1. Introduction
The implementation of grasping technology is crucial for the intelligent automation of robots. Achieving robust grasping requires performing scene sensations, motion planning, and execution control simultaneously for the robotic arm. Grasping tasks are frequently used in structured scenes. Despite this, accurately perceiving the target object in unstructured environments, such as complex backgrounds, and predicting rapid and precise grasping remain challenging problems.
In the past, traditional methods that studied the physical geometric models and kinematics of objects were used to determine grasping poses. These methods are not robust enough to be applied to real-world scenarios [
1,
2,
3]. Recently, deep learning methods have shown promising outcomes in detecting grasps for robots. Deep convolutional neural networks can learn to extract features suitable for specific tasks by simplifying the grasp detection problem definition [
4,
5], thus circumventing the need for manual feature design. Recent researches focused on utilizing convolutional neural networks (CNNs) for grasp detection [
6]. Although these methods show satisfactory performance on simple single-object grasp detection tasks (e.g., Cornell dataset), there is still significant potential for grasp detection performance in complex life scenes. As illustrated in
Figure 1 involving object overlapping and cluttered patterns, the CNN-based grasping network [
7] was unable to achieve appropriate poses when grasping a screwdriver or a stapler. There may be two main reasons why these features have not been fully explored yet. The first is that datasets containing them have not been proposed so far, and the other is that the inherent nature of CNNs limits grasp detection performance (e.g., smaller sensory fields, generalization capability) in real-life situations, which usually contain complex backgrounds with cluttered objects. Thus, in this work, we were particularly motivated to investigate grasping detection considering real-life scenarios and better generalization capabilities, using only existing public datasets.
In this work, a proposed grasping model combines transformer and CNN effectively, modeling both local and global perception, while emphasizing the distinction between graspable objects and complex backgrounds. The self-attention mechanism links information within image patches. Within our framework, the feature fusion bridge (FFB) captures discrete low-level features that are then aggregated into multi-scale high-level semantic features. High-level features are incorporated by the grasping CNN to determine the final grasping pose within complex backgrounds. Experimental results show that the algorithm has good performance in balancing accuracy and computing cost on popular grasping benchmark datasets, e.g., Cornell and VMRD. For complex backgrounds with strong interferences, our method shows much more superior grasp detection performance than the CNN-based method [
7]. In summary, the main contributions are as follows:
We propose a combination of transformer and grasping CNN to be applied to predict grasps in complex backgrounds.
An effective feature fusion bridge is used to smooth the transition from the transformer to CNN, enabling multi-scale feature aggregation.
We evaluated our model on public benchmark datasets, Cornell and VMRD, and achieved excellent accuracy of 97.7% and 72.2%, respectively.
We collected images from real scenes to prove the effectiveness of the proposed method. Experimental results demonstrate that our model is able to make more-appropriate grasping judgments than the raw grasping CNN in complex scenes.
2. Related Work
To enable robots to determine optimal grasp angles and opening distances, it is necessary to have accurate modeling of the position, posture, and contour information of objects for precise grasp detection. Due to the constantly changing and complex characteristics of robot work environments, extracting and mapping relevant features is critical for effective object–background discrimination.
Earlier methods for grasp detection primarily relied on non-data-driven traditional algorithms, including analytical approaches. Such approaches analyze the surface properties of objects related to friction at contact points and apply geometry, kinematics, and dynamics to calculate corresponding grasps [
2]. Despite their potential advantages, such approaches can be challenging to apply in real-world settings primarily due to their requirement for manually engineered features.
Recently, learning-based approaches have gained widespread attention and become the primary focus of research in grasp detection [
4,
5,
8,
9]. Supervised learning is employed to fit detection models in the dataset, allowing direct prediction of the grasp from the image [
8,
9], without the need to construct a three-dimensional model of the object. A new five-dimensional grasp rectangle representation is proposed in [
4] as an alternative to the grasp point prediction model. This representation includes the grasp center point, the opening distance of the end effector, and the rotation angle, directly replacing the grasp representation based on three-dimensional space. The optimum grasp region is determined using a cascaded two-stage support vector machines (SVM) classifier. The deep learning method based on neural networks has achieved great advantages in image classification [
10], and Lenz [
5] introduced deep neural networks (DNNs) as the grasp detection classifier, designing a two-stage DNN to avoid manual feature design and improving the generalization ability of the model. Each potential grasp rectangle is evaluated and ranked. Based on the oriented rectangle, grasp detection is similar to object detection in computer vision, so many classic CNN structures [
10,
11,
12] are applied in grasp detection research to improve the algorithm performance. In [
6], Redmon proposed a one-stage grasp detection network based on AlexNet, treating the calculation of the grasp rectangle as a regression problem, and achieved feature extraction and grasp rectangle prediction evaluation solely based on object image information. Furthermore, S. Kumra [
13] utilized ResNet-50 [
11] to extract features on the image and used linear SVM as the prediction classifier to predict the object’s grasp configuration from the features extracted from the last hidden layer of ResNet-50. Similarly, using CNN structures, ref. [
7] encodes the input image’s features with downsampling convolution layers, increases network depth and abstract generalization ability with ResNet modules, and decodes pixel-level grasp prediction with upsampling layers.
To summarize, existing research on grasp detection using deep learning technology primarily relies on commonly used CNN models for object detection like AlexNet, VGGNet, and ResNet. However, grasp detection and object detection differ significantly in their application scenarios. The former has more diverse application scenarios, and therefore, the grasp configuration of objects is complex and variable, requiring stricter parameters for grasp angle and position.
The VIT [
14] replaces the traditional CNN model with the transformer [
15] to extract image features. It proposes an end-to-end detection architecture that exhibits excellent performance in image classification tasks. The transformer has become a new paradigm in computer vision due to its exceptional ability to model long sequences and extract global features. Wang [
16] demonstrates the feasibility of using the transformer for grasp detection tasks. It does so by proposing a transformer-based grasp detection model that utilizes an encoder–decoder architecture with skip connections.
Previous works have solely focused on grasping in normal scenes and not thoroughly investigated grasping in particular scenes. In such instances, it is essential to enhance the model’s feature extraction and mapping abilities to distinguish objects from diverse environments accurately. This paper focuses on detecting grasps in complex backgrounds. We propose a hybrid method that utilizes both the grasping CNN and transformer for better performance, which has not yet been considered. We introduce self-attention to model global features based on the existing grasping CNN. This approach combines the benefits of each and achieves grasp detection in complex scenes with strong interferences. The results indicate that our method makes more accurate grasping judgments than the CNN model.
3. Problem Definition
For vision-based grasp detection, a visual sensor captures a multi-channel image that includes the object under consideration, while assuming the existence of multiple workable grasping configurations within the image. In this work, we employ an improved variant of the grasp rectangle representation as proposed in [
17]. Specifically, in the case of a parallel-jaw gripper, a grasp rectangle is defined by the position and orientation of the end effector concerning the target object, as well as the quality of the grasp when executed.
where p = {x, y, z} is the center coordinates, σ represents the clockwise rotation angle around the Z-axis,
is the grasp rectangle width and height in the robot frame where
also means the opening width of the end effector, and q is the grasp quality score.
The grasp representations in an image frame are given by:
where
and
denote the center coordinates of the grasp rectangle in the image frame,
represents the rotation angle in the image frame,
denotes the grasp rectangle width and height in the image frame, and q is the same as in Equation (1).
Different from the 5-dimensional grasp in [
4,
6,
13], the grasp quality q expresses the probability of a successful grasp, which is similar to the sample confidence in object detection. In detail, for each pixel, a floating number from 0 to 1, corresponding to the pixel position, is found and quantifies a grasping success, with values close to 1 indicating a higher likelihood.
represents the rotation angle during grasping, with a range defined as [
].
To execute a grasp, the map between the image frame and the robot frame needs to be established, as in the following:
where
is the transform matrix from image frame to camera frame, which is related to the focal length
of the camera.
is the transformation matrix from image frame to robot frame, consisting of a rotation matrix
with a translation matrix
.
is obtained by camera calibration [
18] and
by hand–eye calibration [
19].
In the implementation, we calculate each pixel point of the grasping rectangle to obtain the position in the robot frame. The specific calculation process is as follows:
where
is the depth in camera frame, directly given by the depth camera.
is the point in camera frame.
4. Method
4.1. Overview
The transformer-based visual model proposed in [
20] demonstrates remarkable resilience to severe occlusion, disturbance, and displacement. Taking cues from VIT, we endeavored to leverage the transformer to enhance the contrast between global and local during grasp detection. Furthermore, we designed an efficient and intuitive way to link the transformer with grasping CNN for feature fusion.
An overview of the grasp model is depicted in
Figure 2. We have designed a symmetric structure based on a transformer to effectively map features between parts and the whole in complex backgrounds. More specifically, the input, which is a 2D image, is divided into non-overlapping patches, resulting in a sequence of image-related vectors that act as tokens. These sequences act as the input of multiple attention layers, providing a more comprehensive analysis of the parts and the whole. Additionally, we reshaped the flattened output sequences into the raw size by using a trainable linear projection. These sequences are then concatenated in their original positions, bridging the gaps between the transformer and CNN, resulting in better multi-scale feature fusion. Finally, at the top of the model, the grasping CNN receives the output of the projection as input to predict potential grasps.
4.2. Transformer-Based Feature Extraction
The standard transformer is strict about the size of the input, taking as input a 1D sequence of token embeddings. Before being fed into the transformer blocks, the input is evenly cut into flattened 2D patches of the image, and then each is resized into the 1D shape through a projection layer, which yields the vector sequences as the tokens for the contiguous transformer blocks. Specifically, a visual image is divided into equally sized patches , where is the resolution of the original image, C is the number of channels, P represents the size of each patch, and represents the number of total patches. The immediately following projection layer flattens and maps these image patches within D dimensions, an effective input sequence length for the transformer.
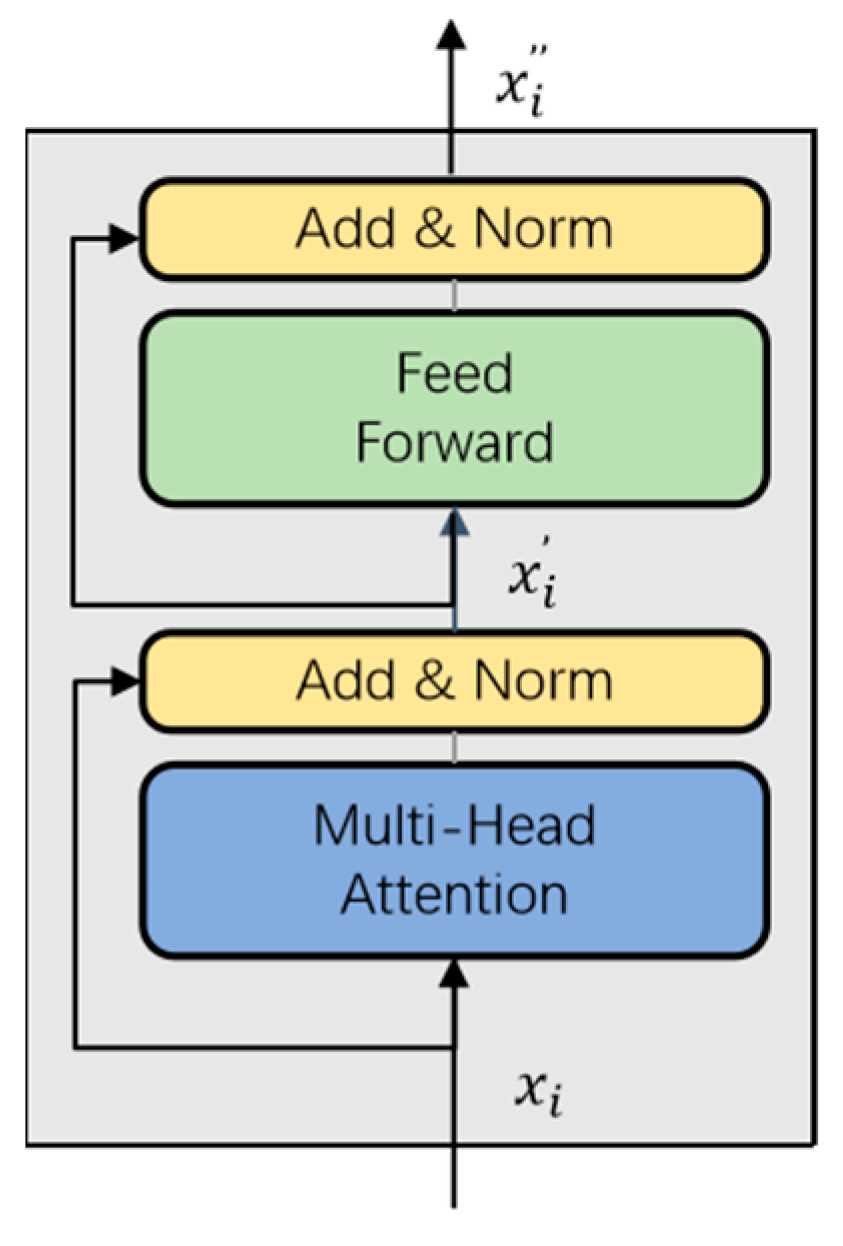
The attention mechanism in the transformer is a crucial component that improves the comparison and combination of local and global features. It has the ability to establish interactions across pixels, regardless of their spatial distance. The structure of the transformer block is presented in
Figure 3.
In particular, we used multiple-head attention (MHA), which does not share the corresponding parameters, provides flexibility on different features, and reduces processing time due to parallel computing. The attention between image tokens is as follows:
where the Q, K, and V vectors are obtained by multiplying the tokens
by the corresponding weight matrix
,
is implemented by the fully connected layer, and d is a scale parameter.
For grasp detection in complex backgrounds, the transformer is very helpful with visual awareness. As with [
14,
15], we rigorously stacked the equal-sized transformer blocks to extract features from images of complex backgrounds. Accounting for the model runtime matching grasp detection in real-life settings, different sets of parameters were carefully designed to create a delicate balance between speed and accuracy without poor imitation; more details are described in the experiments section. The transformer-based feature extraction uses constant latent vector size D through all of its layers and ends up with the token vectors of the same size as the input
, with more holistic semantic information, through a forward propagation. The computation steps of the transformer block are represented as follows:
where
denotes the output from the previous layer. LN refers to layer norm that normalizes each sample rather than a batch, and FFN is a simple fully connected network.
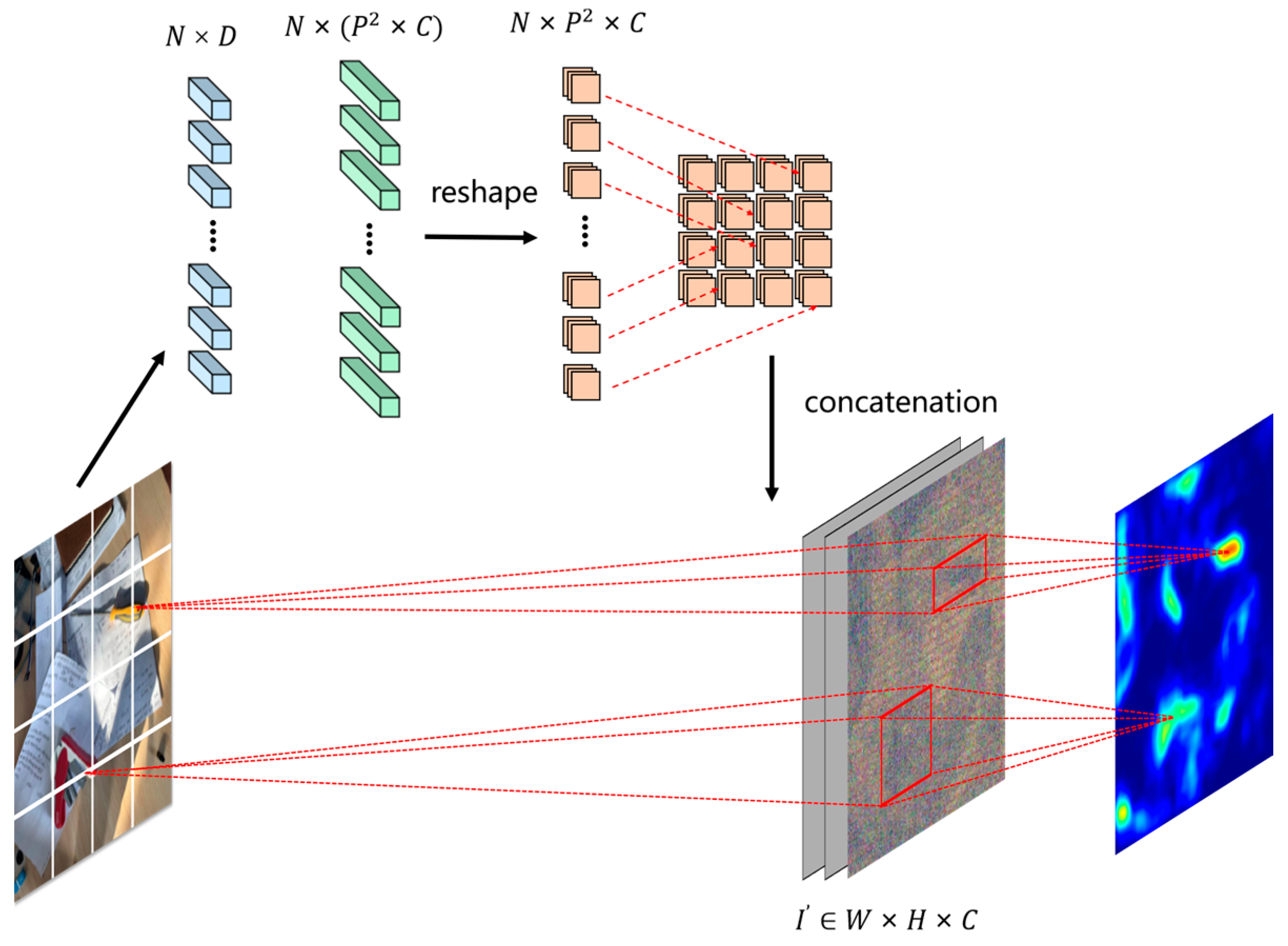
4.3. Feature Fusion Bridge
Previous works on the visual transformer separated the output patch tokens and directly utilized them for different detection heads, such as classification. However, this method is not suitable for grasp detection, particularly in complex backgrounds, as partial aggregation can lead to a loss of better information representation. We figured out a more efficient way to connect that ensures all parts of the model remain in order, while also focusing on the object’s grasp.
In general, the classical transformer relies on flattened 1D sequences, while CNN requires at least 2D, such as an image. To handle that, firstly we used a fully connected layer to adjust the output sequence features of transformer blocks to the original patch token size
, defined as:
where w represents the weight parameters, b represents the bias, and then the tokens
are reshaped into small-scale patch feature
, each of which is an integration of its own location and of the whole. We arranged these vectors according to the spatial position of the original patches to obtain a feature map with the same resolution as the original image
, as shown in
Figure 4.
An advantage of this approach is that all token features are aggregated at the same time in one forward propagation, preserving more global features, and another is that it is not affected by the input patch size of the transformer, because it always corresponds to the input, forming a symmetric structure.
4.4. Grasping CNN
We used GR-ConvNet [
7] as the grasping CNN, which can directly output pixel-level grasping end-to-end without setting prior boxes, as shown in
Figure 5. The network consists of down-sampling layers, residual layers, and up-sampling layers, forming a symmetric encoder–decoder structure. Four grasping detection heads are naturally integrated into the end of the network, generating pixel-wise grasp predictions, outputting the grasp quality feature map
, the gripper angle feature maps including
and
, and the gripper opening width feature map
.
The grasp quality map is composed of 0 to 1, representing the possibility of grasps at the corresponding pixel. The and indicate the rotation angle and opening distance of the grasp, respectively.
4.5. Loss Function
Given the input image I, the model predicts a set of grasp pixel heatmaps
, and the ground truth map
is set to the same format as the grasping CNN’s outputs. We trained the model by calculating the Smooth
L1 loss between the prediction and labels, treating the grasp detection problem as a regression problem, which is beneficial for algorithm implementation. The loss function is defined as follows:
where Smooth
L1 is defined as
5. Experiments
In this section, we conducted extensive experiments to validate the potential improvement of the suggested structure in grasp detection. We evaluated this on public grasp datasets such as Cornell [
5] and VMRD [
21]. We used different parameter sets to determine the optimal performance of the proposed structure on various datasets. We also explored different training strategies to comprehend the data requirements of each model. Moreover, we collected real-world images to demonstrate that the proposed FFB structure improves grasp detection performance, particularly when dealing with complex backgrounds.
5.1. Datasets and Implementation Details
The Cornell dataset [
5], consisting of 885 images, each containing one grasping object from 24 different object categories, has been widely used for grasp detection. Due to the small size of the original dataset, we performed data augmentation, including random cropping, scaling, and rotation, to meet training requirements. Additionally, we conducted experiments on a bigger and more complex multi-object dataset, the VMRD [
21], to validate the model. The VMRD, consisting of 5185 images containing 17,688 object instances from 31 object categories, provides 51,530 manipulation relationship labels in total. Some examples of the datasets are in
Figure 6. In the experiment, all ground truth grasping boxes were used to involve training.
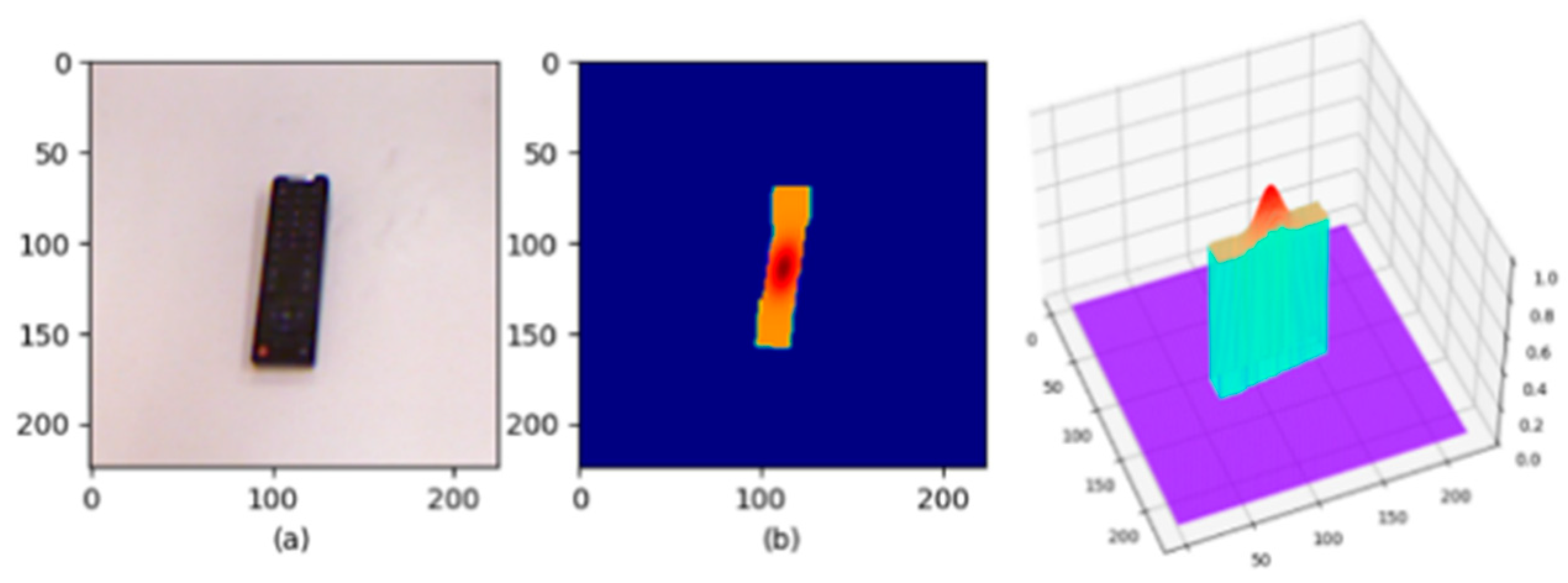
Two-Dimensional Gaussian-Based Grasp Augmentation: The dataset images were cropped, scaled, and normalized to match the input of the model. For the grasping quality ground truth, previous research [
7] filled the grasp rectangle pixels with 0 and 1, assigning equal probabilities to the object edge and center. In [
22], a Gaussian kernel was used to encode the grasp representation and highlight the object center. Furthermore, we adopted and expanded by using a 2D Gaussian kernel to adjust the grasp label at the pixel level in the grasp quality ground truth
. This method not only identifies the object’s center position but also provides some orientation, as shown in
Figure 7.
Specifically defined as:
where
where d = 2 represents the dimension of the vector;
represents
of the mean;
is the covariance matrix, describing the correlation of
.
The covariance matrix is set empirically to conform to the orientation of objects in the data set as much as possible.
Training configuration: The entire grasp system was achieved using Pytorch 1.11.0 with CUDA 11.3 packages on Ubuntu 20.0. During the training period, the model was trained end-to-end on an AMD Ryzen 5 5600X CPU and an Nvidia RTX3080Ti GPU with 12 GB of memory.
Training schedule: We used a three-stage training strategy for the models. First, the grasping CNN of the model was trained on target datasets alone; the best-performing weights were used for the next stage of training. Second, we froze the CNN section and trained the rest sections including the transformer block and the FBB. Third, finally, we unfroze the grasp CNN and trained the entire model end-to-end. During the training process, the stochastic gradient descent (SGD) optimizer was used to optimize the model’s backpropagation, with an initial learning rate of 0.001 and a learning rate decay of 0.1.
For the Cornell dataset, the batch size was set to 16, and the model was trained for a total of 200 epochs, with 50 epochs for the first stage, 50 epochs for the second stage, and 100 epochs for the final stage. For the VMRD, the batch size was set to 8, and the model was trained for a total of 500 epochs, which were split into 100, 150, and 250 epochs, respectively, for each stage. In each training phase, we periodically saved the weight of the model and tested it, and proceeded to the next phase of training when the performance had leveled off.
5.2. Model Variants
We carefully implemented the transformer parameter configurations, without relying on the basis, to determine the potential of the proposed model, as summarized in
Table 1. The resolution of the transformer is affected by the input patch size. Smaller patch sizes will divide the original image more carefully but with a higher computational expense. In this study, we primarily set the input patch size of the transformer blocks to 7 × 7 to achieve more accurate grasp detection. Additionally, we scaled the models by adjusting the hidden size, MLP size, and depth to balance accuracy and computation on the Cornell dataset and VMRD.
5.3. Metrics
Similarly to previous works [
6,
7,
17], we adopted the same evaluation metrics to assess the performance of our model. Specifically, a predicted grasp was considered feasible when it satisfied the following conditions:
- (1)
The angle difference between the predicted rectangle and the annotated rectangle is less than 30°.
- (2)
The intersection over union (IOU) score between the predicted rectangle and the annotated rectangle is more than 25%.
where A is the grasp rectangle label and B is the predicted grasp rectangle. When the overlapping areas of the two are similar and the direction is the same, it is considered to be a good grasp.
5.4. Experiments on Cornell Dataset
Following five-fold cross-validation as in previous works [
7,
16,
22], we used the image-wise split method to test our model, where all images in the dataset were randomly sorted, and the average of five-fold cross-validation was the final result.
Results: We chose the best-performing of all parameter configurations, regardless of calculation cost.
Table 2 shows the performance of our method compared to other works on the Cornell dataset. In the single-object dataset, our proposed model achieved a detection accuracy of 97.7% by taking RGB images as input, outperforming other algorithms. We used GR-ConvNet as the grasping CNN with an inference time of 2.8 ms. Compared to the algorithm in [
16], the proposed transformer-based feature extraction structure only required 1.7 ms, and the total inference time of our model, 4.5 ms, was acceptable and met real-time requirements.
For the single-object grasping Cornell dataset, the highest score point in the quality map was set as the center of the grasping rectangle to obtain the corresponding width and angle. For the selected grasping pixel point, its index was recorded to find the width and angle of the corresponding position. Half of the width was set to the height of the grasp rectangle, and its corner points were easily solved with the angle value. The grasp detection results are visualized in the fourth row. The proposed method provides feasible grasps for objects with different shapes and positions, as shown in
Figure 8.
5.5. Experiments on VMRD
We used the VMRD to test the performance of our model on multiple objects and stacked objects, which better aligns with real-world task requirements. As in [
24,
25,
26], we employed the same dataset partitioning method provided by [
21]. The images in the dataset were resized to 224 × 224 to be fed into the model, and we evaluated the model’s performance in multi-object contexts by selecting the top three grasping candidates with the highest quality score. Meanwhile, we set the pixel distance threshold to avoid overlapping when selecting the most suitable pixel point.
Results: The comparison of our proposed method with other works on the VMRD dataset is shown in
Table 3. In [
24,
25,
26], grasp detection is defined as a two-stage method based on object detection, which complicates the model computation and increases inference time. We tested the one-stage detection method [
7] on the VMRD dataset, and our proposed model achieved a 4.5% performance improvement compared to [
7], demonstrating better detection accuracy. The grasp detection examples on the VMRD dataset are shown in
Figure 9, and we drew the top three grasping boxes of each sample.
5.6. Ablation Study
In Subsection B, the parameter configurations of the transformer layers in the model are described in detail. To further explore the impact of different configurations on grasp detection, we conducted experiments on the Cornell dataset and VMRD separately; the detailed experimental results are shown in
Table 4 and
Table 5. The P, H, M, and L represent patch size, hidden size, MLP size, and layer, respectively.
On Cornell: Five parameter configuration sets were tested on the Cornell dataset to verify the impact of different parameters on the proposed model. For a small dataset such as Cornell, the accuracy of the model was not improved significantly; with the growing parameters, the transformer-based feature extraction structure with small-scale parameter configuration can achieve excellent grasp detection accuracy.
On VMRD: For the larger and more complex dataset, the VMRD, the smaller models hardly fit well. Just stacking transformer layers singularly may not improve the performance further when the hidden size and MPL size are not large enough. The key to improving performance is to scale up the size, but that made the model bloated. We failed to achieve good results in the case of small size H and M (H = 256, M = 512). Instead, with increasing size, the proposed model achieved better detection accuracy, while the 2D Gaussian-based grasp representation also played a positive role.
5.7. Generalization Capability
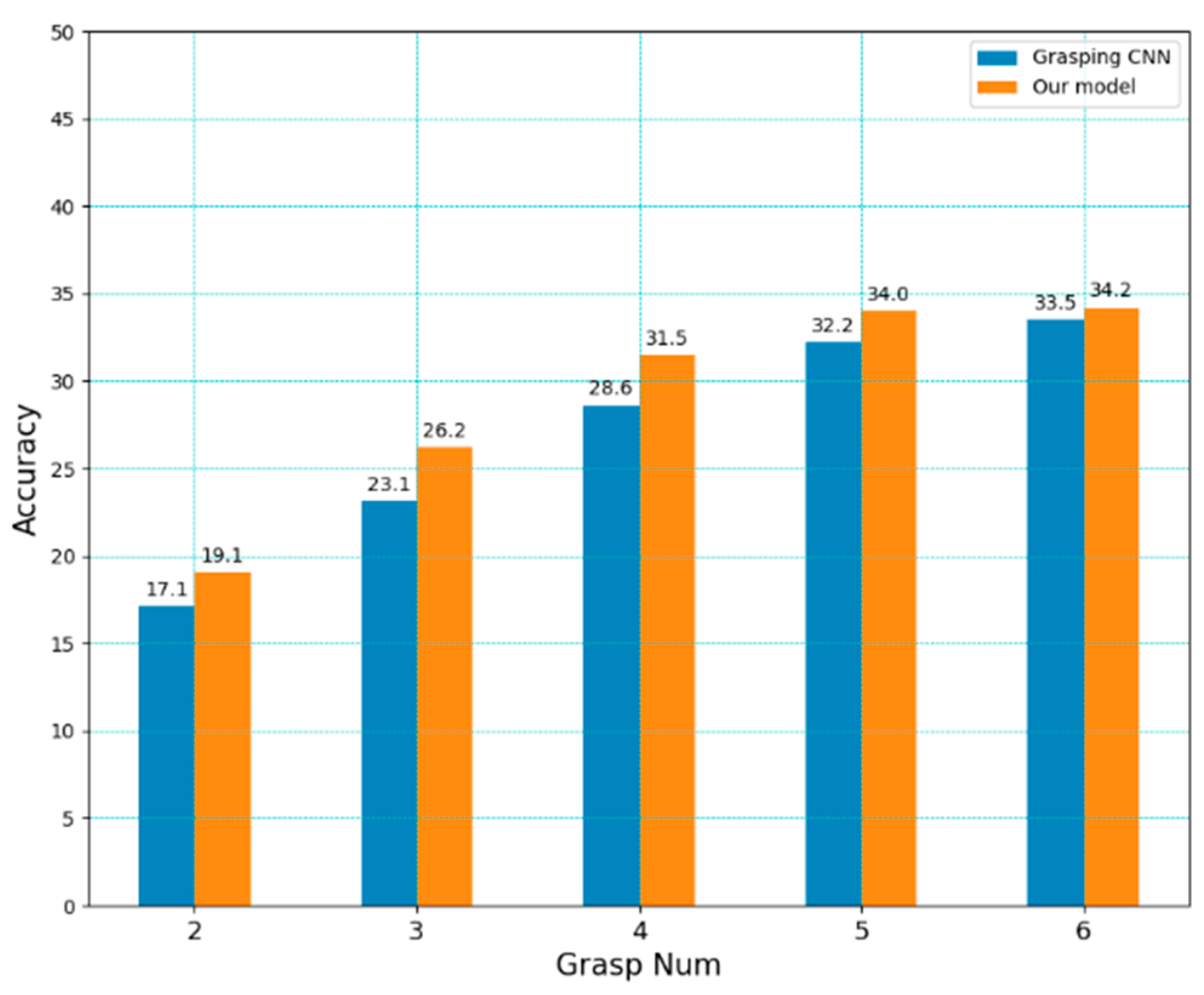
The generalization capability of the model is critical in determining its practical applicability during grasp detection. To compare the generalization capability of the proposed model with that of CNN, we used the optimal weights of both models as grasping feature extractors on the Cornell dataset and tested detection accuracy on VMRD. Note that the models were trained only on the single-object Cornell dataset, and the multi-object VMRD was not part of the training phase.
Figure 10 shows the generalization capability of different models for multi-object grasp detection. The models detected multiple grasping rectangles at once, and we selected the top N as the final result. As shown, even though both used the same Cornell dataset, our model showed better accuracy and generalization performance for multi-object grasp detection.
5.8. Grasp Detection in Complex Backgrounds
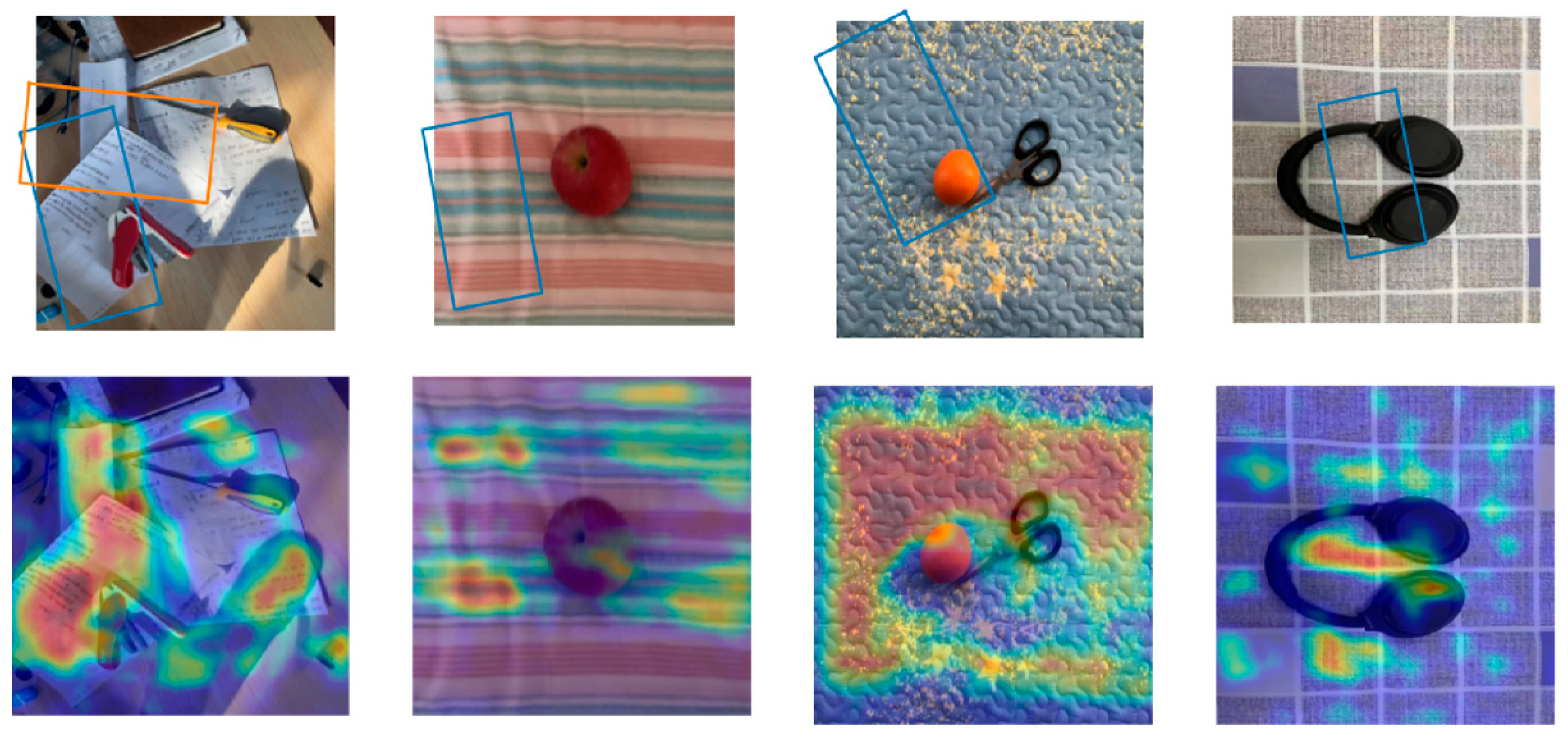
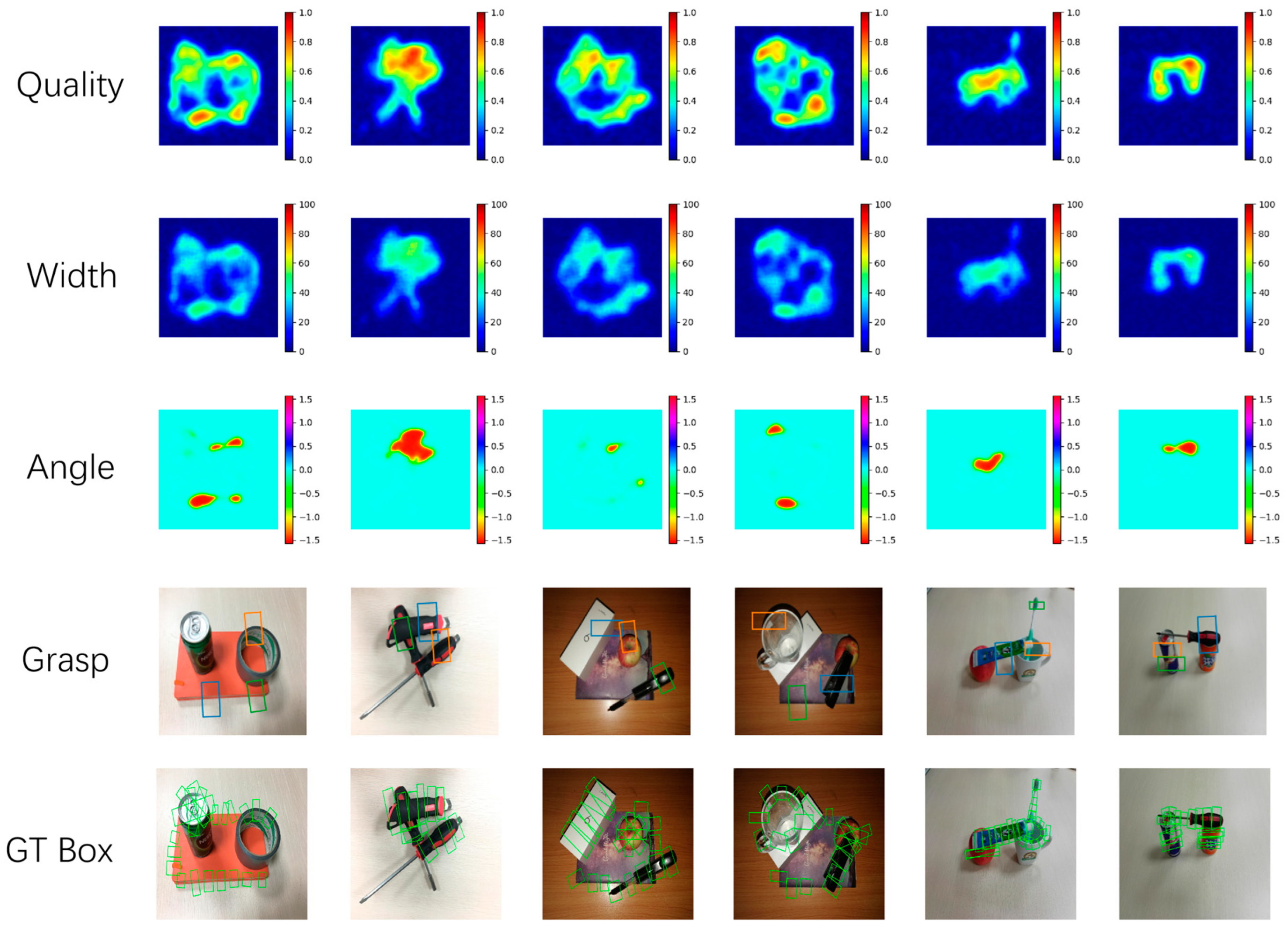
Our main objective was to enable the application of the grasp detection model in complex backgrounds. To evaluate the capabilities of our model in these scenarios, we captured real-life images with objects placed in complex backgrounds and assessed its performance using the model trained on the Cornell dataset, as shown in
Figure 11. To help better understand how the proposed model makes grasping judgments about objects, we visualized the heatmap of the quality feature map, as show in the second and fourth rows.
The validity of the FFB: Is the proposed structure, which comprises transformer blocks and the bridge structure, effective for identifying prediction? To address this question, we visualized the output feature maps of the proposed structure to examine their impact during the prediction process. The visualizations are shown in the fifth row. It is apparent that the proposed structure’s output demonstrates a high degree of similarity to the quality feature map, indicating a significant impact on the final detection results.
Furthermore, we tested the grasp detection performance of the proposed method in more complex backgrounds. These scenes contained wide ranges of irregular patterns, or orderly arranged color patterns. These patterns are difficult to be mitigated by traditional image processing methods and cause strong interference for detection. The results are as shown in
Figure 12.
For Scenes II and III, our model could easily detect suitable grasps. For Scenes I and IV, the more complex patterns in the background became an obstacle, and our model only responded positively to part of the objects. Even though it was trained on the simple single-object Cornell dataset, it showed advantages compared to the grasping CNN.
The experiments showed that our method can model the relationships between objects and the entire scene, as it induced and expressed the visual relationships between object features and background configurations. These designed structures positively impacted the grasping prediction and visually exhibited a segmentation-like effect.
5.9. Failure Case Discussion
In the experiments, a few inappropriate grasping poses could not be ignored. As shown in
Figure 8 and
Figure 11, for irregularly shaped objects like scissors, the correct grip should be perpendicular to the edge. Our model failed to predict the correct grasping position and fell short for complex-shaped objects. Additionally, in
Figure 12, it failed to detect small-scale objects in more complex scenes. This problem could be mitigated by adding objects with more-challenging shapes to the training data or using multimodal data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}