

Adaptive Smoothing for Visual Improvement of Image Quality via the p(x)-Laplacian Operator Effects of the p(x)-Laplacian Smoothing Operator on Digital Image Restoration: Contribution to an Adaptive Control Criterion


Abstract
:1. Introduction
- Section 1 introduces the subject matter of this work and the setting of the problem;
- In Section 2, we present the main mathematical tools associated with a continuous version of the problem and its formulation. The use of graph theory proposes a discretised version of the initial problem by employing an adaptive algorithm. In addition, we recall some current properties of the -Laplacian operator;
- Section 3 discusses the simulation approaches;
- Section 4 proposes some illustrations of usually referenced images which are provided in well-known databases;
- Section 5 addresses some comparative studies between our proposed approach and others.
2. Context and Problems
2.1. Pictures
2.2. Adaptive Smoothing Using the p(x)-Laplacian
3. The Method
3.1. Presentation of Some Models with a Diffusion Term
- stands for the energy that allows one to go from to the desired image;
- denotes the regularisation energy to the real image f;
- interprets the energy of approximation between the real image f and the observed image , also named the fitting term or the fidelity term;
- is the fidelity parameter or the penalty parameter.
3.2. The Formulation of the Present Model
3.3. Preliminaries and Results for the Minimising Problem Associated with (7)
- Step 1 In the first step, we establish the existence of an element of such thatFor this, we can already notice that, for any is strictly positive. This implies that there exists a real number , such thatTo do this, we consider a minimising sequence ofIndeed, since is a minimising sequence of then we specifically haveBy using the triangular inequality and (17), it follows that there exists a constant , such thatOn the other hand, since , the embedding of into is continuous (i.e., there exists a constant such that ). Thus, combined with (18), we find a constant , such thatTo continue, we observe that after combining the equivalence norm properties [11] (Theorem 2.3) with the estimate in (16), we can deduce that there exists a positive constant such thatHence, let us return to the definition in (10) of the norm . By using the estimates from (19) and (20), we obtainIn other words, we obtain the desired estimate (14). Moreover, since is a reflexive space, we can extract from the sequence a sub-sequence that converges weakly in . We denote this weak limit by . Since the application is strictly convex (as a sum of two convex functions on ) and continuous for the topology of the norm , we can apply [12] (Corollary 3.9). In this case, we obtainConsequently, from the existence of , leads to f on one sideOn the other side, taking into account that the sequence has the property from (15), this implies that, after passing to the lower limit on n, the following yieldsTherefore, it is possible to conclude thatThen, estimates from (21) and (22) lead to the conclusion thatwhich establishes that the minimisation problem has a solution in The uniqueness of is due to the strict convexity property of the function Indeed, let us reason by the opposite. This means that, suppose that the application reaches its minimum in and that has two distinct elements. As is strictly convex on particularly for all we haveThus, because we specifically haveBy observing (23), we can thus conclude that a contradiction yields since the left-hand member is estimated below by , while the right-hand member is estimated above by conforming to the hypothesis on and , respectively.The uniqueness of the solution of the minimising problem occurs. □
3.4. The Corresponding Discretised Model by Means of the Graph Theory
- –
- A graph is connected when there is a path between any two vertices.
- –
- A graph is undirected when the set of edges is symmetric, i.e., for each edge , we also have , and the weight function satisfies the symmetry condition In the following, the graphs are always assumed to be connected, undirected, and have no self-loops or multiple edges.
4. Some Illustrations of the Effects of Parameters p and
- In the case , the pictures are partitioned into several homogeneous areas;
- In the case , when p approaches 2, there is a smoothing effect, whereas when p converges on 1 there is no smoothing effect;
- The increase in parameter limits the effects of p.
| Algorithm 1 Algorithm regularisation |
| x and j are positions in IM is the map result is a temporary map Compute gradient map G on image Compute P map values on image such as := 0.01 := user value in For all x in image := Do := For j in neighbours of x While |
4.1. Algorithmic Formulation of the Mathematical Model
4.1.1. Implementation Procedure
4.1.2. Towards an Adaptive Model
- –
- Noise-affected pixels;
- –
- Noise-unaffected pixels;
- –
- Outline pixels.
| Algorithm 2 Algorithm regularisation with dynamic |
| x and j are positions in IM is the map result is a temporary map Compute gradient map G on image Compute P map values on image such as := 0.01 Compute quartile on the gradient norm Compute map on image with quartile such as: For all x in image := Do := For j in neighbours of x While |
5. Results and Discussion
- –
- Lena image, which is widely used in image processing;
- –
- Tiger image, because it contains the most significant data in image processing. The tiger is present within the focal depth, while the rest of the scene, which is less important, should be homogenised.
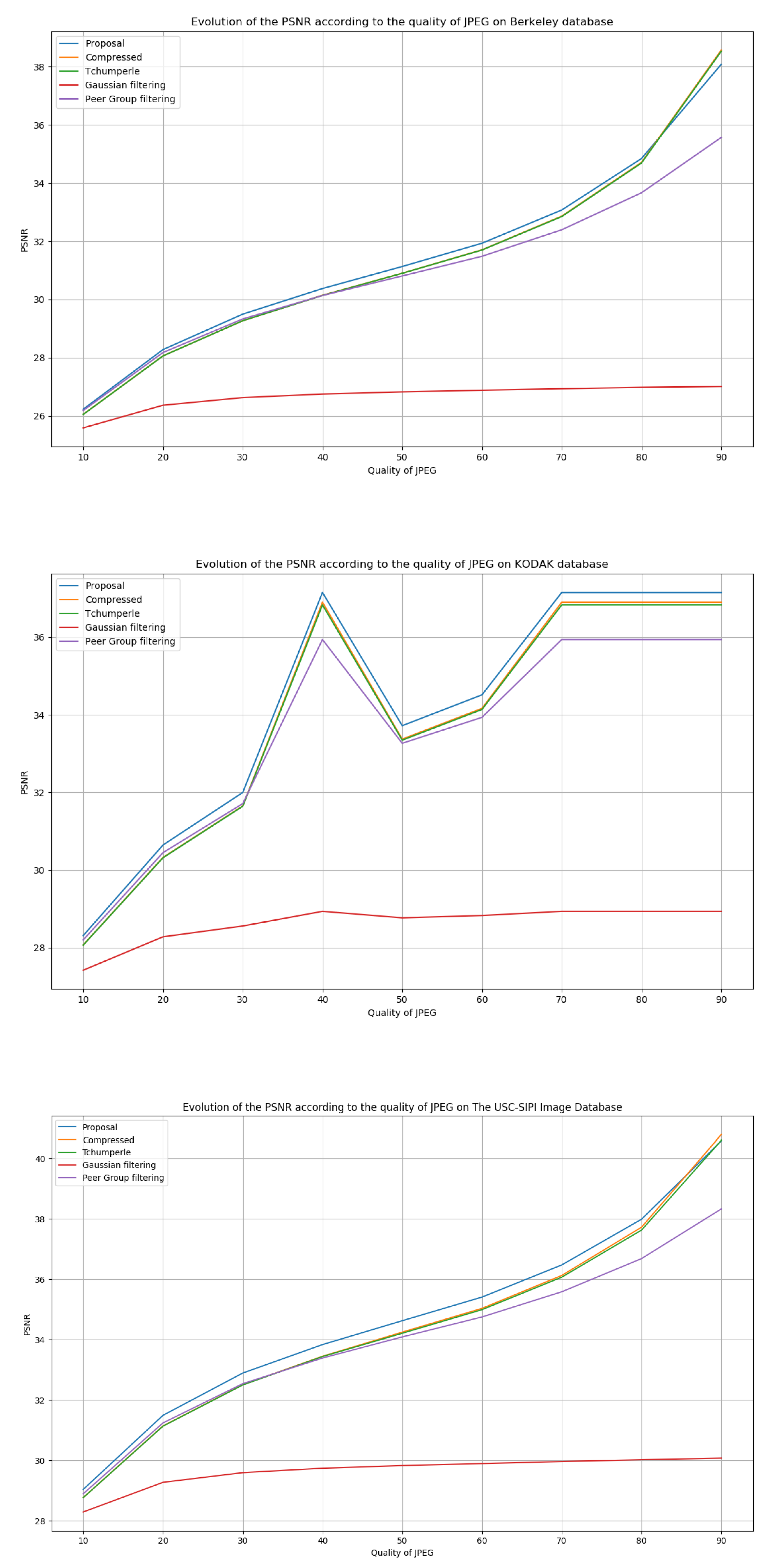
5.1. Results with the Peak Signal-to-Noise Ratio (PSNR)
5.2. Results with the Structural Dissimilarity Measure (DSSIM)
6. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bougleux, S.; Elmoataz, A.; Melkemi, M. Local and nonlocal discrete regularisation on weighted graphs for image and mesh processing. Int. J. Comput. Vis. 2009, 84, 220–236. [Google Scholar] [CrossRef]
- Chambrolle, A.; Lions, P. Image recovery via total variation minimization and related problems. Numer. Math. 1997, 76, 167–188. [Google Scholar] [CrossRef]
- Rudin, L.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithm. Phys. D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Chen, Y.; Levine, S.; Rao, M. Variable exponent, linear growth functionals in image restoration. SIAM J. Appl. Math. 2006, 66, 1383–1406. [Google Scholar] [CrossRef]
- Coren, S.; Girgus, J.S. Principles of perceptual organization and spatial distortion: The gestalt illusions. J. Exp. Psychol. Hum. Percept. Perform. 1980, 6, 404–412. [Google Scholar] [CrossRef] [PubMed]
- Ricard, J.; Baskurt, A.; Idrissi, K.; Lavoue, G. Object of interest-based visual navigation, retrieval, and semantic content identification system. Comput. Vis. Image Underst. 2004, 94, 271–294. [Google Scholar]
- Bollt, E.M.; Chartrand, R.; Esedoglu, S.; Schultz, P.; Vixie, K.R. Graduated adaptive image denoting local compromise between total variation and isotropic diffusion. Adv. Comput. Math. 2009, 61–85. [Google Scholar] [CrossRef]
- Harjuletho, P.; Hästö, P.; Latvala, V. Minimizers of the variable exponents, nonuniformly convex Dirichlet energy. J. Math. Pures Appl. 2008, 89, 174–197. [Google Scholar] [CrossRef]
- Musielak, J. Orlicz Spaces and Modular Spaces; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Diening, L.; Harjulehto, P.; Hasta, P.; Ruzicka, M. Lebesgue and Sobolev Spaces with Variable Exponents; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Kovacik, O.; Rakosnik, J. On spaces Lp(x) and Wk,p(x). Czechoslov. Math. J. 1991, 41, 592–618. [Google Scholar]
- Brezis, H. Analyse Fonctionnelle Théorie et Applications Masson et Cie 1983. Available online: https://cir.nii.ac.jp/crid/1571135649569314304 (accessed on 10 February 2023).
- Elmoataz, A.; Olivier, L.; Bougleux, S. Nonlocal discrete regularisation on weigthed graphs: A framework for image and manifold processing. IEEE Trans. Image Process. 2008, 17, 1047–1060. [Google Scholar] [CrossRef] [PubMed]
- Elmoataz, A.; Desquesnes, X.; Lezoray, O. Non-Local Morphological PDEs and p-Laplacian Equation on Graphs With Applications in Image Processing and Machine Learning. IEEE J. Sel. Top. Signal Process. 2012, 6, 764–779. [Google Scholar] [CrossRef]
- Ta, V.T.; Elmoataz, A.; Lezoraty, O. Nonlocal PDEs-based morphology on weighted graphs for image and data processing. IEEE Trans. Image Process. 2011, 20, 1504–1516. [Google Scholar] [PubMed]
- Zhou, D.; Schölkopf, B. Regularization on Discrete Spaces. In Proceedings of the Pattern Recognition; Kropatsch, W.G., Sablatnig, R., Hanbury, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 361–368. [Google Scholar]
- Albarello, L.; Bourgeois, E.; Guyot, J.L. Statistique Descriptive: Un Outil Pour Les Praticiens Chercheurs; De Boeck Supérieur: Louvain-la-Neuve, Belgium, 2010. [Google Scholar]
- Frigge, M.; Hoaglin, D.C.; Iglewicz, B. Some implementations of the boxplot. Am. Stat. 1989, 43, 50–54. [Google Scholar]
- Martin, D.; Fowlkes, C.; Ta, D.; Malik, J. A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Weber, A.G. The USC-SIPI Image Database Version 5. USC-SIPI Report 1997, 315. Available online: https://cir.nii.ac.jp/crid/1573950399791107200 (accessed on 27 January 2023).
- Franzen, R. Kodak Lossless True Color Image Suite. 1999, 4. Available online: http://r0k.us/graphics/kodak (accessed on 27 January 2023).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Tschumperlé, D. Fast anisotropic smoothing of multi-valued images using curvature-preserving PDE’s. Int. J. Comput. Vis. 2006, 68, 65–82. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSNR | Image Quality |
|---|---|
| 30 | Excellent |
| 24.99 | Good |
| 20 | Reasonable |
| 15.05 | Very noisy |
| 10 | Unreadable |
| PSNR | p = 0.01 | p = 1.00 | p = 2.00 |
|---|---|---|---|
| = 0.01 | 28.98 | 29.61 | 26.57 |
| = 0.10 | 33.80 | 36.46 | 27.49 |
| = 1.00 | 41.47 | 45.81 | 32.83 |
| Image | PSNR | DSSIM | Sobel on Original | Sobel on Adaptive |
|---|---|---|---|---|
| a | 36.247566 | 0.002315 | 15,193 | 10,841 |
| b | 36.034393 | 0.002149 | 19,850 | 17,310 |
| c | 26.577696 | 0.002279 | 55,113 | 54,321 |
| d | 26.364088 | 0.003355 | 55,454 | 54,567 |
| Average | Min | Max | Standard Deviation | |
|---|---|---|---|---|
| PSNR | 31.13 | 26.36 | 36.24 | 2.19 |
| DSSIM | p = 0.01 | p = 1.00 | p = 2.00 |
|---|---|---|---|
| = 0.01 | 0.07 | 0.06 | 0.11 |
| = 0.10 | 0.02 | 0.01 | 0.09 |
| = 1.00 | 0.004 | 0.001 | 0.02 |
| Compression/ | 0.1 | 0.5 | 1.0 | Proposal Model |
|---|---|---|---|---|
| 10% | 0.124749391 | 0.124685624 | 0.126527000 | 0.126313566 |
| 20% | 0.073399066 | 0.067223833 | 0.067583050 | 0.067538158 |
| 30% | 0.0590243333 | 0.0504784583 | 0.050169525 | 0.050176050 |
| 40% | 0.052676424 | 0.0429842166 | 0.042350825 | 0.042386891 |
| 50% | 0.048671533 | 0.0382977916 | 0.0374521999 | 0.0374951749 |
| 60% | 0.045554683 | 0.0346366000 | 0.0336435749 | 0.033697841 |
| 70% | 0.0423388583 | 0.030723008 | 0.02957985 | 0.0296397499 |
| 80% | 0.039299400 | 0.0268465583 | 0.0255539583 | 0.0256166749 |
| 90% | 0.036822691 | 0.023159216 | 0.0215449250 | 0.0216251499 |
| Berkeley Databases | KODAK Databases | USC-SIPI Databases | ||||
|---|---|---|---|---|---|---|
| DSSIM | PSNR | DSSIM | PSNR | DSSIM | PSNR | |
| 10% | 0.13 (0.02) | 26.23 (2.07) | 0.1 (0.01) | 28.31 (2.3) | 0.09 (0.01) | 30.07 (2.63) |
| 20% | 0.07 (0.013) | 28.28 (2.19) | 0.05 (0.009) | 30.64 (2.44) | 0.05 (0.009) | 32.7 (2.97) |
| 30% | 0.05 (0.01) | 29.49 (2.23) | 0.03 (0.007) | 32 (2.45) | 0.04 (0.008) | 34.14 (3.15) |
| 40% | 0.04 (0.01) | 30.37 (2.22) | 0.03 (0.005) | 32.9 (2.43) | 0.03 (0.007) | 35 (3.19) |
| 50% | 0.04 (0.009) | 31.13 (2.19) | 0.02 (0.005) | 33.72 (2.39) | 0.03 (0.007) | 35.6 (3.18) |
| 60% | 0.03 (0.009) | 31.93 (2.14) | 0.02 (0.004) | 34.52 (2.33) | 0.02 (0.007) | 36.36 (3.16) |
| 70% | 0.03 (0.008) | 33.07 (2.03) | 0.02 (0.004) | 35.58 (2.22) | 0.02 (0.007) | 37.23 (3.08) |
| 80% | 0.03 (0.008) | 34.81 (1.84) | 0.01 (0.003) | 37.15 (2) | 0.02 (0.007) | 38.41 (2.9) |
| 90% | 0.02 (0.008) | 38.07 (1.41) | 0.01 (0.003) | 39.88 (1.5) | 0.02 (0.007) | 40.58 (2.33) |
| Average Time in Seconds | |||
|---|---|---|---|
| Berkeley Databases | KODAK Databases | USC-SIPI Databases | |
| 10% | 601.80 | 854.96 | 505.35 |
| 20% | 464.79 | 966.35 | 423.26 |
| 30% | 517.82 | 928.12 | 601.09 |
| 40% | 471.24 | 911.41 | 505.01 |
| 50% | 538.31 | 741.18 | 367.47 |
| 60% | 540.24 | 794.21 | 428.84 |
| 70% | 527.51 | 657.88 | 520.70 |
| 80% | 468.22 | 866.27 | 553.07 |
| 90% | 437.38 | 758.04 | 603.88 |
| Gaussian-Distributed Additive Noise | |||
|---|---|---|---|
| Images | Filtering Method | DSSIM (sd) | PSNR (sd) |
| Berkeley | Proposal (2) | 0.019 (0.007) | 42.495 (1.385) |
| Tchumperle (1) | 0.016 (0.007) | 55.810 (2.214) | |
| Gaussian filtering (4) | 0.069 (0.021) | 27.028 (2.571) | |
| Peer group filtering (3) | 0.020 (0.007) | 37.556 (2.840) | |
| KODAK | Proposal (2) | 0.006 (0.003) | 44.052 (1.085) |
| Tchumperle (1) | 0.005 (0.003) | 54.110 (2.205) | |
| Gaussian filtering (4) | 0.045 (0.020) | 29.020 (2.963) | |
| peer Group filtering (3) | 0.007 (0.003) | 40.094 (2.988) | |
| USC-SIPI | Proposal (2) | 0.014 (0.007) | 44.559 (1.733) |
| Tchumperle (1) | 0.013 (0.007) | 53.738 (3.184) | |
| Gaussian filtering (4) | 0.035 (0.019) | 30.972 (3.031) | |
| Peer group filtering (3) | 0.015 (0.007) | 42.382 (3.374) | |
| Poisson-Distributed Noise | |||
|---|---|---|---|
| Images | Filtering Method | DSSIM (sd) | PSNR (sd) |
| Berkeley | Proposal (2) | 0.019 (0.007) | 42.338 (1.364) |
| Tchumperle (1) | 0.016 (0.007) | 51.841 (0.957) | |
| Gaussian filtering (4) | 0.069 (0.021) | 27.027 (2.571) | |
| Peer group filtering (3) | 0.020 (0.007) | 37.488 (2.792) | |
| KODAK | Proposal (2) | 0.007 (0.003) | 43.908 (1.079) |
| Tchumperle (1) | 0.005 (0.003) | 51.311 (1.205) | |
| Gaussian filtering (4) | 0.045 (0.020) | 29.017 (2.963) | |
| Peer group filtering (3) | 0.007 (0.003) | 39.948 (2.914) | |
| USC-SIPI | Proposal (2) | 0.014 (0.007) | 44.434 (1.716) |
| Tchumperle (1) | 0.013 (0.007) | 51.266 (1.857) | |
| Gaussian filtering (4) | 0.036 (0.019) | 30.971 (3.030) | |
| Peer group filtering (3) | 0.015 (0.007) | 42.167 (3.261) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henry, J.-L.; Nagau, J.; Velin, J.; Moussa, I.-P. Adaptive Smoothing for Visual Improvement of Image Quality via the p(x)-Laplacian Operator Effects of the p(x)-Laplacian Smoothing Operator on Digital Image Restoration: Contribution to an Adaptive Control Criterion. Appl. Sci. 2023, 13, 11600. https://doi.org/10.3390/app132011600
Henry J-L, Nagau J, Velin J, Moussa I-P. Adaptive Smoothing for Visual Improvement of Image Quality via the p(x)-Laplacian Operator Effects of the p(x)-Laplacian Smoothing Operator on Digital Image Restoration: Contribution to an Adaptive Control Criterion. Applied Sciences. 2023; 13(20):11600. https://doi.org/10.3390/app132011600
Chicago/Turabian StyleHenry, Jean-Luc, Jimmy Nagau, Jean Velin, and Issa-Paul Moussa. 2023. "Adaptive Smoothing for Visual Improvement of Image Quality via the p(x)-Laplacian Operator Effects of the p(x)-Laplacian Smoothing Operator on Digital Image Restoration: Contribution to an Adaptive Control Criterion" Applied Sciences 13, no. 20: 11600. https://doi.org/10.3390/app132011600
APA StyleHenry, J.-L., Nagau, J., Velin, J., & Moussa, I.-P. (2023). Adaptive Smoothing for Visual Improvement of Image Quality via the p(x)-Laplacian Operator Effects of the p(x)-Laplacian Smoothing Operator on Digital Image Restoration: Contribution to an Adaptive Control Criterion. Applied Sciences, 13(20), 11600. https://doi.org/10.3390/app132011600