
Reinforcement-Learning-Based Tracking Control with Fixed-Time Prescribed Performance for Reusable Launch Vehicle under Input Constraints


Abstract
:1. Introduction
- An online RL-based, nearly optimal, controller with limited inputs is developed by synthesizing the AC structure and the hyperbolic tangent performance index. In addition, the robustness of the learning-based controller is strengthened by incorporating a super-twisting-like sliding mode control.
- In contrast to existing RL-based control schemes with asymptotic or finite-time convergence [10,11,12,17,21], the proposed control scheme can ensure that the tracking errors converge to a preset region within a preassigned fixed time. Moreover, the prescribed transient and steady-state performance can be guaranteed.
- Comparative numerical simulation investigations show that the proposed method can provide improved performance in terms of the transient response, and steady accuracy with less control effort.
2. Problem Statement and Preliminaries
2.1. Problem Statement
2.2. Preliminaries
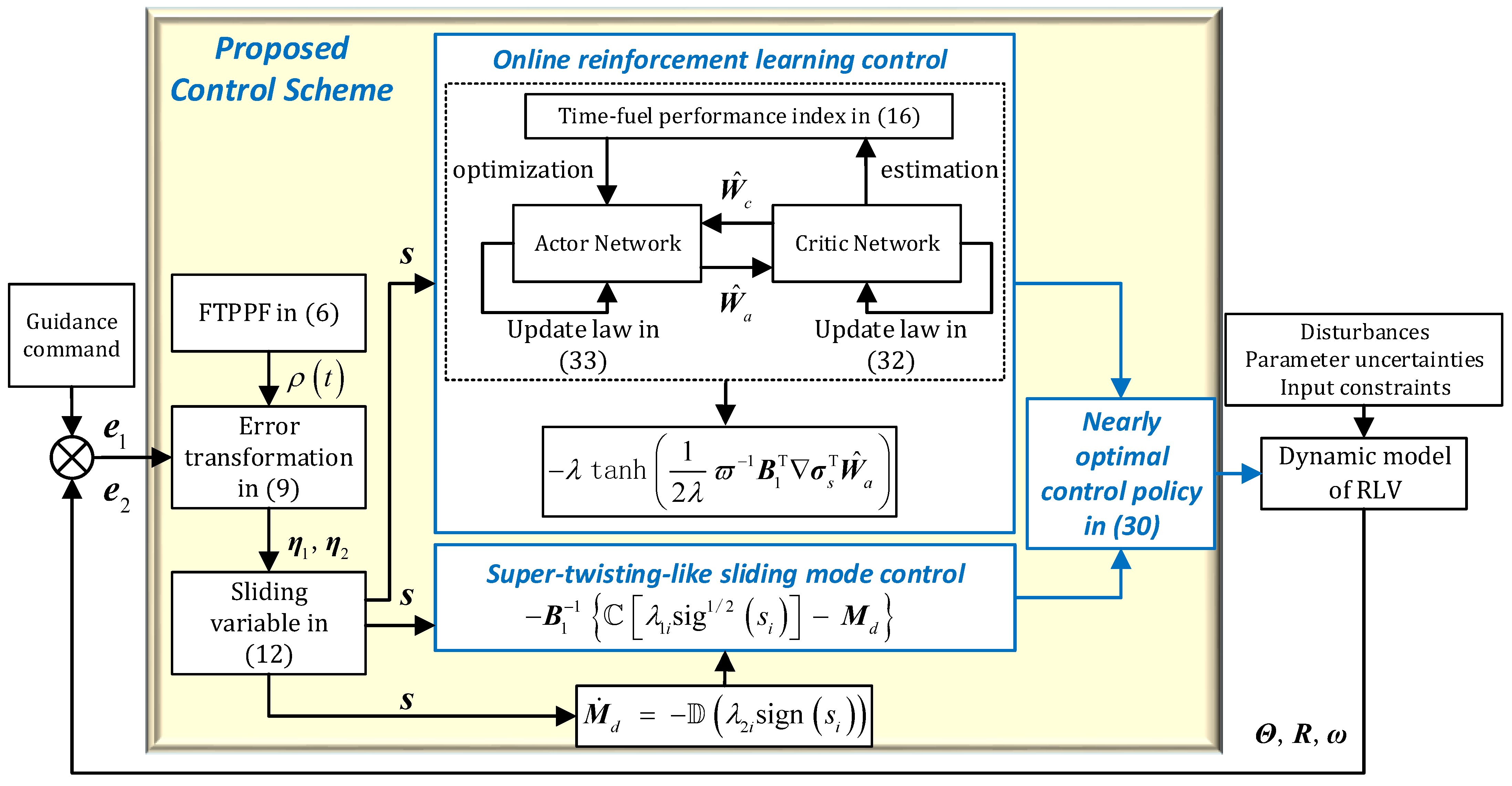
3. Controller Design
3.1. Prescribed Performance Constraint
3.2. Reinforcement Learning-Based Control Design
3.3. Stability Analysis
- the sliding variable , the weight estimation errors and are uniformly ultimately bounded (UUB);
- the attitude tracking errors uniformly obey the fixed-time performance envelops in (8).
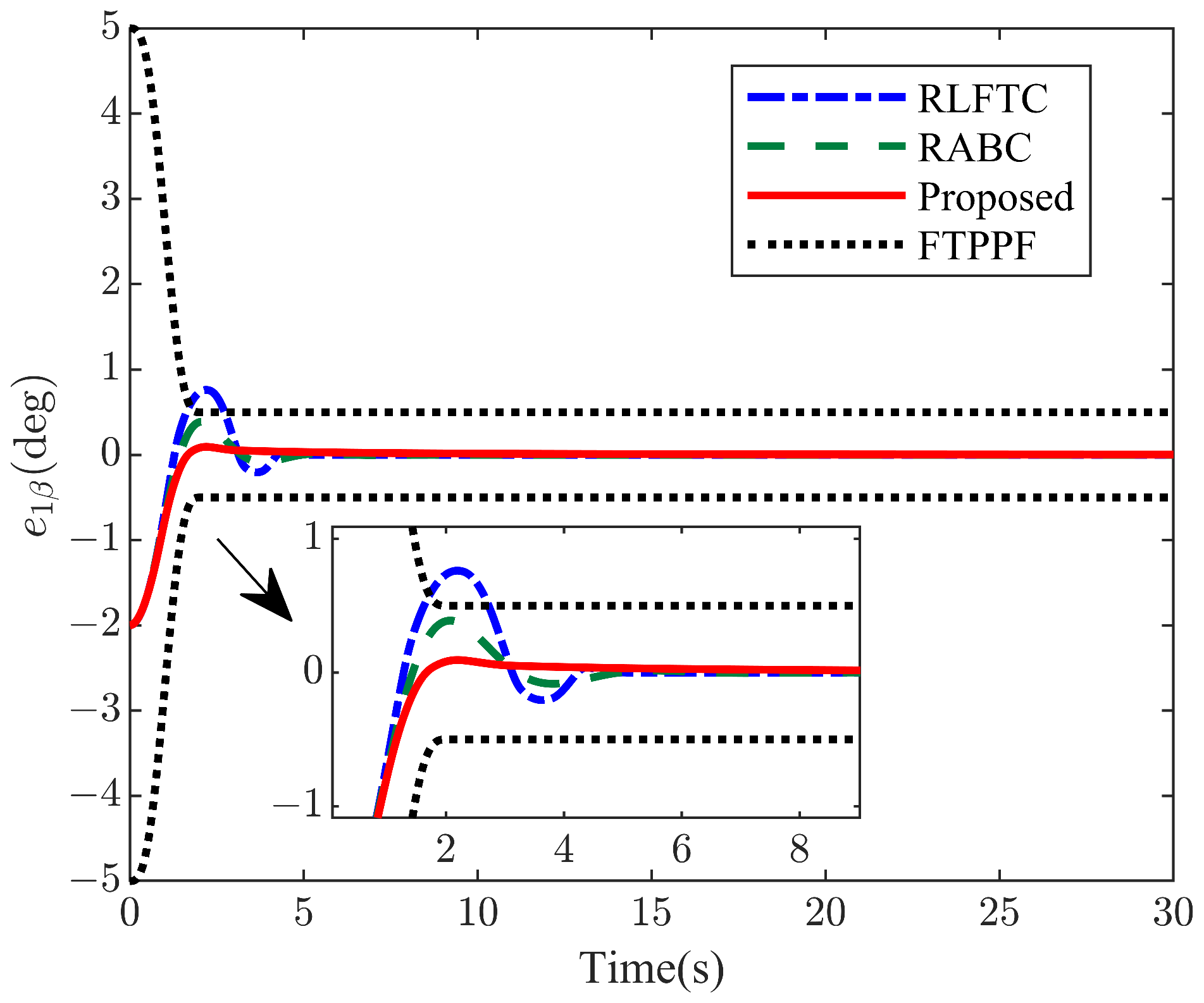
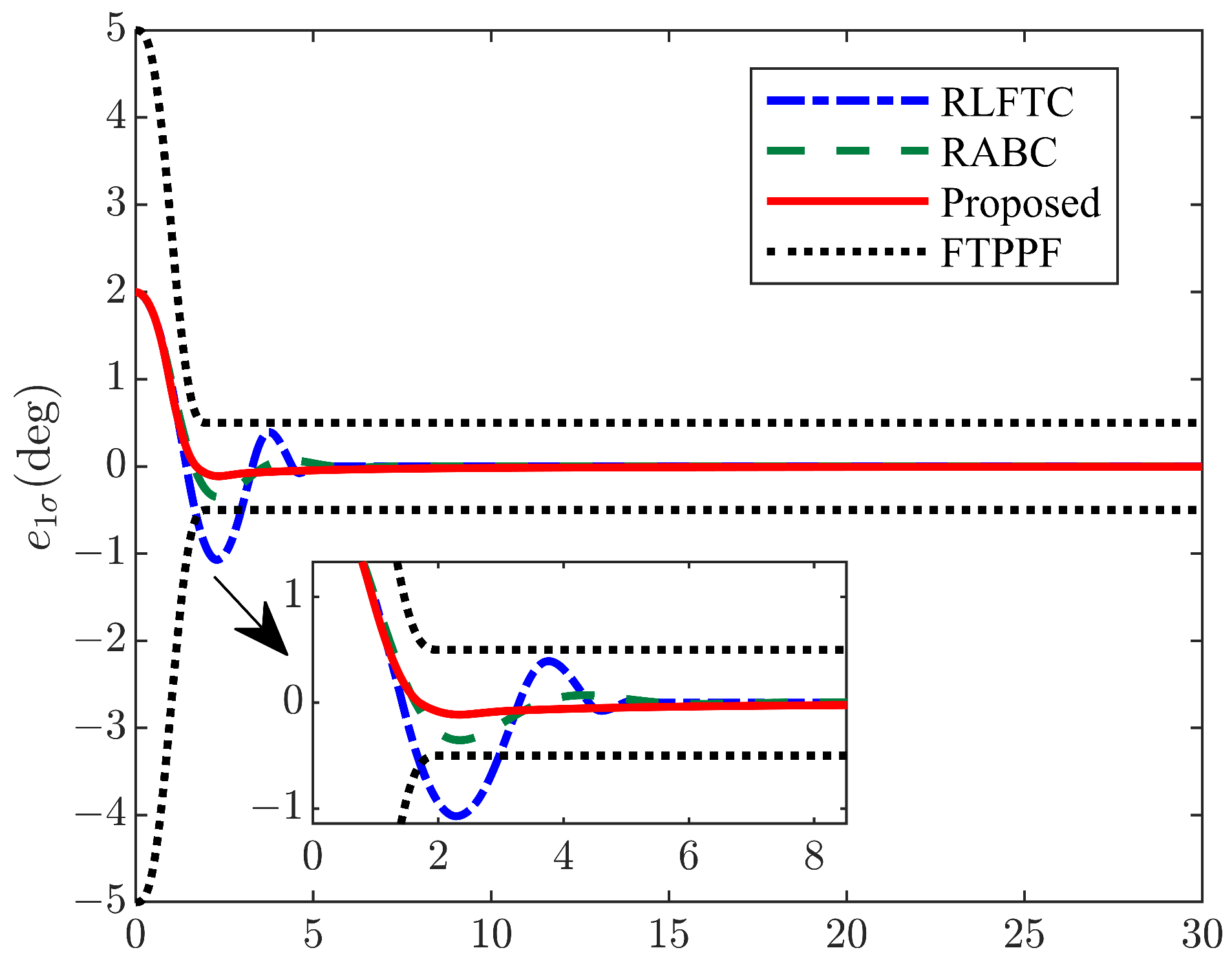
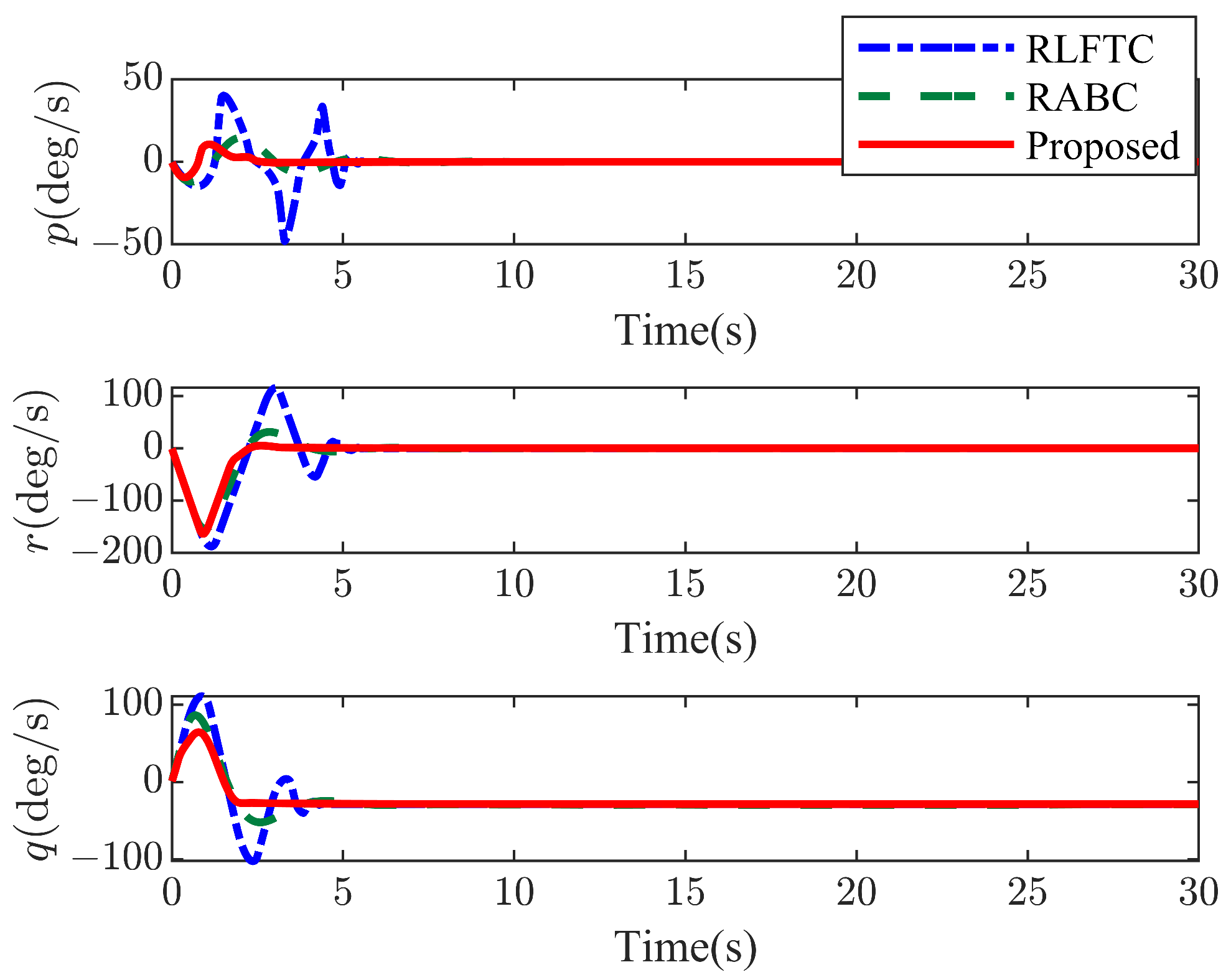
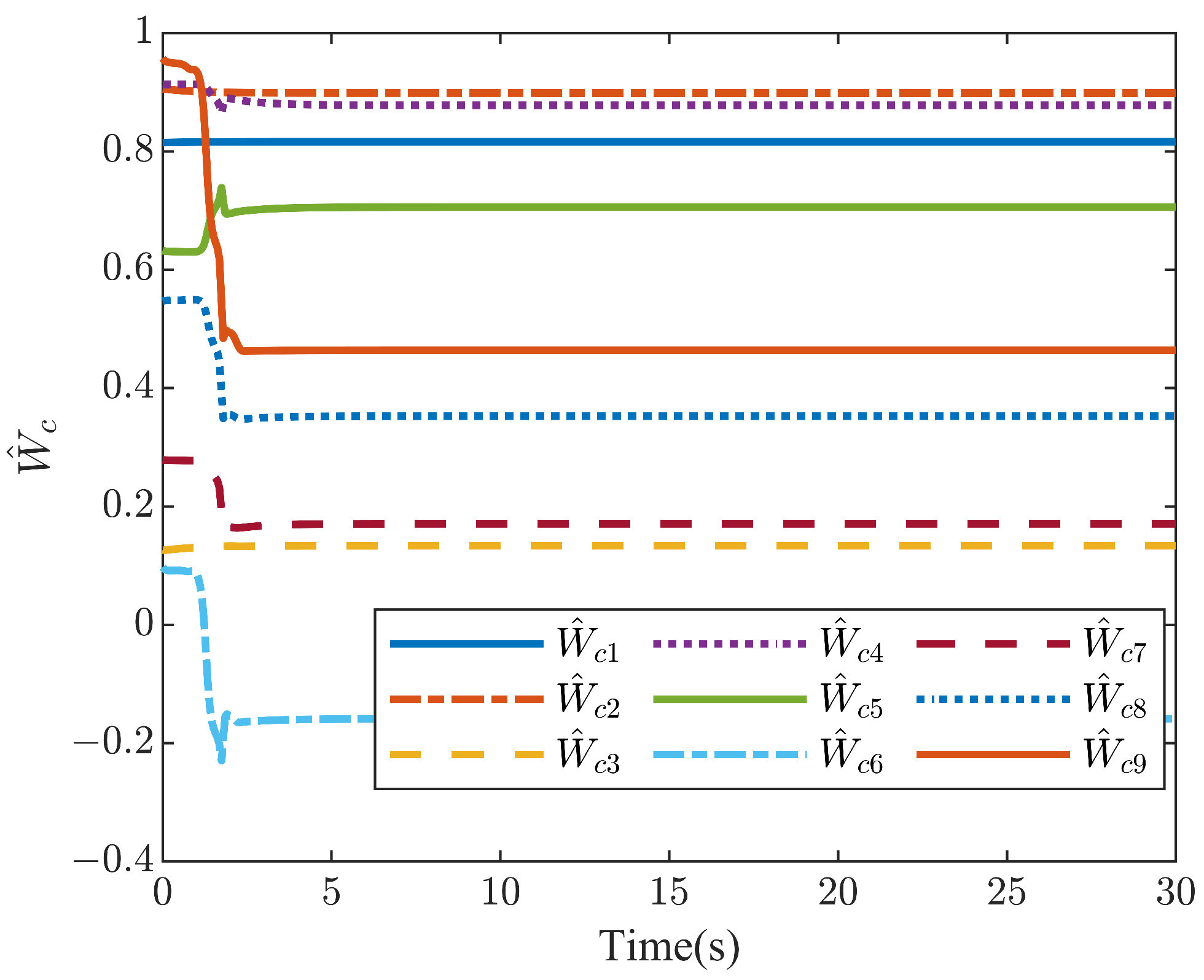
4. Numerical Simulations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RLV | Reusable Launch Vehicles |
| NN | Neural Network |
| RL | Reinforcement Learning |
| AC | Actor-Critic |
| UUB | Uniformly Ultimately Bounded |
| HJB | Hamilton–Jacobi–Bellman |
| PPC | Prescribed Performance Control |
| FTPPF | Fixed-time Prescribed Performance Function |
| RLFTC | Reinforcement-Learning-Based Finite-Time Control |
| RABC | Robust Adaptive Backstepping Control |
| IACE | Integral Absolute Control Effort |
| ITAE | Integral of Time and Absolute Error |
References
- Stott, J.E.; Shtessel, Y.B. Launch vehicle attitude control using sliding mode control and observation techniques. J. Frankl. Inst. B 2012, 349, 397–412. [Google Scholar] [CrossRef]
- Tian, B.L.; Li, Z.Y.; Zhao, X.P.; Zong, Q. Adaptive Multivariable Reentry Attitude Control of RLV With Prescribed Performance. IEEE Trans. Syst. Man Cybern. Syst. 2022, 1–5. [Google Scholar] [CrossRef]
- Acquatella, P.; Briese, L.E.; Schnepper, K. Guidance command generation and nonlinear dynamic inversion control for reusable launch vehicles. Acta Astronaut. 2020, 174, 334–346. [Google Scholar] [CrossRef]
- Xu, B.; Wang, X.; Shi, Z.K. Robust adaptive neural control of nonminimum phase hypersonic vehicle model. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 1107–1115. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, C.Z.; Wu, R.; Cui, N.G. Fixed-time extended state observer based non-singular fast terminal sliding mode control for a VTVL reusable launch vehicle. Aerosp. Sci. Technol. 2018, 82, 70–79. [Google Scholar] [CrossRef]
- Ju, X.Z.; Wei, C.Z.; Xu, H.C.; Wang, F. Fractional-order sliding mode control with a predefined-time observer for VTVL reusable launch vehicles under actuator faults and saturation constraints. ISA Trans. 2022, in press. [CrossRef]
- Cheng, L.; Wang, Z.B.; Gong, S.P. Adaptive control of hypersonic vehicles with unknown dynamics based on dual network architecture. Acta Astronaut. 2022, 193, 197–208. [Google Scholar] [CrossRef]
- Xu, B.; Shou, Y.X.; Shi, Z.K.; Yan, T. Predefined-Time Hierarchical Coordinated Neural Control for Hypersonic Reentry Vehicle. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Werbos, P. Approximate dynamic programming for realtime control and neural modelling. In Handbook of Intelligent Control: Neural, Fuzzy and Adaptive Approaches; Van Nostrand Reinhold: New York, NY, USA, 1992; pp. 493–525. [Google Scholar]
- Vamvoudakis, K.G.; Lewis, F.L. Online actor–critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar] [CrossRef]
- He, H.B.; Ni, Z.; Fu, J. A three-network architecture for on-line learning and optimization based on adaptive dynamic programming. Neurocomputing 2012, 78, 3–13. [Google Scholar] [CrossRef]
- Ma, Z.Q.; Huang, P.F.; Lin, Y.X. Learning-based Sliding Mode Control for Underactuated Deployment of Tethered Space Robot with Limited Input. IEEE Trans. Aerosp. Electron. Syst. 2021, 58, 2026–2038. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Zhao, H.; Ahn, C.K. Reinforcement learning-based optimal tracking control of an unknown unmanned surface vehicle. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3034–3045. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.Y.; Yang, G.H. Adaptive actor–critic design-based integral sliding-mode control for partially unknown nonlinear systems with input disturbances. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 165–177. [Google Scholar] [CrossRef] [PubMed]
- Kuang, Z.; Gao, H.; Tomizuka, M. Precise linear-motor synchronization control via cross-coupled second-order discrete-time fractional-order sliding mode. IEEE/ASME Trans. Mechatronics 2020, 26, 358–368. [Google Scholar] [CrossRef]
- Zhang, H.; Cui, X.; Luo, Y.; Jiang, H. Finite-horizon H∞ tracking control for unknown nonlinear systems with saturating actuators. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1200–1212. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Yang, C.; Zhang, X.F. Reinforcement learning-based finite-time tracking control of an unknown unmanned surface vehicle with input constraints. Neurocomputing 2022, 484, 26–37. [Google Scholar] [CrossRef]
- Bechlioulis, C.P.; Rovithakis, G.A. Robust adaptive control of feedback linearizable MIMO nonlinear systems with prescribed performance. IEEE Trans. Autom. Control 2008, 53, 2090–2099. [Google Scholar] [CrossRef]
- Cui, G.Z.; Yang, W.; Yu, J.P.; Li, Z.; Tao, C.B. Fixed-time prescribed performance adaptive trajectory tracking control for a QUAV. IEEE Trans. Circuits Syst. II 2021, 69, 494–498. [Google Scholar] [CrossRef]
- Bu, X.W. Guaranteeing prescribed performance for air-breathing hypersonic vehicles via an adaptive non-affine tracking controller. Acta Astronaut. 2018, 151, 368–379. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Zhang, X.F. Data-driven performance-prescribed reinforcement learning control of an unmanned surface vehicle. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5456–5467. [Google Scholar] [CrossRef]
- Luo, S.B.; Wu, X.; Wei, C.S.; Zhang, Y.L.; Yang, Z. Adaptive finite-time prescribed performance attitude tracking control for reusable launch vehicle during reentry phase: An event-triggered case. Adv. Space Res. 2022, 69, 3814–3827. [Google Scholar] [CrossRef]
- Modares, H.; Sistani, M.B.N.; Lewis, F.L. A policy iteration approach to online optimal control of continuous-time constrained-input systems. ISA Trans. 2013, 52, 611–621. [Google Scholar] [CrossRef]
- Tan, J.; Guo, S.J. Backstepping control with fixed-time prescribed performance for fixed wing UAV under model uncertainties and external disturbances. Int. J. Control 2022, 95, 934–951. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, Z.; Guo, L.; Liu, H.P. Barrier Lyapunov functions-based adaptive fault tolerant control for flexible hypersonic flight vehicles with full state constraints. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 3391–3400. [Google Scholar] [CrossRef]
- Lyshevski, S.E. Optimal control of nonlinear continuous-time systems: Design of bounded controllers via generalized nonquadratic functionals. In Proceedings of the 1998 American Control Conference, ACC (IEEE Cat. No. 98CH36207). Philadelphia, PA, USA, 26–26 June 1998; Volume 1, pp. 205–209. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural Netw. 1990, 3, 551–560. [Google Scholar] [CrossRef]
- Kamalapurkar, R.; Walters, P.; Dixon, W.E. Model-based reinforcement learning for approximate optimal regulation. Automatica 2016, 64, 94–104. [Google Scholar] [CrossRef] [Green Version]
- Bhasin, S.; Kamalapurkar, R.; Johnson, M.; Vamvoudakis, K.G.; Lewis, F.L.; Dixon, W.E. A novel actor–critic–identifier architecture for approximate optimal control of uncertain nonlinear systems. Automatica 2013, 49, 82–92. [Google Scholar] [CrossRef]
- Moreno, J.A.; Osorio, M. Strict Lyapunov functions for the super-twisting algorithm. IEEE Trans. Autom. Control 2012, 57, 1035–1040. [Google Scholar] [CrossRef]
- Wei, C.Z.; Wang, M.Z.; Lu, B.G.; Pu, J.L. Accelerated Landweber iteration based control allocation for fault tolerant control of reusable launch vehicle. Chin. J. Aeronaut. 2022, 35, 175–184. [Google Scholar] [CrossRef]
- Zhang, C.F.; Zhang, G.S.; Dong, Q. Fixed-time disturbance observer-based nearly optimal control for reusable launch vehicle with input constraints. ISA Trans. 2022, 122, 182–197. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Z.; Du, Y. Robust adaptive backstepping control for reentry reusable launch vehicles. Acta Astronaut. 2016, 126, 258–264. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Index | Proposed Method | RABC | RLFTC |
|---|---|---|---|
| Maximum Overshoot | / | 20.5% | 34.0% |
| Adjustment Time 1 (s) | 3.9 | 5.6 | 4.3 |
| ITAE index () | 1.6407 | 43.2600 | 1.6962 |
| IACE index () |
| Performance Index | Proposed Method | RABC | RLFTC |
|---|---|---|---|
| Maximum Overshoot | 4.5% | 19.0% | 38.2% |
| Adjustment Time (s) | 3.1 | 4.1 | 4.6 |
| ITAE index () | 0.7347 | 1.5192 | 1.1507 |
| IACE index () |
| Performance Index | Proposed Method | RABC | RLFTC |
|---|---|---|---|
| Maximum Overshoot | 5.5% | 17.7% | 53.5% |
| Adjustment Time (s) | 4.1 | 4.8 | 4.7 |
| ITAE index () | 0.8783 | 1.7853 | 1.7242 |
| IACE index () |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Guan, Y.; Wei, C.; Li, Y.; Xu, L. Reinforcement-Learning-Based Tracking Control with Fixed-Time Prescribed Performance for Reusable Launch Vehicle under Input Constraints. Appl. Sci. 2022, 12, 7436. https://doi.org/10.3390/app12157436
Xu S, Guan Y, Wei C, Li Y, Xu L. Reinforcement-Learning-Based Tracking Control with Fixed-Time Prescribed Performance for Reusable Launch Vehicle under Input Constraints. Applied Sciences. 2022; 12(15):7436. https://doi.org/10.3390/app12157436
Chicago/Turabian StyleXu, Shihao, Yingzi Guan, Changzhu Wei, Yulong Li, and Lei Xu. 2022. "Reinforcement-Learning-Based Tracking Control with Fixed-Time Prescribed Performance for Reusable Launch Vehicle under Input Constraints" Applied Sciences 12, no. 15: 7436. https://doi.org/10.3390/app12157436
APA StyleXu, S., Guan, Y., Wei, C., Li, Y., & Xu, L. (2022). Reinforcement-Learning-Based Tracking Control with Fixed-Time Prescribed Performance for Reusable Launch Vehicle under Input Constraints. Applied Sciences, 12(15), 7436. https://doi.org/10.3390/app12157436