In experiments on language corpora, it was successfully verified that the automatically extracted rhythm metrics preserve language-discriminative information. Next, we attempted to verify whether the metrics play a role in automatic language identification. For this work, we developed two types of the conventional LID approaches including i-vector-based LID and CNN-based LID, and then we compared them with our proposed approach in terms of LID performance and computation complexity.
The second baseline is an up-to-date LID approach employing CNN. As this approach uses two different DNN structures to operate consecutive procedures (feature extraction and classification), it can be regarded as an end-to-end LID approach.
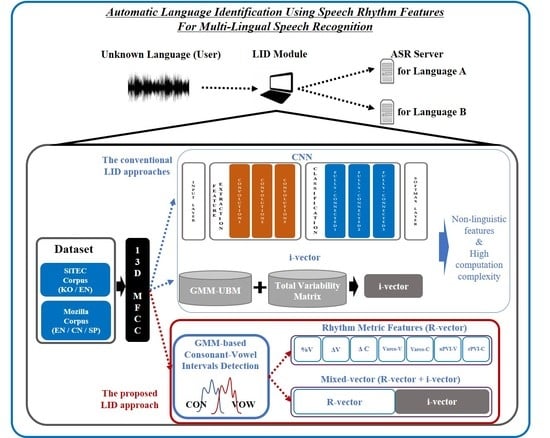
Figure 9 shows the configuration of layers for this operation. A total of 64 packs of 13-dimensional MFCCs extracted from each speech frame enter into an input layer as initial data, consisting of a (64 × 13)-matrix. Then, the input data pass through three convolutional and max pooling layers sequentially. The results of each convolution operation are multiplied by the weights of the corresponding convolution filter. Then, the dimension of the weighted values is reduced by a pooling layer. Among representative pooling ways including max pooling and average pooling, we use the max pooling approach to reflect only the highly highlighted value. After passing the pooling layer, dropout is subsequently performed to exclude some data for reducing overfitting. While selecting hyperparameters, we empirically set the optimal filter size as (2 × 2) and changed the number of filters from 64 to 256, maintaining the dropout rate to 0.5.
4.3.1. Evaluation and Analysis of Automatic LID
Using the two corpora mentioned in
Section 4.1, we investigated the performance of automatic LID for four types of LID approaches including conventional approaches based on i-vector and CNN and proposed approaches based on R-vector with SVM (addressed in
Section 3.4.1) and R-vector with i-vector (addressed in
Section 3.4.2). For a fair evaluation, we partitioned the data in each corpus into five equal sized subsets and performed five-fold cross-validation, sequentially using the respective subsets for testing and the remaining four subsets for training. We investigated the performance using a recognition error rate (%) for each subset and averaged five experimental results.
Table 5 describes the recognition results of two-class (English versus Korean) LID experiments performed on the SiTEC corpus. Most approaches showed outstanding recognition accuracy, achieving more than 95%. Although the conventional CNN-based LID outperformed the other approaches, the proposed R-vector employing SVM achieved notable performance compared to the CNN-based approach. On the other hand, i-vector-based approaches demonstrated relatively lower performance.
The Mozilla corpus provided slightly different aspects of LID performance from the SiTEC corpus, decreasing the overall LID accuracy. The degradation is caused by the differences in speaking styles and recording quality between two corpora. As mentioned in
Section 4.1, the Mozilla corpus retains speech data of natural and dialogic voice recorded in real-life environments, whereas the SiTEC corpus consists of read speech data recorded in a silent studio.
First, we investigated the performance of two-class LID experiments in the same way as the SiTEC experiments, making a pair from three different languages (English, Spanish, and Chinese).
Table 6 summarizes the results of three pairs of languages. The proposed approach employing R-vector with SVM that showed comparable performance to the CNN-based approach in
Table 5 represented the worst accuracy. We consider that the R-vector extracted from the Mozilla data may have an incorrect value, as it was estimated upon an acoustic model constructed from the PRAWN corpus addressed in
Section 3.3.1, which retains phonemically demarcated read speech data differently from the Mozilla data. Although the sole use of R-vector provided poor accuracy, the R-vector showed outstanding performance when combined with the i-vector approach. As shown in
Table 6, the combination of R-vector and i-vector increased the performance of the conventional i-vector, and it even reduced the performance gap from the CNN-based approach.
When analyzing the results in terms of a language pair, the EN–SP set represented the worst performance among three language pairs. The similar result was already found in
Section 4.2, in which the English–Spanish pair showed a lower significance level and more largely overlapped quantiles compared to other two pairs, thus providing an incorrect R-vector. This tendency was also demonstrated in LID experiments. In particular, two conventional approaches also revealed difficulties in discriminating English and Spanish. It is also a unique observation that in the LID experiments targeting Chinese and Spanish, the i-vector approach outperformed the CNN. It is quite a different result from that of other language pairs. We analyzed that the i-vector retains more reliable features discriminating Chinese and Spanish in a comparison of the features that the CNN extracted.
Next, we investigated the performance of three-class LID discriminating English, Spanish, and Chinese. As shown in
Table 7, the accuracy was significantly degraded in comparison with two-class LID. However, the experiment derived a common tendency between LID approaches that was observed in
Table 6. A notable result is that the R-vector employing i-vector achieved the same performance as the CNN-based approach, making the best accuracy.
In order to observe the efficiency of the proposed R-vector-based approach in a more sophisticated manner, we analyzed the results of the confusion matrix shown in
Figure 10. Among the matrices, the experiment on the SiTEC corpus provided more notable LID accuracy compared to that on the Mozilla corpus, showing stable LID performance in both English and Korean. In a three-class LID experiment, our system identified China better than other languages, achieving about 68% accuracy. Meanwhile, English and Spanish indicated similar recognition results.
Finally, we attempted to investigate the efficiency of the proposed approach on an evaluation dataset specialized for the LID task. We selected the ‘2011 National Institute of Standards and Technology (NIST) Language Recognition Evaluation (LRE) Test Set’ published by the Linguistic Data Consortium (LDC), as LRE datasets are known as representative evaluation data for language identification. The dataset is characterized as conversational telephone speech recorded in real-life environments, which is similar to the Mozilla corpus. For this reason, we used classification models trained with the Mozilla data to evaluate the LRE test set in consideration of cross-corpus evaluation. To compare with the Mozilla results, we conducted two-class and three-class LID experiments using English, Spanish, and Chinese.
Table 8 and
Table 9 demonstrate the results. Due to the difference between the training data and test data, the LRE dataset provided lower accuracy compared to the Mozilla results, while showing a similar performance tendency to the Mozilla data. In two-class experiments, the EN–SP pair also represented the worst performance among the three language pairs. Another similar tendency was shown in the CN–SP pair, in which the i-vector approach provided higher performance than that of the CNN. Outstanding results were observed in the performance of the proposed R-vector. Although the proposed R-vector-based approaches indicated the worst performance in the Mozilla results, the approaches demonstrated better or similar accuracy in comparison with the conventional approaches in the LRE evaluation. Next, in three-class experiments, the proposed approaches employing R-vector demonstrated an LID performance comparable to the conventional approaches, while the R-vector-based SVM approach showed significantly poor accuracy in the Mozilla result.
In several LID experiments, the proposed R-vector-based approaches demonstrated slightly different performance according to speech corpora. For read speech recorded in clean environments, the R-vector showed superior performance comparable to CNN when it employs SVM, whereas for dialogic speech data recorded in real environments, the R-vector-based approaches provided better or similar accuracy compared to the conventional LID approaches. The results explain that the R-vector conveys reliable and language-discriminative information as a useful LID feature. In particular, the R-vector-based approach requires much less computation complexity than the conventional techniques.
4.3.2. Analysis of Computation Complexity
As mentioned in
Section 3.2, we expect the proposed R-vector-based approach allows LID operating directly on user devices that have limited hardware resources. For this reason, we compared our approach with the conventional approaches in terms of computation complexity. We used two measures for the comparison: the number of parameters required in a training phase and computational intensity regarding a testing phase.
Table 10 summarizes the results analyzed on the basis of a two-class LID task.
As known commonly, the CNN-based approach requires the highest number of parameters and computational intensity. As addressed in
Figure 9, the CNN-based LID processes seven layers including three layers for feature extraction, three layers for classification, and one layer for softmax. The overall number of parameters to be estimated is calculated as 198,912, comprising 1792 parameters in feature extraction layers (64 × 4 + 128 × 4 + 256 × 4), 196,608 parameters in classification layers (256 × 256 × 3), and 512 parameters in softmax layers (256 × 2). The more that the size of convolution filters or the number of layers increases, the more the number of parameters. In terms of computational intensity, the CNN-based LID requires about 500,000 computations which are obtained by considering the filter size, the number of input channels, and the input size. Feature extraction layers need 315,392 computations (64 × 13 × 64 + 128 × 64 × 16 + 256 × 128 × 4), and classification layers and a softmax layer conduct 197,120 computations (256 × 256 × 3 + 256 × 2).
In the i-vector-based approach, the number of parameters depends on the number of UBM mixtures, the dimension of the input feature, and the i-vector dimension. When using 128 mixtures, 13-dimensional MFCCs, and 10-dimensional i-vectors, the total number of parameters is calculated as 39,936 = 128 × 13 + 128 × 169 + 128 × 13 × 10. During recognition, 19,968 computations are required: 3328 for UBM processing and 16,640 for i-vector processing.
Finally, the R-vector-based approach has the lowest computation complexity. A dominant processing of this approach is to construct GMMs used for consonantal and vocalic intervals. In this study, 13-dimensional GMM mixtures were optimally defined. Thus, the number of parameters is only 2366 = 13 × 13 + 13 × 169, and the computational intensity is regarded as 345 computations consisting of 338 = 13 × 13 × 2 for interval detection and 7 for R-vector estimation.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}