1. Introduction
USVs represent a specialized category of compact, multifunctional, and intelligent unmanned marine platforms, which can be remotely piloted or operated autonomously to execute extensive and enduring marine operations in complex and dangerous waters. For proficient path planning in USVs, a system is required to ensure navigation between two designated points (such as start and target locations) and includes obstacle-avoidance capabilities (Cho et al., 2019; Liu et al., 2019; Woo et al., 2020) [
1,
2,
3]. The efficiency of path planning has a profound impact on the overall quality of the routes created by the USV within its surroundings.
Path-planning strategies can be segmented into two primary types, specifically global and local methods, contingent on environmental visibility (Hong et al., 2011; Yao et al., 2017) [
4,
5]. Global methods are designed for conditions with only static hindrances and complete availability of environmental information in advance. They permit the pre-calculation of the briefest trajectory from the starting to the ending point using classical methods such as the A-star and Dijkstra algorithms (Song et al., 2019; Singh et al., 2018) [
6,
7]. They offer strong convergence and consistency, but they are primarily suitable for static surroundings and, therefore, require further refinement for generating USV-compatible paths (Bibuli et al., 2018) [
8].
For instance, by refining the paths planned by the A-star algorithm through spline fitting, the feasibility of unmanned diving vessels can then be enhanced (Gul et al., 2018) [
9]. However, these methods formulate trajectories by linking unidirectional points linearly, which are commonly at a low resolution, making them inapplicable in dynamic settings with moving obstructions. They also usually exhibit a high time complexity, making them challenging in vast environments.
In contrast, local methods fit dynamic situations better (Yu et al., 2021) [
10]. These methods do not rely on prior information about the environment and are capable of finding high-resolution paths even when mobile objects are present.
Traditional approaches to USV path planning comprise heuristic search-based methods, minimum spanning tree-based methods, and neural network-based methods. Heuristic search-based strategies utilize algorithms like A* and Dijkstra for optimal USV path discovery, but they may suffer from premature convergence and local optimality. Therefore, it is suggested that algorithms, as well as the introduction of intelligent algorithms such as genetic and particle swarm algorithms, should be enhanced (Wang et al., 2021; Fang et al., 2021) [
11,
12].
Minimum spanning tree-based approaches, including Prim’s and Kruskal algorithms (Prim, 1957; Kruskal, 1956) [
13,
14], utilize graph theory to calculate the USV’s optimal path. In contrast, neural network-based methods utilize artificial neural networks for path modeling and calculation (Song et al., 2019; Duguleana et al., 2016) [
15,
16]. The development of technology has brought increasing attention to neural networks.
ML focuses on developing algorithms to enable computers to learn and make their own decisions based on data (Abdalzaher et al., 2023) [
17]. RL (Reinforcement Learning), a branch of machine learning, focuses on actions derived from environmental interactions that amplify anticipated gains (Kaelbling et al., 1996) [
18]. It is influenced by psychological behaviorists, whose theories concern how organisms, motivated by rewards or penalties from their surroundings, develop their expectations and form habits to maximize benefits. RL is a learning approach wherein an agent learns, which correlates states to actions to optimize rewards. The agent should continually test and adapt within the environment, employing feedback (rewards) to refine the state-action alignment. Thus, trial and error, along with delayed rewards, represent RL’s key features. In machine learning, the primary methods are supervised and unsupervised learning (Li, 2017) [
19]. An RL system typically comprises four elements: Policy, Reward, Value, and Environment or Model. The policy outlines intelligent behaviors for a particular state, essentially mapping the state to the corresponding action. The state encompasses both the environmental and intelligent states, which start from the intelligence perceived. The reward signal signifies the RL problem’s goal, where the scalar value from the environment is the main influence on the strategy. The value function assesses long-term gains, while the external environment is often referred to as the model (Model) (Sarker, 2021) [
20].
Wang et al. (2018) [
21] employed a strategy that assigned probabilities to eight discrete actions based on their reward values, devising a Q-learning-based path planning algorithm. However, this method suffers from slow convergence and extensive iterations. Wu et al. (2020) [
22] utilized state value functions and action dominance functions to assess Q, constructing a dual Q-based ANOA algorithm to minimize DQN’s coupling (Sarker, 2021) [
23]. Hado Hasselt (2010) [
24] designed a novel off-policy RL algorithm, Double Q-learning, to mitigate overestimations introduced by positive bias in specific stochastic settings. Despite notable enhancements in precision and efficiency compared with traditional techniques, these approaches have partially addressed USV path planning but remain constrained as USV technology advances.
Silver et al. (2014) [
25] presented deterministic policy gradient algorithms for RL in continuous action contexts. Lillicrap et al. (2015) established DDPG [
26], merging the actor-critic method with insights from the DQN (Deep Q Network)’s recent success (Zhu et al., 2021) [
27]. We introduce an advanced path-planning methodology anchored in DDPG. Using the target position to guide USV in environment exploration, we enhance the learning pace. Substituting collision penalties with reward incentives fosters rapid learning in obstacle avoidance for the unmanned vessel.
USV route planning often involves continuous decision making, including the option from an infinite range of actions rather than a finite set. DDPG is designed for continuous action spaces and is suitable for USV route planning, which often requires continuous decisions such as speed and steering angle selection. In addition, DDPG utilizes a deterministic strategy that directly generates optimal action values instead of action distributions, eliminating the need for distribution sampling and thus speeding up learning. Combined with experience replay, DDPG allows the algorithm to learn from previous experience, which improves the stability of learning. By using the current network and the target network, DDPG reduces policy fluctuations and improves learning stability, which is particularly beneficial in scenarios with a continuous action space. In certain cases that involve continuous action spaces, for instance, DDPG may outperform traditional behavioral methods in terms of convergence speed and final performance. We therefore used DDPG as an extended model for our experiments.
This article is divided into four chapters.
Section 1, Methodology, introduces the DDPG algorithm and the USV motion model in detail;
Section 2, Simulation, provides a detailed introduction to the USV State Space and environment modeling of the USV;
Section 3, Discussion, shows the results of simulation testing;
Section 4, Conclusion, indicates the research conclusions and future improvement directions of the algorithm.
2. Methodology
2.1. DDPG
DDPG (The Deep Deterministic Policy Gradient algorithm) is an enhancement of the DPG (Deterministic Policy Gradient algorithm), inheriting its deterministic policy gradient. In this framework, an intelligent body determines specific actions based on state decisions, utilizing a deep neural network to bolster the decision function fitting. Unlike stochastic policies, DDPG significantly diminishes the required amount of sampled data, thereby improving algorithm efficiency and promoting intelligent learning within continuous action spaces.
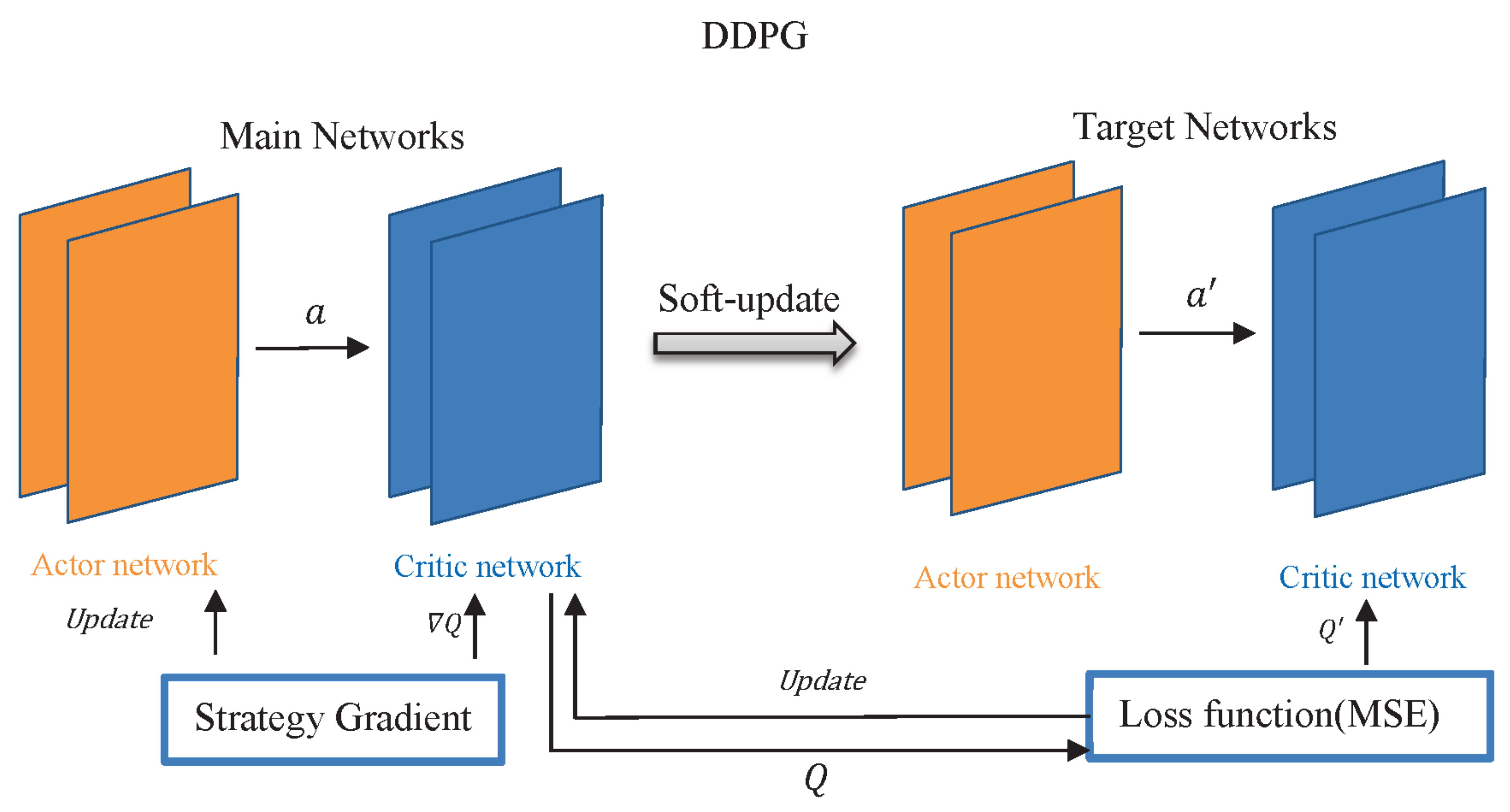
Adhering to an Actor–Critic architecture, the DDPG algorithm primarily consists of two components: the Actor network and the Critic network. The Actor network focuses on generating actions and mediating environmental interactions for the USV, while the Critic network evaluates state and action performance. The insights from this evaluation guide the policy function to formulate the subsequent phase of actions. Both the Actor and Critic components operate through a dual network structure, employing target and eval networks. The overall structure of the DDPG algorithm is visually depicted in
Figure 1. The symbols and their meanings of DDPG are detailed in
Table 1, the DDPG Symbol Definition Table.
In
Figure 1, the network known as Actor-eval primarily deals with the recurrent modification of the policy network parameter denoted by
. It chooses action a based on the prevailing state
, generating the ensuing state
and reward
as a consequence of the current action’s execution during environmental interaction. Concurrently, the Actor-target network has the duty of identifying the best subsequent action
, relying on the following state
, which is sampled from the stored experiences. Periodic copying from
in the Actor-eval network to
in the Actor-target network is undertaken. Additionally, the Critic-eval network is fundamentally engaged in the repeated refinement of the network parameters
through calculation of the present
value:
where the variable
signifies a discount factor impacting the priority given to future over present rewards in the learning process. In the Critic-target network, the principal parameter
is derived by periodically duplicating the
parameter, taking primary responsibility for evaluating
.
Given that the state of the USV is and the action occurs at time , the following operations are conducted:
The Actor-eval network emits real-time actions , which are enforced by the USV to engage with the environment;
The Critic-eval network produces values , utilized to assess the present state-action’s worth;
The Actor-target network delivers , calculating the destination Q value from the next optimal action for state in the observation replay reservoir;
The Critic-target network generates the objective Q value , and the UAV receives environmental rewards to derive the target value.
The elementary notions linked to the DDPG algorithm encompass:
Deterministic Action Strategy : A function to calculate actions at each phase as .
Policy Network: This neural network emulates the function , termed a strategy network with parameters .
Performance Metric : Also known as the performance objective, it gauges policy
’s efficacy. In an off-policy setting, it is described by
In this expression,
is the state created by the Agent-centric behavioral strategy;
is its distribution;
indicates the
value resulting from choices under strategy
.
Strategy Gradient Definition: This represents the gradient of performance objective function relative to .
Action-value Function (Q Function): In state
, following action
, and persistently applying policy
, the anticipated value of
is
During the training phase of RL, the exploration of potentially superior strategies necessitates the introduction of stochastic noise into the action’s decision-making protocol. This transformation alters the decision of action from a fixed pattern to a probabilistic one. Actions are then drawn from this probabilistic process and forwarded to the environment for implementation. This approach is referred to as the behavior policy, symbolized by , and categorized as off-policy. The UO (Uhlenbeck–Ornstein) random procedure, notable for its excellent correlation in temporal sequences, enables effective environmental exploration by the agent. Hence, in the context of this study, the UO stochastic process is employed for DDPG training.
Concerning the training of the network, DDPG’s focus lies in the continuous training and enhancement of the eval parameters within both Actor and Critic. Subsequently, after a specific duration, the target network’s parameters are rejuvenated through the soft update algorithm. The updated formulation can be expressed as
Here,
and
correspond to the target network parameters, while
and
are linked to eval network parameters. The parameter
is commonly set to 0.001. In the context of refining the parameters for the updated Critic network, the Critic network’s loss is conceived as the MSE (mean square error), represented as
In this expression,
. is delineated as
Here,
signifies the target network’s parameters in the Critic, and
represents the parameters of the target network in the Actor. The term
is perceived as a ‘tag’, with network parameters adjusted via the back-propagation algorithm throughout the training phase. Regarding the policy gradient computation for the Actor, it can be illustrated as
The gradient of the strategy is represented by the expected value of
, under the condition where
follows the distribution of
. Utilizing the Monte Carlo algorithm, it is possible to estimate
. The information concerning (transition) state transitions, contained within the empirical storage mechanism, denoted as
, is derived from the agent’s behavior policy
, with the corresponding distribution function
. Hence, when extracting mini-batch data randomly from the replay memory buffer, the Monte Carlo method enables this data to serve as an unbiased approximation of the above-mentioned expectation. This is achieved by applying the previous policy gradient equation. Therefore, the expression for the strategy gradient can be formulated as
The following section will present the pseudocode representation corresponding to the DDPG algorithm (Algorithm 1).
| Algorithm 1 DDPG based on USV |
Require: The number of episodes for training , frequency of training , the size of experience buffer ,
the number of sequences for the first sampling , and the regulator factor of the first sampling a. The
number of samples for the second sampling , the regulator factor of the second sampling . the
discount factor of reward , the end time of training , the update frequency of target network .
Ensure: Optimal network parameters.
Initialize the parameters of Online Policy Net and Target Policy Net with and , the parameters of Online Net and Target Net with and . Initialize experience buffer , the number of sequences in the experience buffer , the storage experience buffer of a single sequenceh, the priority . for episode do Initialize a OU process, for action exploration. Receive initial observation state . for do Select action according to the online policy and exploration noise. Execute action at and observe new state . Store transition in experience buffer . if and episode then for do Calculate the probability of each sample Based on sampling probability P(i), S sequences are sampled from E and stored in experience buffer . for do Calculate the probability of each sample
Based on sampling probability , M sequences are sampled from and stored in experience buffer Using samples in S, Minimize the loss function to update the critic network: Update the online policy using the sampled policy gradient:
Update the target networks:
|
2.2. Motion Model for Unmanned Surface Vehicles
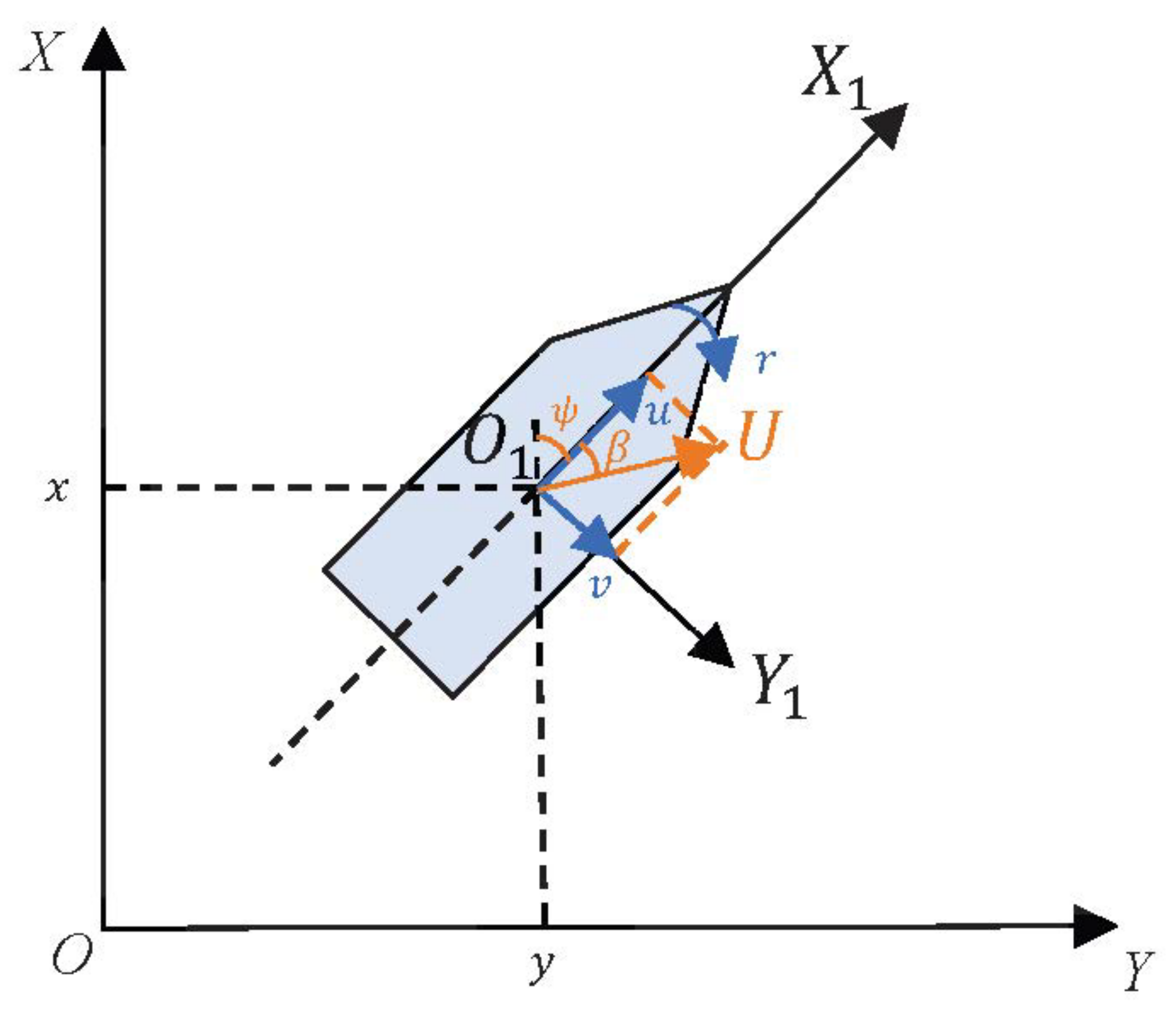
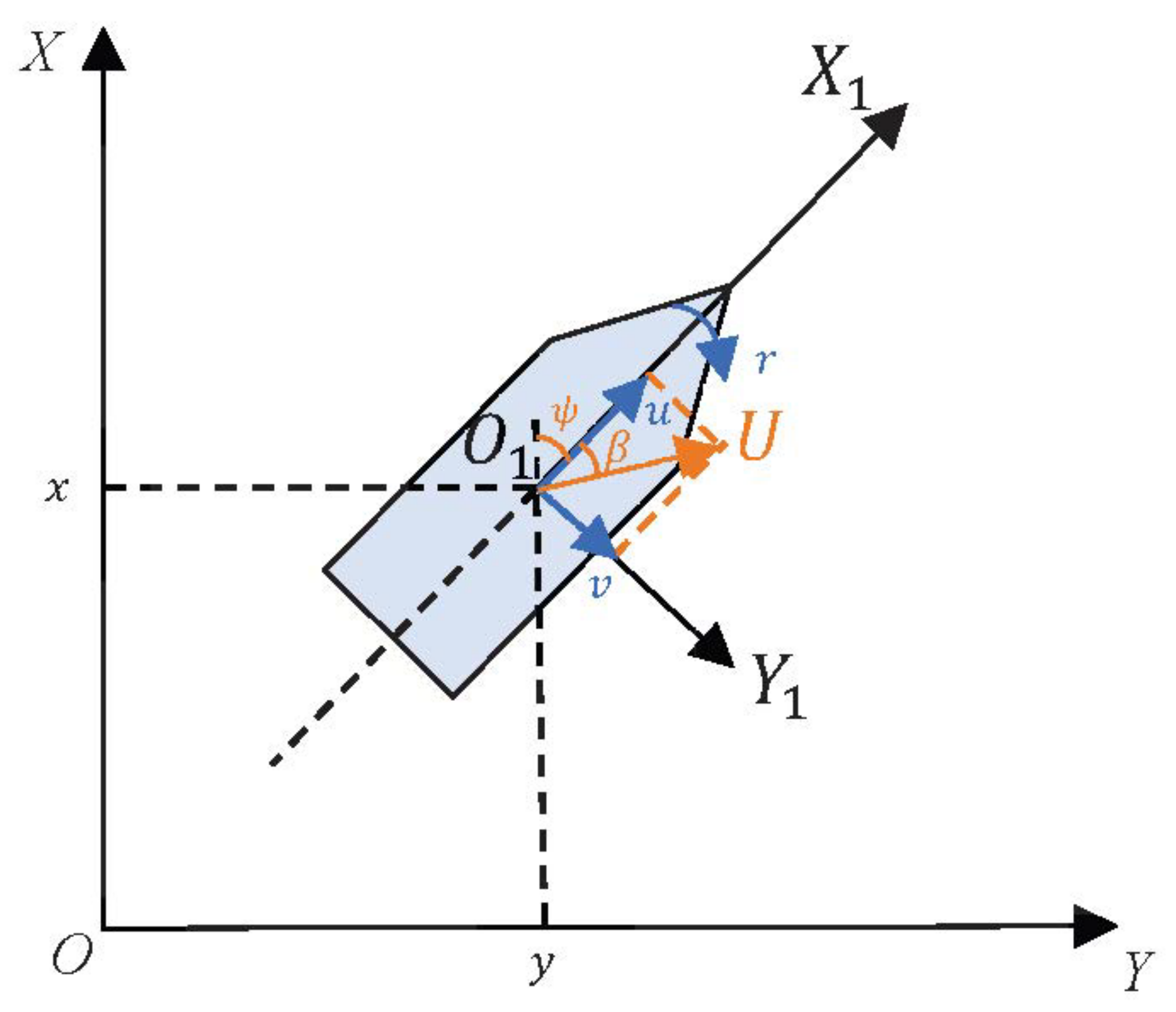
In this study, an underactuated USV is employed as the subject of research for path planning. The position of the USV within the Earth’s coordinate system is depicted by the position state vector , where signifies the location, and denotes the orientation angle. The horizontal velocity of the USV is represented by the velocity vector , in which , and correspond to the forward velocity, lateral velocity, and yaw rate, respectively.
To create a simplified model of the USV that is conducive to the design of a path planning system, the following assumptions have been adopted:
The USV exhibits six degrees of freedom: heave, sway, yaw, roll, pitch, and surge. The last three have a minimal influence on the USV and are thus disregarded.
The USV’s mass is uniformly distributed, and it is symmetric with respect to the OXZ plane; that is, .
The origin of the body coordinate system is located at the center of the USV.
An underactuated ship refers to one that cannot generate thrust in the lateral direction (or has transverse thrusters that are inoperative for other reasons). It has a longitudinal propeller only. Therefore, the thrust vector can be expressed as , where is the main propulsion thrust, and is the turning moment induced by the rudder. As no force is applied in the lateral direction, the value is zero.
Higher-order hydrodynamic terms are disregarded.
Based on these simplifications, the nonlinear three-degree-of-freedom model for the USV on the horizontal plane can be derived as
Here, the transformation matrix
is
is the inertia matrix (including added mass):
is the Coriolis centripetal moment matrix:
where
.
The Coriolis centripetal moment matrix, represented as
, is formulated as
The damping matrix, denoted by
, is expressed as
Here, the values of
,
, and
correspond to
,
, and
, respectively.
,
, and
signify
,
, and
in the inertial parameters.
,
, and
stand for the hydrodynamic derivatives. The Ocean disturbance is represented by
. The symbols and their meanings of the Motion Model for USV are detailed in
Table 2, the USV Symbol Definition Table. A simplified model of USV is shown in
Figure 2. Parameters of unmanned surface vehicles are shown in
Table 3.
3. Simulation
Our experiments were conducted on a computer with an AMD R5 5600 processor and 16 GB of RAM, running on the Ubuntu 22.04 LTS operating system.
Software and Framework:
OpenAI Gym: we chose OpenAI Gym as the main simulation environment framework because it provides a common set of interfaces for reinforcement learning. We used pip in-stall gym for installation.
Tensorflow2-CPU: Used to build and train neural network models. Since a high degree of parallel computing power is not required in our models, we chose the CPU version. Pip install tensorflow-cpu was used for installation.
Python 3.9.10: All implementations were performed in Python, ensuring portability and easy reproduction of the code.
Simulation environment implementation:
Defining the environment: we created a custom Gym environment that simulates the motion of an unmanned boat. This environment implements the necessary methods, such as reset() and step(), and defines the state and action space.
Actor and Critic networks: we defined Actor and Critic neural networks using TensorFlow Keras API. The Actor network learns to map states to actions, while the Critic network learns to estimate the value of states.
DDPG Algorithm Implementation: we implemented the DDPG algorithm, utilizing Actor and Critic networks. In addition, we define the playback buffer, the target network, and the optimization process.
Training loop: in the training loop, we interacted with the environment, collected experience, and updated the Actor and Critic networks according to the DDPG algorithm.
We simulated the seawater environment in the coastal area under mild weather. To ensure the accuracy of wind, water current, water temperature, and seawater density for two groups of experimental tests with the usage of different models, we set the wind, water current, water temperature, and seawater density to the same parameters. To be specific, the direction of the wind flow is from north at a speed of 8 m/s, the direction of the water current is from east to west with an average flow velocity of 0.5 m/s, the temperature is at 20 °C, and the density of seawater is 1025 kg/m3.
3.1. USV State Space
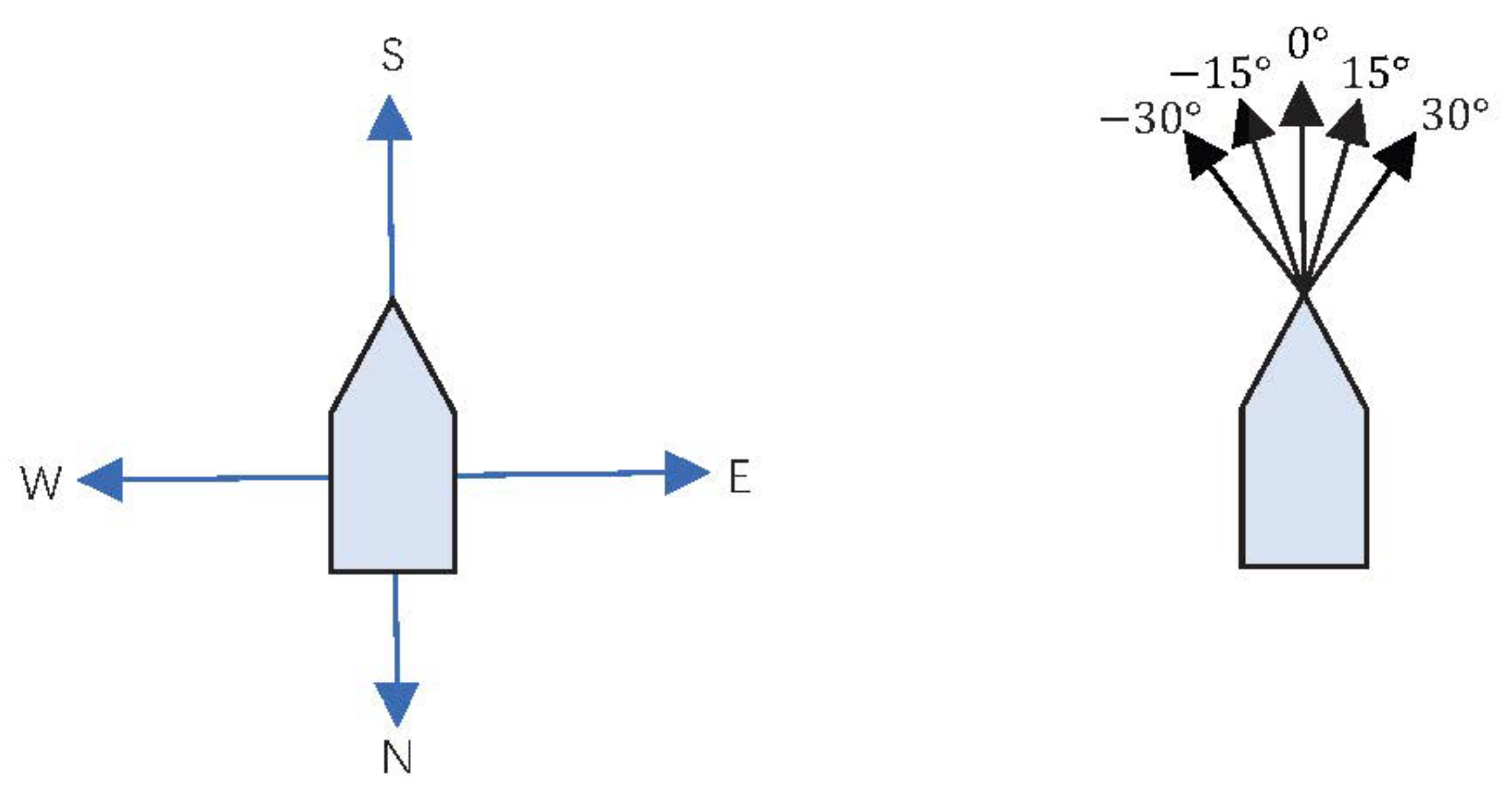
While navigating on open water, an unmanned boat, or drone boat, is programmed to autonomously refine its path by leveraging the available map information to steer clear of hindrances. Throughout this procedure, it is presumed that the vessel advances at a uniform distance during each move, resulting in the movement space of the drone boat corresponding to the steering angle for each individual motion.
Ordinary intelligent entities, such as indoor robots, often travel at angles of 45 or even multiples of 90 degrees. This type of action space is prevalent, but it can result in elongated path trajectories and large-angle turns, including complete about-faces of 180 degrees. These movements are inconsistent with the typical maneuvering characteristics of unmanned vessels, prompting the need for consideration of the specific steering capabilities of the boat.
Therefore, to tailor the maneuvering space for an unmanned boat, it becomes essential to ensure that its heading remains as steady as feasible or that large-angle turns are set as few as possible during navigation and in the process of obstacle avoidance. Such considerations contribute to a more seamless route, enhancing not only the safety of the unmanned boat’s journey but also minimizing power depletion.
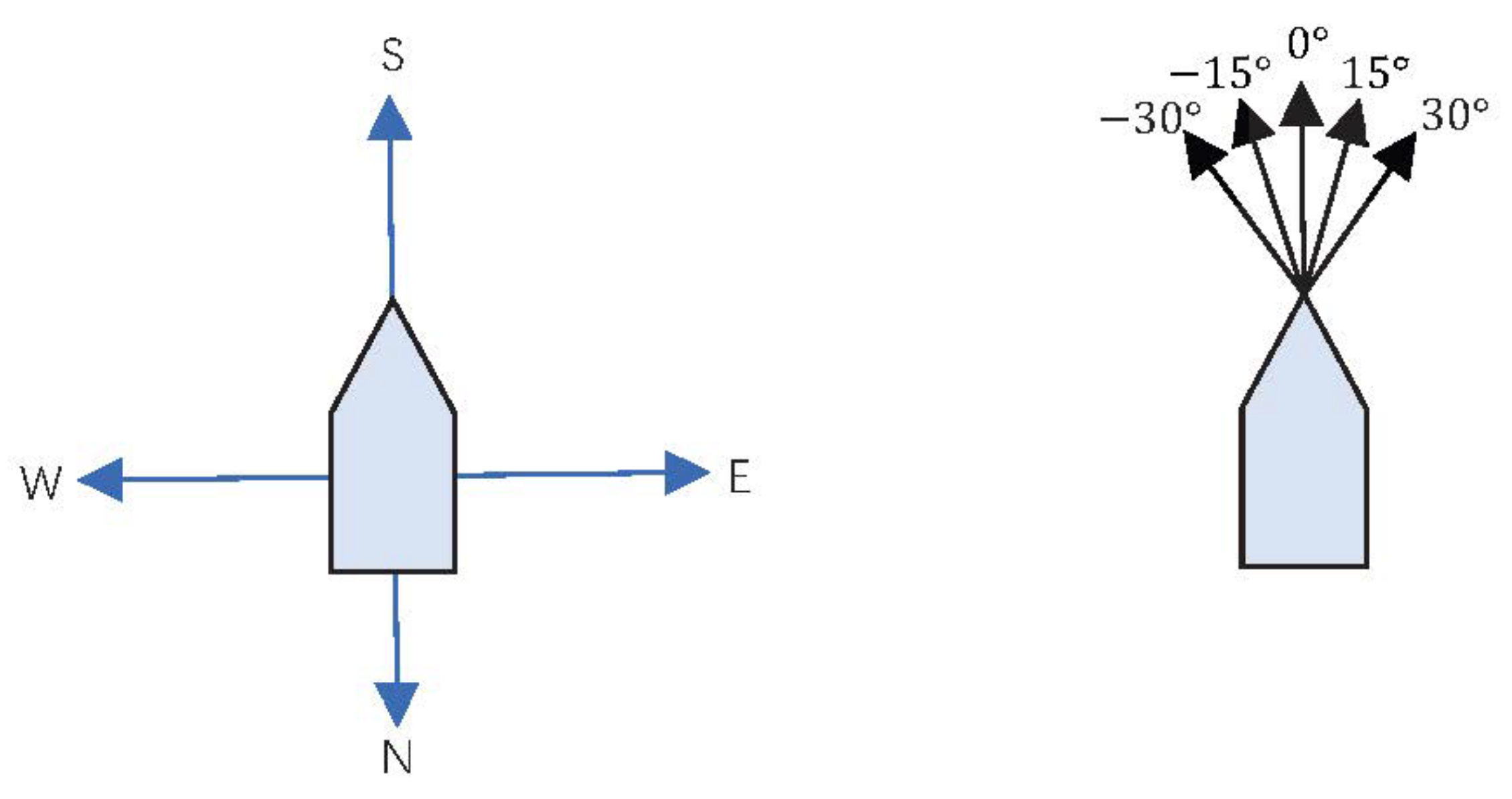
To align the turning angle of the unmanned boat with its actual navigation characteristics, the angle is crafted according to the principle of minimal-angle steering. The action space is defined to allow a single unit’s distance of advancement in a specified direction, with angles fixed at plus or minus 15 degrees, plus or minus 30 degrees, or 0 degrees.
Figure 3 illustrates this concept further, with the left diagram showing the action space as it is depicted in traditional reinforcement learning algorithms. The right diagram displays an optimized action space designed specifically to accommodate the operational attributes of the unmanned boat.
3.2. Environment Modeling
3.2.1. Environment Setting
In our simulation environment, we configure a map of dimensions 320 by 320, with the unmanned boat’s objective being to locate the most efficient route to a specific target point. We represent the state of the unmanned boat with the triplet , where and are the real-time coordinates of the boat within the simulated terrain, and signifies the yaw angle relative to the target.
Starting from the initial coordinates of
, the actual heading angle is given by
. When considering the current coordinates as
and the target coordinates as
, we can derive the desired heading through the following formula:
As the boat carries out actions from the set, each corresponding to a specific heading angle
, the actual heading angle changes accordingly. We can represent this as
, and update the heading angle with
The yaw angle
is then characterized as
And the steering angle
is determined as
3.2.2. Design of Reward Function
Proper reward configuration requires thoughtful consideration. If it is mishandled, an impractical reward scheme might lead to suboptimal results, which is even worse than a random strategy since it can incorrectly direct intelligent behavior. Typically, rewards are structured on a punitive basis until the objective is achieved, and these rules should not be overly complex. Therefore, a common reward scheme might consist of granting a significant bonus for meeting the goal and a minor penalty for failure to do so. To mitigate the drawbacks of sparse rewards, we have refined the incentives for the unmanned boat. The following outlines the guidelines for the interaction between the unmanned boat and its environment:
Goal Achievement: A reward of +100 is given when the drone boat successfully reaches the final target. This substantial positive incentive is designed to guide the drone boat toward the target location;
Collision Penalties: If the drone boat encounters an obstacle or boundary, it incurs a penalty of −2. Since these are undesired actions, the negative penalty encourages avoidance of these elements;
Distance Rewards: The rewards are set at +1 or −1 depending on whether the drone boat’s distance to the target is decreasing or increasing, respectively. This drives the drone boat to approach the target while avoiding diverging from it;
Yaw Angle Rewards: The smaller the yaw angle of the drone boat, the higher the reward. This serves to push the drone boat to minimize the difference between its actual and desired heading, smoothing its path, averting unnecessary trajectories, and shortening the planned route;
Steering Angle Rewards: Likewise, the more the steering angle of the unmanned boat is reduced, the greater the reward is given. This incentivizes the unmanned boat to curtail the steering angle, which in turn decreases the turning torque and the boat’s inclination on the water surface. As a result, this conserves energy, extends range, and diminishes the possibility of capsizing.
To align with points 4 and 5, we utilize the cosine of the corresponding angle as the reward. Also, when applying the memory playback mechanism, we aggregate the rewards for a sequence of states, eight in length, and assign it to this macro-action. Such an arrangement enables the Critic network to appraise the macro action as either positive or negative, augmenting the network’s discernment of different action sequence qualities. Consequently, the network’s proficiency in evaluating the merits of various action sequences is bolstered.
3.2.3. DDPG Based on USV Details
Actor Network Configuration: input layer: state size 19; hidden layer: 2 layers, 256 nodes per layer; output layer: actions of size 2. Critic Network Configuration: input Layer: total state and action size 20; hidden layer: 2 layers, 256 nodes per layer; output layer: 1 node; hyperparameters. Learning rate: 0.001, discount factor: 0.99, soft update rate (): 0.005.
3.3. Design of Environment Settings and Reward Functions
In our simulation, a grid of 320 by 320 units will be employed, where each unit on the map signifies 5 m. And randomly designed obstacles on the map and indicated them with black squares on the map.The unmanned boat will traverse 5 units—or 25 m—in the direction of its current heading during each movement. This setup aims to curtail the amount of motion searches and expedite the algorithm’s validation. The training will be performed on the map 2000 times, with each iteration confined to 500 steps. If the final destination is not reached within those 500 steps, the attempt will be categorized as a failure.
The criteria for comparison include the mean number of steps taken, average rewards earned, success rate, overall path length, and the frequency of substantial-angle turns. To streamline the simulation process, obstacles have been shaped into rectangular forms. Moreover, we will establish a control group by constructing a conventional, fully connected neural network using the traditional Actor–Critic algorithm. To bolster the stability and efficiency of training, we will implement a Q target network to augment the convergence of iterations.
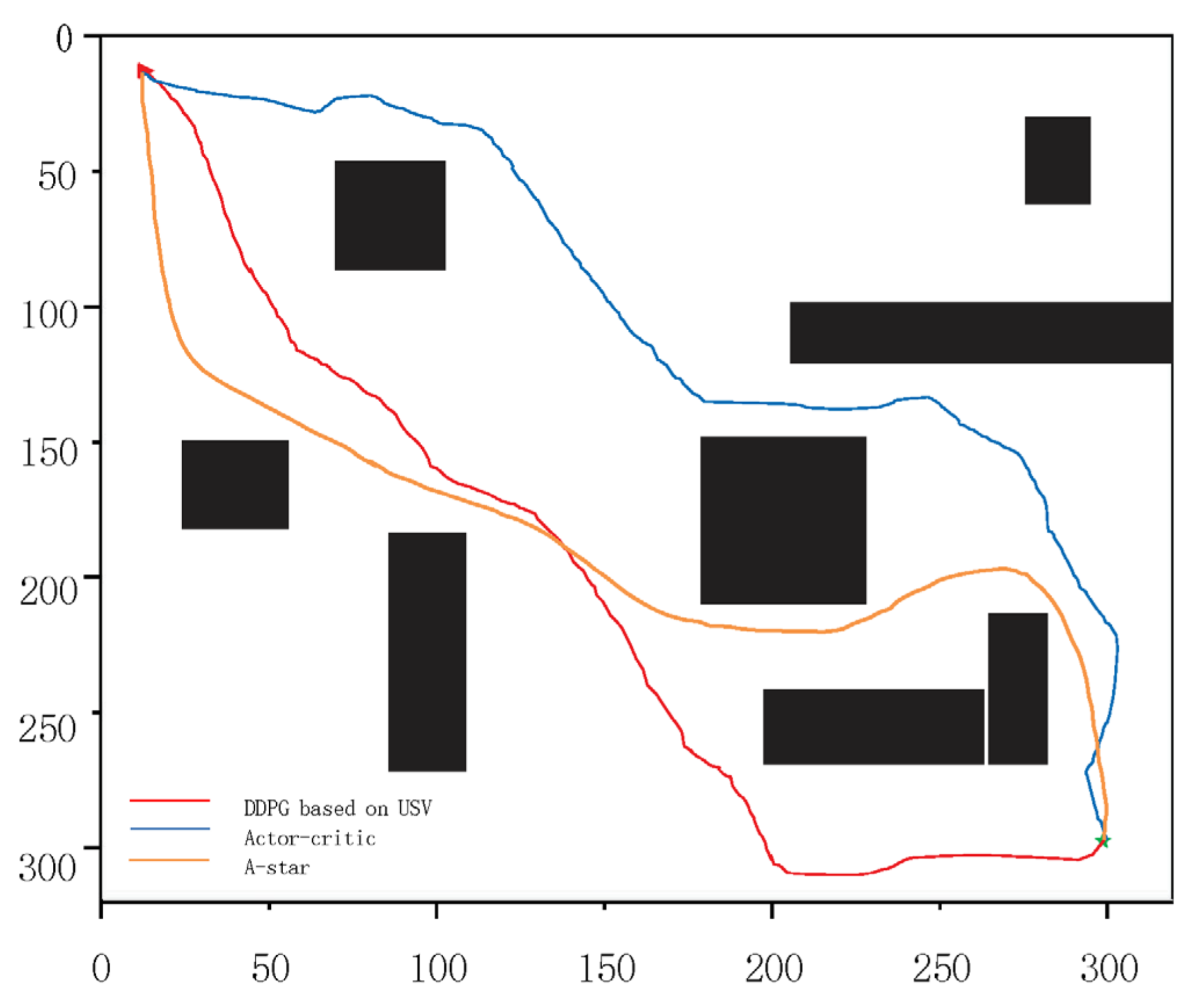
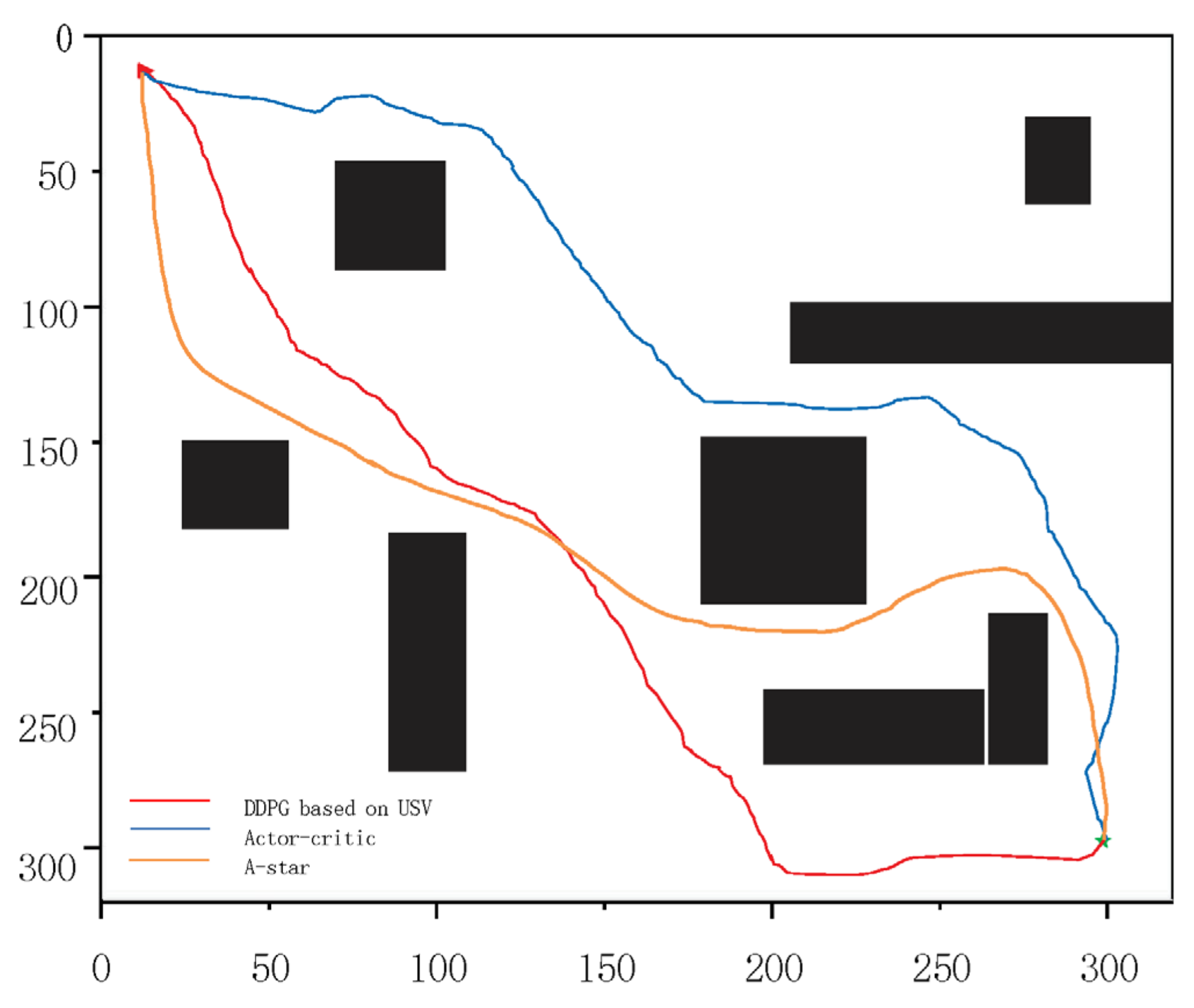
The visual representation of the simulation environment is as follows: obstacles are depicted as black rectangles, the starting point is marked by a red triangle, and the target point is symbolized by a green pentagram. After 2000 times of training, the path-planning trajectories for two algorithms are obtained. The red path illustrates the DDPG algorithm tailored for USV, while the blue path represents the Actor–Critic algorithm.
4. Discussion
Figure 4 depicts the simulation outcomes on the map, where the DDPG method adapted for USV clearly outperforms the traditional Actor–Critic algorithm. Specifically, the track length executed by the USV-focused DDPG is 2315.76 m, in contrast to the Actor–Critic algorithm’s track length of 2513.41 m; the track length executed by the A-star algorithm is 2607.93 m.
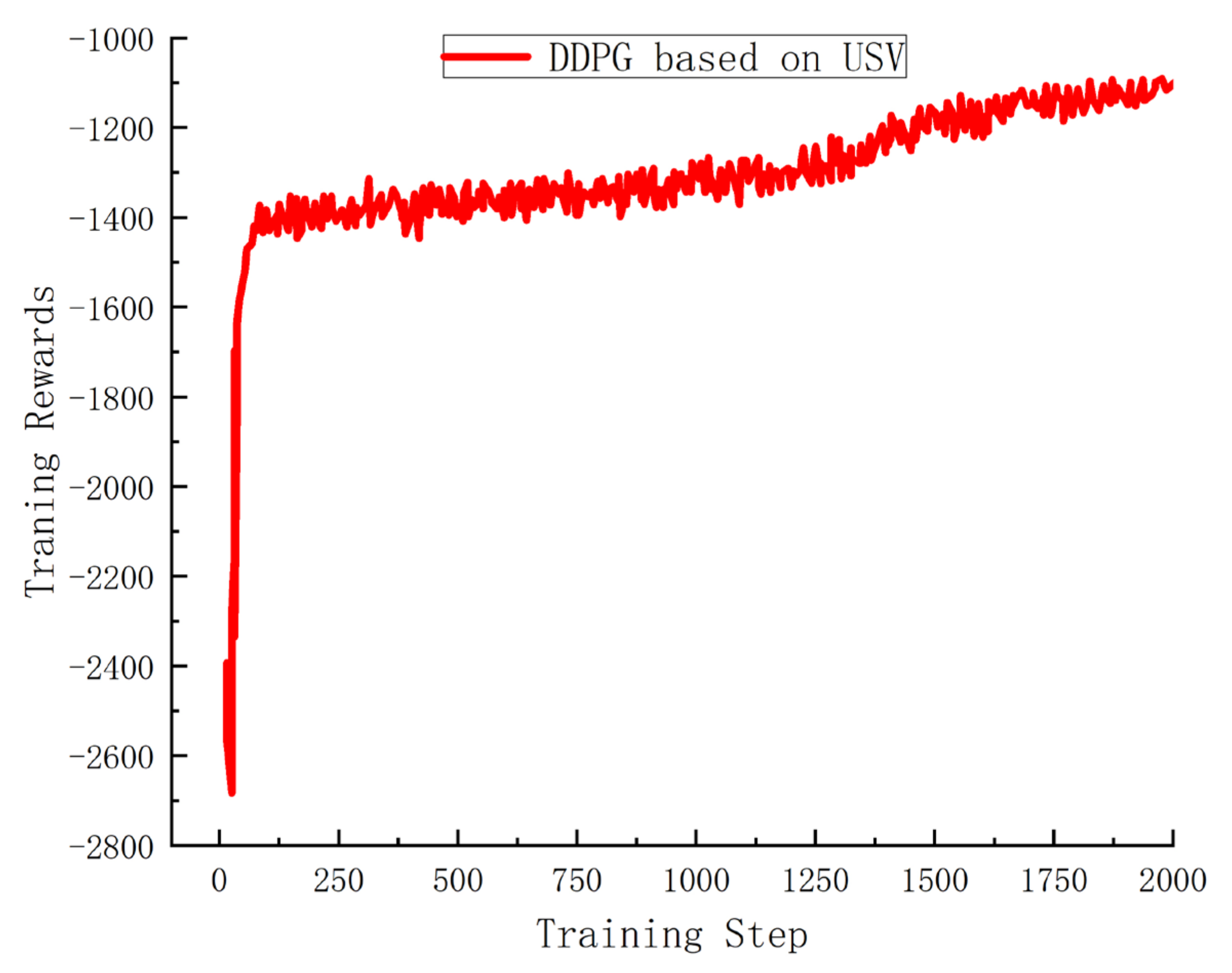
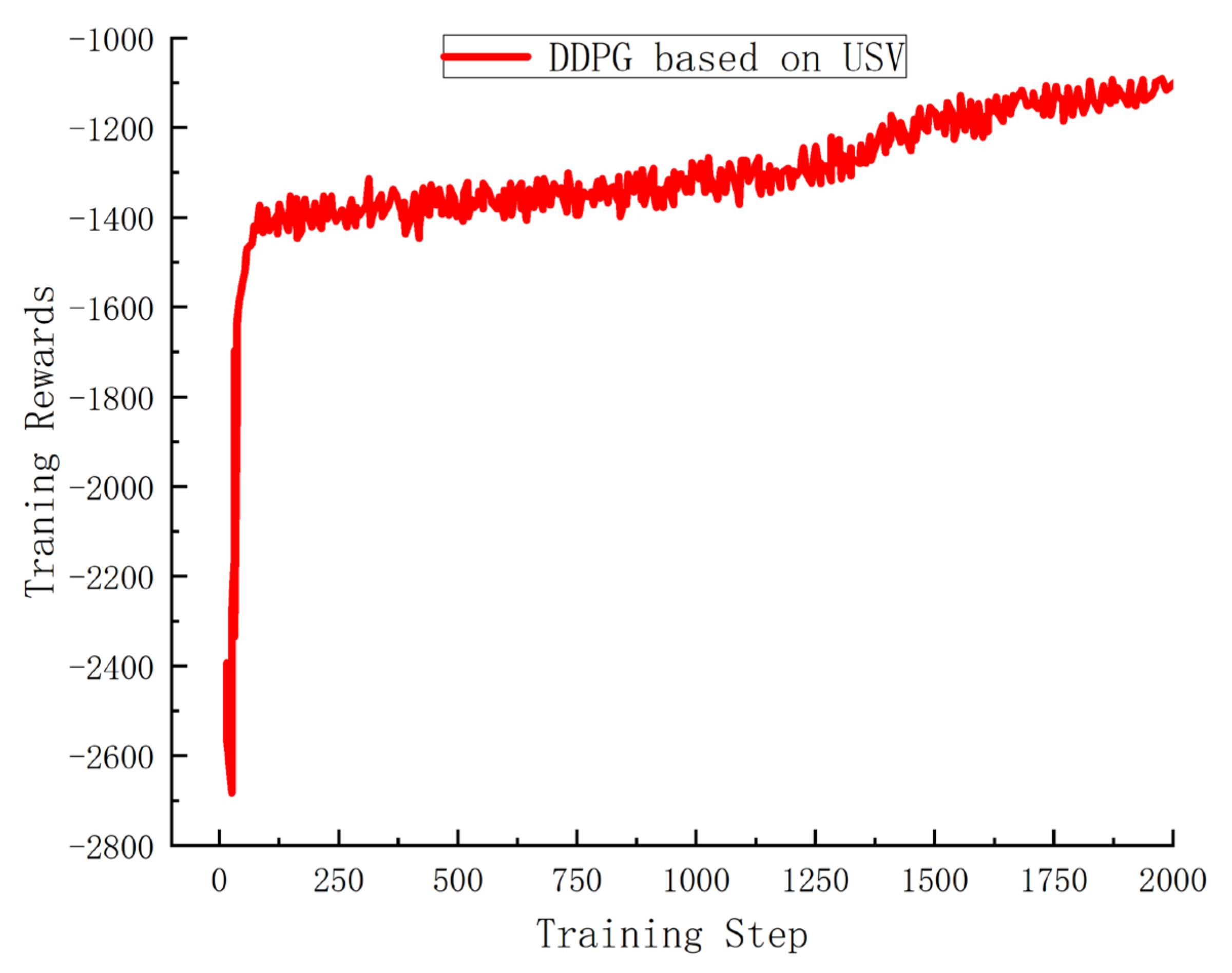
In
Figure 5, the progression of reward alterations during USV’s training is demonstrated. In the graph, the X-axis signifies the count of training iterations (or episodes), while the Y-axis marks the total rewards accumulated by the drones in each round. By analyzing
Figure 5, it is evident that as training advances, although the absolute rewards decline, the rewards themselves exhibit a gradual ascension, reflecting an overall convergence pattern.
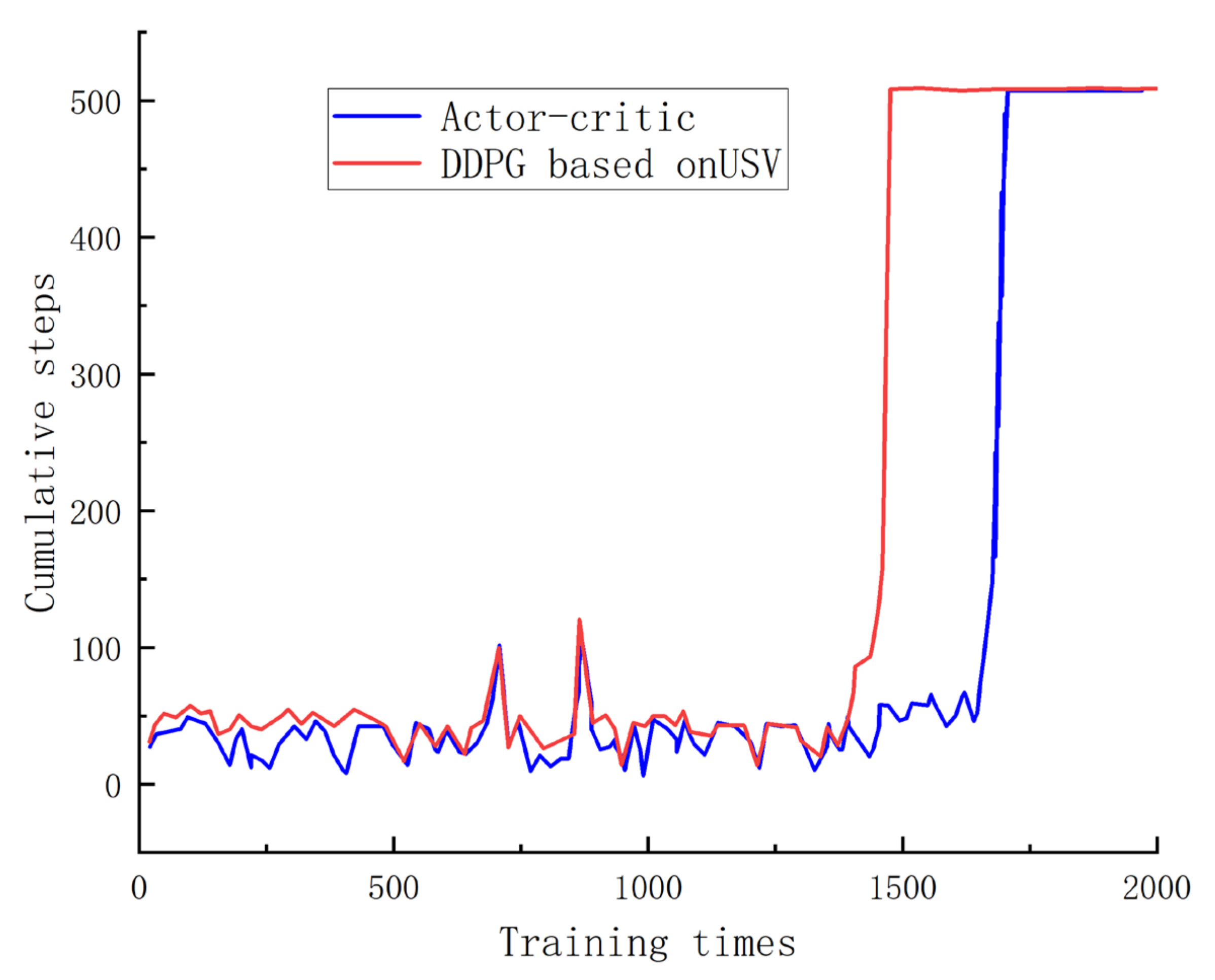
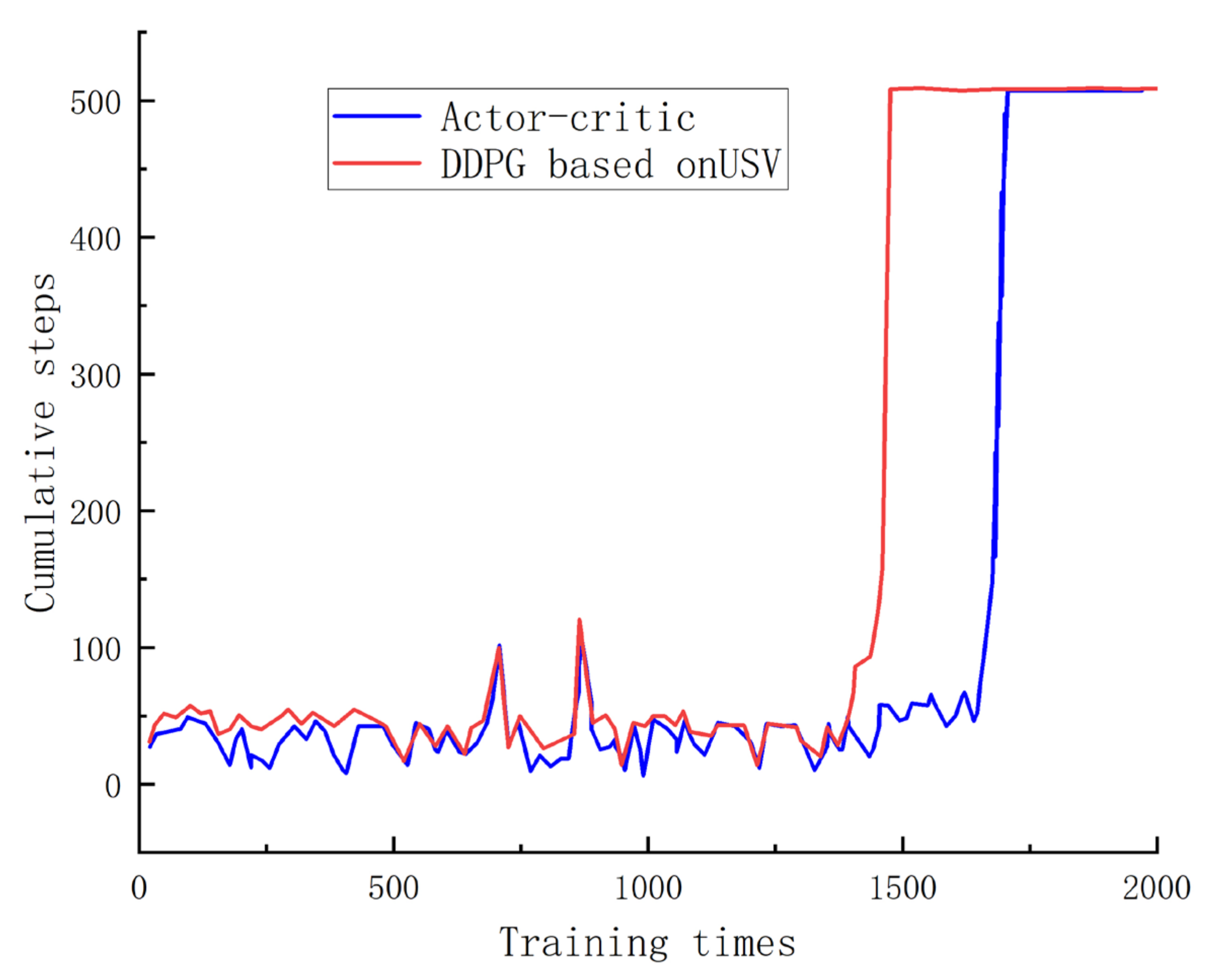
Figure 6 illustrates the correlation between the sum of training steps and cumulative step size. An examination of this figure reveals that the DDPG completes path planning sooner as the training steps are augmented, whereas the AC algorithm accomplishes it later. This pattern indicates superior convergence with the DDPG algorithm in comparison to the AC algorithm.
Table 4 provides statistical information gathered from the simulation experiments. From these data, it can be inferred that the average return of USV-focused DDPG training exceeds that of the traditional full Actor–Critic approach and far exceeds that of the A-star algorithm. In addition, the average number of steps is significantly reduced, the path lengths are shorter, and the frequency of turns is significantly reduced when training with DDPG compared to the paths generated by Actor–Critic as well as the paths generated by the A-star algorithm.
According to the above simulation results, it is obvious that the USV-based DDPG algorithm performs well on the path planning task. Its average reward is 170.65, which is significantly higher than the 163.70 of the Actor–Critic algorithm and 105.63 of the A-star algorithm, which indicates that the algorithm is more successful in selecting effective paths.
In addition, the USV-based DDPG algorithm also outperforms the other two algorithms in terms of the average number of steps, path length, and number of turns. Its average number of steps 366.42 is much less than Actor–Critic’s 432.78 and A-star’s 537.51, indicating that DDPG is more efficient in reaching its destination. Also, the DDPG algorithm has a shorter path length of 2315.76 than the other two algorithms, which indicates that it finds a more direct and optimized path. The most obvious is the number of turns, which is only 3 for DDPG compared to 19 for Actor–Critic and 6 for A-star. A lower number of turns means a smoother and more continuous path, which is very important for unmanned vessels in real-world applications, as too many turns may lead to increased energy consumption and navigation difficulties.
In summary, the USV-based DDPG algorithm excels in obtaining rewards and also outperforms other algorithms in terms of efficiency, path selection, and stability. These results strongly support the use of the DDPG algorithm in unmanned vessel path planning, especially in applications that require fast, efficient, and stable paths.
5. Conclusions
This study provides an in-depth comparison and analysis of the performance of multiple path planning algorithms, including USV-based DDPG, Actor–Critic, and A-star algorithms in a simulated environment. The data show that USV-based DDPG outperforms the other methods in terms of average reward, average number of steps, path length, and number of turns.
Firstly, USV-based DDPG shows significant improvement in average reward compared to other algorithms, which indicates its superior performance in path-planning tasks. Also, its average step count and path length are much lower than other algorithms, which indicates that it can find paths faster, and the paths that have been found are more concise and direct. In addition, USV-based DDPG makes far fewer turns than Actor–Critic, which further proves the efficiency and accuracy of its path planning.
Although the Actor–Critic and A-star algorithms also have their advantages in some aspects, the USV-based DDPG undoubtedly demonstrates its superiority in terms of overall performance. This may be attributed to its deep reinforcement learning nature and specific optimization of USV.
However, any research has its own limitations. In future work, further efforts shall be made to explore different model parameters and settings so that the performance of these algorithms in different contexts can be fully evaluated.
Overall, this study provides valuable insights into the comparison of path-planning algorithms in simulated environments and provides a solid foundation for future research and practical applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}