1. Introduction
Visual impairment (VI) is a significant public health concern that affects people of all ages and is caused by a range of factors, including age-related eye diseases, genetic disorders, injuries, and infections [
1]. The global population of individuals suffering from VI, including those who are completely blind, moderately visually impaired, and severely visually impaired, has reached more than 300 million [
2]. The increasing number of visual impairment (VI) cases highlights the critical need to improve accessibility and mobility for visually impaired individuals, who face significant challenges in navigating public spaces due to the low success rate of obstacle avoidance.
Therefore, governments of different countries are attempting to design various assistive living facilities for individuals with visual impairments. In the United States, guide dogs and white canes remain essential tools. In addition, the emergence of advanced technologies has also enhanced the independent mobility of individuals with visual impairments and blindness. GPS-based navigation systems, such as smartphone applications and standalone devices, provide step-by-step navigation and information about points of interest. Furthermore, obstacle detection devices and electronic travel aids, such as ultrasonic canes and wearable sensors, assist individuals in navigating their surroundings [
3]. In the United Kingdom, tactile pavements and signage have been implemented in public spaces to improve accessibility and orientation [
4]. The “Haptic Radar” system in Japan utilizes vibrations to provide real-time feedback on surrounding objects [
5].
However, the accessibility of these facilities is often inadequate in older districts, leading to the use of personal navigation tools such as white canes and guide dogs [
6]. While white canes are a popular option, their short range and potential interference with other pedestrians may hinder mobility in crowded spaces. Alternatively, guide dogs offer effective guidance, but their high cost and restrictions on public transportation may limit their widespread use [
7]. For the existing advanced technologies, engineers and manufacturers face technical challenges in ensuring the accuracy and reliability of navigation and object detection systems [
3]. In daily life, it is essential to prioritize efforts to address the challenges faced by visually impaired individuals, as the loss of eyesight can be a debilitating experience.
Recently, machine learning techniques have greatly improved object recognition accuracy in computer vision [
8]. This has led to the development of sophisticated models that can recognize objects in complex environments. These advancements have enabled the creation of highly accurate and reliable computer vision systems for applications such as self-driving cars, medical imaging, and surveillance. Near-field object detection can also benefit from these machine-learning techniques [
9], allowing for accurate real-time detection of nearby objects. To locate the fences in the street, object detection is required, and it can be accomplished by a deep learning approach [
10]. The distance information can then be utilized for various applications, including robotics, drone racing, autonomous vehicles, and navigation assistance tools [
11,
12,
13,
14]. Based on the trained model on the dataset, detection of the fences from public objects by the images and videos are captured by the user camera. Detected objects and their categories are remarked on in the corresponding media content. After eliminating duplicated and low-confident detection, the result is then passed to the distance estimation process.
In this article, machine learning is applied to obstacle detection of near distance in front, allowing visually impaired people to walk freely and safely. The objective of this work is to develop a new approach to navigation aid that assists visually impaired people to travel independently with confidence. A solution, Near Front Distance (NFD) for estimating near-front distance using a monocular camera on public objects based on a deep learning approach is proposed, which consists of camera calibration and distance estimation modeling. A distance estimation process is applied to the images taken by the camera on intrinsic parameters after calibration. The position of detected objects on images are converted from the image coordinates to the actual coordinates based on the position or size information and within assumptions. Our distance estimation model can combine deep-learning-based object detection methods to accurately measure the distance between objects and the camera inside the field of view. Ultimately, our work contributes to bridging the gap between computer vision advancements and practical applications, particularly in scenarios where the accurate measurement of distances to obstacles is crucial.
We utilized a published dataset on public objects in the uncontrolled environment, which was specifically designed for navigation-aiding purposes [
15]. The primary contributions of this work can be summarized as follows:
Development of a novel integration algorithm that utilizes image data from a monocular camera and the camera’s pose to estimate the distance to target objects effectively. The algorithm calculates the object’s distance on the front by the pixel on the picture after YOLOv4 detection.
Evaluation of the performance of deep learning models when applied to the novel algorithm for distance estimation.
The remainder of the work is divided into the following sections: The related works are comprehensively addressed in
Section 2. In
Section 3, the methodology used in this study is described in detail, including the approach for measuring distance from various positions and points of interest. The results of the suggested approach are shown in
Section 4, which also presents the empirical findings. Finally, in
Section 5, we offer a comprehensive summary of the study, highlighting the main conclusions, and provide some closing thoughts.
2. Related Works
In this section, conventional and deep learning approaches are investigated for depth estimation. In order to understand the conditions of the surroundings and the distances to the targets or obstacles, sensors such as cameras, radar, and LiDAR are commonly used.
2.1. Sensors for Distance Measurement
The camera is a widely used and cost-effective sensor for environmental perception. It mimics the capabilities of the human visual system, excelling in the recognition of shapes and colors of objects. However, it does have limitations, particularly in adverse weather conditions with reduced visibility.
The radar (radio detection and ranging) is widely used to precisely track the distance, angle, or velocity of objects. Radars can be broken down into a transmitter and receiver. The transmitter sends radio waves in the targeted direction and the waves are reflected when they reach a significant object. The receiver picks up the reflected waves and gives information about the object’s location and speed. The greatest advantage of the radar is that it is not affected by visibility, lighting, and noise in the environment. However, compared to a camera, a radar is low-definition modeling and is weak at providing the precise shape of objects and identifying what the object is.
The mechanism of the LiDAR (light detection and ranging) is similar to the radar but utilize laser light to determine ranges instead of radio wave. The LiDAR is a more advanced version of a radar that can provide extremely low error distance measurement. It is also capable of measuring thousands of points at the same time to model up a precise 3D depiction of an object or surrounding environment [
16]. The disadvantages of the LiDAR are its high cost and the requirement of a remarkable amount of computing resources compared to cameras and radars.
Although the costs of cameras, radar systems, and LiDAR can vary significantly due to factors such as brand, specifications, and quality, a general assessment of equipment costs with comparable capabilities reveals the following: Cameras typically range in price from $100 to several thousand dollars, depending on factors such as resolution, image quality, and additional features. Radar systems used for object detection and tracking start at a few hundred dollars for basic short-range sensors, while more advanced and specialized radar systems can cost several thousand dollars or more. Likewise, LiDAR sensors range in price from a few hundred dollars for entry-level sensors to several thousand dollars for high-end models with extended range, higher resolution, and faster scanning capabilities.
Considering the pros and cons of the three types of sensors for distance measurement, the camera is the most appropriate sensor to be utilized in the research due to its low cost, being less sophisticated, and its high definition. The 2D information recognized by the camera can be adopted directly by the deep learning algorithms of object detection.
2.2. Traditional Distance Estimation
Typical photos taken from a monocular camera are shown in two dimensions that would require extra information for distance estimation. Distance estimation (also known as depth estimation) is an inverse problem [
17] that tries to measure the distance between 3D objects from insufficient information provided in the 2D view.
The earliest algorithms for depth estimation were developed based on stereo vision. Researchers utilize geometry to constrain and replicate the idea of stereopsis mathematically. Scharstein and Szeliski [
18] conducted a comparative evaluation of the best-performing stereo algorithms at that time. Meanwhile, Stein et al. [
19] developed methods to estimate the distance from a monocular camera. They investigated the possibility of performing distance control to an accuracy level sufficient for an Adaptive Cruise Control system. A single camera is installed in a vehicle using the laws of perspective to estimate the distance based on a constrained environment: the camera is at a known height from a planar surface in the near distance and the objects of interest (the other vehicles) lie on that plane. A radar is equipped for obtaining the ground truth. The results show that both distance and relative velocity can be estimated from a single camera and the actual error lies mostly within the theoretical bounds. Park et al. [
20] also proposed a distance estimation method for vision-based forward collision warning systems with a monocular camera. The system estimates the virtual horizon from information on the size and position of vehicles in the image, which is obtained by an object detection algorithm and calculates the distance from vehicle position in the image with the virtual horizon even when the road inclination varies continuously or lane markings are not seen. To enable the distance estimation in vehicles, Tram and Yoo [
21] also proposed a system to determine the distance between two vehicles using two low-resolution cameras and one of the vehicle’s rear LED lights. Since the poses of the two cameras are pre-determined, the distances between the LED and the cameras, as well as the vehicle-to-vehicle distance can be calculated based on the pinhole model of the camera as the focal lengths of the cameras are known. The research also proposes a resolution compensation method to reduce the estimation error by a low-resolution camera. Moreover, Chen et al. [
22] proposed an integrated system that combines vehicle detection, lane detection, and vehicle distance estimation. The proposed algorithm does not require calibrating the camera or measuring the camera pose in advance as they estimate the focal length from three vanishing points and utilize lane markers with the associated 3D constraint to estimate the camera pose. The SVM with Radial Basis Function (RBF) kernel is chosen to be the classifier of vehicle detection and Canny edge detection and Hough transform are employed for the lane detection.
2.3. Depth Estimation Using Deep Learning
Nowadays, to achieve depth estimation using a monocular camera, neural networks are commonly used. Eigen et al. [
23] proposed one of the typical solutions that presented a solution to measure depth relations by employing two deep network stacks: one that makes a coarse global prediction based on the entire image, and another that refines the prediction locally. By applying the raw datasets (NYU Depth and KITTI) as large sources of training data, the method matches detailed depth boundaries without the need for superpixelation.
Another solution that can overcome the weakness of using CNN for depth estimation is that vast amounts of data need to be manually labeled before training [
24]. A CNN for single-view depth estimation that can be trained end-to-end, unsupervised, using data captured by a stereo camera without requiring a pre-training stage or annotated ground-truth depths. To achieve that, an inverse warp of the target image is generated using the predicted depth and known inter-view displacement to reconstruct the source image; the photometric error in the reconstruction is the reconstruction loss for the encoder. Zhou et al. [
25] also presented an unsupervised learning framework for the task of monocular depth and camera motion estimation from unstructured video sequences. The system is trained on unlabeled videos and yet performs comparably with approaches that require ground-truth depth or pose for training. As a whole,
Table 1 highlights the various deep-learning-based approaches to depth estimation.
While deep learning technology has showcased its proficiency in depth perception and measurement, certain challenges persist: (i) Specialized Equipment: Generating media data with depth information necessitates specialized equipment like Kinect cameras, ToF cameras, or LiDAR sensors to create training datasets. Without such equipment, the laborious task of manually labeling each object with ground truth distance becomes inevitable. (ii) Unsupervised Framework: Unsupervised monocular camera depth estimation typically relies on stereo video sequences as input. It leverages geometric disparities, photometric errors, or feature discrepancies between adjacent frames as self-supervised signals for model training.
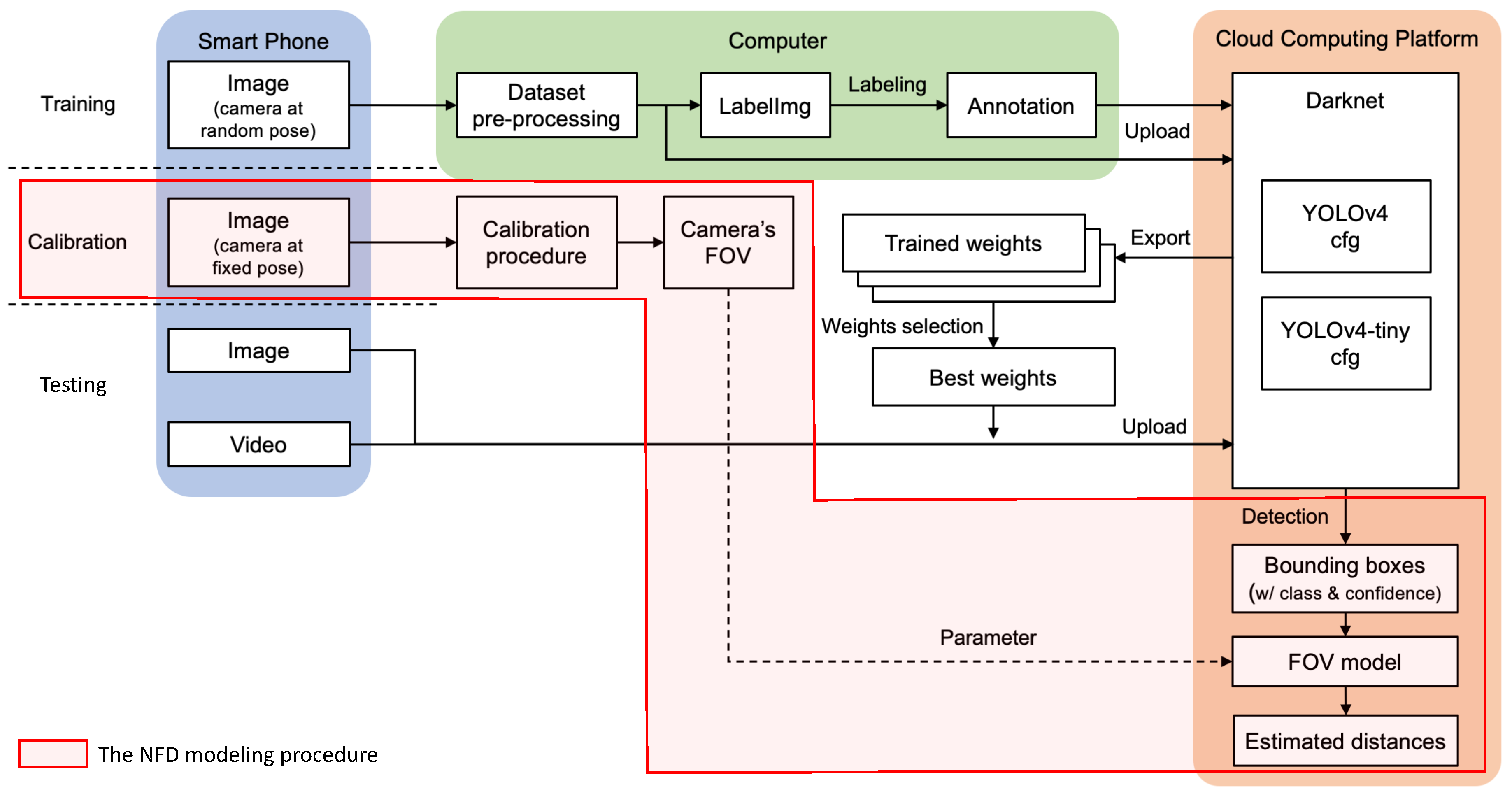
In this study, we propose a novel integration approach for navigation that merges computer vision and deep learning in object detection and distance estimation. This approach is user-friendly, easily maintainable, and cost-effective. Importantly, it demands fewer computational resources, making it suitable for implementation on smartphones and similar devices.
4. Results
This section may be divided by subheadings. Providing a concise and precise description of the experimental results, their interpretation as well as the experimental conclusions that can be drawn.
4.1. Calibration of Camera
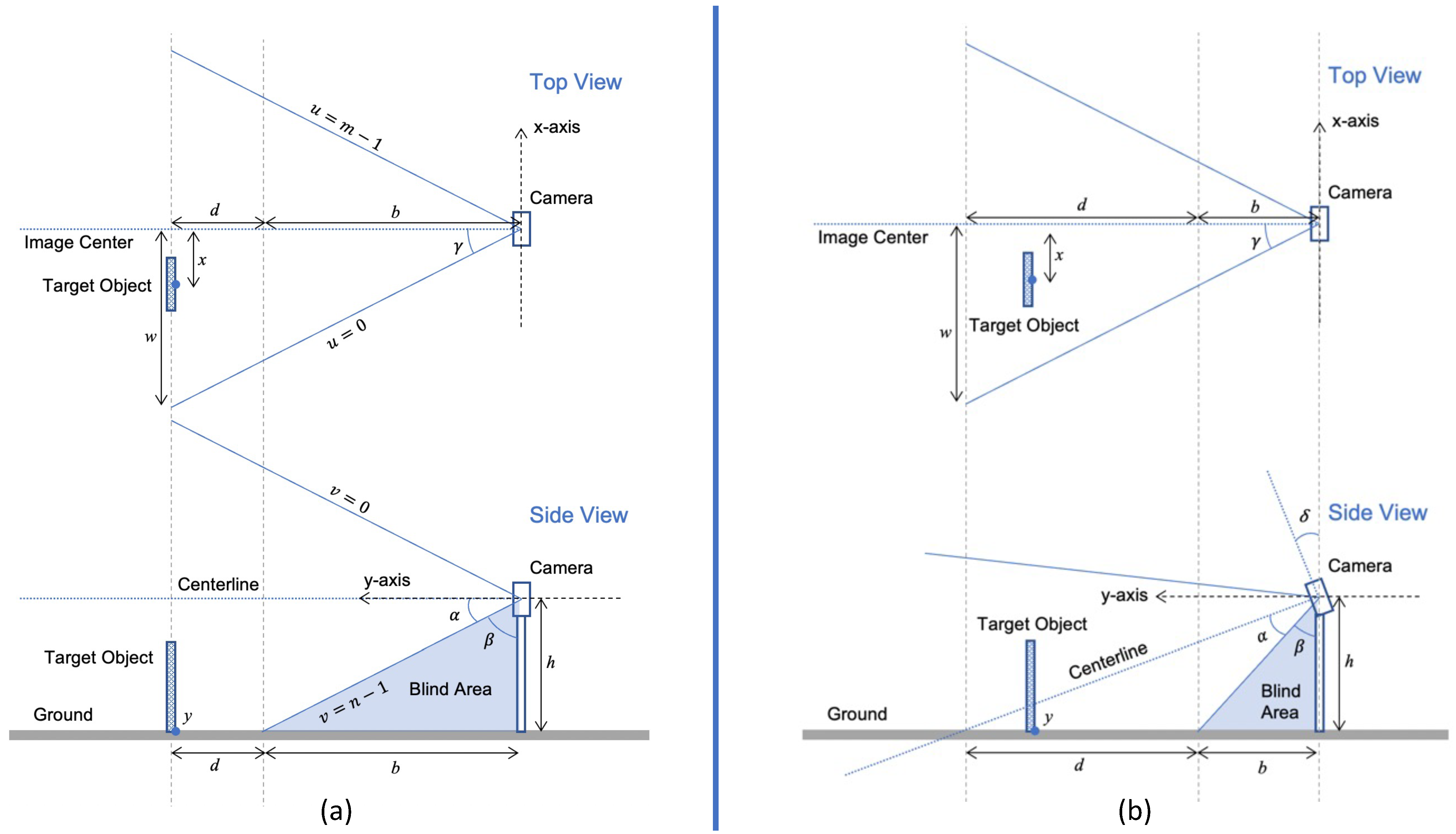
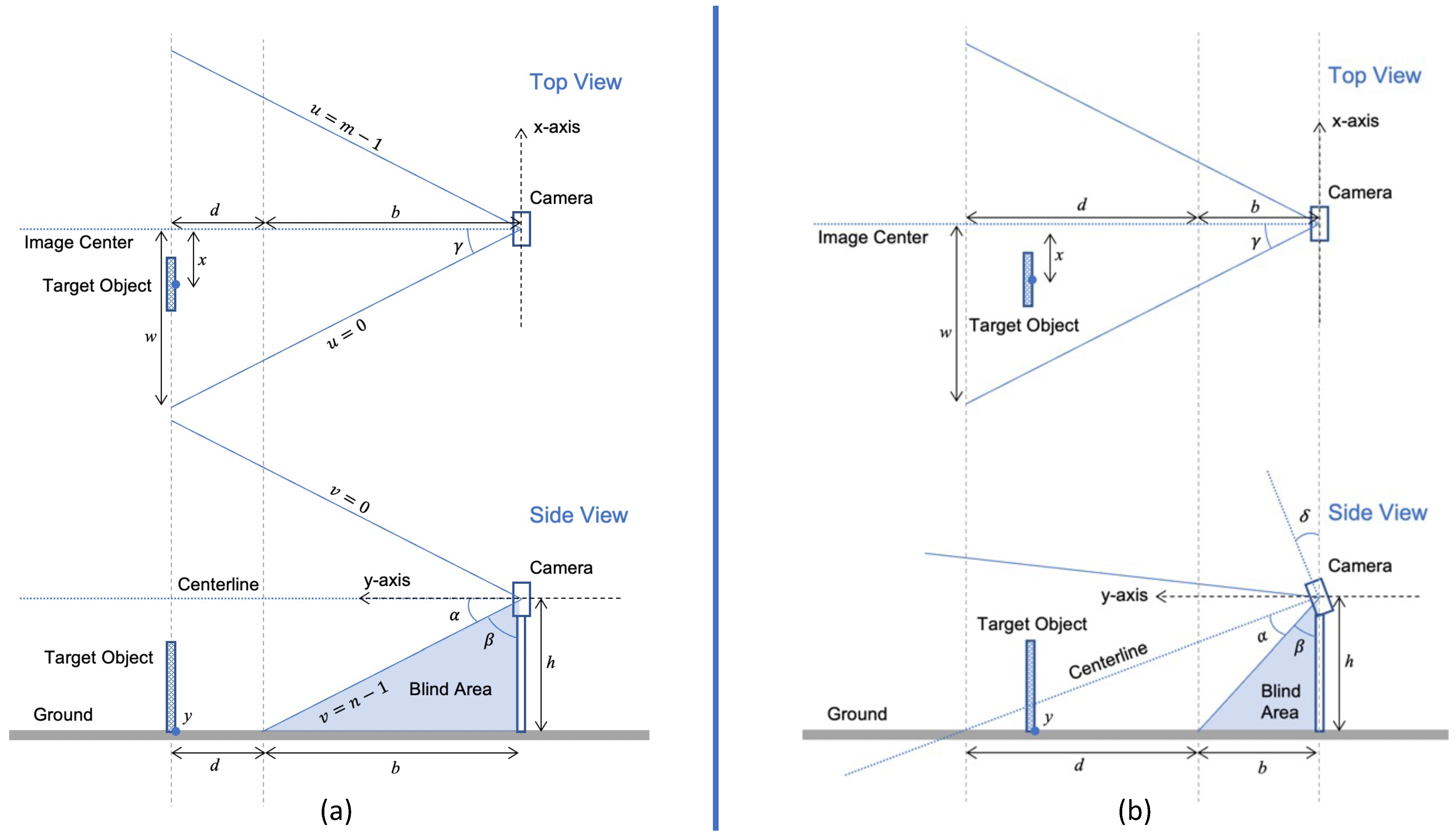
When a new camera is applied in the experiment, calibration is necessary for acquiring the camera’s FOV or focal length, which targets for the position-based estimation or size-based estimation. There are various methods to acquire the FOV. The calibration procedure in this experiment was as follows: (1) set up a camera on a tripod with the camera axis parallel to the ground; (2) place reference markings at particular locations according to the live view of the camera; (3) measure the location of reference markings in real-world coordinates; and (4) calculate the FOV of the camera from Equations (
1)–(
3). To acquire the vertical FOV of the camera, a tape measure was laid on the ground and extended from the bottom of the tripod along with the centerline of the camera. A distinguishable object was placed close to the edge in pixel coordinates (
Figure 5a–e). Read from the tape measure to record the length of the blind area in real-world coordinates. Repeat the measurement at different heights to find the average.
Once the height of camera h and the length of bind area b were measured,
and
could be calculated by Equation (
1). Hence, the average of vertical FOV of the camera used in the experiment is shown in
Table 2.
For the horizontal FOV, similar steps were performed, but two objects were placed at the left and right edge in the pixel coordinate (
Figure 5f–j). The camera was set up at a certain pitch angle, otherwise the width w would be too far away and close to the vanishing point if we set up the camera horizontally. The height of camera h was measured for calculating the actual distance
from the camera to the plane of w when the camera was hoisted at h. The horizontal FOV could be calculated by Equation (
3). The average horizontal FOV of the camera in the experiment is shown in
Table 3, where the height is fixed to 1.183 m.
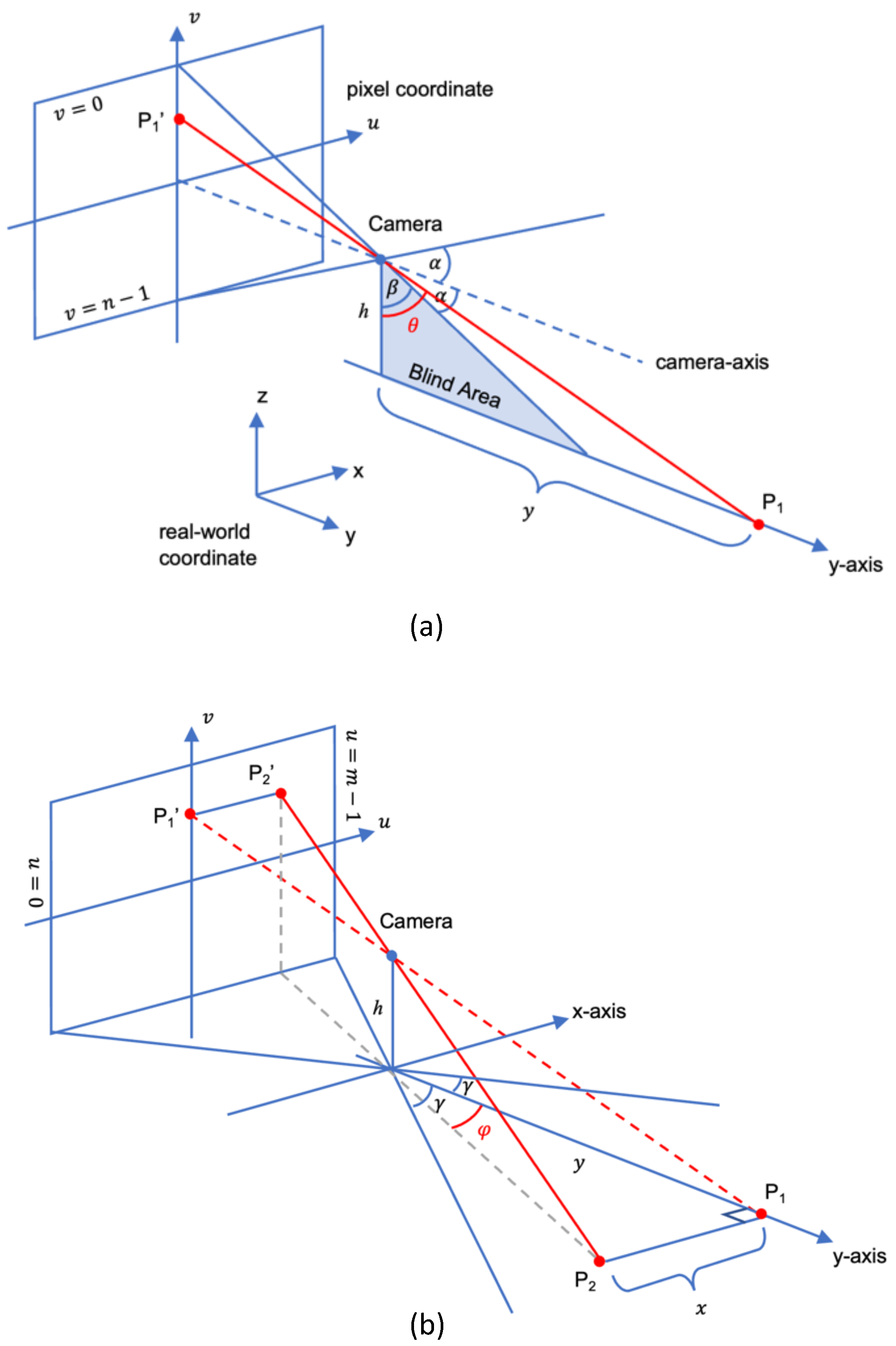
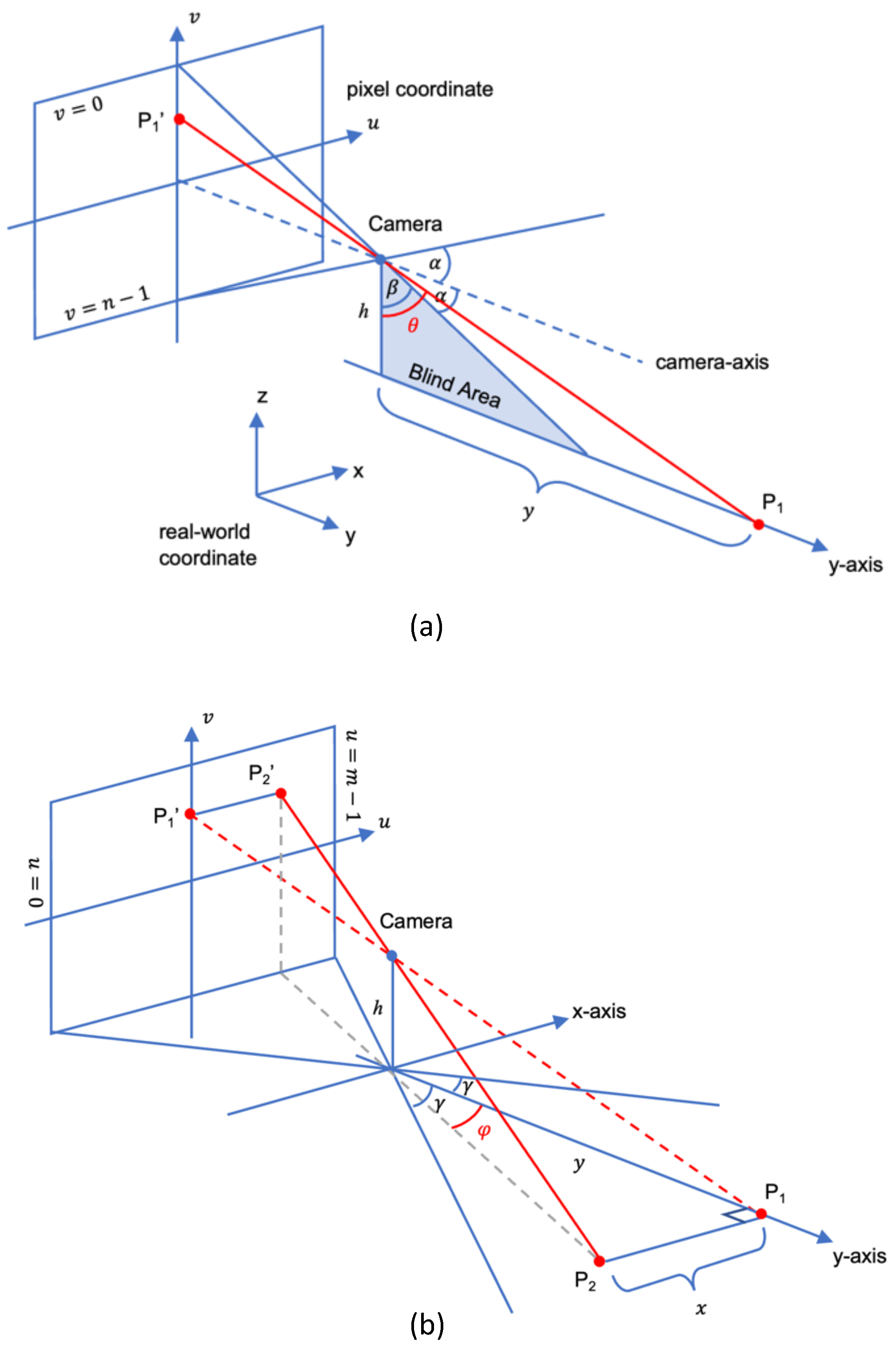
To acquire the focal length of the camera, take several pictures that contain the target objects at different distances (
Figure 6). As long as the size of the objects and the distances are known, the focal length can be calculated by the following Equation (
13).
where the height of the object in pixel
h can be measured by photo editing software.
Table 4 and
Table 5 show a mean camera’s focal length of 424.52 by experiment.
4.2. Effective Distance
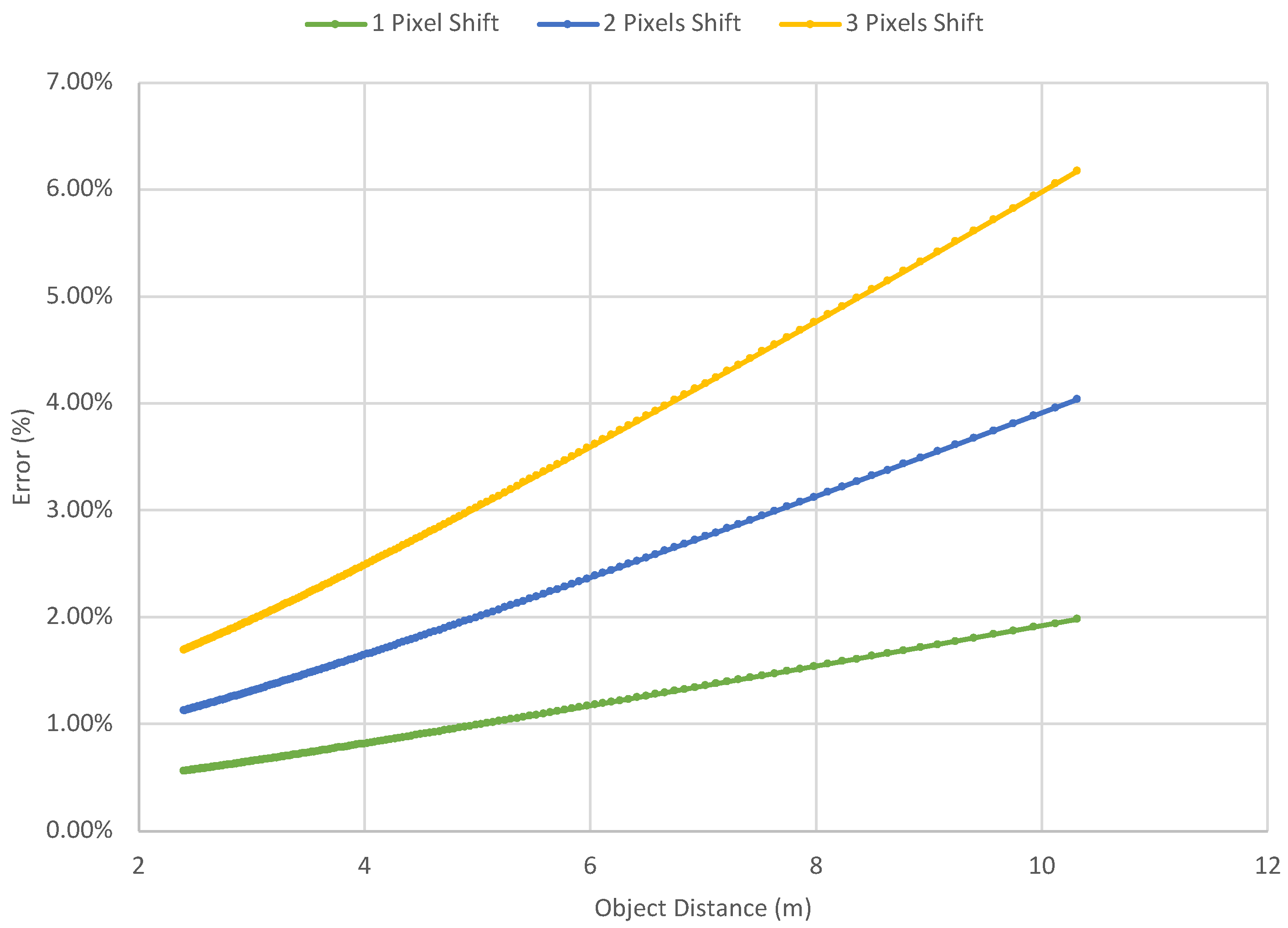
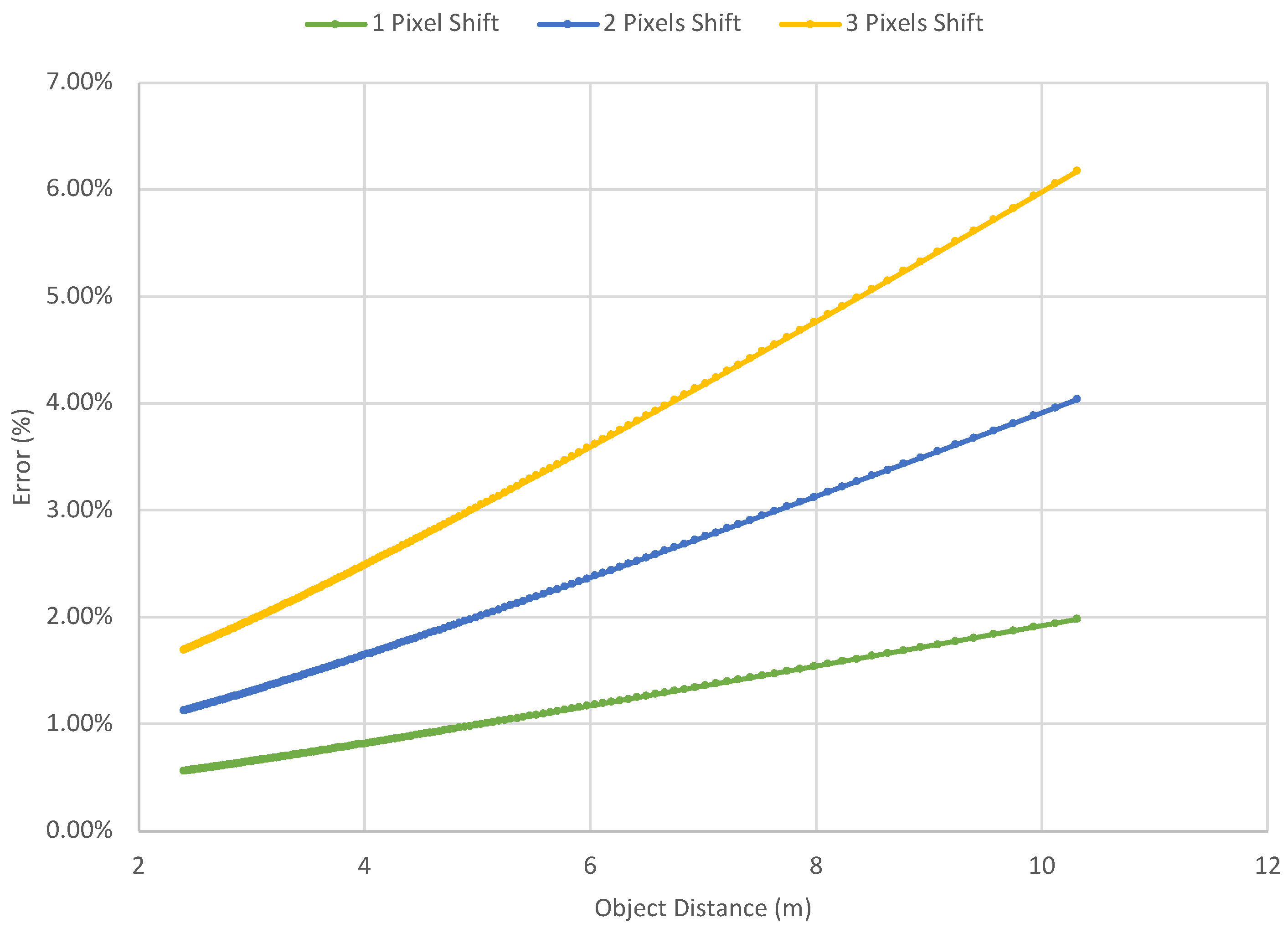
The error introduced by the pixel shift grows with the tangent function in the proposed model. For example, in our case a 416 × 416 image with a horizontal FOV of 63.46° and the camera height
m. Assuming the detection shifts 1 pixel at
m (
in image coordinate),
In Equation (
14), the error is 0.013 m, which is 0.56% of the distance. However, if 1-pixel shifting occurs at
m (
y = 155 in image coordinate), the error becomes 0.196 m, which is 1.94% of the distance.
Figure 7 illustrates the relationship between the object distance and the error introduced by the pixel shifting. For the object at 10 m, 2 to 3 pixels shifting made by the detection will introduce a 3.96% to 6.05% error. It is unignorable and it is necessary to define the effective distance for the proposed model.
According to Sørensen and Dederichs [
39] and Bala et al. [
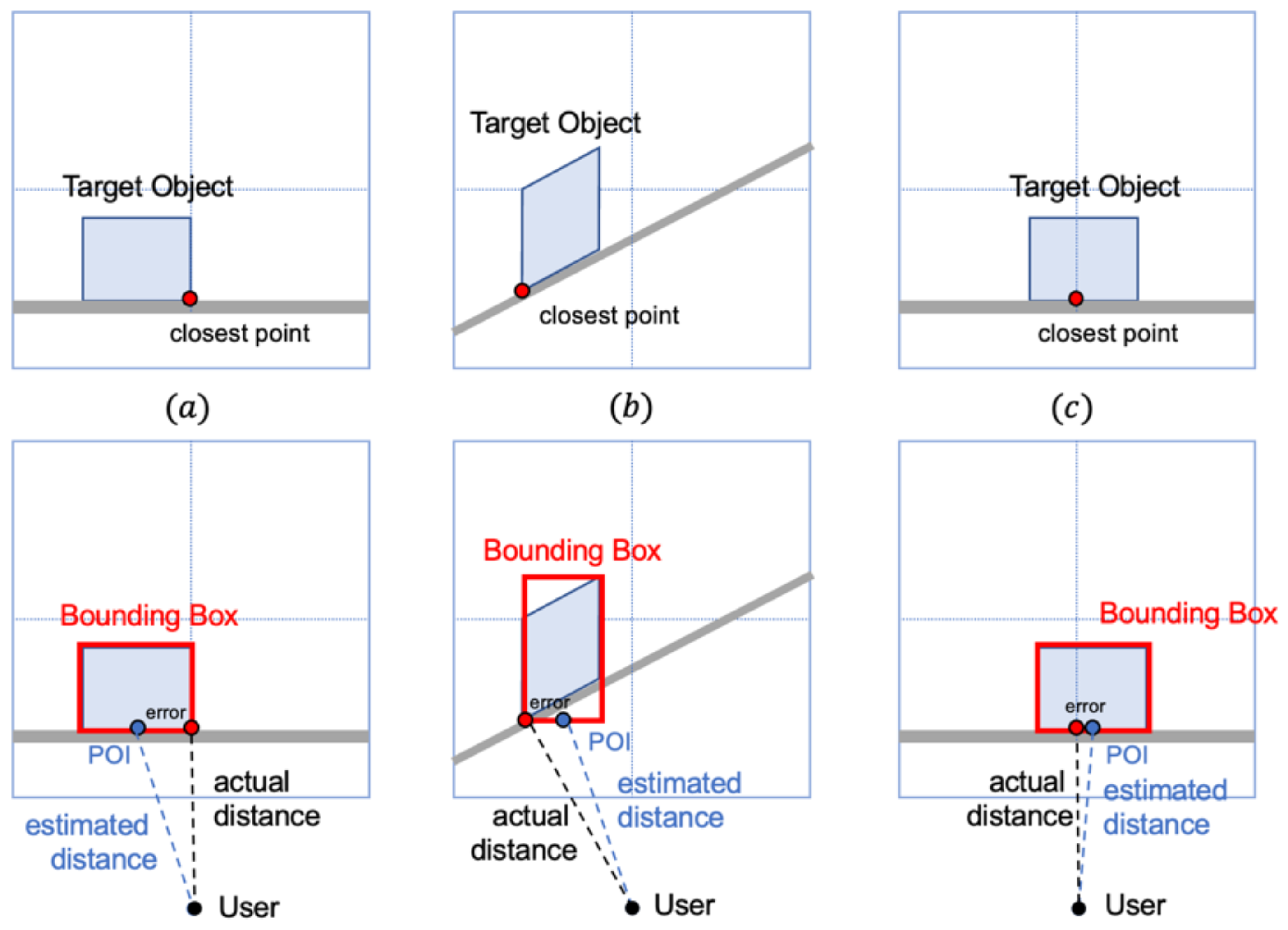
40], the mean walking speed of pedestrians is 1.69 m/s, 1.43 m/s, and 0.792 to 1.53 m/s for younger individuals, older individuals, and visually impaired people, respectively. Therefore, assuming there is an object located 10 m away, it takes 6.5 s (1.53 m/s) for the user to reach it. Assuming the system needs 0.5 s to manipulate, there are 6 s left for the users to respond and adjust their route. On the other hand, if a user is wearing a camera at 1.2 m height (average chest height of a human), the blind area is around 2.4 m. It means that the object closer than 2.4 m could not be or could only be partially detected. Since the position-based model is only effective for the object of which the bottom is completely captured, the partial detection will introduce error to the system (
Figure 8). Hence, the effective distance of NFD is assumed to be 2.4 m to 10 m. For the estimation of the distance of objects shorter than the effective distance, it is suggested to use the previous frames of images for the determination.
4.3. Distance Estimation
In
Table 6 and
Table 7, all detected objects were classified into the correct class in the demonstration, thus the precision was 100%. The recall was up to 94.12% (YOLOv4-tiny) and 97.06% (YOLOv4) within the effective distance (<10 m). The mean absolute percentage error (MAPE) of distance estimation results within an effective distance was 6.18% (YOLOv4-tiny) and 6.24% (YOLOv4), respectively. The error of estimation out of effective distance (>10 m) was relatively large. The MAPE of all detections increased to 14.03% (YOLOv4-tiny) and 16.08% (YOLOv4). Some far objects (around 12 m) were estimated twice the distance to the ground truth due to pixel error. It proved that the proposed FOV model was not compatible with estimating far distance. The result was acceptable to a prototyping solution manipulating low-resolution images with the assumption of no distortion error. Based on the analysis, the errors were caused by two factors. (1) POI error, which could contribute to a maximum of 4% error; (2) bounding box error: since the average IoU of the model was 74.42% (YOLOv4-tiny) and 75.19% (YOLOv4). If a bounding box framed an object inner (or outer) its actual contour, the model would misjudge that the object was located farther (or closer) than its actual location, which is introduced by pixel shift.
To compare the performance between different distance estimation models, the trained deep learning model (80:20 split ratio, labeling method 2, and YOLOv4-tiny) was applied in the position-based (relying on the bottom of the object) and the size-based (relying on the height of the object) models, respectively.
Table 8 summarizes the estimation results of the two models. The overall performance is shown in
Table 9, in which the position-based model in short distances is better as the MAPE (within the effective distance) of the position-based model was 6.18%, but the size-based model was 6.59%. However, when taking the objects out of the effective distance into account, the size-based model gives a much better result. The MAPE of the size-based model was only 5.96% whereas the size-based model climbed to 14.03%. The size-based model shows the capability of estimating distance in dynamic range. Another advantage of the size-based model is that it is free from the assumption of the POI since it refers to the height of the detected objects. One of the limitations of the size-based model is that the detected object has to be completely detected. The misunderstanding of the sizes of occluded and partially out-of-view objects by the deep learning model will lead to a relatively large error. Therefore, a labeling method that ignores the incomplete target object is more suitable for the size-based distance estimation model.
4.4. Discussion and Future Work
The experiment shows that NFD provides a satisfying result in detecting selected near-front objects and estimating their distance from the user. It provides a relatively affordable solution for visually impaired people with the concept of ‘grab, wear, and go’. NFD utilized YOLOv4-tiny for object detection. It provides competitive performance in terms of accuracy among the other solutions for object detection. The training and inference speed outperform other solutions. However, the accuracy of distance estimation of NFD is not better than those with depth sensors, such as ToF cameras and LiDAR. However, inference output can directly locate detected objects in front at comparatively fewer resources (without going through the point cloud). On the other hand, using public objects, NFD can generally work in the entire city, whereas most of the existing solutions could only be utilized for indoor environments or particular areas. However, it can only recognize two types of outdoor public objects currently, implying that it can only work outdoors. Also, moving objects, such as humans and cars, are not detectable yet. To extend it, enhancing the dataset of the trained model for the improvement of the solution is needed in the future. The more high-quality data included in the dataset, the more accurate the prediction it can make using deep learning.
One of the improvements suggested to NFD is the dataset, which includes the image depth information from ToF or RGBD camera. Training images in the dataset can improve the accuracy of prediction, as bias from the lens model and camera posture can be ignored. Additionally, to enhance the robustness of NFD, other common public objects such as fire hydrants, street name signposts, traffic signs, streetlights, and especially humans and cars should be included in the object detection. Such an improved solution will be helpful to the vision-impaired people to fully understand the environment, locate themselves in the street, and avoid static and moving obstacles.
5. Conclusions
This study describes a novel distance estimate method that has undergone time-consuming, costly development, exact calibration, and thorough testing. This unique technique significantly lessens the computing load on edge application devices by utilizing mathematical models to produce reliable estimations. Our method represents a substantial development in the field since it incorporates modern object detection models. The testing results have shown that NFD estimate is accurate within the practical distance range. Based on the findings obtained from our experimental analysis, it is evident that the position-based model achieved a satisfactory mean absolute percentage error (MAPE) of 6.18%, whereas the size-based model yielded a slightly higher MAPE of 6.59%. Notably, both models exhibited commendable precision of 100% and a recall rate of 94.12% within a specified effective distance range of 2.4 to 10 m.
In ideal circumstances, where elements, including the camera’s alignment with the ground’s surface, minimum lens distortion, a well-defined effective distance, and exact POI are guaranteed, NFD emerges as a very effective navigation tool. It is also important to note that our suggested approach for distance estimate holds significant promise outside of its intended use cases. It has enormous promise for autopilot applications for electric cars and drone racing navigation, which advances computer vision and autonomous systems by offering insightful information on distance estimation in a dynamic 3D environment.
These promising findings imply that with further refinement, NFD can be embedded into a wearable device that provides real-time navigation support to those with visual impairments. This advancement allows visually impaired people to move and engage with their environment with greater independence and mobility. We are getting closer to achieving the full potential of this technology and changing the navigation help the market as we continue to refine it.




 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}