
Tire Defect Detection via 3D Laser Scanning Technology


Abstract
:1. Introduction
- Our method is the first work focusing on the detection of low-visibility tire defects and establishes a new 3D dataset consisting of scanned tire surfaces from laser scanners.
- We propose a new detection pipeline for tire defects by combining 3D surface data and a 2D detection model to effectively detect challenging tire defects.
- We design a normal-based rendering strategy to extract surface orientation from scanned raw point clouds, which provides effective 2D depth information for the subsequent detection process.
- We apply a novel transformer-based detection model for detecting accurate areas of target defects.
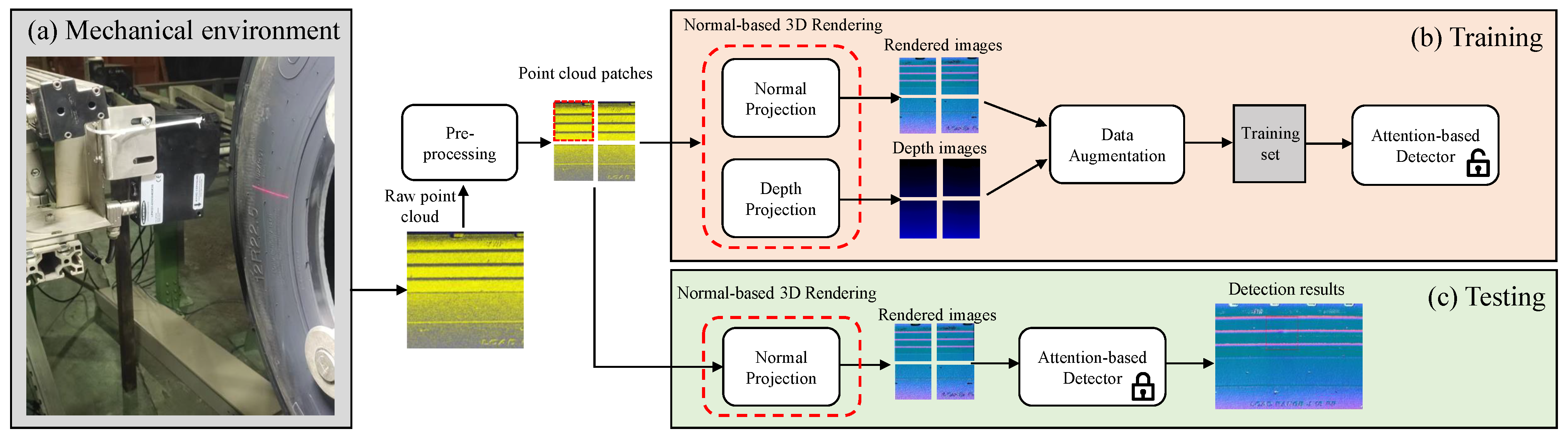
2. Materials and Methods
2.1. Data Preprocessing
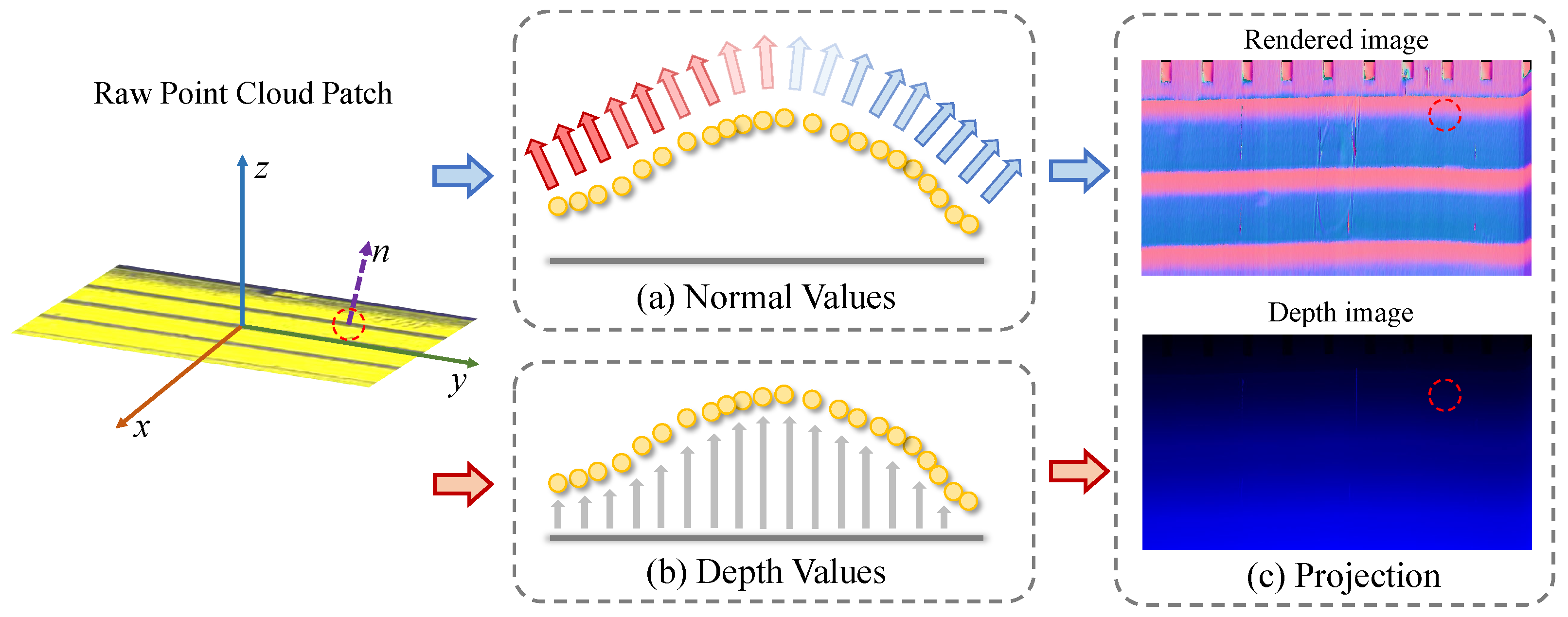
2.2. Normal-Based 3D Rendering
- Surface normal estimation
- Projecting 3D point clouds into 2D features
- Depth images
- Rendered images
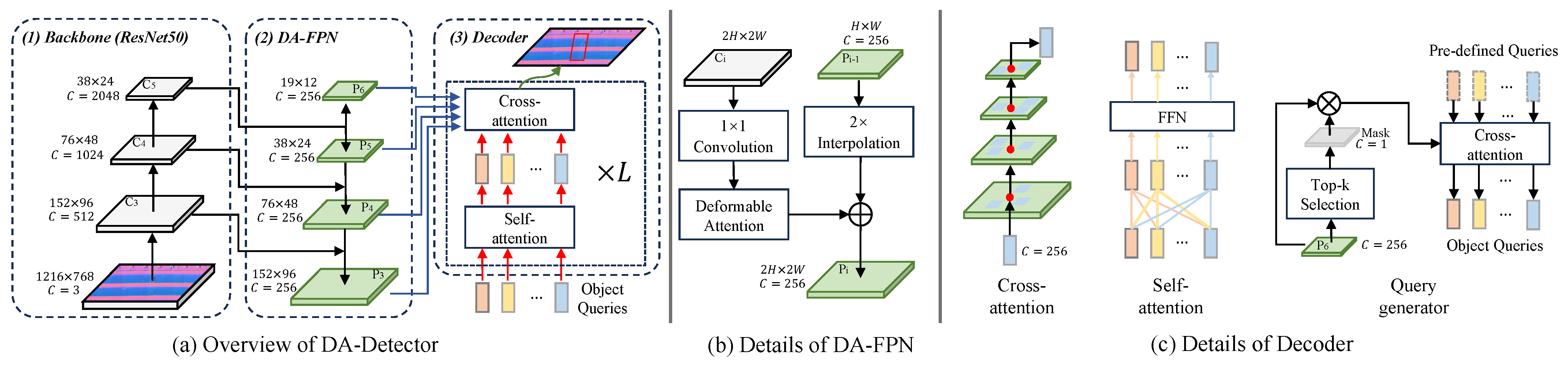
2.3. Attention-Based Detector
- Deformable Attention
- Defect Detector Based on the Proposed Deformable Attention
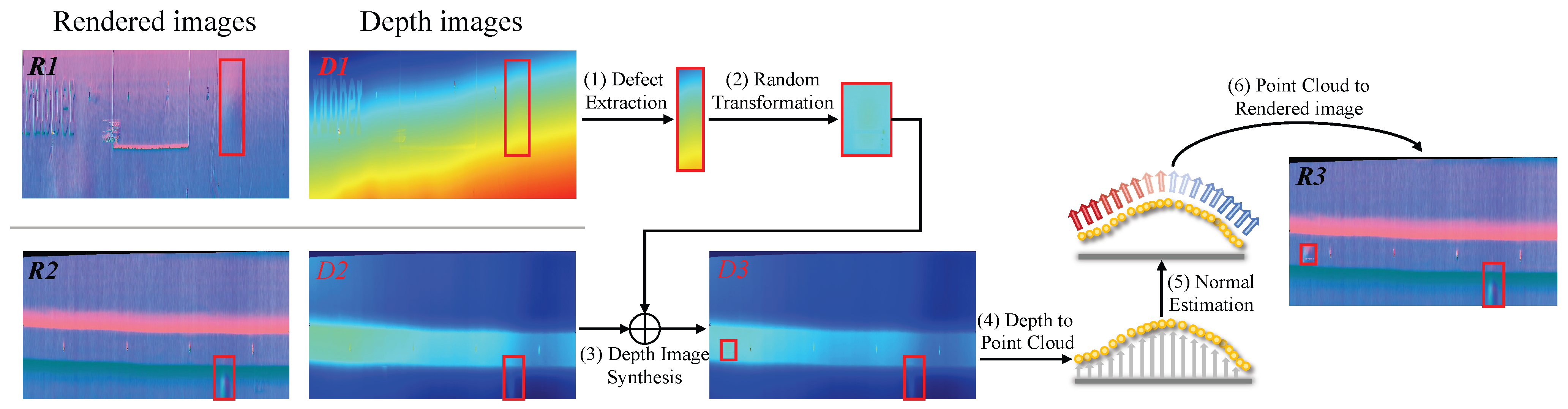
2.4. Data Augmentation
2.5. Details of the 3D Scanner
3. Experiments and Discussion
3.1. 3D Tire Dataset and Evaluation Metrics
3.2. Comparison with X-ray-Based Methods
3.3. Evaluation on the 3D Tire Dataset
- Implementation details
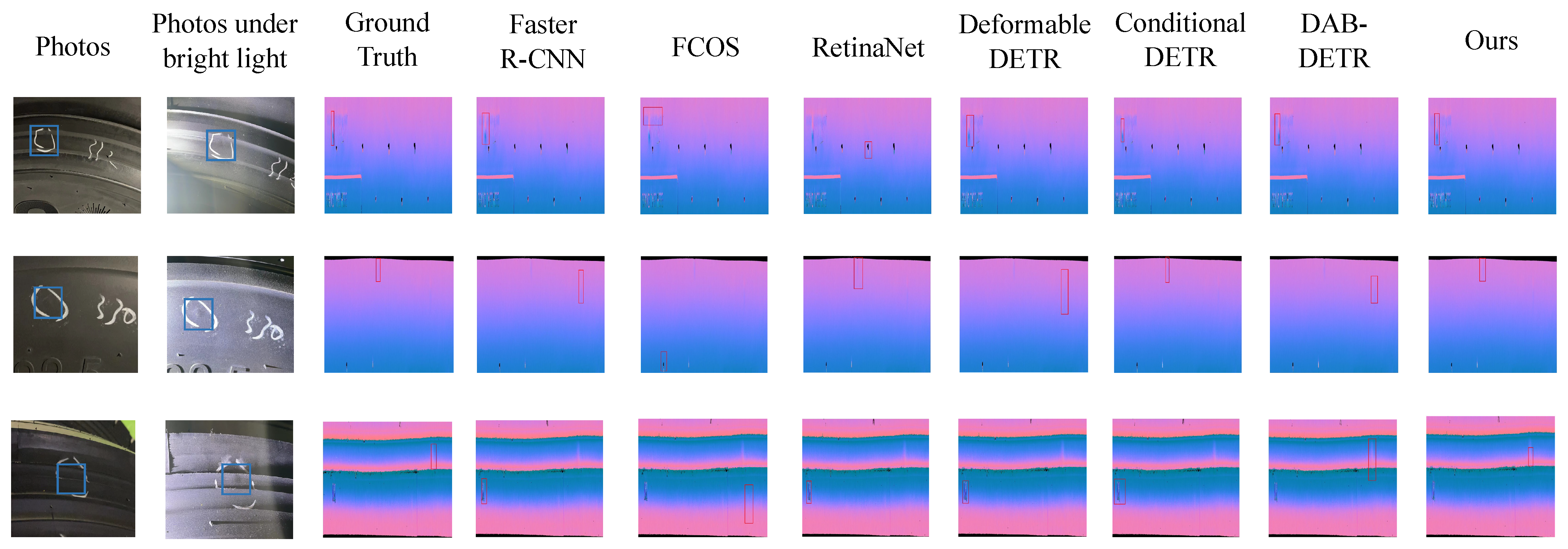
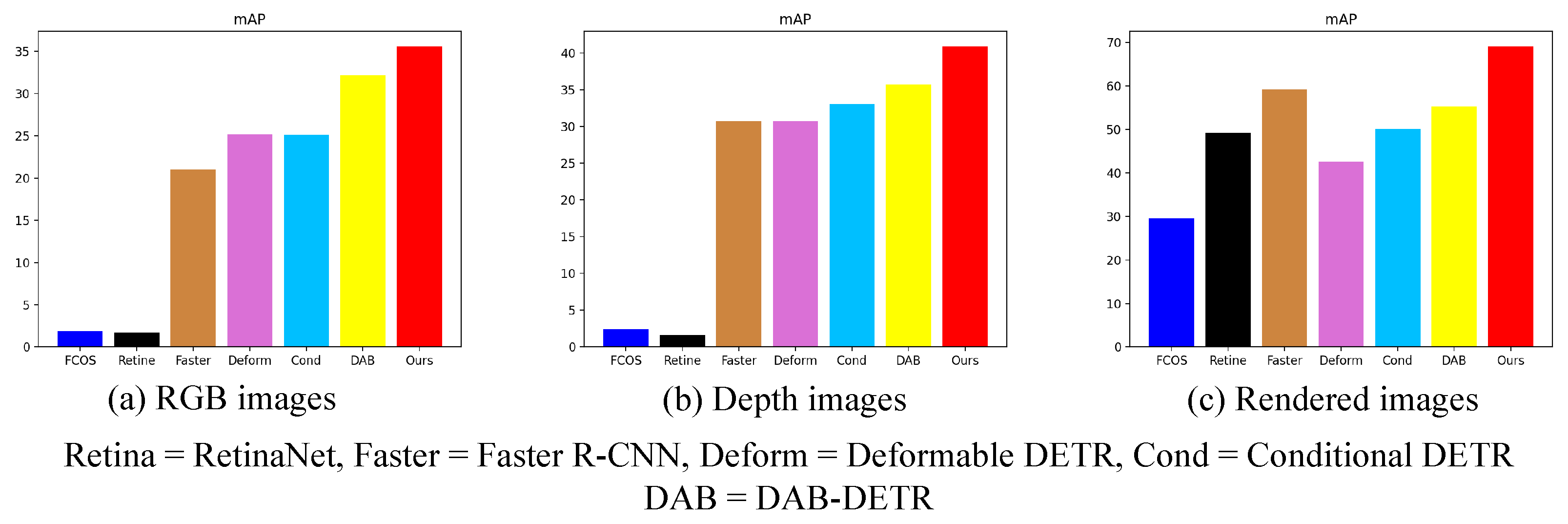
- Experiment on RGB images
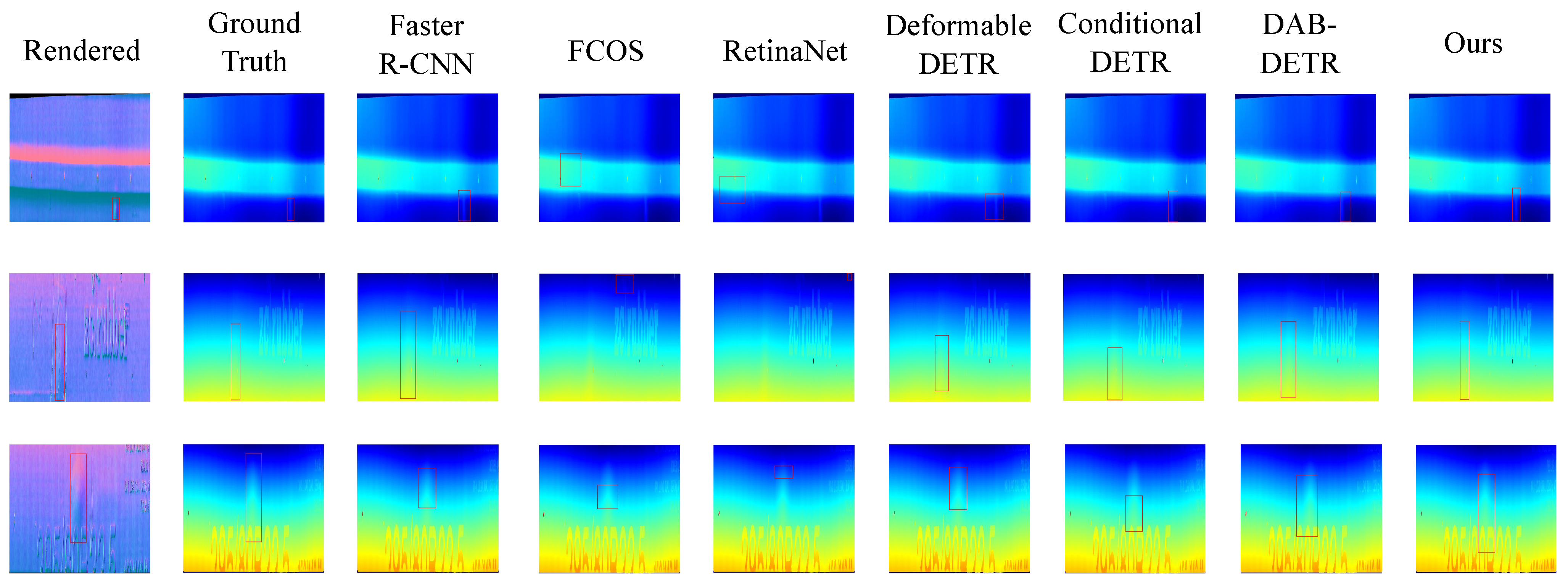
- Experiment on rendered images
- Experiment on depth images
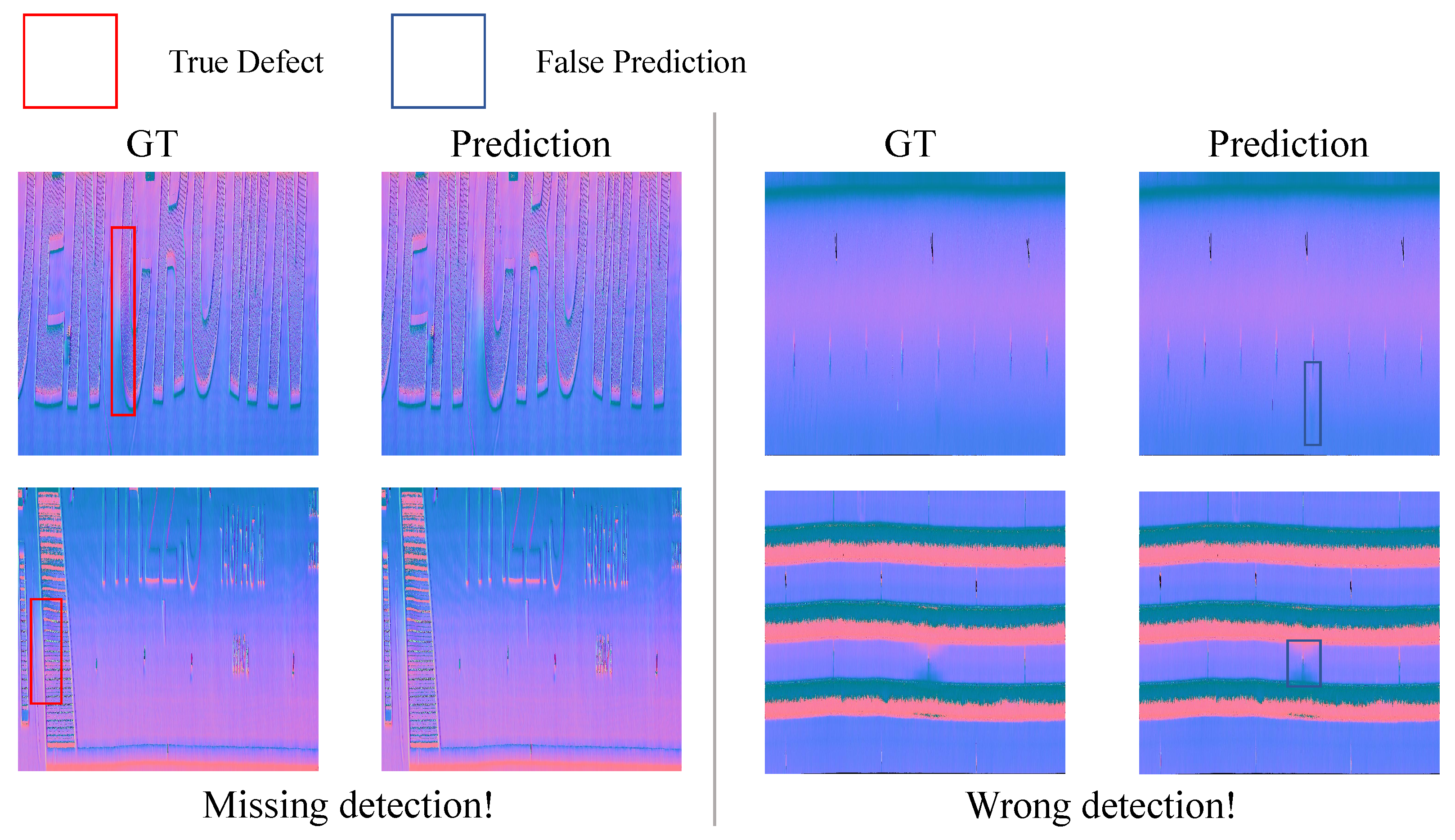
3.4. Ablation Studies
4. Conclusions
- (1)
- The performance of the model was constrained by the scale of training data. However, collecting a large number of data in a short time is hard because of the time-consuming annotation process. While our novel data augmentation eased the lack of training data, synthetic data are not as good as real data.
- (2)
- The normal-based rendering process consisted of reading point cloud data, normal estimation, and 3D-to-2D projection. Because of the large scale of tire point clouds (more than points) and high dependency on the CPU, the first two steps of the rendering strategy consumed most of the time, which was more than of the total time in detecting one tire.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Q.; Fang, X.; Liu, L.; Yang, C.; Sun, Y. Automated visual defect detection for flat steel surface: A survey. IEEE Trans. Instrum. Meas. 2020, 69, 626–644. [Google Scholar] [CrossRef]
- Nikitin, S.; Shpeizman, V.; Pozdnyakov, A.; Stepanov, S.; Timashov, R.; Nikolaev, V.; Terukov, E.; Bobyl, A. Fracture strength of silicon solar wafers with different surface textures. Mater. Sci. Semicond. Process. 2022, 140, 106386. [Google Scholar] [CrossRef]
- Chen, L.; Luo, R.; Xing, J.; Li, Z.; Yuan, Z.; Cai, X. Geospatial transformer is what you need for aircraft detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Liu, L.; Ma, Z.; Zhu, M.; Liu, L.; Dai, J.; Shi, Y.; Gao, J.; Dinh, T.; Nguyen, T.; Tang, L.C.; et al. Superhydrophobic self-extinguishing cotton fabrics for electromagnetic interference shielding and human motion detection. J. Mater. Sci. Technol. 2023, 132, 59–68. [Google Scholar] [CrossRef]
- Lin, G.; Liu, K.; Xia, X.; Yan, R. An efficient and intelligent detection method for fabric defects based on improved YOLOv5. Sensors 2022, 23, 97. [Google Scholar] [CrossRef] [PubMed]
- Fang, B.; Long, X.; Sun, F.; Liu, H.; Zhang, S.; Fang, C. Tactile-based fabric defect detection using convolutional neural network with attention mechanism. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Wu, Z.; Jiao, C.; Sun, J.; Chen, L. Tire defect detection based on faster R-CNN. In Proceedings of the Robotics and Rehabilitation Intelligence: First International Conference, ICRRI 2020, Fushun, China, 9–11 September 2020; Proceedings, Part II 1; Springer: Berlin/Heidelberg, Germany, 2020; pp. 203–218. [Google Scholar]
- Wang, R.; Guo, Q.; Lu, S.; Zhang, C. Tire defect detection using fully convolutional network. IEEE Access 2019, 7, 43502–43510. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, S.; Yu, B.; Li, Q.; Zhang, Y. Defect inspection in tire radiographic image using concise semantic segmentation. IEEE Access 2020, 8, 112674–112687. [Google Scholar] [CrossRef]
- Shakarji, C.M. Least-squares fitting algorithms of the NIST algorithm testing system. J. Res. Natl. Inst. Stand. Technol. 1998, 103, 633. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Solomon, J.M. Object dgcnn: 3D object detection using dynamic graphs. Adv. Neural Inf. Process. Syst. 2021, 34, 20745–20758. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, R.; Ye, Q. Freeanchor: Learning to match anchors for visual object detection. Adv. Neural Inf. Process. Syst. 2019, 32, 1–9. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Liu, C.; Gao, C.; Liu, F.; Liu, J.; Meng, D.; Gao, X. SS3D: Sparsely-supervised 3d object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8428–8437. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder–decoder residual network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7264–7273. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP | AP50 | AP75 | AP | AP | AP |
|---|---|---|---|---|---|---|
| Faster R-CNN [31] | 21.0 | 56.0 | 13.2 | 0.0 | 12.2 | 29.1 |
| FCOS [21] | 1.9 | 8.8 | 0.6 | 0.0 | 0.0 | 5.5 |
| RetinaNet [32] | 1.7 | 10.1 | 1.2 | 0.0 | 0.9 | 4.1 |
| Deformable-DETR [8] | 25.2 | 58.8 | 14.8 | 0.0 | 15.6 | 31.3 |
| Conditional DETR [34] | 25.1 | 59.2 | 13.2 | 0.0 | 15.8 | 32.0 |
| DAB-DETR [33] | 32.2 | 61.2 | 15.5 | 0.0 | 18.2 | 32.5 |
| Ours | 35.6 | 62.1 | 17.4 | 0.0 | 21.0 | 32.5 |
| Methods | mAP | AP50 | AP75 | AP | AP | AP |
|---|---|---|---|---|---|---|
| Faster R-CNN [31] | 59.2 | 89.8 | 65.5 | 23.6 | 52.8 | 73.0 |
| FCOS [21] | 29.6 | 73.0 | 21.1 | 0.7 | 28.0 | 37.5 |
| RetinaNet [32] | 49.2 | 87.4 | 50.0 | 7.1 | 47.3 | 60.0 |
| Deformable-DETR [8] | 42.5 | 88.6 | 39.6 | 8.3 | 29.9 | 72.0 |
| Conditional DETR [34] | 50.1 | 88.2 | 51.2 | 10.0 | 47.2 | 65.0 |
| DAB-DETR [33] | 55.3 | 88.4 | 63.2 | 18.3 | 52.0 | 70.2 |
| Ours | 69.1 | 89.8 | 74.1 | 35.7 | 59.2 | 89.6 |
| Methods | mAP | AP50 | AP75 | AP | AP | AP |
|---|---|---|---|---|---|---|
| Faster R-CNN [31] | 30.7 | 64.9 | 23.4 | 1.1 | 22.9 | 47.2 |
| FCOS [21] | 2.4 | 9.7 | 0.1 | 0.0 | 0.4 | 6.0 |
| RetinaNet [32] | 1.6 | 5.7 | 0.8 | 0.0 | 1.0 | 3.6 |
| Deformable-DETR [8] | 30.7 | 57.1 | 33.8 | 0.0 | 12.4 | 60.1 |
| Conditional DETR [34] | 33.1 | 65.0 | 33.4 | 0.0 | 13.0 | 59.2 |
| DAB-DETR [33] | 35.7 | 69.8 | 36.4 | 0.0 | 11.5 | 62.0 |
| Ours | 40.9 | 72.0 | 38.6 | 8.2 | 30.1 | 62.2 |
| Methods | mAP | AP50 | AP75 | AP | AP | AP |
|---|---|---|---|---|---|---|
| A: FPN [22] | 68.7 | 89.7 | 73.9 | 34.0 | 59.2 | 89.4 |
| B: DA-FPN | 69.1 | 89.8 | 74.1 | 35.7 | 59.2 | 89.6 |
| C: Random selection | 48.0 | 86.0 | 50.0 | 7.1 | 48.0 | 59.0 |
| D: Top-k selection | 69.1 | 89.8 | 74.1 | 35.7 | 59.2 | 89.6 |
| E: | 24.9 | 59.0 | 14.7 | 0.0 | 15.6 | 31.3 |
| E: | 49.3 | 86.0 | 50.1 | 7.2 | 47.3 | 60.0 |
| F: | 58.4 | 87.0 | 73.2 | 30.1 | 58.1 | 85.7 |
| G: | 69.1 | 89.8 | 74.1 | 35.7 | 59.2 | 89.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; Lou, H.; Xu, X.; Lu, J. Tire Defect Detection via 3D Laser Scanning Technology. Appl. Sci. 2023, 13, 11350. https://doi.org/10.3390/app132011350
Zheng L, Lou H, Xu X, Lu J. Tire Defect Detection via 3D Laser Scanning Technology. Applied Sciences. 2023; 13(20):11350. https://doi.org/10.3390/app132011350
Chicago/Turabian StyleZheng, Li, Hong Lou, Xiaomin Xu, and Jiangang Lu. 2023. "Tire Defect Detection via 3D Laser Scanning Technology" Applied Sciences 13, no. 20: 11350. https://doi.org/10.3390/app132011350
APA StyleZheng, L., Lou, H., Xu, X., & Lu, J. (2023). Tire Defect Detection via 3D Laser Scanning Technology. Applied Sciences, 13(20), 11350. https://doi.org/10.3390/app132011350