Abstract
Text-based search engines can extract various types of information when a user enters an appropriate search query. However, a text-based search often fails in image retrieval when image understanding is needed. Deep learning (DL) is often used for image task problems, and various DL methods have successfully extracted visual features. However, as human perception differs for each individual, a dataset with an abundant number of images evaluated by human subjects is not available in many cases, although DL requires a considerable amount of data to estimate space ambiance, and the DL models that have been created are difficult to understand. In addition, it has been reported that texture is deeply related to space ambiance. Therefore, in this study, bag of visual words (BoVW) is used. By applying a hierarchical representation to BoVW, we propose a new interior style detection method using multi-scale features and boosting. The multi-scale features are created by combining global features from BoVW and local features that use object detection. Experiments on an image understanding task were conducted on a dataset consisting of room images with multiple styles. The results show that the proposed method improves the accuracy by 0.128 compared with the conventional method and by 0.021 compared with a residual network. Therefore, the proposed method can better detect interior style using multi-scale features.
1. Introduction
Text-based online search engines can extract various types of valuable information when a user enters an appropriate search query. However, a text-based search often fails at image retrieval when image understanding is needed. For example, in the case of interior images, it is difficult to identify the appropriate keywords as there are various aspects, such as furniture items including sofas or chairs, wallpaper, and floors. Therefore, image retrieval based on image understanding remains unsolved. Visual feature-based methods, which do not require text queries, have been investigated in order to solve this problem [1,2,3,4]. As a result, various deep learning-based methods have been proposed that can successfully extract visual features [5,6,7]. Most methods focus on the visual similarity in the shape of an item in an image to automatically extract visual features known as deep visual features. As deep learning (DL) methods typically show good performance in classification problems, it is easy to extract deep representations for visual similarity. In particular, the Siamese network is often used because it utilizes the similarity between two items or images for learning [8,9,10].
Moreover, among the many aspects included in interior images, space ambiance is one of the essential factors in human perception. However, few studies have focused on understanding the ambiance due to difficulties in estimating optimal space ambiance using deep learning. One of the main difficulties is that the brightness of lighting and wall texture could affect the space ambiance of each pixel [11]. In addition, while DL requires many images to estimate space ambiance, an abundant dataset with a considerable number of evaluated images is not available because human perception differs for each individual, and the DL models that have been created are difficult to understand.
Meanwhile, it is reported that textual information is deeply related to space ambiance in images [12,13]. For this reason, we use bag of visual words (BoVW) for space ambiance extraction. BoVW, often used for image classification, extends the natural language processing technique bag of words (BoW) and can extract textural information using scale-invariant feature transform (SIFT) and speeded-up robust features (SURF). In this study, we propose a new interior style detection method based on multi-scale feature fusion by incorporating spatial pyramid matching (SPM), color information, and object detection into BoVW. The multi-scale feature fusion is then trained with rule-based boosting to facilitate the understanding of the model. The novel method is data-driven, so we collected an interior image dataset of scene images annotated with multiple styles for the performance evaluation. In this study, we first perform interior style detection, but in the future, we will consider the detection of individual preferences. Our main contributions are summarized as follows:
- (1)
- We propose a new multi-scale feature fusion method for interior style detection using BoVW, color information, SPM, and object detection. The proposed method outperforms the conventional BoVW methods and residual network (ResNet) in terms of accuracy.
- (2)
- Our method confirms that using texture and color information can better detect interior style. Specifically, CIELAB is more effective as color information than red green blue (RGB).
2. Related Works
DL is widely used to extract visual features from images. Chen et al., used a CNN to extract visual features of construction waste from a large dataset of over 1000 images [14]. Zheng et al., added semantic constraints to the Siamese network [15]. Specifically, they used a similarity measure that emphasizes feature differences. As a result, the image recognition accuracy improved.
In binary and multi-level image classification, BoVW has been used and shown to be more effective for image features than color histograms and raw image features. Figure 1 shows an image processed using BoVW. BoVW is a method that applies BoW, commonly used for the feature extraction of sentences, to images. In BoVW, feature words are extracted by term frequency-inverse document frequency (TF-IDF) and used as the dimensions of the sentence vector. The calculated weights of TF-IDF are then used as the document vector [16,17]. In BoVW, BoW’s documents correspond to images, and words correspond to local features. Specifically, local features are extracted from the image in BoVW and clustered into K features. Then, the center of gravity of the K clusters is set as the visual word (VW) corresponding to the dictionary, and the image is represented as the frequency vector of the local features. Shrinivasa et al., proposed a new feature descriptor for BoVW [18]. The new feature descriptor for BoVW is directional binary code. Results showed an improved image classification accuracy on the scene dataset. Sun et al., added local region extraction and color information to BoVW [19]. Specifically, they used region segmentation to extract local regions and improved it by using angle histograms of color vectors. Consequently, they were able to improve the accuracy of classification by enabling feature extraction that matches the characteristics of the item image.
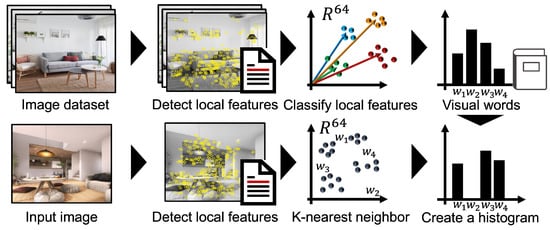
Figure 1.
Overview of BoVW.
In the classification of item images, SPM has been reported to have higher classification accuracy than the conventional BoVW method. Unlike BoVW, SPM can consider location information because it extracts features from the entire image, and from multiple regions by subdividing the image. Figure 2 shows an overview of SPM. Lin Xie et al., used a new image segmentation method in SPM [20]. Specifically, they subdivided images horizontally and vertically, in addition to grid subdivisions. Consequently, image classification accuracy improved.
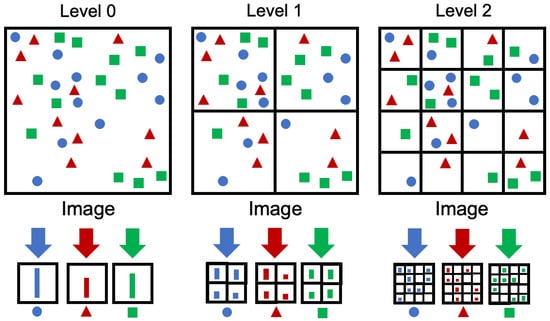
Figure 2.
Overview of SPM.
In, addition, SIFT, SURF, and Oriented FAST and Rotated BRIEF (ORB) are reported to be effective feature descriptors in image recognition [21]. SIFT, SURF, and ORB are effective feature descriptors in image recognition. The effectiveness was verified using recognition accuracy, true positive () rate, false positive () rate, and area under curve, and the dataset was Caltech-101, which consists of 9000 images. In the evaluation experiments, k-NN, Naive Bayes, decision tree, and random forest were used for training, with random forest having the highest accuracy.
3. Proposed Method
Conventional space ambiance extraction methods based on BoVW represent space as a set of VWs created from local features [22]. Thus, conventional methods cannot account for connections among local features or color information. Therefore, we propose a new method that focuses on the frequency of similar local features, color information, and connections between object features. Specifically, we use histograms, color information of each pixel, SPM, object detection (OD), color vector, and color histograms. Figure 3 shows an overview of the proposed methods. The algorithms of the proposed method are shown below.
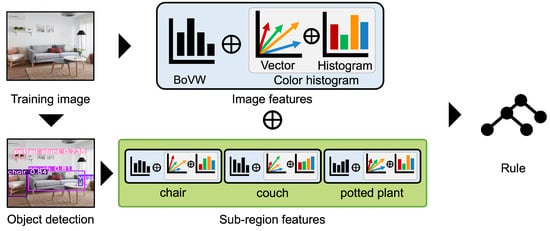
Figure 3.
Overview of the proposed method.
- Step-1:
- Preprocessing Resize each of training images = to 256 × 256 to create the training images = . Note that there are pieces in each of the styles.
- Step-2:
- Extract Local Features Extract 64-dimensional SURF = for each .
- Step-3:
- Create VWs Cluster the local features of all training images to create VWs = of the training images .
- Step-4:
- Create histograms Create histogram = for each training image based on from the local features . Then, normalize the histogram and calculate the image features = for each training image.
- Step-5:
- Extraction of representative colors Cluster the color information of each training image by the number of clusters and extract representative color vector = . Then, the representative color vector is normalized by the maximum value in the color space, and the representative color vector is calculated.
- Step-6:
- Create color histogram Color histogram = based on the representative color vector is created from color information in each training image . Then, normalize to calculate = .
- Step-7:
- Create low-level regions objects are detected from each training image using YOLO to create region = .
- Step-8:
- Create features for low-level regions Create histogram , color vector , and color histogram for as in Steps 2–6.
- Step-9:
- Create image features for low-level regions Histogram , representative color vector , and color histogram multiplied by the weight in each low-level region are concatenated to create image features = .
- Step-10:
- Create image features for scene images Create image features = for each training image based on the image features of the low-level regions.
4. Evaluation Experiment
4.1. Experimental Settings
We created a dataset using 1500 scene images from Houzz.com (accessed on 15 April 2022), a website specializing in architecture, decoration, and interior design [23,24]. We focus only on five styles considered to have a strong influence on human sensibilities: Japanese, modern, rustic, Scandinavian, and traditional. The number of images for each style is 300. Examples of the image dataset are shown in Figure 4. For performance evaluation, the extracted space ambiances were trained using light gradient boosting machine (LightGBM). The dataset was divided into training, validation, and test images using a ratio of 4:1:1. In addition, the experiment used the stratified k-fold cross-validation method to evaluate the performance and eliminate the data imbalance, where k = 3, and the accuracy was the average of three trials. We then compared the validation accuracy of ResNet, the six comparison methods, and the proposed method. ResNet was used as an accuracy index for DL.

Figure 4.
Examples of the image dataset. (a) Japanese. (b) Modern. (c) Rustic. (d) Scandinavian. (e) Traditional.
In this experiment, we compared the accuracy of the proposed method, which incorporates a histogram, color information, and a low-level region, with conventional methods and five other methods in order to verify its effectiveness. The conventional method uses BoVW to extract space ambiance [22]. The local features are SURF features to account for luminance variations and the textures of the furniture, plants, walls, floors, etc. In the comparison methods, steps were excluded from the proposed method and the algorithm was changed. The detailed algorithm of the comparison methods is described in the following section.
4.2. Comparison Method
The names of the six methods in this paper and the algorithmic differences between them and the proposed method are shown in Table 1. Method-HC is a preproposed method [22,25,26]. The other three methods, method-H+CV, method-H+H, and method-H+CH, were compared to verify whether they could account for color information, representative colors, and the percentage of the representative color in the image. In addition, method-S+CH, which uses SPM, was compared to see if it was possible to consider low-dimensional features in an image [19,27,28,29]. Specifically, SPM creates low-dimensional features by subdividing the image into sub-regions, as in Figure 2.

Table 1.
Abbreviations of comparison methods and algorithmic differences between the comparison methods and the proposed method.
4.3. Parameter Settings
As the proposed method uses non-hierarchical clustering, it is necessary to determine the number of clusters in advance. We also performed dimensionality reduction of the final layer of ResNet. In this experiment, the dictionary size of BoVW is 500, and the dimensionality of the final layer of ResNet is 300. The optimal number of clusters for each method in color features is shown in Table 2.
Table 2.
The optimal number of clusters for each method in color features.
The weights , , and of the color features, SPM, and SO in method-H+CV, method-H+CH, method-S+CH, and the proposed method were set to 1 because scaling is unnecessary in gradient boosting. The color space for the color features was CIELAB. The OD targets in the proposed method were the top three objects detected in the dataset, i.e., chair, couch, and potted plant. The number of clusters, the color space of color features, the dimensionality of the last layer in ResNet, and the OD targets were determined through preliminary experiments.
4.4. Performance Evaluation
Figure 5 shows the accuracies of the methods and validation images and Table 3 shows the of the test images for ResNet, the comparison methods, and the proposed method. The equation is expressed as follows:
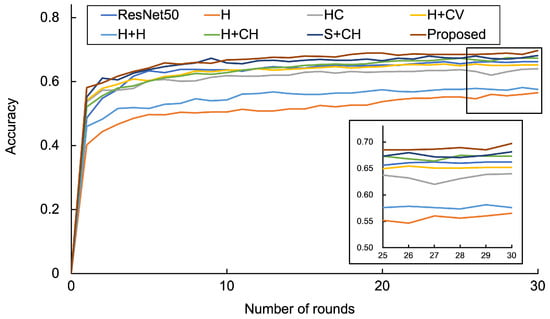
Figure 5.
Validation accuracies of the methods.
Table 3.
F-measures of the test images of the methods.
Figure 5 shows that the conventional method has the lowest accuracy and the proposed method has the highest accuracy. To validate each comparison method, we compared the accuracy of the conventional method, method-HC, method-H+H, method-H+CH, method-S+CH, and the proposed method. Method-H+CH had the highest accuracy among method-HC, method-H+CV, method-H+H, and method-H+CH. The accuracy was highest in terms of the average accuracy in round 0–30 in the following order: the conventional method, method-H+CH, method-S+CH, and the proposed method. Thus, histograms corresponding to the representative colors of the image were effective as a color feature, and the effectiveness of each algorithm in the proposed method was demonstrated. Conventionally, the space ambiance was extracted by BoVW, but the results confirm that the methods using histogram, SPM, and OD are effective for space ambiance extraction and contribute to improving the accuracy of interior style detection. Compared to the conventional method, the accuracy of the proposed method increased by 0.128, which was 0.021 higher than ResNet. Table 3 shows that all methods except ResNet have higher accuracy for the Japanese and Scandinavian styles, whereas the modern and traditional styles have less accurate results for ResNet, and the rustic style has an equal an performance.
To confirm the significant difference between ResNet and the proposed method, the Welch’s t-test was used to evaluate the accuracy of Figure 5 and of Table 3. The results at a 0.050% level of significance are shown in Table 4. Table 4 shows significant differences in the accuracy of Japanese and Scandinavian styles. Moreover, no significant difference was found for modern, rustic, and traditional styles. Therefore, we can conclude that the proposed method is more effective than ResNet for interior style detection. We also found that modern, rustic, and traditional styles are difficult to detect in this feature design, which is analyzed in the following section.
Table 4.
Welch’s t-test results for .
5. Discussion
In the evaluation experiments, we evaluated the accuracy of ResNet, the comparison methods, and the proposed method based on the accuracy of the validation and test images. In this section, we discuss the features extracted by the proposed method, and compare the performances of ResNet and the proposed method in terms of the modern, rustic, and traditional styles. First, we discuss the features extracted by the proposed method. Figure 6 shows the ten most important features in the proposed method, and Figure 7 shows the proportion of features based on its generation style.
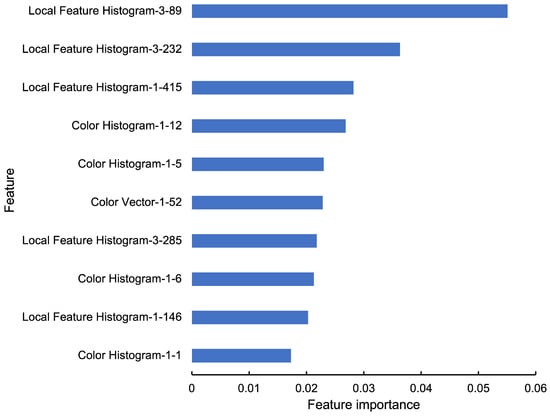
Figure 6.
Most important features in the proposed method.
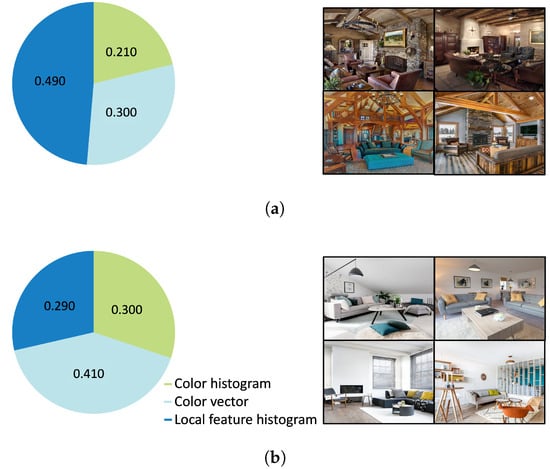
Figure 7.
Proportion of features in the proposed method, which can be categorized into three types: color histogram, color vector, and local feature histogram. (a) Rustic. (b) Scandinavian.
From Figure 6, the most essential features are local feature histograms, followed by the color vectors and color histograms, which are texture features. However, local feature histograms, color vectors, and color histograms are used equally in the output tree, with the ratio of local feature histogram at 0.388, color vector at 0.390, and color histogram at 0.222. Therefore, the results indicated that texture and color information plays a significant role in the space ambiance.
Moreover, we analyzed the feature type proportion of generated rules, shown in Figure 7. The proposed method utilizes 2160 features, categorized into three types; local feature histogram, color vector, and color histogram. Rustic-style room images contain walls and furniture with a rugged surface and are a texture feature style. From Figure 7a, we found that the rustic style employs a more local feature histogram, a texture feature. On the other hand, from Figure 7b, the Scandinavian style employs the color vector, one of the color features, the most for training. Scandinavian-style room images contain a lot of furniture with characteristic colors. From these results, we verified that the proposed method automatically extracts appropriate features according to each room style. This result supports the effectiveness of the proposed method.
Next, we discuss the performances of ResNet and the proposed method in terms of the modern, rustic, and traditional styles. Table 5 shows that of the ResNet method, and Table 6 shows the and false negative () ratio of the modern, rustic, and traditional styles for the proposed method. The and were calculated as follows:
Table 5.
FPproportion and for ResNet.
Table 6.
and for the proposed model.
In Figure 5 and Figure 6, when the models estimated the style as rustic, the most misestimated style was traditional. Figure 8 shows examples of a misestimated image for a more detailed analysis.

Figure 8.
Examples of images estimated as rustic. (a) Image labeled as rustic style. (b) Image labeled as traditional style for ResNet. (c) Image labeled as traditional style for the proposed method.
Figure 8 shows that ResNet and the proposed method have a high probability of misestimating traditional-style rooms with similar features. Therefore, no performance difference between was observed ResNet and the proposed method on the rustic style.
Moreover, focusing on the modern and traditional styles, Figure 5 shows that the proposed method was less accurate than ResNet. Figure 5 and Figure 6 show that the modern style is misestimated as the traditional style and vice versa. Therefore, estimating modern and traditional styles is difficult in the feature design of ResNet and the proposed method. Figure 9 and Figure 10 show example images estimated as modern and traditional styles.

Figure 9.
Examples of images estimated as modern. (a) Image labeled as modern style. (b) Image labeled as traditional for ResNet. (c) Image labeled as traditional for the proposed method.

Figure 10.
Examples of images estimated as traditional. (a) Image labeled as traditional style. (b) Image labeled as modern for ResNet. (c) Image labeled as traditional for the proposed method.
From Figure 9, no significant difference is observed in the spatial atmosphere of the images estimated as modern, such as the inclusion of items with similar textures and the overall colors among Figure 9a–c. In addition, from Figure 10, no significant difference was observed in the space ambiance as in Figure 9. Therefore, the proposed method is not able to estimate the style of a room that contains elements of multiple styles, such as modern and traditional styles.
6. Conclusions and Future Work
In this paper, we proposed a new multi-scale feature fusion method for interior style detection using BoVW, SPM, color information, and object detection. The proposed method detects interior styles by converting the local and color features of an image into a histogram and concatenating the histograms of each level region for fusion. Then, LightGBM was trained using the extracted space ambiance to estimate the room style. From the experimental results, we concluded that the proposed method is more effective as an interior style detection method than the conventional method and ResNet. In addition, the proposed method was confirmed to be significantly different from ResNet based on Welch’s t-test at a 0.05% level of significance. We confirmed that texture and color information play a significant role in interior style detection, and that CIELAB, rather than RGB, is effective as the color information.
In future research, since there were room images with ambiguous styles that were difficult to estimate in the annotated data evaluated by the experts, we will focus on style estimation considering elements of multiple styles. We will also consider the use of the ratio of styles instead of the estimated labels when learning the extracted features. Specifically, we plan to perform multiple-style detection by determining the proportion of multiple styles for a single image in a subject experiment.
Author Contributions
Conceptualization, K.O.; Data curation, A.Y.; Formal analysis, A.Y.; Funding acquisition, K.O. and E.M.; Investigation, A.Y.; Methodology, A.Y. and K.O.; Project administration, K.O.; Software, A.Y.; Supervision, E.M.; Visualization, A.Y.; Writing—original draft, A.Y.; Writing—review editing, N.I. and T.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JSPS KAKENHI Grant Number 21K12097 and JSPS KAKENHI Grant Number 20K14101.
Data Availability Statement
The dataset used in this paper was provided by https://www.houzz.com/ (accessed on 15 April 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Godi, M.; Joppi, C.; Giachetti, A.; Pellacini, F.; Cristani, M. Texel-Att: Representing and Classifying Element-based Textures by Attributes. arXiv 2019, arXiv:1908.11127. [Google Scholar]
- Zhu, J.; Guo, Y.; Ma, H. A data-driven approach for furniture and indoor scene colorization. IEEE Trans. Vis. Comput. Graph. 2017, 24, 2473–2486. [Google Scholar] [CrossRef] [PubMed]
- Tautkute, I.; Możejko, A.; Stokowiec, W.; Trzciński, T.; Brocki, Ł.; Marasek, K. What looks good with my sofa: Multimodal search engine for interior design. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS); Prague, Czech Republic, 3–6 September 2017; pp. 1275–1282. [Google Scholar] [CrossRef]
- Achlioptas, P.; Fan, J.; Hawkins, R.; Goodman, N.; Guibas, L.J. ShapeGlot: Learning language for shape differentiation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8938–8947. [Google Scholar] [CrossRef]
- Tautkute, I.; Trzcinski, T.; Skorupa, A.P.; Brocki, L.; Marasek, K. Deepstyle: Multimodal search engine for fashion and interior design. IEEE Access 2019, 7, 84613–84628. [Google Scholar] [CrossRef]
- Polania, L.F.; Flores, M.; Nokleby, M.; Li, Y. Learning Furniture Compatibility with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 366–367. [Google Scholar] [CrossRef]
- Bermeitinger, B.; Freitas, A.; Donig, S.; Handschuh, S. Object classification in images of Neoclassical furniture using Deep Learning. In Proceedings of the International Workshop on Computational History and Data-Driven Humanities, Dublin, Ireland, 25 May 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 109–112. [Google Scholar] [CrossRef]
- Aggarwal, D.; Valiyev, E.; Sener, F.; Yao, A. Learning style compatibility for furniture. In Proceedings of the German Conference on Pattern Recognition, Stuttgart, Germany, 9–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 552–566. [Google Scholar] [CrossRef]
- Weiss, T.; Yildiz, I.; Agarwal, N.; Ataer-Cansizoglu, E.; Choi, J.W. Image-Driven Furniture Style for Interactive 3D Scene Modeling. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 57–68. [Google Scholar] [CrossRef]
- Filtenborg, M.; Gavves, E.; Gupta, D. Siamese Tracking with Lingual Object Constraints. arXiv 2020, arXiv:2011.11721. [Google Scholar] [CrossRef]
- Kurian, J.; Karunakaran, V. A survey on image classification methods. Int. J. Adv. Res. Electron. Commun. Eng. 2012, 1, 69–72. [Google Scholar] [CrossRef]
- de Lima, G.V.; Saito, P.T.; Lopes, F.M.; Bugatti, P.H. Classification of texture based on bag-of-visual-words through complex networks. Expert Syst. Appl. 2019, 133, 215–224. [Google Scholar] [CrossRef]
- Santani, D.; Hu, R.; Gatica-Perez, D. InnerView: Learning place ambiance from social media images. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 451–455. [Google Scholar]
- Chen, J.; Lu, W.; Xue, F. “Looking beneath the surface”: A visual-physical feature hybrid approach for unattended gauging of construction waste composition. J. Environ. Manag. 2021, 286, 112233. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Tian, Y.; Yuan, C.; Yin, K.; Zhang, F.; Chen, F.; Chen, Q. MDESNet: Multitask Difference-Enhanced Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3775. [Google Scholar] [CrossRef]
- Rawat, R.; Mahor, V.; Chirgaiya, S.; Shaw, R.N.; Ghosh, A. Analysis of darknet traffic for criminal activities detection using TF-IDF and light gradient boosted machine learning algorithm. In Innovations in Electrical and Electronic Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 671–681. [Google Scholar] [CrossRef]
- Kamyab, M.; Liu, G.; Adjeisah, M. Attention-Based CNN and Bi-LSTM Model Based on TF-IDF and GloVe Word Embedding for Sentiment Analysis. Appl. Sci. 2021, 11, 11255. [Google Scholar] [CrossRef]
- Shrinivasa, S.; Prabhakar, C. Scene image classification based on visual words concatenation of local and global features. Multimed. Tools Appl. 2022, 81, 1237–1256. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, X.; Han, X.; Jin, X.; Zhao, Z. Commodity image classification based on improved bag-of-visual-words model. Complexity 2021, 2021, 5556899. [Google Scholar] [CrossRef]
- Xie, L.; Lee, F.; Liu, L.; Yin, Z.; Yan, Y.; Wang, W.; Zhao, J.; Chen, Q. Improved spatial pyramid matching for scene recognition. Pattern Recognit. 2018, 82, 118–129. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M.; Kumar, M. 2D object recognition: A comparative analysis of SIFT, SURF and ORB feature descriptors. Multimed. Tools Appl. 2021, 80, 18839–18857. [Google Scholar] [CrossRef]
- Huang, K. Image Classification Using Bag-of-Visual-Words Model. Master’s Thesis, Technological University Dublin, Dublin, Ireland, 2018. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K. Stochastic Detection of Interior Design Styles Using a Deep-Learning Model for Reference Images. Appl. Sci. 2020, 10, 7299. [Google Scholar] [CrossRef]
- Bell, S.; Bala, K. Learning visual similarity for product design with convolutional neural networks. ACM Trans. Graph. (TOG) 2015, 34, 1–10. [Google Scholar] [CrossRef]
- Yaguchi, A.; Ono, K.; Makihara, E.; Taisho, A.; Nakayama, T. Space Ambiance Extraction using Bag of Visual Words with Color Feature. In Proceedings of the 48th Japan Society of Kansei Engineering, Tokyo, Japan, 2–4 September 2021. (In Japanese). [Google Scholar]
- Wengert, C.; Douze, M.; Jegou, H. Bag-of-colors for Improved Image Search. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1437–1440. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Spatial pyramid matching. In Object Categorization: Computer and Human Vision Perspectives; Dickinson, S.J., Leonardis, A., Schiele, B., Tarr, M.J., Eds.; Cambridge University Press: Cambridge, UK, 2009; pp. 401–415. [Google Scholar]
- Alqasrawi, Y.; Neagu, D.; Cowling, P.I. Fusing integrated visual vocabularies-based bag of visual words and weighted colour moments on spatial pyramid layout for natural scene image classification. Signal Image Video Process. 2013, 7, 759–775. [Google Scholar] [CrossRef]
- Vyas, K.; Vora, Y.; Vastani, R. Using Bag of Visual Words and Spatial Pyramid Matching for Object Classification Along with Applications for RIS. Procedia Comput. Sci. 2016, 89, 457–464. [Google Scholar] [CrossRef][Green Version]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).