mentioned above, the agent should be rewarded positively when it approaches the control goal, i.e., when it has small or no errors to the path. For the path-following control task, the agent should learn to control the vehicle such that the lateral offset , the orientation error and the velocity errors are minimized. However, as mentioned in [14], the agent’s primary control goal should be to minimize the lateral position error , since a large lateral offset could negatively influence safety and possibly cause collisions. After minimizing the lateral position error, the agent should learn to control the vehicle such that it achieves the commanded orientations and velocities and both and approach zero. Furthermore, smooth steering behavior should be favored. Therefore, a hierarchical structure for the reward function is chosen, as in [14]. More specifically, the reward function is set to
with being
and being
Here, the expressions and denote the changes of the front and rear steering angles between the two subsequent time steps and which are given by
Furthermore, and represent their weighting parameters in (7) and are set manually.
In Equations (5) and (6), the functions are Gaussian-like functions
with the properties
For the reward in Equation (5), the function approaches zero for large lateral position errors and approaches for small . Hence, the agent is rewarded for small lateral position errors. This term dominates the overall reward, since it is the only term multiplied by one (cf. Equation (5)), which is in-line with the hierarchical reward structure of prioritizing the minimization of the lateral position error first [14]. Furthermore, the value of is multiplied by the reward term consisting of the Gaussian-like functions and (cf. Equation (6)) for the orientation and velocity errors and in Equation (5), which can further increase the overall reward once the agent has successfully learned to minimize , i.e., maximize the function . Finally, after minimizing the lateral position error , the orientation error , and the velocity error , the agent receives a further reward determined by if it controls the vehicle such that there is a small steering rate between two subsequent time steps to favor smooth control of the vehicle.
3.4. Learning with Dynamics Randomization
Dynamics randomization [8,9,10] allows robust policies to be trained in cases where dynamics parameters are uncertain, difficult to measure, or frequently change over time. When dynamics randomization is applied, the dynamics parameters are sampled from a specific distribution at the beginning of each training episode. Figure 3 depicts this for a representative parameter . Often, a uniform distribution within a predefined parameter range between the values and is chosen [8]. This enables the agent to learn a successful control performance for the entire uniformly distributed parameter range without favoring specific parameter values. In [8] it was shown that dynamics randomization can be interpreted as a trade-off between optimality and robustness. Therefore, the ranges in which the parameters are randomized need to be thoughtfully chosen to prevent the agents from learning overly conservative control behaviors.
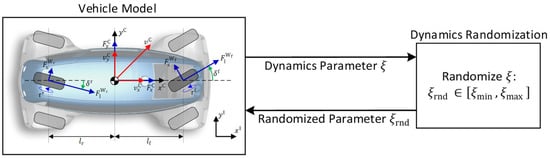
Figure 3.
Dynamics randomization scheme at the beginning of each training episode for a representative dynamics parameter . First, the parameter which should be randomized is selected and forwarded to the dynamics randomization module (top arrow). Afterwards, the randomized value of the parameter is returned to the vehicle model (bottom arrow).
In this work, three agents are trained, whereby each agent experiences randomization for a different parameter of the vehicle model. More specifically, the parameters that are being randomized are the vehicle mass , the yaw inertia of the vehicle, and the tire-road friction coefficient (cf. Appendix B), which are often randomized in such setups [8,9]. More specifically, in this work, these particular randomizations are considered for the path-following control task based on the following reasons: the overall system mass changes every time a different load is placed inside the vehicle and also depends on whether a passenger is onboard. The inertia value is often difficult to measure and can be only estimated roughly. Furthermore, the tire-road friction frequently changes depending on the current weather.
Besides training the three agents experiencing dynamics randomization, an agent with the nominal vehicle dynamics parameters is also trained for the same PFC task, which serves as a benchmark. To allow a straightforward comparison, the agents experiencing randomization are set to have the same reward as well as the same action and observation spaces as the nominal agent experiencing no randomization. The different ranges of the uniform distributions in which the vehicle mass , the yaw inertia and the tire friction are randomized are introduced in the following.
3.4.1. Mass Randomization
The first agent being trained with dynamics randomization experiences randomization for the vehicle mass. The ROboMObil’s nominal mass is . The ROboMObil can either transport no passengers, a maximum of one passenger, or a certain amount of load, leading to an unknown external load that might be placed in the vehicle after training. Therefore, an external mass from a uniform distribution that covers all three application cases is sampled and added to the ROboMObil’s mass, which enables the agent to learn an equally successful control performance for the entire parameter range. This leads to the randomized training mass being
At the beginning of each episode, after sampling and adding it to , the randomized training mass substitutes the vehicle model’s nominal mass . In this work, the uniformly sampled external mass takes a value within the range
3.4.2. Inertia Randomization
The second agent experiences randomization in the yaw inertia. The nominal yaw inertia value for the ROboMObil is . Since this is an estimated value, we assume that it has a significant amount of uncertainty within a range of the nominal inertia value. Therefore, a randomized inertia value within the interval
is sampled beginning with every training episode to enable the agent to learn a successful control performance for the entire range of possible inertia values.
3.4.3. Friction Randomization
The third agent being trained with dynamics randomization experiences randomization for the road-tire friction. By varying the friction during training, the agent has the opportunity to learn how to control the vehicle robustly in various street conditions, such as on a dry surface, a wet surface, or a surface covered in snow. The friction has a proportional influence on the front and rear side wheel forces (cf. Equation (A14) of Pacejka’s Magic Formula (MF) [19] for the side wheel forces in Appendix B). The influence of different friction values on the side wheel forces is demonstrated in Figure 4. Here, the friction coefficient represents a dry, a wet, and a snowy road. It can be seen that, with decreasing friction , the maximal lateral tire forces also decrease. This drastically influences the vehicle’s dynamic behavior and, consequently, affects the control performance.
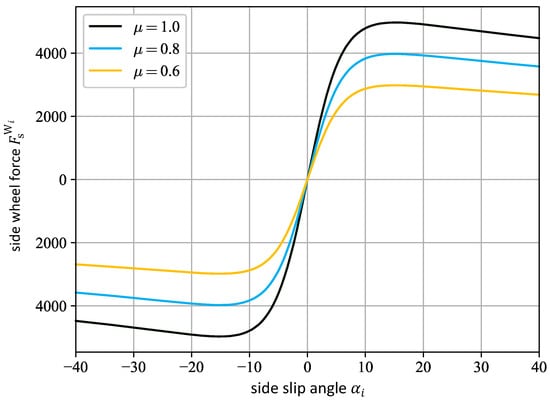
Figure 4.
The side wheel forces over the side slip angle for different values of with denoting the front or rear wheels, respectively, according to Pajecka’s MF [18] in Equation (A14).
To enable the agent to learn an equally robust and successful vehicle control strategy for different street conditions, a uniformly sampled friction value within the range
is selected at the beginning of each episode. This friction value is afterwards used in the vehicle model during a training episode.
4. Training Setup
In this section, the simulation framework of the training setup, including the dynamics randomization process, is introduced. Furthermore, the training procedure for the agents is presented.
4.1. Simulation Framework
The software architecture applied to train the different agents with dynamics randomization is extended from our previous work in [14] and shown in Figure 5.
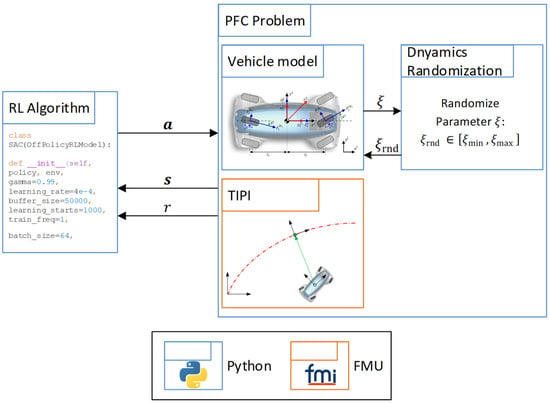
Figure 5.
Training setup of the PFC task including dynamics randomization extended from [14].
Here, the reinforcement learning environment for the PFC problem is implemented using the Python-based OpenAI Gym framework [20]. This framework offers a standardized interface with several reinforcement learning libraries, such as the Stable-Baselines 2 library [21], used in this work. The vehicle model is written in Python as a system of ordinary differential equations (ODEs) and solved by the odeint-function from the Scipy library [22]. Furthermore, time independent path interpolation (TIPI) [12,23] is applied to determine the closest point on the reference path for each time step, which is then used by the agent to learn how to steer the vehicle towards the path. The implementation details of the TIPI are shown in Appendix A. The TIPI is implemented in Modelica [24] and exported by Dymola as a Functional Mock-up Unit (FMU) [25], which contains the compiled code of the TIPI algorithm. This FMU is then incorporated into the Python-based reinforcement learning framework.
4.2. Training Procedure
The agents are trained on the path depicted in Figure 6, which represents a federal highway called “Kesselberg”, located in the German Alps, and is parameterized by the arc length . The corresponding desired velocity profile is shown in Figure 7, calculated by taking the path curvature and the vehicle’s acceleration limits into account [26]. This particular path is chosen for training since it consists of road sections with different characteristics, which are beneficial for learning the RL-based PFC. In Figure 6 and Figure 7, for example, it can be seen that the path demands tight turns between the arc lengths and (cf. Figure 6) with a rather slow velocity around (cf. Figure 7). On the other hand, the path section between and represents an almost straight road, where the vehicle needs to accelerate quickly to successfully track the velocity demanded. All agents are trained for a total of time steps with a step size of , and the reward function introduced in Equation (5). In this work, an episode consists of time steps. During training, we apply the state-of-the-art Soft Actor-Critic (SAC) [27] learning algorithm from the Stable-Baselines 2 library [21]. The SAC algorithm is briefly discussed in Appendix C. The training with the SAC method is conducted with the hyperparameters given in Appendix D. The parameters of the reward function introduced in Equation (5) are set to:
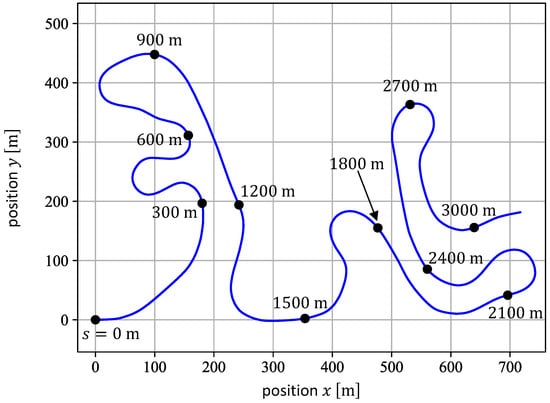
Figure 6.
Top view of the training path (blue line), which represents a federal highway located in the German Alps. The black dots depict different path position at certain arc lengths [14].
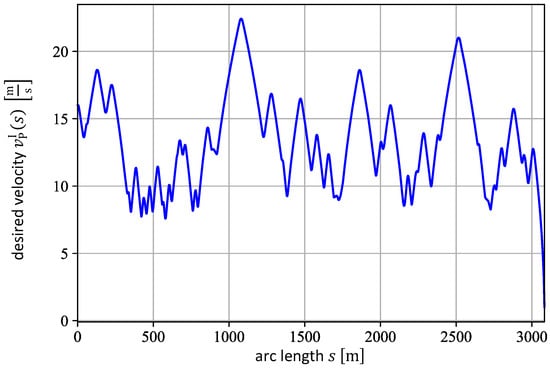
Figure 7.
Velocity profile of the training path, parameterized by the arc length [14].
Furthermore, the weighting parameters and in Equation (7) are both set to to equally penalize large changes in both the front and rear steering angles.
As introduced in [14], it is beneficial to randomly initialize the system with an offset to the path at the beginning of each training episode. This supports the exploration of the observation space since the agents must repeatedly try to successfully follow the path starting from different initial configurations. More specifically, the offset is applied to the initial position error , the initial orientation error , and the initial longitudinal velocity error . At the beginning of each episode, these initial errors to the path are randomly sampled from three different uniform distributions within the following bounds:
To further encourage the agents to only explore important parts of the observation space, several training abortion criteria are introduced, as described in [14]. If one or more of these errors do not remain within their respective pre-defined thresholds, then the training episode is terminated early. In this work, a termination is triggered in the following cases:
Every time an episode is terminated, the negative terminal reward is provoked. Therefore, the agents need to learn to stay within these error thresholds, since a negative reward contradicts the primary reinforcement learning goal of maximizing the expected sum of rewards, also called the return (cf. Equation (A17) in Appendix C). When a new episode starts, the vehicle is reinitialized where the previous episode ended, with an initial offset according to Equation (16).
5. Tests and Performance Comparison
The agent trained with fixed nominal values (nomRL-PFC) is compared separately to the three agents trained with dynamics randomization. The agents are compared based on the returns they are able to achieve while facing changes in specific dynamics parameters during several executions on the path introduced in Figure 6. The return enables the direct comparison of the agents with respect to the control goal, since all agents had to learn how to maximize the same reward function during training. First, the nomRL-PFC is compared with the agent trained with randomized mass (-randRL-PFC), followed by a comparison with the agent trained with randomized inertia (-randRL-PFC). Lastly, the nomRL-PFC is compared with the agent trained with a randomized friction coefficient (-randRL-PFC).
5.1. Tests and Comparison of the nomRL-PFC and the -randRL-PFC
To evaluate the robustness and compare the performance of the nomRL-PFC and the -randRL-PFC, both agents are executed several times on the path in Figure 6, where each time a different external mass is chosen within the interval , i.e., the interval on which the agent with dynamics randomization was trained. The returns both agents obtained during these executions are shown in Figure 8. Here, the dark blue dot represents the return of the nomRL-PFC for the external mass . The light-blue dashed line with the crosses represents the nominal agent’s returns for executions on the path that were aborted due to early termination (cf. Inequalities (17)). The orange line shows the return of the -randRL-PFC for all external masses .
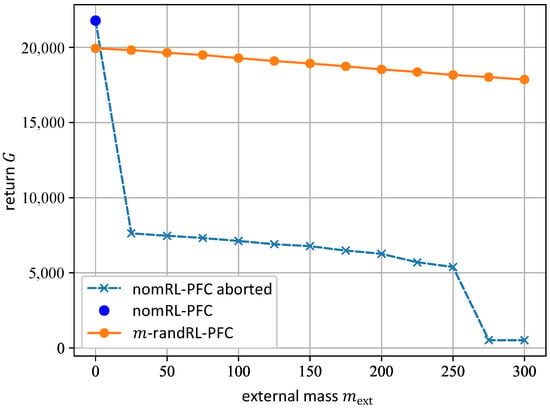
Figure 8.
Return of the normRL-PFC (blue line) and -randRL-PFC (orange line) after executions on the path for different external mass values .
In Figure 8, it can be seen that the nomRL-PFC achieves a higher return than the -randRL-PFC for , which is the value for which the nomRL-PFC was trained. However, the -randRL-PFC outperforms the nominal agent for cases in which . In all cases with an additional mass, the execution of the nominal agent on the path is aborted early because it triggers one or more of the safety-critical termination conditions introduced in Equation (17). In the case of , for example, the execution of the nomRL-PFC is aborted because the position error exceeds the respective pre-defined threshold, i.e., (cf. Inequalities (17)). This is illustrated in Figure 9. Here, the pathway of the nominal agent is depicted in blue, while the pathway of the -randRL-PFC is depicted in orange. The reference path is presented by the dashed black line. The solid black lines represent the path boundaries. It can be observed that the nomRL-PFC starts to slightly deviate from the reference path until the agent eventually leaves the road. However, the -randRL-PFC continues to successfully follow the path closely. Furthermore, for the complete interval of the values considered for , the returns of the -randRL-PFC remain at a relatively high level compared with the nomRL-PFC’s returns, which decrease continually. This underlines the robustness of the -randRL-PFC against varying mass values.
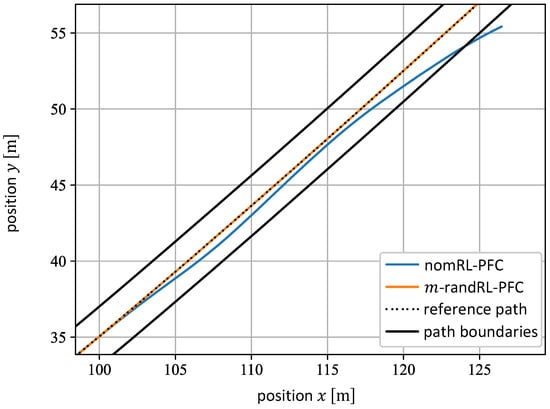
Figure 9.
The pathways of the nomRL-PFC (blue line) and the m-randRL-PFC (orange line) for . The reference path is depicted by the dashed black line, whereas the road boundaries are represented by the solid black lines.
Table 1 shows the root mean square error (RMS) of the lateral position, velocity, and orientation errors , , and of the nomRL-PFC and the 𝑚-randRL-PFC during their execution along the entire path with . More specifically, we consider the cases and , which represent both ends of the randomization interval. The errors of the nomRL-PFC are not provided for since the agent on the path failed to completely execute due to the early termination criteria described above. For , the lateral position error -RMS of the nomRL-PFC is higher than that of the 𝑚-randRL-PFC. However, the nominal agent achieves a smaller RMS for both the velocity error and the orientation error . In summary, the nomRL-PFC is able to achieve a higher overall return for , as shown in Figure 8, resulting from the lower RMS of the velocity and orientation errors throughout the entire execution on the path. For , the 𝑚-randRL-PFC’s returns decrease slightly compared with the case with because the RMS of all errors increases. This is the reason the return in Figure 8 also slightly decreases with higher values of . Nevertheless, the 𝑚-randRL-PFC is able to achieve a high return for all values considered for the external mass .

Table 1.
The root mean square (RMS) errors of the nomRL-PFC and the -randRL-PFC after executing the agents on the path for and . The best metric for each value is marked green.
Observing the results above, we can state that the 𝑚-randRL-PFC shows robustness against mass variations. This agent shows satisfying performances for the complete interval of ∈ [0 kg, 300 kg]. The performance of the nomRL-PFC, however, decreases drastically when the vehicle carries an external mass. This demonstrates that the nomRL-PFC agent is not robust against additional vehicle loads. Therefore, it fails to generalize to other parameter values that impose different dynamic behavior on the vehicle. Here, applying dynamics randomization to the mass during training solves this problem and enables the 𝑚-randRL-PFC to generalize successfully.
5.2. Tests and Comparison of the nomRL-PFC and the 𝐽-randRL-PFC
To examine the robustness of the nomRL-PFC and the 𝐽-randRL-PFC against variations in the yaw inertia, both agents are executed on the training path several times, where each time a different value for is chosen according to the inequalities (13). The returns of both agents are shown in Figure 10, which are evaluated at of the nominal inertia value of the ROboMObil. The blue line represents the returns of the nomRL-PFC, whereas the orange line depicts the returns of the 𝐽-randRL-PFC.
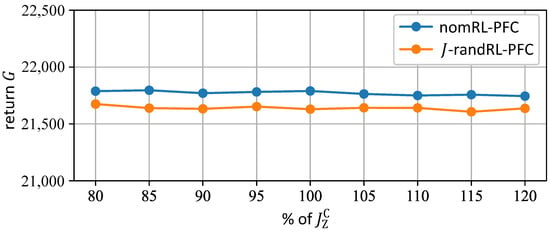
Figure 10.
Return of the nomRL-PFC (blue line) and the 𝐽-randRL-PFC (orange line) for the inertia values considered during the training of the agent with dynamics randomization.
In Figure 10, it can be observed that the returns of the nomRL-PFC and the 𝐽-randRL-PFC both stay at a relatively constant level for all considered inertia values. The reason for this can be explained with the help of Table 2. It shows the RMS errors of the nomRL-PFC and the 𝐽-randRL-PFC for the inertia values , and . The nomRL-PFC and the 𝐽-randRL-PFC each provide constant RMS errors for all three considered inertia values. Therefore, the returns of the agents do not vary notably. A possible explanation for this might be that the inertia does not have an overall major influence on the dynamics of the system for the considered motion control task, which is why the agents are able to perform equally well for all considered inertia values. Furthermore, both agents achieve similar RMS values for the position and orientation errors, with the nomRL-PFC providing slightly higher ones for both errors. For these errors, both agents receive similar overall rewards. Nevertheless, the nomRL-PFC is able to achieve higher overall returns in Figure 10 mainly due to the smaller RMS for the velocity error, which is rewarded higher due to the choice of in Equation (15).
Table 2.
The root mean square (RMS) errors of the nomRL-PFC and the -randRL-PFC after executing the agents on the path for different inertia values. The best metric for each inertia value is marked green.
With these observations, it can be stated that alternating the values of the yaw inertia does not affect the control performances of the agents. The RMS errors of both agents remain at a constant level, which indicates their robustness against different inertia values. More specifically, this shows that the nominal agent can still perform well even under uncertain inertia values and that the randomization of the yaw inertia during training does not provide any advantages.
5.3. Tests and Comparison of the nomRL-PFC and the -randRL-PFC
To evaluate and compare the performance of nomRL-PFC and -randRL-PFC for varying friction values, the agents both control the ROboMObil over the training path from start to finish multiple times, where each time a different tire-road friction coefficient is chosen. The performance of the agents is analyzed for friction values from the interval on which the -randRL-PFC was trained; see Equation (14). The returns of both the nomRL-PFC and the -randRL-PFC are shown in Figure 11 for several different friction values. The blue line represents the return of the nomRL-PFC, whereas the orange line depicts the return of the -randRL-PFC. It can be seen that the nomRLPFC is able to obtain a higher return for friction values close to , which is the friction value for which it was trained. However, for , the nominal agent is outperformed by the -randRL-PFC. Furthermore, the return of the nominal agent decreases significantly for smaller friction values, whereas the return of the agent trained with friction randomization is able to keep the return at a high level for all considered values of , showing robust behavior on varying road conditions.
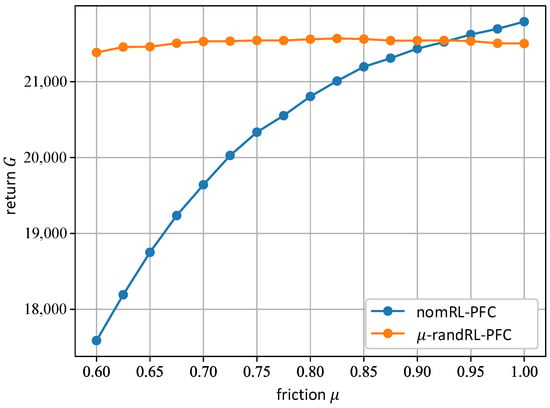
Figure 11.
Return of the nomRL-PFC (blue line) and -randRL-PFC (orange line) for the friction values considered during the training of the agent with dynamics randomization.
Table 3 summarizes the RMS errors of the nomRL-PFC and the -randRL-PFC on the path for the friction values and . It can be stated that both agents achieve a similar RMS for the lateral position error on a dry road surface, i.e., , with the nomRL-PFC providing lower errors for both velocity and orientation tracking. In the case of a snowy road with , however, the path-following performance of the nomRL-PFC declines, which increases its RMS for throughout the path. This is illustrated in Figure 12, which shows the road section around the arc length for , with the blue line depicting the pathway of the nomRL-PFC and the orange one illustrating the pathway of the -randRL-PFC. It can be observed that both agents are able to successfully follow the reference path, while the -randRL-PFC is able to achieve smaller lateral position errors to the reference path. This is the main reason why the overall return of the nomRL-PFC also decreases in Figure 11 for small friction values. The lateral position error determines the value of the Gaussian-like function in Equation (5), which is multiplied with the remainder of the reward function as part of the hierarchical design of the reward function. With increasing lateral position errors , the value of the function decreases. Consequently, this leads to a smaller overall return during the execution on the path. The -randRL-PFC, on the other hand, is able to obtain a similar -RMS for both road conditions (cf. Table 3), which further underlines its robustness against different friction values.
Table 3.
The RMS errors of nomRL-PFC and -randRL-PFC during the evaluation on the training path for the friction values and . The best metric is highlighted green.
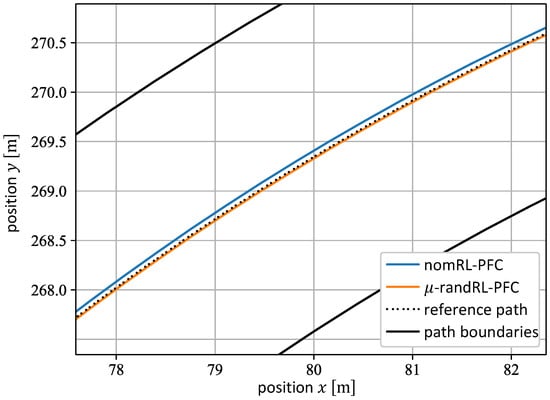
Figure 12.
Pathways of the nomRL-PFC (blue lines) and the -randRL-PFC (orange line) on the road section around the arc length with the friction value . The reference path is represented by the black dashed line, whereas the path boundaries are depicted by the black solid lines.
The performance comparison of the nomRL-PFC and the -randRL-PFC at rather challenging road sections further demonstrates the robustness of the latter agent. The tight road turns between the arc lengths and of the path shown in Figure 6 represent such sections. The lateral position errors induced by executing both agents in this particular part of the path are shown in Figure 13 for the friction value , with the blue line representing the nomRL-PFC and the orange line representing the -randRL-PFC. Here, it can be seen that both agents achieve a reasonable performance with the nomRL-PFC offering a slightly better one since it tracks the reference path more closely with in this section. However, the path-following performance of the nomRL-PFC in this part of the path decreases significantly for , which can be seen in Figure 14. Here, it can be observed that the nomRL-PFC now makes greater position errors up to and that it does not follow the path as closely as it did under dry road conditions (). Furthermore, the -randRL-PFC offers good position tracking performance with for (cf. Figure 14).
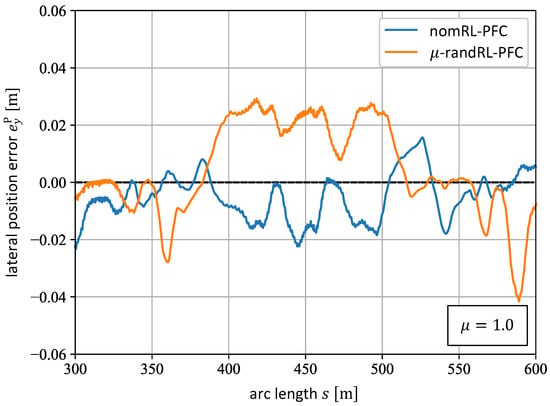
Figure 13.
The position error of the nomRL-PFC (blue line) and the -randRL-PFC (orange line) on the road section between the arc lengths and for the friction value .
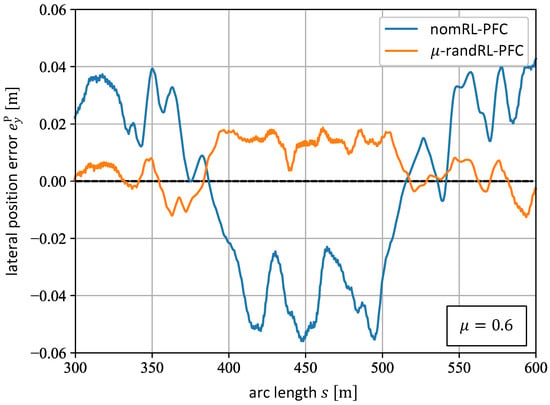
Figure 14.
The position error of the nomRL-PFC (blue line) and the -randRL-PFC (orange line) on the road section between the arc lengths and for the friction value .
Furthermore, in Table 3, it can be seen that the nomRL-PFC outperforms the -randRL-PFC in terms of tracking the demanded velocity. For both friction values, the -randRL-PFC generates a higher RMS of over the entire path. This can be explained by the hierarchical design of the reward function. It prioritizes the minimization of the position error before rewarding small velocity errors. This prioritization motivates the -randRL-PFC to apply a rather conservative velocity tracking performance for all friction values as a trade-off for good position tracking. Therefore, the agent trained with friction randomization applies a slower velocity for the different friction values in order to track the position more successfully for any given friction value .
It can be stated that the randomization of the road-tire friction during training increases the robustness of the agent. The performance of the -randRL-PFC stays at a high level, whereas the performance of the nomRL-PFC steadily decreases for smaller .
6. Conclusions and Outlook
In this work, the reinforcement learning-based path-following control of the ROboMObil has been extended such that dynamics randomization can be applied during training, which enables the learning of robust agents. More specifically, the dynamics randomization method was applied to three different dynamics parameters of the ROboMObil, namely the vehicle mass, the yaw inertia, and the tire-road friction coefficient. In the case of mass randomization, the agent trained with uniformly distributed mass values showed superior performance for the entire range of additional loads, which underlines its robustness against variations in this particular vehicle parameter. In contrast, the nominal agent failed to complete the path-following control task with an additional vehicle load, which further displays the increased robustness of the former agent. Furthermore, the agent trained with randomized friction values performed impressively over all considered friction values, whereas the performance of the nominal agent declines continually under more slippery road conditions. This shows that randomizing the friction during training enables robust control performance for various road conditions. However, the nominal agent showed robustness against uncertainties in the yaw inertia, which reveals that the randomization of the inertia does not provide additional benefits. In summary, the results allow the conclusion that dynamics randomization for certain parameters that have a major impact on the vehicle dynamics, such as the mass and the friction, significantly increases the agents’ robustness against parametric uncertainties. In future work, an agent for the considered path-following control problem should be trained that experiences randomization in multiple parameters simultaneously. Furthermore, the performance of the agents should be validated experimentally in a real-world setup. However, appropriate safety measures need to be guaranteed first to ensure the safety of the system and the environment.
Author Contributions
Conceptualization, K.A., J.U., C.W. and J.B.; methodology, K.A.; software, K.A. and J.U.; validation, K.A., J.U., C.W. and J.B.; writing—original draft preparation, K.A.; writing—review and editing, K.A., J.U., C.W. and J.B.; visualization, K.A.; supervision, J.B., C.W. and J.U. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received DLR basic funding.
Data Availability Statement
Not applicable.
Acknowledgments
The authors’ thanks go to Andreas Pfeiffer for his valuable support.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Path Representation
This section and the path following control problem considered in this work are based on [12,23]. The vehicle should robustly follow a path which is characterized by a motion demand and parameterized by the arc length and is defined by
The superscripts and denote that the individual values are considered in the inertial and path reference frame, respectively. Furthermore, the subscript expresses that the respective value describes a property of the path. Figure A1 shows a graphical depiction of and the values introduced in Equation (A1) at the point . Here, denotes the path reference point in the inertial coordinate system and represents the path orientation. Furthermore, expresses the path curvature and depicts the longitudinal velocity tangential to the path in the direction of the tangent vector at the path reference point .

Figure A1.
Graphical interpretation of the path at the point in the inertial coordinate system adapted from [12].
Given the current vehicle position , the closest point on the reference path is chosen as reference point on the path [23]. The subscript represents that properties of the car are regarded. This reference point then provides the current motion demand which the vehicle should follow. The reference point is calculated by finding the arc length which minimizes the distance between the vehicle position and the reference path , i.e., . This optimization problem is denoted by
Figure A2 illustrates this optimization problem. It can be seen that the optimal solution is the arc length for which the longitudinal position error of the vehicle is zero after transforming it into the path frame centered at , i.e., . In order to obtain through the minimization problem in Equation (A2), the time independent path interpolation (TIPI) [12,23] is applied.
To allow for a successful path following control according to [14], the controller needs to minimize certain errors between the vehicle and the path, more specifically the lateral offset , the velocity error in longitudinal direction of the path and the orientation error .
The lateral offset of the vehicle with respect to the path is denoted by
with being the desired lateral position and being the lateral position of the car, both referenced in the path frame. Since no lateral offset of the vehicle is desired, the desired lateral position is set to zero in Equation (A3), i.e., .

Figure A2.
Graphical representation of finding the optimal arc length adapted from [12].
Furthermore, denotes the velocity error between the desired velocity tangential to the path and the longitudinal velocity of the car in the path frame. The velocity error is represented by
The orientation error denotes the difference between the orientation of the path and the orientation of the vehicle . The orientation error is calculated by
Lastly, the error represents the velocity error between the desired lateral velocity and the lateral velocity of the vehicle in the path frame. This error is observed as part of the observation vector (cf. Equation (1)). Note that is not actively minimized as part of the reward function introduced in Equation (5). The error is calculated by
Appendix B. Vehicle Dynamics of the ROboMObil
Ideally, reinforcement learning is conducted on the real-world system to avoid the reality gap between the simulation setup and the real world. Often, however, training on the real-world system might raise major safety concerns since in safety-critical applications, such as autonomous driving, the system or surrounding humans can be endangered. Therefore, simulation-based reinforcement learning is preferred. For this, a training model needs to be provided that represents the behavior of the system. In this work, agents are trained to control the ROboMObil [12], which is a robotic research vehicle at the German Aerospace Center (DLR). Since certain dynamics parameters of the learning model are actively changed during the training processes, the vehicle model is introduced in detail. This section closely follows the work in [12]. The interested reader is pointed to the aforementioned publication for more detail.
The vehicle configuration of the extended nonlinear single-track model of the ROboMObil is shown in Figure A3. The state vector of the model is given by
with being the vehicle side slip angle, the absolute value of the velocity vector and the yaw rate of the vehicle in the car coordinate system. Furthermore, represents the yaw angle and and denote the position of the ROboMObil in a fixed inertial coordinate system. The control input vector of the model is set to
where and denote the torque set-points to the front and rear in-wheel motors. Furthermore, and denote the steering rates for the front and rear vehicles axles. The differential equations of the vehicle states and the steering angles and are provided by
where denotes the vehicle mass and the yaw inertia. Here, it should be noted that both parameters, namely the mass and the yaw inertia , are being randomized during the reinforcement learning training process. In the first line of Equation (A9), the modified velocity [12] is defined as:
This prevents division by zero if the velocity of the vehicle becomes zero. It should be noted that for . By choosing a small the vehicle dynamics is only altered insignificantly by introducing as defined in Equation (A10).

Figure A3.
Vehicle configuration of the ROboMObil as introduced in [12].
The forces and in Equation (A9) denote the forces on the vehicle’s center of gravity (CoG) and are determined by
with the longitudinal wheel forces and and the lateral wheel forces and of the front and rear wheel, respectively. Furthermore, and denote the external longitudinal and lateral air drag forces.
The longitudinal wheel forces and are calculated by
where denotes the wheel radius, the gravity and the speed dependent rolling resistance. The latter is given by
with the rolling resistance parameters , and .
The lateral wheel forces and are based on Pacejka’s Magic Formula (MF) [19] and are calculated by
with , , and being the parameters of Pacejka’s MF, the friction coefficient between the tires and the street, and and the load on the front and rear axles, respectively. Note that the friction coefficient is being randomized during training. The side slip angles in Equation (A14) of the front and rear wheels are given by
The yaw moment around the center of gravity in Equation (A9) is calculated by
with and representing the distances from the vehicle’s CoG to the front and rear axles, respectively. Furthermore, denotes the distance in front of the CoG at which the lateral air drag force is induced. For more details on the vehicle model, the interested reader is referred to [12].
Appendix C. Deep Reinforcement Learning Fundamentals
In reinforcement learning, Markov Decision Processes (MDPs) are utilized to represent the controlled environment with a set of states and a set of actions (cf. [27,28]). The state transition probability determines the likelihood of observing the state in the next time step after applying the action in the state at time step . After every state transition, a reward is observed. This setup describes the so-called agent-environment interaction and is shown in Figure A4. During this interaction, the agent learns to find an optimal stochastic control policy which maximizes the expected discounted sum of rewards, also called the return , represented by
with denoting the expected value and representing the state-action marginal of the trajectory distribution caused by the stochastic policy [27]. During training, the agent should prefer (exploit) actions that have generated high rewards in the past but also try (explore) new actions that might potentially generate higher rewards. Once the training procedure is completed, a deterministic policy is retrieved by applying the expected value of the stochastic policy in every state .
Recently, several methods have been proposed that solve reinforcement learning tasks by applying artificial neural networks. In this work, we utilize the Soft-Actor-Critic (SAC) [27] algorithm which addresses the maximum entropy learning objective [29] and aims at finding an optimal policy by solving
with denoting the temperature parameter and the entropy of the policy. This objective in Equation (A18), compared with the standard reinforcement learning objective introduced in Equation (A17), initiates the maximization of the entropy in each state, where the entropy is viewed as a measure of randomness. Inherently, the policy is encouraged to apply an increased amount of exploration during the training process. It should be noted that the standard reinforcement learning objective can be restored by setting the temperature parameter to zero.

Figure A4.
The agent-environment interface in a reinforcement learning setting adapted from [27].
Appendix D. Hyperparameters of the Training Algorithm
Table A1 introduces the hyperparameters used in the SAC algorithm for the training of the agents. The entropy coefficient of the SAC algorithm implemented in [21] is set to ‘auto’, which applies the automatic entropy adjustment for the maximum entropy RL objective introduced in [27]. From the Stable-Baselines 2 library, the MlpPolicy is chosen as policy network, which consists of two layers with 64 perceptrons each [21]. As activation function, the rectified linear unit (ReLU) is applied.
Table A1.
The hyperparameters of the SAC training algorithm.
Table A1.
The hyperparameters of the SAC training algorithm.
| Hyperparameter | Value |
|---|---|
| Discount rate | |
| Learning rate | |
| Entropy coefficient | auto |
| Buffer size | |
| Batch size | |
| Policy network | |
| Policy network activation function | ReLU |
References
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3D Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Krasowski, H.; Wang, X.; Althoff, M. Safe Reinforcement Learning for Autonomous Lane Changing Using Set-Based Prediction. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar] [CrossRef]
- Wang, X.; Krasowski, H.; Althoff, M. CommonRoad-RL: A Configurable Reinforcement Learning Environment for Motion Planning of Autonomous Vehicles. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar] [CrossRef]
- Di, X.; Shi, R. A survey on autonomous vehicle control in the era of mixed-autonomy: From physics-based to AI-guided driving policy learning. Transp. Res. Part C Emerg. Technol. 2021, 125, 103008. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Perez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Pérez-Gil, Ó.; Barea, R.; López-Guillén, E.; Bergasa, L.M.; Gómez-Huélamo, C.; Gutiérrez, R.; Díaz-Díaz, A. Deep reinforcement learning based control for Autonomous Vehicles in CARLA. Multimed. Tools Appl. 2022, 81, 3553–3576. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-Real: Learning Agile Locomotion for Quadruped Robots. In Proceedings of the Robotics: Science and Systems XIV Conference, Pennsylvania, PA, USA, 26–30 June 2018; p. 10. [Google Scholar] [CrossRef]
- Bin Peng, X.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-Real Transfer of Robotic Control with Dynamics Randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]
- Antonova, R.; Cruciani, S.; Smith, C.; Kragic, D. Reinforcement Learning for Pivoting Task. arXiv 2017, arXiv:1703.00472. [Google Scholar] [CrossRef]
- Osinski, B.; Jakubowski, A.; Ziecina, P.; Milos, P.; Galias, C.; Homoceanu, S.; Michalewski, H. Simulation-Based Reinforcement Learning for Real-World Autonomous Driving. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar] [CrossRef]
- Brembeck, J. Model Based Energy Management and State Estimation for the Robotic Electric Vehicle ROboMObil. Dissertation Thesis, Technical University of Munich, Munich, Germany, 2018. [Google Scholar]
- Brembeck, J.; Ho, L.; Schaub, A.; Satzger, C.; Tobolar, J.; Bals, J.; Hirzinger, G. ROMO—The Robotic Electric Vehicle. In Proceedings of the 22nd IAVSD International Symposium on Dynamics of Vehicle on Roads and Tracks, Manchester, UK, 11–14 August 2011. [Google Scholar]
- Ultsch, J.; Brembeck, J.; De Castro, R. Learning-Based Path Following Control for an Over-Actuated Robotic Vehicle. In Autoreg 2019; VDI Verlag: Düsseldorf, Germany, 2019; pp. 25–46. [Google Scholar] [CrossRef]
- Winter, C.; Ritzer, P.; Brembeck, J. Experimental investigation of online path planning for electric vehicles. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar] [CrossRef]
- Brembeck, J. Nonlinear Constrained Moving Horizon Estimation Applied to Vehicle Position Estimation. Sensors 2019, 19, 2276. [Google Scholar] [CrossRef] [PubMed]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Brembeck, J.; Winter, C. Real-time capable path planning for energy management systems in future vehicle architectures. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014. [Google Scholar] [CrossRef]
- Pacejka, H. Tire and Vehicle Dynamics, 3rd ed.; Butterworth-Heinemann: Oxford, UK, 2012. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Hill, A.; Raffin, A.; Ernestus, M.; Gleave, A.; Kanervisto, A.; Traore, R.; Dhariwal, P.; Hesse, C.; Klimov, O.; Nichol, A.; et al. Stable Baselines. Available online: https://github.com/hill-a/stable-baselines (accessed on 15 December 2022).
- Virtanen, P.; Gommers, R.; Oliphant, T.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0 Contributors. SciPy 1.0 Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Ritzer, P.; Winter, C.; Brembeck, J. Advanced path following control of an overactuated robotic vehicle. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Republic of Korea, 28 June–1 July 2015. [Google Scholar] [CrossRef]
- Modelica Association. Modelica—A Unified Object-Oriented Language for Systems Modeling. Available online: https://modelica.org/documents/MLS.pdf (accessed on 13 January 2023).
- Modelica Association. Functional Mock-Up Interface. Available online: https://fmi-standard.org/ (accessed on 4 January 2023).
- Bünte, T.; Chrisofakis, E. A Driver Model for Virtual Drivetrain Endurance Testing. In Proceedings of the 8th International Modelica Conference, Dresden, Germany, 20–22 March 2011. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Ziebart, B. Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. Dissertation Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).