Abstract
The current visual simultaneous localization and mapping (SLAM) systems require the use of matched feature point pairs to estimate camera pose and construct environmental maps. Therefore, they suffer from poor performance of the visual feature matchers. To address this problem, a visual SLAM using deep feature matcher is proposed, which is mainly composed of three parallel threads: Visual Odometry, Backend Optimizer and LoopClosing. In the Visual Odometry, the deep feature extractor with convolutional neural networks is utilized for extracting feature points in each image frame. Then, the deep feature matcher is used for obtaining the corresponding feature landmark pairs. Afterwards, a fusion method based on the last and the reference frame is proposed for camera pose estimation. The Backend Optimizer is designed to execute local bundle adjustment for a part of camera poses and landmarks (map points). While LoopClosing, consisting of a lightweight deep loop closure detector and the same matcher as the one used in Visual Odometry is utilized for loop correction based on pose graph. The proposed system has been tested extensively on most of benchmark KITTI odometry dataset. The experimental results show that our system yields better performance than the existing visual SLAM systems. It can not only run in real-time at a speed of 0.08 s per frame, but also reduce estimation error by at least 0.1 m.
1. Introduction
In the last two decades, simultaneous localization and mapping (SLAM) has become a hot area of research in robotics and computer vision. It is a fundamental module for many applications such as mobile robotics, Micro Aerial Vehicles (MAVs), autonomous driving and augmented reality because they all require real-time localization [1]. SLAM techniques use the information acquired by the sensor to build a map of an unknown environment and localize the sensor in the map. Visual SLAM has been widely studied because of the camera’s low price and its ability to acquire rich information about the environment [2,3,4,5,6,7,8].
Most of the currently used Visual SLAM systems rely on hand-crafted visual features [9,10,11,12,13,14]. For example, ORB-SLAM [9,10] performs feature matching and loop closure detection by extracting ORB [15] features in each image frame, and then estimates the camera pose and constructs a map of the environment. However, hand-crafted features may fail to provide consistent feature detection and accurate matching results in complex environments.
With the development of deep learning, feature extraction based on deep neural network (DNN) has replaced hand-crafted features as the mainstream of relevant research [16,17,18,19,20]. DNN-based features have also been widely used in the design and research of visual SLAM systems. For example, Tang et al. [21] designed the GCN-SLAM based on Geometric Correspondence Network [22], Li et al. [23] proposed the DXSLAM based on HF-Net [24], and Deng et al. [25] used a visual SLAM for autonomous driving based on SuperPoint [26]. Although these works have improved the performance of visual SLAM systems by using DNN-based features instead of hand-crafted features, these systems may not be able to track feature points continuously well. This is because they employ the same feature matching method used for hand-crafted features. Such a design severely limits the performance of the system.
To solve the above problems, this paper proposes a visual SLAM system that uses a deep feature extractor, a deep feature matcher, and a lightweight deep loop closure detector. Figure 1 and Figure 2 show the results of some runs of the proposed visual SLAM on the KITTI odometry dataset. The main contributions are as follows:

Figure 1.
The proposed SLAM estimates camera trajectories on 00 of the KITTI odometry dataset (top view).

Figure 2.
The proposed SLAM estimates camera trajectories on 00 of the KITTI odometry dataset (side view).
- A novel Visual Odometry was proposed by reconstructing SuperPoint [26] and SuperGlue [27] as SG-Detector and SG-Matcher and combining them with a fusion estimation method based on last and reference frame for a camera pose.
- A deep LoopClosing module was designed by combining Seq-CALC [28] and SG-Matcher.
- Compared with many existing SLAM systems, the proposed SLAM system reduces estimation error by at least 0.1 m on the KITTI odometry dataset, and it can run in real time at a speed of 0.08 s per frame.
- The rest of the paper is organized as follows. In Section 2, some related work is presented. In Section 3, the system architecture of our visual SLAM and the design principles of each module are explained in detail. In Section 4, the experiments used to test our system are described and the experimental results are analyzed in detail.
2. Related Work
In this section, we review the existing related work in the following three areas: feature extractions for visual SLAM, deep feature matching, and loop closure detection.
2.1. Feature Extractions for Visual SLAM
Many existing visual SLAM systems generate feature pairs for localization and map building by extracting features in each image frame and matching the extracted features between different image frames. For example, ORB-SLAM2 [10] extracts ORB features [15] in each input image frame, constructs corresponding descriptors, and matches these features in the current frame with reference frames and local maps by the Hamming distance between descriptors. Stereo LSD-SLAM [11] treats high-contrast pixels in input image frames as features and matches the features between image frames based on the photoconsistency of all high-contrast pixels. SuperPoint-SLAM [25] uses SuperPoint (a fully convolutional neural network) [26] to extract features and descriptors, and matches these features across image frames by the Euclidean distance between descriptors.
2.2. Deep Feature Matching
Deep-neural-network-based features have gradually replaced hand-crafted features in many computer vision tasks, since simple feature matching methods based on geometric distances between descriptors can no longer achieve satisfactory matching performance. For example, Han et al. proposed MatchNet [29] to use a neural network consisting of three fully connected layers to learn the learned distance metric for feature matching. Sarlin et al. proposed SuperGlue [27] to match two sets of features by using attention graph neural networks and an optimal matching layer. Sun et al. [30] proposed to match local features of two images directly without feature detection by using Transformers [31] (a special class of graph neural networks [32]).
2.3. Loop Closure Detection
Loop closure detection (LCD) requires to recognize a previous visited place from current camera measurements [33]. Most of the current mainstream visual SLAM systems use bag of words (BoW) for LCD. The BoW builds vocabulary trees is based on different point features. As proposed by Gálvez-López et al., DBoW [34] uses the BoW generated by training with hand-crafted point features (e.g., SIFT [35], SURF [36], ORB [15]) to construct the visual vocabulary tree, and then uses the trained vocabulary tree for LCD in visual SLAM.
Recently, deep-neural-network-based methods have been gradually applied to LCD problems. For example, Nate Merrill and Guoquan Huang [37] proposed a very lightweight and effective autoencoder network. In order to simulate the natural variation caused by robot motion, they also added a random perspective transformation to the training data, which improves the performance of the unlabeled data set. Building on work [37], Xiong et al. [28] applied principal component analysis (PCA) to compress the dimensionality of descriptors and combined linear queries with fast approximate nearest neighbor search to reduce execution time and improve the efficiency of sequence matching.
3. The Proposed SLAM
The main idea of the proposed SLAM system is the combination of deep feature extractor, deep feature matcher and deep loop closure detector in the traditional visual SLAM pipeline. The deep feature extractor (SuperPoint [26]) provides stable feature points to the system. The deep feature matcher (SuperGlue [27]) provides consecutive pairs of correctly matched points required for pose estimation. The deep loop closure detector (Seq-CALC [28]) corrects the accumulated error of the system by detecting correct loop closure in the environment. The design of our system is greatly inspired by ORB-SLAM2 [10]. The system framework is illustrated in Figure 3, which consists of four main modules: Visual Odometry, Backend Optimizer, Map, and Loop Closing. It runs three independent threads: Visual Odometry, Backend Optimizer, and Loop Closing in parallel. These three threads synchronize data through the Map module, which is the database.
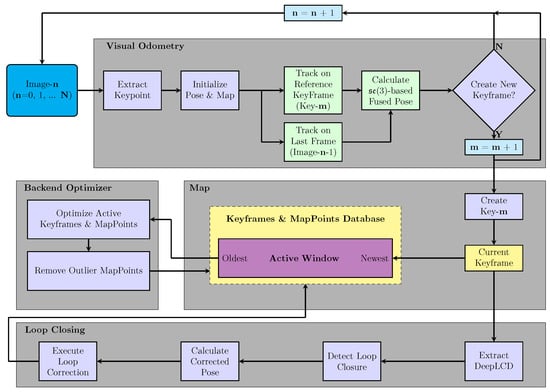
Figure 3.
The overall framework of the proposed visual SLAM system. Image- ( = 0, 1, …) is the current frame. Key- ( = 0, 1, …) is the current reference keyframe, which is created from previous image frames (such as Image--10). After estimating the pose of the current frame, Visual Odometry determines whether to create a new keyframe. The condition for creating keyframes in this system: the current frame has passed 10 frames from the image frame where the keyframe was last created, or the number of map points tracked in the current frame is less than 60%.
In the Visual Odometry, the extracted feature points are used to construct the initial map and calculate the initial camera pose, and then the map points in the reference frame and the temporary map points in the last frame are tracked by feature matching; then, the relative poses are calculated separately, and, finally, the two relative poses are fused and a new keyframe is constructed. The new keyframe is inserted into the Map as the current keyframe.
In the Backend Optimizer, the keyframe sequence and the set of map points in the activation window, intercepted by the current frame, are read to perform the local bundle adjustment optimization and remove the outlier map points.
In the Loop Closing module, a light deep loop closure detector is used to search the Map for the historical keyframes that form a loop closure with the current keyframe; then, the corrected poses of the current keyframe are calculated by feature matching, and finally the poses of the keyframes are corrected for the historical keyframes by the pose graph of the keyframes.
Further, we introduce this system in detail, from feature extraction and matching, (3)-based pose fusion estimation ((3), which is the Lie algebra corresponding to the special Euclidean group [38]), backend optimization, to loop closure correction.
3.1. Feature Extraction and Matching
SuperPoint [26] and SuperGlue [27] networks were used to build feature detector (extractor) and matcher in this system.
As illustrated in Figure 4, the KeyPoint Encoder module of SuperGlue and SuperPoint are combined to form a SG-Detector, and the remaining modules of SuperGlue are combined to form a SG-Matcher. This allows SG-Matcher the matching with only the input descriptors as traditional matchers used in visual SLAM pipelines.
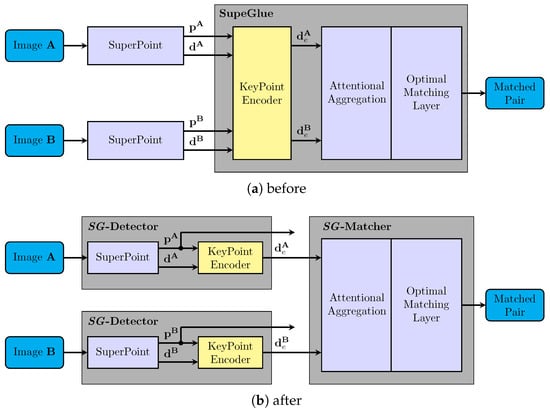
Figure 4.
Comparison of SuperPoint and SuperGlue networks before and after restructuring.
The SG-Detector is only used to propose keypoints (features) of the input image in Visual Odometry. The SG-Matcher is used to track map points in the reference keyframe and temporary map points from the last frame in Visual Odometry, as well as to calculate corrected poses in Loop Closing.
3.2. (3)-Based Pose Fusion Estimation
To further improve the performance of the system, we proposed a novel algorithm for relative positional fusion estimation over (3). The reason for choosing to perform pose fusion on (3) is that the pose can perform vector addition and scalar–vector multiplication on (3). For more details on (3), see [38].
To maintain the correlation of feature points across multiple frames and to control the size of the optimization problem, visual SLAM usually calculates the camera pose by tracking the map points of the reference frame, but tracking only the map points of the reference frame results in fewer feature–landmark pairs participating in pose estimation as the camera moves away from the reference frame, which degrades the pose estimation performance. Our (3)-based pose fusion algorithm uses the map points generated in the last frame so that there are enough feature–landmark pairs to participate in the pose estimation even when the camera is far away from the reference frame to ensure the quality of the estimation. Moreover, since the map points generated in the last frame are “temporary”, they do not increase the size of the optimization problem.
First, map points are tracked in the reference keyframe and temporary map points are tracked in the last frame using SG-Matcher. Then, we calculate the relative poses of the current frame relative to the reference keyframe based on the correspondence between the tracked map points and the keypoints of the current frame, and the relative poses of the current frame relative to the last frame based on the correspondence between the tracked temporary map points and the keypoints of the current frame. Lastly, the final relative pose is obtained by weighted fusion of and ( is the relative pose of the last frame w.r.t. the reference keyframe) on (3), and the absolute pose of the current frame ( is the absolute pose of the reference keyframe) is calculated, as shown in Equations (1) and (2).
where
where and are used to indicate the uncertainties of and , respectively, which can be obtained for free in the calculation of and . They are defined as follows:
where is the keypoint in the current frame corresponding to map point , and is the keypoint in the current frame corresponding to the temporary map point . The projection function is defined as follows:
with as the 3D point, and as the focal lengths of the camera, and as the principal point of the camera.
3.3. Backend Optimization
In the Backend Optimizer thread, the local BA optimization problem is constructed by reading the set of all keyframes in the active window of the Map and the set of all map points seen by these keyframes, as the following:
where is the huber robust kernel function, is the keypoint corresponding to at . Equation (3) is solved by the Levenberg-Marquardt algorithm [39].
3.4. Loop Closure Correction
In the Loop Closing thread, three tasks are completed: the use of Seq-CALC [28] (a lightweight deep loop closure detection network) to detect the historical keyframes that form a loop closure with the current keyframe, the use of SG-Matcher to match the keypoints of the current keyframe and the loop closure keyframe and calculate the corrected absolute pose of the current frame, the optimization of the set of all keyframes on the pose graph and correction of the set of all map points, as follows:
where are the location of corrected map points. Equation (5) is also solved by the Levenberg–Marquardt algorithm [39].
4. Experiments
We tested our proposed system by conducting the following four sets of experiments on the KITTI odometry dataset [40]: Evaluation experiment to evaluate the estimation accuracy, ablation experiment to verify the effectiveness of the (3)-based pose fusion estimation algorithm, validation experiment to demonstrate the necessity of the deep feature matcher, and runtime experiment to show the running speed of our proposed system.
The KITTI odometry dataset is an open-source dataset commonly used to evaluate visual localization accuracy. It consists of 22 stereo image sequences all sampled at 10 Hz (i.e., 100 ms sampling period), of which only 11 sequences (00-10) provide ground truth trajectories. We selected 8 of the 11 sequences that are representative and suitable for pure visual SLAM. The root mean square error (RMSE) [41], which is commonly used to represent the accuracy of localization estimation, was used as the evaluation metric for all experiments.
We performed all experiments on a laptop with a 16 Gb RAM, Intel Core i7-11800H CPU and GeForce RTX 3060 Mobile GPU. The SuperPoint, SuperGlue and Seq-CALC networks in the system all use the officially provided pre-trained models without fine-tuning on the KITTI Odometry Dataset. We only ran the SuperPoint, SuperGlue models on a GeForce RTX 3060 Mobile GPU and the rest of the system on an Intel Core i7-11800H CPU. In order to ensure the generality of the experiments, each set of experiments was repeated five times. The average of the results of the five experiments was then taken as the final measure.
4.1. Evaluation Experiment
To evaluate the accuracy of the proposed system, the results are compared with the data on ORB-SLAM2 [10], LSD-SLAM [11] and DSV-SLAM [12]. The main experimental procedure is to connect each image sequence to our system and other comparison systems, respectively. Each system was run independently five times, and then the results of each system were recorded. Table 1 shows the results on the 8 sequences. Figure 5 shows some examples of the estimated trajectories.

Table 1.
Comparison of accuracy in the KITTI odometry dataset using RMSE (m).
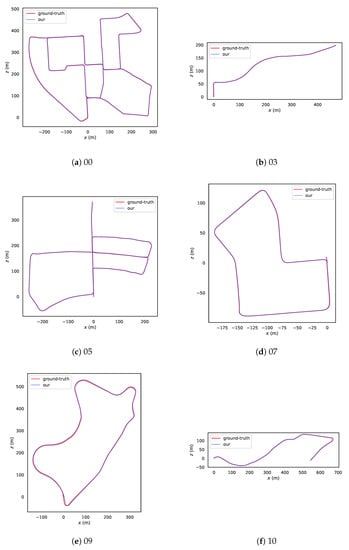
Figure 5.
Estimated trajectory (blue) and ground-truth (red) in 00, 03, 05, 07, 09 and 10 KITTI odometry datasets.
Our system outperforms ORB-SLAM2, LSD-SLAM and DSV-SLAM in most sequences. In addition to Sequence 04, the estimation accuracy of our system is improved by at least 0.1 m (Sequences 03, 06, 07, 09) and at most 0.3 m (Sequence 00) compared to ORB-SLAM2.
Compared to LSD-SLAM, the estimation accuracy of our system is improved by more than 0.1 m in most cases and even more than 1.0 m in some cases, except for Sequences 00 and 04, which are equal. This is mainly due to the presence of many scenes in those sequences (Sequences 03, 05, 06, 07, 09, 10) that cause dramatic changes in light intensity. For example, weaving through a forest, entering a residential area from an open road, etc.
Compared to DSV-SLAM, the estimation accuracy of our system is only more than 0.1 m for Sequence 06, and at least 1.0 m for other sequences. This is because our system, using SuperPoint, extracts features that are less susceptible to changes in light intensity and are robust. The features are then matched continuously and accurately using SuperGlue. Moreover, the use of Seq-CALC, a deep loop closure detector that uses only the original image, avoids the propagation of feature extraction errors in the loop closure detection process.
The accuracy of our system, ORB-SLAM2 and LSD-SLAM, is the same on Sequence 04 because Sequence 04 is a very simple sequence with a slow short-range linear motion on a flat road, as shown in Figure 6.
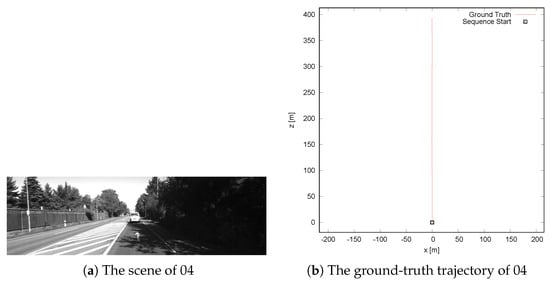
Figure 6.
The scene and trajectory of 04.
4.2. Ablation Experiment
To verify the effectiveness of our proposed (3)-based pose fusion estimation algorithm, we first run our system normally five times on the selected image sequences and record the experimental results. Then, the in the fusion method is forced to 1.0 (so that the position estimation depends only on the map points of the tracked reference frames, see Section 3.2 for details), and the same experiment is repeated five more times and the experimental results are recorded. The results are shown in Table 2.
Table 2.
Verifying fusion pose estimation in the KITTI odometry dataset using RMSE (m).
According to Table 2, after fusing the last frame with the reference frame information using our (3)-based pose fusion estimation algorithm, the pose estimation error is significantly reduced. This is because as the motion gradually moves away from the reference frame, the tracked landmarks gradually decrease and concentrate to some regions of the image (green feature points in Figure 7). This leads to a larger error in the pose estimation. Our (3)-based pose fusion estimation algorithm, by introducing temporary landmarks generated in the last frame (blue feature points in Figure 7), allows the participation of enough landmarks in the pose estimation and ensures that the features corresponding to these landmarks are uniformly distributed over the entire image.

Figure 7.
Tracking the map points (green) of the reference frame and the temporary map points (blue) of the last frame, (a–e) in order away from the reference frame.
4.3. Validation Experiment
To demonstrate the necessity of using the corresponding deep feature matcher in a visual SLAM system that uses a deep feature extractor, we compare our system with SuperPoint-SLAM [25] on selected sequences. Because SuperPoint-SLAM uses SuperPoint as our system (also using the same pre-trained model) but does not use a deep feature matcher, only the Euclidean distance between descriptors is used to match features.
Table 3 shows that using the corresponding deep feature matcher in a visual SLAM system employing depth features can significantly improve the estimation accuracy and stability of the system. For example, on Sequences 00 and 09, SuperPoint-SLAM cannot even run the whole sequence, while our system not only runs stably but also achieves good estimation accuracy. This is mainly due to the fact that our system uses SuperGlue which is adapted to SuperPoint. As shown in Figure 8a, the features extracted by SuperPoint can be correctly matched using SuperGlue. Correct matched features are the basis for accurate pose estimation. However, as can be seen in Figure 8b, the matching method used by SuperPoint-SLAM produces more incorrectly matched pairs when matching the features extracted by SuperPoint. This introduces a larger error in the pose estimation.
Table 3.
Comparison with SuperPoint-SLAM in the KITTI odometry dataset using RMSE (m).

Figure 8.
Comparison of SuperPoint+SuperGlue and SuperPoint+EuclideanDistance matching results in the same pair of images.
4.4. Runtime Experiment
In order to show the running speed of our proposed system, we measured the duration of each image frame from reading to deriving the pose of this image frame as the time consumed to process this image frame. The running speed, denoted as , is defined by the averaged time by an image sequence:
where is number of frames in the image sequence, is the time used for processing the nth frame.
From Table 4, it is obvious that our proposed system only takes 81.8 ms to process an image frame with the GeForce RTX 3060 Mobile GPU running the SuperPoint, SuperGlue model and the Intel Core i7-11800H CPU running the rest of the system. Since the sampling period of the sequence is 100 ms, our system can achieve the performance of real-time operation under the above equipment conditions. According to the results published on the corresponding website of [40], the speed of our system (0.08 s per frame) already exceeds that of many existing SLAM systems.
Table 4.
The runtime of our system in the KITTI odometry dataset using time per frame (the sampling period of the sequence is 100 ms).
5. Conclusions
In this paper, we proposed a novel Visual Odometry combining a SG-Detector, a SG-Matcher and a (3)-based pose fusion estimation algorithms and a deep LoopClosing module based on SG-Matcher and Seq-CALC networks. Then, a complete visual SLAM system was designed using them.
Our proposed system achieves better performance than ORB-SLAM2, LSD-SLAM and DSV-SLAM on most sequences of the KITTI odometry dataset. For example, the estimation error is generally reduced by 0.1 m, and it can run in real time at 0.08 s per frame on GeForce RTX 3060 Mobile GPU and Intel Core i7-11800H CPU.
The experimental results indicated that corresponding feature matchers should be introduced in visual SLAM systems using deep features, since traditional matching methods for hand-crafted features do not match well the deep feature descriptors with the deep feature extractor.
Although our system is currently only tested on the KITTI odometry dataset, the experimental results do yield some indications on the superiority, feasibility and, particularly, the practicality of the proposed SLAM system. This is because the KITTI odometry dataset is real-time data derived from real scenes. In future work, we will focus on the lightweighting of the deep feature matcher and deep feature extractor because these two deep neural network models require a lot of memory and occupy most of the running time of the whole system. If a more lightweight network structure can be designed, it will enable our proposed system to migrate to run in real time in an embedded system. This allows an easier integration of our system into the existing mobile robotics, MAVs, autonomous driving and augmented reality systems.
Author Contributions
B.Z. performed the experiments, wrote and revised the manuscript; A.Y. and B.H. managed the project, acquired the fund, conceived the work, designed the experiments, guided and revised the manuscript; G.L. and Y.Z. analyzed the experimental results and revised the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by “Pioneer” and “Leading Goose” R&D Program of Zhejiang Province (2022C04012), the Key R&D Program of Zhejiang Province (2021C04030), the Natural Science Foundation of Zhejiang Province (LGG20F020007) and the Public Welfare Technology Application Research Project of Zhejiang Province (LGF22F030005).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, IEEE, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Dong, X.; Cheng, L.; Peng, H.; Li, T. FSD-SLAM: A fast semi-direct SLAM algorithm. Complex Intell. Syst. 2022, 8, 1823–1834. [Google Scholar] [CrossRef]
- Wei, S.; Wang, S.; Li, H.; Liu, G.; Yang, T.; Liu, C. A Semantic Information-Based Optimized vSLAM in Indoor Dynamic Environments. Appl. Sci. 2023, 13, 8790. [Google Scholar] [CrossRef]
- Wu, Z.; Li, D.; Li, C.; Chen, Y.; Li, S. Feature Point Tracking Method for Visual SLAM Based on Multi-Condition Constraints in Light Changing Environment. Appl. Sci. 2023, 13, 7027. [Google Scholar] [CrossRef]
- Ni, J.; Wang, L.; Wang, X.; Tang, G. An Improved Visual SLAM Based on Map Point Reliability under Dynamic Environments. Appl. Sci. 2023, 13, 2712. [Google Scholar] [CrossRef]
- Gao, X.; Wang, R.; Demmel, N.; Cremers, D. LDSO: Direct sparse odometry with loop closure. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Madrid, Spain, 1–5 October 2018; pp. 2198–2204. [Google Scholar]
- Bavle, H.; De La Puente, P.; How, J.P.; Campoy, P. VPS-SLAM: Visual planar semantic SLAM for aerial robotic systems. IEEE Access 2020, 8, 60704–60718. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Hamburg, Germany, 28 September–3 October 2015; pp. 1935–1942. [Google Scholar]
- Mo, J.; Islam, M.J.; Sattar, J. Fast direct stereo visual SLAM. IEEE Robot. Autom. Lett. 2021, 7, 778–785. [Google Scholar] [CrossRef]
- Pire, T.; Fischer, T.; Castro, G.; De Cristóforis, P.; Civera, J.; Berlles, J.J. S-PTAM: Stereo parallel tracking and mapping. Robot. Auton. Syst. 2017, 93, 27–42. [Google Scholar] [CrossRef]
- Mo, J.; Sattar, J. Extending monocular visual odometry to stereo camera systems by scale optimization. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, The Venetian Macao, Macau, 3–8 November 2019; pp. 6921–6927. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, IEEE, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature pyramid transformer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 323–339. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Tang, J.; Ericson, L.; Folkesson, J.; Jensfelt, P. GCNv2: Efficient correspondence prediction for real-time SLAM. IEEE Robot. Autom. Lett. 2019, 4, 3505–3512. [Google Scholar] [CrossRef]
- Tang, J.; Folkesson, J.; Jensfelt, P. Geometric correspondence network for camera motion estimation. IEEE Robot. Autom. Lett. 2018, 3, 1010–1017. [Google Scholar] [CrossRef]
- Li, D.; Shi, X.; Long, Q.; Liu, S.; Yang, W.; Wang, F.; Wei, Q.; Qiao, F. DXSLAM: A robust and efficient visual SLAM system with deep features. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Las Vegas, NV, USA, 25–29 October 2020; pp. 4958–4965. [Google Scholar]
- Sarlin, P.E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From coarse to fine: Robust hierarchical localization at large scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12716–12725. [Google Scholar]
- Deng, C.; Qiu, K.; Xiong, R.; Zhou, C. Comparative study of deep learning based features in SLAM. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), IEEE, Nagoya, Japan, 13–15 July 2019; pp. 250–254. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Xiong, F.; Ding, Y.; Yu, M.; Zhao, W.; Zheng, N.; Ren, P. A lightweight sequence-based unsupervised loop closure detection. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), IEEE, Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8922–8931. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Joshi, C. Transformers are graph neural networks. Gradient 2020, 7, 5. [Google Scholar]
- Angeli, A.; Filliat, D.; Doncieux, S.; Meyer, J.A. Fast and incremental method for loop-closure detection using bags of visual words. IEEE Trans. Robot. 2008, 24, 1027–1037. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Merrill, N.; Huang, G. Lightweight unsupervised deep loop closure. arXiv 2018, arXiv:1805.07703. [Google Scholar]
- Stillwell, J. Naive Lie Theory; Springer: New York, NY, USA, 2008. [Google Scholar]
- Moré, J.J. The Levenberg-Marquardt algorithm: Implementation and theory. In Proceedings of the Numerical Analysis, Dundee, UK, 28 June–1 July 1977; Watson, G.A., Ed.; Springer: Berlin/Heidelberg, Germany, 1978; pp. 105–116. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, Vilamoura, Algarve, 7–12 October 2012; pp. 573–580. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).