
Model Predictive Control for Pneumatic Manipulator via Receding-Horizon-Based Extended State Observers


Abstract
1. Introduction
2. Problem Formulation and Preliminaries
2.1. The Model of the Pneumatic Manipulator System
2.2. The Receding-Horizon-Based ESO
2.3. The Tracking Differentiator
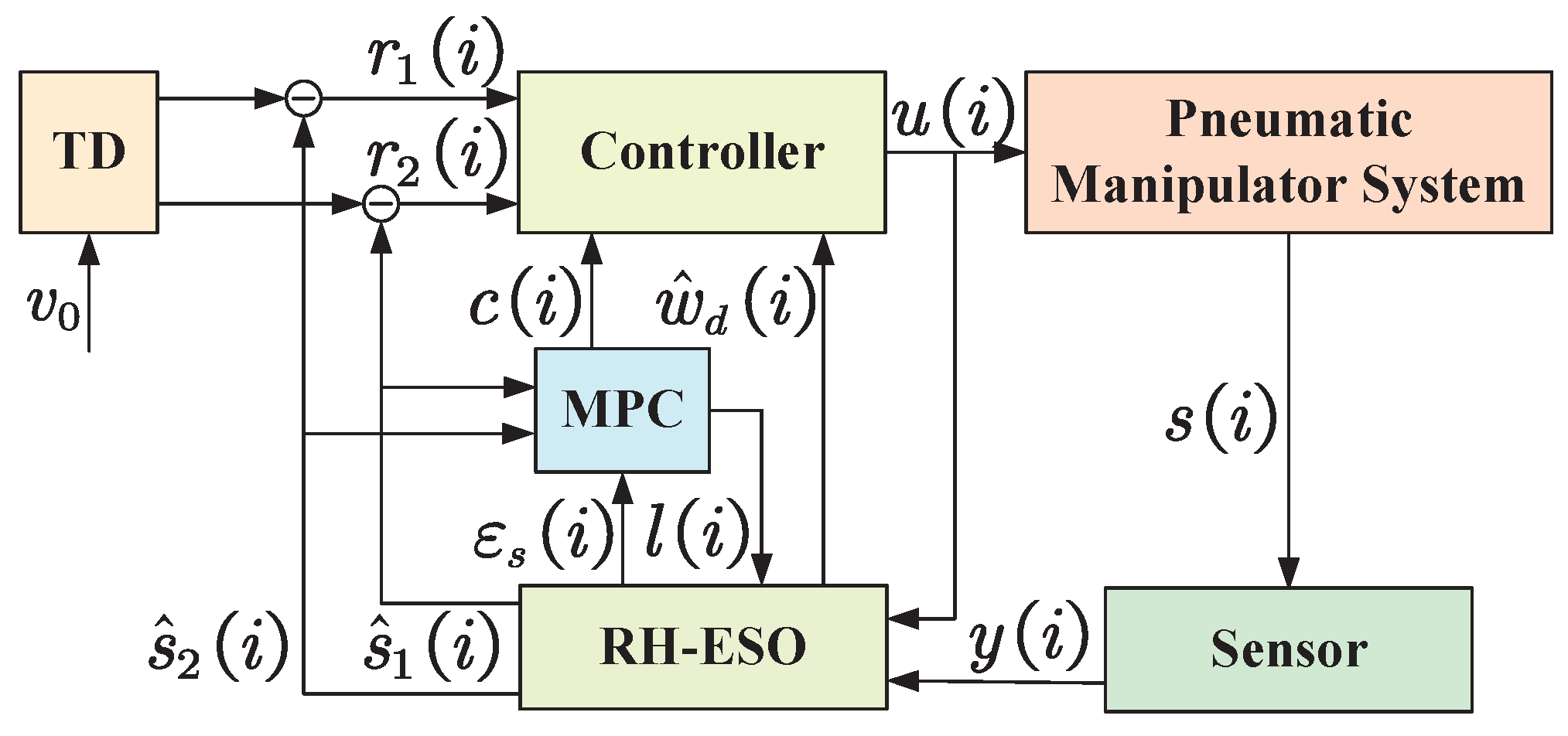
2.4. The MPC-Enabled Disturbance-Rejection Controller
2.5. The MPC Scheme
3. Results
4. Numerical Example
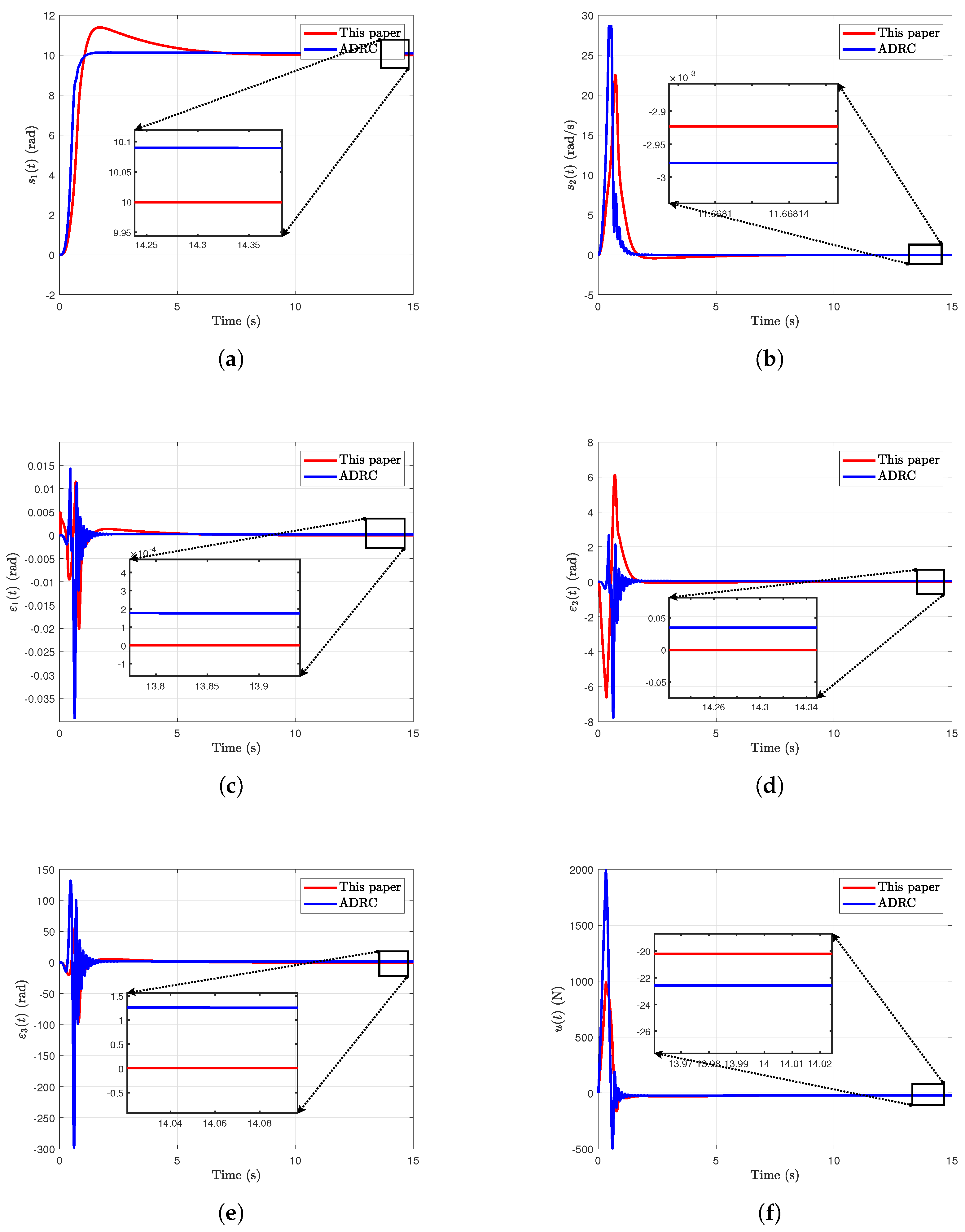
4.1. Time-Invariant Reference Input Signal Tracking
4.2. Time-Varying Reference Input Signal Tracking

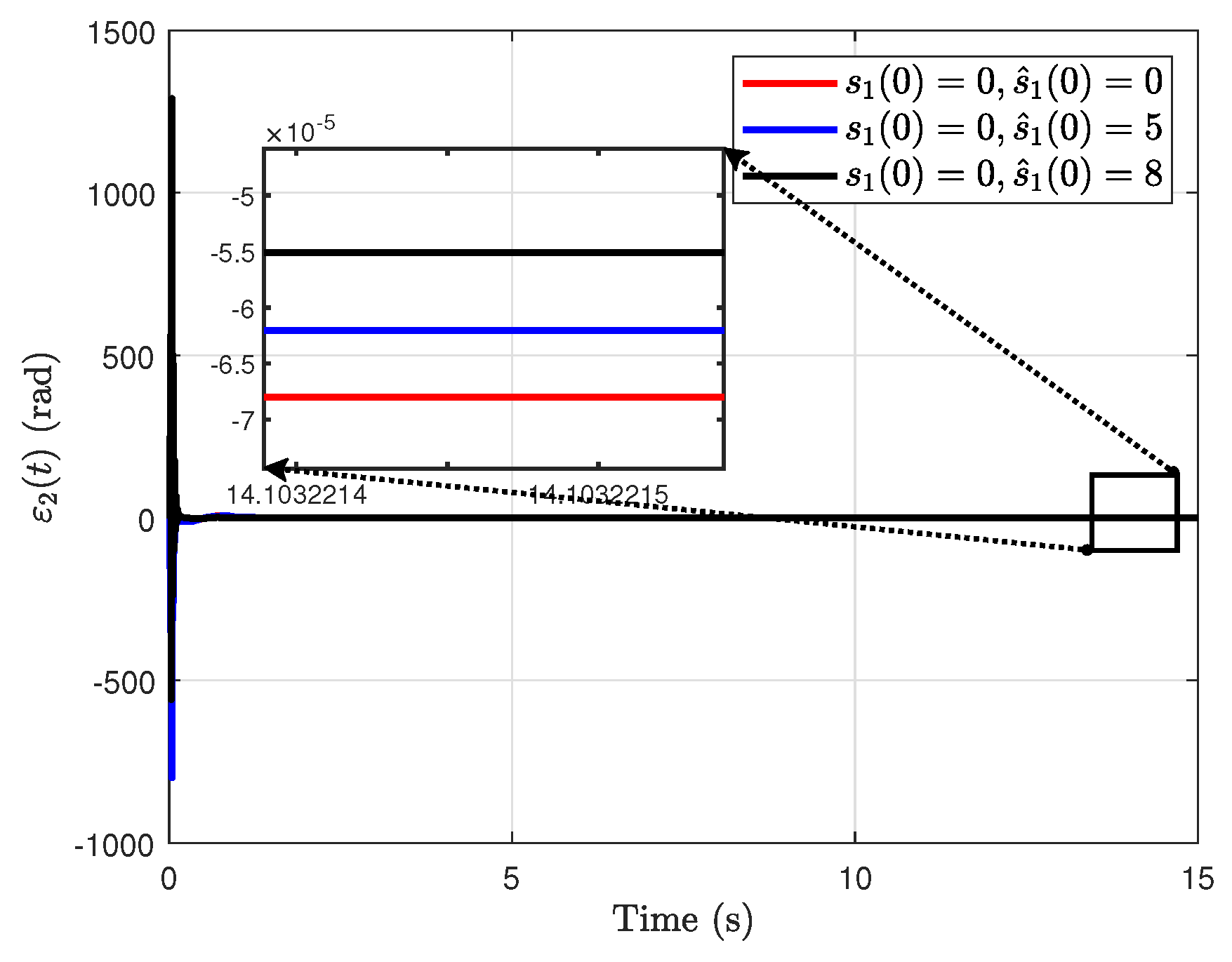
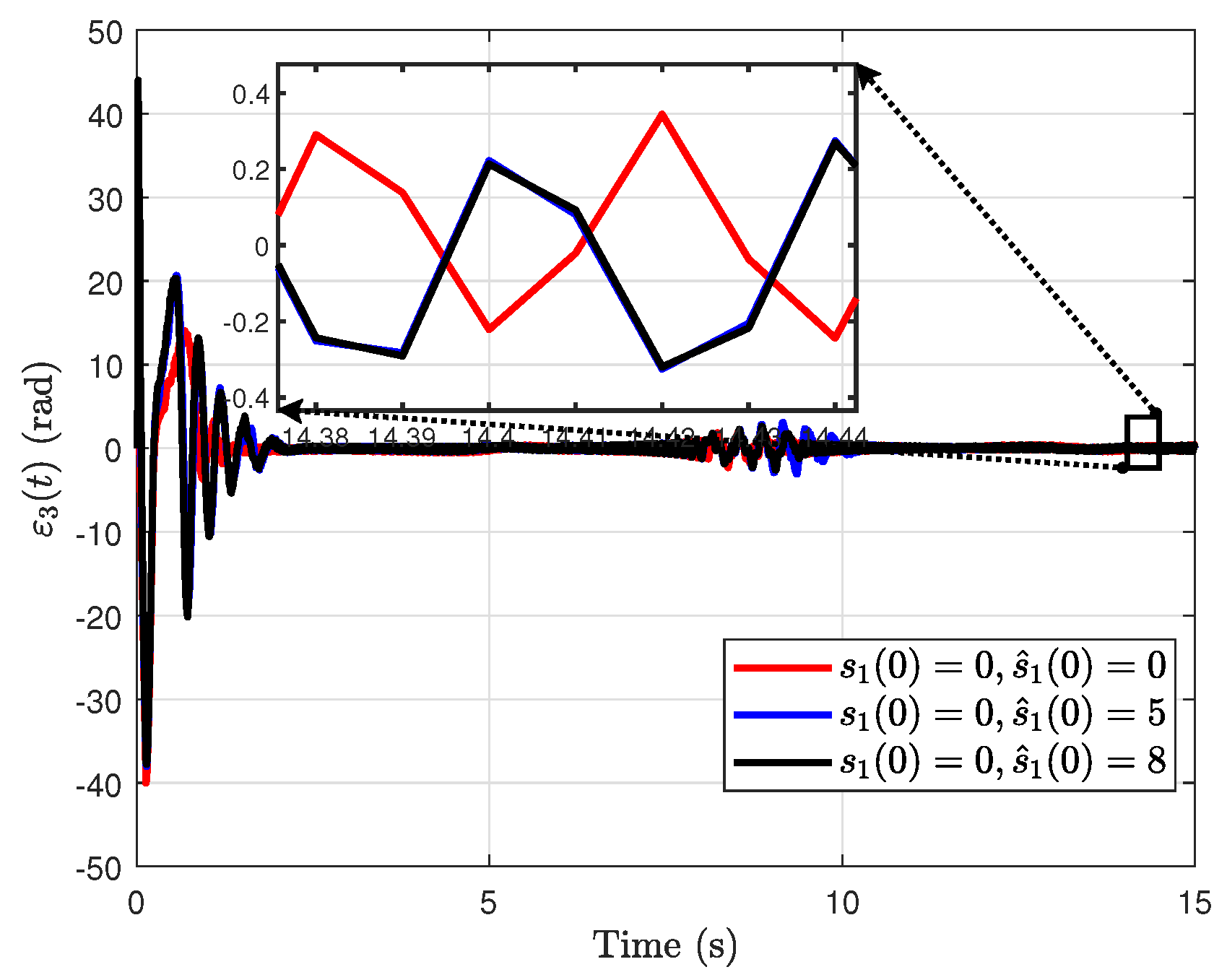
4.3. Analysis of Estimation Error Under Different Observer Initial Values
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MPC | Model predictive control |
| RH-ESO | Receding-horizon-based extended state observer |
| SMC | Sliding mode control |
| ADRC | Active disturbance-rejection control |
| PAMs | Pneumatic artificial muscles |
| LMIs | Linear matrix inequalities |
| TD | Tracking differentiator |
| Nomenclature | |
| The real number set | |
| The non-negative integer set | |
| The set of positive integers | |
| The dimension of A is | |
| Matrix A is positive definite (or negative definite) | |
| The maximum eigenvalue of A | |
| I | The unit matrix with appropriate dimensions |
| The s step ahead prediction of state conditioned on measurements | |
| available at time instant i |
References
- Xie, Z.; Mohanakrishnan, M.; Wang, P.; Liu, J.; Xin, W.; Tang, Z.; Wen, L.; Laschi, C. Soft robotic arm with extensible stiffening layer. IEEE Robot. Autom. Lett. 2023, 8, 3597–3604. [Google Scholar] [CrossRef]
- Low, J.H.; Lee, W.W.; Khin, P.M.; Thakor, N.V.; Kukreja, S.L.; Ren, H.L.; Yeow, C.H. Hybrid tele-manipulation system using a sensorized 3-D-printed soft robotic gripper and a soft fabric-based haptic glove. IEEE Robot. Autom. Lett. 2017, 2, 880–887. [Google Scholar] [CrossRef]
- Yu, N.; Zhai, Y.; Yuan, Y.; Wang, Z. A bionic robot navigation algorithm based on cognitive mechanism of hippocampus. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1640–1652. [Google Scholar] [CrossRef]
- Chi, H.R.; Radwan, A.; Huang, N.F.; Tsang, K.F. Guest editorial: Next-generation network automation for industrial internet-of-things in Industry 5.0. IEEE Trans. Ind. Inform. 2022, 19, 2062–2064. [Google Scholar] [CrossRef]
- Miron, G.; Plante, J.S. Design principles for improved fatigue life of high-strain pneumatic artificial muscles. Soft Robot. 2016, 3, 177–185. [Google Scholar] [CrossRef]
- Kim, W.; Park, H.; Kim, J. Compact flat fabric pneumatic artificial muscle (ffpam) for soft wearable robotic devices. IEEE Robot. Autom. Lett. 2021, 6, 2603–2610. [Google Scholar] [CrossRef]
- Tsai, T.C.; Chiang, M.H. A lower limb rehabilitation assistance training robot system driven by an innovative pneumatic artificial muscle system. Soft Robot. 2023, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Cho, Y.; Kim, W.; Park, H.; Kim, J.; Na, Y. Bidirectional double-spring pneumatic artificial muscle with inductive self-sensing. IEEE Robot. Autom. Lett. 2023, 8, 8160–8167. [Google Scholar] [CrossRef]
- Liu, G.; Diao, S.; Liu, Z.; Zhang, X.; Xiao, X.; Men, S.; Sun, N. Practical Finite-Time Compliant Control for Horizontal Pneumatic Artificial Muscle Systems Under Force-Sensorless Reflecting. IEEE Trans. Autom. Sci. Eng. 2024, 22, 9515–9527. [Google Scholar] [CrossRef]
- Wang, Q.; Yang, T.; Liu, G.; Qin, Y.; Fang, Y.; Sun, N. Adaptive compensation tracking control for parallel robots actuated by pneumatic artificial muscles with error constraints. IEEE Trans. Ind. Inform. 2023, 20, 1585–1595. [Google Scholar] [CrossRef]
- Liang, D.; Sun, N.; Wu, Y.; Liu, G.; Fang, Y. Fuzzy-sliding mode control for humanoid arm robots actuated by pneumatic artificial muscles with unidirectional inputs, saturations, and dead zones. IEEE Trans. Ind. Inform. 2021, 18, 3011–3021. [Google Scholar] [CrossRef]
- Khaled, T.A.; Akhrif, O.; Bonev, I.A. Dynamic path correction of an industrial robot using a distance sensor and an ADRC controller. Ieee/Asme Trans. Mechatronics 2020, 26, 1646–1656. [Google Scholar] [CrossRef]
- Diao, S.; Liu, G.; Liu, Z.; Zhou, L.; Sun, W.; Wang, Y.; Sun, N. Prescribed-Time Adaptive Fuzzy Control for Pneumatic Artificial Muscle-Actuated Parallel Robots With Input Constraints. IEEE Trans. Fuzzy Syst. 2023, 32, 2039–2051. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, H.; Wang, X.; Sun, N.; Han, J. Adaptive set-membership filter based discrete sliding mode control for pneumatic artificial muscle systems with hardware experiments. IEEE Trans. Autom. Sci. Eng. 2023, 21, 1682–1694. [Google Scholar] [CrossRef]
- Hosseini, S.A.; Toulabi, M.; Dobakhshari, A.S.; Ashouri-Zadeh, A.; Ranjbar, A.M. Delay compensation of demand response and adaptive disturbance rejection applied to power system frequency control. IEEE Trans. Power Syst. 2019, 35, 2037–2046. [Google Scholar] [CrossRef]
- Zeng, Y.; Liang, G.; Liu, Q.; Rodriguez, E.; Pou, J.; Jie, H.; Liu, X.; Zhang, X.; Kotturu, J.; Gupta, A. Multiagent soft actor-critic aided active disturbance rejection control of DC solid-state transformer. IEEE Trans. Ind. Electron. 2024, 72, 492–503. [Google Scholar] [CrossRef]
- Fu, C.; Tan, W. Tuning of linear ADRC with known plant information. ISA Trans. 2016, 65, 384–393. [Google Scholar] [CrossRef]
- Guo, B.Z.; Zhao, Z.l. On the convergence of an extended state observer for nonlinear systems with uncertainty. Syst. Control Lett. 2011, 60, 420–430. [Google Scholar] [CrossRef]
- Qin, B.; Yan, H.; Zhang, H.; Wang, Y.; Yang, S.X. Enhanced reduced-order extended state observer for motion control of differential driven mobile robot. IEEE Trans. Cybern. 2021, 53, 1299–1310. [Google Scholar] [CrossRef]
- Li, Z.; Yan, H.; Zhang, H.; Yang, S.X.; Chen, M. Novel extended state observer design for uncertain nonlinear systems via refined dynamic event-triggered communication protocol. IEEE Trans. Cybern. 2022, 53, 1856–1867. [Google Scholar] [CrossRef]
- Sun, H.; Madonski, R.; Li, S.; Zhang, Y.; Xue, W. Composite control design for systems with uncertainties and noise using combined extended state observer and Kalman filter. IEEE Trans. Ind. Electron. 2021, 69, 4119–4128. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Q.; Liu, B.; Cheng, H. Trajectory tracking control of a one degree of freedom manipulator based on a switched sliding mode controller with a novel extended state observer framework. IEEE Trans. Syst. Man Cybern. Syst. 2017, 49, 1110–1118. [Google Scholar] [CrossRef]
- Zhao, L.; Cheng, H.; Wang, T. Sliding mode control for a two-joint coupling nonlinear system based on extended state observer. ISA Trans. 2018, 73, 130–140. [Google Scholar] [CrossRef]
- Mayne, D.Q.; Rawlings, J.B.; Rao, C.V.; Scokaert, P.O. Survey constrained model predictive control: Stability and optimality. Automatica 2000, 36, 789–814. [Google Scholar] [CrossRef]
- Zeilinger, M.N.; Morari, M.; Jones, C.N. Soft constrained model predictive control with robust stability guarantees. IEEE Trans. Autom. Control 2014, 59, 1190–1202. [Google Scholar] [CrossRef]
- Li, T.; Sun, X.; Lei, G.; Guo, Y.; Yang, Z.; Zhu, J. Finite-control-set model predictive control of permanent magnet synchronous motor drive systems—An overview. IEEE/CAA J. Autom. Sin. 2022, 9, 2087–2105. [Google Scholar] [CrossRef]
- Li, P.; Kang, Y.; Wang, T.; Zhao, Y.B. Disturbance prediction-based adaptive event-triggered model predictive control for perturbed nonlinear systems. IEEE Trans. Autom. Control 2022, 68, 2422–2429. [Google Scholar] [CrossRef]
- Li, N.; Zhang, K.; Li, Z.; Srivastava, V.; Yin, X. Cloud-assisted nonlinear model predictive control for finite-duration tasks. IEEE Trans. Autom. Control 2022, 68, 5287–5300. [Google Scholar] [CrossRef]
- Wang, M.; Cheng, P.; Zhang, Z.; Wang, M.; Chen, J. Periodic event-triggered MPC for continuous-time nonlinear systems with bounded disturbances. IEEE Trans. Autom. Control 2023, 68, 8036–8043. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Z.; Li, H.; Liu, B. Backstepping integral sliding mode control for pneumatic manipulators via adaptive extended state observers. ISA Trans. 2024, 144, 374–384. [Google Scholar] [CrossRef]
- Peuteman, J.; Aeyels, D.; Sepulchre, R. Boundedness properties for time-varying nonlinear systems. SIAM J. Control Optim. 2001, 39, 1408–1422. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | b | |||
| Value | (m) | (m) | (m) | (m) |
| Parameter | m | g | ||
| Value | 1 (kpa) | 1 (kg) | () | (s) |
| Parameter | N | |||
| Value | 100 | 8 | 15 | 30 |
| Parameter | ||||
| Value | 1000 | 10 | 1 | 10 |
| Parameter | ||||
| Value | 100 | 300 | 7000 | 1750 |
| Parameter | ||||
| Value | 100 | 30 | 20 | 50 |
| Parameter | d | Q | R | |
| Value | 1 | 5 |
| Parameters of RH-ESO and ADRC | ||||||||
| Value | 150 | 550 | 100 | 70 | 10 | |||
| Parameters of PD | ||||||||
| Value | 100 | 2 | ||||||
| Parameters of BSC | ||||||||
| Value | 2 | 2 | 2 | 150 | 1000 | 100 | 50 |
| Parameters of RH-ESO and ADRC | ||||||||
| Value | 150 | 550 | 100 | 130 | 10 | |||
| Parameters of PD | ||||||||
| Value | 100 | 2 | ||||||
| Parameters of BSC | ||||||||
| Value | 2 | 2 | 2 | 150 | 1000 | 100 | 50 |
| Initial states of the system | Variable | ||
| Value | 0 | 0 | |
| Case 1: Initial states of the RH-ESO | Variable | ||
| Value | 0 | 0 | |
| Case 2: Initial states of the RH-ESO | Variable | ||
| Value | 5 | 0 | |
| Case 3: Initial states of the RH-ESO | Variable | ||
| Value | 8 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Hao, X.; Zhu, D.; Wu, L.; Li, P. Model Predictive Control for Pneumatic Manipulator via Receding-Horizon-Based Extended State Observers. Actuators 2025, 14, 343. https://doi.org/10.3390/act14070343
Xu Y, Hao X, Zhu D, Wu L, Li P. Model Predictive Control for Pneumatic Manipulator via Receding-Horizon-Based Extended State Observers. Actuators. 2025; 14(7):343. https://doi.org/10.3390/act14070343
Chicago/Turabian StyleXu, Yang, Xiaohui Hao, Dongjie Zhu, Liangchao Wu, and Peng Li. 2025. "Model Predictive Control for Pneumatic Manipulator via Receding-Horizon-Based Extended State Observers" Actuators 14, no. 7: 343. https://doi.org/10.3390/act14070343
APA StyleXu, Y., Hao, X., Zhu, D., Wu, L., & Li, P. (2025). Model Predictive Control for Pneumatic Manipulator via Receding-Horizon-Based Extended State Observers. Actuators, 14(7), 343. https://doi.org/10.3390/act14070343