
Chinese Traffic Police Gesture Recognition Based on Graph Convolutional Network in Natural Scene


Abstract
:1. Introduction
- We captured data regarding the gestures used by traffic police in real urban roads and established a complete traffic gesture dataset, including actions used in the gestures of traffic police on duty information regarding their labeling.
- We addressed the problems that the skeleton graph of the ST-GCN basic model only represents the physical structure of the human body and that the global information regarding the gestures used by traffic police is lost; an AGS was proposed to extract the associated feature information regarding traffic police’s skeleton joint data.
- Features in the temporal dimension are crucial to the recognition of gestures used by traffic police; the TAS was proposed in the AGS to collect the temporal sequence feature information regarding gestures used by traffic police in a time series.
2. Related Work
2.1. Traffic Police Gesture Recognition
2.2. Graph Convolutional Neural Networks
3. Methods
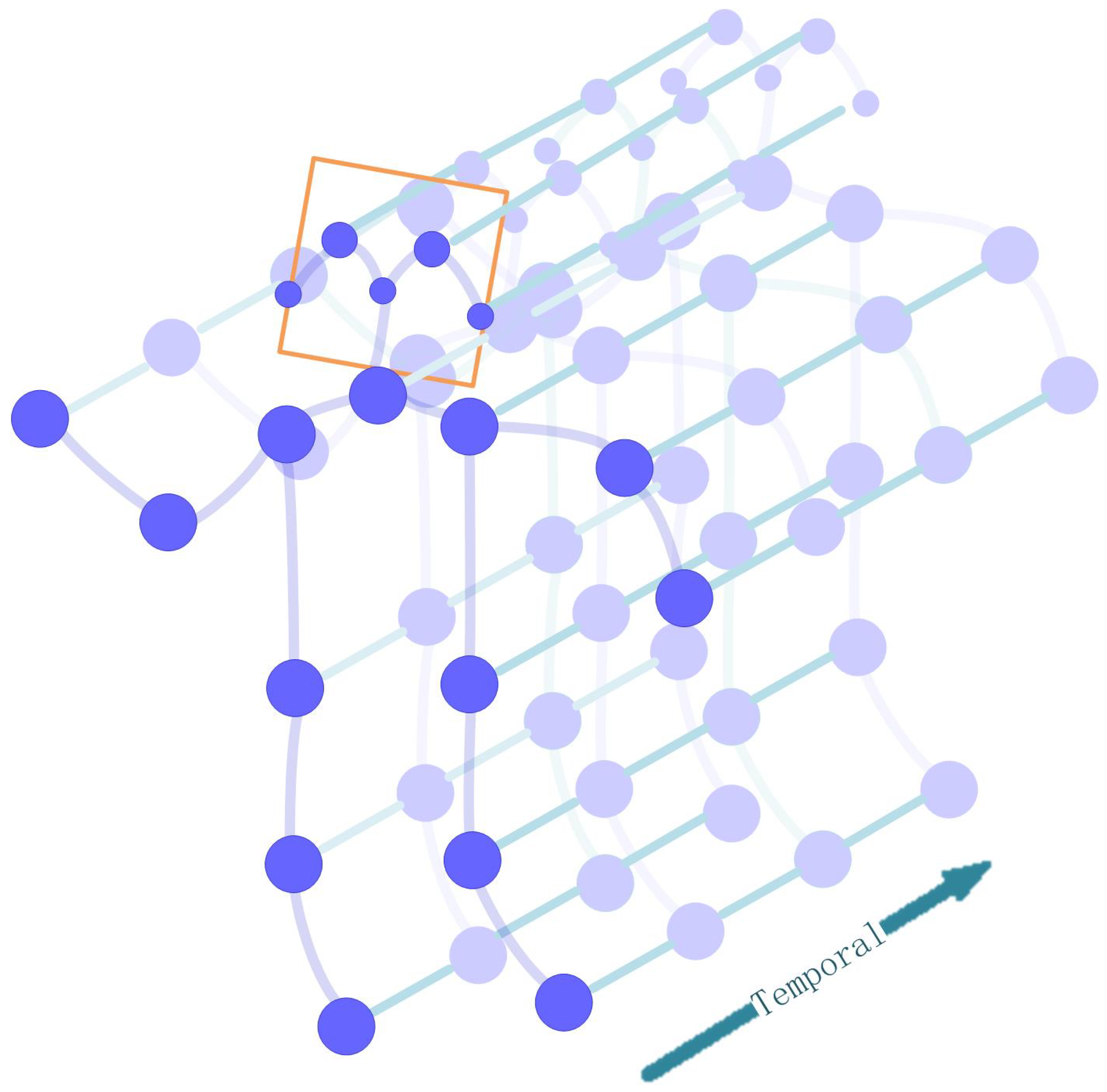
3.1. Traffic Police Gesture Recognition Network
- Use openpose algorithm to process collected videos containing gestures used by traffic police; extract skeleton data.
- Construct the AGS on the collected skeleton data, extract the spatial–temporal features of gestures used by traffic police with the improved ST-GCN, and recognize gestures used by traffic police.
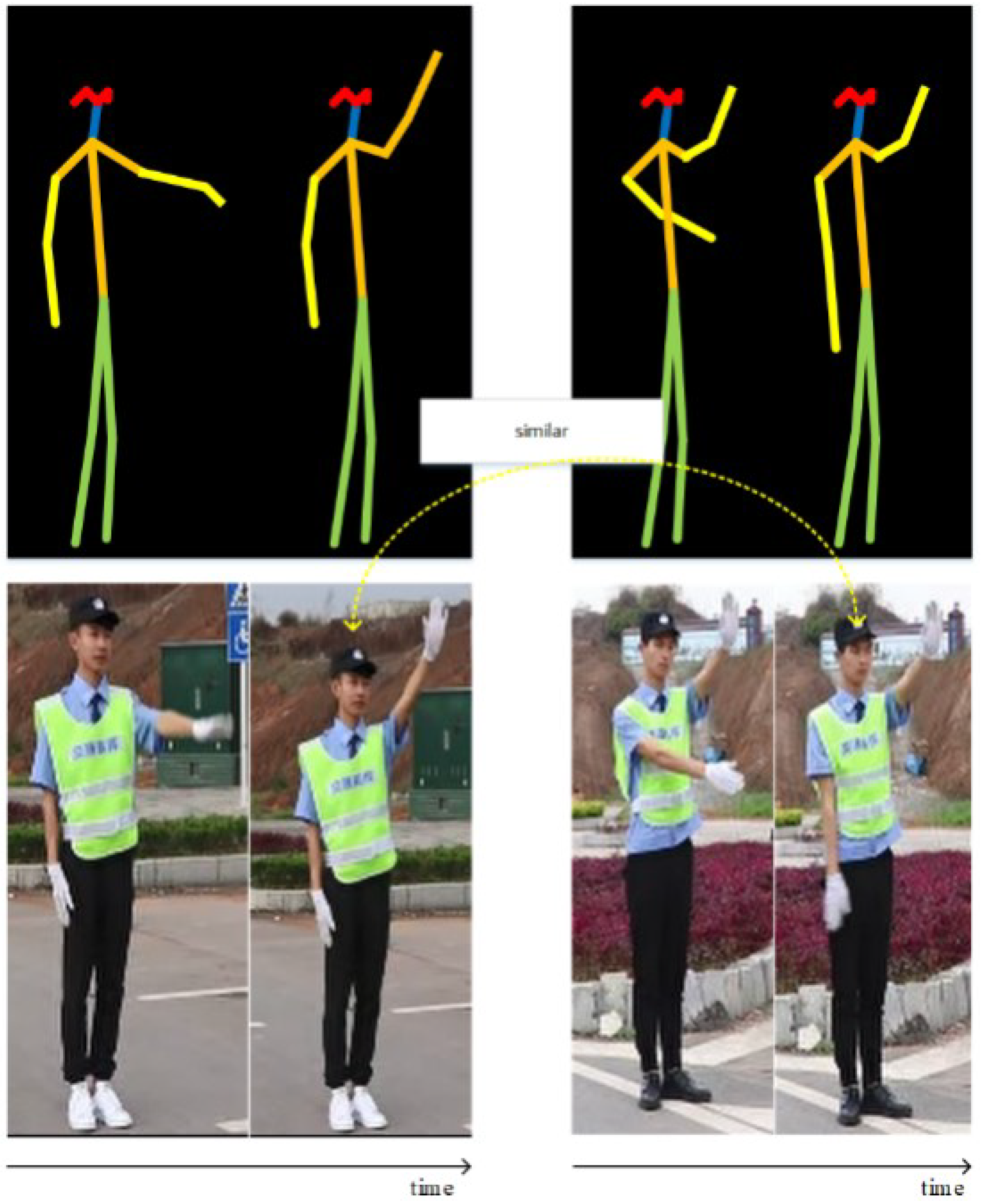
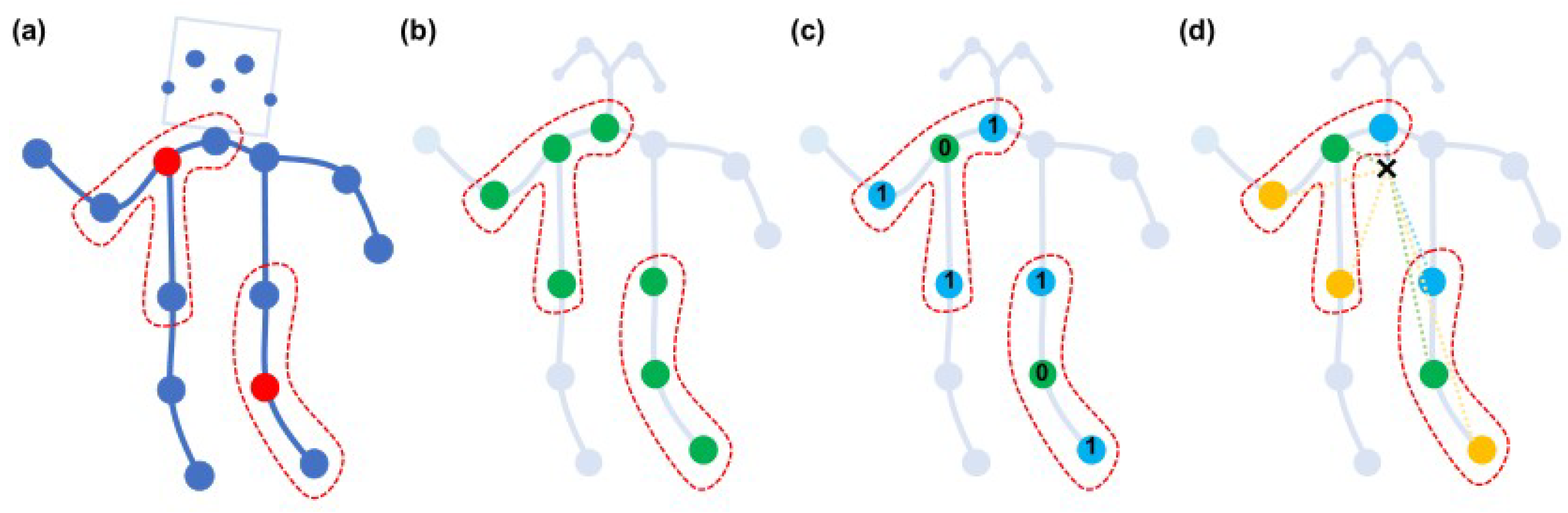
- The skeleton graph, which is the physical structure of the human body, is predefined. It cannot ensure that it is the best skeleton graph for traffic police gesture recognition; for example, the dependency between the two hands of a traffic police member cannot be captured.
- There are layers in the structure of GCN; different semantics are contained in different layers. However, the graph topology structure of the ST-GCN model is fixed in all the network layers and extracts the feature of the same topology, which causes them to lose the flexibility of information modeling.
- A fixed graph structure cannot be the optimal representative method for different gesture actions; joints have different levels of importance in different gestures.
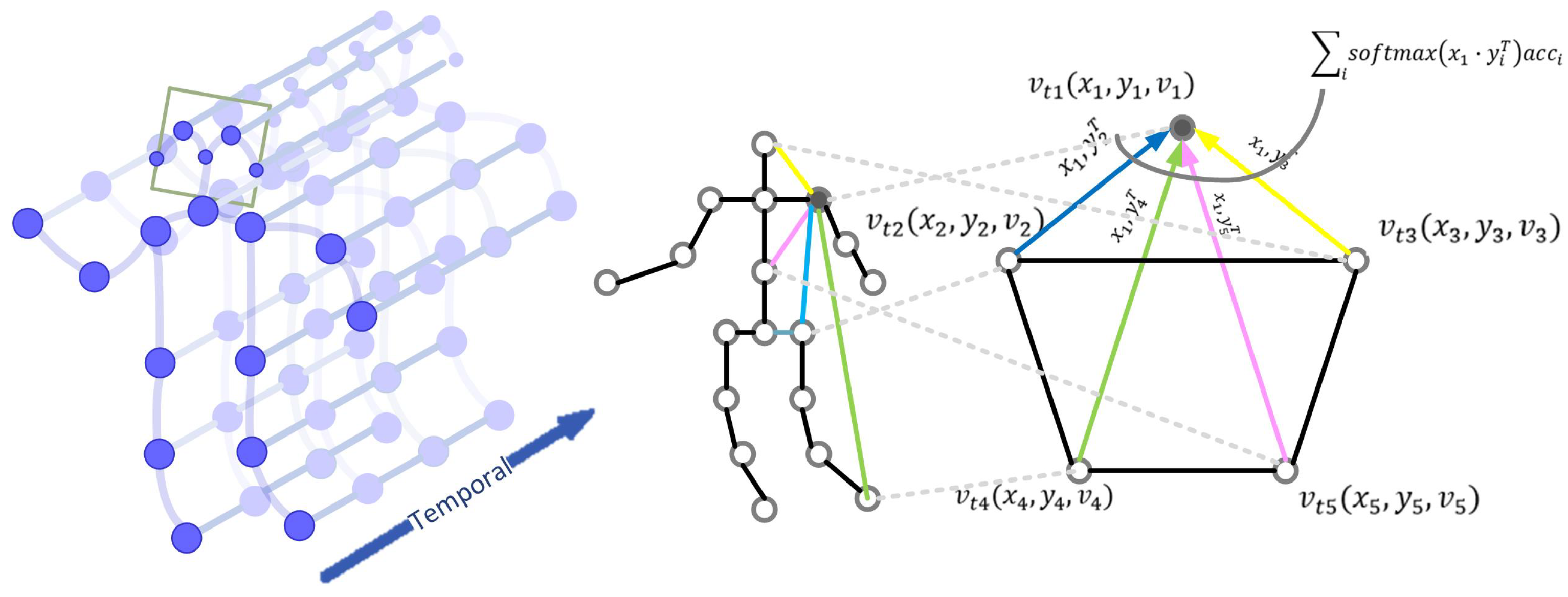
3.2. Spatial Graph Convolution
3.3. Temporal Graph Convolution
- Unlike the connection of skeleton joints in a frame, the connection of skeleton joints in the temporal sequence itself is used as a parameter to train. Furthermore, it can self-learn through a fully connected matrix and learnable weight hyperparameters.
- The size of the convolution kernel determines the connection effect between frames and enriches the contact between frames. It can be regarded as a dynamic recognition process from a certain point of view.
4. Experiments
4.1. Dataset
4.1.1. Traffic Police Gestures Data
4.1.2. Kinetics–Skeleton Dataset
4.2. Evaluation Result
4.2.1. Implement Detail
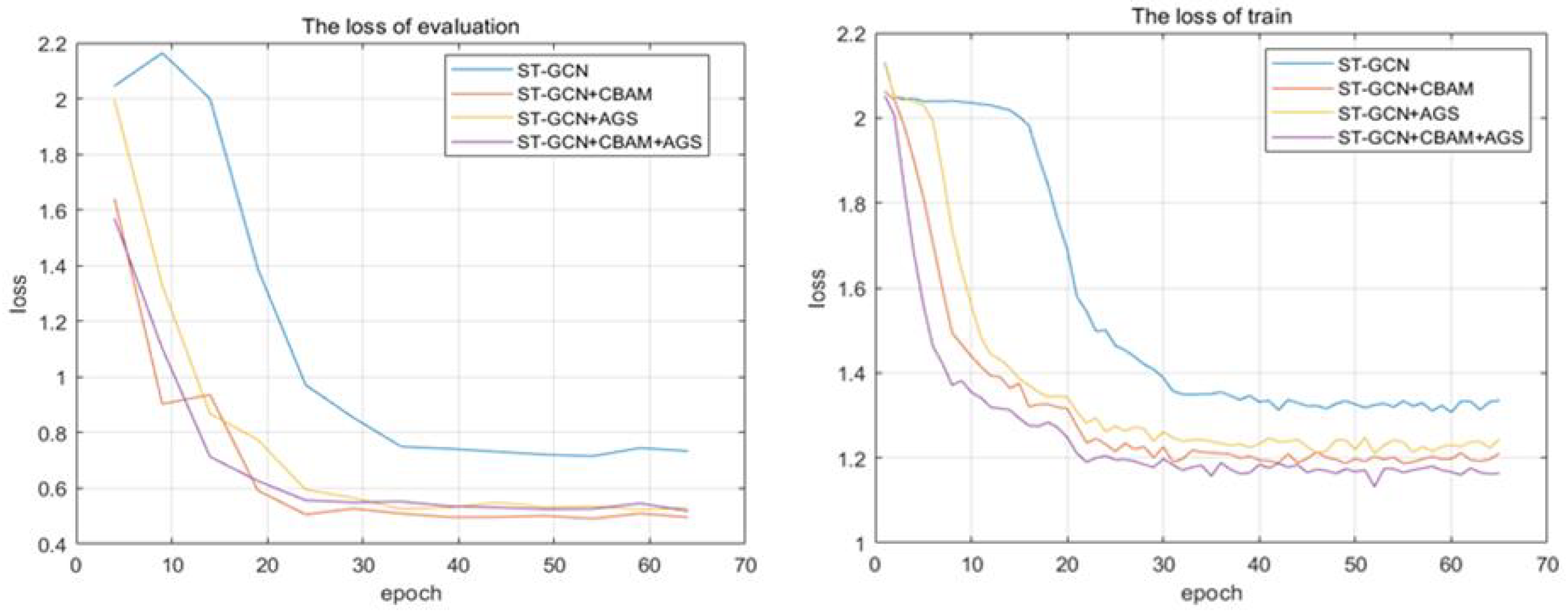
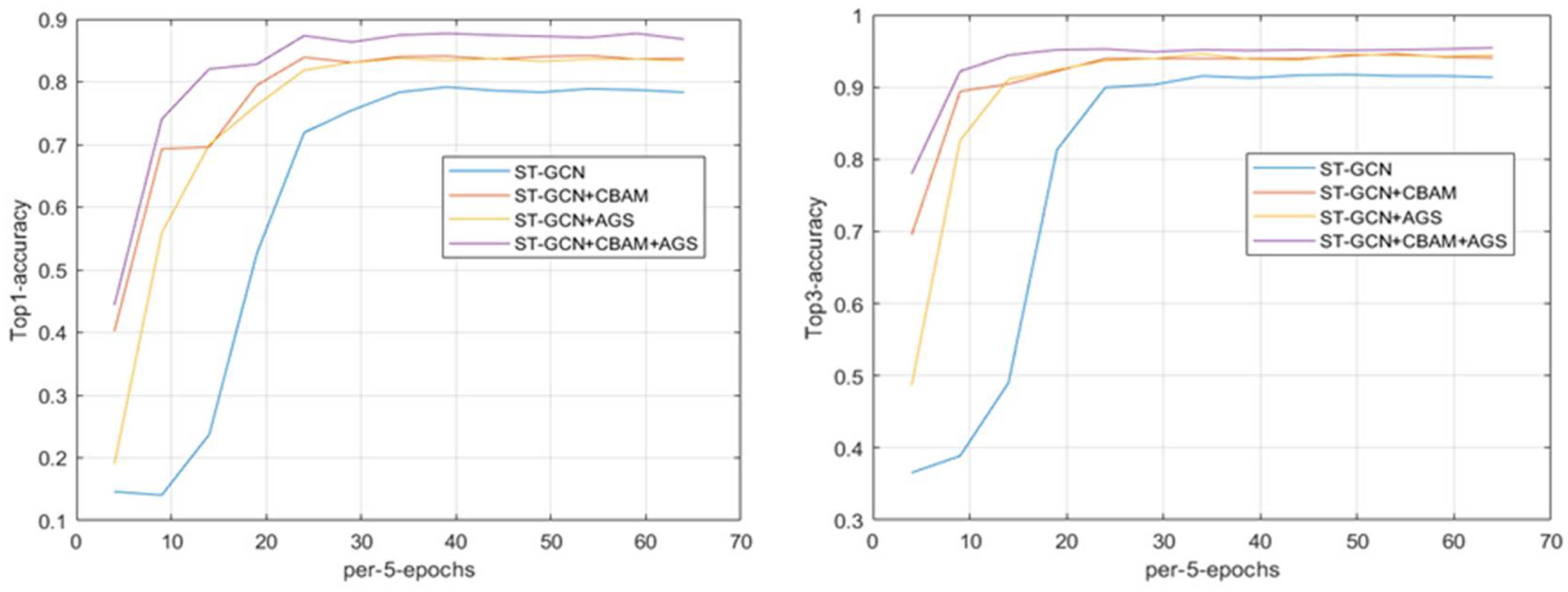
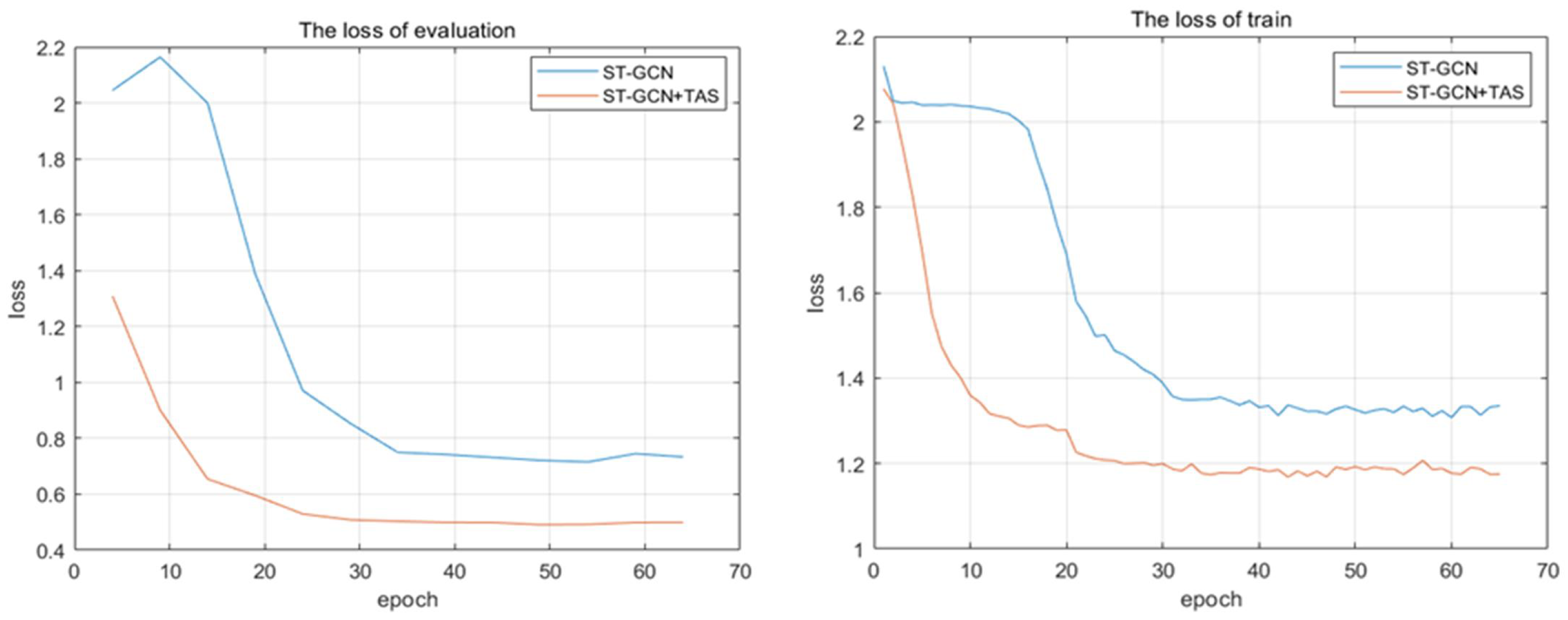
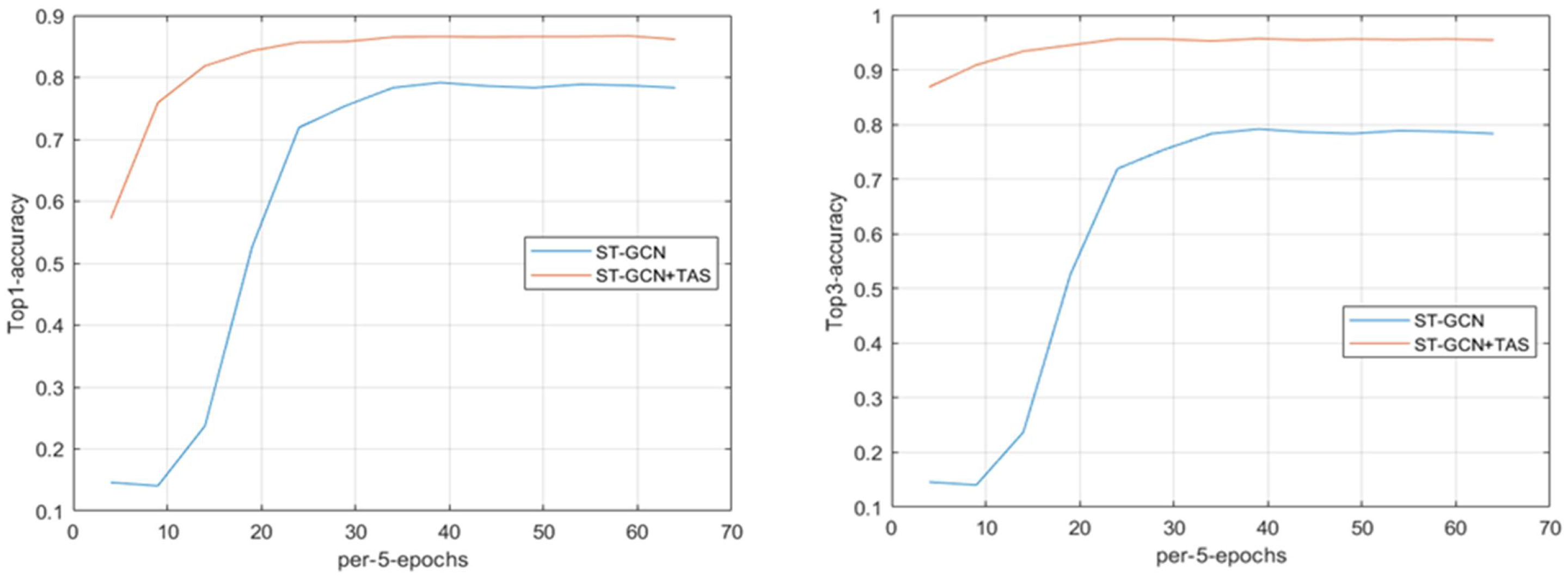
4.2.2. Ablation Study
4.2.3. Comparison with the State-of-Art Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
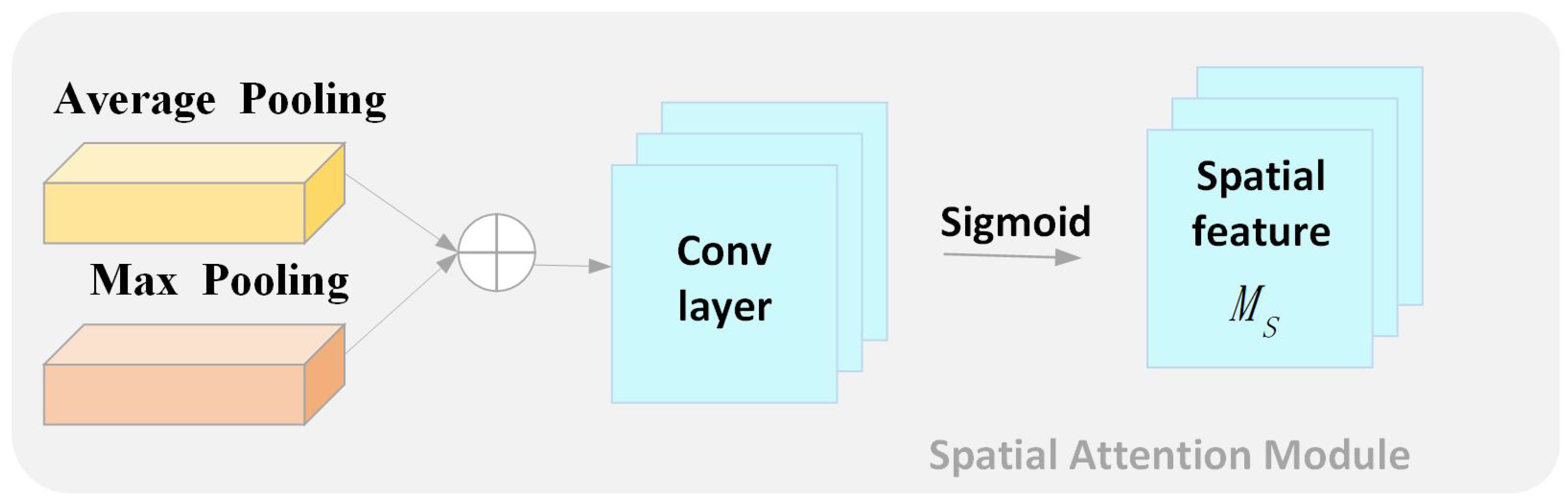
| CBAM | Convolutional block attention module |
| GCN | Graph convolutional networks |
| GNN | Graph neural network |
| LSTM | Long short-term memory |
| ST-GCN | Spatial–temporal graph convolutional network |
| TAS | Temporal attentions mechanism |
| AGS | Adaptive graph structure |
References
- Ma, N.; Li, D.Y.; He, W.; Deng, Y.; Li, J.H.; Gao, Y.; Bao, H.; Zhang, H.; Xu, X.K.; Liu, Y.S.; et al. Future vehicles: Interactive wheeled robots. Sci. China Inf. Sci. 2021, 64, 1–3. [Google Scholar] [CrossRef]
- Li, D.Y.; Ma, N.; Gao, Y. Future Vehicle: Learnable Wheeled Robot. Sci. China Inf. Sci. 2020, 63, 24–54. [Google Scholar] [CrossRef]
- Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. Available online: https://www.sae.org/standards/content/j3016/ (accessed on 30 April 2021).
- Contents and Methods of Field Test Capability Assessment for Automated Vehicle. Available online: http://jtgl.beijing.gov.cn/jgj/jgxx/gsgg/jttg/588465/683743/2020011514485067399.pdf (accessed on 11 February 2018).
- Road Traffic Safety Law of the People’s Republic of China. Available online: http://www.gov.cn/banshi/2005-08/23/content_25575.htm (accessed on 28 October 2003).
- Wang, B.; Yuan, T. Traffic police gesture recognition using accelerometers. J. Hainan Norm. Univ. 2008, 1080–1083. [Google Scholar]
- Tao, Y.; Ben, W. Accelerometer-based Chinese Traffic Police Gesture Recognition System. Chin. J. Electron. 2010, 2, 270–274. [Google Scholar]
- Fan, G.; Cai, Z.; Jin, T. Chinese Traffic Police Gesture Recognition in Complex Scene. In Proceedings of the IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications, Changsha, China, 16–18 November 2011. [Google Scholar]
- Cai, Z.; Fan, G. Max-covering scheme for gesture recognition of Chinese traffic police. Pattern Anal. Appl. 2015, 18, 403–418. [Google Scholar] [CrossRef]
- Fan, G.; Jin, T.; Zhu, C. Gesture Recognition for Chinese Traffic Police. In Proceedings of the International Conference on Virtual Reality and Visualization (ICVRV), Hangzhou, China, 25–26 September 2016. [Google Scholar]
- Sathyaa, R.; Geethaa, M.K. Automation of Traffic Personnel Gesture Recognition. Int. J. Inf. Process. 2015, 9, 67–76. [Google Scholar]
- Sathyaa, R.; Geethaa, M.K. Vision Based Traffic Personnel Hand Gesture Recognition Using Tree Based Classifiers. Comput. Intell. Data Min. 2015, 2, 187–200. [Google Scholar]
- Microsoft Kinect. Available online: https://dev.windows.com/en-us/kinect (accessed on 15 December 2012).
- ASUS Xtion RPO LIVE. Available online: https://www.asus.com/3D-Sensor/Xtion_PRO (accessed on 15 December 2011).
- Ma, C.; Zhang, Y.; Wang, A.; Wang, Y.; Chen, G. Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network. ISPRS Int. J. Geo-Inf. 2018, 7, 37. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Zhang, C.; He, X.L.; Dong, R.H. Visual Recognition of Traffic Police Gestures with Convolutional Pose Machine and Handcrafted Features. Neurocomputing 2020, 390, 248–259. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, Y.X.; Zhang, Z.Q.; Yuan, C.F.; Li, B.; Deng, Y.; Hu, W.M. Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, Italy, 11–17 October 2021. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral Networks and Locally Connected Networks on Graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Henaff, M.; Bruna, J.; Lecun, Y. Deep Convolutional Networks on Graph-Structured Data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Li, R.; Sheng, W.; Zhu, F.; Huang, J. Adaptive Graph Convolutional Neural Networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Duvenaud, D.; Maclaurin, D.; Aguilera-Iparraguirre, J.; Gómez-Bombarelli, R.; Hirzel, T.; Aspuru-Guzik, A. Convolutional Networks on Graphs for Learning Molecular Fingerprints. arXiv 2015, arXiv:1509.09292. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Bronstein, M.M. Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July2017. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.M.; Vandergheynst, P. Geodesic convolutional neural networks on Riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Atwood, J.; Pal, S.; Towsley, D.; Swami, A. Sparse Diffusion-Convolutional Neural Networks. In Proceedings of the Thirty-First Conference on Neural Information Processing Systems, Long Beach, CA, USA, 16–20 June 2017. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Thirty-First Conference on Neural Information Processing Systems, Long Beach, CA, USA, 16–20 June 2017. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. Trellis Networks for Sequence Modeling. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Zisserman, A. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A Short Note about Kinetics-600. arXiv 2018, arXiv:1808.01340. [Google Scholar]
- Smaira, L.; Carreira, J.; Noland, E.; Clancy, E.; Zisserman, A. A Short Note on the Kinetics-700-2020 Human Action Dataset. arXiv 2020, arXiv:2010.10864. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. IEEE Comput. Soc. 2016, 1, 1010–1019. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3D Human Action Analysis with Temporal Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yeh, R.A.; Hu, Y.T.; Schwing, A.G. Chirality Nets for Human Pose Regression. In Proceedings of the Thirty-third Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Settings |
|---|---|
| People | Eight volunteers differing in age, gender, and height |
| Light conditions | Four light conditions: in the morning, noon, late afternoon, and evening |
| Scene | Four scenes: with pedestrians, no pedestrian, T-junction, and criss-cross crossing |
| Clothes | Two kinds of clothes: summer clothes and winter clothes |
| Cameras | Five cameras from different angles |
| Gesture | Eight kinds of standard traffic police gesture as the national standard |
| Distance | 5 meters, 70 meters |
| Total amount | 20,480 |
| ID | ST-GCN | CBAM | AGS | TAS | Top-1 (%) | Top-3 (%) |
|---|---|---|---|---|---|---|
| 1 | √ | 79.16 | 91.72 | |||
| 2 | √ | √ | 84.19 | 94.6 | ||
| 3 | √ | √ | 83.72 | 94.6 | ||
| 4 | √ | √ | 86.7 | 95.72 | ||
| 5 | √ | √ | √ | 86.05 | 94.6 | |
| 6 | √ | √ | √ | 86.5 | 95.44 | |
| 7 | √ | √ | √ | 86.7 | 95.72 | |
| 8 | √ | √ | √ | √ | 87.72 | 95.26 |
| Traffic Police Gesture | Stop | Straight Ahead | Turn Left | Turn Left Waiting |
|---|---|---|---|---|
| Top-1 (%) | 97.96 | 89.68 | 83.09 | 86.90 |
| Top-3 (%) | 99.32 | 92.06 | 94.12 | 97.24 |
| Traffic Police Gesture | Turn Right | Lane Change | Slow Down | Pull Over |
| Top-1 (%) | 86.73 | 75.86 | 90.58 | 83.20 |
| Top-3 (%) | 97.35 | 95.86 | 98.55 | 92.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, K.; Zheng, Y.; Yang, J.; Bao, H.; Zeng, H. Chinese Traffic Police Gesture Recognition Based on Graph Convolutional Network in Natural Scene. Appl. Sci. 2021, 11, 11951. https://doi.org/10.3390/app112411951
Liu K, Zheng Y, Yang J, Bao H, Zeng H. Chinese Traffic Police Gesture Recognition Based on Graph Convolutional Network in Natural Scene. Applied Sciences. 2021; 11(24):11951. https://doi.org/10.3390/app112411951
Chicago/Turabian StyleLiu, Kang, Ying Zheng, Junyi Yang, Hong Bao, and Haoming Zeng. 2021. "Chinese Traffic Police Gesture Recognition Based on Graph Convolutional Network in Natural Scene" Applied Sciences 11, no. 24: 11951. https://doi.org/10.3390/app112411951
APA StyleLiu, K., Zheng, Y., Yang, J., Bao, H., & Zeng, H. (2021). Chinese Traffic Police Gesture Recognition Based on Graph Convolutional Network in Natural Scene. Applied Sciences, 11(24), 11951. https://doi.org/10.3390/app112411951