Abstract
This research paper evaluates the feasibility of cold boot attacks on the Supersingular Isogeny Key Encapsulation (SIKE) mechanism. This key encapsulation mechanism has been included in the list of alternate candidates of the third round of the National Institute of Standards and Technology (NIST) Post-Quantum Cryptography Standardization Process. To the best of our knowledge, this is the first time this scheme is assessed in the cold boot attacks setting. In particular, our evaluation is focused on the reference implementation of this scheme. Furthermore, we present a dedicated key-recovery algorithm for SIKE in this setting and show that the key recovery algorithm works for all the parameter sets recommended for this scheme. Moreover, we compute the success rates of our key recovery algorithm through simulations and show the key recovery algorithm may reconstruct the SIKE secret key for any SIKE parameters for a fixed and small (the probability of a 0 to 1 bit-flipping) and varying values for (the probability of a 1 to 0 bit-flipping) in the set . Additionally, we show how to integrate a quantum key enumeration algorithm with our key-recovery algorithm to improve its overall performance.
1. Introduction
This research paper assesses the viability of cold boot attacks on the Supersingular Isogeny Key Encapsulation (SIKE) Mechanism [1], which is built upon a key-exchange construction known as Supersingular Isogeny Diffie–Hellman (SIDH) [2]. This key encapsulation mechanism has been included in the list of alternate candidates of the third round of the National Institute of Standards and Technology (NIST) post-quantum cryptography standardization process. According to the status report on the second round of this standardization process (NISTIR 8309) [3], the alternate candidates are considered as potential candidates for future standardization. This report also states the main drawback to SIKE is that its performance is approximately an order of magnitude worse than many of its competitors. So improvements on its implementations have been carried out so far to ameliorate this disadvantage [4,5,6,7,8]. The report additionally states that more research is needed to add more side-channel protection on SIKE’s operation. This paper looks into side channel attacks against SIKE and in particular assesses SIKE in the cold boot attack setting. To the best of our knowledge, this is the first time this scheme is assessed in this setting and our evaluation focus on this scheme’s reference implementation, in particular version v3.3 [9].
In the cold boot attack setting, an adversary having physical access to a computer may retrieve any content from the computer’s main memory by carrying out a series of steps on the target computer, such as shutting it down improperly, booting a lightweight operating system (OS) on it and finally using this OS to dump remaining memory contents to an external device. However, as a consequence of some physical effects on the targeted main memory, the retrieved content is altered [10]. This means that on the condition that an attacker gets possession of a chunk of memory content, this content might be noisy, which means that some 0 bits may have flipped to 1 bits and vice-versa. The next attacker’s task is to try to recover secret information stored in the procured memory content, based on what this attacker may learn from the error distribution that occurs during the data acquisition process.
In order to evaluate a public key scheme in this setting, we assume that the attacker procures memory content from a memory region in which the scheme’s secret key was stored, and thus such adversary obtains a noisy version of it. On possession of this noisy memory content, the adversary’s main task is to try to recover the original secret key from its bit-flipped version. More specifically, the evaluation of a public key encryption scheme in this setting entails three main tasks: (1) the attacker is required to learn the in-memory representations of the scheme’s secret key, i.e., the data structures that are used to store the scheme’s secret key, (2) the attacker is required to estimate error probability distributions for the bit-flipping, and (3) finally, the attacker is required to devise and develop a key-recovery algorithm for the scheme’s secret key.
To deal with the first task, the attacker may either study natural in-memory representations for the scheme’s secret key or review scheme’s actual implementations to further learn the scheme’s secret key memory formats. We follow the latter approach, since it is more realistic, and hence we make a deep review of the SIKE reference implementation (Version v3.3) [9]. Regarding the second task, we assume the attacker estimate , the probability for a 0 bit of original content to turn to a 1 bit, and , the probability for a 1 bit of original content to turn to a 0 bit, as per the cold boot model described in Section 2.2. Lastly, we develop our key-recovery algorithm based on a general key-recovery strategy introduced in [11]. Basically, by exploiting and combining the optimal key enumeration algorithm [12], and a non-optimal key enumeration algorithm, as in [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27], we are able to get a suitable algorithm for the key-recovery task. In particular, this algorithm takes advantage of the SIKE secret key in-memory representation and the estimations for both and to generate suitable key candidates for the secret key.
This paper presents two contributions: our first contribution is the evaluation of SIKE against this class of attack. Considering SIKE is one of the alternate candidates, this evaluation represents an important part of the overall assessment of this scheme within the NIST standardization process. Our second contribution is a dedicated key-recovery algorithm for SIKE in the cold boot attack setting. This contribution is in alignment with the current tendency of devising and constructing novel key-recovery algorithms for various schemes in this setting, as our review of the literature, discussed at length in Section 2.3, reveals.
The organization of this research paper is as follows. In Section 2, we discuss the required background on cold boot attacks, detailing on how this attack may be carried out by an attacker. Additionally, we describe the cold boot attack model we assume throughout this paper and also review the literature relevant to our work, focusing on the evaluation of various cryptographic schemes in this setting. Finally, we detail our approach to key-recovery, i.e., the general technique we use to design our key-recovery algorithm. In Section 3, we describe the supersingular isogeny key encapsulation mechanism and its reference implementation, mainly focusing on the key generation algorithm. In Section 4, we give a detailed account of our key-recovery algorithm and our choice for key enumeration algorithms. In Section 5, we evaluate our key-recovery algorithm, focusing on the success rate of our algorithm and how to integrate a quantum key search algorithm with it to improve its overall performance. Finally, in Section 6, we conclude our paper and give insight into a research line to continue with our work.
2. Background
In this section, we give a detailed description of cold boot attacks, the attack model we use through this article and an overview of the previous papers focusing on cold boot attacks on several cryptographic schemes, and finally present a description of the general approach to key recovery we use in this article.
2.1. Cold Boot Attacks
A cold boot attack is a type of data remanence attack in which an attacker could retrieve sensitive data from a computer’s main memory after supposedly having been deleted. This attack relies on the data remanence property of Dynamic RAM (DRAM) and allows an attacker to recover memory content that remains readable for a period of time after the computer’s power has been turned off. The first time this attack was discussed was about a decade ago in [10], and, since then, it has been studied extensively against multiple cryptographic schemes. In this attack, an adversary, who is assumed to have physical access to a computer, might retrieve portions of memory content from a running operating system via carrying out a cold-rebooting on it. This means the running operating system is forced to shut down improperly, making it to bypass all shut-down-related processes, for example, file system synchronization, that would normally take place during an ordinary shutdown. As a consequence of this improper shutdown, the attacker may use an external disk to start and run a lightweight operating system to copy memory contents of pre-boot DRAM to a file. In an alternative way, such attacker may take the memory modules out of the computer and place them in an adversary-controlled computer, which is then booted, allowing the attacker to have access to the memory content and be able to copy chunks of memory content to an external drive.
As soon as the attacker procures data from the main memory, the adversary may carry out a detailed analysis on that data in order to find sensitive information, such as cryptographic keys, via running several key finding algorithms [10]. Due to some physical effects on the main memory, some bits in the memory experience a process of degradation after the computer’s power is turned off. Therefore, the extracted data obtained by the attacker from the target machine’s main memory will be recognizably different from the original memory data. In particular, some 0 bits of the original content may have flipped to 1 bits and vice-versa. The authors in [10] remarked that the degradation of bits in memory can be slowed down via spraying some chemical compounds (liquid nitrogen) on the memory modules and thus the original bits may be preserved for a longer period of time. Nevertheless, the attacker has yet to extract the memory content before restoring any important information (or sensible) from the target machine’s main memory. To this end, the attacker has to handle several possible issues that may occur. For example, the BIOS of the target computer, on rebooting, may overwrite a fraction of memory with its own code and data, even though the affected fractions are usually small. Moreover, the BIOS during its Power-On Self Test (POST) might execute a destructive memory check, yet this test may be disabled or bypassed in some computers.
To properly handle this problem, some small-scale special-purpose programs, like memory-imaging tools, may be used and are expected to produce correct dumps of memory contents to any external device, as was reported in [10]. These programs generally make use of trivial amounts of RAM, and their memory offsets are usually adjusted so as to guarantee that information of interest remains unchanged. Furthermore, if an attacker cannot force boot memory-imaging tools, the attacker could pull out the memory modules and place them in a compatible machine controlled by the attacker and subsequently dump the content, like that mentioned by the authors of [10]. After extracting memory content, the attacker needs to profile it to learn the memory regions and to estimate the probability for both a 1 flipping to 0 and a 0 flipping to 1. Furthermore, according to the results of the experiment reported in [10], almost all memory bits in a memory region tend to decay to predictable “ground” states, with only a portion flipping in the opposite direction. Additionally, the authors of [10] mention the probability of a bit flipping in the opposite direction stays constant and is very small (circa ) as time elapses, while the probability of decaying to the “ground state” increases over time. These results suggest that the attacker could model the decay in a portion of the memory as a binary asymmetric channel, i.e., we can assume that the probability of a 1 flipping to 0 is a fixed number, and that the probability of a 0 flipping to a 1 is another fixed number in a given time. Note that by reading and counting the number of 0 bits and 1 bits, the attacker can discover the “ground state” of a specific memory region. Additionally, the attacker can estimate the bit-flipping probabilities by comparing the bit count of original content in a memory region with its corresponding noisy version.
Finding encryption keys after procuring memory content is another challenge that the attacker has to address. Such problem has been extensively discussed in [10] for Advanced Encryption Standard (AES) and RSA (Rivest–Shamir–Adleman) keys in memory images. Even though the algorithms presented are scheme-specific, their algorithmic rationale may be easily adapted to devise key-finding algorithms for other schemes. These algorithms simply search for special secret-key-identifying characteristics in the secret key in-memory formats as identifying labels for sequences of bytes. More precisely, these algorithms search for byte sequences with low Hamming distance to these identifying labels and verify that the remaining bytes in a possible sequence satisfy some conditions.
Once the previous problems have been dealt with, the attacker now has access to a version with errors of the original secret key obtained from the memory image. Therefore the attacker’s aim is to reconstruct the original secret key from its noisy version, which is a mathematical problem. Moreover, we remark that the attacker may have access to cryptographic data associated with the key to be reconstructed (e.g., ciphertexts for a symmetric key encryption scheme) or the attacker may have access to public parameters of the cryptosystem (e.g., public key for a asymmetric key encryption scheme). The main center of interest of cold boot attacks has been so far to devise, develop and implement key-recovery algorithms to efficiently and effectively reconstruct secret keys from its noisy versions for different cryptographic schemes and testing these algorithms to learn how much noise they can tolerate.
2.2. Cold Boot Attack Model
Based on our previous discussion on cold boot attacks, we assume an adversary has knowledge of the defined structures for the storage of the target private key in memory and has possession of the corresponding public parameters without any noise. Moreover, we assume the attacker procures a noisy version of the target private key via a cold boot attack. However, we do not tackle the issue of locating the memory region where the bits of the private key are stored. Such issue would be of great importance to deal with when carrying out this attack in practice and may be tackled via applying several key finding algorithms [10]. As a result of this assumption, the adversary’s main objective is to reconstruct the original private key.
We denote as the probability of a 0 to 1 bit-flipping, i.e., that a 0 bit in the private key changes to a 1 bit in its noisy version. Moreover, we denote as the probability of a 1 to 0 bit-flipping, i.e., that a 1 bit in the private key changes to a 0 bit in its noisy version. According to our previous discussion on cold boot attacks, one of these values normally may be very small (approximately ) and not liable to variation over time, while the other values do increase over time. Moreover, the adversary may estimate both and and they remain unchanged across the memory region where the bits of the private key are stored. As stated by our previous discussion on cold boot attacks, these suppositions are plausible, since an adversary may estimate the error probabilities by comparing original content with its corresponding noisy version (e.g., using the public key), and the memory regions are normally large.
2.3. Previous Work
Throughout this section, we present our literature review, describing works on cold boot attacks against multiples cryptographic schemes. These studies can be divided into several categories, namely the RSA setting, the discrete logarithm setting, the symmetric key setting and finally the post-quantum setting.
2.3.1. RSA Setting
The research paper by Heninger and Shacham [28] was the first work dealing with this attack on RSA keys. They presented a key-recovery algorithm, which relies on Hansel lifting, and exploited the redundancy found in the common RSA secret key in-memory format. The research papers by Henecka et al. [29] and Paterson et al. [30] followed the inaugural paper and both research papers further exploited the mathematical structure on which RSA is based. Additionally, the research paper by Paterson et al. [30] further centered on the error channel’s asymmetric nature, which is intrinsically connected to the cold boot setting, and also considered the key-recovery problem from an information theoretic perspective.
2.3.2. Discrete Logarithm Setting
The first paper that explored this attack in the discrete logarithm setting was that of Lee et al. [31]. Their key-recovery algorithm is limited due to the cold boot attack model they assumed. In particular, their work focused on recovering the secret key x, given the public key , with g being a field element and x being an integer. Their model, in addition to assuming the attacker has knowledge of the public key and of the noisy version of the private key x, supposes the adversary knows an upper bound on the number of errors found in the noisy version of the secret key. Since knowing such an upper bound may not be practical and small redundancy in the secret key was exploited, their key-recovery algorithm is not expected to recover keys if these are subjected to a high level of noise, or if a bit-flipping model is assumed. A follow-up work by Poettering and Sibborn [32] also studied this attack in the discrete logarithm setting, more concretely in the elliptic curve cryptography setting. Their work was more practical, since they had a deep review of two implementations for elliptic curve cryptography. With such review, they found redundant in-memory formats and focused on two common secret key in-memory formats from two popular ECC implementations from TLS libraries. The first one is the windowed non-adjacent form (wNAF) representation, and the second is the comb-based representation. For each format, they developed dedicated key-recovery algorithms and tested them both in the bit-flipping model.
2.3.3. Symmetric Key Setting
Regarding this attack against symmetric key primitives, there are also a few papers that explored this attack against a few block ciphers. The paper by Albrecht and Cid [33] centered on the recovery of symmetric encryption keys by employing polynomial system solvers. Particularly, they used integer programming techniques to apply them for key-recovery of the Serpent block cipher’s secret key. Furthermore, they also introduced a dedicated key-recovery algorithm to Twofish’s secret keys. Moreover, the paper by Kamal and Youssef [34] introduced key-recovery algorithms based on SAT-solving techniques to the same problem. We refer the interested reader to [33,34,35] for more details.
2.3.4. Post-Quantum Setting
Regarding the viability of carrying out this attack against post-quantum cryptographic schemes, there are already several works showing the feasibility of this attack against some post-quantum cryptographic schemes implementations. The first paper that evaluated a post-quantum cryptographic scheme in this setting was that of Paterson et al. [36]. They looked into this attack against NTRU and their work reviewed two existing NTRU implementations, the ntru-crypto implementation and the tbuktu Java implementation based on Bouncy Castle. For each in-memory format found in these implementations, they introduced dedicated key-recovery algorithms and tested them in the bit-flipping model. According to the results reported in [36], their key-recovery algortihm was able to find the private key, when is fixed and small and ranges from up to , for one of the private key in-memory representations. This paper was followed upon by that of Villanueva [11], which extended previous results and introduced a general key-recovery strategy via key enumeration. Additionally, they applied their general strategy to BLISS and their results are comparable to the results reported for the NTRU case. Another recent paper by Villanueva [37] adapted and applied this general key-recovery strategy to the signature scheme LUOV, exploiting the fact that LUOV’s private key is a 256 bit string, and showed the versatility of this general key-recovery strategy and promising results. Moreover, Albrecht et al. [38] investigated cold boot attacks on post-quantum cryptographic schemes based on the ring—and module—variants of the Learning with Errors (LWE) problem. Their work centered on Kyber key encapsulation mechanism (KEM) and New Hope KEM, where two encodings were considered to store LWE keys (polynomials): coefficient-based in-memory format and number-theoretic-transform (NTT)-based in-memory format. Finally, they presented dedicated key recovery algorithms to tackle both cases in the bit-flipping model.
2.3.5. General Strategy to Key Recovery
According to the work by Villanueva [11,27], we can deal with the key-recovery problem in the cold boot attack setting via key enumeration algorithms.
Let denote a W bit string with the noisy bits of the secret key encoding. Note that may be written as a sequence of chunks, with each chunk being a w bit-string, i.e., with . On the condition that we have access to a suitable key-recovery algorithm, we can generate full key candidates for the original secret key encoding. Based on Bayes’s theorem, the probability of being the right full key candidate given the noisy version ch is given by . Therefore, should be chosen so as to maximize this probability, according to the maximum likelihood estimation method. Note that both and are constants, with the former independent of , and that where counts the positions in which both c and ch contain a 0 bit, counts the positions in which c contains a 0 bit and ch contains a 1 bit, etc. Hence our optimization problem reduces to find the candidate c to maximize this probability . Note that this problem can be stated equivalently as choosing that maximizes the log of these probabilities . Therefore, each candidate can be assigned a score, namely .
If we now assume that the full key candidates c may be written as a sequence of chunks as for , i.e., , with being a sequence of w bits, then we may also assign a score to each of the at most values for a chunk candidate .
where the values count occurrences of bits across the chunks, . Because of , lists of chunk candidates, containing up to entries, may be created. More concretely, each list contains at most 2-tuples of the form , where the first component is a real number (candidate score) and the second component is a w-bit string (candidate value). Now note that the original key-recovery problem reduces to an enumeration problem that consists in traversing the lists of chunk candidates to produce full key candidates of which total scores are obtained by summation. Fortunately for us, the enumeration problem has been previously studied in the side-channel analysis literature [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27], and there are many algorithms that may be useful for our key-recovery setting, in particular those producing full key candidates sorted in descending order based on the score component.
More formally, let be a list of chunk candidates for chunk , with and . Given the chunk candidates , with , we define as a function that outputs a new chunk candidate computed by setting When , is known as a full key candidate.
The key enumeration problem entails choosing a chunk candidate from each list , , to form full key candidates conditioned to a rule on their scores [27]. An algorithm that enumerates full key candidates c is known as a key enumeration algorithm (KEA).
For our key-recovery problem, we use an algorithm that combines two key enumeration algorithms and is based on one introduced in [11,37]. Moreover, we also exploit the in-memory representation of the secret key of SIKE mechanism to improve our results. This key-recovery algorithm will be described in Section 4.2.
3. Supersingular Isogeny Key Encapsulation Mechanism
This section gives a brief account of the Supersingular Isogeny Key Encapsulation mechanism. This mechanism relies on Supersingular Isogeny Diffie–Hellman (SIDH), a key-exchange protocol introduced by Jao and De Feo in 2011 [2]. In particular, we follow the description provided by SIKE’s specification submitted to the NIST post-quantum cryptography standardization process.
3.1. Mathematical Foundations
3.1.1. The Finite Field
Let be a finite field, with p being a prime number. The elements of this field are represented by the integers in the set . These elements are operated with the two common operations, addition and multiplication modulo p.
3.1.2. The Finite Field
The quadratic field extension can be constructed easily from . In particular, the elements of are represented by , where , , with . Note that e can also be represented as a 2-tuple . The addition and multiplication operations are defined as follows:
- If , then , where the additions carries out in . Equivalently,
- If , then , where the element operations take place in . Equivalently,
Since is a field, we can compute the additive inverse of a, denoted by , and also the multiplicative inverse of a, denoted by . To see more details on how all field operations are calculated, we refer the reader to [1].
3.1.3. Montgomery Curves
A Montgomery curve is a special form of an elliptic curve. Let be a finite field, where , p a prime number with , and let be field elements satisfying in . A Montgomery curve defined over , denoted by , is defined to be the set of points of solutions in to the equation
The set of points of together with the point at infinity, denoted by O, form a finite abelian group under a point addition operation, denoted by . That is, given the points P and Q in , we can compute , where is a point in . Consequently, we also can compute , or in general (k times, with ). These operations are called point doubling, point tripling or point multiplication, respectively. To see more details on how to do these computations, we refer the reader to [1].
The order of an elliptic curve E over a finite field , denoted by , is the number of points in E including O. Additionally, the order of a point P is the smallest positive integer n such that .
Given an abelian group G, we say a set of elements forms a basis of the subgroup if every element P of H can be represented by a unique expression of the form , where for .
Consider an elliptic curve and a positive integer m, we define the group of the m-torsion elements of as , where is the algebraic closure of . An elliptic curve over a field of characteristic p is called supersingular if , and ordinary otherwise. Additionally, the j-invariant of the elliptic curve can be calculated as The j-invariant of an elliptic curve over a field is unique up to the isomorphism of the elliptic curve. The SIKE protocol defines a shared secret as a j-invariant of an elliptic curve.
3.1.4. Isogenies
Let and be elliptic curves over a finite field . An isogeny is a non-constant rational map defined over , with being a group homomorphism from to . Additionally, can be written as , where f and g are rational maps over . Note that we can write with polynomials and over , where and do not have a common factor, and similarly for . We define the degree of the isogeny to be , where and are as above. Given an isogeny , denotes the kernel of . Additionally, given a finite subgroup , there is a unique isogeny (up to isomorphism) such that and , where the curve . We can compute the isogeny and the curve for a given a subgroup , using Vélu’s formula [39]. However, it is computationally impractical for arbitrary subgroups. SIKE uses isogenies over subgroups that are powers of 2, 3 and 4 [1].
3.2. Key Encapsulation Mechanism
This section describes the components of the supersingular isogeny key encapsulation mechanism as in [1].
3.2.1. Public Parameters
We start off by describing the public parameters that SIKE makes use of:
- A prime number of the form , where and are two positive integers.
- A starting supersingular elliptic curve defined as , such that and 287,496.
- Two points and in , such that both points have exact order and forms a basis for .
- Two points and in , such that both points have exact order and forms a basis for .
These points are normally encoded for efficiency. Particularly, the points and are encoded as a byte array from the three x-coordinates , and , where . Similarly, the points and are encoded as a byte array from the three x-coordinates , and , where [1].
3.2.2. Secret Keys
Two secret keys, and , are used to compute -isogenies and -isogenies, respectively. On the one hand, the secret key is an integer in the set and is stored as a byte array of length . The corresponding keyspace is denoted . On the other hand, the secret key is an integer in the set and is stored as a byte array of length . The corresponding keyspace is denoted .
3.2.3. Isogeny Algorithms
Let with . The two core isogeny algorithms used in SIKE are and . On the one hand, the algorithm takes in the public parameters and a private key as inputs and returns the corresponding public key . Specifically, it computes and then computes the -degree isogeny via the composition of individual l-degree isogenies, where , and returns the points and encoded as a byte array from three x-coordinates as the public key, i.e., , where
On the other hand, the algorithm receives a secret key and a public key as inputs, and then outputs the corresponding shared key. Specifically, on receiving a private key and an encoded public key , it then decodes to get the corresponding curve and the points and , then computes and the -degree isogeny via the composition of individual l-degree isogenies, where , and finally returns .
3.2.4. The Reference Implementation
In this section, we review the SIKE’s main algorithms as in the reference implementation (see the file sike.c). Reviewing this implementation is of great importance to learn the in-memory representation used to store private keys.
Let denote the length in bits of the messages to be encapsulated, i.e., , and let denote the number of bits of the output shared key, i.e., . Also, denotes hashing the message m and obtaining only d bits from the output, i.e., the output may be regarded as an infinite bit string, of which computation is stopped after the desired number of output bits is produced [40].
The first algorithm to describe is the key generation algorithm. It is the most relevant algorithm for our work, so we describe it in more detail. Algorithm 1 shows a pseudo-code of the key generation algorithm’s implementation. It takes in Params, that contains , , and , and first generates a random byte array, then generates a secret key chosen uniformly at random in the keyspace and finally calls to get the corresponding encoded public key. The in-memory representation of the private key is a byte array of length , where is the length in bytes of the encoded public key. The first bytes correspond to , the next bytes correspond to the secret key and finally the last bytes correspond to the encoded public key . Note that is the only publicly known part stored in the private array.
| Algorithm 1 Key generation algorithm for SIKE. |
|
Regarding the encapsulation mechanism for SIKE, as described by Algorithm 2, it basically generates a message in the message space and hashes it along with the given public key to get , which is passed as key in to to compute the corresponding public key and the shared string . The value is hashed to get , which is xored with to get , and then the shared key is computed and returned, along with the ciphertext .
| Algorithm 2 Encapsulation algorithm for SIKE. |
|
Regarding the decapsulation mechanism for SIKE, as described by Algorithm 3, it basically computes the shared string from and the secret key . It then recomputes , then and then , which is used to compute . At this point, it compares with the given . If they are equal, then the real shared key is computed and returned, otherwise a fake shared key is computed and returned.
| Algorithm 3 Decapsulation algorithm for SIKE. |
|
SIKE Parameters
Table 1 shows relevant entries from each SIKE parameter for our key-recovery attack. For a comprehensive list of all entries defined for each SIKE parameter, such as , ,, , and , we refer the reader to [1,9].

Table 1.
Relevant constants from Supersingular Isogeny Key Encapsulation (SIKE) parameters.
4. Key Recovery
Throughout this section, we give a detailed account of our key-recovery algorithm, which relies on the general key-recovery strategy described in [11,27].
4.1. Assumptions
Based on the model we described in Section 2.2, we suppose that an adversary procures a noisy version of a SIKE’s private key encoding as it is stored by the reference implementation. In particular, the adversary procures an array containing . Additionally, such adversary accesses the corresponding original public parameters (i.e., without noise), so such adversary may use them to properly locate the offset from which the secret key bits () are stored via running key-finding algorithms exploiting identifying features found in the memory formats for storing the SIKE’s private key. These algorithms would be similar to those developed for the RSA setting [10].
Additionally, by we denote the probability for a 0 bit of the original secret key to change for a 1 bit, and by we denote the probability for a 1 bit of the original private key to change for a 0 bit. According to our model, the attacker knows both and , since these values are fixed across the memory region in which the secret key is located and can be easily estimated by comparing any noisy content with its corresponding original one (e.g., the public key). Moreover, memory regions are normally large and the size in bytes of is at most 48 bytes according to Table 1.
4.2. Our Key-Recovery Algorithm
Throughout this section we give a detailed account of our key-recovery strategy, taking into consideration the notation introduced in Section 2.3.5 and the review of SIKE’s reference implementation.
Let be W bit string that represents the noisy version of the secret key encoding . Note that the value for W depends on the SIKE parameters on which SIKE is configured. In particular, (see the fourth column of Table 1). We denote w as the size in bits of a chunk (it is set to 8), and so can be written as a sequence of chunks
with . We define a block as a sequence of consecutive chunks, where and m is the number of chunks in the block. We can now rewrite as a concatenation of blocks, namely
with . Now we are ready to present our key-recovery algorithm.
- Set the array with . Each is the number of chunks in the block .
- Set the array . Each is the number of high-scoring candidates to generate for the block .
- By making use of Equation (1), our algorithm computes the log-likelihood scores for all possible candidate values for each chunk , with . Note that, in the SIKE setting, all candidate values are in the set , except for the last chunk, where all candidate values are in the set with being the number of ones of the binary string Params.MASK. Each tuple generated for a particular chunk is inserted into the list , and this is finally inserted in the corresponding index i of the main list L.
- For each block , with and , then the lists stored in L at indexes for are given as parameters to an optimal key enumeration algorithm, which we denote as OKEA, to produce the list that contains the candidates with the highest scores for the block .
- All lists are given as parameters to an instance of a key enumeration algorithm (KEA). This instance regards each as a list of suitable candidates for the corresponding block and outputs high-scoring full key candidates for the target secret key encoding. Upon generating a full key candidate , our algorithm passes it as input to a testing function (Test in our case) to verify whether the full key candidate is a valid secret key or not.
Algorithm 4 shows a pseudo-code of our key-recovery algorithm. Note that points to the optimal key enumeration algorithm that our key-recovery algorithm runs at step 4, and points to the key enumeration algorithm that our key-recovery algorithm runs at step 5. Additionally, refers to the arguments that the algorithm pointed by may take in and is a pointer to the testing function Test, i.e., Algorithm 5. We next expand on our choice of key enumeration algorithms for our key-recovery algorithm.
On Our Choice of an Optimal Key Enumeration Algorithm
Our key-recovery algorithm requires an optimal key enumeration algorithm run at step 4 to enumerate full key candidate c sorted by their scores in descending order. There are several algorithms suitable for this task [12,27,41], and we use the algorithm (OKEA) from [12], since it is flexible and easy to implement. Additionally, note that OKEA is an inherently sequential algorithm, and so its optimality property is fulfilled only if it is not run in parallel. In addition, its memory consumption may be high if used to enumerate many candidates [27]. In our setting, we select to be a value in the set for all .
On Our Choice of Non-Optimal Key Enumeration Algorithms
Regarding the key enumeration algorithm () that our key-recovery algorithm runs at step 5, this algorithm is required to be parallelizable and memory-efficient, since this step of our approach requires a considerably high amount of computational resources. Here we explore the use of two different key enumeration algorithms. On the one hand, we use an algorithm called NOKEA, which combines several good characteristics from multiples algorithms () [11,37]. This particular algorithm may be configured to search over a well-defined range , where and is the maximum total score that a full key candidate may be given to. In this configuration, this algorithm enumerates each possible full key candidate of which total score lies in the chosen interval [11]. We expand on the use of this algorithm in Section 5.1, in which we also present the success rates of our key-recovery algorithm. On the other hand, we also explore how to combine our key-recovery algorithm with a quantum key enumeration algorithm [42], which we denote by QKEA, that combines a non-optimal key enumeration algorithm and the Grover algorithm [43]. We expand on this in Section 5.2.
| Algorithm 4 Key-recovery algorithm. |
|
| Algorithm 5 Test Function. |
|
5. Evaluation of Our Key-Recovery Algorithm
Throughout this section we assess our key-recovery algorithm. We first give a detailed account of how we compute the success rates for our key-recovery algorithm considering several scenarios, each with a different set of SIKE parameters, and finally show how to integrate a quantum key search algorithm (QKEA) to our key-recovery algorithm to improve its overall performance.
5.1. Performance and Success Rates of Our Key-Recovery Algorithm
This section reports success rates of our key-recovery algorithm. We first note that in this setting the attacker procures a noisy version of via a cold boot attack, as stated in Section 4.1, and so our key-recovery algorithm tries to find a full key candidate for from the noisy version. In order to compute estimates for success rates of our key-recovery algorithm, we analyze the following scenarios. For a given set of instance parameters, we calculate the success rate for our key-recovery algorithm with NOKEA if it is set to (1) enumerate all the possible full key candidates; (2) enumerate an interval with roughly full key candidates; (3) enumerate an interval with roughly full key candidates; (4) enumerate an interval with roughly full key candidates. In this context, by instance parameters we mean setting the array , the array , w (normally 8), , , together with the selected SIKE parameters.
Note that given the noisy version and the instance parameters, our key-recovery algorithm creates the lists at the end of step 4, then these are passed to NOKEA at the beginning of the step 5. Here is where we exploit several features of this algorithm in order to compute estimates for the success rates without actually running an enumeration with NOKEA. In particular, we exploit the fact that NOKEA can enumerate full key candidates of which total scores belong to a given interval in order from the highest to the lowest total score and that many scores of block candidates for a given block are repeated [11,36,44]. In particular, once the lists are created, our tweaked NOKEA creates factorized lists, one per list , that contain entries of the form where represents a score and is the number of block candidates having as score in the corresponding list . These factorized lists are passed to an alternative version of OKEA, where is seen as a candidate value, and it generates another factorized list L with entries of the same form , which is sorted by score in descending order, i.e., from the highest to the lowest score. An entry may be interpreted as there are full key candidates of which total score is equal to .
To calculate estimates for success rates, we run our tweaked key-recovery algorithm with all required parameters a fixed number of times (100 times) and then compute the corresponding success rate. Specifically, at each trial the SIKE key generation algorithm is run to obtain according to the selected set of SIKE parameters, and then is perturbed as per and and then our tweaked key-recovery algorithm is called by passing the noisy version , the instance parameters and the original key as parameters. It then runs until generating the lists and, at such point, checks that each block of the original key is found in the corresponding list . If so, it means that a complete enumeration, carried out by NOKEA, would not fail in finding the secret key (it would fail otherwise). On the condition that the complete enumeration will not fail, the tweaked NOKEA is run to create the factorized list L, which is used to determine if the original key may be found by the instance of NOKEA if it enumerates a range having roughly or or full key candidates. In particular, say, we want to determine if the original key can be found via enumerating a range with approximately full key candidates, , then the algorithm finds an entry at index e in L such that e is the smallest integer satisfying . If the score calculated for the original key (from the noisy version) lies in the interval , then it signifies that an enumeration in such interval (which contains at least candidates) will find the original key. We next describe the instance parameters we used to run our trials.
SIKEp434
For this set of SIKE parameters, has a length of 28 bytes, , which means that only the first bit of the last byte of is used. Also, we set w to 8, to and to r, for , where . Note that the number of chunks is 28 and the number of blocks is 7. Figure 1 and Figure 2 show the obtained results for this set of parameters.
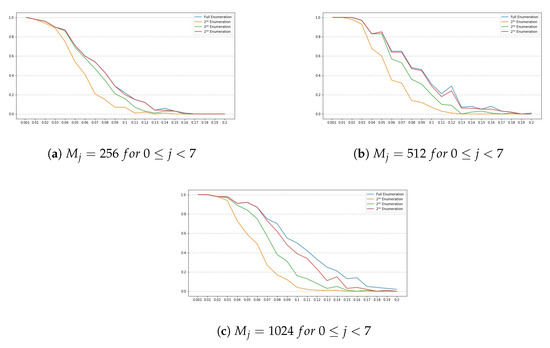
Figure 1.
Success rates for the SIKE parameters SIKEp434 for . The y-axis denotes the success rate, while the x-axis denotes .
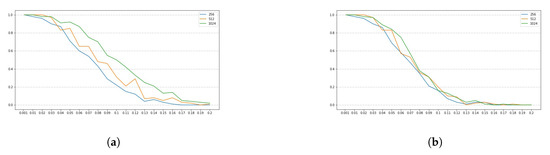
Figure 2.
Success rates for the SIKE parameters SIKEp434 for . The y-axis denotes the success rate, while the x-axis denotes . (a) Comparing success rates for in a full enumeration. (b) Comparing success rates for in a enumeration.
Additionally, the function Test for this set of parameters takes about 5,141,167 cycles to run in a virtual machine type e2-highcpu-16 with 16 vCPUs and 16 GB of memory deployed in the Google Cloud Platform.
SIKEp503
For this set of SIKE parameters, has a length of 32 bytes, , which means that only the four first bits of the last byte of are used. Also, we set w to 8, to and to r, for , where . Note that the number of chunks is 32 and the number of blocks is 8. Figure 3 and Figure 4 show the obtained results for this set of parameters.
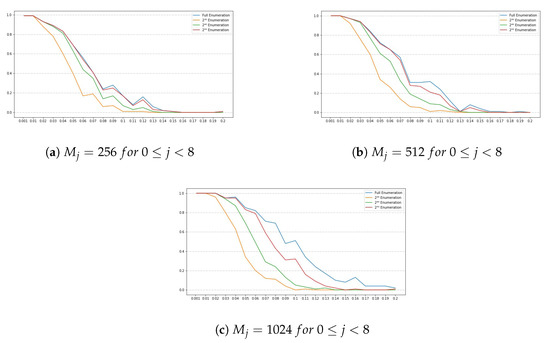
Figure 3.
Success rates for the SIKE parameters SIKEp503 for . The y-axis denotes the success rate, while the x-axis denotes .
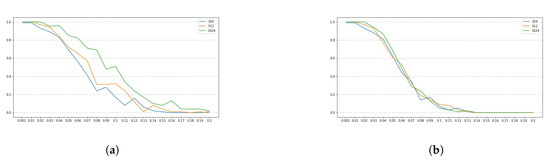
Figure 4.
Success rates for the SIKE parameters SIKEp503 for . The y-axis denotes the success rate, while the x-axis denotes . (a) Comparing success rates for in a full enumeration. (b) Comparing success rates for in a enumeration.
Additionally, the function Test for this set of parameters takes about 7,069,164 cycles to run in a virtual machine type e2-highcpu-16 with 16 vCPUs and 16 GB of memory deployed in the Google Cloud Platform.
We remark that the success rates for this set of parameters and those obtained for LUOV [37] are essentially similar. This is expected since both LUOV’s secret key and SIKE’s secret key for this case are of length 32 bytes.
SIKEp610
For this set of SIKE parameters, has a length of 38 bytes, , which means that all the bits of the last byte of are used. We also set w to 8, to and to r, for , where . Note that the number of chunks is 38 and the number of blocks is 8. Figure 5 and Figure 6 show the obtained results for this set of parameters.
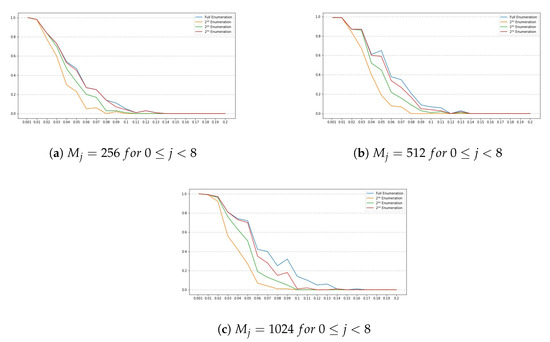
Figure 5.
Success rates for the SIKE parameters SIKEp610 for . The y-axis denotes the success rate, while the x-axis denotes .
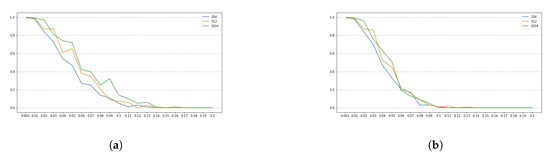
Figure 6.
Success rates for the SIKE parameters SIKEp610 for . The y-axis denotes the success rate, while the x-axis denotes . (a) Comparing success rates for in a full enumeration. (b) Comparing success rates for in a enumeration.
Additionally, the function Test for this set of parameters takes about cycles to run in a virtual machine type e2-highcpu-16 with 16 vCPUs and 16 GB of memory deployed in the Google Cloud Platform.
SIKEp751
For this set of SIKE parameters, has a length of 48 bytes, , which means that only the two first bits of the last byte of are used. Also, we set w to 8, to and to r, for , where . Note that the number of chunks is 48 and the number of blocks is 8. Figure 7 and Figure 8 show the obtained results for this set of parameters.
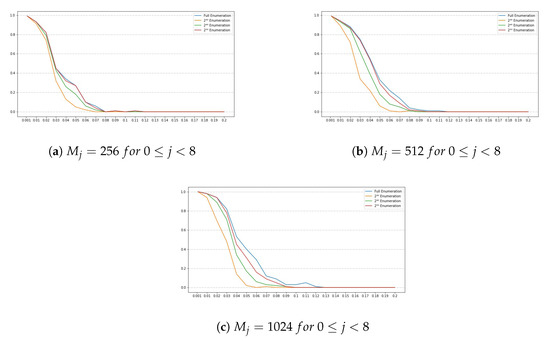
Figure 7.
Success rate for the SIKE parameters SIKEp751 for . The y-axis denotes the success rate, while the x-axis denotes .
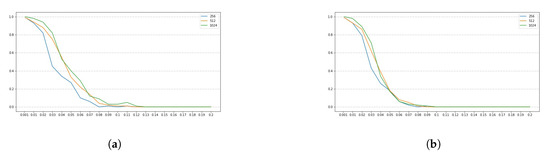
Figure 8.
Success rates for the SIKE parameters SIKEp751 for . The y-axis denotes the success rate, while the x-axis denotes . (a) Comparing success rates for in a full enumeration. (b) Comparing success rates for in a enumeration.
Additionally, the function Test for this set of parameters takes about 21,266,903 cycles to run in a virtual machine type e2-highcpu-16 with 16 vCPUs and 16 GB of memory deployed in the Google Cloud Platform.
Results Discussion
Note that all plots depicted by Figure 1a–c, Figure 3a–c, Figure 5a–c and Figure 7a–c, show a similar trend, namely, for all set of instance parameters and , the success rate for a complete enumeration dominates the success rate for a enumeration, which in turn dominates the success rate for a enumeration, and which in turn dominates the success rate for a enumeration. This is in alignment with what we expected. Moreover, we remark that the success rate decreases as long as increases, although there are a few cases where, given and with , the success rate for is a bit larger than the success rate for . This is due to the manner in which an interval is constructed by the NOKEA algorithm (and hence its tweaked version). However, the general trend is that the success rate decreases while increases, which is also in line with what is expected. Additionally, Figure 2a, Figure 4a, Figure 6a and Figure 8a show similar trends when comparing success rates for in a full enumeration. Analogously, Figure 2b, Figure 4b, Figure 6b and Figure 8b also show similar trends when comparing success rates for in a enumeration.
5.2. Integrating a Quantum Key Search Algorithm with Our Key-Recovery Approach
Throughout this subsection we give a detailed account of a quantum key enumeration algorithm, denoted as [42], and show how to combine it with our key-recovery algorithm to improve its overall performance. We additionally derive the running time of step 5 of our key recovery algorithm (worst case) if is run. Recall that at step 5, the lists , for , will be given as parameters to an instance of the quantum key enumeration algorithm (QKEA).
relies on a non-optimal key enumeration algorithm developed from a rank algorithm (also known as a counting algorithm) by Martin et al. [17]. The core idea is to leverage the rank algorithm to return a single candidate key with a particular rank within a specific range. Additionally, we remark that this algorithm uses a map that associates each score with a weight (a positive integer), where the smallest weight is regarded as the likeliest one [17].
We assume the scores from each block candidate in the list , for , are mapped to weights, as shown in [27,42]. Given the range , the rank algorithm constructs a two dimensional array with entries, and then uses it to compute the number of full key candidates in the range. Algorithm 6 constructs the two dimensional array and its running time is given by
where for , and , , are constants, i.e., upper bounds on the running time consumed by primitive operations, such as return operations, addition operations, comparison operations.
| Algorithm 6 constructs the two dimensional array . |
|
Note that, by construction, is the number of full key candidates of which total scores are in the interval . So the rank algorithm simply returns and is described by Algorithm 7. Concerning its running time, it is given by , where is a constant, i.e., an upper bound on the running time of primitive operations.
| Algorithm 7 computes the number of full key candidates in . |
|
By using Algorithms 7 and 8 returns the full key candidate with rank r in the given range [42]. We remark that Algorithm 8 is deterministic and that the full key candidate returned by it is not necessarily the highest-scoring full key candidate in the given range. Regarding Algorithm 8’s running time, it is given by
where , , are constants, i.e., upper bounds on the running time consumed by primitive operations.
| Algorithm 8 returns the full key candidate with weight in the interval |
|
By calling the getKey function, Algorithm 9 tries to enumerate and test all full key candidates in the given interval [42]. Note that Test is pointer to the testing function (Algorithm 5). Concerning Algorithm 9’s running time, it is given by , where e is the number of full key candidates in the range , and are constants and upper bounds on the running time consumed by primitive operations, and is the running time of the testing function (Algorithm 5).
| Algorithm 9 enumerates and tests all full key candidates with weight in the interval |
|
Algorithm 10 calls the function keySearch to search over partitions selected independently with approximately full key candidates for [42]. Regarding Algorithm 10’s running time, this is given by
where and are upper bounds on the running time consumed by primitive operations, such as return operations, addition operations, comparison operations. The terms and are the running times of steps 5 and 13 of Algorithm 10. Note that this algorithm is similar to NOKEA in the sense that it also enumerates full key candidates of which total scores belongs to the given range. Furthermore, the technique of partitioning the entire interval helps in improving the overall performance of Algorithm 10 when it is searching over an initial range with a large number of full key candidates.
Given the computational burden of Algorithm 10 lies on the execution of the function keySearch (at step 7), then any improvement on this search algorithm implies a speed-up on Algorithm 10’s overall performance. The authors of [42] show how this part may be modified by replacing it for a Grover’s oracle [43], and so improving Algorithm 10’s overall performance. Algorithm 11 results from adjusting Algorithm 10 and relies on a Grover’s oracle, giving a quadratic speed-up on searches over partitions. The function returns 1, on the condition that r is the rank of the real secret key; otherwise, it returns 0. Grover’s algorithm [43] shows that r can be found on a quantum computer in only steps, where is the time to evaluate , i.e., . Therefore Algorithm 11’s overall running time is given by replacing in Equation (6) for (step 7 of Algorithm 11) plus the running time for Grover’s algorithm with (steps from 8 to 9 of Algorithm 11).
| Algorithm 10 performs a non-optimal enumeration over an interval with roughly e full key candidates. |
|
| Algorithm 11 performs a quantum key enumeration over an interval with roughly e full key candidates. |
|
6. Conclusions
This research paper addressed the question of the viability of cold boot attacks on SIKE. To this end, we reviewed SIKE’s reference implementation as it was submitted to the NIST Post-Quantum Cryptography Standardization Process. Furthermore, we presented a dedicated key-recovery algorithm for SIKE in this setting and showed, through simulations, that our algorithm can reconstruct the secret key for SIKE, configured with any SIKE parameters, for varying values and , by only performing a enumeration. We stress these success rates from our algorithm can be improved as long as there are more available resources to run it. Additionally, we showed that our algorithm could be sped-up by integrating a quantum key search algorithm with it, which brings the computation power of quantum computing into the post-processing phase of a side channel attack. Moreover, as a future work, we may extend our work to include a resource estimation of quantum gates resulting from running our quantum key-recovery algorithm against SIKE or other cryptographic primitives in the post-processing phase.
Author Contributions
Conceptualization, R.V.-P.; methodology, R.V.-P.; software, R.V.-P. and E.A.-M.; validation, R.V.-P. and E.A.-M.; formal analysis, R.V.-P. and E.A.-M.; investigation, R.V.-P.; resources, R.V.-P.; data curation, R.V.-P. and E.A.-M.; writing—original draft preparation, R.V.-P. and E.A.-M.; writing—review and editing, R.V.-P. and E.A.-M.; visualization, R.V.-P. and E.A.-M.; supervision, R.V.-P.; project administration, R.V.-P.; funding acquisition, R.V.-P.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Universidad del Norte grant number 2019-029 and the APC was funded by Universidad del Norte.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Costello, C.; De Feo, L.; Jao, D.; Longa, P.; Naehrig, M.; Renes, J. Supersingular Isogeny Key Encapsulation. Post-Quantum Cryptography Standardization. 2020. Available online: https://sike.org/files/SIDH-spec.pdf (accessed on 2 December 2020).
- Jao, D.; De Feo, L. Towards Quantum-Resistant Cryptosystems from Supersingular Elliptic Curve Isogenies; Post-Quantum Cryptography; Yang, B.Y., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 19–34. [Google Scholar]
- Alagic, G.; Alperin-Sheriff, J.; Aponn, D.; Cooper, D.; Dang, Q.; Kelsey, J.; Liu, Y.K.; Miller, C.; Moody, D.; Peralta, R.; et al. Status Report on the Second Round of the NIST Post-Quantum Cryptography Standardization Process. NIST Post-Quantum Cryptography Standardization Process; 2020. Available online: https://nvlpubs.nist.gov/nistpubs/ir/2020/NIST.IR.8309.pdf (accessed on 9 December 2020).
- Faz-Hernández, A.; López, J.; Ochoa-Jiménez, E.; Rodríguez-Henríquez, F. A Faster Software Implementation of the Supersingular Isogeny Diffie–Hellman Key Exchange Protocol. IEEE Trans. Comput. 2017, 67, 1622–1636. [Google Scholar] [CrossRef]
- Seo, H.; Jalali, A.; Azarderakhsh, R. Optimized SIKE Round 2 on 64-bit ARM; Information Security Applications–WISA 2019; You, I., Ed.; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Naehrig, M.; Renes, J. Dual Isogenies and Their Application to Public-Key Compression for Isogeny-Based Cryptography; Advances in Cryptology–ASIACRYPT 2019; Galbraith, S.D., Moriai, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 243–272. [Google Scholar]
- Massolino, P.M.C.; Longa, P.; Renes, J.; Batina, L. A Compact and Scalable Hardware/Software Co-design of SIKE. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 245–271. [Google Scholar] [CrossRef]
- Elkhatib, R.; Azarderakhsh, R.; Mozaffari-Kermani, M. Efficient and Fast Hardware Architectures for SIKE Round 2 on FPGA. Cryptology ePrint Archive, Report 2020/611. 2020. Available online: https://eprint.iacr.org/2020/611.pdf (accessed on 9 December 2020).
- Costello, C.; De Feo, L.; Jao, D.; Longa, P.; Naehrig, M.; Renes, J. Supersingular Isogeny Key Encapsulation: Reference Implementation. Post-Quantum Cryptography Standardization. 2020. Available online: https://github.com/microsoft/PQCrypto-SIDH/releases/tag/v3.3 (accessed on 9 December 2020).
- Halderman, J.A.; Schoen, S.D.; Heninger, N.; Clarkson, W.; Paul, W.; Calandrino, J.A.; Feldman, A.J.; Appelbaum, J.; Felten, E.W. Lest We Remember: Cold Boot Attacks on Encryption Keys. Commun. ACM 2009, 52, 91–98. [Google Scholar] [CrossRef]
- Villanueva-Polanco, R. Cold Boot Attacks on Bliss; Springer: Cham, Switzerland, 2019; pp. 40–61. [Google Scholar] [CrossRef]
- Veyrat-Charvillon, N.; Gérard, B.; Renauld, M.; Standaert, F.X. An Optimal Key Enumeration Algorithm and Its Application to Side-Channel Attacks; Springer: Berlin/Heidelberg, Germany, 2013; pp. 390–406. [Google Scholar] [CrossRef]
- Bogdanov, A.; Kizhvatov, I.; Manzoor, K.; Tischhauser, E.; Witteman, M. Fast and Memory-Efficient Key Recovery in Side-Channel Attacks; Springer: Cham, Switzerland, 2016; pp. 310–327. [Google Scholar] [CrossRef]
- David, L.; Wool, A. A Bounded-Space Near-Optimal Key Enumeration Algorithm for Multi-subkey Side-Channel Attacks; Springer: Cham, Switzerland, 2017; pp. 311–327. [Google Scholar] [CrossRef]
- Longo, J.; Martin, D.P.; Mather, L.; Oswald, E.; Sach, B.; Stam, M. How Low Can You Go? Using Side-Channel Data to Enhance Brute-Force Key Recovery. Cryptology ePrint Archive, Report 2016/609. 2016. Available online: http://eprint.iacr.org/2016/609 (accessed on 20 November 2020).
- Martin, D.P.; Mather, L.; Oswald, E.; Stam, M. Characterisation and Estimation of the Key Rank Distribution in the Context of Side Channel Evaluations; Springer: Berlin/Heidelberg, Germany, 2016; pp. 548–572. [Google Scholar] [CrossRef]
- Martin, D.P.; O’Connell, J.F.; Oswald, E.; Stam, M. Counting Keys in Parallel After a Side Channel Attack; Springer: Berlin/Heidelberg, Germany, 2015; pp. 313–337. [Google Scholar] [CrossRef]
- Poussier, R.; Standaert, F.X.; Grosso, V. Simple Key Enumeration (and Rank Estimation) Using Histograms: An Integrated Approach; Springer: Berlin/Heidelberg, Germany, 2016; pp. 61–81. [Google Scholar] [CrossRef]
- Veyrat-Charvillon, N.; Gérard, B.; Standaert, F.X. Security Evaluations beyond Computing Power; Springer: Berlin/Heidelberg, Germany, 2013; pp. 126–141. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Lange, T.; van Vredendaal, C. Tighter, Faster, Simpler Side-Channel Security Evaluations Beyond Computing Power. Cryptology ePrint Archive, Report 2015/221. 2015. Available online: http://eprint.iacr.org/2015/221 (accessed on 9 November 2020).
- Ye, X.; Eisenbarth, T.; Martin, W. Bounded, yet Sufficient? How to Determine Whether Limited Side Channel Information Enables Key Recovery. In Smart Card Research and Advanced Applications; Joye, M., Moradi, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 215–232. [Google Scholar]
- Choudary, M.O.; Popescu, P.G. Back to Massey: Impressively Fast, Scalable and Tight Security Evaluation Tools; Springer: Cham, Switzerland, 2017; pp. 367–386. [Google Scholar] [CrossRef]
- Choudary, M.O.; Poussier, R.; Standaert, F.X. Core-Based vs. Probability-Based Enumeration- A Cautionary Note; Springer: Cham, Switzerland, 2016; pp. 137–152. [Google Scholar] [CrossRef]
- Glowacz, C.; Grosso, V.; Poussier, R.; Schüth, J.; Standaert, F.X. Simpler and More Efficient Rank Estimation for Side-Channel Security Assessment; Springer: Berlin/Heidelberg, Germany, 2015; pp. 117–129. [Google Scholar] [CrossRef]
- Poussier, R.; Grosso, V.; Standaert, F.X. Comparing Approaches to Rank Estimation for Side-Channel Security Evaluations. In Smart Card Research and Advanced Applications; Homma, N., Medwed, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 125–142. [Google Scholar]
- Grosso, V. Scalable Key Rank Estimation (and Key Enumeration) Algorithm for Large Keys. In Smart Card Research and Advanced Applications; Bilgin, B., Fischer, J.B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 80–94. [Google Scholar]
- Villanueva-Polanco, R. A Comprehensive Study of the Key Enumeration Problem. Entropy 2019, 21, 972. [Google Scholar] [CrossRef]
- Heninger, N.; Shacham, H. Reconstructing RSA Private Keys from Random Key Bits; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–17. [Google Scholar] [CrossRef]
- Henecka, W.; May, A.; Meurer, A. Correcting Errors in RSA Private Keys; Springer: Berlin/Heidelberg, Germany, 2010; pp. 351–369. [Google Scholar] [CrossRef]
- Paterson, K.G.; Polychroniadou, A.; Sibborn, D.L. A Coding-Theoretic Approach to Recovering Noisy RSA Keys; Springer: Berlin/Heidelberg, Germany, 2012; pp. 386–403. [Google Scholar] [CrossRef]
- Lee, H.T.; Kim, H.; Baek, Y.J.; Cheon, J.H. Correcting Errors in Private Keys Obtained from Cold Boot Attacks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 74–87. [Google Scholar]
- Poettering, B.; Sibborn, D.L. Cold Boot Attacks in the Discrete Logarithm Setting; Springer: Cham, Switzerland, 2015; pp. 449–465. [Google Scholar] [CrossRef]
- Albrecht, M.; Cid, C. Cold Boot Key Recovery by Solving Polynomial Systems with Noise; Springer: Berlin/Heidelberg, Germany, 2011; pp. 57–72. [Google Scholar] [CrossRef]
- Kamal, A.A.; Youssef, A.M. Applications of SAT Solvers to AES Key Recovery from Decayed Key Schedule Images. In Proceedings of the 2010 Fourth International Conference on Emerging Security Information, Systems and Technologies, SECURWARE ’10, Venice, Italy, 18–25 July 2010; IEEE Computer Society: Washington, DC, USA, 2010; pp. 216–220. [Google Scholar] [CrossRef]
- Huang, Z.; Lin, D. A New Method for Solving Polynomial Systems with Noise over F2 and Its Applications in Cold Boot Key Recovery. In Selected Areas in Cryptography; Knudsen, L.R., Wu, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 16–33. [Google Scholar]
- Paterson, K.G.; Villanueva-Polanco, R. Cold Boot Attacks on NTRU. In Progress in Cryptology—INDOCRYPT 2017; Patra, A., Smart, N.P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 107–125. [Google Scholar]
- Villanueva-Polanco, R. Cold Boot Attacks on LUOV. Appl. Sci. 2020, 10, 4106. [Google Scholar] [CrossRef]
- Albrecht, M.R.; Deo, A.; Paterson, K.G. Cold Boot Attacks on Ring and Module LWE Keys Under the NTT. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 173–213. [Google Scholar] [CrossRef]
- Vélu, J. Isogénies entre courbes elliptiques. Comptes Rendus De L’Académie Des Sci. De Paris 1971, 273, 238–241. [Google Scholar]
- Dworkin, M.J. Federal Inf. Process. Stds. (NIST FIPS). 2015. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.202.pdf (accessed on 9 November 2020).
- Seshadri, N.; Sundberg, C.W. List Viterbi decoding algorithms with applications. IEEE Trans. Commun. 1994, 42, 313–323. [Google Scholar] [CrossRef]
- Martin, D.P.; Montanaro, A.; Oswald, E.; Shepherd, D.J. Quantum Key Search with Side Channel Advice; Springer: Cham, Switzerland, 2017; pp. 407–422. [Google Scholar] [CrossRef]
- Grover, L.K. A Fast Quantum Mechanical Algorithm for Database Search. In STOC ’96: Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing; Association for Computing Machinery: New York, NY, USA, July 1996; pp. 212–219. [Google Scholar] [CrossRef]
- Beullen, W.; Preneel, B.; Szepieniec, A.; Tjhai, C.; Vercauteren, F. LUOV: Signature Scheme proposal for NIST PQC Project (Round 2 version). Submission to NIST’s Post-Quantum Cryptography Standardization Project. 2018. Available online: https://www.esat.kuleuven.be/cosic/pqcrypto/luov/ (accessed on 29 November 2020).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).